Самый известный алгоритм для нахождения всех простых чисел, не больших заданного, – решето Эратосфена. Он замечательно работает для чисел до миллиардов, может быть, до десятков миллиардов, если аккуратно написан. Однако каждый, кто любит развлекаться с простыми числами, знает, что их всегда хочется иметь под рукой как можно больше. Как-то раз мне для решения одной задачи на хакерранке понадобилась in-memory база данных простых чисел до ста миллиардов. При максимальной оптимизации по памяти, если в решете Эратосфена представлять нечетные числа битовым массивом, его размер будет около 6 гигабайт, что в память моего ноутбука не влезало. Существует модификация алгоритма, гораздо менее требовательная по памяти (делящая исходный диапазон чисел на несколько кусков и обрабатывающая по одному куску за раз) – сегментированное решето Эратосфена, но она сложнее в реализации, и результат целиком в память все равно не влезет. Ниже предлагаю вашему вниманию алгоритм почти такой же простой, как и решето Эратосфена, но дающий двукратную оптимизацию по памяти (то есть, база данных простых чисел до ста миллиардов будет занимать около 3 гигабайт, что уже должно влезать в память стандартного ноутбука).
Для начала вспомним, как работает решето Эратосфена: в массиве чисел от 1 до N вычеркиваются числа, делящиеся на два, потом числа, делящиеся на 3, и так далее. Оставшиеся после вычеркивания числа и будут простыми:
2 3 . 5 . 7 . 9 . 11 . 13 . 15 . 17 . 19 . 21 . 23 . 25 . 27 . 29 ...
2 3 . 5 . 7 . . . 11 . 13 . . . 17 . 19 . . . 23 . 25 . . . 29 ...
2 3 . 5 . 7 . . . 11 . 13 . . . 17 . 19 . . . 23 . . . . . 29 ...
Код на c#
class EratospheneSieve
{
private bool[] Data;
public EratospheneSieve(int length)
{
Data = new bool[length];
for (int i = 2; i < Data.Length; i++) Data[i] = true;
for (int i = 2; i * i < Length; i++)
{
if (!Data[i]) continue;
for (int d = i * i; d < Length; d += i) Data[d] = false;
}
}
public int Length => Data.Length;
public bool IsPrime(int n) => Data[n];
}
На моем ноутбуке до миллирарда считает 15 секунд и потребляет гигабайт памяти.
Алгоритм, который мы будем использовать, называется Wheel Factorization. Чтобы понять его суть, напишем натуральные числа табличкой по 30 штук в ряд:
0 1 2 3 4 5 ... 26 27 28 29
30 31 32 33 34 35 ... 56 57 58 59
60 61 62 63 64 65 ... 86 87 88 89
...
И вычеркнем все числа, делящиеся на 2, 3, и 5:
. 1 . . . . . 7 . . . 11 . 13 . . . 17 . 19 . . . 23 . . . . . 29
. 31 . . . . . 37 . . . 41 . 43 . . . 47 . 49 . . . 53 . . . . . 59
. 61 . . . . . 67 . . . 71 . 73 . . . 77 . 79 . . . 83 . . . . . 89
...
Видно, что в каждом ряду вычеркиваются числа на одних и тех же позициях. Так как мы вычеркивали только составные числа (за исключением, собственно, чисел 2, 3, 5), то простые числа могут быть только на невычеркнутых позициях.
Так как в каждом ряду таких чисел восемь, это дает нам идею представлять каждую тридцатку чисел одним байтом, каждый из восьми бит которого будет обозначать простоту числа на соответствующей позиции. Это совпадение не только эстетически красиво, но и сильно упрощает реализацию алгоритма!

Техническая реализация
Во-первых, наша цель – дойти до ста миллиардов, поэтому четырехбайтными числами уже не обойтись. Поэтому наш алгоритм будет выглядеть как-то так:
class Wheel235
{
private byte[] Data;
public Wheel235(long length)
{
...
}
public bool IsPrime(long n)
{
...
}
...
}
Для простоты реализации, будем округлять length вверх до ближайшего числа, делящегося на 30. Тогда
class Wheel235
{
private byte[] Data;
public Wheel235(long length)
{
// ensure length divides by 30
length = (length + 29) / 30 * 30;
Data = new byte[length/30];
...
}
public long Length => Data.Length * 30L;
...
}
Далее, нам нужны два массива: один переводит индекс 0..29 в номер бита, второй, наоборот, номер бита в позицию в тридцатке. Используя эти массивы и немного битовой арифметики, мы строим однозначное соответствие между натуральными числами и битами в массива Data. Для простоты мы используем только два метода: IsPrime(n), позволяющий узнать, является ли число простым, и ClearPrime(n), устанавливающий соответствующий бит в 0, маркируя число n как составное:
class Wheel235
{
private static int[] BIT_TO_INDEX = new int[] { 1, 7, 11, 13, 17, 19, 23, 29 };
private static int[] INDEX_TO_BIT = new int[] {
-1, 0,
-1, -1, -1, -1, -1, 1,
-1, -1, -1, 2,
-1, 3,
-1, -1, -1, 4,
-1, 5,
-1, -1, -1, 6,
-1, -1, -1, -1, -1, 7,
};
private byte[] Data;
...
public bool IsPrime(long n)
{
if (n <= 5) return n == 2 || n == 3 || n == 5;
int bit = INDEX_TO_BIT[n % 30];
if (bit < 0) return false;
return (Data[n / 30] & (1 << bit)) != 0;
}
private void ClearPrime(long n)
{
int bit = INDEX_TO_BIT[n % 30];
if (bit < 0) return;
Data[n / 30] &= (byte)~(1 << bit);
}
}
Заметим, что, если число делится на 2, 3 или 5, то номер бита будет -1, что означает, что число заведомо составное. Ну и, конечно, мы обрабатываем специальный случай n <= 5.
Теперь, собственно, сам алгоритм, который практически дословно повторяет решето Эратосфена:
public Wheel235(long length)
{
length = (length + 29) / 30 * 30;
Data = new byte[length / 30];
for (long i = 0; i < Data.Length; i++) Data[i] = byte.MaxValue;
for (long i = 7; i * i < Length; i++)
{
if (!IsPrime(i)) continue;
for (long d = i * i; d < Length; d += i) ClearPrime(d);
}
}
Соответственно, целиком получившийся класс:
выглядит так
class Wheel235
{
private static int[] BIT_TO_INDEX = new int[] { 1, 7, 11, 13, 17, 19, 23, 29 };
private static int[] INDEX_TO_BIT = new int[] {
-1, 0,
-1, -1, -1, -1, -1, 1,
-1, -1, -1, 2,
-1, 3,
-1, -1, -1, 4,
-1, 5,
-1, -1, -1, 6,
-1, -1, -1, -1, -1, 7,
};
private byte[] Data;
public Wheel235(long length)
{
// ensure length divides by 30
length = (length + 29) / 30 * 30;
Data = new byte[length / 30];
for (long i = 0; i < Data.Length; i++) Data[i] = byte.MaxValue;
for (long i = 7; i * i < Length; i++)
{
if (!IsPrime(i)) continue;
for (long d = i * i; d < Length; d += i) ClearPrime(d);
}
}
public long Length => Data.Length * 30L;
public bool IsPrime(long n)
{
if (n >= Length) throw new ArgumentException("Number too big");
if (n <= 5) return n == 2 || n == 3 || n == 5;
int bit = INDEX_TO_BIT[n % 30];
if (bit < 0) return false;
return (Data[n / 30] & (1 << bit)) != 0;
}
private void ClearPrime(long n)
{
int bit = INDEX_TO_BIT[n % 30];
if (bit < 0) return;
Data[n / 30] &= (byte)~(1 << bit);
}
}
Есть только одна маленькая проблемка: этот код не работает для чисел, больших примерно 65 миллиардов! При попытке её запустить с такими числами программа падает с ошибкой:
Unhandled Exception: System.OverflowException: Array dimensions exceeded supported range.
Проблема в том, что в c# массивы не могут иметь больше 2^31 элементов (видимо, потому что внутренняя имплементация использует четырехбайтный индекс массива). Один из вариантов – вместо массива byte[] создавать, например, массив long[], но это немного усложнит битовую арифметику. Для простоты мы пойдем другим путем, создав специальный класс, симулирующий нужный массив, держащий внутри два коротких массива. Заодно мы ему дадим возможность сохранять себя на диск, чтобы можно было один раз вычислить простые числа, и потом пользоваться базой повторно:
class LongArray
{
const long MAX_CHUNK_LENGTH = 2_000_000_000L;
private byte[] firstBuffer;
private byte[] secondBuffer;
public LongArray(long length)
{
firstBuffer = new byte[Math.Min(MAX_CHUNK_LENGTH, length)];
if (length > MAX_CHUNK_LENGTH) secondBuffer = new byte[length - MAX_CHUNK_LENGTH];
}
public LongArray(string file)
{
...
}
public long Length => firstBuffer.LongLength + (secondBuffer == null ? 0 : secondBuffer.LongLength);
public byte this[long index]
{
get => index < MAX_CHUNK_LENGTH ? firstBuffer[index] : secondBuffer[index - MAX_CHUNK_LENGTH];
set
{
if (index < MAX_CHUNK_LENGTH) firstBuffer[index] = value;
else secondBuffer[index - MAX_CHUNK_LENGTH] = value;
}
}
public void Save(string file)
{
...
}
}
Наконец, объединим все шаги в
окончательный вариант алгоритма
class Wheel235
{
class LongArray
{
const long MAX_CHUNK_LENGTH = 2_000_000_000L;
private byte[] firstBuffer;
private byte[] secondBuffer;
public LongArray(long length)
{
firstBuffer = new byte[Math.Min(MAX_CHUNK_LENGTH, length)];
if (length > MAX_CHUNK_LENGTH) secondBuffer = new byte[length - MAX_CHUNK_LENGTH];
}
public LongArray(string file)
{
using(FileStream stream = File.OpenRead(file))
{
long length = stream.Length;
firstBuffer = new byte[Math.Min(MAX_CHUNK_LENGTH, length)];
if (length > MAX_CHUNK_LENGTH) secondBuffer = new byte[length - MAX_CHUNK_LENGTH];
stream.Read(firstBuffer, 0, firstBuffer.Length);
if(secondBuffer != null) stream.Read(secondBuffer, 0, secondBuffer.Length);
}
}
public long Length => firstBuffer.LongLength + (secondBuffer == null ? 0 : secondBuffer.LongLength);
public byte this[long index]
{
get => index < MAX_CHUNK_LENGTH ? firstBuffer[index] : secondBuffer[index - MAX_CHUNK_LENGTH];
set
{
if (index < MAX_CHUNK_LENGTH) firstBuffer[index] = value;
else secondBuffer[index - MAX_CHUNK_LENGTH] = value;
}
}
public void Save(string file)
{
using(FileStream stream = File.OpenWrite(file))
{
stream.Write(firstBuffer, 0, firstBuffer.Length);
if (secondBuffer != null) stream.Write(secondBuffer, 0, secondBuffer.Length);
}
}
}
private static int[] BIT_TO_INDEX = new int[] { 1, 7, 11, 13, 17, 19, 23, 29 };
private static int[] INDEX_TO_BIT = new int[] {
-1, 0,
-1, -1, -1, -1, -1, 1,
-1, -1, -1, 2,
-1, 3,
-1, -1, -1, 4,
-1, 5,
-1, -1, -1, 6,
-1, -1, -1, -1, -1, 7,
};
private LongArray Data;
public Wheel235(long length)
{
// ensure length divides by 30
length = (length + 29) / 30 * 30;
Data = new LongArray(length / 30);
for (long i = 0; i < Data.Length; i++) Data[i] = byte.MaxValue;
for (long i = 7; i * i < Length; i++)
{
if (!IsPrime(i)) continue;
for (long d = i * i; d < Length; d += i) ClearPrime(d);
}
}
public Wheel235(string file)
{
Data = new LongArray(file);
}
public void Save(string file) => Data.Save(file);
public long Length => Data.Length * 30L;
public bool IsPrime(long n)
{
if (n >= Length) throw new ArgumentException("Number too big");
if (n <= 5) return n == 2 || n == 3 || n == 5;
int bit = INDEX_TO_BIT[n % 30];
if (bit < 0) return false;
return (Data[n / 30] & (1 << bit)) != 0;
}
private void ClearPrime(long n)
{
int bit = INDEX_TO_BIT[n % 30];
if (bit < 0) return;
Data[n / 30] &= (byte)~(1 << bit);
}
}
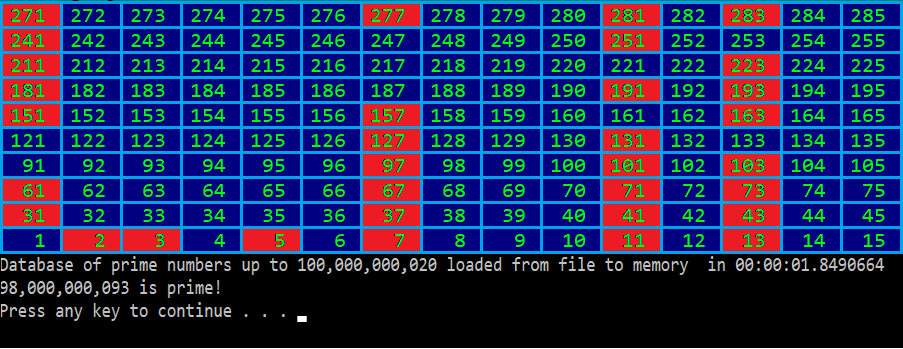
В результате, мы получили класс, который может вычислить простые числа, не превосходящие ста миллиардов, и сохранить результат на диск (у меня этот код на ноутбуке работал 50 минут; размер созданного файла получился примерно 3 гигабайта, как и ожидалось):
long N = 100_000_000_000L;
Wheel235 wheel = new Wheel235(N);
wheel.Save("./primes.dat");
А потом зачитать с диска и использовать:
DateTime start = DateTime.UtcNow;
Wheel235 loaded = new Wheel235("./primes.dat");
DateTime end = DateTime.UtcNow;
Console.WriteLine($"Database of prime numbers up to {loaded.Length:N0} loaded from file to memory in {end - start}");
long number = 98_000_000_093L;
Console.WriteLine($"{number:N0} is {(loaded.IsPrime(number) ? "prime" : "not prime")}!");

")
