
Эта статья — своеобразный мастер-класс «DVC для автоматизации ML экспериментов и версионирования данных», который прошел 18 июня на митапе ML REPA (Machine Learning REPA:
Reproducibility, Experiments and Pipelines Automation) на площадке нашего банка.
Тут я расскажу об особенностях внутренней работы DVC и способах применения его в проектах.
Примеры кода, используемые в статье доступны здесь. Код тестировался на MacOS и Linux (Ubuntu).

Часть 1
Часть 2
Data Version Control — это инструмент, который создан для управления версиями моделей и данных в ML-проектах. Он полезен как на этапе экспериментов, так и для развертывания ваших моделей в эксплуатацию.
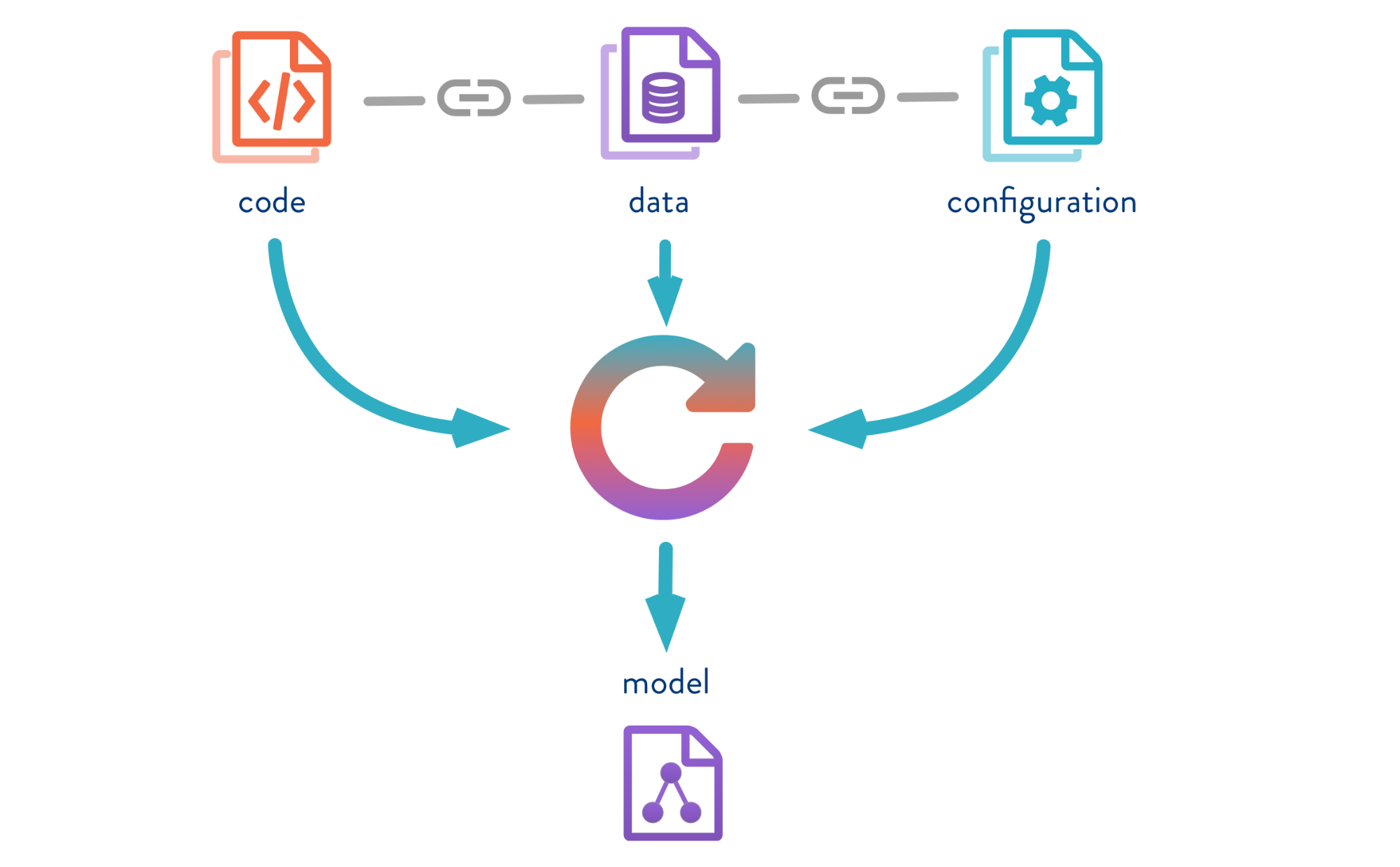
DVC позволяет версионировать модели, данные и пайплайны в DS проектах.
Источник тут.
Давайте рассмотрим работу DVC на примере задачи классификации цветов ириса. Для этого будет использовать известный датасет Iris Data Set . Остальные примеры работы с DVC показаны Jupyter Notebook.
Что нужно сделать:
Итак, клонируем репозиторий, создаем виртуальное окружение и устанавливаем нужные пакеты. Инструкции по установке и запуску есть в README репозитория.
Для установки DVC воспользуемся командой
DVC работает поверх Git, использует его инфраструктуру и имеет похожий синтаксис.
В процессе работы DVC создает мета файлы для описания пайплайнов и версионируемых файлов, которые необходимо сохранять в Git историю вашего проекта. Поэтому после исполнения
В вашем репозитории появится папка
Содержимое
Config — это конфигурация DVC, а cache — это системная папка, в которую DVC будет складывать все данные и модели, которые вы будете версионировать.
Также DVC создаст файл
Теперь нужно установить все зависимости, а потом сделать
Версионирование моделей и данных

Источник тут.
Напомню, что если передать под контроль DVC какие-то данные, то он начнет отслеживать все изменения. А мы можем работать с этими данными точно так же, как с Git: сохранять версию, отправлять в удалённый репозиторий, получать нужную версию данных, изменять и переключаться между версиями. Интерфейс у DVC очень простой.
Введём команду
Внутри сгенерированного dvc-файла хранится его хэш со стандартными параметрами.

Автоматизация ML пайплайнов
Помимо контроля версий данных мы можем создавать пайплайны (pipeline) — цепочки вычислений, между которыми задаются зависимости. Вот стандартный пайплайн обучения и оценки классификатора:
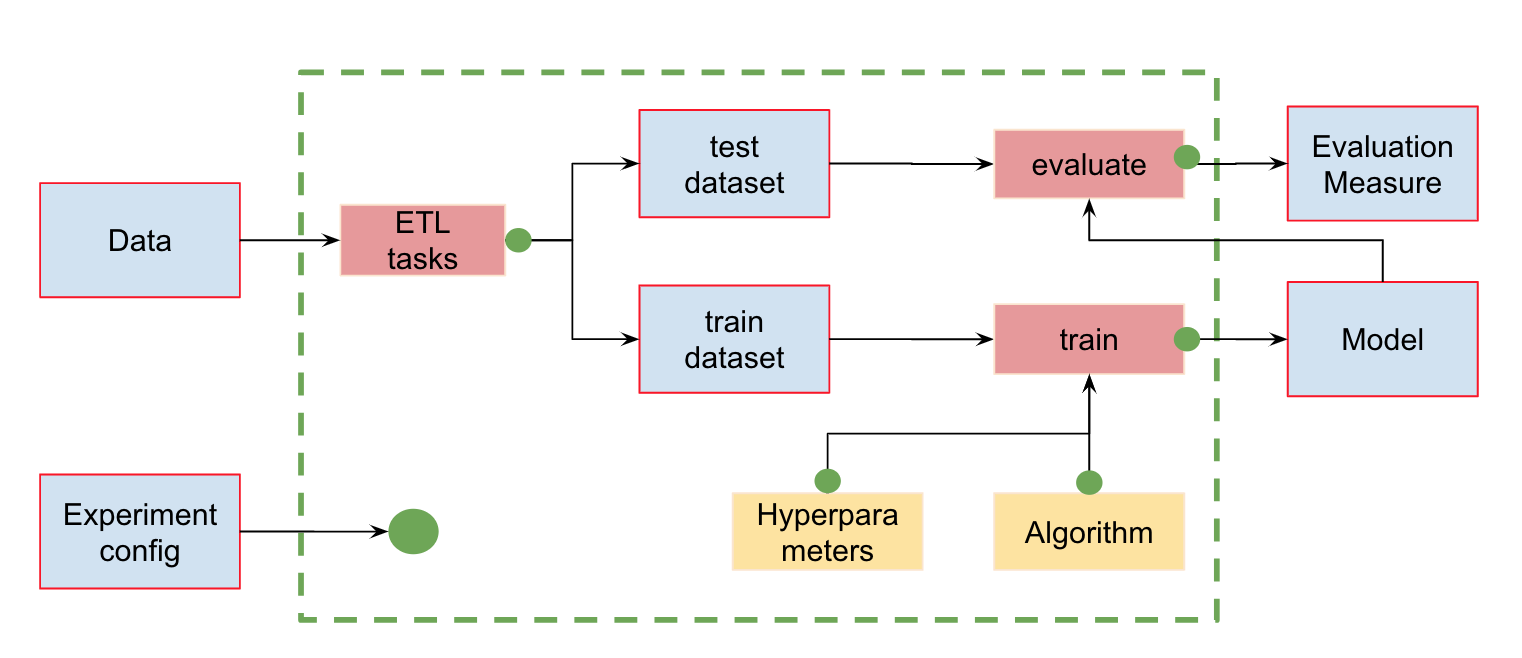
На входе у нас есть данные, которые нужно предварительно обработать, разделить на train и test, рассчитать признаки и уже потом обучить модель и оценить её. Этот пайплайн можно разбить на отдельные кусочки. Например, выделить этап загрузки и предобработки данных, разбиение данных, оценку и т. д., и соединить эти цепочки между собой.
Для этого в DVC есть замечательная команда
Теперь — к примеру запуска этапа расчёта признаков. Сначала посмотрим содержимое модуля featureization.py:
Этот код берёт датасет, рассчитывает признаки и сохраняет их в iris_featurized.csv. Расчёт дополнительных признаков мы оставили на следующий этап.
Для создания пайплайна необходимо для каждого этапа вычислений выполнить команду

Сначала в команде
DVC создаст метафайл и будет отслеживать изменения в питоновском модуле и файле iris.csv.
Если в них произойдут изменения, то DVC перезапустит этот этап расчёта в пайплайне.
Получившийся файл stage_feature_extraction.dvc будет содержать свой хэш, команду запуска, зависимости и выходные данные (для них есть дополнительные параметры, которые можно посмотреть в метаданных).
Теперь необходимо сохранить этот файл в историю Git коммитов. Таким образом, мы можем создать новую ветку и запушить её в Git-репозиторий. Можно коммитить в Git-историю либо создание каждого этапа в отдельности, либо всех этапов сразу.
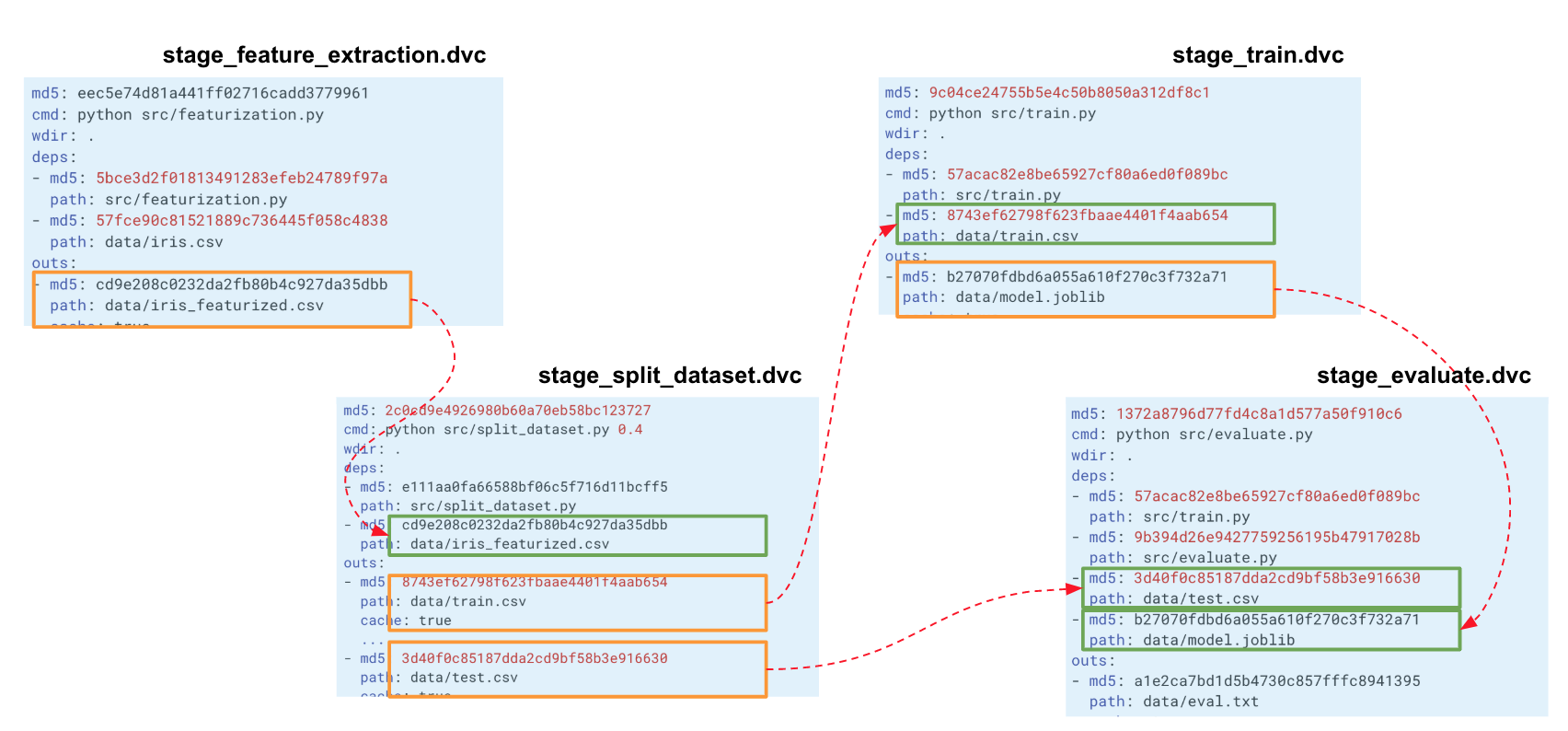
Когда мы выстраиваем такую цепочку для всего нашего эксперимента, DVC выстраивает граф вычислений (DAG), по которым может запускать либо пересчёт всего пайплайна, либо какой-то части. Хэши выходных данных одного этапа идут на входы другого. По ним DVC отслеживает зависимости и выстраивает граф вычислений. Если вы поменяли код где-то в split_dataset.py, то DVC не будет загружать данные и, возможно, пересчитывать признаки, а перезапустит этот этап и следующие за ним этапы обучения и оценки.
Отслеживание метрик
С помощью команды
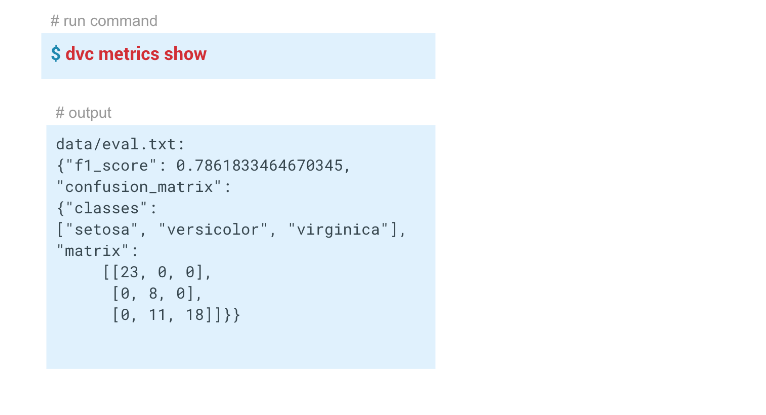
В этом примере у нас получились вот такие результаты:
Воспроизводимость пайплайнов
Те, кто работал с этим датасетом, знают, что на нём очень сложно построить хорошую модель.
Теперь у нас есть пайплайн, созданный с помощью DVC. Система отслеживает историю данных и модель, может перезапускать себя целиком или по частям, может показывать метрики. Мы выполнили всю необходимую автоматизацию.
У нас была модель с f1 = 0,78. Мы хотим её улучшать, меняя какие-то параметры. Для этого нужно перезапустить весь пайплайн, в идеале, какой-то одной командой. Кроме того, если вы работаете в команде, вы можете захотеть передать модель и код коллегам, чтобы они могли продолжить работу над ними.
Команда
Выполнив команду
В данном случае DVC не увидел изменений в зависимостях этапа stage_evaluate и отказался перезапускать. А если мы укажем параметр
Возможность перезапускать пайплайны и отслеживать зависимости каждого этапа позволяет быстрее экспериментировать с моделями.
Например, можно изменить признаки (‘раскомментить’ строки расчёта признаков в
Сохранение данных в удаленном репозитории
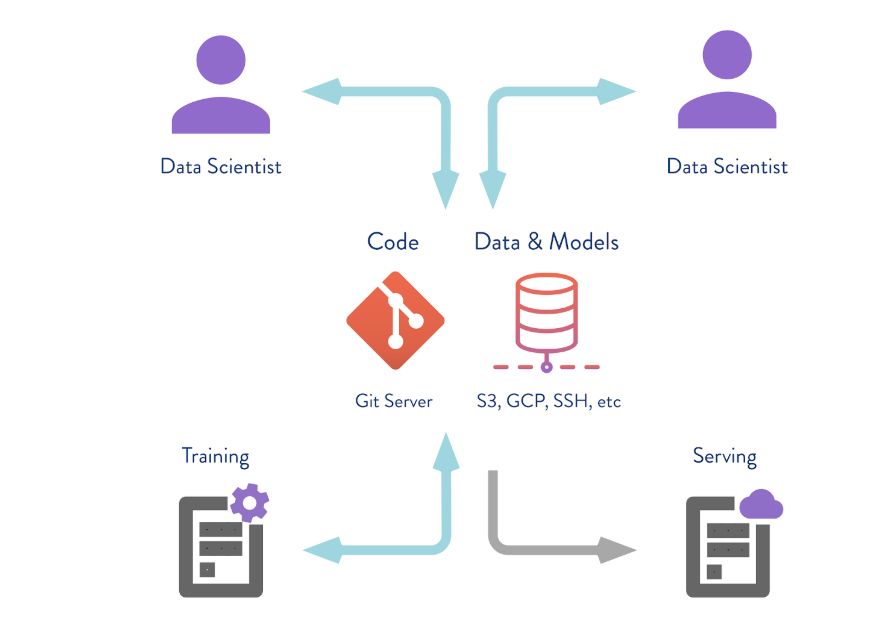
DVC может работать не только с локальными хранением версий. Если выполнить команду
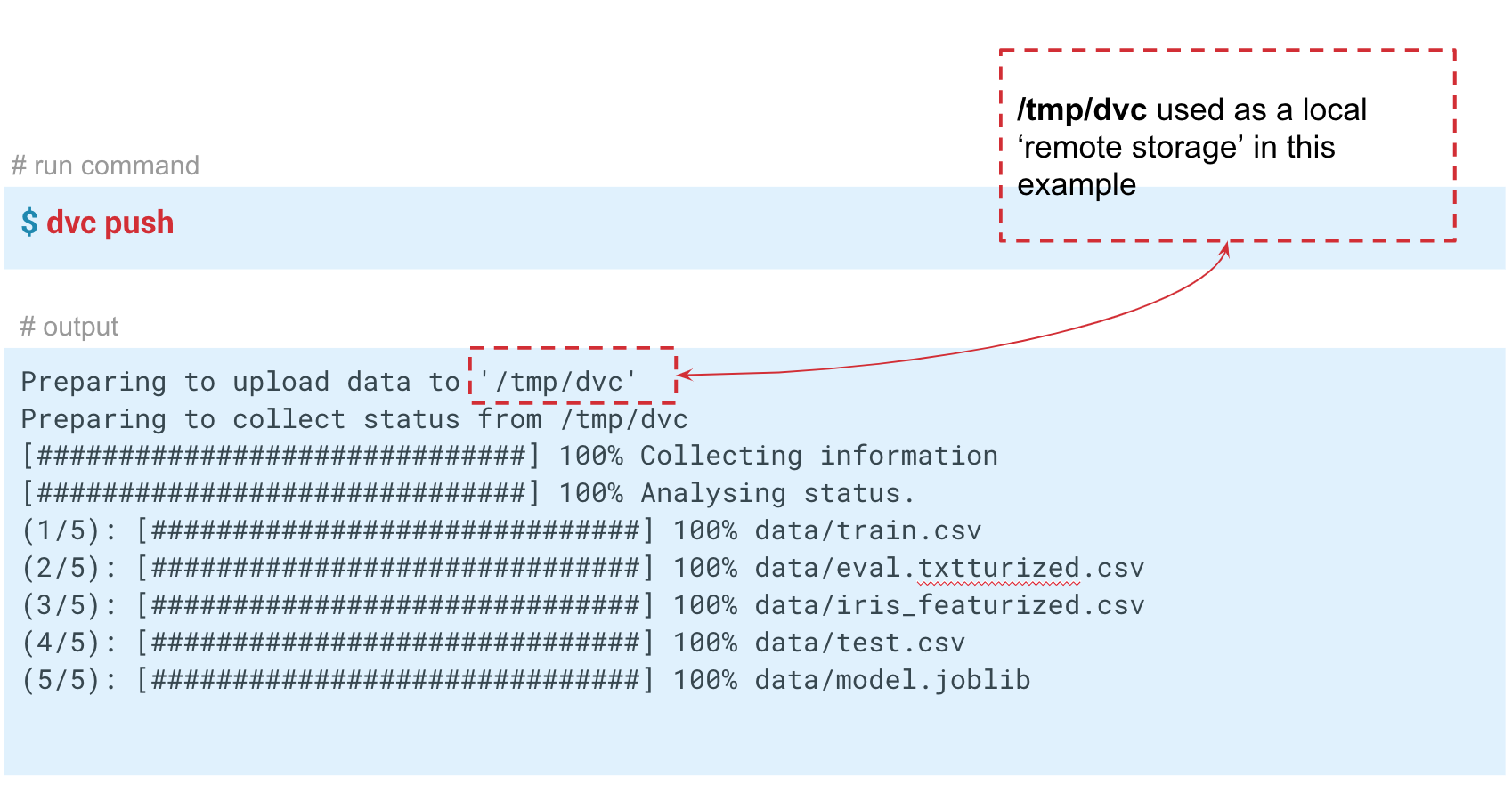
В данном случае мы имитируем «удалённое» хранилище в папке temp/dvc. Примерно таким же образом создается удалённое хранилище и в облаке. Коммитим это изменение, чтобы оно осталось в Git-истории. Теперь мы можем выполнить
Итак, мы рассмотрели три ситуации, в которых полезен DVC и основной функционал:
Как внедрить DVC в ваших проектах?
Для обеспечения воспроизводимости проекта необходимо соблюдать определённые требования.
Вот основные из них:
Если всё это сделано, то проект с большей вероятностью будет воспроизводимым. DVC позволяет выполнить 3 первых требования в этом списке.
Пытаясь внедрить в своей компании DVC, вы можете столкнуться с нежеланием: «Зачем нам это надо? У нас есть Jupyter Notebook». Возможно, некоторые ваши коллеги работают только с Jupyter Notebook, и им гораздо сложнее писать такие пайплайны и код в IDE. В таком случае можно пойти путем пошагового внедрения.
Если у вас есть новый проект и пара энтузиастов в команде, то лучше сразу использовать DVC. Так, например, получилось у нас в команде! При запуске нового проекта меня поддержали мои коллеги, и мы самостоятельно начали использовать DVC. Потом стали делиться с другими коллегами и командами. Кто-то подхватил наше начинание. Сегодня DVC пока не является общепринятым инструментом в нашем банке, однако он используется в нескольких проектах.
Reproducibility, Experiments and Pipelines Automation) на площадке нашего банка.
Тут я расскажу об особенностях внутренней работы DVC и способах применения его в проектах.
Примеры кода, используемые в статье доступны здесь. Код тестировался на MacOS и Linux (Ubuntu).
Содержание
Часть 1
- Настройка DVC
- Возможности DVC
- Версионирование моделей и данных
- Автоматизация ML пайплайнов
- Отслеживание метрик
- Воспроизводимость пайплайнов
- Сохранение данных в удаленном репозитории
Часть 2
- Как внедрить DVC в ваших проектах?
Настройка DVC
Data Version Control — это инструмент, который создан для управления версиями моделей и данных в ML-проектах. Он полезен как на этапе экспериментов, так и для развертывания ваших моделей в эксплуатацию.
DVC позволяет версионировать модели, данные и пайплайны в DS проектах.
Источник тут.
Давайте рассмотрим работу DVC на примере задачи классификации цветов ириса. Для этого будет использовать известный датасет Iris Data Set . Остальные примеры работы с DVC показаны Jupyter Notebook.
Что нужно сделать:
- клонировать репозиторий;
- создать виртуальное окружение;
- установить необходимые пакетов python;
- инициализировать DVC.
Итак, клонируем репозиторий, создаем виртуальное окружение и устанавливаем нужные пакеты. Инструкции по установке и запуску есть в README репозитория.
1. Clone this repository
git clone https://gitlab.com/7labs.ru/tutorials-dvc/dvc-1-get-started.git cd dvc-1-get-started
2. Create and activate virtual environment
pip install virtualenv virtualenv venv source venv/bin/activate
3. Install python libraries (including dvc)
pip install -r requirements.txt
Для установки DVC воспользуемся командой
pip install dvc. После установки необходимо инициализировать DVC в папке проекта dvc init, которая сгенерирует набор папок для дальнейшей работы DVC. 4. checkout new branch in demo repository (to not wipe content of master branch)
git checkout -b dvc-tutorial
5. Initialize DVC
dvc init commit dvc init git commit -m "Initialize DVC"
DVC работает поверх Git, использует его инфраструктуру и имеет похожий синтаксис.
В процессе работы DVC создает мета файлы для описания пайплайнов и версионируемых файлов, которые необходимо сохранять в Git историю вашего проекта. Поэтому после исполнения
dvc init необходимо выполнить git commit, чтобы зафиксировать все сделанные настройки.В вашем репозитории появится папка
.dvc, в которой будут лежать cache и config. Содержимое
.dvc будет выглядеть так:./
../
.gitignore
cache/
configConfig — это конфигурация DVC, а cache — это системная папка, в которую DVC будет складывать все данные и модели, которые вы будете версионировать.
Также DVC создаст файл
.gitignore, в который будет записывать те файлы и папки, которые не нужно коммитить в репозиторий. Когда вы передаете DVC какой-либо файл для версионирования в Git, будут сохраняться версии и метаданные, а сам файл будет храниться в cache. Теперь нужно установить все зависимости, а потом сделать
checkout в новую ветку dvc-tutorial, в которой мы будем работать. И загрузить датасет Iris. Get data
wget -P data/ https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
Возможности DVC
Версионирование моделей и данных
Источник тут.
Напомню, что если передать под контроль DVC какие-то данные, то он начнет отслеживать все изменения. А мы можем работать с этими данными точно так же, как с Git: сохранять версию, отправлять в удалённый репозиторий, получать нужную версию данных, изменять и переключаться между версиями. Интерфейс у DVC очень простой.
Введём команду
dvc add и укажем путь к файлу, который нам нужно версионировать. DVC создаст метафайл iris.csv с расширением .dvc, а информацию о нём запишет в папку cache. Закоммитим эти изменения, чтобы в Git-истории появилась информация о начале версионирования.dvc add data/iris.csvВнутри сгенерированного dvc-файла хранится его хэш со стандартными параметрами.
Output — путь к файлу в папке dvc, который мы добавили под контроль DVC. Система берет данные, кладет в cache и создаёт в рабочей директории ссылку на это кэш. Этот файл можно добавить в Git-историю и таким образом версионировать его. Управление самими данными берет на себя DVC. Первые два символа хэша используются в качестве папки внутри cache, а остальные символы используются в качестве названия создаваемого файла.Автоматизация ML пайплайнов
Помимо контроля версий данных мы можем создавать пайплайны (pipeline) — цепочки вычислений, между которыми задаются зависимости. Вот стандартный пайплайн обучения и оценки классификатора:
На входе у нас есть данные, которые нужно предварительно обработать, разделить на train и test, рассчитать признаки и уже потом обучить модель и оценить её. Этот пайплайн можно разбить на отдельные кусочки. Например, выделить этап загрузки и предобработки данных, разбиение данных, оценку и т. д., и соединить эти цепочки между собой.
Для этого в DVC есть замечательная команда
dvc run, в которой мы передаем определённые параметры и указываем Python-модуль, который нам нужно запустить. Теперь — к примеру запуска этапа расчёта признаков. Сначала посмотрим содержимое модуля featureization.py:
import pandas as pd
def get_features(dataset):
features = dataset.copy()
# uncomment for step 5.2 Add features
# features['sepal_length_to_sepal_width'] = features['sepal_length'] / features['sepal_width']
# features['petal_length_to_petal_width'] = features['petal_length'] / features['petal_width']
return features
if __name__ == '__main__':
dataset = pd.read_csv('data/iris.csv')
features = get_features(dataset)
features.to_csv('data/iris_featurized.csv', index=False)Этот код берёт датасет, рассчитывает признаки и сохраняет их в iris_featurized.csv. Расчёт дополнительных признаков мы оставили на следующий этап.
Для создания пайплайна необходимо для каждого этапа вычислений выполнить команду
dvc run. Сначала в команде
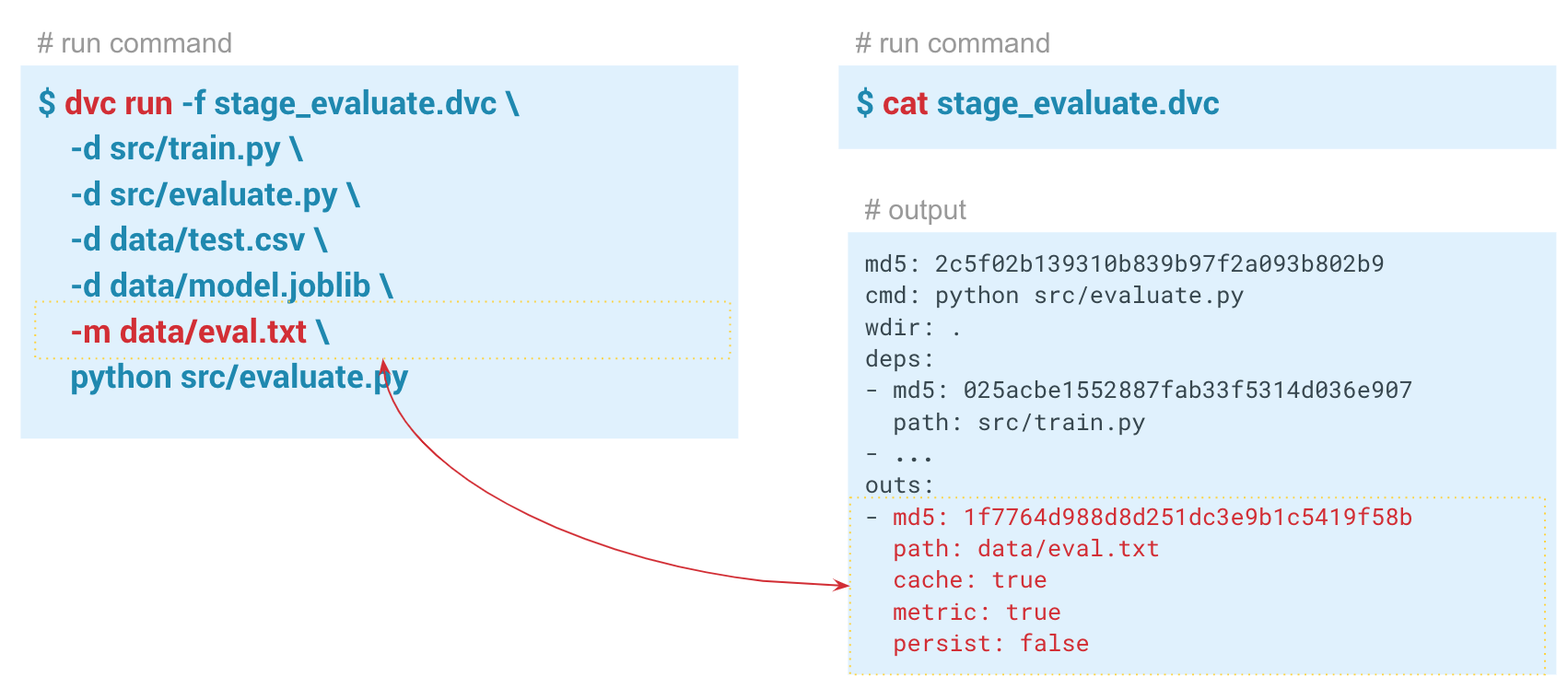
dvc run укажем название метафайла stage_feature_extraction.dvc, в который DVC запишет необходимые метаданные о этапе вычислений. Через аргумент -d укажем необходимые зависимости: модуль featureization.py и файл с данными iris.csv. Также укажем файл iris_featurized.csv, в который сохраняются признаки, и саму команду запуска python src/featurization.py.dvc run -f stage_feature_extraction.dvc \
-d src/featurization.py \
-d data/iris.csv \
-o data/iris_featurized.csv \
python src/featurization.pyDVC создаст метафайл и будет отслеживать изменения в питоновском модуле и файле iris.csv.
Если в них произойдут изменения, то DVC перезапустит этот этап расчёта в пайплайне.
Получившийся файл stage_feature_extraction.dvc будет содержать свой хэш, команду запуска, зависимости и выходные данные (для них есть дополнительные параметры, которые можно посмотреть в метаданных).
Теперь необходимо сохранить этот файл в историю Git коммитов. Таким образом, мы можем создать новую ветку и запушить её в Git-репозиторий. Можно коммитить в Git-историю либо создание каждого этапа в отдельности, либо всех этапов сразу.
Когда мы выстраиваем такую цепочку для всего нашего эксперимента, DVC выстраивает граф вычислений (DAG), по которым может запускать либо пересчёт всего пайплайна, либо какой-то части. Хэши выходных данных одного этапа идут на входы другого. По ним DVC отслеживает зависимости и выстраивает граф вычислений. Если вы поменяли код где-то в split_dataset.py, то DVC не будет загружать данные и, возможно, пересчитывать признаки, а перезапустит этот этап и следующие за ним этапы обучения и оценки.
Отслеживание метрик
С помощью команды
dvc metrics show можно вывести метрики текущего запуска, той ветки, в которой мы находимся. А если передадим параметр -a, то DVC покажет все метрики, которые есть в Git-истории. Чтобы DVC начал отслеживать метрики, мы при создании этапа evaluate передаем параметр -m через data/eval.txt. В этот файл модуль evaluate.py записывает метрики, в данном случае f1 и confusion metrics. В папке output в dvc-файле этого этапа для cache и metrics заданы значения true. То есть команда dvc metrics show выведет в консоль содержимое файла eval.txt. Также с помощью аргументов этой команды можно показать только f1_score или только confusion_matrix.В этом примере у нас получились вот такие результаты:
Воспроизводимость пайплайнов
Те, кто работал с этим датасетом, знают, что на нём очень сложно построить хорошую модель.
Теперь у нас есть пайплайн, созданный с помощью DVC. Система отслеживает историю данных и модель, может перезапускать себя целиком или по частям, может показывать метрики. Мы выполнили всю необходимую автоматизацию.
У нас была модель с f1 = 0,78. Мы хотим её улучшать, меняя какие-то параметры. Для этого нужно перезапустить весь пайплайн, в идеале, какой-то одной командой. Кроме того, если вы работаете в команде, вы можете захотеть передать модель и код коллегам, чтобы они могли продолжить работу над ними.
Команда
dvc repro позволяет перезапускать пайплайны или отдельные этапы (в этом случае нужно после команды указать воспроизводимый этап).Выполнив команду
dvc repro stage_evaluate, этап попробует перезапустить весь пайплайн. Но если мы это сделаем в текущем состоянии, то DVC не увидит никаких изменений и перезапускать не станет. А если мы что-то изменим, он сам найдёт изменение и перезапустит пайплайн с этого момента. $ dvc repro stage_evaluate.dvc
Stage 'data/iris.csv.dvc' didn't change.
Stage 'stage_feature_extraction.dvc' didn't change.
Stage 'stage_split_dataset.dvc' didn't change.
Stage 'stage_train.dvc' didn't change.
Stage 'stage_evaluate.dvc' didn't change.
Pipeline is up to date. Nothing to reproduce.В данном случае DVC не увидел изменений в зависимостях этапа stage_evaluate и отказался перезапускать. А если мы укажем параметр
-f, тогда он перезапустит все предварительные этапы и покажет предупреждение о том, что удаляет предыдущие версии данных, которые от отслеживал. Каждый раз, когда DVC перезапускает этап, он удаляет предыдущий кэш, фактически перезаписывает его, чтобы не дублировать данные. В момент запуска файла DVC проверят его хэш, и если он изменился, пайплайн перезапускается и затирает все output, которые у этого пайплайна есть. Если вы хотите этого избежать, то нужно предварительно запушить конкретную версию данных в какой-то удалённый репозиторий.Возможность перезапускать пайплайны и отслеживать зависимости каждого этапа позволяет быстрее экспериментировать с моделями.
Например, можно изменить признаки (‘раскомментить’ строки расчёта признаков в
featurization.py). DVC увидит эти изменения и перезапустит весь пайплайн. Сохранение данных в удаленном репозитории
DVC может работать не только с локальными хранением версий. Если выполнить команду
dvc push, то DVC отправит текущую версию модели и данных в предварительно настроенное удаленное хранилище репозиторий. Если потом ваш коллега сделает git clone вашего репозитория и выполнит dvc pull, он получит ту версию данных и моделей, которая предназначена для этой ветки. Главное, чтобы у всех был доступ к этому репозиторию. В данном случае мы имитируем «удалённое» хранилище в папке temp/dvc. Примерно таким же образом создается удалённое хранилище и в облаке. Коммитим это изменение, чтобы оно осталось в Git-истории. Теперь мы можем выполнить
dvc push для отправки данных в это хранилище, а ваш коллега, чтобы получить их, просто выполняет dvc pull.Итак, мы рассмотрели три ситуации, в которых полезен DVC и основной функционал:
- Версионирование данных и моделей. Если вам не нужны пайплайны и удалённые репозитории, вы можете версионировать данные для конкретного проекта, работая на локальной машине. DVC позволяет очень быстро работать с данными в десятки гигабайт.
- Обмен данными и моделями между командами. Для хранения данных можно использовать облачные решения. Это удобный вариант, если у вас распределенная команда или есть ограничения на размер файлов, пересылаемых по почте. Также эту методику можно использовать в ситуациях, когда вы шлёте друг другу Notebook, а они не запускаются.
- Организация работы команды внутри большого сервера. Команда может работать с локальной версией больших данных, к примеру, несколько десятков или сотен гигабайт, чтобы вы не копировали их туда-сюда, а использовали одно удалённое хранилище, которое будет отправлять и сохранять только критические версии моделей или данных.
Часть 2
Как внедрить DVC в ваших проектах?
Для обеспечения воспроизводимости проекта необходимо соблюдать определённые требования.
Вот основные из них:
- все пайплайны автоматизированы;
- контроль параметров запуска каждого этапа вычислений;
- контроль версий кода, данных и моделей;
- контроля окружения;
- документация.
Если всё это сделано, то проект с большей вероятностью будет воспроизводимым. DVC позволяет выполнить 3 первых требования в этом списке.
Пытаясь внедрить в своей компании DVC, вы можете столкнуться с нежеланием: «Зачем нам это надо? У нас есть Jupyter Notebook». Возможно, некоторые ваши коллеги работают только с Jupyter Notebook, и им гораздо сложнее писать такие пайплайны и код в IDE. В таком случае можно пойти путем пошагового внедрения.
- Проще всего начать с версионирования кода и моделей.
И затем перейти к автоматизации пайплайнов. - Сначала автоматизировать этапы, которые часто перезапускают и изменяются,
а затем весь пайплайн.
Если у вас есть новый проект и пара энтузиастов в команде, то лучше сразу использовать DVC. Так, например, получилось у нас в команде! При запуске нового проекта меня поддержали мои коллеги, и мы самостоятельно начали использовать DVC. Потом стали делиться с другими коллегами и командами. Кто-то подхватил наше начинание. Сегодня DVC пока не является общепринятым инструментом в нашем банке, однако он используется в нескольких проектах.


")

