

Как backend-разработчик понимает, что SQL-запрос будет хорошо работать на «проде»? В крупных или быстро растущих компаниях доступ к «проду» есть далеко не у всех. Да и с доступом далеко не все запросы можно безболезненно проверить, а создание копии БД часто занимает часы. Чтобы решить эти проблемы, мы создали искусственного DBA — Joe. Он уже успешно внедрен в несколько компаний и помогает не одному десятку разработчиков.
Видео:

Всем привет! Меня зовут Анатолий Станслер. Я работаю в компании Postgres.ai. Мы занимаемся тем, что ускоряем процесс разработки, убирая задержки, связанные с работой Postgres, у разработчиков, DBA и QA.
У нас классные клиенты и сегодня часть доклада будет посвящена кейсам, которые мы встречали в работе с ними. Я расскажу о том, как мы помогли им решить достаточно серьезные проблемы.

Когда мы ведем разработку и делаем сложные нагруженные миграции, мы задаем себе вопрос: «Взлетит ли это миграция?». Мы пользуемся review, мы пользуемся знаниями более опытных коллег, DBA-экспертов. И они могут сказать – полетит она или не полетит.
Но, возможно, было бы лучше, если бы мы могли сами протестировать это на полноразмерных копиях. И сегодня мы как раз поговорим про то, какие сейчас есть подходы к тестированию и как это можно лучше делать и с помощью каких инструментов. А также поговорим, какие плюсы и минусы есть в таких подходах, и что мы можем здесь исправить.
Кто когда-нибудь прямо на prod делал индексы или какие-то изменения вносил? Довольно много. А у кого это приводило к тому, что данные терялись или простои были? Тогда вам знакома эта боль. Слава богу, бэкапы есть.

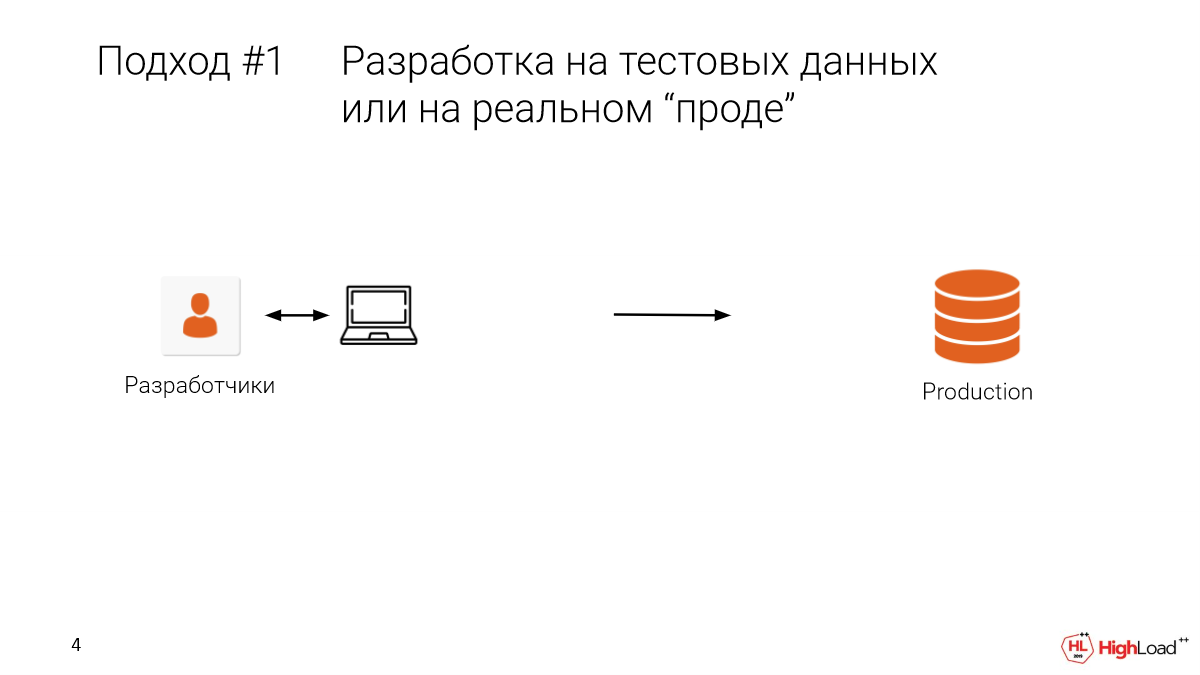
Первый подход – это тестирование в prod. Или, когда разработчик сидит с локальной машины, у него тестовые данные, есть какая-то ограниченная выборка. И мы выкатываем на prod, и получаем вот такую ситуацию.

Это больно, это дорого. Наверное, так лучше не делать.
А как лучше сделать?
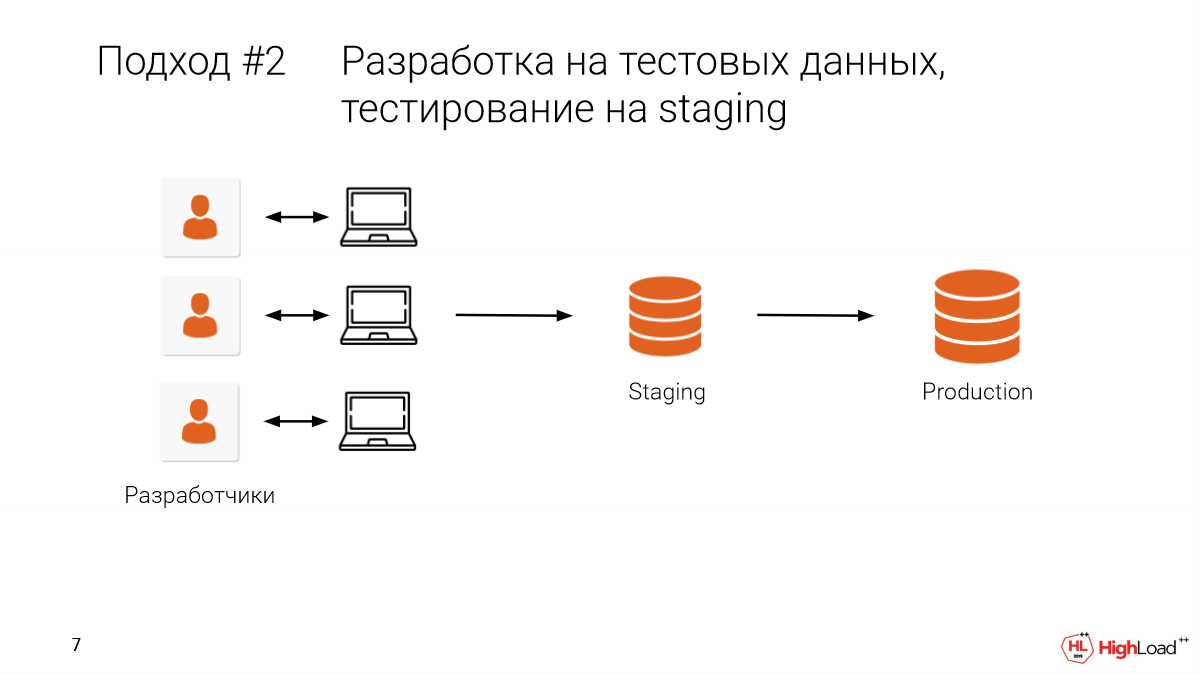
Давайте возьмем staging и выделим туда какую-то часть prod. Или в лучшем случае возьмем настоящим prod, все данные. И после того, как локально разработали, будем дополнительно проверять еще и на staging.
Это нам позволит какую-то часть ошибок убрать, т. е. не допустить на prod.
Какие есть проблемы?
- Проблема в том, что этот staging мы делим с коллегами. И очень часто так бывает, что ты делаешь какое-то изменение, бам – и никаких данных нет, работа насмарку. Staging был многотерабайтным. И нужно долго ждать, пока он снова поднимется. И мы решаем доработать это завтра. Все, у нас разработка встала.
- И, конечно, у нас работает там много коллег, много команд. И нужно согласовывать вручную. А это неудобно.

И стоит сказать, что у нас есть только одна попытка, один выстрел, если мы хотим какие-то изменения внести в базу данных, потрогать данные, поменять структуру. И если что-то пошло не так, если в миграции была ошибка, то мы быстро уже не откатимся.
Это лучше, чем предыдущий подход, но все равно есть большая вероятность, что какая-то ошибка уйдет на production.

Что нам мешает дать каждому разработчику тестовый стенд, полноразмерную копию? Я думаю, что понятно, что мешает.
У кого база данных больше, чем терабайт? Больше, чем у половины зала.
И понятно, что держать машины для каждого разработчика, когда такой большой production, это очень дорого, а к тому же еще и долго.
У нас есть клиенты, которые поняли, что очень важно все изменения тестировать на полноразмерных копиях, но у них база меньше терабайта, а ресурсов, чтобы для каждого разработчика держать тестовый стенд, нет. Поэтому им приходится скачивать дампы к себе локально на машину и тестировать таким образом. Это занимает кучу времени.

Даже если вы это делаете внутри инфраструктуры, то скачать один терабайт данных в час – это уже очень хорошо. Но они используют логический дампы, они скачивают локально с cloud. Для них скорость порядка 200 гигабайтов в час. И еще нужно время, чтобы из логического дампа развернуться, накатить индексы и т. д.
Но они этот подход используют, потому что это позволяет держать prod надежным.
Что мы здесь можем сделать? Давайте сделаем так, чтобы тестовые стенды были дешевыми и будем каждому разработчику давать свой собственный тестовый стенд.
И такое возможно.
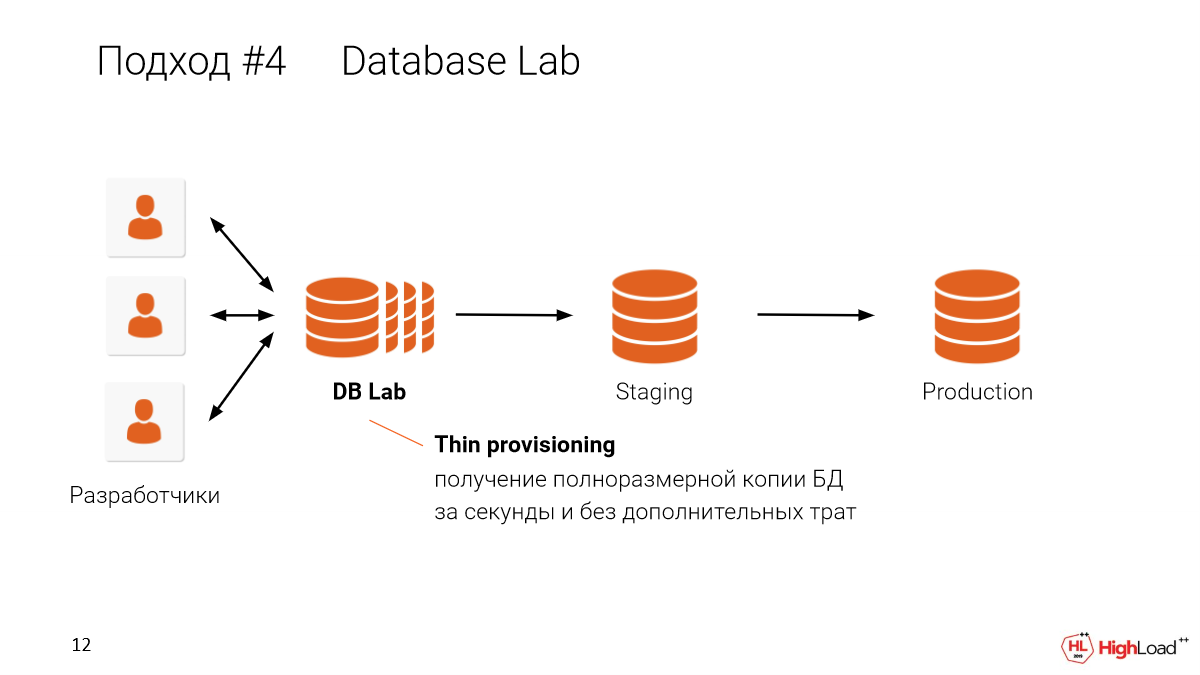
И в этом подходе, когда мы делаем тонкие клоны для каждого разработчика, мы можем пошерить это на одной машине. Например, если у вас четырехтерабайтная база и вы хотите дать ее 10 разработчикам, вам не нужно иметь 10 х четырехтерабайтных баз. Вам достаточно одной машины, чтобы делать тонкие изолированные копии для каждого разработчика, используя одну машину. Как это работает чуть позже расскажу.

Реальный пример:
БД – 4,5 терабайта.
Мы можем получать независимые копии за 30 секунд.
Вам не нужно ждать тестовый стенд и зависеть оттого, какого он размера. Вы можете получить его за секунды. Это будет полностью изолированные среды, но которые делят данные между собой.
Это круто. Здесь мы говорим про магию и параллельную вселенную.

В нашем случае это работает с помощью системы OpenZFS.

OpenZFS – это copy-on-write файловая система, которая сама из коробки поддерживает снапшоты и клоны. Она надежная и масштабируемая. Ей очень просто управлять. Ее буквально в две команды можно развернуть.
Есть другие варианты:
LVM,
СХД (например, Pure Storage).
Database Lab, про который я рассказываю, он модульный. Можно реализовать при использовании таких вариантов. Но пока мы сосредоточились на OpenZFS, потому что конкретно с LVM были проблемы.
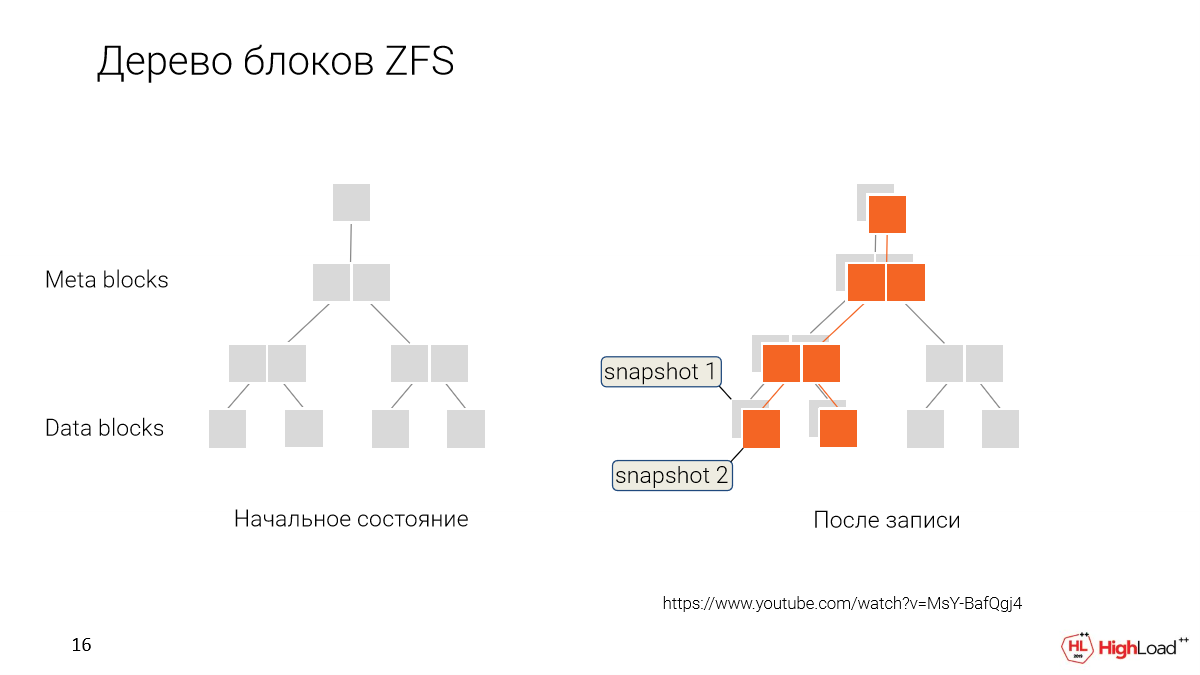
Как это работает? Вместо того, чтобы переписывать данные каждый раз, когда мы их меняем, мы их сохраняет, просто помечая, что вот эти новые данные относятся к новому моменту времени, к новому снапшоту.
И в дальнейшем, когда мы хотим откатиться или мы хотим сделать новый клон с какой-то более старой версии, мы просто говорим: «Ок, дайте нам вот эти блоки данных, которые вот так-то помечены».
И вот этот пользователь будет работать с таким набором данных. Он их будет постепенно изменять, делать свои снапшоты.
И у нас будет ветвление. У каждого разработчика в нашем случае будет возможность иметь свой собственный клон, который он редактирует, а те данные, которые общие, они будут шариться между всеми.
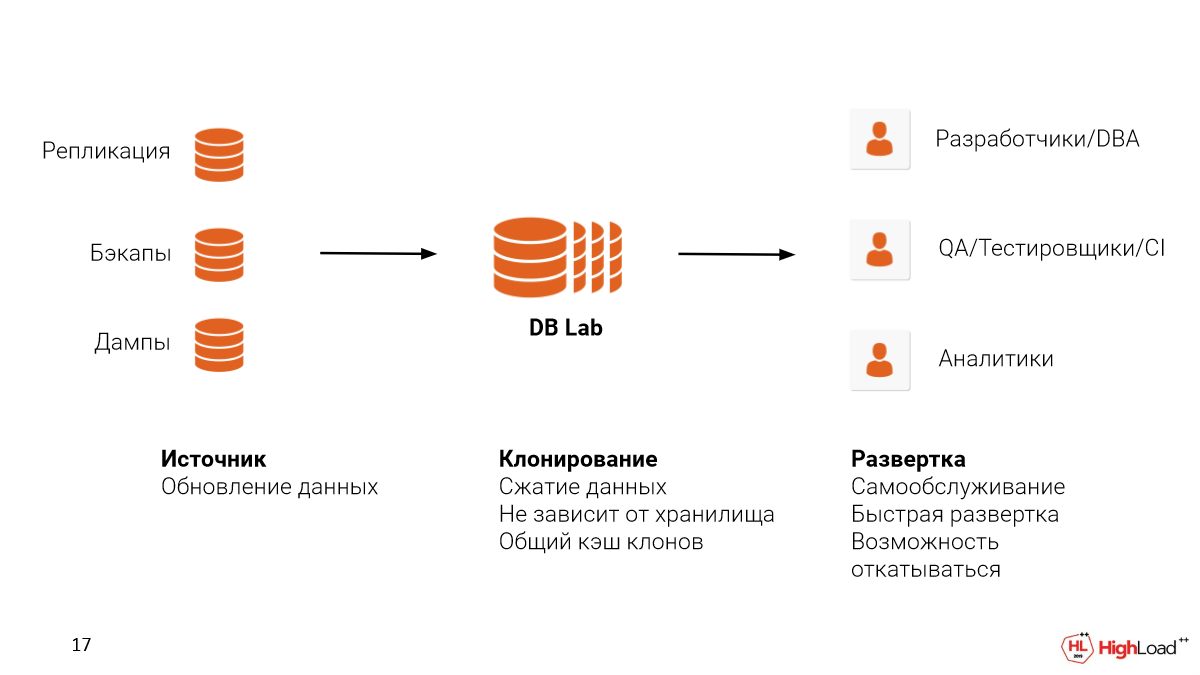
Чтобы развернуть у себя такую систему, нужно решить две проблемы:
Первая – это источник данных, откуда вы будете их брать. Можно настроить репликацию с production. Можно использовать уже бэкапы, которые у вас настроены, я надеюсь. WAL-E, WAL-G или Barman. И даже, если вы используете какое-то Cloud-решение, например, RDS или Cloud SQL, то вы можете использовать логические дампы. Но мы все-таки вам советуем использовать бэкапы, потому что при таком подходе у вас сохранится еще и физическая структура файлов, что позволит быть еще более ближе к тем метрикам, которые вы бы увидели на production, чтобы отлавливать те проблемы, которые есть.
Вторая – это место, где вы хотите похостить Database Lab. Это может быть Cloud, это может быть On-premise. Здесь важно сказать, что ZFS поддерживает сжатие данных. И достаточно хорошо это делает.
Представьте, что у каждого такого клона в зависимости от тех операций, которые мы с базой делаем, будет нарастать какой-то dev. Для этого dev тоже нужно будет место. Но за счет того, что мы взяли базу в 4,5 терабайта, ZFS ее сожмет до 3,5 терабайт. В зависимости от настроек это можно варьировать. И у нас еще для dev останется место.
Такую систему можно использовать для разных кейсов.
Это разработчики, DBA для проверки запросов, для оптимизации.
Это можно использовать в QA-тестировании для проверки конкретной миграции перед тем, как мы будем выкатывать это в prod. И также мы можем поднимать специальные environment для QA с реальными данными, где они могут потестировать новый функционал. И это будет занимать секунды вместо того, чтобы ждать часы, а, может быть, и сутки в каких-то других случаях, где тонкие копии не используются.
И еще отдельный кейс. Если в компании не настроена система аналитики, то мы можем выделить тонкий клон продуктовой базы и отдать ее под долгие запросы или под специальные индексы, которые в аналитике могут использоваться.

С таким подходом:
Низкая вероятность ошибок на «проде», потому что мы все изменения протестировали на полноразмерных данных.
У нас появляется культура тестирования, поскольку теперь не нужно часами ждать свой собственный стенд.
И нет преграды, нет ожидания между тестированиями. Ты реально можешь пойти и проверить. И так будет лучше, поскольку мы ускорим разработку.
Будет меньше рефакторинга. Меньше багов попадет в prod. Мы меньше их отрефакторим потом.
Мы можем обращать необратимые изменения. Этого в стандартных подходах нет.
- Это выгодно, потому что мы делим ресурсы тестовых стендов.
Уже хорошо, а что еще можно было бы ускорить?

Благодаря такой системе мы можем сильно снизить порог вхождения в такое тестирование.
Сейчас есть замкнутый круг, когда разработчик, чтобы получить доступ к реальным полноразмерным данным, должен стать экспертом. Ему должны доверить такой доступ.
Но как расти, если его нет. А что, если тебе доступен только очень маленький набор тестовых данных? Тогда получить реальный опыт не получится.
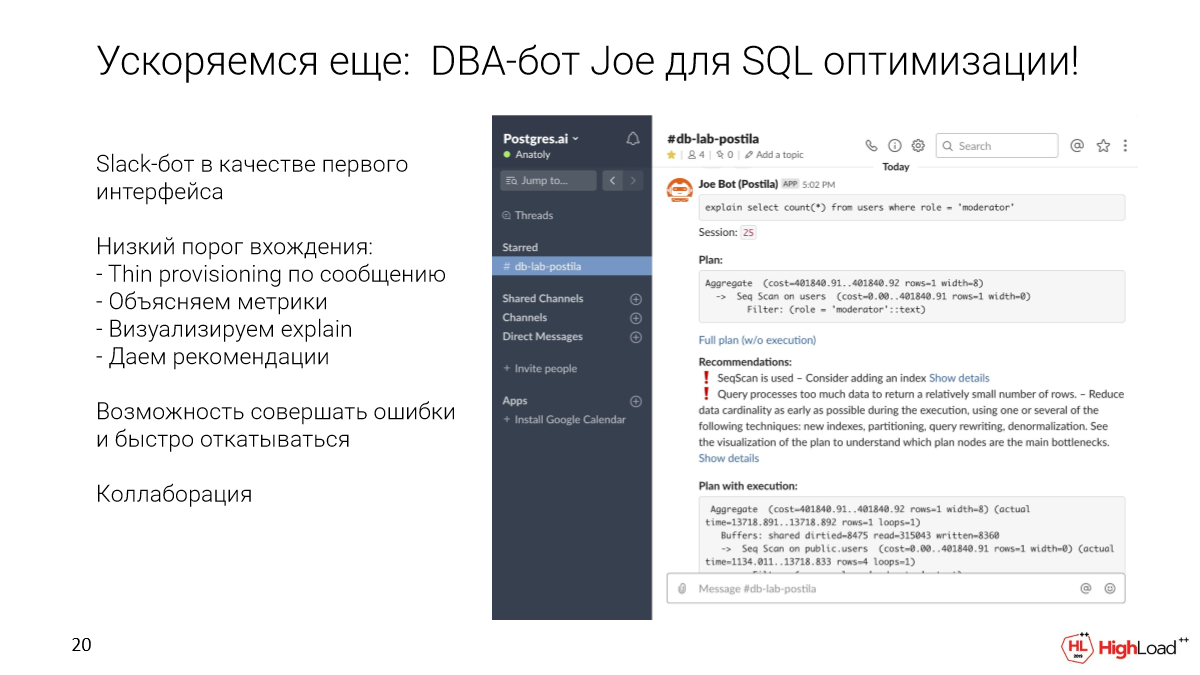
Как выйти из этого круга? В качестве первого интерфейса, удобного для разработчиков любого уровня, мы выбрали Slack-бот. Но это может быть любой другой интерфейс.
Что он позволяет делать? Можно взять конкретный запрос и отправить его в специальный канал для базы данных. Мы автоматически за секунды развернем тонкий клон. Прогоним этот запрос. Соберем метрики и рекомендации. Покажем визуализацию. И дальше этот клон останется для того, чтобы этот запрос можно было как-то оптимизировать, добавить индексы и т. д.
И также Slack нам дает возможности для коллаборации из коробки. Поскольку это просто канал, можно прямо там в thread для такого запроса начать этот запрос обсуждать, пинговать своих коллег, DBA, которые есть внутри компании.

Но есть, конечно, и проблемы. Поскольку это реальный мир, и мы используем сервер, на котором хостим сразу много клонов, нам приходится сжимать количество памяти и количество процессорной мощности, которые клонам доступны.
Но чтобы эти тесты были правдоподобными, нужно как-то эту проблему решить.
Понятно, что важным моментом являются одинаковые данные. Но это у нас уже есть. И нам хочется добиться одинаковой конфигурации. И мы такую практически одинаковую конфигурацию можем дать.
Круто было бы иметь такое же железо как на production, но оно может отличаться.
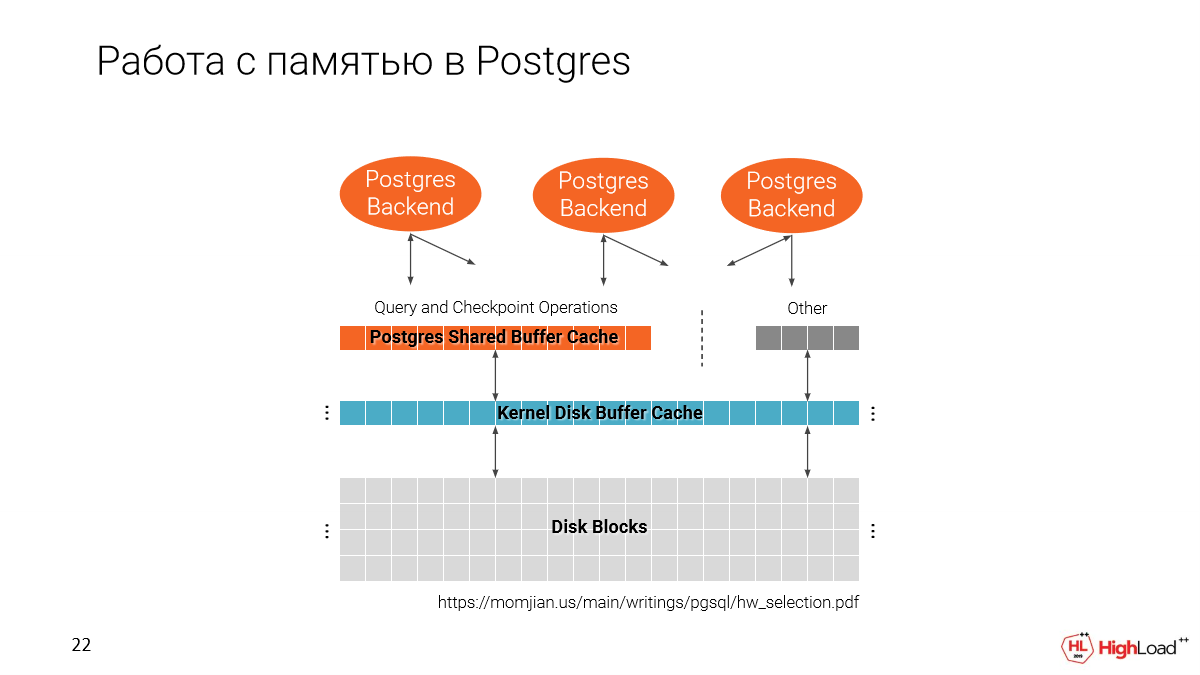
Давайте вспомним как Postgres работает с памятью. У нас есть два кэша. Один от файловой системы и один собственный Postgres, т. е. Shared Buffer Cache.
Важно отметить, что Shared Buffer Cache аллоцируется при старте Postgres в зависимости оттого, какой размер вы зададите в конфигурации.
А второй кэш используется все доступное пространство.
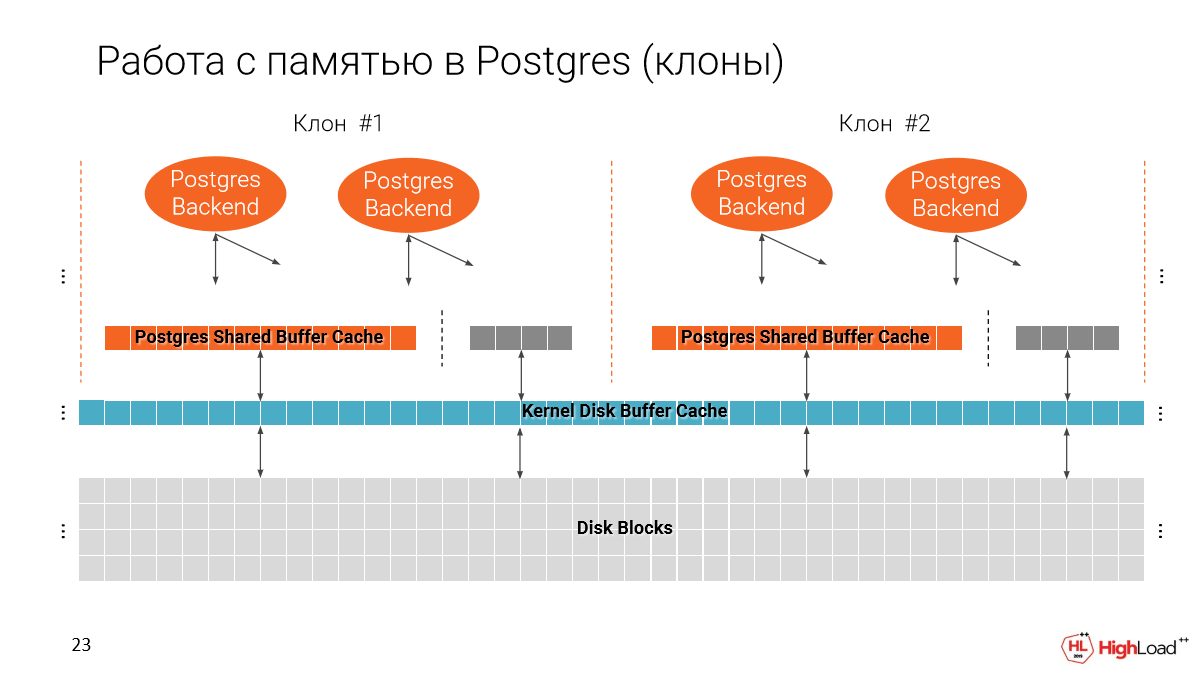
И когда мы делаем несколько клонов на одной машине, получается, что мы постепенно память заполняем. И по-хорошему Shared Buffer Cache – это 25 % от всего объема памяти, который на машине доступен.
И получается, что если мы не будем этот параметр менять, то мы сможем на одной машине запускать всего 4 instance, т. е. 4 всего таких тонких клона. И это, конечно, плохо, потому что нам хочется их иметь гораздо больше.
Но с другой стороны, Buffer Cache используется для выполнения запросов, для индексов, т. е. план зависит оттого, какого размера у нас кэши. И если мы просто так возьмем этот параметр и уменьшим, то у нас планы могут сильно поменяться.
Например, если на prod у нас кэш большой, то у нас Postgres будет предпочитать использовать индекс. А если нет, то тогда будет SeqScan. И какой был бы смысл, если у нас эти планы не совпадали бы?
Но здесь мы приходим к такому решению, что на самом деле план в Postgres не зависит от конкретного заданного в Shared Buffer размера в плане, он зависит от effective_cache_size.

Effective_cache_size – это предполагаемый объем кэша, который нам доступен, т. е. в сумме Buffer Cache и кэш файловой системы. Это задается конфигом. И эта память не аллоцируется.
И за счет этого параметра мы можем как бы обмануть Postgres, сказав, что нам на самом-то деле доступно много данных, даже если этих данных у нас нет. И таким образом, планы будут полностью совпадать с production.
Но это может повлиять на тайминг. И мы запросы оптимизируем по таймингу, но важно, что тайминг зависит от многих факторов:
Он зависит от той нагрузки, которая сейчас есть на prod.
Он зависит от характеристик самой машины.
И это косвенный параметр, но на самом деле мы можем оптимизировать именно по количеству данных, которые этот запрос прочитают, чтобы получить результат.
И если хочется, чтобы тайминг был приближен к тому, что мы увидим в prod, то нам нужно взять максимально похожее железо и, возможно, даже больше, чтобы все клоны поместились. Но это компромисс, т. е. вы получите такие же планы, вы увидите, сколько данных прочитает конкретный запрос и сможете сделать вывод – этот запрос хороший (или миграция) или плохой, его нужно еще оптимизировать.
Давайте разберем, как конкретно с Joe проходит оптимизация.
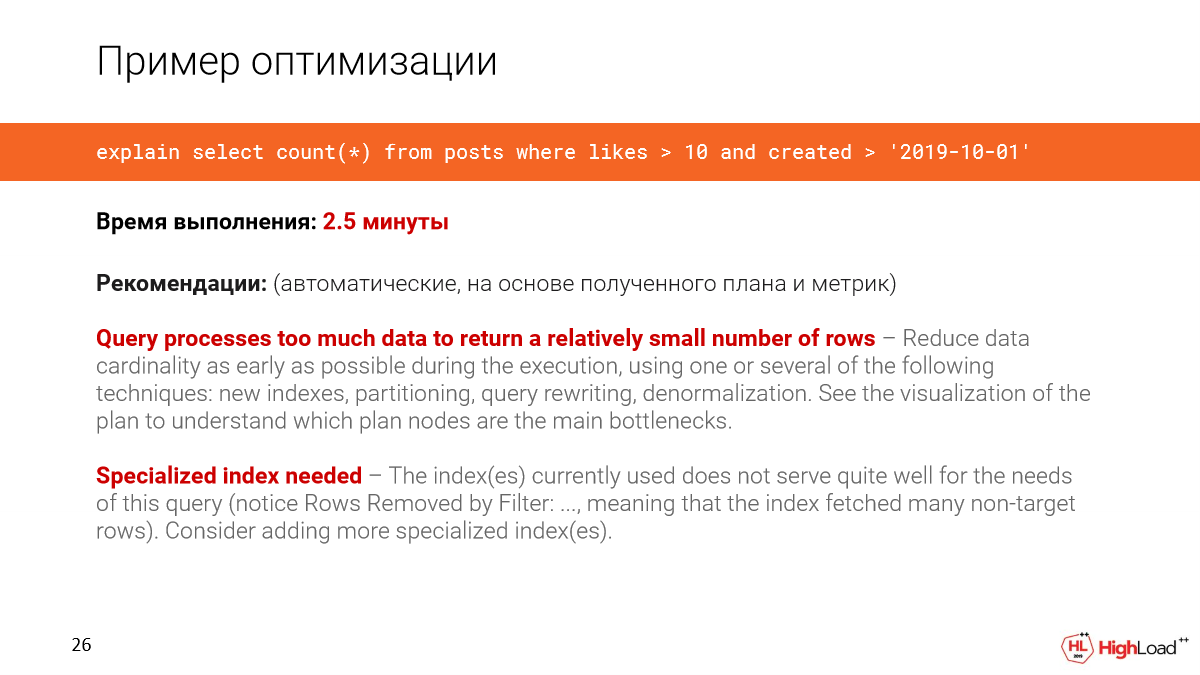
Возьмем запрос из реальной системы. В данном случае база данных – это 1 терабайт. И мы хотим посчитать количество свежих постов, у которых было больше 10 лайков.
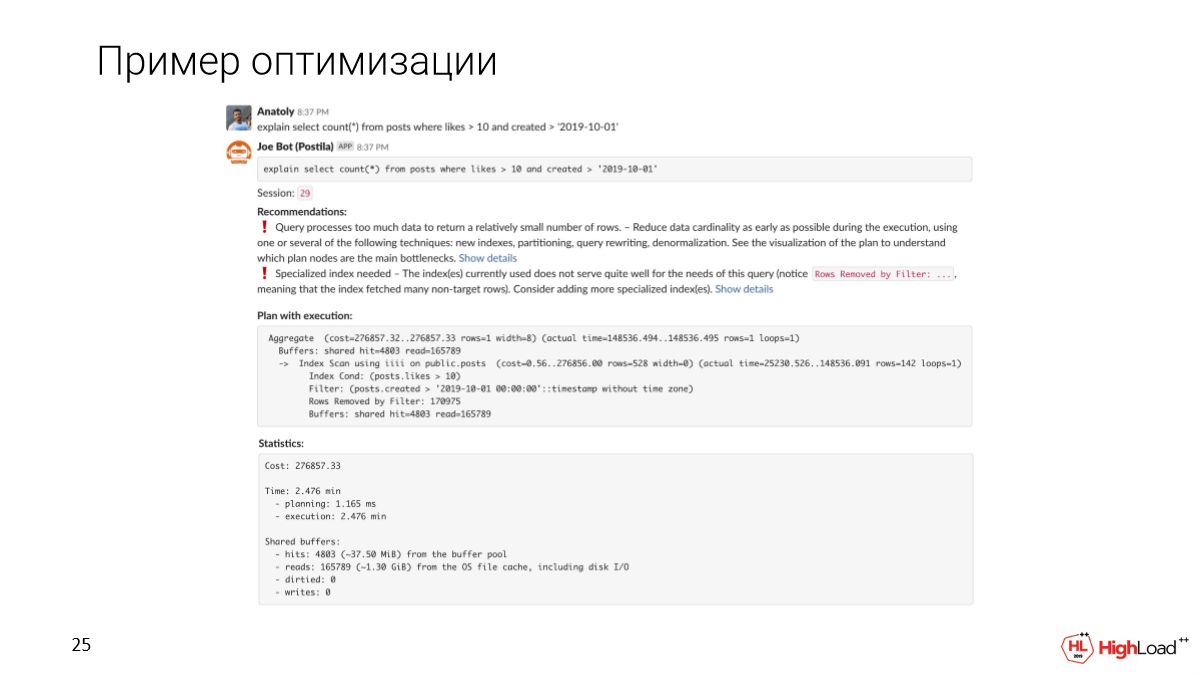
Мы пишем сообщение в канал, развернулся для нас клон. И мы увидим, что такой запрос отработает за 2,5 минуты. Это первое, что мы заметим.
B Joe покажет автоматические рекомендации, основанные на плане и метриках.
Мы увидим, что запрос обрабатывает слишком много данных, чтобы получить относительно небольшое количество строк. И нужен какой-то специализированный индекс, поскольку мы заметили, что в запросе слишком много отфильтрованных строк.

Давайте посмотрим подробнее, что произошло. Действительно, мы видим, что мы прочитали почти полтора гигабайта данных с файлового кэша или даже с диска. И это нехорошо, поскольку мы достали всего 142 строки.
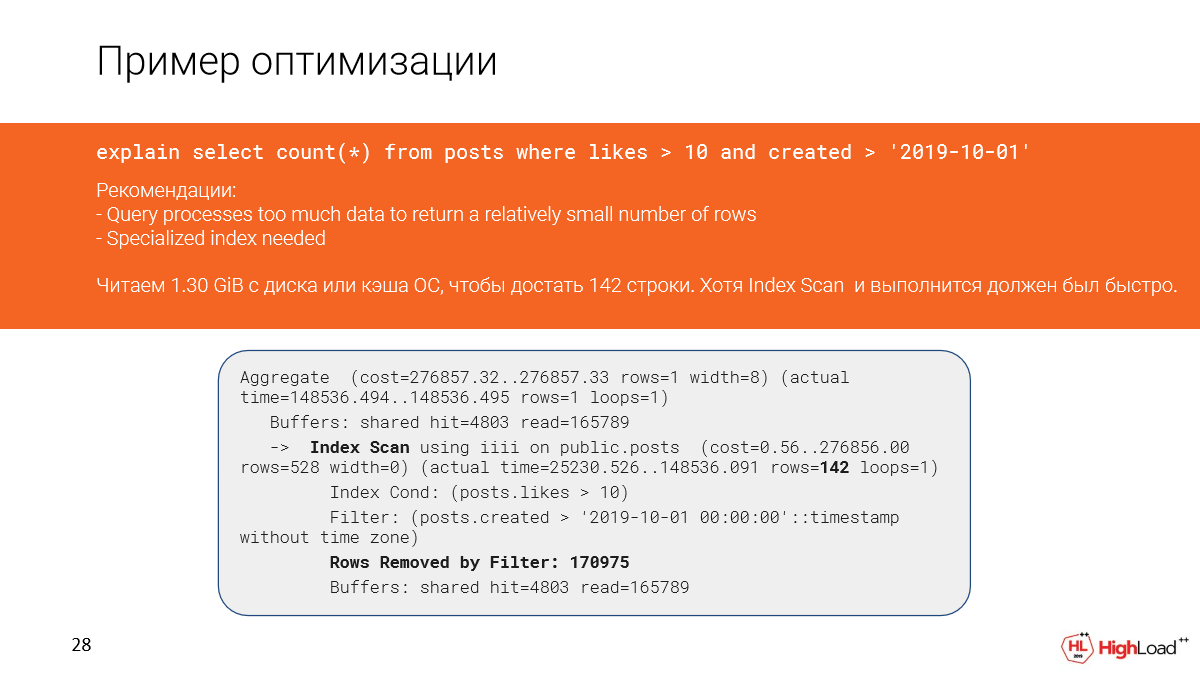
И, казалось бы, у нас здесь index scan и должно было быстро отработать, но, поскольку мы отфильтровали слишком много строк (нам пришлось их считать), то запрос медленно отработал.
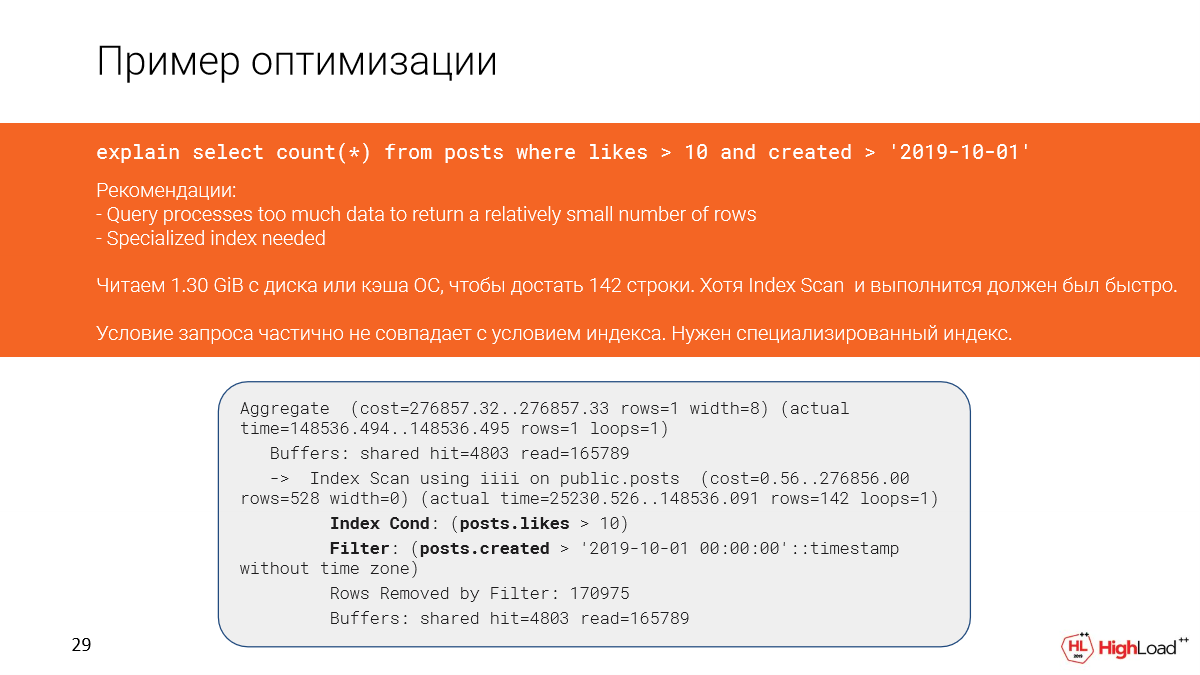
И это произошло в плане из-за того, что частично не совпадают условия в запросе и условия в индексе.
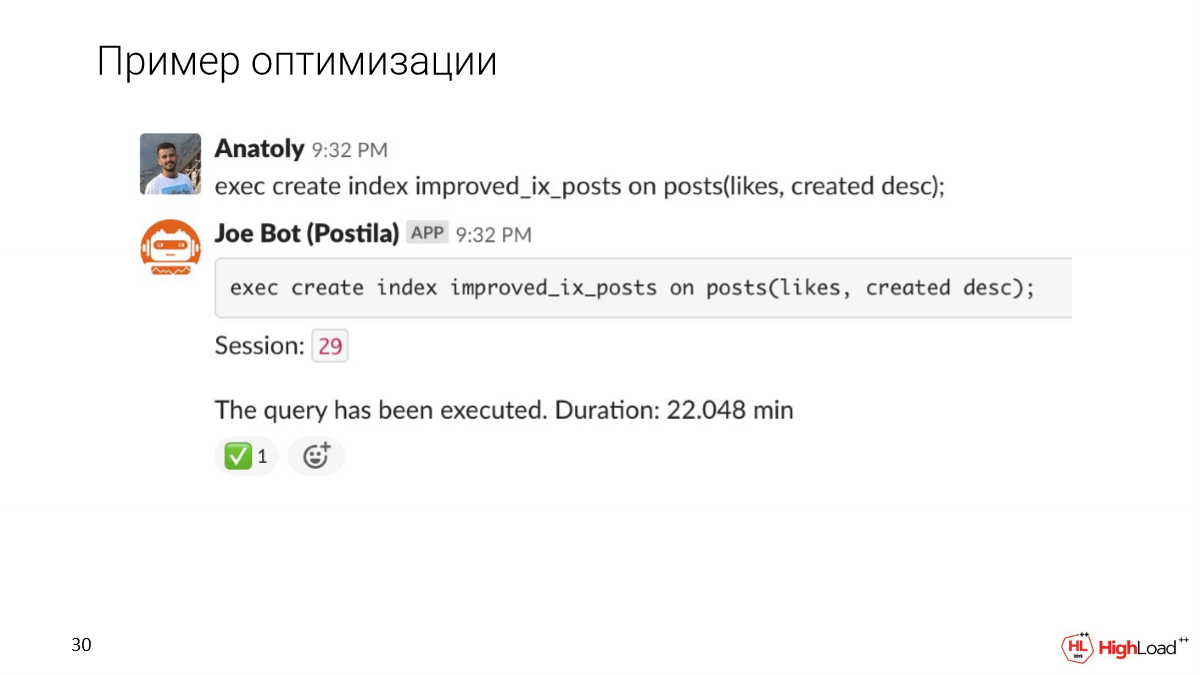
Давайте попробуем сделать индекс поточнее и посмотрим, как изменится выполнение запроса после этого.
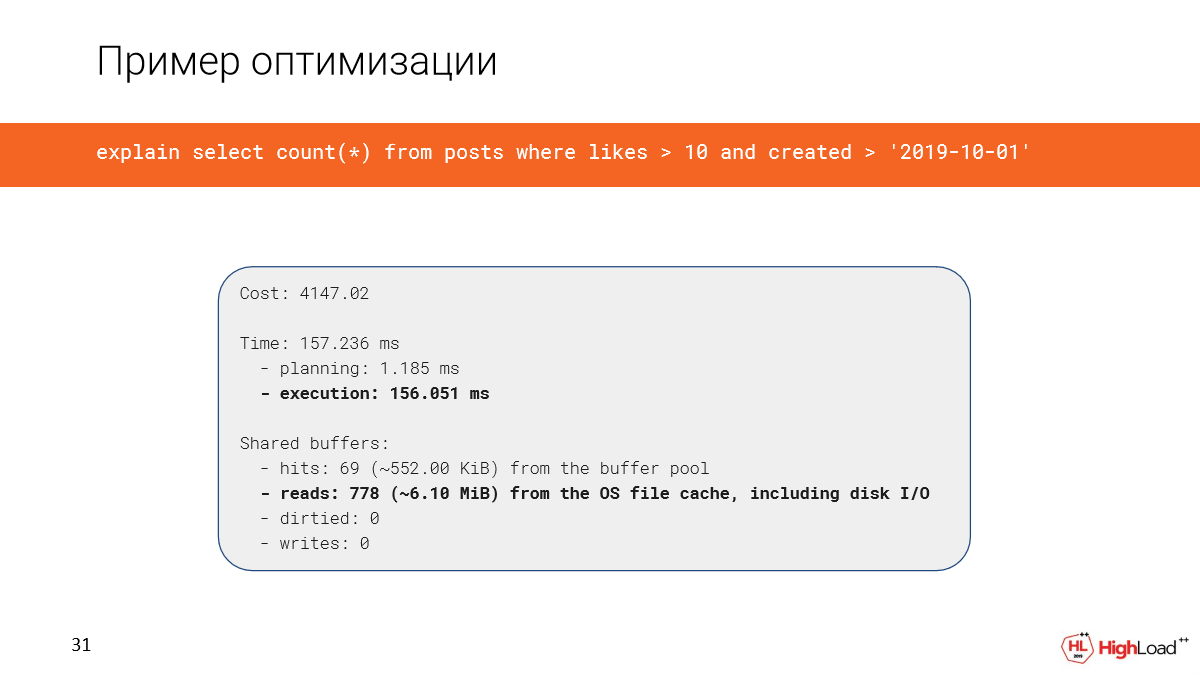
Создание индекса заняло достаточно много времени, но теперь мы проверяем запрос и видим, что время вместо 2,5 минут стало всего 156 миллисекунд, что достаточно хорошо. И мы читаем всего 6 мегабайт данных.
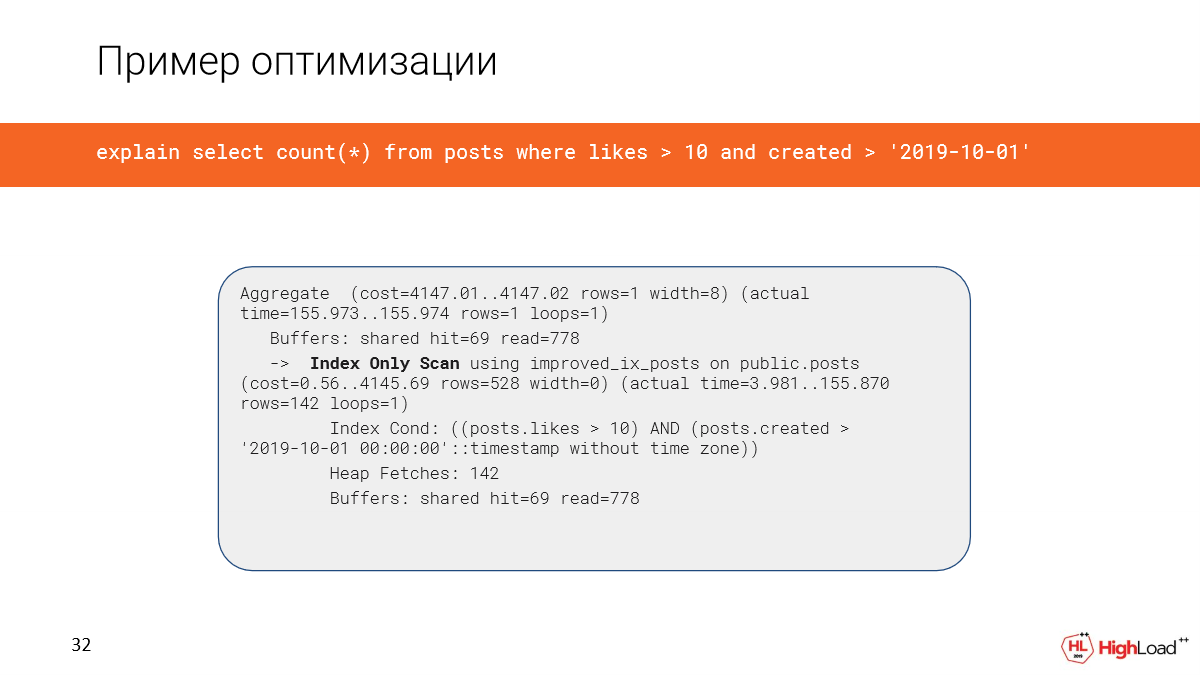
И теперь у нас используется index only scan.
Другая важная история в том, что нам хочется план представить каким-то более понятным способом. Мы у себя внедрили визуализацию с помощью Flame Graphs.
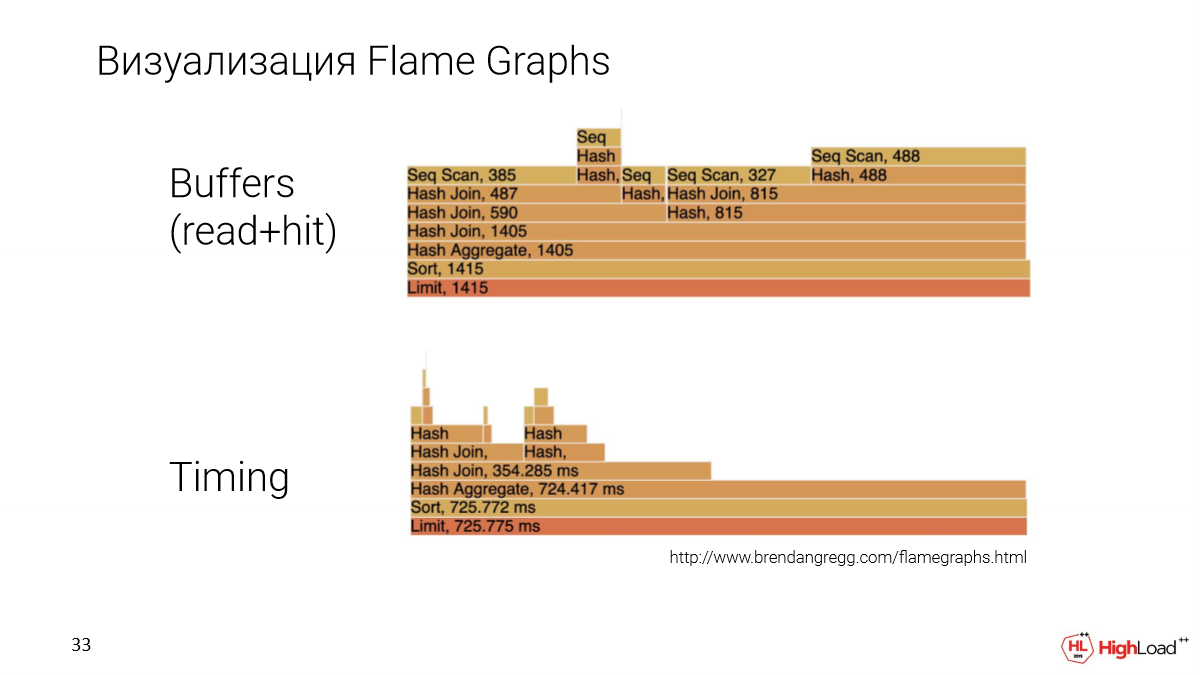
Это другой запрос, более насыщенный. И Flame Graphs мы строим по двум параметрам: это количество данных, которые конкретная нода в плане считала и тайминг, т. е. время выполнения ноды.
Здесь мы можем сравнивать конкретно ноды между собой. И будет понятно, какая из них больше или меньше занимает, что обычно бывает сложно делать в других способах визуализации.
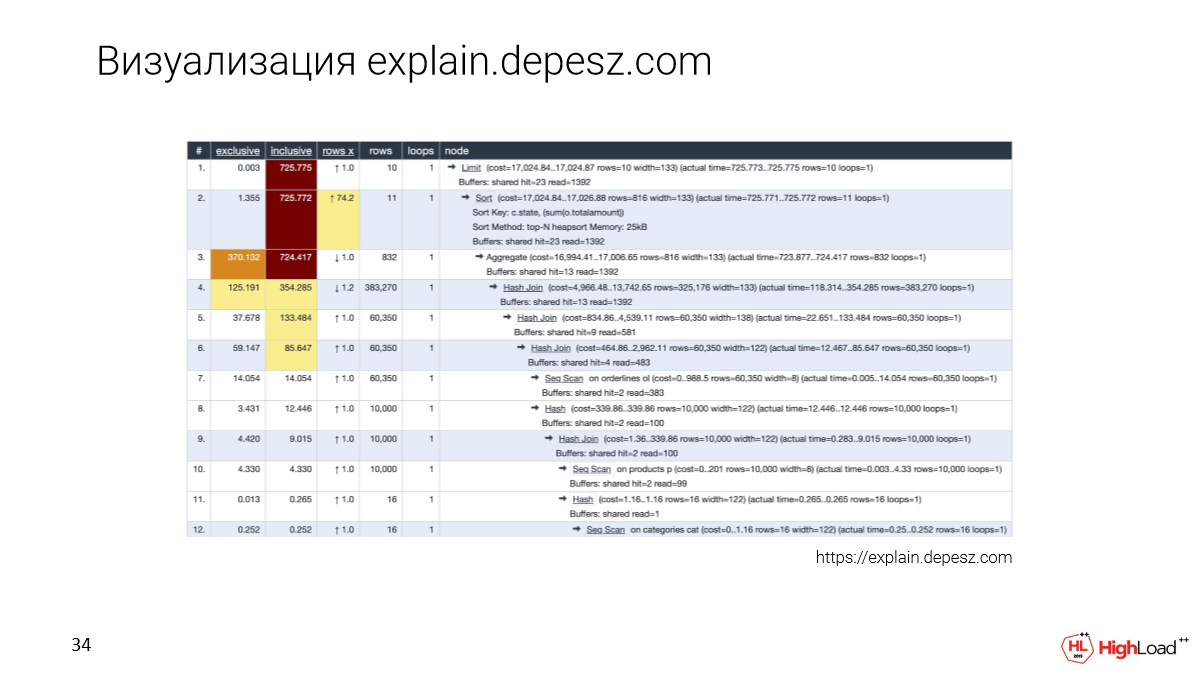
Конечно, все знают explain.depesz.com. Хорошей фичей этой визуализации является то, что мы сохраняет текстовый план и также выносим какие-то основные параметры в таблицу, для того, чтобы можно было отсортировать.
И разработчики, которые еще не углублялись в эту тему, тоже пользуются explain.depesz.com, потому что как раз им проще разобраться какие метрики важны, а какие нет.
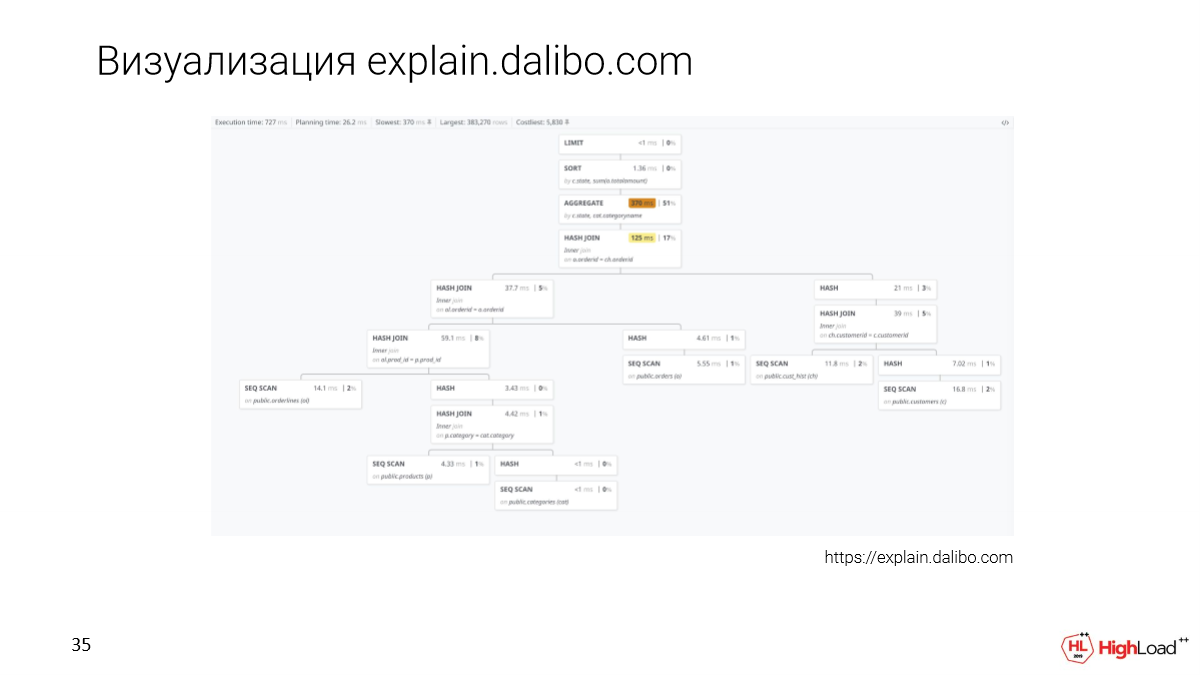
Есть новый подход к визуализации – это explain.dalibo.com. Они делают древовидную визуализацию, но здесь очень тяжело сравнить ноды между собой. Здесь хорошо можно понять структуру, правда, если будет большой запрос, то нужно будет скролить туда-сюда, но тоже вариант.
Коллаборация
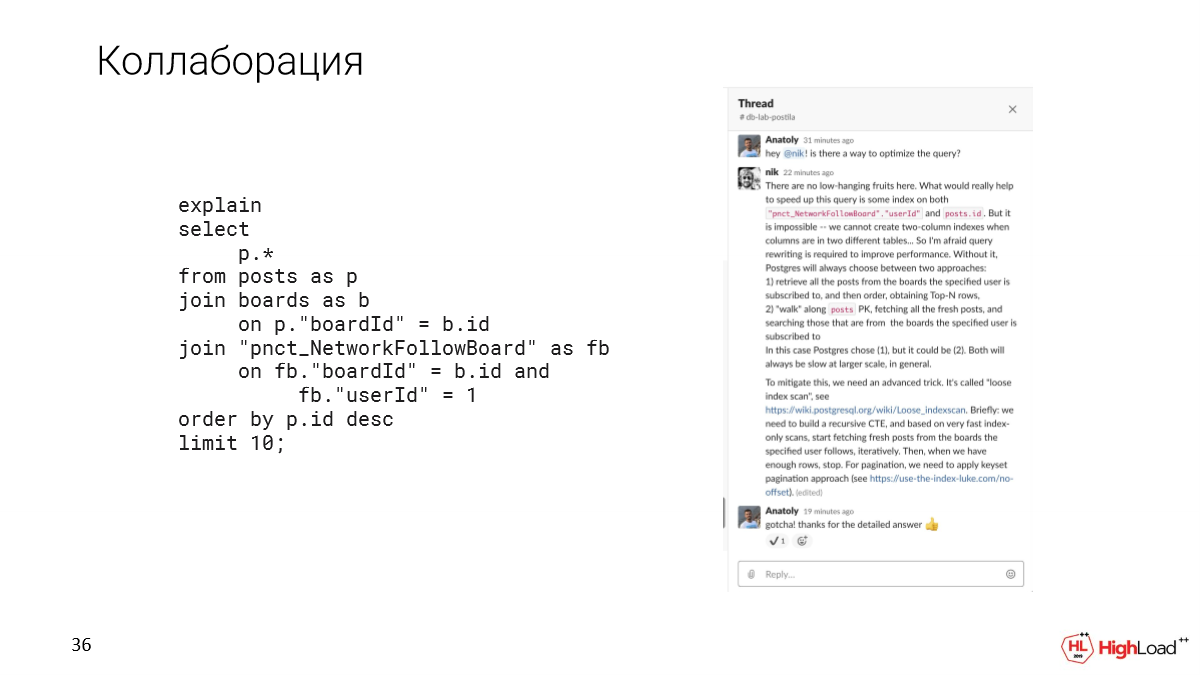
И, как я уже сказал, Slack нам дает возможность коллаборации. Например, если мы встретили сложный запрос, который непонятно, как оптимизировать, мы можем в thread в Slack этот вопрос уточнить со своими коллегами.

Нам кажется, что важно тестировать на полноразмерных данных. Для этого мы сделали инструмент Update Database Lab, который доступен в open source. Вы можете использовать бот Joe тоже. Вы можете брать его прямо сейчас и внедрять у себя. Все гайды там доступны.
Важно также отметить, что само по себе решение не является каким-то революционным, потому что есть Delphix, но это enterprise-решение. Оно полностью закрыто, стоит очень дорого. Мы именно специализируемся на Postgres. Это все продукты open source. Присоединяйтесь к нам!
На этом я заканчиваю. Спасибо!
Вопросы
Здравствуйте! Спасибо за доклад! Очень интересно, особенно мне, потому что я примерно такую же задачу решал некоторое время назад. И поэтому у меня целый ряд вопросов. Надеюсь, я хотя бы часть задам.
Интересно, как вы рассчитываете место под эту среду? Технология подразумевает, что при определенных обстоятельствах ваши клоны могут вырасти до максимального размера. Грубо говоря, если у вас десятитерабайтная база и 10 клонов, то легко смоделировать такую ситуацию, когда каждый клон будет весить по 10 уникальных данных. Как вы рассчитываете это место, т. е. ту дельту, о которой вы говорили, в которой будут жить эти клоны?
Хороший вопрос. Здесь важно следить за конкретными клонами. И если какое-то слишком большое изменение у клона, он начинает расти, то мы можем сначала выдать предупреждение пользователю про это, либо сразу этот клон остановить, чтобы у нас не произошла fail-ситуация.
Да, у меня вложенный вопрос. Т. е. как вы обеспечиваете жизненный цикл этих модулей? У нас это проблема и целая отдельная история. Как это происходит?
Есть какой-то ttl у каждого клона. В принципе, у нас фиксированный ttl.
Какой, если не секрет?
1 час, т. е. idle – 1 час. Если он не используется, то мы его грохаем. Но здесь никакого удивления нет, поскольку мы можем клон поднимать за секунды. И если он снова понадобится, то – пожалуйста.
Мне по поводу выбора технологий тоже интересно, потому что мы, например, параллельно используем несколько способов по тем или иным причинам. Почему именно ZFS? Почему вы не использовали LVM? Вы упомянули, что c LVM были проблемы. Какие были проблемы? На мой взгляд, наиболее оптимальным является вариант с СХД, с точки зрения производительности.
В чем главная проблема с ZFS? В том, что ты должен запускать на одном хосте, т. е. все instances будут жить в рамка одной операционки. А в случае с СХД, ты можешь подключать разное оборудование. И узким местом являются только те блоки, которые на СХД. И интересен вопрос именно выбора технологий. Почему не LVM?
Конкретно про LVM сможем обсудить на meetup. Про СХД – это просто дорого. Систему ZFS мы можем внедрить где угодно. Вы можете ее у себя на машине развернуть. Вы можете просто скачать репозиторий и развернуть ее. ZFS ставится практически везде, если мы про Linux говорим. Т. е. мы получаем очень гибкое решение. И сам по себе ZFS из коробки очень многое дает. Можно загружать туда сколько угодно данных, подключать большое количество дисков, есть снапшоты. И, как я уже говорил, его просто администрировать. Т. е. он кажется очень приятным в использовании. Он проверен, ему много лет. У него есть очень большое community, которое растет. ZFS – очень надежное решение.
Николай Самохвалов: Можно я еще прокомментирую? Меня Николай зовут, мы вместе с Анатолием работаем. Я согласен, что СХД – это классно. И у некоторых наших клиентов есть Pure Storage и т. д.
Анатолий правильно отметил, что мы нацелены на модульность. И в будущем можно реализовать один интерфейс – сделай снапшот, сделай клон, уничтожь клон. Это все легко. И СХД классно, если он есть.
Но ZFS доступен всем. Уже хватит DelPhix, у них 300 клиентов. Из них в fortune 100 — 50 клиентов, т. е. они нацелены на NASA и т. д. Пора получить эту технологию всем. И поэтому у нас open source Core. У нас есть часть интерфейсная, которая не open source. Это платформа, которую мы покажем. Но мы хотим, чтобы это было доступно каждому. Мы хотим сделать революцию, чтобы все тестировщики перестали гадать на ноутбуках. Мы должны писать SELECT и сразу видеть, что он медленный. Хватить ждать, когда DBA об этом расскажет. Вот это главная цель. И я думаю, что мы к этому придем все. И эту штуку мы делаем, чтобы она была у всех. Поэтому ZFS, потому что он будет доступен везде. Спасибо community за решение проблем и за то, что там open source лицензия и т. д.*
Приветствую! Спасибо за доклад! Меня Максим зовут. Мы решали такие же проблемы. У себя порешали. Как вы разделяете ресурсы между этими клонами? Каждый клон в каждый момент времени может заниматься своим: один одно тестирует, другой другое, у кого-то индекс строится, у кого-то job работает тяжелая. И если по CPU можно еще разделить, то по IO, как вы делите? Это первый вопрос.
И второй вопрос про непохожесть стендов. Допустим, у меня здесь ZFS и все классно, а у клиента на prod не ZFS, а ext4, например. Как в этом случае?
Вопросы очень хорошие. Я немного упомянул эту проблему с тем, что мы делим ресурсы. И решение заключается в следующем. Представьте, что вы на staging тестируете. У вас тоже может быть одновременно такая ситуация, что кто-то нагрузку одну дает, кто-то другую. И в итоге вы видите метрики непонятные. Даже такая же проблема может быть с prod. Когда вы хотите проверить какой-то запрос и видите, что с ним какая-то проблема – он медленно отрабатывает, то на самом деле проблема не в запросе была, а в том, что нагрузка какая-то есть параллельная.
И поэтому здесь важно сосредоточиться на том, какой будет план, по каким шагам в плане пойдем и сколько данных мы для этого поднимем. То, что у нас диски, допустим, будут нагружены чем-то, оно повлияет конкретно на тайминг. Но мы можем по количеству данных оценить, насколько этот запрос нагруженный. Это не так важно, что одновременно с ним еще будет какое-то выполнение.
У меня два вопроса. Это очень крутая штука. Были ли кейсы, когда данные на production критично важные, например, номера кредитных кард? Есть ли уже что-то готовое или это отдельная задача? И второй вопрос – есть ли что-то такое для MySQL?
По поводу данных. Мы будем делать обфусцирование, пока мы это не делаем. Но если вы разворачиваете именно Joe, если вы не даете доступа разработчикам, то доступа к данным нет. Почему? Потому что Joe не показывает данные. Он показывает только метрики, планы и все. Так специально было сделано, поскольку – это одно из требований нашего клиента. Они хотели иметь возможность оптимизировать, но при это не давать всем подряд доступ.
По поводу MySQL. Эту систему можно использовать для чего угодно, что хранит state на диске. И поскольку мы занимаемся Postgres, мы сейчас в первую очередь делаем полностью всю автоматизацию для Postgres. Мы хотим автоматизировать получение данных из бэкапа. Мы правильно конфигурируем Postgres. Мы знаем, как сделать так, чтобы планы совпадали и т. д.
Но поскольку система расширяемая, ее можно будет также использовать для MySQL. И такие примеры есть. Похожая штука есть у Яндекса, но они ее не публикуют нигде. Они ее используют внутри Яндекс.Метрики. И там как раз про MySQL история. Но технологии те же самые, ZFS.
Спасибо за доклад! У меня тоже пара вопросов. Вы упомянули, что клонирование можно использовать для аналитики, например, чтобы строить там дополнительные индексы. Можете немножко подробней рассказать, как это работает?
И второй вопрос сразу задам на счет одинаковости стендов, одинаковости планов. План зависит в том числе от статистики, собранной Postgres. Как вы эту проблему решаете?
По аналитике конкретных кейсов нет, потому что мы так еще не использовали, но такая возможность есть. Если мы говорим про индексы, то представьте, что гоняется запрос по таблице с сотней миллионов записей и по колонке, которая обычно в prod не проиндексирована. И мы какие-то там хотим посчитать данные. Если этот запрос прогнать на prod, то есть возможность того, что на prod будет простой, потому что запрос там будет минуту отрабатывать.
Ок, давайте сделаем тонкий клон, который не страшно на несколько минут остановить. И для того чтобы комфортнее было считать аналитику, добавим индексы по тем колонкам, в которых нас данные интересуют.
Индекс будет каждый раз создаваться?
Можно сделать так, что мы данные потрогаем, сделаем снапшоты, потом с этого снапшота будем восстанавливаться и гонять новые запросы. Т. е. можно сделать так, что получится поднимать новые клоны с уже проставленными индексами.
Что касается вопроса насчет статистики, то, если мы восстанавливаемся из бэкапа, если мы делаем репликацию, то у нас статистика будет точно такая же. Потому что у нас полностью вся физическая структура данных, т. е. данные как есть со всеми метриками статистики привезем тоже.
Тут другая проблема. Если у вас cloud-решение используется, то там только логические дампы доступны, потому что Google, Amazon не дают взять физическую копию. Там такая проблема будет.
Спасибо про доклад. Здесь прозвучало два хороших вопроса про MySQL и про разделение ресурсов. Но, по сути, все сводится к тому, что это тема не конкретных СУБД, а в целом файловой системы. И, соответственно, вопросы разделения ресурсов тоже должны решаться оттуда, не в конце, что это Postgres, а в файловой системе, в сервере, в instance.
Мой вопрос чуть о другом. Он более приближен к многослойности базы данных, где несколько слоев. Мы, например, настроили обновление десятитерабайтного образа, у нас репликация идет. И мы конкретно используем это решение для баз данных. Идет репликация, происходит обновление данных. Тут параллельно работает 100 сотрудников, которые постоянно запускают эти разные снимки. Что делать? Как сделать так, чтобы не было конфликта, что они запустили одно, а потом файловая система подменилась, и эти снимки все поехали?
Они не поедут, потому что так ZFS работает. Мы можем держать отдельно в одном потоке изменения файловой системы, которые благодаря репликации приходят. И на старых версиях данных держать клоны, которые разработчики используют. И это у нас работает, с этим все в порядке.
Получается, что обновление будет происходить как дополнительный слой, а все новые снимки будут идти уже, исходя из этого слоя, да?
Из предыдущих слоев, которые были с предыдущих репликаций.
Предыдущие слои отвалятся, но они будут ссылаться на старый слой, а новые образы они будут с последнего слоя брать, который был получен в обновлении?
В общем, да.
Тогда как следствие у нас будет до фига слоев. И со временем их надо будет сжимать?
Да, все правильно. Есть какое-то окно. Мы сохраняем недельные снапшоты. Это зависит оттого, какой у вас есть ресурс. Если у вас есть возможность хранить много данных, можно за долгое время хранить снапшоты. Они сами не удалятся. Никакого data corruption не будет. Если снапшоты устарели, как нам кажется, т. е. это зависит от политики в компании, то мы можем их просто удалить и освободить место.
Здравствуйте, спасибо за доклад! По поводу Joe вопрос. Вы сказали, что заказчик не хотел доступ всем подряд давать к данным. Строго говоря, если у человека есть результат Explain Analyze, то он может данные подсматривать.
Все так. Например, мы можем написать: «SELECT FROM WHERE email = тому то». Т. е. мы не увидим сами данные, но какие-то косвенные признаки мы можем посмотреть. Это нужно понимать. Но с другой стороны это все видно. У нас есть аудит логов, у нас есть контроль других коллег, которые тоже видят, чем занимаются разработчики. И если кто-то попробует так сделать, то к ним служба безопасности придет и поработает над этим вопросом.
Добрый день! Спасибо за доклад! У меня короткий вопрос. Если в компании Slack не используется, то какая-то к нему привязка сейчас есть или можно для разработчиков развернуть instances, чтобы подключить к базам приложение тестовое?
Сейчас есть привязка к Slack, т. е. нет никакого другого мессенджера, но очень хочется сделать поддержку других мессенджеров тоже. Что вы можете сделать? Вы можете развернуть у себя DB Lab без Joe, ходить с помощью REST API или с помощью нашей платформы и создавать клоны, и подключаться PSQL’ем. Но так можно сделать, если вы готовы дать своим разработчикам доступ к данным, т. к. тут уже никакого экрана не будет.
Мне эта прослойка не нужна, а нужна такая возможность.
Тогда – да, это можно сделать.




