
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Современная ИТ-инфраструктура – это живая экосистема, которая пребывает в динамическом состоянии. Она расширяется, меняется, обрастает новыми элементами и связями. Это полноценный организм, за которым нужно следить и ухаживать, не забывая при этом учитывать все его изменения.
Представим ситуацию: решили вы повысить производительность информационной системы. Команда девелоперов для этой цели развернула новые ноды, добавила элементы ИС, зарелизила изменения, система работает эффективнее, и, казалось бы, все счастливы. Да только от радости забыли поставить новые элементы на мониторинг. Так и будете вы спокойно пить кофе, любуясь зелеными огоньками на экране рядом с каждым компонентом системы, пока разъяренные пользователи не cымитируют DDoS атаку на внешний интерфейс вашего хелпдеска, когда один из новых элементов откажет.

А теперь представьте, чтобы избежать подобных инцидентов и при этом не просыпаться в холодном поту среди ночи, вспоминая, поставили ли вы новую конфигурационную единицу на мониторинг, машины научились брать ответственность за эти процессы на себя. Расскажу как в данной статье.
Для этого нам понадобятся базовые системы мониторинга, Zabbix, Prometheus или что-то похожее, какая конкретно система вообще не важно, важно подобрать правильный оркестратор и агрегатор событий. Возьмем AIOps платформу Monq, которую можно бесплатно скачать с сайта разработчика. С помощью нее мы автоматически построим ресурсно-сервисную модель на основе данных из Zabbix и применение политик эскалации. Нашей задачей будет один раз настроить систему мониторинга и забыть о добавлении объектов, триггеров, правил и действий. Гартнер уже больше года размышляет над термином Hyperautomation. Сегодня как раз на деле опишу один из таких кейсов.
Причем тут AIOps
В современном мире стремительная цифровизация бизнеса непрерывно трансформирует IT. Внедрение или доработка информационных систем и приложений, сложность и гибридность инфраструктуры часто требуют наличия дополнительных ресурсов и делают традиционные методы управления IT не подходящими для быстрых изменений и не способными отвечать на вызовы новых реалий. Тут на передний план выходят технологии AIOps.
AIOps, или Artificial Intelligence for IT Operations, - это многослойная платформа для управления IT, на основе искусственного интеллекта позволяющая автоматизировать обработку и принятие решений на основе больших данных, поступающих в режиме реального времени из IT-инфраструктуры. Следовательно, AIOps освобождает IT-специалистов от рутинных задач мониторинга отдельных событий, позволяя полностью положиться на машинное обучение.

О Monq уже написано не мало статей на Хабре (тут или тут, например) и повторяться не хотелось бы, это российская разработка для проактивного мониторинга и автоматизации, на ней строятся автоматизированные ситуационные центры от маленького домашнего фрилансного сисадминского уровня до уровня крупных корпораций, где прилетают тысячи событий в минуту. Мне нравится то, что это система, созданная инженерами для инженеров. В одном из последних обновлений у них появилась функция автоматического построения ресурсно-сервисных моделей, а с их помощью намного легче проводить автоматический анализ основной причины сбоя (Root Cause Analysis) и настраивать сценарии автодействий и автоправил. Также недавно вышел новый движок автоматизации. Если бы не он, статьи бы этой не было.
Сначала кейс с полной автоматизацией был построен на продуктивной системе, в которой есть и Zabbix (несколько серверов: отдельно сеть, отдельно инфра), и Prometheus (мониторинг микросервисов), и Jager (для трассировки приложений), и vCenter. Но описывать весь кейс я не могу, так что для статьи поднял упрощенную конфигурацию с одним Zabbix, взял его, так как это, пожалуй, самый распространенный источник событий. Подобным образом можно подключать любые другие источники, содержащие информацию, которую можно отрисовать на ресурсно-сервисной модели.
Статью постарался оформить как туториал, чтобы вы смогли это у себя повторить. Если будет что-то не понятно - пишите в комментарии. А теперь поехали!
Агрегация и анализ событий из внешних систем
Прежде чем начать получать данные из первичной системы, необходимо настроить их поток. В разделе Сбор данных - Потоки данных через основное меню нажимаем кнопку Добавить поток в верхнем правом углу, заполняем поля и тем самым конфигурируем необходимый поток.

Для потоков данных в Monq доступны предустановленные шаблоны конфигурации, предназначенные для интеграции Monq с системами мониторинга. Например, шаблон Zabbix, который мы применяем в данном случае, уже содержит следующие задания и обработчики:
| Задания | Обработчики |
Zabbix | - Zabbix - Version Check" - получение актуальной версии подключенного сервера Zabbix Во всех заданиях применяется агент SharedAgents - системный агент по умолчанию, доступен для изменения на внешние агенты | Routing for Zabbix stream, который проставляет: labels_add('type', 'Zabbix') Пользователю доступно добавление новых обработчиков к имеющемуся. |
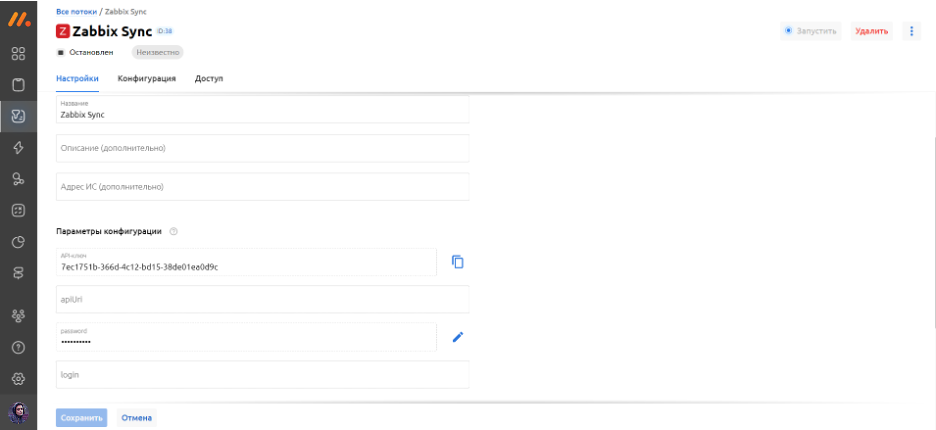
Чтобы связать Zabbix и Monq, прописываем URL подключения к Zabbix, логин и пароль от Zabbix.
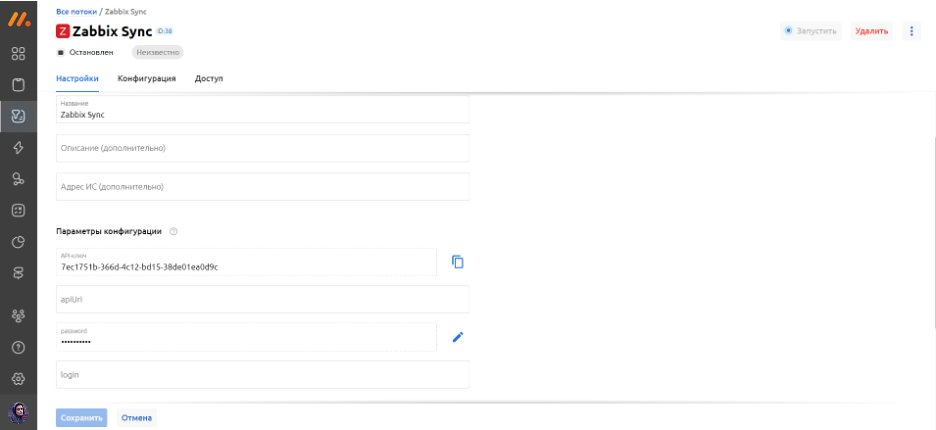
Если вы решили интегрировать данные из Zabbix, то логично предположить, что у вас уже имеется аккаунт в этой системе. Если нет, то вы можете создать новый. На скриншоте ниже представлен процесс создания нового пользователя в Zabbix.
Как было отмечено выше, в предустановленном шаблоне конфигурации уже содержатся задания для привязки Zabbix к Monq. Однако в нашем случае необходимо добавить ещё одно кастомное задание, благодаря которому будут тянуться данные из Zabbix для дальнейшего построения топологии.
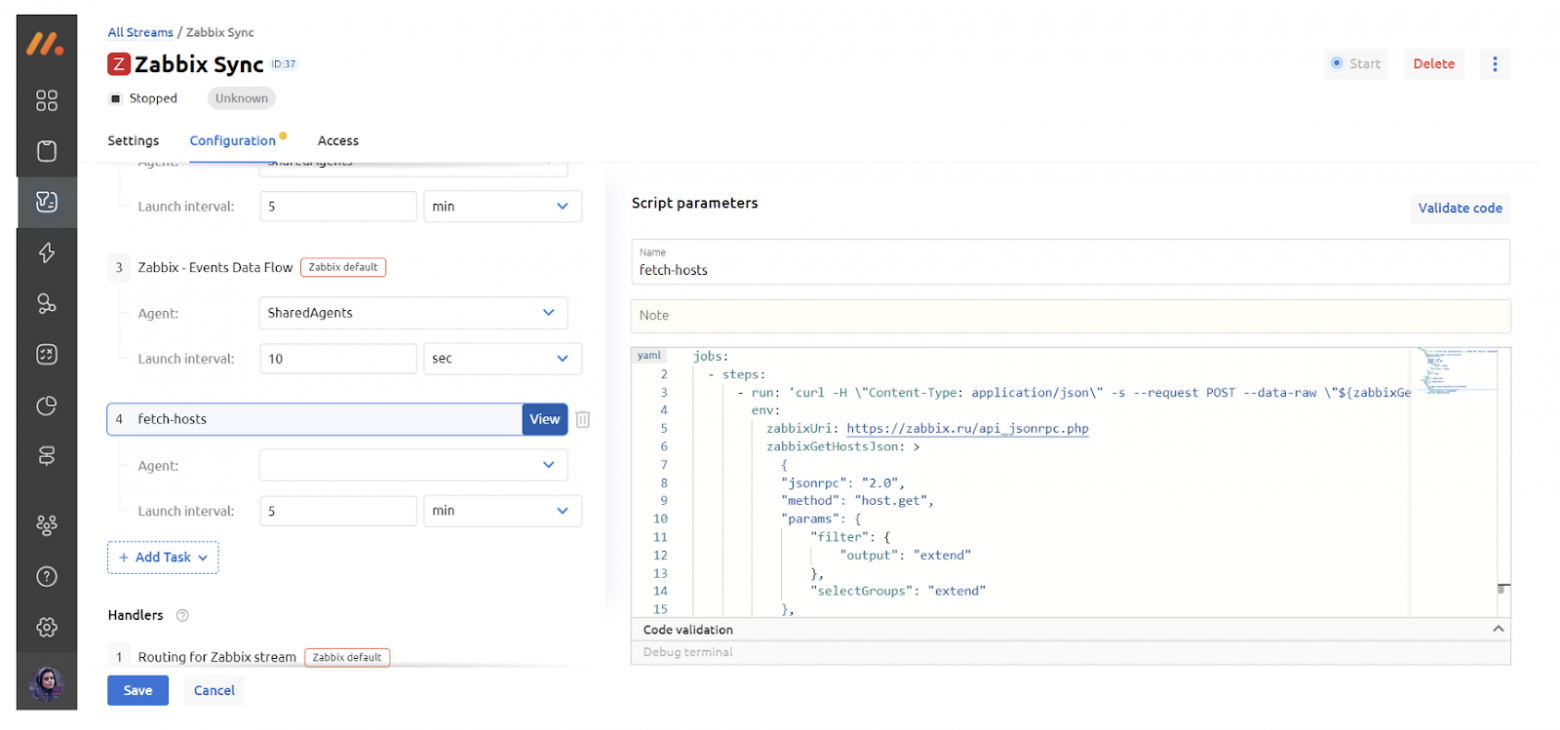
Задание пишется на yaml и будет выполнять запрос на API Zabbix:
jobs:
- steps:
- run: 'curl -H \"Content-Type: application/json\" -s --request POST --data-raw \"${zabbixGetHostsJson}\" ${zabbixUri}'
env:
zabbixUri: https://zabbix.ru/api_jsonrpc.php
zabbixGetHostsJson: >
{
"jsonrpc": "2.0",
"method": "host.get",
"params": {
"filter": {
"output": "extend"
},
"selectGroups": "extend"
},
"id": 1,
"auth": "token"
}
outputs:
data: $._outputs.shell
artifacts:
- data: '{{ outputs.data }}'
send-to:
api:
uri: https://monq.ru/api/public/cl/v1/stream-data
headers:
x-smon-stream-key: $.vars.stream.key
x-smon-userspace-id: $.userspaceId
media-type: application/json
Вы можете запросто использовать данный скрипт как шаблон, вставив его вручную и поменяв следующие строки в соответствии с вашими данными:
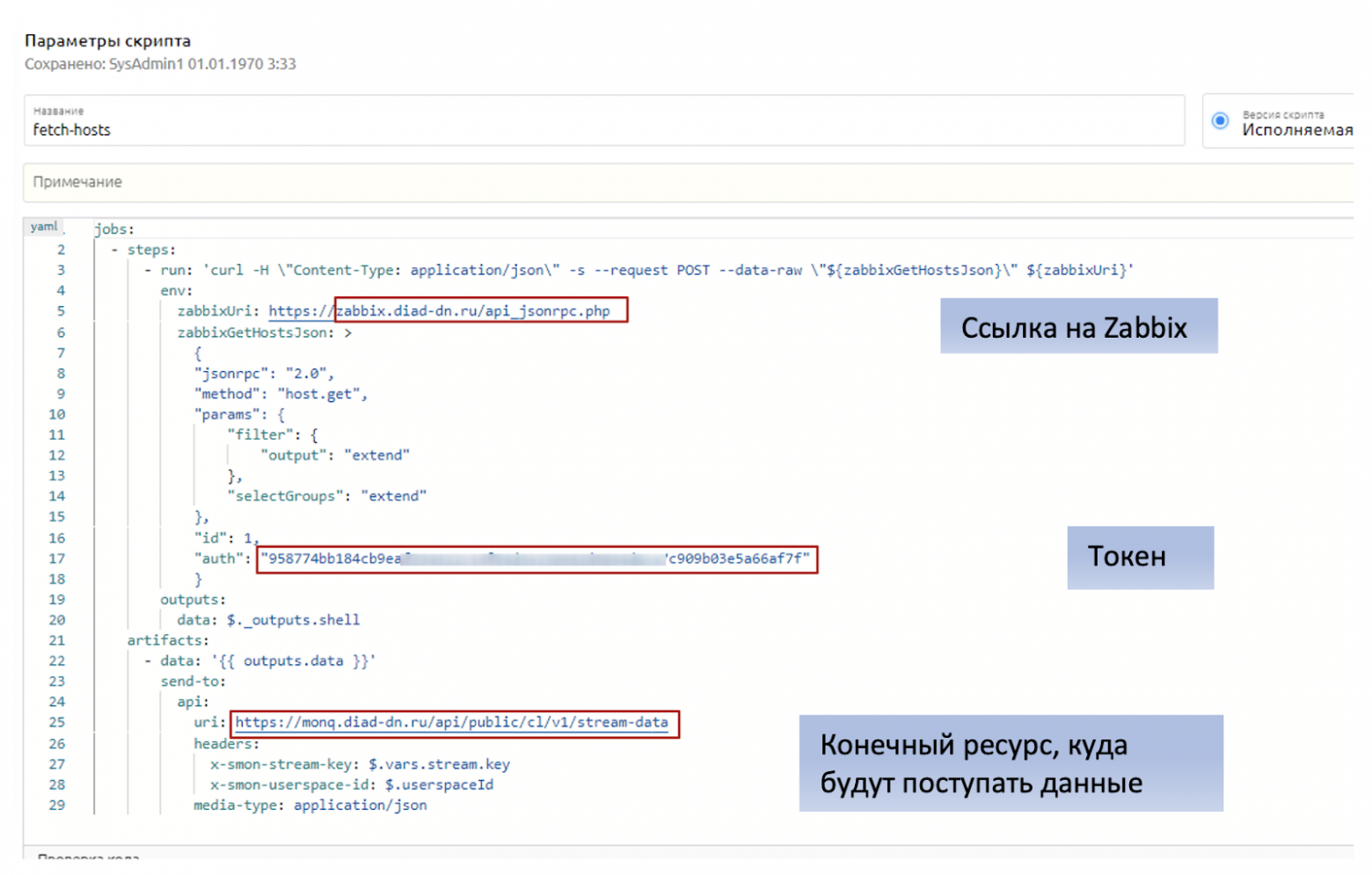
API токен берем (или создаем в случае его отсутствия) также в Zabbix.

Сохраняем изменения. Вжух! И необходимый поток добавлен в Monq.

Но на этом магия конфигурации не заканчивается. Стоит отметить, что задание по сбору данных топологии не может выполняться на внутреннем агенте по политикам безопасности Monq, поэтому перед его запуском необходимо подключить внешний агент.
Добавляем Новый координатор, внутри которого настраиваем агент.
Процесс настройки агента и добавления данных в поля подробно описан в документации Monq, которая хранится в открытом доступе, поэтому в этой статье мы не будет акцентировать внимание на данном процессе, чтобы поскорее перейти к самому интересному – автоматизации.
После настройки возвращаемся в наш поток и меняем агент в добавленном вручную задании на только что созданный.

Теперь запускаем поток. В “Событиях и логах” можем проверить наличие в нём событий, чтобы убедиться, что данные поступают в систему.
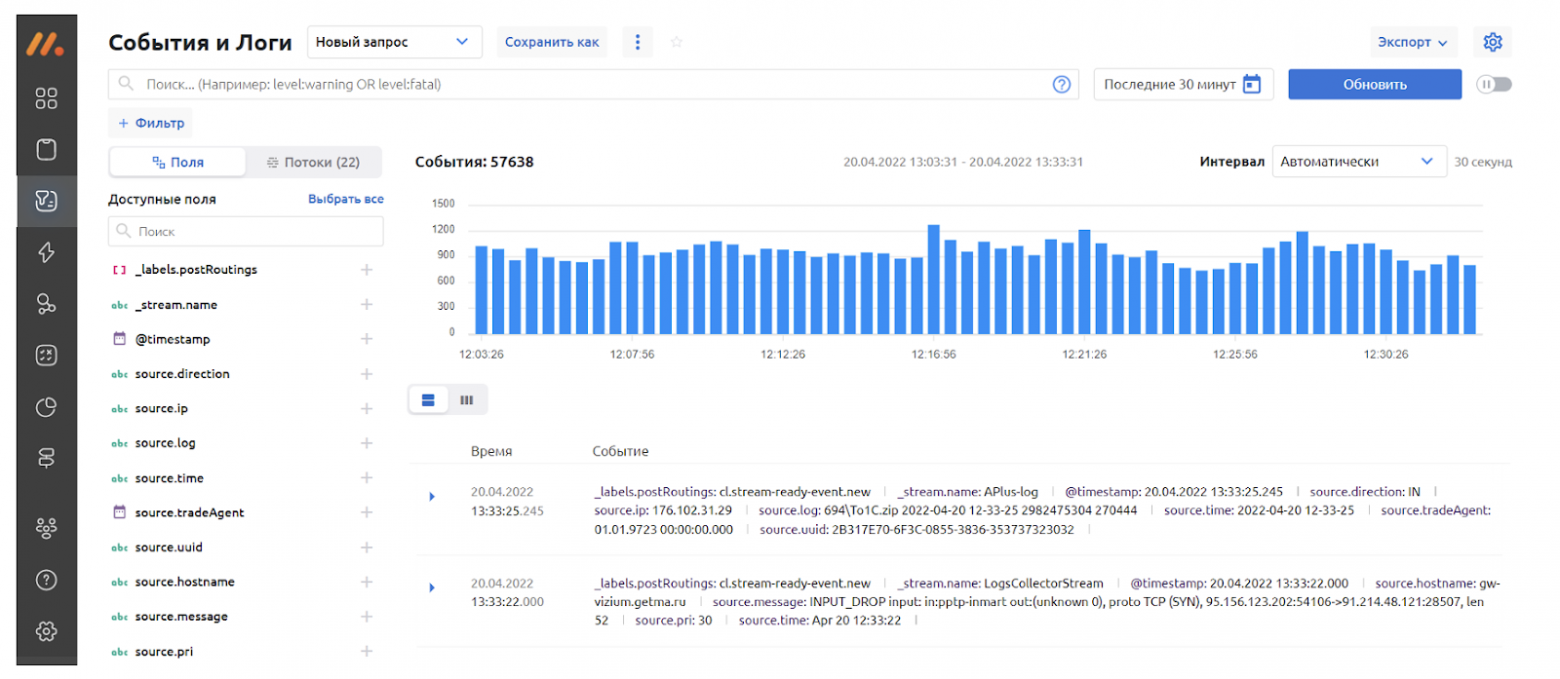
“Провалившись” в одно из событий, сообщающее о проблеме, увидим не только его табличное представление, откуда сможем вытянуть информацию обо всех элементах, содержащихся в Zabbix, но также стандартную для Zabbix структуру JSON, например:


На основе событий, приходящих из первичных систем мониторинга, сможем построить ресурсно-сервисную модель (РСМ).
Строим ресурсно-сервисную модель
Ресурсно-сервисная модель (РСМ) – это перечень конфигурационных единиц (КЕ) системы, а также массив связей между ними. В Monq РСМ основана на топологии. Но не будем пока забегать вперёд и вернемся к структуре JSON первичного события, на которой мы остановились в предыдущем разделе. В ней обратим внимание на следующие параметры, по которым и будет строить ресурсно-сервисную модель:
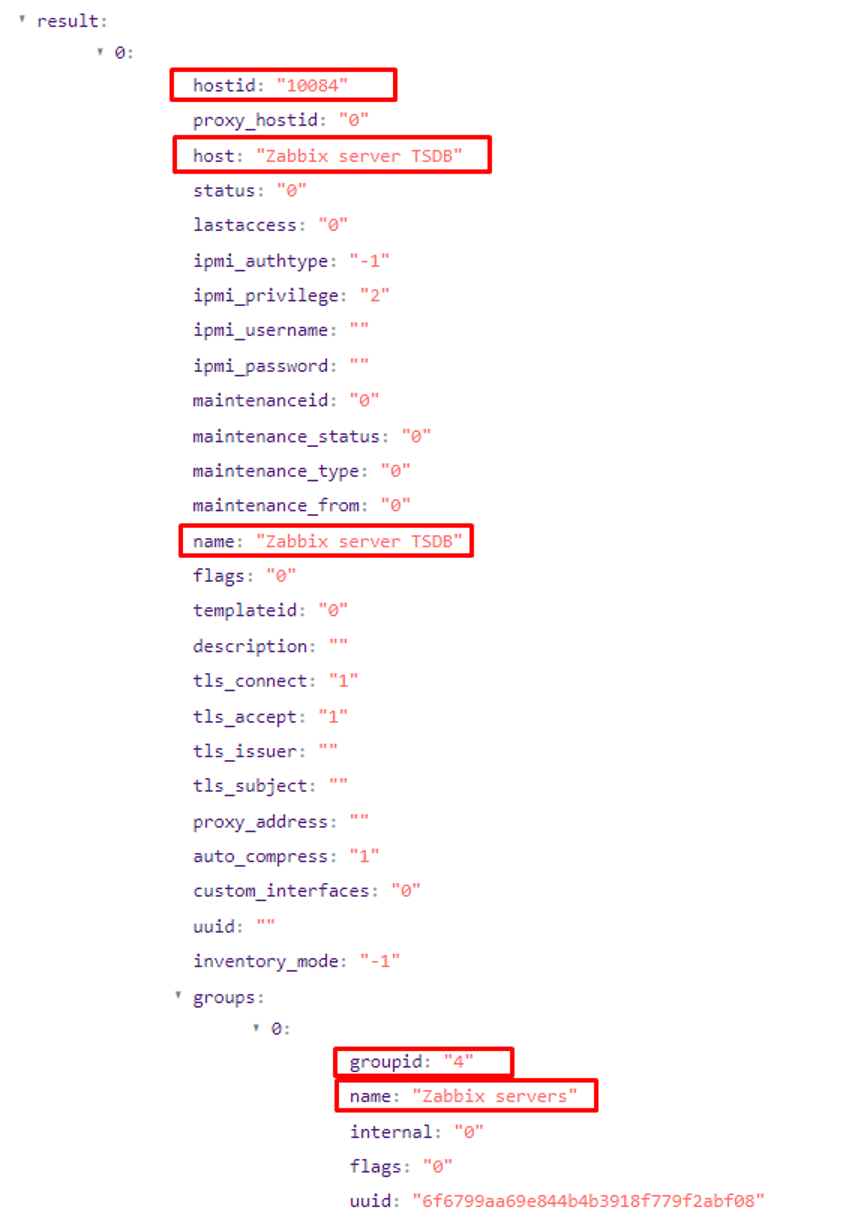
При дальнейшем автоматическом создании конфигурационных единиц будем определять, что:
Название КЕ == host.name (Наименование узла Zabbix)
Название родительской КЕ == host.groups[0].name
Связанный объект => Узел Zabbix
В разделе Автоматизации создаем новый сценарий для Zabbix, владельцем которого является наша Рабочая группа.
Добавленные сценарии увидим в разделе Автоматизация.
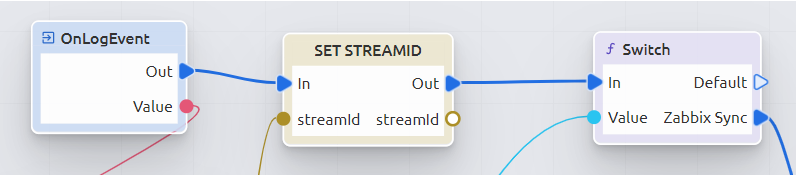
Проектирование сценария начинается с блока “OnLogEvent”, куда приходят события о топологии, и производится при помощи визуального движка программирования (low-code).

Затем производится проверка потоков: если название потока совпадает со значением в сценарии (в нашем случае – Zabbix Sync), то скрипт выполняется дальше, если нет – скрипт выполняться не будет.
Чтобы “куст” топологии разрастался из одной информационной системы, можно вручную создать корневую КЕ через опцию создания КЕ в окне графа РСМ.
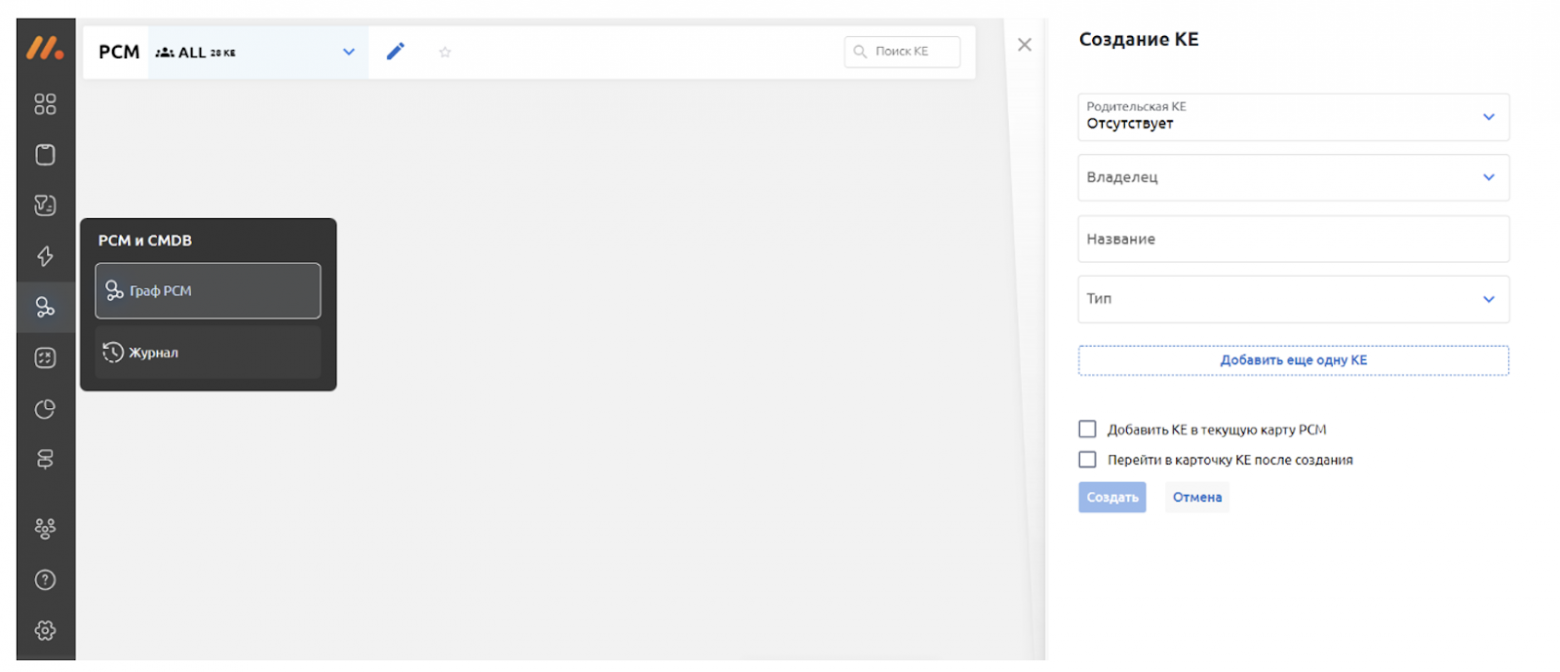
Создав КЕ, берем её ID из ссылки и вставляем в следующий блок в скрипте.

Тем самым при создании сценария все группы будут привязываться к данной корневой КЕ, которая будет отображать на топологии здоровье всей системы в целом.

Но не будем пока спойлерить и вернёмся к построению единого скрипта, который условно можно разделить на две части:
Создание конфигурационных единиц (КЕ)
Привязывание узлов первичных систем мониторинга (для дальнейшей привязки триггеров).
В дальнейшем скрипт совершенствуется, производятся различные проверки, добавляется автоматическое создание КЕ и создаются связи подчинения между ними. Подробный процесс создания сценария, получения атрибутов КЕ, создания связей влияния и подчинения описан в документации Monq.
Затем выполняем компиляцию и запускаем сценарий:
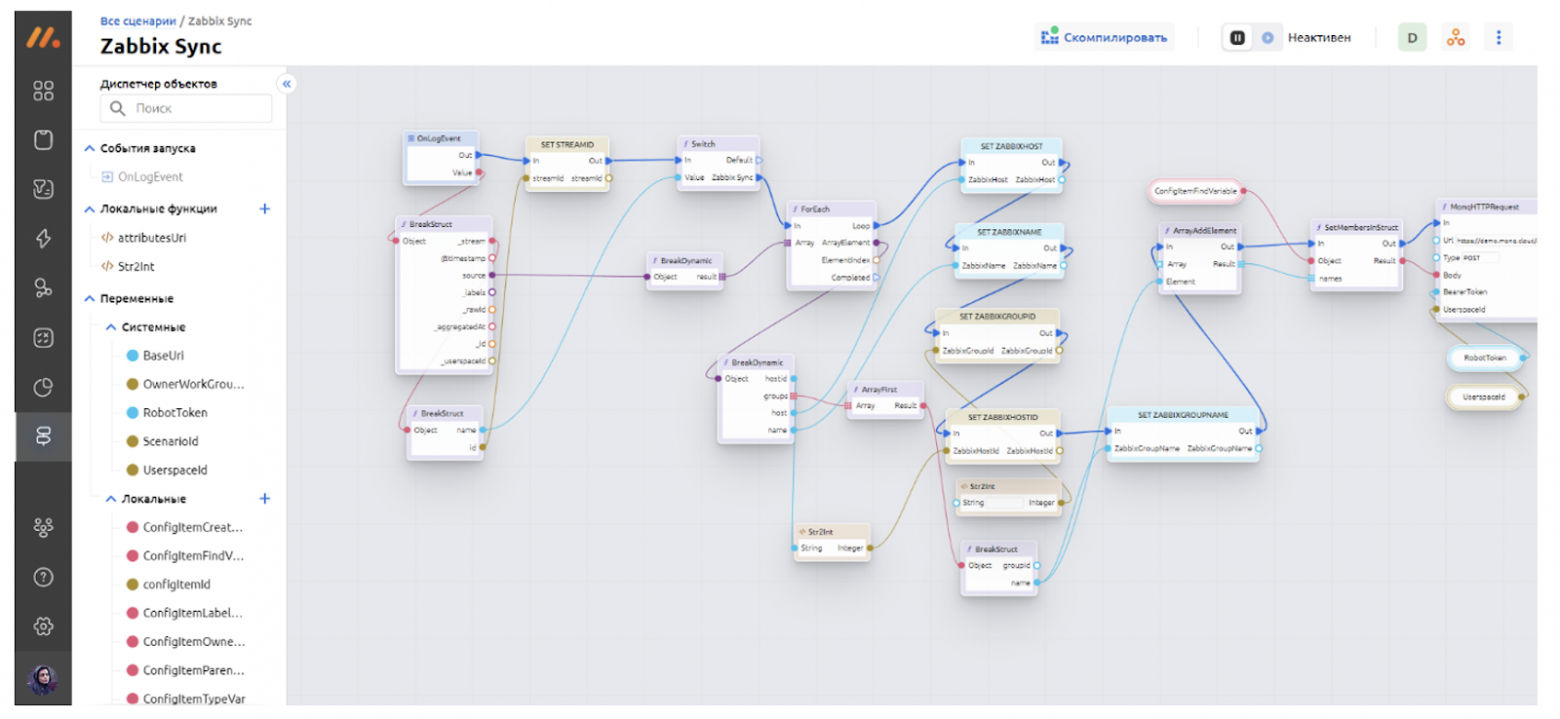
В результате выполнения этого скрипта создается полноценный граф РСМ, на котором отображаются статусы всех компонентов и здоровье системы в режиме реального времени.
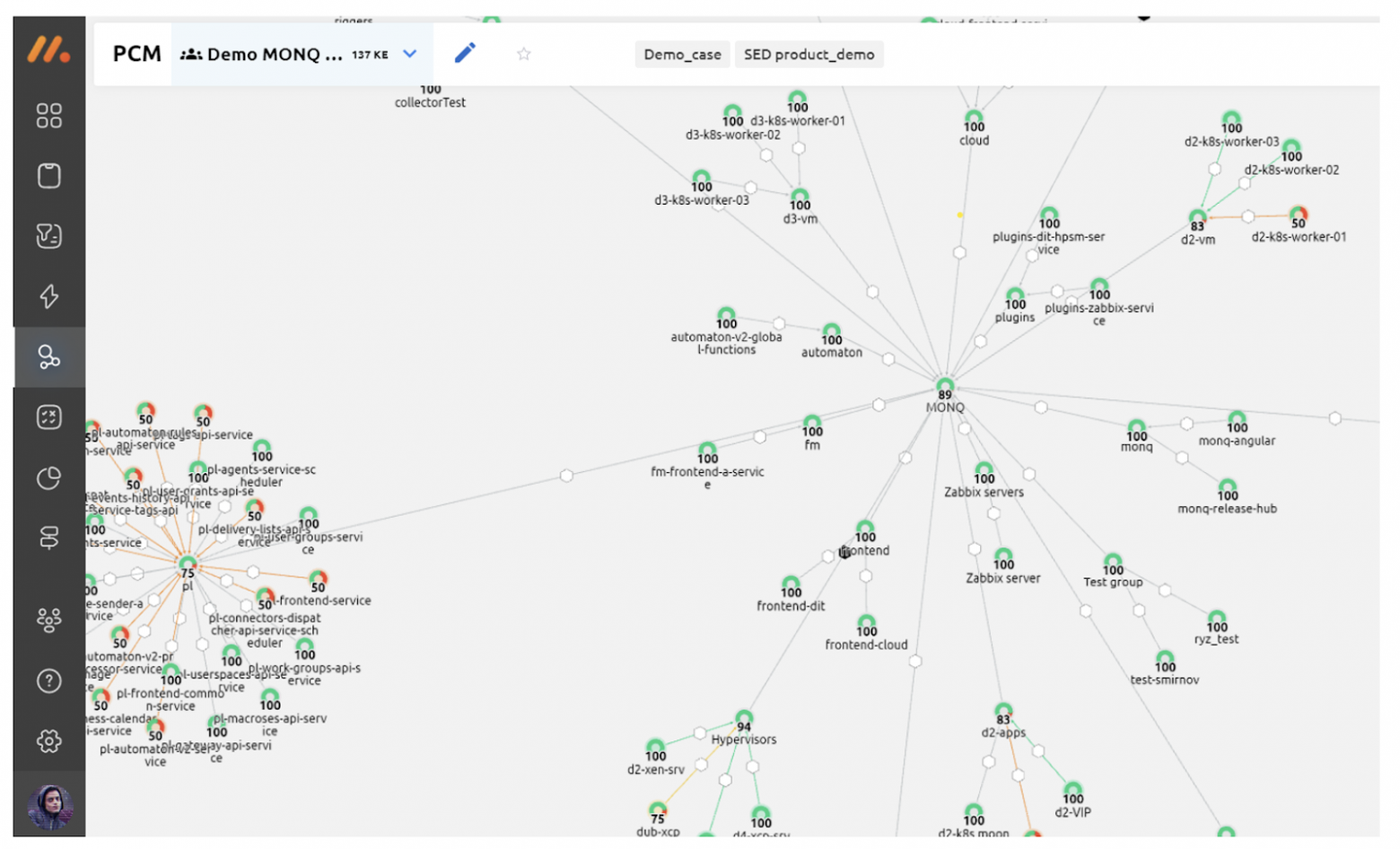
После получения события с топологией и его обработки сценарием видим и построенную модель, и статусы привязанных триггеров. Отображение карты настраивается автоматически в соответствии с правилами: в данном случае показываются все КЕ, связанные с Monq на расстоянии бесконечности.
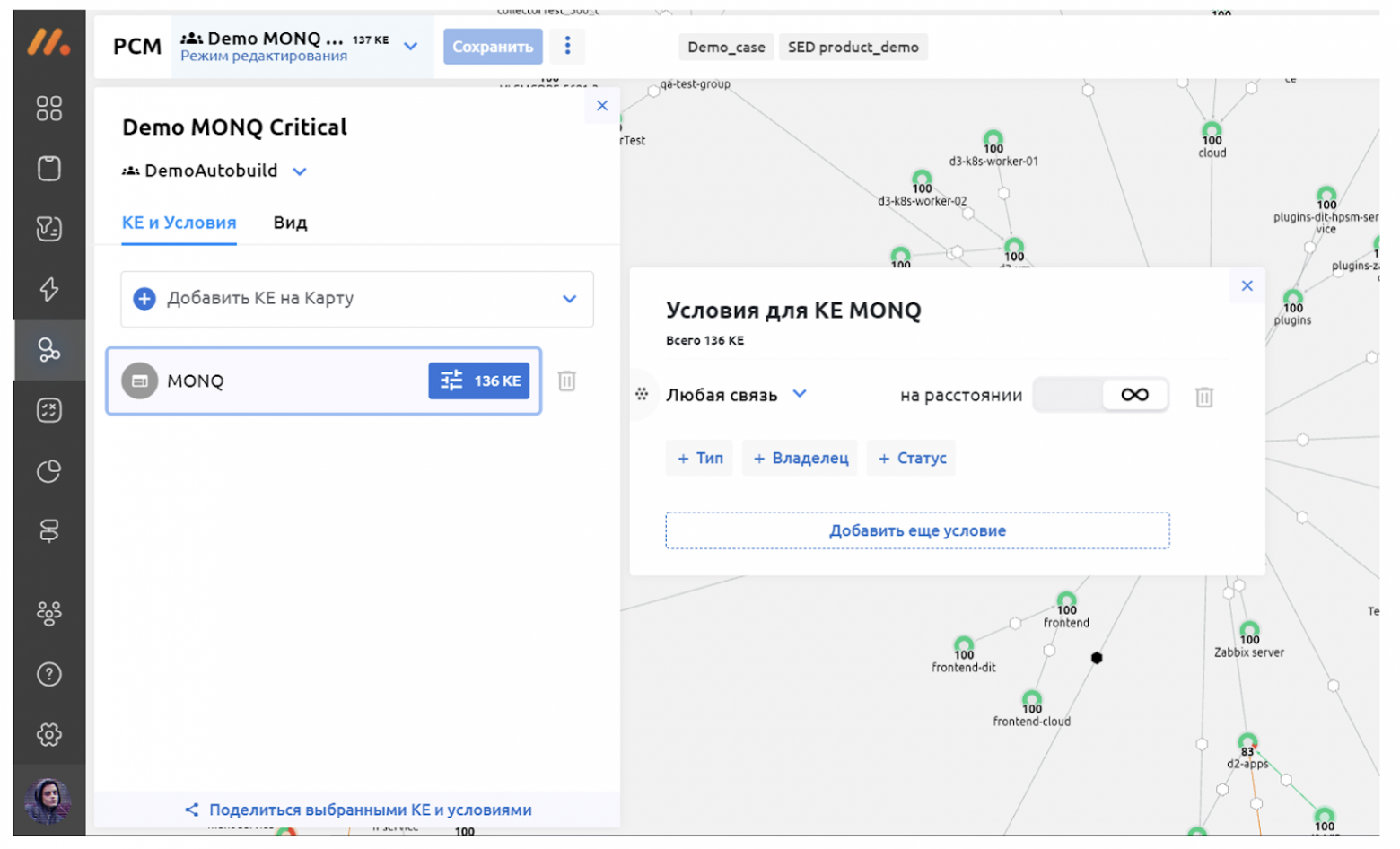
Если во время автодискаверинга будет обнаружена новая КЕ, то мы сразу увидим её на карте. Чтобы быть уверенным, что система точно не подвела, можно проверить добавление новых элементов в Журнале событий.
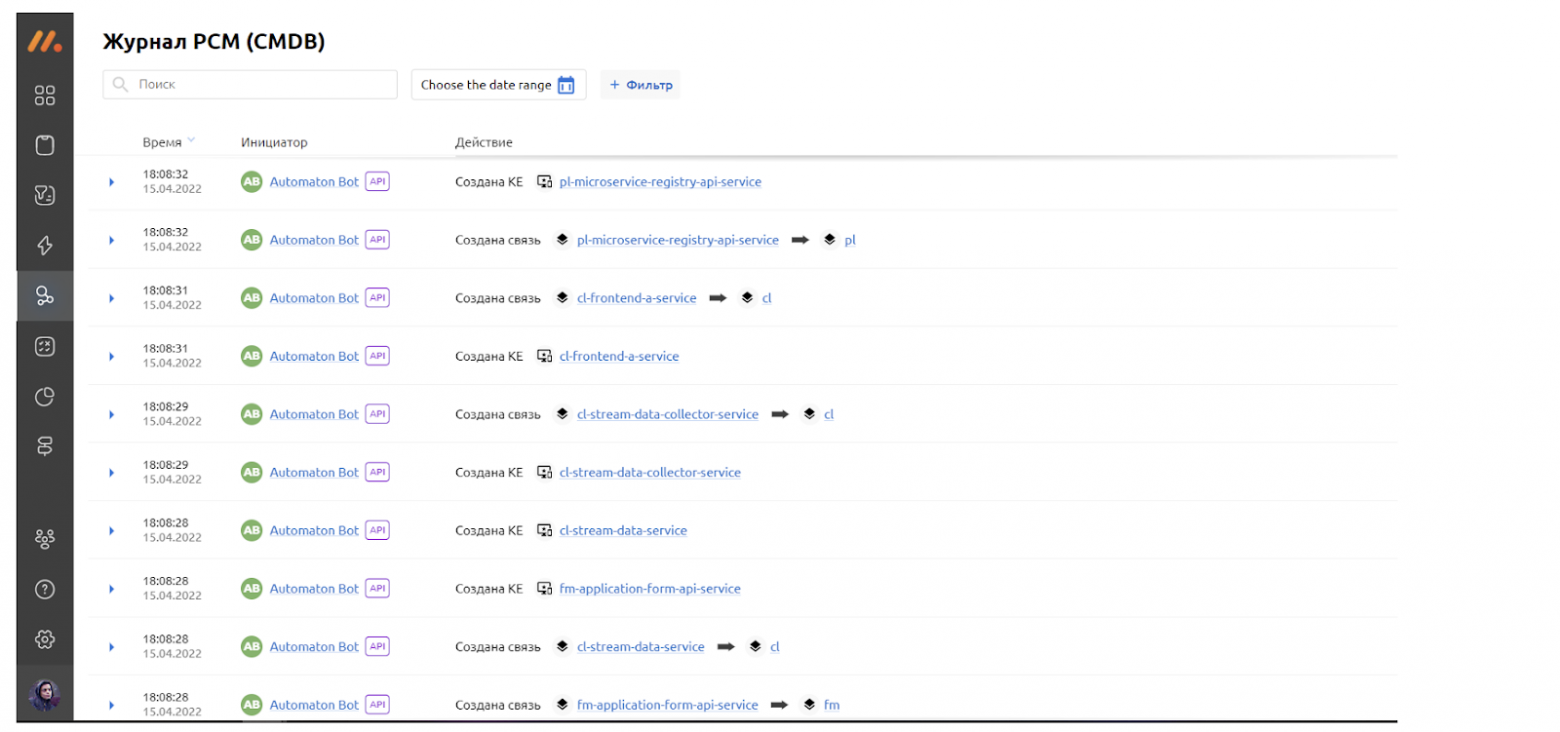
Как видно из скриншота, все новые КЕ и связи были добавлены автоматически.
Автоправила и автодействия
Как вы уже поняли, Monq берет на себя некоторые задачи и автоматизирует рутинные процессы, которые раньше выполнялись вручную. Для каждого элемента системы можно настроить не только автоматическое добавление, но и автоматические правила, которые будут срабатывать при определенных изменениях в КЕ.
Открываем раздел “Правила и действия” и добавляем Новое правило. Например, создадим правило для всех КЕ и событий с приоритетом 2 или выше.
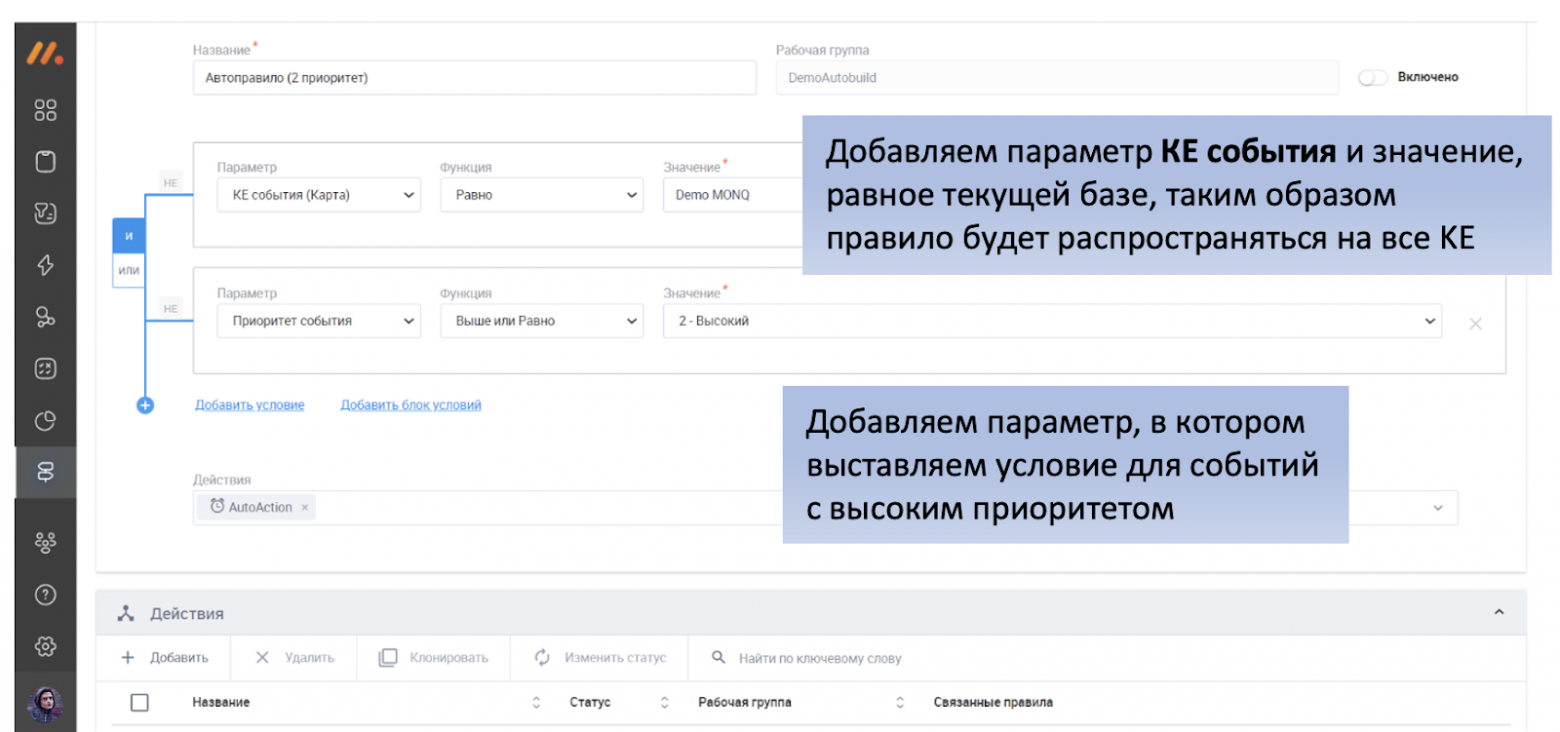
Далее прописываем автоматическое действие, которое будет выполняться в случае срабатывания данного правила. В нашем случае это – два оповещения по e-mail и в Telegram с интервалом в 2 и 30 мин и выполнение скрипта автопочинки в случае, если за это время инцидент не был устранен.
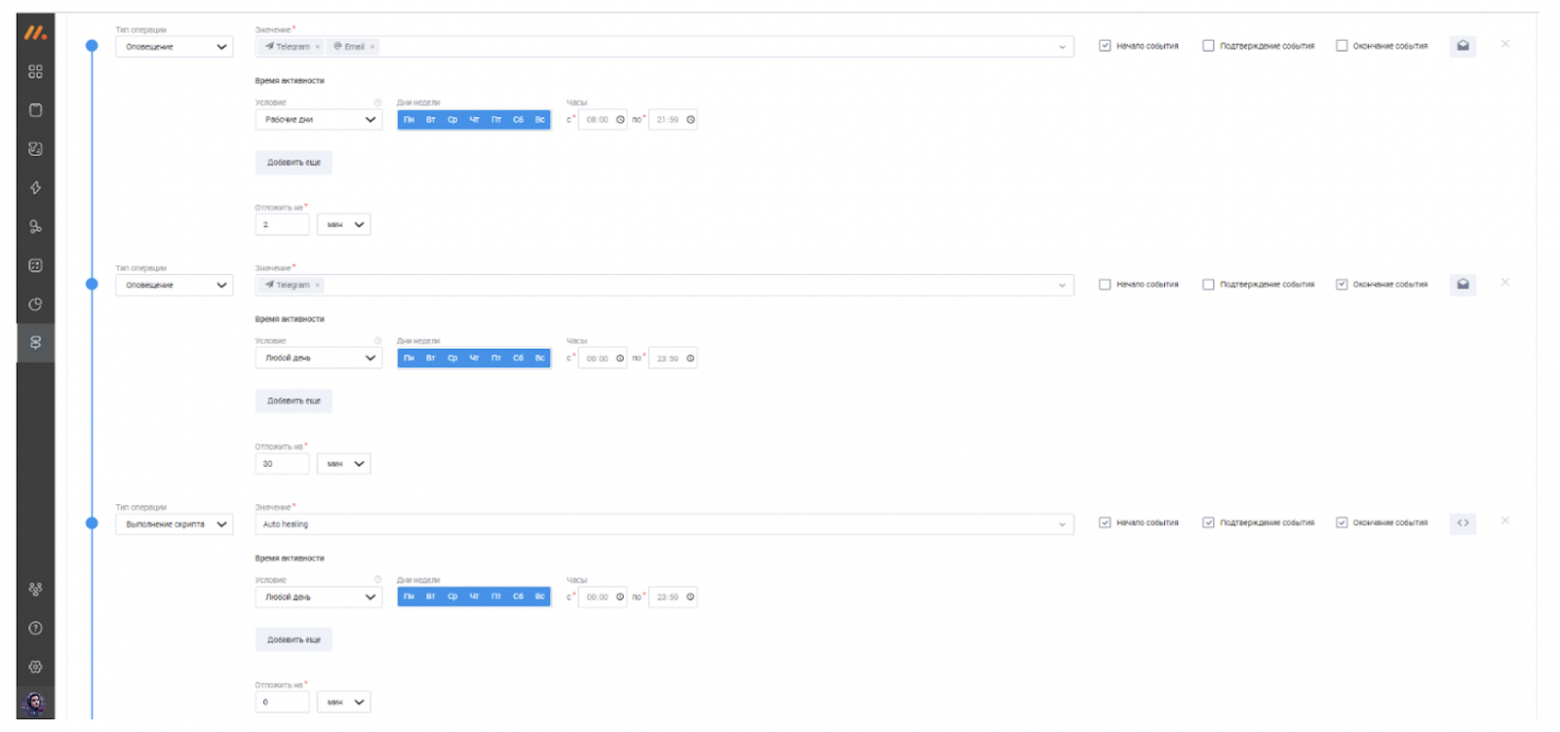
Шаблоны оповещений также настраиваются внутри Monq. Вы можете добавить любой текст, прикрепить необходимые файлы, используя для разметки Markdown и HTML.

Таким образом при обнаружении события с высоким приоритетом будет срабатывать данный сценарий автодействия: отправятся необходимые оповещения и запустится скрипт починки. И все это будет совершено АВТОМАТИЧЕСКИ! Пока вы будете попивать кофеек.
Заключение
Когда в систему приходит событие, оно изменяет либо саму РСМ, либо её состояние. Monq автоматически позволяет отследить все эти изменения и выполнить связанные с ними действия. Автоматически добавляются объекты, автоматически привязываются триггеры первичных локальных систем мониторинга, автоматически распространяются политики эскалации, автоматически рассчитывается здоровье системы и запускаются сценарии автоматизации.
Приведенный выше пример, это была искусственная упрощенная демонстрация. В продуктиве систем и объектов больше, и все это нормально уживается в одном экране и это здорово. Выполнив необходимую первичную настройку, описанную выше, вы полностью передадите пласт некогда ручных работ в Monq, освободив ресурсы для других важных задач.

К слову, у вас есть возможность лично протестировать описанный выше кейс. Пошаговый рецепт с готовым сценарием автоматизации доступен по ссылке. Вы можете перетянуть его в свою систему и попробовать все описанные выше функции, возможности и фишки Monq. Делитесь опытом в комментах – обсудим
Интересные статьи
Интересные статьи




