
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
ИИ на отечественном железе
Рассказываем о том, как мы портировали свой фреймворк для нейронных сетей и систему распознавания лиц на российские процессоры Эльбрус.
Это была интересная задача, весной 2019 года мы рассказывали об этом в офисе Яндекса на большом митапе про Эльбрус, теперь делимся с Хабром.
Кратко – что такое Эльбрус
Это российский процессор со своей собственной архитектурой, разрабатываемый в МЦСТ. Хорошо о нём рассказывает на своём канале Максим Горшенин: www.youtube.com/watch?v=H8eBgJ58EPY
Кратко – что такое PuzzleLib
Это наша платформа для нейронных сетей, которую мы разрабатываем и используем с 2015 года. Аналог Google TensorFlow и Facebook PyTorch. Интересно, что PuzzleLib поддерживает не только процессоры NVIDIA и Intel, но и видеокарты AMD.
Хотя у нас небольшая библиотека (у TensorFlow порядка 2 млн строк, у нас – 100 тысяч), мы лучше по скорости – немного, но лучше =)
Сейчас мы пока не в open source, библиотека используется для наших проектов. Библиотека полноценная: поддерживает как стадию обучения (training), так и стадию вывода (inference) нейронных сетей. Можно строить рекуррентные, свёрточные нейросети, также есть интерфейс для создания произвольных графов вычислений.
В PuzzleLib есть
- Модули для сборки нейросетей (Activation (Sigmoid, Tanh, ReLU, ELU, LeakyReLU, SoftMaxPlus), AvgPool (1D, 2D, 3D), BatchNorm (1D, 2D, 3D, ND), Conv (1D, 2D, 3D, ND), CrossMapLRN, Deconv (1D, 2D, 3D, ND), Dropout (1D, 2D) и др.)
- Оптимизаторы (AdaDelta, AdaGrad, Adam, Hooks, LBFGS, MomentumSGD, NesterovSGD, RMSProp и др.)
- Готовые к использованию нейросети (Resnet, Inception, YOLO, U-Net и др.)
Это привычные, знакомые всем, кто занимается нейросетями, блоки для нейросетевых конструкторов (так как любые фреймворки – это конструкторы, состоящие из типовых вычислительных блоков и алгоритмов).
У нас возникла идея запустить нашу библиотеку на архитектуре Эльбрус.
Почему мы захотели поддержать Эльбрус?
- Это единственный российский процессор, хотелось понять, как с ним обстоят дела, насколько легко с ним работать.
- Мы подумали, что государственным организациям может быть интересно, чтобы российское ПО, которое мы разрабатываем, работало на российском железе.
- И конечно, нам было просто интересно, т. к. Эльбрус это VLIW-процессор, то есть, процессор с длинными инструкциями, и таких полноценных, общего положения, процессоров в мире нет.
Началось все с того, что мы познакомились с МЦСТ, пообщались, одолжили для разработки компьютер Эльбрус 401.
Что понравилось: на Эльбрусе работает Linux, в этом Linux есть python, причём работает он не в режиме эмуляции – это полноценный, нативный python, собранный под Эльбрус. Также есть пачка стандартных библиотек python, например, numpy, которую все разработчики очень любят.
Были какие-то задачи, под которые нам приходилось дополнительно собирать библиотеки: например, в PuzzleLib мы используем формат hdf для хранения весов нейросетей, и, соответственно, нам пришлось собрать библиотеки libhdf и h5py с помощью компилятора lcc. Но никаких проблем сборки у нас не было.
Библиотека компьютерного зрения OpenCV также уже была собрана, но к ней не было биндинга к python – его мы собирали отдельно.
Известная библиотека dlib тоже довольно легко собралась. Здесь были лишь небольшие трудности: некоторые файлы этого open source проекта были без bom-маркера для определения utf-8, что расстраивало лексёр lcc. Собственно, просто был некорректный формат файлов, который пришлось в исходниках поправить.
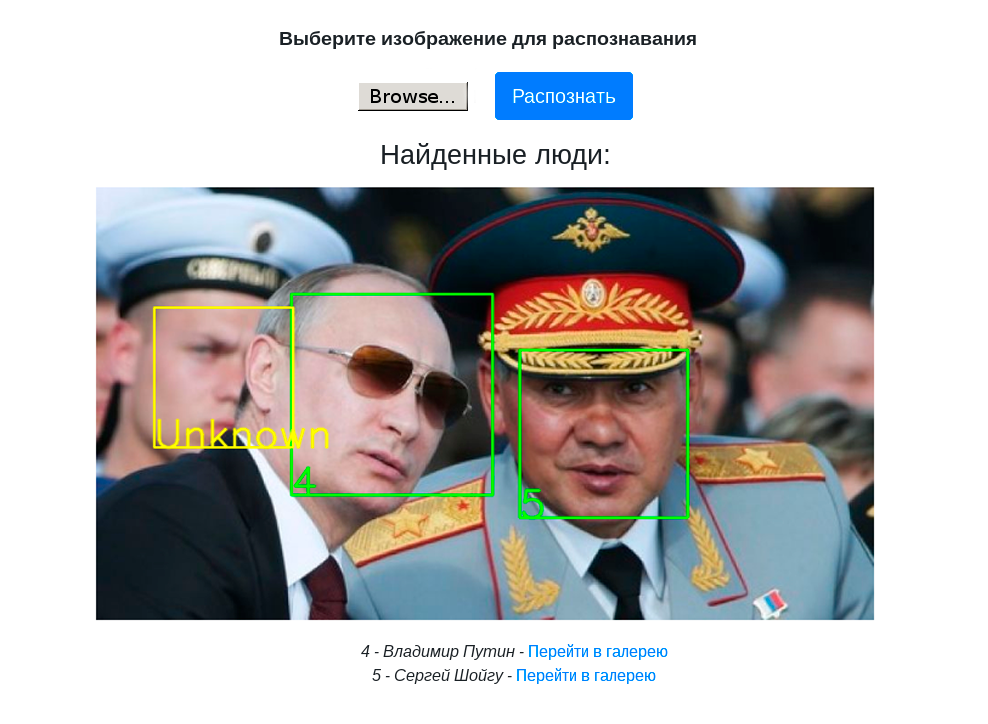
Мы решили сначала запустить распознавание лиц. Это понятный всем use case, много где эта технология используется. В PuzzleLib, как и в других библиотеках, довольно большая бэкендовая часть, то есть база кода, специфичного для разных процессорных архитектур.
Наши бэкенды:
- CUDA (NVIDIA)
- Open CL + MI Open (AMD)
- mlkDNN (Intel)
- CPU (numpy)
На Эльбрусе мы запустили numpy-бэкенд, что было очень просто, т. к. от платформы требуется минимум всего:
Платформа -> с90-компилятор -> python -> numpy
У нас библиотека без каких-либо усложняющих факторов (например, без каких-то особенных систем сборки) – кроме того, что нам необходимо было собрать определённые биндинги. Мы запустили тесты, всё работает – и свёрточные сетки, и рекуррентные. То распознавание лиц, которое мы запускали, довольно простое, базируется на Inception-ResNet.
Первые результаты работы
На Intel Core i7 7700 время обработки одного изображения было 0.1 секунды, а здесь – 15. Надо было оптимизировать.
Конечно, рассчитывать, что numpy будет с ходу хорошо работать – было бы неправильно.
Как мы оптимизировали вычисления
Мы замерили скорость inference через профайлер python и выяснили, что почти всё время тратилось на перемножение матриц в numpy. Для пробы написали самое простое, ручное перемножение матрицы, и оно уже оказалось быстрее, хотя было непонятно, почему.
Казалось бы, numpy.dot должен был быть написан чуть менее наивно, чем такое простое перемножение. Тем не менее, мы сбилдили, проверили – получилось уже быстрее (12 секунд на кадр вместо 15).
Далее мы узнали о библиотеке линейной алгебры EML, которая разрабатывается в МЦСТ, заменили вызовы np.dot на cblas_sgemm. Стало в 10 раз быстрее (1.5 секунды) – мы были очень довольны.
Далее следовало несколько пошаговых оптимизаций. Т. к. мы запускаем только распознавание лиц, а не в целом произвольные данные, мы решили заточить наши операции только под 4d-тензоры и сделать Fusion – после чего время обработки снизилось в 2 раза – до 0.75 секунд.
Пояснение: Fusion – это когда несколько операций объединяются в одну, к примеру, свёртка, нормализация и активация. Вместо того, чтобы делать проход по трём циклам, делается один проход.
Такие библиотеки есть у NVIDIA (TensorRT). В неё загружается вычислительный граф, а библиотека выдаёт оптимизированный, ускоренный граф, в частности за счёт того, что она умеет схлопывать операции в одну. Подобная есть и у Intel (nGraph и OpenVINO).
Потом мы увидели, что поскольку было много свёрток 1х1 в Inception-ResNet, у нас происходило лишнее копирование данных. Мы решили специализироваться под то, что работаем на батчах из 1 фотографии (то есть, не пачками обрабатывать 100 фотографий, а обеспечить потоковый режим) – есть такие use cases, когда нужно работать не с архивами, а с потоком (например, для видеонаблюдения или СКУД). Мы создали специализированный проход без im2col (убрали большие копии) – стало 0.45 секунды.
Потом мы снова посмотрели профайлер, у нас было всё так же – хоть все стадии и сжались по времени, у нас всё равно 80% времени уходило на вычисление свёрточных инференс-блоков.
Мы поняли, что нужно параллелить gemm (general matrix multiply). Тот gemm, который в EML, оказался однопоточным. Соответственно, нам пришлось написать многопоточный gemm самостоятельно. Идея такая: большая матрица дробится на подблоки, и потом уже идёт перемножение этих маленьких матриц. Мы написали gemm с OpenMP, но он не заработал, вылетали ошибки. Мы взяли ручной пул потоков, параллелизация дала 0.33 секунды на кадр.
Далее нам дали удалённый доступ к более мощному серверу с Эльбрус 8С, на котором скорость увеличилась до 0.2 секунды на кадр.
На следующем видео показана работа демо-стенда с распознаванием лиц на компьютере Эльбрус 401-PC с процессором Эльбрус 4С:
Выводы и дальнейшие планы
- У нас работает не просто распознавание лиц, а в принципе нейросетевой фреймворк, поэтому мы можем собирать любые детекторы, классификаторы и запускать их на Эльбрусе.
- У нас есть собранный демо-стенд с Web-UI для демонстрации распознавания лиц на PuzzleLib.
- Распознавание лиц на Эльбрусе работает уже достаточно быстро для практических задач, дальше можно ускорять, если возникнет потребность.
- С Эльбрусом можно работать. Нам доводилось работать с экзотическими процессорами – например, с тензорными российскими процессорами, которые ещё разрабатываются, с видеокартами AMD и их софтом. Там всё совсем не так хорошо и просто. То есть, если мы берём библиотеку MI Open от AMD – это очень плохо написанная библиотека, в которой не все комбинации страйдов, паддингов и размеров фильтров приводят к успешным вычислениям. Качество инструментария от Эльбруса хорошее – если у вас есть проект на Python, C или C++, запустить его на Эльбрусе совсем несложно.
- Ещё стоит отметить, что те работы по пошаговой оптимизации, про которые мы рассказывали – это не специфичные операции по работе в Эльбрусе. Это стандартные операции по работе с многоядерными процессорами. На наш взгляд, это хороший признак, что с процессором можно работать как с обычным процессором от Intel/NVIDIA.
Планы:
- Поскольку у Эльбруса есть особенность в том, что это VLIW-процессор, можно произвести какие-то специфичные для Эльбруса оптимизации.
- Сделать квантизацию (работа с int8 вместо float32), что экономит память и увеличивает скорость. Соответственно, при этом, конечно, может быть просадка по качеству вычислений – но этого может и не быть. Мы на практике замечали оба случая.
Мы планируем дальше разбираться, изучать возможности VLIW-процессора. По сути мы пока что просто доверяли компилятору в том, что если мы напишем хороший код, то компилятор его хорошо оптимизирует, потому что он знает особенности Эльбруса.
В общем, это было интересно, будем разбираться дальше. Времени заняло это не очень много – все операции по портированию заняли в общей сложности неделю.
В январе 2020 планируем выложить PuzzleLib в open source, об этом мы здесь ещё напишем =)
Спасибо за внимание!




