
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В большом проекте может возникнуть задача идентификации изменений для конечного пользователя по отличиям в коде фронтенда приложения. Разработчик из Яндекс.Маркета Никита Сидоров рассказал, как мы решали эту проблему при помощи библиотеки Diffector, о построении и анализе графа модулей в Node.js-приложениях и о поиске дефектов в коде до его запуска.

— Сегодня я постараюсь быть с вами максимально откровенным. Я работаю в Яндекс.Маркете уже чуть больше, чем полтора года. Вебом занимаюсь столько же, и я начал замечать в себе изменения, вы их тоже можете заметить. У меня средняя длина волос увеличилась и борода начала появляться. И вы знаете, сегодня я посмотрел на своих коллег: на Сергея Бережного veged, на Вову Гриненко tadatuta, и понял — это хороший критерий того, что я уже почти созрел как настоящий фронтенд-разработчик.
И приходя к этой матерости, я решил поговорить с вами о жизни, о той, в которой мы все с вами участвуем. В основном — о жизни до рантайма. Сейчас объясню, о чем все это будет.

О жизни чего? О жизни кода, конечно. Код — это то, что мы с вами делаем. Напомню, я тут решил быть искренним с вами, поэтому первый слайд был максимально простой. Я взял прописную истину, первая стадия — принятие, согласитесь, с этой аксиомой никто не поспорит.

И тут я понял, что придется доработать, но так, чтобы было понятно. Пусть это какое-то принятие требований. Любой код начинается с того, что вы смотрите на задачу и пытаетесь принять требования, которые вам ставят.

После этого мы, конечно, начинаем стадию написания — пишем наш код. Затем покрываем его тестами, сами проверяем его результативность. После этого мы уже проверяем, работает ли с нашим кодом наше приложение целиком. После этого отдаем тестировщику — пускай он проверяет. Как думаете, что после этого? Напоминаю, жизнь до рантайма. Следует ли за этим рантайм, как вы думаете? На самом деле выходит вот так. И это не ошибка в презентации. Очень часто на любом этапе проверок — а их может быть намного больше, чем я указал, — у вас может быть некий вызов goto опять к написанию. Согласитесь, это может стать довольно большой проблемой. Это может замедлить доставку какой-то фичи в продакшен и в принципе, замедлить вас как разработчика, потому что тикет будет висеть на вас. И тут вот это все проходит, проходит. Тут еще какие-то M раз по N проверок, и только потом код попадает к пользователю в браузер. А ведь это наша цель. Наша цель — написать код, который действительно будет доступен пользователю и действительно будет работать на его благо.
Сегодня поговорим о первой части. О том, что происходит до, но не совсем о тестах.

Выглядит оно, кстати, примерно так. Я взял нашу очередь в трекере, собрал свои, посчитал медиану. Получается, что у меня тикеты в разработке находятся намного меньше, чем в проверке. А как вы понимаете, чем дольше оно в проверке, тем выше шанс, что здесь возникнет либо goto в начало, либо в конце возникнет goto — и вот этого вообще не хочется.
А еще, если вы обратите внимание, здесь на слайде есть два слова, — разработка (этим занимаемся мы, разработчики) и проверка (этим занимаемся в том числе мы, но и тестировщики). Поэтому проблема актуальна, на самом деле, и для тестировщиков.

Цель довольно прозаичная. Я вообще люблю говорить о том, что жизнь нужно упрощать: мы и так с вами много трудимся. Цель выглядит как-то так, но согласитесь, она довольно эфемерна, поэтому давайте выделим какие-то основные критерии, от чего цель может зависеть.
Конечно, чем меньше кода, тем нам проще. Чем быстрее у нас CI-проверки, тем быстрее мы поймем, правы мы или нет. То есть локально, оно, может вообще вечно запускаться. Скорость проверки — это уже относится непосредственно к тестировщику. Если у нас приложение большое и его нужно проверять целиком — это огромное количество времени. Скорость релиза зависит от всего этого. В том числе нельзя релизить, пока у нас не пройдут все проверки, и пока мы не поймем, что код именно тот, который мы хотим.
Чтобы решить часть проблем, о которых мы говорим, давайте будем анализировать граф зависимостей модулей в нашем языке программирования. И, собственно, давайте его опишем.

Граф ориентированный: у него есть ребра с направлениями. В узлах графа у нас будут как раз модули языка, о котором мы говорим. Ребра — это определенный тип связи. Типов связи мы выделим несколько.
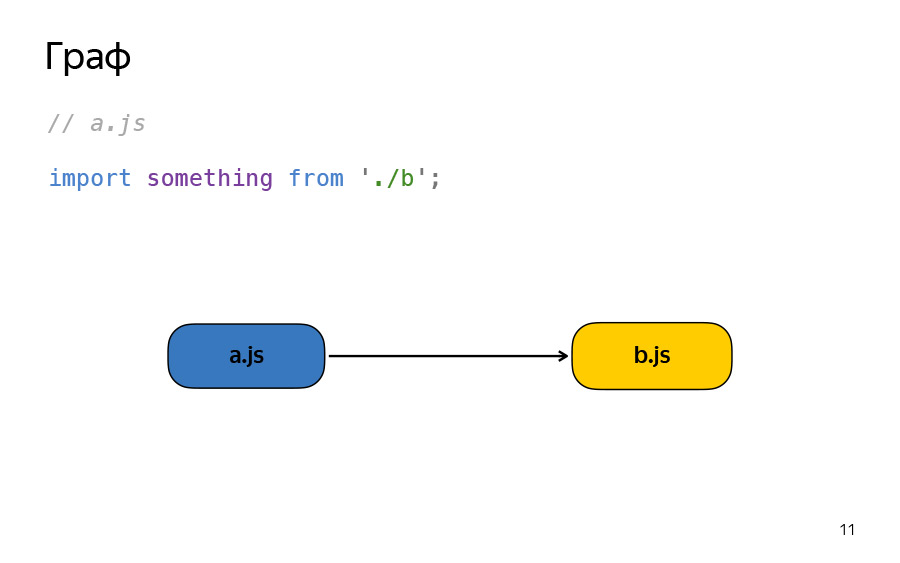
Давайте рассмотрим банальный пример. Вот есть файлик A. Тут в нем в импортируется что-то из файлика B, и это такая зависимость между узлами.

То же самое будет, если вы замените import на require. На самом деле, тут все не так просто.
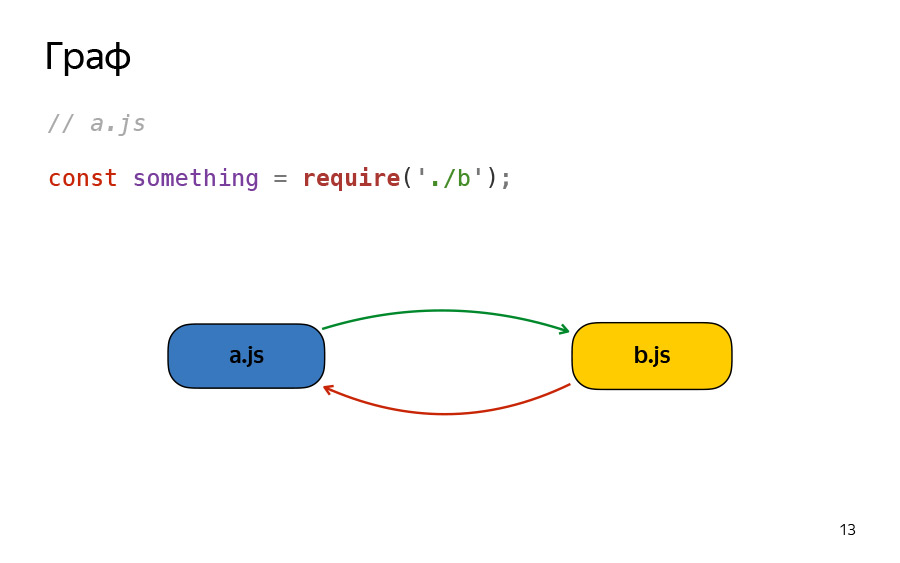
Я предлагаю, раз уж говорим о типе зависимости, рассматривать два типа как минимум — для ускорения вашего pipeline, для ускорения обхода графа. Нужно смотреть не только зависимый модуль, но и зависящий. Предлагаю называть модуль A — родителем, B — ребенком, и ссылки советую хранить всегда как double linked list. Это упростит вам жизнь, заранее сообщаю.
Раз мы как-то описали граф, давайте договоримся, как будем его строить.

Тут два пути. Либо ваша любимая тулза на вашем любимом языке программирования при помощи тех же AST (абстрактных синтаксических деревьев) или регулярок. Здесь в чем профит? В том, что тут вы не завязываетесь ни на кого, но при этом вам придется реализовывать все самим. Вам придется описать все типы связей всех тех вещей и технологий, которые вы используете, будь то отдельный какой-то CSS-сборщик, еще что-то в этом роде. Но у вас полный свободы полет, так скажем.
Кроме этого, второй вариант, я его немножко тоже буду пиарить, это вариант как раз для большинства людей, у кого уже настроена система сборки. Дело в том, что система сборки собирает граф в зависимости by design, by default.

Давайте рассмотрим одну из самых любимых в Яндексе систем сборок, это webpack. Здесь я привел пример, как можно собрать весь результат работы webpack в отдельный файлик, который потом можно скормить уже нашему или каким-то другим анализаторам. Собирает он его при помочи AST, используется библиотечка acorn. Вы могли замечать ее, когда у вас чего-то падало. Я замечал.
И какие плюсы есть. Дело в том, что когда вы описали систему сборки свою, вы абсолютно по-честному задали entry. Это те файлики, начиная с которых раскручиваются ваши зависимости, начальные точки обхода. Это уже хорошо, ведь вам не придется их записывать снова. Кроме этого, webpack и babel, и все вот это, и acorn, в том числе, это все-таки мейнтейнится не вами. И поэтому всякие новые фичи языка, всякие баги и все остальное, правятся быстрее, чем если бы это делали вы, особенно, если у вас не очень большая команда. Да, даже, если и большая, то тоже не настолько большая, как open source.
Это и плюс, и минус, на самом деле. Это как бы такой double edge (палка о двух концах) получается. Дело в том, что этот граф строится при сборке. Это как бы и хорошо, то есть мы можем собрать проект и сразу переиспользовать результат сборки. Но что, если нам не хочется собирать проект, а хочется просто получить этот граф?
И еще такой главный минус, на самом деле. Если у вас какие-то кастомные вещи подключены, мы поговорим сейчас много позже о связях, то система сборки вам не даст этого сделать. Либо, вам придется интегрировать это, как, например свой webpack плагин.

Рассмотрим конкретный пример. Я выполнил команду на своем проектике, где всего лишь три файла, и получил такой output. И это я только один ключ показываю, который называется modules. Мы как раз с вами говорим о графе зависимости модулей, поэтому смотрим на modules, все логично.

Довольно много информации, но нам не вся нужна. Оставим какие-то моменты и давайте проговорим их. Допустим, рассмотрим первый модуль. У него есть имя, есть reasons (причины). Причины — это как раз связь, собственно, “зависящями” модулями, получается те, кто импортят этот модуль к себе. Это основные данные, чтобы построить по ним граф.

Кроме этого, прошу обратить внимание на usedExports и providedExports. О них мы поговорим чуть позже. Но это тоже очень важные вещи.

И если описывать свое решение, то нужно говорить о типах связей, которые бывают между модулями. То есть у нас есть, конечно же, наша система модулей внутри нашего языка: будь то cjs-модули, или esm-модули. Кроме этого, согласитесь, что у нас может быть связь между файлами в файловой системе на уровне самой файловой системы. Это какие-то фреймворки: какой-нибудь фреймворк собирается, в зависимости от того, как папочки лежат.
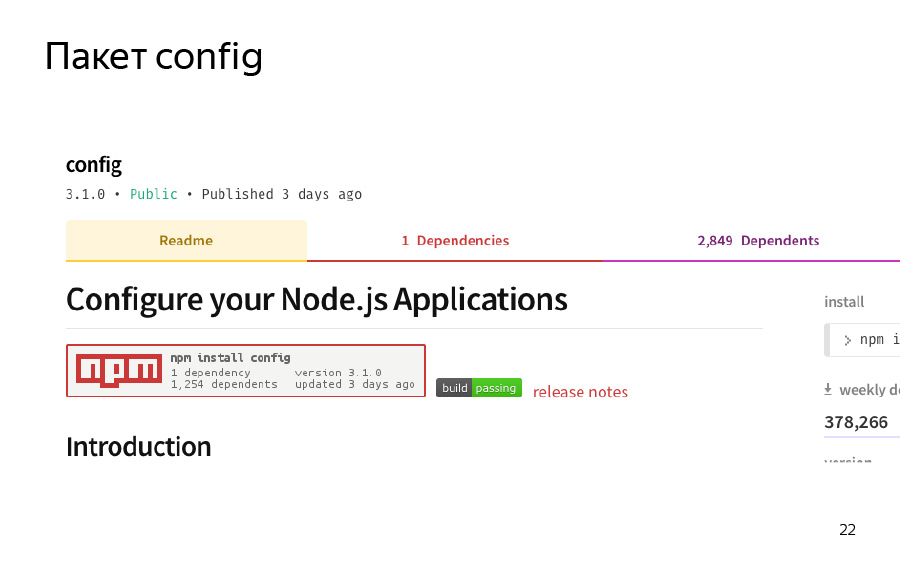
И такой банальный пример — если вы писали серверную часть Node, то довольно часто могли видеть такой популярный npm-пакет как Config. Он позволяет довольно удобно определить ваши конфигурации.

Чтобы его использовать, нужно завести папочку config, где у вас NODE_PATH, и указать несколько JavaScript-файлов — как раз для того, чтобы там предъявить config, для разных сред. Как пример — я создал папочку, указал default, development и production.

И, на самом деле, весь config работает примерно так. То есть, когда вы пишете require(‘config’), он внутри себя просто читает нужный модуль и берет имя модуля из переменного окружения. Как вы понимаете, там не понятно было, что эти файлы как-то используются, потому что никакого прямого import/require нет, webpack даже бы не узнал.

Сегодня еще говорили о Dependency Injection. Я не то, что вдохновился, но в поддержку рассмотрел тут одну из библиотек. Она называется inversify JS. Как вы видите, она предоставляет довольно кастомный синтаксис: lazyInject, nameProvider, и вот здесь вот это все. И, согласитесь, тут не понятно, что за провайдер, что за модуль сюда, действительно, инжектится. А нам это нужно, и нам предстоит это понять. То есть, опять-таки, системой сборки не решится, и нам придется делать это самим.
Предположим, что мы граф построили, и я вам предлагаю начать с того, чтобы его где-то хранить. Что нам это позволит сделать? Это позволит нам сделать какой-то эвристический анализ, чуть-чуть поиграть в Data Science, и делать его, ориентируясь на срез по времени.

В чем идея? Здесь, действительно, прямо наши данные. Это мы недавно как раз заимплементили свою дизайн-систему в Яндекс.Маркете и, в том числе, заимпелементили библиотеку компонент как часть этой дизайн-системы. И здесь можно посмотреть: мы считаем количество импортов, компонент реактовый из нашей библиотеки, компонент общий. И можно распределить по директориям. В данном случае, у нас такой недомонорепозиторий, и поэтому у нас platform.desktop есть, platform.touch и src.
Что мы можем подумать, когда видим эти цифры? Мы можем выдвинуть гипотезу, что команда touch, она как бы не растит использование общих компонент. Это значит, либо компоненты плохие для мобильных — плохо сделаны, либо команда touch ленивая. Но так ли это в действительности?
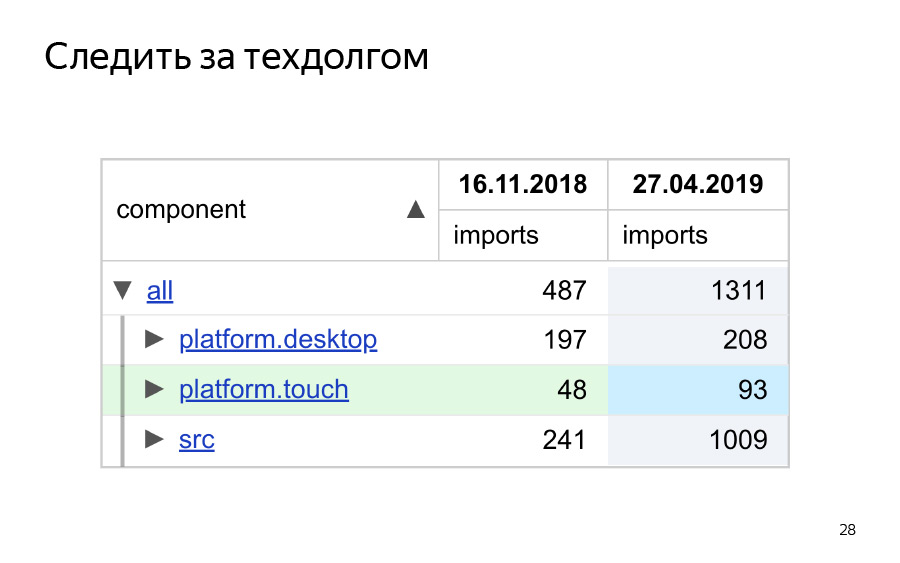
Если мы посмотрим в более длительном периоде, в более длительном срезе времени, это нам позволяет сделать как раз хранение графов после каждого релиза, то мы поймем, что, на самом деле, для touch все ок, в нем показатель растет. Для src еще лучше, для desktop, оказывается, нет.

Тут еще был вопрос из зала, как объяснять менеджерам важность. Здесь общее количество импортов библиотеки, тоже в срезе по времени. Какие менеджеры не любят графики? Можно построить такой график и увидеть, что использование библиотеки растет, а значит, это как минимум полезное дело.
Одна из моих любимых частей. Я ее довольно кратко освещу. Это поиск дефектов в графе. Сегодня я хотел поговорить с вами о двух видах дефектов: это циклическая зависимость модулей и неиспользуемый модуль какой-то, то есть dead code elimination проблеме.

Давайте начнем с циклической зависимости.

Тут, кажется, все довольно просто. У вас и так уже есть ориентированный граф, там нужно просто найти цикл. Объясню, почему я о таком говорю. Дело в том, что раньше я писал, в основном, серверную часть на Node.js, и мы не использовали, в принципе, никакой webpack/babel, ничего. То есть запускали as is. И там был require. Кто помнит, чем отличатся import от require? Все правильно. Если вы написали код плохо, а я, действительно, так делал, вы на вашем сервере можете узнать, что у вас модуль в какой-то циклической зависимости, только когда какой-то запрос придет от пользователей, или еще сработает какой-то ивент. То есть получается довольно глобальная проблема. До рантайма не понять. То есть с import намного все лучше, не будет такой проблемы.

Тут просто берете любой понравившийся алгоритм. Вот здесь я взял довольно простой алгоритм. Мы должны найти вершину, у которой есть только один тип ребер, — либо входящий, либо исходящий. Если такая вершина есть, — удаляем ее, удаляем ребра, и, собственно, продолжаем этот процесс, мы найдем и докажем, что в этом графе был цикл длиной в пять.
Согласитесь, если бы вы это смотрели по коду, то есть там цикл длиной два-три еще можно найти, но, больше уже нереально, а у нас в проекте реально был цикл длиной семь, но не в production.
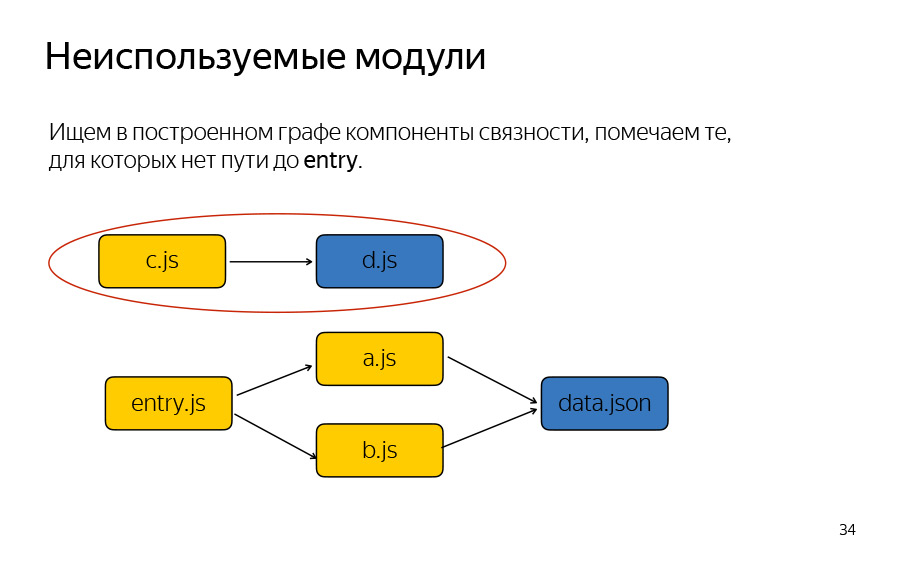
Про неиспользуемые модули. Тут тоже довольно тривиальный алгоритм. Мы должны выделить компоненты связанности в нашем графе, и просто посмотреть, найти те компоненты, в который не входит ни один из entry узлов. В данном случае, это вот этот компонент связанности, обе вершины, получается, оба узла. Тут entry.js назвал. На самом деле, неважно, как он называется, это то, что у вас описано в config сборки entry имеется в виду.

Но есть еще и другой подход. Если вы граф не собирали, а у вас есть просто система сборки, то, как это дешевле всего сделать? Давайте просто во время сборки помечать все файлы, которые попали в сборку. Помечать их и создавать множество. После этого мы должны получить множество всех файлов, которые у вас есть в проекте, и просто их вычесть. То есть очень простые операции.

И вот я вам не просто теоретическое что-то говорю, я вдохновился, пришел к себе в проект, и сделал вот это. И, внимание! Я даже не удалял node_modules. Это я оставил как точку роста на следующее ревью. И, короче, я настолько собой вдохновился, что решил этот слайд как-то по-другому сделать, переооформить. Пускай он выглядит вот так, потому что реально круто!
Хорошие цифры, представляете, как стало всем хорошо? И тут меня загнало в такую степь, что я почувствовал себя дизайнером, и подумал, что это такое достижение, которое хотелось бы в рамочку добавить. И, как вы понимаете, я встал, посмотрел и понял, что я скорее не дизайнер, а, действительно, веб-разработчик. Но я же не дурак. Я взял эту рамочку, добавил к себе на сайт к SEO-амулетам.
Можете пользоваться, даже ссылка есть. И чтобы вы не думали, что я вас обманываю — мы же сегодня откровенничаем — я реально посмотрел отзывы. Считаю, можно им верить.
Ладно, если быть честным, то это выглядело как-то вот так. Я увидел новую хайповую библиотеку thanos-js, взял, создал пул-реквест. По секрету, у меня есть администраторские права в нашем репозитории. И я взял и смёржил мастер. Как вам такое? Ладно, мы с вами откровенны, и, на самом деле, это все выглядело вот так. Если кто не знает, thanos-js — библиотека, которая просто удаляет 50% вашего кода рандомно.
На самом деле я там все равно использовал библиотеку, но библиотека называется по-другому. Она называется diffector, и сейчас мы о ней с вами поговорим. И здесь я хотел бы отметить, что пул-реквест довольно весомый, минус 44 тысячи строк кода, и вы представляете — он прошел тестирование с первого раза. То есть то, о чем я говорю, реально может работать.

Diffector. На самом деле, он занимается не только задачей удаления неиспользуемых модулей, поиска дефектов в графе, но и более важной задачей. То, что я вначале декларировал, — помочь разработчику и тестировщику, сейчас об этом пойдет речь. И работает он примерно так.
Мы получаем список измененных файлов при помощи системы контроля версий. У нас уже построен граф — diffector его строит. И для каждого такого измененного файла мы ищем путь до entry и помечаем измененный entry. А entry у нас будет соотноситься со страницами приложений, которые увидит пользователь. Но это довольно логично.
И что нам это дает? Для тестирования — мы знаем, какие странички в приложении изменились. Мы можем сказать тестировщику, что тестировать стоит только их. Мы также можем сказать нашей ci-job, которая запускает автотесты, что тестировать стоит также только эти страницы. А для разработчиков все намного проще, потому что теперь вам не пишут тестировщики и не спрашивают: «А чего надо тестировать?»
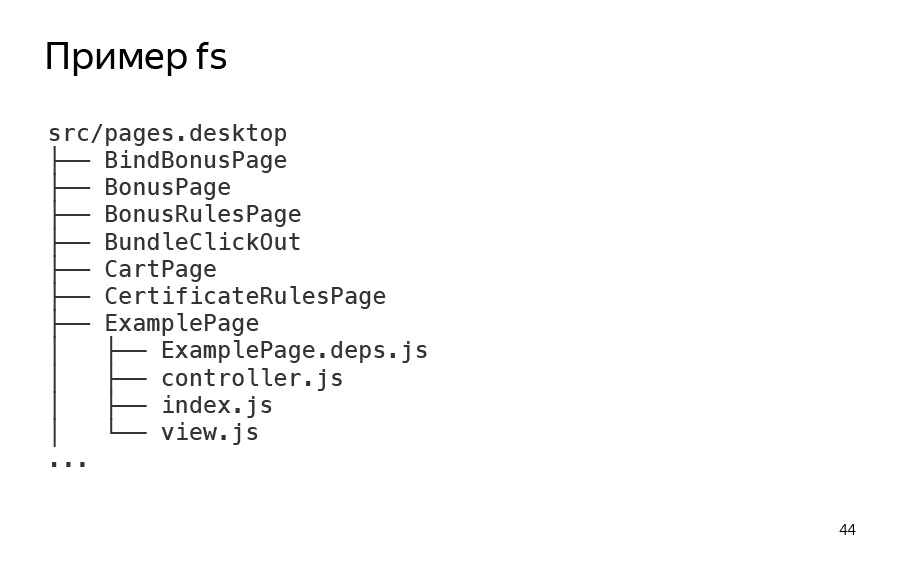
Давайте рассмотрим пример того, как работает diffector. Вот у нас есть некая директория, pages.desktop/*. В ней содержится просто какой-то список самих страниц. И страницы описываются тоже несколькими файлами. Контроллер — серверная часть странички. View — какая-то react-часть. И deps, это из другой системы сборки. У нас не только webpack, но и ENB.

И я внес какие-то изменения в проект, в пустой файл, структуру которого вы видели. Вот что мне выдает diffector. Я его просто запустил, diffector это command line-приложение. Я его запустил, он мне говорит, что у меня изменилась одна страница, которая называется BindBonusPage.

Я могу также запустить его в режиме verbose, посмотреть более подробный отчет, и, действительно, увидеть, что он как минимум работает в таком простом кейсе. Как мы видим, у нас в BindBonusPage изменился index-файлик и controller.
Но давайте посмотрим, что будет, если мы изменим что-то другое.

Я изменил что-то другое. И diffector мне сказал, что у меня изменилось девять страниц. И вот это меня уже не радует, как бы он мне не особо помог.
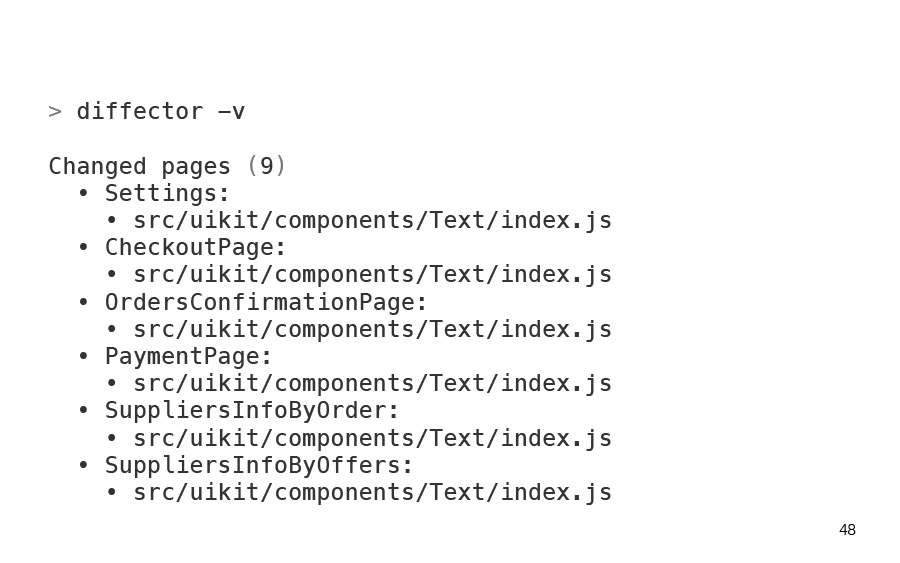
Давайте посмотрим, почему? Здесь сейчас показаны причины того, почему данная страница посчиталась измененной. И как мы видим, здесь одно и то же. Это какой-то компонент текста из uikit.
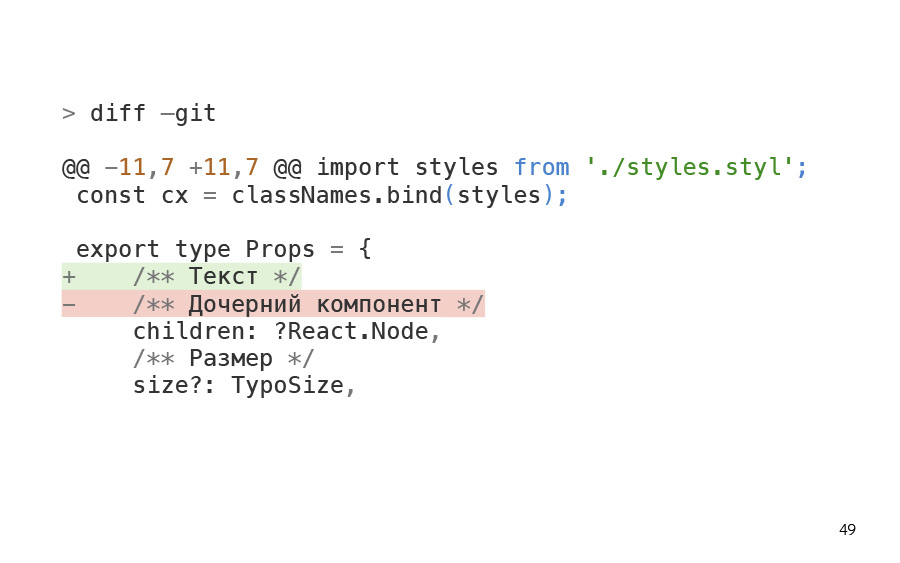
И давайте посмотрим diff. Я взял и просто поменял в типах комментарий. Но согласитесь, в данном случае diffector отработал неправильно. На самом деле не стоит на все эти девять страниц, которые попали только из-за текста, запускать тесты и добавлять их в регресс.

И это, действительно, проблема. Если у нас существуют файлики, которые много используются, по проекту любое изменение в файле затригерит изменение всех ваших entry, а, значит, все ваши страницы приложения попадут в test-scope, и тогда эффективность просто нулевая. Вот так ее надо решать.
Тришейкинг. Надеюсь, большинству знаком этот термин, и, в общем, в чем он состоит.

В первую очередь еще раз скажу про проблематику. У нас есть какой-то файлик, его часто используют. Как пример — i18n, который сделан на коленке, где просто хранятся ключи. Изменив его, вы, по сути, изменили все приложение с точки зрения связи в графе. А по факту, вы изменили только места, где используется какой-то ключ.
И как его сделать у нас? Если раньше у нас модуль был одним файликом в файловой системе, то теперь у нас модуль, это, действительно, экспорты, которые есть в нашем файле.

То есть как-то так. Если раньше было вот так, то теперь мы делим файлик B на экспорты, и получается, что у экспорта-2 даже нет никакого ребра. То есть он нам даже не нужен. Так работает тришейкинг и в вашей системе сборки, если esm.

Но здесь не все так радужно.

Рассмотрим вот такой код.

Представьте, если мы изменим здесь value, то на самом деле мы изменим не только эту константу. Мы также изменим и статический метод класса, а также и метод класса, который вызывал статический метод класса. То есть у нас появляется вторая часть задачи, где нам нужно резолвить зависимости внутри самого файла.
Да, это можно попробовать сделать при помочи AST, но подскажу, что конкретно для такого случая там будет около 250 строк кода, и не факт, что это все будет работать. А, на самом деле, там может быть и по-другому инверсированы зависимости, и все в этом духе, поэтому это довольно сложная задача.

Также представьте, что у вас есть какой-то GlobalContext и какая-то функция, которая его изменяет. Как здесь вообще понять, что при изменении функции modify, что у нас изменилось, действительно? В этом модуле, или как-то при изменении GlobalContext. Но это очень сложно. Поэтому мы не стали реализовать полноценный тришейкинг. Кстати, такие вещи называются side effects. Вы, может быть, когда настраивали webpack, видели такой флажок, его там можно указать. То есть, если вы ставите модуль в webpack sideEffects: true, то вам как раз не будет тришейкаться. Но будет гарантироваться вот это.

Чтобы решить эту проблему, мы решили все-таки чуть-чуть попинать наших разработчиков и ввели интерактивный режим. Объясню, что и зачем. Вместо того чтобы просто запускать diffector, его теперь можно запускать как полноценное консольное приложение. Здесь, как мы видим, я его запустил в интерактивном режиме. И здесь он мне показал изменения — все, которые были сделаны в моем коде. И те страницы, которые он затронул.
Как мы видим, у меня здесь есть агенда, то есть diff, expand, log, а кроме этого, мы здесь видим то изменение, о котором я вам уже говорил, изменение в тексте.
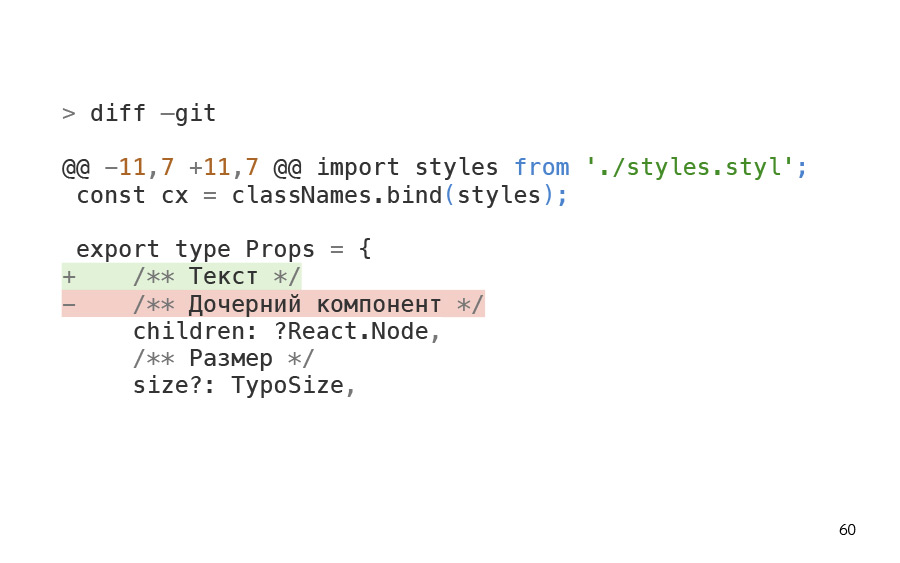
Вот оно, напомню. Мы его можем посмотреть при помощи кнопочки D, увидеть diff. И уже сам разработчик может понять, что текст ему, допустим, не нужно включать. Изменения в компоненте текста, на самом деле, не затронут контент для пользователя. Поэтому мы спокойно можем выключить его из этого списка изменений, сократив количество страниц, которые нам нужно протестировать. То есть мы взяли и убрали восемь страниц.
Здесь, на самом деле, тоже может быть несколько подходов. Можно рассматривать изменения текста для каждой из этих восьми страниц. Но это огромная работа. Представьте, восемь — на самом деле, не совсем честная цифра. Таких страниц может быть и больше. Текст много где используется. И заставлять разработчика размечать каждое из этих использований, и влияет оно или нет, это, собственно, возвращение к проблеме, которую я декларировал в начале доклада. Поэтому мы решили поступить таким образом. В сами изменения попадет только вторая строка, потому что ее мы оставили после нашего экспертного анализа.
И сама соль — для чего мы будем diffector использовать? Не только для того, чтобы в консольках разработчику играться, а для того, чтобы жизнь лучше делать.

Вот у нас есть какая-то сущность, абстракция над страницей приложения, к которой имеет доступ пользователь.

Мы с вами обсудили вот такую связь, обсудили, как связана страница приложения с entry. У одной странички приложения может быть несколько entry. И эту связь ищет diffector.

Еще нужно рассмотреть другую связь. Для страницы есть тест-кейсы. Эта связь находится в хранилище кейсов, ее оттуда можно получить.

Таким образом, по изменениям entry мы можем получить те тест-кейсы, которые мы задели.

Работает оно примерно так. Мы запускаем diffector. У него есть несколько видов репорта. Помимо того, что он сообщает нам, что какие-то странички у нас изменились, он генерирует запрос в наше хранилище тест-кейсов. Или в ваше, как захотите. Здесь он говорит: смотрите, изменился BindBonusPage, отдай мне все тест-кейсы, которые провязаны с этой страницей. Это для ручного регресса. А для автотестов, собственно, чуть-чуть меняем запрос. Выглядит примерно так.


Теперь самое важное — переносим всё в CI. Это просто скриншот комментария из тикета. Здесь то же самое: сбилжен определенный запрос, который увидит тестировщик, когда зайдет к вам в тикет и начнет его проверять.
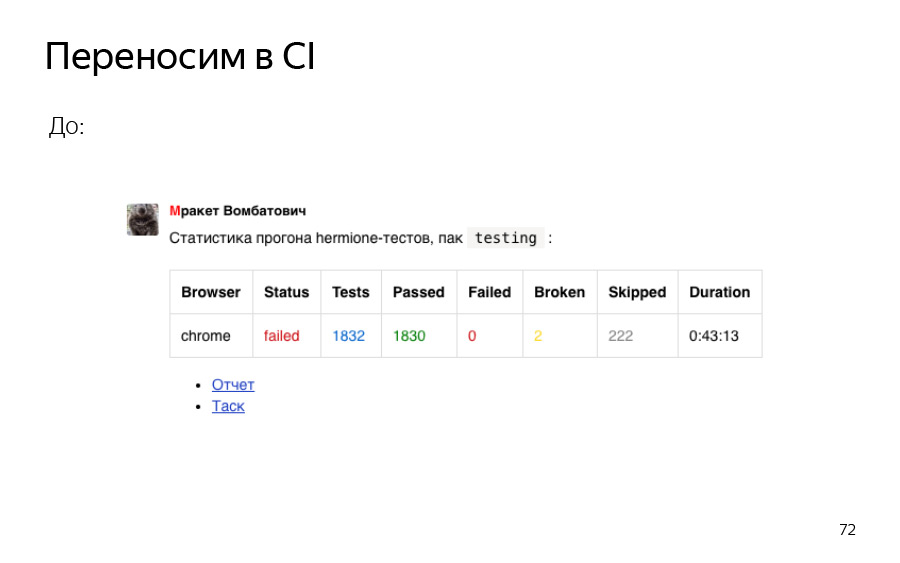
Кроме того, раньше было вот так. 43 минуты — это только testing, и это у нас покоммитно, каждый коммит в репозиторий Маркета.

А стало вот так. Не всегда, конечно, но это один из хороших показателей.

Вообще хотелось бы сказать, что в идеальном мире такой задачи особо не должно возникать. Дело в следующем: вы должны организовывать ваши бандлы таким образом, чтобы туда попадали только те файлы, до которых действительно может добраться пользователь. Я понимаю, что это очень сложная задача, и она вряд ли вообще реализуема, но если бы было так, вы бы могли просто из бандлов получить список модулей, которые там есть. Если эти модули изменяются, это практически гарантия того, что и у пользователя что-то изменится.

Резюмирую. Действительно, все, о чем мы с вами говорили, имеет практическую пользу для больших команд. Если у вас приложение разрабатывают два-три человека, они вполне могут сами следить за чужими пул-реквестами и за тем, как изменяется код, понимать, как связано приложение. Но в больших проектах одному разработчику это делать сложно.
Кроме того, если вы действительно захотите использовать статический анализ, граф зависимости модулей, то лучше начните с использования output вашей системы сборки. Для начала просто поймите, нужно оно вам или нет. Если вы собираете — храните. Если храните — анализируйте и улучшайте жизнь ваших разработчиков. Спасибо!
— Сегодня я постараюсь быть с вами максимально откровенным. Я работаю в Яндекс.Маркете уже чуть больше, чем полтора года. Вебом занимаюсь столько же, и я начал замечать в себе изменения, вы их тоже можете заметить. У меня средняя длина волос увеличилась и борода начала появляться. И вы знаете, сегодня я посмотрел на своих коллег: на Сергея Бережного veged, на Вову Гриненко tadatuta, и понял — это хороший критерий того, что я уже почти созрел как настоящий фронтенд-разработчик.
И приходя к этой матерости, я решил поговорить с вами о жизни, о той, в которой мы все с вами участвуем. В основном — о жизни до рантайма. Сейчас объясню, о чем все это будет.
О жизни чего? О жизни кода, конечно. Код — это то, что мы с вами делаем. Напомню, я тут решил быть искренним с вами, поэтому первый слайд был максимально простой. Я взял прописную истину, первая стадия — принятие, согласитесь, с этой аксиомой никто не поспорит.
И тут я понял, что придется доработать, но так, чтобы было понятно. Пусть это какое-то принятие требований. Любой код начинается с того, что вы смотрите на задачу и пытаетесь принять требования, которые вам ставят.
После этого мы, конечно, начинаем стадию написания — пишем наш код. Затем покрываем его тестами, сами проверяем его результативность. После этого мы уже проверяем, работает ли с нашим кодом наше приложение целиком. После этого отдаем тестировщику — пускай он проверяет. Как думаете, что после этого? Напоминаю, жизнь до рантайма. Следует ли за этим рантайм, как вы думаете? На самом деле выходит вот так. И это не ошибка в презентации. Очень часто на любом этапе проверок — а их может быть намного больше, чем я указал, — у вас может быть некий вызов goto опять к написанию. Согласитесь, это может стать довольно большой проблемой. Это может замедлить доставку какой-то фичи в продакшен и в принципе, замедлить вас как разработчика, потому что тикет будет висеть на вас. И тут вот это все проходит, проходит. Тут еще какие-то M раз по N проверок, и только потом код попадает к пользователю в браузер. А ведь это наша цель. Наша цель — написать код, который действительно будет доступен пользователю и действительно будет работать на его благо.
Сегодня поговорим о первой части. О том, что происходит до, но не совсем о тестах.
Выглядит оно, кстати, примерно так. Я взял нашу очередь в трекере, собрал свои, посчитал медиану. Получается, что у меня тикеты в разработке находятся намного меньше, чем в проверке. А как вы понимаете, чем дольше оно в проверке, тем выше шанс, что здесь возникнет либо goto в начало, либо в конце возникнет goto — и вот этого вообще не хочется.
А еще, если вы обратите внимание, здесь на слайде есть два слова, — разработка (этим занимаемся мы, разработчики) и проверка (этим занимаемся в том числе мы, но и тестировщики). Поэтому проблема актуальна, на самом деле, и для тестировщиков.
Цель довольно прозаичная. Я вообще люблю говорить о том, что жизнь нужно упрощать: мы и так с вами много трудимся. Цель выглядит как-то так, но согласитесь, она довольно эфемерна, поэтому давайте выделим какие-то основные критерии, от чего цель может зависеть.
Конечно, чем меньше кода, тем нам проще. Чем быстрее у нас CI-проверки, тем быстрее мы поймем, правы мы или нет. То есть локально, оно, может вообще вечно запускаться. Скорость проверки — это уже относится непосредственно к тестировщику. Если у нас приложение большое и его нужно проверять целиком — это огромное количество времени. Скорость релиза зависит от всего этого. В том числе нельзя релизить, пока у нас не пройдут все проверки, и пока мы не поймем, что код именно тот, который мы хотим.
Чтобы решить часть проблем, о которых мы говорим, давайте будем анализировать граф зависимостей модулей в нашем языке программирования. И, собственно, давайте его опишем.
Граф ориентированный: у него есть ребра с направлениями. В узлах графа у нас будут как раз модули языка, о котором мы говорим. Ребра — это определенный тип связи. Типов связи мы выделим несколько.
Давайте рассмотрим банальный пример. Вот есть файлик A. Тут в нем в импортируется что-то из файлика B, и это такая зависимость между узлами.
То же самое будет, если вы замените import на require. На самом деле, тут все не так просто.
Я предлагаю, раз уж говорим о типе зависимости, рассматривать два типа как минимум — для ускорения вашего pipeline, для ускорения обхода графа. Нужно смотреть не только зависимый модуль, но и зависящий. Предлагаю называть модуль A — родителем, B — ребенком, и ссылки советую хранить всегда как double linked list. Это упростит вам жизнь, заранее сообщаю.
Раз мы как-то описали граф, давайте договоримся, как будем его строить.
Тут два пути. Либо ваша любимая тулза на вашем любимом языке программирования при помощи тех же AST (абстрактных синтаксических деревьев) или регулярок. Здесь в чем профит? В том, что тут вы не завязываетесь ни на кого, но при этом вам придется реализовывать все самим. Вам придется описать все типы связей всех тех вещей и технологий, которые вы используете, будь то отдельный какой-то CSS-сборщик, еще что-то в этом роде. Но у вас полный свободы полет, так скажем.
Кроме этого, второй вариант, я его немножко тоже буду пиарить, это вариант как раз для большинства людей, у кого уже настроена система сборки. Дело в том, что система сборки собирает граф в зависимости by design, by default.
Давайте рассмотрим одну из самых любимых в Яндексе систем сборок, это webpack. Здесь я привел пример, как можно собрать весь результат работы webpack в отдельный файлик, который потом можно скормить уже нашему или каким-то другим анализаторам. Собирает он его при помочи AST, используется библиотечка acorn. Вы могли замечать ее, когда у вас чего-то падало. Я замечал.
И какие плюсы есть. Дело в том, что когда вы описали систему сборки свою, вы абсолютно по-честному задали entry. Это те файлики, начиная с которых раскручиваются ваши зависимости, начальные точки обхода. Это уже хорошо, ведь вам не придется их записывать снова. Кроме этого, webpack и babel, и все вот это, и acorn, в том числе, это все-таки мейнтейнится не вами. И поэтому всякие новые фичи языка, всякие баги и все остальное, правятся быстрее, чем если бы это делали вы, особенно, если у вас не очень большая команда. Да, даже, если и большая, то тоже не настолько большая, как open source.
Это и плюс, и минус, на самом деле. Это как бы такой double edge (палка о двух концах) получается. Дело в том, что этот граф строится при сборке. Это как бы и хорошо, то есть мы можем собрать проект и сразу переиспользовать результат сборки. Но что, если нам не хочется собирать проект, а хочется просто получить этот граф?
И еще такой главный минус, на самом деле. Если у вас какие-то кастомные вещи подключены, мы поговорим сейчас много позже о связях, то система сборки вам не даст этого сделать. Либо, вам придется интегрировать это, как, например свой webpack плагин.
Рассмотрим конкретный пример. Я выполнил команду на своем проектике, где всего лишь три файла, и получил такой output. И это я только один ключ показываю, который называется modules. Мы как раз с вами говорим о графе зависимости модулей, поэтому смотрим на modules, все логично.
Довольно много информации, но нам не вся нужна. Оставим какие-то моменты и давайте проговорим их. Допустим, рассмотрим первый модуль. У него есть имя, есть reasons (причины). Причины — это как раз связь, собственно, “зависящями” модулями, получается те, кто импортят этот модуль к себе. Это основные данные, чтобы построить по ним граф.
Кроме этого, прошу обратить внимание на usedExports и providedExports. О них мы поговорим чуть позже. Но это тоже очень важные вещи.
И если описывать свое решение, то нужно говорить о типах связей, которые бывают между модулями. То есть у нас есть, конечно же, наша система модулей внутри нашего языка: будь то cjs-модули, или esm-модули. Кроме этого, согласитесь, что у нас может быть связь между файлами в файловой системе на уровне самой файловой системы. Это какие-то фреймворки: какой-нибудь фреймворк собирается, в зависимости от того, как папочки лежат.
И такой банальный пример — если вы писали серверную часть Node, то довольно часто могли видеть такой популярный npm-пакет как Config. Он позволяет довольно удобно определить ваши конфигурации.
Чтобы его использовать, нужно завести папочку config, где у вас NODE_PATH, и указать несколько JavaScript-файлов — как раз для того, чтобы там предъявить config, для разных сред. Как пример — я создал папочку, указал default, development и production.
И, на самом деле, весь config работает примерно так. То есть, когда вы пишете require(‘config’), он внутри себя просто читает нужный модуль и берет имя модуля из переменного окружения. Как вы понимаете, там не понятно было, что эти файлы как-то используются, потому что никакого прямого import/require нет, webpack даже бы не узнал.
Ссылка со слайда
Сегодня еще говорили о Dependency Injection. Я не то, что вдохновился, но в поддержку рассмотрел тут одну из библиотек. Она называется inversify JS. Как вы видите, она предоставляет довольно кастомный синтаксис: lazyInject, nameProvider, и вот здесь вот это все. И, согласитесь, тут не понятно, что за провайдер, что за модуль сюда, действительно, инжектится. А нам это нужно, и нам предстоит это понять. То есть, опять-таки, системой сборки не решится, и нам придется делать это самим.
Предположим, что мы граф построили, и я вам предлагаю начать с того, чтобы его где-то хранить. Что нам это позволит сделать? Это позволит нам сделать какой-то эвристический анализ, чуть-чуть поиграть в Data Science, и делать его, ориентируясь на срез по времени.
В чем идея? Здесь, действительно, прямо наши данные. Это мы недавно как раз заимплементили свою дизайн-систему в Яндекс.Маркете и, в том числе, заимпелементили библиотеку компонент как часть этой дизайн-системы. И здесь можно посмотреть: мы считаем количество импортов, компонент реактовый из нашей библиотеки, компонент общий. И можно распределить по директориям. В данном случае, у нас такой недомонорепозиторий, и поэтому у нас platform.desktop есть, platform.touch и src.
Что мы можем подумать, когда видим эти цифры? Мы можем выдвинуть гипотезу, что команда touch, она как бы не растит использование общих компонент. Это значит, либо компоненты плохие для мобильных — плохо сделаны, либо команда touch ленивая. Но так ли это в действительности?
Если мы посмотрим в более длительном периоде, в более длительном срезе времени, это нам позволяет сделать как раз хранение графов после каждого релиза, то мы поймем, что, на самом деле, для touch все ок, в нем показатель растет. Для src еще лучше, для desktop, оказывается, нет.
Тут еще был вопрос из зала, как объяснять менеджерам важность. Здесь общее количество импортов библиотеки, тоже в срезе по времени. Какие менеджеры не любят графики? Можно построить такой график и увидеть, что использование библиотеки растет, а значит, это как минимум полезное дело.
Одна из моих любимых частей. Я ее довольно кратко освещу. Это поиск дефектов в графе. Сегодня я хотел поговорить с вами о двух видах дефектов: это циклическая зависимость модулей и неиспользуемый модуль какой-то, то есть dead code elimination проблеме.
Давайте начнем с циклической зависимости.
Тут, кажется, все довольно просто. У вас и так уже есть ориентированный граф, там нужно просто найти цикл. Объясню, почему я о таком говорю. Дело в том, что раньше я писал, в основном, серверную часть на Node.js, и мы не использовали, в принципе, никакой webpack/babel, ничего. То есть запускали as is. И там был require. Кто помнит, чем отличатся import от require? Все правильно. Если вы написали код плохо, а я, действительно, так делал, вы на вашем сервере можете узнать, что у вас модуль в какой-то циклической зависимости, только когда какой-то запрос придет от пользователей, или еще сработает какой-то ивент. То есть получается довольно глобальная проблема. До рантайма не понять. То есть с import намного все лучше, не будет такой проблемы.
Тут просто берете любой понравившийся алгоритм. Вот здесь я взял довольно простой алгоритм. Мы должны найти вершину, у которой есть только один тип ребер, — либо входящий, либо исходящий. Если такая вершина есть, — удаляем ее, удаляем ребра, и, собственно, продолжаем этот процесс, мы найдем и докажем, что в этом графе был цикл длиной в пять.
Согласитесь, если бы вы это смотрели по коду, то есть там цикл длиной два-три еще можно найти, но, больше уже нереально, а у нас в проекте реально был цикл длиной семь, но не в production.
Про неиспользуемые модули. Тут тоже довольно тривиальный алгоритм. Мы должны выделить компоненты связанности в нашем графе, и просто посмотреть, найти те компоненты, в который не входит ни один из entry узлов. В данном случае, это вот этот компонент связанности, обе вершины, получается, оба узла. Тут entry.js назвал. На самом деле, неважно, как он называется, это то, что у вас описано в config сборки entry имеется в виду.
Но есть еще и другой подход. Если вы граф не собирали, а у вас есть просто система сборки, то, как это дешевле всего сделать? Давайте просто во время сборки помечать все файлы, которые попали в сборку. Помечать их и создавать множество. После этого мы должны получить множество всех файлов, которые у вас есть в проекте, и просто их вычесть. То есть очень простые операции.
И вот я вам не просто теоретическое что-то говорю, я вдохновился, пришел к себе в проект, и сделал вот это. И, внимание! Я даже не удалял node_modules. Это я оставил как точку роста на следующее ревью. И, короче, я настолько собой вдохновился, что решил этот слайд как-то по-другому сделать, переооформить. Пускай он выглядит вот так, потому что реально круто!
Хорошие цифры, представляете, как стало всем хорошо? И тут меня загнало в такую степь, что я почувствовал себя дизайнером, и подумал, что это такое достижение, которое хотелось бы в рамочку добавить. И, как вы понимаете, я встал, посмотрел и понял, что я скорее не дизайнер, а, действительно, веб-разработчик. Но я же не дурак. Я взял эту рамочку, добавил к себе на сайт к SEO-амулетам.
Можете пользоваться, даже ссылка есть. И чтобы вы не думали, что я вас обманываю — мы же сегодня откровенничаем — я реально посмотрел отзывы. Считаю, можно им верить.
Ладно, если быть честным, то это выглядело как-то вот так. Я увидел новую хайповую библиотеку thanos-js, взял, создал пул-реквест. По секрету, у меня есть администраторские права в нашем репозитории. И я взял и смёржил мастер. Как вам такое? Ладно, мы с вами откровенны, и, на самом деле, это все выглядело вот так. Если кто не знает, thanos-js — библиотека, которая просто удаляет 50% вашего кода рандомно.
На самом деле я там все равно использовал библиотеку, но библиотека называется по-другому. Она называется diffector, и сейчас мы о ней с вами поговорим. И здесь я хотел бы отметить, что пул-реквест довольно весомый, минус 44 тысячи строк кода, и вы представляете — он прошел тестирование с первого раза. То есть то, о чем я говорю, реально может работать.
Diffector. На самом деле, он занимается не только задачей удаления неиспользуемых модулей, поиска дефектов в графе, но и более важной задачей. То, что я вначале декларировал, — помочь разработчику и тестировщику, сейчас об этом пойдет речь. И работает он примерно так.
Мы получаем список измененных файлов при помощи системы контроля версий. У нас уже построен граф — diffector его строит. И для каждого такого измененного файла мы ищем путь до entry и помечаем измененный entry. А entry у нас будет соотноситься со страницами приложений, которые увидит пользователь. Но это довольно логично.
И что нам это дает? Для тестирования — мы знаем, какие странички в приложении изменились. Мы можем сказать тестировщику, что тестировать стоит только их. Мы также можем сказать нашей ci-job, которая запускает автотесты, что тестировать стоит также только эти страницы. А для разработчиков все намного проще, потому что теперь вам не пишут тестировщики и не спрашивают: «А чего надо тестировать?»
Давайте рассмотрим пример того, как работает diffector. Вот у нас есть некая директория, pages.desktop/*. В ней содержится просто какой-то список самих страниц. И страницы описываются тоже несколькими файлами. Контроллер — серверная часть странички. View — какая-то react-часть. И deps, это из другой системы сборки. У нас не только webpack, но и ENB.
И я внес какие-то изменения в проект, в пустой файл, структуру которого вы видели. Вот что мне выдает diffector. Я его просто запустил, diffector это command line-приложение. Я его запустил, он мне говорит, что у меня изменилась одна страница, которая называется BindBonusPage.
Я могу также запустить его в режиме verbose, посмотреть более подробный отчет, и, действительно, увидеть, что он как минимум работает в таком простом кейсе. Как мы видим, у нас в BindBonusPage изменился index-файлик и controller.
Но давайте посмотрим, что будет, если мы изменим что-то другое.
Я изменил что-то другое. И diffector мне сказал, что у меня изменилось девять страниц. И вот это меня уже не радует, как бы он мне не особо помог.
Давайте посмотрим, почему? Здесь сейчас показаны причины того, почему данная страница посчиталась измененной. И как мы видим, здесь одно и то же. Это какой-то компонент текста из uikit.
И давайте посмотрим diff. Я взял и просто поменял в типах комментарий. Но согласитесь, в данном случае diffector отработал неправильно. На самом деле не стоит на все эти девять страниц, которые попали только из-за текста, запускать тесты и добавлять их в регресс.
И это, действительно, проблема. Если у нас существуют файлики, которые много используются, по проекту любое изменение в файле затригерит изменение всех ваших entry, а, значит, все ваши страницы приложения попадут в test-scope, и тогда эффективность просто нулевая. Вот так ее надо решать.
Тришейкинг. Надеюсь, большинству знаком этот термин, и, в общем, в чем он состоит.
В первую очередь еще раз скажу про проблематику. У нас есть какой-то файлик, его часто используют. Как пример — i18n, который сделан на коленке, где просто хранятся ключи. Изменив его, вы, по сути, изменили все приложение с точки зрения связи в графе. А по факту, вы изменили только места, где используется какой-то ключ.
И как его сделать у нас? Если раньше у нас модуль был одним файликом в файловой системе, то теперь у нас модуль, это, действительно, экспорты, которые есть в нашем файле.
То есть как-то так. Если раньше было вот так, то теперь мы делим файлик B на экспорты, и получается, что у экспорта-2 даже нет никакого ребра. То есть он нам даже не нужен. Так работает тришейкинг и в вашей системе сборки, если esm.
Но здесь не все так радужно.
Рассмотрим вот такой код.
Представьте, если мы изменим здесь value, то на самом деле мы изменим не только эту константу. Мы также изменим и статический метод класса, а также и метод класса, который вызывал статический метод класса. То есть у нас появляется вторая часть задачи, где нам нужно резолвить зависимости внутри самого файла.
Да, это можно попробовать сделать при помочи AST, но подскажу, что конкретно для такого случая там будет около 250 строк кода, и не факт, что это все будет работать. А, на самом деле, там может быть и по-другому инверсированы зависимости, и все в этом духе, поэтому это довольно сложная задача.
Также представьте, что у вас есть какой-то GlobalContext и какая-то функция, которая его изменяет. Как здесь вообще понять, что при изменении функции modify, что у нас изменилось, действительно? В этом модуле, или как-то при изменении GlobalContext. Но это очень сложно. Поэтому мы не стали реализовать полноценный тришейкинг. Кстати, такие вещи называются side effects. Вы, может быть, когда настраивали webpack, видели такой флажок, его там можно указать. То есть, если вы ставите модуль в webpack sideEffects: true, то вам как раз не будет тришейкаться. Но будет гарантироваться вот это.
Чтобы решить эту проблему, мы решили все-таки чуть-чуть попинать наших разработчиков и ввели интерактивный режим. Объясню, что и зачем. Вместо того чтобы просто запускать diffector, его теперь можно запускать как полноценное консольное приложение. Здесь, как мы видим, я его запустил в интерактивном режиме. И здесь он мне показал изменения — все, которые были сделаны в моем коде. И те страницы, которые он затронул.
Как мы видим, у меня здесь есть агенда, то есть diff, expand, log, а кроме этого, мы здесь видим то изменение, о котором я вам уже говорил, изменение в тексте.
Вот оно, напомню. Мы его можем посмотреть при помощи кнопочки D, увидеть diff. И уже сам разработчик может понять, что текст ему, допустим, не нужно включать. Изменения в компоненте текста, на самом деле, не затронут контент для пользователя. Поэтому мы спокойно можем выключить его из этого списка изменений, сократив количество страниц, которые нам нужно протестировать. То есть мы взяли и убрали восемь страниц.
Здесь, на самом деле, тоже может быть несколько подходов. Можно рассматривать изменения текста для каждой из этих восьми страниц. Но это огромная работа. Представьте, восемь — на самом деле, не совсем честная цифра. Таких страниц может быть и больше. Текст много где используется. И заставлять разработчика размечать каждое из этих использований, и влияет оно или нет, это, собственно, возвращение к проблеме, которую я декларировал в начале доклада. Поэтому мы решили поступить таким образом. В сами изменения попадет только вторая строка, потому что ее мы оставили после нашего экспертного анализа.
И сама соль — для чего мы будем diffector использовать? Не только для того, чтобы в консольках разработчику играться, а для того, чтобы жизнь лучше делать.
Вот у нас есть какая-то сущность, абстракция над страницей приложения, к которой имеет доступ пользователь.
Мы с вами обсудили вот такую связь, обсудили, как связана страница приложения с entry. У одной странички приложения может быть несколько entry. И эту связь ищет diffector.
Еще нужно рассмотреть другую связь. Для страницы есть тест-кейсы. Эта связь находится в хранилище кейсов, ее оттуда можно получить.
Таким образом, по изменениям entry мы можем получить те тест-кейсы, которые мы задели.
Работает оно примерно так. Мы запускаем diffector. У него есть несколько видов репорта. Помимо того, что он сообщает нам, что какие-то странички у нас изменились, он генерирует запрос в наше хранилище тест-кейсов. Или в ваше, как захотите. Здесь он говорит: смотрите, изменился BindBonusPage, отдай мне все тест-кейсы, которые провязаны с этой страницей. Это для ручного регресса. А для автотестов, собственно, чуть-чуть меняем запрос. Выглядит примерно так.
Теперь самое важное — переносим всё в CI. Это просто скриншот комментария из тикета. Здесь то же самое: сбилжен определенный запрос, который увидит тестировщик, когда зайдет к вам в тикет и начнет его проверять.
Кроме того, раньше было вот так. 43 минуты — это только testing, и это у нас покоммитно, каждый коммит в репозиторий Маркета.
А стало вот так. Не всегда, конечно, но это один из хороших показателей.
Вообще хотелось бы сказать, что в идеальном мире такой задачи особо не должно возникать. Дело в следующем: вы должны организовывать ваши бандлы таким образом, чтобы туда попадали только те файлы, до которых действительно может добраться пользователь. Я понимаю, что это очень сложная задача, и она вряд ли вообще реализуема, но если бы было так, вы бы могли просто из бандлов получить список модулей, которые там есть. Если эти модули изменяются, это практически гарантия того, что и у пользователя что-то изменится.
Резюмирую. Действительно, все, о чем мы с вами говорили, имеет практическую пользу для больших команд. Если у вас приложение разрабатывают два-три человека, они вполне могут сами следить за чужими пул-реквестами и за тем, как изменяется код, понимать, как связано приложение. Но в больших проектах одному разработчику это делать сложно.
Кроме того, если вы действительно захотите использовать статический анализ, граф зависимости модулей, то лучше начните с использования output вашей системы сборки. Для начала просто поймите, нужно оно вам или нет. Если вы собираете — храните. Если храните — анализируйте и улучшайте жизнь ваших разработчиков. Спасибо!



