
Часть 1
Часть 2
Часть 3
В этой статье вы узнаете:
-О том, что такое transfer learning и как это работает
-О том, что такое semantic/instance segmentation и как это работает
-О том, что такое object detection и как это работает
Для задач обнаружения объектов выделяют два метода (источник и подробнее— тут):
— Двухэтапные методы (англ. two-stage methods), они же «методы, основанные на регионах» (англ. region-based methods) — подход, разделённый на два этапа. На первом этапе селективным поиском или с помощью специального слоя нейронной сети выделяются регионы интереса (англ. regions of interest, RoI) — области, с высокой вероятностью содержащие внутри себя объекты. На втором этапе выбранные регионы рассматриваются классификатором для определения принадлежности исходным классам и регрессором, уточняющим местоположение ограничивающих рамок.
— Одноэтапные методы (англ. one-stage methods) — подход, не использующий отдельный алгоритм для генерации регионов, вместо этого предсказывая координаты определённого количества ограничивающих рамок с различными характеристиками, такими, как результаты классификации и степень уверенности и в дальнейшем корректируя местоположение рамок.
В данной статье рассматриваются одноэтапные методы.
Transfer learning — это метод обучения нейронных сетей, при котором мы берем уже обученную на каких-то данных модель для дальнейшего дообучения для решения другой задачи. Например, у нас есть модель EfficientNet-B5, которая обучена на ImageNet-датасете (1000 классов). Теперь, в самом простом случае, мы изменяем ее последний classifier-слой (скажем, для классификации объектов 10-ти классов).
Взгляните на картинку ниже:
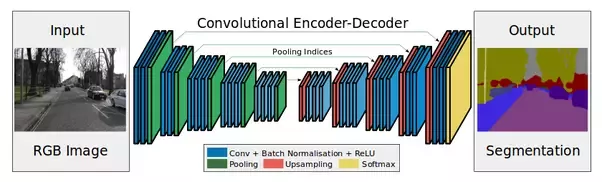
Encoder — это слои subsampling'а (свертки и пулинги).
Замена последнего слоя в коде выглядит так (фреймворк — pytorch, среда — google colab):
Загружаем обученную модель EfficientNet-b5 и смотрим на ее classifier-слой:

Изменяем этот слой на другой:
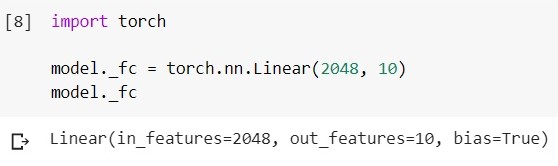
Decoder нужен, в частности, в задаче сегментации (об этом далее).
Стоит добавить, что по умолчанию все слои модели, которые мы хотим обучать дальше, обучаемы. Мы можем «заморозить» веса некоторых слоев.
Для заморозки всех слоев:

Чем меньше слоев мы обучаем — тем меньше нам нужно вычислительных ресурсов для обучения модели. Всегда ли эта техника оправданна?
В зависимости от количества данных, на которых мы хотим обучить сеть, и от данных, на которых была обучена сеть, есть 4 варианта развития событий для transfer learning'а (под «мало» и «много» можно принять условную величину 10k):
— У Вас мало данных, и они похожи на данные, на которых была обучена сеть до этого. Можно попробовать обучать только несколько последних слоев.
—У Вас мало данных, и они не похожи на данные, на которых была обучена сеть до этого. Самый печальный случай. Тут уже, скорее всего, придется просто подбирать модель под объем данных, т.к. даже обучение всех слоев может не помочь.
— У Вас много данных, и они похожи на данные, на которых была обучена сеть до этого. Можно попробовать не обучать всю сеть целиком, а обойтись лишь обучением нескольких последний слоев.
— У Вас много данных, и они не похожи на данные, на которых была обучена сеть до этого. Лучше обучать практически всю сеть.
Семантическая сегментация — это когда мы на вход подаем изображение, а на выходе хотим получить что-то в духе:

Выражаясь более формально, мы хотим классифицировать каждый пиксель нашего входного изображения — понять, к какому классу он принадлежит.
Подходов и нюансов здесь очень много. Чего стоит только архитектура сети ResNeSt-269 :)
Интуиция — на входе изображение (h, w, c), на выходе хотим получить маску (h, w) или (h, w, c), где c — количество классов (зависит от данных и модели). Давайте теперь после нашего encoder'а добавим decoder и обучим их.
Decoder будет состоять, в частности, из слоев upsampling'а (повышения размерности). Повышать размерность можно просто «вытягивая» по высоте и ширине наш feature map на том или ином шаге. При «вытягивании» можно использовать билинейную интерполяцию (в коде это будет просто один из параметров метода).
Архитектура сети deeplabv3+:
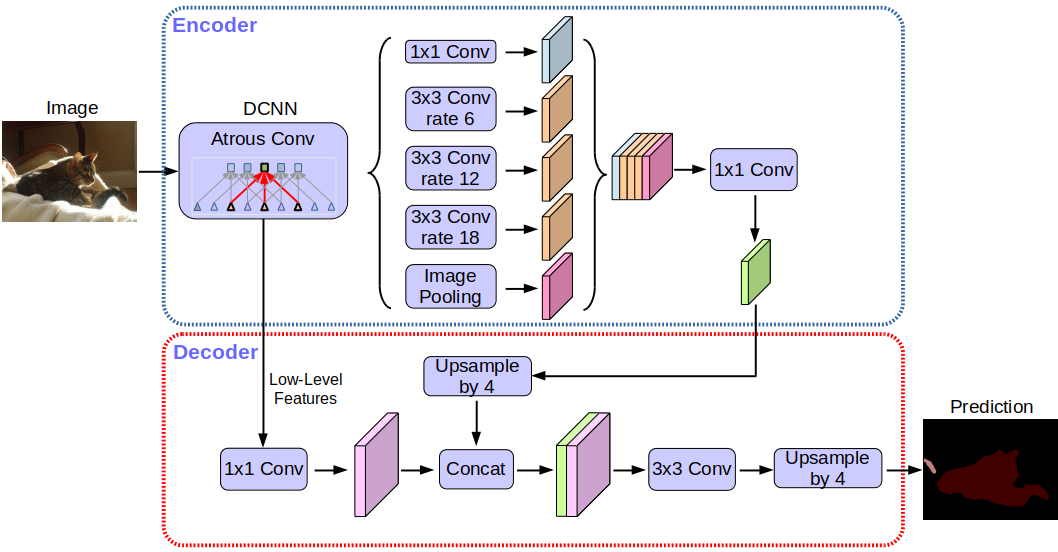
Если не углубляться в детали, то можно заметить, что сеть использует архитектуру encoder-decoder.
Более классический вариант, архитектура сети U-net:
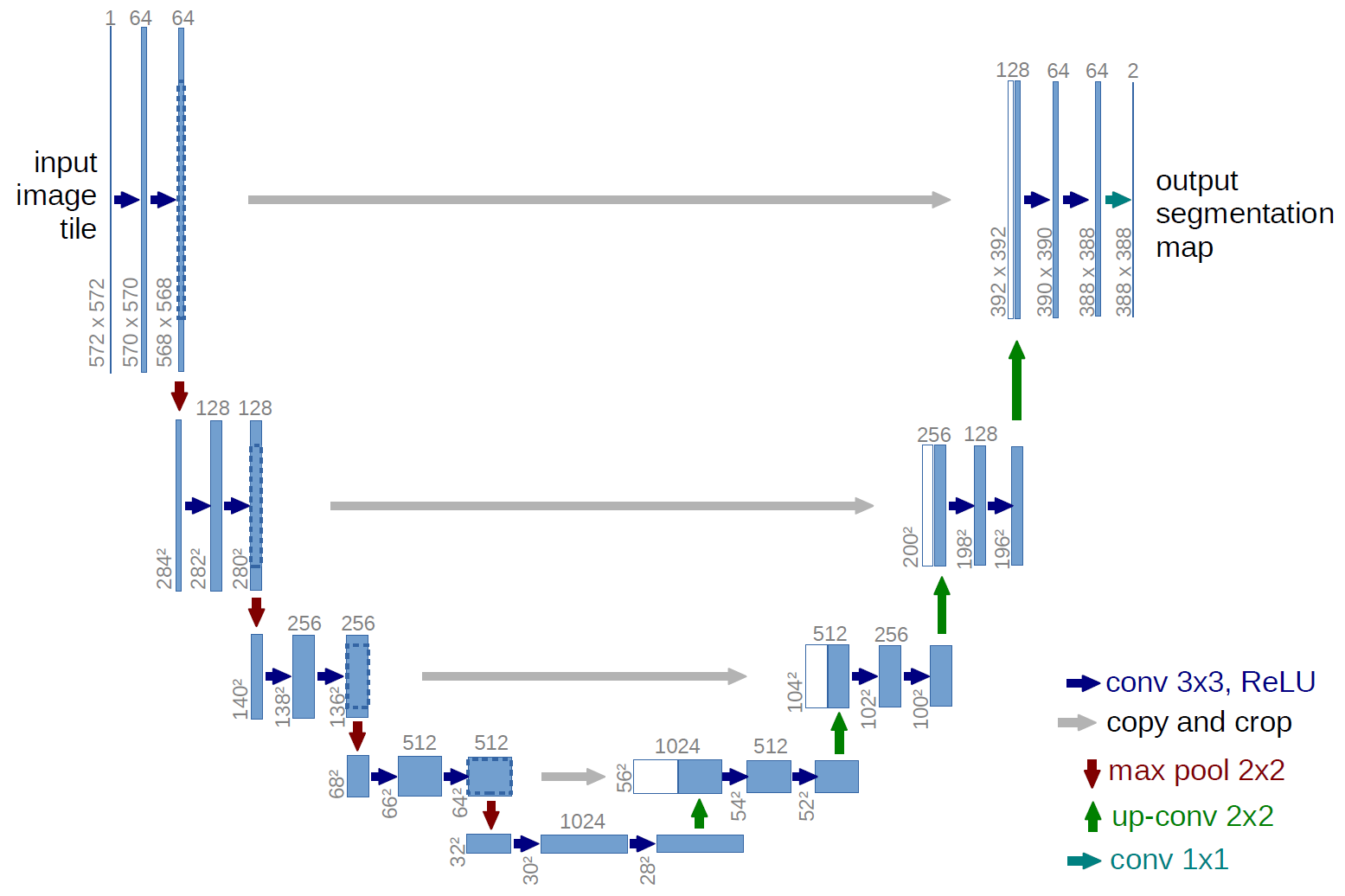
Что это за серые стрелочки? Это, так называемые, skip connections. Дело в том, что encoder «кодирует» наше входное изображение с потерями. Для того, чтобы минимизировать такие потери — как раз и используют skip connections.
В этой задаче мы можем применить transfer learning — например, можем взять сеть с уже обученным encoder'ом, дописать decoder и обучить его.
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Более сложный вариант задачи сегментации. Его суть в том, что мы хотим не только классифицировать каждый пиксель входного изображения, а еще и как-то выделять различные объекты одного класса:
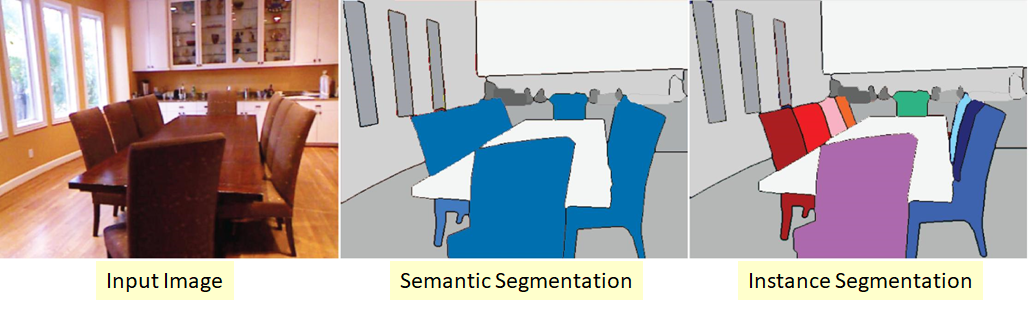
Бывает так, что классы «слипшиеся» или между ними нет видимой границы, но мы хотим разграничить объекты одного класса друг от друга.
Подходов здесь тоже несколько. Самый простой и интуитивный состоит в том, что мы обучаем две разные сети. Первую мы обучаем классифицировать пиксели для каких-то классов (semantic segmentation), а вторую — для классификации пикселей между объектами классов. Мы получаем две маски. Теперь мы можем вычесть из первой вторую и получить то, что хотели :)
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Подаем на вход изображение, а на выходе хотим увидеть что-то в духе:

Самое интуитивное, что можно сделать — «бегать» по изображению различными прямоугольниками и, используя уже обученный классификатор, определять — есть ли на данном участке интересующий нас объект. Такая схема имеет место быть, но она, очевидно, не самая лучшая. У нас ведь есть сверточные слои, которые каким-то образом иначе интерпретируют feature map «до»(А) в feature map «после»(Б). При этом мы знаем размерности фильтров свертки => знаем какие пиксели из А в какие пиксели Б преобразовались.
Давайте взглянем на YOLO v3:
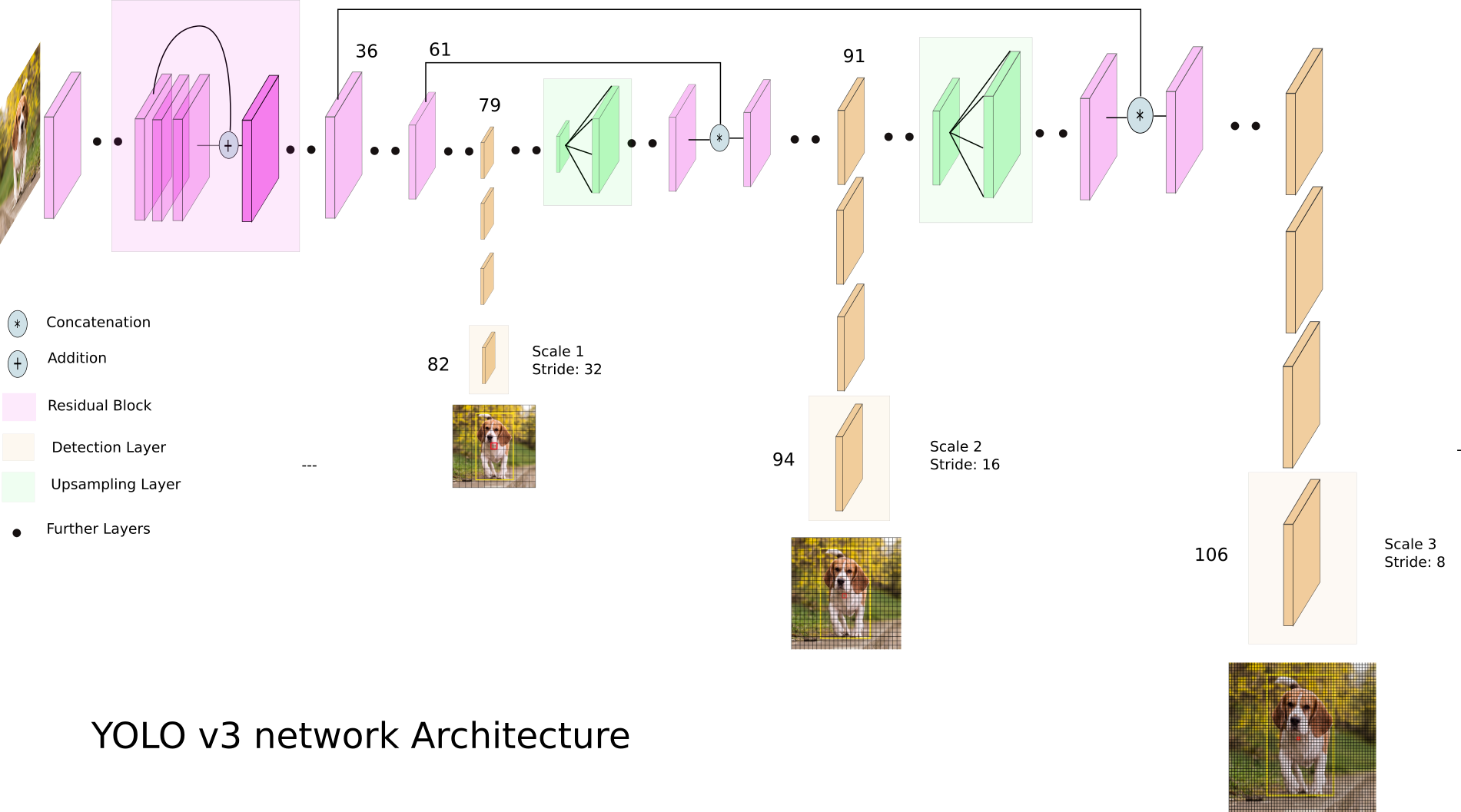
YOLO v3 использует разные размерности feature map'ов. Это делается, в частности, для того, чтобы корректно детектировать объекты разного размера.
Далее происходит конкатенация всех трех scale'ов:
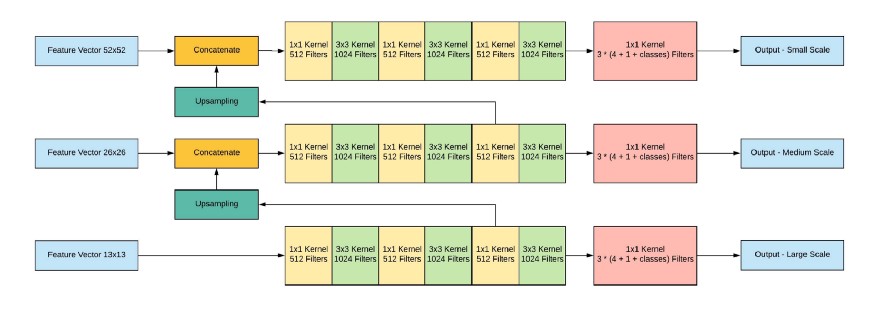
Выход сети, при входном изображении 416х416, 13х13х(B * (5 + С)), где С — количество классов, B — количество боксов для каждого региона (у YOLO v3 их 3). 5 — это такие параметры, как: Px, Py — координаты центра объекта, Ph, Pw — высота и ширина объекта, Pobj — вероятность того, что объект находится в этом регионе.
Давайте посмотрим на картинку, так будет чуть более понятно:

YOLO отсеивает данные предсказания изначально по objectness score по какому-то значению (обычно 0.5-0.6), а затем по non-maximum suppression.
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Различных моделей и подходов к задачам сегментации и локализации объектов в наши дни очень много. Существуют определенные идеи, поняв которые, станет легче разбирать тот зоопарк моделей и подходов. Эти идеи я попытался выразить в данной статье.
В следующих статьях поговорим про style transfer и GAN'ы.
Часть 2
Часть 3
В этой статье вы узнаете:
-О том, что такое transfer learning и как это работает
-О том, что такое semantic/instance segmentation и как это работает
-О том, что такое object detection и как это работает
Введение
Для задач обнаружения объектов выделяют два метода (источник и подробнее— тут):
— Двухэтапные методы (англ. two-stage methods), они же «методы, основанные на регионах» (англ. region-based methods) — подход, разделённый на два этапа. На первом этапе селективным поиском или с помощью специального слоя нейронной сети выделяются регионы интереса (англ. regions of interest, RoI) — области, с высокой вероятностью содержащие внутри себя объекты. На втором этапе выбранные регионы рассматриваются классификатором для определения принадлежности исходным классам и регрессором, уточняющим местоположение ограничивающих рамок.
— Одноэтапные методы (англ. one-stage methods) — подход, не использующий отдельный алгоритм для генерации регионов, вместо этого предсказывая координаты определённого количества ограничивающих рамок с различными характеристиками, такими, как результаты классификации и степень уверенности и в дальнейшем корректируя местоположение рамок.
В данной статье рассматриваются одноэтапные методы.
Transfer learning
Transfer learning — это метод обучения нейронных сетей, при котором мы берем уже обученную на каких-то данных модель для дальнейшего дообучения для решения другой задачи. Например, у нас есть модель EfficientNet-B5, которая обучена на ImageNet-датасете (1000 классов). Теперь, в самом простом случае, мы изменяем ее последний classifier-слой (скажем, для классификации объектов 10-ти классов).
Взгляните на картинку ниже:
Encoder — это слои subsampling'а (свертки и пулинги).
Замена последнего слоя в коде выглядит так (фреймворк — pytorch, среда — google colab):
Загружаем обученную модель EfficientNet-b5 и смотрим на ее classifier-слой:
Изменяем этот слой на другой:
Decoder нужен, в частности, в задаче сегментации (об этом далее).
Стратегии transfer learning
Стоит добавить, что по умолчанию все слои модели, которые мы хотим обучать дальше, обучаемы. Мы можем «заморозить» веса некоторых слоев.
Для заморозки всех слоев:
Чем меньше слоев мы обучаем — тем меньше нам нужно вычислительных ресурсов для обучения модели. Всегда ли эта техника оправданна?
В зависимости от количества данных, на которых мы хотим обучить сеть, и от данных, на которых была обучена сеть, есть 4 варианта развития событий для transfer learning'а (под «мало» и «много» можно принять условную величину 10k):
— У Вас мало данных, и они похожи на данные, на которых была обучена сеть до этого. Можно попробовать обучать только несколько последних слоев.
—У Вас мало данных, и они не похожи на данные, на которых была обучена сеть до этого. Самый печальный случай. Тут уже, скорее всего, придется просто подбирать модель под объем данных, т.к. даже обучение всех слоев может не помочь.
— У Вас много данных, и они похожи на данные, на которых была обучена сеть до этого. Можно попробовать не обучать всю сеть целиком, а обойтись лишь обучением нескольких последний слоев.
— У Вас много данных, и они не похожи на данные, на которых была обучена сеть до этого. Лучше обучать практически всю сеть.
Semantic segmentation
Семантическая сегментация — это когда мы на вход подаем изображение, а на выходе хотим получить что-то в духе:
Выражаясь более формально, мы хотим классифицировать каждый пиксель нашего входного изображения — понять, к какому классу он принадлежит.
Подходов и нюансов здесь очень много. Чего стоит только архитектура сети ResNeSt-269 :)
Интуиция — на входе изображение (h, w, c), на выходе хотим получить маску (h, w) или (h, w, c), где c — количество классов (зависит от данных и модели). Давайте теперь после нашего encoder'а добавим decoder и обучим их.
Decoder будет состоять, в частности, из слоев upsampling'а (повышения размерности). Повышать размерность можно просто «вытягивая» по высоте и ширине наш feature map на том или ином шаге. При «вытягивании» можно использовать билинейную интерполяцию (в коде это будет просто один из параметров метода).
Архитектура сети deeplabv3+:
Если не углубляться в детали, то можно заметить, что сеть использует архитектуру encoder-decoder.
Более классический вариант, архитектура сети U-net:
Что это за серые стрелочки? Это, так называемые, skip connections. Дело в том, что encoder «кодирует» наше входное изображение с потерями. Для того, чтобы минимизировать такие потери — как раз и используют skip connections.
В этой задаче мы можем применить transfer learning — например, можем взять сеть с уже обученным encoder'ом, дописать decoder и обучить его.
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Instance segmentation
Более сложный вариант задачи сегментации. Его суть в том, что мы хотим не только классифицировать каждый пиксель входного изображения, а еще и как-то выделять различные объекты одного класса:
Бывает так, что классы «слипшиеся» или между ними нет видимой границы, но мы хотим разграничить объекты одного класса друг от друга.
Подходов здесь тоже несколько. Самый простой и интуитивный состоит в том, что мы обучаем две разные сети. Первую мы обучаем классифицировать пиксели для каких-то классов (semantic segmentation), а вторую — для классификации пикселей между объектами классов. Мы получаем две маски. Теперь мы можем вычесть из первой вторую и получить то, что хотели :)
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Object detection
Подаем на вход изображение, а на выходе хотим увидеть что-то в духе:
Самое интуитивное, что можно сделать — «бегать» по изображению различными прямоугольниками и, используя уже обученный классификатор, определять — есть ли на данном участке интересующий нас объект. Такая схема имеет место быть, но она, очевидно, не самая лучшая. У нас ведь есть сверточные слои, которые каким-то образом иначе интерпретируют feature map «до»(А) в feature map «после»(Б). При этом мы знаем размерности фильтров свертки => знаем какие пиксели из А в какие пиксели Б преобразовались.
Давайте взглянем на YOLO v3:
YOLO v3 использует разные размерности feature map'ов. Это делается, в частности, для того, чтобы корректно детектировать объекты разного размера.
Далее происходит конкатенация всех трех scale'ов:
Выход сети, при входном изображении 416х416, 13х13х(B * (5 + С)), где С — количество классов, B — количество боксов для каждого региона (у YOLO v3 их 3). 5 — это такие параметры, как: Px, Py — координаты центра объекта, Ph, Pw — высота и ширина объекта, Pobj — вероятность того, что объект находится в этом регионе.
Давайте посмотрим на картинку, так будет чуть более понятно:
YOLO отсеивает данные предсказания изначально по objectness score по какому-то значению (обычно 0.5-0.6), а затем по non-maximum suppression.
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Заключение
Различных моделей и подходов к задачам сегментации и локализации объектов в наши дни очень много. Существуют определенные идеи, поняв которые, станет легче разбирать тот зоопарк моделей и подходов. Эти идеи я попытался выразить в данной статье.
В следующих статьях поговорим про style transfer и GAN'ы.


