
Последние несколько лет я занимался проектированием и изготовлением машины, которая сможет распознавать и сортировать детали LEGO. Важнейшая часть машины — это Capture Unit, небольшое, почти полностью закрытое отделение, в котором есть конвейерная лента, освещение и камера.

Освещение вы увидите чуть ниже.
Камера делает фотографии поступающих по конвейеру деталей LEGO, а затем передаёт изображения по беспроводному каналу на сервер, выполняющий алгоритм искусственного интеллекта для распознавания детали среди тысяч возможных элементов LEGO. Подробнее об ИИ-алгоритме я расскажу в будущих статьях, а эта статья будет посвящена обработке, которая выполняется между «сырым» выводом видео камеры и входом в нейросеть.
Основная проблема, которую мне нужно было решить — это преобразование видеопотока с конвейера в отдельные изображения деталей, которые бы могла использовать нейросеть.

Конечная цель: перейти от «сырого» видео (слева) к набору изображений одинакового размера (справа) для их передачи в нейросеть. (по сравнению с реальной работой gif замедлен примерно вдвое)
Это отличный пример задачи, которая на поверхности кажется простой, но на самом деле ставит множество уникальных и интересных препятствий, многие из которых уникальны для платформ машинного зрения.
Извлечение нужных частей изображения таким образом часто называют распознаванием объектов (object detection). Именно это мне и нужно сделать: распознать наличие объектов, их расположение и размер, чтобы можно было сгенерировать ограничивающие прямоугольники для каждой детали на каждом кадре.

Самое важное — найти хорошие ограничивающие прямоугольники (выше показаны зелёным цветом)
Я рассмотрю три аспекта решения задачи:
В случае подобных задач перед применением техник машинного зрения лучше всего устранить как можно больше переменных. Например, меня не должны волновать условия окружающей среды, разные положения камеры, потери информации из-за перекрытия одних деталей другими. Конечно, можно (хоть и очень сложно) разрешить все эти переменные программно, но к счастью для меня, эта машина создаётся с нуля. Я сам могу подготовиться к успешному решению, устранив все помехи ещё до того, как начал писать код.
Первый шаг — это жёсткая фиксация положения, угла и фокусировки камеры. С этим всё просто — в системе камера закреплена над конвейером. Не нужно мне волноваться и о помехах от других деталей; нежелательные объекты почти не имеют шанса попасть в capture unit. Немного сложнее, но очень важно обеспечить постоянные условия освещённости. Мне не нужно, чтобы распознаватель объектов ошибочно интерпретировал тень от движущейся по ленте детали как физический объект. К счастью, capture unit очень мал (вся область обзора камеры меньше буханки хлеба), поэтому у меня был более чем достаточный контроль над окружающими условиями.

Capture unit, вид изнутри. Камера находится в верхней трети кадра.
Одно из решений — сделать отсек полностью замкнутым, чтобы никакое освещение снаружи не поступало. Я попробовал такой подход, использовав в качестве источника освещения светодиодные ленты. К сожалению, система оказалась очень капризной — достаточно одной небольшой дырочки в корпусе и свет проникает в отсек, делая невозможным распознавание объектов.
В конечном итоге наилучшим решением оказалось «забивание» всех других источников света при помощи заливки небольшого отсека сильным освещением. Оказалось, что источники света, которые можно использовать для освещения жилых помещений, очень дёшевы и просты в использовании.

Получайте, тени!
При направлении источника в крошечный отсек он полностью забивает все потенциальные внешние световые помехи. У такой системы есть и удобный побочный эффект: благодаря большому количеству света в камере можно использовать очень высокую скорость затвора, получая идеально чёткие изображения деталей даже при быстром перемещении по конвейеру.
Как же мне удалось превратить это красивое видео с равномерным освещением в нужные мне ограничивающие прямоугольники? Если вы работаете с ИИ, то могли бы предложить мне реализовать нейросеть для распознавания объектов наподобие YOLO или Faster R-CNN. Эти нейронные сети легко могут справиться с задачей. К сожалению, я выполняю код распознавания объектов на Raspberry pi. Даже у мощного компьютера возникали бы проблемы с выполнением этих свёрточных нейросетей при нужной мне частоте около 90FPS. А уж Raspberry pi, у которой нет ИИ-совместимого GPU, не справилась бы и с очень урезанной версией одного из подобных ИИ-алгоритмов. Я могу выполнять потоковую передачу видео с Pi на другой компьютер, но передача видео в реальном времени — очень капризный процесс, а задержки и ограничения пропускной способности вызывают серьёзные проблемы, особенно когда нужна высокая скорость передачи данных.
YOLO очень крута! Но мне не нужны все её функции.
К счастью, я мог избежать сложного решения на основе ИИ, воспользовавшись «олдскульными» техниками машинного зрения. Первая техника — это вычитание фона (background subtraction), которое пытается выделить все изменившиеся части изображения. В моём случае единственное, что движется в поле зрения камеры — это детали LEGO. (Разумеется, лента тоже движется, но поскольку она имеет однородный цвет, камере она кажется неподвижной). Отделим эти детали LEGO от фона, и половина задачи решена.
Чтобы вычитание фона работало, объекты переднего плана должны значительно отличаться от фона. Детали LEGO имеют широкий диапазон цветов, поэтому мне нужно было очень тщательно выбирать цвет фона, чтобы он был как можно более далёк от цветов LEGO. Именно поэтому лента под камерой изготовлена из бумаги — она не только должна быть очень однородной, но и не может состоять из LEGO, иначе будет иметь цвет одной из деталей, которые мне нужно распознавать! Я выбрал бледно-розовый, но подойдёт и любой другой пастельный цвет, непохожий на обычные цвета LEGO.
В чудесной библиотеке OpenCV уже есть несколько алгоритмов для вычитания фона. Вычитатель фонов MOG2 — самый сложный из них, и при этом он работает невероятно быстро даже на raspberry pi. Однако подача кадров видео напрямую в MOG2 работает не совсем хорошо. Светло-серые и белые фигуры слишком близки к яркости бледного фона и теряются на нём. Мне нужно было придумать способ, чтобы отчётливей отделить ленту от находящихся на ней деталей, приказав вычитателю фона внимательнее смотреть на цвет, а не на яркость. Для этого мне достаточно было увеличить насыщенность изображений перед передачей его в вычитатель фонов. Результаты при этом значительно улучшились.
После вычитания фона мне нужно было использовать морфологические операции, чтобы избавиться от как можно большего количества шума. Для поиска контуров белых областей можно использовать функцию findContours() библиотеки OpenCV. Применив различные эвристики для отклонения контуров, содержащих шум, можно легко преобразовать эти контуры в готовые ограничивающие прямоугольники.

Нейронная сеть — прожорливое существо. Для получения наилучших результатов при классификации ей требуются изображения максимального разрешения и в как можно больших количествах. Это значит, что мне нужно снимать их с очень высокой частотой кадров, сохраняя при этом качество и разрешение изображения. Я должен выжать из камеры и GPU Raspberry PI максимум возможного.
В очень подробной документации к picamera написано, что чип камеры V2 может выдавать изображения размером 1280x720 пикселей с максимальной частотой 90 кадров в секунду. Это невероятный объём данных, и хотя камера может его генерировать, это не означает, что с ним справится компьютер. Если бы я обрабатывал сырые 24-битные RGB-изображения, то мне пришлось бы передавать данные со скоростью примерно 237 МБ/с, а это слишком много и для бедного GPU компьютера Pi, и для SDRAM. Даже при использовании ускоренной с помощью GPU компрессии в JPEG частоты 90fps достичь невозможно.
Камера Raspberry Pi способна выводить сырое неотфильтрованное YUV-изображение. Хотя с ним работать сложнее, чем с RGB, у YUV на самом деле есть множество удобных свойств. Самое важное из них заключается в том, что оно хранит всего 12 бит на пиксель (у RGB это 24 бита).
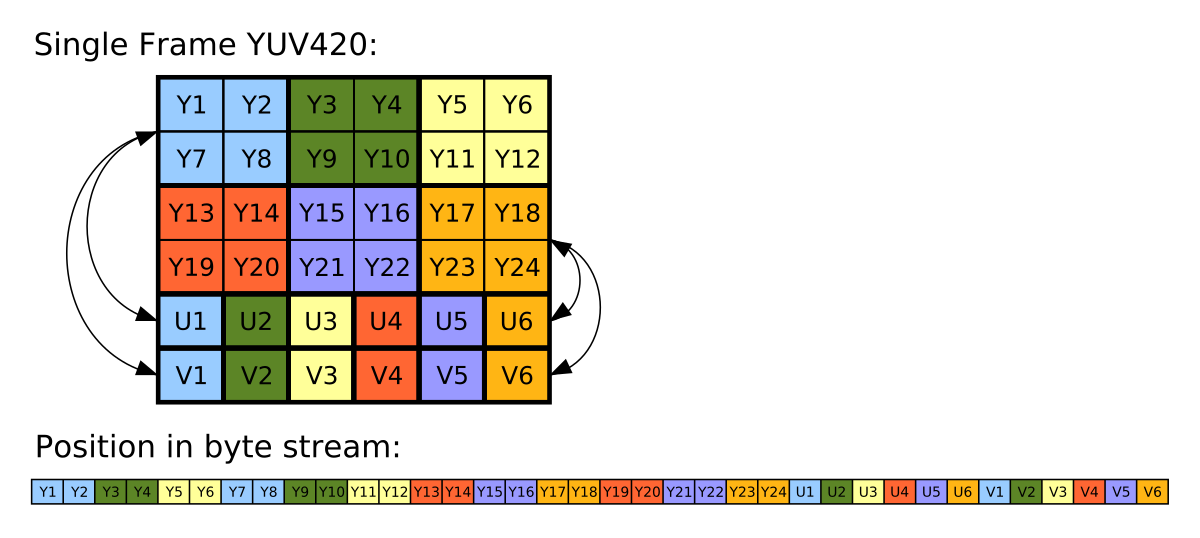
Каждые четыре байта Y имеют один байт U и один байт V, то есть на пиксель приходится 1,5 байта.
Это означает, что по сравнению с RGB-кадрами я могу обрабатывать в два раза больше YUV-кадров, и это ещё не считая дополнительного времени, которое GPU экономит на преобразовании в RGB-изображение.
Однако такой подход накладывает уникальные ограничения на процесс обработки. На большинство операций с полноразмерным кадром видео будет тратиться чрезвычайно много памяти и ресурсов ЦП. В пределах моих строгих временных ограничений невозможно даже декодировать полноэкранный YUV-кадр.
К счастью, мне и не нужно обрабатывать кадр целиком! Для распознавания объектов ограничивающие прямоугольники не обязаны быть точными, достаточно приблизительной точности, поэтому весь процесс распознавания объектов можно выполнять с гораздо меньшим кадром. Операция уменьшения масштаба не обязана учитывать все пиксели полноразмерного кадра, поэтому кадры можно уменьшать очень быстро и без затрат. Затем масштаб получившихся ограничивающих прямоугольников снова увеличивается и используется для вырезания объектов из полноразмерного YUV-кадра. Благодаря этому мне не нужно декодировать или иным образом обрабатывать весь кадр высокого разрешения.
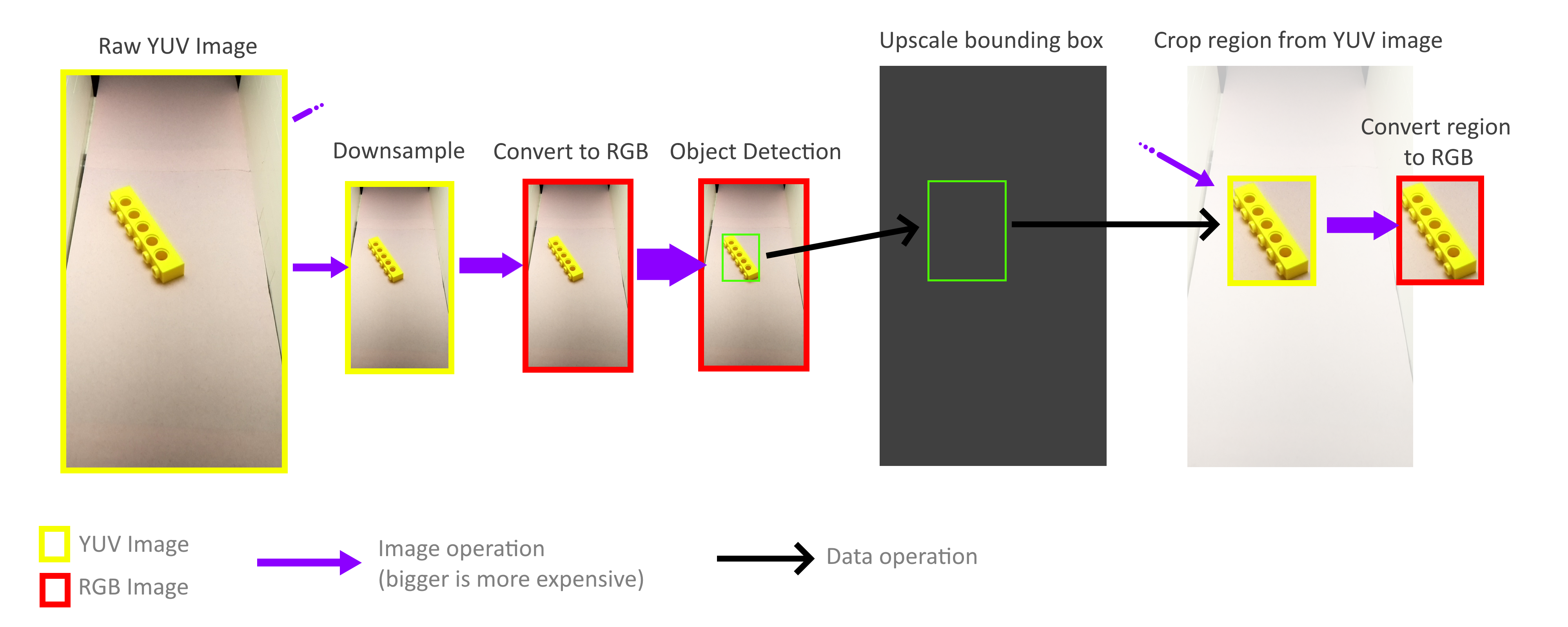
К счастью, благодаря способу хранения этого формата YUV (см. выше) очень легко реализовать быстрые операции обрезки и уменьшения масштаба, работающие непосредственно с форматом YUV. Кроме того, весь процесс без особых проблем можно распараллелить на четыре ядра Pi. Однако я выяснил, что не все ядра используются в полную силу, и это говорит нам, что «бутылочным горлышком» по-прежнему остаётся пропускная способность памяти. Но даже при этом мне удалось на практике достичь 70-80FPS. Более глубокий анализ использования памяти возможно помог бы ещё больше ускорить работу.
Если вам хочется узнать больше о проекте, то прочитайте мою предыдущую статью «Как я создал более 100 тысяч размеченных изображений LEGO для обучения».
Видео работы всей сортировальной машины:
Освещение вы увидите чуть ниже.
Камера делает фотографии поступающих по конвейеру деталей LEGO, а затем передаёт изображения по беспроводному каналу на сервер, выполняющий алгоритм искусственного интеллекта для распознавания детали среди тысяч возможных элементов LEGO. Подробнее об ИИ-алгоритме я расскажу в будущих статьях, а эта статья будет посвящена обработке, которая выполняется между «сырым» выводом видео камеры и входом в нейросеть.
Основная проблема, которую мне нужно было решить — это преобразование видеопотока с конвейера в отдельные изображения деталей, которые бы могла использовать нейросеть.
Конечная цель: перейти от «сырого» видео (слева) к набору изображений одинакового размера (справа) для их передачи в нейросеть. (по сравнению с реальной работой gif замедлен примерно вдвое)
Это отличный пример задачи, которая на поверхности кажется простой, но на самом деле ставит множество уникальных и интересных препятствий, многие из которых уникальны для платформ машинного зрения.
Извлечение нужных частей изображения таким образом часто называют распознаванием объектов (object detection). Именно это мне и нужно сделать: распознать наличие объектов, их расположение и размер, чтобы можно было сгенерировать ограничивающие прямоугольники для каждой детали на каждом кадре.
Самое важное — найти хорошие ограничивающие прямоугольники (выше показаны зелёным цветом)
Я рассмотрю три аспекта решения задачи:
- Подготовка с устранением лишних переменных
- Создание процесса из простых операций машинного зрения
- Поддержание достаточной производительности на платформе Raspberry Pi, имеющей ограниченные ресурсы
Устранение лишних переменных
В случае подобных задач перед применением техник машинного зрения лучше всего устранить как можно больше переменных. Например, меня не должны волновать условия окружающей среды, разные положения камеры, потери информации из-за перекрытия одних деталей другими. Конечно, можно (хоть и очень сложно) разрешить все эти переменные программно, но к счастью для меня, эта машина создаётся с нуля. Я сам могу подготовиться к успешному решению, устранив все помехи ещё до того, как начал писать код.
Первый шаг — это жёсткая фиксация положения, угла и фокусировки камеры. С этим всё просто — в системе камера закреплена над конвейером. Не нужно мне волноваться и о помехах от других деталей; нежелательные объекты почти не имеют шанса попасть в capture unit. Немного сложнее, но очень важно обеспечить постоянные условия освещённости. Мне не нужно, чтобы распознаватель объектов ошибочно интерпретировал тень от движущейся по ленте детали как физический объект. К счастью, capture unit очень мал (вся область обзора камеры меньше буханки хлеба), поэтому у меня был более чем достаточный контроль над окружающими условиями.
Capture unit, вид изнутри. Камера находится в верхней трети кадра.
Одно из решений — сделать отсек полностью замкнутым, чтобы никакое освещение снаружи не поступало. Я попробовал такой подход, использовав в качестве источника освещения светодиодные ленты. К сожалению, система оказалась очень капризной — достаточно одной небольшой дырочки в корпусе и свет проникает в отсек, делая невозможным распознавание объектов.
В конечном итоге наилучшим решением оказалось «забивание» всех других источников света при помощи заливки небольшого отсека сильным освещением. Оказалось, что источники света, которые можно использовать для освещения жилых помещений, очень дёшевы и просты в использовании.
Получайте, тени!
При направлении источника в крошечный отсек он полностью забивает все потенциальные внешние световые помехи. У такой системы есть и удобный побочный эффект: благодаря большому количеству света в камере можно использовать очень высокую скорость затвора, получая идеально чёткие изображения деталей даже при быстром перемещении по конвейеру.
Распознаватель объектов
Как же мне удалось превратить это красивое видео с равномерным освещением в нужные мне ограничивающие прямоугольники? Если вы работаете с ИИ, то могли бы предложить мне реализовать нейросеть для распознавания объектов наподобие YOLO или Faster R-CNN. Эти нейронные сети легко могут справиться с задачей. К сожалению, я выполняю код распознавания объектов на Raspberry pi. Даже у мощного компьютера возникали бы проблемы с выполнением этих свёрточных нейросетей при нужной мне частоте около 90FPS. А уж Raspberry pi, у которой нет ИИ-совместимого GPU, не справилась бы и с очень урезанной версией одного из подобных ИИ-алгоритмов. Я могу выполнять потоковую передачу видео с Pi на другой компьютер, но передача видео в реальном времени — очень капризный процесс, а задержки и ограничения пропускной способности вызывают серьёзные проблемы, особенно когда нужна высокая скорость передачи данных.
YOLO очень крута! Но мне не нужны все её функции.
К счастью, я мог избежать сложного решения на основе ИИ, воспользовавшись «олдскульными» техниками машинного зрения. Первая техника — это вычитание фона (background subtraction), которое пытается выделить все изменившиеся части изображения. В моём случае единственное, что движется в поле зрения камеры — это детали LEGO. (Разумеется, лента тоже движется, но поскольку она имеет однородный цвет, камере она кажется неподвижной). Отделим эти детали LEGO от фона, и половина задачи решена.
Чтобы вычитание фона работало, объекты переднего плана должны значительно отличаться от фона. Детали LEGO имеют широкий диапазон цветов, поэтому мне нужно было очень тщательно выбирать цвет фона, чтобы он был как можно более далёк от цветов LEGO. Именно поэтому лента под камерой изготовлена из бумаги — она не только должна быть очень однородной, но и не может состоять из LEGO, иначе будет иметь цвет одной из деталей, которые мне нужно распознавать! Я выбрал бледно-розовый, но подойдёт и любой другой пастельный цвет, непохожий на обычные цвета LEGO.
В чудесной библиотеке OpenCV уже есть несколько алгоритмов для вычитания фона. Вычитатель фонов MOG2 — самый сложный из них, и при этом он работает невероятно быстро даже на raspberry pi. Однако подача кадров видео напрямую в MOG2 работает не совсем хорошо. Светло-серые и белые фигуры слишком близки к яркости бледного фона и теряются на нём. Мне нужно было придумать способ, чтобы отчётливей отделить ленту от находящихся на ней деталей, приказав вычитателю фона внимательнее смотреть на цвет, а не на яркость. Для этого мне достаточно было увеличить насыщенность изображений перед передачей его в вычитатель фонов. Результаты при этом значительно улучшились.
После вычитания фона мне нужно было использовать морфологические операции, чтобы избавиться от как можно большего количества шума. Для поиска контуров белых областей можно использовать функцию findContours() библиотеки OpenCV. Применив различные эвристики для отклонения контуров, содержащих шум, можно легко преобразовать эти контуры в готовые ограничивающие прямоугольники.
Производительность
Нейронная сеть — прожорливое существо. Для получения наилучших результатов при классификации ей требуются изображения максимального разрешения и в как можно больших количествах. Это значит, что мне нужно снимать их с очень высокой частотой кадров, сохраняя при этом качество и разрешение изображения. Я должен выжать из камеры и GPU Raspberry PI максимум возможного.
В очень подробной документации к picamera написано, что чип камеры V2 может выдавать изображения размером 1280x720 пикселей с максимальной частотой 90 кадров в секунду. Это невероятный объём данных, и хотя камера может его генерировать, это не означает, что с ним справится компьютер. Если бы я обрабатывал сырые 24-битные RGB-изображения, то мне пришлось бы передавать данные со скоростью примерно 237 МБ/с, а это слишком много и для бедного GPU компьютера Pi, и для SDRAM. Даже при использовании ускоренной с помощью GPU компрессии в JPEG частоты 90fps достичь невозможно.
Камера Raspberry Pi способна выводить сырое неотфильтрованное YUV-изображение. Хотя с ним работать сложнее, чем с RGB, у YUV на самом деле есть множество удобных свойств. Самое важное из них заключается в том, что оно хранит всего 12 бит на пиксель (у RGB это 24 бита).
Каждые четыре байта Y имеют один байт U и один байт V, то есть на пиксель приходится 1,5 байта.
Это означает, что по сравнению с RGB-кадрами я могу обрабатывать в два раза больше YUV-кадров, и это ещё не считая дополнительного времени, которое GPU экономит на преобразовании в RGB-изображение.
Однако такой подход накладывает уникальные ограничения на процесс обработки. На большинство операций с полноразмерным кадром видео будет тратиться чрезвычайно много памяти и ресурсов ЦП. В пределах моих строгих временных ограничений невозможно даже декодировать полноэкранный YUV-кадр.
К счастью, мне и не нужно обрабатывать кадр целиком! Для распознавания объектов ограничивающие прямоугольники не обязаны быть точными, достаточно приблизительной точности, поэтому весь процесс распознавания объектов можно выполнять с гораздо меньшим кадром. Операция уменьшения масштаба не обязана учитывать все пиксели полноразмерного кадра, поэтому кадры можно уменьшать очень быстро и без затрат. Затем масштаб получившихся ограничивающих прямоугольников снова увеличивается и используется для вырезания объектов из полноразмерного YUV-кадра. Благодаря этому мне не нужно декодировать или иным образом обрабатывать весь кадр высокого разрешения.
К счастью, благодаря способу хранения этого формата YUV (см. выше) очень легко реализовать быстрые операции обрезки и уменьшения масштаба, работающие непосредственно с форматом YUV. Кроме того, весь процесс без особых проблем можно распараллелить на четыре ядра Pi. Однако я выяснил, что не все ядра используются в полную силу, и это говорит нам, что «бутылочным горлышком» по-прежнему остаётся пропускная способность памяти. Но даже при этом мне удалось на практике достичь 70-80FPS. Более глубокий анализ использования памяти возможно помог бы ещё больше ускорить работу.
Если вам хочется узнать больше о проекте, то прочитайте мою предыдущую статью «Как я создал более 100 тысяч размеченных изображений LEGO для обучения».
Видео работы всей сортировальной машины:




