
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Часто разметка данных оказывается самой серьёзной преградой для машинного обучения — сбор больших объёмов данных, их обработка и разметка для создания достаточно производительной модели могут занимать недели или даже месяцы. Активное обучение позволяет обучать модели машинного обучения на гораздо меньшем количестве размеченных данных. Лучшие компании в сфере ИИ, например, Tesla, уже используют активное обучение. Мы считаем, что и вам тоже оно необходимо.
В этом посте мы расскажем, что такое активное обучение, рассмотрим инструменты для его практического применения и продемонстрируем, как мы сами упрощаем внедрение активного обучения в процесс NLP.
Сравнение традиционного подхода и активного обучения: создание спам-фильтра
Представьте, что вам нужно создать спам-фильтр для ваших электронных писем. Традиционный подход (по крайней мере, с 2002 года) заключается в сборе большого количества писем, разметке их как «спам» и «не спам» с последующим обучением классификатора машинного обучения, позволяющего отличать эти два класса. При традиционном подходе считается, что все данные равноценны, но в большинстве наборов данных существуют дисбаланс классов, шумные данные и сильная избыточность.
В традиционном подходе время впустую тратится на разметку данных, не улучшающую производительность вашей модели. И вы даже не узнаете, работает ли ваша модель, пока не завершите разметку данных.
Людям не нужны тысячи случайно размеченных примеров, чтобы понять разницу между спамом и обычной почтой. Если вы обучаете человека решению этой задачи, то ожидаете, что ему можно дать несколько примеров того, что вам нужно, он быстро обучится, а потом будет задавать вопросы в случае неуверенности.
Активное обучение использует тот же принцип — применяет обучаемую модель для поиска и разметки только самых ценных данных.
При активном обучении вы сначала передаёте небольшое количество размеченных примеров. Модель обучается на этом «порождающем» наборе данных. Затем модель «задаёт вопросы», выбирая неразмеченные примеры данных, относительно которых у неё нет уверенности, чтобы человек мог «отвечать» на них, создавая метки этих примеров. Модель снова обновляется и процесс повторяется, пока не будет достигнута достаточно хорошая точность. Благодаря тому, что человек итеративно обучает модель, можно улучшить её за меньшее время и при гораздо меньшем количестве размеченных данных.
Как же модель находит следующий пример данных, которому нужна разметка? Вот самые распространённые способы:
- выбор примера, в котором предсказательное распределение имеет наибольшую энтропию
- выбор примера, в котором выбранный прогноз модели обладает наименьшей определённостью
- обучение нескольких моделей и выбор тех примеров, в которых у них нет согласия.
Мы используем собственные методы с применением байесовского глубокого обучения, чтобы получить более качественные оценки неопределённости.
Три преимущества использования активного обучения
1. Вы тратите меньше времени и денег на разметку данных
Доказано, что активное обучение обеспечивает большую экономию при разметке данных в широком спектре задач и наборов данных, от компьютерного зрения до NLP. Так как разметка данных — один из самых затратных аспектов обучения современных моделей машинного обучения, это само по себе является важным фактором!
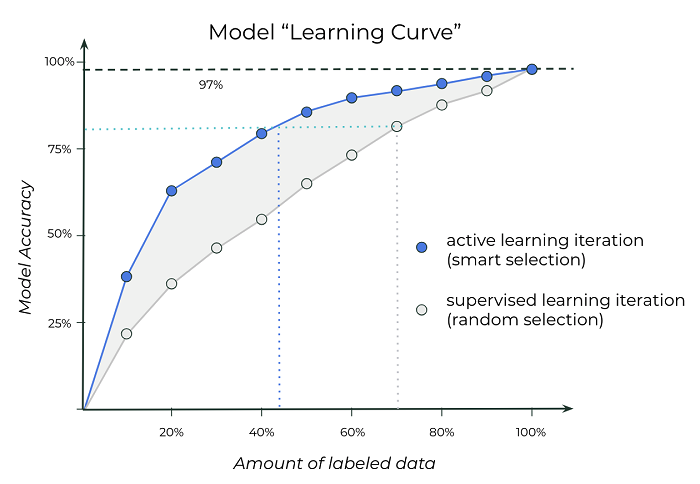
Использование машинного обучения приводит к увеличению точности моделей при меньшем количестве размеченных данных
2. Вы получаете гораздо более быструю обратную связь о производительности модели
Обычно разметка данных выполняется до того, как начинается обучение каких-либо моделей или возникает обратная связь. Часто требуются дни или недели повторной работы с гайдлайнами по аннотированию и разметке, после чего выясняется, что производительность модели не дотягивает до необходимого, или что требуются иначе размеченные данные. Так как активное обучение многократно обучает модель во время процесса разметки данных, можно получать обратную связь и устранять проблемы, которые могли бы всплыть гораздо позже.
3. В конечном итоге точность модели оказывается гораздо выше
Людей часто удивляет, что модели, обученные при помощи активного обучения, не только учатся быстрее, то и сходятся к более качественной готовой модели (с меньшим количеством данных). Нам часто говорят, что чем больше данных, тем лучше, поэтому легко забыть, что качество данных столь же важно, как и количество. Если набор данных содержит противоречивые примеры, которые сложно разметить точно, это может привести к деградации производительности готовой модели.
Также важен порядок, в котором модель видит примеры. Существует целый подраздел машинного обучения, называемый curriculum learning, изучающий вопрос улучшения производительности моделей благодаря тому, что сначала их обучают простым концепциям, а потом более сложным. Это похоже на обучение сначала арифметике, а потом алгебре. Активное обучение естественным образом создаёт учебный план для моделей и помогает им достигать повышенной точности.
Если активное обучение настолько хорошо, то почему им не пользуются все?
Большинство инструментов и процессов для создания моделей машинного обучения разрабатывалось без учёта активного обучения. В компаниях разметкой данных и обучением моделей занимаются разные отделы, а для активного обучения необходимо объединение этих процессов. Но если вам и удастся организовать совместную работу этих отделов, вам всё равно понадобится большая инфраструктура для обеспечения связи между обучением модели и интерфейсами аннотирования. Большинство используемых программных библиотек подразумевает, что все данные уже размечены до обучения модели, поэтому для применения активного обучения необходимо переписывать кучу бойлерплейта. Также вам нужно разбираться, как лучше хостить модель, обеспечить её взаимодействие с командой аннотаторов и обеспечить её обновление при асинхронном получении данных от разных аннотаторов.
Кроме того, современные модели глубокого обучения очень медленно обновляются, поэтому их частое повторное обучение — это мучительный процесс. Никто не хочет размечать сотню примеров, а потом ждать 24 часа до полного повторного обучения модели, прежде чем размечать следующую сотню. Кроме того, модели глубокого обучения обычно имеют миллионы или миллиарды параметров, и получение качественных оценок от таких моделей по-прежнему остаётся активно исследуемой научной задачей.
Если почитать научные статьи по активному обучению, то можно решить, что оно позволяет немного сэкономить на разметке, но требует большого объёма работы. Однако эти статьи сбивают с толку, поскольку они работают с научными наборами данных, которые обычно сбалансированы и очищены. Они почти всегда размечают по одному примеру за раз и авторы статей забывают, что не каждый пример данных одинаково легко размечать. При более приближенных к жизни проблемах с большим дисбалансом классов, шумными данными и меняющимися затратами на разметку преимущества могут быть гораздо больше, чем предполагается в литературе. В некоторых случаях экономия затрат на разметку может быть десятикратной.
Как использовать активное обучение сегодня
Одно из самых важных препятствий для применения активного обучения — это вопрос наличия подходящей инфраструктуры. Подобно тому, как инструменты наподобие Keras и PyTorch значительно снизили количество мучений с получением градиентов, появляются новые инструменты, сильно облегчающие активное обучение.

Существуют библиотеки Python в open source, например, modAL, берущие на себя большую часть бойлерплейта. ModAL построена на основе scikitlearn, она позволяет комбинировать различные модели с любой нужной вам стратегией машинного обучения. Она берёт на себя большую часть работы по реализации различных метрик, имеет открытый исходный код и обладает модульной структурой. Плюсами ModAL являются широкий набор предоставляемых ею методов и открытость кода. Недостаток библиотек наподобие modAL заключается в том, что они не содержат интерфейсов аннотирования и оставляют на долю разработчиков задачи хостинга модели и её связи с интерфейсами аннотирования.
Это приводит нас к вопросу интерфейсов аннотирования:
Вероятно, самым популярным инструментом для работающих в одиночку дата-саентистов является Prodigy. Это интерфейс аннотирования, созданный авторами Spacy; естественно, его можно скомбинировать с их потрясающей библиотекой NLP для использования простого активного обучения. Его исходный код закрыт, но его можно скачать как pip wheel и установить локально. Хотя Prodigy и хорошо подходит для одиночек, он не предназначен для работы с командами аннотаторов и реализует только самые простые формы активного обучения. Чтобы он работал с командами, вам всё равно придётся хостить Prodigy самостоятельно, а создание такой системы может потребовать много труда.
Labelbox предоставляет интерфейсы для множества аннотаций изображений и недавно добавил поддержку текста. В отличие от Prodigy, Labelbox проектировался с учётом взаимодействия с командами аннотаторов и имеет больше инструментов для проверки корректности меток. Он не имеет нативной поддержки активного обучения или обучения моделей, но позволяет загружать прогнозы из модели в интерфейс аннотирования через API. Это значит, что если вы реализовали функцию выбора для активного обучения и обучаете модель, то можете создать цикл активного обучения. Однако основной объём работ всё равно придётся выполнять вам.
Подведём итог
Активное обучение:
- Уменьшает количество данных, необходимых для разметки, значительно снижая один из компонентов расходов.
- Обеспечивает более быструю обратную связь о производительности модели.
- Создаёт модели с повышенной точностью.



