
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Когда мы говорим о CI&CD, мы часто углубляемся в базовые инструменты автоматизации сборки, тестирования и доставки приложения — фокусируемся на инструментах, но забываем осветить процессы, которые протекают во время отрезания и стабилизации релизов. Однако, не все готовые инструменты одинаково полезны, а какие-то кастомные процессы не укладываются в их покрытие. Приходится исследовать процессы и находить пути автоматизации для их оптимизации.
В нашей компании QA-инженеры используют Zephyr для отслеживания хода регресса, так как ручное и исследовательское тестирование нам не заменить автотестами. Но несмотря на это, автотесты у нас гоняются часто и в больших количествах, поэтому хочется иметь возможность опустить какие-то банальные проверки, которые были автоматизированы и дать тестировщикам заниматься более производительной и полезной работой.
У нас есть ночные прогоны, когда гоняются полные наборы тестов. Но на самой заре освоения Zephyr, нашим тестировщикам во время регресса приходилось скачивать xcresult, или ещё ранее plist, или junit xml, а затем проставлять соответствия зелёных и красных тестов в зефире руками. Это довольно рутинная операция, да и занимает она много времени, чтобы руками пройти 500-600 тестов. Такие вещи хочется отдать на откуп бездушной машине. Так родился ZERG.
Рождение зерга
Zephyr Enterprise Report Generator — небольшая утилита, которая изначально умела только искать соответствия в отчёте тестов и отправлять в Zephyr их актуальные статусы. Позже утилита получила новые функции, но сегодня мы остановимся на поиске и отправке отчётов.
В Zephyr нам предлагается оперировать версиями, циклами и проходами (execution) тест кейсов. Каждая версия содержит произвольное количество циклов, а каждый цикл содержит в себе проходы кейсов. Такие проходы содержат в себе информацию о задаче (zephyr прекрасно интегрируется с jira и тест кейс — это, по сути, задачка в jira), авторе, о статусе кейса, а также о том, кто занимается этим кейсом и о других необходимых деталях.
Для автоматизации проблемы, которую мы обозначили выше, нам важно разобраться в проставлении статуса кейса.
Работа с кодом
Но как соотнести тест в коде и тест в зефире? Здесь мы выбрали довольно простой и прямолинейный подход: для каждого теста мы добавляем в секцию комментариев ссылки на задачи в jira.
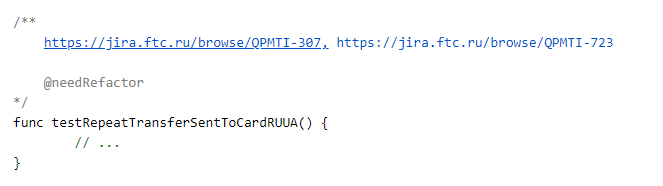
В комментариях также могут размещаться дополнительные параметры, но об этом позже.
Так, один тест в коде может покрывать несколько задач. Но работает и обратная логика. Для одной задачи может быть написано несколько тестов в коде. Их статусы будут учитываться при составлении отчёта.
Нам надо пройти по исходникам, извлечь все тест-классы и тесты, слинковать задачи с методами и соотнести это с отчётом о прохождении тестов ( xcresult или junit ).
Работать с самим кодом можно разными путями:
— просто читать файлы и через регулярные выражения извлекать информацию
— использовать SourceKit
Как бы то ни было, даже при использовании SourceKit мы не обойдёмся без регулярных выражений для извлечения идентификаторов задач из ссылок в комментариях.
На данном этапе нас не интересуют детали, поэтому отгородимся от них протоколом:

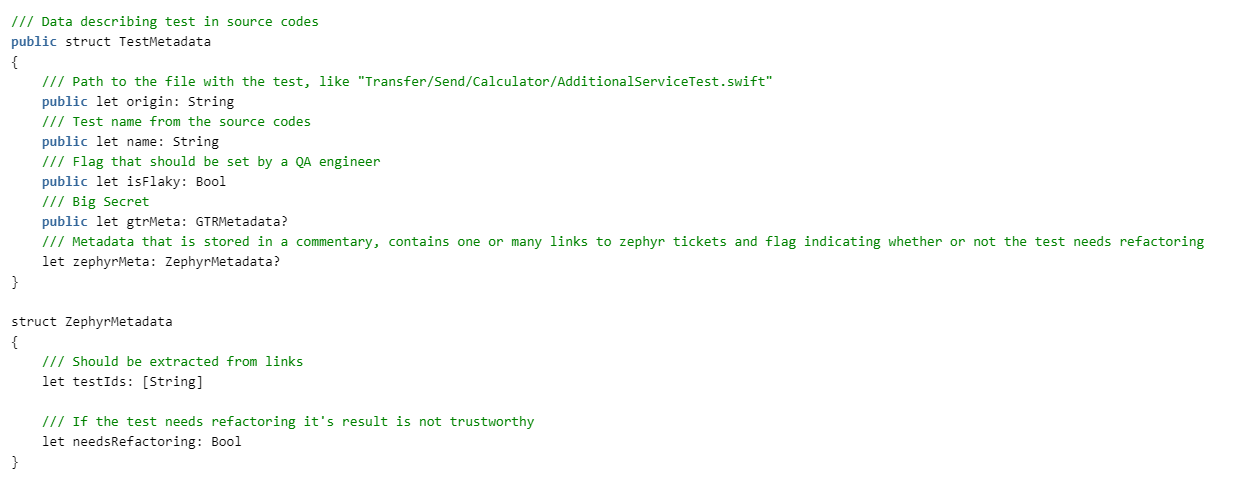
Нам надо получить тесты. Для этого опишем структуры:
Затем нам надо прочитать отчёт о прохождении тестов. ZERG был рождён ещё до переезда на xcresult, и поэтому умеет парсить plist и junit. Детали в этой статье нас всё ещё не интересуют, они будут приложены в коде. Поэтому отгородимся протоколам

Остается только слинковать тесты в коде с результатами тестов из отчетов.
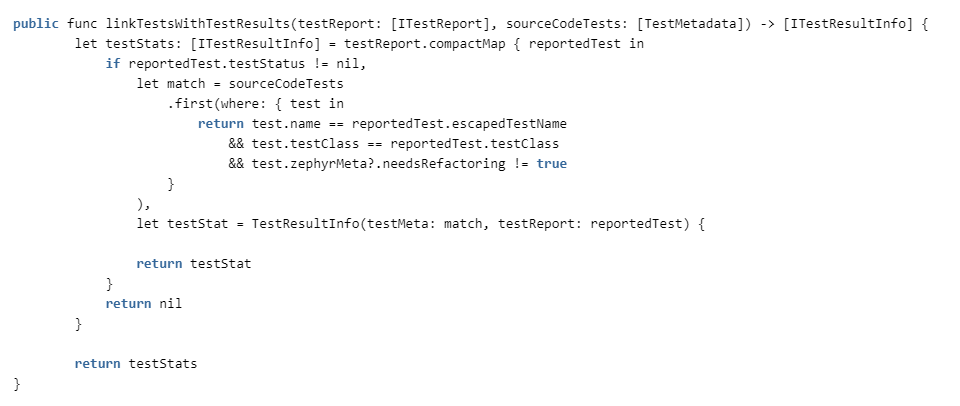
Проверяем соответствие по имени класса и имени теста (в разных классах могут быть методы с одинаковыми именами) и нужен ли рефакторинг для теста. Если он нужен, то считаем, что он ненадёжный и выкидываем из статистики.
Работаем с зефиром
Теперь, когда мы прочитали отчёты о тестировании, нам надо их перевести в контекст zephyr. Для этого надо получить список версий проекта, соотнести с версией приложения (чтобы это так работало, необходимо, чтобы версия в зефире совпадала с версией в Info.plist вашего приложения, например, 2.56), выкачать циклы и проходы. А дальше соотнести проходы с нашими уже имеющимися отчётами.
Для этого нам надо реализовать в ZephyrAPI следующие методы:
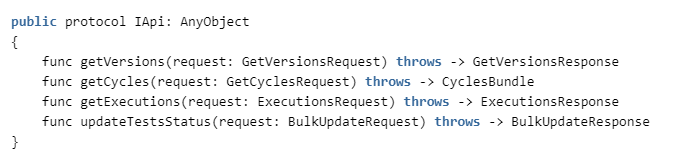
Cпецификацию можно увидеть здесь: getzephyr.docs.apiary.io, а реализацию клиента в нашем репозитории.
Общий алгоритм довольно простой:
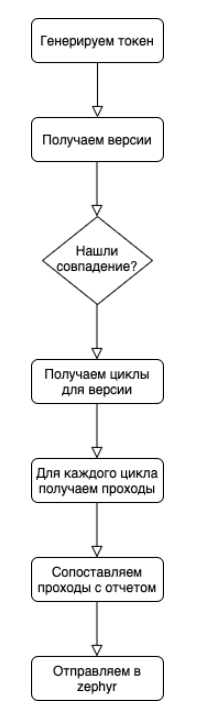
На этапе сопоставления проходов с отчётами есть тонкий момент, который необходимо учитывать: в zephyr api обновление execution отправлять удобнее всего пачками, где передаётся общий статус и список идентификаторов проходов. Нам нужно развернуть наши отчёты относительно тикетов и учесть n-m соотношение. Для одного кейса в зефире может быть несколько тестов в коде. Один тест в коде может покрывать несколько кейсов. Если для одного кейса есть n тестов в коде и один из них красный, то для такого кейса общий статус — красный, однако если один из таких тестов покрывает m кейсов и он зелёный, то остальные кейсы не должны стать красными.
Поэтому мы оперируем сетами и ищем пересечение красных и зелёных. Всё, что попадает в пересечение, мы отнимаем из зелёных результатов и отправляем отредактированные сведения в zephyr.

Здесь ещё нужно отметить, что внутри команды мы договорились, что zerg не будет менять статус прохода, если:
1. Текущий статус blocked или failed (раньше для failed мы меняли статус, но сейчас отказались от практики, потому что хотим, чтобы тестировщики обращали внимание на красные автотесты во время регресса).
2. Если текущий статус pass и его поставил человек, а не zerg.
3. Если тест помечен как флакающий.
Интересности Zephyr API
При запросе циклов нам приходит json, который с первого взгляда невозможно систематизировать для десериализации. Всё дело в том, что запрос на получение циклов для версии, хотя по смыслу и должен возвращать массив циклов, на самом деле возвращает один объект, где каждое поле уникально и называется идентификатором цикла, который лежит в значении. Чтобы такое обработать, мы применяем несложные хаки:

Статусы прохождения тестов приходят в одном из запросов рядом с объектом запроса. Но их можно вынести заранее в enum:

При запросе циклов нужно передавать в параметры запроса версию и целочисленный идентификатор проекта. Но в запросе проходов для цикла надо этот же идентификатор проекта передавать в формате строки.

Вместо заключения
Если есть много рутинной работы, то, скорее всего, что-то можно автоматизировать. Синхронизация прохождения автотестов с системой ведения тестов — один из таких кейсов.
Таким образом, каждую ночь у нас проходит полный прогон тестов, а во время регресса отчёт отправляется QA-инженерам. Это снижает время регресса и даёт время на исследовательское тестирование.
Если правильно реализовать парсер андроид-исходников, то его можно с тем же успехом применять и для второй платформы.
Наш Zerg помимо сопоставления тестов ещё умеет в начальный импакт анализ, но об этом, возможно, в следующий раз.



