
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Когда вы запускаете ML-систему в продакшен-среде, все только начинается. С системой могут возникнуть проблемы, и вам придется с ними разбираться.
Команда VK Cloud Solutions перевела статью о том, что делать с дрейфом данных и концепций: откуда берутся проблемы, как их распознать и предотвратить.
О чем мы будем говорить
Представим, что вы собрали и очистили данные, поэкспериментировали с разными моделями машинного обучения и вариантами предварительной обработки данных, настроили гиперпараметры модели — все для грамотного решения вашей задачи. Потом настроили надежный автоматический пайплайн, написали для модели API, поместили ее в контейнер и развернули в продакшен-среде. И даже проверили, нормально ли модель показывает себя в деле. Отлично, все готово! Или не все? На самом деле вы только в начале пути.
Все потенциальные проблемы с ML-системами, которые могут возникнуть после развертывания на проде, делятся на статистические и инфраструктурные. Ко второй группе относятся проблемы с вычислительными ресурсами и памятью (хватает ли?), задержкой (быстро ли реагирует система?), пропускной способностью (успеваем ли мы обработать все входящие запросы?) и так далее.
В этой статье мы разберем статистические проблемы. Они делятся на две группы: дрейф данных и дрейф концепций.
Дрейф данных
Его еще называют ковариантным сдвигом. Это изменение распределения входных данных модели. Такое может произойти по разным причинам, например:
- датчик, который собирает данные, выходит из строя или для него обновляют софт — и это влияет на способ сбора;
- данные от людей меняются с изменением демографии или приходом новой моды.
В результате данные, на которых модель обучали, не соответствуют приходящим в модель во время работы в продакшене.
Приведем пример. Допустим, P(x) — безусловная вероятность входных признаков x, а P(y|x) — условная вероятность таргетов y при входных признаках. Дополнительно обозначим вероятности как Pₜ для обучающих данных и Pₛ для Serving Data, то есть данных, для которых модель составляет прогнозы в продакшен-среде.
Мы можем определить дрейф данных следующим образом:
Pₜ(y|x) = Pₛ(y|x)
Pₜ(x) ≠ Pₛ(x)
Это значит, что произошел сдвиг в распределении входных признаков между обучающими данными и Serving Data, но отношение между входными фичами и таргетом не изменилось.
Дрейф данных — это сдвиг в распределении входных признаков между обучающими данными и Serving Data.
В некоторых случаях дрейф данных негативно влияет на метрики модели. Но так бывает не всегда. Посмотрим на пример:

Во время обучения модель научилась отличать класс «синий» от класса «оранжевый». После развертывания произошел дрейф данных. В верхнем сценарии изменилось распределение примеров класса «оранжевый»: теперь наблюдаются только малые значения признака по оси Y.
В этом сценарии разделяющая поверхность, на которую модель опирается при классификации новых примеров, все еще работает без сбоев.
Иногда дрейф данных снижает метрики модели, а иногда нет.
Во втором сценарии распределение класса «оранжевый» также изменилось, и по оси Y появились большие значения признака. В этом случае метрики модели, скорее всего, снизятся.
Дрейф концепций
Это изменение отношения между входными и выходными данными модели. Мир не стоит на месте: мода приходит и уходит, компании выходят на новые рынки или сокращают бизнес, конкуренты завоевывают или уступают доли рынка, меняются макроэкономические условия.
Дрейф концепций выглядит следующим образом:
Pₜ(y|x) ≠ Pₛ(y|x)
Pₜ(x) = Pₛ(x)
Распределение входных данных не меняется, а вот связь между входными признаками и целевыми значениями меняется.
Дрейф концепций почти всегда вредит метрикам системы машинного обучения. Посмотрите на рисунок:
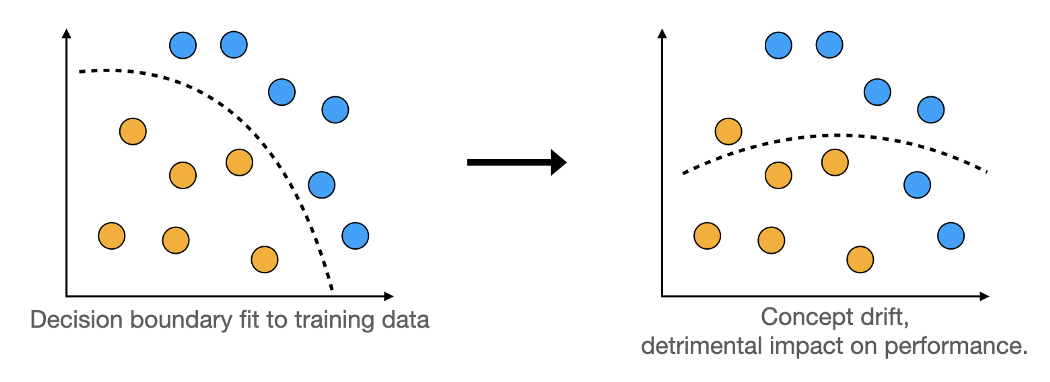
После дрейфа концепций соответствие между X и Y поменялось в реальном мире, но модель не может узнать об этом. Следовательно, она будет неправильно классифицировать некоторые примеры, основываясь на устаревшем сопоставлении, которое она освоила на этапе обучения.
Как обнаружить дрейфы
Чтобы вовремя обнаружить дрейфы, нужно мониторить входные признаки, предсказания модели, а также истинные значения целевого признака во входных данных. Делать это необходимо как на тренировочных данных, так и на обслуживаемых моделью новых данных.
- Дрейф данных можно вычислить, если сравнить распределение входных признаков в обучающей выборке и в новых поступающих данных.
- А чтобы обнаружить дрейф концепций, нужно посмотреть на условное распределение истинных и спрогнозированных целевых значений по конкретному набору входных признаков.
Поскольку Serving Data чаще всего поступают в систему непрерывно, заниматься мониторингом и сравнением распределений нужно регулярно, максимально автоматизировав этот процесс. Проблема в том, чтобы понять, относятся ли две выборки данных к одному вероятностному распределению. Как это сделать?
Мониторинг статистики данных с помощью TensorFlow Data Validation
Самый простой способ понять, относятся ли две выборки к одному и тому же распределению, — рассчитать простые статистические показатели по обеим выборкам и сравнить их. Для этой задачи подойдет TensorFlow Data Validation — полезный набор инструментов для мониторинга данных. У него есть две сервисные программы:
generate_statistics_from_dataframe()— вычисляет статистику по датафрейму, включая арифметическое среднее, стандартное отклонение, минимальные и максимальные значения, % недостающих данных или % нулевых значений;
visualize_statistics()— строит интерактивные диаграммы, с помощью которых можно визуально проверять и сравнивать статистику по данным.
Давайте посмотрим, как все это работает. Возьмем дата-сет Kaggle по недвижимости, произвольно разделим его на обучающий и тестовый дата-сеты и сравним статистику данных в TFDV.
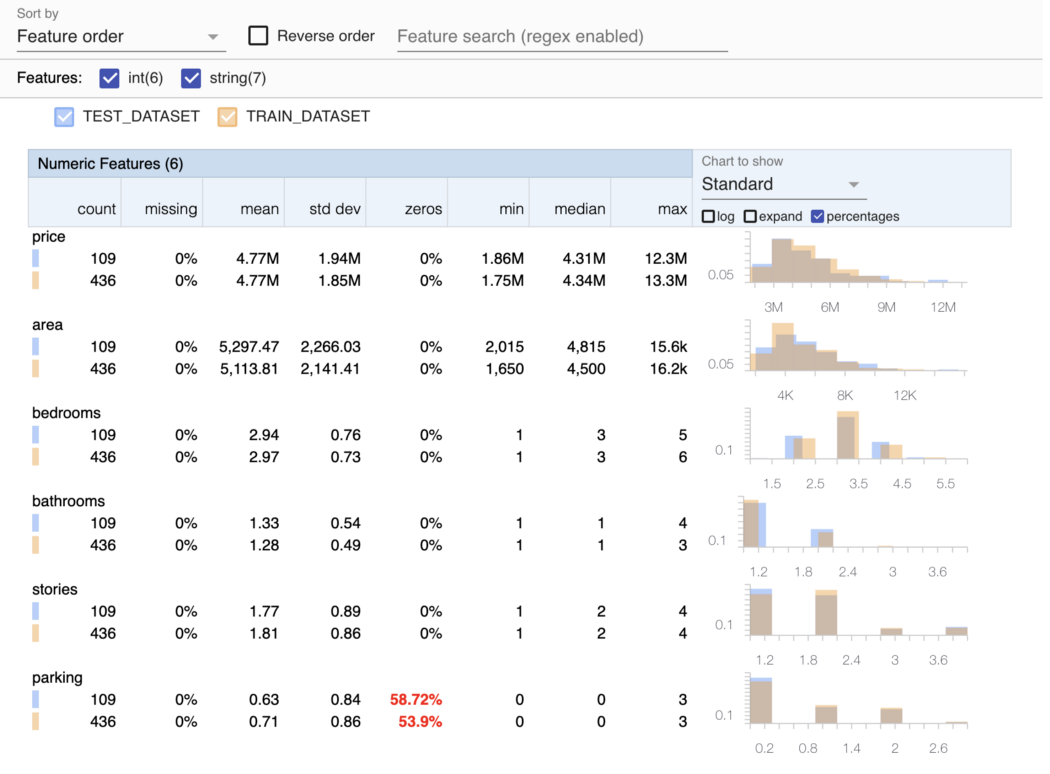
Онлайн-сравнение статистики данных в TFDV для дата-сета
Это диаграмма для численных признаков, такие можно построить и для категориальных признаков. С помощью библиотеки нетрудно сравнивать распределения признаков и выявлять тревожные симптомы — например, когда у признака много нулевых значений.
Проверка гипотез
Визуальная проверка и сравнение простых статистик обучающих данных и Serving Data всегда субъективны и плохо поддаются автоматизации. Надежнее полагаться на проверку статистических гипотез — автоматизированный метод сравнения распределения признаков.
Если две выборки данных для сравнения являются нормально распределенными, можно запустить t-тест. Это статистический метод, позволяющий проверить равенство средних значений в двух выборках. Давайте посмотрим, одинакова ли средняя цена в обучающих и тестовых данных.
Ttest_indResult(
statistic=0.0021157257949561813,
pvalue=0.9983126733473535
)Большое p-значение — почти единица — говорит, что у нас нет причин для опровержения нулевой гипотезы о том, что средние цены одинаковы.
Можно одновременно проверять несколько признаков. Чтобы проверить, совпадают ли средние значения нескольких числовых признаков, можно запустить тест ANOVA. Частотность категориальных переменных можно сравнить с помощью теста «хи-квадрат». Подробные описания обоих тестов, а также примеры на Python можно прочитать в моей статье о распределении вероятностей. Для ANOVA просто пролистайте до раздела «F-распределение», а для теста χ2-test — до раздела «Хи-квадрат-распределение».
Если выборки данных не являются нормально распределенными, их все равно можно сравнить по непараметрическим критериям. И тест Краскела — Уоллиса, и тест Колмогорова — Смирнова позволяют проверить, относятся ли две выборки данных к одному и тому же распределению. В частности, тесты Краскела — Уоллиса проверяют нулевую гипотезу о равенстве медиан обеих выборок. Такую проверку можно представить себе как непараметрическую версию ANOVA. А тест Колмогорова — Смирнова непосредственно выясняет, взяты ли обе выборки из одного распределения, проверяя расстояние между эмпирическим распределением (подходит только для непрерывных признаков).
KruskalResult(statistic=0.03876427, pvalue=0.8439164)
KstestResult(statistic=0.05504587, pvalue=0.9469318)В случае цены на дома в наших данных оба теста показывают, что распределение цен в обучающих и тестовых данных одинаково. В этом есть смысл — ведь мы произвольно разделили данные на обучающие и тестовые.
Боремся с дрейфами
Что делать, если мы обнаружили дрейф в системе? Повторно обучить! Но вопрос в том, как именно это сделать.

Это не так просто, как кажется на первый взгляд
Самое легкое, что можно сделать, — это просто повторно обучить параметры модели на недавних данных, включая данные, собранные после дрейфа. Но если вы заметили дрейф достаточно рано, после него могло накопиться не так уж много данных. В этом случае повторное обучение модели само по себе проблему не решит.
Другой подход — присвоить точкам обучающей выборки такие веса, чтобы модель учитывала с бо̒льшим весом данные, появившиеся после дрейфа. Но есть риск, что эти недавние данные не репрезентативны для решаемой задачи. Например, в периоде после дрейфа не хватает событий, которые случились до него и с ним не связаны. Тогда, если придать больше веса примерам после дрейфа, модель не сможет выучить полезные паттерны.
На практике правильное решение обычно зависит от поставленной задачи и области, к которой она относится. Решение может заключаться в ансамбле моделей, использующих старые и новые данные, или в добавлении новых источников. И наконец, при значительном дрейфе иногда имеет смысл перенастроить гиперпараметры модели, чтобы адаптироваться к новому миру — миру после дрейфа.
Команда VK Cloud Solutions развивает собственные ML-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.




