
Выступление на Go 1.10 Release Party @ Badoo
Артемий рассказал про подходы к безопасному завершению работы многопоточных программ на Go, в частности о том, как контролировать горутины и управлять ими. Объяснил, почему во время выкатки сервисов в Kubernetes пользователям может возвращаться множество ошибок. Чтобы подробнее раскрыть, почему так происходит, схематично показал, как работает Kubernetes внутри, и почему он не позволяет сделать выкатку сервисов бесшовной.
Артемий Рябинков (АР): – Не считаю себя хорошим спикером – всего во второй раз выступаю, но, надеюсь, вам понравится.
Мне интересно, кто здесь собрался? Кто считает себя гуру в Go? Тяните руку!.. Вам не будет интересно. Всем остальным должно быть интересно – новичков здесь больше, поэтому, думаю, доклад зайдёт.
Тема простая – Graceful Shutdown. Мы хотим, чтобы наши сервисы завершались аккуратно.

Меня зовут Артемий, я работаю в «Авито», в команде мессенджера. В «Авито» мы используем Kubernetes, пишем на Go и PHP. На Go сейчас более активно стали, больше народу начинает писать. Появляется Boilerplate Go-шного сервиса, который начинает включать много функционала. Функционал, которого у нас раньше не было, но он появился – это Graceful Shutdown, и о нём я хочу рассказать (и почему он не работает в «Кубернетес»).
Во-первых, мы хотим, чтобы наше приложение завершалось всегда предсказуемо, то есть чтобы мы понимали, что произойдёт при завершении работы. Также мы не хотим терять данные, когда приложение завершается.
Данные могут быть разные… Например, когда у вас идёт какая-то транзакция в базу данных, в этот момент операционная система говорит сервису: «Умри!», и транзакция повисает. Мы хотим, чтобы транзакция завершилась, и только потом сервис закончил свою работу.
Это могут быть входящие соединения от пользователей. Соединение пришло; в момент, когда оно пришло, операционка убила процесс; пользователь не получил ответ – это плохо, мы так не хотим. Мы хотим как-то это обрабатывать.
Вообще, есть манифест, и ребята из Heroku рассказывают как раз о том, как нужно писать сервисы, чтобы они хорошо работали в облаке. И один из пунктов – https://12factor.net/disposability – рассказывает о том, что сервис должен иметь Graceful Shutdown, а по-хорошему сервис (и вообще, ваш софт) должен иметь crash-only design. В любой момент что угодно может произойти: метеорит упал, а ваш сервис всё равно знает, как себя вести.
Graceful Shutdown в плане инфраструктуры даст нам бесшовные выкатки. Что такое выкатка? Мы убиваем одну версию кода, поднимаем другую версию. И если наш сервис не умеет Graceful Shutdown, то в момент смерти старой версии кода запросы пользователей будут оборваны. Этого мы не хотим.
В целом как будет выглядеть бесшовная выкатка для нас? Следующим образом:
Таким образом, пользователи будут счастливы. А это – когда пользователи не счастливы:

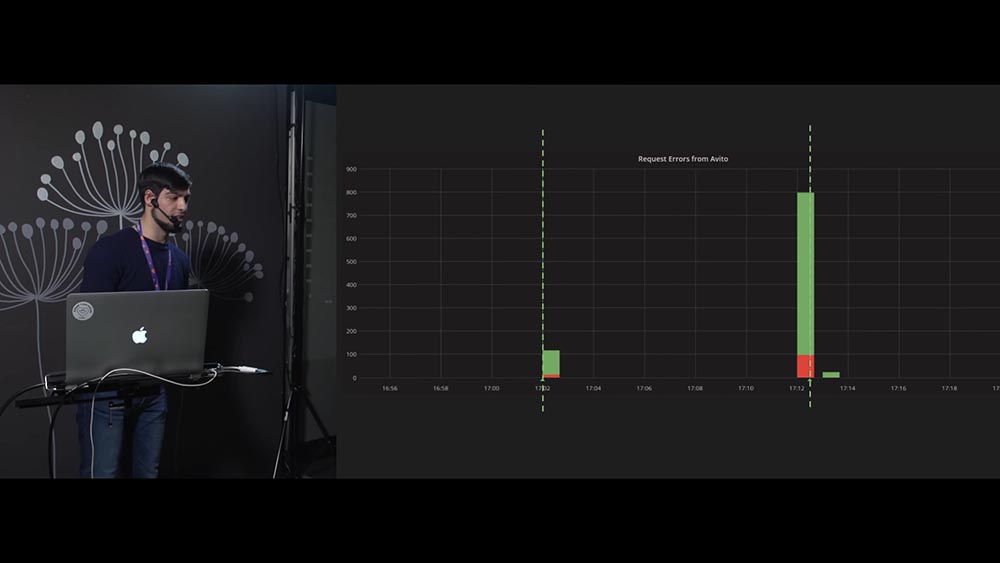
Почему? Потому что на графиках наблюдается аномалии. Именно эти графики оказались предпосылкой к данному докладу: у нас было несколько сервисов, которые общаются между собой, и в моменты выкаток на наших графиках мы видели именно эту картину. Здесь нет осей (не надо придираться к этому), но видно, что в момент выкатки увеличивается количество ошибок и возрастает время ответа сервиса. Если один сервис входит в другой сервис в момент в выкатки второго сервиса, то первый получает…
Graceful Shutdown на тот момент не был у нас реализован. Идея была такая: раз запросы рвутся, сервис получает ошибки – в результате мы видим такие аномалии на графиках. Давайте это решать! Мы хотим вот так:
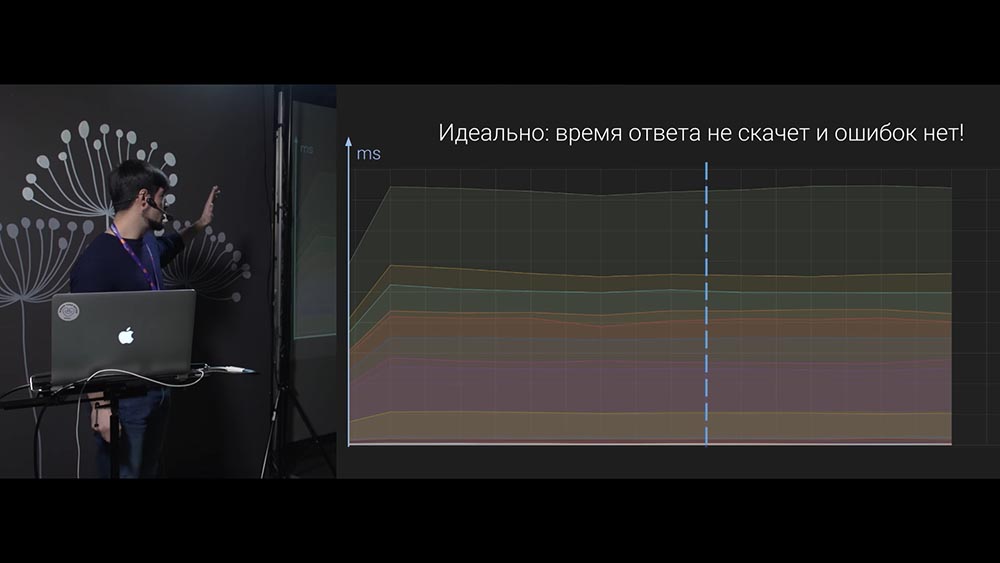
Чтобы время ответа от сервиса как шло постоянно, так и осталось бы идентичным в момент выкатки.
Нужно проделать несколько шагов, чтобы сервис научился завершаться. Во-первых, мы должны научить ОС каким-то образом сообщать сервису о том, что ему необходимо быть завершённым. Сервис при этом должен уметь «слушать» эти сигналы ОС и обрабатывать их.
Такой механизм есть в Linux – это сигналы, с помощью которых мы можем сообщить процессу о необходимости совершить действие. Следующие сигналы отвечают за завершение работы:

Это те сигналы, которые нужно обрабатывать. Их операционная система будет присылать сервису в момент завершения работы. В частности, при выкатке сервиса в Kubernetes ему [сервису] придёт SIGTERM.
Схематически это выглядит так: стартовал процесс, стартовал его основной поток, потом – дочерние потоки, эти дочерние потоки могут породить своих «детей». Получается древовидная структура потоков внутри программы:

Когда приходит сигнал, основной поток должен сообщить всем своим потокам о необходимости совершить действие (например, завершиться). Другие потоки, которые находятся ниже по дереву, должны уже своим «детям» сообщить.
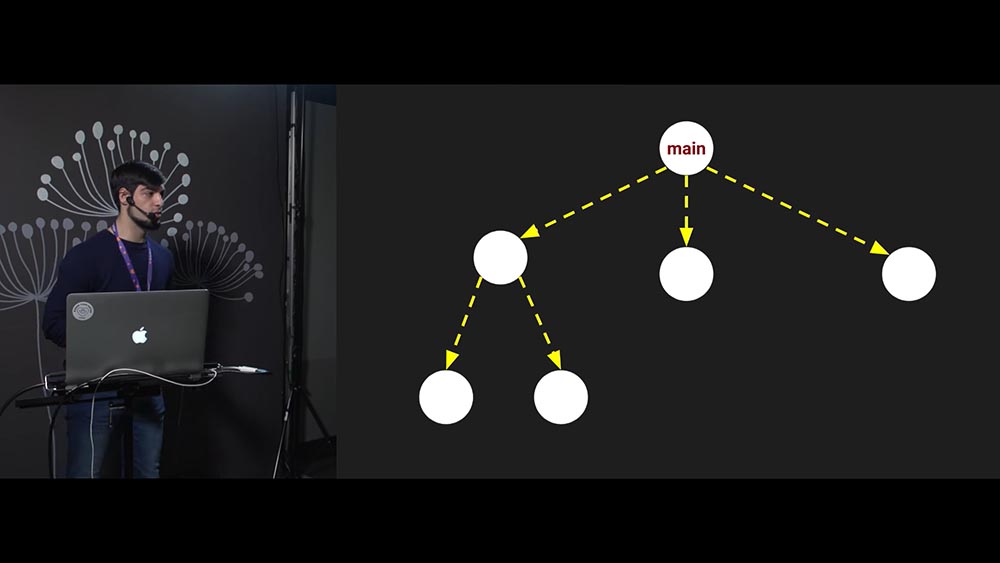
Самое главное, мы должны дождаться завершения всех дочерних потоков перед тем, как завершить основной поток. Таким образом, дожидаемся завершения дочерних и только после этого глушим основной поток. Это схема того, как должен происходить Graceful Shutdown.
Теперь перейдём Go. Буду показывать и рассказывать, как всё это работает в Go и как это реализовать. Для ветеранов это понятно, для новичков разберём более подробно:

Сигнал нужно поймать. Для этого мы должны зарегистрировать обработчик сигнала. Если ОС знает, что обработчика сигнала у процесса нет, она его просто сразу убьёт (без какой-либо информации). А если мы зарегистрировали обработчик сигнала, то ОС передаст управление процессу, и процесс может проделать свою работу.
В данном случае мы регистрируем обработчик – в Go используется механизм каналов для получения событий, данных, и здесь мы говорим обработчику: «Положи информацию о том, что совершился сигнал в этот канал». Когда же в этом канале появилось новое сообщение, мы знаем, что сигнал появился, и эта строка кода отвечает за то, чтобы поймать сигнал от ОС.
Поток в Go – это горутина. На самом деле горутина – это не поток… Легковесный какой-то поток; и он на самом деле он может быть в одном потоке ОС, много горутин…
Но мы сейчас думаем так: одна горутина – один так, они все могут располагаться параллельно (нам неважно). В терминах Go, когда мы говорим о потоках, мы будем говорить о горутинах.
Нужно завершить дочерний поток. Как это сделать? Для начала нужно породить новый поток, просто поставив оператор go перед функцией:
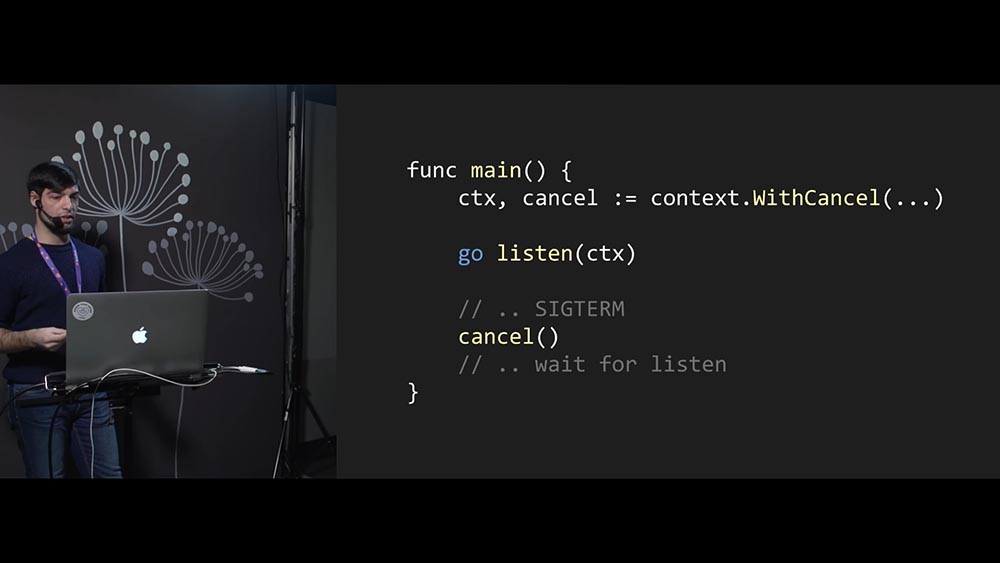
Оператор go запустит нашу функцию в отдельном потоке. Как нам сообщить функции listen, которая может обрабатывать входящие соединения, что её нужно завершиться? Будем использовать механизм каналов: создаём канал, передаём в канал функцию listen и в некотором смысле «заключаем договор»: «Если в этом канале появится какая-то информация, то, функция listen, пожалуйста, завершись»!
Теперь самое важное, что разработчик функции listen должен поддержать этот функционал. Он должен понимать, что мы пришлём какую-то информацию. Когда информация появится в канале, функции нужно завершить свою работу.
Далее, когда приходит сигнал ОС, мы просто закрываем канал. Закрытие канала – это тоже информация, событие. Благодаря этому событию разработчик функции Listen сможет получить идентификацию о необходимости завершить работу. Если функция listen обрабатывает соединение пользователя, то когда появляется информация в канале – она должна обработать активное соединение и лишь потом завершить свою работу.
Но с Go 1.7 появилась такая абстракция, как context (ctx). То, что я рассказывал о канале – это абсолютно правильный, хороший способ отсылать какие-то нотификации, но для реализации конкретного use case (сообщать о необходимости завершить работу) в Go 1.7 была введена абстракция context.
Сейчас стоит использовать именно её, потому что это как минимум сделает код более читаемым. Разработчик, который будет писать функцию listen, знает, что вы ему context передадите, и благодаря этому context будет обрабатываться весь этот весь этот Boilerplate, связанный с завершением работы.
Чтобы использовать context, мы его создаём. При этом мы создаем его таким образом, чтобы у нас была возможность его закрыть: функция cancel, которая вернулась нам – это возможность закрыть context:

Далее мы просто передаём context в listen и закрываем его, когда надо. Таким образом, listen получил идентификацию о необходимости завершиться.
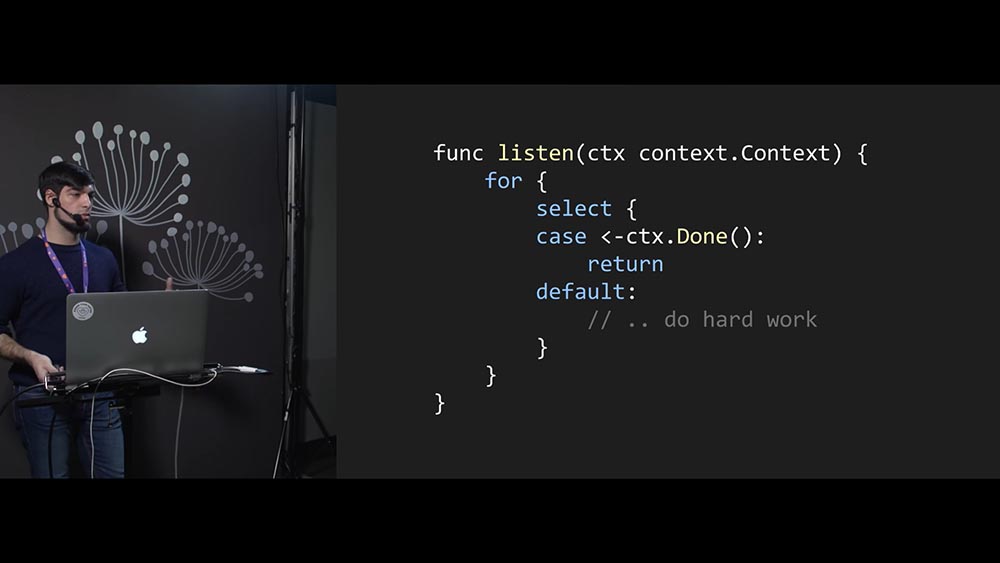
А как написать listen? Что должен сделать разработчик функции listen, чтобы она правильно работала? Пример такой:
Для того чтобы завершать работу потока (функции, которая выполняется в отдельном потоке) в Go, нам нужно использовать context.Context. Это хорошая практика, это правильно – используйте context.
После того как мы сообщили потоку, что ему необходимо завершиться, нужно теперь каким-то образом дождаться завершения потока: когда мы просто сообщили ему, то вообще не знаем, что произойдёт – может, никогда не завершится, поэтому нужно дождаться, когда он действительно будет завершён и таким образом усилит наш контроль над работой программы.
Мы уже познакомились с механизмом наших каналов – его и будем использовать:
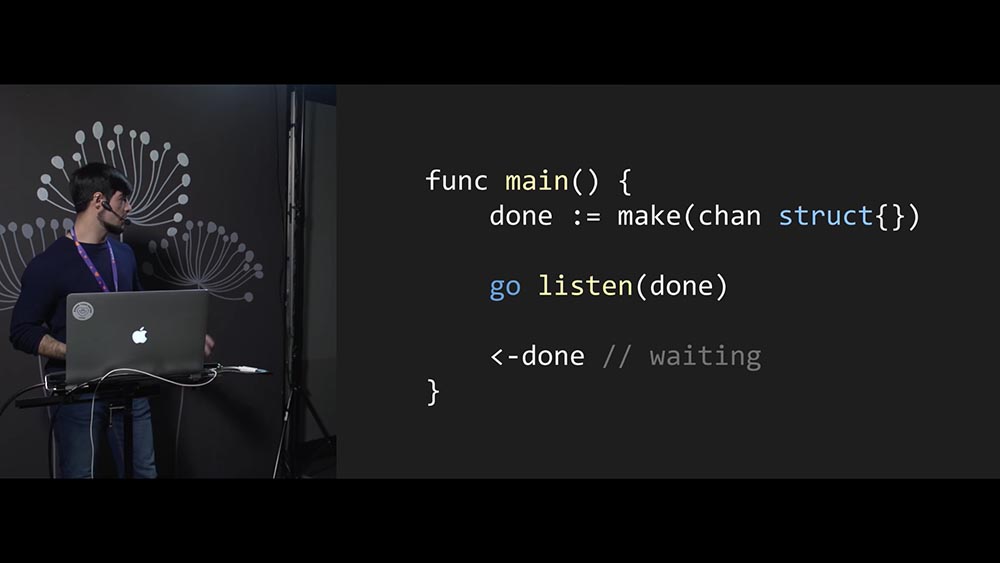
Создаём канал, точно так же передаём функцию listen первым аргументом. Но теперь мы указываем, что функция listen не будет слушать этот канал – она запишет в этот канал какую-то информацию, когда она будет завершена.
То есть мы говорим разработчику функции listen: «Слушай, друг, когда будешь завершаться – перед тем как завершиться, ты нам пошли событие какое-нибудь, а мы поймаем и обработаем». Такой «контракт» заключаем. Это нормальный способ, он будет работать.
Каким образом реализовать функцию listen, чтобы это работало хорошо? Всего-то и надо в конце выполнения функции listen вставить отправку информации в канал:

Какие тут есть проблемы? Во-первых, разработчик функции listen может вставить отправку информации в канал вообще до начала работы функции либо вообще никогда не воткнуть – в этом случае мы вообще не получим никакой валидной информации о том, когда была завершена функция listen. А нам это не нужно, поскольку мы хотим знать, в какой момент времени будет завершён наш поток.
Разработчику приходится писать какой-то лишний код (функция listen), а он вообще не хочет этого делать – хочет просто обрабатывать входящие соединения. Кроме того мы ещё и не знаем, была ли listen завершена, или нет:

Давайте бороться!
Есть пакет Sync, у которого есть механизм WaitGroup. Он создан как раз для того, чтобы дождаться завершения работы функции или отдельного потока. Его использовать несложно.
Сначала мы его создаём, а потом указываем, сколько запустим отдельных горутин. Мы явно указываем количество: в данном случае – одна горутина:
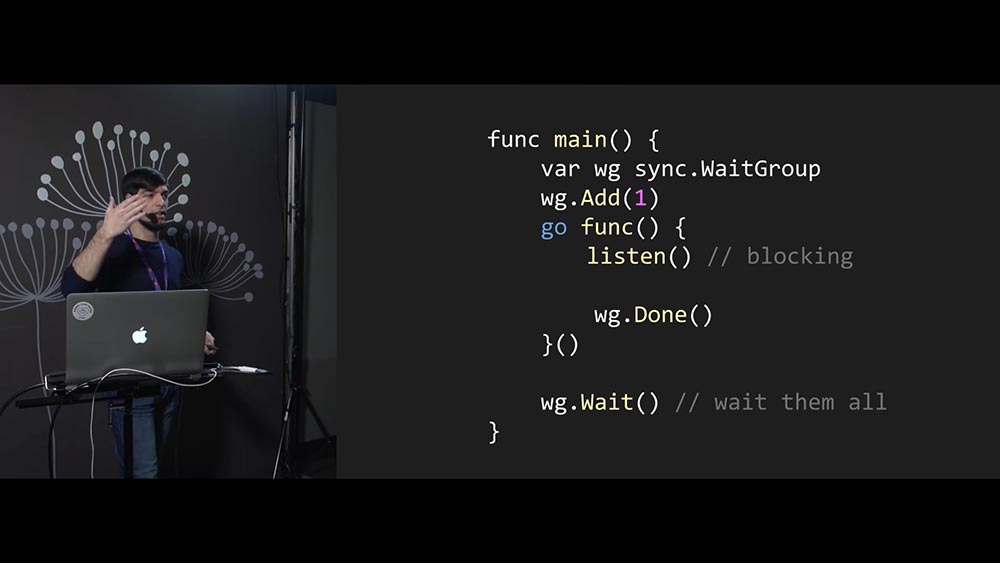
Далее (внизу на слайде) wg.Wait будет ждать, когда завершится конкретное количество горутин. В данном случае wg.Wait подождёт, когда завершится одна горутина.
Как на самом деле нужно писать эту функцию, которая исполняется внутри горутины, для того чтобы wg.Wait могло работать? Мы внутри потока запускаем listen как блокирующую функцию. Это значит, что пока listen не выполнится, этот код дальше не пойдёт (wg.Done не будет вызван). Когда же wg.Done будет вызван, WaitGroup узнает, что горутина была завершена.
Получается, что для разработчика функции listen вообще не нужно думать, как, что и куда сообщить – он просто пишет обычную блокирующую функцию, которая работает линейным кодом.
При этом мы всё равно можем контролировать весь поток исполнения нашей программы, притом очень точно – благодаря тому, что код перенесён на нашу сторону, и WaitGroup позволяет нам очень явно получить информацию, в какой момент времени была завершена данная функция. Это хороший способ контролировать выполнение ваших горутин!
Используйте context для информирования горутин о необходимости их завершения, а WaitGroup – чтобы дождаться их завершения. Вместе это (context.Context + sync.WaitGroup) даст вам силу, а выглядит примерно так:
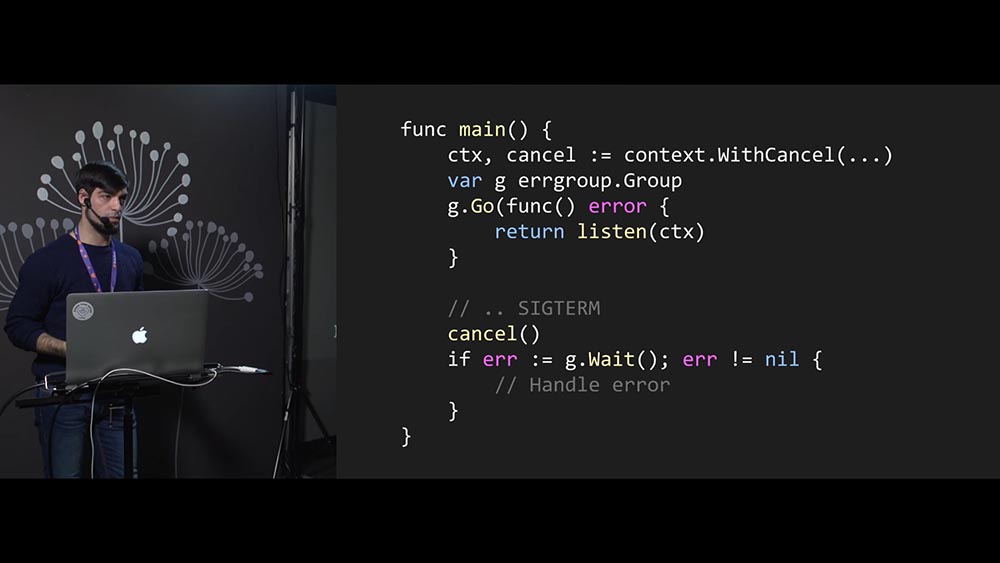
Мы используем context. Туда передаём функцию listen(ctx). При этом говорим WaitGroup, сколько функций запустим. При получении сигнала ОС мы сначала завершим context – потом будем ждать, когда всё завершится.
Однако есть способ лучше…
Есть такой пакет как errgroup, который не только позволяет очень удобно работать с потоками / горутинами, но ещё и даёт возможность удобно обрабатывать и оркестрировать ошибки. Это пакет не стандартной библиотеки, но при этом в x-репозитории экспериментальных пакетов, которые когда-нибудь могут войти в официальные пакеты Go. Он создаётся следующим образом:
Вместо WaitGroup мы создаём errgroup. В остальном работа происходит точно так же. Но errgroup в данном случае не требует от нас количества функций, которые мы запустим в отдельном потоке. Есть у него такой метод Go, и он запустит нашу функцию в отдельном потоке.
При этом сигнатура его функции говорит: «Если какая-то ошибка произойдёт, ты верни её мне, а я с ней разберусь». Получается, что разработчик функции listen может писать не только без оглядки на необходимость сообщать, он ещё и с ошибками будет легко разбираться (return error). Это очень просто, очень круто!
Дальше мы так же, как и в предыдущем случае, вызываем cancel. Но теперь – не просто Wait, мы ещё и ошибку ловим от этого Wait! В итоге, если у нас в несколько потоков запущен компонент нашей программы, то если в одном из них произошла ошибка, то мы её получим: errgroup запомнит первую произошедшую ошибку и вернёт её нам, а мы сможем её залогировать. Удобно!
Ещё одна важная функция, которую errgroup в себе несёт – это возможность управлять context, когда у нас есть программы из нескольких компонентов (например, server, consumer…) и мы хотим завершить их в тот момент времени, когда в одном из них произошла ошибка. Мы не хотим, чтобы наш консьюмер работал без сервера.
Мы хотим написать программу так, что, если у нас consumer упал, то пусть и сервер падает (будет завершён). Мы не хотим их иметь в работоспособном состоянии по отдельности. И errgroup.WithContext позволяет вернуть тот context, который будет завершён в момент, когда один из компонентов упадёт:

В данном случае я хочу рассказать о кейсе, который связан c Graceful Shutdown.
Допустим, у нас есть три основных компонента. Четвёртый компонент – обработчик сигналов ОС, запущенный в отдельном потоке. Его я назвал «ловушка сигналов» (SIG Trap).
Когда ОС даст нам сигнал, что необходимо завершиться, то всё, что мы сделаем в этом компоненте – уроним с ошибкой. И в этом случае errgroup подумает: «Оп-па! Программа накрылась медным тазом – надо завершать», и завершит все остальные компоненты:

Таким образом, минимальными усилиями мы получим мощную систему оркестрации потоков в нашей программе. Так что errgroup – это хорошо, используйте его. Хоть он и экспериментальный, но в целом он сейчас очень стабильный.
Реализовав всё это, Graceful Shutdown подготовили. Мы реализовали это у себя и надеялись на хорошие графики, у которых нет проблем. На самом деле мы увидели, что ничего не изменилось:

После того как мы добавили в наш сервис Graceful Shutdown, всю эту механику, не изменилось ничего – осталось как было. Возник вопрос: «Почему так?» Тут начинается интересная часть доклада…
Копать мы решили в сторону Kubernetes. Кто ещё будет заниматься завершением наших сервисов и кто вообще этим работает? Это количество ошибок, которое осталось прежним:
Чтобы разобраться, почему такое произошло, я расскажу, как работает Kubernetes и как на самом деле выкатываются ваши сервисы внутри «Кубернетеса».
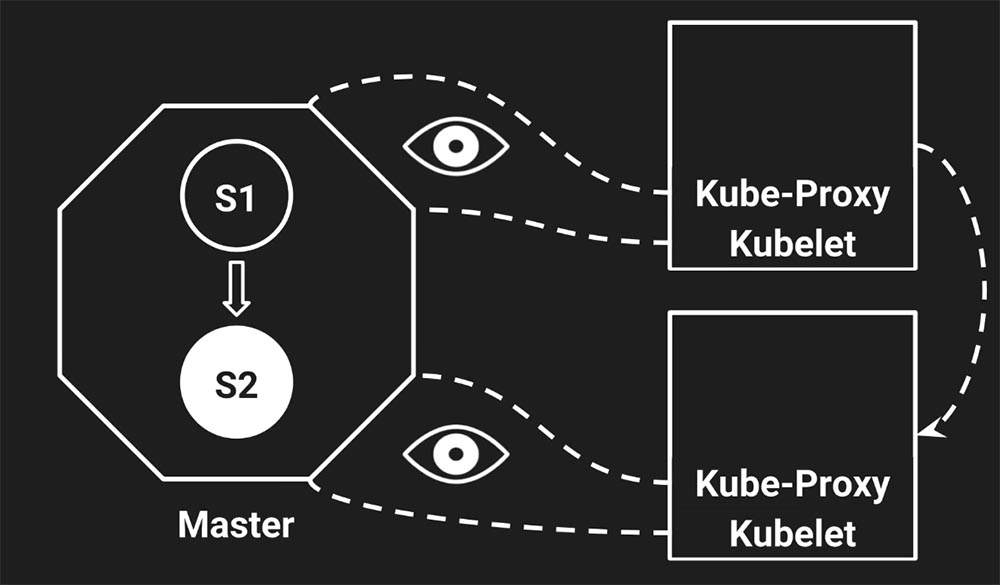
Это «Кубернетес» и кластер «Кубернетеса», в котором есть кластер, мастер-ноды (Master Node), есть две ноды, которые запускают ваш сервис:

Сейчас этот кластер находится в состоянии «1» (на слайде это состояние символизирует S1). Так работает синхронизация кластера «Кубернетес».
Есть два демона (daemons) на каждой ноде, на каждом сервере запущено два демона, которые только и делают, что получают информацию от Master (приходят, получают новую информацию и пытаются подогнать состояние своего ноды под состояние мастера). Один демон отвечает за интернет (за сеть, прокси), а второй – за инстансы (instants) сервиса – это Kubelet.
Kubelet запускает сервисы, а прокси настраивает сеть. Очень важно, что работают они независимо друг от друга. Они даже ничего не знают друг о друге – это настраивают вашу железку под то состояние, которое имеется сейчас на мастере. «Глаза» на слайде означают, что они «слушают» мастер (смех и бурные овации в зале).
А эта стрелка показывает, что Kube-Proxy знает о том, что трафик необходимо посылать в какую-то часть кластера. В какую – это не важно; стрелочка показывает, что Kube-Proxy находится в состоянии S1 и посылает трафик в определённое место:
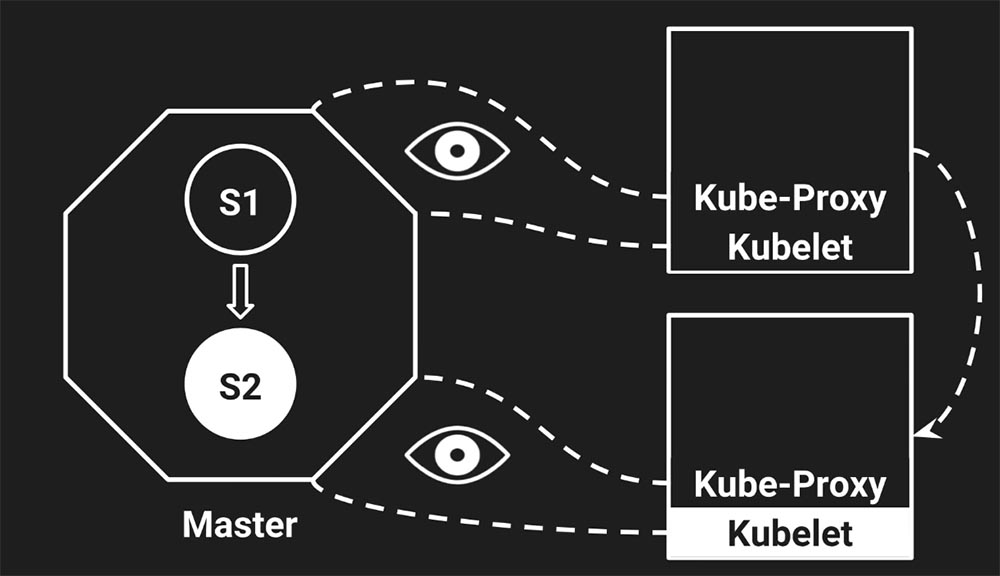
Настал момент деплоя (deploy). Мы деплоим наш сервис с версией «2» и говорим «Кубернетесу»: «Пожалуйста, вот тебе image – давай, разберись!» Он отвечает: «Окей, друг, сейчас в S2 переведём».
Кластер перешёл в новое состояние, но пока перешёл только мастер. Он получил от нас информацию о том, что необходимо обновить состояние кластера и версию нашего сервиса. А в этот момент прокси и Kubelet вообще ничего знают…
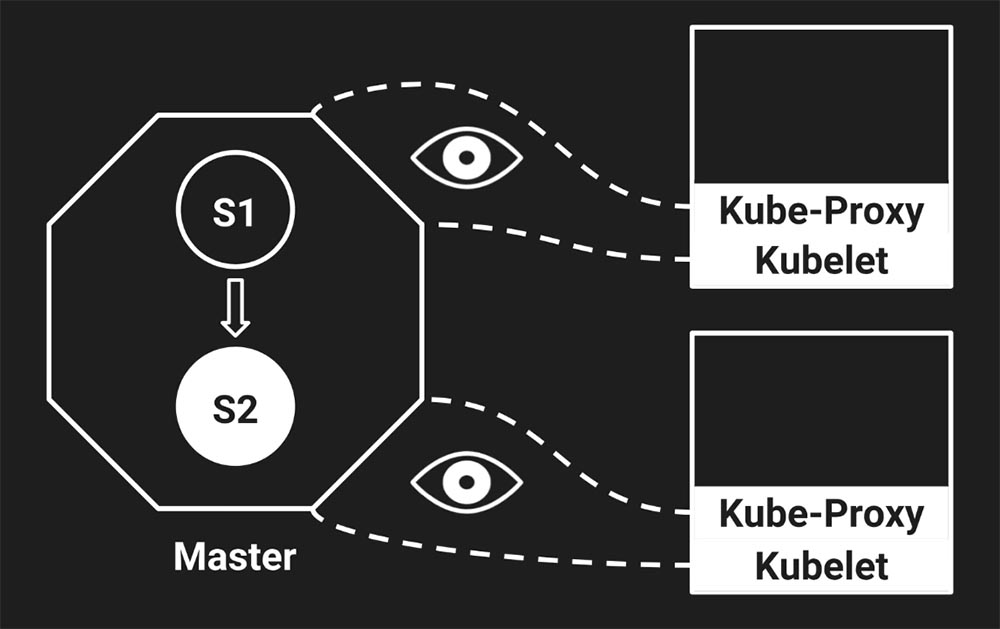
Но в какой-то момент происходит что-то невероятное: Kubelet узнаёт о том, что кластер перешёл в состояние S2. Естественна его реакция: «У меня же всё не так на самом деле. На моей ноде состояние находится ещё в S1. Давай-ка я обновлю свои сервисы»!
Обновил. Но сеть осталась прежней, потому что Kube-Proxy ещё ничего не знает об изменениях…
Далее какой-то другой компонент нашего кластера узнал об изменениях (Kubelet с другой ноды). Потом – Kube-Proxy.
Когда Kube-Proxy с верхней ноды узнал об изменениях, то перестал пускать трафик (на слайде стрелочка пропала – трафик перестал идти) – отлично. И лишь четвёртым обновился Kube-Proxy на нижней.
Здесь важно, что каждый из этих компонентов работает независимо друг от друга. Они ничего не знают друг о друге, поэтому, когда мы переводим кластер в состояние S2, то все компоненты обновляются не единовременно, а рандомно, в разном порядке. Мы не знаем о текущем состоянии кластера в один момент времени. Когда же все компоненты перешли в состояние S2, можно сказать, что переход завершён.

Заметьте, что когда мы попросили Kubernetes задеплоить наши сервисы, Kubelet первым подхватил изменения. А что делает Kubelet, когда его просят задеплоить новый сервис? Он тушит старые сервисы и только потом поднимает новый (в зависимости от настроек, конечно). При этом вы можете заметить, что стрелочка, которая отвечает за сеть, не изменилась, поскольку Kube-Proxy не знает об изменении состояния кластера.
А это значит, что произошло следующее:
С этим нужно было как-то бороться! Решили вопрос очень просто.
Почему так? Нам нужно какое-то время, чтобы кластер обновился до требуемого состояния. Давайте 5 секунд подождём – наверное, этого хватит. И на самом деле – да, этого стало хватать!
Sleep5 – это решение ваших проблем, связанных с «Кубернетесом», притом это официальное решение. Вот, пожалуйста – есть даже Issues с обсуждением этих проблем:
https://github.com/kubernetes-retired/contrib/issues/1140
И действительно, контрибьютор «Кубернететеса» предлагает: «Дождитесь пяти секунд перед тем как завершаться».
Как это реализовать в конфигурациях «Кубернетеса»? Чтобы дать указание «Кубернетесу» подождать перед завершением, можно поставить такой хук – preStop:

Что он сделает? При получении сигнала (от мастер-ноды) о необходимости завершить работу сервиса, он ответит: «5 секунд подожду и только потом отправлю сигнал операционной системы».
Когда мы внедрили этот подход (вместе с Graceful Shutdown), время ответа снизилось (слева – до, справа – после):

Всё идеально!
Спасибо!
Вопрос из аудитории (В): – Спасибо за доклад! Что с helth cheсk’ом старого сервера? Не решает ли эту же проблему просто heath check при деплое нового сервера, чтобы он отвечал «Кубернетесу», что жив, только после того, как действительно начала принимать соединение?
АР: – Новая версия кода действительно отвечает, что жива только после того, как начала принимать соединение. Допустим, у тебя новая версия кода уже поднялась, с ней уже всё хорошо – она принимает соединение. Но при этом Kube-Proxy до сих пор шлёт соединение на старую версию кода.
Получается, что есть момент времени, когда здесь новая версия поднялась:
Она helth check’у говорит: «True, всё окей у меня». Но при этом «Кубернетес» ещё не знает о том, что трафик нужно направлять на новую версию кода. Это связано с тем, что они работают независимо друг от друга. Именно поэтому helth check’и в данном случае не решают эту проблему.
В: – Давай вернёмся к неинтересной части, первой… Там есть несколько проблем. Что ты будешь делать, если у тебя есть некая функция, написанная не тобой (предположим, что она есть даже в стандартной библиотеке; форкнуть её нельзя, например), и она очень долгая – не укладывается не в 5 секунд, ни в 10. Ты при этом хочешь завершить весь сервис и понимаешь, что одна из горутин у тебя просто не завершается…
АР: – Тогда она умрёт.
В: – И второе. Ты говорил про Boilerplate, но не показал, как вы туда добавили на архитектурном уровне сервисы, которые основаны Boilerplate и умели бы Graceful Shutdown…
АР: – Слайд специально для Олега:

В: – Спасибо. А можно на GitHub выложить?
АР: – На GitHub нельзя. Это внутренний Boilerplate.
В: – То есть сделали?
АР: – Я лично сделал Pull requests c Graceful Shutdown, а потом – вот этим lifecycle-preStop хуком:

Теперь у нас реально «из коробки» работает всё так, как я рассказал.
В: – Теперь самое интересное: а как покрывать тестами те механизмы, которые по идее должны поддерживать убийство самих себя в случае, когда сервис закрывается?
АР: – Не знаю. Нужно думать и как-то покрывать. С другой стороны, у нас это тестами не покрыто – можете нас камнями закидать.
В: – Я поясню. У тебя есть две штуки, которые друг с дружкой работают. Когда одна закрывается, соответственно, должна закрыться вторая. Этот механизм, как правило, добавляют разработчики этих штук.
АР: – То есть ты не про «Кубернетес» сейчас?
В: – Я конкретно о вашем коде. Суть в чём? Тебе нужно объединить два механизма (если ты, конечно, не используешь errgroup) – и на эту часть очень нужны тесты! Потому что, если одна штука умрёт, а вторая всё-таки не помрёт из-за этого, будет очень серьёзный «косяк». Но вы не тестируете ничего…
АР: – Я обычно пишу тесты так: в начале функции – «пусть через 5 секунд будет паника». И всё. Тест покрывает кейс. У меня получается, что context не слушается, т. е. у меня функция не умеет слушать context. Это значит, что в момент, когда я попрошу её завершиться, она не завершится. Это значит, что через 5 секунд у меня паника – тест покрывает этот кейс.
В: – Сколько времени у тебя выполняется такой тест? Пять секунд?
АР: – В худшем случае, если функция не имеет обрабатывать context – 5 секунд (можно секунду поставить, можно 200 миллисекунд, если ты знаешь, что там за тест).
В: – Спасибо за весёлый доклад! Допустим, у нас есть сервис, который обслуживает клиента, и сессия у него достаточно продолжительная. Если я хочу выкатить бесшовно (поднять версию сервиса), чтобы не заметил клиент, то мне нужно, чтобы я в какой-то момент поднял два инстанса (старый сервис и новый); чтобы старый сервис обслуживал старых клиентов, пока их сессия не отвалится (по тайм-ауту или когда клиент завершит), а новые чтобы переправлялись на новый сервис (одновременное существование). Позволяет ли «Кубернетес» реализовать такую схему?
АР: – «Кубернетес» об этом вообще ничего знать не должен. У нас такой же кейс связан с сокетом… Есть сокет-соединение, которое висит, терминируется на каком-то сервисе. Что нужно сделать для правильного завершения работы? Нужно просто на клиентах поддержать механизм завершения работы! То есть в какой-то момент, когда ОС попросила нас завершиться, мы говорим клиентам: «Ребята, мы сейчас будем ложиться. Вы через 5 секунд приходите – мы вам ответим новым сервисом». Всё!
Таким образом, когда пришёл сигнал от ОС, ты отправил сигнал клиентам, и они отключились – для них это нормальное поведение (обработка ошибок, crash-only design). Дальше они переподключаются на новую версию кода.
В: – Значит, вы решаете на стороне клиента…
АР: – Да. Нужно клиент писать так, чтобы он это умел.
В: – Я хотел бы дополнить – вопрос по разрыву соединения. У Kubernetes есть rolling updates: поднимается сервис, проверяется то, что новая версия поднялась и работает, и только в этот момент на неё трафик переключается. Тогда этой ситуации просто не может быть!
АР: – На самом деле происходит как? Поднимается новая версия кода, а трафик на неё ещё не переключился. При этом старая уже умерла. Kubernetes считает, что новая версия кода уже поднялась (лайф-чеки надо делать, конечно).
В: – В том-то и дело, что она её не убивает до того момента, как новая версия не заработает полностью!
АР: – Есть такой момент, когда у тебя Kubelet поднял новую версию, и она health check’ается уже. Он на неё начинает переключать трафик. Допустим, он переключил трафик (верхний Kube-Proxy), а запросы с [нижнего] Kube-Proxy до сих пор идут на старую версию кода:
При этом Kubelet уже убил старую версию кода – в этом проблема.
В: – Но он [код] будет убит в тот момент, когда все прокси переключатся уже на новую версию…
АР: – Если бы это было так – вообще всё было бы хорошо. Но проблема в том, что Kube Proxy на разных нодах ничего не знает о состоянии кластера в целом. Они знают только о состоянии своей ноды. Чтобы это работало, необходимо поднять новую версию кода; далее на всех нодах (например, у тебя 1000 железных машин) переключить трафик; далее – указать, что трафик на всех нодах кластера переключён; и только потом начать обновлять Kube-Proxy. Тогда всё это будет работать.
А сейчас это работает не так, потому что в Kubernetes в какой-то момент происходит обновление Kubelet, и прокси не знает о том, что там что-то произошло, и даже не задумывается об этом. Он, когда ему дали команду, просто трафик переключил. Момент, когда ему дали эту команду, наступает не тогда, когда у тебя старая версия кода умерла, а новая поднята, а в тот момент, когда прокси узнал, что состояние надо обновить.
В: – Ты говоришь, что старая версия в любой момент убивается без контроля того, что происходит в кластере.
АР: – Убивается не в любой момент, а когда в новой версии прошли health check’и. А health check’ами в данном случае занимается Kubelet: у него прошли health check’и – старая версия кода умирает. Вот так.
У тебя трафик не завязан на инстансы – вот в чём проблема. Сеть никак не связана с инстансами сервисов. Получается, что у тебя всякие чеки не обеспечивают механизма синхронизации трафика. Они только обеспечивают механизм синхронизации состояний подов – всё.
В: – Насколько я помню, хак в виде sleep на 5 секунд можно решить с помощью readiness-пробы в «Кубернетесе». Вы не пробовали? Там же есть два типа health checks – типичный (liveness) и readiness. Ты можешь поставить тайм-аут, когда у тебя сервис будут гасить. Пробовали с его помощью решать?
АР: – Вот эти чеки… Я об этом и говорю!
В: – Нет, это ты про health check говоришь.
АР: – А readiness как будет узнавать, что сервис готов?
В: – Допустим, ты ему говоришь: «Сервис запустился – 20 секунд ничего с ним не делай».
АР: – А чем хуже этот (указывает на слайд) подход: перед тем как затушить, подожди 5 секунд?
В: – Тем, что он уже в «яму» «Кубернетеса» введён… Может, с ним [“20 секунд”] будет как-то получше?
АР: – Так это тоже в «яму» «Кубернетеса» – вот:

В: – Ну, это просто ваша команда какая-то, нет?
АР: – Да, можно решить тем, что в момент, когда тебе приходит запрос «а жив ли я?», сервис первые 20 секунд будет отвечать: «Нет, я не жив». Но это то же самое, ты же видишь!
Знаешь, как ещё можно решить? Green/Blue deployment поддержать в Kubernetes, т. е. у тебя никогда не будет старой версии кода.
В: – А можешь ещё рассказать, как у вас Network в «Кубернетесе» реализован? Вы что используете – kube-dns? И не следит ли он за такими ситуациями?
АР: – Призовём в тред Михаила Прокопчука, потому что он может ответить лучше, чем я. По сути у нас механизм построен на IPtables. Через Kube-Proxy у нас проксирование не идёт.
АР: – У нас через IPtables всё резолвится. Напрямую нет прокси. Есть механизм, когда Kube-Proxy можно держать как прокси запросов. Если бы мы её держали как прокси запросов, возможно, ситуация была бы другой. Но когда мы используем как IPtables, то именно такая ситуация возникает.
Михаил Прокопчук: – Обновляется IP-адрес, запись фактически ещё не меняется… Если коротко, то вся эта проблема – про то, что асинхронная работа компонентов, связанных с настройкой образов и сети, и тот временной лог, который происходит, неизлечим. Как бы мы не пытались описать кубернетсовскую спеку, приходится делать вещи вроде Sleep5.
В: – А в каком году у вас будет Blue/Green?
АР: – У нас не знаю, в «Кубернетесе»…
В: – Это понятно…
АР: – Так как мы используем «Кубернетес», то нам придётся, когда он появится там, либо самим его туда законтрибьютить.
В: – Для этого не обязательно же ничего контрибьютить – можно и на «Кубернетесе» нагородить!
АР: – Мы можем делать аналог B/G deployment, задерживая… В «Кубернетесе» нет механизма. У тебя есть деплоймент-стратегии, и там нет сейчас B/G deployment. Если мы захотим его руками накостылять, наверное, сможем это сделать, но не хотим.
В: – Ты сейчас говоришь, что вам нужна какая-то дополнительная магия. Но по сути что такое B/G? Ты полностью поднимаешь ещё одну копию сервиса, которая состоит не из одного интенса, а из сотен, а то и тысяч, притом разных. И только после этого переключаете пользовательский трафик… Тут вообще может быть два Kubernetes-кластера, и между ними – стоящий балансировщик, который в нужный момент всё переключит.
АР: – Вот-вот! Тут ещё появляется какой-то балансировщик, который где-то там стоит… Это всё история от лукавого.
В: – Вы рассматривали какой-нибудь сервис межсети для того, чтобы вместо Kube-Proxy внутри Kubelet, внутри сервиса контейнер поднимается, и он уже принимает решения? Когда он поднят, он в принципе вытянет какие-то данные, где находятся новые сервисы. Вы не рассматривали такой вариант?
АР: – Mesh-сети. У нас есть идеи, хотелки что-то такое попробовать…
В: – А вы уже экспериментировали? Они избавят от таких проблем – когда Kube-Proxy ещё не успел получить данные?
АР: – Команды инфраструктуры у нас сейчас пытаются экспериментировать. Но это очень нишевые эксперименты. У нас пока нет ответа на вопрос, будем ли мы mesh использовать и как решать эти проблемы. Могут ответить сейчас так: нет, мы такое не используем и не знаем, как это будет работать.
Но надеюсь, что будем пробовать такие подходы – новые, современные (mesh-сети и проч.). Не уверен, что это сходу зайдёт, потому что «Кубернетес» итак с трудом внедряется. С потом и кровью выстрадали – уже почти два года мы работаем над этим.
В: – Что будет в случае, если у нас сервис вылезает за лимиты. Которые мы ему выставили в «кубах», и «кубы» решают дропнуть этот контейнер. Как отработает Graceful Shutdown в таком случае?
АР: – Если по памяти, то приходит OOM killer и убивает… Ответ – никак, сервис умер.
В: – То есть эта стратегия не сработает в таком случае?
АР: – Да, эта стратегия не сработает. Если ты пытаешься сделать сервис, который умеет выживать в любых обстоятельствах, то должен закладываться на то, что придёт OOM killer, или придёт админ и просто kill -9 сделает. Это нормально. Более того, у тебя может полкластера отвалиться, и ты должен с этим жить.
Конкретно этот доклад – о том, как решить проблему деплойментов. Кажется, что деплоймент в «Кубернетесе» должен «из коробки» решать проблему бесшовной выкатки, ведь мы хотим его использовать именно для этого! Почему он не решает эту проблему? Доклад как раз о том, как нам сделать хотелку, с которой кластер находится в нормальном состоянии: 10 раз мы выкатили – 10 раз он выкатился бесшовно.
В: – Не рассматривали вариант выкатывать второй деплоймент, чтобы они существовали параллельно, сделав небольшую настройку?
АР: – Это Blue/Green deployment. У тебя выкатится второй деплоймент, старый продолжит существовать. Ты же это имеешь в виду? Нет, не рассматривали, потому что не хотим костылять.
В «Куберентесе», по –хорошему, надо поддержать стратегию B/G деплоймента. Другой вопрос, как это сделать – это нюансы. Но если бы она там была, то мы могли бы просто поменять одну настройку в конфигурации, и всё – у нас бы эта проблема исчезла, потому что у нас не умирал бы старый pod. Но так как сейчас нет такого деплоймента (только rolling updates), то живём как получается…
В: – У вас используются базы в ваших сервисах? Как у вас мигрируют схемы, если у вас реляционная? Это вопрос к тому, что у вас и старая и новая версии параллельно работают.
АР: – Очень хороший вопрос, хорошо относится к теме… Вообще, подход к миграциям базы – трёхфазный. Тебе, получается, всегда нужно поддерживать миграцию в состоянии, при котором старая версия кода тоже умеет с ней работать.
В: – Это именно так? У вас трёхфазная схема?
АР: – Ну-у-у, да… (аудитория ликует)
В: – Я только что попробовал поиграться с errgroup, и, как вижу, WaitGroup возвращает только последнюю ошибку. Каков use case по отлову других?
АР: – Как можно ловить? Если нам нужно поймать одну ошибку от компонента системы, нам errgroup идеально подходит. Если мы хотим ловить каждую ошибочку, её стоит, во-первых, логировать на месте (тогда нам, может быть, и не нужно будет её ловить). Если нам нужно поймать каждую, то можно написать код, который в глобальном scope объявит три ошибки, а потом инициализирует их внутри этих потоков, внутри горутин. В errgroup конкретно одну позволяет поймать (только первую).
В: – Он последнюю ловит. Но суть ясна – спасибо!
В: – Меня слегка смущает то, что я вижу в документации к «Куберу» – есть такая штука как terminationGracePeriodSeconds. Выглядит примерно, как ваш Sleep, а по документации не видно, в чём разница… Зачем городить Sleep, когда есть уже одна строчка с секундами?
АР: – Только эта строка делает совсем не то. Что она делает? Не говорим сейчас о хаке со Sleep – просто говорим о том, что мы реализовали Graceful Shutdown. Что происходит, допустим, если у нас висит и никогда не умирает активное соединение? В этом случае сервис никогда не завершится, потому что он ждёт, когда соединение умрёт.
Что нам нужно? Убить его форсировано (используя строку с force) – форсировано убить pod! Через 30 секунд pod просто умрёт формировано. Это решает проблему, например, с тем, что у нас клиент может никогда не закрыть висящие соединения. Не более того. Эта строка [terminationGracePeriodSeconds] совершенно не решает никаких проблем, кроме той, что pod висит в состоянии «Завершение работы бесконечно». Больше никаких проблем не решает. Этот хак о другом.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Артемий рассказал про подходы к безопасному завершению работы многопоточных программ на Go, в частности о том, как контролировать горутины и управлять ими. Объяснил, почему во время выкатки сервисов в Kubernetes пользователям может возвращаться множество ошибок. Чтобы подробнее раскрыть, почему так происходит, схематично показал, как работает Kubernetes внутри, и почему он не позволяет сделать выкатку сервисов бесшовной.
Артемий Рябинков (АР): – Не считаю себя хорошим спикером – всего во второй раз выступаю, но, надеюсь, вам понравится.
Мне интересно, кто здесь собрался? Кто считает себя гуру в Go? Тяните руку!.. Вам не будет интересно. Всем остальным должно быть интересно – новичков здесь больше, поэтому, думаю, доклад зайдёт.
Тема простая – Graceful Shutdown. Мы хотим, чтобы наши сервисы завершались аккуратно.
Меня зовут Артемий, я работаю в «Авито», в команде мессенджера. В «Авито» мы используем Kubernetes, пишем на Go и PHP. На Go сейчас более активно стали, больше народу начинает писать. Появляется Boilerplate Go-шного сервиса, который начинает включать много функционала. Функционал, которого у нас раньше не было, но он появился – это Graceful Shutdown, и о нём я хочу рассказать (и почему он не работает в «Кубернетес»).
Graceful Shutdown: что это и зачем нужно?
Во-первых, мы хотим, чтобы наше приложение завершалось всегда предсказуемо, то есть чтобы мы понимали, что произойдёт при завершении работы. Также мы не хотим терять данные, когда приложение завершается.
Данные могут быть разные… Например, когда у вас идёт какая-то транзакция в базу данных, в этот момент операционная система говорит сервису: «Умри!», и транзакция повисает. Мы хотим, чтобы транзакция завершилась, и только потом сервис закончил свою работу.
Это могут быть входящие соединения от пользователей. Соединение пришло; в момент, когда оно пришло, операционка убила процесс; пользователь не получил ответ – это плохо, мы так не хотим. Мы хотим как-то это обрабатывать.
Вообще, есть манифест, и ребята из Heroku рассказывают как раз о том, как нужно писать сервисы, чтобы они хорошо работали в облаке. И один из пунктов – https://12factor.net/disposability – рассказывает о том, что сервис должен иметь Graceful Shutdown, а по-хорошему сервис (и вообще, ваш софт) должен иметь crash-only design. В любой момент что угодно может произойти: метеорит упал, а ваш сервис всё равно знает, как себя вести.
Бесшовная выкатка
Graceful Shutdown в плане инфраструктуры даст нам бесшовные выкатки. Что такое выкатка? Мы убиваем одну версию кода, поднимаем другую версию. И если наш сервис не умеет Graceful Shutdown, то в момент смерти старой версии кода запросы пользователей будут оборваны. Этого мы не хотим.
В целом как будет выглядеть бесшовная выкатка для нас? Следующим образом:
- новую версию выкатили (при этом старая работает);
- переключили трафик на новую версию;
- и только затем потушили старую версию кода.
Таким образом, пользователи будут счастливы. А это – когда пользователи не счастливы:
Почему? Потому что на графиках наблюдается аномалии. Именно эти графики оказались предпосылкой к данному докладу: у нас было несколько сервисов, которые общаются между собой, и в моменты выкаток на наших графиках мы видели именно эту картину. Здесь нет осей (не надо придираться к этому), но видно, что в момент выкатки увеличивается количество ошибок и возрастает время ответа сервиса. Если один сервис входит в другой сервис в момент в выкатки второго сервиса, то первый получает…
Graceful Shutdown на тот момент не был у нас реализован. Идея была такая: раз запросы рвутся, сервис получает ошибки – в результате мы видим такие аномалии на графиках. Давайте это решать! Мы хотим вот так:
Чтобы время ответа от сервиса как шло постоянно, так и осталось бы идентичным в момент выкатки.
Как программе узнать о необходимости завершиться?
Нужно проделать несколько шагов, чтобы сервис научился завершаться. Во-первых, мы должны научить ОС каким-то образом сообщать сервису о том, что ему необходимо быть завершённым. Сервис при этом должен уметь «слушать» эти сигналы ОС и обрабатывать их.
Такой механизм есть в Linux – это сигналы, с помощью которых мы можем сообщить процессу о необходимости совершить действие. Следующие сигналы отвечают за завершение работы:
Это те сигналы, которые нужно обрабатывать. Их операционная система будет присылать сервису в момент завершения работы. В частности, при выкатке сервиса в Kubernetes ему [сервису] придёт SIGTERM.
Какой план?
- Слушаем сигнал ОС.
- Просим потоки завершиться. У нас, скорее всего, поточное приложение, поэтому для его завершения необходимо завершить все потоки приложения.
- Когда дождались завершения этих потоков, мы просто завершаем процесс. Всё просто.
Схематически это выглядит так: стартовал процесс, стартовал его основной поток, потом – дочерние потоки, эти дочерние потоки могут породить своих «детей». Получается древовидная структура потоков внутри программы:
Когда приходит сигнал, основной поток должен сообщить всем своим потокам о необходимости совершить действие (например, завершиться). Другие потоки, которые находятся ниже по дереву, должны уже своим «детям» сообщить.
Самое главное, мы должны дождаться завершения всех дочерних потоков перед тем, как завершить основной поток. Таким образом, дожидаемся завершения дочерних и только после этого глушим основной поток. Это схема того, как должен происходить Graceful Shutdown.
Ловим сигнал ОС
Теперь перейдём Go. Буду показывать и рассказывать, как всё это работает в Go и как это реализовать. Для ветеранов это понятно, для новичков разберём более подробно:
Сигнал нужно поймать. Для этого мы должны зарегистрировать обработчик сигнала. Если ОС знает, что обработчика сигнала у процесса нет, она его просто сразу убьёт (без какой-либо информации). А если мы зарегистрировали обработчик сигнала, то ОС передаст управление процессу, и процесс может проделать свою работу.
В данном случае мы регистрируем обработчик – в Go используется механизм каналов для получения событий, данных, и здесь мы говорим обработчику: «Положи информацию о том, что совершился сигнал в этот канал». Когда же в этом канале появилось новое сообщение, мы знаем, что сигнал появился, и эта строка кода отвечает за то, чтобы поймать сигнал от ОС.
Завершаем Goroutine
Поток в Go – это горутина. На самом деле горутина – это не поток… Легковесный какой-то поток; и он на самом деле он может быть в одном потоке ОС, много горутин…
Но мы сейчас думаем так: одна горутина – один так, они все могут располагаться параллельно (нам неважно). В терминах Go, когда мы говорим о потоках, мы будем говорить о горутинах.
Нужно завершить дочерний поток. Как это сделать? Для начала нужно породить новый поток, просто поставив оператор go перед функцией:
Оператор go запустит нашу функцию в отдельном потоке. Как нам сообщить функции listen, которая может обрабатывать входящие соединения, что её нужно завершиться? Будем использовать механизм каналов: создаём канал, передаём в канал функцию listen и в некотором смысле «заключаем договор»: «Если в этом канале появится какая-то информация, то, функция listen, пожалуйста, завершись»!
Теперь самое важное, что разработчик функции listen должен поддержать этот функционал. Он должен понимать, что мы пришлём какую-то информацию. Когда информация появится в канале, функции нужно завершить свою работу.
Далее, когда приходит сигнал ОС, мы просто закрываем канал. Закрытие канала – это тоже информация, событие. Благодаря этому событию разработчик функции Listen сможет получить идентификацию о необходимости завершить работу. Если функция listen обрабатывает соединение пользователя, то когда появляется информация в канале – она должна обработать активное соединение и лишь потом завершить свою работу.
Но с Go 1.7 появилась такая абстракция, как context (ctx). То, что я рассказывал о канале – это абсолютно правильный, хороший способ отсылать какие-то нотификации, но для реализации конкретного use case (сообщать о необходимости завершить работу) в Go 1.7 была введена абстракция context.
Сейчас стоит использовать именно её, потому что это как минимум сделает код более читаемым. Разработчик, который будет писать функцию listen, знает, что вы ему context передадите, и благодаря этому context будет обрабатываться весь этот весь этот Boilerplate, связанный с завершением работы.
Чтобы использовать context, мы его создаём. При этом мы создаем его таким образом, чтобы у нас была возможность его закрыть: функция cancel, которая вернулась нам – это возможность закрыть context:
Далее мы просто передаём context в listen и закрываем его, когда надо. Таким образом, listen получил идентификацию о необходимости завершиться.
А как написать listen? Что должен сделать разработчик функции listen, чтобы она правильно работала? Пример такой:
- в бесконечном цикле принимаем входящие соединения;
- при этом перед тем, как принять новое входящее соединение, мы проверяем, был ли завершён context;
- если context завершён (это по сути работа с каналом внутри), то мы завершаем работу функции; если нет – принимаем новое соединение и обрабатываем его.
Используем context.Context для завершения
Для того чтобы завершать работу потока (функции, которая выполняется в отдельном потоке) в Go, нам нужно использовать context.Context. Это хорошая практика, это правильно – используйте context.
После того как мы сообщили потоку, что ему необходимо завершиться, нужно теперь каким-то образом дождаться завершения потока: когда мы просто сообщили ему, то вообще не знаем, что произойдёт – может, никогда не завершится, поэтому нужно дождаться, когда он действительно будет завершён и таким образом усилит наш контроль над работой программы.
Мы уже познакомились с механизмом наших каналов – его и будем использовать:
Создаём канал, точно так же передаём функцию listen первым аргументом. Но теперь мы указываем, что функция listen не будет слушать этот канал – она запишет в этот канал какую-то информацию, когда она будет завершена.
То есть мы говорим разработчику функции listen: «Слушай, друг, когда будешь завершаться – перед тем как завершиться, ты нам пошли событие какое-нибудь, а мы поймаем и обработаем». Такой «контракт» заключаем. Это нормальный способ, он будет работать.
Каким образом реализовать функцию listen, чтобы это работало хорошо? Всего-то и надо в конце выполнения функции listen вставить отправку информации в канал:
Проблемы канала
Какие тут есть проблемы? Во-первых, разработчик функции listen может вставить отправку информации в канал вообще до начала работы функции либо вообще никогда не воткнуть – в этом случае мы вообще не получим никакой валидной информации о том, когда была завершена функция listen. А нам это не нужно, поскольку мы хотим знать, в какой момент времени будет завершён наш поток.
Разработчику приходится писать какой-то лишний код (функция listen), а он вообще не хочет этого делать – хочет просто обрабатывать входящие соединения. Кроме того мы ещё и не знаем, была ли listen завершена, или нет:
Давайте бороться!
Используем sync.WaitGroup для ожидания
Есть пакет Sync, у которого есть механизм WaitGroup. Он создан как раз для того, чтобы дождаться завершения работы функции или отдельного потока. Его использовать несложно.
Сначала мы его создаём, а потом указываем, сколько запустим отдельных горутин. Мы явно указываем количество: в данном случае – одна горутина:
Далее (внизу на слайде) wg.Wait будет ждать, когда завершится конкретное количество горутин. В данном случае wg.Wait подождёт, когда завершится одна горутина.
Как на самом деле нужно писать эту функцию, которая исполняется внутри горутины, для того чтобы wg.Wait могло работать? Мы внутри потока запускаем listen как блокирующую функцию. Это значит, что пока listen не выполнится, этот код дальше не пойдёт (wg.Done не будет вызван). Когда же wg.Done будет вызван, WaitGroup узнает, что горутина была завершена.
Получается, что для разработчика функции listen вообще не нужно думать, как, что и куда сообщить – он просто пишет обычную блокирующую функцию, которая работает линейным кодом.
При этом мы всё равно можем контролировать весь поток исполнения нашей программы, притом очень точно – благодаря тому, что код перенесён на нашу сторону, и WaitGroup позволяет нам очень явно получить информацию, в какой момент времени была завершена данная функция. Это хороший способ контролировать выполнение ваших горутин!
Используйте context для информирования горутин о необходимости их завершения, а WaitGroup – чтобы дождаться их завершения. Вместе это (context.Context + sync.WaitGroup) даст вам силу, а выглядит примерно так:
Мы используем context. Туда передаём функцию listen(ctx). При этом говорим WaitGroup, сколько функций запустим. При получении сигнала ОС мы сначала завершим context – потом будем ждать, когда всё завершится.
Однако есть способ лучше…
Как использовать errgroup и почему этот пакет хорош?
Есть такой пакет как errgroup, который не только позволяет очень удобно работать с потоками / горутинами, но ещё и даёт возможность удобно обрабатывать и оркестрировать ошибки. Это пакет не стандартной библиотеки, но при этом в x-репозитории экспериментальных пакетов, которые когда-нибудь могут войти в официальные пакеты Go. Он создаётся следующим образом:
Вместо WaitGroup мы создаём errgroup. В остальном работа происходит точно так же. Но errgroup в данном случае не требует от нас количества функций, которые мы запустим в отдельном потоке. Есть у него такой метод Go, и он запустит нашу функцию в отдельном потоке.
При этом сигнатура его функции говорит: «Если какая-то ошибка произойдёт, ты верни её мне, а я с ней разберусь». Получается, что разработчик функции listen может писать не только без оглядки на необходимость сообщать, он ещё и с ошибками будет легко разбираться (return error). Это очень просто, очень круто!
Дальше мы так же, как и в предыдущем случае, вызываем cancel. Но теперь – не просто Wait, мы ещё и ошибку ловим от этого Wait! В итоге, если у нас в несколько потоков запущен компонент нашей программы, то если в одном из них произошла ошибка, то мы её получим: errgroup запомнит первую произошедшую ошибку и вернёт её нам, а мы сможем её залогировать. Удобно!
Errgroup.WithContext
Ещё одна важная функция, которую errgroup в себе несёт – это возможность управлять context, когда у нас есть программы из нескольких компонентов (например, server, consumer…) и мы хотим завершить их в тот момент времени, когда в одном из них произошла ошибка. Мы не хотим, чтобы наш консьюмер работал без сервера.
Мы хотим написать программу так, что, если у нас consumer упал, то пусть и сервер падает (будет завершён). Мы не хотим их иметь в работоспособном состоянии по отдельности. И errgroup.WithContext позволяет вернуть тот context, который будет завершён в момент, когда один из компонентов упадёт:
В данном случае я хочу рассказать о кейсе, который связан c Graceful Shutdown.
Допустим, у нас есть три основных компонента. Четвёртый компонент – обработчик сигналов ОС, запущенный в отдельном потоке. Его я назвал «ловушка сигналов» (SIG Trap).
Когда ОС даст нам сигнал, что необходимо завершиться, то всё, что мы сделаем в этом компоненте – уроним с ошибкой. И в этом случае errgroup подумает: «Оп-па! Программа накрылась медным тазом – надо завершать», и завершит все остальные компоненты:
Таким образом, минимальными усилиями мы получим мощную систему оркестрации потоков в нашей программе. Так что errgroup – это хорошо, используйте его. Хоть он и экспериментальный, но в целом он сейчас очень стабильный.
Реализовав всё это, Graceful Shutdown подготовили. Мы реализовали это у себя и надеялись на хорошие графики, у которых нет проблем. На самом деле мы увидели, что ничего не изменилось:
После того как мы добавили в наш сервис Graceful Shutdown, всю эту механику, не изменилось ничего – осталось как было. Возник вопрос: «Почему так?» Тут начинается интересная часть доклада…
Как на самом деле происходит выкатка в Kubernetes
Копать мы решили в сторону Kubernetes. Кто ещё будет заниматься завершением наших сервисов и кто вообще этим работает? Это количество ошибок, которое осталось прежним:
Чтобы разобраться, почему такое произошло, я расскажу, как работает Kubernetes и как на самом деле выкатываются ваши сервисы внутри «Кубернетеса».
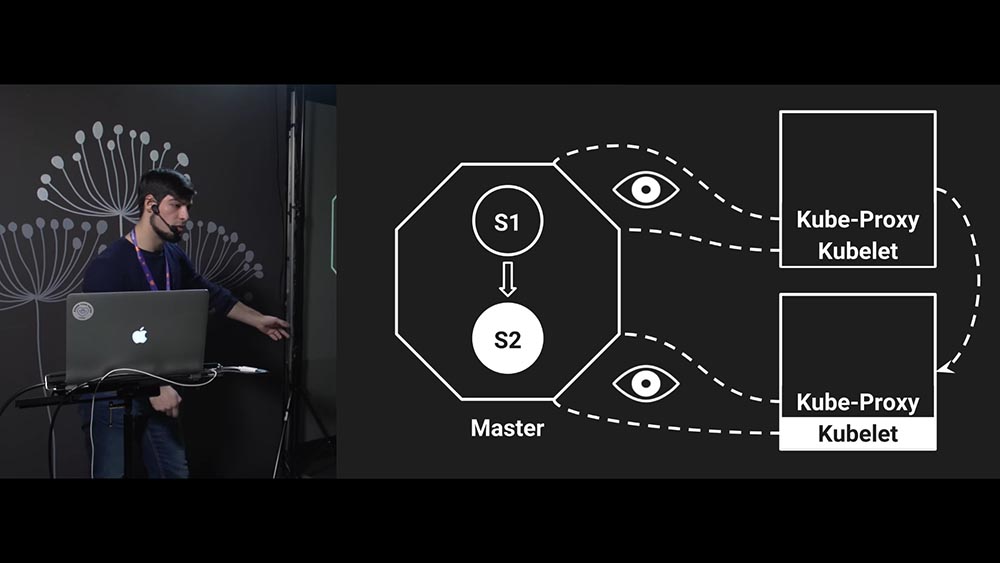
Это «Кубернетес» и кластер «Кубернетеса», в котором есть кластер, мастер-ноды (Master Node), есть две ноды, которые запускают ваш сервис:
Сейчас этот кластер находится в состоянии «1» (на слайде это состояние символизирует S1). Так работает синхронизация кластера «Кубернетес».
Есть два демона (daemons) на каждой ноде, на каждом сервере запущено два демона, которые только и делают, что получают информацию от Master (приходят, получают новую информацию и пытаются подогнать состояние своего ноды под состояние мастера). Один демон отвечает за интернет (за сеть, прокси), а второй – за инстансы (instants) сервиса – это Kubelet.
Kubelet запускает сервисы, а прокси настраивает сеть. Очень важно, что работают они независимо друг от друга. Они даже ничего не знают друг о друге – это настраивают вашу железку под то состояние, которое имеется сейчас на мастере. «Глаза» на слайде означают, что они «слушают» мастер (смех и бурные овации в зале).
А эта стрелка показывает, что Kube-Proxy знает о том, что трафик необходимо посылать в какую-то часть кластера. В какую – это не важно; стрелочка показывает, что Kube-Proxy находится в состоянии S1 и посылает трафик в определённое место:
Настал момент деплоя (deploy). Мы деплоим наш сервис с версией «2» и говорим «Кубернетесу»: «Пожалуйста, вот тебе image – давай, разберись!» Он отвечает: «Окей, друг, сейчас в S2 переведём».
Кластер перешёл в новое состояние, но пока перешёл только мастер. Он получил от нас информацию о том, что необходимо обновить состояние кластера и версию нашего сервиса. А в этот момент прокси и Kubelet вообще ничего знают…
Но в какой-то момент происходит что-то невероятное: Kubelet узнаёт о том, что кластер перешёл в состояние S2. Естественна его реакция: «У меня же всё не так на самом деле. На моей ноде состояние находится ещё в S1. Давай-ка я обновлю свои сервисы»!
Обновил. Но сеть осталась прежней, потому что Kube-Proxy ещё ничего не знает об изменениях…
Далее какой-то другой компонент нашего кластера узнал об изменениях (Kubelet с другой ноды). Потом – Kube-Proxy.
Когда Kube-Proxy с верхней ноды узнал об изменениях, то перестал пускать трафик (на слайде стрелочка пропала – трафик перестал идти) – отлично. И лишь четвёртым обновился Kube-Proxy на нижней.
Здесь важно, что каждый из этих компонентов работает независимо друг от друга. Они ничего не знают друг о друге, поэтому, когда мы переводим кластер в состояние S2, то все компоненты обновляются не единовременно, а рандомно, в разном порядке. Мы не знаем о текущем состоянии кластера в один момент времени. Когда же все компоненты перешли в состояние S2, можно сказать, что переход завершён.
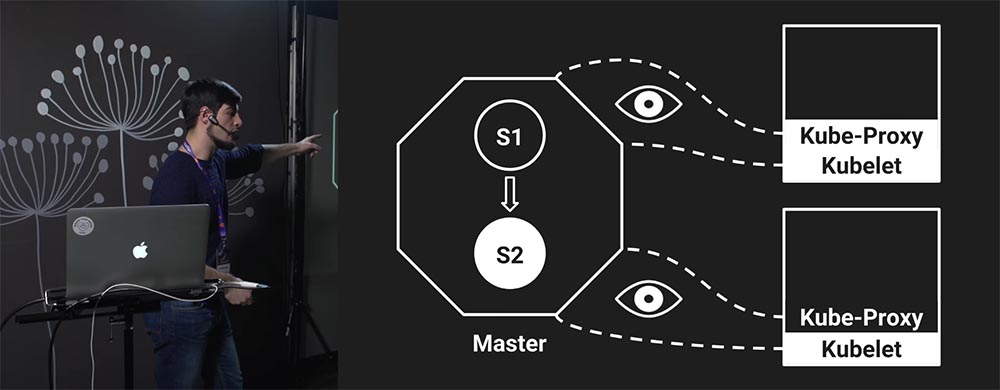
Заметьте, что когда мы попросили Kubernetes задеплоить наши сервисы, Kubelet первым подхватил изменения. А что делает Kubelet, когда его просят задеплоить новый сервис? Он тушит старые сервисы и только потом поднимает новый (в зависимости от настроек, конечно). При этом вы можете заметить, что стрелочка, которая отвечает за сеть, не изменилась, поскольку Kube-Proxy не знает об изменении состояния кластера.
А это значит, что произошло следующее:
- Kubelet увидел изменение состояния;
- потушил старую версию кода;
- при этом запросы на старую версию сервиса продолжают приходить – есть такой лаг, при котором запросы идут на старую версию кода, хотя этой версии уже не существует, потому что Kubelet её потушил (так и работает Kubernetes);
- всё стабилизируется в тот момент, когда Kube-Proxy узнал об изменениях (в этот момент можно считать, что сеть дошла до правильного состояния);
- но пока этого не произошло (пока всё не обновилось ещё до конца), мы получаем ошибки, потому что запросы были отправлены на сервис, которого уже не существует.
С этим нужно было как-то бороться! Решили вопрос очень просто.
Sleep5
Почему так? Нам нужно какое-то время, чтобы кластер обновился до требуемого состояния. Давайте 5 секунд подождём – наверное, этого хватит. И на самом деле – да, этого стало хватать!
Sleep5 – это решение ваших проблем, связанных с «Кубернетесом», притом это официальное решение. Вот, пожалуйста – есть даже Issues с обсуждением этих проблем:
https://github.com/kubernetes-retired/contrib/issues/1140
И действительно, контрибьютор «Кубернететеса» предлагает: «Дождитесь пяти секунд перед тем как завершаться».
Как это реализовать в конфигурациях «Кубернетеса»? Чтобы дать указание «Кубернетесу» подождать перед завершением, можно поставить такой хук – preStop:
Что он сделает? При получении сигнала (от мастер-ноды) о необходимости завершить работу сервиса, он ответит: «5 секунд подожду и только потом отправлю сигнал операционной системы».
Когда мы внедрили этот подход (вместе с Graceful Shutdown), время ответа снизилось (слева – до, справа – после):
Всё идеально!
Спасибо!
Вопросы
Вопрос из аудитории (В): – Спасибо за доклад! Что с helth cheсk’ом старого сервера? Не решает ли эту же проблему просто heath check при деплое нового сервера, чтобы он отвечал «Кубернетесу», что жив, только после того, как действительно начала принимать соединение?
АР: – Новая версия кода действительно отвечает, что жива только после того, как начала принимать соединение. Допустим, у тебя новая версия кода уже поднялась, с ней уже всё хорошо – она принимает соединение. Но при этом Kube-Proxy до сих пор шлёт соединение на старую версию кода.
Получается, что есть момент времени, когда здесь новая версия поднялась:
Она helth check’у говорит: «True, всё окей у меня». Но при этом «Кубернетес» ещё не знает о том, что трафик нужно направлять на новую версию кода. Это связано с тем, что они работают независимо друг от друга. Именно поэтому helth check’и в данном случае не решают эту проблему.
В: – Давай вернёмся к неинтересной части, первой… Там есть несколько проблем. Что ты будешь делать, если у тебя есть некая функция, написанная не тобой (предположим, что она есть даже в стандартной библиотеке; форкнуть её нельзя, например), и она очень долгая – не укладывается не в 5 секунд, ни в 10. Ты при этом хочешь завершить весь сервис и понимаешь, что одна из горутин у тебя просто не завершается…
АР: – Тогда она умрёт.
В: – И второе. Ты говорил про Boilerplate, но не показал, как вы туда добавили на архитектурном уровне сервисы, которые основаны Boilerplate и умели бы Graceful Shutdown…
АР: – Слайд специально для Олега:
В: – Спасибо. А можно на GitHub выложить?
АР: – На GitHub нельзя. Это внутренний Boilerplate.
В: – То есть сделали?
АР: – Я лично сделал Pull requests c Graceful Shutdown, а потом – вот этим lifecycle-preStop хуком:
Теперь у нас реально «из коробки» работает всё так, как я рассказал.
О покрытии тестами
В: – Теперь самое интересное: а как покрывать тестами те механизмы, которые по идее должны поддерживать убийство самих себя в случае, когда сервис закрывается?
АР: – Не знаю. Нужно думать и как-то покрывать. С другой стороны, у нас это тестами не покрыто – можете нас камнями закидать.
В: – Я поясню. У тебя есть две штуки, которые друг с дружкой работают. Когда одна закрывается, соответственно, должна закрыться вторая. Этот механизм, как правило, добавляют разработчики этих штук.
АР: – То есть ты не про «Кубернетес» сейчас?
В: – Я конкретно о вашем коде. Суть в чём? Тебе нужно объединить два механизма (если ты, конечно, не используешь errgroup) – и на эту часть очень нужны тесты! Потому что, если одна штука умрёт, а вторая всё-таки не помрёт из-за этого, будет очень серьёзный «косяк». Но вы не тестируете ничего…
АР: – Я обычно пишу тесты так: в начале функции – «пусть через 5 секунд будет паника». И всё. Тест покрывает кейс. У меня получается, что context не слушается, т. е. у меня функция не умеет слушать context. Это значит, что в момент, когда я попрошу её завершиться, она не завершится. Это значит, что через 5 секунд у меня паника – тест покрывает этот кейс.
В: – Сколько времени у тебя выполняется такой тест? Пять секунд?
АР: – В худшем случае, если функция не имеет обрабатывать context – 5 секунд (можно секунду поставить, можно 200 миллисекунд, если ты знаешь, что там за тест).
Ещё раз о бесшовной выкатке сервисов
В: – Спасибо за весёлый доклад! Допустим, у нас есть сервис, который обслуживает клиента, и сессия у него достаточно продолжительная. Если я хочу выкатить бесшовно (поднять версию сервиса), чтобы не заметил клиент, то мне нужно, чтобы я в какой-то момент поднял два инстанса (старый сервис и новый); чтобы старый сервис обслуживал старых клиентов, пока их сессия не отвалится (по тайм-ауту или когда клиент завершит), а новые чтобы переправлялись на новый сервис (одновременное существование). Позволяет ли «Кубернетес» реализовать такую схему?
АР: – «Кубернетес» об этом вообще ничего знать не должен. У нас такой же кейс связан с сокетом… Есть сокет-соединение, которое висит, терминируется на каком-то сервисе. Что нужно сделать для правильного завершения работы? Нужно просто на клиентах поддержать механизм завершения работы! То есть в какой-то момент, когда ОС попросила нас завершиться, мы говорим клиентам: «Ребята, мы сейчас будем ложиться. Вы через 5 секунд приходите – мы вам ответим новым сервисом». Всё!
Таким образом, когда пришёл сигнал от ОС, ты отправил сигнал клиентам, и они отключились – для них это нормальное поведение (обработка ошибок, crash-only design). Дальше они переподключаются на новую версию кода.
В: – Значит, вы решаете на стороне клиента…
АР: – Да. Нужно клиент писать так, чтобы он это умел.
В: – Я хотел бы дополнить – вопрос по разрыву соединения. У Kubernetes есть rolling updates: поднимается сервис, проверяется то, что новая версия поднялась и работает, и только в этот момент на неё трафик переключается. Тогда этой ситуации просто не может быть!
АР: – На самом деле происходит как? Поднимается новая версия кода, а трафик на неё ещё не переключился. При этом старая уже умерла. Kubernetes считает, что новая версия кода уже поднялась (лайф-чеки надо делать, конечно).
В: – В том-то и дело, что она её не убивает до того момента, как новая версия не заработает полностью!
АР: – Есть такой момент, когда у тебя Kubelet поднял новую версию, и она health check’ается уже. Он на неё начинает переключать трафик. Допустим, он переключил трафик (верхний Kube-Proxy), а запросы с [нижнего] Kube-Proxy до сих пор идут на старую версию кода:
При этом Kubelet уже убил старую версию кода – в этом проблема.
В: – Но он [код] будет убит в тот момент, когда все прокси переключатся уже на новую версию…
АР: – Если бы это было так – вообще всё было бы хорошо. Но проблема в том, что Kube Proxy на разных нодах ничего не знает о состоянии кластера в целом. Они знают только о состоянии своей ноды. Чтобы это работало, необходимо поднять новую версию кода; далее на всех нодах (например, у тебя 1000 железных машин) переключить трафик; далее – указать, что трафик на всех нодах кластера переключён; и только потом начать обновлять Kube-Proxy. Тогда всё это будет работать.
А сейчас это работает не так, потому что в Kubernetes в какой-то момент происходит обновление Kubelet, и прокси не знает о том, что там что-то произошло, и даже не задумывается об этом. Он, когда ему дали команду, просто трафик переключил. Момент, когда ему дали эту команду, наступает не тогда, когда у тебя старая версия кода умерла, а новая поднята, а в тот момент, когда прокси узнал, что состояние надо обновить.
В: – Ты говоришь, что старая версия в любой момент убивается без контроля того, что происходит в кластере.
АР: – Убивается не в любой момент, а когда в новой версии прошли health check’и. А health check’ами в данном случае занимается Kubelet: у него прошли health check’и – старая версия кода умирает. Вот так.
У тебя трафик не завязан на инстансы – вот в чём проблема. Сеть никак не связана с инстансами сервисов. Получается, что у тебя всякие чеки не обеспечивают механизма синхронизации трафика. Они только обеспечивают механизм синхронизации состояний подов – всё.
В: – Насколько я помню, хак в виде sleep на 5 секунд можно решить с помощью readiness-пробы в «Кубернетесе». Вы не пробовали? Там же есть два типа health checks – типичный (liveness) и readiness. Ты можешь поставить тайм-аут, когда у тебя сервис будут гасить. Пробовали с его помощью решать?
АР: – Вот эти чеки… Я об этом и говорю!
В: – Нет, это ты про health check говоришь.
АР: – А readiness как будет узнавать, что сервис готов?
В: – Допустим, ты ему говоришь: «Сервис запустился – 20 секунд ничего с ним не делай».
АР: – А чем хуже этот (указывает на слайд) подход: перед тем как затушить, подожди 5 секунд?
В: – Тем, что он уже в «яму» «Кубернетеса» введён… Может, с ним [“20 секунд”] будет как-то получше?
АР: – Так это тоже в «яму» «Кубернетеса» – вот:
В: – Ну, это просто ваша команда какая-то, нет?
АР: – Да, можно решить тем, что в момент, когда тебе приходит запрос «а жив ли я?», сервис первые 20 секунд будет отвечать: «Нет, я не жив». Но это то же самое, ты же видишь!
Знаешь, как ещё можно решить? Green/Blue deployment поддержать в Kubernetes, т. е. у тебя никогда не будет старой версии кода.
В: – А можешь ещё рассказать, как у вас Network в «Кубернетесе» реализован? Вы что используете – kube-dns? И не следит ли он за такими ситуациями?
АР: – Призовём в тред Михаила Прокопчука, потому что он может ответить лучше, чем я. По сути у нас механизм построен на IPtables. Через Kube-Proxy у нас проксирование не идёт.
АР: – У нас через IPtables всё резолвится. Напрямую нет прокси. Есть механизм, когда Kube-Proxy можно держать как прокси запросов. Если бы мы её держали как прокси запросов, возможно, ситуация была бы другой. Но когда мы используем как IPtables, то именно такая ситуация возникает.
Михаил Прокопчук: – Обновляется IP-адрес, запись фактически ещё не меняется… Если коротко, то вся эта проблема – про то, что асинхронная работа компонентов, связанных с настройкой образов и сети, и тот временной лог, который происходит, неизлечим. Как бы мы не пытались описать кубернетсовскую спеку, приходится делать вещи вроде Sleep5.
В: – А в каком году у вас будет Blue/Green?
АР: – У нас не знаю, в «Кубернетесе»…
В: – Это понятно…
АР: – Так как мы используем «Кубернетес», то нам придётся, когда он появится там, либо самим его туда законтрибьютить.
В: – Для этого не обязательно же ничего контрибьютить – можно и на «Кубернетесе» нагородить!
АР: – Мы можем делать аналог B/G deployment, задерживая… В «Кубернетесе» нет механизма. У тебя есть деплоймент-стратегии, и там нет сейчас B/G deployment. Если мы захотим его руками накостылять, наверное, сможем это сделать, но не хотим.
В: – Ты сейчас говоришь, что вам нужна какая-то дополнительная магия. Но по сути что такое B/G? Ты полностью поднимаешь ещё одну копию сервиса, которая состоит не из одного интенса, а из сотен, а то и тысяч, притом разных. И только после этого переключаете пользовательский трафик… Тут вообще может быть два Kubernetes-кластера, и между ними – стоящий балансировщик, который в нужный момент всё переключит.
АР: – Вот-вот! Тут ещё появляется какой-то балансировщик, который где-то там стоит… Это всё история от лукавого.
Mesh-сети. Эксперименты
В: – Вы рассматривали какой-нибудь сервис межсети для того, чтобы вместо Kube-Proxy внутри Kubelet, внутри сервиса контейнер поднимается, и он уже принимает решения? Когда он поднят, он в принципе вытянет какие-то данные, где находятся новые сервисы. Вы не рассматривали такой вариант?
АР: – Mesh-сети. У нас есть идеи, хотелки что-то такое попробовать…
В: – А вы уже экспериментировали? Они избавят от таких проблем – когда Kube-Proxy ещё не успел получить данные?
АР: – Команды инфраструктуры у нас сейчас пытаются экспериментировать. Но это очень нишевые эксперименты. У нас пока нет ответа на вопрос, будем ли мы mesh использовать и как решать эти проблемы. Могут ответить сейчас так: нет, мы такое не используем и не знаем, как это будет работать.
Но надеюсь, что будем пробовать такие подходы – новые, современные (mesh-сети и проч.). Не уверен, что это сходу зайдёт, потому что «Кубернетес» итак с трудом внедряется. С потом и кровью выстрадали – уже почти два года мы работаем над этим.
В: – Что будет в случае, если у нас сервис вылезает за лимиты. Которые мы ему выставили в «кубах», и «кубы» решают дропнуть этот контейнер. Как отработает Graceful Shutdown в таком случае?
АР: – Если по памяти, то приходит OOM killer и убивает… Ответ – никак, сервис умер.
В: – То есть эта стратегия не сработает в таком случае?
АР: – Да, эта стратегия не сработает. Если ты пытаешься сделать сервис, который умеет выживать в любых обстоятельствах, то должен закладываться на то, что придёт OOM killer, или придёт админ и просто kill -9 сделает. Это нормально. Более того, у тебя может полкластера отвалиться, и ты должен с этим жить.
Конкретно этот доклад – о том, как решить проблему деплойментов. Кажется, что деплоймент в «Кубернетесе» должен «из коробки» решать проблему бесшовной выкатки, ведь мы хотим его использовать именно для этого! Почему он не решает эту проблему? Доклад как раз о том, как нам сделать хотелку, с которой кластер находится в нормальном состоянии: 10 раз мы выкатили – 10 раз он выкатился бесшовно.
В: – Не рассматривали вариант выкатывать второй деплоймент, чтобы они существовали параллельно, сделав небольшую настройку?
АР: – Это Blue/Green deployment. У тебя выкатится второй деплоймент, старый продолжит существовать. Ты же это имеешь в виду? Нет, не рассматривали, потому что не хотим костылять.
В «Куберентесе», по –хорошему, надо поддержать стратегию B/G деплоймента. Другой вопрос, как это сделать – это нюансы. Но если бы она там была, то мы могли бы просто поменять одну настройку в конфигурации, и всё – у нас бы эта проблема исчезла, потому что у нас не умирал бы старый pod. Но так как сейчас нет такого деплоймента (только rolling updates), то живём как получается…
В: – У вас используются базы в ваших сервисах? Как у вас мигрируют схемы, если у вас реляционная? Это вопрос к тому, что у вас и старая и новая версии параллельно работают.
АР: – Очень хороший вопрос, хорошо относится к теме… Вообще, подход к миграциям базы – трёхфазный. Тебе, получается, всегда нужно поддерживать миграцию в состоянии, при котором старая версия кода тоже умеет с ней работать.
В: – Это именно так? У вас трёхфазная схема?
АР: – Ну-у-у, да… (аудитория ликует)
В: – Я только что попробовал поиграться с errgroup, и, как вижу, WaitGroup возвращает только последнюю ошибку. Каков use case по отлову других?
АР: – Как можно ловить? Если нам нужно поймать одну ошибку от компонента системы, нам errgroup идеально подходит. Если мы хотим ловить каждую ошибочку, её стоит, во-первых, логировать на месте (тогда нам, может быть, и не нужно будет её ловить). Если нам нужно поймать каждую, то можно написать код, который в глобальном scope объявит три ошибки, а потом инициализирует их внутри этих потоков, внутри горутин. В errgroup конкретно одну позволяет поймать (только первую).
В: – Он последнюю ловит. Но суть ясна – спасибо!
В: – Меня слегка смущает то, что я вижу в документации к «Куберу» – есть такая штука как terminationGracePeriodSeconds. Выглядит примерно, как ваш Sleep, а по документации не видно, в чём разница… Зачем городить Sleep, когда есть уже одна строчка с секундами?
АР: – Только эта строка делает совсем не то. Что она делает? Не говорим сейчас о хаке со Sleep – просто говорим о том, что мы реализовали Graceful Shutdown. Что происходит, допустим, если у нас висит и никогда не умирает активное соединение? В этом случае сервис никогда не завершится, потому что он ждёт, когда соединение умрёт.
Что нам нужно? Убить его форсировано (используя строку с force) – форсировано убить pod! Через 30 секунд pod просто умрёт формировано. Это решает проблему, например, с тем, что у нас клиент может никогда не закрыть висящие соединения. Не более того. Эта строка [terminationGracePeriodSeconds] совершенно не решает никаких проблем, кроме той, что pod висит в состоянии «Завершение работы бесконечно». Больше никаких проблем не решает. Этот хак о другом.
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?


 с CRM Битрикс24")

