
Приветствую, господа. Я Маша, мне 23, и я уже почти полгода изучаю и внедряю на практике Apache NiFi.
Должна отметить, что спустя месяц после знакомства с этой технологией — я начала употреблять антидепрессанты. Был ли NiFi триггером или последней каплей достоверно неизвестно, как и его причастность к данному факту. Но, раз уж, я взялась изложить все, что ждет потенциального новичка на этом пути — я должна быть максимально откровеннной.
В тот час, когда технически Apache NiFi — мощное связующее звено между различными сервисами (осуществляет обмен данными между ними, по пути позволяя их обогащать и модифицировать), смотрю я на него с точки зрения аналитика. А все потому, что NiFi весьма удобный инструмент для ETL. В часности, в команде мы ориентируемся на построение им SaaS архитектуры.
Опыт автоматизации одного из своих рабочих процессов, а именно формирование и рассылка еженедельной отчетности по Jira Software, я и хочу раскрыть в данной статье. К слову, методику аналитики таск-треккера, которая наглядно отвечает на вопрос — а чем же занимаются сотрудники — я также опишу и опубликую в ближайшее время.
Несмотря на посвящение данной статьи новичкам, считаю правильным и полезным если более опытные архитекторы (гуру, так скажем) отрецензируют ее в кромментариях или поделятся своими кейсами использования NiFi в различных сферах деятельности. Много ребят, включая меня, скажет вам спасибо.
Apache NiFi — opensource продукт для автоматизации и управления потоками данных между системами. Приступая к нему важно сразу осознать две вещи.
Первое — это зона Low Code. Что я имею ввиду? Предполагается, что все манипуляции с данными с момента их попадания в NiFi вплоть до извлечения можно выполнить его стандартными инструментами (процессорами). Для особых случаев существует процессор для запуска скриптов из bash-а.
Это говорит о том, что сделать что-то в NiFi неправильно — довольно сложно (но мне удалось! — об этом второй пункт). Сложно потому, что любой процессор будет прямо таки пинать тебя — А куда отправлять ошибки? А что с ними делать? А сколько ждать? А тут ты выделил мне маловато места! А ты докумментацию точно внимательно читал? и т.д.

Второе (ключевое) — это концепция потокового программирования, и только. Тут, я лично, не сразу врубилась (прошу, не судите). Имея опыт функционального программирования на R, я неосознанно формировала функции и в NiFi. В конечном счете — переделывай — сказали мне коллеги, когда увидели мои тщетные попытки эти «функции» подружить.
Думаю, хватит на сегодня теории, лучше узнаем все из практики. Давайте сформулируем подобие ТЗ для недельной аналитики Jira.
Дабы принести миру больше пользы, я не остановилась на недельном периоде и разрабатывала процесс с возможностью выгрузки гораздо большего объема данных.
Давайте же разбираться.
В Apache NiFi нету такого понятия как отдельный проект. У нас есть только общее рабочее пространство и возможность формирования в нем групп процессов. Этого вполне достаточно.
Находим в панели инструментов Process Group и создаем группу Jira_report.
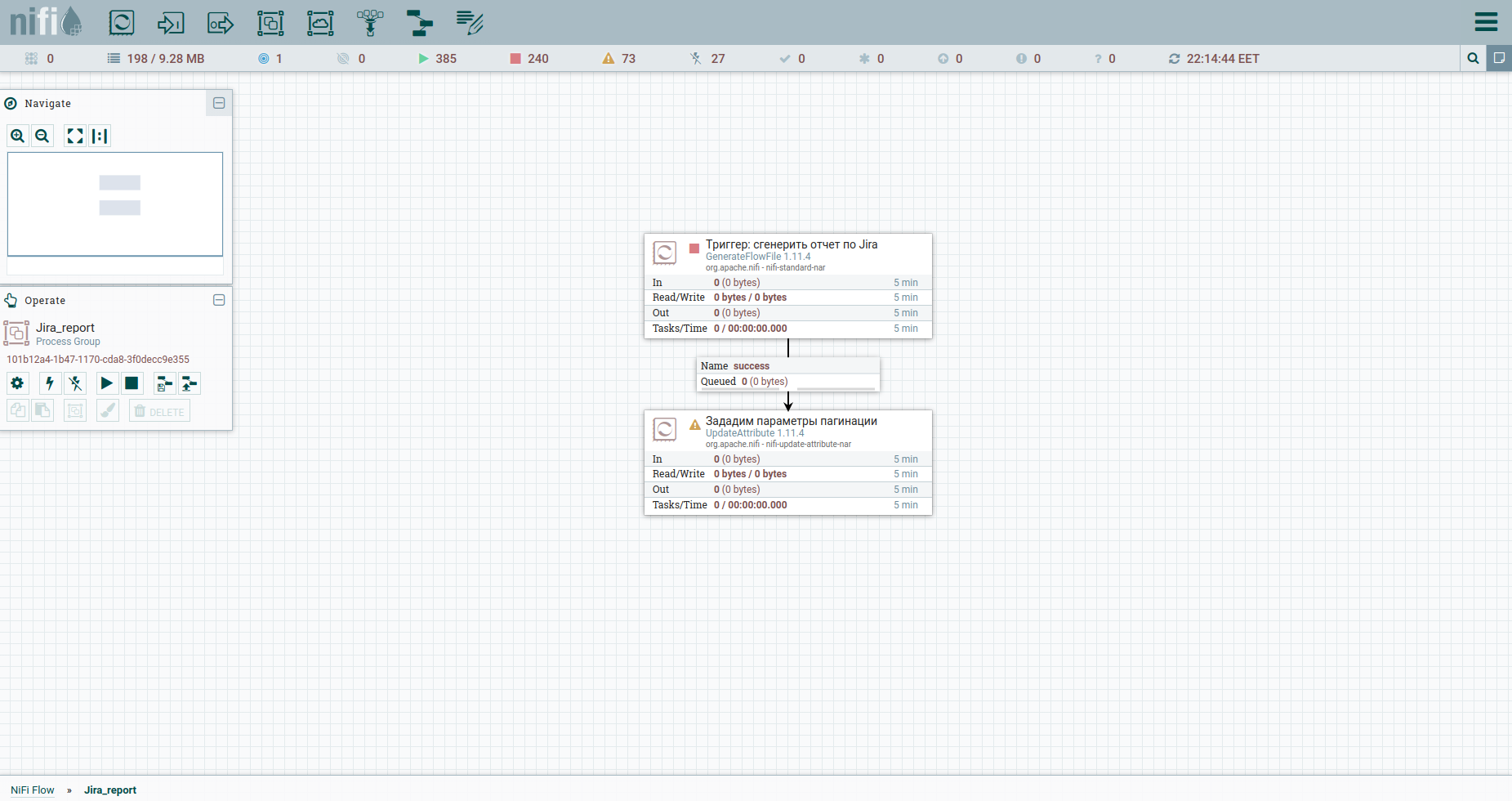
Идем в группу и начинаем строить поток (workflow). Большинство процессоров из которых его можно собрать требуют Upstream Connection. Простыми словами это триггер, по которому процессор будет срабатывать. Потому логично, что и весь поток будет начинаться с обычного триггера — в NiFi это процессор GenerateFlowFile.
Что он делает. Создает потоковый файл, который состоит из набора атрибутов и контента. Атрибуты — это строковые пары ключ / значение, которые ассоциируются с контентом.
Контент — обычный файл, набор байтов. Представьте что контент это аттач к FlowFile.
Делаем Add Processor →GenerateFlowFile. В настройках, в первую очередь, настоятельно рекомендую задать имя процессора (это хороший тон) — вкладка Settings. Еще момент: по умолчанию GenerateFlowFile генерит потоковые файлы непрерывно. Вряд ли это вам когда-нибуть понадобится. Сразу увеличиваем Run Schedule, к примеру до 60 sec — вкладка Scheduling.

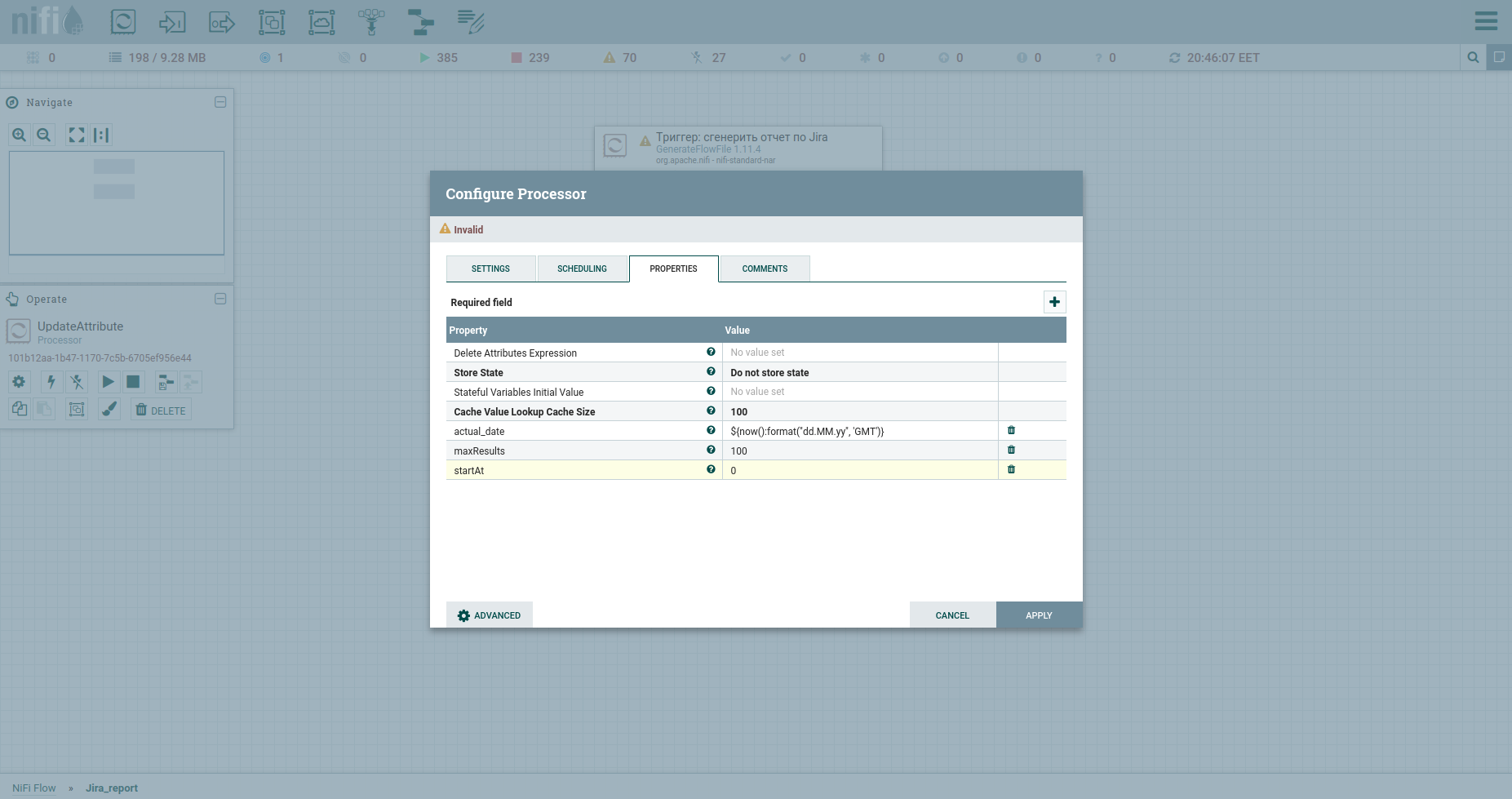
Также на вкладке Properties укажем дату начала отчетного периода — атрибут report_from со значением в формате — yyyy/mm/dd.
Согласно документации Jira API, у нас есть ограничение на выгрузку issues — не больше 1000. Потому, чтобы получить все таски, мы должны будем сформировать JQL запрос, в котором указываются параметры пагинации: startAt и maxResults.
Зададим их атрибутами с помощью процессора UpdateAttribute. Заодно прикрутим и дату генерации отчета. Она понадобится нам позже.
Вы наверняка обратили внимание на атрибут actual_date. Его значение задано с помощью Expression Language. Ловите крутую шпаргалку по нему.
Все, можем формировать JQL к жире — укажем параметры пагинации и нужные поля. В последующем он будет телом HTTP запроса, следовательно, отправим его в контент. Для этого используем процессор ReplaceText и укажем его Replacement Value примерно таким:
Обратите внимание как прописываются ссылки на атрибуты.
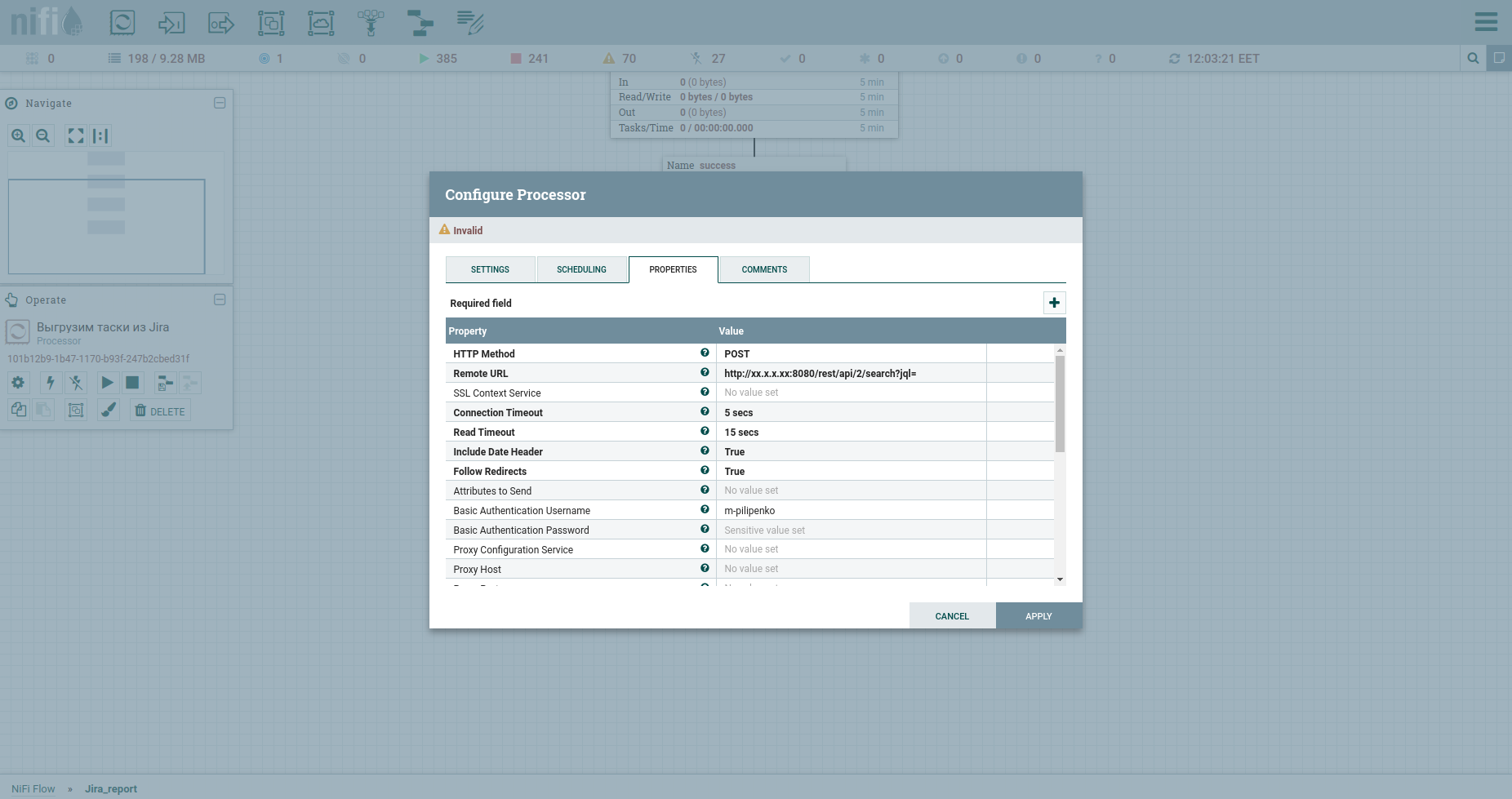
Поздравляю, мы готовы делать HTTP запрос. Тут впору будет процессор InvokeHTTP. Кстати он может по всякому… Я имею ввиду методы GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS. Модифицируем его свойства следующим образом:
HTTP Method у нас POST.
Remote URL нашей жиры включает IP, порт и приставочку /rest/api/2/search?jql=.
Basic Authentication Username и Basic Authentication Password — это креды к жире.
Меняем Content-Type на application/json b ставим true в Send Message Body, что значит переслать JSON, который прийдет из предыдущего процессора в теле запроса.
APPLY.
Ответом апишки будет JSON файл, который попадет в контент. В нем нам интересны две вещи: поле total cодержащее общее количество тасок в системе и массив issues, в котором уже лежит часть из них. Распарсим же ответочку и познакомимся с процессором EvaluateJsonPath.
В случае, когда JsonPath указывает на один обьект, результат парсинга будет записан в атрибут флоу файла. Тут пример — поле total и следующий скрин.

В случае же, когда JsonPath указывает на массив обьектов, в результате парсинга флоу файл будет разбит на множество с контентом соответствующим каждому обьекту. Тут пример — поле issue. Ставим еще один EvaluateJsonPath и прописываем: Property — issue, Value — $.issue.
Теперь наш поток будет состоять теперь не из одного файла, а из множества. В контенте каждого из них будет находиться JSON с инфо об одной конкретной таске.
Идем дальше. Помните, мы указали maxResults равным 100? После предыдущего шага у нас будет сто первых тасок. Получим же больше и реализуем пагинацию.
Для этого увеличим номер стартовой таски на maxResults. Снова заюзаем UpdateAttribute: укажем атрибут startAt и пропишем ему новое значение ${startAt:plus(${maxResults})}.
Ну и без проверки на достижение максимума тасок не обойдемся — процессор RouteOnAttribute. Настройки следующие:
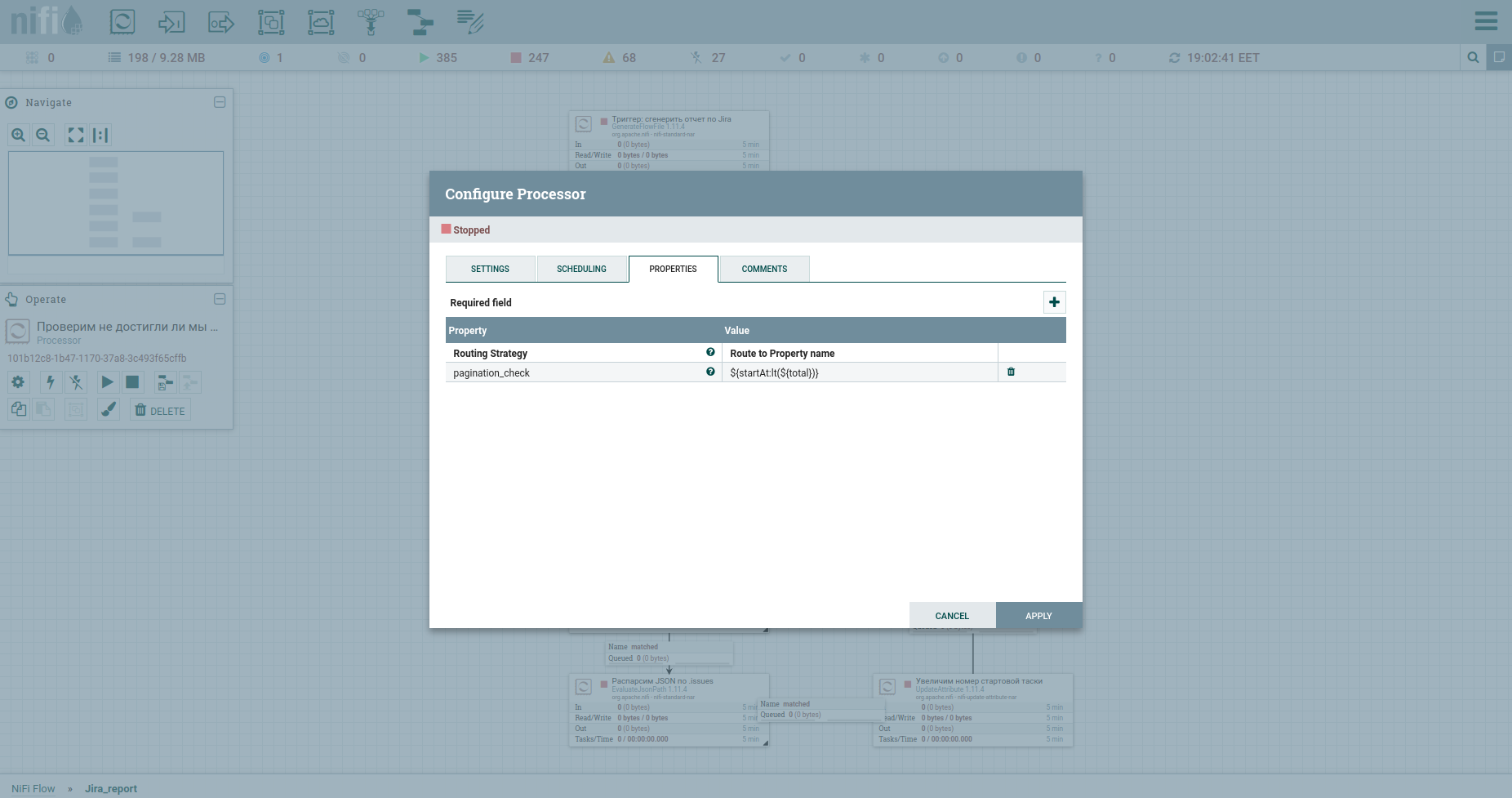
И зациклим. Итого, цикл будет работать, пока номер стартовой таски меньше чем общее к-во тасок. На выходе из него — поток тасок. Вот как процесс выглядит сейчас:

Да, друзья, знаю — вы подустали читать мои каменты к каждому квадратику. Вам хочется понять сам принцип. Ничего не имею против.
Данный раздел, должен облегчить абсолютному новичку этап вхождения в NiFi. Дальше же, имея на руках, щедро подаренный мною шаблон — вникнуть в детали не составит труда.
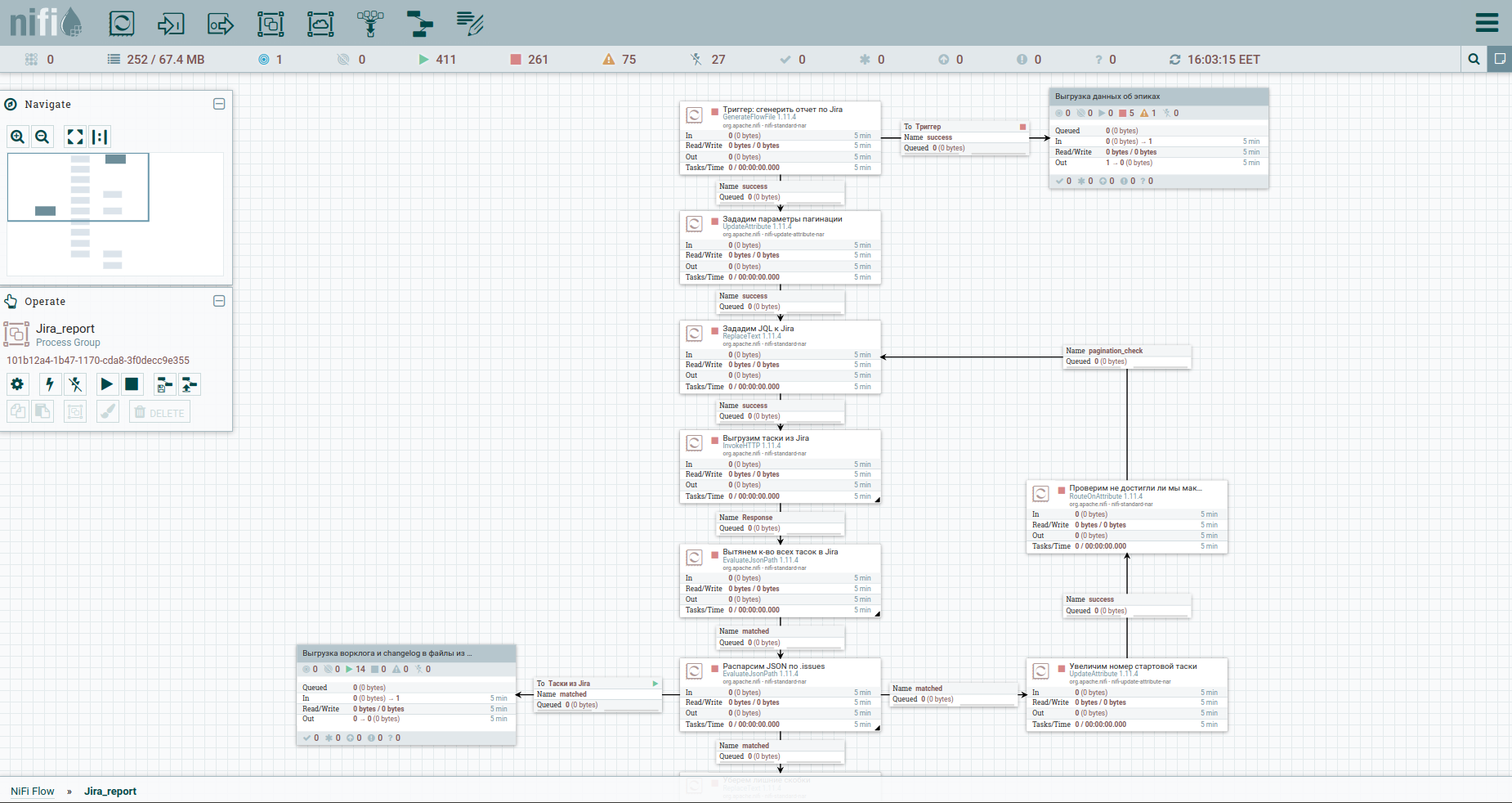
Ну, что, ускоримся. Как говорится, найдите отличия:
Для более легкого восприятия, процесс выгрузки ворклога и истории изменений я вынесла в отдельную группу. Вот и она:
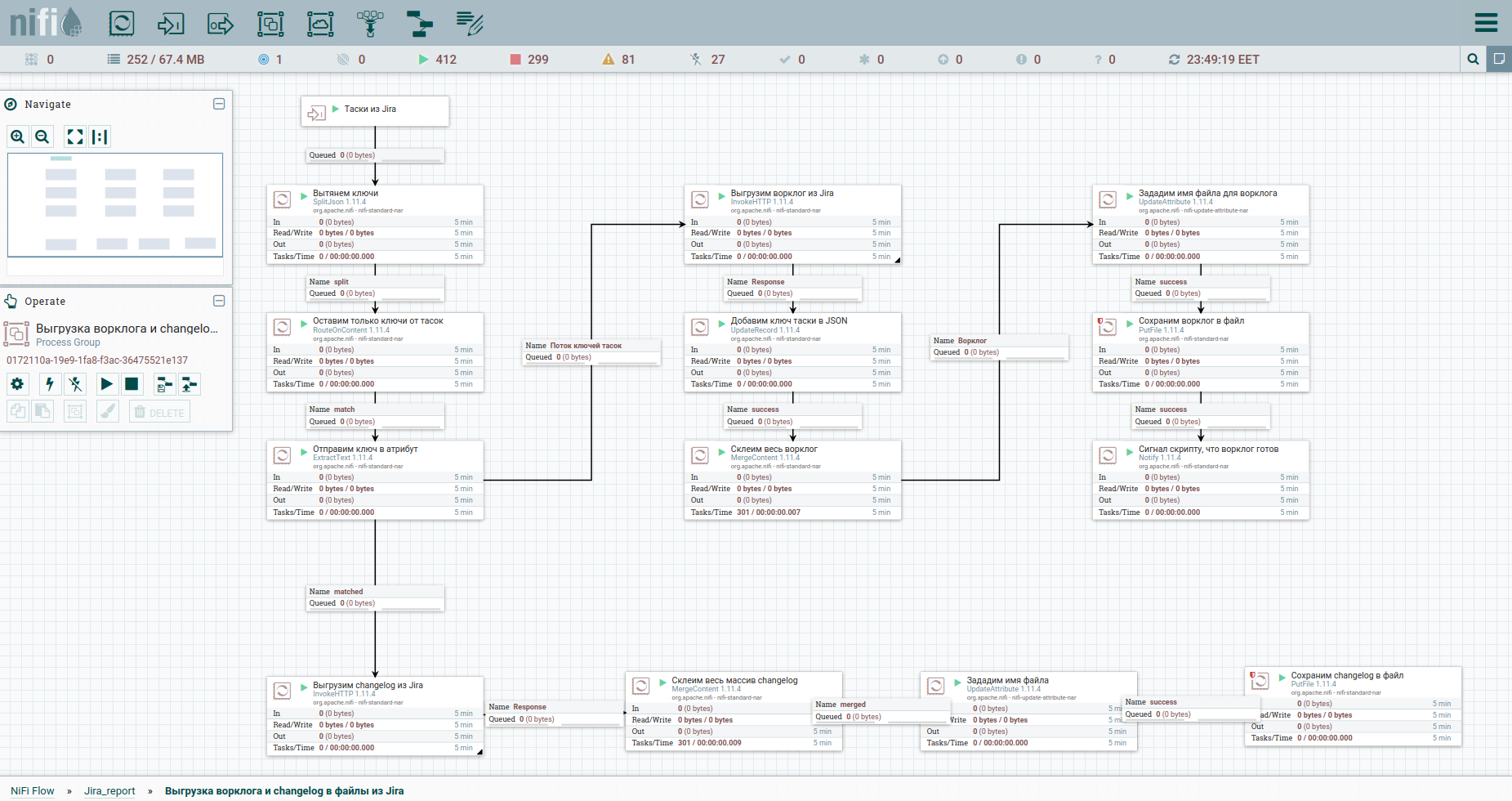
Чтобы обойти ограничения при автоматической выгрузке ворклога из Jira, целесообразно обращаться к каждой таске отдельно. Потому нам нужны их ключи. Первый столбец как раз и преобразует поток тасок в поток ключей. Далее обращаемся к апишке и сохраняем ответ.
Нам удобно будет оформить worklog и changelog по всем таскам в виде отдельных документов. Поэтому, воспользуемся процессором MergeContent и склеим им содержимое всех флоу файлов.
Также в шаблоне вы заметите группу для выгрузки данных по эпикам. Эпик в Jira — это обычная таска, к которой привязывается множество других. Данная группа будет полезна в случае когда добывается лишь часть задач, чтобы не потерять информацию об эпиках некоторых из них.
Окей. Тасочки все выгрузились и отправились двумя путями: в группу для выгрузки ворклога и к скрипту для генерации отчета. К последнему у нас STDIN один, поэтому нам необходимо собрать все задачи в одну кучу. Сделаем это в MergeContent, но перед этим чуть подправим контент, чтобы итоговый json получился корректным.

Перед квадратиком генерации скрипта (ExecuteStreamCommand) присутствует интересный процессор Wait. Он ожидает сигнала от процессора Notify, который находиться в группе выгрузки ворклога, о том что там уже все готово и можно идти дальше. Дальше запускаем скрипт из bash-a — ExecuteStreamCommand. Ии отправляем отчетик с помощью PutEmail всей комманде.
Подробно о скрипте, а также об опыте реализации аналитики Jira Software в нашей компании я поведаю в отдельной статье, которая уже на днях будет готова.
Кратко скажу, что разработанная нами отчетность дает стратегическое представление о том чем занимается подразделение или команда. А это бесценно для любого босса, согласитесь.
Зачем изнурять себя если можно сразу сделать все это скриптом, — спросите вы. Да, согласна, но частично.
Apache NiFi не упрощает процесс разработки, он упрощает процесс эксплуатации. Мы можем в любой момент остановить любой поток, внести правку и запустить заново.
Кроме того, NiFi дает нам взгляд сверху на процессы, которыми живет компания. В соседней группе у меня будет другой скрипт. В еще одной будет процесс моего коллеги. Улавливаете, да? Архитектура на ладони. Как подшучивает наш босс — мы внедряем Apache NiFi, чтобы потом вас всех уволить, а я один нажимал на кнопки. Но это шутка.
Ну а в данном примере, плюшки в виде задачи расписания для генерации отчетности и рассылка писем — также весьма и весьма приятны.
Признаюсь, планировала еще поизливать вам душу и рассказать о граблях на которые я наступила в процессе изучения технологии — их ого сколько. Но тут и так уже лонгрид. Если тема интересна, прошу, дайте знать. А пока, друзья, спасибо и жду вас в комментариях.
Гениальная статья, которая прямо на пальчиках и по буковкам освещает что такое Apache NiFi.
Краткое руководство на русском языке.
Крутая шпаргалка по Expression Language.
Англоязычное комьюнити Apache NiFi — открыто к вопросам.
Русскоязычное сообщество Apache NiFi в Telegram — живее всех живых, заходите.
Должна отметить, что спустя месяц после знакомства с этой технологией — я начала употреблять антидепрессанты. Был ли NiFi триггером или последней каплей достоверно неизвестно, как и его причастность к данному факту. Но, раз уж, я взялась изложить все, что ждет потенциального новичка на этом пути — я должна быть максимально откровеннной.
В тот час, когда технически Apache NiFi — мощное связующее звено между различными сервисами (осуществляет обмен данными между ними, по пути позволяя их обогащать и модифицировать), смотрю я на него с точки зрения аналитика. А все потому, что NiFi весьма удобный инструмент для ETL. В часности, в команде мы ориентируемся на построение им SaaS архитектуры.
Опыт автоматизации одного из своих рабочих процессов, а именно формирование и рассылка еженедельной отчетности по Jira Software, я и хочу раскрыть в данной статье. К слову, методику аналитики таск-треккера, которая наглядно отвечает на вопрос — а чем же занимаются сотрудники — я также опишу и опубликую в ближайшее время.
Несмотря на посвящение данной статьи новичкам, считаю правильным и полезным если более опытные архитекторы (гуру, так скажем) отрецензируют ее в кромментариях или поделятся своими кейсами использования NiFi в различных сферах деятельности. Много ребят, включая меня, скажет вам спасибо.
Концепция Apache NiFi — кратко.
Apache NiFi — opensource продукт для автоматизации и управления потоками данных между системами. Приступая к нему важно сразу осознать две вещи.
Первое — это зона Low Code. Что я имею ввиду? Предполагается, что все манипуляции с данными с момента их попадания в NiFi вплоть до извлечения можно выполнить его стандартными инструментами (процессорами). Для особых случаев существует процессор для запуска скриптов из bash-а.
Это говорит о том, что сделать что-то в NiFi неправильно — довольно сложно (но мне удалось! — об этом второй пункт). Сложно потому, что любой процессор будет прямо таки пинать тебя — А куда отправлять ошибки? А что с ними делать? А сколько ждать? А тут ты выделил мне маловато места! А ты докумментацию точно внимательно читал? и т.д.
Второе (ключевое) — это концепция потокового программирования, и только. Тут, я лично, не сразу врубилась (прошу, не судите). Имея опыт функционального программирования на R, я неосознанно формировала функции и в NiFi. В конечном счете — переделывай — сказали мне коллеги, когда увидели мои тщетные попытки эти «функции» подружить.
Думаю, хватит на сегодня теории, лучше узнаем все из практики. Давайте сформулируем подобие ТЗ для недельной аналитики Jira.
- Достать из жиры ворклог и историю изменений за неделю.
- Вывести базовую статистику за этот период и дать ответ на вопрос: чем же занималась команда?
- Отправить отчет боссу и коллегам.
Дабы принести миру больше пользы, я не остановилась на недельном периоде и разрабатывала процесс с возможностью выгрузки гораздо большего объема данных.
Давайте же разбираться.
Первые шаги. Забор данных из API
В Apache NiFi нету такого понятия как отдельный проект. У нас есть только общее рабочее пространство и возможность формирования в нем групп процессов. Этого вполне достаточно.
Находим в панели инструментов Process Group и создаем группу Jira_report.
Идем в группу и начинаем строить поток (workflow). Большинство процессоров из которых его можно собрать требуют Upstream Connection. Простыми словами это триггер, по которому процессор будет срабатывать. Потому логично, что и весь поток будет начинаться с обычного триггера — в NiFi это процессор GenerateFlowFile.
Что он делает. Создает потоковый файл, который состоит из набора атрибутов и контента. Атрибуты — это строковые пары ключ / значение, которые ассоциируются с контентом.
Контент — обычный файл, набор байтов. Представьте что контент это аттач к FlowFile.
Делаем Add Processor →GenerateFlowFile. В настройках, в первую очередь, настоятельно рекомендую задать имя процессора (это хороший тон) — вкладка Settings. Еще момент: по умолчанию GenerateFlowFile генерит потоковые файлы непрерывно. Вряд ли это вам когда-нибуть понадобится. Сразу увеличиваем Run Schedule, к примеру до 60 sec — вкладка Scheduling.
Также на вкладке Properties укажем дату начала отчетного периода — атрибут report_from со значением в формате — yyyy/mm/dd.
Согласно документации Jira API, у нас есть ограничение на выгрузку issues — не больше 1000. Потому, чтобы получить все таски, мы должны будем сформировать JQL запрос, в котором указываются параметры пагинации: startAt и maxResults.
Зададим их атрибутами с помощью процессора UpdateAttribute. Заодно прикрутим и дату генерации отчета. Она понадобится нам позже.
Вы наверняка обратили внимание на атрибут actual_date. Его значение задано с помощью Expression Language. Ловите крутую шпаргалку по нему.
Все, можем формировать JQL к жире — укажем параметры пагинации и нужные поля. В последующем он будет телом HTTP запроса, следовательно, отправим его в контент. Для этого используем процессор ReplaceText и укажем его Replacement Value примерно таким:
{"startAt": ${startAt}, "maxResults": ${maxResults}, "jql": "updated >= '2020/11/02'", "fields":["summary", "project", "issuetype", "timespent", "priority", "created", "resolutiondate", "status", "customfield_10100", "aggregatetimespent", "timeoriginalestimate", "description", "assignee", "parent", "components"]}Обратите внимание как прописываются ссылки на атрибуты.
Поздравляю, мы готовы делать HTTP запрос. Тут впору будет процессор InvokeHTTP. Кстати он может по всякому… Я имею ввиду методы GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS. Модифицируем его свойства следующим образом:
HTTP Method у нас POST.
Remote URL нашей жиры включает IP, порт и приставочку /rest/api/2/search?jql=.
Basic Authentication Username и Basic Authentication Password — это креды к жире.
Меняем Content-Type на application/json b ставим true в Send Message Body, что значит переслать JSON, который прийдет из предыдущего процессора в теле запроса.
APPLY.
Ответом апишки будет JSON файл, который попадет в контент. В нем нам интересны две вещи: поле total cодержащее общее количество тасок в системе и массив issues, в котором уже лежит часть из них. Распарсим же ответочку и познакомимся с процессором EvaluateJsonPath.
В случае, когда JsonPath указывает на один обьект, результат парсинга будет записан в атрибут флоу файла. Тут пример — поле total и следующий скрин.
В случае же, когда JsonPath указывает на массив обьектов, в результате парсинга флоу файл будет разбит на множество с контентом соответствующим каждому обьекту. Тут пример — поле issue. Ставим еще один EvaluateJsonPath и прописываем: Property — issue, Value — $.issue.
Теперь наш поток будет состоять теперь не из одного файла, а из множества. В контенте каждого из них будет находиться JSON с инфо об одной конкретной таске.
Идем дальше. Помните, мы указали maxResults равным 100? После предыдущего шага у нас будет сто первых тасок. Получим же больше и реализуем пагинацию.
Для этого увеличим номер стартовой таски на maxResults. Снова заюзаем UpdateAttribute: укажем атрибут startAt и пропишем ему новое значение ${startAt:plus(${maxResults})}.
Ну и без проверки на достижение максимума тасок не обойдемся — процессор RouteOnAttribute. Настройки следующие:
И зациклим. Итого, цикл будет работать, пока номер стартовой таски меньше чем общее к-во тасок. На выходе из него — поток тасок. Вот как процесс выглядит сейчас:
Да, друзья, знаю — вы подустали читать мои каменты к каждому квадратику. Вам хочется понять сам принцип. Ничего не имею против.
Данный раздел, должен облегчить абсолютному новичку этап вхождения в NiFi. Дальше же, имея на руках, щедро подаренный мною шаблон — вникнуть в детали не составит труда.
Галопом по Европам. Выгрузка ворклога и др.
Ну, что, ускоримся. Как говорится, найдите отличия:
Для более легкого восприятия, процесс выгрузки ворклога и истории изменений я вынесла в отдельную группу. Вот и она:
Чтобы обойти ограничения при автоматической выгрузке ворклога из Jira, целесообразно обращаться к каждой таске отдельно. Потому нам нужны их ключи. Первый столбец как раз и преобразует поток тасок в поток ключей. Далее обращаемся к апишке и сохраняем ответ.
Нам удобно будет оформить worklog и changelog по всем таскам в виде отдельных документов. Поэтому, воспользуемся процессором MergeContent и склеим им содержимое всех флоу файлов.
Также в шаблоне вы заметите группу для выгрузки данных по эпикам. Эпик в Jira — это обычная таска, к которой привязывается множество других. Данная группа будет полезна в случае когда добывается лишь часть задач, чтобы не потерять информацию об эпиках некоторых из них.
Заключительный этап. Генерация отчета и отправка по Email
Окей. Тасочки все выгрузились и отправились двумя путями: в группу для выгрузки ворклога и к скрипту для генерации отчета. К последнему у нас STDIN один, поэтому нам необходимо собрать все задачи в одну кучу. Сделаем это в MergeContent, но перед этим чуть подправим контент, чтобы итоговый json получился корректным.
Перед квадратиком генерации скрипта (ExecuteStreamCommand) присутствует интересный процессор Wait. Он ожидает сигнала от процессора Notify, который находиться в группе выгрузки ворклога, о том что там уже все готово и можно идти дальше. Дальше запускаем скрипт из bash-a — ExecuteStreamCommand. Ии отправляем отчетик с помощью PutEmail всей комманде.
Подробно о скрипте, а также об опыте реализации аналитики Jira Software в нашей компании я поведаю в отдельной статье, которая уже на днях будет готова.
Кратко скажу, что разработанная нами отчетность дает стратегическое представление о том чем занимается подразделение или команда. А это бесценно для любого босса, согласитесь.
Послесловие
Зачем изнурять себя если можно сразу сделать все это скриптом, — спросите вы. Да, согласна, но частично.
Apache NiFi не упрощает процесс разработки, он упрощает процесс эксплуатации. Мы можем в любой момент остановить любой поток, внести правку и запустить заново.
Кроме того, NiFi дает нам взгляд сверху на процессы, которыми живет компания. В соседней группе у меня будет другой скрипт. В еще одной будет процесс моего коллеги. Улавливаете, да? Архитектура на ладони. Как подшучивает наш босс — мы внедряем Apache NiFi, чтобы потом вас всех уволить, а я один нажимал на кнопки. Но это шутка.
Ну а в данном примере, плюшки в виде задачи расписания для генерации отчетности и рассылка писем — также весьма и весьма приятны.
Признаюсь, планировала еще поизливать вам душу и рассказать о граблях на которые я наступила в процессе изучения технологии — их ого сколько. Но тут и так уже лонгрид. Если тема интересна, прошу, дайте знать. А пока, друзья, спасибо и жду вас в комментариях.
Полезные ссылки
Гениальная статья, которая прямо на пальчиках и по буковкам освещает что такое Apache NiFi.
Краткое руководство на русском языке.
Крутая шпаргалка по Expression Language.
Англоязычное комьюнити Apache NiFi — открыто к вопросам.
Русскоязычное сообщество Apache NiFi в Telegram — живее всех живых, заходите.


