
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Прим. перев.: Эта статья, ставшая хитом на Medium, — обзор ключевых (за 2010-2019 годы) изменений в мире языков программирования и связанной с ними экосистемы технологий (особое внимание уделяется Docker и Kubernetes). Её оригинальным автором является Cindy Sridharan, которая специализируется на инструментах для разработчиков и распределённых системах — в частности, она написала книгу «Distributed Systems Observability» — и достаточно популярна в интернет-пространстве среди IT-специалистов, особенно интересующихся темой cloud native.

2019-й подошел к концу, поэтому я хотела бы поделиться своими мыслями о некоторых наиболее важных технологических достижениях и инновациях прошедшего десятилетия. Кроме того, я попытаюсь немного заглянуть в будущее и обозначить основные проблемы и возможности предстоящей декады.
Хочу сразу оговориться, что в этой статье я не охватываю изменения в таких областях, как наука о данных (data science), искусственный интеллект, frontend engineering и т.п., поскольку лично у меня отсутствует достаточный опыт в них.
Одной из самых позитивных тенденций 2010-х стало возрождение языков со статической типизацией. Впрочем, подобные языки никуда и не исчезали (С++ и Java востребованы сегодня; доминировали они и десять лет назад), однако языки с динамической типизацией (динамические) пережили значительный рост популярности после возникновения движения Ruby on Rails в 2005 году. Этот рост достиг своего максимума в 2009 году с открытием исходного кода Node.js, благодаря которому Javascript-на-сервере стал реальностью.
Со временем динамические языки растеряли часть своей притягательности в области создания серверного ПО. Язык Go, популяризированный в ходе контейнерной революции, казался лучше приспособленным к созданию высокопроизводительных, ресурсоэффективных серверов с параллельной обработкой информации (с чем согласен сам создатель Node.js).
Rust, представленный в 2010-м, включил в себя достижения в теории типов в попытке стать безопасным и типизированным языком. В первой половине десятилетия отношение к Rust в отрасли было довольно прохладным, однако во второй половине его популярность значительно возросла. Среди примечательных примеров использования Rust можно назвать его применение для Magic Pocket в Dropbox, Firecracker от AWS (мы рассказывали о нём в этой статье — прим. перев.), досрочном WebAssembly-компиляторе Lucet от Fastly (ныне входит в bytecodealliance) и др. В условиях, когда Microsoft рассматривает возможность переписать некоторые части ОС Windows на Rust, можно с уверенностью сказать, что в 2020-х этот язык ожидает светлое будущее.
Даже динамические языки получили новые возможности вроде опциональных типов (optional types). Впервые они были реализованы в TypeScript — языке, позволяющем создавать типизированный код и компилировать его в JavaScript. PHP, Ruby и Python обзавелись собственными системами опциональной типизации (mypy, Hack), которые успешно используются в production.
NoSQL — еще одна технология, которая в начале десятилетия была гораздо более популярной, чем в конце. Думаю, для этого есть две причины.
Во-первых, модель NoSQL с отсутствием схемы, транзакций и более слабыми гарантиями согласованности, оказалась сложнее в реализации, нежели модель SQL. В блог-заметке с названием «Почему следует предпочитать строгую согласованность при любом удобном случае» (Why you should pick strong consistency, whenever possible) Google пишет:
Вторая причина связана с ростом «масштабируемых» распределенных баз данных SQL (таких как Cloud Spanner и AWS Aurora) в публичном облачном пространстве, а также Open Source-альтернатив вроде CockroachDB (про неё мы тоже писали — прим. перев.), которые решают многие из технических проблем, из-за которых традиционные SQL-базы «не масштабировались». Даже MongoDB, когда-то бывшая олицетворением движения NoSQL, теперь предлагает распределенные транзакции.
Apache Kafka, без сомнения, стал одним из самых важных изобретений прошедшего десятилетия. Его исходный код был открыт в январе 2011-го, и за эти годы Kafka произвел настоящую революцию в работе бизнеса с данными. Kafka использовался во всех компаниях, в которых мне довелось работать, начиная от стартапов и заканчивая крупными корпорациями. Предоставляемые им гарантии и варианты использования (pub-sub, потоки, событийно-ориентированные архитектуры) применяются в различных задачах: от организации хранения данных до мониторинга и потоковой аналитики, — востребованных во многих областях, таких как финансы, здравоохранение, госсектор, розничная торговля и т.д.
Непрерывная интеграция (Continuous Integration) появилась не в последние 10 лет, однако именно за прошедшую декаду она распространилась до такой степени, что стала частью стандартного рабочего процесса (run-тесты на всех pull request'ах). Становление GitHub в качестве платформы по разработке и хранению кода и, что более важно, развитие рабочего процесса на основе GitHub flow означает, что проведение тестов до принятия pull request'а в мастер — это единственный workflow в разработке, знакомый инженерам, начавшим свои карьеры в последние десять лет.
Непрерывное развертывание (Continuous Deployment; развертывание каждого коммита в том виде и в тот момент, когда он попадает в мастер) не так широко распространено, как непрерывная интеграция. Впрочем, со множеством различных облачных API для развертывания, растущей популярностью платформ вроде Kubernetes (предоставляющих стандартизованный API для развертываний) и появление мульти-платформенных, мульти-облачных инструментов вроде Spinnaker (построенных поверх упомянутых стандартизованных API), процессы развертывания стали более автоматизированными, упорядоченными и, в общем, более безопасными.
Контейнеры, пожалуй, можно назвать самой хайповой, обсуждаемой, рекламируемой и неверно понимаемой технологией 2010-х. С другой стороны, это одна из самых важных инноваций предыдущей декады. Частично причина всей этой какофонии лежит в смешанных сигналах, которые мы получали практически отовсюду. Теперь, когда шумиха немного поутихла, некоторые моменты приобрели более отчетливые оттенки.
Контейнеры стали популярны вовсе не потому, что это лучший способ запустить приложение, удовлетворяющий запросам глобального сообщества разработчиков. Контейнеры стали популярны потому, что удачно вписались в маркетинговый запрос на некий инструмент, решающий совершенно иную задачу. Docker оказался фантастическим инструментом для разработки, решающим насущную проблему совместимости («работает на моей машине»).
Точнее говоря, революцию произвел Docker-образ, поскольку решил проблему паритета между средами и обеспечил истинную переносимость не только файла приложения, но и всех его программных и операционных зависимостей. Тот факт, что этот инструмент каким-то образом подстегнул популярность «контейнеров», которые по сути представляют собой весьма низкоуровневую деталь реализации, для меня остается, пожалуй, главной загадкой прошедшего десятилетия.
Готова поспорить, что появление «бессерверных» вычислений даже важнее, чем контейнеров, поскольку оно действительно позволяет воплотить в реальность мечту о вычислениях по запросу (on-demand). В последние пять лет я наблюдала за постепенным расширением сферы применения бессерверного подхода (добавлялась поддержка новых языков и сред выполнения). Возникновение таких продуктов, как Azure Durable Functions, представляется верным шагом на пути реализации stateful-функций (попутно решающим некоторые проблемы, связанные с ограничениями FaaS). С интересом понаблюдаю, как эта новая парадигма будет развиваться в ближайшие годы.
Пожалуй, больше всего от этого тренда выиграло сообщество инженеров по эксплуатации, поскольку именно он позволил воплотить в жизнь концепции вроде «инфраструктура как код» (IaC). Кроме того, страсть к автоматизации совпала с ростом «культуры SRE», целью которой является более программно-ориентированный подход к эксплуатации.
Еще одной любопытной особенностью прошедшего десятилетия стала API-фикация различных задач разработки. Хорошие, гибкие API позволяют разработчику создавать инновационные рабочие процессы и инструменты, которые в свою очередь помогают с обслуживанием и повышают удобство работы.
Кроме того, API-фикация — это первый шаг к SaaS-фикации некоторого функционала или инструмента. Эта тенденция также совпала с ростом популярности микросервисов: SaaS стал просто еще одним сервисом, с которым можно работать по API. В настоящее время имеется множество SaaS- и FOSS-инструментов в таких областях, как мониторинг, платежи, балансировка нагрузки, непрерывная интеграция, оповещения, переключение функциональности (feature flagging), CDN, инжиниринг трафика (например, DNS) и т.д., которые процветали в прошлом десятилетии.
Стоит отметить, что сегодня нам доступны намного более продвинутые инструменты для мониторинга и диагностики поведения приложений, чем когда-либо ранее. Систему мониторинга Prometheus, получившую статус Open Source в 2015 году, можно назвать, пожалуй, лучшей системой мониторинга из тех, с которыми мне доводилось работать. Она не совершенна, однако значительное число вещей в ней реализованы совершенно правильным образом (например, поддержка измерений [dimensionality] в случае метрик).
Распределенная трассировка стала еще одной технологией, вышедшей в мейнстрим в 2010-х благодаря таким инициативам, как OpenTracing (и ее преемнице OpenTelemetry). Хотя трассировка по-прежнему довольно сложна в применении, некоторые из последних разработок позволяют надеяться, что в 2020-х мы раскроем ее истинный потенциал. (Прим. перев.: Читайте также в нашем блоге перевод статьи «Распределённая трассировка: мы всё делали не так» этого же автора.)
Увы, существует множество болевых точек, которые ждут своего разрешения в наступившем десятилетии. Вот мои мысли по их поводу и некоторые потенциальные идеи о том, как от них избавиться.
Конец закона масштабирования Деннарда и отставание от закона Мура требуют новых инноваций. John Hennessy в своей лекции объясняет, почему проблемно-зависимые (domain specific) архитектуры вроде TPU могут стать одним из решений проблемы отставания от закона Мура. Тулкиты вроде MLIR от Google уже представляются хорошим шагом вперед в этом направлении:
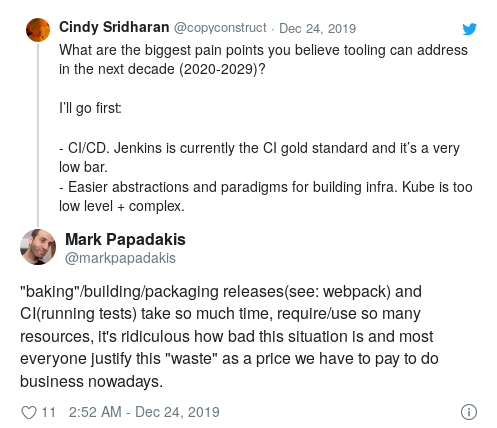
Хотя рост популярности CI стал одним из главных трендов 2010-х, Jenkins по-прежнему остается золотым стандартом CI.
Это пространство остро нуждается в инновациях в следующих областях:
Как отрасль, мы начали создавать все более сложное и впечатляющее программное обеспечение. Однако когда речь заходит о наших собственных инструментах, можно сказать, что ситуация могла бы быть намного лучше.
Совместное и удаленное (по ssh) редактирование приобрели некоторую популярность, однако так и не стали новым стандартным способом разработки. Если вы, как и я, отвергаете саму мысль о необходимости постоянного подключения к интернету только для того, чтобы иметь возможность заниматься программированием, то работа через ssh на удаленной машине вас вряд ли устроит.
Локальные среды разработки, особенно для инженеров, работающих над крупными сервис-ориентированными архитектурами, все еще остаются проблемой. Некоторые проекты пытаются ее решить, и мне было бы интересно узнать, как будет выглядеть самый эргономичный UX для данного сценария использования.
Также было бы интересно развить концепцию «переносимых сред» на другие области разработки, такие как воспроизведение ошибок (или flaky tests), встречающихся в определенных условиях или при определенных настройках.
Также я хотела бы видеть больше инноваций в таких областях, как семантический и контекстно-зависимый поиск кода, инструменты, позволяющие соотносить инциденты в production с конкретными частями кодовой базы, и т.д.
На фоне всеобщего ажиотажа по поводу контейнеров и serverless в 2010-х спектр решений в публичном облачном пространстве значительно расширился в последние несколько лет.

В связи с этим возникают несколько интересных вопросов. Прежде всего, список доступных вариантов в публичном облаке постоянно растет. У поставщиков облачных услуг имеется персонал и ресурсы, позволяющие им с легкостью идти в ногу с последними достижениями в мире Open Source и выпускать продукты вроде «serverless pod'ов» (подозреваю, просто делая их собственные FaaS runtime'ы совместимыми с OCI) или другие похожие причудливые штуки.
Тем, кто пользуется этими облачными решениями, можно только позавидовать. В теории облачные предложения Kubernetes (GKE, EKS, EKS на Fargate и т.д.) предоставляют независимые от облачного провайдера API для запуска рабочих нагрузок. Если вы пользуетесь подобными продуктами (ECS, Fargate, Google Cloud Run и др.), то, вероятно, уже максимально задействуете наиболее интересные функции, предлагаемые поставщиком услуг. Кроме того, при появлении новых продуктов или вычислительных парадигм миграция, скорее всего, будет простой и беззаботной.
Учитывая то, как быстро развивается спектр подобных решений (я очень удивлюсь, если в ближайшее время не появится пара-тройка новых вариантов), небольшим «платформенным» командам (командам, связанным с инфраструктурой и отвечающим за создание платформ on-premise для запуска рабочих нагрузок в компаниях) будет невероятно трудно конкурировать в плане функциональных возможностей, простоты использования и общей надежности. 2010-е прошли под знаком Kubernetes как инструмента для создания PaaS (платформа-как-услуга), поэтому мне кажется совершенно бессмысленным создание внутренней платформы на базе Kubernetes, предлагающей те же возможности выбора, простоту и свободу, доступные в публичном облачном пространстве. Представление об основанной на «контейнерах» PaaS как о «стратегии Kubernetes» равносильно умышленному отказу от использования самых инновационных возможностей облака.
Если посмотреть на доступные сегодня вычислительные возможности, становится очевидно, что создание собственной PaaS исключительно на базе Kubernetes равносильно тому, чтобы собственноручно загнать себя в угол (не слишком дальновидный подход, да?). Даже если кто-то решит сегодня создать контейнерную PaaS на базе Kubernetes, через пару лет она будет выглядеть устаревшей по сравнению с облачными возможностями. Хотя Kubernetes начинал свое существование как проект с открытым исходным кодом, его прародителем и идейным вдохновителем выступает соответствующий внутренний инструмент Google. Однако он изначально разрабатывался в начале/середине 2000-х, когда вычислительный ландшафт был совершенно другим.
Кроме того, в очень широком смысле компании и не должны становиться экспертами в работе с кластером Kubernetes, равно как они не занимаются созданием и поддержанием собственных центров обработки данных. Обеспечение надежной вычислительной основы — это основная задача поставщиков облачных услуг.
Наконец, у меня складывается ощущение, что мы немного регрессировали как отрасль в плане опыта взаимодействия (UX). Heroku была запущена в 2007 году и до сих пор остается одной из самых простых в использовании платформ. Спору нет, Kubernetes обладает гораздо большей мощностью, расширяемостью и программируемостью, однако я скучаю по тому, насколько просто начать работу и провести развертывание в Heroku. Чтобы пользоваться этой платформой, достаточно знать Git.
Все это подводит меня к следующему умозаключению: для работы нам необходимы лучшие, более высокоуровневые абстракции (особенно это справедливо для абстракций самого высокого уровня).
Docker — это отличный пример необходимости лучшего разделения задач одновременно с правильной реализацией API высочайшего уровня.
Проблема Docker'а в том, что (по крайней мере) изначально перед проектом были поставлены слишком глобальные цели: все ради решения проблемы совместимости («работает на моей машине») с помощью контейнерной технологии. Docker был и форматом образов, и runtime'ом с собственной виртуальной сетью, и инструментом CLI, и демоном, работающим под root'ом, и многим другим. Во всяком случае, обмен сообщениями был более запутанным, не говоря уже о «легковесных VM», контрольных группах, пространствах имен, многочисленных проблемах с безопасностью и функций вперемешку с маркетинговым призывом «создавать, поставлять, запускать любое приложение где угодно».

Как и со всеми хорошими абстракциями, требуется время (а также опыт и боль), чтобы разбить различные проблемы на логически слои, которые можно скомбинировать друг с другом. Увы, прежде чем Docker сумел достичь подобной зрелости, в борьбу вступил Kubernetes. Он настолько монополизировал хайп-цикл, что теперь все старались не отставать от изменений в экосистеме Kubernetes, а экосистема контейнеров приобрела вторичный статус.
Kubernetes во многих отношениях разделяет те же проблемы, что и Docker. Несмотря на все разговоры о крутой и составляемой (composable) абстракции, разделение различных задач на слои не слишком хорошо инкапсулировано. В своей основе это оркестратор контейнеров, запускающий контейнеры в кластере, состоящем из различных машин. Это довольно низкоуровневая задача, применимая только к инженерам, эксплуатирующим кластер. С другой стороны, Kubernetes это также абстракция высочайшего уровня, CLI-инструмент, с которым пользователи взаимодействуют через YAML.
Docker был (и остается) классным инструментом для разработки, несмотря на все его недостатки. В попытке угнаться сразу за всеми «зайцами» его разработчикам удалось правильным образом реализовать абстракцию высочайшего уровня. Под абстракцией высочайшего уровня я подразумеваю подмножество функциональности, в которой действительно была заинтересована целевая аудитория (в данном случае разработчики, проводившие большую часть времени в своих локальных средах разработки) и которое отлично работало «из коробки».
Dockerfile и CLI-утилита
Kubernetes предназначен для различных целевых групп:
Подход «один API подходит для всего», примененный в Kubernetes, представляет собой недостаточно инкапсулированную «гору сложности» без указания того, как ее масштабировать. Все это приводит к неоправданно затяжной траектории обучения. Как пишет Adam Jacob, «Docker принёс пользователям трансформирующий опыт, который до сих пор не превзошли. Спросите у любого, кто использует K8s, хотели бы они, чтобы он работал как их первый

Я бы сказала, что основная часть инфраструктурной технологии сегодня слишком низкоуровневая (и, следовательно, считается «слишком сложной»). Kubernetes реализован на довольно низком уровне. Распределенная трассировка в ее нынешней форме (множество span'ов, сшитых вместе, чтобы сформировать traceview) также реализована на слишком низком уровне. Инструменты для разработчиков, реализующие «абстракции самого высокого уровня», как правило, оказываются наиболее успешными. Это умозаключение оказывается справедливым в удивительном числе случаев (если технология слишком комплексна или сложна в использовании, то «API/UI высочайшего уровня» для этой технологии еще только предстоит открыть).
Прямо сейчас экосистема cloud native смущает своей зацикленностью на низкоуровневости. Как отрасль мы должны внедрять инновации, экспериментировать и обучать тому, как выглядит правильный уровень «максимальной, высочайшей абстракции».
В 2010-х цифровой опыт в розничной торговле почти не изменился. С одной стороны, легкость онлайн-покупок должна была ударить по классическим розничным магазинам, с другой — онлайн-шоппинг фундаментально почти не поменялся за десятилетие.
Хотя у меня нет конкретных мыслей относительно развития этой отрасли в следующем десятилетии, я буду сильно разочарована, если в 2030-м мы будем совершать покупки так же, как делаем это в 2020-м.
Я все больше разочаровываюсь в состоянии мировой журналистики. Становится все труднее находить беспристрастные новостные ресурсы, которые вещают объективно и педантично. Очень часто граница между самой новостью и мнением о ней стирается. Как правило, информация преподносится предвзято. Это особенно справедливо в случае некоторых стран, где исторически не существовало разделения между новостью и мнением о ней. В недавней статье, опубликованной после последних всеобщих выборов в Великобритании, Alan Rusbridger, бывший редактор The Guardian, пишет:
Учитывая достаточно сомнительную репутацию Кремниевой долины, когда речь заходит об этике, я бы ни при каких обстоятельствах не доверила технологиям «революцию» в журналистике. При этом я (и многие мои знакомые) была бы рада, если бы появился беспристрастный, бескорыстный и заслуживающий доверия новостной ресурс. Пока я не представляю, как могла бы выглядеть подобная платформа, но уверена, что в эпоху, когда правду становится все труднее разглядеть, потребность в честной журналистике выше, чем когда-либо.
Социальные сети и коллективные новостные платформы выступают основным источником информации для многих людей в различных уголках мира, и недостаток точности и нежелание некоторых платформ проводить хотя бы базовою проверку основных фактов приводят к таким плачевным последствиям, как геноцид, вмешательство в выборы и т.д.
Социальные сети также являются самым мощным медийным средством из всех когда-либо существовавших. Они кардинально изменили политическую практику. Они изменили рекламу. Они изменили поп-культуру (например, основной вклад в развитие т.н. cancel culture [культуры остракизма — прим. перев.] вносят именно социальные сети). Критики утверждают, что социальные сети оказались плодородной почвой для быстрых и «капризных» изменений в моральных ценностях, однако они также обеспечили представителям маргинальных групп возможность объединяться (ранее у них никогда не было такой возможности). В сущности, социальные сети изменили способ общения и способ самовыражения людей в XXI веке.
Тем не менее, я также убеждена, что социальные сети способствуют проявлению худших человеческих импульсов. Внимательностью и вдумчивостью часто пренебрегают в угоду популярности, и становится практически невозможно выражать аргументированное несогласие с определенными мнениями и позициями. Поляризация часто выходит из-под контроля, в результате публика попросту не слышит отдельные мнения, в то время как абсолютисты контролируют вопросы онлайн-этикета и приемлемости.
Я задаюсь вопросом, можно ли создать «лучшую» платформу, способствующую повышению качества дискуссий? Ведь именно то, что движет «вовлеченностью», часто и приносит основную прибыль этим платформам. Как пишет Kara Swisher в New York Times:
Было бы действительно прискорбно, если бы через пару десятилетий единственным наследием социальных сетей стало бы размывание нюансов и адекватности в публичном дискурсе.
Читайте также в нашем блоге:
2019-й подошел к концу, поэтому я хотела бы поделиться своими мыслями о некоторых наиболее важных технологических достижениях и инновациях прошедшего десятилетия. Кроме того, я попытаюсь немного заглянуть в будущее и обозначить основные проблемы и возможности предстоящей декады.
Хочу сразу оговориться, что в этой статье я не охватываю изменения в таких областях, как наука о данных (data science), искусственный интеллект, frontend engineering и т.п., поскольку лично у меня отсутствует достаточный опыт в них.
Типизация наносит ответный удар
Одной из самых позитивных тенденций 2010-х стало возрождение языков со статической типизацией. Впрочем, подобные языки никуда и не исчезали (С++ и Java востребованы сегодня; доминировали они и десять лет назад), однако языки с динамической типизацией (динамические) пережили значительный рост популярности после возникновения движения Ruby on Rails в 2005 году. Этот рост достиг своего максимума в 2009 году с открытием исходного кода Node.js, благодаря которому Javascript-на-сервере стал реальностью.
Со временем динамические языки растеряли часть своей притягательности в области создания серверного ПО. Язык Go, популяризированный в ходе контейнерной революции, казался лучше приспособленным к созданию высокопроизводительных, ресурсоэффективных серверов с параллельной обработкой информации (с чем согласен сам создатель Node.js).
Rust, представленный в 2010-м, включил в себя достижения в теории типов в попытке стать безопасным и типизированным языком. В первой половине десятилетия отношение к Rust в отрасли было довольно прохладным, однако во второй половине его популярность значительно возросла. Среди примечательных примеров использования Rust можно назвать его применение для Magic Pocket в Dropbox, Firecracker от AWS (мы рассказывали о нём в этой статье — прим. перев.), досрочном WebAssembly-компиляторе Lucet от Fastly (ныне входит в bytecodealliance) и др. В условиях, когда Microsoft рассматривает возможность переписать некоторые части ОС Windows на Rust, можно с уверенностью сказать, что в 2020-х этот язык ожидает светлое будущее.
Даже динамические языки получили новые возможности вроде опциональных типов (optional types). Впервые они были реализованы в TypeScript — языке, позволяющем создавать типизированный код и компилировать его в JavaScript. PHP, Ruby и Python обзавелись собственными системами опциональной типизации (mypy, Hack), которые успешно используются в production.
Возвращение SQL в NoSQL
NoSQL — еще одна технология, которая в начале десятилетия была гораздо более популярной, чем в конце. Думаю, для этого есть две причины.
Во-первых, модель NoSQL с отсутствием схемы, транзакций и более слабыми гарантиями согласованности, оказалась сложнее в реализации, нежели модель SQL. В блог-заметке с названием «Почему следует предпочитать строгую согласованность при любом удобном случае» (Why you should pick strong consistency, whenever possible) Google пишет:
Одна из вещей, которую мы уяснили в Google, состоит в том, что код приложения проще, а сроки разработки короче, если инженеры могут положиться на имеющиеся хранилища при обработке сложных транзакций и поддержании порядка данных. Цитируя оригинальную документацию к Spanner, «мы считаем, что лучше, если программисты будут заниматься проблемами с производительностью приложения из-за злоупотребления транзакциями по мере возникновения узких мест, нежели чем постоянно будут держать в уме отсутствие транзакций».
Вторая причина связана с ростом «масштабируемых» распределенных баз данных SQL (таких как Cloud Spanner и AWS Aurora) в публичном облачном пространстве, а также Open Source-альтернатив вроде CockroachDB (про неё мы тоже писали — прим. перев.), которые решают многие из технических проблем, из-за которых традиционные SQL-базы «не масштабировались». Даже MongoDB, когда-то бывшая олицетворением движения NoSQL, теперь предлагает распределенные транзакции.
Для ситуаций, требующих атомарности операций чтения и записи в несколько документов (в одной или нескольких коллекциях), MongoDB поддерживает транзакции со множеством документов. В случае распределенных транзакций, транзакции можно использовать для множества операций, коллекций, баз данных, документов и шардов.
Тотальная стримификация
Apache Kafka, без сомнения, стал одним из самых важных изобретений прошедшего десятилетия. Его исходный код был открыт в январе 2011-го, и за эти годы Kafka произвел настоящую революцию в работе бизнеса с данными. Kafka использовался во всех компаниях, в которых мне довелось работать, начиная от стартапов и заканчивая крупными корпорациями. Предоставляемые им гарантии и варианты использования (pub-sub, потоки, событийно-ориентированные архитектуры) применяются в различных задачах: от организации хранения данных до мониторинга и потоковой аналитики, — востребованных во многих областях, таких как финансы, здравоохранение, госсектор, розничная торговля и т.д.
Непрерывная интеграция (и в меньшей степени непрерывное развертывание)
Непрерывная интеграция (Continuous Integration) появилась не в последние 10 лет, однако именно за прошедшую декаду она распространилась до такой степени, что стала частью стандартного рабочего процесса (run-тесты на всех pull request'ах). Становление GitHub в качестве платформы по разработке и хранению кода и, что более важно, развитие рабочего процесса на основе GitHub flow означает, что проведение тестов до принятия pull request'а в мастер — это единственный workflow в разработке, знакомый инженерам, начавшим свои карьеры в последние десять лет.
Непрерывное развертывание (Continuous Deployment; развертывание каждого коммита в том виде и в тот момент, когда он попадает в мастер) не так широко распространено, как непрерывная интеграция. Впрочем, со множеством различных облачных API для развертывания, растущей популярностью платформ вроде Kubernetes (предоставляющих стандартизованный API для развертываний) и появление мульти-платформенных, мульти-облачных инструментов вроде Spinnaker (построенных поверх упомянутых стандартизованных API), процессы развертывания стали более автоматизированными, упорядоченными и, в общем, более безопасными.
Контейнеры
Контейнеры, пожалуй, можно назвать самой хайповой, обсуждаемой, рекламируемой и неверно понимаемой технологией 2010-х. С другой стороны, это одна из самых важных инноваций предыдущей декады. Частично причина всей этой какофонии лежит в смешанных сигналах, которые мы получали практически отовсюду. Теперь, когда шумиха немного поутихла, некоторые моменты приобрели более отчетливые оттенки.
Контейнеры стали популярны вовсе не потому, что это лучший способ запустить приложение, удовлетворяющий запросам глобального сообщества разработчиков. Контейнеры стали популярны потому, что удачно вписались в маркетинговый запрос на некий инструмент, решающий совершенно иную задачу. Docker оказался фантастическим инструментом для разработки, решающим насущную проблему совместимости («работает на моей машине»).
Точнее говоря, революцию произвел Docker-образ, поскольку решил проблему паритета между средами и обеспечил истинную переносимость не только файла приложения, но и всех его программных и операционных зависимостей. Тот факт, что этот инструмент каким-то образом подстегнул популярность «контейнеров», которые по сути представляют собой весьма низкоуровневую деталь реализации, для меня остается, пожалуй, главной загадкой прошедшего десятилетия.
Serverless
Готова поспорить, что появление «бессерверных» вычислений даже важнее, чем контейнеров, поскольку оно действительно позволяет воплотить в реальность мечту о вычислениях по запросу (on-demand). В последние пять лет я наблюдала за постепенным расширением сферы применения бессерверного подхода (добавлялась поддержка новых языков и сред выполнения). Возникновение таких продуктов, как Azure Durable Functions, представляется верным шагом на пути реализации stateful-функций (попутно решающим некоторые проблемы, связанные с ограничениями FaaS). С интересом понаблюдаю, как эта новая парадигма будет развиваться в ближайшие годы.
Автоматизация
Пожалуй, больше всего от этого тренда выиграло сообщество инженеров по эксплуатации, поскольку именно он позволил воплотить в жизнь концепции вроде «инфраструктура как код» (IaC). Кроме того, страсть к автоматизации совпала с ростом «культуры SRE», целью которой является более программно-ориентированный подход к эксплуатации.
Всеобщая API-фикация
Еще одной любопытной особенностью прошедшего десятилетия стала API-фикация различных задач разработки. Хорошие, гибкие API позволяют разработчику создавать инновационные рабочие процессы и инструменты, которые в свою очередь помогают с обслуживанием и повышают удобство работы.
Кроме того, API-фикация — это первый шаг к SaaS-фикации некоторого функционала или инструмента. Эта тенденция также совпала с ростом популярности микросервисов: SaaS стал просто еще одним сервисом, с которым можно работать по API. В настоящее время имеется множество SaaS- и FOSS-инструментов в таких областях, как мониторинг, платежи, балансировка нагрузки, непрерывная интеграция, оповещения, переключение функциональности (feature flagging), CDN, инжиниринг трафика (например, DNS) и т.д., которые процветали в прошлом десятилетии.
Наблюдаемость
Стоит отметить, что сегодня нам доступны намного более продвинутые инструменты для мониторинга и диагностики поведения приложений, чем когда-либо ранее. Систему мониторинга Prometheus, получившую статус Open Source в 2015 году, можно назвать, пожалуй, лучшей системой мониторинга из тех, с которыми мне доводилось работать. Она не совершенна, однако значительное число вещей в ней реализованы совершенно правильным образом (например, поддержка измерений [dimensionality] в случае метрик).
Распределенная трассировка стала еще одной технологией, вышедшей в мейнстрим в 2010-х благодаря таким инициативам, как OpenTracing (и ее преемнице OpenTelemetry). Хотя трассировка по-прежнему довольно сложна в применении, некоторые из последних разработок позволяют надеяться, что в 2020-х мы раскроем ее истинный потенциал. (Прим. перев.: Читайте также в нашем блоге перевод статьи «Распределённая трассировка: мы всё делали не так» этого же автора.)
Заглядывая в будущее
Увы, существует множество болевых точек, которые ждут своего разрешения в наступившем десятилетии. Вот мои мысли по их поводу и некоторые потенциальные идеи о том, как от них избавиться.
Решение проблемы закона Мура
Конец закона масштабирования Деннарда и отставание от закона Мура требуют новых инноваций. John Hennessy в своей лекции объясняет, почему проблемно-зависимые (domain specific) архитектуры вроде TPU могут стать одним из решений проблемы отставания от закона Мура. Тулкиты вроде MLIR от Google уже представляются хорошим шагом вперед в этом направлении:
Компиляторы должны поддерживать новые приложения, легко портироваться на новое аппаратное обеспечение, связывать многие уровни абстракции, начиная от динамических, управляемых языков и до векторных ускорителей и программно-управляемых запоминающих устройств, в то же время предоставляя высокоуровневые переключатели для автонастройки, обеспечивая функциональность just-in-time, диагностику и распространяя отладочную информацию о функционировании и производительности систем по всему стеку, и при этом в большинстве случаев обеспечивать производительность, достаточно близкую к написанному вручную ассемблеру. Мы намерены делиться своим видением, прогрессом и планами в отношении разработки и публичной доступности подобной компилирующей инфраструктуры.
CI/CD
Хотя рост популярности CI стал одним из главных трендов 2010-х, Jenkins по-прежнему остается золотым стандартом CI.
Это пространство остро нуждается в инновациях в следующих областях:
- пользовательский интерфейс (DSL для кодирования тестовых спецификаций);
- детали реализации, которые сделают его по-настоящему масштабируемым и быстрым;
- интеграция с различными средами (staging, prod и т. д.) для осуществления более продвинутых форм тестирования;
- непрерывная проверка и развертывание.
Инструменты разработчиков
Как отрасль, мы начали создавать все более сложное и впечатляющее программное обеспечение. Однако когда речь заходит о наших собственных инструментах, можно сказать, что ситуация могла бы быть намного лучше.
Совместное и удаленное (по ssh) редактирование приобрели некоторую популярность, однако так и не стали новым стандартным способом разработки. Если вы, как и я, отвергаете саму мысль о необходимости постоянного подключения к интернету только для того, чтобы иметь возможность заниматься программированием, то работа через ssh на удаленной машине вас вряд ли устроит.
Локальные среды разработки, особенно для инженеров, работающих над крупными сервис-ориентированными архитектурами, все еще остаются проблемой. Некоторые проекты пытаются ее решить, и мне было бы интересно узнать, как будет выглядеть самый эргономичный UX для данного сценария использования.
Также было бы интересно развить концепцию «переносимых сред» на другие области разработки, такие как воспроизведение ошибок (или flaky tests), встречающихся в определенных условиях или при определенных настройках.
Также я хотела бы видеть больше инноваций в таких областях, как семантический и контекстно-зависимый поиск кода, инструменты, позволяющие соотносить инциденты в production с конкретными частями кодовой базы, и т.д.
Вычисления (будущее PaaS)
На фоне всеобщего ажиотажа по поводу контейнеров и serverless в 2010-х спектр решений в публичном облачном пространстве значительно расширился в последние несколько лет.
В связи с этим возникают несколько интересных вопросов. Прежде всего, список доступных вариантов в публичном облаке постоянно растет. У поставщиков облачных услуг имеется персонал и ресурсы, позволяющие им с легкостью идти в ногу с последними достижениями в мире Open Source и выпускать продукты вроде «serverless pod'ов» (подозреваю, просто делая их собственные FaaS runtime'ы совместимыми с OCI) или другие похожие причудливые штуки.
Тем, кто пользуется этими облачными решениями, можно только позавидовать. В теории облачные предложения Kubernetes (GKE, EKS, EKS на Fargate и т.д.) предоставляют независимые от облачного провайдера API для запуска рабочих нагрузок. Если вы пользуетесь подобными продуктами (ECS, Fargate, Google Cloud Run и др.), то, вероятно, уже максимально задействуете наиболее интересные функции, предлагаемые поставщиком услуг. Кроме того, при появлении новых продуктов или вычислительных парадигм миграция, скорее всего, будет простой и беззаботной.
Учитывая то, как быстро развивается спектр подобных решений (я очень удивлюсь, если в ближайшее время не появится пара-тройка новых вариантов), небольшим «платформенным» командам (командам, связанным с инфраструктурой и отвечающим за создание платформ on-premise для запуска рабочих нагрузок в компаниях) будет невероятно трудно конкурировать в плане функциональных возможностей, простоты использования и общей надежности. 2010-е прошли под знаком Kubernetes как инструмента для создания PaaS (платформа-как-услуга), поэтому мне кажется совершенно бессмысленным создание внутренней платформы на базе Kubernetes, предлагающей те же возможности выбора, простоту и свободу, доступные в публичном облачном пространстве. Представление об основанной на «контейнерах» PaaS как о «стратегии Kubernetes» равносильно умышленному отказу от использования самых инновационных возможностей облака.
Если посмотреть на доступные сегодня вычислительные возможности, становится очевидно, что создание собственной PaaS исключительно на базе Kubernetes равносильно тому, чтобы собственноручно загнать себя в угол (не слишком дальновидный подход, да?). Даже если кто-то решит сегодня создать контейнерную PaaS на базе Kubernetes, через пару лет она будет выглядеть устаревшей по сравнению с облачными возможностями. Хотя Kubernetes начинал свое существование как проект с открытым исходным кодом, его прародителем и идейным вдохновителем выступает соответствующий внутренний инструмент Google. Однако он изначально разрабатывался в начале/середине 2000-х, когда вычислительный ландшафт был совершенно другим.
Кроме того, в очень широком смысле компании и не должны становиться экспертами в работе с кластером Kubernetes, равно как они не занимаются созданием и поддержанием собственных центров обработки данных. Обеспечение надежной вычислительной основы — это основная задача поставщиков облачных услуг.
Наконец, у меня складывается ощущение, что мы немного регрессировали как отрасль в плане опыта взаимодействия (UX). Heroku была запущена в 2007 году и до сих пор остается одной из самых простых в использовании платформ. Спору нет, Kubernetes обладает гораздо большей мощностью, расширяемостью и программируемостью, однако я скучаю по тому, насколько просто начать работу и провести развертывание в Heroku. Чтобы пользоваться этой платформой, достаточно знать Git.
Все это подводит меня к следующему умозаключению: для работы нам необходимы лучшие, более высокоуровневые абстракции (особенно это справедливо для абстракций самого высокого уровня).
Правильный API самого высокого уровня
Docker — это отличный пример необходимости лучшего разделения задач одновременно с правильной реализацией API высочайшего уровня.
Проблема Docker'а в том, что (по крайней мере) изначально перед проектом были поставлены слишком глобальные цели: все ради решения проблемы совместимости («работает на моей машине») с помощью контейнерной технологии. Docker был и форматом образов, и runtime'ом с собственной виртуальной сетью, и инструментом CLI, и демоном, работающим под root'ом, и многим другим. Во всяком случае, обмен сообщениями был более запутанным, не говоря уже о «легковесных VM», контрольных группах, пространствах имен, многочисленных проблемах с безопасностью и функций вперемешку с маркетинговым призывом «создавать, поставлять, запускать любое приложение где угодно».
Как и со всеми хорошими абстракциями, требуется время (а также опыт и боль), чтобы разбить различные проблемы на логически слои, которые можно скомбинировать друг с другом. Увы, прежде чем Docker сумел достичь подобной зрелости, в борьбу вступил Kubernetes. Он настолько монополизировал хайп-цикл, что теперь все старались не отставать от изменений в экосистеме Kubernetes, а экосистема контейнеров приобрела вторичный статус.
Kubernetes во многих отношениях разделяет те же проблемы, что и Docker. Несмотря на все разговоры о крутой и составляемой (composable) абстракции, разделение различных задач на слои не слишком хорошо инкапсулировано. В своей основе это оркестратор контейнеров, запускающий контейнеры в кластере, состоящем из различных машин. Это довольно низкоуровневая задача, применимая только к инженерам, эксплуатирующим кластер. С другой стороны, Kubernetes это также абстракция высочайшего уровня, CLI-инструмент, с которым пользователи взаимодействуют через YAML.
Docker был (и остается) классным инструментом для разработки, несмотря на все его недостатки. В попытке угнаться сразу за всеми «зайцами» его разработчикам удалось правильным образом реализовать абстракцию высочайшего уровня. Под абстракцией высочайшего уровня я подразумеваю подмножество функциональности, в которой действительно была заинтересована целевая аудитория (в данном случае разработчики, проводившие большую часть времени в своих локальных средах разработки) и которое отлично работало «из коробки».
Dockerfile и CLI-утилита
docker должны стать примером построения хорошего «пользовательского интерфейса высочайшего уровня». Рядовой разработчик может приступить к работе с Docker'ом, ничего не зная о тонкостях реализации, вносящих вклад в эксплуатационный опыт, таких как пространства имен, контрольные группы, ограничения памяти и CPU и т.д. В конечном счете написание Dockerfile'а не сильно отличается от написания shell-сценария.Kubernetes предназначен для различных целевых групп:
- администраторов кластера;
- инженеров-программистов, занимающихся вопросами инфраструктуры, расширяющих возможности Kubernetes и создающих платформы на его основе;
- конечных пользователей, взаимодействующих с Kubernetes посредством
kubectl.
Подход «один API подходит для всего», примененный в Kubernetes, представляет собой недостаточно инкапсулированную «гору сложности» без указания того, как ее масштабировать. Все это приводит к неоправданно затяжной траектории обучения. Как пишет Adam Jacob, «Docker принёс пользователям трансформирующий опыт, который до сих пор не превзошли. Спросите у любого, кто использует K8s, хотели бы они, чтобы он работал как их первый
docker run. Ответ будет утвердительным»:Я бы сказала, что основная часть инфраструктурной технологии сегодня слишком низкоуровневая (и, следовательно, считается «слишком сложной»). Kubernetes реализован на довольно низком уровне. Распределенная трассировка в ее нынешней форме (множество span'ов, сшитых вместе, чтобы сформировать traceview) также реализована на слишком низком уровне. Инструменты для разработчиков, реализующие «абстракции самого высокого уровня», как правило, оказываются наиболее успешными. Это умозаключение оказывается справедливым в удивительном числе случаев (если технология слишком комплексна или сложна в использовании, то «API/UI высочайшего уровня» для этой технологии еще только предстоит открыть).
Прямо сейчас экосистема cloud native смущает своей зацикленностью на низкоуровневости. Как отрасль мы должны внедрять инновации, экспериментировать и обучать тому, как выглядит правильный уровень «максимальной, высочайшей абстракции».
Розничная торговля
В 2010-х цифровой опыт в розничной торговле почти не изменился. С одной стороны, легкость онлайн-покупок должна была ударить по классическим розничным магазинам, с другой — онлайн-шоппинг фундаментально почти не поменялся за десятилетие.
Хотя у меня нет конкретных мыслей относительно развития этой отрасли в следующем десятилетии, я буду сильно разочарована, если в 2030-м мы будем совершать покупки так же, как делаем это в 2020-м.
Журналистика
Я все больше разочаровываюсь в состоянии мировой журналистики. Становится все труднее находить беспристрастные новостные ресурсы, которые вещают объективно и педантично. Очень часто граница между самой новостью и мнением о ней стирается. Как правило, информация преподносится предвзято. Это особенно справедливо в случае некоторых стран, где исторически не существовало разделения между новостью и мнением о ней. В недавней статье, опубликованной после последних всеобщих выборов в Великобритании, Alan Rusbridger, бывший редактор The Guardian, пишет:
Главная мысль состоит в том, что на протяжении многих лет я смотрел на американские газеты и жалел тамошних коллег, которые отвечали исключительно за новости, возлагая комментирование на совершенно других людей. Однако со временем жалость превратилась в зависть. Теперь я думаю, что всем британским национальным газетам следует отделить ответственность за новости от ответственности за комментарии. Увы, рядовому читателю — особенно онлайн-читателю — слишком сложно разглядеть разницу.
Учитывая достаточно сомнительную репутацию Кремниевой долины, когда речь заходит об этике, я бы ни при каких обстоятельствах не доверила технологиям «революцию» в журналистике. При этом я (и многие мои знакомые) была бы рада, если бы появился беспристрастный, бескорыстный и заслуживающий доверия новостной ресурс. Пока я не представляю, как могла бы выглядеть подобная платформа, но уверена, что в эпоху, когда правду становится все труднее разглядеть, потребность в честной журналистике выше, чем когда-либо.
Социальные сети
Социальные сети и коллективные новостные платформы выступают основным источником информации для многих людей в различных уголках мира, и недостаток точности и нежелание некоторых платформ проводить хотя бы базовою проверку основных фактов приводят к таким плачевным последствиям, как геноцид, вмешательство в выборы и т.д.
Социальные сети также являются самым мощным медийным средством из всех когда-либо существовавших. Они кардинально изменили политическую практику. Они изменили рекламу. Они изменили поп-культуру (например, основной вклад в развитие т.н. cancel culture [культуры остракизма — прим. перев.] вносят именно социальные сети). Критики утверждают, что социальные сети оказались плодородной почвой для быстрых и «капризных» изменений в моральных ценностях, однако они также обеспечили представителям маргинальных групп возможность объединяться (ранее у них никогда не было такой возможности). В сущности, социальные сети изменили способ общения и способ самовыражения людей в XXI веке.
Тем не менее, я также убеждена, что социальные сети способствуют проявлению худших человеческих импульсов. Внимательностью и вдумчивостью часто пренебрегают в угоду популярности, и становится практически невозможно выражать аргументированное несогласие с определенными мнениями и позициями. Поляризация часто выходит из-под контроля, в результате публика попросту не слышит отдельные мнения, в то время как абсолютисты контролируют вопросы онлайн-этикета и приемлемости.
Я задаюсь вопросом, можно ли создать «лучшую» платформу, способствующую повышению качества дискуссий? Ведь именно то, что движет «вовлеченностью», часто и приносит основную прибыль этим платформам. Как пишет Kara Swisher в New York Times:
Можно развивать цифровое взаимодействие, не провоцируя ненависть и нетерпимость. Причина, по которой большинство социальных сетей кажутся настолько токсичными, состоит в том, что они создавались ради скорости, вирусности и привлечения внимания, а не ради содержания и точности.
Было бы действительно прискорбно, если бы через пару десятилетий единственным наследием социальных сетей стало бы размывание нюансов и адекватности в публичном дискурсе.
P.S. от переводчика
Читайте также в нашем блоге:
- «Трансформация Docker: продажа Docker Enterprise в Mirantis и обновлённый путь»;
- «Прошлое, настоящее и будущее Docker и других исполняемых сред контейнеров в Kubernetes»;
- «Новая статистика CNCF о контейнерах, cloud native и Kubernetes»;
- «Сколько разработчиков думают, что Continuous Integration не нужна?».




