
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Всем привет. Выходим на финишную прямую: сегодня финальная статья о том, какие ответы может дать data science о прогнозировании COVID-19.
Первая статья здесь. Вторая здесь.
Сегодня мы общаемся с Александром Желубенковым о его решениях по предсказанию распространения COVID-19.
Условия у нас следующие:
Дано: Колоссальные возможности data science, три талантливых специалиста.
Найти: Способы предсказать распространение COVID-19 на неделю вперёд.
И вот решение от Александра Желубенкова
— Александр, привет. Для начала расскажи немного о себе и своей работе.
— Я работаю в компании Lamoda руководителем группы анализа данных и машинного обучения. Мы занимаемся поисковым движком и алгоритмами ранжирования товаров в каталоге. Data Science меня заинтересовал, когда я учился в МГУ на факультете вычислительной математики и кибернетики.
— Знания и умения пригодились. Ты сделал качественную модель: достаточно простую, чтобы она была не переобученная. Расскажи, как удалось этого добиться?
— Задача прогнозирования временных рядов хорошо изучена, и какие к ней можно применять подходы — понятно. В нашей задаче достаточно маленькие по меркам машинного обучения выборки — несколько тысяч наблюдений в тренировочных данных и всего 560 предсказаний нужно делать для каждой недели (прогноз для 80 регионов на каждый день следующей недели). В таких случаях используют более грубые модели, которые неплохо проявляют себя на практике. По факту, у меня и получился в итоге аккуратно сделанный бейзлайн (baseline).
В качестве модели я использовал градиентный бустинг на деревьях. Можно заметить, что деревянные модели «из коробки» не умеют предсказывать тренды, но, если перейти к таргетам-приращениям, тогда спрогнозировать тренд станет возможным. Получается, нужно научить модель прогнозировать, на сколько вырастет количество заболевших относительно текущего дня в течение следующих Х дней, где Х от 1 до 7 — горизонт прогнозирования.
Какая еще была особенность – качество прогнозов модели оценивалось в логарифмической шкале, то есть штраф был не за то, на сколько ты ошибаешься, а за то, во сколько раз прогнозы модели оказались неточными. И это несло следующий эффект: на итоговое качество прогнозов по всем регионам очень сильно влияла точность прогнозов в маленьких регионах.
Были известны таймлайны для каждого региона: количество заболевших в каждый из дней в прошлом и буквально несколько качественных характеристик, таких как численность населения и доля городских жителей. По сути, это всё. На таких данных сложно переобучиться, если нормально сделать валидацию и определить, где в обучении бустинга стоит остановиться.
— Какую библиотеку градиентного бустинга ты использовал?
— Я по старинке — XGBoost. Знаю про LightGBM и CatBoost, но для такой задачи, мне кажется, выбор не столь важен.
— Окей. А вот всё-таки таргет. Что ты брал за таргет? Это логарифм отношений двух дней или логарифм абсолютного значения?
— В качестве таргета брал разность логарифмов количества заболевших. Например, если на сегодняшний день было 100 заболевших, а завтра стало 200 – то при прогнозе на один день вперед нужно научиться прогнозировать логарифм двукратного роста.
В целом известно, что первые недели идет экспоненциальный рост распространения вируса. А это означает, что если в качестве таргетов использовать приращения в логарифмической шкале, то по сути можно будет каждый день просто константу предсказывать, умноженную на горизонт прогнозирования. Градиентный бустинг – универсальная модель, и с такими задачами справляется хорошо.
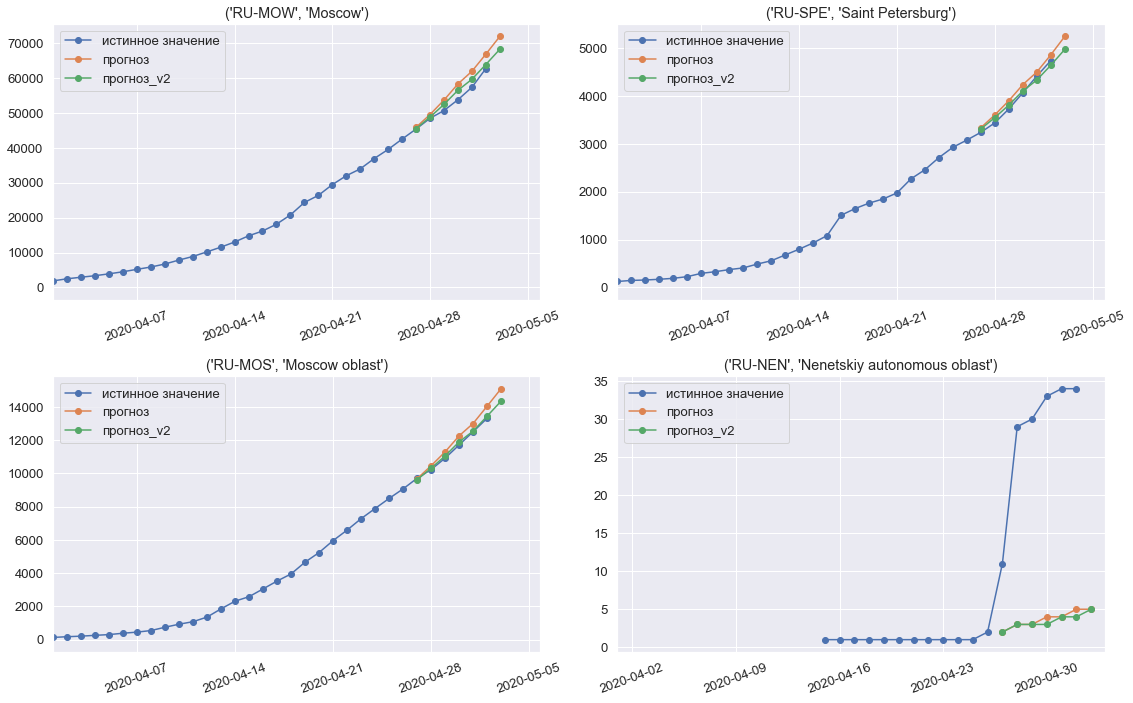
Прогнозы модели на третью, финальную неделю конкурса
— А обучающую выборку ты какую брал?
— Для прогнозирования регионов я брал информацию о распространении по странам. Кажется, это помогало, так как где-то уже резкий рост замедлялся, и страны начинали выходить на плато. По регионам России начальный период я отрезал, когда какие-то единичные случаи были. Для обучения использовал данные, начиная с февраля.
— Валидировался ты как?
— Валидировался по времени, как для временных рядов и принято делать. Для теста использовал две последние недели. Если прогнозируем последнюю неделю, то для обучения используем все данные до неё. Если прогнозируем предпоследнюю — то используем все данные, без последних двух недель.
— А использовал ты что-то ещё? Какие-то дни, 10-й или 20-й день, значения оттуда?
— Основные факторы, которые были важны — разные статистики: средние, медиана, приросты, которые были за последние N дней. Для каждого региона можно посчитать отдельно. Можно ещё отдельно рядом сложить такие же факторы, только посчитанные для всех регионов сразу.
— Вопрос про валидацию. Ты больше смотрел на стабильность или на точность? Что было критерием?
— Смотрел на среднее качество модели, которое получалось на двух последних неделях, выбранных для валидации. При добавлении некоторых факторов получалась такая картина, что при фиксированной конфигурации бустинга и варьировании только параметра random seed качество прогнозов могло сильно скакать – то есть большая получалась дисперсия. Чтобы не переобучиться и получить более стабильную модель, такие сомнительные факторы в финальной модели в итоге не использовал.
— А что тебе запомнилось? Удивило? Фича, которая заработала, или какой-нибудь трюк с бустингом?
— Два урока я извлёк. Первый: когда я решил поблендить две модели: линейную и бустинг, и при этом для каждого региона коэффициенты, с которыми брать эти две модели (они разные получались), настроить просто на последней неделе – то есть на семи днях. По факту, 1-2 коэффициента я настраивал для каждого региона на 7 днях. Но открытие было такое: прогноз получился существенно хуже относительно того, если бы я их этих настроек не делал. На некоторых регионах модель сильно переобучилась, и в итоге прогнозы в них получились плохими. На третьем этапе конкурса я решил так не делать.
И второй момент: кажется, что в качестве фичи должно быть полезно количество дней от начала: от первого заболевшего, от десятого заболевшего. Пробовал их добавлять, но на валидации это ухудшало ситуацию. Объяснил это так: распределение значений в выборках со временем смещается. Если обучаться на 20-й день от начала распространения вируса, то при прогнозировании распределение значений этой фичи уедет на семь дней вперед, и, возможно, это не позволяет такого рода факторы применять с пользой.
— Ты говорил, что доля городского населения играла какую-то роль. А что ещё?
— Да, доля городского населения и для стран, и для регионов России всегда использовалась. Этот фактор стабильно давал небольшой буст к качеству прогнозов. В итоге кроме самого временного ряда я больше ничего в финальную модель не взял. Пробовал добавлять разное, но не работало.
— Твое мнение: SARIMA – это прошлый век?
— Модели авторегрессии – скользящего среднего – тяжелее настраивать, и в них более затратно добавлять дополнительные факторы, хотя, уверен, что и с (S)ARIMA(X) моделями можно было бы неплохие прогнозы сделать, но не такие качественные по сравнению с бустингом.
— А на более длительный период, чем неделя, можно прогнозы делать, как ты думаешь?
— Было бы интересно. Изначально у организаторов была идея собрать долгосрочные прогнозы. Месяц кажется переломным сроком, когда ещё можно попробовать те подходы, которые я делал.
— Как ты думаешь, что будет дальше?
— Нужно модель перестраивать, смотреть. Кстати, моё решение можно найти здесь:
https://github.com/Topspin26/sberbank-covid19-challenge
Познакомиться с последними новостями data science по COVID от международного сообщества можно здесь: https://www.kaggle.com/tags/covid19. И, конечно, приглашаем в канал #coronavirus в opendatascience.slack.com (по приглашению от ods.ai)



