
Тема нейросетей будоражит сердца разработчиков, учёных и маркетологов уже не первый год, а кого-то даже не первое десятилетие. Но все мы знаем, что частенько под проектами на основе нейронок прячется простая биг дата и маркетинговый булшит, раздутый на фоне кликбейтного заголовка. Мы постарались избежать такой истории и разработали проект нейропиццы, основанный на исследовании молекулярной сочетаемости ингредиентов, анализе 300 тыс. рецептов и чистого творчества. Под катом вы можете узнать детали и найти ссылку с открытым кодом на GitHub.

Может ли машина придумать что-то новое или она ограничена тем, что знает? Пока что никто не знает ответа на этот вопрос. Но уже сейчас искусственный интеллект отлично решает задачи анализа больших нестандартных данных.
Однажды в Dodo Pizza решили провести эксперимент: систематизировать и структурно описать то, что во всём мире считается хаотичным и субъективным – вкус. Искусственный интеллект, помог найти самые сумасшедшие сочетания ингредиентов, которые, несмотря на свою необычность, оказались вкусными для большинства людей.
Я и мой коллега выступили в качестве специалистов по нейросетям от МФТИ и Сколтеха в этом необычном проекте. Мы разработали и обучили нейросеть, способную решать задачу генерации кухонных рецептов. В ходе работы было проанализировано более 300 000 рецептов, а также результаты научных исследований на тему молекулярной сочетаемости ингредиентов. На основе этого ИИ научился находить неочевидные связи между ингредиентами и понимать, как они сочетаются между собой и как наличие каждого из них влияет на сочетаемость всех остальных.
Всё, как оно обычно бывает, произошло внезапно. Был период короткого тайм-аута перед летней практикой, мы только закончили курс по Deep Learning, защитили проект и пытались перестроиться на более спокойный ритм учебы/жизни. Но не смогли: случайно нарвались на репосты в личке запроса от BBDO о поиске ребят, способных написать нейросеть для генерации новых рецептов. Конкретнее: новых рецептов пиццы для Dodo. Не долго думая, мы решили, что хотим попробовать.
Когда проект только начинался, мы до конца не понимали, пойдёт ли это куда-то дальше, будет ли практическая реализация, нас просто заинтересовала задача. Много редбула и быстрого интернета помогали и двигали нас вперёд. Оглядываясь назад, мы понимаем, что некоторые вещи можно было сделать по-другому, но ведь это нормально.
В любом случае, через несколько недель рабочая модель нейросети была готова, наступил этап её запуска в продакшн. Нам очень повезло, что проект нельзя назвать индустриальным или техническим в строгом понимании этих слов. Ему больше подходит статус эксперимента.
С помощью нашей модели были сгенерированы разные варианты рецептов пиццы, которые мы передали в руки очень крутых поваров Dodo для запуска продуктовых тестов. Момент дегустирования пиццы в Dodo R&D Lab стал переломным в плане осознания ценности проделанной нами работы. Было очень захватывающе увидеть реализованный продукт. Ведь зачастую все разработки и решения – вещь довольно эфемерная, неосязаемая, а тут результат можно было не только потрогать, но и попробовать на вкус.
Для работы любой модели нужны данные. Поэтому для обучения нашего ИИ мы собрали 300 000 кулинарных рецептов со всех доступных источников. Для нас было важно собрать не только рецепты пицц, но как можно больше диверсифицировать выборку, стараясь при этом не выходить за рамки разумного (например, игнорировать рецепты коктейлей, понимая, что их семантика не будет сильно влиять на рецептурную семантику пиццы).
После сбора данных у нас получилось более 100 000 уникальных ингредиентов. Большой проблемой стало приведение их к одному виду. Но откуда вообще взялось столько наименований? Всё просто, например, перец чили в рецептах указывают так: chili, chilli, chiles, chillis. Для нас с вами очевидно, что это один и тот же перец, но нейросеть воспринимает разные написания, как отдельные сущности. Мы это исправили. После того, как мы почистили данные и привели их к одному виду, у нас осталась всего 1 000 позиций.
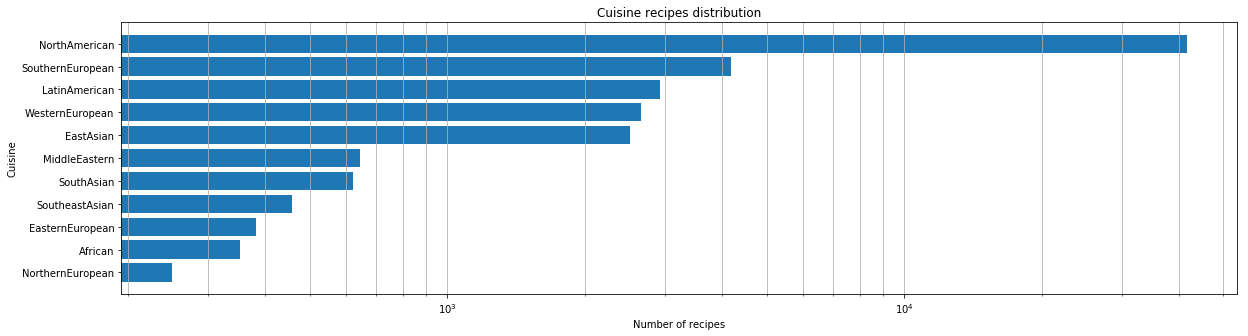
После того, как мы получили готовый для работы датасет, мы провели первоначальный анализ. Сначала мы посмотрели, какие кухни мира представлены в нашем датасете в количественном соотношении.
Для каждой из кухонь мы определили самые популярные ингредиенты.
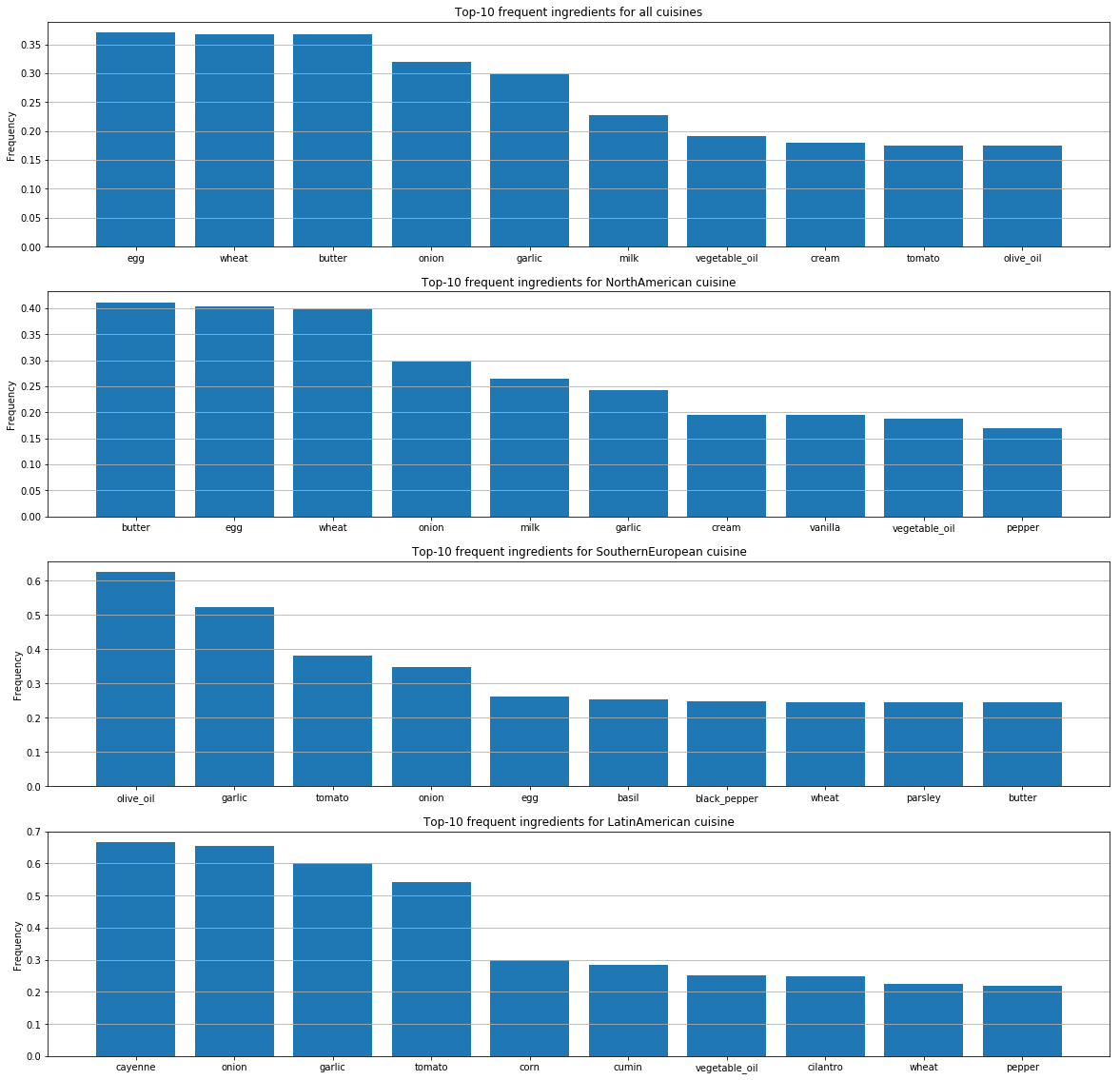
На этих графиках заметны отличия во вкусовых предпочтениях людей по странам. Ещё из этих предпочтений становится понятно, как люди из разных стран сочетают ингредиенты между собой.
После этого глобального анализа мы решили подробнее изучить рецепты пицц со всего мира, чтобы найти закономерности в их составлении. Вот такие выводы мы сделали:
Найти реальные вкусовые сочетания – это не то же самое, что выявить сочетаемость молекул. У всех сыров похожий молекулярный состав, но это не значит, что удачные сочетания лежат только в области ближайших ингредиентов.
Однако мы должны увидеть именно сочетаемость похожих на молекулярном уровне ингредиентов, когда переведём всё в математику. Потому что похожие объекты (те же сыры) должны оставаться похожими, как бы мы их не описали. Так мы сможем определить, что описали эти объекты правильно.
Чтобы представить рецепт в понятном для нейросети виде, мы использовали Skip-Gram Negative Sampling (SGNS) — алгоритм word2vec, который основан на встречаемости слов в контексте. Мы решили не использовать предобученные модели word2vec, потому что наш рецепт заведомо отличается по семантической структуре от простых текстов. При использовании таких моделей мы могли бы потерять важную информацию.
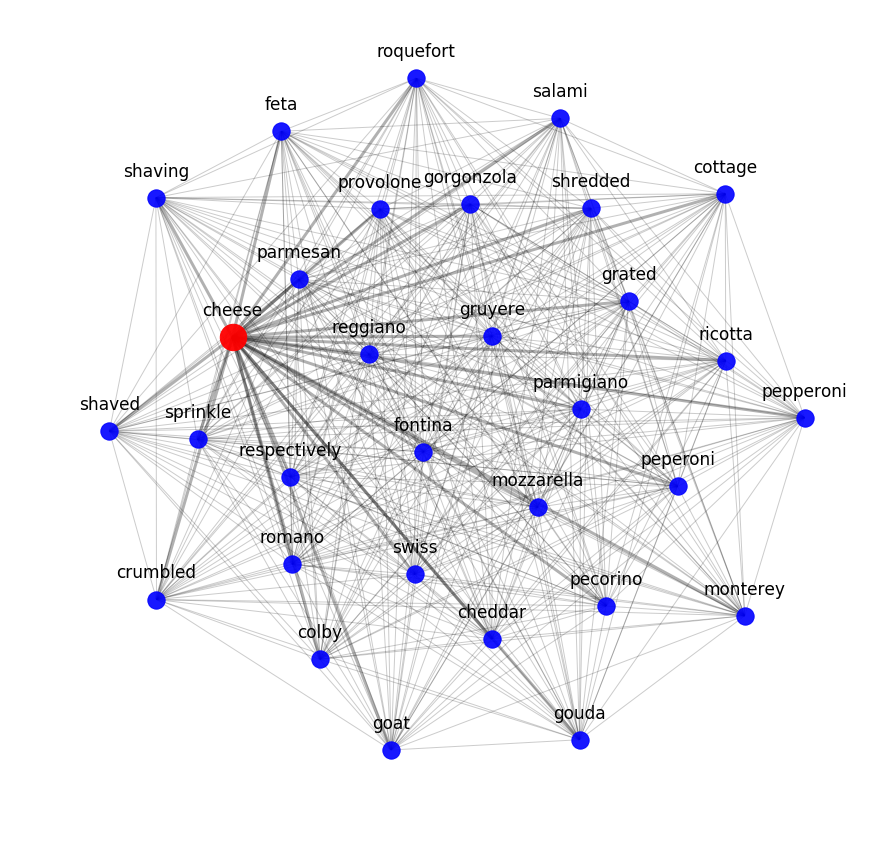
Можно оценить результат работы word2vec, посмотрев на ближайших семантических соседей. Например, вот что наша модель знает про сыр:
Для проверки того, насколько семантические модели могут уловить рецептурные взаимодействия ингредиентов, мы применили модель тематического моделирования для всех рецептов из выборки. То есть попытались разбить датасет рецептов на кластеры по математически выявленным закономерностям.

Зная заранее принадлежность некоторой выборки рецептов к различным реальным классам, полученным из данных, мы построили распределение принадлежности каждого реального класса к выявленным сгенерированным.

Самым явным оказался класс десертов, которые легли в тему 0 и 1, сгенерированную тематической моделью. В этих тематиках помимо десертов не лежат почти никакие другие классы, что говорит о том, что десерты легко отделились от других классов блюд. Также в каждой тематике есть класс, который описывает её лучше всего. Это значит, что наши модели хорошо справились с математическим описанием неочевидного смысла «вкуса».
Для создания новых рецептов мы использовали две рекуррентных нейросети. Для этого мы предположили, что в общем пространстве рецептов существует подпространство, которое отвечает за рецепты пицц. Чтобы нейросеть научилась придумывать новые рецепты пицц, нам надо было найти это подпространство.
Такая задача по смыслу похожа на автокодирования изображений, когда мы представляем изображение в виде вектора небольшой размерности. В таком случае векторы могут содержать большое количество специфической информации об изображении.
Например, для распознавания лиц на фото, такие векторы могут хранить в отдельной ячейке информацию о цвете волос человека. Мы выбрали этот подход именно из-за уникальных свойств скрытого подпространства.
Чтобы выявить подпространство пицц, мы прогнали рецепты через две рекуррентные нейросети. Первая получала на вход рецепт пиццы и искала его представление в виде скрытого вектора. Вторая получала на вход скрытый вектор от первой нейросети и должна была предложить рецепт на его основе. Рецепты на входе первой нейросети и на выходе второй должны были совпадать.
Так две нейросети в формате энкод-декодинга учились правильно ретранслировать рецепт в скрытый (латентный) вектор и обратно. На основе этого мы смогли обнаружить скрытое подпространство, которое отвечает за всё множество рецептов пицц.
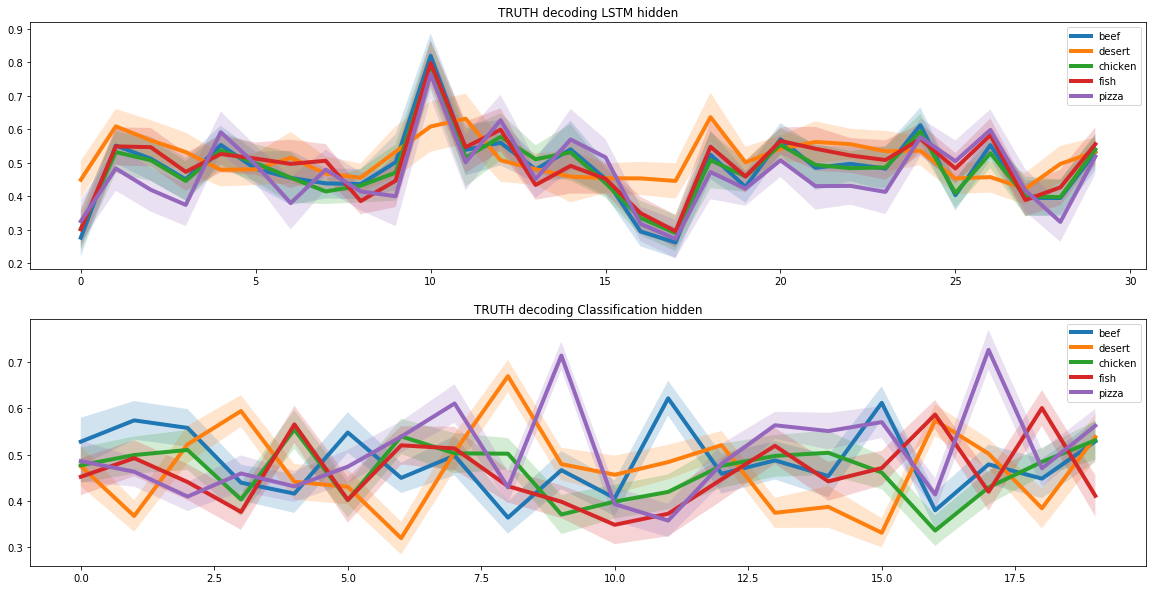
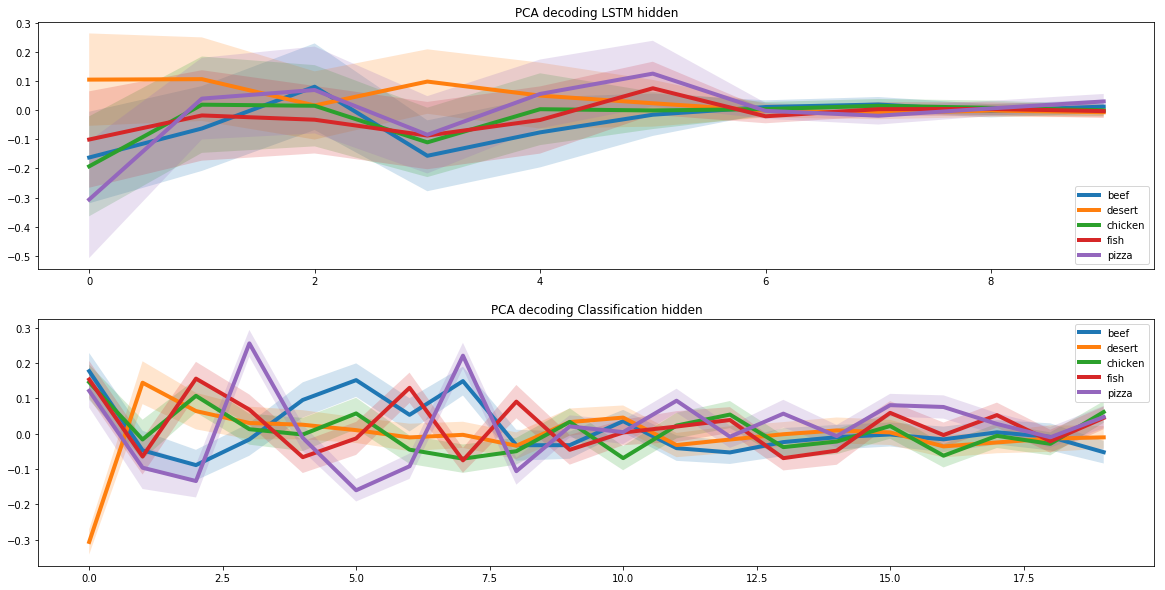
Когда мы решили задачу создания рецепта пиццы, мы должны были добавить в модель критерий молекулярной сочетаемости. Для этого мы использовали результаты совместного исследования учёных из Кембриджа и нескольких университетов США.
В результате исследования было установлено, что лучше всего сочетаются ингредиенты с наибольшим количеством общих молекулярных пар. Поэтому при создании рецепта нейросеть отдавала предпочтение ингредиентам с похожей молекулярной структурой.
В итоге наша нейросеть научилась успешно создавать рецепты пицц. С помощью регулировки коэффициентов, ИИ может выдавать как классические рецепты (типа Маргариты или Пепперони), так и сумасшедшие. Один такой крейзи рецепт лёг в основу первой в мире молекулярно идеальной пиццы из десяти ингредиентов: томатный соус, дыня, груша, цыплёнок, томаты Черри, тунец, мята, брокколи, сыр Моцарелла, мюсли. Лимитед эдишн даже можно было купить в одной из пиццерий Dodo. А вот ещё несколько занятных рецептов, которые вы можете попробовать приготовить дома:
Может ли машина придумать что-то новое или она ограничена тем, что знает? Пока что никто не знает ответа на этот вопрос. Но уже сейчас искусственный интеллект отлично решает задачи анализа больших нестандартных данных.
Однажды в Dodo Pizza решили провести эксперимент: систематизировать и структурно описать то, что во всём мире считается хаотичным и субъективным – вкус. Искусственный интеллект, помог найти самые сумасшедшие сочетания ингредиентов, которые, несмотря на свою необычность, оказались вкусными для большинства людей.
Я и мой коллега выступили в качестве специалистов по нейросетям от МФТИ и Сколтеха в этом необычном проекте. Мы разработали и обучили нейросеть, способную решать задачу генерации кухонных рецептов. В ходе работы было проанализировано более 300 000 рецептов, а также результаты научных исследований на тему молекулярной сочетаемости ингредиентов. На основе этого ИИ научился находить неочевидные связи между ингредиентами и понимать, как они сочетаются между собой и как наличие каждого из них влияет на сочетаемость всех остальных.
Как мы попали в проект Dodo AI-pizza
Всё, как оно обычно бывает, произошло внезапно. Был период короткого тайм-аута перед летней практикой, мы только закончили курс по Deep Learning, защитили проект и пытались перестроиться на более спокойный ритм учебы/жизни. Но не смогли: случайно нарвались на репосты в личке запроса от BBDO о поиске ребят, способных написать нейросеть для генерации новых рецептов. Конкретнее: новых рецептов пиццы для Dodo. Не долго думая, мы решили, что хотим попробовать.
Когда проект только начинался, мы до конца не понимали, пойдёт ли это куда-то дальше, будет ли практическая реализация, нас просто заинтересовала задача. Много редбула и быстрого интернета помогали и двигали нас вперёд. Оглядываясь назад, мы понимаем, что некоторые вещи можно было сделать по-другому, но ведь это нормально.
В любом случае, через несколько недель рабочая модель нейросети была готова, наступил этап её запуска в продакшн. Нам очень повезло, что проект нельзя назвать индустриальным или техническим в строгом понимании этих слов. Ему больше подходит статус эксперимента.
С помощью нашей модели были сгенерированы разные варианты рецептов пиццы, которые мы передали в руки очень крутых поваров Dodo для запуска продуктовых тестов. Момент дегустирования пиццы в Dodo R&D Lab стал переломным в плане осознания ценности проделанной нами работы. Было очень захватывающе увидеть реализованный продукт. Ведь зачастую все разработки и решения – вещь довольно эфемерная, неосязаемая, а тут результат можно было не только потрогать, но и попробовать на вкус.
Первичный сбор датасета и перец чили
Для работы любой модели нужны данные. Поэтому для обучения нашего ИИ мы собрали 300 000 кулинарных рецептов со всех доступных источников. Для нас было важно собрать не только рецепты пицц, но как можно больше диверсифицировать выборку, стараясь при этом не выходить за рамки разумного (например, игнорировать рецепты коктейлей, понимая, что их семантика не будет сильно влиять на рецептурную семантику пиццы).
После сбора данных у нас получилось более 100 000 уникальных ингредиентов. Большой проблемой стало приведение их к одному виду. Но откуда вообще взялось столько наименований? Всё просто, например, перец чили в рецептах указывают так: chili, chilli, chiles, chillis. Для нас с вами очевидно, что это один и тот же перец, но нейросеть воспринимает разные написания, как отдельные сущности. Мы это исправили. После того, как мы почистили данные и привели их к одному виду, у нас осталась всего 1 000 позиций.
Анализ вкусов мира
После того, как мы получили готовый для работы датасет, мы провели первоначальный анализ. Сначала мы посмотрели, какие кухни мира представлены в нашем датасете в количественном соотношении.
Для каждой из кухонь мы определили самые популярные ингредиенты.
На этих графиках заметны отличия во вкусовых предпочтениях людей по странам. Ещё из этих предпочтений становится понятно, как люди из разных стран сочетают ингредиенты между собой.
Два вывода о пицце
После этого глобального анализа мы решили подробнее изучить рецепты пицц со всего мира, чтобы найти закономерности в их составлении. Вот такие выводы мы сделали:
- Рецептов пицц на порядок меньше, чем рецептов блюд с мясом/курицей и десертов.
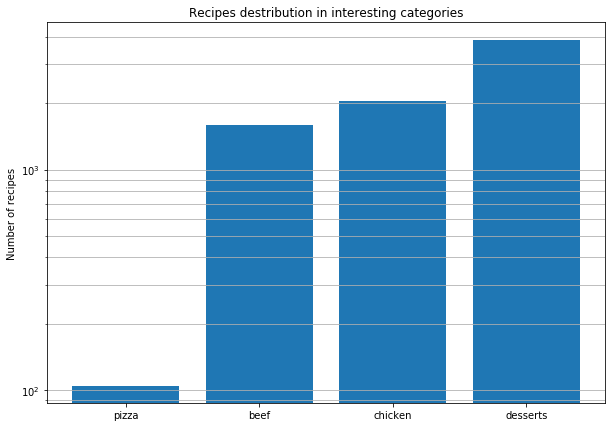
- Множество ингредиентов, которые встречаются в рецептах пицц, ограничено. Сама вариативность продуктов гораздо ниже, чем в других блюдах.

Как мы проверяли модель
Найти реальные вкусовые сочетания – это не то же самое, что выявить сочетаемость молекул. У всех сыров похожий молекулярный состав, но это не значит, что удачные сочетания лежат только в области ближайших ингредиентов.
Однако мы должны увидеть именно сочетаемость похожих на молекулярном уровне ингредиентов, когда переведём всё в математику. Потому что похожие объекты (те же сыры) должны оставаться похожими, как бы мы их не описали. Так мы сможем определить, что описали эти объекты правильно.
Преобразование рецепта в математический вид
Чтобы представить рецепт в понятном для нейросети виде, мы использовали Skip-Gram Negative Sampling (SGNS) — алгоритм word2vec, который основан на встречаемости слов в контексте. Мы решили не использовать предобученные модели word2vec, потому что наш рецепт заведомо отличается по семантической структуре от простых текстов. При использовании таких моделей мы могли бы потерять важную информацию.
Можно оценить результат работы word2vec, посмотрев на ближайших семантических соседей. Например, вот что наша модель знает про сыр:
Для проверки того, насколько семантические модели могут уловить рецептурные взаимодействия ингредиентов, мы применили модель тематического моделирования для всех рецептов из выборки. То есть попытались разбить датасет рецептов на кластеры по математически выявленным закономерностям.
Зная заранее принадлежность некоторой выборки рецептов к различным реальным классам, полученным из данных, мы построили распределение принадлежности каждого реального класса к выявленным сгенерированным.
Самым явным оказался класс десертов, которые легли в тему 0 и 1, сгенерированную тематической моделью. В этих тематиках помимо десертов не лежат почти никакие другие классы, что говорит о том, что десерты легко отделились от других классов блюд. Также в каждой тематике есть класс, который описывает её лучше всего. Это значит, что наши модели хорошо справились с математическим описанием неочевидного смысла «вкуса».
Генерация рецептов
Для создания новых рецептов мы использовали две рекуррентных нейросети. Для этого мы предположили, что в общем пространстве рецептов существует подпространство, которое отвечает за рецепты пицц. Чтобы нейросеть научилась придумывать новые рецепты пицц, нам надо было найти это подпространство.
Такая задача по смыслу похожа на автокодирования изображений, когда мы представляем изображение в виде вектора небольшой размерности. В таком случае векторы могут содержать большое количество специфической информации об изображении.
Например, для распознавания лиц на фото, такие векторы могут хранить в отдельной ячейке информацию о цвете волос человека. Мы выбрали этот подход именно из-за уникальных свойств скрытого подпространства.
Чтобы выявить подпространство пицц, мы прогнали рецепты через две рекуррентные нейросети. Первая получала на вход рецепт пиццы и искала его представление в виде скрытого вектора. Вторая получала на вход скрытый вектор от первой нейросети и должна была предложить рецепт на его основе. Рецепты на входе первой нейросети и на выходе второй должны были совпадать.
Так две нейросети в формате энкод-декодинга учились правильно ретранслировать рецепт в скрытый (латентный) вектор и обратно. На основе этого мы смогли обнаружить скрытое подпространство, которое отвечает за всё множество рецептов пицц.
Молекулярная сочетаемость
Когда мы решили задачу создания рецепта пиццы, мы должны были добавить в модель критерий молекулярной сочетаемости. Для этого мы использовали результаты совместного исследования учёных из Кембриджа и нескольких университетов США.
В результате исследования было установлено, что лучше всего сочетаются ингредиенты с наибольшим количеством общих молекулярных пар. Поэтому при создании рецепта нейросеть отдавала предпочтение ингредиентам с похожей молекулярной структурой.
Результат и AI-пицца
В итоге наша нейросеть научилась успешно создавать рецепты пицц. С помощью регулировки коэффициентов, ИИ может выдавать как классические рецепты (типа Маргариты или Пепперони), так и сумасшедшие. Один такой крейзи рецепт лёг в основу первой в мире молекулярно идеальной пиццы из десяти ингредиентов: томатный соус, дыня, груша, цыплёнок, томаты Черри, тунец, мята, брокколи, сыр Моцарелла, мюсли. Лимитед эдишн даже можно было купить в одной из пиццерий Dodo. А вот ещё несколько занятных рецептов, которые вы можете попробовать приготовить дома:
- spinach, cheese, tomato, black_olive, olive, garlic, pepper, basil, citrus, melon, sprout, buttermilk, lemon, bass, nut, rutabaga;
- onion, tomato, olive, black_pepper, bread, dough;
- chicken, onion, black_olive, cheese, sauce, tomato, olive_oil, mozzarella_cheese;
- tomato, butter, cream_cheese, pepper, olive_oil, cheese, black_pepper, mozzarella_cheese;
Всё бы это было фигнёй, если бы мы не дали ссылки на самое интересное:
- На этом сайте ИИ генерит рецепты новых пицц.
- Исходный код и технические подробности проекта.




