
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Парсим данные с сайтов при помощи XPath и Screaming Frog без помощи программистов. Синтаксис XPath для выбора, ссылка на удобное расширение для извлечения пути, примеры для парсинга любых данных + запись моего мастер-класса в гостях у Михаила Шакина.

Всем привет. Меня зовут Толстенко Александр. Я частный SEO специалист. В сфере разработки и продвижения бизнеса в интернете я с 2009 года. Ознакомиться с другими статьями, можно в профиле habr.
XPath - Что это такое
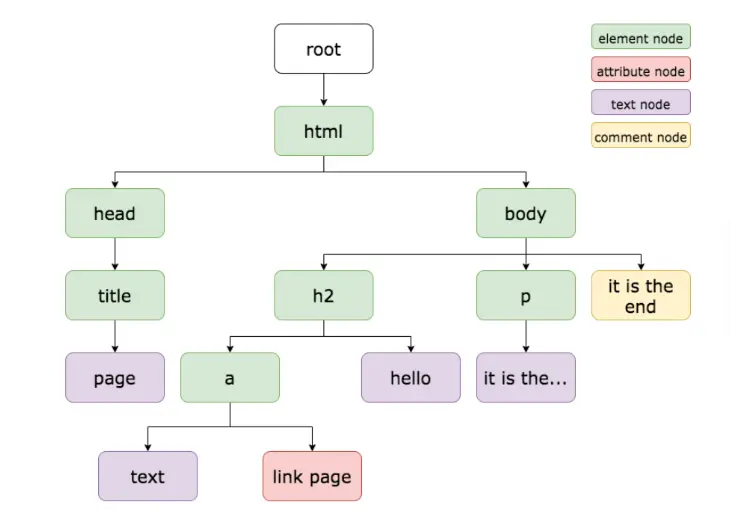
XPath (XML Path Language) - это язык запросов, используемый для навигации и поиска информации в XML-документах. Он позволяет точно указать путь к элементам, атрибутам и текстовым данным, которые нужно найти в структуре XML файлов и получить данные при необходимости.
XPath предлагает набор выражений, операторов и функций для указания конкретных путей обхода XML-деревьев и фильтрации данных с помощью различных критериев. Эти выражения состоят из элементов и операторов, которые можно комбинировать, чтобы получить нужные результаты.
Для чего нужен XPath
XPath используется для навигации и выбора элементов XML-документов. Он позволяет находить пути к элементам и их атрибутам, а также выполнять операции с ними: поиск, фильтрация, выборка.
Вот некоторые основные случаи использования XPath:
1.) Поиск элементов: XPath позволяет найти определенные элементы в XML-документе с помощью путей и фильтров. Например, можно найти все элементы определенного типа или имеющие определенное значение атрибута.
2.) Извлечение данных: XPath позволяет извлекать конкретные значения из XML-документа. Например, можно получить содержимое элемента или значение его атрибута.
3.) Проверка условий: XPath позволяет задавать условия и проверять их в XML-документе. Например, можно проверить, что значение атрибута соответствует определенному критерию или что в XML-документе есть определенный элемент.
4.) Навигация по структуре: XPath позволяет перемещаться по структуре XML-документа, находить конкретные узлы и выполнять с ними операции. Например, можно перейти к родительскому или дочернему элементу, выбрать первый или последний элемент, перейти на следующий или предыдущий элемент, а также совершать другие действия для исследования структуры XML-документа.
Использование XPath позволяет эффективно и удобно работать с XML-данными, особенно при обработке и анализе больших объемов информации.
Кому и зачем нужен Xpath
Если коротко — XPath нужен всем, кто работает с XML.
XPath широко используется в различных областях: программирование, веб-скрапинг, автоматизацию тестирования и анализ данных. Язык запросов позволяет легко и эффективно обращаться к нужным элементам в структурированных документах XML к нужным элементам, совершать какие то операции или получить необходимые данные.
Это лишь часть сценариев, в когда язык XPath может помочь — на самом деле, сценариев может быть намного больше.
Синтаксис XPath

Для выбора узлов в XML документе с помощью XPath используются выражения путей. Выборка узла производится следуя по заданному пути или по, так называемым, шагам.
Синтаксис XPath описывает правила для создания выражений, которые позволяют точно указать, какие элементы и атрибуты должны быть выбраны из XML-структуры. Точно указать, какой элемент выбрать нужно с помощью XPath можно при помощи:
1.) Выбора узлов
2.) Пути выбора элементов
3.) Оси направления выбора
4.) Функций
5.) Предикатов
Выбор узлов

Чтобы выбрать нужный узел в XML документе, нужно обратиться к нему при помощи языка запросов XPath, указав путь к нужному элементу. Узел выбирается следуя по заданному пути.
Базовый синтаксис XPath для парсинга элементов:
1.) * — Выбрать любой элемент.
2.) [] — Найти конкретный элемент. Пример: //li[1]
имя_узла — Выбирает все узлы с указанным именем узла. Пример: div, p и т.д.
3.) / — Ищет от корневого узла html
4.) // — Ищет узлы в документе от текущего узла, который соответствует выбору, независимо от того, где они находятся
5.) . — Ищет текущий узел
6.) .. — Ищет родителя текущего узла
7.) @ — Ищет нужный атрибут. Пример: //p[@value="2008"]
Абсолютные и относительные пути обращения к элементам

К конкретному элементу можно обратиться двумя способами:
1.) Абсолютным. Абсолютный xpath начинается со слеша ( / ) и указывает на полный путь от корневого узла до целевого узла.
Пример выражения в XPath: /html/body/div[1]/h1
Конструкция означает: "выбрать первый элемент div, который находится по пути html > body > div и затем выбрать его дочерний элемент h1".
2.) Относительным. Относительный путь начинается с двух слешей (//) и указывает на путь от любого узла, который соответствует определенным критериям, до целевого узла. Пример: //div[@id='main']
Конструкция означает: "выбрать любой элемент div, который имеет атрибут id со значением 'main'".
Общие функции XPath
Язык XPath имеет набор встроенных функций, которые позволяют осуществлять различные операции с XML-документами. Вот некоторые из основных функций XPath:
1.) text() - возвращает текстовое содержимое элемента.
2.) count() - возвращает количество элементов, соответствующих указанному выражению.
3.) normalize-space() - удаляет лишние пробелы из строки и заменяет последовательности пробелов на одиночные пробелы.
4.) starts-with(x,y) - проверяет, начинается ли строка с x-y.
5.) contains(x,y) - проверяет, содержит ли строка x-y.
6.) last() - возвращает последнюю позицию элемента в выборке.
7.) position() - возвращает позицию текущего элемента в выборке.
8.) name() - возвращает имя текущего элемента.
9.) sum() - суммирует значения элементов выборки.
10.) string() - преобразует узел в строку.
11.) lower-case() - преобразует текст в нижний регистр.
12.) @attribute - выбирает значение указанного атрибута.
13.) concat() - объединяет две или более строки.
14.) string-length() - возвращает длину строки.
15.) substring() - возвращает подстроку из строки, начиная с указанной позиции.
Кроме этих основных функций, XPath также предоставляет более сложные функции, такие как функции математических операций (например, floor(), round(), sum()), функции работы с датами и временем и другие.
Оси XPath
Ось в XPath - это специальная концепция, которая используется для указания направления движения при поиске элементов в документе. Оси позволяют выбирать элементы, которые относятся к определенным отношениям с другими элементами в дереве XML или HTML.
В XPath есть несколько осей, которые можно использовать при создании выражений:
1.) child::note — Выбирает все узлы note, которые являются прямыми потомками текущего узла
2.) attribute::date — Выбирает атрибут date текущего узла
3.) child::* — Выбирает всех прямых потомков текущего узла
4.) attribute::* — Выбирает все атрибуты текущего узла
5.) child::text() — Выбирает все текстовые узлы текущего узла
6.) child::node() — Выбирает всех прямых потомков текущего узла
7.) descendant::note — Выбирает всех потомков note текущего узла
8.) ancestor::note — Выбирает всех предков note текущего узла
9.) ancestor-or-self::note — Выбирает всех предков note текущего узла, а также сам текущий узел, если это узел note
10.) child::*/child::heading — Выбирает всех прямых потомков прямых потомков (“внуков") heading текущего узла
11.) last() — Выделяет последний элемент в дереве.
Предикаты (Коллекции)
Предикаты — конструкции, которые используются для фильтрации элементов и выбора конкретных элементов с помощью определенных условий.
Вот несколько примеров использования предикатов в XPath для :
1.) //a — Выберите все элементы в документе
2.)//a[@class='active'] — Выберите все элементы, у которых атрибут class равен "active"
3.) //input[@type='checkbox'] — Выберите все элементы input, у которых атрибут type равен "checkbox"
4.) //input[@type='text'] — Выберите все элементы input с атрибутом type равным "text"
5.) //p[contains(text(), 'Lorem')] — Выберите все элементы
, у которых текст содержит слово "Lorem"
6.) //div[count(p) > 3] — Выберите все элементы
, у которых количество дочерних элементов
больше 3
7.) //a[starts-with(@href, 'https://')] — Выберите все элементы, у которых атрибут href начинается с "https://"
8.) //input[matches(@value, '^\d+$')] — Выберите все элементы input, у которых атрибут value содержит только цифры
9.) //p[@value="01/2008"] — Выбирает все элементы p, у которых есть атрибут value со значением "01/2008"
10.) //p[@value] — Выбирает все элементы p, у которых есть атрибут value
11.) //p/text() — Выделит все текстовые узлы внутри всех элементов p
12.) //div[not(p)] — Выберите все элементы
, у которых не существует дочернего элемента
13.) /div/p[position()<3] — Выбирает первые два элемента p, которые являются прямыми потомками элемента div
14.) //tag[position()=1] — Выбирает первый элемент с тегом "tag"
15.) /div/ul/li[1] — Выбирает первый элемент li, который является прямым потомком элемента ul в div
16.) //li[a] — Выделяет элементы li, в которых есть элемент a
17.) //li[last()] — Выделяет последний элемент li в документе
18.) //a | //h2 - Выделить все элементы a и h2 с помощью оператора объединения |
19.) //tag[@value > 9] — Получить узлы tag, value которых больше 9-ти.
20.) //div[note[@value > 9]]/а — Получить только имена узлов, value которых больше 9-ти
21.) //div[4]/h2[text() = "Текст"] — Выделит четвертый элемент div, h2 которого содержит слово: Текст
22.) /div/note[last()] — Выбирает последний элемент note, который является прямым потомком элемента div
23.) /div/note[last()-1] — Выбирает предпоследний элемент note, который является прямым потомком элемента div
24.) //*[@id] — Выберите все элементы с атрибутом id
25.) //div[contains(@class, 'content')]/p — Выберите все элементы, которые являются дочерними элементами
с классом "content"
26.) //img[contains(@src, 'logo')] — Выберите все элементы , у которых атрибут src содержит слово "logo"
27.) //*[@href[contains(text(), '.pdf')]] — Выберите все элементы со значением атрибута href, оканчивающимся на .pdf
28.) //*[@data-toggle='modal'] — Выберите все элементы с атрибутом data-toggle и значением "modal"
29.) //tag[@attribute>5] — Выбирает все элементы с тегом "tag" и атрибутом "attribute", значение которого больше 5
30.) //tag[@attribute="value"] — Выбирает все элементы с тегом "tag" и атрибутом "attribute" со значением "value"
Это лишь некоторые примеры запросов для получения данных. Существует много других комбинаций формирования запросов XPath.
Какие данные можно извлечь с сайта при помощи XPath и парсера

XPath и парсеры могут извлекать различные данные с веб-сайтов. Вот несколько типов данных, которые можно получить при помощи этих инструментов:
Количество товаров в категориях;
Описание, характеристики и цену товара;
Изображения;
Наличие и количество отзывов;
Количество просмотров статей;
Количество лайков у статей;
Почтовые ящики;
Хлебные крошки;
Страницы с видео;
Какие страницы, имеют сколько отзывов;
На каких страницах размещен определенный текстовый блок или нет;
Даты публикаций статей или товаров;
Рейтинги товаров или статей.
Это лишь некоторые примеры того, что можно извлечь с помощью XPath. Фактически, вы можете извлекать любые данные или атрибуты, доступные на веб-странице в зависимости от ее структуры и организации информации.
Формулы по извлечению HTML атрибутов которые будут полезны СЕОшникам
1.) //@href — Извлечь все ссылки
2.) //a[starts-with(@href,'mailto')]/@href — Получить ссылки, которые содержат “mailto” (email адрес)
3.) //a[contains(@href,'tel:')]/@href — Получить все телефоны
4.) //img/@src — Получить все URL адреса картинок
5.) //img[contains(@class,'name-class')]/@src — Получить все URL адреса источников изображений с именем класса
6.) //div[@class='class'] — Получить элементы в тегах
с определенным классом, указанным в кавычках
7.) count(//h2) — Посчитать количество элементов на странице
8.) //*[@itemtype]/@itemtype — Извелчь какие типы микроразметок есть на странице
9.) //*[@itemprop='price']/@content — Узнать значение поля свойства разметки
10.) //iframe[contains(@src,'https://www.youtube.com/')]/@src — Найти ссылки на все видео с ютуба
11.) //table[@class='product-table']//td/text() — Извлечь текст всех ячеек таблицы с классом "product-table"
12.) //td[contains(text(),'Weight')]/following-sibling::td — Извлечение данных из ячеек таблиц
13.) contains(//meta[@name='description']/@content, 'таргетированное-ключевое-слово') — Проверяет наличие ключевого слова в мета теге
14.) //link[@rel=’amphtml’]/@href — Получить URL-адрес AMP
15.) //form[*]/input[@type='text']/@name — Имена всех текстовых полей внутри форм
Это далеко не весь список, чего можно достать с сайта конкурента. Более того, в конкретном случае, синтаксис будет разный. Составить формулу можно при помощи расширения XPath Helper или нажав правой кнопкой на html элементе и выбрать скопировать XPath

Как извлечь данные при помощи XPath со страницы
Для извлечения данных со страниц, я использую расширение "XPath Helper".
1.) Установите XPath Helper для браузера Google Chrome https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl
2.) После установки, обновите страницу или откройте новую вкладку и перейдите на любую веб-страницу.
3.) Нажмите Ctrl-Shift-X (или Command-Shift-X в OS X) или нажмите кнопку XPath Helper на панели инструментов, чтобы открыть консоль XPath Helper.

3.) Удерживая нажатой клавишу Shift, наведите указатель мыши на элементы на странице. Поле запроса будет постоянно обновляться, чтобы отображать запрос XPath для элемента под указателем мыши, а в окне результатов будут отображаться результаты для текущего запроса.
4. При желании отредактируйте XPath-запрос прямо в консоли. В окне результатов немедленно отразятся ваши изменения.

5. Повторите шаг (3), чтобы закрыть консоль.
Если консоль вам мешает, удерживайте нажатой клавишу Shift, а затем наведите на нее указатель мыши; он переместится на противоположную сторону страницы.
Что можно сделать с помощью Screaming Frog SEO Spider

Запись можно посмотреть на канале Михаила Шакина тут: https://www.youtube.com/live/91h9vEbFQa4?feature=share
На этом все, спасибо за внимание.
Есть, чем поделиться или дополнить? Буду только рад! Пишите в комменты. Спасибо.
или пишите в личку.



