

Сегодня, 4 мая, в день Звездных войн мы подготовили для Вас подробный гайд по основным функциям библиотеки dplyr. Почему именно в день Звездных войн? А потому что разбирать мы все будем на примере датасета starwars.
Ну что, начнем!
Если Вы хотите получать еще больше интересных материалов по программированию, Data Science и математике, то подписывайтесь на нашу группу ВК, канал в Телеграме и Инстаграм. Каждый день мы публикуем полезный контент и вопросы с реальных собеседований.
Кстати говоря, а Вы знаете, почему день Звездных войн отмечается именно 4 мая? Все очень просто - знаменитая фраза «May the fource be with you» крайне созвучна с «May, the 4th», т.е. 4 мая :)
Знакомство с датасетом
Для начала, давайте подключим библиотеку dplyr. Делается это с помощью функции library.

Вместе с этой библиотекой нам становится доступен и датасет starwars. Давайте выведем первые несколько строк на экран и посмотрим, какую информацию он в себе хранит.
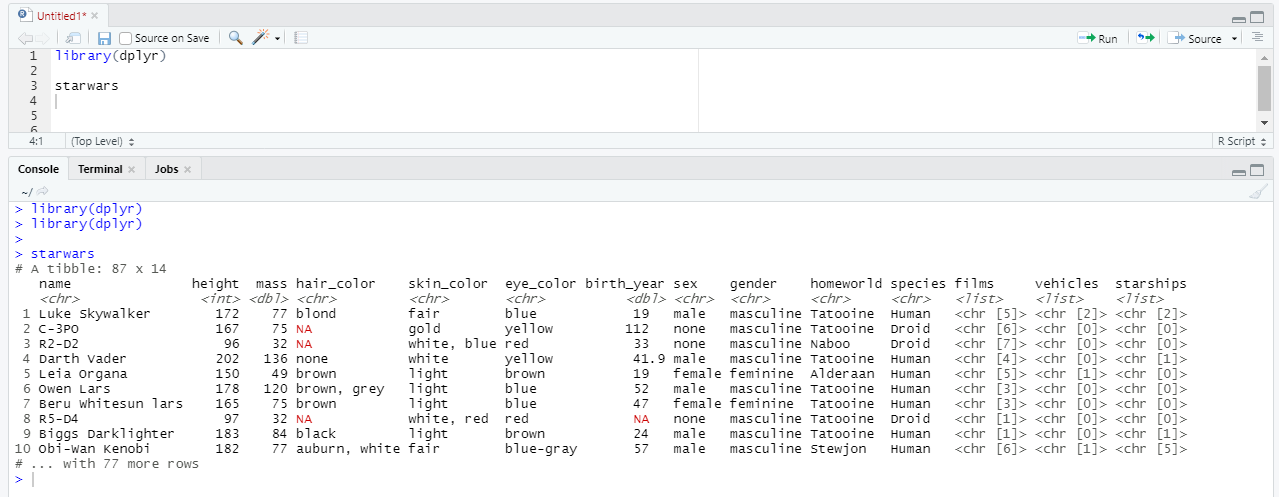
name - имя или прозвище героя вселенной Звездных войн. Например, Оби-Ван Кеноби.
height - высота персонажа
mass - масса персонажа
hair_color - цвет волос
skin_color - цвет кожи
eye_color - цвет глаз
birth_year - год рождения (до битвы на Явине)
sex - биологический пол (есть существа без пола и гермафродиты)
gender - поведенческий пол персонажа (например, на какой пол запрограммированы дроиды)
homeworld - из какой вселенной существо
species - биологический вид
films - список фильмов, в которых появилось существо
vehicles - список транспорта, которым существо управляло
starships - список космических кораблей, которыми существо управляло
В принципе, все предельно понятно, поэтому можем переходить к знакомству с dplyr и обработке нашего датасета. Дадим полет нашей фантазии и немного покрутим-повертим наши данные :)
Знакомство с dplyr
dplyr - это один из основных пакетов семейства tidyverse. Его ближайший аналог в Python - библиотека Pandas. Библиотека dplyr служит для манипуляции с данными: фильтрация, сортировка, создание вычислимых столбцов и так далее.
По своему функционалу библиотека
dplyrочень похожа на стандартный синтаксисSQL. Немного ранее мы вместе с Алексеем Селезневым из Netpeak делали карточки: сравнение глаголовdplyrи операторовSQL. Вы можете посмотреть их здесь.
Перед тем, как переходить к рассмотрению глаголов библиотеки dplyr, нужно упомянуть, что все пакеты tidyverse основаны на концепции tidy data. Если коротко, то «аккуратные данные» - это способ организации датафреймов по трем основным постулатам:
Каждая переменная находится в отдельном столбце
Каждое измерение находится в отдельной строке
Каждое значение находится в отдельной ячейке

Кстати говоря, наш датасет starwars не совсем соответствует этим правилам. Нам это не помешает, но сможете ли Вы найти, в чем именно несоответствие? ;)
Если Вы хотите поподробней познакомиться с
tidy data, рекомендуем нашу статью.
Итак, вернемся к глаголам dplyr. Пакет dplyr позволяет делать несколько основных операций:
Отбор столбцов
Фильтрация строк
Сортировка строк
Группировка
Агрегирование
Создание вычислимых столбцов
Объединение таблиц
Давайте переходить к практике - хватит теории!

Отбор столбцов
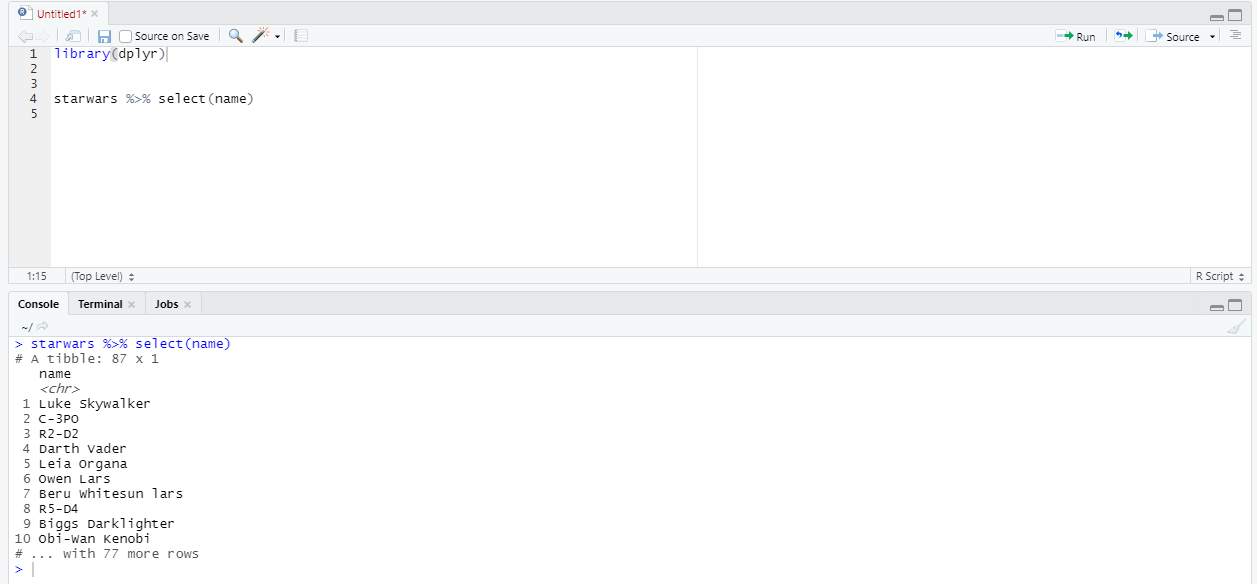
Давайте начнем с самого простого - как выбрать только определенные столбцы из таблицы? Очень просто - с помощью функции select.
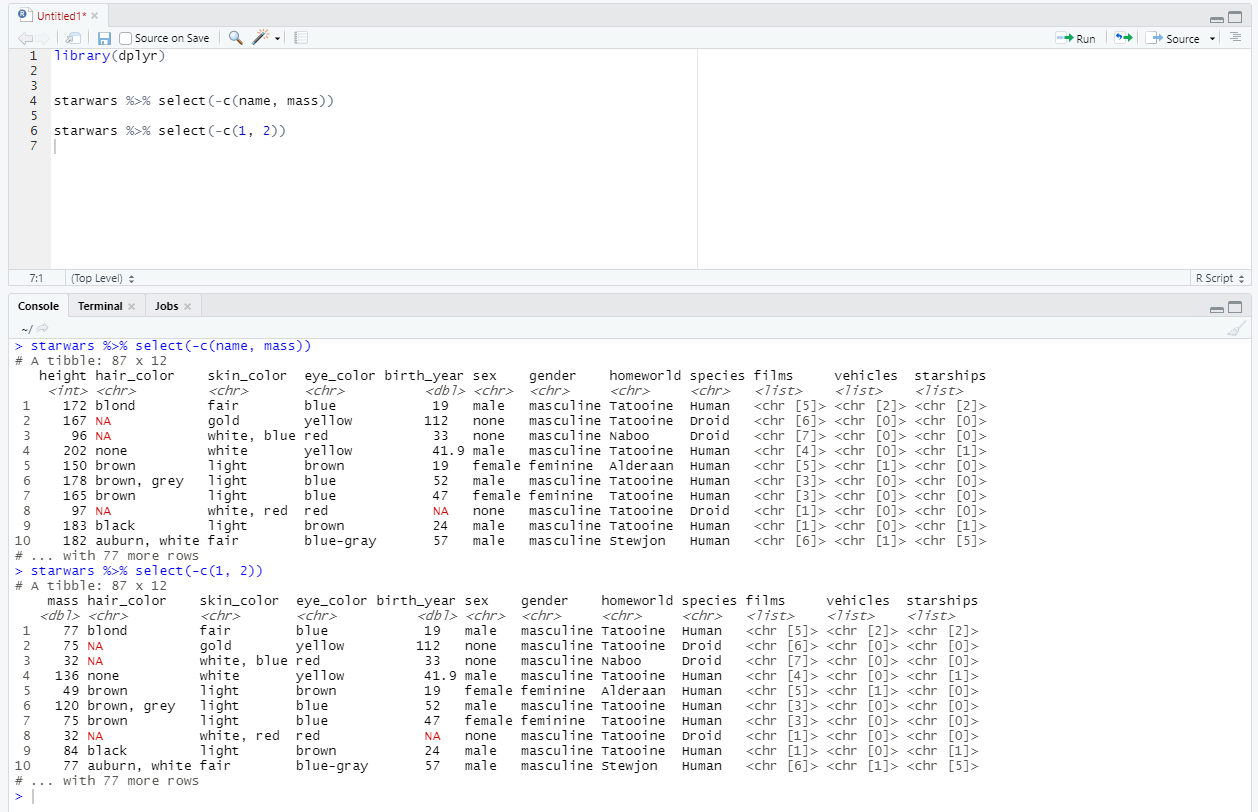
А что если нам проще указать, какие столбцы не надо отбирать? Например, в таблице 20 столбцов, а нам нужно исключить только первый столбец. Или столбец с определенными названиями. Не проблема - просто добавьте знак минус:
Но и это не все возможности функции select. Мы можем воспользоваться вспомогательными функциями, чтобы кастомизировать отбор столбцов. Вот список этих функций:
contains: название столбца содержитends_with: название столбца заканчивается наmatches: название столбца соответствует регулярному выражениюnum_range: поиск занумерованных столбцов, например, «V1, V2, V3...»one_of: название столбца соответствует одному из вариантовstarts_with: название столбца начинается с
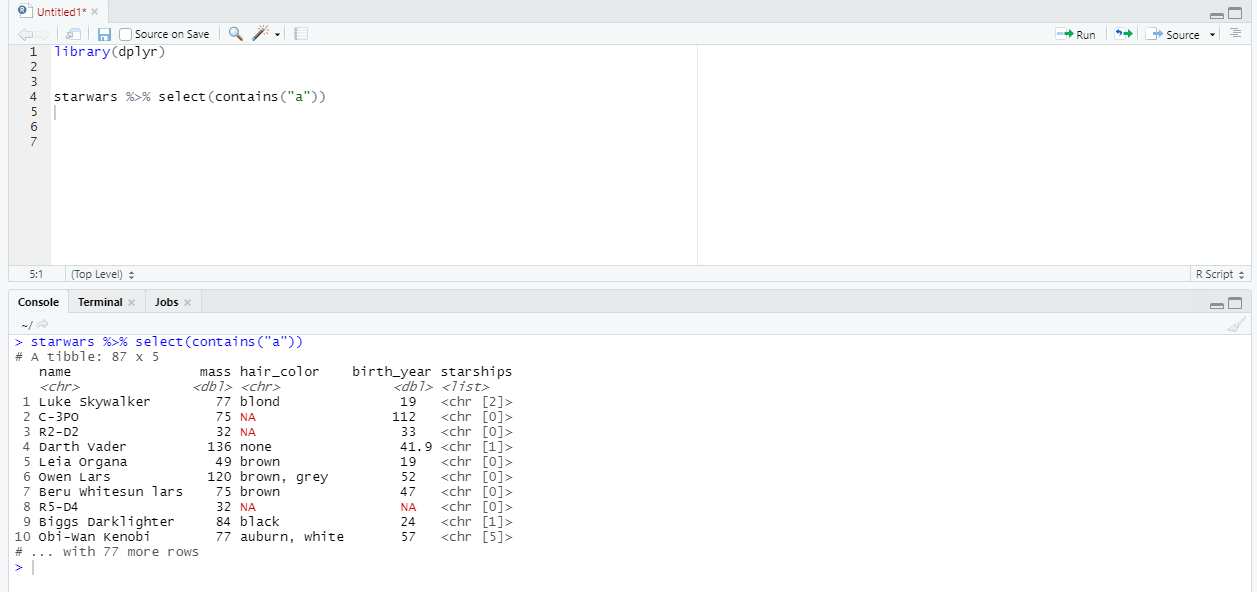
Давайте рассмотрим несколько примеров. Для начала отберем столбцы, название которых содержит букву «а».
Теперь отберем столбцы, название которых является одним из указанных.
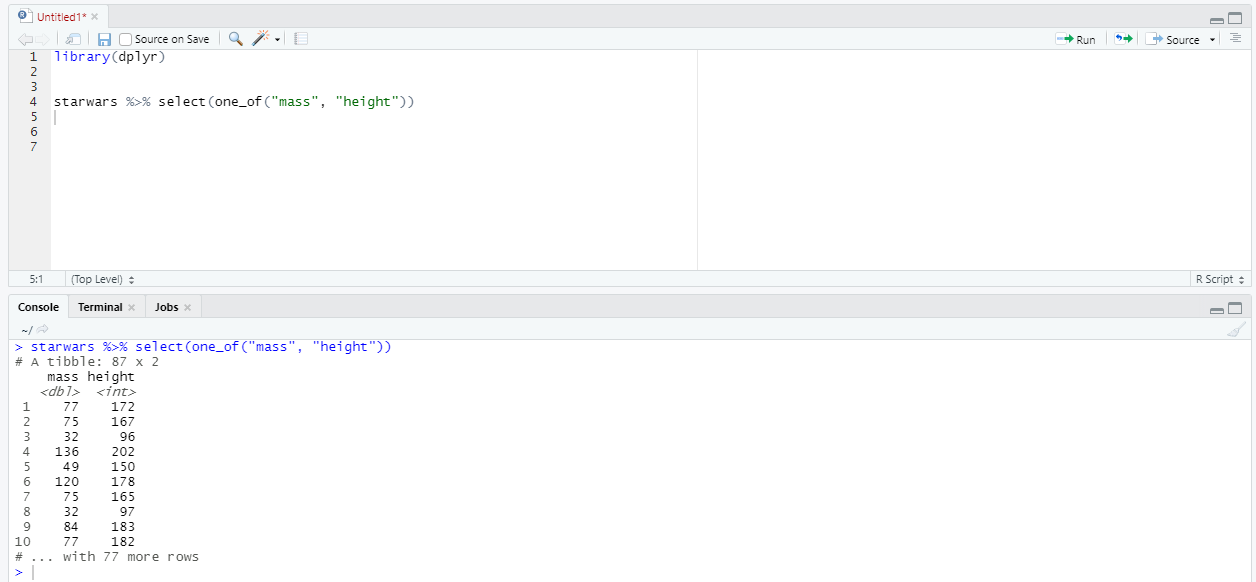
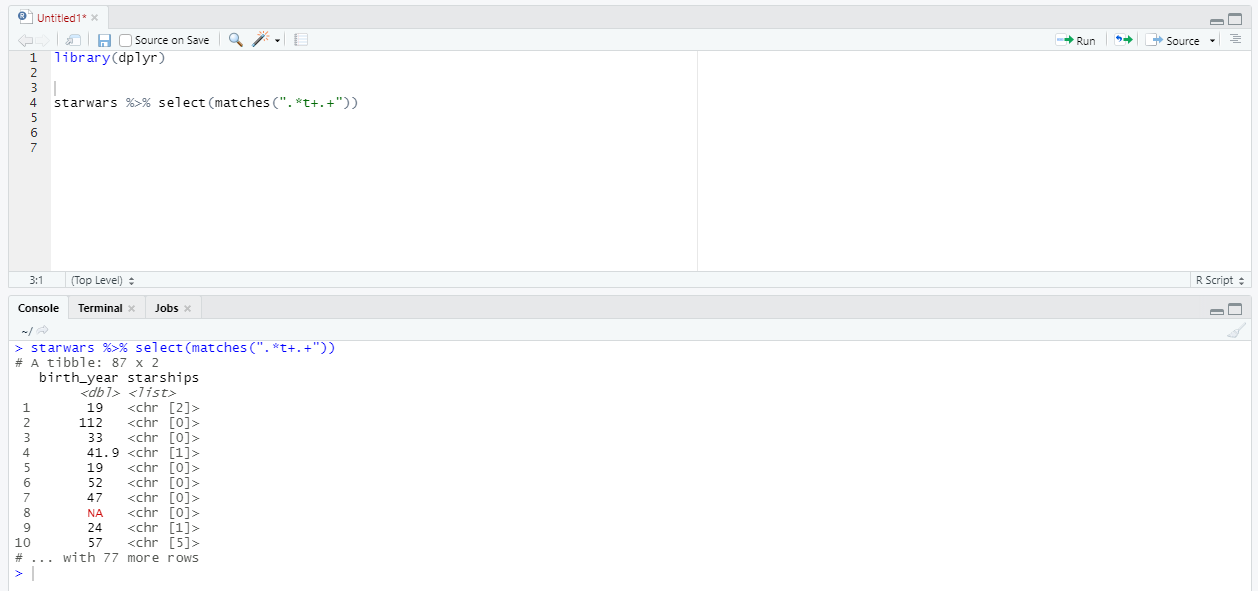
И в заключение - поиск по регулярному выражению: отбираем столбцы, в названии которых буква «t» стоит на любом месте, но после нее обязательно идет хотя бы 1 символ.
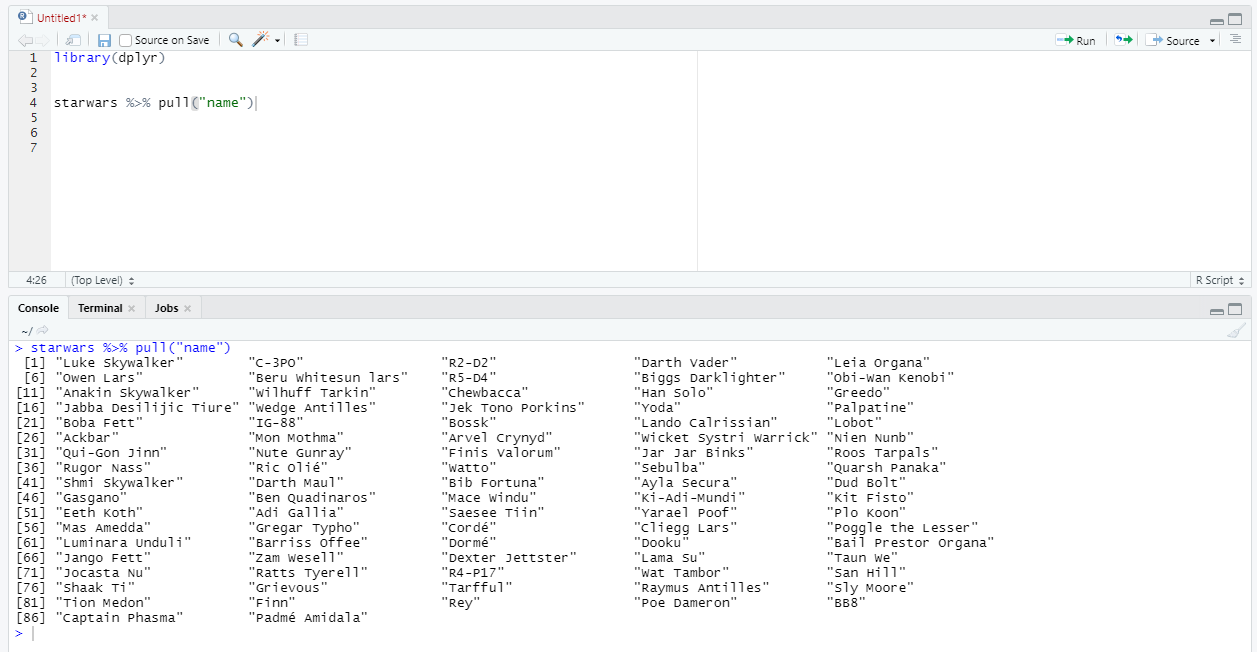
Обратите внимание, все наши запросы возвращали таблицу tibble. А что, если мы хотим отобрать столбец и сразу начать работать с ним, как с вектором? Мало кто знает, но для этого в dplyr есть специальная функция pull. Она возвращает не таблицу, как остальные глаголы dplyr, а вектор.
В целом, это весь основной функционал для отбора столбцов. Едва ли Вы не сможете найти решение своей задачи с помощью этих функций, так что мы переходим дальше :)
Фильтрация строк
Фильтрация строк по значениям - это аналог привычного оператора WHERE в SQL. В синтаксисе dplyr же для этого используется глагол filter (как неожиданно, правда?).
Использовать filter очень просто - задаем некое логическое выражение и функция вернет только те строки, для которых это выражение True. Например:

Вы можете комбинировать несколько условий с помощью & и |:

Логические выражения Вы можете конструировать не только с помощью >/<, но и с помощью других логических операторов:
>=<=is.na!is.na%in%!
Например:
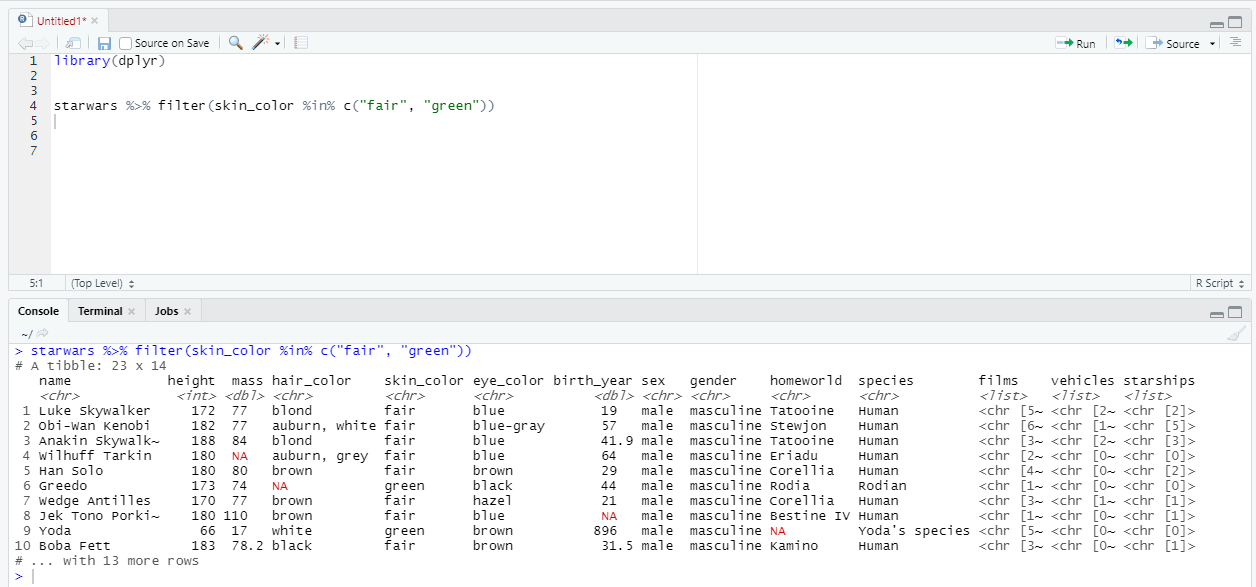
Помимо функции filter, отбирать строки можно и с помощью других глаголов. Например, функция distinct позволяет исключить дублирующиеся значения в определенном столбце.

Другая функция, sample_n, отбирает n случайных строк.
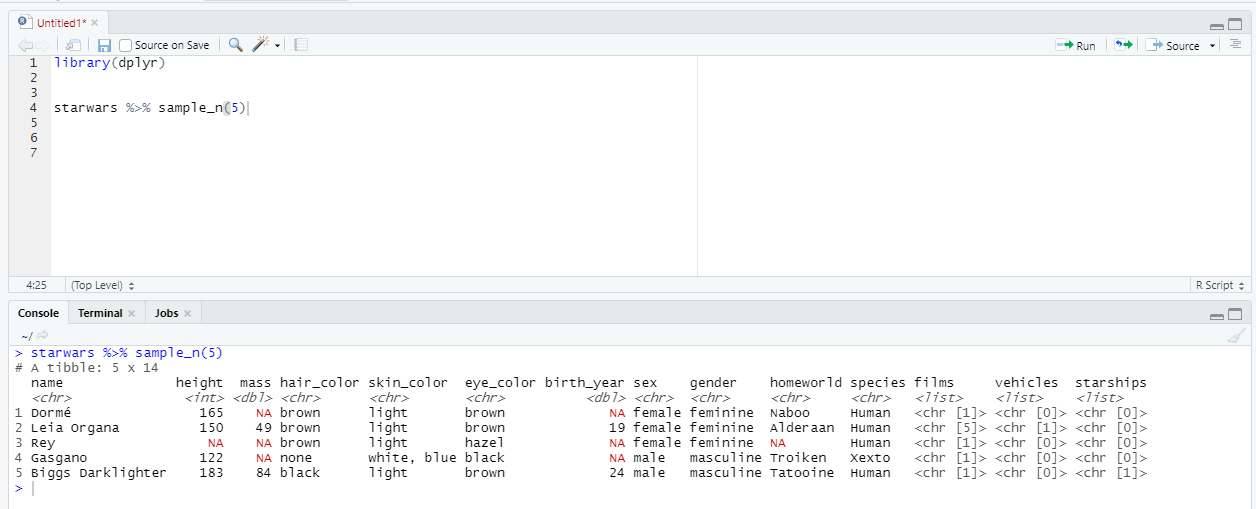
Функция slice же, например, позволяет отбирать строки по их индексу:

Функция sample_frac делает случайную подвыборку из таблицы. Нужно указать долю строк из общего числа, которые должны быть в итоговой таблице. Например, при параметре 0.5 вернется половина строк из таблицы, выбранные случайным образом.
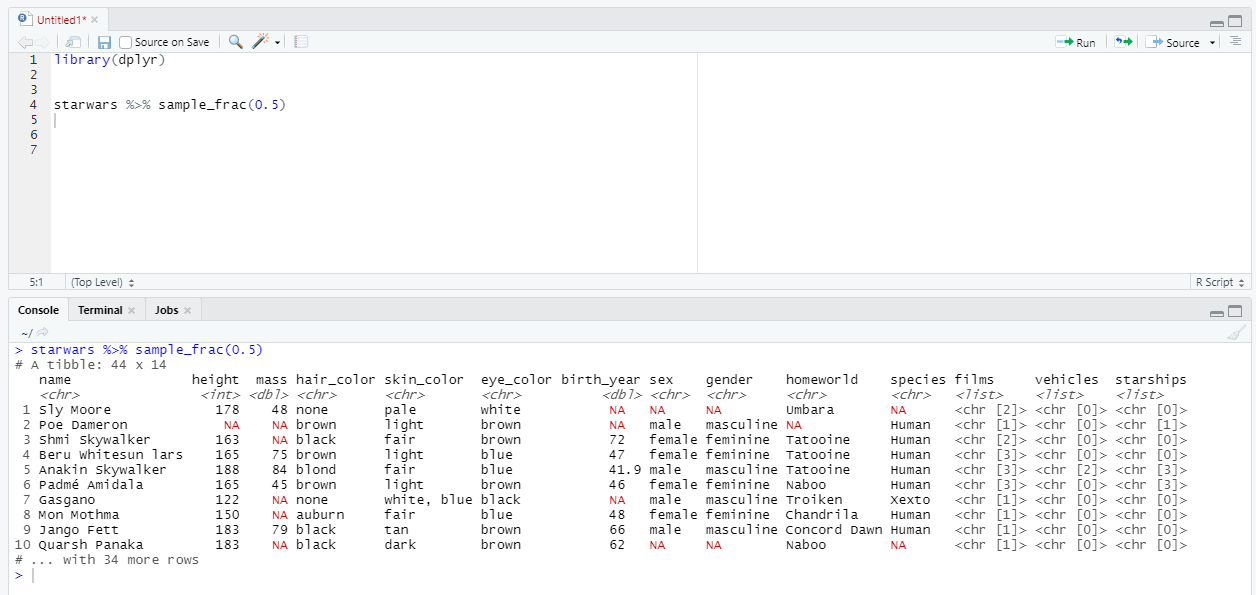
Итак, с фильтрацией строк мы тоже разобрались, переходим к следующему разделу.
Сортировка строк
За сортировку строк в SQL отвечает оператор ORDER BY. В dplyr для этого существует функция arrange.
Синтаксис максимально прост - достаточно указать столбец, по которому выполняется сортировка.
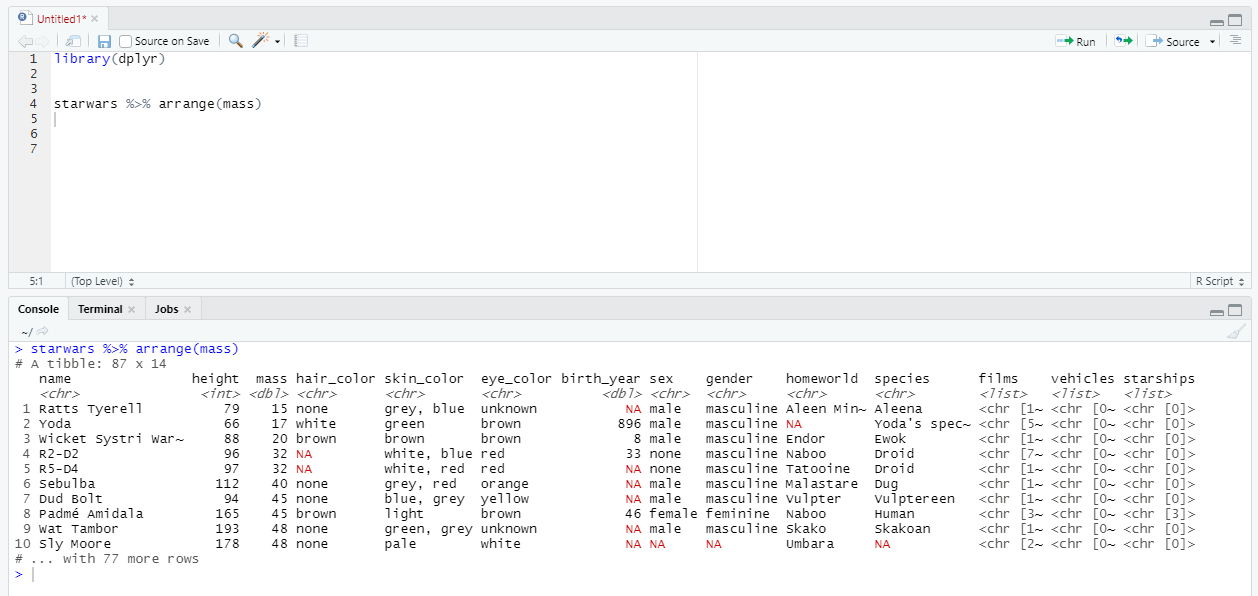
Чтобы отсортировать строки по убыванию, достаточно добавить функцию desc.

А если отсортировать нужно по нескольким столбцам? Легко, просто указываем их названия :)
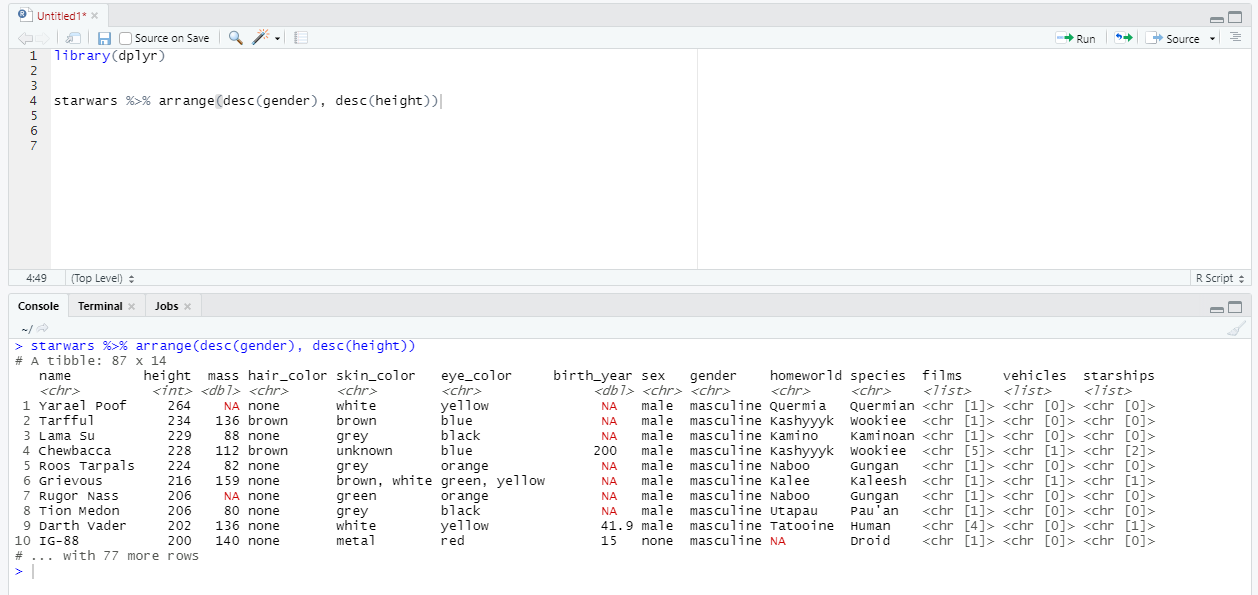
Кстати говоря, с arrange Вы можете также использовать вспомогательные глаголы, которые мы обсуждали в блоке с select. Для этого нужно использовать функцию across. Например:
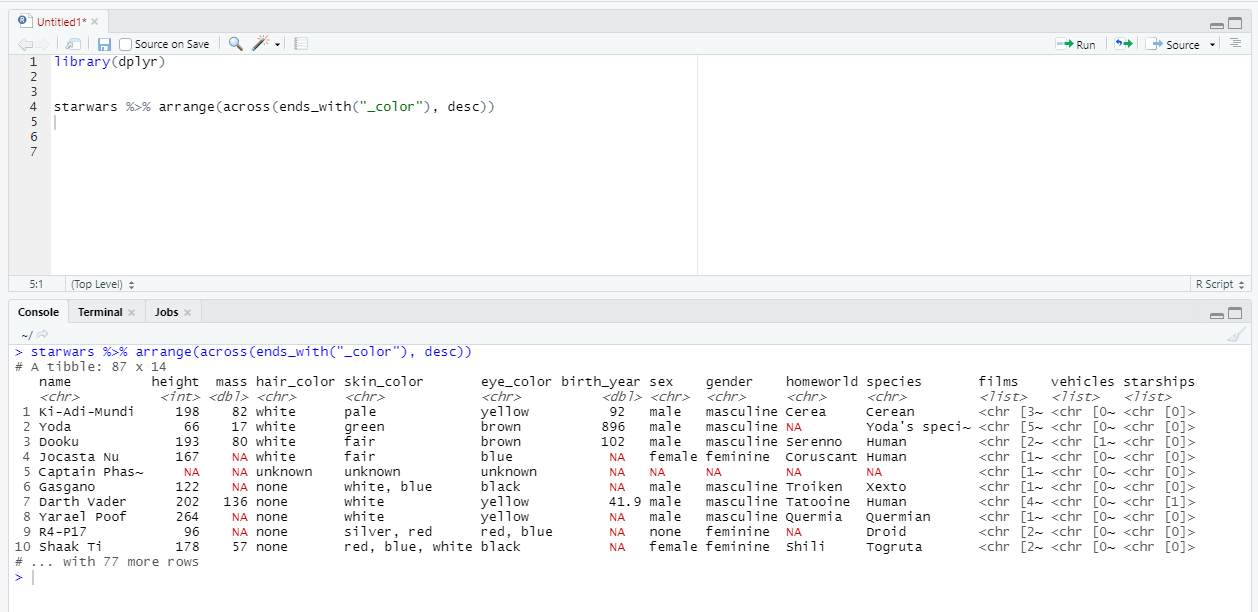
Про сортировку, пожалуй, сказать больше нечего - переходим к группировкам.
Группировка и агрегатные функции
Группировка - базовая операция, которая необходима для расчета различных характеристик - средних значений, медиан, сумм, количества строк в группе и так далее. В SQL для этого используется оператор GROUP BY и агрегатные функции sum, min, max и так далее. В dplyr же… все то же самое :) Ну, почти.
Давайте для начала сгруппируем наши строки по полю eye_color:
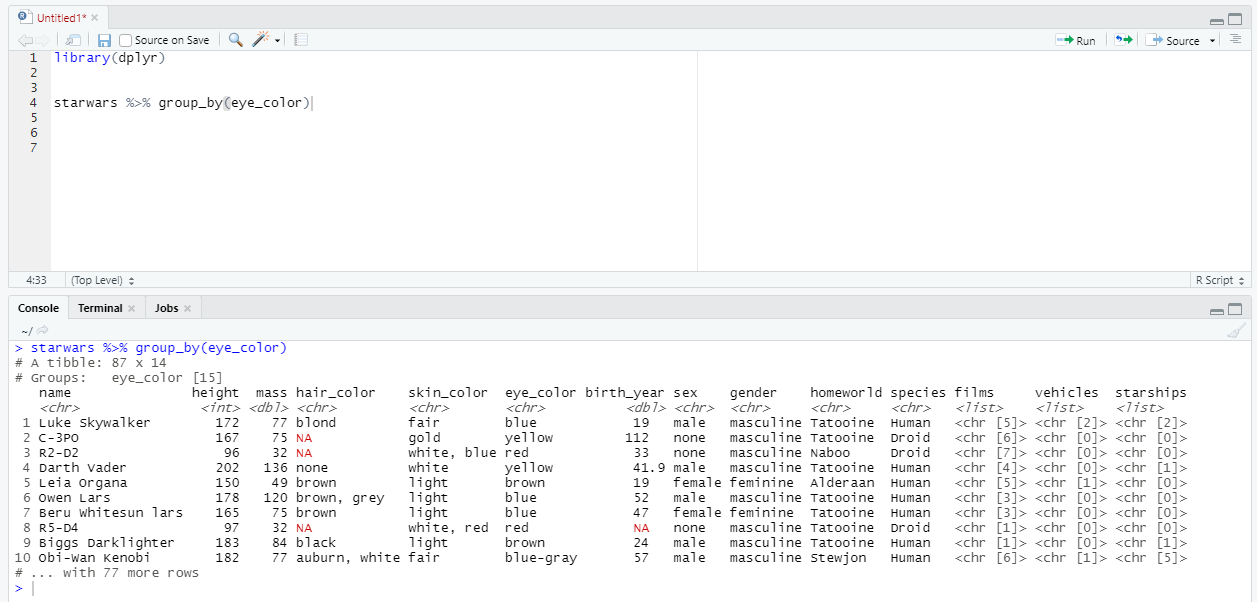
Мы получили сгруппированную таблицу из 15 групп, но внешне пока ничего не изменилось. В группировке как таковой смысла особо нет - нужно произвести какой-нибудь расчет. Для этого используется функция summarise и соответствующие агрегатные функции.
Давайте посчитаем для каждой группы среднюю массу, максимальную массу, минимальную массу, медианную массу, самую первую массу в группе и количество элементов в каждой группе.
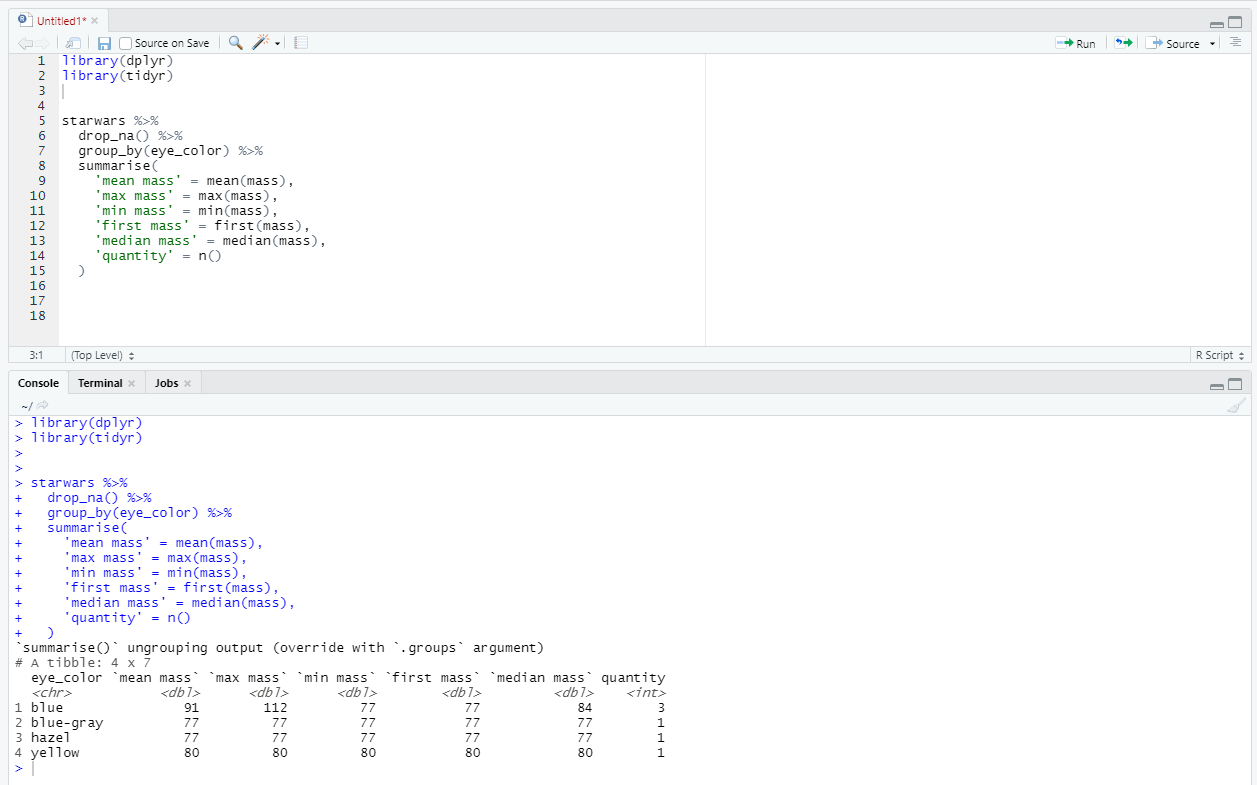
Обратите внимание, здесь мы дополнительно воспользовались функцией drop_na из пакета tidyr, чтобы удалить строки, в которых есть пропуски. Сделали мы это, чтобы при расчете наших максимальных/минимальных/других агрегатных значений не вылезали значения NA.
На выходе мы получили 4 группы (во всех остальных были пропуски, по всей видимости) и рассчитанные для них характеристики. Также каждому столбцу присвоено то имя, которое мы дали ему в функции summarise.
Мы с Вами здесь использовали только несколько агрегатных функций, но вообще говоря, их больше:
n_distinct- считает количество уникальных элементов в группеlast- возвращает последнее значение в группеnth- возвращает n-ое значение из группыquantile- возвращает заданную квантильIQR- межквартильный размах, inter-quartile rangemad- медианное абсолютное отклонение, median absolute deviationsd- стандартное отклонениеvar- вариация
Хорошо, с базовой группировкой мы разобрались. А что если пойти дальше…
Продвинутая группировка
А как Вам такая задача - рассчитать все те же самые характеристики, что и в прошлый раз, но сразу для нескольких столбцов? Например, мы делали для mass, а теперь давайте сделаем для mass и height.
Без проблем - достаточно применить уже известную функцию across.

Видно, что характеристики рассчитались по полю mass и height для каждой группы в отдельности. Если не устраивает название столбцов, которое система дала по умолчанию («столбец_характеристики»), то можно менять шаблон с помощью параметра .names.
Итак, на этом закончим раздел группировки и перейдем к вычислимым столбцам.
Вычислимые столбцы
Создание вычислимого столбца - стандартная задача. Например, есть столбец A, столбец B, а мы хотим вывести столбец A/B. Или другой вариант - мы хотим проранжировать строки нашей таблицы. Все это можно сделать с помощью функции mutate.
Для начала базовая вещь - создадим вычислимый столбец отношения веса к росту.
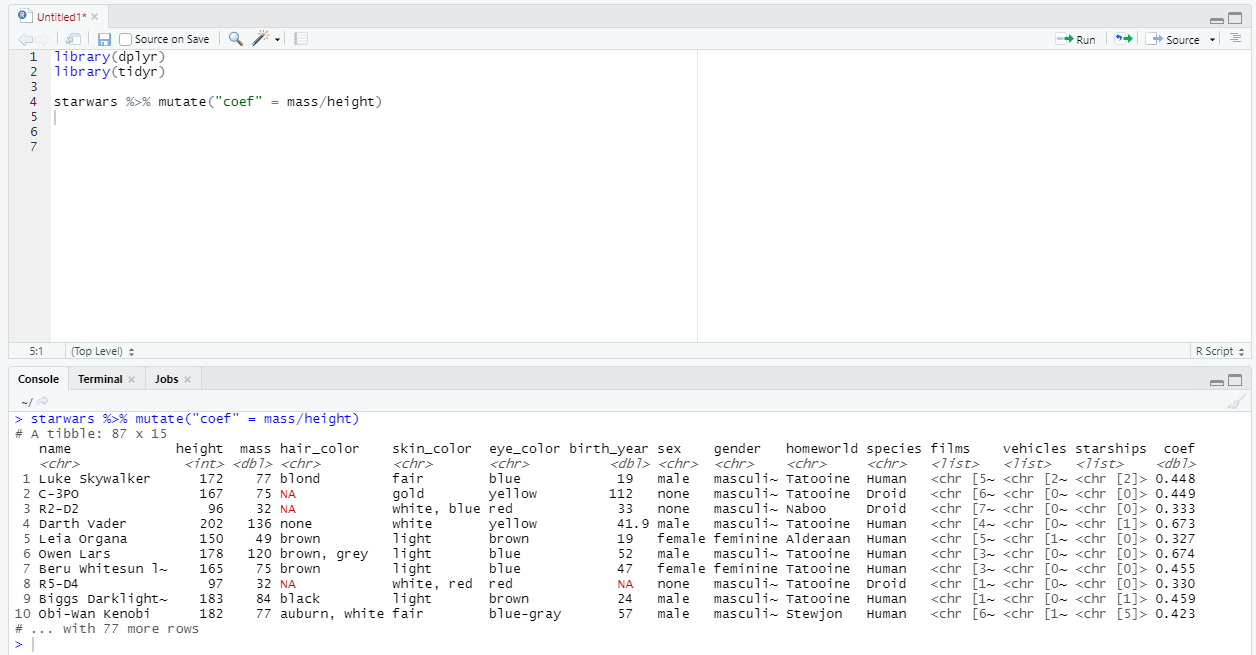
А если нам нужно применить одну и ту же функцию к нескольким столбцам? Без проблем - снова нас выручит across. Например, давайте умножим на 10 все столбцы с численным типом данных. При этом мы не будем создавать новые столбцы - мы модифицируем старые.

Видно, что в столбцах с весом, ростом и возрастом все значения умножились на 10.
Давайте и с текстом немного поработаем - ко всем строковым значениям добавим суффикс «_new». Для этого нам понадобится библиотека stringr все из того же семейства tidyverse.
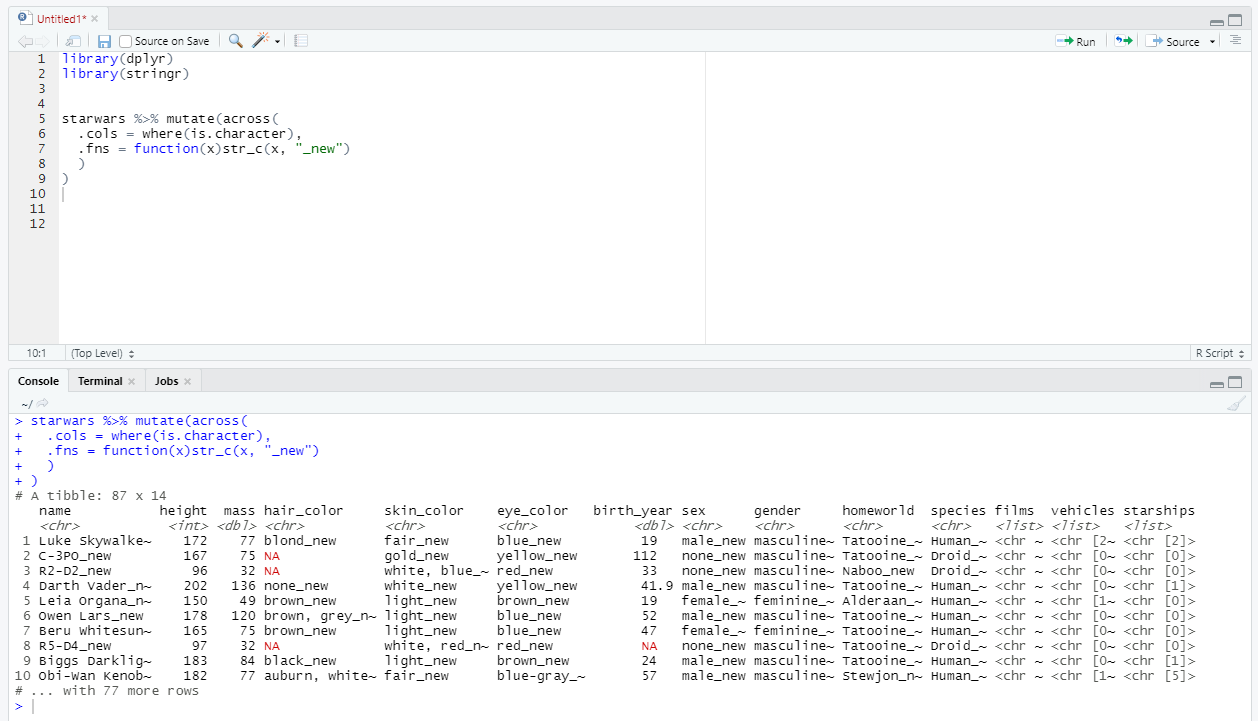
Хорошо видно, что ко всем строковым значениям добавился суффикс _new. Таким же образом можно работать и с датой, со временем и с любым другим типом данных.
Помимо всего прочего, mutate позволяет реализовать аналог оконных функций в SQL. Например, давайте проранжируем строки без разрывов по полю mass с помощью функции dense_rank:
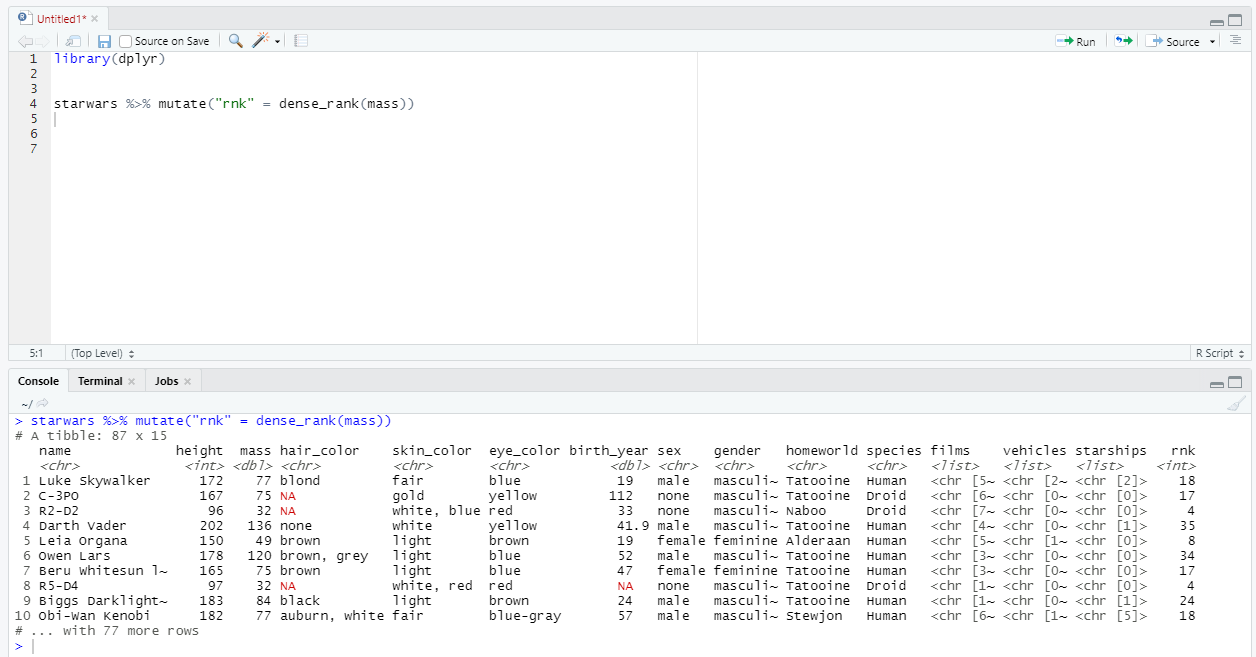
Видно, что в конец таблицы добавился новый столбец rnk с рангами для каждой строки.
Таких функций, на самом деле, масса. Вот некоторые из них:
lagleadcumsumdense_rankntilerow_numbercase_whencoalesce
Это, пожалуй, самые популярные и все они на 100% перекликаются с SQL. Приведем несколько примеров.
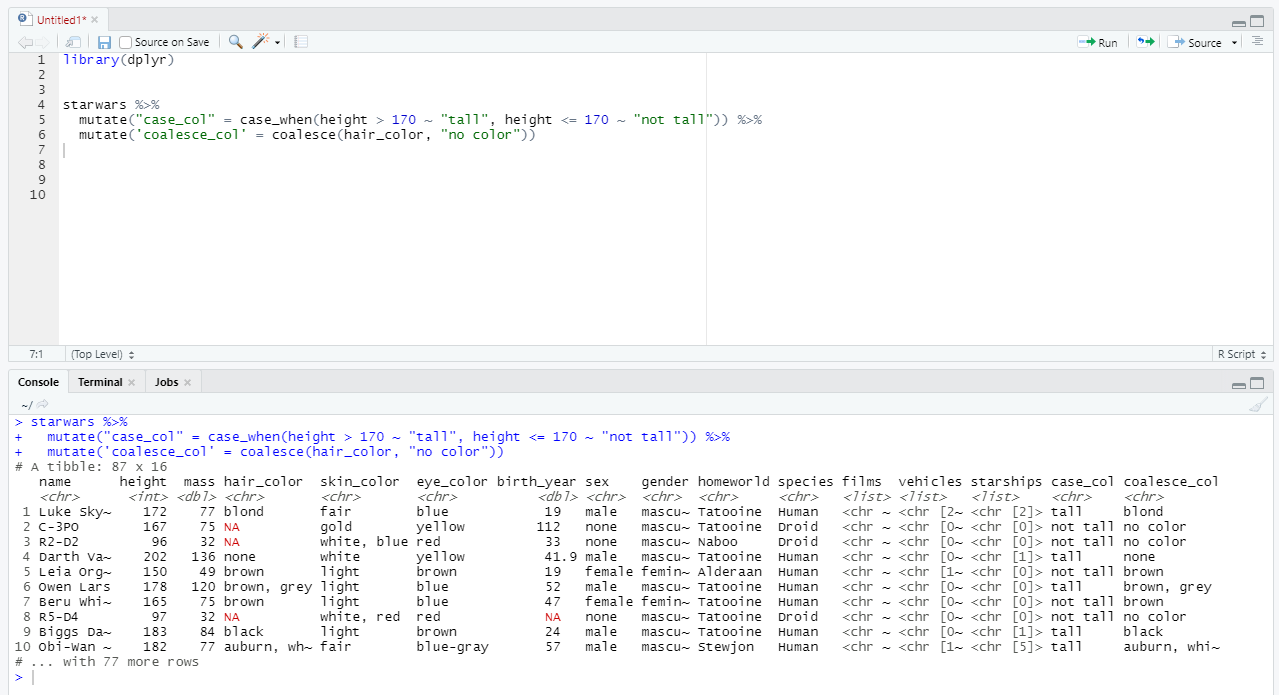
Ну что, давайте переходить к последнему пункту - к объединению таблиц.
Объединение таблиц
Пожалуй, последняя необходимая для полноценной работы с датафреймами операция - объединение таблиц. Операция объединения в dplyr тесно связана с джоинами в SQL. Вот перечень основных функций:
left_joinright_joininner_joinfull_join
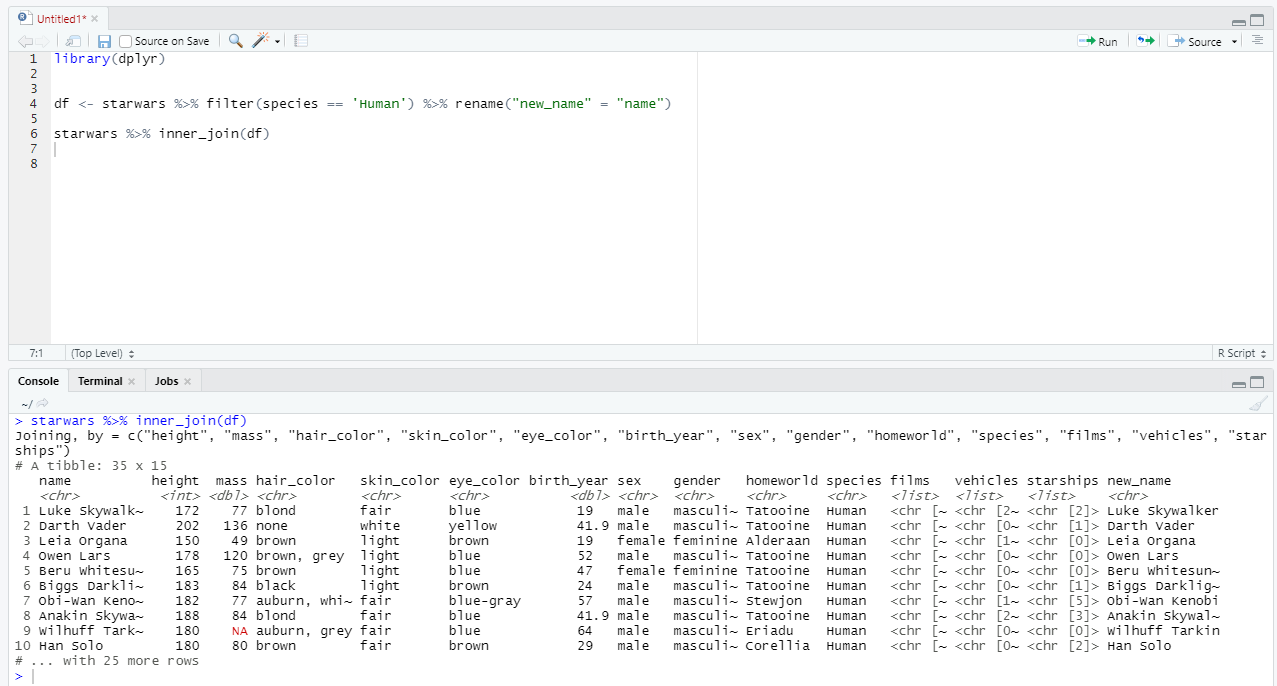
Аналогичные глаголы присутствуют и в стандартном SQL. Давайте создадим новую таблицу - возьмем датасет starwars и оставим только те строки, где вид существа - человек. А после попробуем различные виды джоинов.
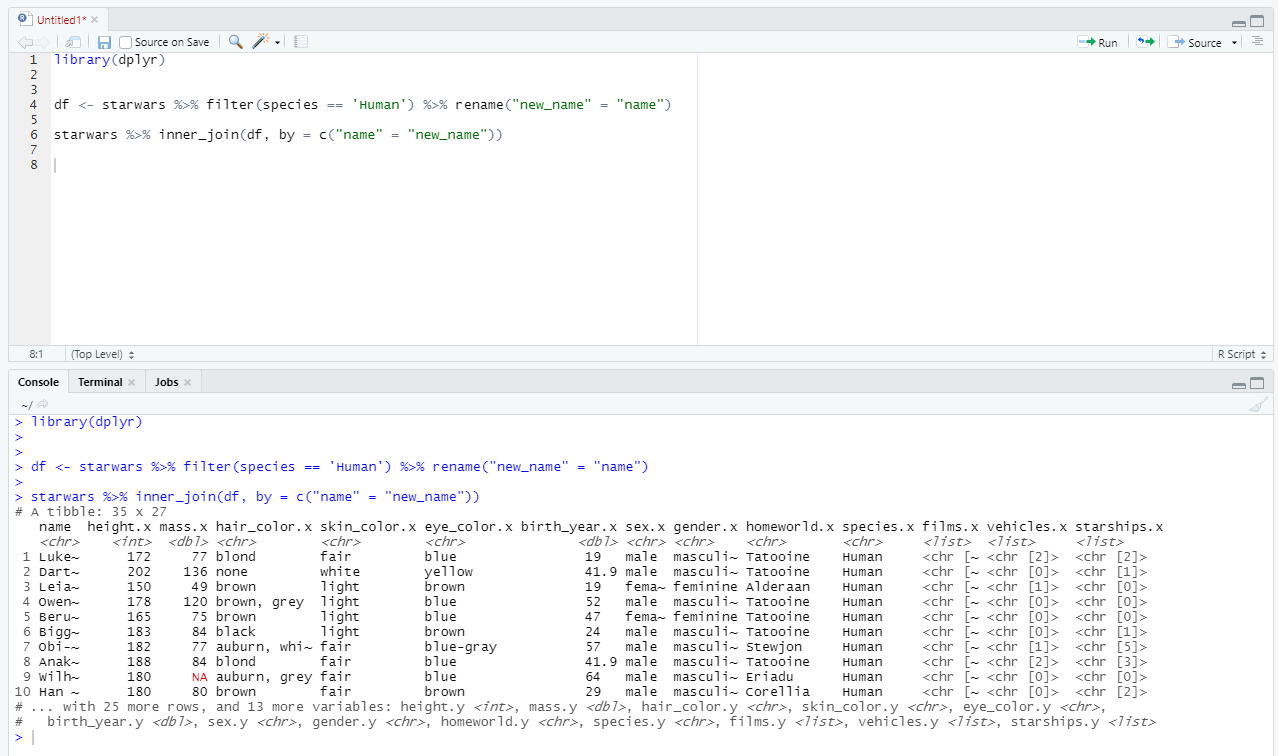
Обратите внимание, мы воспользовались функцией rename и переименовали поле name. Сделали мы это намеренно, чтобы показать работу аргумента
by(аналогONвSQL) для связи столбцов при джоине.
Делаем inner_join, на выходе получаем только 35 строк, т.к. в таблице df строк именно 35. Аргумент by позволил нам указать, через какие столбцы таблицы связаны между собой.
Если сделать full_join аналогичным образом, то строк в итоговой таблице будет 87, т.к. в таблице starwars их 87.
Внимательный читатель может заметить, что при джоине одни и те же столбцы продублировались из двух таблиц. Т.е. столбец
mass, например, в итоговой таблице фигурирует с суффиксом.xи.y. Как от этого избавиться?
1 вариант:
Если название столбцов позволяет, то Вы можете убрать аргумент by из джоина. Тогда соединяться таблицы будут по всем столбцам, у которых совпадает названием. В нашем случае этот вариант подходит - названия одинаковые и в результат добавится только один столбец - new_name.
2 вариант:
В реальной жизни, к сожалению, все не так сказочно, поэтому можно сделать небольшую предварительную обработку и джойнить не всю таблицу, а только нужные столбцы. Например, так:

Помимо различных джоинов, в dplyr есть еще другие функции для соединения таблиц:
bind_rows- помещает одну таблицу «под» другойbind_cols- ставит одну таблицу «справа» от другойintersect- находит пересекающиеся строкиsetdiff- разность таблиц, т.е. строки из первой таблицы, которых нет во второйunion- возвращает строки, которые есть в любой из таблиц (дубликаты исключаются)union_all- аналогичноunion, но оставляет дуликаты
Эпилог
Мы с Вами рассмотрели все основные операции библиотеки dplyr и почти все основные функции. Все остальное - практика, практика и еще раз практика. Если у Вас будут вопросы - рады будем помочь и ответить в комментариях :)
Если Вы хотите получать еще больше интересных материалов по программированию, Data Science и математике, то подписывайтесь на нашу группу ВК, канал в Телеграме и Инстаграм. Каждый день мы публикуем полезный контент и вопросы с реальных собеседований.
А, и совсем забыли. May the fource be with you!
P.S. Здесь Вы можете найти официальную шпаргалку по всем функциям dplyr. Все удобно и компактно собрано в одном месте :)
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Любите звездные войны?
-
0,0%Обожаю!0
-
100,0%Пришел твой час, щенок с Татуина!1
-
0,0%Это какой-то мультик? -_-0




