
Привет! Меня зовут Сергей Иванов, я ведущий разработчик Android в Redmadrobot. С 2016 использую автотесты различных категорий и успел в этом набить немало шишек. Именно поэтому решил поделиться опытом. Возможно, что кому-то статья поможет систематизировать знания или начать применять эту практику в работе.

Автоматизированное тестирование — одна из самых сложных и холиварных тем в сфере разработки ПО. По моим наблюдениям, немногие в сообществе пишут автотесты, а те, кто это делают, не всегда получают реальную пользу. Кроме того, подступиться к теме не так-то просто: материалы в основном разрозненные, не всегда актуальны для нужной платформы, а в чем-то и противоречивы. В общем, чтобы начать нормально писать тесты, нужно очень много искать и разбираться.
В статье подсвечу основные аспекты автоматизированного тестирования, его специфику на Android, дам рекомендации для решения популярных вопросов и эффективного внедрения практики на проекте — то, к чему я сам пришел на текущий момент.
Подробнее расскажу про тесты на JVM, а не про UI-тесты, о которых в последнее время пишут часто. Материал будет хорошей отправной точкой для изучения темы, а также поможет дополнить уже имеющиеся знания.
Дисклеймер: статья получилась большой, поэтому указал основные темы, которые рассмотрю.
базовые понятие автоматизированного тестирования;
категории тестов их специфика на Android;
как писать тестируемый код;
как и какие инструменты использовать для тестирования;
как писать полезные и поддерживаемые тесты;
что тестировать;
как и когда применять методологию Test Driven Development.
При производстве приложений автотесты помогают:
Находить баги на раннем этапе разработки. Это позволяет раньше устранять проблемы, при этом расходуя меньше ресурсов.
Локализовать проблему. Чем более низкоуровневым является тест, тем более точно он способен указать на причину ошибки.
Ускорить разработку. Это вытекает из предыдущих пунктов и из того, что благодаря автотестам разработка разных частей фичи может быть оперативно разделена на несколько разработчиков. Установив контракты между компонентами приложения, разработчик может разработать свой компонент и проверить его корректность при отсутствии остальных (например, при полном отсутствии UI).
Служат документацией. При правильном оформлении тестов и поддержке их в актуальном состоянии покрытый тестами код всегда будет иметь последовательную документацию. Это упростит его понимание новым разработчикам, а также поможет автору, забредшему в забытый уголок проекта спустя несколько месяцев.
Но есть и проблемы:
Нужно время на внедрение, написание и поддержку.
При некорректном внедрении практики могут принести больше вреда, чем пользы.
Важные базовые понятия автоматизированного тестирования
System Under Test (SUT) — тестируемая система. В зависимости от типа теста системой могут быть разные сущности (о них подробнее написал в разделе «категории тестов»).
Для различия уровня тестирования по использованию знаний о SUT существуют понятия:
Black box testing — тестирование SUT без знания о деталях его внутреннего устройства.
White box testing — тестирование SUT с учётом деталей его внутреннего устройства.
Выделяют также Gray box testing, комбинацию подходов, но ради упрощения он будет опущен.
Для обеспечения базового качества автотестов важно соблюдать некоторые правила написания. Роберт Мартин сформулировал в книге "Clean Code" глобальные принципы F.I.R.S.T.
Fast — тесты должны выполняться быстро.
Independent — тесты не должны зависеть друг от друга и должны иметь возможность выполняться в любом порядке.
Repeatable — тесты должны выполняться с одинаковым результатом независимо от среды выполнения.
Self-validating — тесты должны однозначно сообщать о том, успешно их прохождение или нет.
Timely — тесты должны создаваться своевременно. Unit-тесты пишутся непосредственно перед кодом продукта.
Структура теста состоит как минимум из двух логических блоков:
cовершение действия над SUT,
проверка результата действия.
Проверка результата заключается в оценке:
состояния SUT или выданного ею результата,
cостояний взаимодействующих с SUT объектов,
поведения (набор и порядок вызовов функций других объектов, которые должен совершить SUT, переданные в них аргументы).

При необходимости также добавляются блоки подготовки и сброса тестового окружения, отчасти связанные с первыми тремя принципам F.I.R.S.T.
Подготовка окружения заключается в создании SUT, установке исходных данных, состояний, поведения и др., необходимых для имитации ситуации, которую будет проверять тест.
На этапе сброса окружения может осуществляться очистка среды после выполнения теста для экономии ресурсов и исключения влияния одного теста на другой.
Зачастую для настройки окружения применяются тестовые дублеры.
Test doubles (Тестовые дублёры) — фиктивные объекты, заменяющие реальные объекты, от которых зависит SUT, для достижения целей теста.
Тестовые дублеры позволяют:
зафиксировать тестовое окружение, имитируя неважные, нереализованные, нестабильные или медленные внешние объекты (например, БД или сервер),
совершать проверки своих вызовов (обращений к функциям, свойствам).
Самая популярная классификация включает 5 видов тестовых дублеров, различных по своим свойствам: Dummy, Fake, Stub, Spy, Mock.
Stub — объект, который при вызовах его функций или свойств возвращает предустановленные (hardcoded) результаты, а не выполняет код реального объекта. Если же функция не имеет возвращаемого значения, то вызов просто игнорируется.
Mock — объект, позволяющий проверять поведение SUT путём отслеживания обращений к функциям и свойствам объекта: были ли в ходе теста вызваны функции мока, в правильном ли порядке, ожидаемые ли аргументы были в них переданы и т.д. Может также включать функциональность Stub.
Почитать об этих и остальных видах дублеров можно в первоисточнике.
Эта классификация не является стандартом, и в фреймворках для создания тестовых дублёров часто ради удобства API несколько типов обобщают термином Mock. А вот чем они на самом деле будут являться, зависит от их последующей конфигурации и применения в тесте. Например, при использовании фреймворка Mockito, экземпляр тестового дублера может быть создан как Dummy, а потом превращен в Stub и в Mock.
При именовании созданных с помощью фреймворка дублеров уместно использовать именования, продиктованные фреймворком. Вообще, в мировом сообществе многие оперируют термином Mock и вне кода, подразумевая на самом деле дублёры разных типов. Бывает, что это путает. Но, в большинстве случаев в тестах используются стабы, а вовсе не моки.
В русскоязычной среде встречается мнение, что разница между Stub-ом и Mock-ом заключается в том, что первый — это дублер, написанный вручную, а второй — созданный с помощью специального фреймворка. Но это заблуждение.
Различия полезно знать, чтобы не путаться в общении с коллегами, когда в контексте обсуждения тип дублера важен.
Категории тестов
Есть разные версии категоризации тестов, по разным характеристикам, поэтому существует некоторая путаница.
Покажу основные категории уровней тестов, на которых тестируется система, на примере одного из самых распространенных вариантов пирамиды тестирования:
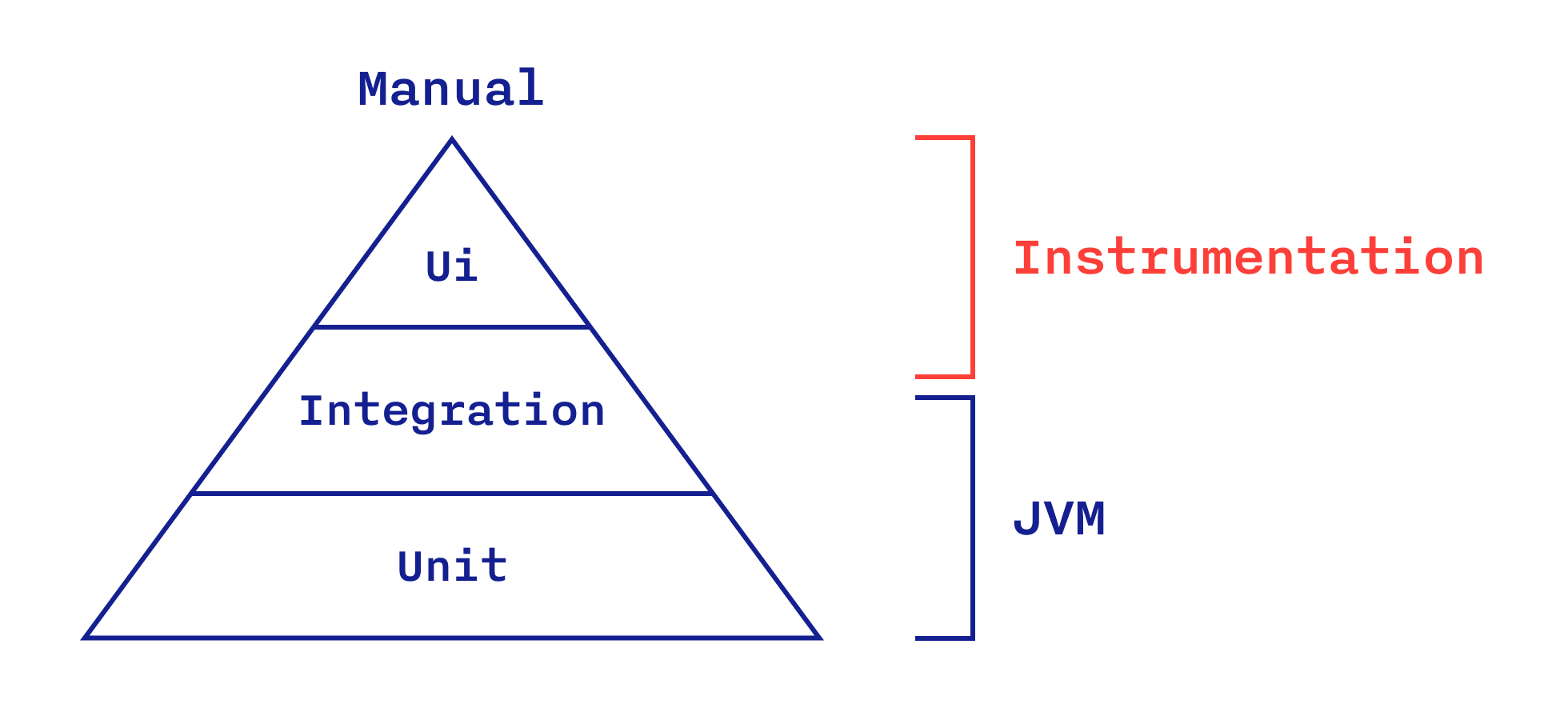
Unit-тесты проверяют корректность работы отдельного unit-а (модуля). Unit-ом (то есть SUT данного типа тестирования) может быть класс, функция или совокупность классов.
Integration-тесты (в приложении) проверяют корректность взаимодействия модулей или наборов этих модулей (компонентов). Определение SUT данной категории является еще более расплывчатым, т.к. в свою очередь зависит от того, что считается модулем.
Грань между Unit- и Integration-тестированием довольно тонкая. Интеграционными тестами, в зависимости от масштаба и контекста, в принципе могут называть тесты, проверяющие взаимодействие чего-либо с чем-либо с определенной долей абстракции: приложение(клиент)-сервер, приложение-приложение, приложение-ОС и др. Но в дальнейшем я буду говорить об интеграционном тестировании в рамках приложения.
End-to-end-тесты (E2E) — интеграционные тесты, которые воздействуют на приложение и проверяют результат его работы через самый высокоуровневый интерфейс (UI), то есть на уровне пользователя. Использование тестовых дублеров на этом уровне исключено, а значит обязательно используются именно реальные сервер, БД и т.д.
Кстати, визуализация автоматизированных тестов в виде пирамиды говорит о том, что тесты более низкого уровня — основа более высокоуровневых, а также о рекомендуемом количественном соотношении тестов того или иного уровня в проекте.
Вернёмся к категориям. В Android сложность категоризации автотестов усугубляется еще и тем, что они могут работать на JVM или в Instrumentation-среде (эмулятор или реальное устройство). Последние называют инструментальными.
Чтобы было удобнее ориентироваться в видах тестов, не путаясь в терминологии, предлагаю такую категоризацию для мобильного приложения на Android:
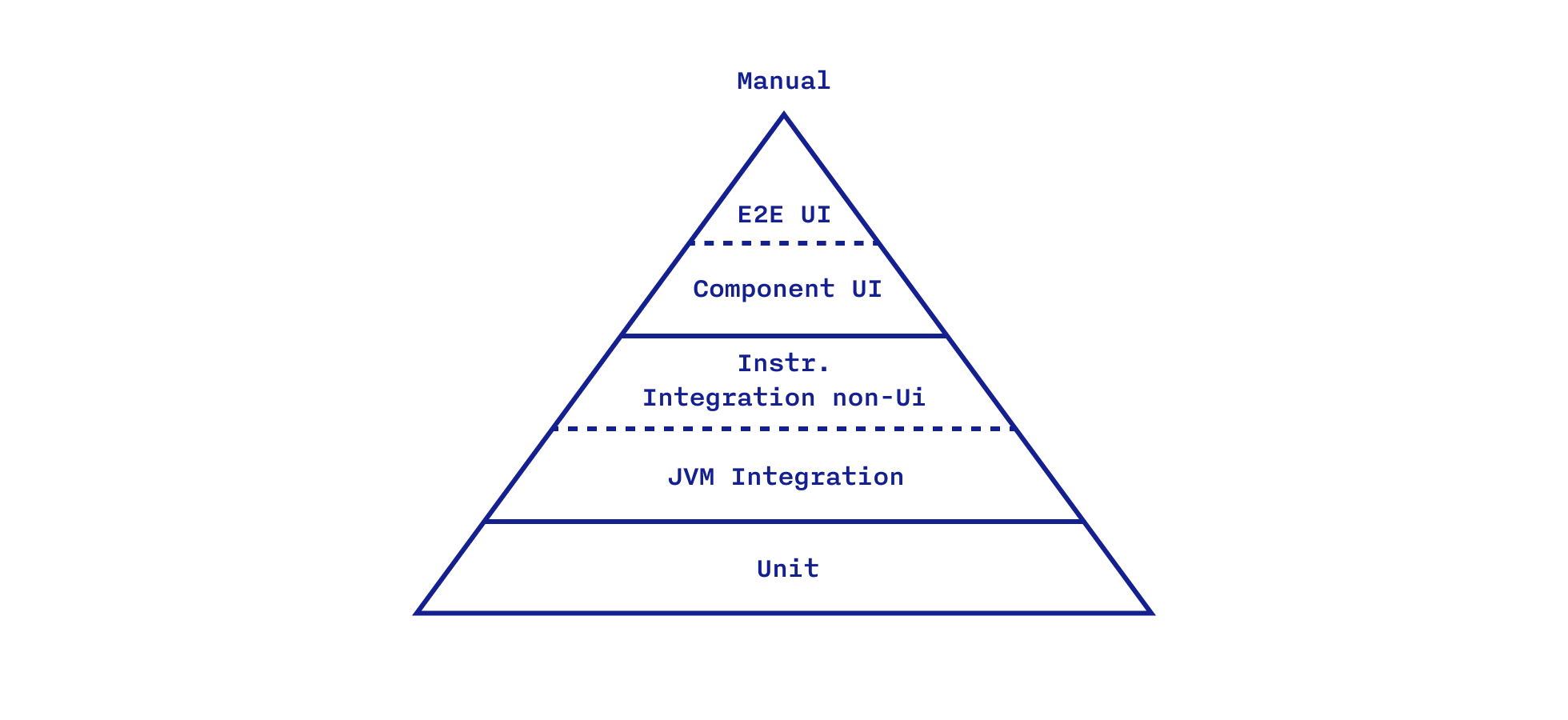
JVM Integration tests — интеграционные тесты, проверяющие взаимодействие модулей или совокупностей модулей без использования Instrumentation. Характеризуются они высокой скоростью исполнения, сравнимой с Unit-тестами, также выполняющимися на JVM.
Instrumentation Integration non-UI tests — интеграционные тесты, исполняемые уже в реальной Android-среде, но без UI.
Component UI tests — интеграционные инструментальные тесты с использованием UI и фиктивных сервера и БД, если таковые требуются. Тест может состоять как из одного экрана, запущенного в изоляции, так и из нескольких экранов с соблюдением их реального флоу.
E2E UI tests — интеграционные инструментальные UI-тесты без тестовых дублеров только с реальным флоу экранов. Максимально приближены к ручным тестам.
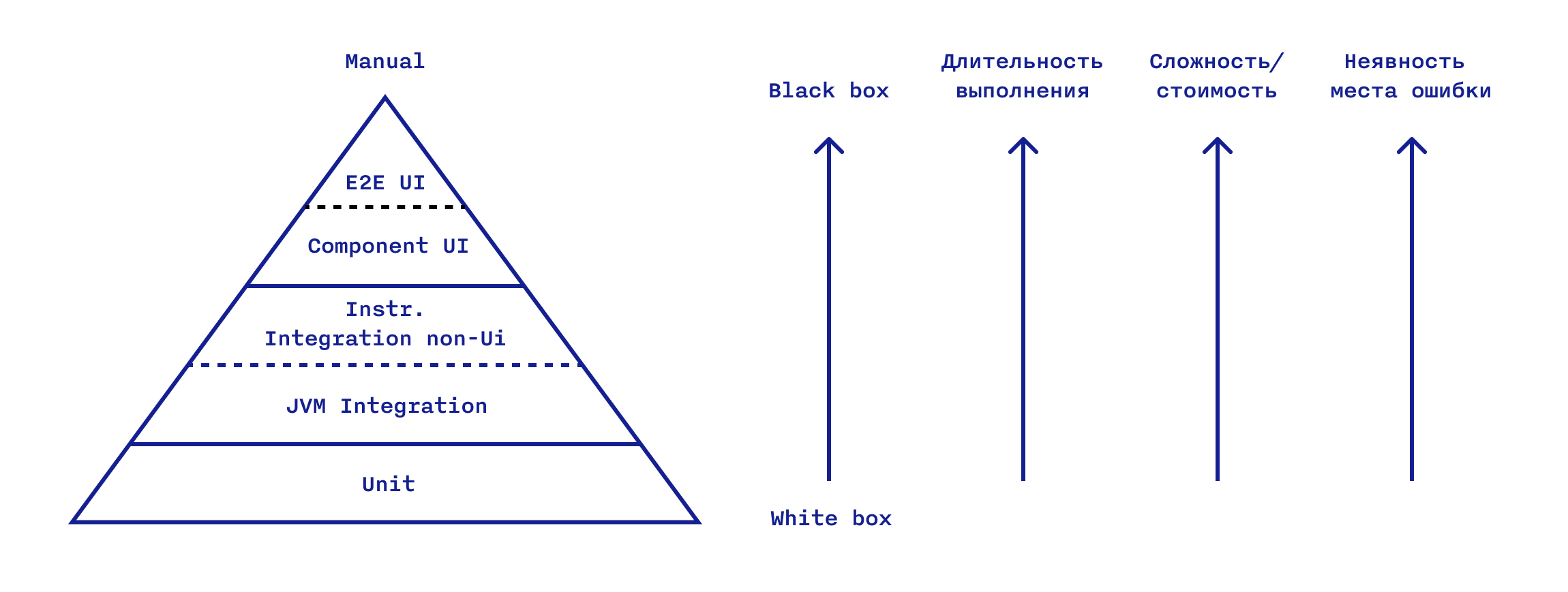
Если Unit-тесты являются сильно завязанными на детали реализации, очень быстро выполняются, относительно легко пишутся и наиболее точно при поломке указывают на причину ошибки, то в случае E2E UI ситуация противоположная. Изменение этих характеристик происходит постепенно от низа к верху пирамиды.
При переходе от тестов на JVM к тестам на Instrumentation из-за использования настоящей Android-среды происходит резкое падение скорости выполнения этих тестов. Это становится серьезным ограничением. Особенно когда тесты необходимо запускать часто и много раз подряд. Поэтому к написанию инструментальных тестов следует прибегать лишь в случаях, когда использование настоящих Android-зависимостей действительно необходимо.
UI-тесты
Несмотря на малую зависимость от низкоуровневых деталей реализации SUT, UI-тесты являются самыми хрупкими. Вызвано это их зависимостью от самого UI. Изменение разметки, реализации отображения, анимации и т.д. могут потребовать длительных манипуляций для обеспечения работоспособности теста.
Часто они оказываются нестабильны в своём поведении и могут то выполняться, то падать, даже если не вносилось никаких изменений в реализацию (нестабильные тесты называют Flaky). Мало того, UI-тесты могут совершенно по-разному себя вести на разных устройствах, эмуляторах и версиях Android. Когда же UI-тесты являются еще и E2E, добавляется хрупкость и снижается скорость выполнения из-за реальных внешних зависимостей. Причем в случае ошибки найти её причину бывает затруднительно, поскольку проверки в таких тестах осуществляются на уровне состояния UI. В таких ситуациях выгоднее обойтись силами QA-инженеров.
Конечно, UI-тесты способны приносить и весьма существенную пользу. Мобильные приложения имеют свойство разрастаться, и в какой-то момент их ручное регрессионное тестирование выходит за адекватные временные рамки. Тогда часть проверок может быть делегирована E2E UI-тестам, что при удачном исполнении может здорово сократить время тестирования.
Поэтому, для написания UI-тестов желательно иметь разработчиков или QA-инженеров-автоматизаторов, которые будут заниматься именно ими бÓльшую часть времени.
Unit-тесты
Unit-тесты тоже в определенной мере хрупкие, но уже из-за того, что они больше связаны с деталями реализации, которым свойственно периодически меняться. При сильном изменении реализации SUT и связанных с нею сущностей может потребоваться почти полностью переписать unit-тест. Но unit-тесты стабильны.
Степень хрупкости же можно снизить за счет использования black box-стиля написания даже на этом уровне, когда возможно. Но не следует злоупотреблять применением тестовых дублеров: если уже реализованная сущность имеет тривиальную логику или наличие логики не подразумевается, стоит использовать ее настоящую реализацию.
А заменять дублером следует только то, что действительно необходимо для приемлемой изоляции SUT в конкретном случае. Иногда (но далеко не всегда!) бывает оптимальнее сделать переиспользуемый рукописный дублер, чем конфигурировать его фреймворком для создания дублеров в множестве мест.
Хочу отметить, что какими бы хорошими не были автотесты, полностью отказываться от ручного тестирования нельзя. Человеческий глаз и смекалка пока что незаменимы.
Подытожим
Как я отметил несколько пунктов назад: тесты более низкого уровня — основа тестов более высокого уровня. Проверять высокоуровневыми тестами всё то, что спокойно проверяется низкоуровневыми, может быть слишком сложно, долго и невыгодно. Каждая категория тестов должна решать свою задачу и применяться на соответствующем этапе создания приложения — чем выше уровень, тем позже.
Ручные тесты — самые достоверные и важные тесты. Unit-тесты, имеющие меньше всего общего с ручными, могут позволить проверить такие ситуации, краевые кейсы, которые проверять вручную будет чрезвычайно дорого. Unit-тесты являются наиболее важными среди автоматизированных.
Лучше делать акцент на быстро выполняющиеся тесты. Так, после Unit-тестов рекомендую проверять JVM Integration-тестами интеграцию в том масштабе, который можно комфортно обеспечить без использования Instrumentation — от ViewModel до слоя данных.
Дальше я буду говорить преимущественно о тестах на JVM. Но некоторые моменты актуальны и для остальных категорий.
Инструментарий
Раньше для написания JVM-тестов наши разработчики использовали фреймворки Junit 4 и Junit 5, но потом переключились на молодой перспективный Spek 2. Junit 4 нужен для инструментальных тестов — с другими фреймворками они не работают.
Для проверок (assert) используем AssertJ — отличную библиотеку с богатым набором читабельных ассертов и удобных дополнительных функций.
Для создания тестовых дублеров применяем Mockito-Kotlin 2 — Mockito 2, адаптированный для Kotlin.
Для стаббинга и мокирования сервера — MockWebServer — библиотеку от Square, рассчитанную на работу с OkHttp.
Фреймворки PowerMock и Robolectric не используем из соображений скорости выполнения тестов и их надёжности. Кроме того, эти фреймворки поощряют «плохо пахнущий код» — это дополнительные зависимости, без которых вполне можно обойтись. Для этого код должен быть тестируемым.
Дизайн кода
Признаки нетестируемого кода:
Наличие неявных зависимостей, сильная связанность. Это затрудняет изолированное unit-тестирование, тестирование на раннем этапе развития фичи, распараллеливание разработки. Использование статических функций, создание сложных объектов внутри класса, ServiceLocator исключают возможность использования тестовых дублеров.
Обилие Android-зависимостей. Они требуют Instrumentation или объемную подготовку среды на JVM с тестовыми дублерами, если их использование вообще возможно (см. прошлый пункт).
Наличие явного управления асинхронным и многопоточным поведением. Если результат работы SUT зависит от выполнения асинхронной работы, особенно порученной другому потоку (или нескольким), то не получится просто так гарантировать правильность и стабильность выполнения тестов. Тест может совершить проверки и завершиться раньше, чем асинхронная работа будет выполнена, и результат не будет соответствовать желаемому. При этом принудительное ожидание в тестах (в первую очередь на JVM) — плохая практика, поскольку нарушается принцип Fast.
Пример
class ExampleViewModel constructor(val context: Context) : BaseViewModel() {
private lateinit var timer: CountDownTimer
fun onTimeAccepted(seconds: Long) {
val milliseconds = MILLISECONDS.convert(seconds, SECONDS)
// Неявная зависимость, Android-зависимость, запуск асинхронной работы
timer = object : CountDownTimer(milliseconds, 1000L) {
override fun onTick(millisUntilFinished: Long) {
showTimeLeft(millisUntilFinished)
}
override fun onFinish() {
// Неявная зависимость. Вызов статической функции с Android-зависимостью
WorkManager.getInstance(context)
.cancelUniqueWork(SeriousWorker.NAME)
}
}
timer.start()
}Как сделать код тестируемым
Следовать принципам SOLID, использовать слоистую архитектуру. Грамотное разделение и реализация сущностей позволит писать изолированные тесты именно на интересующую часть функционала, не допускать чрезмерного разрастания тестового файла и, при необходимости, осуществлять распараллеливание разработки. DI позволит подменять настоящие реализации тестовыми дублёрами.
Стремиться к чистоте функций. Это функции, которые:
При одинаковом наборе входных данных возвращают одинаковый результат.
Не имеют побочных эффектов, т.е. не модифицируют внешние переменные (класса, глобальные) и переданные в качестве входных данных параметры.
Пример теста такой функции:
val result = formatter.toUppercase("адвокат")
assertThat(result).isEqualTo("АДВОКАТ")Минимизировать количество Android-зависимостей. Часто прямое использование Android-зависимостей в SUT не является необходимым. Тогда их следует выносить вовне, оперируя в SUT типами, поддерживающимися на JVM.
Самая распространенная Android-зависимость в потенциально тестируемых классах — ресурсы, и их выносить из, скажем, ViewModel, ну, совсем не хочется. В таком случае можно внедрить Resources во ViewModel, чтобы стаббить конкретные ресурсы (их id актуальны на JVM) и проверять конкретные значения:
mock<Resources> { on { getString(R.string.error_no_internet) } doReturn "Нет интернета" }Но лучше поместить Resources во Wrapper, предоставляющий только необходимый функционал работы с ресурсами, и сделать его тестовую реализацию. Это избавит SUT от прямой зависимости от фреймворка и упростит подготовку окружения в тестах:
interface ResourceProvider {
fun getString(@StringRes res: Int, vararg args: Any): String
}
class ApplicationResourceProvider(private val resources: Resources) : ResourceProvider {
override fun getString(res: Int, vararg args: Any): String {
return resources.getString(res, *args)
}
}
class TestResourceProvider : ResourceProvider {
override fun getString(res: Int, vararg args: Any): String = "$res"
}При таком поведении TestResourceProvider по умолчанию правильность строки в ожидаемом результате можно сверять по id ресурса:
val string = TestResourceProvider().getString(R.string.error_no_internet)
assertThat(string).isEqualTo(R.string.error_no_internet.toString())В общем случае лучше вообще не заменять дублерами типы, принадлежащие сторонним библиотекам и фреймворкам. Это может привести к проблемам при обновлении их API. Обезопасить себя можно также с помощью Wrapper. Подробнее ситуация разобрана в статье “Don’t Mock Types You Don’t Own”.
Использовать Wrapper-ы для статический функций, управления асинхронным и многопоточным поведением. Существует немало стандартных статических функций или Android-зависимостей в виде таких функций. Если нужно иметь с ними дело, то следует помещать их во Wrapper-ы и внедрять в SUT для последующей подмены.
Это поможет и при работе с асинхронностью и многопоточностью: инкапсулирующий управление ими Wrapper можно заменить тестовым дублером, который позволит проверяемому коду выполняться в одном потоке и синхронно вызвать асинхронный код. Для RxJava и Kotlin Coroutines есть стандартные решения от их авторов.
Дизайн тестов
Важно оформлять тесты качественно. Иначе они помогут в момент написания, но в будущем будет уходить много времени на их понимание и поддержку.
Например, при падении теста, который сложно сходу понять и исправить, есть шанс, что его пометят как «игнорируемый» или удалят. Особенно если таких тестов много, ведь они тормозят продолжение разработки. Вот старый пример не самого удачного теста из опенсорса:
Spoiler
public void testSubClassSerializerInvokedForBaseClassFieldsHoldingArrayOfSubClassInstances() {
Gson gson = new GsonBuilder()
.registerTypeAdapter(Base.class, new BaseSerializer())
.registerTypeAdapter(Sub.class, new SubSerializer())
.create();
ClassWithBaseArrayField target = new ClassWithBaseArrayField(new Base[] {new Sub(), new Sub()});
JsonObject json = (JsonObject) gson.toJsonTree(target);
JsonArray array = json.get("base").getAsJsonArray();
for (JsonElement element : array) {
JsonElement serializerKey = element.getAsJsonObject().get(Base.SERIALIZER_KEY);
assertEquals(SubSerializer.NAME, serializerKey.getAsString());
}
}Чтобы достичь желаемого эффекта от тестов, необходимо уделить внимание качеству их дизайна.
Наименование теста и разделение на блоки
Чтобы сделать содержимое теста более читабельным, его следует разделять на блоки соответствующих этапов. Я выбрал BDD-стиль, где есть этапы:
Given — настройка SUT и среды;
When — действие, инициирующее работу SUT, результат работы которой нужно проверить;
Then — проверка результатов на соответствие ожиданиям.
Пример разделения тела теста:
@Test
fun `when create - while has 1 interval from beginning of day and ending not in end of day - should return enabled and disabled items`() {
// given
val intervalStart = createDateTime(BEGINNING_OF_DAY)
val intervalEnd = createDateTime("2019-01-01T18:00:00Z")
val intervals = listOf(
ArchiveInterval(startDate = intervalStart, endDate = intervalEnd)
)
// when
val result = progressItemsfactory.createItemsForIntervalsWithinDay(intervals)
// then
val expected = listOf(
SeekBarProgressItem.createEnabled(intervalStart, intervalEnd),
SeekBarProgressItem.createDisabled(intervalEnd, createDateTime(END_OF_DAY))
)
assertThat(result).isEqualTo(expected)
}«Лицо» теста — его название. Оно должно быть читабельным и ёмко передавать информацию о содержимом, чтобы для ориентации не приходилось каждый раз анализировать это самое содержимое.
В тестах на JVM Kotlin позволяет использовать пробел и дефис при обрамлении названия функции обратными кавычками. Это здорово повышает читабельность. В инструментальных тестах это не работает, поэтому текст пишется в CamelCase, а вместо дефисов используются нижние подчеркивания.
Для тестов на Junit применим следующий паттерн именования в простых случаях:
when … - should …
when — аналогично блоку When;
should — аналогично блоку Then.
В более сложных случаях, когда есть дополнительные условия:
when … - while/and … - should … , где
while — предусловие до вызова целевой функции SUT;
and — условие после вызова функции SUT.
Пример:
@Test
fun `when doesValueSatisfyRegex - while value is incorrect - should return false`() {Так имя теста написано в виде требования, и в случае падения будет сразу видно, какой сценарий отработал некорректно:

Фреймворк Spek 2 выводит всё это на новый уровень. Он предоставляет «из коробки» DSL в стиле Gherkin (BDD).
object GetCameraGroupsInteractorTest : Spek({
Feature("Transform cached cameras to groups of cameras") {
...
Scenario("subscribe while has non-grouped camera and unsorted by groups order cameras") {
...
Given("non-grouped camera and unsorted by groups order cameras") {
...
}
When("subscribe") {
...
}
Then("should return four groups") {
...
}
...
}
}
})
Блоки Given, When, Then — подтесты глобального теста, описанного с помощью блока Scenario. Теперь нет необходимости ставить всё описание в названии, можно просто расположить все части в соответствующих блоках.
Результат выполнения имеет иерархический вид:

Эти блоки могут присутствовать внутри Scenario в любом количестве, а для придания еще более «человекочитаемого» вида можно использовать блок And. Теперь насыщенный сценарий можно оформить, не растянув при этом название теста далеко за границу экрана:

Благодаря блокам типа Feature можно удобно разделять тесты для разных фич, если в одном тестовом файле их несколько.
Чтобы добиться схожего разделения и отображения результатов с помощью Junit 5, понадобилось бы написать в тестах много бойлерплейта с аннотациями.
Устранение лишнего кода
Чтобы сделать содержимое тестов читабельнее, нужно следовать нескольким правилам:
1. Если проверки результатов выполнения одного действия над SUT тесно связаны, допустимо иметь несколько проверок в тесте. В противном случае это должны быть отдельные тесты. Основная проблема в том, что если в тесте несколько проверок и одна из них фейлится, то последующие проверки осуществлены не будут.
В Spek 2 вместо создания полностью отдельных тестов, если они концептуально относятся к одному сценарию, разделение проверок можно сделать с помощью блоков Then/And внутри Scenario:
...
Then("should return four groups") {...}
And("they should be alphabetically sorted") {...}
And("other group should contain one camera") {...}
And("other group should be the last") {...}
...В Junit 4 такой возможности нет. На помощь приходит механизм SoftAssertions из AssertJ, который гарантирует выполнение всех assert в тесте. Например:
// then
assertSoftly {
it.assertThat(capabilityState)
.describedAs("Capability state")
.isInstanceOf(Available::class.java)
it.assertThat((capabilityState as Available).disclaimer)
.describedAs("Disclaimer")
.isNull()
}2. Если проверки объемные, нежелательные к разделению и повторяющиеся, следует выносить их в отдельную функцию с говорящим названием.
3. Использовать обобщающие конструкции тестового фреймворка для одинаковой настройки окружения, если настройка повторяется для большого количества тестов, находящихся на одном уровне иерархии (например, beforeEachScenario и afterEachScenario в случае Spek 2). Если настройка одинакова для нескольких тестовых файлов, можно использовать Extension для Junit 5, Rule для Junit 4, а для Spek 2 подобного механизма «из коробки» нет, поэтому нужно обходиться конструкциями before…/after….
4. Объемные схожие настройки тестового окружения следует также выносить в отдельную функцию.
5. Использовать статические импорты для повсеместно применяемых функций вроде функций проверок AssertJ и Mockito.
6. Если создание вспомогательных объектов объемное, используется в разных тестовых файлах и с разными параметрами, следует завести генератор с дефолтными значениями:
Пример генератора
object DeviceGenerator {
fun createDevice(
description: String? = null,
deviceGroups: List<String> = emptyList(),
deviceType: DeviceType = DeviceType.CAMERA,
offset: Int = 0,
id: String = "",
photoUrl: String? = null,
isActive: Boolean = false,
isFavorite: Boolean = false,
isPublic: Boolean = false,
model: String? = null,
vendor: String? = null,
title: String = "",
serialNumber: String = "",
streamData: StreamData? = null
): Device {
return Device(
description = description,
deviceGroups = deviceGroups,
deviceType = deviceType,
offset = offset,
id = id,
photoUrl = photoUrl,
isActive = isActive,
isFavorite = isFavorite,
isPublic = isPublic,
model = model,
vendor = vendor,
title = title,
serialNumber = serialNumber,
streamData = streamData
)
}
}
Given("initial favorite camera") {
val devices = listOf(
createDevice(id = deviceId, isFavorite = true)
)
...
}
Очень важно не переборщить с созданием вспомогательных функций и архитектурных изысков, поскольку KISS и единообразие в автотестах важнее, чем DRY. Когда все тесты в проекте написаны однотипно и прозрачно, они гораздо лучше воспринимаются.
Тесты как документация
Когда предыдущие пункты соблюдены, тесты уже можно применять как документацию, свернув тестовые функции в IDE.
Для сворачивания и разворачивания всех блоков кода в файле в случае Mac используются комбинации клавиш “Shift” + “⌘” + “-” и “Shift” + “⌘” + “+”, для управления конкретным блоком — “⌘” + “-” и “⌘” + “+” соответственно.
В тестах на Junit 4 можно сделать еще лучше, сгруппировав тесты по регионам, ведь их тоже можно сворачивать.
Пример

В тестах на Spek 2 нет нужды делать разделение тестов по регионам, поскольку их можно хорошо сгруппировать с помощью блоков Scenario и Feature.
Если в файле с тестами присутствуют некоторые вспомогательные свойства или функции, их также стоит поместить в регион. Это поспособствует улучшению фокусировки внимания на названиях тестовых функций.
Наконец пример тестов на Spek 2 в режиме документации

Так тесты сформированы в виде последовательных требований к SUT, в которых удобно ориентироваться. Теперь они отличная документация для ваших коллег и вас самих, которая поможет быстро разобраться или вспомнить, что делает SUT.
Она лучше обычной текстовой, поскольку в отличие от тестов, обычную документацию можно забыть актуализировать. Чем тесты более высокоуровневые, тем более близкими к составленным аналитиком функциональным требованиям будут их названия. Это будет заметно в разделе "JVM Integration Testing".
Параметрические тесты
Если нужно протестировать корректность работы SUT с разнообразным набором входных данных, но при этом основная реализация тестов меняться не должна, можно использовать параметрический тест.
Он может быть запущен много раз, каждый раз принимая разные аргументы. Поэтому отпадает надобность писать множество одинаковых тестов, у которых отличаются только входные данные и ожидаемый результат. Достаточно написать один тест и указать набор данных, которые будут поочередно в него передаваться. Часто параметрические тесты оказываются подходящим выбором для тестирования валидаторов, форматтеров, конвертеров и т.д.
В документации Spek 2 не написано о возможности написания параметрических тестов, хотя она есть, и писать их проще, чем в Junit 4 и Junit 5. Для этих целей удобно использовать стиль тестов Specification.
Пример параметрического теста в Speck 2
class OrientationTypeTest : Spek({
describe("Orientation type") {
mapOf(
-1 to Unknown,
-239 to Unknown,
361 to Unknown,
2048 to Unknown,
340 to Portrait,
350 to Portrait,
360 to Portrait,
0 to Portrait,
...
).forEach { (tiltAngle, expectedOrientation) ->
describe("get orientation by tilt angle $tiltAngle") {
val result = OrientationType.getOrientation(tiltAngle)
it("return $expectedOrientation type") {
assertThat(result).isEqualTo(expectedOrientation)
}
}
}
}
})
Результат выполнения:
Снижение хрупкости non-UI тестов
Я писал, что степень хрупкости unit-тестов при изменениях исходного кода, обусловленную их привязкой к деталям реализации модуля, можно снизить. Это применимо для всех non-UI тестов.
Написание тестов в стиле White box искушает расширять видимость функций/свойств SUT для проверок или установки состояний. Это простой путь, который влечет за собой не только увеличение хрупкости тестов, но и нарушение инкапсуляции SUT.
Избежать этого помогут правила. Можно сказать, что взаимодействие с SUT будет в стиле Black box.
Тестировать следует только публичные функции. Если SUT имеет приватную функцию, логику которой нужно протестировать, делать это следует через связанную с ней публичную функцию. Если сделать это проблематично, то, возможно, код приватной функции так сложен, что должен быть вынесен в отдельный класс и протестирован напрямую.
Нужно стараться делать функции чистыми. Об этом я говорил выше.
Проверки в тесте следует осуществлять по возвращаемому значению вызываемой публичной функции, публичным свойствам или, в крайнем случае, по взаимодействию с mock-объектами (с помощью функции verify() и механизма ArgumentCaptor в Mockito)
Делать только необходимые проверки в рамках теста. Например, если в тесте проверяется, что при вызове функции “A” у SUT происходит вызов функции “X” у другого класса, то не следует до кучи проверять значения её публичных полей, особо не имеющих отношения к делу, и что у SUT не будет более никаких взаимодействий с другими функциями связанного класса (функция verifyNoMoreInteractions() в Mockito).
Если для проведения определенного теста невозможно привести SUT в требуемое предварительное состояние с помощью аргументов целевой функции, моков/стабов или изменения полей, то следует вызвать другие публичные функции, вызов которых приводит SUT в интересующее состояние в условиях реальной работы приложения. Например, вызвать функции onLoginInputChanged и onPasswordInputChanged для подготовки теста onEnterButtonClick во ViewModel
Существует аннотация-маркер @VisibleForTesting для выделения функций/свойств, модификатор доступа которых расширили для тестирования. Благодаря этому маркеру Lint подскажет разработчику, обратившемуся к функции/свойству в таком месте исходного кода, в котором они на самом деле не должны быть доступны, что видимость функции расширена только для тестирования. Несмотря на возможность использования такого маркера, прибегать к расширению видимости всё равно не рекомендуется.

Тестирование асинхронного кода с RxJava
Лучше избегать прямого управления асинхронным и многопоточным поведением в SUT. Для тестирования же кода, использующего RxJava или Coroutines, применяются специфичные решения. Сейчас в большинстве наших проектов используется RxJava, поэтому расскажу именно про нее.
Для тестирования SUT, осуществляющей планирование Rx-операций, нужно произвести замену реализаций Scheduler-ов так, чтобы весь код выполнялся в одном потоке. Также важно иметь в виду, что на JVM нельзя использовать AndroidSchedulers.mainThread().
В большинстве случаев все Scheduler-ы достаточно заменить на Schedulers.trampoline(). В случаях, когда нужен больший контроль над временем события, лучше использовать io.reactivex.schedulers.TestScheduler с его функциями triggerActions(), advanceTimeBy(), advanceTimeTo().
Замену реализаций можно совершить двумя способами:
RxPlugins (RxJavaPlugins & RxAndroidPlugins);
Подход Schedulers Injection.
Первый способ — официальный и может быть применен независимо от того, как спроектирована SUT. Он имеет не самое удачное API и неприятные нюансы работы, усложняющие применение в некоторых ситуациях (например, когда внутри тестового файла в одних тестах нужно использовать Schedulers.trampoline(), а в других — TestScheduler).
Суть подхода Schedulers Injection заключается в следующем: экземпляры Scheduler-ов попадают в SUT через конструктор, благодаря чему в тесте они могут быть заменены на иные реализации. Этот подход является очень прозрачным и гибким. Также он останется неизменным независимо от выбранного тестового фреймворка (Junit 4, Junit 5, Spek 2…) — чего нельзя сказать об RxPlugins, которыми придется в каждом управлять по-своему.
Из минусов Shedulers Injection можно выделить необходимость внедрения дополнительного аргумента в SUT и необходимость использования вместо rx-операторов с Sheduler по умолчанию (таких как delay()) их перегруженные варианты с явным указанием Scheduler.
Есть две неплохие статьи на тему обоих подходов: раз, два. Но там упомянуты не все нюансы RxPlugins.
Я предпочитаю второй подход. Чтобы упростить внедрение и подмену реализаций в тесте, я написал SchedulersProvider:
Реализация и применение SchedulersProvider
interface SchedulersProvider {
fun ui(): Scheduler
fun io(): Scheduler
fun computation(): Scheduler
}
class SchedulersProviderImpl @Inject constructor() : SchedulersProvider {
override fun ui(): Scheduler = AndroidSchedulers.mainThread()
override fun io(): Scheduler = Schedulers.io()
override fun computation(): Scheduler = Schedulers.computation()
}
fun <T> Single<T>.scheduleIoToUi(schedulers: SchedulersProvider): Single<T> {
return subscribeOn(schedulers.io()).observeOn(schedulers.ui())
}
// другие необходимые функции-расширения...
Его применение в коде:
class AuthViewModel(
...
private val schedulers: SchedulersProvider
) : BaseViewModel() {
...
loginInteractor
.invoke(login, password)
.scheduleIoToUi(schedulers)
...
А вот и его тестовая реализация с Scheduler-ами по умолчанию, вместо которых при надобности можно передать TestScheduler:
class TestSchedulersProvider(
private val backgroundScheduler: Scheduler = Schedulers.trampoline(),
private val uiScheduler: Scheduler = Schedulers.trampoline()
) : SchedulersProvider {
override fun ui(): Scheduler = uiScheduler
override fun io(): Scheduler = backgroundScheduler
override fun computation(): Scheduler = backgroundScheduler
}
Применение в тесте:
authViewModel = AuthViewModel(
...
router = mock(),
schedulers = TestSchedulersProvider(),
loginInteractor = loginInteractor,
...
)
Вообще, RxJava «из коробки» имеет и другие полезные инструменты для тестирования (TestObserver, TestSubscriber), но они не входят в рамки статьи.
JVM Integration Testing
JVM Integration-тесты проверяют взаимодействие модулей или совокупностей модулей на JVM. Какие именно связки стоит тестировать, зависит от конкретных случаев.
В самых масштабных тестах этого типа проверяется взаимодействие всей цепочки модулей от ViewModel до Http-клиента, поскольку в этом промежутке обычно располагается основная логика, требующая проверки. Обеспечивать работу View на JVM обычно накладно и не имеет большого смысла.

Тест взаимодействует с SUT через ViewModel, инициируя действия и проверяя результат.
Чтобы достичь максимальной степени проверки SUT в данном случае следует заменять тестовыми реализациями только те сущности, которые действительно в этом нуждаются. Типичный набор таких сущностей:
android.content.res.Resources или собственный Wrapper. Обычно достаточно стаба, обеспечивающего исправный возврат строк из ресурсов.
androidx.arch.core.executor.TaskExecutor. Требуется в любых тестах на JVM, у которых SUT использует LiveData, поскольку стандартная реализация имеет Android-зависимость. Подробнее можно почитать в этой статье. Google предлагает готовое решение этой проблемы в форме Rule лишь для Junit 4, поэтому для Spek 2 и Junit 5 использую рукописный класс, содержащий код из того самого решения:
object TestLiveDataExecutionController {
fun enableTestMode() {
ArchTaskExecutor.getInstance()
.setDelegate(object : TaskExecutor() {
override fun executeOnDiskIO(runnable: Runnable) = runnable.run()
override fun postToMainThread(runnable: Runnable) = runnable.run()
override fun isMainThread(): Boolean = true
})
}
fun disableTestMode() {
ArchTaskExecutor.getInstance().setDelegate(null)
}
}
Соответствующие функции достаточно вызывать перед первым и после последнего теста в тестовом файле. Пример применения в Spek 2:
object DeviceDetailViewModelIntegrationTest : Spek({
beforeGroup { TestLiveDataExecutionController.enableTestMode() }
afterGroup { TestLiveDataExecutionController.disableTestMode() }
...
Сервер. Для имитации сервера используется MockWebServer от создателей OkHttp. Он позволяет предустанавливать ответы на конкретные запросы, проверять состав запросов, факты их вызова и др.
Interceptors с Android-зависимостями. Не следует пренебрегать добавлением интерцепторов в тестовую конфигурацию клиента OkHttp, соблюдая тот же порядок, что и в настоящем клиенте, чтобы серверные запросы и ответы правильно обрабатывались. Однако некоторые интерцепторы могут иметь Android-зависимости — их следует подменить. Например, это могут быть интерцепторы логирования. Интерцепторы последовательно передают данные друг другу и эту цепочку нельзя прерывать, поэтому фиктивный интерцептор должен выполнять это минимальное требование:
// StubInterceptor
Interceptor { chain ->
return@Interceptor chain.proceed(chain.request().newBuilder().build())
}Персистентные хранилища данных (SharedPreferences, Room и т.д.)
Базовая логика управления тестовым сетевым окружением сконцентрирована в классе BaseTestNetworkEnvironment. Он используется на JVM и в Instrumentation. За специфическую конфигурацию под каждую из сред отвечают его классы-наследники: JvmTestNetworkEnvironment и InstrumentationTestNetworkEnvironment.
Сервер запускается при создании экземпляра *NetworkEnvironment до запуска теста и отключается функцией shutdownServer() после завершения теста (в случае Gherkin-стиля Spek 2 — до и после Scenario соответственно).
Для удобной настройки ответов на конкретные запросы используется функция dispatchResponses. При необходимости к mockServer можно обратиться напрямую.
Реализация BaseTestNetworkEnvironment
abstract class BaseTestNetworkEnvironment {
companion object {
private const val BASE_URL = "/"
private const val ENDPOINT_TITLE = "Mock server"
}
val mockServer: MockWebServer = MockWebServer().also {
it.startSilently()
}
// класс, специфичный для инфраструктуры проекта
protected val mockNetworkConfig: NetworkConfig
init {
val mockWebServerUrl = mockServer.url(BASE_URL).toString()
mockNetworkConfig = TestNetworkConfigFactory.create(mockWebServerUrl, BASE_URL)
}
/**
* Используется для предустановки фиктивных ответов на конкретные запросы к [MockWebServer].
*
* [pathAndResponsePairs] пара путь запроса - ответ на запрос.
*
* Если [MockWebServer] получит запрос по пути, которого нет среди ключей [pathAndResponsePairs],
* то будет возвращена ошибка [HttpURLConnection.HTTP_NOT_FOUND].
*/
fun dispatchResponses(vararg pathAndResponsePairs: Pair<String, MockResponse>) {
val pathAndResponseMap = pathAndResponsePairs.toMap()
val dispatcher = object : Dispatcher() {
override fun dispatch(request: RecordedRequest): MockResponse {
val mockResponse = request.path?.let {
pathAndResponseMap[it]
}
return mockResponse ?: mockResponse(HttpURLConnection.HTTP_NOT_FOUND)
}
}
mockServer.dispatcher = dispatcher
}
fun shutdownServer() {
mockServer.shutdown()
}
/**
* Запуск сервера с отключенными логами
*/
private fun MockWebServer.startSilently() {
Logger.getLogger(this::class.java.name).level = Level.WARNING
start()
}
}
Содержимое JvmTestNetworkEnvironment уже сильно зависит от специфики конкретного проекта, но цель его неизменна — заменить некоторые сущности локального сетевого окружения тестовыми дублерами, чтобы код работал на JVM.
Пример реализации JvmTestNetworkEnvironment
// Если не передавать в конструктор класса специфические экземпляры тестовых дублеров, то будут использоваться
// стабы с минимальным предустановленным поведением, необходимым для функционирования сетевого флоу.
class JvmTestNetworkEnvironment(
val mockPersistentStorage: PersistentStorage = mockPersistentStorageWithMockedAccessToken(),
val mockResources: ResourceProvider = TestResourceProvider()
) : BaseTestNetworkEnvironment() {
private val nonAuthZoneApiHolderProvider: NonAuthZoneApiHolderProvider
private val authZoneApiHolderProvider: AuthZoneApiHolderProvider
init {
val moshiFactory = MoshiFactory()
val serverErrorConverter = ServerErrorConverter(moshiFactory, mockResources)
val stubInterceptorProvider = StubInterceptorProvider()
val interceptorFactory = InterceptorFactory(
ErrorInterceptorProvider(serverErrorConverter).get(),
AuthInterceptorProvider(mockPersistentStorage).get(),
stubInterceptorProvider.get(),
stubInterceptorProvider.get()
)
nonAuthZoneApiHolderProvider = NonAuthZoneApiHolderProvider(
interceptorFactory,
moshiFactory,
mockNetworkConfig
)
authZoneApiHolderProvider = AuthZoneApiHolderProvider(
interceptorFactory,
moshiFactory,
UserAuthenticator(),
mockNetworkConfig
)
}
fun provideNonAuthZoneApiHolder() = nonAuthZoneApiHolderProvider.get()
fun provideAuthZoneApiHolder() = authZoneApiHolderProvider.get()
}
Функции для упрощения создания серверных ответов:
fun mockResponse(code: Int, body: String): MockResponse = MockResponse().setResponseCode(code).setBody(body)
fun mockResponse(code: Int): MockResponse = MockResponse().setResponseCode(code)
fun mockSuccessResponse(body: String): MockResponse = MockResponse().setBody(body)Тела фиктивных серверных ответов сгруппированы по object-ам, соответствующим разным запросам. Это делает тестовые файлы чище и позволяет переиспользовать ответы и значения их полей в разных тестах. Одни и те же ответы используются тестами на JVM и Instrumentation (в том числе UI).
После добавления комментария "language=JSON" IDE подсвечивает синтаксис JSON. Подробнее о Language injections можно почитать тут.
С помощью выноса значений интересующих полей ответов в константы, можно использовать их при проверках в тестах, не дублируя строки. Например, убедиться, что описание ошибки из серверного ответа корректно передано в Snackbar. Тело ответа получается посредством вызова функции с параметрами, которые при надобности позволяют конфигурировать ответ из теста.
Пример object с фиктивными серверными ответами
object LoginResponses {
const val INVALID_CREDENTIALS_ERROR_DESCRIPTION = "Неверный логин или пароль"
fun invalidCredentialsErrorJson(
errorDescription: String = INVALID_CREDENTIALS_ERROR_DESCRIPTION
): String {
// language=JSON
return """
{
"error": {
"code": "invalid_credentials",
"description": "$errorDescription",
"title": "Введены неверные данные"
}
}
""".trimIndent()
}
...
}
Схожим образом вынесены и пути запросов:
const val LOGIN_REQUEST_PATH = "/auth/login"
object GetCameraRequest {
const val DEVICE_ID = "1337"
const val GET_CAMERA_REQUEST_PATH = "/devices/camera/$DEVICE_ID"
}
...
Общие для JVM и Instrumentation файлы должны находиться в директории, доступной обоим окружениям. Доступ настраивается в build.gradle:
android {
sourceSets {
// Instrumentation
androidTest {
java.srcDirs += 'src/androidTest/kotlin'
java.srcDirs += 'src/commonTest/kotlin'
}
// JVM
test {
java.srcDirs += 'src/test/kotlin'
java.srcDirs += 'src/commonTest/kotlin'
}
}
}
Взаимодействие View и ViewModel построено особым способом, благодаря которому очень удобно писать unit-тесты ViewModel и integration-тесты. Публичные функции ViewModel представляют события со стороны View (обычно они соответствуют действиям со стороны пользователя) и именуются в событийном стиле:

ViewModel воздействует на View посредством двух LiveData:
state — описание состояния View
events — однократные события, не сохраняющиеся в state
Этот подход в более удобном виде реализован в нашей библиотеке.
Пример организации ViewModel, ViewState и ViewEvents
class AuthViewModel(...) {
val state = MutableLiveData<AuthViewState>()
val events = EventsQueue<ViewEvent>()
...
}
sealed class AuthViewState {
object Loading : AuthViewState()
data class Content(
val login: String = "",
val password: String = "",
val loginFieldState: InputFieldState = Default,
val passwordFieldState: InputFieldState = Default,
val enterButtonState: EnterButtonState = Disabled
) : AuthViewState() {
sealed class InputFieldState {
object Default : InputFieldState()
object Error : InputFieldState()
object Blocked : InputFieldState()
}
...
}
}
class EventsQueue<T> : MutableLiveData<Queue<T>>() {
fun onNext(value: T) {
val events = getValue() ?: LinkedList()
events.add(value)
setValue(events)
}
}
// ViewEvents:
interface ViewEvent
data class ShowSnackbarError(val message: String) : ViewEvent
class OpenPlayStoreApp : ViewEvent
...
Наконец, пример JVM Integration-теста
object AuthViewModelIntegrationTest : Spek({
Feature("Login") {
// region Fields and functions
lateinit var authViewModel: AuthViewModel
lateinit var networkEnvironment: JvmTestNetworkEnvironment
val login = "log"
val password = "pass"
fun setUpServerScenario() {
networkEnvironment = JvmTestNetworkEnvironment()
val authRepository = networkEnvironment.let {
AuthRepositoryImpl(
nonAuthApi = it.provideNonAuthZoneApiHolder(),
authApi = it.provideAuthZoneApiHolder(),
persistentStorage = it.mockPersistentStorage,
inMemoryStorage = InMemoryStorage()
)
}
val clientInfo = ClientInfo(...)
val loginInteractor = LoginInteractor(authRepository, clientInfo)
authViewModel = AuthViewModel(
resources = networkEnvironment.mockResources,
schedulers = TestSchedulersProvider(),
loginInteractor = loginInteractor
analytics = mock()
)
}
beforeFeature { TestLiveDataExecutionController.enableTestMode() }
afterFeature { TestLiveDataExecutionController.disableTestMode() }
beforeEachScenario { setUpServerScenario() }
afterEachScenario { networkEnvironment.shutdownServer() }
// endregion
Scenario("input credentials") {...}
Scenario("click enter button and receive invalid_credentials error from server") {
Given("invalid_credentials error on server") {
networkEnvironment.dispatchResponses(
LOGIN_REQUEST_PATH to mockResponse(HTTP_UNAUTHORIZED, invalidCredentialsErrorJson())
)
}
When("enter not blank credentials") {
authViewModel.onCredentialsChanged(login, password)
}
And("click enter button") {
authViewModel.onEnterButtonClick(login, password)
}
Then("reset password, mark login and password input fields as invalid and disable enter button") {
val state = authViewModel.state.value
val expectedState = Content(
login = login,
password = "",
loginFieldState = Content.InputFieldState.Error,
passwordFieldState = Content.InputFieldState.Error,
enterButtonState = Content.EnterButtonState.Disabled
)
assertThat(state).isEqualTo(expectedState)
}
And("create snackbar error event with message from server") {
val expectedEvent = authViewModel.events.value!!.peek()
assertThat(expectedEvent).isEqualTo(ShowSnackbarError(INVALID_CREDENTIALS_ERROR_DESCRIPTION))
}
}
...
}
...
})
Так тестируется основная логика пользовательских сценариев. Эти сценарии с теми же данными затем могут быть проверены в UI-тестах.
Что в итоге нужно тестировать?
Не нужно тестировать чужие библиотеки — это ответственность разработчиков библиотек (исследовательское тестирование — исключение). Тестировать нужно свой код.
Unit-тесты следует писать на логику, в которой есть реальная вероятность совершения ошибки. Это могут быть ViewModel, Interactor, Repository, функции форматирования (денег, дат и т.д.) и другие стандартные и нестандартные сущности. Тривиальную логику тестировать не стоит. Но нужно следить за изменением непокрытой тестами логики, если она при очередном изменении перестанет быть тривиальной, то тогда её нужно протестировать.
100%-е покрытие кода тестами несёт с собой вред: трата лишнего времени на написание бесполезных тестов, боль при изменении реализации, при поддержке бесполезных тестов, иллюзия хорошо протестированной системы. Процент покрытия не отражает реальной картины того, насколько хорошо система протестирована.
Я предпочитаю не устанавливать минимальный порог тестового покрытия для нового кода. Однако для разработчика всё же может быть полезной точечная проверка покрытия SUT, над которой он работает.
Тестами нужно проверять не только основные сценарии, но и краевые. Обычно там кроется наибольшее число багов.
При исправлении бага в коде, который не покрыт тестами, следует его ими покрыть.
JVM Integration-тесты от ViewModel до слоя данных следует писать для каждого экрана. Менее масштабные JVM Integration — при надобности. Возможны случаи, когда большинство модулей, включая ViewModel, сами по себе являются слишком простыми, чтобы их стоило покрывать unit-тестами. Однако создание масштабного JVM integration-теста на всю цепочку будет очень кстати, тем более что пишутся такие тесты достаточно просто и однотипно.
Нужно стараться не проверять в тестах более высокоуровневых категорий то, что проверено в более низкоуровневых, но повторы проверок основных сценариев во всё большей интеграции — это нормально.
Тесты Instrumentation Integration non-UI — только когда нужно проверить что-то, что нельзя адекватно проверить на JVM.
E2E UI- и Component UI-тесты нужны для замены части ручных тестов при регрессионном тестировании. Разумно доверить их написание QA-инженерам. В настоящее время мы с коллегами ищем оптимальный подход к тому, как организовывать UI-тесты, в каком количестве их писать и как сочетать с более низкоуровневыми тестами.
Test Driven Development
Можно подумать, что о написании тестов уже известно достаточно и пора идти в бой, но есть еще один момент… Вы, вероятно, собрались написать очередную фичу и затем покрыть её тестами? Замечательная идея. Именно так и стоит делать, пока навык написания тестов не будет более менее отработан. Такой подход называют Test Last. Конечно же, среди пишущих тесты разработчиков он наиболее распространен. Но он имеет серьезные недостатки:
несмотря на знания о том, каким должен быть тестируемый код, всё равно может получиться реализация, протестировать которую сходу не получится. Может понадобиться рефакторинг, чтобы появилась возможность написать тесты и сделать их «не корявыми» :)
по моим наблюдениям, при покрытии кода тестами, разработчику свойственно подстраивать тесты под существующую реализацию, которая уже «засела у него в голове». Поэтому вероятность упустить какой-то кейс возрастает. И это чревато пропущенными багами.
тесты остаются на последнюю очередь и на них зачастую не остается времени.
Решить эти проблемы можно, используя принцип Test First, придуманным Кентом Беком. Он основан на идее: "Never write a single line of code unless you have a failing automated test" (не стоит писать код реализации, пока для него не написан падающий тест).
На базе этого принципа Кент Бек создал методологию Test Driven Development (TDD, разработка через тестирование). Согласно ей, разработка должна вестись итеративно, путем цикличного повторения шагов Red-Green-Refactor (микро-цикл):
написать тест на логику, которую предстоит реализовать, и убедиться, что он падает;
написать простейшую реализацию, чтобы тест выполнился успешно;
провести рефакторинг реализации, не сломав тесты.
Подразумевается, что в итерации падающий тест должен быть только один.
Позже Роберт Мартин развил TDD, сформулировав Three Laws of TDD (нано-цикл):
перед написанием какого-либо кода реализации необходимо написать падающий тест;
тест не должен содержать больше, чем нужно для его падения или провала компиляции;
не нужно писать больше кода реализации, чем достаточно для того, чтобы падающий тест прошел.
Из-за второго правила работа сводится к поочерёдному написанию строчки реализации SUT за строчкой теста. Нано-циклы заставляют фокусироваться на очень маленькой подзадаче. Это также помогает, когда не знаешь, с чего начать реализацию.
Со временем Робертом были сформулированы еще два более масштабных цикла. Про всех них можно почитать в его статье.
Технику применения нано-циклов я использую далеко не всегда. Частые перескакивания в сложной задаче приводят к потере фокуса и снижают продуктивность. Несмотря на то, что более крупные циклы должны помогать этого избегать. Считаю, что эту технику лучше применять точечно и комфортный размер шага следует выбирать каждому самостоятельно. Жесткое следование всем правилам на практике не всегда идёт на пользу, но полезно при обучении.
Я несколько отступился от канонов и нашел эффективным такой алгоритм работы при реализации новой фичи:
1. Вникнуть в задачу, спроектировать связи между модулями, определить их ответственность.
2. Создать SUT, описать его интерфейс.
Если функции должны возвращать какой-то результат, можно писать в их теле TODO(), чтобы код мог скомпилироваться, тогда при вызове функции тест будет прерван эксепшеном. Другой вариант — хардкодить возврат простого объекта или null. Так тесты смогут совершить проверки после вызова функции, но тут лучше быть поаккуратнее.
fun doSomething(): Boolean { TODO() }3. Создать тестовый файл для SUT, объявить тесты-требования.
Описать столько кейсов, сколько получится. Нормально, если в ходе написания реализации на ум придут еще какие-то кейсы.
В пустые тесты/блоки можно добавлять вызов функции fail() (из Junit или AssertJ), чтобы не забыть реализовать какой-то из тестов, поскольку пустой тест при запуске выдает положительный результат.
@Test
fun `when invoke - should do something`() {
fail { "not implemented" }
}4. Реализовать тест(ы)
Методология подразумевает написание только одного теста и необходимой реализации SUT для его прохождения за микроцикл, но это может быть не продуктивно, если несколько тестов-требований тесно связаны. Вполне нормально написать несколько тестов и потом перейти к реализации. Если же тестов у SUT получается много и они направлены на проверку разных аспектов её работы, то написание всех тестов перед началом реализации будет приводить к потере фокуса с подзадач, которые предстоит в ходе реализации решить. Как именно поступать, стоит определять в зависимости от конкретного случая и от того, как получается комфортнее.
5. Реализовать SUT, чтобы реализованные тесты успешно выполнились.
По умолчанию в момент времени стоит фокусироваться на прохождении одного конкретного теста.
6. Отрефакторить SUT, сохранив успешность выполнения реализованных тестов.
7. Если остались нереализованные тесты, перейти к пункту #4.
Алгоритм доработки SUT, которая уже покрыта тестами:
Объявить новые тесты согласно новым требованиям,
Реализовать новые тесты,
Реализовать доработку в SUT, чтобы новые тесты выполнились успешно
Если старые тесты упали:
Они актуальны при новых требованиях — исправить реализацию SUT и/или эти тесты,
Они неактуальны — удалить.
Отрефакторить SUT, сохранив успешность выполнения реализованных тестов,
Если остались нереализованные тесты, перейти к пункту 2.
Но если к началу работы над задачей невозможно получить достаточного представления о том, какие будут модули, их ответственность и связи, и для формирования представления требуется начать писать реализацию, экспериментировать, то TDD применять не стоит. В противном случае может быть потеряно много времени на переписывание тестов.
Приступаем к реализации по принципу Test Last, но как только достаточное представление сформируется, делаем паузу и переходим к тестам, продолжая дальнейшую разработку уже по TDD. Незачем также применять TDD для реализации тривиальной логики, если вы не собираетесь покрывать её тестами.
По итогу получаем от подхода следующие преимущества:
Предварительное написание тестов вынуждает реализовывать SUT заведомо тестируемой. Тесты оказываются слабо связанными с деталями реализации.
Тесты являются спецификацией SUT (если при этом соблюдать правила их именования). Часто они вытекают напрямую из функциональных требований к задаче. Сфокусированное перечисление тестов-требований до начала реализации помогает лучше понять и запомнить требования, лучше продумать детали интерфейса SUT. Увеличивается вероятность заблаговременного выявления всех необходимых краевых кейсов. Это само по себе уже помогает допускать меньше ошибок в будущей реализации, а возможность запуска готовых тестов в любой момент дает уверенность в том, что реализация осуществляется правильно.
Наличие тестов делает рефакторинг реализации безопасным. После каждого изменения реализации можно быстро прогнать все тесты SUT и в случае обнаружения поломки сразу же её устранить. Время, затрачиваемое на отладку, очень сильно сокращается.
На тесты хватает времени, ведь они неотъемлемая часть процесса разработки
Все эти факторы в совокупности сокращают время, затрачиваемое на разработку и на развитие приложения в будущем.
Приятно видеть, как красные тесты один за другим превращаются в зелёные
TDD — это в первую очередь подход к разработке. Методология замечательно показывает себя при реализации SUT с unit- и JVM integration-тестами, поскольку их можно быстро и часто запускать. С Instrumentation non-UI-тестами применять её можно, но из-за длительности запуска придется запускать тесты реже. Применять же TDD с UI-тестами крайне не рекомендуется.
Порог входа в TDD высок. Сперва следует закрепить базовые навыки написания тестов. Применять методологию в повседневности или нет — личное дело каждого, но не стоит отказываться, не попробовав. На моей практике встречались фичи со столь сложной логикой, требования к которой много раз менялись, что благополучную реализацию этих фич без TDD я себе не представляю.
Заключение
Применение автоматизированного тестирования способно вывести разработку ПО на качественно новый уровень. Главное — подходить к делу осознанно.
Разработчикам рекомендуется делать акцент на написании тестов на JVM. Чтобы поддержка тестов и изменения в кодовой базе не становились болью, следует писать только те тесты, которые действительно представляют ценность. Важно внимательно отнестись к дизайну продуктового и тестового кода, соблюдать ряд правил, стандартизировать подходы среди всех разработчиков проекта.
Можно извлекать существенную пользу за счет применения TDD с тестами на JVM. Применять его следует не всегда. Разработчику нужно самостоятельно подобрать комфортный размер шага в цикле разработки по TDD.
Полезные материалы
Воркшоп с объяснением основ написания unit-тестов на практике в Junit 4;
Доклад «Эффективное автоматизированное тестирование Android-приложений. Тестирование на JVM»;
xUnit Patterns: Test Double;
Mocks Aren't Stubs;
GivenWhenThen;
«Следует ли тестировать приватные функции?»;
Google: Testing On The Toilet — блог Google с заметками-рекомендациями по написанию автотестов;
The Three Laws of TDD — Robert C. Martin;
The Cycles Of TDD — Robert C. Martin;
История развития идеи Test First;
Доклад «Test Last, Test First, TDD: когда применять тот или иной подход».



