
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Таск-треккер как исправный источник данных для стратегического управления. Звучит красиво. А в нашей компании это даже работает и приносит пользу.
Данная статья является углублением к предыдущей: Автоматизация аналитики Jira средствами Apache NiFi. Теперь хочу подробнее раскрыть наш взгляд на отчетность по Jira Software и опыт ее реализации при помощи R. Язык тут, конечно же, не догма. Сегодня наше все — это концепция.

Картинка позаимствована тут.
Давайте представим себе таск-треккер. Какие данные я, как аналитик, могу из него добыть? Или любая готовая аналитическая платформа? Количество задач за период, статистику логирования, базовую разбивку на проекты, картинки какие-нить о продуктивности сотрудников… да и все, навскидку.
А ведь все, что ни делается — заносится в жиру. Следовательно, наверняка можно вычленить нечто более глобальное: чем занимается команда и в каком направлении она двигается.
Таки да, нам это удалось. Правда, не обошлось без помощи PM-a попервой.
Разумеется каждая конкретная Jira существенно отличается от какой-либо другой. И наше решение вполне может не быть для вас самым эффективным или же вообще применимым.
Прошу расценивать это лишь как идею организации таск-треккера, на примере нашей аутсорсинговой компании.
Мы сделали всего два движения.
Первое и самое простое. Приняли, что все задачи в рамках одного направления должны быть привязаны к эпику, обязательно. Эпики это наиболее крупные объекты в Jira, представляющие собой множества задач. Они помогают создавать иерархию и структуру, а также могут охватывать несколько спринтов и версий.
О втором чуть подробнее. Нам удасться увидеть общую картину и ответить на стратегические вопросы, если рабочий процесс будет представлен в виде некого потока, в который каждый сотрудник делает свой вклад. Для этого, в нашем случае, идеально подходит концепция IT4IT, со своей операционной моделью, базирующейся на четырехпотоковой цепочке создания ценности:

Собственно, что мы сделали. Воспользовавшись IT4IT, добавили такое понятие как компонента задачи в Jira. У нас они следующие:
На данном этапе, наверное самое сложное — убедить сотрудников, что лишний пункт в треккере не просто так и он обязателен к корректному заполнению.
Теперь препятствий для реализации отчетности быть не должно. Сформулирую подобие ТЗ.
Поскольку в начале каждой недели команда собирается на мит для планирования — отчет должен быть еженедельным. Нам важно видеть статистику появления и продвижения задач, логирование сотрудников и вклад каждого из них в общую картину. Ответить на вопрос: чем занимается команда — в разрезе эпиков и компонент.
Зная что нам нужно добыть — идем выгружать данные. Через Jira API запрашиваем все таски (issue), обновленные на прошедшей неделе. Добываем из них ключи и к каждой таске догружаем историю логирования (worklog) и историю изменений (changelog). Извращения с догрузкой необходимы, чтобы обойти ограничения апишки.
Далее начинается зона ответственности R, т.к предобработка полученых данных это составляющая скрипта генерации отчета.
В ней нету чего-то заумного, необходимо просто распарсить JSON-ы, пришедшие от апи и оставить только необходимые свойства (пункты в Jira). Единственный момент, при обработке changelog-а нам интересны только изменения статуса задачи, остальное можно смело удалять.
Ну и, наконец-то — мы подобрались к аналитике.
Узнаем сколько задач открыто, было в работе, закрыто и отложено за прошедшую неделю. Взгляните-ка на R код:
Не напоминает ли вам это псевдокод? А если я скажу что оператор '%>%' передает данные от предыдущей функции к следующей. А последняя модификация во всей цепочке будет сохранена в переменную. Представьте себе, мы только что поднялись на порог вхождения в R!
Вы еще не влюбились в него? Тогда, если позволите, я насыплю еще немного инфы.
Словеса из Википедии:
И последнее на сегодня. В этом году R ворвался в десятку самых популярных языков в мире (пруф). Горжусь им.
Прошу простить мне сие отступление. Об R я могу говорить часами. Просто он насквозь окутан мифами, а я люблю их разрушать — хобби, знаете ли.
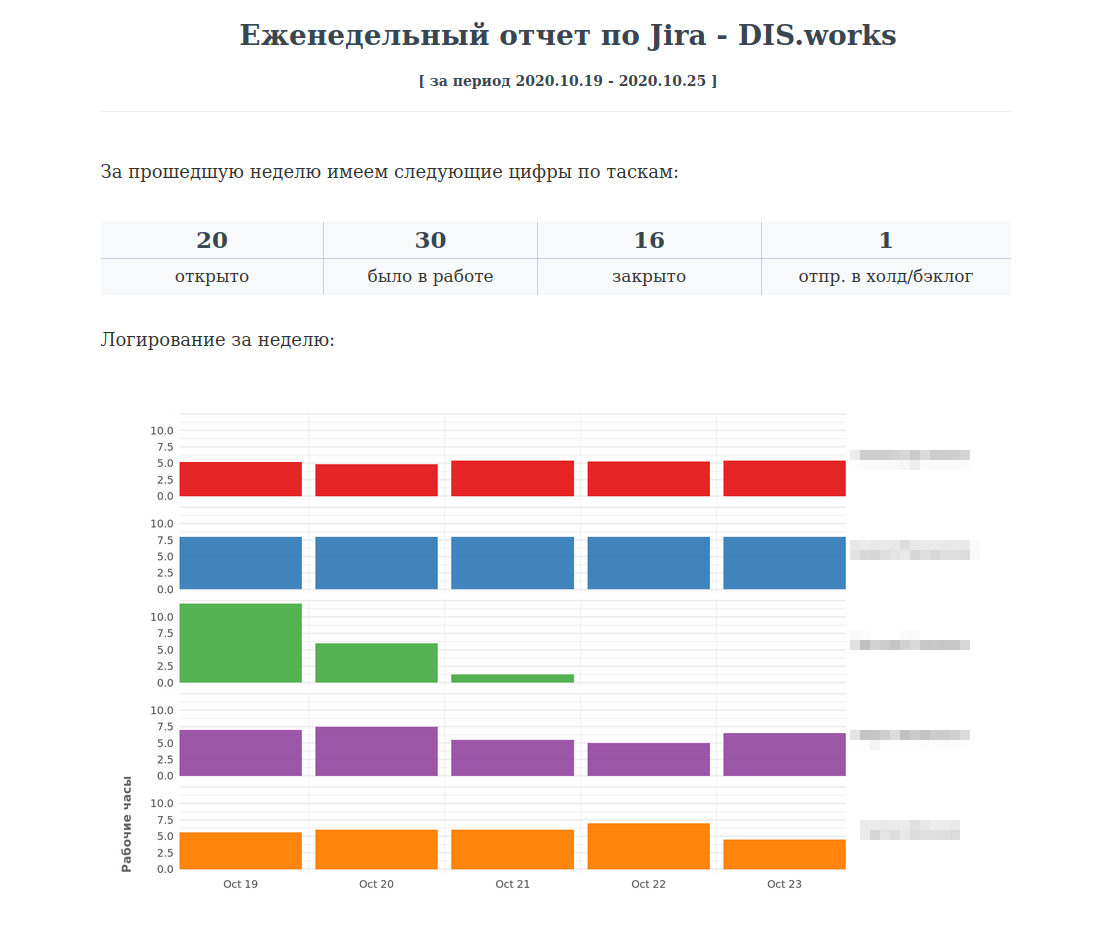
Вернемся к отчету. Имея искомые цифры, визуализируем их. После этого оформляем логирование сотрудников. Вот как выглядит данная часть у нас:
Продолжу показывать вам итоговые картинки из этого же реального отчета.
Направление нашей деятельности отражает следующий график. Он также позволяет оценить загруженость сотрудников операционной деятельностью.

А вот и разрез всех задач по компонентам. Он и дает ответ на вопрос чем мы занимаемся. Картину дополняю цифрами.

Ну и обещанный вклад каждого сотрудника в общую картину, приведенную выше.
Вы, уверена, сразу же заметите где у нас разработчик, а где админ. К этой наглядности мы и стремились.

Реальный отчет так же дополнен сводкой движения задач. Это дополнение к общей статистике, размещенной в самом начале, с названиями задач и именами ответственных людей.
Настроить автоматическую генерацию отчета, например, по понедельникам из R скрипта можно с помощью пакета cronR, это исключительно просто.
У нас же все сложнее и изящнее. Еженедельную выгрузку данных из Jira API, запуск скрипта генерации отчета и отправку отчета всем сотрудникам по Email мы реализовали с помощью Apache NiFi. Эта тема насколько обширная, что вполне себе заслужила отдельную статью.
Количество реализаций Jira Software, как и количество компаний где она используется — уйма. Каждый босс, при этом, нуждается в своей уникальньной базе метрик для тактически верного управления. Да, существует eazyBI и другие плагины для Jira аналитики, но в результате это как покупка костюма в магазине, вместо пошитого на заказ Bespoke.
Рассмотренный отчет пошит по лекалам. По словам босса он дает стратегическое представление о том чем занимается подразделение или команда. Надеюсь данная статья поможет вам реализовать нечто подобное и у себя дома.
Спасибо.
Данная статья является углублением к предыдущей: Автоматизация аналитики Jira средствами Apache NiFi. Теперь хочу подробнее раскрыть наш взгляд на отчетность по Jira Software и опыт ее реализации при помощи R. Язык тут, конечно же, не догма. Сегодня наше все — это концепция.
Картинка позаимствована тут.
Давайте представим себе таск-треккер. Какие данные я, как аналитик, могу из него добыть? Или любая готовая аналитическая платформа? Количество задач за период, статистику логирования, базовую разбивку на проекты, картинки какие-нить о продуктивности сотрудников… да и все, навскидку.
А ведь все, что ни делается — заносится в жиру. Следовательно, наверняка можно вычленить нечто более глобальное: чем занимается команда и в каком направлении она двигается.
Таки да, нам это удалось. Правда, не обошлось без помощи PM-a попервой.
Реорганизация таск-треккера
Разумеется каждая конкретная Jira существенно отличается от какой-либо другой. И наше решение вполне может не быть для вас самым эффективным или же вообще применимым.
Прошу расценивать это лишь как идею организации таск-треккера, на примере нашей аутсорсинговой компании.
Мы сделали всего два движения.
Первое и самое простое. Приняли, что все задачи в рамках одного направления должны быть привязаны к эпику, обязательно. Эпики это наиболее крупные объекты в Jira, представляющие собой множества задач. Они помогают создавать иерархию и структуру, а также могут охватывать несколько спринтов и версий.
О втором чуть подробнее. Нам удасться увидеть общую картину и ответить на стратегические вопросы, если рабочий процесс будет представлен в виде некого потока, в который каждый сотрудник делает свой вклад. Для этого, в нашем случае, идеально подходит концепция IT4IT, со своей операционной моделью, базирующейся на четырехпотоковой цепочке создания ценности:
Собственно, что мы сделали. Воспользовавшись IT4IT, добавили такое понятие как компонента задачи в Jira. У нас они следующие:
- Service to Portfolio (Demand and Selection) — стадия “раскурки“, поиска, выбора сервиса, технологии.
- Request to Deploy (Plan and Design) — обсуждение, планирование разработки, развития услуг, сервисов.
- Request to Deploy (Develop) — разработка услуги, сервиса чего либо.
- Request to Deploy (Deploy) — развертывание чего либо.
- Request to Deploy (Test) — тестирование сервиса, услуги.
- Request to Fulfill — этап эксплуатации разработанных сервисов, предоставление услуг.
- Detect to Correct (Correct) — исправление, доработка внутренних сервисов и услуг.
- Detect to Correct (Monitor&Feedback) — тоже самое, только + общение с клиентом.
На данном этапе, наверное самое сложное — убедить сотрудников, что лишний пункт в треккере не просто так и он обязателен к корректному заполнению.
Аналитика данных в R
Теперь препятствий для реализации отчетности быть не должно. Сформулирую подобие ТЗ.
Поскольку в начале каждой недели команда собирается на мит для планирования — отчет должен быть еженедельным. Нам важно видеть статистику появления и продвижения задач, логирование сотрудников и вклад каждого из них в общую картину. Ответить на вопрос: чем занимается команда — в разрезе эпиков и компонент.
Зная что нам нужно добыть — идем выгружать данные. Через Jira API запрашиваем все таски (issue), обновленные на прошедшей неделе. Добываем из них ключи и к каждой таске догружаем историю логирования (worklog) и историю изменений (changelog). Извращения с догрузкой необходимы, чтобы обойти ограничения апишки.
Далее начинается зона ответственности R, т.к предобработка полученых данных это составляющая скрипта генерации отчета.
В ней нету чего-то заумного, необходимо просто распарсить JSON-ы, пришедшие от апи и оставить только необходимые свойства (пункты в Jira). Единственный момент, при обработке changelog-а нам интересны только изменения статуса задачи, остальное можно смело удалять.
Ну и, наконец-то — мы подобрались к аналитике.
Узнаем сколько задач открыто, было в работе, закрыто и отложено за прошедшую неделю. Взгляните-ка на R код:
# Открыто тасок
this_week_opened <- jira_changelog_data %>%
filter(issue_type != "Epic") %>%
filter(as.Date(issue_created) >= start_date) %>%
filter(as.Date(issue_created) <= end_date) %>%
select(key, issue_created) %>% unique() %>% nrow()
# В работе
this_week_processed <- jira_worklog_data %>%
filter(as.Date(started) >= start_date) %>%
filter(as.Date(started) <= end_date) %>%
select(key) %>% unique() %>% nrow()
# Закрыто
this_week_closed <- jira_changelog_data %>%
filter(issue_type != "Epic") %>%
filter(as.Date(issue_resolutiondate) >= start_date) %>%
filter(as.Date(issue_resolutiondate) <= end_date) %>%
select(key, issue_created) %>% unique() %>% nrow()
# Отправлено в холд / бэклог
this_week_holded <- issue_history %>%
filter(change_date >= start_date) %>%
filter(change_date <= end_date) %>%
filter(toString == "Hold" | toString == "Backlog") %>%
select(key) %>% unique() %>% nrow()Не напоминает ли вам это псевдокод? А если я скажу что оператор '%>%' передает данные от предыдущей функции к следующей. А последняя модификация во всей цепочке будет сохранена в переменную. Представьте себе, мы только что поднялись на порог вхождения в R!
Вы еще не влюбились в него? Тогда, если позволите, я насыплю еще немного инфы.
Словеса из Википедии:
В целом, как язык программирования, R довольно прост и даже примитивен. Его наиболее сильная сторона — возможность неограниченного расширения с помощью пакетов.
В базовую поставку R включен основной набор пакетов, а всего по состоянию на 2019 год доступно более 15 316 пакетов.
И последнее на сегодня. В этом году R ворвался в десятку самых популярных языков в мире (пруф). Горжусь им.
Прошу простить мне сие отступление. Об R я могу говорить часами. Просто он насквозь окутан мифами, а я люблю их разрушать — хобби, знаете ли.
Вернемся к отчету. Имея искомые цифры, визуализируем их. После этого оформляем логирование сотрудников. Вот как выглядит данная часть у нас:
Продолжу показывать вам итоговые картинки из этого же реального отчета.
Направление нашей деятельности отражает следующий график. Он также позволяет оценить загруженость сотрудников операционной деятельностью.
А вот и разрез всех задач по компонентам. Он и дает ответ на вопрос чем мы занимаемся. Картину дополняю цифрами.
Ну и обещанный вклад каждого сотрудника в общую картину, приведенную выше.
Вы, уверена, сразу же заметите где у нас разработчик, а где админ. К этой наглядности мы и стремились.
Реальный отчет так же дополнен сводкой движения задач. Это дополнение к общей статистике, размещенной в самом начале, с названиями задач и именами ответственных людей.
Генерация отчета
Настроить автоматическую генерацию отчета, например, по понедельникам из R скрипта можно с помощью пакета cronR, это исключительно просто.
У нас же все сложнее и изящнее. Еженедельную выгрузку данных из Jira API, запуск скрипта генерации отчета и отправку отчета всем сотрудникам по Email мы реализовали с помощью Apache NiFi. Эта тема насколько обширная, что вполне себе заслужила отдельную статью.
Заключение
Количество реализаций Jira Software, как и количество компаний где она используется — уйма. Каждый босс, при этом, нуждается в своей уникальньной базе метрик для тактически верного управления. Да, существует eazyBI и другие плагины для Jira аналитики, но в результате это как покупка костюма в магазине, вместо пошитого на заказ Bespoke.
Рассмотренный отчет пошит по лекалам. По словам босса он дает стратегическое представление о том чем занимается подразделение или команда. Надеюсь данная статья поможет вам реализовать нечто подобное и у себя дома.
Спасибо.



