
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Данная статья описывает небольшой пример того, как использование языка моделирования Alloy может помочь при разработке программного обеспечения.
О качестве программного обеспечения и инструментарии
В Typeable мы придаем огромное значение качеству программного обеспечения и прикладываем все усилия, чтобы обеспечить это качество. В настоящее время мы искореняем ошибки следующими способами:
- Анализ и создание спецификаций
- Устранение простых ошибок с использованием системы типов Haskell
- Стандартные юнит-тесты и интеграционные тесты
- Непрерывная интеграция
- Обязательные ревью кода
- Тестирование на стендах, проводимое QA инженерами
(мы используем Octopod для оптимизации процесса разработки и QA) - Тестирование в pre-production среде
- Ведение логов и контроль ошибок на этапе эксплуатации
Такое большое число шагов обеспечивает высокое качество кода, но при этом сказывается на затратах. Для выполнения этих шагов нужно и время, и труд.
Один из способов сокращения этих затрат заключается в выявлении ошибок на ранней стадии. По грубой оценке, если система типов обнаруживает вашу ошибку, это происходит в течение 30 секунд после сохранения файла. Если ошибка найдена во время CI, получение информации об ошибке займёт до 30 минут. Кроме того, после исправления ошибки вам придётся ждать еще 30 минут, пока CI не отработает снова.
Чем дальше вы продвигаетесь по цепочке, тем длиннее становятся эти перерывы и тем больше ресурсов уходит на исправление ошибок: чтобы достигнуть этапа QA-тестирования могут потребоваться дни, после чего инженер-тестировщик еще должен будет заняться вашей задачей. А если на этом этапе будет обнаружена ошибка, то не только тестировщикам придется снова провести тесты после исправления ошибки, но и разработчики опять должны будут пройти все предыдущие стадии!
Итак, каков самый ранний этап, на котором мы можем выявить ошибки? Удивительно, но мы можем существенно повысить шансы на выявление ошибок ещё до того, как будет написана первая строка кода!
Alloy выходит на сцену
Вот здесь появляется Alloy. Alloy – это невероятно простой и эргономичный инструмент моделирования, позволяющий строить пригодные для тестирования спецификации на системы, для которых вы только собираетесь писать код.
По сути, Alloy предлагает простой язык для построения абстрактной модели вашей идеи или спецификации. После построения модели Alloy сделает всё возможное, чтобы показать вам все проблемные места в рамках вашей спецификации. Также можно провести проверку всех свойств модели, которые вы сочтете важными.
Давайте приведем пример. Недавно у нас возникла неприятная проблема со следующим куском кода:
newAuthCode
:: (MonadWhatever m)
=> DB.Client
-> DB.SessionId
-> m DB.AuthorizationCode
newAuthCode clid sid = do
let codeData = mkAuthCodeFor clid sid
void $ DB.deleteAllCodes clid sid
void $ DB.insertAuthCode codeData
return codeЗдесь реализовывался обработчик HTTP-запроса и предполагалось, что функция будет обращаться к базе данных, удалять все существующие коды авторизации пользователя и записывать новый. По большому счету, код именно это и делал. Однако он также медленно заполнял наши логи сообщениями «нарушение требования уникальности» (uniqueness constraint violation).
Как это получилось?
Моделирование
Проблема, указанная выше, представляет собой хороший пример задачи для Alloy. Давайте попробуем представить ее, построив модель. Обычно мы начинаем моделирование конкретной проблемы с описания нашего представления об операциях newAuthCode для Alloy. Иными словами, необходимо сначала построить модель операций, затем дополнить ее, построив модель базы данных и привязав поведение базы данных к операциям.
Однако в данном случае оказывается, что для выявления проблемы достаточно просто формализовать представление о том, как могут выглядеть наши операции.
Процесс, описанный в приведенном фрагменте кода, имеет две интересующие нас части. Он производит удаление в некоторый момент времени, а затем вставляет новый токен в другой момент времени. Вот одна из моделей Alloy, используемая для описания этого поведения:
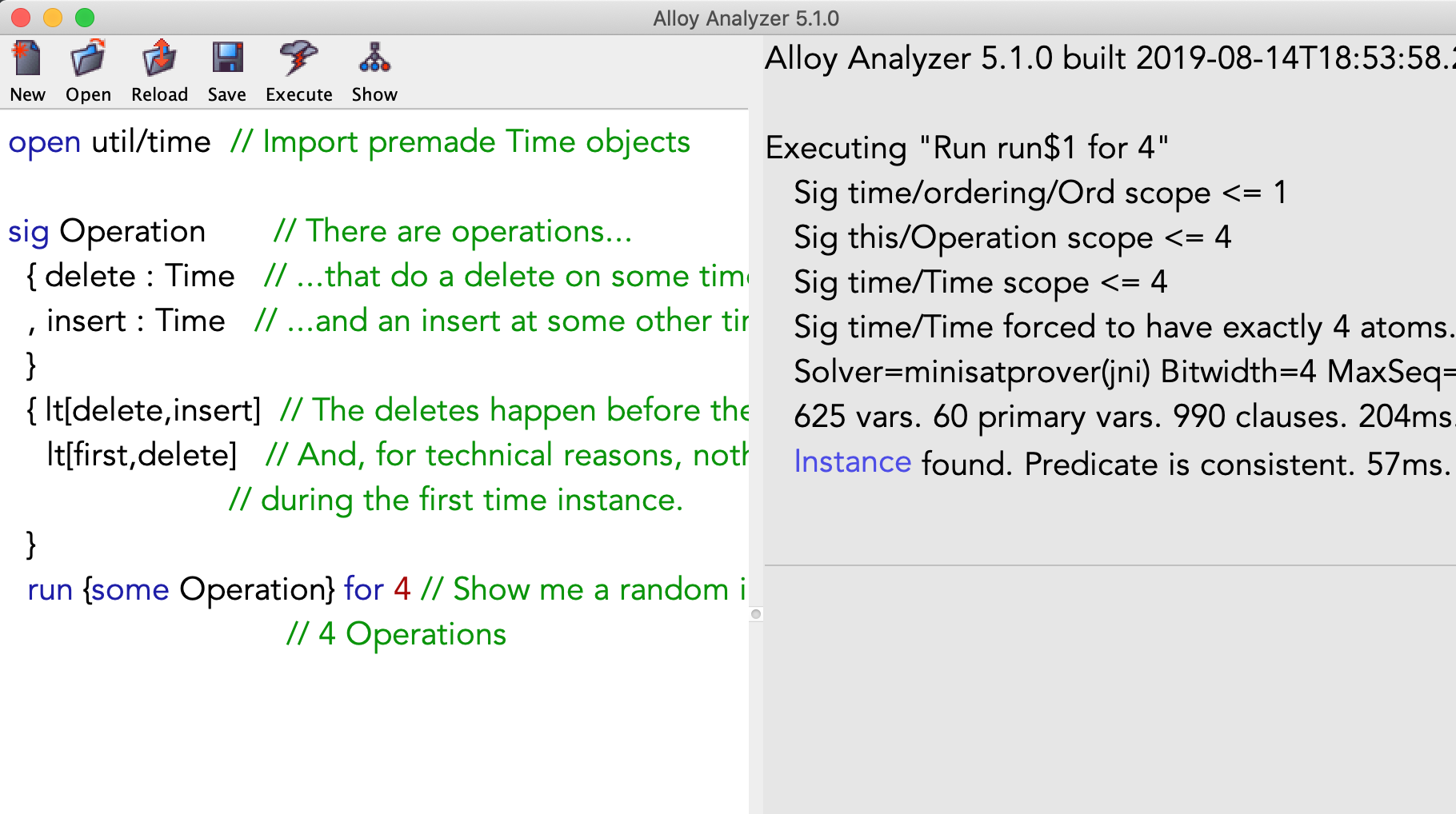
open util/time // Импортируем предопределённые объекты Time
sig Operation // У нас есть операции...
{ delete : Time // ...которые удаляют в какой-то момент времени
, insert : Time // ...и производят вставку в какой-то другой
}
{ lt[delete,insert] // Удаления происходят до вставок
lt[first,delete] // По техническим причинам в первый
// момент времени ничего не происходит
}
run {some Operation} for 4 // Показать произвольный пример модели
// с <= 4 операциямиПриведенная выше модель описывает систему абстрактных объектов и отношений между этими объектами. Выполнение модели далее приведет к образованию произвольного пространства, содержащего некоторые операции Operation, которые распределяются по определенным правилам.
Если вы хотите проследить этот процесс, скачайте alloy и скопируйте в него приведенный выше фрагмент кода. Затем нажмите 'execute' и 'show', чтобы получить модель следующего вида:

Чтобы Alloy показал другие модели, можно нажать 'next'.
Вот один из таких случайных экземпляров, представленный в виде таблицы отношений (нужно несколько раз нажать 'next’ и выбрать вид 'Table'):
┌──────────────┬──────┬──────┐
│this/Operation│delete│insert│
├──────────────┼──────┼──────┤
│Operation⁰ │Time¹ │Time³ │ ← Operation⁰ удаляет в момент Time¹ и
├──────────────┼──────┼──────┤ вставляет в момент Time³
│Operation¹ │Time² │Time³ │ ← Operation¹ удаляет в момент Time² и
└──────────────┴──────┴──────┘ и вставляет в момент Time³
↑
ОЙ!Как правило, на данном этапе мы начинаем моделировать таблицы базы данных и семантику операций, но оказалось, что Alloy уже смог показать, почему наши логи содержат нарушение требований!
Обращения к нашему обработчику происходят одновременно, и последовательности операций накладываются друг на друга: есть две операции, обе из которых производят удаление примерно в одно и то же время, а затем обе делают вставку в одно время. Кроме того, поскольку это не считывание, уровень изоляции по умолчанию postgresql ничего не делает, чтобы остановить этот процесс.
Проблема найдена!
Давайте её исправим!
Как только я нашел причину проблемы, я написал для нее следующее исправление.
code <- run $ do
handleJust constraintViolation
(launchPG $ selectCodeForSession clid scope sid
(launchPG . pgWithTransaction $ newAuthCode clid scope sid)Моя идея заключалась в том, что если операции действительно накладываются, а вставка действительно не срабатывает, то мы знаем, что новый код авторизации только что был вставлен. Следовательно, мы можем просто сделать select и вернуть этот существующий код, так как он был создан всего моментом ранее.
Будет ли это работать сейчас?
Давайте быстро построим модель Alloy для нашего исправления, чтобы проверить его корректность:
open util/time // Импортируем Time
sig Token {} // Объекты с названием Token
one sig DBState // База данных с токенами
{userToken : Token lone -> Time}
// В БД не более одного токена в каждый момент врвмени
// (т.к. ограничения БД не позволяют хранить больше одного)
sig Operation {
delete : Time
, insert : Time
, select : Time // Наши операции теперь могут выполнять select
}
{
lt[first,delete] // Ничего не происходит в первый момент времени
// по техническим причинам
lt[delete,insert] // Первой выполняется операция delete
lte[insert,select] // select выполняется после или во время insert'а
no userToken.(insert.prev) // Если вставка сработала (т.е. таблица
=> insert = select // была пустой во время выполнения),
// получаем значение в тот же самый
// момент времени (т.е. у нас запрос
// 'INSERT RETURNING').
// В противном случае вызываем обработчик
// исключения, и select выполняется чуть позже
}До этого момента модель очень похожа на предыдущую. Мы добавили DBState для моделирования таблицы, где хранятся наши токены, и наши операции теперь выполняют select, так же, как и в нашем коде. То есть если таблица пуста, мы получаем токен во время его вставки, а если таблица заполнена, мы выбираем его позднее в обработчике исключений.
Затем мы переходим к интересному аспекту модели, который заключается в описании взаимодействия между операциями и состоянием базы данных. К счастью, для нашей модели это довольно просто:
fact Trace { // Факт Trace описывает поведение системы
all t : Time - first | { // на всех шагах, кроме первого:
some delete.t => no userToken.t // Если происходит удаление, таблица пуста
some insert.t => some userToken.t // Если происходит вставка, таблица не пуста
no delete.t and no insert.t // Если не происходит ни вставок, ни удалений,
=> userToken.t = userToken.(t.prev) // таблица не меняется
}
}То есть мы описываем, как состояние базы данных изменяется в зависимости от некоторых происходящих событий.
Выполнение этой модели приводит к созданию многочисленных экземпляров, но вопреки обыкновению, их простой просмотр не позволяет найти очевидную ошибку. Однако мы можем потребовать от Alloy проверить для нас некоторые факты. Здесь придется немного подумать, но кажется, что исправление будет работать, если правильно работают все вызовы select.
Давайте примем это за утверждение и попросим Alloy проверить его.
assert selectIsGood { // То, что мы хотим проверить
all s : Operation.select | // Всегда, когда выполняется select,
some userToken.s // в базе присутствуем токен
}
check selectIsGood for 6 // Проверить, что selectIsGood всегда истинноК сожалению, запуск этой проверки дает нам следующий контрпример:
┌────────┬────────────┐
│DBState │userToken │
├────────┼──────┬─────┤
│DBState⁰│Token²│Time³│
│ │ ├─────┤ ← Token² находится в БД в моменты Time³ и Time⁵
│ │ │Time⁵│
│ ├──────┼─────┤
│ │Token³│Time²│ ← Token³ в БД в момент Time².
└────────┴──────┴─────┘
↑
Токены есть в таблице только
моменты Time², Time³ и Time⁵
Заменит, что в момент
Time⁴ токенов нет!
┌──────────────┬──────┬──────┬──────┐
│Operation │delete│insert│select│
├──────────────┼──────┼──────┼──────┤
│Operation⁰ │ TIME⁴│ Time⁵│ Time⁵│
├──────────────┼──────┼──────┼──────┤
│Operation¹ │ Time¹│ Time³│ TIME⁴│ ← Таблица пуста в момент Time⁴ и
├──────────────┼──────┼──────┼──────┤ select не работает для Operation¹!
│Operation² │ Time¹│ Time²│ Time²│
└──────────────┴──────┴──────┴──────┘
↑ ↑ ↑
Это моменты времени, когда
происходят соответствующие действияНа этот раз контрпример усложняется. К неудаче нашего исправления приводят три операции, происходящие одновременно. Во-первых, две из этих операций производят удаление и очистку базы данных. Далее, одна из этих двух операций вставляет новый токен в базу данных, в то время как другая не может сделать вставку, поскольку в таблице уже есть токен. Неудачная операция начинает выполнять обработку исключений, но еще до ее завершения запускается третья операция и снова очищает таблицу, в результате чего select в обработчике исключений теперь не может ничего выбрать.
Итак, предлагаемое исправление, которое было проверено на согласование типов, протестировано, прошло интеграцию и проверку коллегами, оказалось ошибочным!
Параллельная обработка легко не дается.
Мои выводы
Мне понадобилось примерно полчаса, чтобы написать вышеуказанные модели Alloy. Для сравнения, изначально у меня уходило вдвое больше времени на то, чтобы понять проблему и исправить ее. После этого я также ждал в течение получаса завершения непрерывной интеграции, а потом мои коллеги некоторое время проверяли мой код.
Учитывая, что исправление даже не работает, можно сказать, что решение проблемы определенно заняло больше времени, чем если бы я остановился и смоделировал проблему, как только обнаружил ее. Однако к сожалению, я вовсе не притрагивался к Alloy, поскольку проблема была «простой».
Думается, в этом и заключается сложность с использованием подобных инструментов. Когда они нужны? Конечно, не для каждой проблемы, но, возможно, чаще, чем я ими пользуюсь сейчас.
Где взять Alloy?
Для тех, кто заинтересовался, ниже мы приводим несколько ссылок, чтобы начать работу с Alloy:
- https://alloytools.org/ < — Здесь можно скачать
- https://alloy.readthedocs.io/en/latest/ < — Эта документация намного лучше официальной
- https://mitpress.mit.edu/books/software--abstractions-revised-edition < — книга об Alloy, написанная понятным языком. В ней описываются большинство основных схем, с которых можно начать.
- https://alloytools.org/citations/case-studies.html < — Здесь авторы Alloy перечисляют способы использования своего инструмента. Этот перечень довольно полный и содержит разнообразные примеры использования.
P.S. Правильное решение этой проблемы заключается в том, чтобы использовать сериализуемые транзакции и не возиться с параллельной обработкой.



 из телемедицинской компании")