
WAL-G — простой и эффективный инструмент для резервного копирования PostgreSQL в облака. По своей основной функциональности он является наследником популярного инструмента WAL-E, но переписанным на Go. Но в WAL-G есть одна важная новая особенность — дельта-копии. Дельта-копии WAL-G хранят страницы файлов, изменившиеся с предыдущей версии резервной копии. В WAL-G реализовано довольно много технологий по распараллеливанию бэкапов. WAL-G работает гораздо быстрее чем, WAL-E.
Подробности работы wal-g можно прочитать в статье: Разгоняем бэкап. Лекция Яндекса
Протокол хранения S3 стал популярным для хранения данных. Одно из преимуществ S3 — возможность доступа через API, что позволяет организовать гибкое взаимодействие с хранилищем, включая публичный доступ на чтение, в то время как обновление информации в хранилище происходит только авторизованными лицами.
Существует несколько как открытых, так и частных реализаций хранилищ, работающих по протоколу S3. Сегодня мы рассмотрим популярное решение для организации малых хранилищ — Minio.
Для тестирования wal-g подойдет один сервер PostgreSQL, а в качестве замены S3 используется Minio.
Сервер Minio
Установка Minio
yum -y install yum-plugin-copr
yum copr enable -y lkiesow/minio
yum install -y minioПравим AccessKey и SecretKey в /etc/minio/minio.conf
vi /etc/minio/minio.confЕсли вы не будете использовать nginx перед Minio, то нужно изменить
--address 127.0.0.1:9000--address 0.0.0.0:9000Запускаем Minio
systemctl start minioЗаходим в web-интерфейс Minio http://ip-адрес-сервера-minio:9000 и создаем бакет (например, pg-backups).
Сервер БД
WAL-G в rpm собираю я (Антон Пацев). Github, Fedora COPR.
У кого не RPM-based система используйте официальную инструкцию по установке.
Вместе с бинарником wal-g в rpm присутствуют скрипты, которые импортируют переменные из файла /etc/wal-g.d/server-s3.conf.
backup-fetch.sh
backup-list.sh
backup-push.sh
wal-fetch.sh
wal-g-run.sh
wal-push.shУстанавливаем wal-g.
yum -y install yum-plugin-copr
yum copr enable -y antonpatsev/wal-g
yum install -y wal-gПроверяем версию wal-g.
wal-g --version
wal-g version v0.2.14Редактируем /etc/wal-g.d/server-s3.conf по свои нужды.
Файлы конфигурации и файлы данных, используемые кластером базы данных, традиционно хранятся вместе в каталоге данных кластера, который обычно называют PGDATA
#!/bin/bash
export PG_VER="9.6"
export WALE_S3_PREFIX="s3://pg-backups" # бакет, который мы создали в S3
export AWS_ACCESS_KEY_ID="xxxx" # AccessKey из /etc/minio/minio.conf
export AWS_ENDPOINT="http://ip-адрес-сервера-minio:9000"
export AWS_S3_FORCE_PATH_STYLE="true"
export AWS_SECRET_ACCESS_KEY="yyyy" # SecretKey из /etc/minio/minio.conf
export PGDATA=/var/lib/pgsql/$PG_VER/data/
export PGHOST=/var/run/postgresql/.s.PGSQL.5432 # Сокет для подключения к PostgreSQL
export WALG_UPLOAD_CONCURRENCY=2 # Кол-во потоков для закачки
export WALG_DOWNLOAD_CONCURRENCY=2 # Кол-во потоков для скачивания
export WALG_UPLOAD_DISK_CONCURRENCY=2 # Кол-во потоков на диске для закачки
export WALG_DELTA_MAX_STEPS=7
export WALG_COMPRESSION_METHOD=brotli # Какой метод сжатия использовать.
При настройке WAL-G вы указываете WALG_DELTA_MAX_STEPS — количество шагов, на которые максимально отстоит от base-бэкапа дельта-бэкап, и указываете политику дельта-копии. Либо вы делаете копию с последней существующей дельты, либо делаете дельту от изначального полного бэкапа. Это нужно на тот случай, когда у вас в базе данных всегда меняется одна и та же составляющая БД, одни и те же данные постоянно изменяются.
Устанавливаем БД.
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.
noarch.rpm
yum install -y postgresql96 postgresql96-server mcИнициализируем бд.
/usr/pgsql-9.6/bin/postgresql96-setup initdb
Initializing database ... OKЕсли вы тестируете на 1 сервере, то нужно перенастроить параметр wal_level на archive для PostgreSQL меньше 10 версии, и replica для PostgreSQL 10 версии и старше.
wal_level = archiveСделаем бекапирование WAL архивов каждые 60 секунд с помощью самого PostgreSQL. На проде у вас будет другое значение archive_timeout.
archive_mode = on
archive_command = '/usr/local/bin/wal-push.sh %p'
archive_timeout = 60 # Каждые 60 секунд будет выполнятся команда archive_command.Стартуем PostgreSQL
systemctl start postgresql-9.6В отдельной консоли смотрим логи PostgreSQL на предмет ошибок: (postgresql-Wed.log меняете на текущий).
tail -fn100 /var/lib/pgsql/9.6/data/pg_log/postgresql-Wed.logЗаходим в psql.
su - postgres
psqlВ psql создаем БД.
Создаем таблицу в бд test1.
create database test1;Переключаемся на бд test.
postgres=# \c test1;Создаем таблицу indexing_table.
test1=# CREATE TABLE indexing_table(created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW());Добавление данных.
Запускаем вставку данных. Ждем 10-20 минут.
#!/bin/bash
# postgres
while true; do
psql -U postgres -d test1 -c "INSERT INTO indexing_table(created_at) VALUES (CURRENT_TIMESTAMP);"
sleep 60;
doneОбязательно делаем полный бекап.
su - postgres
/usr/local/bin/backup-push.shСмотрим записи в таблице в бд test1
select * from indexing_table;
2020-01-29 09:41:25.226198+
2020-01-29 09:42:25.336989+
2020-01-29 09:43:25.356069+
2020-01-29 09:44:25.37381+
2020-01-29 09:45:25.392944+
2020-01-29 09:46:25.412327+
2020-01-29 09:47:25.432564+
2020-01-29 09:48:25.451985+
2020-01-29 09:49:25.472653+
2020-01-29 09:50:25.491974+
2020-01-29 09:51:25.510178+Строка это текущее время.
Смотрим список полных бекапов
/usr/local/bin/backup-list.shТестирование восстановления
Полное восстановление с накатываем всех доступных WAL.
Останавливаем Postgresql.
Удаляем все из папки /var/lib/pgsql/9.6/data.
Запускаем скрипт /usr/local/bin/backup-fetch.sh от пользователя postgres.
su - postgres
/usr/local/bin/backup-fetch.shBackup extraction complete.
Добавляем recovery.conf в папку /var/lib/pgsql/9.6/data со следующим содержимым.
restore_command = '/usr/local/bin/wal-fetch.sh "%f" "%p"'Запускаем PostgreSQL. PostgreSQL запустит процесса recovery из архивных WAL, и только потом база откроется.
systemctl start postgresql-9.6
tail -fn100 /var/lib/pgsql/9.6/data/pg_log/postgresql-Wed.logВосстановление на определенное время.
Если хотим восстановить базу до определенный минуты, то в recovery.conf добавляем параметр recovery_target_time — указываем на какое время восстановить базу.
restore_command = '/usr/local/bin/wal-fetch.sh "%f" "%p"'
recovery_target_time = '2020-01-29 09:46:25'После восстановления смотрим на таблицу indexing_table
2020-01-29 09:41:25.226198+00
2020-01-29 09:42:25.336989+00
2020-01-29 09:43:25.356069+00
2020-01-29 09:44:25.37381+00
2020-01-29 09:45:25.392944+00Запускаем PostgreSQL. PostgreSQL запустит процесса recovery из архивных WAL, и только потом база откроется.
systemctl start postgresql-9.6
tail -fn100 /var/lib/pgsql/9.6/data/pg_log/postgresql-Wed.logТестирование
Генерируем 1GB базу данных как описано тут https://gist.github.com/ololobus/5b25c432f208d7eb31051a5f238dffff
Запрашиваем размер бакета после генерации 1GB данных.
postgres=# SELECT pg_size_pretty(pg_database_size('test1'));
pg_size_pretty
----------------
1003 MBs4cmd — бесплатный инструмент командной строки для работы с данными, расположенными в хранилище Amazon S3. Утилита написана на языке программирования python, и благодаря этому может использоваться в операционных системах и Windows, и Linux.
Устанавливаем s4cmd
pip install s4cmdLZ4
s4cmd --endpoint-url=http://ip-адрес-сервера-minio:9000 --access-key=xxxx --secret-key=yyyy du -r s3://pg-backups
840540822 s3://pg-backups/wal_005/
840 МБ в формате lz4 только WAL логов
Полный бекап с lz4 - 1GB данных
time backup_push.sh
real 0m18.582s
Размер S3 бакета после полного бекапа
581480085 s3://pg-backups/basebackups_005/
842374424 s3://pg-backups/wal_005
581 МБ занимает полный бекапLZMA
После генерации 1ГБ данных
338413694 s3://pg-backups/wal_005/
338 мб логов в формате lzma
Время генерации полного бекапа
time backup_push.sh
real 5m25.054s
Размер бакета в S3
270310495 s3://pg-backups/basebackups_005/
433485092 s3://pg-backups/wal_005/
270 мб занимает полный бекап в формате lzmaBrotli
После генерации 1ГБ данных
459229886 s3://pg-backups/wal_005/
459 мб логов в формате brotli
Время генерации полного бекапа
real 0m23.408s
Размер бакета в S3
312960942 s3://pg-backups/basebackups_005/
459309262 s3://pg-backups/wal_005/
312 мб занимает полный бекап в формате brotli
Сравнение результатов на графике.
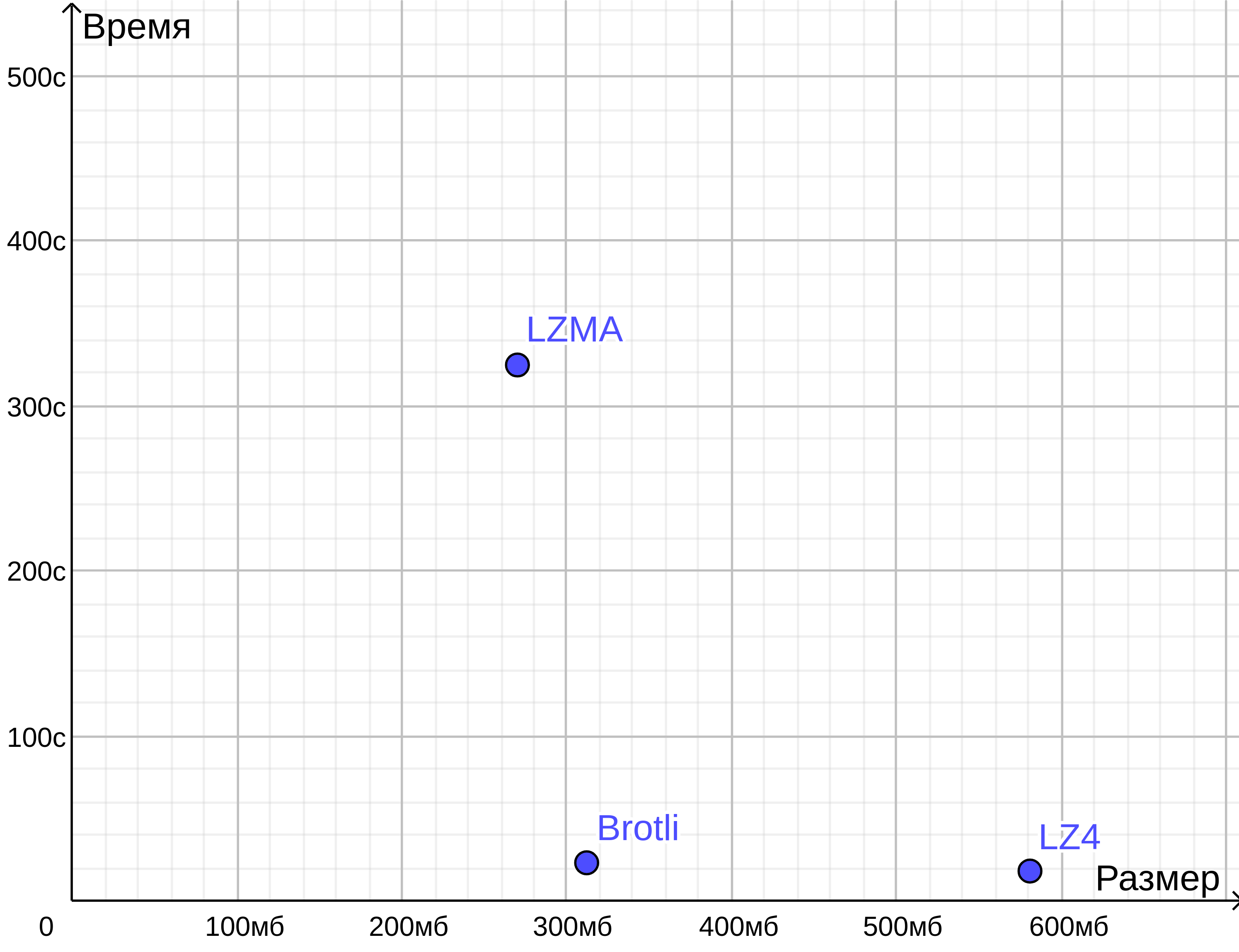
Как видим, что Brotli сопоставим по размеру с LZMA, но бекап выполняется за время LZ4.
Чат русскоязычного сообщества PostgreSQL: https://t.me/pgsql
Поставьте, пожалуйста, звезду на Github, если вы используете wal-g




