
Машинное обучение. Все о нём говорят. Много кто. Большая тема – но покрытая этой жуткой мистикой. Как магия – есть дар, сможешь что угодно сделать. Если нет... вообще не понятно, как подступиться. Постоянно фигурируют какие-то numpy, pandas, scikit-learn. На каждую из них фигурирует по двухтомному учебнику и куче доков.

Хочу в этой статье развеять мистику. Давайте чего-нибудь обучим, и найдём закономерности в большом наборе данных. Может и предскажем что-нибудь, даже. На простом, добром питоне – без всякой библиотеки в два гигабайта, и с минимальным входным порогом знаний.
Интересно? Прошу под кат.
1. Вступление

Есть игра. Популярная довольно игра, The Binding of Isaac называется. Идея простая - ты ходишь по подвалу и собираешь с пола всякие вещи. В зависимости от вещей, которые игрок набрал, игра может стать легче или сложнее. Надо применять стратегию.
Есть ещё человек. Этот человек регулярно играет в игру. Больше тысячи получасовых (а то и больше) эпизодов. Ветеран как игры, так и лёгких и непринуждённых рассказов про свою жизнь. Очень рекомендую его старые эпизоды, кстати, если вражеский язык не проблема – вот ссылка.
Есть ещё приятный сюрприз.

Какие-то люди, очень преданные любимому видеоблоггеру, сделали в его славу очень удобоваримую базу данных. Каждое из (ох господи, как их много) тысяч разных прохождений удобно расчерчено в SQL табличке, и с помощью пары простых запросов можно узнать почти всё про то, что происходило в видео. Вот ссылка, если интересно кому. Давайте используем это.
Вопрос возникает естественно – вот бегает человек по подвалу, собирает хлам. Кладёт это на YouTube. Люди потом его судят – палец вверх, или, может, палец вниз. Люди судят его по тому, как интересно им смотреть. Обычно, это харизма и качество повествования самого Northernlion-а. Но их в таблице нет. ...Но есть собранные им вещи.
А какие вещи делают видео интересным?
Узнаем.
2. Готовимся к работе
Прежде чем углубиться в теорию, давайте чуть поговорим, как загнать эту таблицу в наш любимый язык программирования.

Если ваш любимый язык программирования не Python, то я с вами не согласен.
Что нам нужно?
Нам нужно понятное преобразование того, что мы видим в базе в большую кучу примеров. Пример – то же самое, что пара из кучи всех вещей, которые собрали в одном видео, и рейтинга этого видео на YouTube. Мы поговорим об этом поглубже в следующей части, когда будем обсуждать машинное обучение как идею.
Вот образец (внимание, сложная структура данных):

Я пошутил. Она совсем не сложная.
У нас есть простой кортеж (tuple), в нём ID видео (чисто с декоративной целью), счётчик (словарь счетов – сколько раз вещь подобрали) для подобранных вещей и количество лайков в этом видео.
Ещё у нас есть файл в 21,5 мегабайт.
Как сделать из второго первое?
Идея 1: SQLite 3
Python это славный язык. Особенно славная в нём стандартная библиотека. Про один модуль unittest можно писать и писать... но это не наша тема. Давайте поговорим про модуль sqlite3.
Обычная идея базы данных в SQL заключается в специальном сервере, который всю жизнь свою занимается запросами к нему со стороны других модулей вашей программы. Это не самая приятная парадигма, если вы не хотите хостить сервер.
Однако в таком случае, таким как вы на помощь приходит SQLite 3 - друг, товарищ и альтернативная парадигма. Вместо отдельного сервера SQLite оперирует обычным файлом, который хранит в себе сущность нашей базы. Этим файлом мы можем оперировать прямо из стандартной библиотеки языка. Это очень приятно – приятнее, чем хостить сервер.
Но наш файл – не база данных SQLite 3. Наш файл – дамп PostgreSQL. Если заглянуть внутрь, увидим там последовательность команд. Запустив их все в консоли Postgres, мы как раз получим нашу базу. Это хорошо, но с модулем sqlite3 в языке Python это не сработает.
Давайте проведём исследование.
Исследование показало, что есть много хороших инструментов и подходов. Конвертировать вряд ли будет сложно, да и сам язык SQL вроде везде один и тот же... Но проблема ждёт впереди.
Все диалекты SQL очень разные. Казалось бы, язык один – но то, что работало бы, скажем, на MySQL, может и не сработать на PostgreSQL – или на SQLite, опять же. Конечно, база языка одна, и во многих случаях всё работает – это не так дико, как, скажем, конвертировать Java в Javascript.
Но конкретно в нашем случае не сработало. Переходим к плану Б.
Идея 2: PostgreSQL и Psycopg2
Давайте просто запустим сервер.
С кучей документации по быстрой установке это совершенно несложно. Простым запуском пары команд мы получаем сервер – специальная библиотека psycopg2 (её нужно скачать) позволяет нам легко работать с серверами PostgreSQL. Может быть, и с другими серверами. Но с PostgreSQL точно.
Напишем запрос!
Любой ресурс-вступление в SQL вам скажет, что краеугольный камень любого запроса к базе данных – следующее выражение.
SELECT * FROM table
Оно даёт нам всё, что есть в таблице table.
Давайте запустим это и посмотрим.
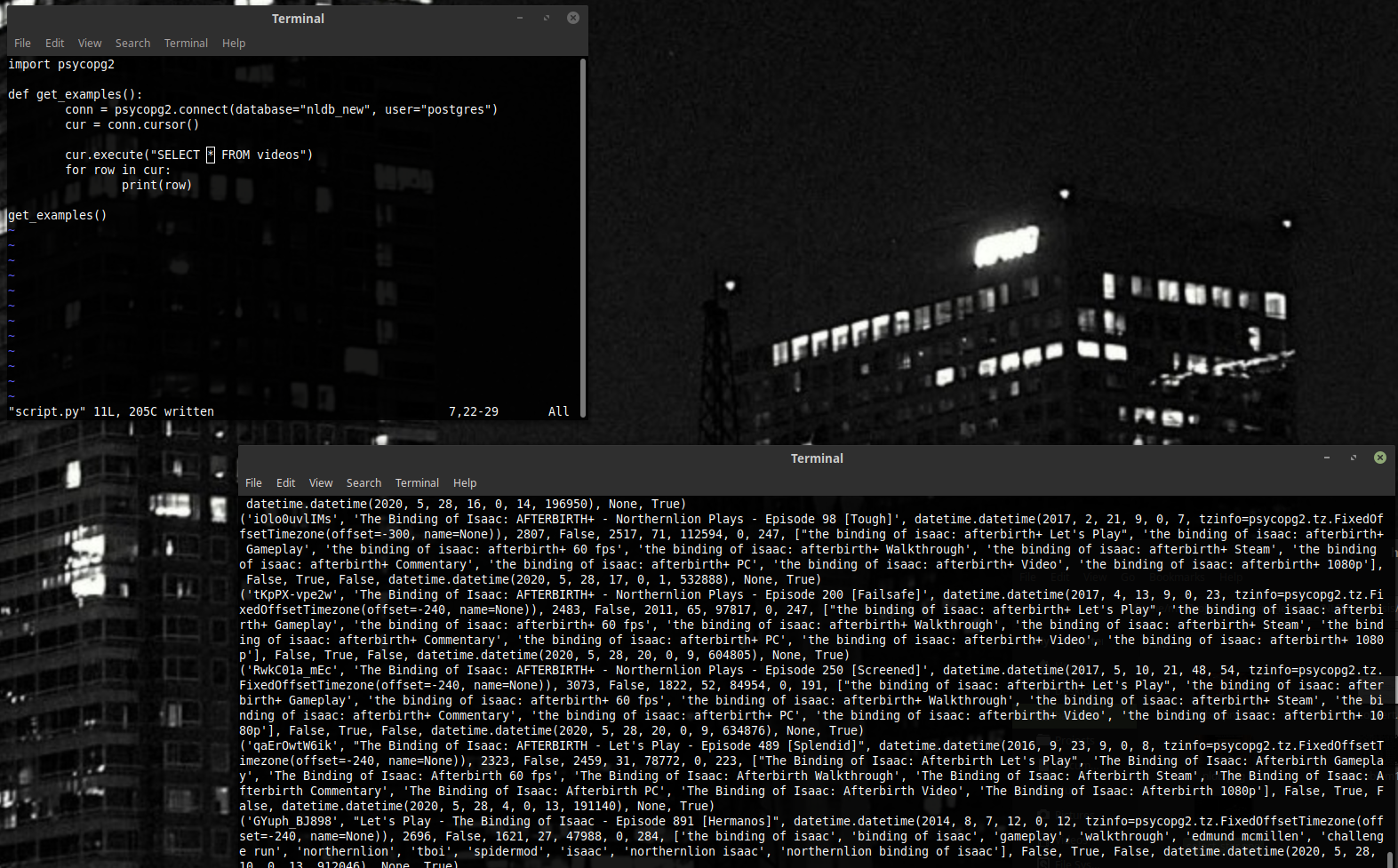
Сверху видим код, снизу результат. Круто.
Вместо * можно поставить один столбец. Или несколько столбцов. Так мы можем собирать только те данные, которые нас интересуют.
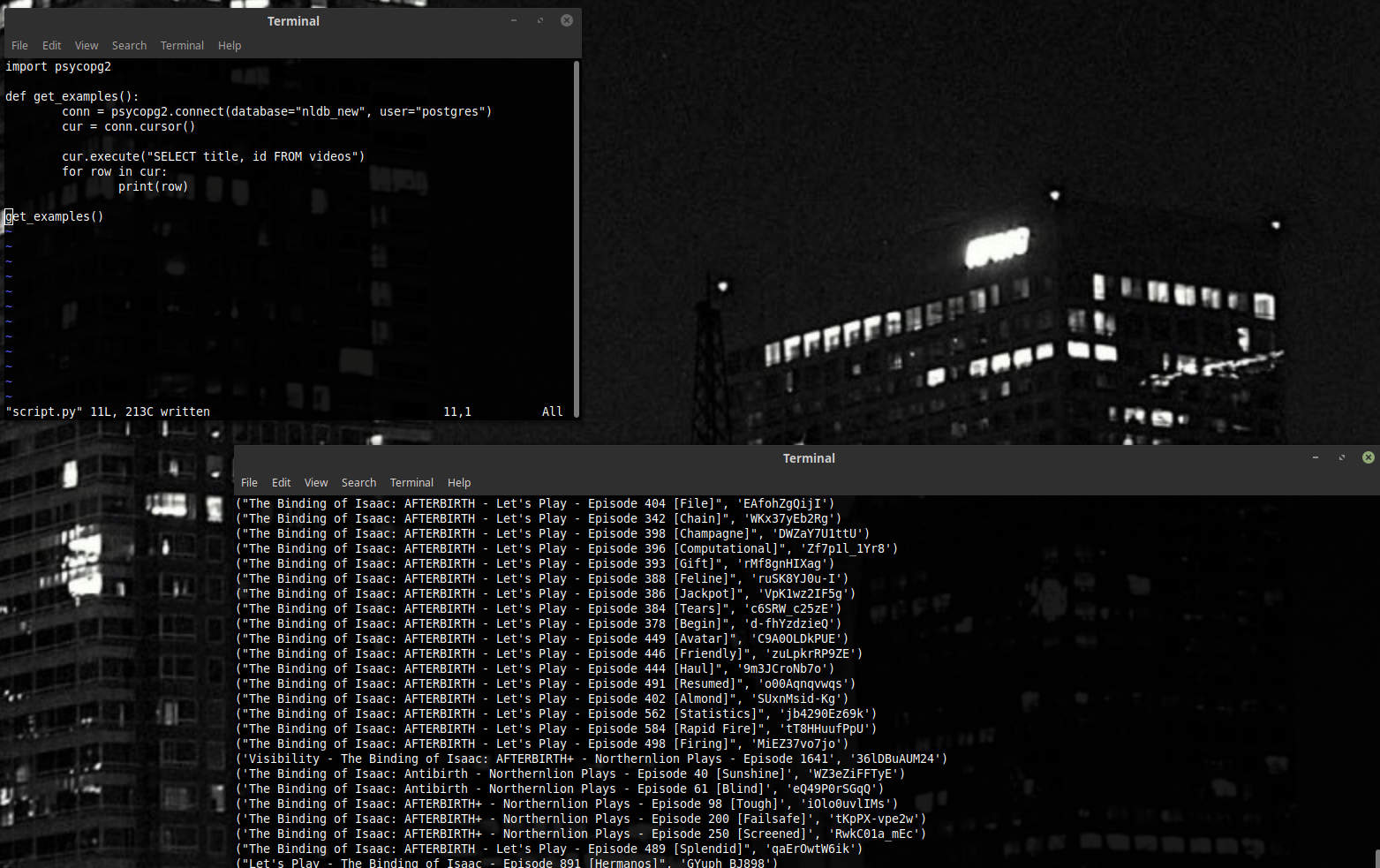
Вот так, например.
Если посмотреть в нашу таблицу поглубже, мы увидим – она содержит ID. Эти ID очень полезны – они помогают найти элемент в другой таблице.
Давайте напишем скрипт, который для каждого прохождения (в одной таблице) добывает название видео, в котором это прохождение было (из другой таблицы).
Мы возьмём и добавим такую вещь как WHERE, которая фильтрует все ряды – и даёт нам только тот, который совпадает с каким-нибудь условием.
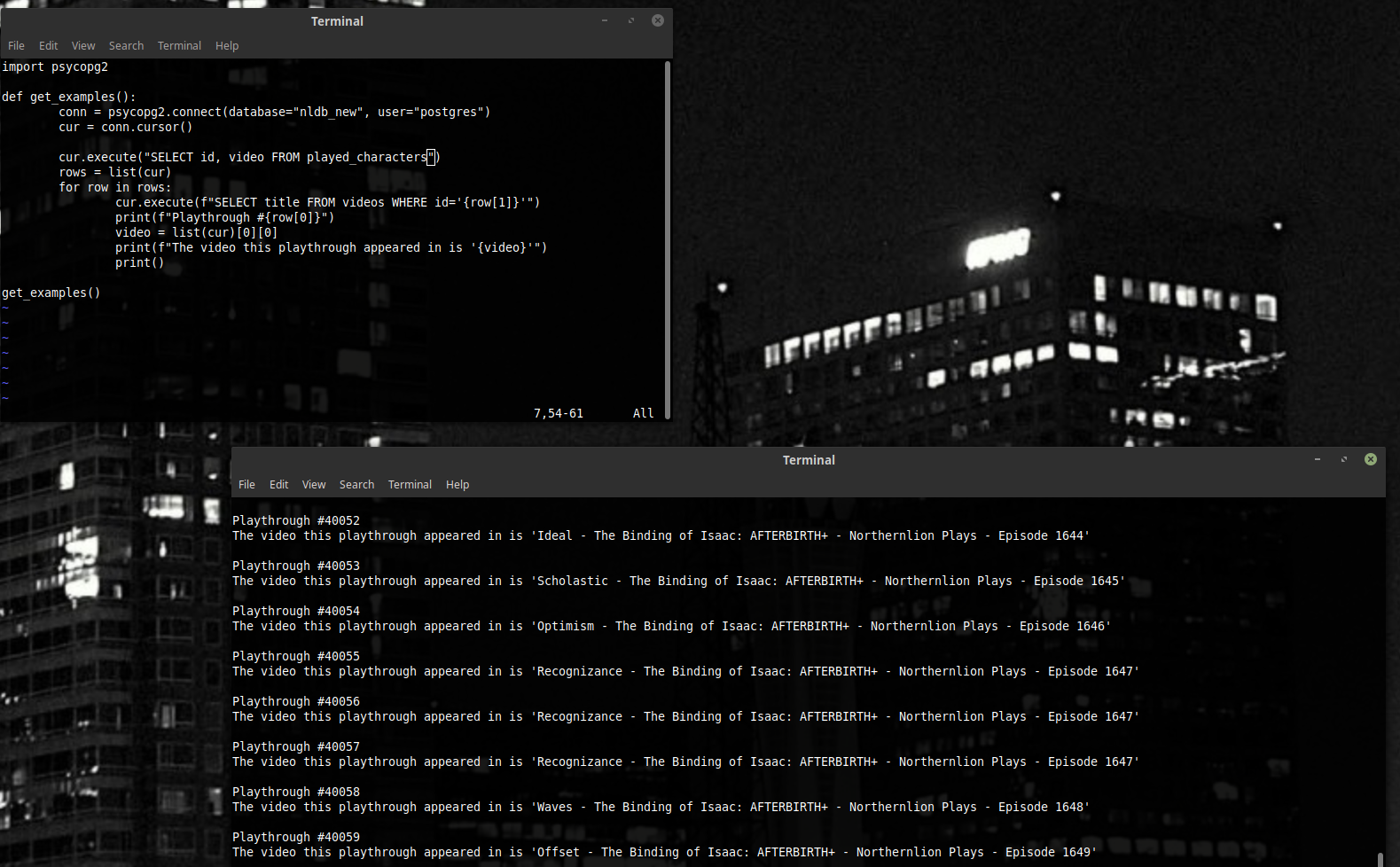
Это плохой скрипт. Не верьте мне на слово просто так – посчитайте, сколько запросов к базе данных (нашему Postgres, который пришлось запустить в предыдущей части) он делает. На каждый ряд таблицы он делает по запросу – и ещё один запрос, чтобы получить эти ряды. Это очень много – бедный Postgres. Давайте сделаем, чтобы запросов было меньше.
JOIN – команда, которая сделана специально для такой ситуации. Она берёт таблицу, в которой есть ID (или любой другой параметр) из другой таблицы – и вместо каждого ID нашлёпывает оттуда целый элемент.
Тут есть много нюансов – что если элементов с таким ID несколько? Если такого элемента нет? Если кому интересны подробности, рекомендую читать документацию. А тут можно посмотреть на исходный код и порадоваться, как мало запросов получилось.
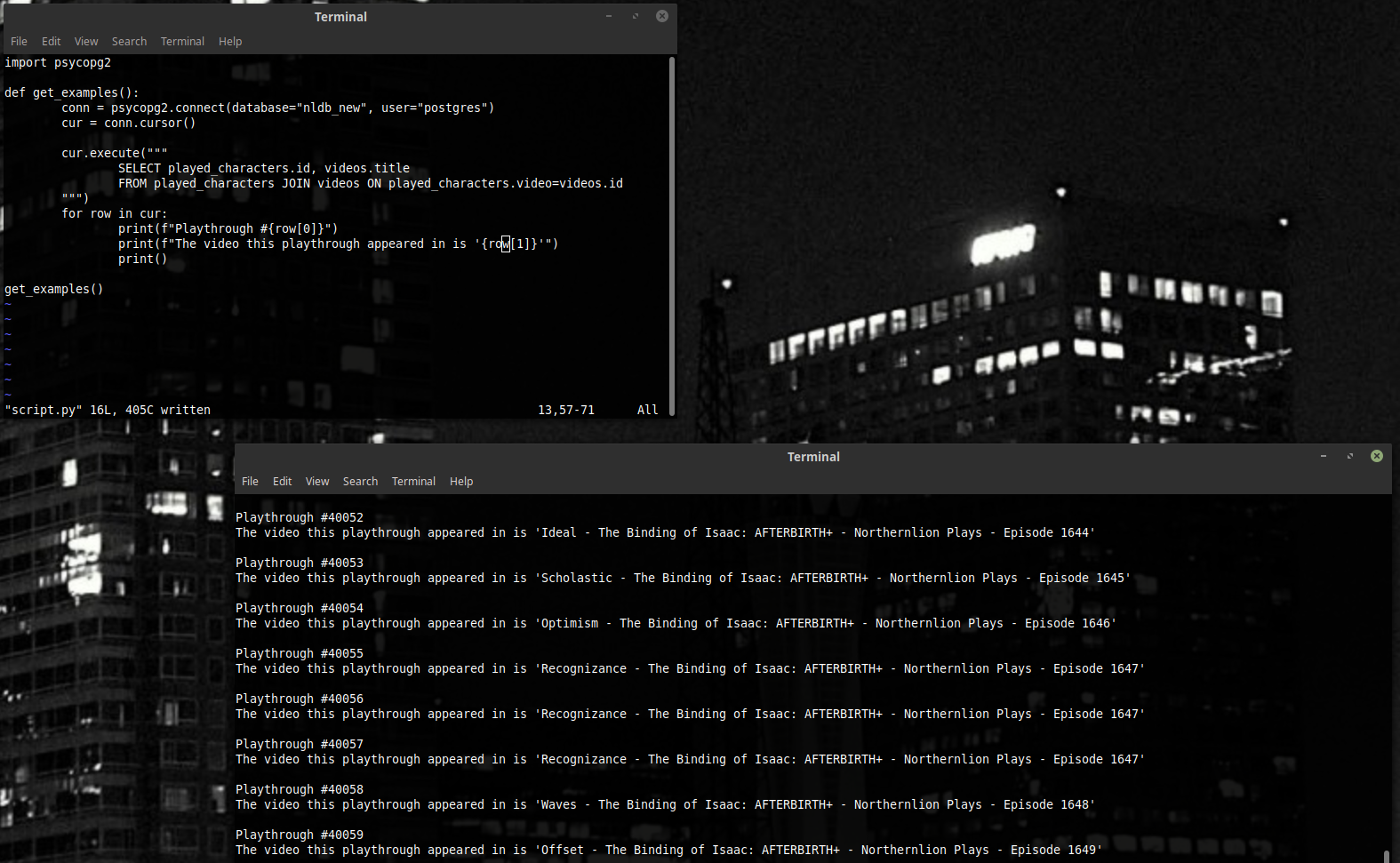
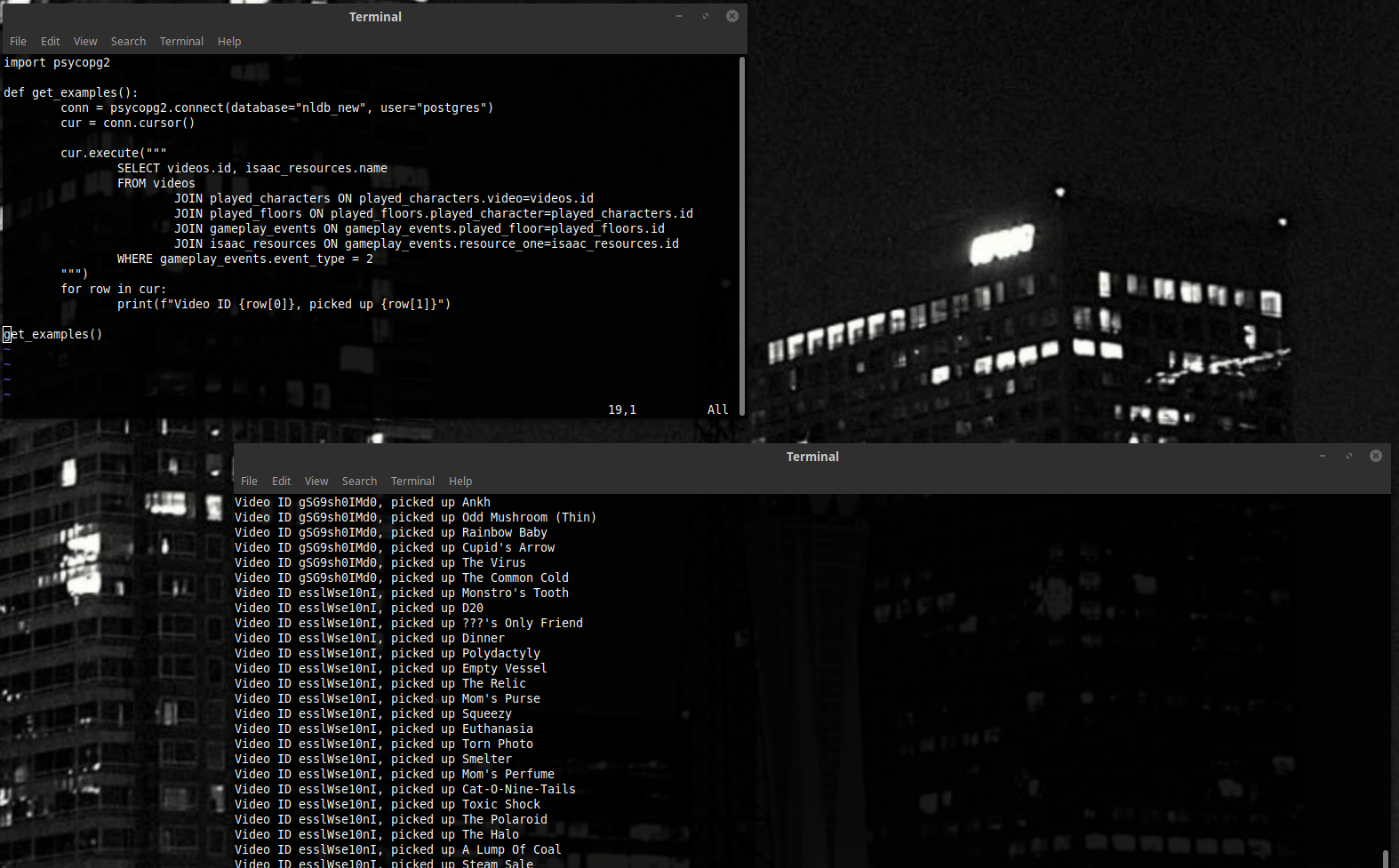
Теперь, если мы хотим получить кучу пар типа (видео, название вещи, которую мы подобрали), вот таким запросом (снизу) мы можем воспользоваться. Про значения всех этих полей можно почитать в документации нашей конкретной базы данных – event_type = 2, например, означает событие типа “игрок подобрал вещь”. Это больше JOINов, чем то, с чем мы сталкивались выше – но принцип работает, и получаем мы как раз то, что нужно.
На этом можно и закончить – написать ещё по запросу на лайки к каждому видео, забить всё в массив и жить хорошо... но давайте поговорим ещё про GROUP BY.
GROUP BY позволяет нам превращать большие множества рядов в один. Тут на каждое видео у нас есть много пар – если мы превратим все эти пары в массив, наша жизнь будет чуть-чуть проще. Давайте объединим все пары с одинаковым videos.id в один ряд.
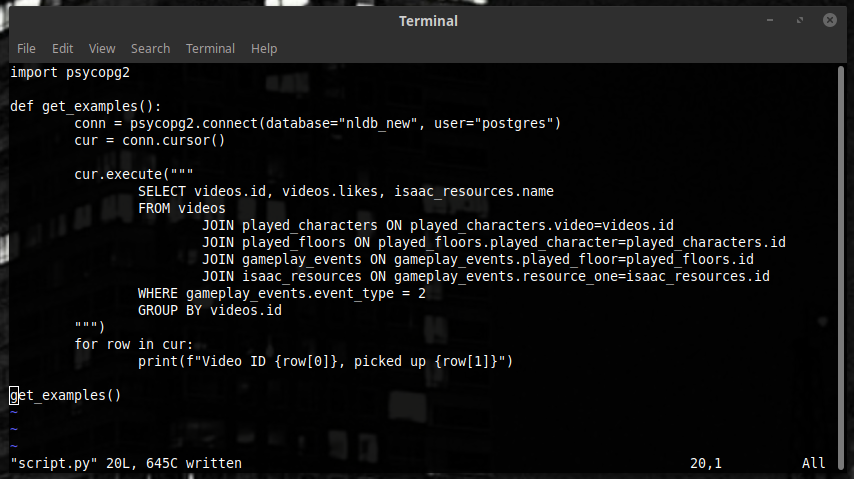
(Примечание – этот запрос не работает.)
Почему же не работает? Ответ простой - непонятно, что делать с videos.likes и isaac_resources.name.
Когда мы объединяем много разных рядов, из кучи разных значений в этих рядах всегда должно получиться одно. Куда пихать тогда все значения - в массив? Но массивы (по парадигме) в SQL считаются ересью. В отличие от столбцов, в которых значение всегда одно (или нет вовсе, но это тоже значение в своём роде), в массиве может быть несколько значений. Например, 5. Или 6. Или даже 8. Заранее неизвестно, а такую неизвестность в SQL не любят.
Обычно в GROUP BY для этого надо использовать агрегатные функции. Мы можем получить (если в столбце числа), например, среднее. Это одно число. Или сумму – тоже одно число. Не пять, не восемь. Проблема усугубляется тем, что в разных диалектах (PostgreSQL, MySQL, SQLite) эти функции разные – и тут мы стоим на зыбком дне спецификации.
К счастью, несмотря на недостаток массивов в самом языке SQL, много серверов их кое-как всё же поддерживают. Так, например, в PostgreSQL есть такая функция ARRAY_AGG() - которая нам и вернёт массив всех значений в столбце.
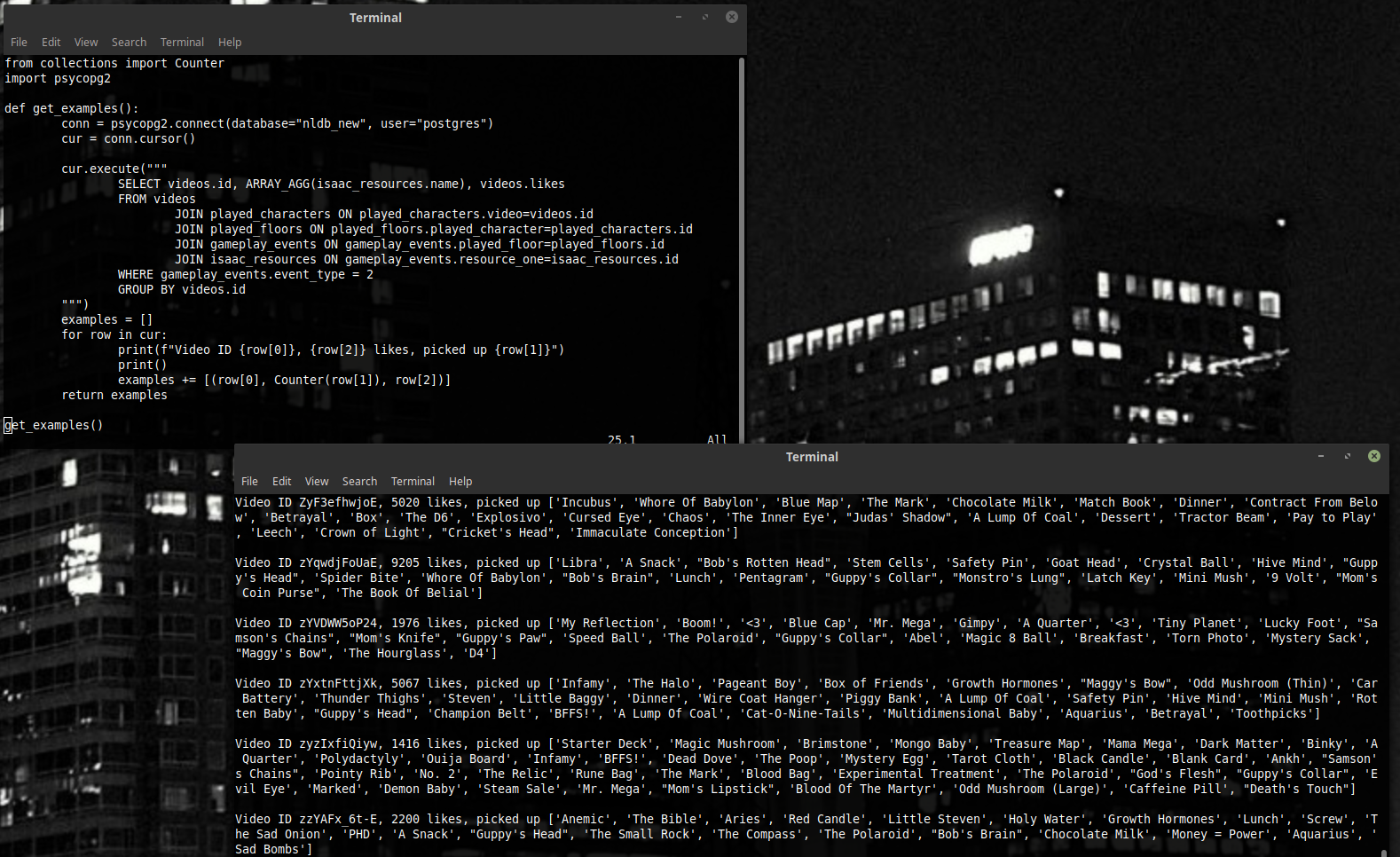
Так мы получаем наши примеры.
(P.S.: Counter из модуля collections – хорошая штука, если вам надо что-то легко и изящно посчитать. Возьмите на заметку!)
3. Что такое это обучение вообще?
Ведущая парадигма в написании софта – писать код, чтобы решить проблему. Соответственно, чем сложнее проблема, тем сложнее код этот будет. Это называется software – наверное, читателю уже приходилось столкнуться с таким.
Машинное обучение даёт нам другую парадигму – написать код, умеющий учиться на примерах (или взять готовый), а потом вместо того, чтобы обрабатывать проблему вручную, как раз научить машину на примерах проблемы, ответ к которой надо найти. Это иногда называют Software 2.0. Звучит, несомненно, громко. Можно сказать, не заслуживает имени даже. Но в некоторых местах всё же применяется. Сама идея того, что есть алгоритмы, в которые достаточно запихать много данных, очень хороша – хотя бы тем, что отслеживать закономерности вручную это дело затратное и сложное.
Сегодня поговорим о такой вещи, как линейная регрессия. Крайне простая, но очень красивая штука, которая позволит нам сделать предсказание количества лайков, а потом смотреть и радоваться – таким точным оно в итоге будет.
Идея за линейной регрессией такова. Есть у нас N ситуаций, и каждой пусть соответствует число – ответ, который мы хотим знать. Число чего угодно может быть – лайков, долларов, секунд – система не дискриминирует.
И пусть из каждой ситуации мы можем каким-то алгоритмом выдёргивать признаки – любые свойства, которые можно описать каким-то числом. Или булевой переменной – то есть, числом 1 или 0. Такие признаки в литературе ещё называются фичами.
И вот, если дать компьютеру много пар типа (признаки, ответ) – то он будет искать числа - веса. На каждый признак по числу – чтобы если для примеров просуммировать значения всех их признаков, помноженных каждый на своё число-вес, получилось бы в среднем как можно ближе к ответу. Говоря технически, алгоритм минимизирует сумму квадратов разностей ответов и скалярных произведений соответствующих векторов признаков на один общий вектор весов.
Предположим, что у нас веса уже есть – напишем функцию predict, которая даст нам ответ, который мы будем тогда ожидать.
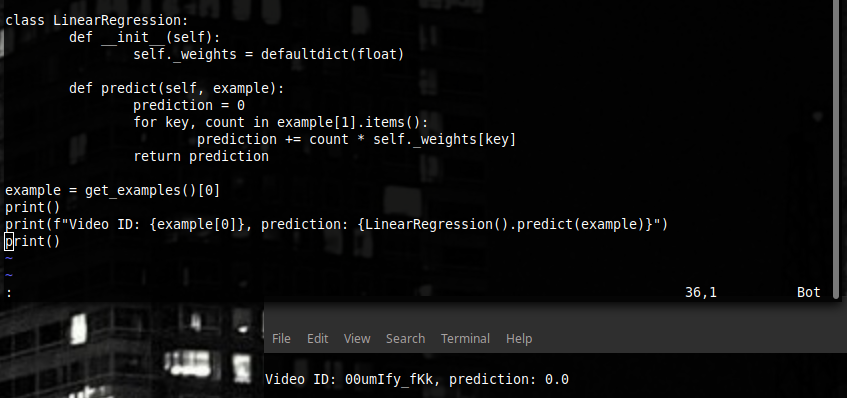
Возьмите на заметку - defaultdict из того же модуля collections здесь уж очень хорош. Работает он как обычный словарь – но если ключа в нём нет, он возвращает значение по умолчанию. Как, например, 0 здесь. Про ошибки вроде KeyError можно вообще забыть!
Но весов у нас нет. Как их будем добывать?
Делается это методом градиентного спуска – тут тоже просто. Главная идея – смотреть, в какую сторону надо менять вектор весов, чтобы эта сумма квадратов уменьшилась – и просто менять его туда, раз за разом. Если у нас есть функция – f(x) некий, то мы от x отнимаем градиент от f по x, помноженный на какое-нибудь постоянное число – большое, если мы хотим быстро, и маленькое, если точно. Градиент – это как производная функции, скорость её изменения - только вместо одного числа, это несколько чисел. Это потому, что весов несколько. Если был бы один вес, мы бы смотрели на производную.
А чтобы не смотреть на все примеры каждый раз, когда мы хотим посчитать шаг спуска (медленно!), был придуман ещё один хитрый трюк. Вместо того, чтобы обновлять наши числа-веса, используя все примеры за раз – мы можем каждый раз брать по одному, или по совсем немного примеров – и обновлять на них. Это стохастический градиентный спуск, и работает он тоже неплохо.
Так вот, какой же градиент у функции, которую мы хотим минимизировать, для одного примера? Так уж получилось, что это просто разница между нашим теперешним предсказанием и ответом, только помноженная на значение каждого признака.
Для первого признака, (предсказание – ответ) * первый признак, для второго (предсказание – ответ) * второй, и так далее. Считать наш градиент несложно, и осуществлять по нему спуск тоже.
Давайте такой напишем.
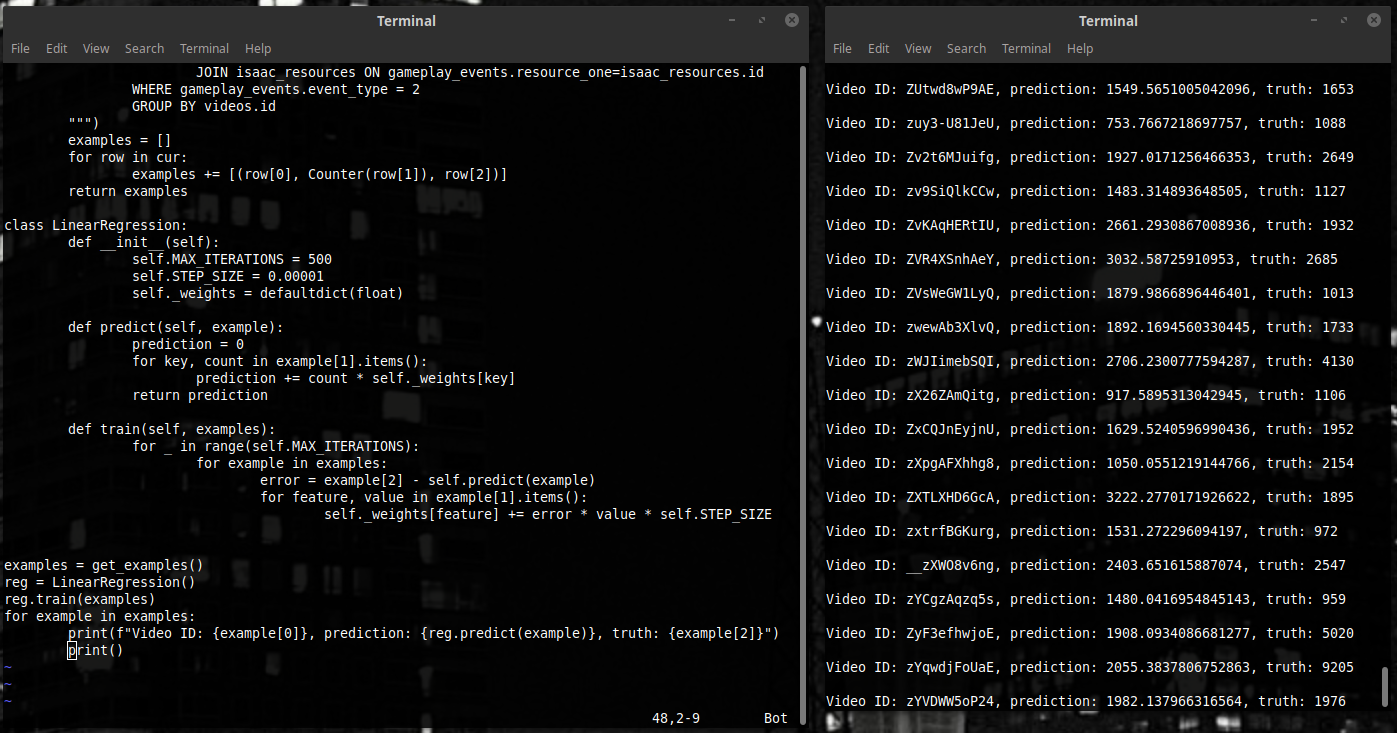
Мы добавили функцию train - пять строчек кода. Для каждого примера двигаем веса, чтобы квадрат разницы был немного поменьше. И всё - можно тестить.
4. И что это только что было?
Хорошо. У нас есть... что-то. Оно выдаёт какие-то числа, даже. Это очень хорошо – но ведь это далеко не результат. Давайте рассмотрим, куда стоит копать дальше.
Во-первых, не совсем понятно, как мы будем считать, насколько этот алгоритм хорош. Давайте введём среднюю ошибку, как нашу главную метрику.
Во-вторых, мы даём нашему алгоритму все данные, а потом проверяем его на них же. В машинном обучении это не самая лучшая идея. Сами посудите - мы хотим, чтобы алгоритм хорошо справлялся в общем случае. Если ему дать все ответы, он просто их заучит – и совершенно не факт, что будет разбираться в общем случае - с теми примерами, где ответов он не видел. Как с билетами на экзамене – если студенту дать ответы на все вопросы, то ответить он правильно может – но не факт, что материал он понял.
Для этого обычно примеры делятся на три набора: train, validation и test.
Train – это тренировочный набор. На нём мы наш алгоритм тренируем – учим.
Validation (или dev) – набор, который мы кормим нашему алгоритму после тренировки. Как экзамен – смотря на среднюю ошибку на нём, мы смотрим, как хорошо программа разбирает случаи, конкретно которых она не видела. Проверять вместе с этим на тренировочном наборе (те случаи, которые она видела) - это тоже хорошо. Обычно смотрят на эти два числа – по мере тренировки мы будем ожидать, что оба будут падать, и train будет немного ниже dev.
Test – набор, который мы используем для финальной проверки. По мере того, как мы пишем алгоритм, у нас появляется много параметров, которые можно менять – размер шага в градиентном спуске, количество разных признаков, и много других вещей, о которых мы не упомянули. (Но поскольку имя “параметры” уже занято весами (в некоторых терминологиях) – эти параметры мы называем гиперпараметрами.)
Меняя гиперпараметры, мы хотим, чтобы ошибка на нашем dev-наборе стала как можно ниже. Но делая это, легко можно начать подгонять под ответ – если по какой-то случайности с шагом 0.01301 ошибка будет на самую малость ниже, чем с шагом 0.013, то не факт что это мастерское оттачивание гиперпараметров помогло – тут просто могла быть удача, на которую в какой-нибудь научной публикации полагаться не стоит. Поэтому во время разработки обычно берётся третий набор, и даётся священная клятва этот набор особо часто не тестить – а когда приходит время тестить, не менять гиперпараметры по итогам результатов.
В игрушечной программе, такой как наша, test-набор не обязателен.
Давайте введём среднюю ошибку, как нашу метрику - и начнём отслеживать её в наших двух наборах.
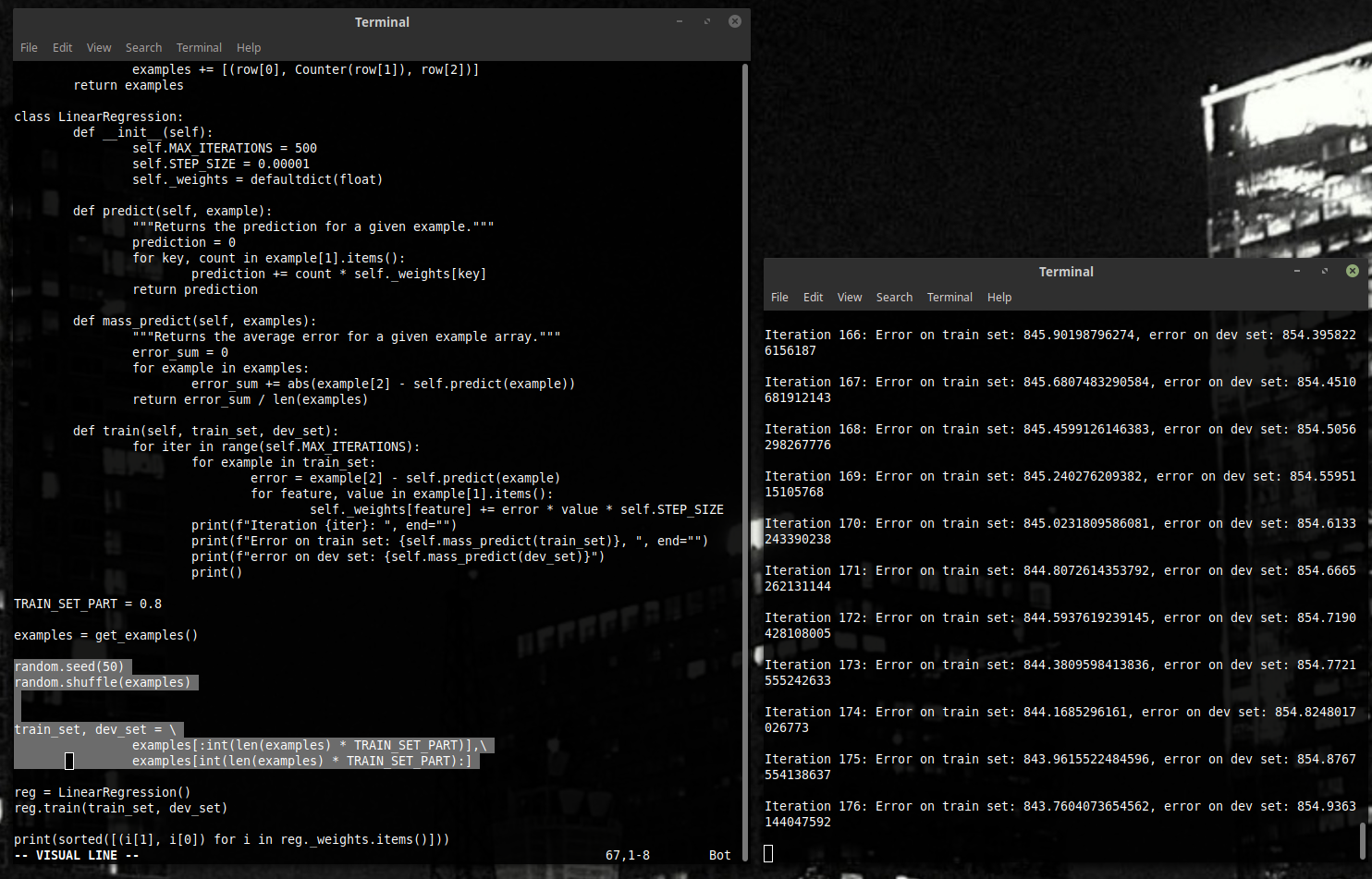
Дальше будем смотреть на график ошибок. Вот такой.
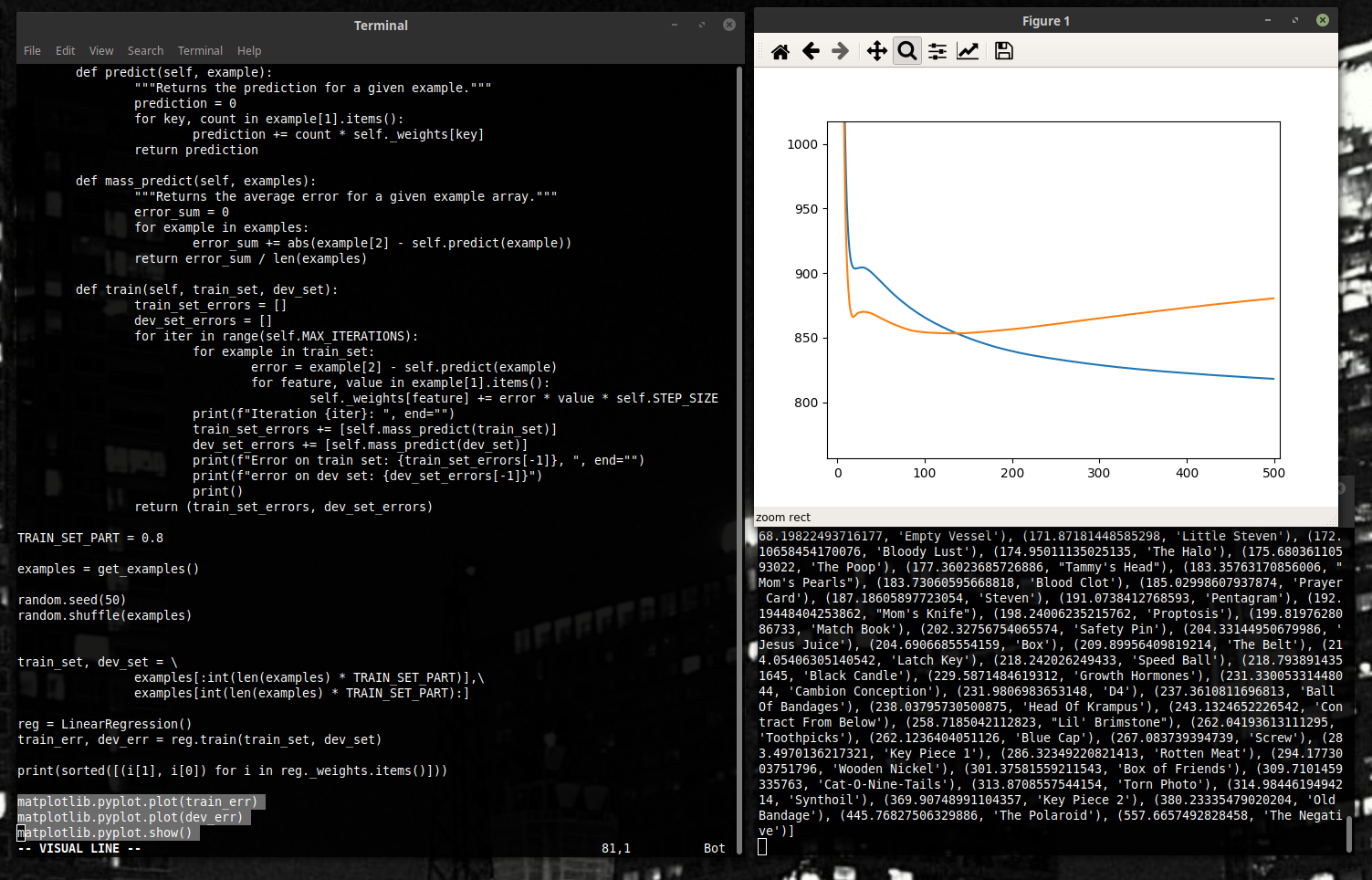
Здесь средняя ошибка на тренировочном наборе отрисована синим, а на проверочном – оранжевым.
Консоль уже ничего интересного нам выводить не будет. В весах, конечно, можно уследить много чего интересного, но для этого нужно знать саму игру, и что какие вещи значат для игрока. А статья всё же по машинному обучению, а не по The Binding of Isaac.
Для сравнения посмотрим на среднюю ошибку, которую мы бы получили, просто выбирая среднее количество лайков каждый раз. (Если мы ничего не знаем про видео, то этот способ даст нам наименьшую ошибку из всех.) Чему она равна? Легко узнать.
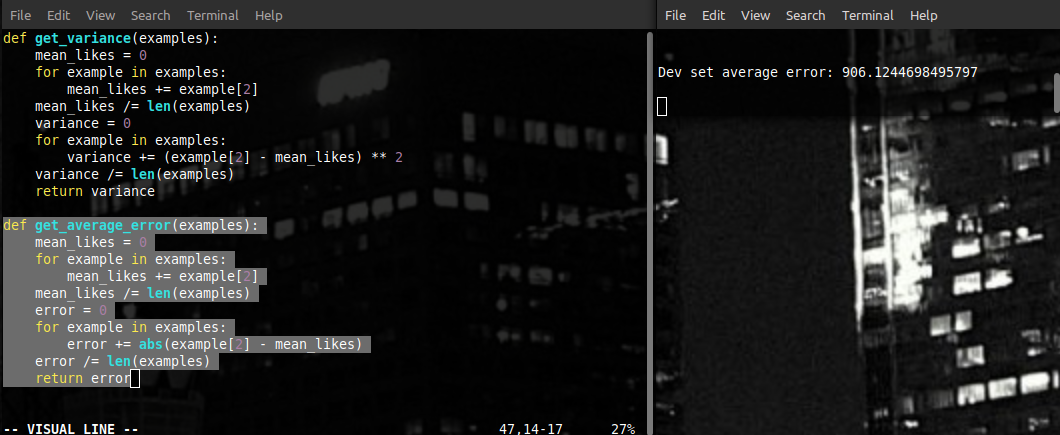
906! А наш результат даёт где-то 850... Это очень даже неплохо. Вспоминаем – мы не показывали нашему алгоритму ни примера из этого набора. А ошибку он даёт меньше простого выбора среднего значения. Существуют, значит, эти закономерности – можно даже к игре как-то отследить. Давайте улучшим наш результат ещё немного.
Сначала вспомним самое начало статьи – там мы упоминали, что харизма самого комментатора наверняка оказывает самое сильное влияние на лайки. С чего б нам её не учесть? Добавим ещё один признак, и назовём его “INTERCEPT”. Он будет равен единице в каждом примере. Натренируем модель снова...
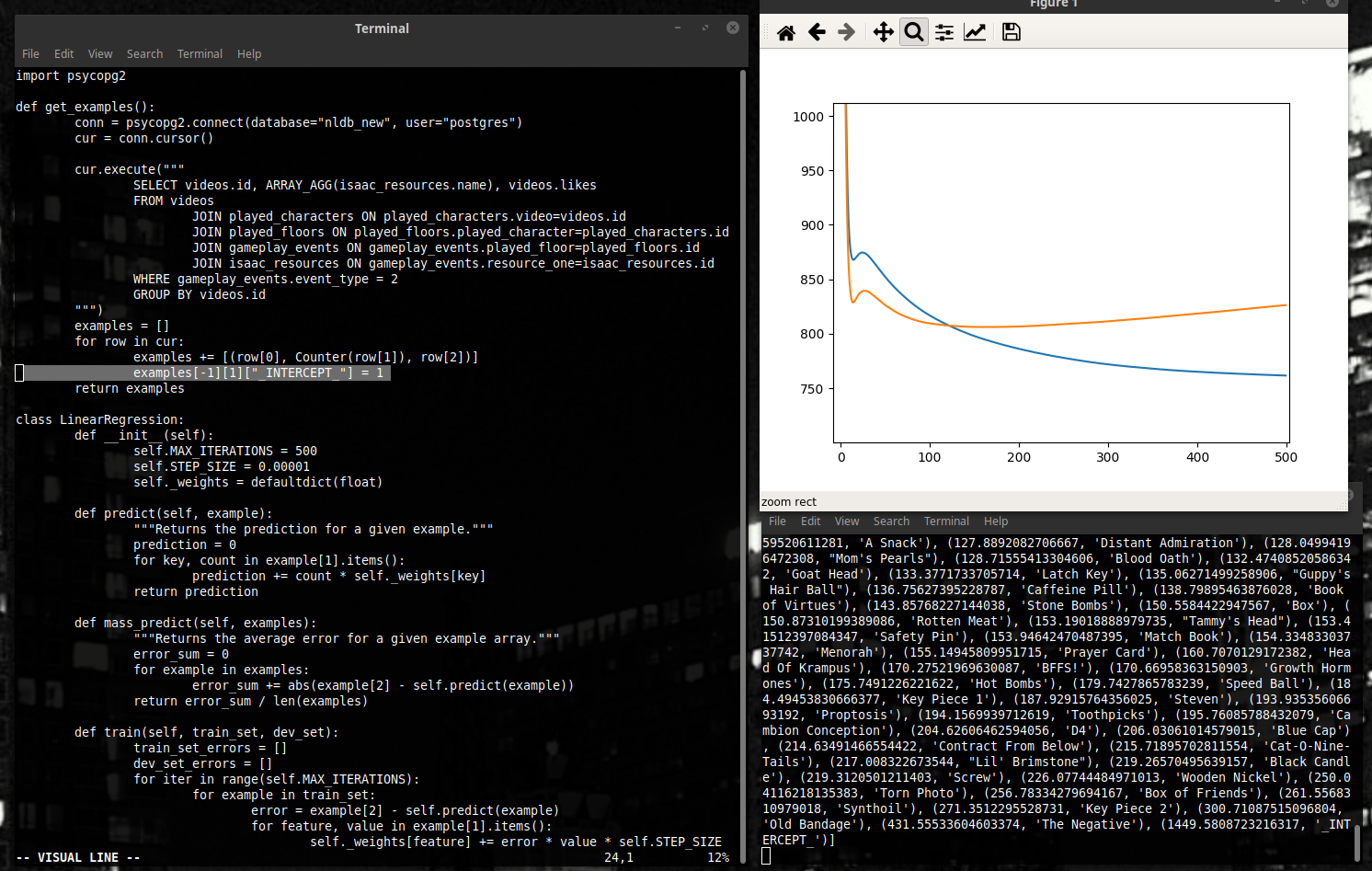
Большой минус нашего представления на данный момент в том, что любое видео, в котором наш товарищ Northernlion не собрал ни одной вещи, будет всегда предсказываться, как набравшее ровно ноль лайков. Чтобы избежать подобных казусов, в машинном обучении к набору признаков часто принято добавлять ещё один, равный единице для всех примеров. Это позволяет учесть факторы, которые одинаково влияют на все случаи.
Как видим, ошибка нашей модели упала. Лайков на 50 – это прогресс.
Давайте, кстати, заметим, что график наш выглядит немного странно. С обучением ошибка на нашем тренировочном наборе падает, а на проверочном... начинает подниматься.
Заметно, например, в примере снизу, где мы сделали пять тысяч шагов – в десять раз больше обычного.
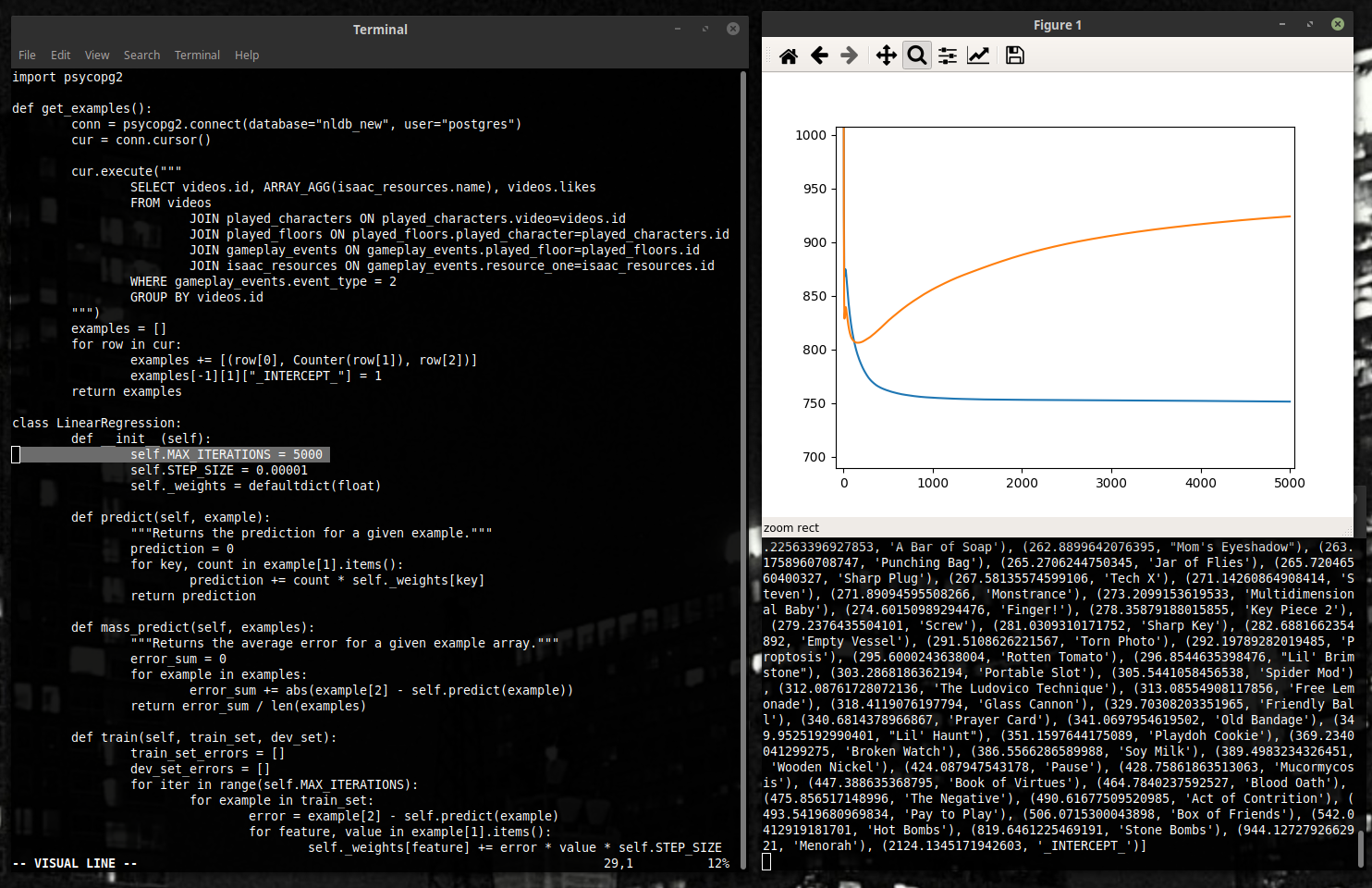
Это типичный случай переобучения (также известного как overfitting). Оставив программу искать закономерности там, где их нет, мы обрекаем её на суеверия. В попытках объяснить то, что, кроме как удачей, ничем объяснить и нельзя, программа изобретает всё более и более дикие мнения о том, как устроен этот мир. Эти мнения, конечно, неплохо описывают тренировочный набор – но в общем случае совершенно неуместны. Психологи подобное с голубями делали.
Чтобы такого не происходило, надо сделать нашу программу менее чувствительной к мелким стимулам. Менее зоркой, более забывчивой. Для этого применяется такая техника как регуляризация.
Сама идея регуляризации проста. Наш традиционный градиентный спуск старается “тянуть” веса к тому, чтобы сумма квадратов ошибок была как можно меньше – нам надо просто сделать, чтобы веса “тянуло” ещё и к нулю.
Математически говоря, наша функция потерь (т.е., мерка того, как неприятны нам эти веса) вместо суммы квадратов становится суммой квадратов плюс нормой нашего вектора весов (помноженного на постоянное число). Градиент меняется соответственно.
Один из самых простых способов исполнения – после изменения множить вес на какое-то постоянное число, немного меньшее единицы. На выделенных строчках мы добавили этот функционал.
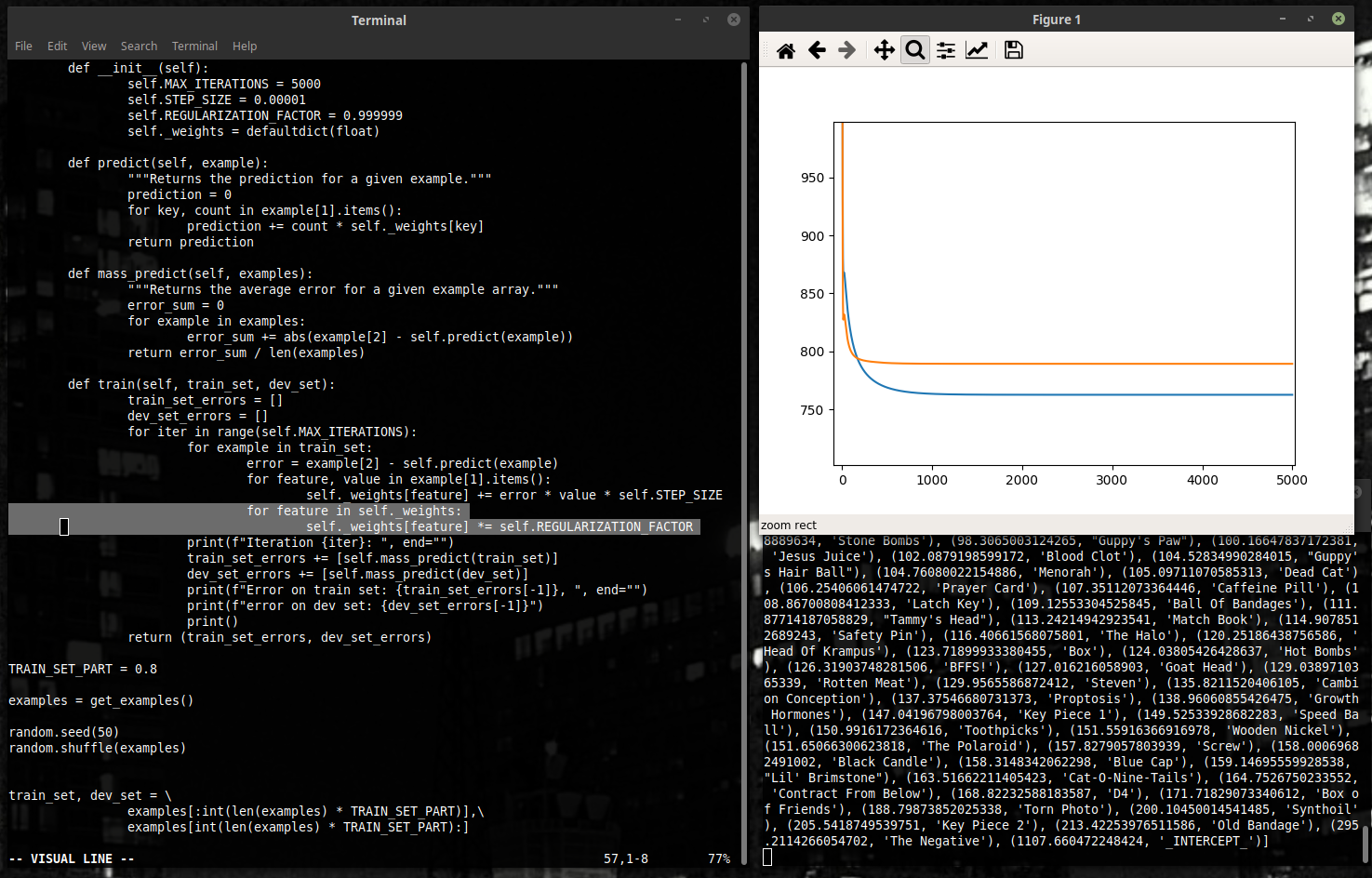
Ценой такого плавного графика может быть повышение в средней ошибке... здесь важно найти правильный REGULARIZATION_FACTOR.
Бывают и другие методы улучшения результатов.
Здесь мы предполагаем линейную зависимость – то есть, если найти вещь два раза, смотреть на результат станет ровно в два раза веселее, чем если бы мы её нашли один раз. (Или в два раза грустнее.) Оно так не всегда – поэтому используют так называемый биннинг. Вместо использования числа (счёта обьектов, например) как значение признака, возможные значения делят на несколько интервалов (например, 0, 1, 2-3, 4+) - и потом дают каждому интервалу по своему признаку, со значением либо 0, либо 1. Таким образом, наш признак “вещь: 3” превращается в “вещь_0:0, вещь_1:0, вещь_2-3:1, вещь_4+:0” - и подстраиваться уже можно, исходя из этого.
Можно добавить больше признаков. База данных большая, и в видео происходит очень много вещей, которые могли бы повлиять на наш рейтинг. Но чем больше признаков, тем больше комбинаций. Тем больше и примеров, на которых нужно учить – и тем больше шанс переучить слишком сильно.
Да и сама линейная регрессия – это самый простой алгоритм. Впереди ЛДА, Байесовские сети, нейронки... Машинное обучение – глубокое поле, и эта статья – простое болтание ногами на его мели. Посмотрите в воду – и быть может, глубина тоже позовёт вас.

Нырнёте?
(Весь код из этой статьи можно найти здесь.)



