
Вышедшая чуть больше месяца назад ChatGPT уже успела нашуметь: школьникам в Нью-Йорке запрещают использовать нейросеть в качестве помощника, её же ответы теперь не принимаются на StackOverflow, а Microsoft планирует интеграцию в поисковик Bing - чем, кстати, безумно обеспокоен СЕО Alphabet (Google) Сундар Пичаи. Настолько обеспокоен, что в своём письме-обращении к сотрудникам объявляет "Code Red" ситуацию. В то же время Сэм Альтман, CEO OpenAI - компании, разработавшей эту модель - заявляет, что полагаться на ответы ChatGPT пока не стоит:
Насколько мы действительно близки к внедрению продвинутых чат-ботов в поисковые системы, как может выглядеть новый интерфейс взаимодействия, и какие основные проблемы есть на пути интеграции? Могут ли модели сёрфить интернет бок о бок с традиционными поисковиками? На эти и многие другие вопросы постараемся ответить под катом.
Данная статья в сущности представляет собой разбор подхода WebGPT (одного из предков ChatGPT), но с большим количеством сопроводительной и уточняющей информации, а также моих комментариев и мнений. Предполагается, что целевая аудитория не погружена глубоко в технические детали обучения языковых моделей, да и в тему NLP в целом, однако статья будет полезна и экспертам этих областей. Сначала будет дано верхнеуровневое описание ситуации и проблем, а затем - более подробное, обильно снабжённое пояснениями потенциальное решение.
Даже если у вас нет знаний в машинном обучении - эта статья будет полезна и максимально информативна. Все примеры проиллюстрированы и объяснены.
План статьи
Языковые модели и факты;
А врут ли модели?
Ответы, подкрепленные источниками и фактами;
Базовый принцип обучения WebGPT с учителем;
Шаг обучения WebGPT для продвинутых: готовим данные;
Шаг обучения WebGPT для продвинутых: учим модель учить модель;
Регуляризация при обучении WebGPT;
Альтернатива RL: меняем шило на мыло;
Метрики и восприятие людьми;
Заключение.
Глоссарий (читать перед самой статьей не обязательно - это выжимка определений, вводимых и используемых далее.)
LM, Language Models, Языковые модели - модели машинного обучения, моделирующие структуру языка с вероятностной точки зрения. Они берут на вход часть предложения или текста и предсказывают вероятности для следующего слова. Самый простой и понятный пример - клавиатура смартфона, предсказывающая по введеному тексту то, что будет написано дальше.
LLM, Large Language Models - то же, что и LM, однако очень большого размера. Под размером понимается количество параметров в модели, и для LLM это число превосходит несколько миллиардов. Такие модели работают медленнее, не могут, например, быть запущены на смартфоне, однако они лучше решают задачу моделирования языка.
Трансформер - конкретный тип архитектуры языковой модели. Основан на механизме внимания, когда для предсказания следующего слова все предыдущие слова перевзвешиваются и корректируют предсказанные вероятности. Появился в 2017м году (разработка компании Google), набрал популярность и теперь используется повсеместно - в том числе и за пределами задачи языкового моделирования.
Токен - слово или часть слова, которым оперируют трансформеры. Обычно составляет собой какую-то осмысленную часть информации, например, окончание или приставку.
Сэмплинг - процесс выборки конкретных величин из предсказанного распределения. Самый понятный пример - игральный кубик. Он моделируется равномерным распределением вероятности, где каждая величина выпадает в 1/6 случаев. При семплинге происходит "подбрасывание" кубика, и получается финальное значение. Чем больше вероятность этого значения, тем в большем количестве случаев оно будет получаться. В контексте статьи подразумевается семплинг токенов из предсказаний языковой модели.
Референс, источник - в контексте WebGPT это конкретный сайт и цитата из него, которая используется для формирования ответа на вопрос.
Демонстрации - набор записанных пользователями действий при поиске ответов на вопросы (поисковых сессий). Содержит в себе историю поисковой выдачи, кликнутые ссылки, выделенный текст и финальный ответ на вопрос, написанный вручную живым человеком.
Контекст, промпт, prompt - первая часть предложения, которая подается в языковую модель для оценки вероятости следующих слов. После промпта модель начинает генерировать текст токен за токеном. Через промпт и контекст можно корректировать вероятности возникновения токенов в генерации языковой модели.
Сравнения, пары сравнений - пара ответов на вопрос, каждый из которых содержит источники, которые использовались для написания ответа. Данная пара сравнивается живым человеком по нескольким критериям, и выносится финальный вердикт: какой ответ лучше. Получается отношение вида "А лучше, чем Б", где А и Б - ответы на один вопрос.
175B, 16B - размер модели, количество параметров (или весов) в ней. Модели указанных размеров являются LLM (Large Language Models). 16B означает 16 миллиардов параметов, а, например, 175B - 175 миллиардов параметров (175,000,000,000). На момент создания в 2020 году такая модель была наикрупнейшей. Обучить подобную модель безумно сложно с инженерной точки зрения. Подразумевается семейство моделей GPT-3, разработанное и обученное компанией OpenAI.
BC, BC модель - GPT-3, дообученная на наборе демонстраций на задачу поиска ответа на вопросы через текстовый "браузер". Принимает на вход вопрос, генерирует набор команд для браузера, и выдаёт текстовый ответ. Обучается на наборе демонстраций, произведенных людьми.
RM, Reward Model - GPT-3, обученная предсказывать предпочтения людей при сравнении пары ответов. Принимает на вход вопрос и один ответ (с референсами), выдаёт одно вещественное число. Чем больше число - тем выше вероятность того, что данный ответ будет оценен человеком выше, чем какой-либо другой. Обучается на наборе сравнений, произведенных людьми.
Reward - значение, предсказываемое Reward Model для конкретного ответа на конкретный вопрос. В некотором смысле может быть расценено как ELO-рейтинг ответа. Чем значение выше, тем, как мы верим, лучше ответ.
RL, Reinforcement Learning - семейство методов машинного обучения для ситуаций, когда присутствуют некоторые особенности получения данных, и их качество зависит от самого подхода. Именно методы из этой категории учатся играть в шахматы, в го и любые компьютерные игры (чтобы получить данные - надо играть, и чем выше уровень игры, тем лучше данные). Также в статье RL может упоминаться в значении "RL модель", то есть модель, обученная с применением техник RL.
Environment, среда, окружение - программа или процедура, которая принимает на вход действия и, согласно некоторой логике, возвращает своё состояние и Reward. Среда может быть как очень простой и понятной (крестики-нолики), так и непредсказумой - игра в покер, сёрфинг интернета. В последнем случае действия - это клики по ссылкам и прокрутка браузера, а награда определяется исходя из задачи.
BoN, Best-of-N, Rejection Sampling - подход к получению предсказаний на основе BC и RM модели. Сначала обученной BC моделью генерируется N разных ответов на исходный запрос, затем каждый из них оценивается RM-моделью. После чего ответ с наивысшей оценкой выдается в качестве финального.
Языковые модели и факты
Языковые модели, или Language Models (LM), решают очень простую задачу: предсказание следующего слова (или токена, части слова). Через такой простой фреймворк можно решать огромное множество задач: перевод текста, ответы на вопросы, классификация, регрессия (предсказывать слова вроде "3.7" или "0451", если задача сгенерировать вещественное число или код для сейфа), рекомендация, поиск... Даже команды роботам можно давать! Для обученной языковой модели на вход можно подать текст, а она допишет его, сгенерировав продолжение. Самый простой и понятный пример - клавиатура смартфона, предсказывающая по введеному тексту то, что будет написано дальше.
, соответствующих запросу. Генерация происходит токен за токеном, последовательно, по одному, а не всё предложение за раз.")
Если вам хочется глубже и в деталях разобраться в принципах работы LMок, то рекомендую начать вот с этих ссылок: раз, два, три.
А что такое токен?
Токен - это символ или набор символов, которые можно подать в языковую модель. Токенизация делается по принципу схлопывания наиболее частых сочетаний символов и повторяется раз за разом до тех пор, пока размер "словаря" (набора токенов) не достигнет предела (50к или 250к, как пример). Часто токены могут представлять собой целые слова, если это - одни из самых популярных слов в языке. Слово "unhappy" можно токенизировать как un+happy, а "don't" - как don + 't (потому что окончание 't, выражающее отрицание, встречается часто).
. Обратите внимание на цифры: длинная последовательность разбивается на отдельные группы, токены, которые часто встречаются по отдельности: 123, 678, 90. Но для обозначений годов (особенно в 21м веке) разбиения нет - потому что эти комбинации цифр встречаются КРАЙНЕ часто в интернет-текстах.")
Токенизация - процесс перевода текста в упорядоченный набор токенов - позволяет представить любой набор символов как набор понятных модели частиц. Иными словами, нейронным сетям так проще работать с текстовой информацией. Языковые модели генерируют по одному токену за раз. В дальнейшем в статье "токен" и "слово" будут упоминаться как взаимозаменяемые.
Посмотреть на примеры токенизации вашего произвольного текста для ChatGPT/WebGPT/GPT3 можно вот тут. Все эти модели используют один и тот же словарь, поэтому и разбиения получаются одинаковыми.
Если задуматься, что находится внутри языковой модели, что она выучивает для решения задачи предсказания следующего токена, то условно всё можно разделить на две большие группы: факты/знания реального мира и общеязыковая информация. Ответ на вопрос "В каком году состоялся релиз фильма X?" требует фактической информации, и необходимо быть предельно точным в ответе - ведь ошибка на +-1 год делает ответ неверным. С другой стороны, в предложении "Катя не смогла перейти дорогу, потому что она была мокрая" слово "она" в придаточной части явно относится к объекту "дорога", а не к Кате. Это ясно нам, человекам, и как показывают современные языковые модели - это понятно и им. Но для установления этой связи не нужно знать фактов, только структуру языка.
Проблема в том, что и ту, и другую составляющую модель будет учить одновременно, сохраняя информацию в свои веса (параметры). Отсюда логичный вывод - чем больше модель, тем больше она запоминает (ведь количество общеязыковой информации ограничено). Меморизация может порой удивлять - GPT-3, к примеру, знает точный MD5-hash строки "b", и выводит его по запросу. Но у всего есть пределы, и, к сожалению, в языковых моделях мы пока не научились их определять (хотя работы в этом направлении ведутся). На текущем этапе их (или нашего?) развития невозможно заведомо сказать, знает ли модель что-то, и знает ли она, что она не знает. А главное - как менять факты в ее "голове"? Как их добавлять? Как сделать оценку "количества знаний" (что бы это не значило)? Как контролировать генерацию, не давая модели возможность искажать информацию и откровенно врать?
А врут ли модели?
Именно неспособность ответить на эти вопросы, привела к тому, что демо модели Galactica, недавней разработки компании META, было свернуто. Еще недавно можно было зайти на сайт, вбить какую-то научную идею, а великий AI выдавал целую статью или блок формул по теме. Сейчас он только хранит набор отобранных примеров, ну и ссылку на оригинальную статью. Жила эта модель открыто почти неделю, но, как это часто бывает (привет от Microsoft), в Твиттере произошел хлопок – и демку закрыли (но веса и код остались доступны). Для справки: это была огромная (120 миллиардов параметров, в GPT-3 175B, то есть это модели одного порядка) языковая модель, натренированная на отфильтрованных статьях и текстах, умеющая работать с LaTeX-формулами, с ДНК-последовательностями, и все это с опорой на научные работы. Причина "провала" очень проста и доступна любому, кто понимает принцип генерации текста LM'ками - модель выдает ссылки на несуществующие статьи, ошибается в фактах (как и практически все языковые модели), и вообще с полной уверенностью заявляет нечто, что человек с экспертизой расценит как несусветный бред (но не сразу, конечно, это еще вчитаться в текст надо).
Несколько примеров работы модели Galactica
Разлетевишийся по новостям тред с другими примерами:
Занятен тот факт, что Galactica вышла (и умерла) незадолго до ChatGPT, хотя примеров лжи и подтасовки фактов у последней куда больше (особенно с фактической информацией) - как минимум потому, что модель завирусилась. По некоторым причинам популярность ChatGPT взлетела просто до небес в кратчайшие сроки - уже на 5й день количество пользователей превысило миллион!
 обучить модель удовлетворять человека своими ответами 2) бесплатно выпустить ее в интернет для всех желающих")
И несмотря на то, что команда OpenAI проделала хорошую работу по улучшению безопасности модели - заученный ответ "я всего лишь большая языковая модель" на странные вопросы даже стал мемом - нашлись умельцы, которые смогли ее разболтать, заставив нейронку притвориться кем-либо (даже терминалом линукс с собственной файловой системой).
Ответы, подкрепленные источниками и фактами
Если упростить все вышенаписанное, то получится, что
Языковые модели врут. Много и бесконтрольно.
Ещё раз, а почему врут?
Языковые модели иногда могут генерировать ответы, содержащие неверную или вводящую в заблуждение информацию, поскольку они обучаются на больших объемах текстовых данных из Интернета и других источников, которые, в свою очередь, могут содержать ошибки или неточности. Кроме того, языковые модели не могут проверять точность обрабатываемой ими информации и не способны рассуждать или критически мыслить, как это делают люди. Поэтому нужно проявлять осторожность, полагаясь на информацию, сгенерированную LMками, и проверять точность любой получаемой информации.
Важно отметить, что в процессе обучения моделей никак не оптимизируется правильность информации. Можно сказать, что оптимизационная задача, которая решается в ходе обучения, не пересекается с задачей оценки точности генерируемых фактов.
Еще одна причина - это принцип, по которому происходит предсказание. Мы уже обсудили, что такое токен, и что для модели заранее создается словарь токенов, который используется для подачи входного текста. На этапе предсказания (и это же происходит во время обучения) модель выдает вероятности появления каждого токена из словаря в заданном контексте.

Выше на изображении вы можете видеть пример генерации моделью, словарь которой состоит из 5 токенов. В качестве первого слова в предложении LM предсказывает 93% вероятности на появление токена "I", так как с него - среди всех остальных - логичнее всего начать предложение. Далее, как только это слово было выбрано, то есть подано в модель, предсказания меняются (потому что меняется контекст - у нас появилось слово "I"). И так итеративно языковая модель дописывает предложение "I am a student".
Но в вышеописанной логике мы всегда выбираем слово с наибольшей вероятностью. Однако существуют несколько стратегий семплинга (выбора) продолжения. Можно всегда брать слово с наибольшей вероятностью - это называется greedy decoding, то, что изображено выше. А можно производить выбор согласно вероятностям, выданным моделью. Но тогда легко представить ситуацию, что несколько разных токенов получили высокие вероятности - и по сути выбор между ними происходит случайно, по результату броска монетки. И если модель ошибется в одном важном токене - в имени, дате, ссылке или названии - то в последующей генерации она не имеют способа исправить написанное. Поэтому ничего не остается, кроме как дописывать бредовые ложные факты. Еще хуже, если во время выбора токена пропорционально вероятностям мы выбрали редкий токен с низкой вероятностью. Подобное происходит редко (в среднем с той частотой, что и предсказана моделью). Такое слово почти наверняка плохо смотрится в тексте, но что поделать - зато описанный принцип семплинга позволяет генерировать более разношерстные текста. Более детальный гайд про методы генерации, их плюсы и минусы (и еще один).

На картинке выше первым словом, подающимся в модель, был токен "The". Для него слово "nice" по каким-то причинам получило оценку 50%, а "car" - лишь 10%. Но если мы выберем слово "car", то логично изменить вероятности последующих слов. И эти вероятности меняются после каждого дописанного токена.

Если подводить итог этой части, то можно сказать просто: у модели есть выбор сгенерировать "19..." или "18..." в ответ на вопрос про даты. И эти выборы примерно равновероятны, +-10%. Дело случая - выбрать неправльное начало года, и всё. Одна ошибка - и ты ошибся.
Настолько много, что META решает отключить свою модель, а люди в Twitter высказывают недовольство подлогом фактов и нерелевантными ссылками. Мы не замечаем несовершества моделей в режиме болталки, но это критично важно для поисковых систем (напомню, что мы рассматриваем языковые модели в контексте их внедрения в Bing/Google/другие поисковые движки). Как мы уже обсудили, есть два типа данных - факты и языковая информация. В контексте поиска логично разделить их, и научить модель работать с чем-то вроде Базы Данных Фактов. Я вижу к этому два принципиально разных подхода:
Создать отдельное хранилище, с которым модель умеет работать каким-либо образом. Хранилище поддерживает быстрое точечное изменение фактов, их добавление;
Научить модель пользоваться интерфейсами реального мира, подобно человеку. Это может быть браузер, поисковое API, исполнение скриптов, etc.

Дальше в статье сфокусируемся на втором подходе. Отмечу, что первый зародился примерно в 2019м году с выходом статьи kNN-LM, и получил активное развитие от команды DeepMind в лице архитектуры RETRO. Про обе этих статьи у меня есть детальные видео-лекции с разбором: part 1, part 2. Про этот подход далее говорить не будем.
Идея предоставить модели доступ в Сеть давно будоражит умы человечеста - третий "Терминатор" со Скайнетом вышел 20 лет назад. Главное, что такой подход будет мимикрировать под процесс, который выполняет человек при поиске информации. В идеале для каждого тезиса или вывода, который пишет модель в своем ответе, можно найти и указать референс, источник, в котором модель "подсмотрела" его. Конечно, за скобками остается вопрос надежности источников, тем более в современном то интернете, но сама идея научить нейросеть сёрфить Веб кажется интересной. На новом примере попробуем посмотреть, как это может выглядеть:
Пример ответа на вопрос, какая река из двух длиннее

Вопрос: Which river is longer, the Nile or the Yangtze?
Ответ: The Nile is longer than the Yangtze River.[1][2][3] The Nile runs 6,650 kilometers (4,130 miles) between Lake Victoria and the Mediterranean Sea.[2] The Yangtze River runs 6,300 kilometers (3,915 miles) from its source in the Tanggula Mountains in Qinghai to the East China Sea.[3]
References:
World's Longest Rivers | Amazon, Nile & Mississippi Rivers | Live Science (www.livescience.com)
Nile - Wikipedia (en.wikipedia.org)
Yangtze River Length - 6,300 Kilometers (3,915 Miles) (www.travelchinaguide.com)
How Long is the Yangtze River? Yangtze River's Length (www.chinatraveldiscovery.com)
Не буду нагонять интригу - демонстрация поиска ответа на вопрос выше выполнена WebGPT, а не человеком. Команда OpenAI разработала подход, который сможет решать задачу long-form question-answering (LFQA), в которой текст длиной порядка одного-двух параграфов генерируется в ответ на открытый вопрос.
Что за LFQA?
Открытые вопросы, или open-ended questions - это вопросы, на которые нельзя ответить «да» или «нет» или статичным предзаготовленным ответом. Открытые вопросы формулируются как утверждение, требующее более продолжительного ответа. Эти вопросы поощряют размышления, дискуссии и выражение мнений и идей. Обычно они начинаются с вспомонательных слов "what", "how", "why" или "describe".
Long-form question-answering (LFQA) включает в себя создание подробного ответа на открытый вопрос.
Больше примеров работы модели можно найти по этой ссылке - сайт предоставляет удобный UI для демонстрации процесса поиска ответа.

Но как именно научить языковую модель выполнять поиск ответов на вопрос? Как мы выяснили выше - они всего лишь продолжают написанное, генерируя по токену за раз. Во время процедуры предобучения такие модели видят миллионы текстов, и на основе них учатся определять вероятности появления того или иного слова в контексте. Если же модели вместо обычного человеческого языка показывать, скажем, код на разных языках программирования - для нее задача не изменится. Это все еще предсказание следующего токена - названия переменной, метода, атрибута или класса. На этом принципе основана другая GPT-like модель Codex. Обучение новому языку или новым типам задач (перевод, сокращение текста - суммаризация, выявление логических связей) - всё это достижимо при дообучении модели, если подобранны правильные данные и они "скармливаются" модели в понятном формате (с изображениями такая модель работать не будет - просто не ясно, как их перевести в текст).
Базовый принцип обучения WebGPT с учителем
А что такое правильные данные в контексте поиска информации в интернете? Это поисковые сессии реальных пользователей, или демонстрации. Важно разработать метод, как последовательность действий будет представляться модели (причем, языковой модели - то есть хочется еще и переиспользовать ее знания об естественном языке), чтобы получился "понятный" формат. Следует начать со списка действий, которые доступны человеку (и модели):
Отправить поисковый запрос в API/строку поиска (авторы используют Bing, и вообще коллаборация OpenAI - Microsoft всё масштабнее и масштабнее) и получить ответ;
Кликнуть на ссылку в выдаче;
Найти текст на стрице;
Прокрутить страницу вверх или вниз;
Вернуться на страницу назад.
Это действия связанны с "браузером", но так как мы решаем задачу генерации ответа на вопрос (именно генерации, а не просто поиска - ведь сам поисковый движок Bing выдаст ответ, но он может быть неполным, неточным), то логично добавить еще два шага: это "цитировать/выписать" (то есть запомнить найденных текст со страницы для себя на будущее) и "сформулировать ответ" - чтобы мы могли понять, что модель закончила работу, и последний написанный текст стоит воспринимать как ответ. Опционально можно ограничивать количество действий, предпринимаемых моделью, что на самом деле важно, ведь для получения очередной команды от модели необходимо ждать существенное количество времени (большие модели размерами в несколько десятков миллиардов параметров тратят на генерацию ответа 0.3-20 секунд, в зависимости от длины текста, размера модели и используемых GPU/TPU). Ожидание ответа на вопрос больше минуты явно не способствует улучшению пользовательского опыта.
Команда OpenAI предлагет оригинальное решение перевода пользовательских демонстраций в виртуальный "браузер" для модели, который полностью представлен текстом:

И соответствующий этому cостоянию UI, который видел бы пользователь условного браузера (side-by-side для удобства соотнесения элементов):

Первое изображение представляет собой текстовое описание текущего состояния, которое подается в модель. Та, в свою очередь, должна предсказать следующее действие (из уже приведенного выше списка). Текст, подающийся в модель, состоит из нескольких блоков (отмечены красными цифрами):
Основной вопрос, который задан модели. Он не меняется в течение всей работы над одним ответом;
Блок цитат, которые модель сама себе выписывает. Она сама определяет, с какой части текста по какую цитировать источник. В целом можно сказать, что из этого блока знаний модель и будет генерировать финальный ответ, опираясь на информацию, "отложенную" на будущее в этом блоке. На каждом этапе работы модели видны все цитаты, и LM может понимать, какую информацию сверх этого нужно найти для полного ответа на вопрос, что позволяет писать и отправлять новые запросы в Bing;
Блок последних выполненных в браузере действий, добавленный для консистентности, чтобы модель не повторялась, и не заходила в петлю одних и тех же команд. Важно понимать, что между двумя соседними "прогонами" текста через LM информация никак не сохраняется, и её веса не меняются. Можно сказать, что у модели нет памяти, и именно этот блок помогает отслеживать траекторию ответа на вопрос, чтобы не запутаться;
Заголовок текущей страницы. Тут будет отражен реальный заголовок, если модель "кликнула" на какую-либо ссылку;
Блок текущего окна браузера. Здесь представлено то, что видел бы человек в UI. В конкретном случае предудущее действие - это запрос в API ("how to train crows to bring you gifts", как видно из блока 3), а значит в блоке 5 представлена часть поисковой выдачи (для примера - 2 ссылки, и их краткие описания). Сейчас модель видит строчки 0-11, и, если будет сгенерирована соответствующая команда, страница прокрутится, и станут доступны новые поисковые результаты;
Вторая ссылка из выдачи поисковика, по сути то же самое, что и блок 5;
Счетчик оставшихся действий (каждый раз уменьшается на единицу) и запрос следующей команды от модели (Next Action), которая должна быть сгенерирована.
Всё это описано текстом, и подается в текстовую модель как контекст в надежде на то, что в ответ LM сгенериурет следующую команду (вроде "кликни на ссылку один" или "промотай страницу вниз"). Такой контекст называется prompt (промпт). Чем он "качественнее", чем ближе он к тому, что понимают модели (что они видели во время тренировки), тем лучше модель генерирует ответы.

Интересный факт про промпты
Вообще работа над промптами - вещь очень важная. Вы могли об этом слышать или даже заметить самостоятельно, если пытались сгенерировать что-то в MidJourney / DALL-E 2 / Stable Diffusion. Простой запрос на генерацию изображения может вас не удовлетворить, но если добавить теги "screenshot in a typical pixar movie, disney infinity 3 star wars style, volumetric lighting, subsurface scattering, photorealistic, octane render, medium shot, studio ghibli, pixar and disney animation, sharp, rendered in unreal engine 5, anime key art by greg rutkowski and josh black, bloom, dramatic lighting" - то результат может приятно удивить :)
Еще важнее роль промптов при генерации текста языковыми моделями. Мой любимый пример - это добавление фразы "Let's think step by step" в конец запроса с задачей на несколько действий (было представлено в этой статье).

Данная фраза "включает" режим CoT, что означает "chain-of-thought", или цепочка рассуждений/мыслей. Включает не в прямом смысле - скорее просто заставляет модель следовать этой инструкции, и писать выкладки одну за другой. Интересно, что такой эффект значимо проявляется только у больших языковых моделей (Large Language Models, LLMs) - обратите внимание на ось OX, где указаны размеры моделей (в миллиардах параметров):
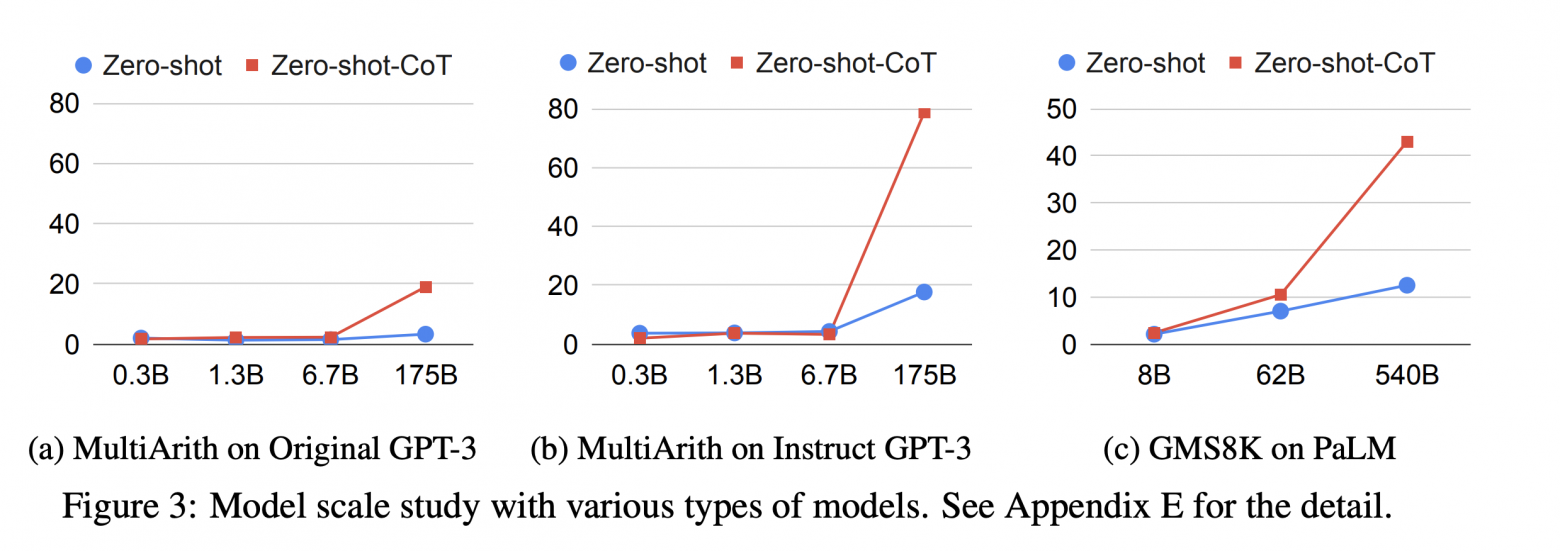
По оси OY указаны метрики на некоторых датасетах. Видно, как добавление всего лишь одной фразы магическим образом существенно увеличивает качество - но только при соответствующих размерах.
Описание (ссылка на телеграм) еще одного примера промптинга для выполнения сложных задач.
На мой взгляд, важны тут две вещи: то, что модель сама формулирует запросы в браузер, и то, что она умеет выписывать ответы во "внешнюю память" (на листочек :) ). Именно с помощью этих двух механизмов и удается на основе цитат сформулировать полный ответ, подкрепленный фактами и источниками.
Итак, человеческие демонстрации собраны, поисковые сессии переведены в текстовую информацию, и теперь можно дообучить уже существующую языковую модель в классическом режиме предсказания следующего слова, чтобы она скопировала поведение реальных людей при поиске ответов. На этапе тренировки модель каждый раз видит, какой Next Action был выполнен человеком, и учится по промпту (текущему состоянию, с цитатами и поисковой выдачей) это следующее действие угадывать. На этапе предсказания же, как было показано на скриншотах выше (блок 7) промпт в конце содержит фразу "Next Action", а модель в режиме генерации текста уже сама отдает команду. Всего для обучения использовалось 6,209 демонстраций (из интересного - публично доступна инструкция для краудсорсеров; оцените полноту описания задачи и действий. Из своего опыта знаю, что собрать данные от разных людей с разными мнениями бывает очень тяжело, данные друг другу противоречат, и тем важнее максимально подробно донести до исполнителей, что от них требуется). Полученную модель назовем BC-моделью, где BC означает Behavioral Cloning (клонирование поведения), потому что она училась повторять за людьми.
Готова ли наша модель?
Шаг обучения WebGPT для продвинутых: готовим данные
На самом деле нет :) эти демонстрации лишь показали модели, как взаимодействовать с браузером, что от модели ожидается в качестве команд к действию (Next Action), и как в общем генерировать запросы в Bing API. Финальная цель - сделать модель, которая оптимизрована под качество ответов (измеренное людским мнением), включая, но не ограничиваясь, правдивостью ответа. Тренировка на демонстрациях же не оптимизирует эту метрику каким либо образом. Обратите внимание, это в целом очень частая проблема в машинном обучении - модели обучаются на какую-то прокси-функцию, которая, как мы верим, сильно скоррелированна с метрикой реального мира. Скажем, можно минимизировать квадрат ошибки предсказания продаж в магазине на следующей неделе, но ведь реальная метрика - это деньги, заработанные или полученные компанией. Не всегда удается достигнуть высокой корреляции между этими двумя вещами. Как же обучить модель напрямую оптимизировать предпочтения реальных людей?
В самом слове "предпочтение" есть что-то, что наталкивают на идею сравнений. Оценить какой-то объект в вакууме (абстрактной цифрой от 1 до 10, например, как это часто бывает с фильмами или играми) куда сложнее, чем отранжировать его относительно другого схожего объекта. Само определение подсказывает: "Предпочтение - преимущественное внимание, одобрение, уважение к одному из нескольких вариантов, желание выбрать один из нескольких вариантов". Тогда, чтобы обучить модель производить ответы, которые наиболее предпочтительны с точки зрения людей, необходимо создать набор пар для сравнения. В контексте ответов на вопросы с помощью поисковой системы это означает, что на один и тот же вопрос предлагается два разных ответа (возможно даже с разным выводом из этих ответов), разные наборы источников, из которых этот ответ собран/сгенерирован.
Такие пары для сравнения (имея обученную на демонстрациях модель) получать очень легко - LMки это алгоритмы вероятностные, как было упомянуто ранее, поэтому можно семплировать действия при генерации команд или ответе на вопрос. Простой пример: модель после получения запроса предсказывает команду "кликни на ссылку 1" с вероятностью 40%, и команду "промотай вниз, к следующему набору ссылок" с вероятностью 37%. Уже на этом этапе доступна развилка в дальнейшей логике поиска информации, и можно запустить эти два процесса в параллель. Таким образом, через сколько-то действий каждая модель придет к ответу, но разными путями. Их мы и предложим сравнить человеку (финальные ответы и подкрепляющие их источники, не пути).
. Сначала предлагается оценить каждый ответ по отдельности по нескольким критериям Затем уже по ним сравниваются два ответа, и выносится финальный вердикт. Идеальная иллюстрация процесса декомпозиции сложной непонятной задачи в четко формализованную.")
При оценке каждого из двух ответов используются следующие критерии:
Содержит ли ответ неподкрепленную источниками информацию?
Предоставлен ли ответ на основной вопрос?
Присутствует ли дополнительная полезная информация, которая не требуется для ответа на вопрос?
Насколько ответ последователен, и есть ли в нем ошибки цитирования источников/самого себя?
Сколько нерелевантной информации в тексте ответа?
По этим критериям ответы сравниваются, и человек выбирает из 5 обобщённых опций, которые используются в качестве разметки на следующем этапе обучения (А сильно лучше Б, А лучше Б, А и Б одинаковые, А хуже Б, А сильно хуже Б). Полная инструкция для исполнителей также доступна. Интересный факт: исполнители не обязаны делать проверку фактов, указанных в источниках, процитированных моделью. Получается, люди оценивают то, насколько хорошо модель умеет опираться на уже предоставленные факты (размещенные на страницах в интернете), без факт-чеккинга.
WebGPT не сёрфят
Как во время обучения, так и во время генерации ответов WebGPT имеет прямой доступ к сети Интернет - однако все заимодействия ограничены возможностью отправки запросов в единственное API. Это позволяет модели давать актуальные ответы на широкий круг вопросов, но потенциально создает риски как для пользователя (некорректные ответы), так и для других юзеров. Например, если бы у модели был доступ к веб-формам/веб-редакторам, она могла бы исправить данные в Википедии, чтобы создать надежную ссылку с указанием источника конкретного ложного факта. Даже если бы люди-демонстраторы не вели себя подобным образом во время сбора тренировочных данных, такое поведение, скорее всего, было бы подкреплено и закреплено во время обучения, если бы модель наткнулась на него случайно. Подробнее про эксплуатацию несовершества среды и фунцкции награды см. ниже.
Более мощные модели могут представлять серьёзные риски. По этой причине авторы статьи считают, что по мере расширешния возможностей обучаемых моделей бремя доказательства безопасности при предоставлении доступа к системам реального мира должно лежать на плечах людей - даже во время процедуры тренировки.
Авторы подчеркивают, что это проблема для будущих исследований и статей. Я добавлю, что её абсолютно точно необходимо будет решить перед переносом аналога WebGPT в продакшен - например, добавить рейтинги доверия сайтам; указывать, что источник ненадежный; учиться фильтровать источники по агрегированной информации (4 сайта указывают дату, отличную от выбранного источника? тогда этот факт как ненадежный, и не используем в цитировании); наконец, оценка верности факта самой моделью: насколько вероятно, что обычная LM дала бы тот же ответ?
Заметка про надежность сайтов и фактов
Вообще, оценка правдивости ответа и надежность источников - вещь нетривиальная. Некоторые вопросы требуют того, чтобы оценщик разбирался в узкой области (программирование, медицина, языковедение). Даже с опорой на источники и интернет можно столкнуться с неочевидной проблемой - достаточно мощная модель будет выбирать источники, которые, по ее мнению, люди сочтут убедительными, даже если они не отражают реальные факты. Таким образом, нейросеть может "взломать" наше восприятие, и подкидывать ложную информацию, но под красивой и аккуратной обёрткой - а мы и не заметим.
Еще стоит рассмотреть вопрос психологии - ответы с указанием источников всегда кажутся более авторитетными. Это идёт вразрез с фактом, что сами модели всё еще могут делать простейшие ошибки.
Теперь, когда мы обсудили, как собрать данные предпочтений, чтобы "выровнять" нашу модель относительно намерений пользователей во время поиска информации, поговорим про принцип обучения. Проблема с предпочтениями и сравнениями в том, что процесс разметки таких данных занимает много времени. Нужно погрузиться в каждый вопрос, ответ, проанализировать источники, выставить оценки. Получение большого количества данных либо займет много времени, либо будет стоить огромных денег. Но что если нам не нужно размечать каждую пару? Что если мы, как инженеры машинного обучения, научим другую модель сравнивать пары ответов за людей?
Шаг обучения WebGPT для продвинутых: учим модель учить модель
В предшествующих исследованиях OpenAI было эмпирически выяснено, что модели в целом хорошо предсказывают реакции людей и их оценки в задачах, связанных с генерацией комплексных ответов. Вырисовывается следующая схема, которая является ключевой для обучения по обратной связи от людей (human feedback):
Генерируем набор пар для сравнения, используя модель, обученную на демонстрациях (она уже умеет "серфить" интернет, писать запросы и "кликать" по ссылкам, то есть выдавать соответствующие команды в виде текста);
Размечаем пары с использованием людей;
Тренируем другую модель предсказывать разметку людей (какой ответ из пары получит более высокий ответ) на парах из п.2. Назовем такую модель Reward Model (RM). Она принимает на вход вопрос и финальный сгенерированный ответ (без промежуточных шагов вроде прокрутки браузера), а выдаёт одно вещественное число (оно еще называется наградой, или Reward - по историческим причинам). Чем больше это число - тем выше вероятность того, что человек высоко оценит этот ответ по сравнению с остальными. Можно считать, что это условный ELO-рейтинг, как в шахматах;
Обучаем основную модель (BC) на основе оценок от модели из п. 3; По сути LM учится решать задачу "как мне поменять свой сгенерированный ответ так, чтобы получить большую оценку RM?";
Повторяем пункты 1-4 итеративно.
, размечаем (п.2), тренируем RM (п.3)
Step 3 справа: на новых данных производим оценку новых пар сгенерированных ответов, дообучаем WebGPT (п.4)")
Этот пайплайн имеет две ключевые особенности. Во-первых, его можно повторять итеративно, улучшая именно текущую модель, со всеми ее минусами и плюсами. Если LM в какой-то момент начала обманывать, или использовать несуществующие факты (дефект обучения) - это будет заметно на разметке людьми, и соответствующие ответы получат низкие оценки. В будущем модели будет невыгодно повторять подобное (возникнет negative feedback). А во-вторых, и это просто прекрасно - используя RM из пункта 3, мы можем сгенерировать оценки для куда большего количества пар (и гораздо быстрее), чем если бы это делали люди. Следите за руками: берем любые доступные вопросы из интернета, из датасетов или даже специально заготовленные, на которых модель еще не обучалась, генерируем ответы, оцениваем их автоматически, без привлечения людей, и уже на основе этих оценок дообучаем основную WebGPT. Если люди могут за, скажем 10,000$ разметить 5,000 пар за неделю, то 1 землекоп RM может за день отранжировать десятки и сотни тысяч пар ответов фактически за копейки.
Каким методом производить обучение в таком необычном случае?
В машинном обучении выделяют несколько "царств" (или скорее направлений) алгоритмов обучения. Детали меняются от одной классификации к другой, где-то происходит обобщение по конкретным критериям, но практически всегда и везде упоминается три основных подхода:
Обучение с учителем (Supervised Learning) - когда есть размеченные данные, и нужно научиться на их основе обобщать знания на генеральную совокупность всех объектов. Сюда относятся модели для классификации, регрессии (предсказание числовых величин);
Обучение без учителя (Unsupervised Learning) - когда разметки нет, но хочется каким-то образом извлечь знания из данных. Популярный пример - разнообразные кластеризации и выделение когорт;
Обучение с подкреплением (Reinforcement Rearning, RL) - когда есть некоторые особенности получения данных, и их качество зависит от самого подхода. Именно методы из этой категории учатся играть в шахматы, в го и любые компьютерные игры (чтобы получить данные - надо играть, и чем выше уровень игры, тем лучше данные).

Как легко догадаться по описанию пайплана обучения WebGPT - нам подходит третий вариант. RL методы взаимодействуют со средой (или окружением, environment), посылают в нее выбранные действия, получают обновленное состояние (описание мира), и пытаются найти лучшую стратегию. Очень часто система получения награды, которую и старается максимизировать алгоритм, недоступна: для игры го нельзя сказать, является ли в моменте одна позиция выигрышнее другой (ведь партию можно доиграть по-разному); в игре Minecraft вообще почти не ясна связь деревянной кирки и добычи алмаза - по крайней мере до тех пор, пока сам игрок один раз не пройдет путь от начала и до конца. Поэтому в мире обучения с подкреплением используют моделирование награды, и это в точности то, для чего мы обучали Reward Model - предсказывать предпочтения человека. Таким образом снижается требование к количеству реальных взаимодействий со средой (людьми-разметчиками с почасовой оплатой) - ведь можно опираться на выученную из предоставленной разметки закономерность.
За долгие годы развития направления RL было придумано множество алгоритмов, с разными трюками и ухищрениями (чаще всего - под конкретные типы задач, без возможности обобщиться на любые произвольные цели). Иногда для успешного обучения нужно вручную конструировать принцип оценки действий модели - то есть вручную указывать, что, например, действие А в ситуации Б нанесет урон вашему персонажу, и тот получит меньшую награду. Все это плохо масштабируется, и потому ценятся стабильные методы, выступающие в роли швейцарского ножа. Они хорошо обобщаются, не требуют тончайшей настройки и просто работают "из коробки".
Один из таких методов - Proximal Policy Optimization, или PPO. Он был разработан командой OpenAI в 2017м году, и как раз соответствовал требованиям простого прикладного инструмента, решающего большой спектр задач. Мы не будем погружаться в детали его работы, так как по этой теме можно прочитать не то что отдельную лекцию - целый курс. Общий смысл алгоритма в том, что мы обучаем модель-критика, которая оценивает наш текущий результат, и мы стараемся взаимодействовать со средой лучше, чем в среднем предсказывает критик. Критик в оригинале очень похож на описанную раннее Reward Model.
Сам же алгоритм был протестирован командой OpenAI на разнообразных задачах, включая сложную компьютерную игру, требующую кооперации нескольких игроков (или моделей) и далёкий горизонт планирования - DotA 2. Полученная модель (с некоторыми игровыми ограничениями) выигрывала у чемпионов мира - более подробно об этом можно прочитать в официальном блоге (даже записи всех игр доступны!).


Важное замечение по Reward Model для графиков ниже по статье: часто по оси OY будет Reward Value (оно же RM Score). Для удобства сравнения, во всех случаях предсказания RM были стандартизированы, то есть из предсказанного значения вычитали среднее по всем генерациям (поэтому среднее значение теперь равно нулю; и больше нуля - значит лучше среднего), и полученную разность делили на стандартное отклонение (поэтому в большинстве случаев Reward находится в интервале [-1; 1]). Однако основная логика сохраняется - чем больше значение, тем лучше оценен ответ.
В такой постановке задачи оптимизации очень легко переобучить модель под конкретную Reward Model, а не под оценки разметчиков, под общую логику. Если это произойдет, то LM начнет эксплуатировать несовершества RM - а они обязательно будут, как минимум потому, что количество данных, на которых она тренируется, очень мало (суммарно на всех итерациях оценено порядка 21,500 пар, но для тренировки доступно 16,000), и её оценка не в точности повторяет оценки людей. Можно представить случай, что RM в среднем дает более высокую оценку ответам, в которых встречается какое-то конкретное слово. Тогда WebGPT, чрезмерно оптимизирующая оценку RM (вместо людской оценки, как прокси-метрику), начнет по поводу и без вставлять такое слово в свои ответы. Подобное поведение продемонстрировано в другой, более ранней статье OpenAI, с первыми попытками обучения моделей по обратной связи от людей:

Поэтому очень важно подойти основательно к процессу итеративного обучения двух моделей.
Заметка про актуальность проблемы
Так считает и сама OpenAI - аккурат перед выходом ChatGPT была опубликована статья с глубоким анализом процесса излишней оптимизации под RM: Scaling Laws for Reward Model Overoptimization. В ней исследователи пытаются разобраться, как долго можно тренировать LM-модель относительно RM, без добавления новых данных от людей, чтобы не терять в качестве генерации, и в то же время максимально эффективно использовать существующую разметку. Интересно то, что эксперименты ставятся по отношению к другой, второй RM (Gold на графике ниже), которая выступает в роли "реальных людей" - и экспериментально показывается, что ее оценка начинает с какого-то момента падать, хотя по основной RM, на основе которой тренируется аналог WebGPT, виден рост. Это демонстрирует ровно описанный выше эффект овероптимизации, переобучения, когда оценки RM перестают соответствовать ощущению людей-разметчиков.

По оси OX - длительность обучения модели (измеренная в отклонении предсказаний от исходной модели, обученной на демонстрациях. Чем больше отклонение - тем дольше учится модель, при прочих равных). По оси OY - оценка RM. Пунктирные линии - оценки основной RM, сплошные - оценки "настоящей" RM, имитирующей оценки людей (не дообучается в процессе эксперимента). Обратите внимание, что ось OY начинается в нуле - потому что это среднее значение оценки Reward после стандартизации (формулу и процесс см. выше). Чем выше RM Score, тем больше модель "выигрывает" в оценке своих ответов относительно исходной модели.
Видно, что пунктирные линии показывают рост, так как мы оптимизируем их предсказания напрямую. В это же время оценки "настоящие", полученные как будто бы от людей, падают - при чём тем быстрее, чем меньше размер RM. Так, оптимизация против самой "толстой" модели на 3 миллиарда параметров не приводит к деградации - оценка выходит на плато. Второй интересный вывод - чем больше параметров в RM (чем светлее линия), тем выше средняя оценка модели, полученная обучением против такой RM. Это, конечно, не открытие - мол, бери модель потолще, и будет обучаться лучше - однако подтверждает тезис о том, что переобучения при тренировке RM на разметку людей не происходит (при правильном подходе и гиперпараметрах), а еще позволяет численно оценить эффект прироста в качестве генерации.
Курьёзные случаи эксплуатации неидеальности условий награды
С методами в RL есть одна проблема - они очень эффективны в эксплуатации уязвимостей среды. Они пойдут на любые меры, чтобы получить как можно большую награду (максимизируют Reward). Некоторыми подобными примерами мне захотелось поделиться с вами, для наглядности:
Предположим, у вас есть двуногий собаковидный робот, ограниченный вертикальной плоскостью, то есть он может бегать только вперед или назад. Цель – научиться бегать. В качестве награды выступает ускорение робота. Нейросеть должна управлять сокращением мышц, чтобы контролировать движение. Что может пойти не так?
Произошел "reward hacking", или взлом принципа начисления награды. Со стороны это действительно может выглядеть глупо. Но мы можем это сказать только потому, что мы можем видеть вид от третьего лица и иметь кучу заранее подготовленных знаний, которые говорят нам, что бегать на ногах лучше. RL-алгоритм этого не знает! Он видит текущее состояние, пробует разные действия и знает, что получает какое-то положительное вознаграждение за ускорение. Вот и все! Если вы думаете, что в реальной жизни такого не бывает, то...

Более простой пример, когда ожидания могут не совпадать с получаемым поведением. Пусть есть балка, закрепленная на вращающемся шарнире в двумерной плоскости. Модель может давать команды вращать балку по часовой стрелке или против. Всего два действия. Задача - держать балку в стабильном сбалансированном положении и выше нижней половины. Всё очень просто - ставим её идеально вертикально, и готово!
Или не совсем готово. Мы не штрафуем алгоритм за приложение излишних усилий. Мы не формулируем задачу как "выровняй балку наименьшими усилиями". Почему бы тогда не держать её на весу, постоянно прокручивая шарнир по часовой стрелке? Великалепная стратегия, просто, блин, чудесная, если я правильно понял. Надёжная как швейцарские часы. Больше примеров и рассуждений можно найти тут.
И последнее - блогпост OpenAI про модели для игры в прятки, где были найдены и выучены очень сложные паттерны действий. Сами по себе эти действия не являются "обманами" среды или функции награды (Reward), но служат ответами на изменившееся поведение оппонента, эксплуатируя его предсказуемость. Враг закрылся в углу стенами? Принесу лестницу и перелезу. Соперник несет лестницу? Превентивно отберу её. И так далее, и так далее... Видео с объяснением:
Интересный факт про RL-подход: для улучшения сходимости, а также уменьшения количества необходимых данных при общей процедуре обучения, авторы раз в несколько шагов добавляли 15 эпизодов генерации финального текстового ответа по уже набранным источникам информации. Это позволяет писать более связные и консистентные ответы, и наилучшим образом (с точки зрения Reward Model, то есть почти человеческой оценки) использовать источники и текст из них.
Регуляризация при обучении WebGPT

Регуляризация - краеугольный камень машинного обучения. Обычно это работает так: добавляешь в большую математическую формулу для оптимизации еще пару членов, которые, как кажется на первый взгляд, взяты на ходу из головы - и модель начинает учиться лучше, учиться стабильнее, или просто хотя бы начинает учиться. В целом регуляризация направлена на предотвращение переобучения, и часто зависит от способа тренировки и самой архитектуры модели.
Так как мы переживаем, что модель начнет эксплуатировать неидеальность Reward Model, и это выльется в бессмысленные или некорректные генерации, то стоит задуматься над добавлением штрафа за, собственно, бессмыслицу. Но как её оценить? Существует ли инструмент, который позвоялет определить общую адекватность и связанность текста?
Нам очень повезло: мы работаем с языковыми моделями, натренированными на терабайтах текста, и они хороши в оценке правдоподобности предложений (вероятности из появления в естественной среде, в речи или скорее в интернете. Можно рассчитать как произведение вероятностей каждого отлельного токена). Особенно остро это проявляется в случаях, когда одно и то же слово повторяется по многу раз подряд - ведь в языке такое встретишь нечасто. Получается, что при обучении модели мы можем добавить штраф за генерацию неестественного текста. Для того, чтобы модель не сильно отклонялась от уже выученных текстовых зависимостей, введем член регуляризации, отвечающий за разницу между распределениями вероятностей слов, предсказанными новой обучаемой моделью и оригинальной BC (после тренировки на демонстрациях).
, y - генерируемая моделью часть, RL/SFT - указание на тип модели (в числителе - новая, обучаемая модель, в знаменателе - зафиксированная и обученная на демонстрациях). Pi означает конкретную модель и её оценки вероятностей токенов y при промпте x.")
Чаще всего для этой цели используется Дивергенция Кульбака-Лейблера: это нессиметричная неотрицательная мера удаленности двух вероятностных распределений. Чем более похожи распределения, тем меньше её значение, и наоборот. Это значение вычитается из общей награды, и - так как мы решаем задчачу максимизации - мешает достижению цели. Таким образом, мы вынуждаем модель найти баланс между отступлением от исходной BC с точки зрения генерируемых вероятностей для текста и общей наградой за генерацию. Приведённый подход - не панацея, и он не позволит бесконечно тренировать модель относительно зафиксированной RM, однако может продлить процесс, увеличивая тем самым эффективность использования разметки.
Альтернатива RL: меняем шило на мыло
Обучение с применением RL - задача не из лёгких, тем более на такой необычной проблеме, как "оптимизация генерируемого текста согласно фидбеку людей". Пользуясь тем, что WebGPT представляет собой языковую модель, оперирующую вероятностями, из которых можно семплить, авторы предлагают альтернативный способ, который не требует дообучения модели (относительно BC, после использования датасета демонстраций), однако потребляет куда больше вычислительных ресурсов.
Этот метод называется Best-of-N, или Rejection Sampling, и он до смешного прост. После полученя первой группы размеченных пар сравнений ответов WebGPT, согласно плану пайплана, обучается Reward Model. Эта модель может выступать в качестве ранжировщика для десятка (или N, если быть точным. Best-of-64 означает ранжирование 64 вариантов) потенциальных ответов одновременно, ее задача - проставление оценки (согласно предсказанию) и упорядочивание всех ответов. Самый высокооценённый ответ из всех и является финальным.
Разные ответы получаются за счет разных действий, сгенерированных WebGPT - на самом раннем этапе это может быть слегка изменённая формулировка вопроса в Bing API; чуть позже - прокрутка на 3-4 страницу поисковой выдачи вместо проверки топа; под конец - финальные формулировки, используемые для связывания процитированных фактов. Развилок достаточно много (во время генерации каждой команды! А ведь их может быть и 100), и потому варианты получаются действительно неоднородными. Более того, у модели появляется шанс "прокликать" как можно больше ссылок (в разных сессиях, но при ответе на один и тот же вопрос - то есть паралелльно). Быть может, лучший ответ на поступивший запрос спрятан в сайте с невзрачным описанием, которое видит модель в поисковой выдаче, однако внутри предоставлен наиболее точный ответ - в таком случае обилие посещённых сайтов играет лишь на руку. А главное - никакого обучения, как только получена версия Reward Model. Для генерации используется LM, обученная только на демонстрациях (BC, порядка 6,200 примеров - очень мало по меркам Deep Learning /современного NLP).

А сколько разнообразных ответов оптимально генерировать для ранжирования, и что вообще такое "оптимально"? Ответы на эти вопросы представлены на картинке слева. Чем больше модель, тем больше генераций можно пробовать ранжировать, и тем больший прирост к метрике это даст. В целом, это логично - большие модели хранят больше знаний, их выдача более разнообразна, а значит может привести к таким сайтам и, как следствие, ответам, которые не встречаются у других моделей. Оптимальными считаются точки перегиба на графике, где прирост метрики за счет наращивания ресурсов начинает уменьшаться. Это значит, что можно взять модель чуть-чуть побольше, натренировать ее и получить метрику немного выше. Однако видно, что даже маленькая модель на 760M параметров может тягаться с 175B гигантом - просто нужно генерировать порядка сотни вариантов (и это всё еще будет на порядок вычислительно эффективнее 2-3 вариантов от LLM GPT-3). Отмеченные на графике звёздочками точки являются оптимальными для рассматриваемых моделей, и именно эти значения будут использовать для рассчета метрик ниже (например, N=16 для средней модели на 13B параметров).
Метрики и восприятие людьми
Начнем с конца - попробуем оценить, какой из методов генерации ответов показывает себя лучше: RL (обучение через моделирование функции оценки ответа) или BoN (без дообучения; множественное семплирование из модели). Может ли их комбинация прирастить качество генерируемых ответов еще сущестеннее?
Попробуем разобраться, как производить такое сравнение. У нас есть модель, обученная исключительно на 6,200 демонстрациях, без прочих трюков, и в режиме языкового моделирования. Напомню, что её называют BC (Behavioral Cloning). Относительно ответов, порождаемых этой моделью, можно проводить сравнения по уже описанному выше принципу с ответами от других моделей. Если качество ответов в среднем одинаковое, то можно ожидать ситуации 50/50 - когда в половине случаев люди предпочтут ответ первой модели, а в половине - второй. Если ответы одной модели стабильно выигрывают в 55% случаев - можно сказать, что - согласно оценке людей - её ответы качественнее.
 с использованием или без использования BoN-семплинга (справа и слева соответственно). Маленькие чёрточки сверху представляют +-1 стандартное отклонение при измерении метрики (доверительный интервал).")
Именно поэтому величина в 50% отмечена пунктирной линией на графике - это наша отправная точка, и мы хотим видеть прирост доли выигранных сравнений относительно заданного уровня. Из графика можно сделать несколько выводов. Во-первых, RL позволяет улучшить модель, натренированную на демонстрациях (то есть все эти трюки с RM и разметкой были не зря!). Во-вторых, самый лучший результат - 58% побед для 175B Bo1 модели. В-третьих, RL и Rejection Sampling плохо сочетаются, и либо ухудшают результат, либо не меняют его существенно (исключение 13B-Bo16 модель, однако это скорее выброс, случившийся из-за маленького размера выборки для оценки).

Если же сравнить отдельно BoN модель (генерация N ответов BC-моделью и ранжирование через оценку RM) с самой BC моделью (то есть параметры сетей одинаковые, отличается только способ получения ответа, и как следствие вычислительная мощность, необходимая для генерации), то процент побед будет равняться 68% (при N=64, что, согласно приведенной оценке выше в статье, является оптимальным значением). Получается, что одной и той же BC модели Bo64 проигрывает в 32% случаев, а RL - в 42%. Разница существенна, если учесть, что метрика рассчитана на реальных человеческих оценках, восприятии. По этой причине дальше авторы статьи большинство экспериментов делают именно с BoN-моделями, а не RL. Но вообще интересно разобраться, почему так может происходить, что дообученная модель хуже показывает себя, чем модель, видевшая лишь 6,200 демонстраций. Можно выдвинуть несколько гипотез или связать это со следующими фактами:
Исходя из специфики задачи, может быть существенно выгоднее посетить бОльшее количество сайтов, сделать больше попыток запросов в API, чтобы сгенерировать качественный ответ;
Среда, в которую "играет" наша модель (интернет и вебсайты, поисковый движок), безумно сложна для прогнозирования. В то же время с применением Rejection Sampling модель может попытаться посетить гораздо больше веб-сайтов, и затем оценить полученную информацию через RM;
RM была натренирована в основном на сравнениях, сгенерированных BC и BoN-моделями, что ведет к смещению в данных. Быть может, если собирать датасет сравнений исключительно под PPO-алгоритм, то проигравший и победитель поменяются местами;
В конце концов, как было упомянуто выше, RL-алгоритмы требуют настройки гиперпараметров, и хоть PPO в достаточной мере нечувствивтелен к их выбору, всё равно нельзя утверждать, что полученная в результате обучения модель оптимальна, и ее нельзя существенно улучшить;
Вполне возможно, что в результате неоптимального выбора параметров в пункте 4 произошло переобучение под RM, и модель потеряла обобщающую способность. Как следствие - получает более низкие оценки ответов от людей;
Стоит дополнительно отметить, что немало усилий было приложено и к обучению исходной BC модели. Авторы долго и тщательно подбирали гиперпараметры, и в итоге это привело к существенному сокращению разрыва в метриках, который изначально наблюдался между BC и RL подходами. Таким образом, сам по себе бейзлайн в виде BC достаточно сильный, производящий осмысленные и высокооцененные ответы.
Следующим логичным шагом становится сравнение лучшей модели (175B Bo64) с ответами, написанными самими живыми людьми. Это не упоминалось ранее, однако исходные вопросы для сбора демонстраций и генерации пар на сравнение (в RL/RM частях) были выбраны из датасета ELI5. Он сформирован следующим образом: на Reddit есть сабреддит Explian me Like I'm Five (ELI5), где люди задают вопросы, и в комментариях получают ответы. Для сбора демонстраций при тренировке BC разметчики сами искали ответы на вопрос, прикрепляли источники информации/ссылки (как было описано далеко в начале статьи). Однако в самом датасете ответами считаются самые высокооцененные (залайканные) комментарии, с некоторыми фильтрациями и ограничениями. И формат таких ответов существенно отличается от производимого моделью: там (зачастую) нет ссылок-источников, упоминаемые факты не сопровождаются аннотацией ([1][2] для указания на первый и второй источник, к примеру).

Указанные особенности подводят нас к развилке:
С одной стороны, мы можем сравнить результаты модели на новых вопросах, демонстрации для которых не участвовали в тренировочной выборке, и для которых есть аннотированные ответы с указанием источников. Такие ответы с нуля написаны живым человеком по результатам его поиска;
С другой, если на этапе постобработки вырезать блок ссылок из ответа модели, а также их упоминания-референсы в тексте, то такие ответы, в теории, можно сравнить с исходными комментариями людей на Reddit.
Поэтому проведём два сравнения! Однако стоит учесть, что люди, участвовавшие в генерации демонстраций или же в сравнении двух ответов по разным факторам (влкючающим корректность цитирования источника), имеют некоторую смещенную точку зрения на задачу: они уже видели инструкцию по разметке, представляют примерный процесс ответа на вопрос, знакомы с критериями оценки. Их мнение в слегка измененной задаче нельзя назвать незамыленным. Исходя из этого, для человеческой оценки качества оригинальных ответов на Reddit против ответов модели были наняты новые разметчики, которым было сообщено куда меньше деталей о проекте (инструкция занимает буквально пару страниц). Они практически идеально представляют собой усредненное мнение человека, который просто хочет получить вразумительный ответ на свой вопрос.
![Результаты человеческой оценки ответов модели против сгенерированных. Слева - метрики для случая [1], с указанием источников и ссылок, справа - метрики предпочтений против оригинальных ответов с Reddit, написанных добрыми и готовыми помочь людьми.](https://habrastorage.org/r/w1560/getpro/habr/upload_files/479/679/bdb/479679bdb7d46245a69ace6de91501c5.png "Результаты человеческой оценки ответов модели против сгенерированных. Слева - метрики для случая [1], с указанием источников и ссылок, справа - метрики предпочтений против оригинальных ответов с Reddit, написанных добрыми и готовыми помочь людьми.")
Оценивалось всего три показателя - общая полезность ответа, согласованность и фактическая точность. На графике слева видно, что большая модель 175B Bo64 генерирует ответы, которые в 56% случаев признаны более полезными, чем ответы, полученные ручным поиском живого человека с последующей ручной компиляцией ответа по источникам. Немного страдает согласованность, а фактическая аккуратность держится на уровне. Можно сказать, что таким сгенерированным ответам стоит доверять, как если бы вы сами искали ответ на вопрос в интернете (не то что ответы ChatGPT или Galactica!). Главный вывод тут - модель выигрывает у написанных людьми ответов в более чем 50% случаев - то есть достигает уровня человека в использовании браузера для поиска информации. Также стоит отметить, что использование обратной связи от людей (пары сравнений для обучения Reward Model) имеет важнейшее значение, поскольку нельзя ожидать превышения планки 50% предпочтений только за счет подражания исходным демонстрациям (в лучшем случае мы научимся делать точно так же, и получится 50/50).
На графике справа, иллюстрирующем сравнение относительно оригинальных ответов из комментариев на Reddit, метрики еще лучше (ответ модели выбирается лучшим из пары 69% случаев). В целом, это не удивительно - люди пишут ответы в свободное время, ничего за это не получая (кроме апвоутов и кармы), и иногда ссылаются на знания из памяти, и не проверяют факты в интернете.
Заключение
Да, полученная модель не гарантирует выверенных и 100% фактологически точных ответов на запросы, однако это гораздо сильнее приближает описанный подход (и ChatGPT вместе с ним) к надежным поисковым системам, которые можно не перепроверять на каждом шагу. Более того, такие модели уже сейчас способны сами добровольно предоставлять источники информации, на которые опираются - а там дело за вами. Для самых терпиливых читателей, добравшихся до заключения, у меня подарок - три сайта, в которых реализованы поисковики на принципах обучения моделей, описываемые в статье:
https://phind.com/
https://you.com/
https://www.perplexity.ai/

Уже сейчас они предоставляют возможность получать ответ в режиме диалога, и это только начало. У меня очень большие ожидания от 2023го года, и надеюсь, что у вас теперь тоже!
P.S.: разумеется, от метода, разобранного в статье, до готового к внедрению в продакшен решения необходимо преодолеть огромное количество других проблем и инженерных задач. Я выбрал данную тему исходя из ситуации, которую наблюдаю в разнообразных телеграм, слак и прочих чатах: люди массово жалуются и упрекают ChatGPT в том, что она врет, подтасовывает факты. "Как это внедрять в поиск? Оно же даже дату развала СССР не знает!!!". В этом массовому потребителю и видится основная проблема. Надеюсь, что сейчас стало более понятно, как близки мы к новой парадигме обращения с поисковыми системами.

Об авторе
Статья подготовлена и написана Котенковым Игорем (@stalkermustang). Буду рад ответить на вопросы из комментариев и добавить обучающие заметки в текст материала по запросу.
Подписывайтесь на авторский телеграм-канал, где вас ждёт ещё больше новостей, разборов и объяснений из мира NLP, ML и не только! Кроме того, в чате канала можно обсудить идеи из статьи с другими участниками сообщества.




