
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В постоянно развивающемся мире ИТ-инфраструктур и окружений мониторинг имеет решающее значение для поддержания непрерывности работы ваших систем и сервисов. Важность показателей мониторинга остается очевидной, и никто сейчас не сомневается в том, что мониторинг необходим и его не заменит тревожный клиент на проводе разрывающегося от аварий телефона.
К классическим данным мониторинга ИТ-окружения и инфраструктуры относятся логи, события, метрики и трейсы. Все это по мнению аналитиков Gartner должно лететь в AIOps систему и на базе логики правил, сценариев автоматизации и машинного обучения должно превращаться в инсайты, которые могут быть сразу переданы дежурной смене для реагирования. Стоит отметить, что это лишь видение и оно разбивается о реальность, когда в организации одна рабочая группа отвечает за приложения, другая за поддержку k8s, третья за вычислительные ресурсы или облака, четвертая за сети, пятая за безопасность и т.д. И каждая команда выбирает свой инструмент для мониторинга, в нем находятся все важные данные. Так, например, Prometheus хорош для микросервисов, Zabbix - для классических статичных инфраструктур, а Jager для анализа производительности приложений. Но эти инструменты и другие локальные системы мониторинга не могут напрямую использоваться бизнесом - они ему не понятны, в них нет метрик здоровья сервисов целиком и не понятно, какой элемент инфраструктуры повлиял на развитие конкретной аварии или просадки SLA сервиса. Все эти данные можно построить лишь в зонтичных системах мониторинга.
Зонтичный мониторинг и комплексный анализ состояния ИТ и бизнеса
Зонтичный мониторинг — это мониторинг, объединяющий в себе данные о состоянии и производительности всех значимых для бизнеса элементов ИТ-окружения, коррелирующий и дедуплицирующий события и аномалии метрик, предоставляющий данные для анализа влияния, анализа первопричин аварий, и рассчитывающий SLA сервисов. При этом данные собираются из разных систем мониторинга, управления, инженерных и системных программных средств, а также данные с конечных устройств. Таким образом, инженеры поддержки вместо 3-4 экранов, за которыми нужно постоянно следить и вручную анализировать паттерны и зависимости и прогнозировать влияние, имеют один экран, на котором отображается карта цифрового здоровья бизнеса. То есть метрические и текстовые данные собираются под один зонтик. Отсюда и родилось это название.

Так, а что же метрики? Нужно ли метрики использовать в зонтичном мониторинге, или он может оперировать лишь событиями из других систем мониторинга? Опыт крупных внедрений решения Monq, которое до 7ой версии было событийно-ориентированным, показал, что однозначно нужны. Централизованное управление порогами, создание единой точки правды, единого дашборда, будущих предсказаний, более точного расчета состояния здоровья сервисов и SLA часто невозможны без сырых метрических данных. Хотя журналы событий, логи и ивенты и играют важную роль в решении проблем и в ретроспективной оценке, они часто не обеспечивают необходимой детализации реагирования в реальном времени для эффективного управления ИТ-инфраструктурой. В отличие от них, метрики предлагают более количественный и оперативный подход к мониторингу, обеспечивая точные измерения основных показателей производительности (KPI).
Такой подход позволяет распознавать закономерности, выявлять нарушения и предвидеть возможные проблемы до того, как они перерастут в серьезные инциденты.
Ценность метрик
1. Контроль степени покрытия мониторингом
Метрики в зонтичном мониторинге нужны для возможности контроля качества генерируемых событий на средствах мониторинга 1-го уровня (Zabbix, SCOM, PRTG, Prometheus и т.п.) – каким образом они собирают метрики и в каком объеме покрывают мониторинг.
Наблюдая за элементами в системе, основанной только на событиях, мы не знаем - а собираются ли метрики с объектов мониторинга в принципе? События приходят только в случае, если что-то сломалось. Мы же хотим управлять качеством непосредственно самих метрик в системе, чтобы иметь возможность отслеживать и корректировать их работу.
2. Единое хранилище событий и метрик
Хранение событий журналов и данных метрик в одном месте упрощает процесс поиска причин аварий, траблшутинга и анализа данных.
Также снижается нагрузка на информационные системы, поскольку для анализа не требуется выполнять разные запросы к разным системам.
Кроме того, улучшается целостность данных: события журналов и метрики могут быть связаны друг с другом, что позволяет создавать более полную картину происходящего в системе.
Так как вся метрическая история храниться в одной системе, проще настраивать дашборды и ту же централизованую Grafana.
3. Предсказания и ML
Сбор и обработка метрик позволяют хорошо и быстро интегрировать в систему продвинутые технологии, такие как искусственный интеллект и машинное обучение. Математические модели и модели ML построенные только на событиях не могут точно предсказать наступление аварии, так как не видят ее предвестников, если только на них не выставлены алерты и пороги (а это обычно не делается, так как для целей инцидент-менеджмента является избыточным).
Архитектура «зонтика» метрик в Monq
СУБД: VictoriaMetrics
В качестве инструмента для хранения и работы с метриками в Monq была выбрана VictoriaMetrics по нескольким причинам:
Высокая производительность: является одним из самых быстрых инструментов для сбора, хранения и анализа метрик. Она может обрабатывать миллионы метрик и сотни тысяч записей в секунду.
Открытый исходный код: позволяет свободно сделать форк, обеспечивает прозрачность и гарантированную доступность продукта даже в условиях возможных санкций или политических проблем.
Высокая доступность: поддерживает кластеризацию и репликацию, что обеспечивает высокую доступность данных. Она также может автоматически масштабироваться в зависимости от объема метрик и запросов.
Безопасность: обеспечивает высокий уровень безопасности и поддерживает множество методов аутентификации и авторизации.
Широкий набор функций: предоставляет множество функций для агрегации, фильтрации и анализа временных рядов.
Экономия ресурсов: использует гораздо меньше ресурсов, чем другие инструменты для работы с метриками.
На наш взгляд VictoriaMetrics является идеальным выбором для работы с метриками, особенно для больших и сложных систем.
Подходы обработки метрик: Zabbix vs Prometheus
Zabbix-подход, когда метрика это отдельная сущность, не позволяет проводить онлайн-расчеты больших данных, поскольку это может потребовать выполнения отдельных миллионов запросов в минуту к базе данных при необходимости расчета по каждой отдельной метрике.
При таком подходе все достоинства VictoriaMetrics нивелируются. Ее работа предполагает образование временных рядов в момент запроса. Она как раз рассчитана на обработку метрик на лету и может проводить математические вычисления в режиме реального времени.
Кроме того, подход Zabbix не подходит для динамической среды: когда появилась новая Конфигурационная единица (КЕ – это сервис, pod, vm, и т.д.) мы должны для нее настроить метрики, пороги, триггеры. Это тяжеловесно, трудоемко и неэффективно в конечном счете.
Prometheus-подход позволяет задавать пороги в одном правиле, что дает возможность вычислять пороги для множества КЕ одновременно.
Можно полностью использовать заложенные в VictoriaMetrics преимущества и особенности.
Однако возникает проблема привязки порогов к Конфигурационным Единицам, для решения которой нам потребовалось создание дополнительного узла ThresholdProcessor. Также настройка порогов может быть неочевидной, ведь для привязки порогов к КЕ требуются дополнительные действия. Но этот подход обеспечивает большую гибкость в реализации различных сценариев и может обрабатывать большие объемы данных, вплоть до 50 миллионов метрик в минуту.
Пайплайн обработки данных
В связи с внедрением Метрик мы изменили схему прохождения данных в Monq.

Как и прежде, система собирает информацию из внешних источников в Потоки данных.
Однако теперь отличается точка приема, указываемая в задании. Таким образом, в каждом потоке могут быть как события, так и метрики, которые складываются в разные системы: события - в колоночную СУБД ClickHouse, а метрики - СУБД VictoriaMetrics.
Сырые метрики, в свою очередь, собираются в формате Prometheus, который включает в себя 3 обязательных свойства:
Значение
Время, в которое это значение было актуально (Timestamp)
Набор Меток (Labels), которые эту метрику характеризуют
Когда данные накапливаются, формируются временные ряды, которые можно визуализировать с помощью графиков.

Задача инженеров мониторинга заключается в настройке правил, по которым в зависимости от получаемых значений метрик будут приниматься решения и выполняться сигнализация о существующих проблемах.
Новый пайплайн обработки данных метрик включает следующие шаги:
Сбор метрик
Запись их в VictoriaMetrics
Применение правил порогов:
запрос данных
подсчет скалярного значения
сравнение с условием
создание или закрытие порога
Привязка порогов к КЕ с помощью сценариев автоматизации
Для реализации этого этапа понадобился новый маршрутный узел - ThresholdProcessorСоздание или закрытие сигнала, привязанного к КЕ

Как внедрить зонтичный мониторинг и единое хранилище метрик
Процесс внедрения Monq существенно изменился в 2023 году, когда появились метрики. Конечно, можно остаться только на событиях и логах, использовать синтетические тесты и проверки на агентах. Но чтобы в полной мере ощутить силу AIOps и зонтичного мониторинга стоит перейти к агрегации и анализу метрик.
Процесс теперь состоит из следующих шагов:
Обеспечение доставки метрик и событий до Монка
Настройка порогов
Привязка порогов к КЕ
Настройка правил автопостроения РСМ
Настройка корреляций и сигналов по порогам и событиям
Настройка автоматизации (оповещение, скрипты, генерация инцидентов и т.д.)
Настройка дашбордов и отчетов
Для сокращения трудозатрат во время внедрения зонтичного мониторинга в Monq версии 7.8.0 выходит мастер установки дополнений, который автоматизирует процесс внедрения и на всех его стадиях до настройки автоматизации позволяет быстро настроить все необходимые правила и сущности в системе. Первым таким дополнением станет настраиваемый в несколько кликов мониторинг Kubernetes, где вы сможете уже через 5 минут внедрения увидеть вашу топологию кластера, метрики, логи и события, а также текущие проблемы в виде важных Сигналов. Об этом мы обязательно напишем отдельную статью.
Следом за k8s будут и другие популярные объекты мониторинга.
Сбор данных в единое хранилище метрик
Для сбора метрик можно пользоваться несколькими способами:
Принять метрики в Prometheus-формате непосредственно через API Монка (особенно актуально для Prometheus, но не только)
Использовать стандартные коннекторы Монк для метрик (например, для Zabbix или k8s)
Разработать свои собственные плагины для агента Монк, если не хватает готовых
Разработать свои средства трансформации и отправки в Prometheus-формате метрик в Монк
Чтобы максимально эффективно использовать метрики, необходимо установить пороговые значения, которые представляют собой приемлемые и критические пределы для каждого отслеживаемого KPI. Пороги в Monq — это короткоживущие сущности, которые создаются, когда текущее состояние метрики изменяется в соответствии с заданными уровнями.
Связывая пороговые значения с Конфигурационными Единицами, можно визуализировать текущее состояние ИТ-инфраструктуры на карте РСМ, что позволит быстро выявлять местоположение проблем и степень их серьезности и приоритетности.
Далее в этой статье мы подробнее рассмотрим работу с Порогами и Правилами в Monq.
Что такое пороги метрик
Пороги — это, по сути, дискретизация временного ряда на интервалы. Они позволяют оценить состояние рядов: хорошо / плохо.
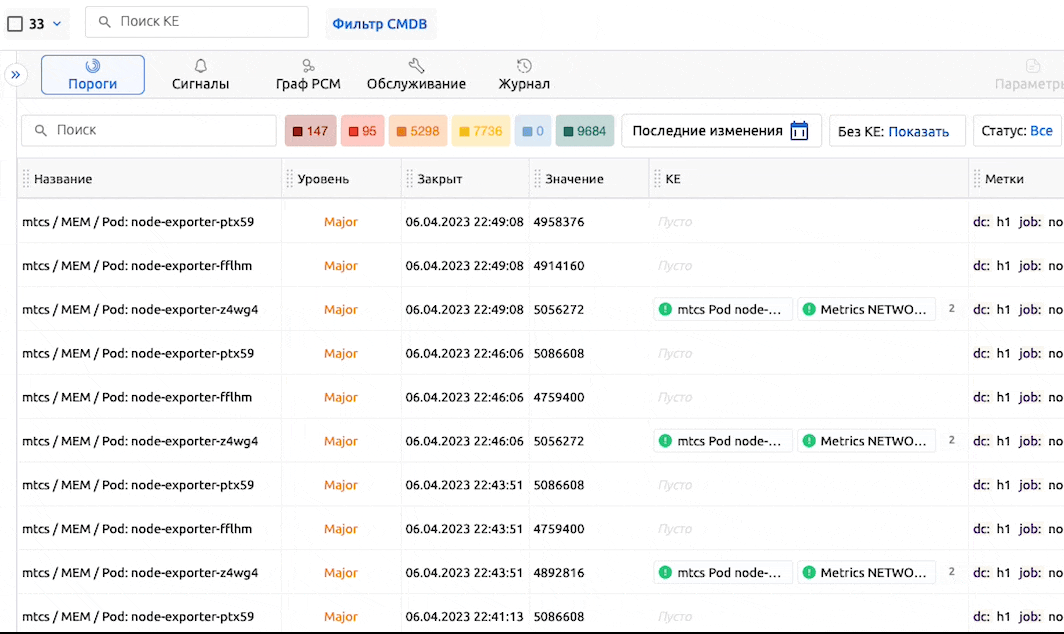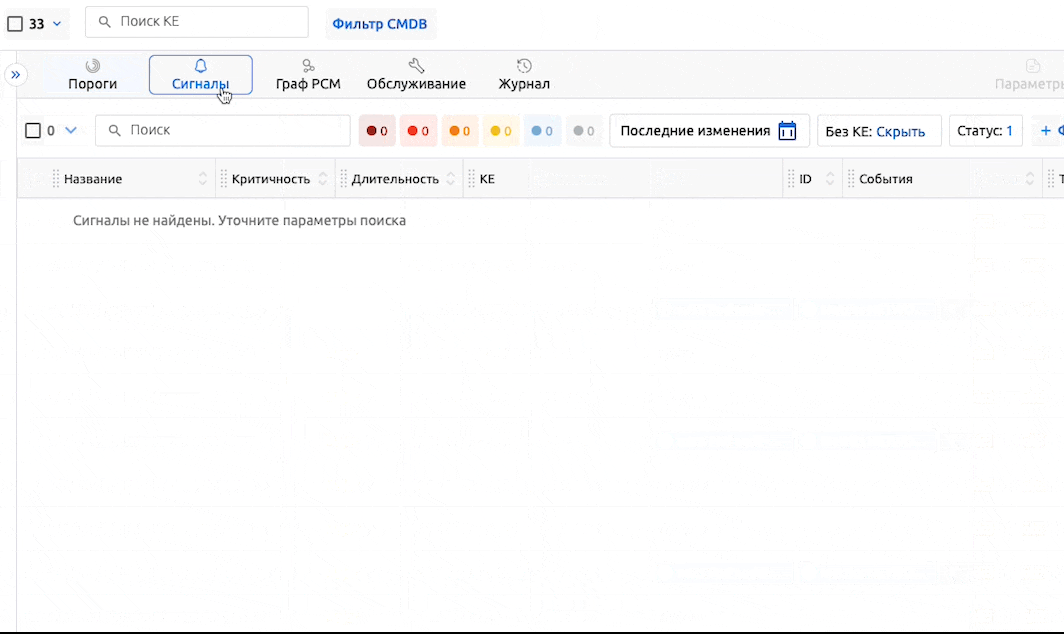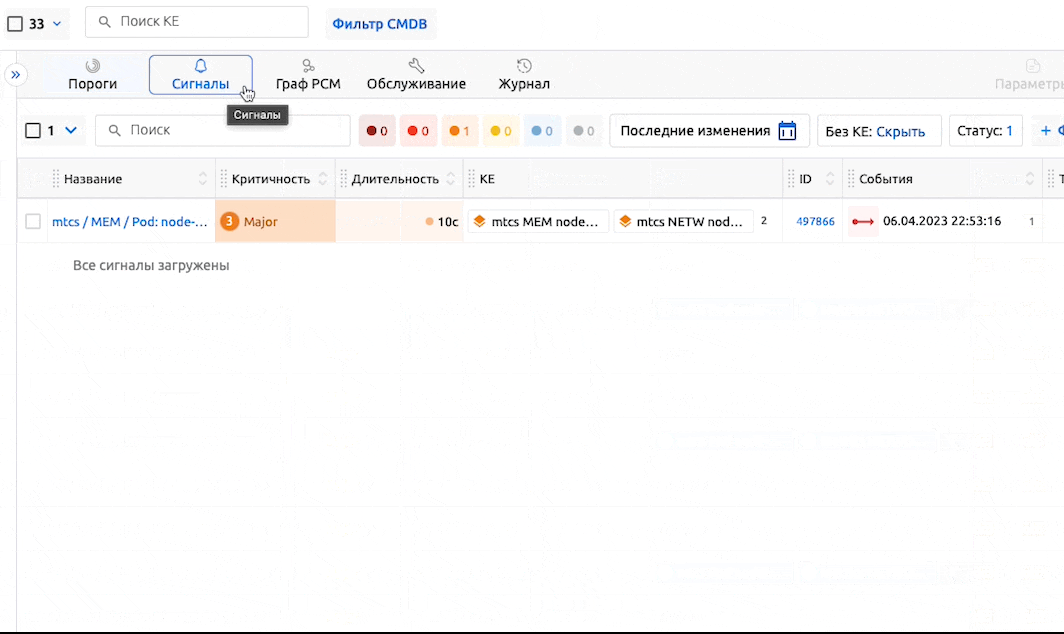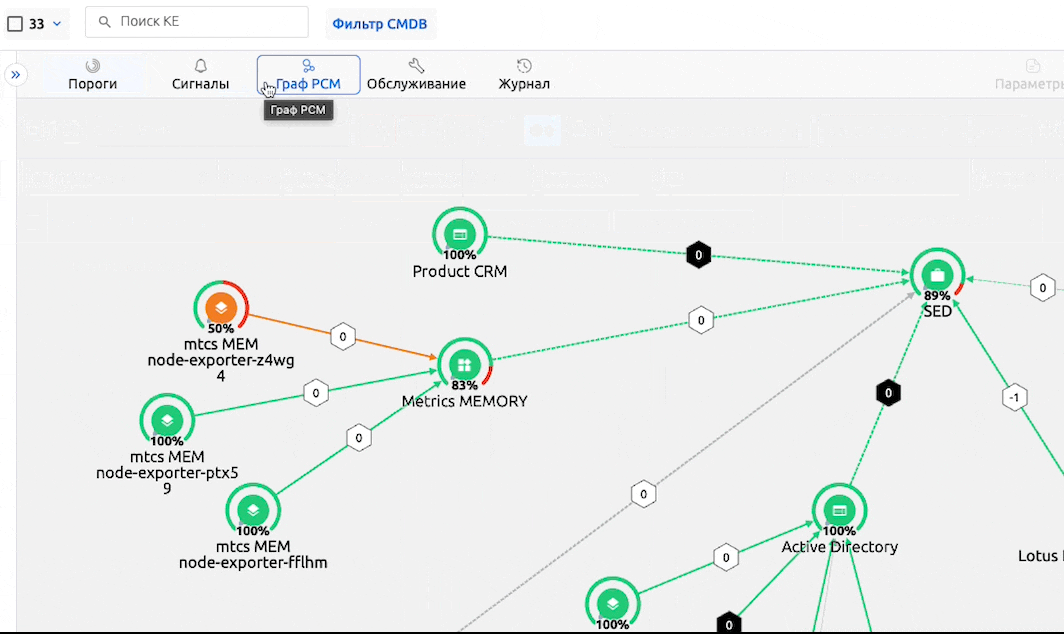
Новый экран: Пороги
Начиная с версии 7.6.0 у нас появился одноименный экран в разделе Карты РСМ:

Аналогично Сигналам, Пороги представляют собой “смертные” объекты: у них есть время начала и время завершения (в отличие от “вечных” триггеров в том же Zabbix).
В окне просмотра подробностей порога можно задать временной диапазон для отображения таймлайна.
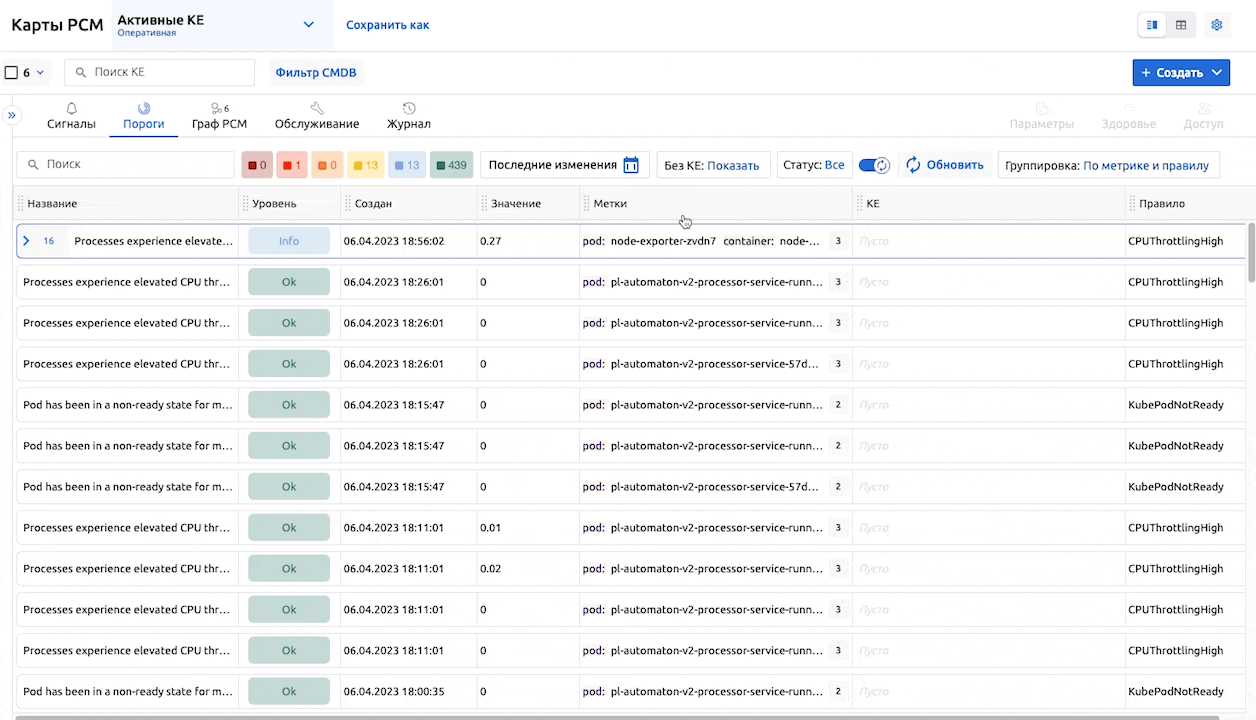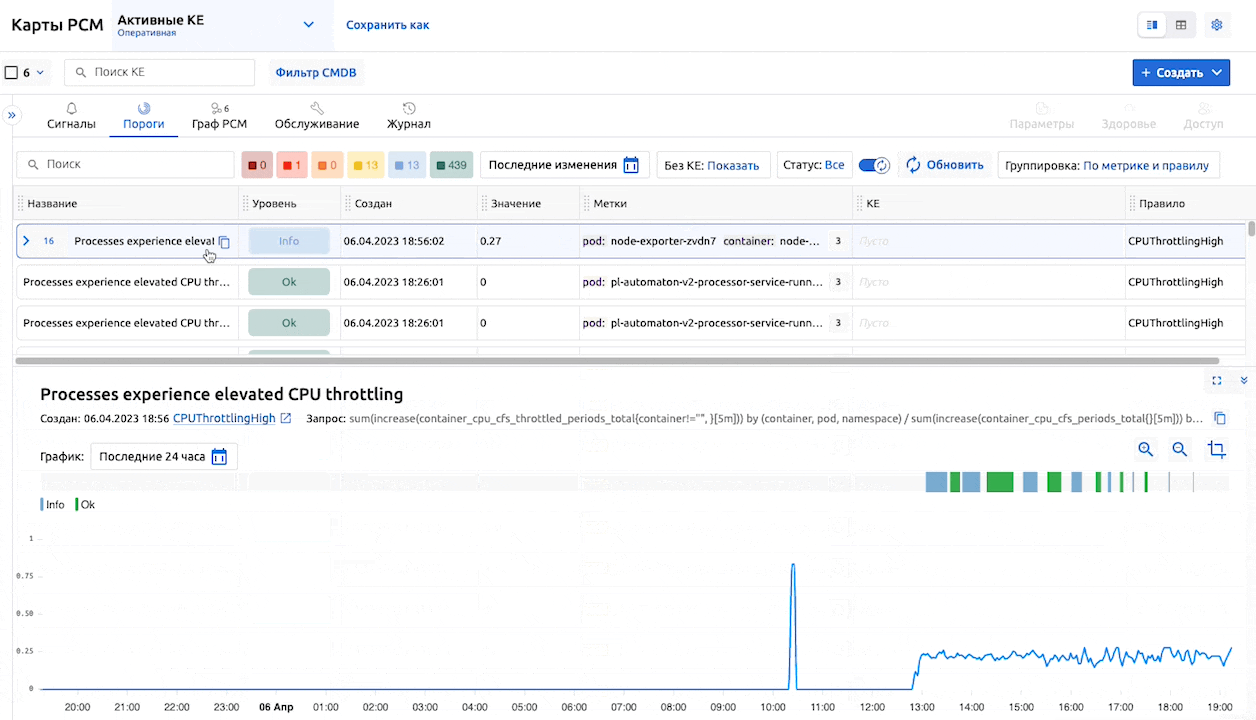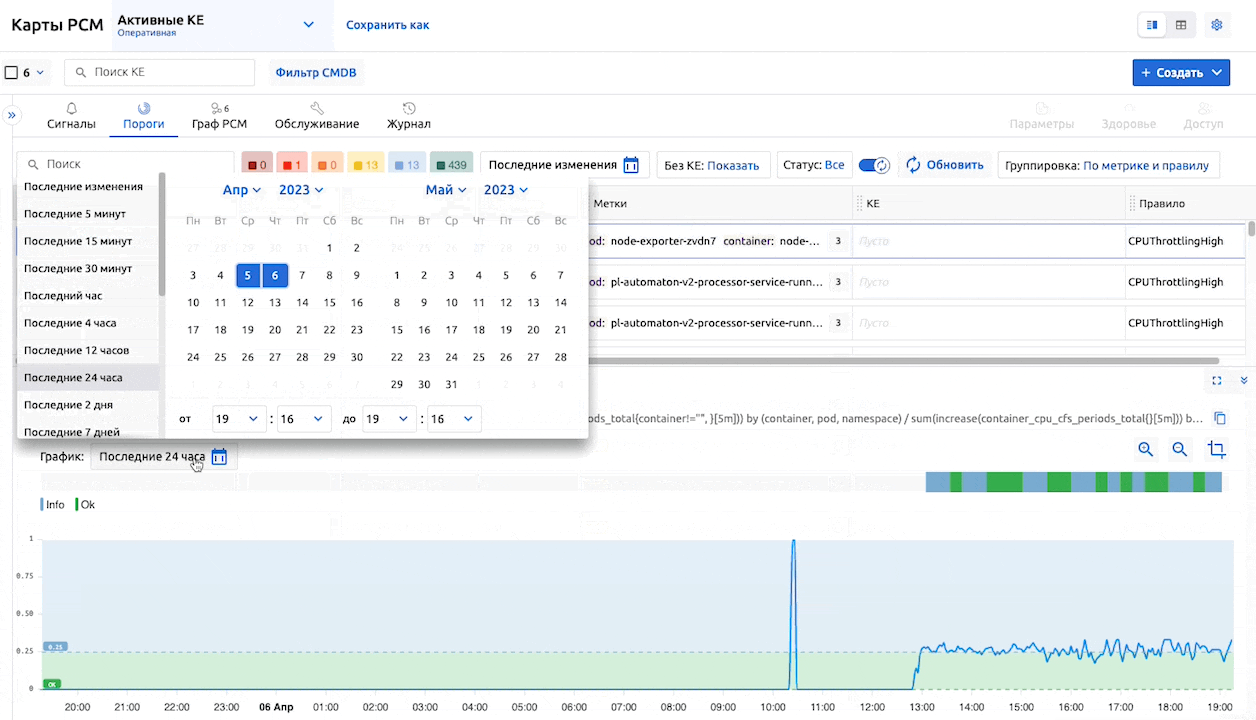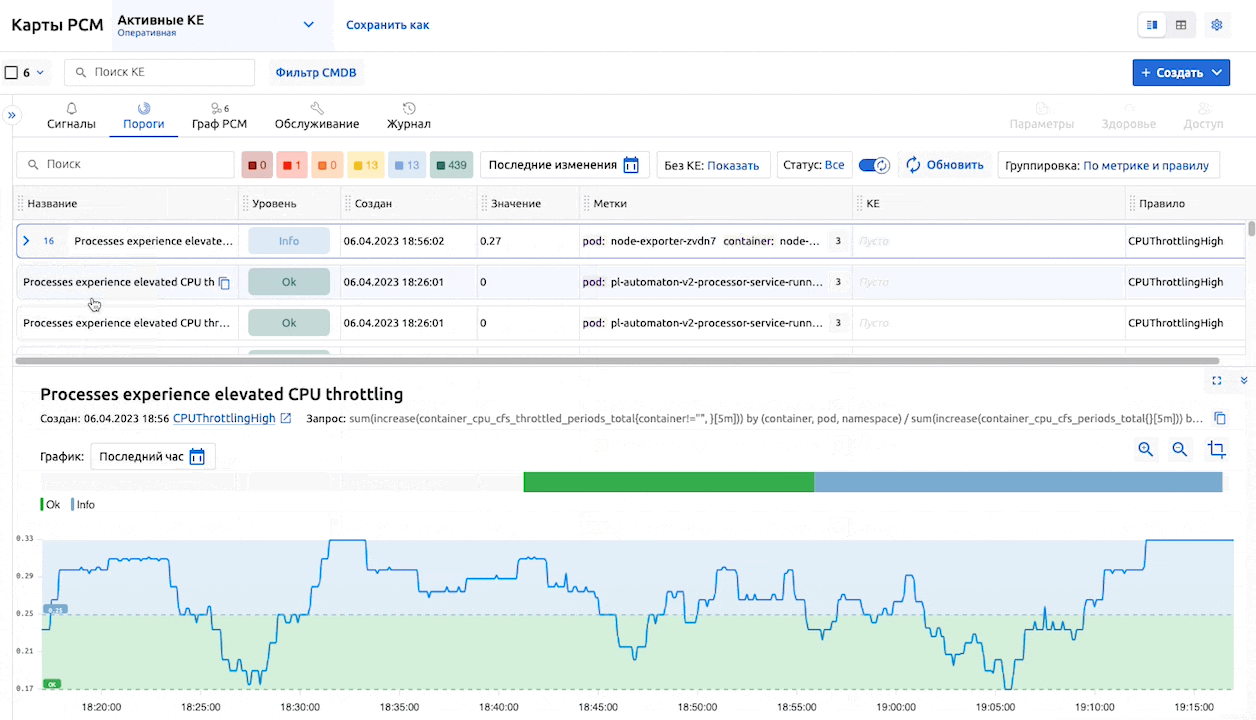
Также, как и на остальных вкладках, доступна персонализация: можно отключать или активировать необходимые столбцы, менять их порядок.

Порог может быть связан как с одной КЕ, так и с несколькими, или вообще не иметь связей. Привязка происходит при помощи сценариев нашего low -code движка под названием «Автоматон» уже после создания самого порога.
Идентичный порог не может находиться одновременно на разных уровнях (статусах) - уровень всегда один. В случае, если происходит переход метрики в интервал с другим уровнем - текущий порог закрывается и открывается новый.

Нет дискриминации положительных статусов
В Monq порог со статусом “ОК” - тоже порог.

Если есть временной ряд, подпадающий под правило - на КЕ всегда будет порог по нему. Как плохой, так и хороший.
Благодаря этому можно оценивать состояние как метрик на КЕ, так и покрытие их мониторингом в принципе: если не приходят не только плохие метрики, но и вообще никакие – это сигнал, что что-то не так. Во многих системах мониторинга такой проверки нет.
Динамическое окружение
Архитектура спроектирована с учетом возможности работы с динамическим окружением, где используются технологии контейнеризации, виртуализации и автоматического управления конфигурациями.
В таких условиях существует множество короткоживущих объектов, которые могут быть созданы и удалены в зависимости от потребностей. Например, Kubernetes может автоматически масштабировать приложение, добавляя новые поды, а затем сокращая их число.
Ручная настройка при этом становится непрактичной и неэффективной.
Для работы с динамическим окружением у нас предусмотрено время жизни порога и его Автозакрытие. Например, если под в Kubernetes живет час, то порог для этого пода будет существовать в течение часа + заданного периода, после чего будет автоматически закрыт.

Такая настройка позволяет избежать накопления неиспользуемых порогов, но при этом сохранять историю по всем ранее созданным и закрытым.
Настройка Правил
Новый экран: Правила порогов
В системе появился новый экран в разделе Сбор данных ETL → Правила порогов.

В соответствии с установленной частотой, сервис запускает расчет правила и выполняет запрос к VictoriaMetrics для получения искомого значения.

Самое главное, что необходимо выполнить при настройке правила – указать запрос, по которому предполагается получение конкретных метрик.
Здесь используется синтаксис MetricsQL (практически то же самое, что PromQL – синтаксис Prometheus).
Также указывается окно вычисления и функция агрегации: Last, Average, Max, Min или Sum.
В случае, например, с Last, функция высчитывает какое значение было последним за предыдущие 10 минут и возвращает его нам.
В случае, если запрос возвращает значения нескольких временных рядов - правило выполняется для каждого ряда независимо (аналогичная логика в Prometheus).

Далее расчетчик проверяет возвращенное значение на соответствие настроенным нами Условиям создания порога – сверху вниз.

После выполнения запроса правила полученный результат сравнивается с таблицей текущих открытых порогов:
Если порога с таким идентификатором нет - создается новый порог
Если порог с таким идентификатором есть и уровень совпадает (подтверждение порога) - обновляется время жизни порога
Если порог с таким идентификатором есть и уровень не совпадает - старый порог закрывается и открывается новый, с новым уровнем.
Последний блок позволяет задать название для порогов.
Его можно задать статично, тогда у всех порогов по этому правилу названия будут одинаковыми
Либо название может генерироваться динамически: для этого применяются макросы, извлекающие значения из самого правила или из метрик
Список всех доступных для макросов параметров приведен в подсказке рядом с полем.

Автозакрытие, как упоминалось ранее, предназначается для закрытия более неактуальных порогов, метрики по которым не приходят в течение указанного времени. Актуально для динамических короткоживущих объектов инфраструктуры.
Аннотации – это дополнительные кастомные поля, которыми будут обогащены метрики. В качестве значения также можно пользоваться макросами или задавать их жестко.

Далее они могут пригодиться при построении более гибкой и сложной логики сценариев автоматизации, как тут:

Привязка Порогов к КЕ
При расчете правила формируется событие открытия порогов, оно поступает на маршрутный узел ThresholdProcessor и через сценарий автоматизации выполняется привязка Порога к КЕ.
Готовый базовый сценарий можно скачать и импортировать в процессе создания.

В базовом сценарии используется простая функция фильтрации КЕ по ее Личным меткам – их необходимо добавить к целевой КЕ:

А также указать в базовом сценарии:
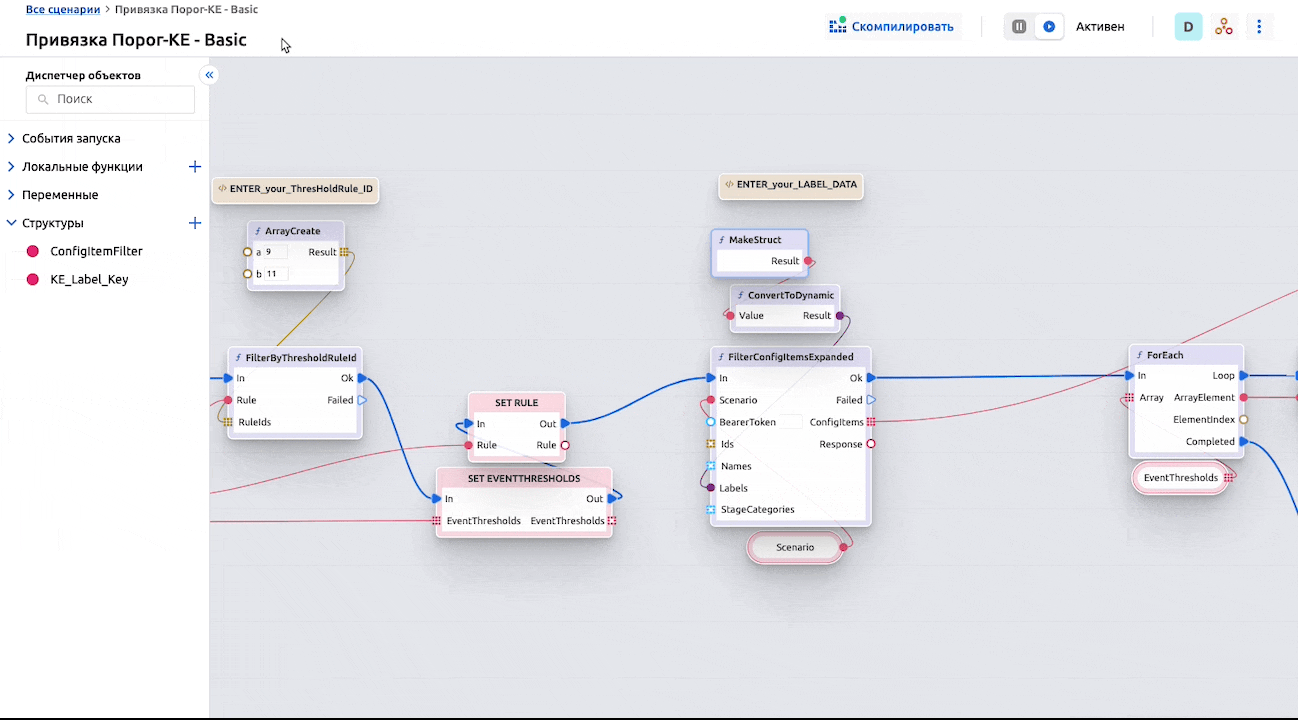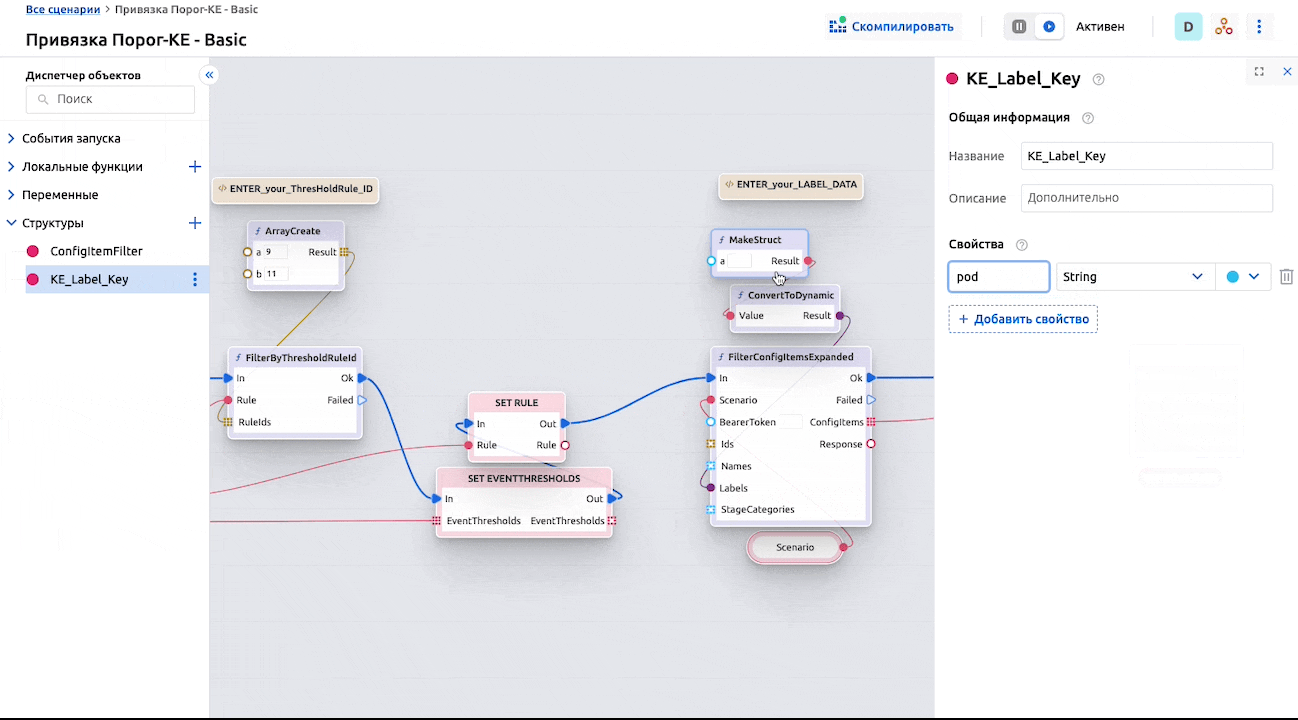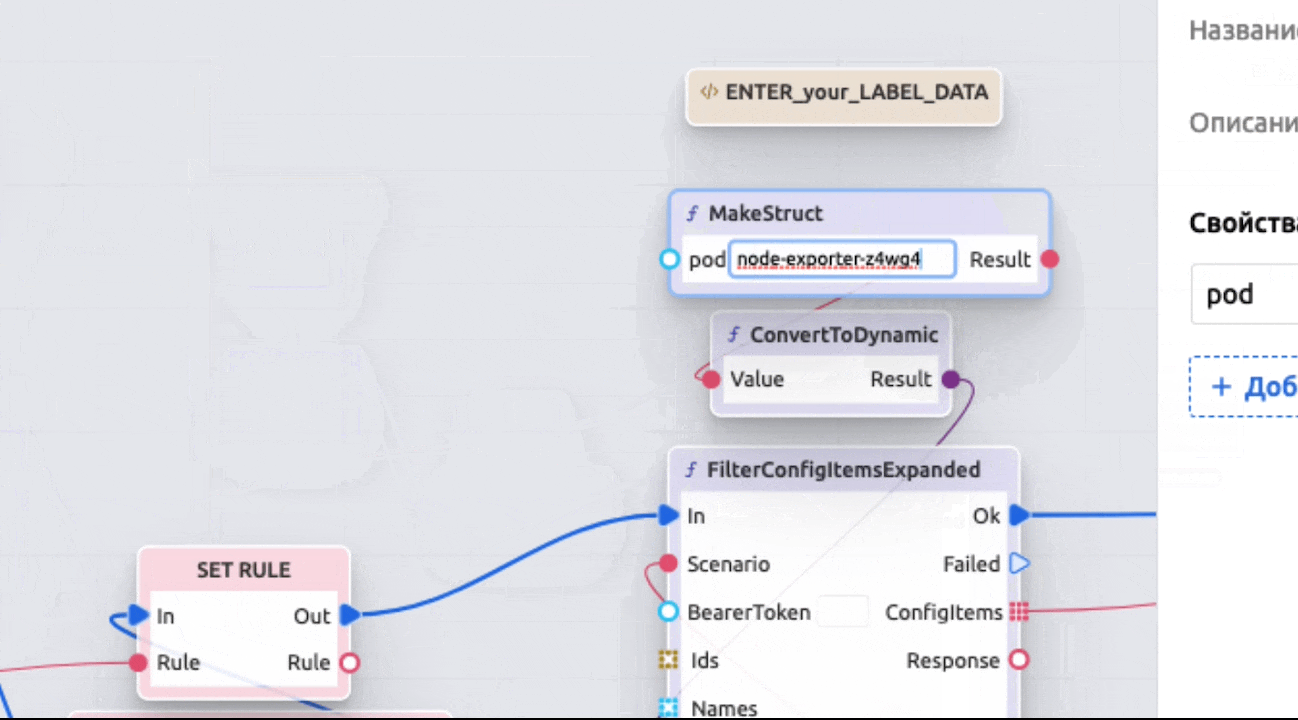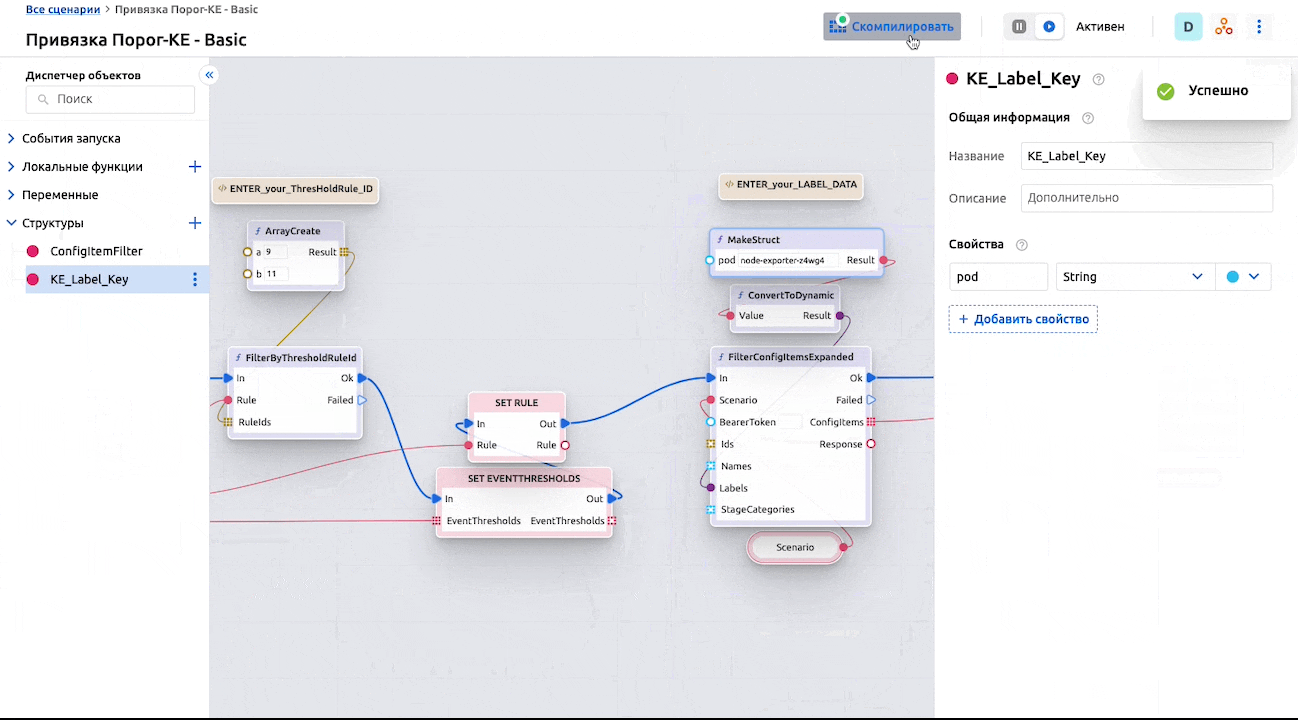
Ввиду гибкости и широких возможностей как самих сценариев автоматизации, так и настроек КЕ и их типов, логику привязки можно задать практически любую.
Создание Сигнала
Поскольку все действия, такие как рассылка уведомлений и запуск скриптов, в Monq ориентируются на Сигналы, события открытия и закрытия Порогов также необходимо обрабатывать в Сигналах, аналогично всем остальным событиям из внешних систем мониторинга.
Для этого используется второй базовый сценарий. Его также можно скачать и импортировать в процессе создания нового сценария:

В обычном случае, когда планируется прямое сопоставление уровня порога и статуса сигнала - редактирование базового сценария не требуется.
Тем не менее, под свои нужды настраивать его можно очень гибко, например делать более сложные проверки, условия, фильтрации и т.п.
После отправки результирующей модели на расчет сигналов, метрики начинают влиять на статус КЕ.
Порог переходит на новый уровень → открывается Сигнал → меняется Здоровье КЕ
Вместо заключения
Дабы не перегружать материалом данную статью, все конкретные прикладные применения метрик в концепции зонтичного мониторинга предприятия мы расскажем в следующих статьях. В этой мы постарались раскрыть суть важности применения метрик в зонтичном мониторинге на примере внедрения Монк. Но стоит понимать, что, включив метрики в свою стратегию мониторинга, вы сможете:
Управлять производительностью: Мониторинг метрик позволяет оптимизировать распределение ресурсов, выявлять узкие места и уменьшать задержки, что в конечном итоге повышает общую производительность ИТ-инфраструктуры.
Повысить надежность: Настроив оповещения на основе определенных пороговых значений метрик, вы сможете заблаговременно выявлять и устранять потенциальные проблемы, сокращая время простоя и обеспечивая надежность ваших систем.
Оптимизировать расходы: Отслеживая и анализируя показатели использования ресурсов, вы можете выявлять области неэффективности и принимать обоснованные решения по планированию мощностей и управлению затратами.
P.S. Скачать бесплатную версию можно тут, а канал с новостями разработки прукта здесь.


