
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Обучение больших языковых моделей — это одно из самых актуальных направлений в машинном обучении. Крупнейшие IT-компании бьются над созданием всё более совершенных моделей. В том числе и Яндекс: мы создаём и применяем в наших сервисах нейросети YaLM уже больше двух лет.
В этом году улучшение моделей стало приоритетным на уровне всей компании. Внутри эта работа известна как проект «Генезис» или YaLM 2.0. Её результатом стал большой скачок в качестве наших моделей.
Новая модель получила название YandexGPT (YaGPT), вы могли впервые попробовать её в Алисе по запросу «Давай придумаем» чуть больше двух недель назад. Сегодня мы обновили YaGPT: Алиса научилась писать ответы с учётом истории предыдущих сообщений. В честь этого хотим рассказать Хабру историю всего проекта. Уже в ближайшее время новая модель станет частью и других сервисов Яндекса.
В 2021 году мы впервые рассказали о семействе наших GPT-подобных языковых моделей YaLM. На тот момент в него входили модели от 1 до 13 млрд параметров. Позднее появилась модель на 28 млрд. Ну и наконец — та самая модель на 100 млрд, которую мы выложили в опенсорс в прошлом году. Мы применили YaLM в поиске для генерации кратких описаний объектных ответов, для поддержания диалога в Алисе и много где ещё.
Технически процесс обучения YaLM можно разбить на два последовательных этапа: Pretraining и P-tuning.
На первом этапе терабайты текста из интернета, книг и прочих общедоступных источников разбиваются на небольшие фрагменты и подаются в обучение модели. В процессе обучения мы заставляем модель угадывать следующее слово во фрагменте текста на основе всех предыдущих.
Чтобы успешно решать эту задачу, модель вынуждена выучивать как структуру языка (части речи, члены предложения, пунктуацию), так и факты о мире. Например, чтобы хорошо угадывать слова и числа в тексте «Скорость света в вакууме равна 299 792 458 метров в секунду» модель должна запомнить, чему равна скорость света. Именно Pretrain определяет «эрудицию» нейросети.
Второй этап рассмотрим на примере. Допустим, вы задаёте нейросети такие вопросы:
Вы получите очень разные ответы на свои вопросы: префиксы «ответь покороче», «ответь развернуто» и «ответь стишком» сильно на них влияют. Предположим, пользователь спрашивает просто «что такое радуга». Тогда задача P-tuning в том, чтобы автоматически подобрать хороший префикс. Если дописать такой префикс к запросу пользователя, то ответ получится лучше.
Более формально: P-tuning — это дешёвый метод решить конкретную задачу. В этой статье мы рассказывали, как P-tuning применяется в быстрых ответах поиска.
Всё, что будет знать и уметь модель, закладывается в неё на этапе Pretrain. Раньше мы фокусировались на размере Pretrain-датасета, считая, если положить в него много данных, то и модель многое выучит. Сейчас же мы сфокусировались именно на качестве данных в датасете, это позволило значительно улучшить качество итоговой модели. Под качеством мы понимаем два важных требования к датасету.
Во-первых, требование к полноте фактов. Мы взяли реальный поток запросов наших пользователей и собрали такой датасет, который содержит ответы на большинство из них. Для оценки качества мы даже подняли отдельную, внутреннюю версию поиска Яндекса по датасету претрейна. Так мы убеждаемся, что у модели есть возможность выучить все полезные знания о мире.
Во-вторых, к чистоте данных. Бесполезные тексты вхолостую тратят время на обучение и учат модель неправильным фактам и знаниям. Представьте, что в Pretrain будет запись «Скорость света в вакууме равна 999 метров в секунду». Такие данные просто портят модель, заставляют её учить ошибочные знания. Бороться с источниками такого мусора — важная часть подготовки данных. Для YaGPT нам удалось сократить количество некачественных данных в pretrain-датасете в 4 раза.
P-tuning хорош тем, что позволяет быстро решить конкретную задачу, но обладает важной проблемой — у него есть ограничение в качестве. Это связано с тем, что P-tuning оптимизирует тысячи параметров (инпутов модели). Как в них уместить всю глубину личности Алисы? Все факты о ней, её историю, её предпочтения? А ведь кроме хранения фактов о персонаже, P-tuning должен ещё научить модель красиво отвечать на произвольный запрос, не грубить и многое другое.
Чтобы научить модель всему этому, мы собрали большой датасет из сотен тысяч примеров с хорошими ответами включающий все аспекты, указанные выше. Для такого количества данных лучше подходит Fine-tuning. Это такой же процесс обучения, как и обучение на Pretrain. Он оптимизирует миллиарды параметров модели. Такое обучение сложнее, чем P-tuning, требует большой обучающей выборки, но результат получается лучше.
Важно, чтобы в датасете для Fine-tuning были представлены примеры максимально разнообразных задач (такие задачи ещё называют инстрактами). Чем больше разных задач будет собрано, тем лучше получится модель. Но собрать их не так просто. Попробуйте придумать хотя бы сотню непохожих друг на друга просьб к Алисе. Скорее всего, многие вопросы окажутся однообразными.
Чтобы собрать большое количество разнообразных инстрактов, мы распараллелили эту работу: часть добыли из запросов в поиск, другую — из обращений к Алисе. Кроме того, бросили клич внутри компании и получили десятки тысяч подобных задач от неравнодушных коллег.
Очень важно, чтобы все ответы на собранные инстракты были максимально качественными. Для обучения модели нужны сотни тысяч таких ответов. Их написание — это очень масштабная задача, потому что от людей требуется каждый раз разбираться в незнакомой для себя области. На это может уйти и час, и два. У такой необычной для России специальности уже даже существует название — AI-тренер. С этого года мы ищем таких людей. Около ста AI-тренеров уже помогают нам готовить ответы на инстракты. Кроме того, мы воспользовались нашим опытом в краудсорсинге и привлекли более тысячи асессоров в помощь тренерам.
Отдельный повод для гордости — наш внутренний марафон. Мы обратились ко всем нашим коллегам через Этушку (внутренняя соцсеть), хурал (аналог All-hands meeting), корпоративную рассылку и объявили марафон по написанию эталонных ответов на инстракты для последующего обучения модели. За одну неделю 826 участников написали для нас более 36 тыс. ответов! Вы можете заметить, что мы уже во второй раз за статью упоминаем коллективную помощь наших коллег. Активная, массовая помощь яндексоидов, которые даже не были связаны с проектом, позволила нам повысить качество модели и быстрее запустить проект.
С помощью AI-тренеров, асессоров и коллег из других направлений нам удалось собрать несколько сотен тысяч ответов на инстракты. Примерно половина из них оказалась достаточно качественной и легла в основу датасета.
Не все люди пишут одинаково хорошо. Хороших ответов значительно меньше, чем остальных, но они ощутимо лучше. На практике хорошо сработала схема, при которой более качественные тексты передаются на обучение на более позднем этапе, а не смешиваются в одну большую кучу.

Наша лучшая схема на момент старта в Алисе
Примерно месяц назад у нас обучилась базовая модель YaGPT. Мы начали тестировать её всей командой и быстро убедились, что модель классная, но внедрять её в Алису нельзя. Требовались продуктовые доработки. Например, модель не знала, что она Алиса (не могла назвать своё имя, своих создателей, интересы и многое другое).
Чтобы научить модель быть Алисой, нужно собрать датасет с вопросами вида «Как тебя зовут», «Кто тебя создал», «Что ты любишь» и ответами на них. Для упрощения этого процесса мы придумали хитрость.
В итоге получили пары вопрос-ответ, из которых сформировали новый датасет и дообучили на нём модель. Наша модель частично обучила сама себя!
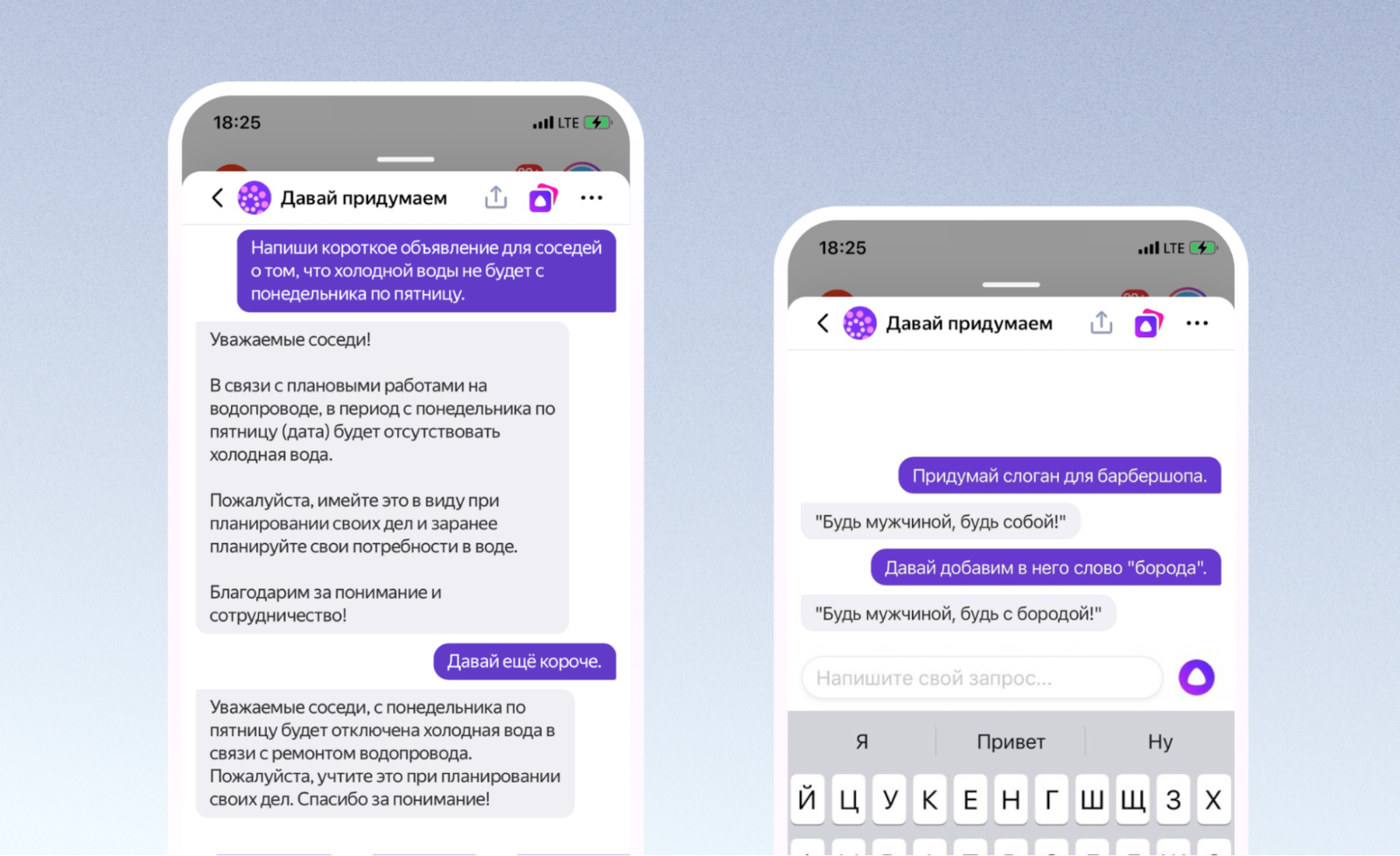
17 мая мы выкатили эту модель в виде навыка «Давай придумаем» в Алисе.
Сегодня мы выпустили первое большое обновление для YaGPT в Алисе. Наша модель научилась учитывать историю диалога при написании ответов. Это полезно, потому что позволяет доуточнить свою просьбу.
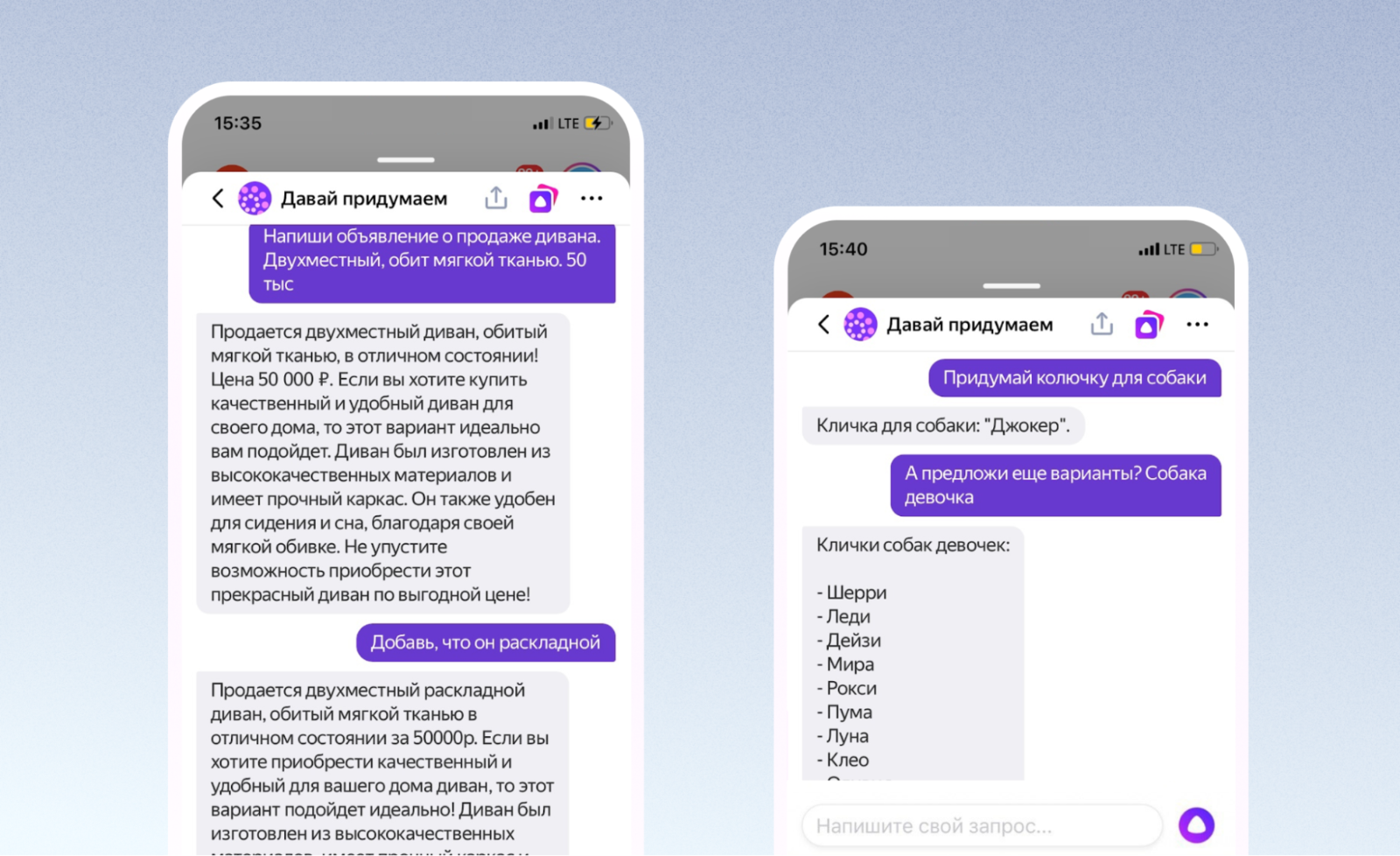
Оказалось, что наша базовая модель YaGPT уже сразу после обучения неплохо умела работать с контекстом. Возможно, из-за того, что какие-то диалоги оказались в претрейне, возможно, из-за разнообразия задач Fine-tune модель научилась совсем новым задачам. Навыки диалога проверяли так: переписывались с моделью и в каждом сообщении посылали на вход весь предыдущий диалог. Модель отвечала разумно.
Главной проблемой оказалось то, что она слишком сильно цепляется за контекст и не понимает, что он изменился. Нужно было научить модель игнорировать часть истории сообщений. Для этого мы сцепили несколько не связанных запросов с ответами в один диалог и учили модель предсказывать последний ответ. Так модель выучила, что иногда контекст может мешать.
Кроме того, мы дообучили модель на диалогах, которые выложили в опенсорс участники проекта Open Assistant.
Другая задача, которую мы должны были решить, — поиск баланса между длиной контекста и скоростью генерации ответов. Если ответ пишется долго — это плохо, потому что пользователи ожидают от Алисы мгновенной реакции. Наша модель YaGPT умеет работать с 8 тыс. токенов (это примерно 40 тыс. символов) на входе. В продакшене контекст такой длины приведёт к значительному ожиданию ответа. К счастью, обычно такая длина и не нужна. Поэтому сейчас модель учитывает 2 тыс. токенов (10 тыс. символов) или 50 отдельных запросов (в зависимости от того, какой лимит будет достигнут раньше). Это значительно ускоряет ответы модели.
В этом году мы проделали огромную работу над качеством наших моделей. Но этот пост не про завершение проекта, а про начало большого пути. Запуск YandexGPT в Алисе это лишь первое внедрение. И вот что мы будем делать в будущем.
1. Продолжим улучшать качество наших датасетов (Pretrain и Fine-tune).
2. Внедрим новый этап обучения — RLHF.
3. Обучим модели больших размеров (для исследований и применения в офлайне).
4. Вложимся в количество AI-тренеров. Мы верим, что в будущем обучение языковых моделей нового поколения невозможно без помощи подобных специалистов.
5. Внедрим YaGPT и в другие наши сервисы.
В этом году улучшение моделей стало приоритетным на уровне всей компании. Внутри эта работа известна как проект «Генезис» или YaLM 2.0. Её результатом стал большой скачок в качестве наших моделей.
Новая модель получила название YandexGPT (YaGPT), вы могли впервые попробовать её в Алисе по запросу «Давай придумаем» чуть больше двух недель назад. Сегодня мы обновили YaGPT: Алиса научилась писать ответы с учётом истории предыдущих сообщений. В честь этого хотим рассказать Хабру историю всего проекта. Уже в ближайшее время новая модель станет частью и других сервисов Яндекса.
Напомним про YaLM
В 2021 году мы впервые рассказали о семействе наших GPT-подобных языковых моделей YaLM. На тот момент в него входили модели от 1 до 13 млрд параметров. Позднее появилась модель на 28 млрд. Ну и наконец — та самая модель на 100 млрд, которую мы выложили в опенсорс в прошлом году. Мы применили YaLM в поиске для генерации кратких описаний объектных ответов, для поддержания диалога в Алисе и много где ещё.
Технически процесс обучения YaLM можно разбить на два последовательных этапа: Pretraining и P-tuning.
На первом этапе терабайты текста из интернета, книг и прочих общедоступных источников разбиваются на небольшие фрагменты и подаются в обучение модели. В процессе обучения мы заставляем модель угадывать следующее слово во фрагменте текста на основе всех предыдущих.
Чтобы успешно решать эту задачу, модель вынуждена выучивать как структуру языка (части речи, члены предложения, пунктуацию), так и факты о мире. Например, чтобы хорошо угадывать слова и числа в тексте «Скорость света в вакууме равна 299 792 458 метров в секунду» модель должна запомнить, чему равна скорость света. Именно Pretrain определяет «эрудицию» нейросети.
Второй этап рассмотрим на примере. Допустим, вы задаёте нейросети такие вопросы:
- «ответь покороче что такое радуга»,
- «ответь развернуто что такое радуга»,
- «ответь стишком что такое радуга».
Вы получите очень разные ответы на свои вопросы: префиксы «ответь покороче», «ответь развернуто» и «ответь стишком» сильно на них влияют. Предположим, пользователь спрашивает просто «что такое радуга». Тогда задача P-tuning в том, чтобы автоматически подобрать хороший префикс. Если дописать такой префикс к запросу пользователя, то ответ получится лучше.
Более формально: P-tuning — это дешёвый метод решить конкретную задачу. В этой статье мы рассказывали, как P-tuning применяется в быстрых ответах поиска.
Что мы сильно улучшили в YaGPT (YaLM 2.0)
Новые требования к Pretrain
Всё, что будет знать и уметь модель, закладывается в неё на этапе Pretrain. Раньше мы фокусировались на размере Pretrain-датасета, считая, если положить в него много данных, то и модель многое выучит. Сейчас же мы сфокусировались именно на качестве данных в датасете, это позволило значительно улучшить качество итоговой модели. Под качеством мы понимаем два важных требования к датасету.
Во-первых, требование к полноте фактов. Мы взяли реальный поток запросов наших пользователей и собрали такой датасет, который содержит ответы на большинство из них. Для оценки качества мы даже подняли отдельную, внутреннюю версию поиска Яндекса по датасету претрейна. Так мы убеждаемся, что у модели есть возможность выучить все полезные знания о мире.
Во-вторых, к чистоте данных. Бесполезные тексты вхолостую тратят время на обучение и учат модель неправильным фактам и знаниям. Представьте, что в Pretrain будет запись «Скорость света в вакууме равна 999 метров в секунду». Такие данные просто портят модель, заставляют её учить ошибочные знания. Бороться с источниками такого мусора — важная часть подготовки данных. Для YaGPT нам удалось сократить количество некачественных данных в pretrain-датасете в 4 раза.
Создание большого Alignment-датасета и использование Fine-tuning вместо P-tuning
P-tuning хорош тем, что позволяет быстро решить конкретную задачу, но обладает важной проблемой — у него есть ограничение в качестве. Это связано с тем, что P-tuning оптимизирует тысячи параметров (инпутов модели). Как в них уместить всю глубину личности Алисы? Все факты о ней, её историю, её предпочтения? А ведь кроме хранения фактов о персонаже, P-tuning должен ещё научить модель красиво отвечать на произвольный запрос, не грубить и многое другое.
Чтобы научить модель всему этому, мы собрали большой датасет из сотен тысяч примеров с хорошими ответами включающий все аспекты, указанные выше. Для такого количества данных лучше подходит Fine-tuning. Это такой же процесс обучения, как и обучение на Pretrain. Он оптимизирует миллиарды параметров модели. Такое обучение сложнее, чем P-tuning, требует большой обучающей выборки, но результат получается лучше.
Fine-tuning: максимально разнообразные инстракты
Важно, чтобы в датасете для Fine-tuning были представлены примеры максимально разнообразных задач (такие задачи ещё называют инстрактами). Чем больше разных задач будет собрано, тем лучше получится модель. Но собрать их не так просто. Попробуйте придумать хотя бы сотню непохожих друг на друга просьб к Алисе. Скорее всего, многие вопросы окажутся однообразными.
Чтобы собрать большое количество разнообразных инстрактов, мы распараллелили эту работу: часть добыли из запросов в поиск, другую — из обращений к Алисе. Кроме того, бросили клич внутри компании и получили десятки тысяч подобных задач от неравнодушных коллег.
Fine-tuning: качественные ответы на инстракты
Очень важно, чтобы все ответы на собранные инстракты были максимально качественными. Для обучения модели нужны сотни тысяч таких ответов. Их написание — это очень масштабная задача, потому что от людей требуется каждый раз разбираться в незнакомой для себя области. На это может уйти и час, и два. У такой необычной для России специальности уже даже существует название — AI-тренер. С этого года мы ищем таких людей. Около ста AI-тренеров уже помогают нам готовить ответы на инстракты. Кроме того, мы воспользовались нашим опытом в краудсорсинге и привлекли более тысячи асессоров в помощь тренерам.
Отдельный повод для гордости — наш внутренний марафон. Мы обратились ко всем нашим коллегам через Этушку (внутренняя соцсеть), хурал (аналог All-hands meeting), корпоративную рассылку и объявили марафон по написанию эталонных ответов на инстракты для последующего обучения модели. За одну неделю 826 участников написали для нас более 36 тыс. ответов! Вы можете заметить, что мы уже во второй раз за статью упоминаем коллективную помощь наших коллег. Активная, массовая помощь яндексоидов, которые даже не были связаны с проектом, позволила нам повысить качество модели и быстрее запустить проект.
С помощью AI-тренеров, асессоров и коллег из других направлений нам удалось собрать несколько сотен тысяч ответов на инстракты. Примерно половина из них оказалась достаточно качественной и легла в основу датасета.
Последовательность обучения
Не все люди пишут одинаково хорошо. Хороших ответов значительно меньше, чем остальных, но они ощутимо лучше. На практике хорошо сработала схема, при которой более качественные тексты передаются на обучение на более позднем этапе, а не смешиваются в одну большую кучу.
Наша лучшая схема на момент старта в Алисе
Как мы внедряли YaGPT в Алису
Учим модель быть Алисой
Примерно месяц назад у нас обучилась базовая модель YaGPT. Мы начали тестировать её всей командой и быстро убедились, что модель классная, но внедрять её в Алису нельзя. Требовались продуктовые доработки. Например, модель не знала, что она Алиса (не могла назвать своё имя, своих создателей, интересы и многое другое).
Чтобы научить модель быть Алисой, нужно собрать датасет с вопросами вида «Как тебя зовут», «Кто тебя создал», «Что ты любишь» и ответами на них. Для упрощения этого процесса мы придумали хитрость.
- Собрали список таких вопросов об Алисе.
- С помощью YaGPT сгенерировали множество других похожих вопросов.
- Написали подводку, кратко описывающую личность Алисы с просьбой ответить от её имени на вопрос.
- Задали сгенерированные вопросы YaGPT, используя подводку.
В итоге получили пары вопрос-ответ, из которых сформировали новый датасет и дообучили на нём модель. Наша модель частично обучила сама себя!
17 мая мы выкатили эту модель в виде навыка «Давай придумаем» в Алисе.
Учим модель работать с контекстом
Сегодня мы выпустили первое большое обновление для YaGPT в Алисе. Наша модель научилась учитывать историю диалога при написании ответов. Это полезно, потому что позволяет доуточнить свою просьбу.
Оказалось, что наша базовая модель YaGPT уже сразу после обучения неплохо умела работать с контекстом. Возможно, из-за того, что какие-то диалоги оказались в претрейне, возможно, из-за разнообразия задач Fine-tune модель научилась совсем новым задачам. Навыки диалога проверяли так: переписывались с моделью и в каждом сообщении посылали на вход весь предыдущий диалог. Модель отвечала разумно.
Главной проблемой оказалось то, что она слишком сильно цепляется за контекст и не понимает, что он изменился. Нужно было научить модель игнорировать часть истории сообщений. Для этого мы сцепили несколько не связанных запросов с ответами в один диалог и учили модель предсказывать последний ответ. Так модель выучила, что иногда контекст может мешать.
Кроме того, мы дообучили модель на диалогах, которые выложили в опенсорс участники проекта Open Assistant.
Другая задача, которую мы должны были решить, — поиск баланса между длиной контекста и скоростью генерации ответов. Если ответ пишется долго — это плохо, потому что пользователи ожидают от Алисы мгновенной реакции. Наша модель YaGPT умеет работать с 8 тыс. токенов (это примерно 40 тыс. символов) на входе. В продакшене контекст такой длины приведёт к значительному ожиданию ответа. К счастью, обычно такая длина и не нужна. Поэтому сейчас модель учитывает 2 тыс. токенов (10 тыс. символов) или 50 отдельных запросов (в зависимости от того, какой лимит будет достигнут раньше). Это значительно ускоряет ответы модели.
Завершение
В этом году мы проделали огромную работу над качеством наших моделей. Но этот пост не про завершение проекта, а про начало большого пути. Запуск YandexGPT в Алисе это лишь первое внедрение. И вот что мы будем делать в будущем.
1. Продолжим улучшать качество наших датасетов (Pretrain и Fine-tune).
2. Внедрим новый этап обучения — RLHF.
3. Обучим модели больших размеров (для исследований и применения в офлайне).
4. Вложимся в количество AI-тренеров. Мы верим, что в будущем обучение языковых моделей нового поколения невозможно без помощи подобных специалистов.
5. Внедрим YaGPT и в другие наши сервисы.




