
В статье показано, как в Go реализовать обработку ошибок и логирование по принципу "Сделал и забыл". Способ расчитан на микросервисы на Go, работающие в Docker-контейнере и построенные с соблюдением принципов Clean Architecture.
Эта статья является развёрнутой версией доклада с недавно прошедшего митапа по Go в Казани. Если вас интересует язык Go и вы живёте в Казани, Иннополисе, прекрасной Йошкар-Оле или в другом городе неподалёку, вам стоит посетить страницу сообщества: golangkazan.github.io.
На митапе наша команда в двух докладах показала, как мы разрабатываем микросервисы на Go — какие принципы соблюдаем и как упрощаем себе жизнь. Эта статья посвящена нашей концепции обработки ошибок, которую мы теперь распространяем на все наши новые микросервисы.
Соглашения о структуре микросервиса
Прежде чем коснуться правил обработки ошибок, стоит решить, какие ограничения мы соблюдаем при проектировании и кодировании. Для этого стоит рассказать, как выглядят наши микросервисы.
Прежде всего, мы соблюдаем чистую архитектуру. Код разделяем на три уровня и соблюдаем правило зависимостей: пакеты на более глубоком уровне не зависят от внешних пакетов и нет циклических зависимостей. К счастью, в Go прямые циклические зависимости пакетов запрещены. Косвенные зависимости через заимствование терминологии, предположения о поведении или приведение к типу всё ещё могут появиться, их следует избегать.
Так выглядят наши уровни:
- Уровень domain содержит правила бизнес-логики, продиктованные предметной областью
- иногда мы обходимся без domain, если задача простая
- правило: код на уровне domain зависит только от возможностей Go, стандартной библиотеки Go и избранных библиотек, расширяющих язык Go
- Уровень app содержит правила бизнес-логики, продиктованные задачами приложения
- правило: код на уровне app может зависеть от domain
- Уровень infrastructure содержит инфраструктурный код, связывающий приложение с различными технологиями для хранения (MySQL, Redis), транспорта (GRPC, HTTP), взаимодействия с внешним окружением и с другими сервисами
- правило: код на уровне infrastructure может зависеть от domain и app
- правило: только одна технология на один Go пакет
- Пакет main создаёт все объекты — "синглтоны времени жизни", связывает их между собой и запускает долгоживущие сопрограммы — например, начинает обрабатывать HTTP-запросы с порта 8081
Так выглядит дерево каталогов микросервиса (та часть, где лежит код на Go):

Для каждого из контекстов (модулей) приложения структура пакетов выглядит так:
- пакет app объявляет интерфейс Service, содержащий все возможные на данном уровне действия, реализующую интерфейс структуру service и функцию
func NewService(...) Service - изоляция работы с базой данных достигается за счёт того, что пакет domain или app объявляет интерфейс Repository, который реализуется на уровне инфраструктуры в пакете с наглядным названием "mysql"
- транспортный код располагается в пакете
infrastructure/transport
- мы используем GRPC, поэтому у нас из proto-файла генерируется server stubs (т.е. интерфейс сервера, структуры Response/Request и весь код взаимодействия с клиентами)
Всё это показано на диаграмме:

Принципы обработки ошибок
Тут всё просто:
- Мы считаем, что ошибки и паники возникают при обработке запросов к API — значит, ошибка или паника должна влиять только на один запрос
- Мы считаем, что логи нужны лишь для анализа инцидентов (а для отладки есть отладчик), поэтому в лог попадает информация о запросах, и прежде всего неожиданные ошибки при обработке запросов
- Мы считаем, что для обработки логов выстроена целая инфраструктура (например, на базе ELK) — и микросервис играет в ней пассивную роль, записывая логи в stderr
Мы не будем заострять внимание на паниках: просто не забывайте обрабатывать панику в каждой горутине и при обработке каждого запроса, каждого сообщения, каждой запущенной запросом асинхронной задачи. Почти всегда панику можно превратить в ошибку, чтобы не дать завершить всё приложение.
Идиома Sentinel Errors
На уровне бизнес-логики обрабатываются только ожидаемые ошибки, определённые бизнес-правилами. Определить такие ошибки вам помогут Sentinel Errors — мы используем именно эту идиому вместо написания собственных типов данных для ошибок. Пример:
package app
import "errors"
var ErrNoCake = errors.New("no cake found")Здесь объявляется глобальная переменная, которую по нашему джентельменскому соглашению мы нигде не должны изменять. Если вам не нравятся глобальные перемменные и вы используете линтер для их обнаружения, то вы можете обойтись одними константами, как предлагает Dave Cheney в посте Constant errors:
package app
type Error string
func (e Error) Error() string {
return string(e)
}
const ErrNoCake = Error("no cake found")Если вам по нраву такой подход, возможно, вам стоит добавить в свою корпоративную библиотеку языка Go тип ConstError.Композиция ошибок
Главное преимущество Sentinel Errors — возможность легко выполнять композицию ошибок. В частности, при создании ошибки или при получении ошибки извне хорошо бы добавлять к ней stacktrace. Для таких целей есть два популярных решения
- пакет xerrors, который в Go 1.13 войдёт в стандартную библиотеку в качестве эксперимента
- пакет github.com/pkg/errors авторства Dave Cheney
- пакет заморожен и не расширяется, но тем не менее он хорош
Наша команда пока ещё использует github.com/pkg/errors и функции errors.WithStack (когда нам нечего добавить, кроме stacktrace) либо errors.Wrap (когда нам есть что сказать об этой ошибке). Обе функции принимают на вход ошибку и возвращают новую ошибку, но уже со stacktrace. Пример из инфраструктурного слоя:
package mysql
import "github.com/pkg/errors"
func (r *repository) FindOne(...) {
row := r.client.QueryRow(sql, params...)
switch err := row.Scan(...) {
case sql.ErrNoRows:
// Дополняем внешнюю ошибку текущим stacktrace
return nil, errors.WithStack(app.ErrNoCake)
}
}Мы рекомендуем каждую ошибку оборачивать только один раз. Это легко сделать, если следовать правилам:
- любые внешние ошибки оборачиваются один раз в одном из инфраструктурных пакетов
- любые ошибки, порождаемые правилами бизнес-логики, дополняются stacktrace в момент создания
Первопричина ошибки
Все ошибки ожидаемо делятся на ожидаемые и неожиданные. Чтобы обработать ожидаемую ошибку, вам нужно избавиться от последствий композиции. В пакетах xerrors и github.com/pkg/errors есть всё необходимое: в частности, в пакете errors есть функция errors.Cause, которая возвращает первопричину ошибки. Эта функция в цикле одну за другой извлекает более ранние ошибки, пока очередная извлечённая ошибка имеет метод Cause() error.
Пример, к котором мы извлекаем первопричину и прямо сравниваем её с sentinel error:
func (s *service) SaveCake(...) error {
state, err := s.repo.FindOne(...)
if errors.Cause(err) == ErrNoCake {
err = nil // No cake is OK, create a new one
// ...
} else if err != nil {
// ...
}
}Обработка ошибок в defer
Возможно, вы используете linter, который заставляет вас маниакально проверять все ошибки. В этом случае вас наверняка бесит, когда linter просит проверять ошибки методах .Close() и других методах, которые вы вызываете только в defer. Вы когда нибудь пробовали корректно обработать ошибку в defer, особенно если до этого была ещё одна ошибка? А мы — пробовали и спешим поделиться рецептом.
Представим, что у нас вся работа с БД происходит строго через транзакции. Согласно правилу зависимостей, уровни app и domain не должны прямо или косвенно зависеть от infrastructure и технологии SQL. Это означает, что на уровнях app и domain нет слова "транзакция".
Самое простое решение — заменить слово "транзакция" на что-то абстрактное; так рождается паттерн Unit of Work. В нашей реализации сервис в пакете app получает фабрику по интерфейсу UnitOfWorkFactory, и при выполнении каждой операции создаёт объект UnitOfWork, скрывающий за собой транзакцию. Объект UnitOfWork позволяет получить Repository.
Чтоб лучше понять использование Unit of Work, взгляните на диаграмму:
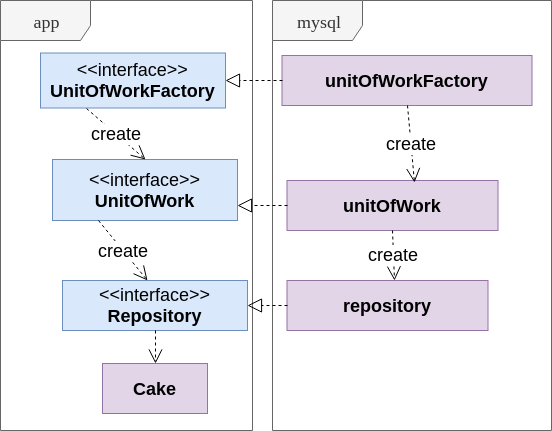
- Repository представляет абстрактную персистентную коллекцию объектов (например, аггрегатов уровня domain) опрелённого типа
- UnitOfWork скрывает за собой транзакцию и создаёт объекты Repository
- UnitOfWorkFactory просто позволяет сервису создавать новые транзакции, ничего не зная о транзакциях
Не является ли чрезмерным создание транзакции на каждую операцию, даже изначально атомарную? Вам решать; мы считаем, что сохранение независимости бизнес-логики важнее, чем экономия на создании транзакции.
Можно ли объединить UnitOfWork и Repository? Можно, но мы считаем, что это нарушит принцип Single Responsibility.
Так выглядт интерфейс:
type UnitOfWork interface {
Repository() Repository
Complete(err *error)
}Интефейс UnitOfWork предоставляет метод Complete, принимающий один in-out параметр: указатель на интерфейс error. Да, именно указатель, и именно in-out параметр — в любых других вариантах код на вызывающей стороне окажется гораздо более сложным.
Пример операции с unitOfWork:
Внимание: ошибка должна быть объявлена как named return value. Если вместо именованного возвращаемого значения err вы примените локальную переменную err, то использовать её в defer нельзя! И ни один linter этого пока не обнаружит — см. go-critic#801
func (s *service) CookCake() (err error) {
unitOfWork, err := s.unitOfWorkFactory.New()
if err != nil {
return err
}
defer unitOfWork.Complete(&err)
repo := unitOfWork.Repository()
}
// ... выполняем операциюТак реализуется завершение транзакции UnitOfWork:
func (u *unitOfWork) Complete(err *error) {
if *err == nil {
// Ошибки ранее не было - выполняем commit
txErr := u.tx.Commit()
*err = errors.Wrap(txErr, "cannot complete transaction")
} else {
// Ранее была ошибка - выполняем rollback
txErr := return u.tx.Rollback()
// При rollback могла произойти ошибка, выполняем слияние ошибок
*err = mergeErrors(*err, errors.Wrap(txErr,
"cannot rollback transaction"))
}
}Функция mergeErrors выполняет слияние двух ошибок, но без проблем обработает nil вместо одной или обоих ошибок. При этом мы считаем, что обе ошибки случились при выполнении одной операции на разных этапах, и первая ошибка является более важной — поэтому, когда обе ошибки не nil, мы сохраняем первую, а от второй ошибки сохраняем только сообщение:
package errors
func mergeErrors(err error, nextErr error) error {
if err == nil {
err = nextErr
} else if nextErr != nil {
err = errors.Wrap(err, nextErr.Error())
}
return err
}Возможно, вам стоит добавить функцию mergeErrors в свою корпоративную библиотеку для языка GoПодсистема логирования
Статья Чек-лист: что нужно было делать до того, как запускать микросервисы в prod советует:
- логи пишутся в stderr
- логи должны быть в JSON, по одному компактному JSON-объекту на строку
- должен быть стандартный набор полей:
- timestamp — время события с миллисекундами, желательно в формате RFC 3339 (пример: "1985-04-12T23:20:50.52Z")
- level — уровень важности, например, "info" или "error"
- app_name — имя приложения
- и другие поля
Мы предпочитаем к сообщениям об ошибке добавлять ещё два поля: "error" и "stacktrace".
Для языка Golang есть много качественных библиотек логирования, например, sirupsen/logrus, которую мы используем. Но мы не применяем библиотеку напрямую. В первую очередь, мы в своём пакете log сокращаем черезчур обширный интерфейс библиотеки до одного интерфейса Logger:
package log
type Logger interface {
WithField(string, interface{}) Logger
WithFields(Fields) Logger
Debug(...interface{})
Info(...interface{})
Error(error, ...interface{})
}Если программист хочет писать логи, он должен получать извне интерфейс Logger, причём делать это следует на уровне инфраструктуры, а не app или domain. Интерфейс логгера лаконичен:
- он уменьшает количество уровей важности до debug, info и error, как советует статья Давайте поговорим о ведении логов
- он вводит особые правила для метода Error: метод всегда принимает объект ошибки
Такая строгость позволяет направить программистов в правильное русло: если кто-то хочет внести улучшение в саму систему ведения логов, он должен сделать это с учётом всей инфраструктуры их сбора и обработки, которая в микросервисе только начинается (а заканчивается обычно где-нибудь в Kibana и Zabbix).
Впрочем, в пакете log есть ещё один интерфейс, который позволяет прервать работу программы при фатальной ошибке и потому может использоваться только в пакете main:
package log
type MainLogger interface {
Logger
FatalError(error, ...interface{})
}Пакет jsonlog
Реализует интерфейс Logger наш пакет jsonlog, выполняющий настройку библиотеки logrus и абстрагирующий работу с ней. Схематично выглядит так:

Собственный пакет позволяет связать потребности микросервиса (выраженные интерфейсом log.Logger), возможности библиотеки logrus и особенности вашей инфраструктуры сборка логов.
Например, мы используем ELK (Elastic Search, Logstash, Kibana), и поэтому в пакете jsonlog мы:
- устанавливаем для logrus формат
logrus.JSONFormatter
- при этом задаём опцию FieldMap, с помощью которой превращаем поле
"time"в"@timestamp", а поле"msg"— в"message"
- при этом задаём опцию FieldMap, с помощью которой превращаем поле
- выбираем log level
- добавляем hook, извлекающий stacktrace из переданного в метод
Error(error, ...interface{})объекта ошибки
Микросервис инициализирует логгер в функции main:
func initLogger(config Config) (log.MainLogger, error) {
logLevel, err := jsonlog.ParseLevel(config.LogLevel)
if err != nil {
return nil, errors.Wrap(err, "failed to parse log level")
}
return jsonlog.NewLogger(&jsonlog.Config{
Level: logLevel,
AppName: "cookingservice"
}), nil
}Обработка ошибок и логирование с помощью Middleware
Мы переходим на GRPC в своих микросервисах на Go. Но даже если вы используете HTTP API, общие принципы вам подойдут.
Прежде всего, обработка ошибок и запись логов должны происходить на уровне infrastructure в пакете, отвечающем за транспорт, потому что именно он сочетает в себе знание правил транспортного протокола и знание методов интерфейса app.Service. Напомним, как выглядит взаимосвязь пакетов:

Обрабатывать ошибки и вести логи удобно с помощью паттерна Middleware (Middleware — это название паттерна Decorator в мире Golang и Node.js):
Куда следует добавлять Middleware? Сколько их должно быть?
Есть разные варианты добавления Middleware, выбирать вам:
- Вы можете декорировать интерфейс
app.Service, но мы не рекомендуем так делать, потому что данный интерфейс не получает информации транспортного уровня, такой как IP клиента - С GRPC вы можете повесить один обработчик на все запросы (точнее, два — unary и steam), но тогда все методы API будут логироваться в одинаковом стиле с одинаковым набором полей
- С GRPC генератор кода создаёт для нас интерфейс сервера, в котором мы вызываем метод
app.Service— именно этот интерфейс мы декорируем, потому что в нём есть информация уровня транспорта и возможность по-разному логировать разные методы API
Схематично выглядит так:
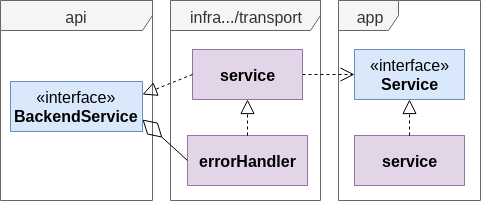
Вы можете создать разные Middleware для обработки ошибок (и panic) и для логирования. Можете скрестить всё в один. Мы рассмотрим пример, в котором всё скрещивается в один Middleware, который создаётся так:
func NewMiddleware(next api.BackendService, logger log.Logger) api.BackendService {
server := &errorHandlingMiddleware{
next: next,
logger: logger,
}
return server
}Мы получаем на вход интерфейс api.BackendService и декорируем его, возвращая на выходе свою реализацию интерфейса api.BackendService.
Произвольный метод API в Middleware реализуется так:
func (m *errorHandlingMiddleware) ListCakes(
ctx context.Context, req *api.ListCakesRequest)
(*api.ListCakesResponse, error) {
start := time.Now()
res, err := m.next.ListCakes(ctx, req)
m.logCall(start, err, "ListCakes", log.Fields{
"cookIDs": req.CookIDs,
})
return res, translateError(err)
}Здесь мы выполняем три задачи:
- Вызываем метод ListCakes декорируемого объекта
- Вызываем свой метод
logCall, передавая в него всю важную информацию, в том числе индивидуально подобранный набор полей, попадающих в лог - В конце подменяем ошибку путём вызова translateError.
Трансляцию ошибок обсудим позже. А запись лога выполняет метод logCall, который просто вызывает правильный метод интерейса Logger:
func (m *errorHandlingMiddleware) logCall(start time.Time, err error, method string, fields log.Fields) {
fields["duration"] = fmt.Sprintf("%v", time.Since(start))
fields["method"] = method
logger := m.logger.WithFields(fields)
if err != nil {
logger.Error(err, "call failed")
} else {
logger.Info("call finished")
}
}Трансляция ошибок
Мы должны получить первопричину ошибки и превратить её в ошибку, понятную на транспортном уровне и задокументированную в API вашего сервиса.
В GRPC это просто — используйте функцию status.Errorf для создания ошибки с кодом статуса. Если у вас HTTP API (REST API), вы можете создать свой тип ошибки, о котором не должны знать уровни app и domain
В первом приближении трансляция ошибки выглядит так:
// !ПЛОХАЯ ВЕРСИЯ! - не обработает err типа status.Error
func translateError(err error) error {
switch errors.Cause(err) {
case app.ErrNoCake:
err = status.Errorf(codes.NotFound, err.Error())
default:
err = status.Errorf(codes.Internal, err.Error())
}
return err
}Декорируемый интерфейс при валидации входных аргументов может вернуть ошибку типа status.Status с кодом статуса, и первая версия translateError этот код статуса потеряет.
Смастерим улучшенную версию с помощью приведения к типу интерфейса (да здравствует утиная типизация!):
type statusError interface {
GRPCStatus() *status.Status
}
func isGrpcStatusError(er error) bool {
_, ok := err.(statusError)
return ok
}
func translateError(err error) error {
if isGrpcStatusError(err) {
return err
}
switch errors.Cause(err) {
case app.ErrNoCake:
err = status.Errorf(codes.NotFound, err.Error())
default:
err = status.Errorf(codes.Internal, err.Error())
}
return err
}Функция translateError создаётся индивидуально для каждого контекста (независимого модуля) в вашем микросервисе и транслирует ошибки бизнес-логики в ошибки транспортного уровня.
Подведём итоги
Мы предлагаем вам несколько правил обработки ошибок и работы с логами. Следовать им или нет, решать вам.
- Следуйте принципам Clean Architecture, не позволяйте прямо или косвенно нарушать правило зависимостей. Бизнес-логика должна зависеть только от языка программирования, а не от внешних технологий.
- Используйте пакет, предлагающий композицию ошибок и создание stacktrace. Например, "github.com/pkg/errors" или пакет xerrors, который скоро войдёт в стандартную библиотеку Go
- Не используйте в микросервисе сторонние библиотеки логирования — создайте свою библиотеку с пакетами log и jsonlog, которая скроет детали реализации логирования
- Используйте паттерн Middleware, чтобы обрабатывать ошибки и писать логи на транспортном направлении инфраструктурного уровня программы
Здесь мы ничего не говорили о технологиях трассировки запросов (например, OpenTracing), мониторинга метрик (например, производительности запросов к БД) и других вещах, подобных логированию. Вы и сами с этим разберётесь, мы в вас верим .




