
Напомню, что мы уже поговорили о блокировках отношений, о блокировках на уровне строк, о блокировках других объектов (включая предикатные), и о взаимосвязи разных типов блокировок.
Сегодня я заканчиваю этот цикл статьей про блокировки в оперативной памяти. Мы поговорим о спин-блокировках, легких блокировках и закреплении буфера, а также про средства мониторинга ожиданий и семплирование.
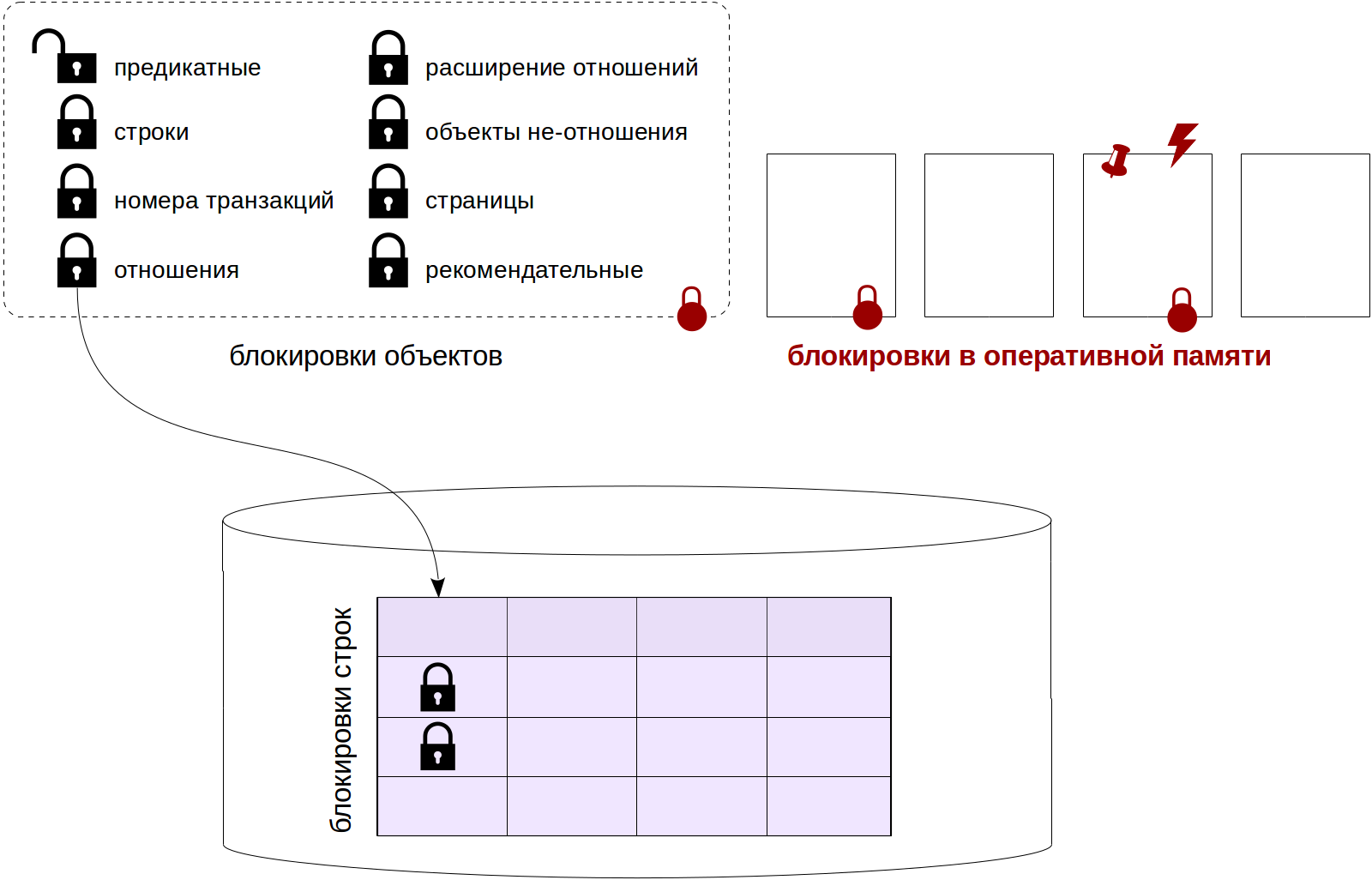
В отличие от обычных, «тяжелых» блокировок, для защиты структур в разделяемой оперативной памяти используются более легкие и дешевые (в смысле накладных расходов) блокировки.
Самые простые из них — спин-блокировки или спинлоки (spinlock). Они предназначены для захвата на очень короткое время (несколько инструкций процессора) и защищают отдельные участки памяти от одновременного изменения.
Спин-блокировки реализуются на основе атомарных инструкций процессора, таких, как compare-and-swap. Они поддерживают единственный исключительный режим. Если блокировка занята, ожидающий процесс выполняет активное ожидание — команда повторяется («крутится» в цикле, отсюда и название) до тех пор, пока не выполнится успешно. Это имеет смысл, поскольку спин-блокировки применяются в тех случаях, когда вероятность конфликта оценивается как очень низкая.
Спин-блокировки не обеспечивают обнаружения взаимоблокировок (за этим следят разработчики PostgreSQL) и не предоставляют никаких средств мониторинга. По большому счету, единственное, что мы можем сделать со спин-блокировками — знать о их существовании.
Следом идут так называемые легкие блокировки (lightweight locks, lwlocks).
Их захватывают на короткое время, которое требуется для работы со структурой данных (например, с хеш-таблицей или списком указателей). Как правило, легкая блокировка удерживается недолго, но в некоторых случаях легкие блокировки защищают операции ввода-вывода, так что в принципе время может оказаться и значительным.
Поддерживаются два режима: исключительный (для изменения данных) и разделяемый (только для чтения). Как таковой очереди ожидания нет: если несколько процессов ждут освобождения блокировки, один из них получит доступ более или менее случайным образом. В системах с высокой степенью параллельности и большой нагрузкой это может приводить к неприятным эффектам (см., например, обсуждение).
Механизма проверки взаимоблокировок не предусмотрено, это остается на совести разработчиков ядра. Однако легкие блокировки имеют средства для мониторинга, поэтому, в отличие от спин-блокировок, их можно «увидеть» (чуть позже я покажу, как).
Еще один вид блокировки, который мы уже рассматривали в статье про буферный кеш — закрепление буфера (buffer pin).
С закрепленным буфером можно выполнять разные действия, включая изменение данных, но с условием, что эти изменения не будут видны другим процессам благодаря многоверсионности. То есть, скажем, на страницу можно добавить новую строку, но нельзя заменить страницу в буфере на другую.
Если процессу мешает закрепление, он, как правило, просто пропускает такой буфер и выбирает другой. Но в некоторых случаях, когда требуется именно данный буфер, процесс встает в очередь и засыпает — система разбудит его, когда закрепление снимется.
Ожидания, связанные с закреплением, доступны для мониторинга.
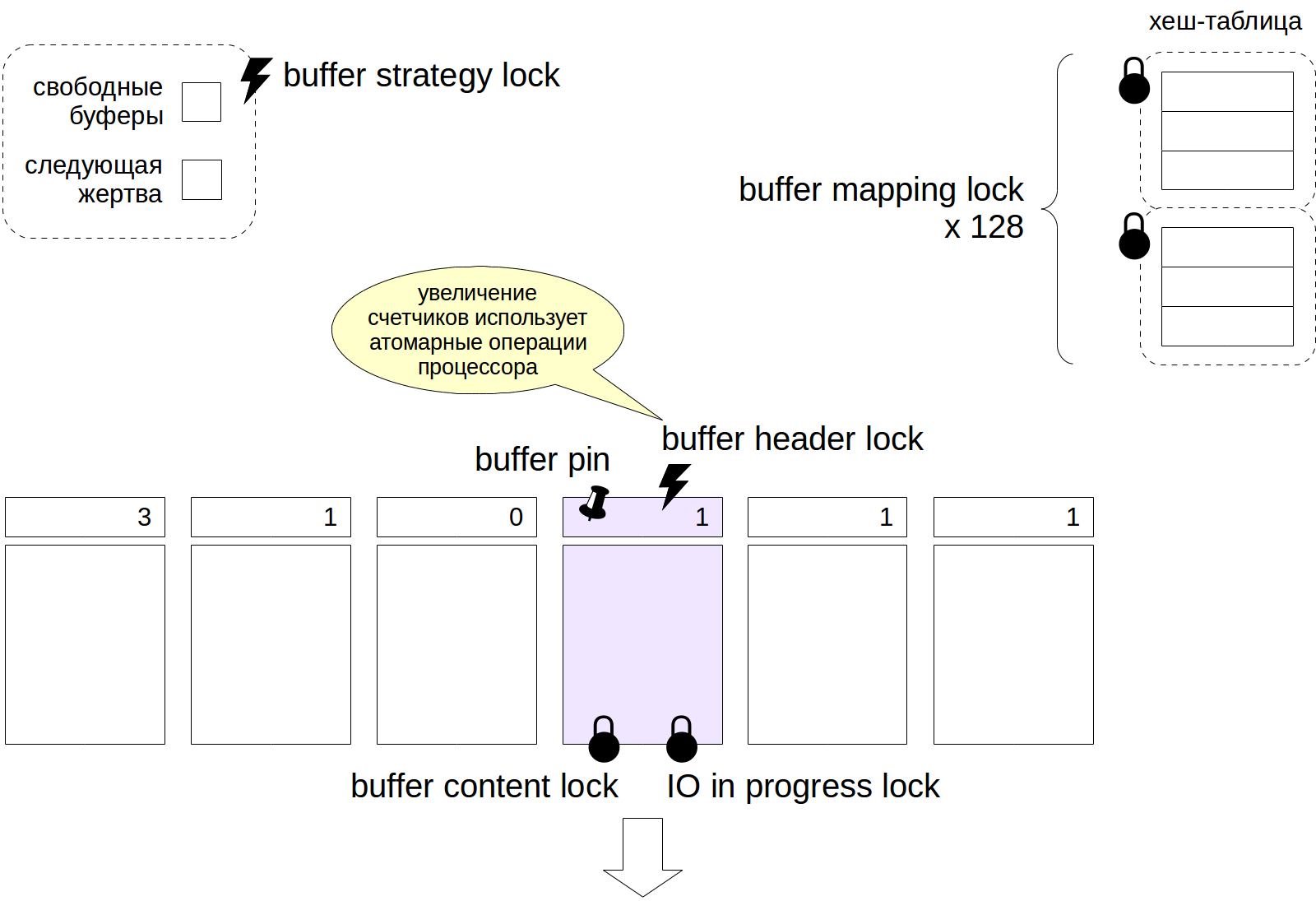
Теперь, чтобы получить некоторое (неполное!) представление о том, как и где используются блокировки, рассмотрим пример буферного кеша.
Чтобы обратиться к хеш-таблице, содержащей ссылки на буферы, процесс должен захватить легкую блокировку buffer mapping lock в разделяемом режиме, а если таблицу требуется изменять — то в исключительном режиме. Чтобы уменьшить гранулярность, эта блокировка устроена как транш, состоящий из 128 отдельных блокировок, каждая из которых защищает свою часть хеш-таблицы.
Доступ к заголовку буфера процесс получает с помощью спин-блокировки. Отдельные операции (такие как увеличение счетчика) могут выполняться и без явных блокировок с помощью атомарных инструкций процессора.
Чтобы прочитать содержимое буфера, требуется блокировка buffer content lock. Обычно она захватывается только на время, необходимое для чтения указателей на версии строк, а дальше достаточно защиты, предоставляемой закреплением буфера. Для изменения содержимого буфера эта блокировка должна захватываться в исключительном режиме.
При чтении буфера с диска (или записи на диск) захватывается также блокировка IO in progress, которая сигнализирует другим процессам, что страница читается (или записывается) — они могут встать в очередь, если им тоже нужно что-то сделать с этой страницей.
Указатели на свободные буферы и на следующую жертву защищены одной спин-блокировкой buffer strategy lock.
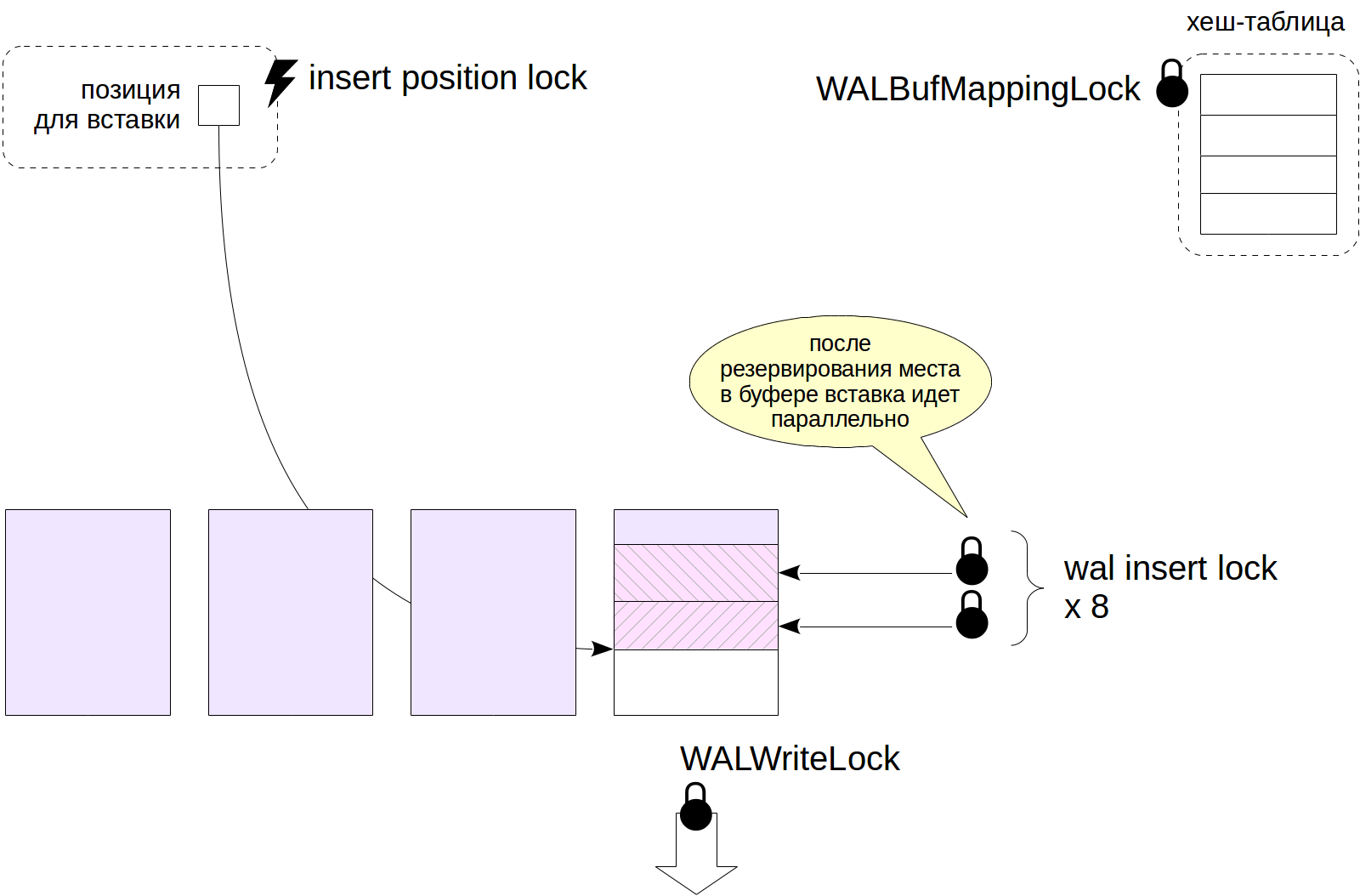
Еще один пример: буферы журнала.
Для журнального кеша тоже используется хеш-таблица, содержащая отображение страниц в буферы. В отличие от буферного кеша эта хеш-таблица защищена единственной легкой блокировкой WALBufMappingLock, поскольку размер журнального кеша меньше (обычно 1/32 буферного кеша) и обращение к буферам более упорядочено.
Запись страниц на диск защищена легкой блокировкой WALWriteLock, чтобы только один процесс одновременно мог выполнять эту операцию.
Чтобы создать журнальную запись, процесс должен сначала зарезервировать место в странице WAL. Для этого он захватывает спин-блокировку insert position lock. После того, как место зарезервировано, процесс копирует содержимое своей записи в отведенное место. Копирование может выполняться несколькими процессами одновременно, для чего запись защищена траншем из 8 легких блокировок wal insert lock (процесс должен захватить любую из них).
На рисунке представлены не все блокировки, имеющие отношение к журналу предзаписи, но этот и предыдущий пример должны дать некоторое представление об использовании блокировок в оперативной памяти.
Начиная с версии PostgreSQL 9.6 средства мониторинга ожиданий встроены в представление pg_stat_activity. Когда процесс (системный или обслуживающий) не может выполнять свою работу и ждет чего-либо, это ожидание можно увидеть в представлении: столбец wait_event_type показывает тип ожидания, а столбец wait_event — имя конкретного ожидания.
Следует учитывать, что представление показывает только те ожидания, которые соответствующим образом обрабатываются в исходном коде. Если представление не показывает ожидание, это вообще говоря не означает со 100-процентной вероятностью, что процесс действительно ничего не ждет.
К сожалению, единственная доступная информация об ожиданиях — информация на текущий момент. Никакой накопленной статистики не ведется. Единственный способ получить картину ожиданий во времени — семплирование состояния представления с определенным интервалом. Встроенных средств для этого не предусмотрено, но можно использовать расширения, например, pg_wait_sampling.
Надо учитывать вероятностный характер семплирования. Чтобы получить более или менее достоверную картину, число измерений должно быть достаточно велико. Семплирование с низкой частотой может не дать достоверной картины, а повышение частоты будет приводить к увеличению накладных расходов. По той же причине семплирование бесполезно для анализа короткоживущих сеансов.
Все ожидания можно разделить на несколько типов.
Ожидания рассмотренных блокировок составляют большую категорию:
Но процессы могут ожидать и другие события:
Бывают ситуации, когда процесс просто не выполняет полезной работы. К этой категории относятся:
Как правило, такие ожидания «нормальны» и не говорят о каких-либо проблемах.
Тип ожидания сопровождается именем конкретного ожидания. Полную таблицу можно посмотреть в документации.
Если имя ожидания не определено, процесс не находится в состоянии ожидания. Такое время следует считать неучтенным, так как на самом деле неизвестно, что именно происходит в этот момент.
Однако пора уже и посмотреть.
Видно, что все фоновые служебные процессы “бездельничают". Пустые значения в wait_event_type и wait_event говорят о том, что процесс ничего не ждет — в нашем случае обслуживающий процесс занят выполнением запроса.
Чтобы получить более или менее полную картину ожиданий с помощью семплирования, воспользуемся расширением pg_wait_sampling. Его необходимо собрать из исходных кодов; эту часть я опущу. Затем прописываем библиотеку в параметр shared_preload_libraries и перезапускаем сервер.
Теперь установим расширение в базе данных.
Расширение позволяет просмотреть историю ожиданий, которая хранится в кольцевом буфере. Но наиболее интересно увидеть профиль ожиданий — накопленную статистику за все время работы.
Вот что примерно мы увидим через несколько секунд:
Поскольку за прошедшее после запуска сервера время ничего не происходило, основные ожидания относятся к типу Activity (служебные процессы ждут, пока появится работа) и Client (psql ждет, пока пользователь пришлет запрос).
С установками по умолчанию (параметр pg_wait_sampling.profile_period) период семплирования равен 10 миллисекундам, то есть значения сохраняются 100 раз в секунду. Поэтому чтобы оценить длительность ожиданий в секундах, значение count надо делить на 100.
Чтобы понять, к какому процессу относятся ожидания, добавим к запросу представление pg_stat_activity:
Дадим нагрузку с помощью pgbench и посмотрим, как изменится картина.
Сбрасываем собранный профиль в ноль и запускаем тест на 30 секунд в отдельном процессе.
Запрос надо успеть выполнить, пока процесс pgbench еще не завершился:
Конечно, ожидания процесса pgbench будут получаться несколько разными в зависимости от конкретной системы. В нашем случае с большой вероятностью будет представлено ожидание записи журнала (IO/WALWrite), однако большую часть времени процесс не простаивал, а занимался чем-то предположительно полезным.
Всегда нужно помнить, что отсутствие какого-либо ожидания при семплинге не говорит о том, что ожидания не было. Если оно было короче, чем период семплирования (сотая часть секунды в нашем примере), то могло просто не попасть в выборку.
Поэтому легкие блокировки и не появились в профиле — но появятся, если собирать данные в течении длительного времени. Чтобы гарантированно посмотреть на них, можно искусственно замедлить работу файловой системы, например, использовать проект slowfs, построенный на файловой системе FUSE.
Вот что мы можем увидеть на том же тесте, если любая операция ввода-вывода будет занимать 1/10 секунды.
Теперь основное ожидание процесса pgbench связано с вводом-выводом, точнее с записью журнала, которая выполняется в синхронном режиме при каждой фиксации. Поскольку (как было показано в выше в одном из примеров) запись журнала на диск защищена легкой блокировкой WALWriteLock, эта блокировка также присутствует в профиле — как раз на нее мы и хотели посмотреть.
Чтобы увидеть закрепление буфера, воспользуемся тем фактом, что открытые курсоры удерживают закрепление, чтобы чтение следующей строки выполнялось быстрее.
Начнем транзакцию, откроем курсор и выберем одну строку.
Проверим, что буфер закреплен (pinning_backends):
Теперь выполним очистку таблицы:
Как мы видим, страница была пропущена (Skipped 1 page due to buffer pins). Действительно, очистка не может ее обработать, потому что из страницы в закрепленном буфере запрещено физически удалять версии строк. Но и ждать очистка не будет — страница будет обработана в следующий раз.
А теперь выполним очистку с заморозкой:
При явно запрошенной заморозке нельзя пропустить ни одну страницу, не отмеченную в карте заморозки — иначе невозможно уменьшить максимальный возраст незамороженных транзакций в pg_class.relfrozenxid. Поэтому очистка зависает до закрытия курсора.
Ну и посмотрим в профиль ожиданий второго сеанса psql, в котором выполнялись команды VACUUM:
Тип ожидания BufferPin говорит о том, что очистка ждала освобождения буфера.
На этом будем считать, что с блокировками мы завершили. Всем спасибо за внимание и за комментарии!
Сегодня я заканчиваю этот цикл статьей про блокировки в оперативной памяти. Мы поговорим о спин-блокировках, легких блокировках и закреплении буфера, а также про средства мониторинга ожиданий и семплирование.
Спин-блокировки
В отличие от обычных, «тяжелых» блокировок, для защиты структур в разделяемой оперативной памяти используются более легкие и дешевые (в смысле накладных расходов) блокировки.
Самые простые из них — спин-блокировки или спинлоки (spinlock). Они предназначены для захвата на очень короткое время (несколько инструкций процессора) и защищают отдельные участки памяти от одновременного изменения.
Спин-блокировки реализуются на основе атомарных инструкций процессора, таких, как compare-and-swap. Они поддерживают единственный исключительный режим. Если блокировка занята, ожидающий процесс выполняет активное ожидание — команда повторяется («крутится» в цикле, отсюда и название) до тех пор, пока не выполнится успешно. Это имеет смысл, поскольку спин-блокировки применяются в тех случаях, когда вероятность конфликта оценивается как очень низкая.
Спин-блокировки не обеспечивают обнаружения взаимоблокировок (за этим следят разработчики PostgreSQL) и не предоставляют никаких средств мониторинга. По большому счету, единственное, что мы можем сделать со спин-блокировками — знать о их существовании.
Легкие блокировки
Следом идут так называемые легкие блокировки (lightweight locks, lwlocks).
Их захватывают на короткое время, которое требуется для работы со структурой данных (например, с хеш-таблицей или списком указателей). Как правило, легкая блокировка удерживается недолго, но в некоторых случаях легкие блокировки защищают операции ввода-вывода, так что в принципе время может оказаться и значительным.
Поддерживаются два режима: исключительный (для изменения данных) и разделяемый (только для чтения). Как таковой очереди ожидания нет: если несколько процессов ждут освобождения блокировки, один из них получит доступ более или менее случайным образом. В системах с высокой степенью параллельности и большой нагрузкой это может приводить к неприятным эффектам (см., например, обсуждение).
Механизма проверки взаимоблокировок не предусмотрено, это остается на совести разработчиков ядра. Однако легкие блокировки имеют средства для мониторинга, поэтому, в отличие от спин-блокировок, их можно «увидеть» (чуть позже я покажу, как).
Закрепление буфера
Еще один вид блокировки, который мы уже рассматривали в статье про буферный кеш — закрепление буфера (buffer pin).
С закрепленным буфером можно выполнять разные действия, включая изменение данных, но с условием, что эти изменения не будут видны другим процессам благодаря многоверсионности. То есть, скажем, на страницу можно добавить новую строку, но нельзя заменить страницу в буфере на другую.
Если процессу мешает закрепление, он, как правило, просто пропускает такой буфер и выбирает другой. Но в некоторых случаях, когда требуется именно данный буфер, процесс встает в очередь и засыпает — система разбудит его, когда закрепление снимется.
Ожидания, связанные с закреплением, доступны для мониторинга.
Пример: буферный кеш
Теперь, чтобы получить некоторое (неполное!) представление о том, как и где используются блокировки, рассмотрим пример буферного кеша.
Чтобы обратиться к хеш-таблице, содержащей ссылки на буферы, процесс должен захватить легкую блокировку buffer mapping lock в разделяемом режиме, а если таблицу требуется изменять — то в исключительном режиме. Чтобы уменьшить гранулярность, эта блокировка устроена как транш, состоящий из 128 отдельных блокировок, каждая из которых защищает свою часть хеш-таблицы.
Доступ к заголовку буфера процесс получает с помощью спин-блокировки. Отдельные операции (такие как увеличение счетчика) могут выполняться и без явных блокировок с помощью атомарных инструкций процессора.
Чтобы прочитать содержимое буфера, требуется блокировка buffer content lock. Обычно она захватывается только на время, необходимое для чтения указателей на версии строк, а дальше достаточно защиты, предоставляемой закреплением буфера. Для изменения содержимого буфера эта блокировка должна захватываться в исключительном режиме.
При чтении буфера с диска (или записи на диск) захватывается также блокировка IO in progress, которая сигнализирует другим процессам, что страница читается (или записывается) — они могут встать в очередь, если им тоже нужно что-то сделать с этой страницей.
Указатели на свободные буферы и на следующую жертву защищены одной спин-блокировкой buffer strategy lock.
Пример: буферы журнала
Еще один пример: буферы журнала.
Для журнального кеша тоже используется хеш-таблица, содержащая отображение страниц в буферы. В отличие от буферного кеша эта хеш-таблица защищена единственной легкой блокировкой WALBufMappingLock, поскольку размер журнального кеша меньше (обычно 1/32 буферного кеша) и обращение к буферам более упорядочено.
Запись страниц на диск защищена легкой блокировкой WALWriteLock, чтобы только один процесс одновременно мог выполнять эту операцию.
Чтобы создать журнальную запись, процесс должен сначала зарезервировать место в странице WAL. Для этого он захватывает спин-блокировку insert position lock. После того, как место зарезервировано, процесс копирует содержимое своей записи в отведенное место. Копирование может выполняться несколькими процессами одновременно, для чего запись защищена траншем из 8 легких блокировок wal insert lock (процесс должен захватить любую из них).
На рисунке представлены не все блокировки, имеющие отношение к журналу предзаписи, но этот и предыдущий пример должны дать некоторое представление об использовании блокировок в оперативной памяти.
Мониторинг ожиданий
Начиная с версии PostgreSQL 9.6 средства мониторинга ожиданий встроены в представление pg_stat_activity. Когда процесс (системный или обслуживающий) не может выполнять свою работу и ждет чего-либо, это ожидание можно увидеть в представлении: столбец wait_event_type показывает тип ожидания, а столбец wait_event — имя конкретного ожидания.
Следует учитывать, что представление показывает только те ожидания, которые соответствующим образом обрабатываются в исходном коде. Если представление не показывает ожидание, это вообще говоря не означает со 100-процентной вероятностью, что процесс действительно ничего не ждет.
К сожалению, единственная доступная информация об ожиданиях — информация на текущий момент. Никакой накопленной статистики не ведется. Единственный способ получить картину ожиданий во времени — семплирование состояния представления с определенным интервалом. Встроенных средств для этого не предусмотрено, но можно использовать расширения, например, pg_wait_sampling.
Надо учитывать вероятностный характер семплирования. Чтобы получить более или менее достоверную картину, число измерений должно быть достаточно велико. Семплирование с низкой частотой может не дать достоверной картины, а повышение частоты будет приводить к увеличению накладных расходов. По той же причине семплирование бесполезно для анализа короткоживущих сеансов.
Все ожидания можно разделить на несколько типов.
Ожидания рассмотренных блокировок составляют большую категорию:
- ожидание блокировок объектов (значение Lock в столбце wait_event_type);
- ожидание легких блокировок (LWLock);
- ожидание закрепленного буфера (BufferPin).
Но процессы могут ожидать и другие события:
- ожидания ввода-вывода (IO) возникают, когда процессу требуется записать или прочитать данные;
- процесс может ждать данные, необходимые для работы, от клиента (Client) или от другого процесса (IPC);
- расширения могут регистрировать свои специфические ожидания (Extension).
Бывают ситуации, когда процесс просто не выполняет полезной работы. К этой категории относятся:
- ожидание фоновых процессов в своем основном цикле (Activity);
- ожидание таймера (Timeout).
Как правило, такие ожидания «нормальны» и не говорят о каких-либо проблемах.
Тип ожидания сопровождается именем конкретного ожидания. Полную таблицу можно посмотреть в документации.
Если имя ожидания не определено, процесс не находится в состоянии ожидания. Такое время следует считать неучтенным, так как на самом деле неизвестно, что именно происходит в этот момент.
Однако пора уже и посмотреть.
=> SELECT pid, backend_type, wait_event_type, wait_event
FROM pg_stat_activity;
pid | backend_type | wait_event_type | wait_event
-------+------------------------------+-----------------+---------------------
28739 | logical replication launcher | Activity | LogicalLauncherMain
28736 | autovacuum launcher | Activity | AutoVacuumMain
28963 | client backend | |
28734 | background writer | Activity | BgWriterMain
28733 | checkpointer | Activity | CheckpointerMain
28735 | walwriter | Activity | WalWriterMain
(6 rows)
Видно, что все фоновые служебные процессы “бездельничают". Пустые значения в wait_event_type и wait_event говорят о том, что процесс ничего не ждет — в нашем случае обслуживающий процесс занят выполнением запроса.
Семплирование
Чтобы получить более или менее полную картину ожиданий с помощью семплирования, воспользуемся расширением pg_wait_sampling. Его необходимо собрать из исходных кодов; эту часть я опущу. Затем прописываем библиотеку в параметр shared_preload_libraries и перезапускаем сервер.
=> ALTER SYSTEM SET shared_preload_libraries = 'pg_wait_sampling';
student$ sudo pg_ctlcluster 11 main restart
Теперь установим расширение в базе данных.
=> CREATE EXTENSION pg_wait_sampling;
Расширение позволяет просмотреть историю ожиданий, которая хранится в кольцевом буфере. Но наиболее интересно увидеть профиль ожиданий — накопленную статистику за все время работы.
Вот что примерно мы увидим через несколько секунд:
=> SELECT * FROM pg_wait_sampling_profile;
pid | event_type | event | queryid | count
-------+------------+---------------------+---------+-------
29074 | Activity | LogicalLauncherMain | 0 | 220
29070 | Activity | WalWriterMain | 0 | 220
29071 | Activity | AutoVacuumMain | 0 | 219
29069 | Activity | BgWriterMain | 0 | 220
29111 | Client | ClientRead | 0 | 3
29068 | Activity | CheckpointerMain | 0 | 220
(6 rows)
Поскольку за прошедшее после запуска сервера время ничего не происходило, основные ожидания относятся к типу Activity (служебные процессы ждут, пока появится работа) и Client (psql ждет, пока пользователь пришлет запрос).
С установками по умолчанию (параметр pg_wait_sampling.profile_period) период семплирования равен 10 миллисекундам, то есть значения сохраняются 100 раз в секунду. Поэтому чтобы оценить длительность ожиданий в секундах, значение count надо делить на 100.
Чтобы понять, к какому процессу относятся ожидания, добавим к запросу представление pg_stat_activity:
=> SELECT p.pid, a.backend_type, a.application_name AS app,
p.event_type, p.event, p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
ORDER BY p.pid, p.count DESC;
pid | backend_type | app | event_type | event | count
-------+------------------------------+------+------------+----------------------+-------
29068 | checkpointer | | Activity | CheckpointerMain | 222
29069 | background writer | | Activity | BgWriterMain | 222
29070 | walwriter | | Activity | WalWriterMain | 222
29071 | autovacuum launcher | | Activity | AutoVacuumMain | 221
29074 | logical replication launcher | | Activity | LogicalLauncherMain | 222
29111 | client backend | psql | Client | ClientRead | 4
29111 | client backend | psql | IPC | MessageQueueInternal | 1
(7 rows)
Дадим нагрузку с помощью pgbench и посмотрим, как изменится картина.
student$ pgbench -i test
Сбрасываем собранный профиль в ноль и запускаем тест на 30 секунд в отдельном процессе.
=> SELECT pg_wait_sampling_reset_profile();
student$ pgbench -T 30 test
Запрос надо успеть выполнить, пока процесс pgbench еще не завершился:
=> SELECT p.pid, a.backend_type, a.application_name AS app,
p.event_type, p.event, p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
WHERE a.application_name = 'pgbench'
ORDER BY p.pid, p.count DESC;
pid | backend_type | app | event_type | event | count
-------+----------------+---------+------------+------------+-------
29148 | client backend | pgbench | IO | WALWrite | 8
29148 | client backend | pgbench | Client | ClientRead | 1
(2 rows)
Конечно, ожидания процесса pgbench будут получаться несколько разными в зависимости от конкретной системы. В нашем случае с большой вероятностью будет представлено ожидание записи журнала (IO/WALWrite), однако большую часть времени процесс не простаивал, а занимался чем-то предположительно полезным.
Легкие блокировки
Всегда нужно помнить, что отсутствие какого-либо ожидания при семплинге не говорит о том, что ожидания не было. Если оно было короче, чем период семплирования (сотая часть секунды в нашем примере), то могло просто не попасть в выборку.
Поэтому легкие блокировки и не появились в профиле — но появятся, если собирать данные в течении длительного времени. Чтобы гарантированно посмотреть на них, можно искусственно замедлить работу файловой системы, например, использовать проект slowfs, построенный на файловой системе FUSE.
Вот что мы можем увидеть на том же тесте, если любая операция ввода-вывода будет занимать 1/10 секунды.
=> SELECT pg_wait_sampling_reset_profile();
student$ pgbench -T 30 test
=> SELECT p.pid, a.backend_type, a.application_name AS app,
p.event_type, p.event, p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
WHERE a.application_name = 'pgbench'
ORDER BY p.pid, p.count DESC;
pid | backend_type | app | event_type | event | count
-------+----------------+---------+------------+----------------+-------
29240 | client backend | pgbench | IO | WALWrite | 1445
29240 | client backend | pgbench | LWLock | WALWriteLock | 803
29240 | client backend | pgbench | IO | DataFileExtend | 20
(3 rows)
Теперь основное ожидание процесса pgbench связано с вводом-выводом, точнее с записью журнала, которая выполняется в синхронном режиме при каждой фиксации. Поскольку (как было показано в выше в одном из примеров) запись журнала на диск защищена легкой блокировкой WALWriteLock, эта блокировка также присутствует в профиле — как раз на нее мы и хотели посмотреть.
Закрепление буфера
Чтобы увидеть закрепление буфера, воспользуемся тем фактом, что открытые курсоры удерживают закрепление, чтобы чтение следующей строки выполнялось быстрее.
Начнем транзакцию, откроем курсор и выберем одну строку.
=> BEGIN;
=> DECLARE c CURSOR FOR SELECT * FROM pgbench_history;
=> FETCH c;
tid | bid | aid | delta | mtime | filler
-----+-----+-------+-------+----------------------------+--------
9 | 1 | 35092 | 477 | 2019-09-04 16:16:18.596564 |
(1 row)
Проверим, что буфер закреплен (pinning_backends):
=> SELECT * FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('pgbench_history')
AND relforknumber = 0 \gx
-[ RECORD 1 ]----+------
bufferid | 190
relfilenode | 47050
reltablespace | 1663
reldatabase | 16386
relforknumber | 0
relblocknumber | 0
isdirty | t
usagecount | 1
pinning_backends | 1 <-- буфер закреплен 1 раз
Теперь выполним очистку таблицы:
| => SELECT pg_backend_pid();
| pg_backend_pid
| ----------------
| 29367
| (1 row)
| => VACUUM VERBOSE pgbench_history;
| INFO: vacuuming "public.pgbench_history"
| INFO: "pgbench_history": found 0 removable, 0 nonremovable row versions in 1 out of 1 pages
| DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 732651
| There were 0 unused item pointers.
| Skipped 1 page due to buffer pins, 0 frozen pages.
| 0 pages are entirely empty.
| CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
| VACUUM
Как мы видим, страница была пропущена (Skipped 1 page due to buffer pins). Действительно, очистка не может ее обработать, потому что из страницы в закрепленном буфере запрещено физически удалять версии строк. Но и ждать очистка не будет — страница будет обработана в следующий раз.
А теперь выполним очистку с заморозкой:
| => VACUUM FREEZE VERBOSE pgbench_history;
При явно запрошенной заморозке нельзя пропустить ни одну страницу, не отмеченную в карте заморозки — иначе невозможно уменьшить максимальный возраст незамороженных транзакций в pg_class.relfrozenxid. Поэтому очистка зависает до закрытия курсора.
=> SELECT age(relfrozenxid) FROM pg_class WHERE oid = 'pgbench_history'::regclass;
age
-----
27
(1 row)
=> COMMIT; -- курсор закрывается автоматически
| INFO: aggressively vacuuming "public.pgbench_history"
| INFO: "pgbench_history": found 0 removable, 26 nonremovable row versions in 1 out of 1 pages
| DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 732651
| There were 0 unused item pointers.
| Skipped 0 pages due to buffer pins, 0 frozen pages.
| 0 pages are entirely empty.
| CPU: user: 0.00 s, system: 0.00 s, elapsed: 3.01 s.
| VACUUM
=> SELECT age(relfrozenxid) FROM pg_class WHERE oid = 'pgbench_history'::regclass;
age
-----
0
(1 row)
Ну и посмотрим в профиль ожиданий второго сеанса psql, в котором выполнялись команды VACUUM:
=> SELECT p.pid, a.backend_type, a.application_name AS app,
p.event_type, p.event, p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
WHERE p.pid = 29367
ORDER BY p.pid, p.count DESC;
pid | backend_type | app | event_type | event | count
-------+----------------+------+------------+------------+-------
29367 | client backend | psql | BufferPin | BufferPin | 294
29367 | client backend | psql | Client | ClientRead | 10
(2 rows)
Тип ожидания BufferPin говорит о том, что очистка ждала освобождения буфера.
На этом будем считать, что с блокировками мы завершили. Всем спасибо за внимание и за комментарии!

 с CRM Битрикс24")

