
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Самостоятельный хостинг простого сайта — вполне нормальная вещь, таких примеров немало, и в этом нет ничего особо сложного. В принципе, веб-сервер со статичным контентом вообще сохраняется в виде одного исполняемого файла, который можно запустить на любом компьютере. Контейнер или VM тоже легко поднять на подходящем сервере/хостинге.
Но при этом не хочется тратить много времени на поддержку таких проектов. В идеале — вообще не тратить. Запустил — и забыл. В этом случае нужна самая простая, минимальная система мониторинга с критическими алертами и автоматическим перезапуском сервера.
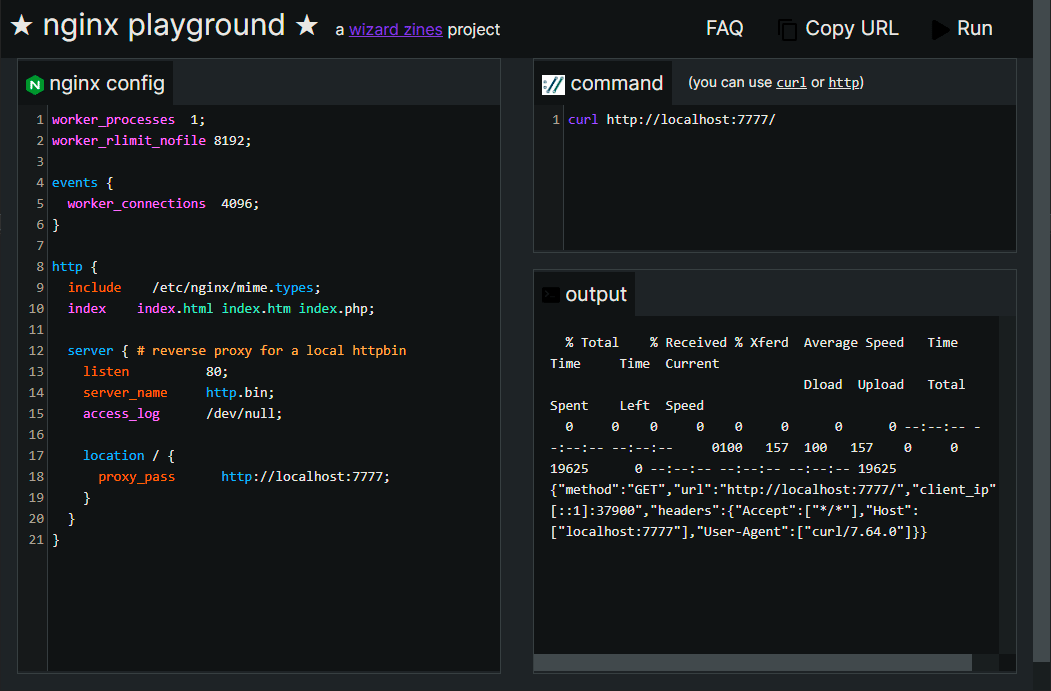
Известный разработчик из Mozilla — Джулия Эванс как раз недавно писала на эту тему. Она запустила несколько маленьких обучающих проектов для себя и других программистов (песочница nginx, эксперименты с DNS, инструмент DNS lookup). Например, песочница работает как codepen для nginx — вы копируете в окошко конфигурацию, а сервер запускает для вас nginx в указанной конфигурации. На нём можно выполнять любые команды
curl или http и сгенерировать уникальную ссылку на конфигурацию nginx и выполненную команду.Джулия решила наладить мониторинг для того, чтобы тратить на поддержку своих сайтов самый минимум своего времени.
Вот как выглядит самая простая схема мониторинга:
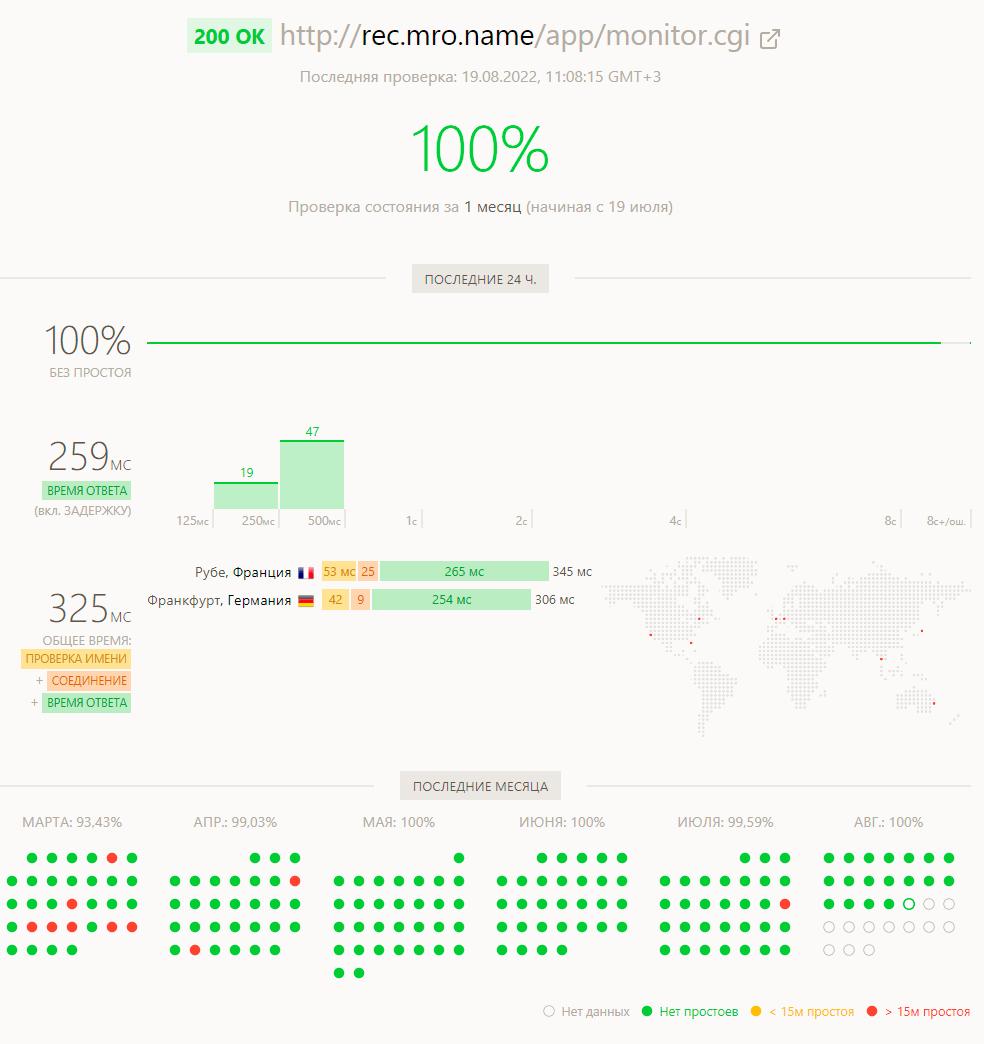
- Проверка аптайма. Есть много подобных инструментов, в данном случае Эванс выбрала updown.io и UptimeRobot. Они работают по простой схеме: проверяют аптайм по графику и в случае падения отправляют письмо. Это вполне приемлемый вариант нотификаций для любительского проекта, потому что письмо не разбудит вас и не оторвёт от важного дела. Для простого мониторинга отлично подойдут бесплатные cron-job.org, healthchecks.io или cronitor.io (бесплатно для хакеров).
Пример проверки updown.io:
- Сквозной тест. Нужно понять, что сайт функционирует как положено, а не просто откликается на входящие запросы. Поэтому Джулия написала нечто вроде сквозного теста, который запускает задачу на сайте и проверяет ответ. Например, песочница nginx может сама проверять себя. Тест делает запрос к
localhost:8080, возвращая статус200 OKили500.
func healthHandler(w http.ResponseWriter, r *http.Request) { // make a request to localhost:8080 with `healthcheckJSON` as the body // if it works, return 200 // if it doesn't, return 500 client := http.Client{} resp, err := client.Post("http://localhost:8080/", "application/json", strings.NewReader(healthcheckJSON)) if err != nil { log.Println(err) w.WriteHeader(http.StatusInternalServerError) return } if resp.StatusCode != http.StatusOK { log.Println(resp.StatusCode) w.WriteHeader(http.StatusInternalServerError) return } w.WriteHeader(http.StatusOK) }
- Автоматический перезапуск в случае падения. Поскольку у многих сервисов есть грешок с утечкой памяти, логично их периодически перезапускать, чтобы предотвратить глюки. Другой вариант — перезапуск по факту HTTP-проверки (у многих хостеров есть такая опция).
Вот такой простой процедуры хватит для многих простеньких веб-сервисов. Если для обычного статического сайта достаточно проверить аптайм и статус, то для интерактивного сервиса можно добавить маленький сквозной тест.
Если сервис автоматически перезапускается после падения, то обслуживание сводится к минимуму. Достаточно периодически проверять, что перезапуски не стали слишком частыми, и устранять обнаруженные баги.
Как девопсы скрестили Slack и RSS
В случае высоконагруженного, коммерческого сервиса уведомлений по электронной почте недостаточно. В этом случае требуется оперативный канал доставки критически важных оповещений. Интересно, что некоторые системные администраторы скрестили для этого старую добрую технологию RSS и модный Slack.
RSS идеальным образом подходит для нотификаций, в том числе для системных алертов. По сути, стандарт был придуман именно для этого (для нотификаций), так что мы используем его по прямому назначению. Только не для медийных сообщений, а для системных.
При этом Slack используется как среда для трансляции уведомлений.
Схема такая:
- Импорт RSS-фидов в Slack
- Отдельный канал для предупреждений безопасности. Например, срочные предупреждения безопасности CISA, критические уведомления об обнаруженных уязвимостях.
- Отдельный канал для статусов. Сюда поступают фиды со страниц мониторинга сервисов AWS, DigitalOcean и GitHub.
- Отдельный канал для предупреждений безопасности. Например, срочные предупреждения безопасности CISA, критические уведомления об обнаруженных уязвимостях.
- Программирование Slack — указание автоматических действий, в ответ на поступление определённой информации по RSS. Например, автоматическое открытие тикета JIRA или уведомление по SMS.
Чем отличаются простые системы
Конечно, для более сложных систем нужен более сложный мониторинг. В последнее время программные архитектуры значительно усложнились. Сложные, комплексные системы по определению менее предсказуемы, а причинно-следственные связи в них не так очевидны для человека на уровне интуиции, даже для эксперта, потому что эти связи могут быть разделены в пространстве и времени.
Там уже не обойтись без продвинутого мониторинга, даже с элементами дата-майнинга. Кстати, по модели Кеневин существуют ещё хаотичные системы, в которых причинно-следственные связи вовсе не просматриваются. Что интересно, по этой модели системы могут переходить из одного состояния в другое под воздействием внешних и внутренних процессов:

Рис. 1
Например, мониторинг показывает, что в веб-приложении увеличивается количество ошибок API. Оператор на основе опыта знает, что повышенное количество ошибок часто связано либо с перегруженным сервером БД, либо с неким сторонним сервисом, который ушёл в даун. Оператор уже знает, какие вопросы задавать и на какие метрики смотреть. Он проверит настроенные панели мониторинга и конкретные показатели, чтобы проверить загрузку БД и количество ошибок сторонних служб. На основе полученной информации оператор реагирует — например, отключает зависимость от внешней службы и наблюдает за тем, снижается ли уровень ошибок (sense — analyze — respond на рис. 1).
Однако в самых сложных комплексных системах требуется иной подход, потому что возможные причины деградации сервиса нам неизвестны. Тут нужен другой подход: изменять разные параметры работы — и смотреть, как реагирует система, пытаясь выявить паттерны (probe — sense — respond). Здесь нужен и более продвинутый инструментарий, который даёт возможность пробинга, то есть изменения параметров системы с просмотром результатов воздействия в разных измерениях (дата-майнинг), формулировкой новых теорий и проверкой уже их — всё это в едином цикле с обратной связью. Вот такие инструменты мониторинга нам понадобятся в будущем для комплексных программных систем. А с каждым годом сложность систем возрастает, как мы уже заметили выше.
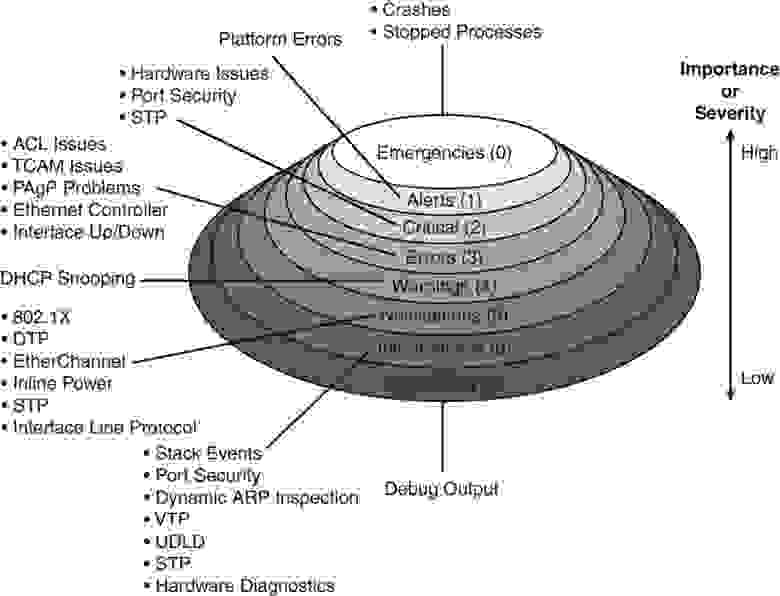
Степень тяжести (или сложности) по классификации syslog:
Софт в 2022 году гораздо сложнее понять, чем в 2001 году, по естественным причинам. Современные архитектуры фундаментально более сложные, и это вряд ли изменится в ближайшее время. Поэтому и инструменты для observability тоже эволюционируют. И немножко усложняются. Например, вот более продвинутый индикатор с прогнозом времени выполнения progress-estimator Брайана Вона. Чисто для сравнения, как эволюционируют даже самые простые инструменты:
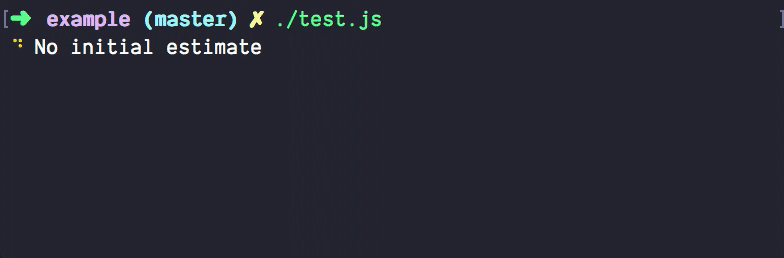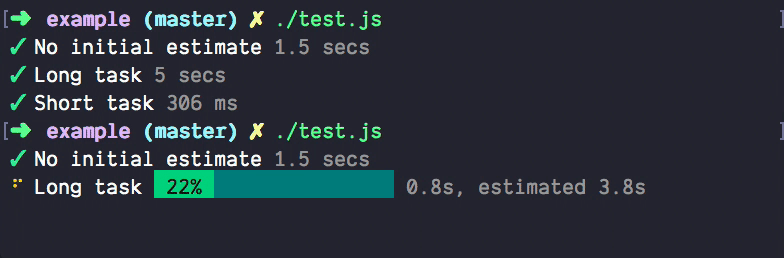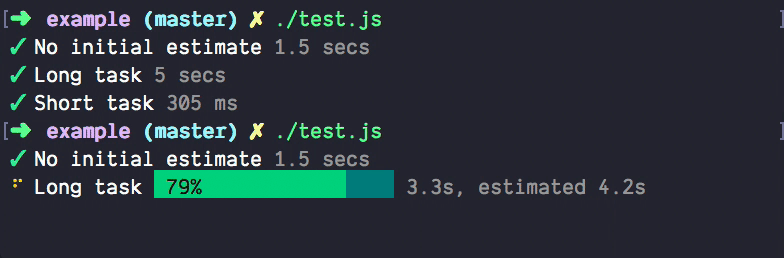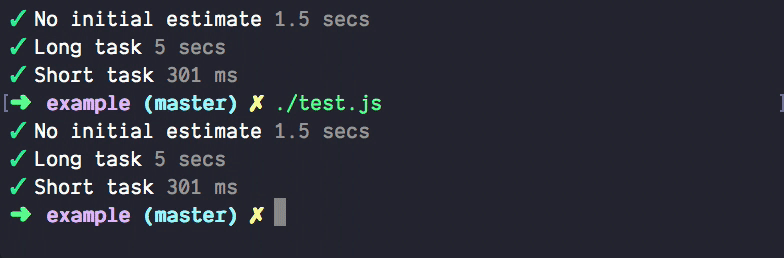
Ну а в примитивных сервисах с очевидной архитектурой нет нужды вводить лишние уровни сложности — и можно довольствоваться самыми простыми способами мониторинга, как и придумала Джулия Эванс. В принципе, это входит в понятие best practices для «очевидных» систем на рис. 1.
Личный хостинг маленьких инструментов
Свой личный хостинг маленьких серверных инструментов — тоже логичное решение, особенно если у вас на своём домашнем компьютере размещается личный сайт. В таком случае действительно удобно анализировать логи и отслеживать состояние сервера тоже локально, например, из соседнего контейнера.
Например, можно взять готовый сервис мониторинга вроде вышеупомянутого healthchecks.io и захостить его у себя, на маленькой домашнем сервере.
Маленький домашний сервер
Обычному домашнему серверу не всегда требуется огромная вычислительная мощность десктопа, если мы не собираемся транскодировать видеопотоки 4K или нагружать его другими вычислительными задачами. В противном случае тут и GPU не слишком используется.
Мощный сервер — это шум вентиляторов, большое энергопотребление и дорогое железо. А если мы хотим прямо противоположное — маленький, тихий и дешёвый сервер, то можно посмотреть в сторону одноплатников.
Кстати говоря, недавно появился новый класс миниатюрных устройств, ориентированных на домашний хостинг. Одно из таких устройств — PiBox.

Это крошечный SSD NAS для домашнего хостинга, собранный построенный на базе Raspberry Pi CM4.

Мы приводим его здесь чисто в качестве примера и отнюдь не рекламируем, конкретно эта железка стоит необоснованно дорого. Но каждый энтузиаст может сам собрать подобное устройство из подходящего одноплатника и HDD/SSD и напечатать корпус на 3D-принтере в случае необходимости.

Конечно, Raspberry Pi (даже модель 8G) или другой одноплатник по производительности не вытянет некоторые приложения, например, домашний сервер Minecraft или транскодирование видео с камер наблюдения в реальном времени, это следует учитывать. С другой стороны, Raspberry Pi аппаратно поддерживает декодирование до 4К, так что с воспроизведением скачанных фильмов через Plex проблем не будет.

Такой домашний мини-сервер позволяет отказаться от платных сервисов типа Dropbox, Google Photos и Netflix. Здесь всё своё, бесплатно, надёжно и в лучшем качестве.
Крошечный NAS+SSD оптимально подходит для приложений типа NextCloud, Plex, BitTorrent, Gitea, PiHole (работает как DNS-воронка), WireGuard (+UI) и других сетевых сервисов. Если мощный системник греет балкон на холостом ходу — это не так приятно, как маленький трудяга PiBox или старый дешёвый NUC, нагруженный на 70% в типичных задачах. Такую коробочку можно использовать и для личного хостинга, и для мониторинга маленьких веб-сервисов.
А какие решения используете вы?
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.



