
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В Skyeng есть команда коммуникаций. Она предоставляет инструменты для связи оператора с пользователем. Например, ученику плохо слышно преподавателя на уроке и он хочет связаться с поддержкой, чтобы решить проблему. Мы помогаем.
На старте было просто: связаться с нами можно было только через почту. Входящим ящиком был IMAP, исходящим — SaaS сервис по отправке почты, забрать письма с которого было то еще приключение. Мы смотрели на заголовки и соединяли письма в цепочки, как в любом почтовике: Gmail, Outlook. В таком виде передавали операторам.
Но оказалось, что с теми метаданными, которые мы предоставляли операторам, им было неудобно работать — много времени отнимал поиск пользователей в базе по адресу почты и теме сообщений. Так появился проект линковка. Мы стали подвязывать к цепочкам писем id наших пользователей. Пришлось придумывать дополнительные поля, как все соединить и куда вместить в базе.
Еще нужно было подвязать id той услуги, которую мы предоставляем пользователю. Например, он занимается у нас английским или математикой. А может у него подписка сразу на несколько предметов, то есть услуг.
Со временем увеличилось и число ящиков, куда мог написать клиент. Появились ящики техподдержки, кризис-менеджеров, сейлзов. Чем дальше, тем оказалось сложнее добавлять новые. Чтобы не прийти к ситуации: «Ребята, сколько времени нужно, чтобы добавить новый ящик? В смысле месяц?» — мы задумались о новой архитектуре.
Все решила новость о том, что к нам также заезжают телефония, WhatsApp и внутренний чат сайта...
Шорт-лист проблем
Мы стали придумывать архитектуру и вот с какими проблемами столкнулись:
Отсутствие архитектуры. Ее не было. Ни гексагональной, ни чистой, ни MVC. Просто нагромождение всего или Big ball of mud.
Нереально добавить новые каналы связи с пользователем. Например, Telegram.
Тестировали на проде. Даже настроить тестирование на стейджинге или, не дай бог, автоматическое разворачивание на тестинге — долго и больно.
Много багов. Приходили ребята из других команд и жаловались на долгий ответ наших сервисов.
Высокий порог входа для новичков.
Итак, список проблем есть. Нужно искать решение.
Сели сравнивать подходы (на самом деле нет)
Пришли новогодние каникулы и я из интереса написал сборщик писем по IMAP на NodeJS. Хотелось понять, как быстро удастся собрать и обработать все письма в ящике.
Запустил. И тут сборщик в 5-6 потоков, загрузив почти на полную процессор, выкачал 200 000 писем за 30 минут. В сравнении — наш экстеншн на PHP + IMAP выгружал 30 сообщений в минуту. При этом лаг сообщения от пользователя до оператора мог достигать 5 минут. Если у вас был более положительный опыт с таким экстеншеном, поделитесь, пожалуйста, в комментариях.
Начали крутить, как запустить IMAP + NodeJS сборщик у нас и выстроить архитектуру.
На этом моменте советую посмотреть доклад Юлии Николаевой из iSpring про модульный монолит — там больше теории. Мы решили тоже попробовать сделать микросервисы, взяв от них самое лучшее и не вытаскивая из монолита.
Лучшее из мира микросервисов
Это декомпозиция и инкапсулирование. То есть берем, декомпозируем код и инкапсулируем в маленькие бандлы / сервисы. Для этого мы посмотрели, какие у нас есть адаптеры:
IMAP (email), написанный на NodeJS.
Customer IO (email).
Телефония.
Neuronet — бот обзвона, тоже связанный с телефонией.
InfoBip — прослойка между сообщениями из WhatsApp.
Chat Service.
Затем выделили полиморфные сущности. Вот есть адаптеры IMAP и Customer IO. Они получают данные с разных структур, но приводят к одному полиморфному типу — email.
Еще один плюс микросервисов — они легковесны и у них нет привязки к стеку. То есть мы легко можем воткнуть наше NodeJS-приложение. Это отлично.
Грабли микросервисов, на которые не хотелось наступать
1. CAP-теорема. У нее много противников, много приверженцев. Я ее принимаю как данность, потому что при работе с микросервисами она всегда присутствует.
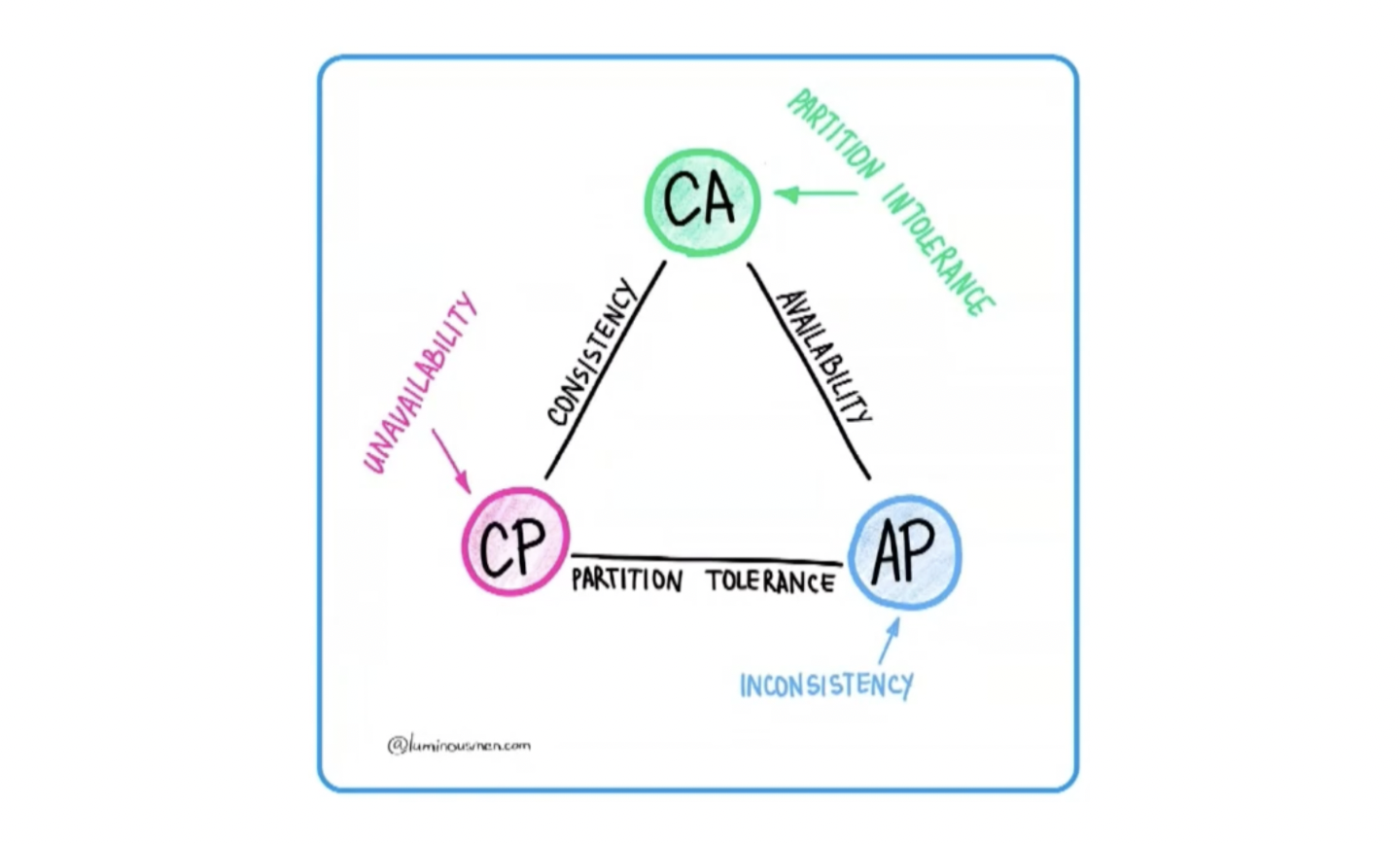
Итак, согласованность (consistency), доступность (availability), устойчивость к разделению (partition tolerance).
Выбирай любые два.
Начну с устойчивости к разделению. Это возможность системы восстанавливаться и работать после проблем с сетью. Микросервисы общаются по сетевому протоколу, они разрознены, а проблема с сетью рано или поздно может произойти. Поэтому мы всегда выбираем устойчивость к разделению.
Остаются согласованность и доступность.
Представим, пользователь совершил покупку, но личный кабинет потерял связь с биллингом. Что будем делать? Покажем пользователю личный кабинет, но без отображения информации о покупке? То есть сохраним доступность. Или выберем согласованность — отключим личный кабинет и покажем ошибку, пока связь не восстановится? Здесь решение нужно обсуждать с бизнесом.
К другим проблемам.
2. Discovery — как познакомить сервисы между собой? Как нам добавить новый сервис, оповестить все остальные и как аккуратно вывести?
3. CI/CD + DevOps — это отдельный челлендж. Если будем сильно дробить или возникнут нестандартные ситуации — ввод новых сервисов затянется.
4. Тяжело распутывать, что произошло в микросервисах. Здесь помогают Open Tracing библиотеки, чтобы сквозным образом логировать действие пользователя от начала его пути через микросервисы и до конца.
Чаще всего приходится настраивать Open Tracing самим и что-то дописывать, потому что на PHP библиотеки для работы с RabbitMQ или обертки для HTTP из коробки не поддерживают Open Tracing.
5. End-to-end testing. Как нам проверить все точки, на которые может повлиять действие пользователя?
Переходим к реализации
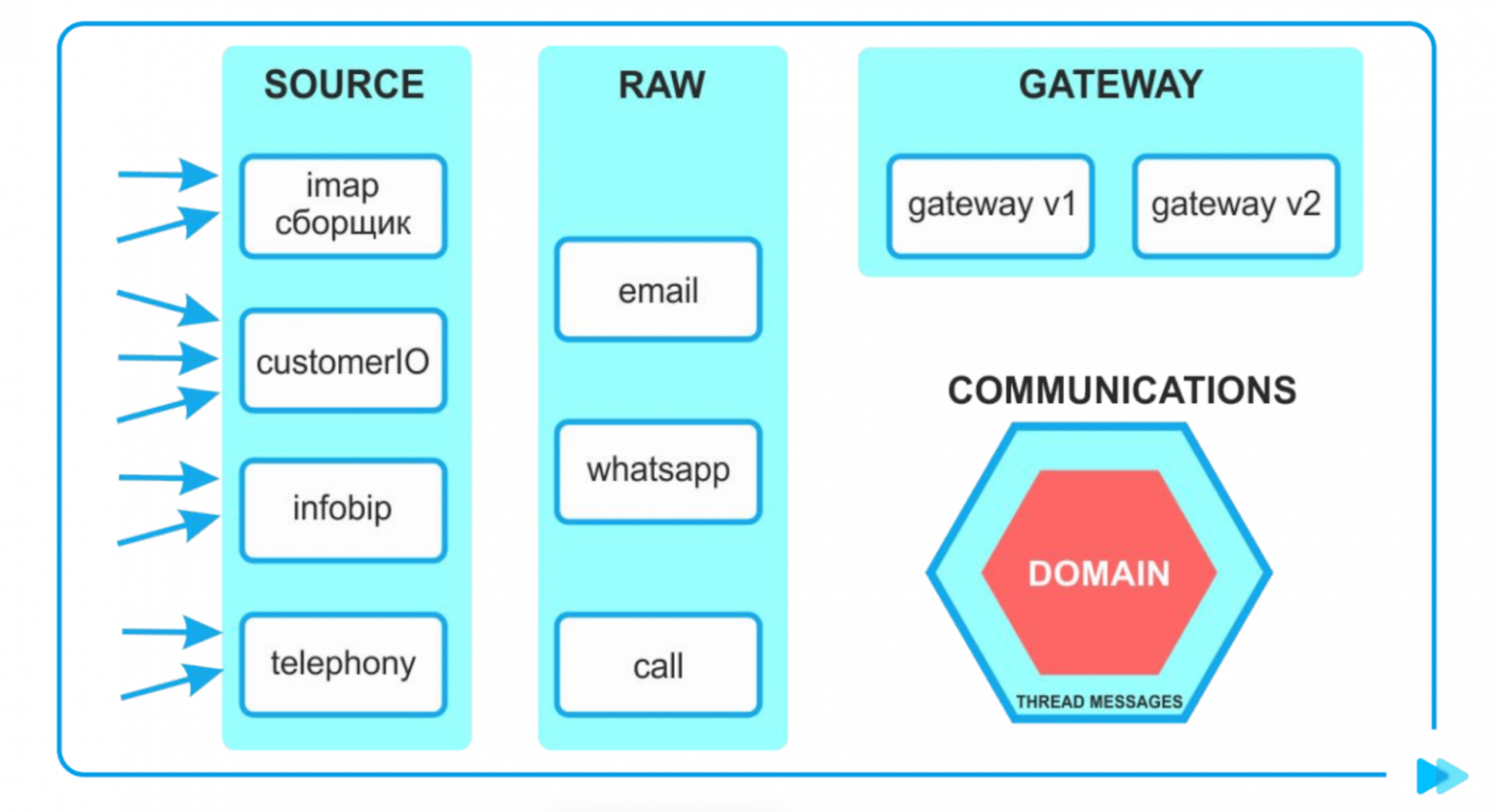
У нас получилось несколько папок:

Первая Source — туда прилетают исходные данные. Дальше распаршенные исходные данные отправляются в Raw. В папке Top хранится бизнес-логика — линковка, объединение в цепочки писем, хитрые выборки. В Top нет ничего о том, с какими данными он работает.

Наш старый-добрый Big ball of mud засунули в папку Legacy.
В Packages отнесли все, что можем переиспользовать в разных микросервисах: интеграции с внешними сервисам, которые могут повторяться, хелперы (например, по работе с временем), API-интерфейсы.
Как сервисы общаются между собой
Примерно таким же образом, как подключаются Cache-библиотеки.
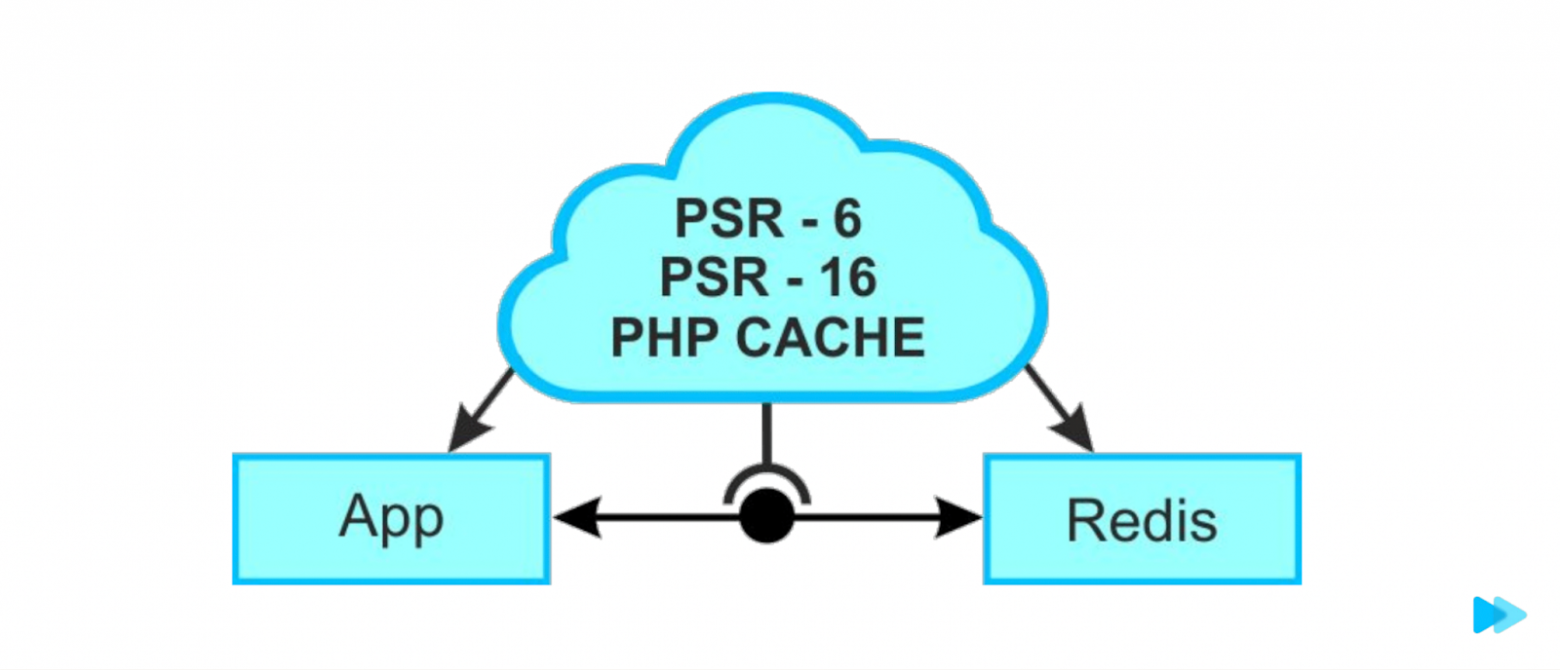
Облачко PSR-6, PSR-16, PHP Cache — это все интерфейс. Имплементации этого интерфейса используются различными библиотеками. Например, Redis.
На уровне приложения мы точно также подключаем интерфейс, но даже не выбираем драйвер, а где-то на уровне конфига говорим «драйвер такой-то», докачиваем нужные библиотеки. И все.
Наше приложение даже не знает, с чем оно общается. То есть оно коммуницирует с Redis через интерфейс — это та самая буква D из SOLID, принцип инверсии зависимостей. Модули верхних уровней не должны импортировать сущности из модулей нижних уровней. Оба типа модулей должны зависеть от абстракций. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Мы решили повторить эту логику:
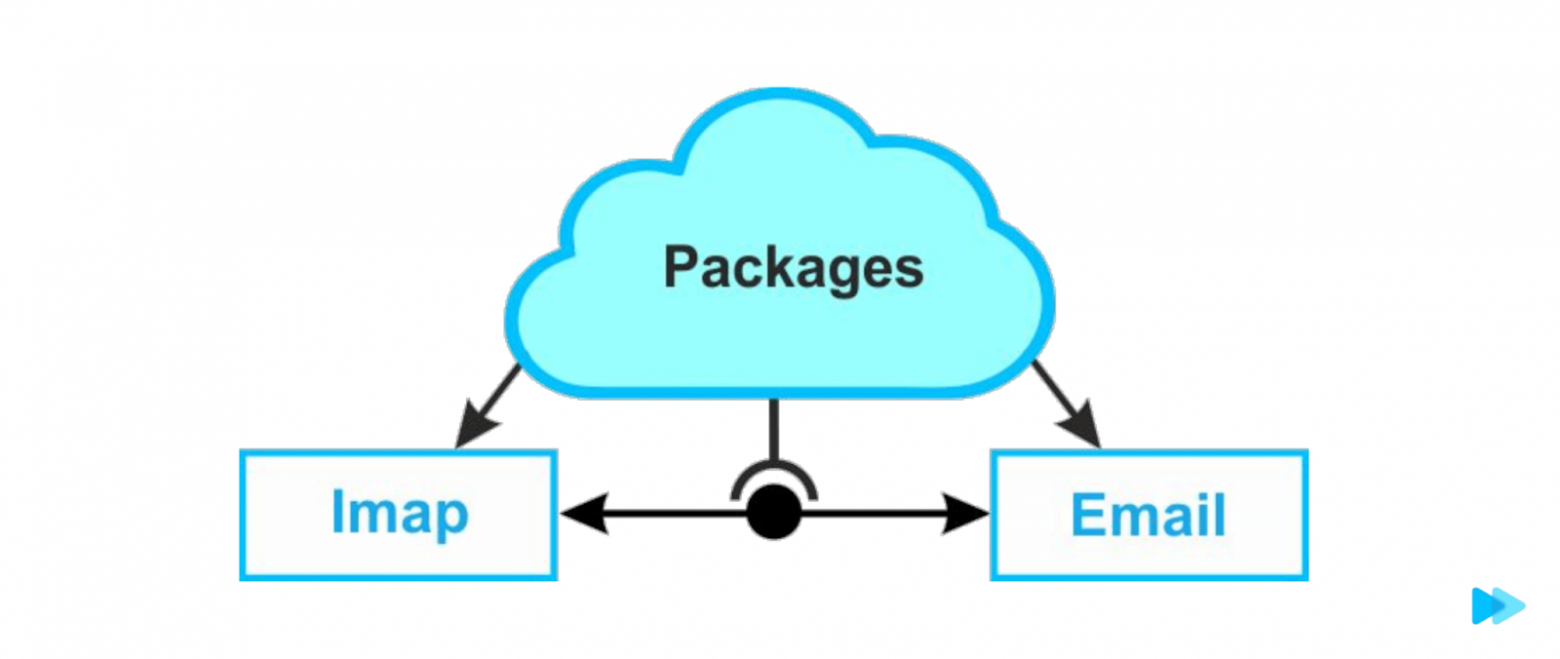
Вот у нас есть сервис по сбору IMAP писем и распаршенные письма. А между ними интерфейс без деталей реализации. Если понадобится, можем поменять шину данных, по которой идет общение. Можем дописать HTTP-протокол, подключить веб-сокеты и так далее.
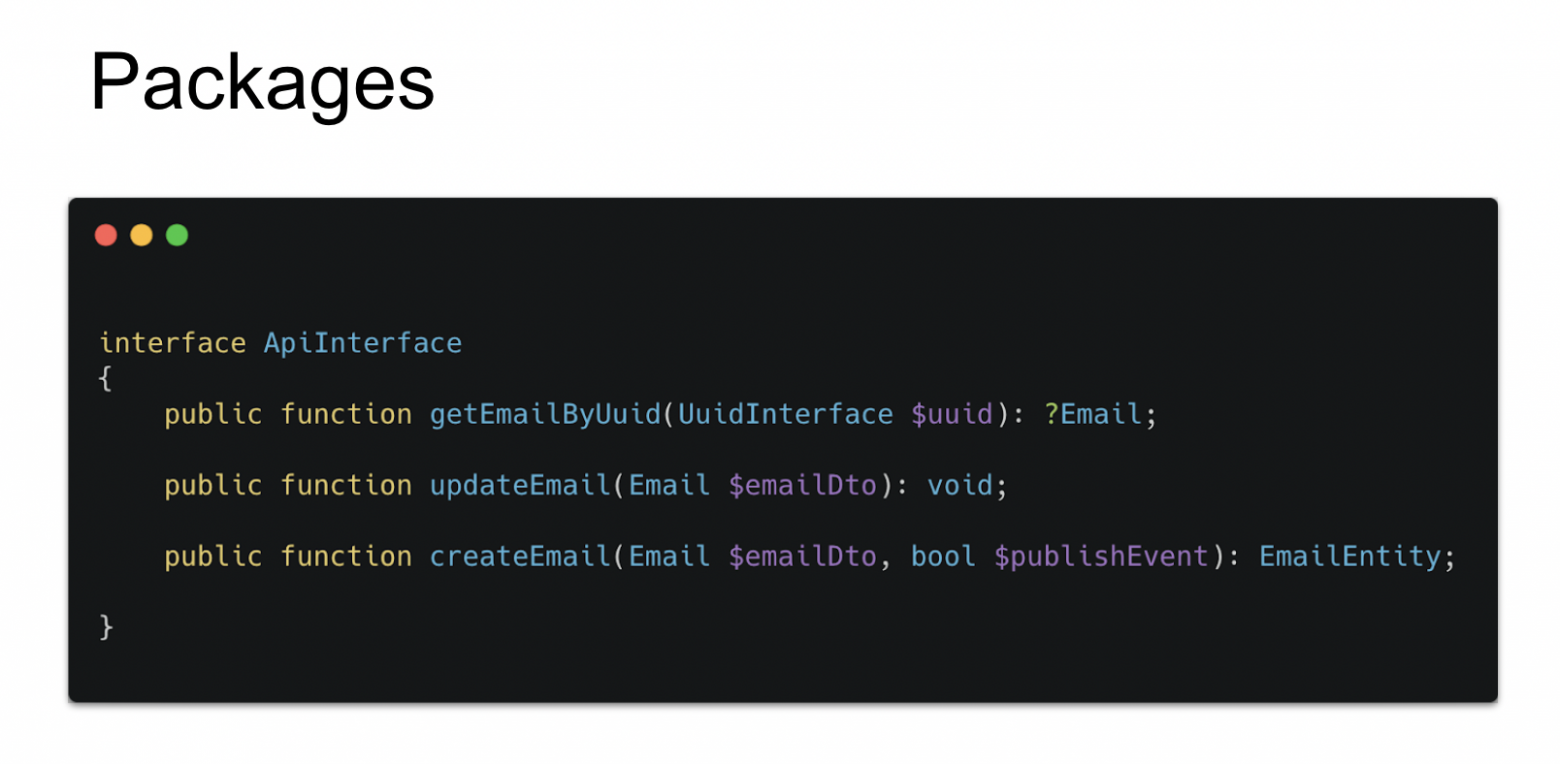
ApiInterface находится в пакетах. В нем getEmailByUuid, updateEmail, createEmail и Dto.

Source\IMAP подключает к себе интерфейс в конструктор и дальше с ним работает. Raw\Email имплементит интерфейс.
Проверяем, что нет нарушений и никто не работает напрямую с интерфейсом
В начале нам хватило договоренности в команде. Делали код-ревью и отлавливали редкие проблемы. Но поняли, что так «бить по рукам» не очень конструктивно. Подключили Deptrac (альтернатива — PHPat).
Deptrac — библиотека, где мы описываем наши сервисы. Это можно сделать с помощью namespace, префиксов классов или натравить Deptrac на определенные папки.
Дальше описываем для них правила: «Этот сервис может знать о том сервисе, а вот этот нет». В нашем случае сервисы могли знать о пакетах, но не о друг друге.
Запускаем Deptrac, смотрим, что показывает в консоли, добавляем в CI/CD. После CI/CD все ошибки вываливаются и разработчик видит, если он нарушил наши соглашения.

База
Мы рассмотрели код и пакеты, но не стоит забывать о базе. Было много вариантов, как ее разделить. Пошли по схожему пути экономии — добавили префиксы. Миграции прошли быстро.

В моделях и репозитории переписали, что таблицы теперь с префиксами.
Нам понадобилось убрать джойны между сервисами. Использовали для этого микросервисный pattern Gateaway.
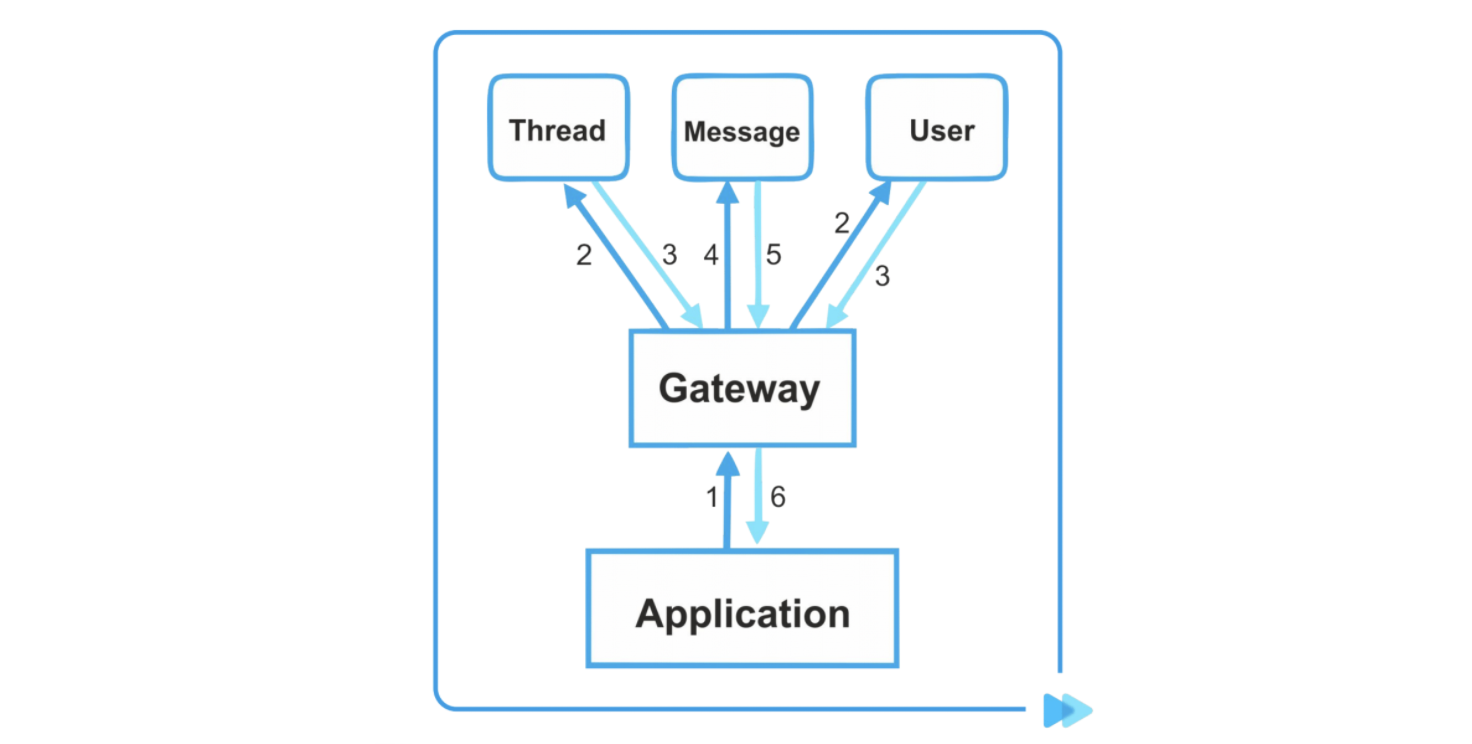
Предположим какой-то виджет обращается в Gateway, а дальше мы распараллеливаем, обращаемся в Thread и запрашиваем метаинформацию о пользователе. Thread возвращает количество сообщений. Получаем их id, все вместе склеиваем и возвращаем в Application. Так мы отказались от джойнов, каждый сервис работает со своими данными.
Плюс победили вторую трудность — убрали вызовы «чужих» баз.
Что с транзакциями? У нас после разделения транзакции между разными сервисами исчезли.
Еще раз ключевые моменты. А также итоги
У нас получились папки Source, Raw, Gateaway и Top (Communications).
В Source прилетают в сыром виде данные. Он их обрабатывает, а дальше мы берем интерфейс из пакета и отправляем данные в Raw.
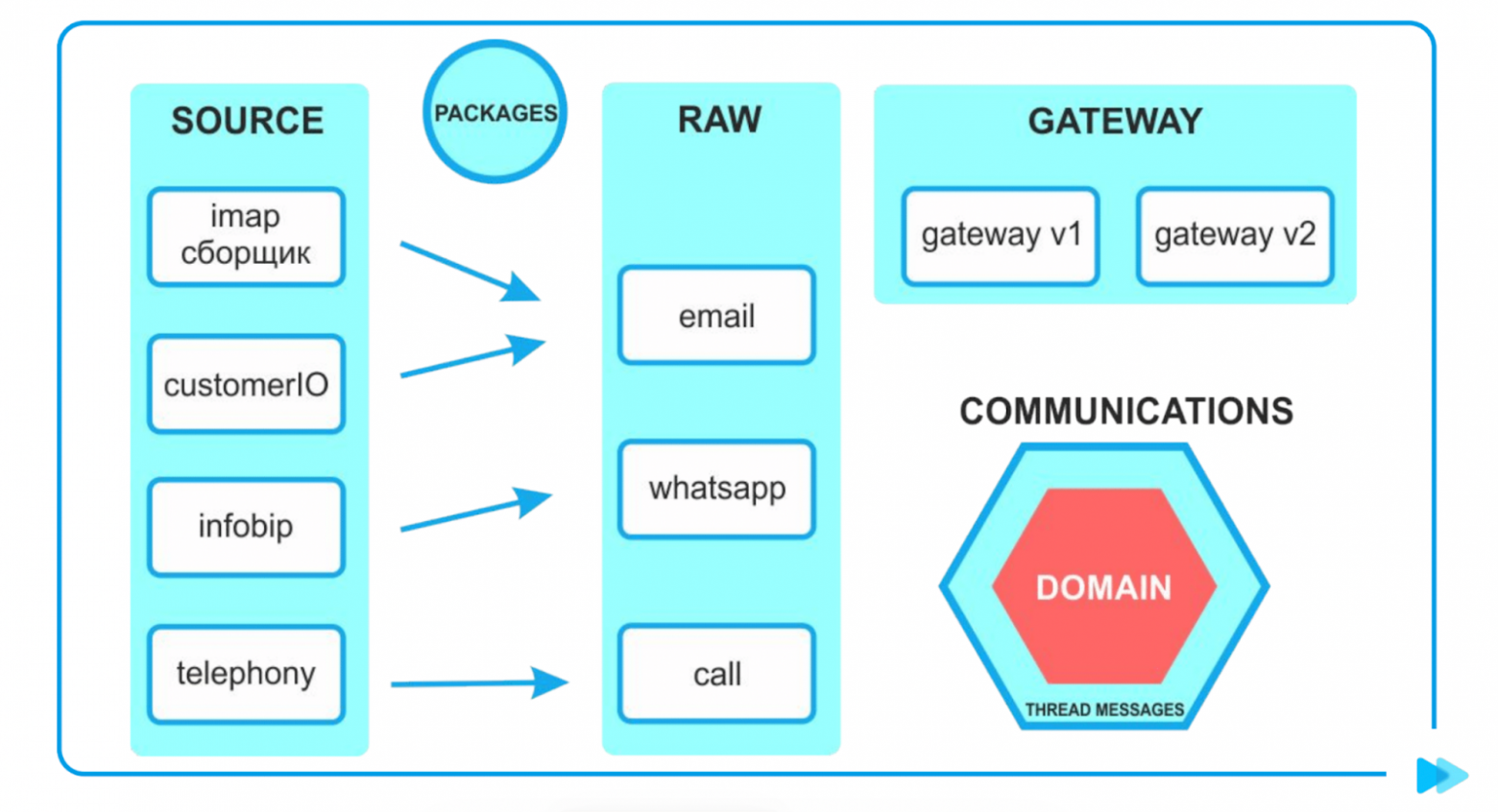
Сохраняем сущность в Raw, выбрасываем доменный ивент в Communications о том, что у нас есть новое сообщение.
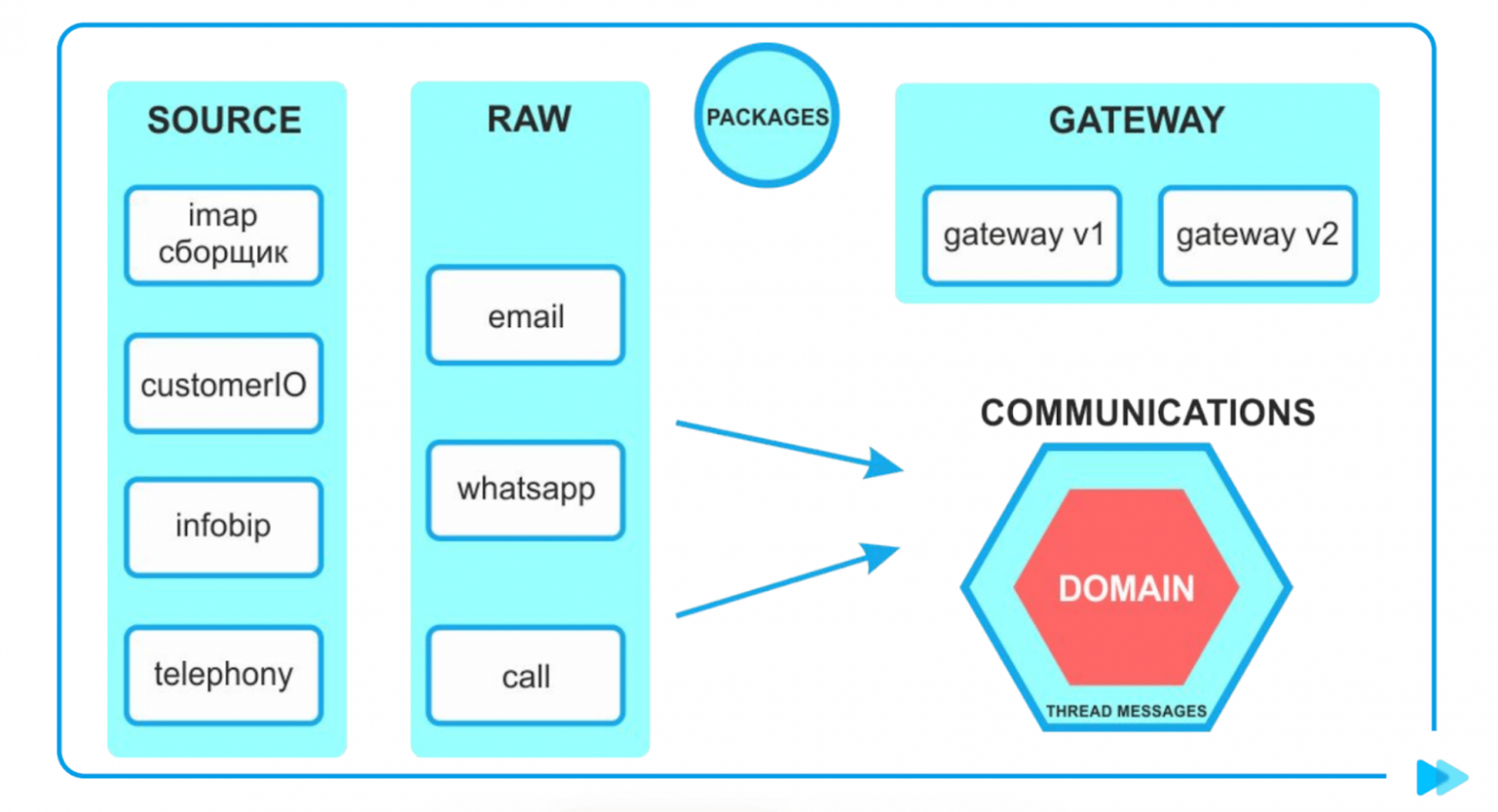
Коммуникации смотрят на тип сообщения, линкуют сообщения в треды и привязывают к услуге.
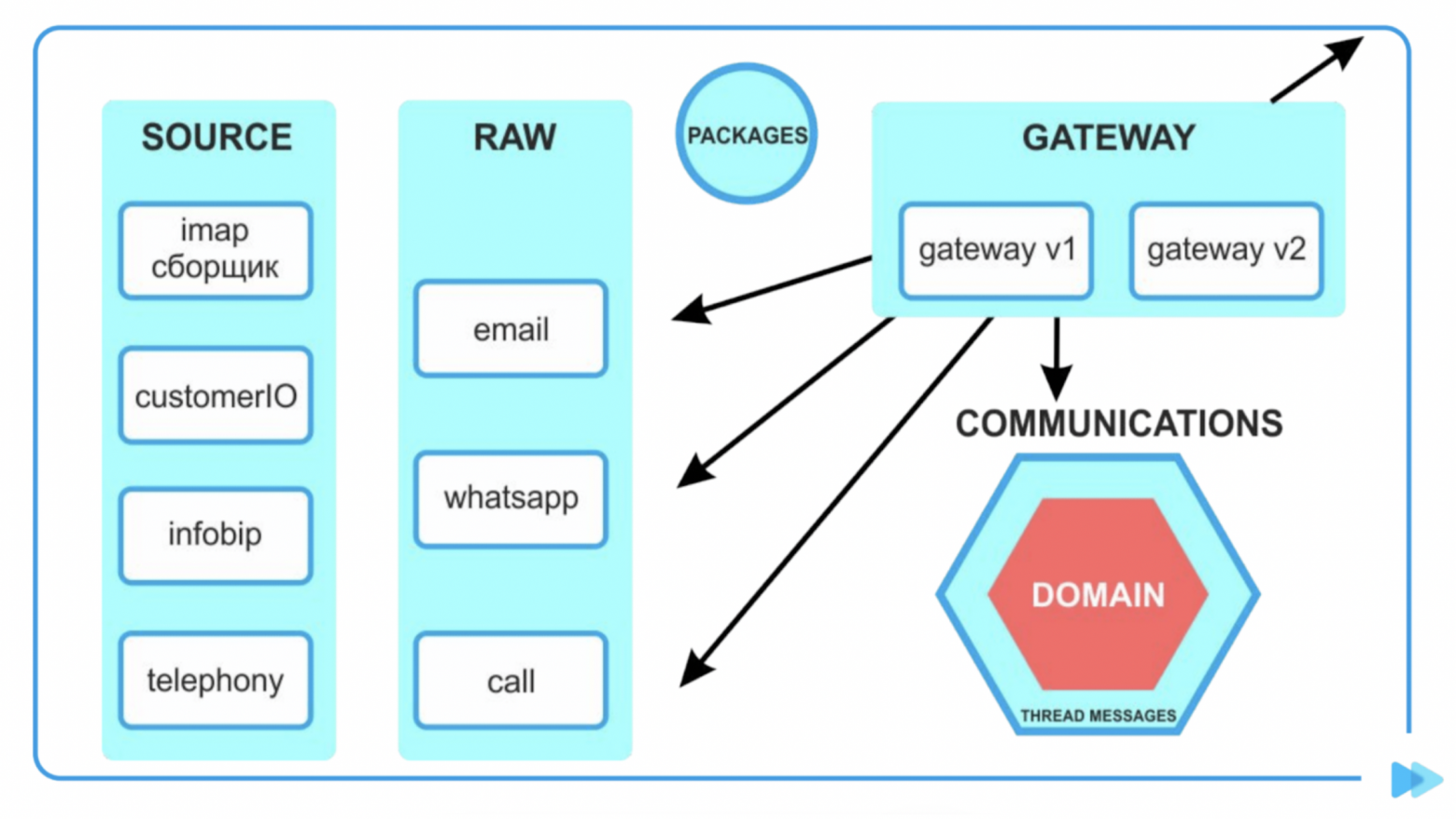
Создали тред, обработка завершилась в коммуникациях, приложение приходит в Gateway, который все собирает и отдает. Gateway у нас десятки — пишем отдельные под виджеты и команды. Они спокойно собирают разные данные под разную логику.
Таким образом:
Разработка стала легче и дешевле. Но есть другие подходы, которыми мы могли бы пойти. Может профит был бы выше.
Не было переезда, строили архитектуру с нуля. Все что было в легаси — засунули в отдельную папку.
Легче проверять бизнес-сценарии. Может проверить сценарий на моке, не отправляя на прод.
Команда выдохнула. Теперь работаем не с комом грязи, а с микросервисами. Ребята прокачиваются, а новичкам проще разобраться что к чему.
Если начнутся проблемы с производительностью на каком-то участке — сможем минимальными усилиями вытащить сервис из инфраструктуры, дописать api-интерфейсы, опубликовать пакет и задеплоить сервис. Ничего не сломается, все будет работать.
Кстати, Node-IMAP приложение, с которого все началось, нас спасло. Как-то Node-IMAP одновременно решил отвалиться у двух независимых сервисов, собиравших почту — нашего и еще одного очень дремучего.
Гуглили ошибку, нашли на каком-то китайском сайте. Посчитали, что наша архитектура готова, Node-IMAP на ней работает… И решили даже не дебажить легаси. Переключили за пару часов и поехали дальше :)
Полезные ссылки
Полная презентация.
Доклад Юлии Николаевой про монолит.
О CAP теореме.
Про паттерн Getaway.
Запись моего доклада с PHP Russia:




