
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Вряд ли сейчас можно встретить разработчика, который ничего не слышал об очередях сообщений. Самые известные брокеры сообщений это: Apache Kafka, RabbitMQ и IBM MQ. Все также наверняка знают об облачных решениях, предлагаемых Amazon. Есть у них и стандартизованные API для работы с очередями.
Одно из них, Simple Queue Service, мы взяли за основу и разработали распределенную очередь для запуска в облаке Mail.ru. SQS это стандартный API для облаков, его широко используют многие компании, от BMW до NASA.
В статье описано, что такое распределенные очереди и зачем они могут понадобиться, какие в них есть особенности, и о том, какое у нас получилось распределенное решение на базе Tarantool.
Содержание
1. Немного про распределенные очереди
1.1. Немного об Amazon SQS и Tarantool
1.2. Standard vs FIFO
1.3. Особенности работы распределенной очереди
2. Архитектура решения
2.1. Роли Tarantool Cartridge
2.2. Как реализовано хранение
3. Жизненный цикл сообщения
3.1. Как работает PUT
3.2. Как работает TAKE
3.2.1. Как работает Long polling
3.3. Как работает Dead-letter queue
4. Разработка
5. Заключение
1. Немного про распределенные очереди
При разработке программных продуктов очереди используются очень часто и примеров можно привести много. Обычно очереди используются для взаимодействия между различными элементами системы. Второй главный сценарий — балансировка нагрузки, чтобы избежать чрезмерной загрузки некоторого компонента системы запросами из внешнего мира.
В этой статье речь идет о распределенных очередях, которые сами собой представляют распределенную систему. Такие очереди предоставляют возможность роста производительности за счет горизонтального масштабирования, обеспечивают надежность и отказоустойчивость. При отказе одного компонента его функции подхватывает другой, и отказ не приводит к критическим ошибкам.
Распределенные очереди полезны для реализации паттерна продюсер-консьюмер в высоконагруженных приложениях. Продюсеры генерируют задачи, отправляют их в очередь, после чего консьюмеры берут эти задачи из очереди и обрабатывают их.
От таких очередей требуются надежность работы, производительность и персистентность. Все сообщения должны быть обработаны очередью и доставлены до консьюмеров. При возникновении каких-либо неполадок должна быть возможность повторно обработать сообщения.

Существует множество реализаций брокеров сообщений, самыми известными из которых являются Apache Kafka и RabbitMQ. Не будем останавливаться на их особенностях, сходствах и различиях, об этом можно почитать в других статьях (статья 1, статья 2).
Брокеры работают поверх различных протоколов, таких как AMQP, MQTT, и могут реализовывать различные модели очередей. Самые известные из них:
- Модель put-take — сообщение получает и обрабатывает только один консьюмер
- Модель publish-subscribe — очередь в такой модели называется топик, сообщение получают все подписанные на топик получатели).
Брокеры сообщений в той или иной мере реализуют одну или несколько моделей.Нашей задачей являлась реализация облачной распределенной очереди, предоставляющей API, совместимый с Amazon Simple Queue Service (SQS).
Итого:
- Очереди используются для взаимодействия элементов системы и для балансировки нагрузки.
- Распределенные очереди дают возможность горизонтального масштабирования, обеспечивают надежность и отказоустойчивость.
- Две основные модели: put-take, publish-subscribe.
- Мы сделали распределенную очередь по модели put-take.
1.1. Немного об Amazon SQS и Tarantool
SQS — это API для работы с очередью в облачной системе, разработанный в Amazon, с моделью put-take. В своем приложении можно использовать API, чтобы отправлять и получать сообщения через облачную платформу. После этого достаточно выбрать любое облако с распределенной очередью, реализующей SQS.
Использование облачного решения позволяет избежать проблем с администрированием и обслуживанием распределенной очереди, при этом простота SQS и наличие SDK практический под любой язык программирования позволяет быстро интегрировать приложение с облачной системой.
SQS обеспечивает базовые операции с очередью: положить сообщение в очередь (put) и взять сообщение (или несколько сообщений) из очереди (take). Если требуется другая модель (publish-subscribe или put-take с более сложной логикой), то стоит выбрать другое решение (например, Amazon SNS для модели publish-subscribe).
Мы решили реализовать распределенную очередь на платформе для in-memory вычислений Tarantool, точнее на Tarantool Cartridge (статья на хабре) — open-source фреймворке для построения кластера. Cartridge дает возможность разрабатывать отказоустойчивые высокопроизводительные распределенные решения благодаря хранению данных в памяти, обеспечивает персистентность и предоставляет гибкую модель работы с компонентами кластера. Полученную реализацию впоследствии внедрили в Mail.ru Cloud Solutions, и теперь ее можно использовать при работе в облаке Mail.ru.
Итого:
- SQS — это API для работы с очередью в облачной системе.
- Облачное решение облегчает разработку, администрирование и обслуживание.
- Простота SQS и SDK под многие ЯП позволяет быстро интегрировать приложение.
- Мы реализовали SQS на Tarantool, реализацию внедрили в Mail.ru cloud Solutions.
1.2. Standard vs FIFO
Amazon SQS поддерживает два типа очередей: FIFO (first-in first-out) и Standard.
FIFO обеспечивает строгий порядок выдачи сообщений: в каком порядке пришли, в таком и будут выданы. В мире распределенных приложений такая гарантия может быть обеспечена за счет существенного снижения производительности.
Предположим, что в очереди имеется 100 последовательных сообщений и 10 консьюмеров. Один из консьюмеров берет 10 сообщений и начинает их обрабатывать. Строгий порядок выдачи подразумевает, что другие 9 консьюмеров будут ждать, когда первый консьюмер подтвердит, что сообщения обработаны. Без такого подтверждения нет гарантии, что этот консьюмер не упадет и сообщения придется повторно обрабатывать в том же порядке.
Standard queue, который основывается на принципе быстрой выдачи сообщений (Best-effort), позволяет избежать указанного недостатка распределенной FIFO-очереди. Best-effort «пытается» всегда выдавать сообщения в порядке их поступления в очередь, однако не ожидает подтверждения от консьюмеров и не гарантирует строго последовательной выдачи.
Рекомендуется по возможности всегда отдавать предпочтение Best-effort, и выбирать FIFO, только если действительно существует потребность в строго последовательной обработке сообщений. Мы начали с реализации Best-effort, FIFO — в дальнейших планах.
Итого:
- Amazon SQS поддерживает два типа очередей: FIFO и Standard.
- FIFO обеспечивает строгий порядок выдачи сообщений, что снижает производительность.
- Standard основан на принципе Best-effort: выдает сообщения, не ожидая подтверждения предыдущих сообщений.
- Мы начали с реализации Best-effort, FIFO — в дальнейших планах.
1.3. Особенности работы распределенной очереди
Есть несколько особенностей, возникающих при работе с распределенными очередями. Я опишу три основные для нашего решения.
Первая особенность. Требование надежности подразумевает, что каждое сообщение должно храниться, пока его не обработает некоторый консьюмер. Предположим, что сообщение было выдано некоторому консьюмеру. Сообщение должно быть помечено как выданное и не выдаваться никакому другому консьюмеру. Если консьюмер обработал сообщение, он должен подтвердить обработку, чтобы сообщение могло быть удалено из очереди. Для этого используется вызов DELETE (удаляет сообщение из очереди).
Однако консьюмер может неожиданно завершиться и не подтвердить обработку, и в этом случае сообщение должно вернуться в очередь. Очередь не может точно определить, упал консьюмер или продолжает обрабатывать сообщение, поэтому используется Visibility timeout — таймаут, по истечении которого другие консьюмеры могут заново взять это сообщение на обработку. Этот таймаут следует настраивать таким образом, чтобы консьюмеры успевали обрабатывать сообщения.
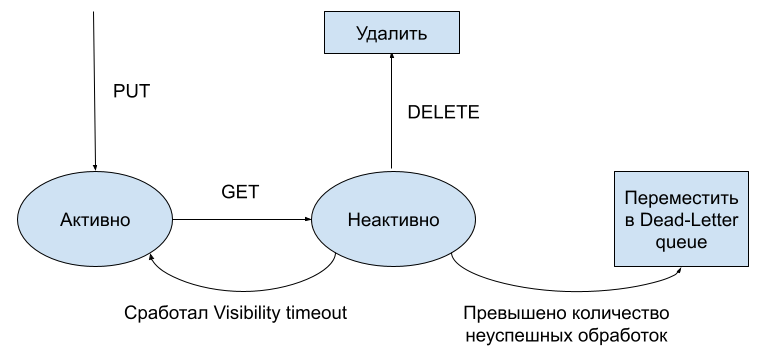
Диаграмма состояний сообщения.
Вторая особенность. Иногда полезно уметь выдавать не одно, а сразу несколько сообщений, чтобы сократить количество сетевых обращений. Длительность сетевого обращения может многократно превышать время обработки сообщения. Консьюмер может запросить 10 сообщений, в то время как в очереди их есть всего 5. В таком случае есть две стратегии выдачи сообщений:
- Немедленно выдать на запрос консьюмера все сообщения.
- Подождать какое-то время до наступления некоторого таймаута или до того, как в очередь придет недостающее количество сообщений.
Для последней из указанных стратегий существует специальный термин — long polling. В SQS достаточно в запросе указать время ожидания недостающих сообщений (Wait time). Если его не указать (или указать 0), то все имеющиеся в очереди сообщения будут сразу выданы консьюмеру.
Третья особенность это необходимость защиты от «некорректных» сообщений. Пусть некоторое сообщение из-за ошибки разработки или частичного обновления системы всегда приводит к падению консьюмера. Такие сообщения могут остаться в очереди навечно. Best-effort пытается работать максимально похоже на FIFO и выдавать сообщения сразу после их возврата в очередь, поэтому при наличии нескольких некорректных сообщений очередь может быть заблокирована.
Для борьбы с такими ситуациями существует Dead-letter queue — очередь, куда складываются такие «неисправные» сообщения. Если сообщение несколько раз было возвращено в очередь, то оно перемещается из нее в Dead-letter queue. Администратор системы должен посмотреть на содержимое неисправных сообщений и принять соответствующие меры: оповестить разработчиков об ошибке и/или просто удалить бракованное сообщение.
Итого:
- Требование надежности: каждое сообщение должно храниться, пока его не обработает консьюмер. Visibility timeout — таймаут, по истечении которого другие консьюмеры могут заново взять сообщение на обработку.
- Полезно уметь выдавать сразу несколько сообщений, чтобы сократить количество сетевых обращений. long polling — позволяет выдавать несколько сообщений за раз; система ждет, пока накопится нужное количество.
- Защита от некорректных сообщений. Dead-letter queue — очередь, куда складываются «неисправные» сообщения.
2. Архитектура решения
2.1. Роли Tarantool Cartridge
Распределенное приложение на Tarantool Cartridge строится путем описания ролей и создания кластера «по кирпичикам» из инстансов с назначенными ролями. Роль для инстанса — это как класс для переменной, она нужная для описания логики работы группы инстансов. Самым простым примером являются роли storage и app. Storage нужен для распределенного хранения данных, app — для сбалансированной обработки запросов.
В нашем случае разработаны следующие роли:
- api — точка входа в кластер, обеспечивает реализацию API SQS.
- auth — обеспечивает аутентификацию и авторизацию пользователей. Здесь хранится информацию о аккаунтах и ключевых парах, которые привязаны к ним.
- app — реализует балансировку запросов, логику хранения состояния очередей и выборку/вставку сообщений в хранилища (storage).
- storage — отвечает за хранение сообщений.
- broker — обеспечивает обратную связь между storage и app.

Архитектура кластера с назначенными им ролями изображена на рисунке выше. Для обеспечения отказоустойчивости и распределения нагрузки на чтение (для storage) можно объединять инстансы в реликационные группы (репликасеты).
Репликасет — это множество инстансов одного типа, снаружи видимых как один элемент, внутри реализованный как несколько реплицирующих друг друга инстансов. Обычно во время работы кластера в репликасете выбирается мастер, через который проходит запись и реплицируется на слейвы. При чтении запросы распределяются на все реплики. В очереди полезно создавать репликасеты для всех инстансов ролей storage и auth.
Итого:
- Приложение на Tarantool Cartridge строится через описание ролей.
- Роль для инстанса — как класс для переменной.
- В нашей реализации SQS заготовлены роли для входа в кластер, авторизации и аутентификации, балансировки запросов, хранения сообщений.
- Для отказоустойчивости объединяем инстансы в репликационные группы.
2.2. Как реализовано хранение
Как только сообщение попало в кластер, оно должно быть сохранено на некотором storage-е. В Tarantool Cartridge есть стандартная роль vshard-storage, которая реализует распределенного хранение на базе шардов с помощью библиотеки vshard.
В очереди мы решили отойти от использования этой библиотеки и шардировать на основе меток времени постановки сообщений в очередь. Для этого ввели понятие период. Период представляет собой непрерывный временной интервал и вычисляется как timestamp % base для некоторого фиксированного целочисленного base. Все сообщения с одинаковым периодом попадут в один storage.
Периоды удобны тем, что они являются упорядоченными и что по ним можно запрашивать сообщения из хранилищ согласно времени их прихода в очередь. App хранит мета-информацию о периодах и при очередном запросе TAKE определяет, на каком из storage-ей хранятся самые старые еще не обработанные сообщения и, соответственно, обращается сначала к этим storage-ам.
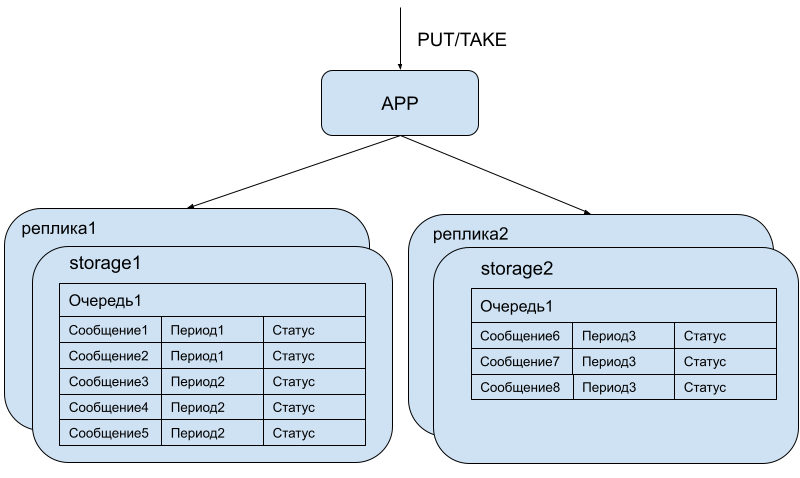
Вместе с самим сообщением и его периодом в storage-ах хранится и другая метаинформация о сообщении:
- статус: активно, если не отдано, или неактивно, если отдано некоторому консьюмеру;
- количество неуспешных обработок — для того, чтобы переместить в Dead-letter queue при превышении порогового значения;
- для неактивного сообщения: время, когда было отдано консьюмеру — чтобы определять, когда сработает Visibility timeout.
Так как app-ы хранят метаинформацию о сообщения, при обновлении состояния storage через broker посылает обновленное состояние app-ам.
Состояние обновляется также при выполнении запроса (PUT/TAKE/DELETE), поэтому возможно возникновение состояния гонки. Гонка может возникнуть, если обновления приходят в app не в том порядке, в котором они реально были выполнены на storage-е. Для корректного разрешения таких ситуаций используются метки Лампорта: вместе с каждым обновлением состояния приходит метка, которая представляет собой счетчик, увеличивающийся при каждом обновлении. На app-е применяется только то обновление, метка которого больше, чем на предыдущем примененном обновлении.
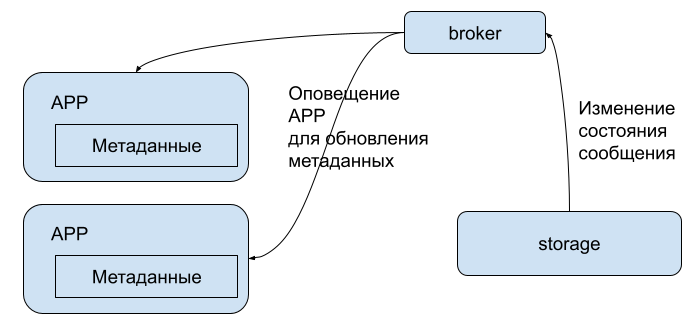
Итого:
- Шардируем на основе меток времени постановки сообщений в очередь.
- Это удобно тем, что можно запрашивать сообщения согласно времени их прихода в очередь.
- Вместе с сообщением хранится метаинформация: статус, количество неуспешных обработок, время передачи консьюмеру.
3. Жизненный цикл сообщения
Легче всего понять архитектуру разработанной нами распределенной очереди можно, рассмотрев жизненный цикл сообщения.
Сообщение сначала попадает в очередь при выполнении операции PUT. Далее оно хранится в очереди и выдается некоторому консьюмеру на обработку при выполнении операции TAKE. В этот момент сообщение помечается как отданное. После обработки сообщения консьюмер присылает DELETE, и сообщение удаляется из очереди. Рассмотрим подробнее реализацию указанных операций.
3.1. Как работает PUT
При отправке любого запроса в распределенную очередь он сначала попадает в один из инстансов с ролью api. Здесь происходит валидация запроса, проверка соответствия запроса стандартам SQS.
Далее идет обращение в роль auth для аутентификации и авторизации пользователя. Используется стандартная авторизация, как у Amazon, о которой можно почитать в документации.
Если пользователь успешно авторизован, то идет обращение в любой из инстансов роли app. В app-ах производится определение, на какое из репликасетов storage-ей должно быть отправлено сообщение. Это делается с помощью вычисления специального хэша, который строится по метке времени поступления сообщения в очередь (подробнее про хранение сообщений описано выше). После этого app отправляет сообщение в нужный storage, на котором сообщение сохраняется и реплицируется (при наличии реплик).
Итого:
- Запрос попадает на инстанс с ролью api для валидации.
- Идет обращение в auth для аутентификации и авторизации.
- app выбирает, на какой storage положить сообщение.
- Отправляем сообщение на нужный storage.
3.2. Как работает TAKE
Как и для PUT, запрос проходит стадию авторизации на auth и валидации на api, после чего попадает на app.
Рассмотрим для начала случай, когда запрашивается только одно сообщение.
Роль app хранит состояние хранения данных, то есть каждый app знает, на каком storage-е находится первое активное сообщение. Идет запрос на этот storage, сообщение в нем помечается как неактивное, сохраняется метка времени его выдачи. После этого сообщение можно выдавать консьюмеру. Через брокер остальные app-ы оповещаются, что сообщение стало неактивным.
Далее от консьюмера ожидается DELETE — запрос, который удалит сообщения, если оно все еще неактивно.
Для реализации Visibility timeout на storage-е работает специальный файбер (в терминологии тарантул файбер — аналог корутины, работающей в рамках кооперативной многозадачности). Файбер обнаруживает все неактивные сообщения, для которых истекло время ожидания DELETE, и меняет их статус на «активное», возвращая тем самым в очередь. Через брокер app-ы оповещаются об изменении состояния таких сообщений.
Итого:
- Запрос попадает на инстанс с ролью api для валидации.
- Идет обращение в auth для аутентификации и авторизации.
- app определяет, в какой storage пойти, идет запрос на этот storage.
- Сообщение помечается как неактивное, сохраняется метка времени его выдачи.
- Сообщение можно выдавать консьюмеру.
- Ждем DELETE от консьюмера, чтобы удалить сообщение.
3.2.1. Как работает Long polling
Если пришел TAKE с указанием количества сообщений, то на app-е нужно потенциально собрать указанное количество сообщений с одного или нескольких storage. App начинает собирать сообщения со storage-а с самым старым активным сообщением с указанием максимального числа возвращаемых результатов.
Если запрашиваемое количество не набралось, app обращается к следующему storage-у и т.д. Если нужного количества сообщений нет, то либо все набранные сообщения возвращаются консьюмеру (при
Wait time = 0), либо начинается long polling.При long polling-е производится запрос на текущий активный storage — это тот storage, куда будут приходить новые сообщения. Так как storage определяется по метке времени входящего сообщения, то app может однозначно определить этот storage. Далее, storage ждет указанное в запросе количество времени и набирает все входящие сообщения до истечения таймаута или пока не набралось нужного числа сообщений. Результат выдается app-у и он возвращает ответ консьюмеру.
Чтобы не произошло преждевременного срабатывания Visibility timeout, в момент отправки результата идут запросы storage-ам на обновление метки времени взятия сообщения из очереди.
Итого:
- Запросили несколько сообщений.
- Запрос попадает на инстанс с ролью api для валидации.
- Идет обращение в auth для аутентификации и авторизации.
- App собирает сообщения со storage-й:
- Если собрал, то отправляет их консьюмеру.
- Если не собрал, то ждет по таймауту, сколько не хватает сообщений.
- Либо дождался таймаута, либо собрал — идет отправка консьюмеру.
3.3. Как работает Dead-letter queue
Как уже упоминалось ранее, для каждой очереди, созданной пользователем, создается Dead-letter queue. При возврате сообщения в очередь у него увеличивается счетчик неуспешных обработок. При превышении порогового значения сообщение удаляется из очереди и создается его копия в Dead-letter queue, после чего пользователь/администратор очереди может проанализировать причины такого срабатывания.
4. Разработка
При разработке использовались следующие средства автоматизации тестирования:
- Docker
- luatest (аналог Pytest для тестов на lua)
- continuous integration (CI).
Использование Tarantool Cartridge помогло организовать для ролей кластера как набор изолированных, так и интеграционных тестов. Были реализованы функциональные тесты, проверяющие корректную реализацию API SQS, тесты на корректную обработку различных сценариев работы очереди (таких как срабатывание Visibility timeout, Long polling, Dead-letter queue), тесты надежности.
Также в отдельном стенде развернут небольшой кластер, на котором периодически проводятся тесты производительности. Наличие таких тестов позволило улучшить производительности очереди и избежать деградации при внесении изменений. Стенд также используется для проведения исследовательских тестов с определением оптимальной конфигурации системы под конкретные требования.
Для удобства эксплуатации в системе реализованы множество различных метрик, такие как время выполнения PUT и TAKE запросов для каждой очереди, количество активных/неактивных сообщений в очереди, количество срабатываний Visibility timeout и др. Также реализована трассировка запросов для выявления узких мест при высокой нагрузке.
5. Заключение
Распределенные очереди широко используются для балансировки нагрузки и взаимодействия элементов сложных систем. Облачные очереди облегчают разработку, администрирование и обслуживание. Именно такую очередь мы сделали на Tarantool Cartridge.
Распределенное приложение на Tarantool Cartridge строится путем описания ролей и создания кластера «по кирпичикам». Роль для инстанса — это как класс для переменной, она нужная для описания логики работы группы инстансов. В нашей реализации SQS есть роли для входа в кластер, авторизации и аутентификации, балансировки запросов и хранения сообщений. Это позволяет быстро из коробки собрать кластер по требованиям.
Наша реализация дает возможность создавать Standard очереди согласно API SQS. Мы планируем добавить и тип FIFO со временем. Кроме того, планируется сделать on-premise реализацию, которую можно будет разворачивать в закрытом контуре.
Если вы уже используете API SQS, то вы можете сразу использовать и нашу очередь. Попробуйте ее в облаке MCS.
Попробуйте Tarantool на нашем сайте и приходите с вопросами в Telegram-чат.




