
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

TL;DR
В этой статье мы начнем решать проблему того, как сделать печатные ссылки в книгах или журналах кликабельными используя камеру смартфона.
С помощью TensorFlow 2 Object Detection API мы научим TensorFlow модель находить позиции и габариты строк https:// в изображениях (например в каждом кадре видео из камеры смартфона).
Текст каждой ссылки, расположенный по правую сторону от https://, будет распознан с помощью библиотеки Tesseract. Работа с библиотекой Tesseract не является предметом этой статьи, но вы можете найти полный исходный код приложения в репозитории links-detector repository на GitHub.
Запустить Links Detector со смартфона, чтобы увидеть конечный результат.
Открыть репозиторий links-detector на GitHub с полным исходным кодом приложения.
Вот так в итоге будет выглядеть процесс распознавания печатных ссылок:

На данный момент приложение находится в экспериментальной стадии и имеет множество недоработок и ограничений. Поэтому, до тех пор, пока вышеуказанные недоработки не будут ликвидированы, не ожидайте от приложения слишком многого. Также стоит отметить, что целью данной статьи является экспериментирование с TensorFlow 2 Object Detection API, а не создание production-ready приложения.
В случае, если блоки с исходным кодом в этой статье будут отображаться без подсветки кода вы можете перейти на GitHub версию этой статьи
Проблема
Я работаю программистом, и в свободное от работы время учу Machine Learning в качестве хобби. Но проблема не в этом.
Я купил книгу по машинному обучению и, читая первые главы, столкнулся с множеством печатных ссылок на подобии https://tensorflow.org/ или https://some-url.com/which/may/be/even/longer?and_with_params=true.

К сожалению, кликать по печатным ссылкам не представлялось возможным (спасибо, Кэп!). Чтобы открыть ссылки в браузере мне приходилось набирать их посимвольно в адресной строке, что было довольно медленно. К тому же опечатки никто не отменял.
Возможное решение
Я подумал, а что если, по аналогии с распознавателем QR кодов, мы "научим" смартфон (1) определять местоположение и (2) распознавать печатные гипер-ссылки и делать их кликабельными? В таком случае читатель делал бы всего один клик вместо посимвольного ввода с множеством нажатий на клавиши. Операционная сложность всей этой операции уменьшилась бы с O(N) до O(1).
Вот так бы этот процесс выглядел:
Требования к решению
Как я уже упомянул выше, я не эксперт в машинном обучении. Для меня это больше как хобби. Поэтому и цель этой статьи заключается больше в экспериментировании и обучении работе с TensorFlow 2 Object Detection API, чем в попытке создания production-ready приложения.
С учетом вышесказанного, я упростил требования к финальному решению и свел их к следующим пунктам:
- Производительность процесса обнаружения и распознавания должна быть близка к реальному времени (например,
0.5-1кадров в секунду на устройстве схожем по производительности с iPhone X). Это будет означать, что весь процесс обнаружения + распознавания должен происходить не более чем за2секунды. - Должны поддерживаться только ссылки на английском языке.
- Должны поддерживаться только ссылки черного (темно-серого) цвета на белом (светло-сером) фоне.
- Должны поддерживаться только
https://ссылки (допускается, чтоhttp://,ftp://,tcp://и прочие ссылки не будут распознаны).
Находим решение
Общий подход
Вариант №1: Модель на стороне сервера
Алгоритм действий:
- Получаем видео-поток (кадр за кадром) на стороне клиента.
- Отправляем каждый кадр на сервер.
- Осуществляем обнаружение и распознавание ссылок на сервере и отправляем результат клиенту.
- Отображаем распознанные ссылки ни стороне клиента и делаем их кликабельными.

Преимущества:
- ✓ Скорость обнаружения и распознавания ссылок не ограничена производительностью клиентского устройства. При желании мы можем ускорить скорость обнаружения ссылок масштабируя наши сервера горизонтально (больше серверов) или вертикально (больше ядер и GPUs).
- ✓ Модель может иметь больший размер (и, возможно, большую точность), поскольку отсутствует необходимость ее загрузки на сторону клиента. Загрузить модель размером
~10Mbна сторону клиента выглядит реалистичным, но все-же загрузить модель размером~100Mbможет быть довольно проблематичным с точки зрения пользовательского UX (user experience). - ✓ У нас появляется возможность контролировать доступ к модели. Поскольку модель "спрятана" за публичным API, мы можем контролировать каким клиентам она будет доступна.
Недостатки:
- ✗ Сложность системы растет. Вместо использования одного лишь
JavaScriptна стороне клиента нам необходимо будет так же создать, например,Pythonинфраструктуру на стороне сервера. Нам так же будет необходимо позаботиться об автоматическом масштабировании сервиса. - ✗ Работа приложения в режиме оффлайн невозможна поскольку для работы приложения требуется доступ к интернету.
- ✗ Множество HTTP запросов к сервису со стороны клиента может стать слабым местом системы с точки зрения производительности. Предположим, мы хотим улучшить производительность обнаружения и распознавания ссылок с
1до10+кадров в секунду. В таком случае каждый клиент будет слать10+запросов в секунду на сервер. Для10клиентов, работающих одновременно, это уже будет означать100+запросов в секунду. На помощь могут прийти двусторонний стримингHTTP/2иgRPC, но мы снова возвращаемся к первому пункту, связанному с растущей сложностью системы. - ✗ Стоимость системы растет. В основном это связано с оплатой за аренду серверов.
Вариант №2: Модель на стороне клиента
Алгоритм действий:
- Получаем видео-поток (кадр за кадром) на стороне клиента.
- Осуществляем обнаружение и распознавание ссылок на стороне клиента (без отправки на сервер).
- Отображаем распознанные ссылки ни стороне клиента и делаем их кликабельными.
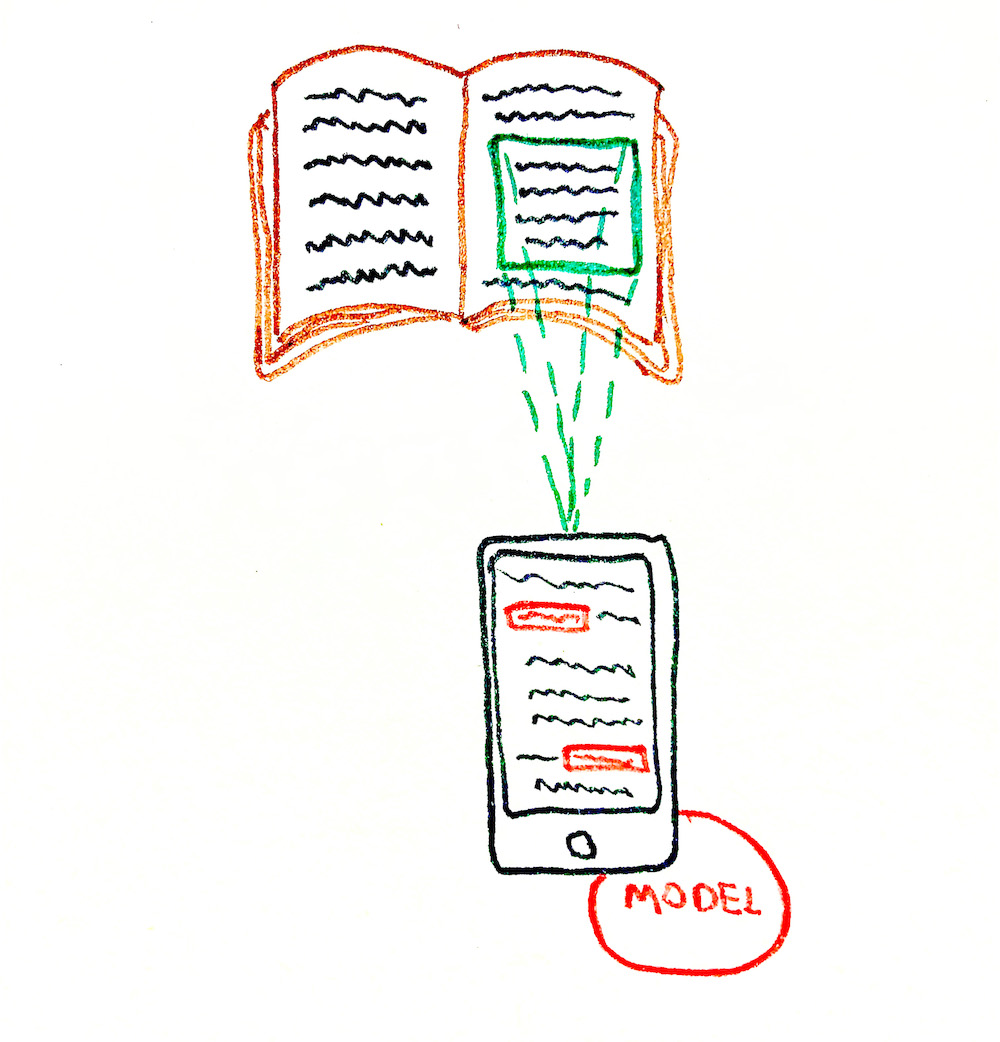
Преимущества:
- ✓ Менее сложная система. Нет необходимости в разработке серверной части приложения и создания API.
- ✓ Приложение может работать в режиме оффлайн. Модель загружена на сторону клиента и нет необходимости в доступе к интернету (см. Progressive Web Application)
- ✓ Система "почти" автоматически масштабируема. Каждый новый клиент приложения "приходит" со своим процессором и видеокартой. Это конечно же неполноценное масштабирование (мы затронем причины ниже).
- ✓ Система гораздо дешевле. Нам необходимо заплатить только за сервер со статическими данными (
HTML,JS,CSS, файлы модели и пр.). В случае с GitHub, такой сервер может быть предоставлен бесплатно. - ✓ Отсутствует (так же как и серверы) проблема большого количества HTTP запросов в секунду к серверам.
Недостатки:
- ✗ Возможно только горизонтальное масштабирование, когда каждый клиент автоматически имеет свои собственные процессоры и графическую карту. Вертикальное масштабирование невозможно поскольку мы не можем повлиять на производительность клиентского устройства. В результате мы не можем гарантировать быстрого обнаружения и распознавания ссылок для медленных устройств.
- ✗ Невозможно контролировать использование модели клиентами. Каждый может загрузить к себе модель и использовать ее где и как угодно.
- ✗ Скорость расхода батареи клиентского устройства может стать проблемой. Модель при работе потребляет вычислительные ресурсы. Пользователи приложения могут быть недовольны тем, что их iPhone становится все теплее и теплее во время работы.
Выбираем общий подход
Поскольку целю этой статьи и проекта в целом является обучение, а не создание приложения коммерческого уровня мы можем выбрать второй вариант и хранить модель на стороне клиента. Это сделает весь проект менее затратным и у нас будет возможность больше сфокусироваться на машинном обучении, а не на создании автоматически масштабируемой серверной инфраструктуры.
Углубляемся в детали
Итак, мы выбрали вариант приложения без серверной части. Предположим теперь, что у нас на входе есть изображение (кадр) из видео-потока камеры, который выглядит так:

Нам необходимо решить две подзадачи:
- Обнаружение ссылок (найти позицию и габариты ссылок на странице)
- Распознавание ссылок (распознать текст ссылок)
Вариант №1: Решение на основе библиотеки Tesseract
Первым и наиболее очевидным вариантом решением задачи оптического распознавания символов (OCR) может быть распознавания текста всего изображения с помощью, например, библиотеки Tesseract.js. Она принимает изображение на вход и выдает распознанные параграфы, текстовые строки, блоки текста и слова и вместе с габаритами и координатами.

Далее мы можем попытаться найти ссылки в распознанном тексте с помощью регулярного выражения похожего на это (пример на TypeScript):
const URL_REG_EXP = /https?:\/\/(www\.)?[-a-zA-Z0-9@:%._+~#=]{2,256}\.[a-z]{2,4}\b([-a-zA-Z0-9@:%_+.~#?&/=]*)/gi;
const extractLinkFromText = (text: string): string | null => {
const urls: string[] | null = text.match(URL_REG_EXP);
if (!urls || !urls.length) {
return null;
}
return urls[0];
};✓ Похоже, что задача решена довольно прямолинейным и простым способом:
- Мы знаем габариты и координаты ссылок.
- Мы так же знаем текст ссылок и можем сделать их кликабельными.
✗ Проблема в том, что время обнаружения + распознавания может варьироваться от 2 до 20+ секунд в зависимости от размера изображения, его качества и "похожих на текст" объектов в изображении. В итоге будет очень сложно достичь той близкой к реальному времени производительности в 0.5-1 кадров в секунду.
✗ Также, если подумать, то мы просим библиотеку распознать весь текст на картинке, даже если в тексте совсем нет ссылок или если в тексте есть одна-две ссылки, которые составляют, пускай, ~10% от всего объема текста. Это звучит как неэффективная трата вычислительных ресурсов.
Вариант №2: Решение на основе библиотек Tesseract и TensorFlow (+1 модель)
Мы могли бы заставить Tesseract работать быстрее используя еще один дополнительный "алгоритм-советчик" перед тем, как приступить к распознаванию ссылок. Этот "алгоритм-советчик" должен обнаруживать (но не распознавать) начало ссылок (координаты самой левой границы ссылки) для каждой ссылки в изображении. Это позволит нам ускорить задачу распознавания текста ссылок, если мы будем следовать следующим правилам:
- Если изображение не содержит ни одной ссылки мы должны полностью избежать распознавания текста библиотекой Tesseract.
- Если изображение содержит ссылки, то мы должны "попросить" Tesseract распознать только те части изображения, которые содержат текст ссылок. Мы хотим тратить время на распознавание "полезного" для нашей задачи текста.
Этот "алгоритм-советчик", который будет срабатывать перед вызовом Tesseract должен выполняться каждый раз за одно и то же время, независимо от качества и содержимого изображения. Он также должен быть достаточно быстрым и должен определять наличие и позиции ссылок быстрее чем за 1 секунду (например, на iPhone X). В таком случае мы сможем попытаться заставить наше приложение работать в режиме близком к реальному времени (определения "близости" мы дали выше).
Итак, что если мы воспользуемся еще одним алгоритмом (еще одной моделью) обнаружения объектов, который поможет нам найти строкиhttps://в изображении (каждая защищенная ссылка начинается сhttps://, не так ли?). Тогда, зная расположение и габариты префиксовhttps://в изображении, мы сможем отправить на распознавание текста с помощью библиотеки Tesseract только те части изображения, которые находятся по правую сторону от префиксовhttps://и являются их продолжением.
Обратите внимание на изображение ниже:

На этом изображении можно заметить, что Tesseract будет выполнять гораздо меньше работы по распознаванию текста, если мы подскажем ему, где в тексте могут находиться ссылки (обратите внимание на количество голубых прямоугольников, чем не доказательство).
Итак, вопрос, на который нам необходимо ответить теперь, какую же модель обнаружения объектов нам выбрать и как "научить" ее находить на изображении префиксы https://.
Наконец-то мы подобрались ближе к TensorFlow
Выбираем подходящую модель обнаружения объектов
Тренировка новой модели обнаружения объектов с нуля не является хорошим вариантом в нашем случае по следующим причинам:
- ✗ Тренировка может занять дни/недели и стоить много денег (за аренду тех-же серверов с GPU).
- ✗ У нас скорее всего не получится собрать набор данных, состоящий из сотен тысяч фотографий книг и журналов со ссылками. Тем-более, что нам нужны не только изображения, но еще и координаты префиксов
https://для каждого из них. С другой стороны мы можем попытаться сгенерировать такой набор данных, но об этом ниже.
Итак, вместо создания новой модели обнаружения объектов, мы будем обучать уже существующую и натренированную модель обнаруживать новый для нее класс объектов (см. transfer learning). В нашем случае под "новым классом" объектов мы имеем в виду изображения префикса https://. Такой подход имеет следующие преимущества:
- ✓ Набор данных может быть гораздо меньшим. Нет необходимости собирать сотни тысяч изображений с локализациями (координатами объектов в изображении). Вместо этого мы можем обойтись сотней изображений и сделать локализацию объектов вручную. Это возможно по той причине, что модель уже натренированна на общем наборе данных типа COCO и уже умеет извлекать основные характеристики изображения (научить "первокурсника" линейной алгебре, как правило, легче, чем "первоклассника").
- ✓ Время тренировки так же будет гораздо меньшим (на GPU получим минуты/часы вместо дней/недель). Время сокращается за счет меньшего объема данных (меньших партий данных во время тренировки) и меньшего количества тренируемых параметров модели.
Мы можем выбрать существующую модель из "зоопарка" моделей TensorFlow 2, который представляет собой коллекцию моделей натренированных на наборе данных COCO 2017. На данный момент эта коллекция включает в себя ~40 разных вариаций моделей.
Для того, чтобы "научить" модель обнаруживать новые, ранее неизвестные ей объекты, мы можем воспользоваться TensorFlow 2 Object Detection API. TensorFlow Object Detection API — это фреймворк на основе TensorFlow, который позволяет конструировать и тренировать модели обнаружения объектов.
Если вы перейдете по ссылке на "зоопарк" моделей вы увидите, что для каждой модели там указана скорость и точность обнаружения объектов.
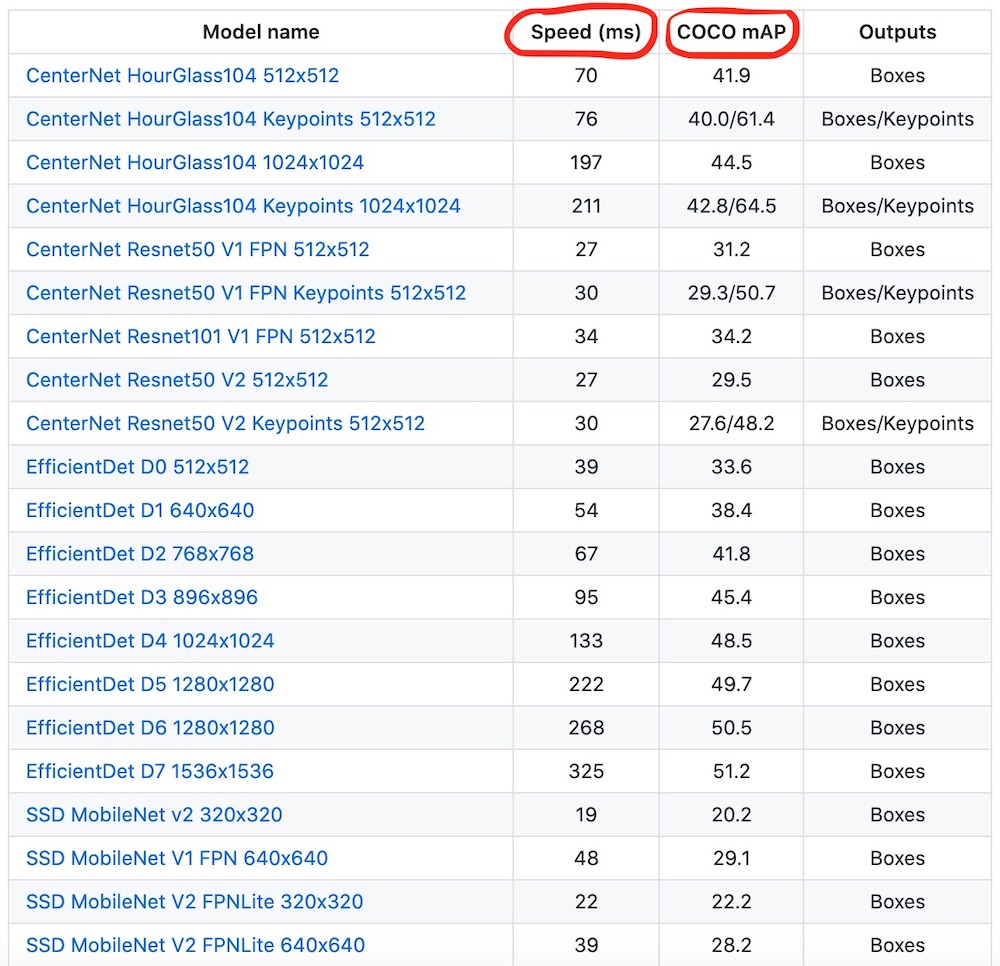
_Изображение взято с репозитория TensorFlow Model Zoo_
Конечно же, для того, чтобы выбрать подходящую модель, нам важно найти правильный баланс между скоростью и точностью обнаружения. Но что еще важнее в нашем случае, это размер модели, поскольку мы планируем загружать ее на сторону клиента.
Размер архива с моделью может варьироваться от ~20Mb до ~1Gb. Вот несколько примеров:
1386 (Mb)centernet_hg104_1024x1024_kpts_coco17_tpu-32330 (Mb)centernet_resnet101_v1_fpn_512x512_coco17_tpu-8195 (Mb)centernet_resnet50_v1_fpn_512x512_coco17_tpu-8198 (Mb)centernet_resnet50_v1_fpn_512x512_kpts_coco17_tpu-8227 (Mb)centernet_resnet50_v2_512x512_coco17_tpu-8230 (Mb)centernet_resnet50_v2_512x512_kpts_coco17_tpu-829 (Mb)efficientdet_d0_coco17_tpu-3249 (Mb)efficientdet_d1_coco17_tpu-3260 (Mb)efficientdet_d2_coco17_tpu-3289 (Mb)efficientdet_d3_coco17_tpu-32151 (Mb)efficientdet_d4_coco17_tpu-32244 (Mb)efficientdet_d5_coco17_tpu-32376 (Mb)efficientdet_d6_coco17_tpu-32376 (Mb)efficientdet_d7_coco17_tpu-32665 (Mb)extremenet427 (Mb)faster_rcnn_inception_resnet_v2_1024x1024_coco17_tpu-8424 (Mb)faster_rcnn_inception_resnet_v2_640x640_coco17_tpu-8337 (Mb)faster_rcnn_resnet101_v1_1024x1024_coco17_tpu-8337 (Mb)faster_rcnn_resnet101_v1_640x640_coco17_tpu-8343 (Mb)faster_rcnn_resnet101_v1_800x1333_coco17_gpu-8449 (Mb)faster_rcnn_resnet152_v1_1024x1024_coco17_tpu-8449 (Mb)faster_rcnn_resnet152_v1_640x640_coco17_tpu-8454 (Mb)faster_rcnn_resnet152_v1_800x1333_coco17_gpu-8202 (Mb)faster_rcnn_resnet50_v1_1024x1024_coco17_tpu-8202 (Mb)faster_rcnn_resnet50_v1_640x640_coco17_tpu-8207 (Mb)faster_rcnn_resnet50_v1_800x1333_coco17_gpu-8462 (Mb)mask_rcnn_inception_resnet_v2_1024x1024_coco17_gpu-886 (Mb)ssd_mobilenet_v1_fpn_640x640_coco17_tpu-844 (Mb)ssd_mobilenet_v2_320x320_coco17_tpu-820 (Mb)ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-820 (Mb)ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8369 (Mb)ssd_resnet101_v1_fpn_1024x1024_coco17_tpu-8369 (Mb)ssd_resnet101_v1_fpn_640x640_coco17_tpu-8481 (Mb)ssd_resnet152_v1_fpn_1024x1024_coco17_tpu-8480 (Mb)ssd_resnet152_v1_fpn_640x640_coco17_tpu-8233 (Mb)ssd_resnet50_v1_fpn_1024x1024_coco17_tpu-8233 (Mb)ssd_resnet50_v1_fpn_640x640_coco17_tpu-8
Модель ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8 выглядит наиболее подходящей в нашем случае:
- ✓ Она относительно небольшая —
20Mbв архиве. - ✓ Она достаточно быстрая —
39msна одно обнаружение. - ✓ Она использует сеть MobileNet v2 в качестве экстрактора свойств изображения (feature extractor), которая в свою очередь оптимизирована под работу на мобильных устройствах и обеспечивает меньший расход батареи.
- ✓ Она производит обнаружение всех известных ей объектов в изображении за один проход независимо от содержимого изображения (отсутствует шаг regions proposal, что делает работу сети быстрее).
- ✗ В то же время это не самая точная модель (все является компромиссом ️)
Название модели включает в себя ее несколько важных характеристик, с которыми вы при желании можете ознакомиться детальнее:
- Ожидаемый размер изображения на входе —
640x640px. - Модель построена на основе Single Shot MultiBox Detector (SSD) и Feature Pyramid Network (FPN).
- Сверточная нейронная сеть (CNN) MobileNet v2 используется в качестве экстрактора свойств изображения (feature extractor).
- Модель была обучена на наборе данных COCO
Устанавливаем Object Detection API
В этой статье мы будем устанавливать Tensorflow 2 Object Detection API в виде пакета Python. Это достаточно удобно, в случае если вы экспериментируете в Google Colab (предпочтительно) или в Jupyter. В обоих случаях вы можете избежать локальной инсталляции пакетов и проводить эксперименты непосредственно в браузере.
Также есть возможность установки Object Detection API используя Docker, о котором вы можете прочитать в документации.
Если у вас возникнут трудности во время установки API или во время создания набора данных (следующие разделы), вы можете обратиться к статье TensorFlow 2 Object Detection API tutorial, в которой есть много полезных деталей и советов.
Для начала давайте клонируем репозиторий с API:
git clone --depth 1 https://github.com/tensorflow/modelsoutput →
Cloning into 'models'...
remote: Enumerating objects: 2301, done.
remote: Counting objects: 100% (2301/2301), done.
remote: Compressing objects: 100% (2000/2000), done.
remote: Total 2301 (delta 561), reused 922 (delta 278), pack-reused 0
Receiving objects: 100% (2301/2301), 30.60 MiB | 13.90 MiB/s, done.
Resolving deltas: 100% (561/561), done.Теперь можем скомпилировать файлы-прототипы API в Python формат, используя protoc:
cd ./models/research
protoc object_detection/protos/*.proto --python_out=.Следующим шагом будет установка API для версии TensorFlow 2 используя pip и файл setup.py`:
cp ./object_detection/packages/tf2/setup.py .
pip install . --quietЕсли на этом шаге вы обнаружите ошибки, связанные установкой зависимых пакетов, попробуйте запустить pip install . --quiet во второй раз.Проверить успешность установки вы можете запустив тест:
python object_detection/builders/model_builder_tf2_test.pyВ итоге вы должны будете увидеть в консоли, что-то вроде этого:
[ OK ] ModelBuilderTF2Test.test_unknown_ssd_feature_extractor
----------------------------------------------------------------------
Ran 20 tests in 45.072s
OK (skipped=1)TensorFlow Object Detection API установлена! Теперь мы можем использовать скрипты, предоставляемы этой API, для обнаружения объектов в изображениях, тренировки или доработки моделей.
Загружаем заранее обученную модель
Давайте загрузим ранее выбранную нами модель ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8 из коллекции моделей TensorFlow и посмотрим, как мы можем использовать ее для обнаружения общих объектов, таких как "кот", "собака", "машина" и пр. (объектов с классами, поддерживаемыми набором данных COCO).
Мы воспользуемся утилитой TensorFlow get_file() для загрузки архивированной модели по URL и для дальнейшей ее распаковки.
import tensorflow as tf
import pathlib
MODEL_NAME = 'ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8'
TF_MODELS_BASE_PATH = 'http://download.tensorflow.org/models/object_detection/tf2/20200711/'
CACHE_FOLDER = './cache'
def download_tf_model(model_name, cache_folder):
model_url = TF_MODELS_BASE_PATH + model_name + '.tar.gz'
model_dir = tf.keras.utils.get_file(
fname=model_name,
origin=model_url,
untar=True,
cache_dir=pathlib.Path(cache_folder).absolute()
)
return model_dir
# Start the model download.
model_dir = download_tf_model(MODEL_NAME, CACHE_FOLDER)
print(model_dir)output →
/content/cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8Вот как на данный момент выглядит структура папок:

Папка checkpoint содержит "слепок" параметров обученной модели.
Файл pipeline.config содержит настройки обнаружения. Мы еще вернемся к этому файлу ниже, когда будем обучать нашу модель.
Обнаружение объектов с помощью загруженной модели
На данный момент модель способна обнаруживать объекты классов, поддерживаемых набором данных COCO (их всего 90), таких, как car, bird, hot dog и пр. Эти классы еще могут называть ярлыками (labels).

Источник изображения: сайт COCO
Попробуем, обнаружит ли модель объекты этих классов.
Загружаем ярлыки COCO
Object Detection API уже содержит файл с полным набор классов (ярлыков) COCO для нашего удобства.
import os
# Import Object Detection API helpers.
from object_detection.utils import label_map_util
# Loads the COCO labels data (class names and indices relations).
def load_coco_labels():
# Object Detection API already has a complete set of COCO classes defined for us.
label_map_path = os.path.join(
'models/research/object_detection/data',
'mscoco_complete_label_map.pbtxt'
)
label_map = label_map_util.load_labelmap(label_map_path)
# Class ID to Class Name mapping.
categories = label_map_util.convert_label_map_to_categories(
label_map,
max_num_classes=label_map_util.get_max_label_map_index(label_map),
use_display_name=True
)
category_index = label_map_util.create_category_index(categories)
# Class Name to Class ID mapping.
label_map_dict = label_map_util.get_label_map_dict(label_map, use_display_name=True)
return category_index, label_map_dict
# Load COCO labels.
coco_category_index, coco_label_map_dict = load_coco_labels()
print('coco_category_index:', coco_category_index)
print('coco_label_map_dict:', coco_label_map_dict)output →
coco_category_index:
{
1: {'id': 1, 'name': 'person'},
2: {'id': 2, 'name': 'bicycle'},
...
90: {'id': 90, 'name': 'toothbrush'},
}
coco_label_map_dict:
{
'background': 0,
'person': 1,
'bicycle': 2,
'car': 3,
...
'toothbrush': 90,
}Создаем функцию обнаружения
В этом разделе мы создадим так называемую функцию обнаружения, которая будет использовать загруженную нами ранее модель, собственно, для обнаружения объектов в изображении.
import tensorflow as tf
# Import Object Detection API helpers.
from object_detection.utils import config_util
from object_detection.builders import model_builder
# Generates the detection function for specific model and specific model's checkpoint
def detection_fn_from_checkpoint(config_path, checkpoint_path):
# Build the model.
pipeline_config = config_util.get_configs_from_pipeline_file(config_path)
model_config = pipeline_config['model']
model = model_builder.build(
model_config=model_config,
is_training=False,
)
# Restore checkpoints.
ckpt = tf.compat.v2.train.Checkpoint(model=model)
ckpt.restore(checkpoint_path).expect_partial()
# This is a function that will do the detection.
@tf.function
def detect_fn(image):
image, shapes = model.preprocess(image)
prediction_dict = model.predict(image, shapes)
detections = model.postprocess(prediction_dict, shapes)
return detections, prediction_dict, tf.reshape(shapes, [-1])
return detect_fn
inference_detect_fn = detection_fn_from_checkpoint(
config_path=os.path.join('cache', 'datasets', MODEL_NAME, 'pipeline.config'),
checkpoint_path=os.path.join('cache', 'datasets', MODEL_NAME, 'checkpoint', 'ckpt-0'),
)Функция inference_detect_fn принимает на входе изображение и возвращает информацию об обнаруженных в нем объектах.
Загружаем тестовые изображения
Давайте попробуем найти объекты на следующем изображении:

Для этого сохраним это изображение в папку inference/test/ нашего проекта. Если вы используете Google Colab, вы можете создать эту папку и произвести загрузку файла вручную.
Вот как структура папок должна выглядеть на данный момент:

import matplotlib.pyplot as plt
%matplotlib inline
# Creating a TensorFlow dataset of just one image.
inference_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory='inference',
image_size=(640, 640),
batch_size=1,
shuffle=False,
label_mode=None
)
# Numpy version of the dataset.
inference_ds_numpy = list(inference_ds.as_numpy_iterator())
# You may preview the images in dataset like this.
plt.figure(figsize=(14, 14))
for i, image in enumerate(inference_ds_numpy):
plt.subplot(2, 2, i + 1)
plt.imshow(image[0].astype("uint8"))
plt.axis("off")
plt.show()Запускаем обнаружение для тестового изображения
На данном этапе мы готовы запустить обнаружение. Первый элемент массива inference_ds_numpy[0] содержит наше первое тестовое изображение в формате массива Numpy.
detections, predictions_dict, shapes = inference_detect_fn(
inference_ds_numpy[0]
)Проверим размерность массивов, которые нам вернула функция:
boxes = detections['detection_boxes'].numpy()
scores = detections['detection_scores'].numpy()
classes = detections['detection_classes'].numpy()
num_detections = detections['num_detections'].numpy()[0]
print('boxes.shape: ', boxes.shape)
print('scores.shape: ', scores.shape)
print('classes.shape: ', classes.shape)
print('num_detections:', num_detections)output →
boxes.shape: (1, 100, 4)
scores.shape: (1, 100)
classes.shape: (1, 100)
num_detections: 100.0Модель вернула нам массив со 100 "обнаружениями". Это не означает, что модель нашла 100 объектов в изображении. Это скорее говорит нам, что модель имеет 100 ячеек и поддерживает обнаружение максимум 100 объектов одновременно в одном изображении. Каждое "обнаружение" имеет соответствующий рейтинг (вероятность, score), который говорит об уверенности модели в том, что обнаружен именно этот объект. Габариты каждого найденного объекта хранятся в массиве boxes. Рейтинг каждого обнаружения хранится в массиве scores. Массив classes хранит ярлыки для каждого "обнаружения".
Давайте проверим первые 5 таких "обнаружений":
print('First 5 boxes:')
print(boxes[0,:5])
print('First 5 scores:')
print(scores[0,:5])
print('First 5 classes:')
print(classes[0,:5])
class_names = [coco_category_index[idx + 1]['name'] for idx in classes[0]]
print('First 5 class names:')
print(class_names[:5])output →
First 5 boxes:
[[0.17576033 0.84654826 0.25642633 0.88327974]
[0.5187813 0.12410264 0.6344235 0.34545377]
[0.5220358 0.5181462 0.6329132 0.7669856 ]
[0.50933677 0.7045719 0.5619138 0.7446198 ]
[0.44761637 0.51942706 0.61237675 0.75963426]]
First 5 scores:
[0.6950246 0.6343004 0.591157 0.5827219 0.5415643]
First 5 classes:
[9. 8. 8. 0. 8.]
First 5 class names:
['traffic light', 'boat', 'boat', 'person', 'boat']Модель видит светофор (traffic light), три лодки (boats) и человека (person). И мы можем подтвердить, что эти объекты действительно существуют в изображении.
В массиве scores мы видим, что модель наиболее уверенна (с 70% вероятностью) в найденном объекте класса traffic light.
Каждый элемент массива boxes представляет собой координаты [y1, x1, y2, x2], где (x1, y1) и (x2, y2) соответственно координаты левого верхнего и правого нижнего углов габаритного прямоугольника.
Попробуем визуализировать габаритные прямоугольники:
# Importing Object Detection API helpers.
from object_detection.utils import visualization_utils
# Visualizes the bounding boxes on top of the image.
def visualize_detections(image_np, detections, category_index):
label_id_offset = 1
image_np_with_detections = image_np.copy()
visualization_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'][0].numpy(),
(detections['detection_classes'][0].numpy() + label_id_offset).astype(int),
detections['detection_scores'][0].numpy(),
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=200,
min_score_thresh=.4,
agnostic_mode=False,
)
plt.figure(figsize=(12, 16))
plt.imshow(image_np_with_detections)
plt.show()
# Visualizing the detections.
visualize_detections(
image_np=tf.cast(inference_ds_numpy[0][0], dtype=tf.uint32).numpy(),
detections=detections,
category_index=coco_category_index,
)В итоге мы увидим:

В то же время, если мы попробуем обнаружить объекты на текстовом изображении мы увидим следующее:

Модель не смогла найти ничего в этом изображении. Это как-раз то, что мы собираемся исправить и чему хотим научить нашу модель — видеть приставки https:// в текстовых изображениях.
Подготавливаем набор данных для тренировки
Для того, чтобы научить модель ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8 обнаруживать объекты, которые не были описаны в наборе данных COCO нам необходимо подготовить свой набор данных и "доучить" модель на нем.
Наборы данных для задачи обнаружения объектов состоят из двух компонентов:
- Собственно само изображение (например, изображение печатной странички книги или журнала)
- Габаритные прямоугольники, которые показывают где именно в изображении расположены объекты.

В примере выше координаты левого верхнего и правого нижнего углов имеют абсолютные значения (в пикселях). Также существуют альтернативные способы записи параметров таких габаритных прямоугольников. Например, мы можем описать прямоугольник с помощью его координат центра, а так же ширины и высоты. Мы также можем использовать относительные значения координат (процент от ширины или высоты изображения). Но в целом, думаю идея понятна: модель должна знать где именно в изображении находится тот или иной объект.
Вопрос в том, где же нам взять такие данные для тренировки. У нас есть три варианта:
- Воспользоваться имеющимся набором данных.
- Сгенерировать новый искусственный набор данных.
- Создать набор данных вручную путем фотографирования или загрузки реальных изображений с текстом и
https://ссылками и дальнейшей аннотацией (указанием позиций объектов) каждого изображения вручную.
Вариант №1: Использование существующих наборов данных
Есть множество общедоступных наборов данных. Мы можем воспользоваться следующими ресурсами для поиска подходящего набора:
- Google Dataset Search
- Kaggle Datasets
- репозиторий awesome-public-datasets
- и пр.
✓ Если у вас получится найти подходящий набор данных с лицензией, позволяющей его использовать, то это, пожалуй, наиболее быстрый способ начать тренировку модели.
✗ Но проблема в том, что мне не удалось найти набор данных, содержащий изображения книг со ссылками и их координатами.
Этот вариант нам прийдется пропустить.
Вариант №2: Генерирование искусственного набора данных
Существуют библиотеки (например keras_ocr), которые могли бы нам помочь сгенерировать случайный текст, поместить в него ссылку и отрисовать текст на различных фонах и с различными искажениями.
✓ Преимущество данного подхода заключается в том, что он дает нам возможность сгенерировать экземпляры данных с разными шрифтами, лигатурами, цветами текста и фона. Это помогло бы нам избежать проблемы переученности модели. Модель могла-бы легко обобщать свои "знания" в случае с изображениями, которые она не видела ранее.
✓ Этот подход дает нам возможность сгенерировать разные типы ссылок, таких как: http://, http://, ftp://, tcp:// и пр. Ведь найти множество реальных изображений с разными типами ссылок могло бы стать проблемой.
✓ Еще одним преимуществом этого подхода является то, что мы можем сгенерировать столько изображений сколько хотим. Мы не ограничены количеством страниц со ссылками в книге, которую нам удалось найти. Увеличение набора данных может в итоге улучшить точность модели.
✗ С другой стороны, существует возможность неправильного использования такого генератора, что в итоге может привести к набору
данных, который будет существенно отличаться от реальных изображений. Например, мы можем ошибочно применить неправдоподобные изгибы страниц (волна вместо дуги) или неправдоподобные фоны. Модель в таком может не обобщить свои "знания" на изображения из реального мира.
Этот подход мне кажется очень многообещающим. Он может помочь нам преодолеть множество недостатков модели (о них мы упомянем ниже в статье). Я пока еще не пробовал применить этот подход, но, возможно, это будет предметом отдельной статьи.
Вариант №3: Создание набора данных вручную
Наиболее прямолинейный способ — это взять книгу (или книги), сфотографировать странички, содержащие ссылки и обозначить локации префиксов https:// для каждой странички вручную.
Хорошая новость в том, что набор данных, который нам нужен, может быть достаточно небольшим (сотни изображений будет достаточно). Это обусловлено тем, что мы не собираемся тренировать модель с нуля. Вместо этого мы будем "доучивать" уже обученную модель (см. transfer learning и few-shot learning).
✓ В данном случае набор данных будет максимально приближен к реальному миру. Мы в буквальном смысле возьмем книгу, сфотографируем странички с реальными шрифтами, изгибами, тенями и цветами.
✗ С другой стороны, даже с учетом того, что нам нужны всего сотни страничек, работа по сбору таких страничек и их дальнейшей аннотации может занять достаточно много времени.
✗ Тяжело найти разные книги и журналы с разными шрифтами, типами ссылок, с разными фонами и лигатурами. В итоге набора данных будет достаточно узконаправленным (у пользователей должны будут быть книги со шрифтами и фонами похожими на ваши).
Поскольку целью этой статьи, как было упомянуто выше, не является создание модели, которая должна выиграть соревнование по обнаружению объектов, мы можем пойти по пути создания модели вручную.
Обрабатываем фото для набора данных
Я сфотографировал 125 страничек одной книги, в которых нашел https:// ссылки.

Все изображения были помещены в папку dataset/printed_links/raw.
Следующим шаг — обработка изображений. Давайте применим следующие преобразования:
- Изменим размер каждого изображения так, чтобы их ширина составила
1024px(изначально изображения были чересчур большими с шириной в3024px) - Обрежем каждое изображение так, чтобы оно стало квадратным (это делать не обязательно, можно просто сжать изображение до квадратных пропорций, не обрезая его, но я хотел сохранить естественные пропорции префиксов
https:перед обучением). - Развернем каждое изображения до правильной ориентации, применив метаданные из тега exif.
- Сделаем каждое изображение черно-белым, поскольку мы не хотим, чтобы модель брала во внимание цвет.
- Увеличим яркость
- Увеличим контраст
- Увеличим резкость
Стоить отметить, что в будущем, мы должны будем применять эти же манипуляции над изображениями перед тем, как отправлять их на вход нашей модели (если тренировочные изображения были черно-белыми и квадратными, то и реальные изображения, которые мы будем отправлять в нашу модель должны быть такими же квадратными и черно-белыми).
Мы можем применить все вышеописанные трансформации используя Python:
import os
import math
import shutil
from pathlib import Path
from PIL import Image, ImageOps, ImageEnhance
# Resize an image.
def preprocess_resize(target_width):
def preprocess(image: Image.Image, log) -> Image.Image:
(width, height) = image.size
ratio = width / height
if width > target_width:
target_height = math.floor(target_width / ratio)
log(f'Resizing: To size {target_width}x{target_height}')
image = image.resize((target_width, target_height))
else:
log('Resizing: Image already resized, skipping...')
return image
return preprocess
# Crop an image.
def preprocess_crop_square():
def preprocess(image: Image.Image, log) -> Image.Image:
(width, height) = image.size
left = 0
top = 0
right = width
bottom = height
crop_size = min(width, height)
if width >= height:
# Horizontal image.
log(f'Squre cropping: Horizontal {crop_size}x{crop_size}')
left = width // 2 - crop_size // 2
right = left + crop_size
else:
# Vetyical image.
log(f'Squre cropping: Vertical {crop_size}x{crop_size}')
top = height // 2 - crop_size // 2
bottom = top + crop_size
image = image.crop((left, top, right, bottom))
return image
return preprocess
# Apply exif transpose to an image.
def preprocess_exif_transpose():
# @see: https://pillow.readthedocs.io/en/stable/reference/ImageOps.html
def preprocess(image: Image.Image, log) -> Image.Image:
log('EXif transpose')
image = ImageOps.exif_transpose(image)
return image
return preprocess
# Apply color transformations to the image.
def preprocess_color(brightness, contrast, color, sharpness):
# @see: https://pillow.readthedocs.io/en/3.0.x/reference/ImageEnhance.html
def preprocess(image: Image.Image, log) -> Image.Image:
log('Coloring')
enhancer = ImageEnhance.Color(image)
image = enhancer.enhance(color)
enhancer = ImageEnhance.Brightness(image)
image = enhancer.enhance(brightness)
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(contrast)
enhancer = ImageEnhance.Sharpness(image)
image = enhancer.enhance(sharpness)
return image
return preprocess
# Image pre-processing pipeline.
def preprocess_pipeline(src_dir, dest_dir, preprocessors=[], files_num_limit=0, override=False):
# Create destination folder if not exists.
Path(dest_dir).mkdir(parents=False, exist_ok=True)
# Get the list of files to be copied.
src_file_names = os.listdir(src_dir)
files_total = files_num_limit if files_num_limit > 0 else len(src_file_names)
files_processed = 0
# Logger function.
def preprocessor_log(message):
print(' ' + message)
# Iterate through files.
for src_file_index, src_file_name in enumerate(src_file_names):
if files_num_limit > 0 and src_file_index >= files_num_limit:
break
# Copy file.
src_file_path = os.path.join(src_dir, src_file_name)
dest_file_path = os.path.join(dest_dir, src_file_name)
progress = math.floor(100 * (src_file_index + 1) / files_total)
print(f'Image {src_file_index + 1}/{files_total} | {progress}% | {src_file_path}')
if not os.path.isfile(src_file_path):
preprocessor_log('Source is not a file, skipping...\n')
continue
if not override and os.path.exists(dest_file_path):
preprocessor_log('File already exists, skipping...\n')
continue
shutil.copy(src_file_path, dest_file_path)
files_processed += 1
# Preprocess file.
image = Image.open(dest_file_path)
for preprocessor in preprocessors:
image = preprocessor(image, preprocessor_log)
image.save(dest_file_path, quality=95)
print('')
print(f'{files_processed} out of {files_total} files have been processed')
# Launching the image preprocessing pipeline.
preprocess_pipeline(
src_dir='dataset/printed_links/raw',
dest_dir='dataset/printed_links/processed',
override=True,
# files_num_limit=1,
preprocessors=[
preprocess_exif_transpose(),
preprocess_resize(target_width=1024),
preprocess_crop_square(),
preprocess_color(brightness=2, contrast=1.3, color=0, sharpness=1),
]
)В результате все обработанные изображения будут сохранены в папке dataset/printed_links/processed.

Мы можем просмотреть полученные изображения следующим образом:
import matplotlib.pyplot as plt
import numpy as np
def preview_images(images_dir, images_num=1, figsize=(15, 15)):
image_names = os.listdir(images_dir)
image_names = image_names[:images_num]
num_cells = math.ceil(math.sqrt(images_num))
figure = plt.figure(figsize=figsize)
for image_index, image_name in enumerate(image_names):
image_path = os.path.join(images_dir, image_name)
image = Image.open(image_path)
figure.add_subplot(num_cells, num_cells, image_index + 1)
plt.imshow(np.asarray(image))
plt.show()
preview_images('dataset/printed_links/processed', images_num=4, figsize=(16, 16))Указываем позиции и габариты объектов для нашего набора данных
Для того, чтобы указать позиции и габариты объектов (префиксов https://) в нашем наборе данных мы можем воспользоваться программой аннотации изображений LabelImg.
Вам понадобится установить LabelImg локально на ваш компьютер. Детальную инструкцию по установке вы сможете найти в документации LabelImg
После установки LabelImg, вы можете запустить программу из консоли, указав папку с изображениями (в нашем случае dataset/printed_links/processed), которую вы хотите аннотировать:
labelImg dataset/printed_links/processedВ открывшемся окне вам необходимо аннотировать все изображения из папки dataset/printed_links/processed и сохранить все изображения в формате XML в папку dataset/printed_links/labels/xml/.


После завершения процесса аннотирования для каждого изображения мы должны получить XML файл с позицией и габаритами каждого объекта:

Разбиваем общий набор данных на тренировочный и тестовый наборы
Для того, чтобы идентифицировать проблему переучивания или недоучивания модели, нам необходимо разбить наш общий набор данных на тренировочный и тестовый наборы. Мы можем использовать 80% всех изображений для тренировки и 20% изображений для тестирования модели. Задача тестового набора — понять насколько наша модель может обобщить свои "знания" на данных, которые она не "видела" раньше.
В этой статье мы будем разбивать файлы путем их перемешивания и копирования в разные папки (в папкиtestиtrain). Стоит отметить, что такой подход, возможно, не является оптимальным. Вместо физического размещения файлов в разных папках мы так же можем разбивать набор данных на подгруппы на лету с помощью tf.data.Dataset.
import re
import random
def partition_dataset(
images_dir,
xml_labels_dir,
train_dir,
test_dir,
val_dir,
train_ratio,
test_ratio,
val_ratio,
copy_xml
):
if not os.path.exists(train_dir):
os.makedirs(train_dir)
if not os.path.exists(test_dir):
os.makedirs(test_dir)
if not os.path.exists(val_dir):
os.makedirs(val_dir)
images = [f for f in os.listdir(images_dir)
if re.search(r'([a-zA-Z0-9\s_\\.\-\(\):])+(.jpg|.jpeg|.png)$', f, re.IGNORECASE)]
num_images = len(images)
num_train_images = math.ceil(train_ratio * num_images)
num_test_images = math.ceil(test_ratio * num_images)
num_val_images = math.ceil(val_ratio * num_images)
print('Intended split')
print(f' train: {num_train_images}/{num_images} images')
print(f' test: {num_test_images}/{num_images} images')
print(f' val: {num_val_images}/{num_images} images')
actual_num_train_images = 0
actual_num_test_images = 0
actual_num_val_images = 0
def copy_random_images(num_images, dest_dir):
copied_num = 0
if not num_images:
return copied_num
for i in range(num_images):
if not len(images):
break
idx = random.randint(0, len(images)-1)
filename = images[idx]
shutil.copyfile(os.path.join(images_dir, filename), os.path.join(dest_dir, filename))
if copy_xml:
xml_filename = os.path.splitext(filename)[0]+'.xml'
shutil.copyfile(os.path.join(xml_labels_dir, xml_filename), os.path.join(dest_dir, xml_filename))
images.remove(images[idx])
copied_num += 1
return copied_num
actual_num_train_images = copy_random_images(num_train_images, train_dir)
actual_num_test_images = copy_random_images(num_test_images, test_dir)
actual_num_val_images = copy_random_images(num_val_images, val_dir)
print('\n', 'Actual split')
print(f' train: {actual_num_train_images}/{num_images} images')
print(f' test: {actual_num_test_images}/{num_images} images')
print(f' val: {actual_num_val_images}/{num_images} images')
partition_dataset(
images_dir='dataset/printed_links/processed',
train_dir='dataset/printed_links/partitioned/train',
test_dir='dataset/printed_links/partitioned/test',
val_dir='dataset/printed_links/partitioned/val',
xml_labels_dir='dataset/printed_links/labels/xml',
train_ratio=0.8,
test_ratio=0.2,
val_ratio=0,
copy_xml=True
)После разбития нашего набора данных структура папок должна выглядеть так:
dataset/
└── printed_links
├── labels
│ └── xml
├── partitioned
│ ├── test
│ └── train
│ ├── IMG_9140.JPG
│ ├── IMG_9140.xml
│ ├── IMG_9141.JPG
│ ├── IMG_9141.xml
│ ...
├── processed
└── rawЭкспортируем набор данных
Последней манипуляцией над данными, которую нам необходимо произвести, будет конвертация данных в формат TFRecord. Формат TFRecord используется TensorFlow для хранения последовательности записей (в нашем случае для хранения последовательности изображений).
Сначала создадим две папки: одну для хранения аннотаций в формате CSV, другую для хранения нашей финальной версии набора данных в формате TFRecord.
mkdir -p dataset/printed_links/labels/csv
mkdir -p dataset/printed_links/tfrecordsТеперь нам необходимо создать файл-прототип dataset/printed_links/labels/label_map.pbtxt с классами объектов, которые наша модель должна научиться распознавать. В нашем случае у нас будет всего один класс, который мы назовем http. Содержимое файла должно быть следующим:
item {
id: 1
name: 'http'
}Теперь мы готовы конвертировать набор данных в формат TFRecord из набора jpg изображений и аннотаций в xml формате:
import os
import io
import math
import glob
import tensorflow as tf
import pandas as pd
import xml.etree.ElementTree as ET
from PIL import Image
from collections import namedtuple
from object_detection.utils import dataset_util, label_map_util
tf1 = tf.compat.v1
# Convers labels from XML format to CSV.
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def class_text_to_int(row_label, label_map_dict):
return label_map_dict[row_label]
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
# Creates a TFRecord.
def create_tf_example(group, path, label_map_dict):
with tf1.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class'], label_map_dict))
tf_example = tf1.train.Example(features=tf1.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def dataset_to_tfrecord(
images_dir,
xmls_dir,
label_map_path,
output_path,
csv_path=None
):
label_map = label_map_util.load_labelmap(label_map_path)
label_map_dict = label_map_util.get_label_map_dict(label_map)
tfrecord_writer = tf1.python_io.TFRecordWriter(output_path)
images_path = os.path.join(images_dir)
csv_examples = xml_to_csv(xmls_dir)
grouped_examples = split(csv_examples, 'filename')
for group in grouped_examples:
tf_example = create_tf_example(group, images_path, label_map_dict)
tfrecord_writer.write(tf_example.SerializeToString())
tfrecord_writer.close()
print('Successfully created the TFRecord file: {}'.format(output_path))
if csv_path is not None:
csv_examples.to_csv(csv_path, index=None)
print('Successfully created the CSV file: {}'.format(csv_path))
# Generate a TFRecord for train dataset.
dataset_to_tfrecord(
images_dir='dataset/printed_links/partitioned/train',
xmls_dir='dataset/printed_links/partitioned/train',
label_map_path='dataset/printed_links/labels/label_map.pbtxt',
output_path='dataset/printed_links/tfrecords/train.record',
csv_path='dataset/printed_links/labels/csv/train.csv'
)
# Generate a TFRecord for test dataset.
dataset_to_tfrecord(
images_dir='dataset/printed_links/partitioned/test',
xmls_dir='dataset/printed_links/partitioned/test',
label_map_path='dataset/printed_links/labels/label_map.pbtxt',
output_path='dataset/printed_links/tfrecords/test.record',
csv_path='dataset/printed_links/labels/csv/test.csv'
)В результате мы должны получить файлы test.record и train.record в папке dataset/printed_links/tfrecords/:
dataset/
└── printed_links
├── labels
│ ├── csv
│ ├── label_map.pbtxt
│ └── xml
├── partitioned
│ ├── test
│ ├── train
│ └── val
├── processed
├── raw
└── tfrecords
├── test.record
└── train.recordЭти два файла test.record и train.record являются конечной версией нашего набора данных, который мы будем использовать для обучения модели ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8.
Работаем с набором данных в формате TFRecord
В этом разделе мы посмотрим, какие инструменты для исследования наборов данных в формате TFRecord имеются в TensorFlow 2 Object Detection API.
Проверяем количество экземпляров в наборе данных
Посчитать количество экземпляров мы можем следующим образом:
import tensorflow as tf
# Count the number of examples in the dataset.
def count_tfrecords(tfrecords_filename):
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
# Keep in mind that the list() operation might be
# a performance bottleneck for large datasets.
return len(list(raw_dataset))
TRAIN_RECORDS_NUM = count_tfrecords('dataset/printed_links/tfrecords/train.record')
TEST_RECORDS_NUM = count_tfrecords('dataset/printed_links/tfrecords/test.record')
print('TRAIN_RECORDS_NUM: ', TRAIN_RECORDS_NUM)
print('TEST_RECORDS_NUM: ', TEST_RECORDS_NUM)output →
TRAIN_RECORDS_NUM: 100
TEST_RECORDS_NUM: 25Итак, мы будем тренировать нашу модель на 100 экземплярах и проверять ее способность к обобщению на 25 изображениях.
Отображаем габариты и локализацию объектов в изображениях
Отобразить габариты и позицию объектов в изображении мы можем следующим образом:
import tensorflow as tf
import numpy as np
from google.protobuf import text_format
import matplotlib.pyplot as plt
# Import Object Detection API.
from object_detection.utils import visualization_utils
from object_detection.protos import string_int_label_map_pb2
from object_detection.data_decoders.tf_example_decoder import TfExampleDecoder
%matplotlib inline
# Visualize the TFRecord dataset.
def visualize_tfrecords(tfrecords_filename, label_map=None, print_num=1):
decoder = TfExampleDecoder(
label_map_proto_file=label_map,
use_display_name=False
)
if label_map is not None:
label_map_proto = string_int_label_map_pb2.StringIntLabelMap()
with tf.io.gfile.GFile(label_map,'r') as f:
text_format.Merge(f.read(), label_map_proto)
class_dict = {}
for entry in label_map_proto.item:
class_dict[entry.id] = {'name': entry.name}
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
for raw_record in raw_dataset.take(print_num):
example = decoder.decode(raw_record)
image = example['image'].numpy()
boxes = example['groundtruth_boxes'].numpy()
confidences = example['groundtruth_image_confidences']
filename = example['filename']
area = example['groundtruth_area']
classes = example['groundtruth_classes'].numpy()
image_classes = example['groundtruth_image_classes']
weights = example['groundtruth_weights']
scores = np.ones(boxes.shape[0])
visualization_utils.visualize_boxes_and_labels_on_image_array(
image,
boxes,
classes,
scores,
class_dict,
max_boxes_to_draw=None,
use_normalized_coordinates=True
)
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.show()
# Visualizing the training TFRecord dataset.
visualize_tfrecords(
tfrecords_filename='dataset/printed_links/tfrecords/train.record',
label_map='dataset/printed_links/labels/label_map.pbtxt',
print_num=3
)В результате мы должны увидеть несколько изображений с прямоугольными габаритами для каждого из объектов,

Устанавливаем TensorBoard
Перед тем, как начать тренировку мы можем запустить TensorBoard.
TensorBoard поможет нам в мониторинге тренировочного процесса. Он поможет нам увидеть, действительно ли модель обучается или же нам лучше остановить тренировку и подправить параметры тренировки. TensorBoard также поможет нам какие объекты и где именно на изображении наша модель обнаруживает.
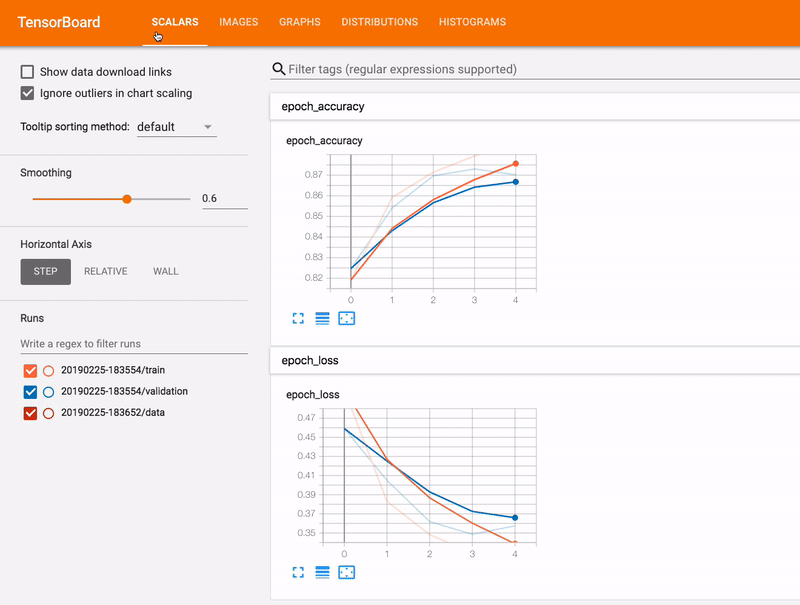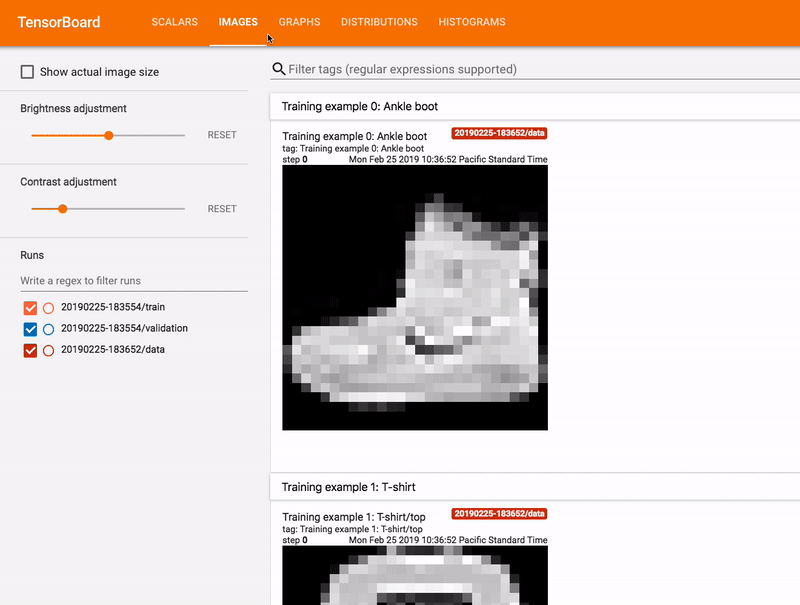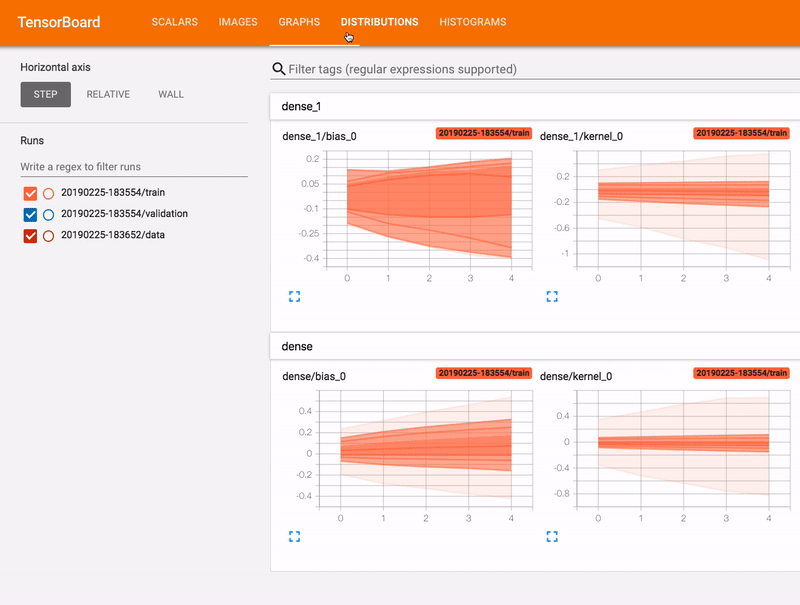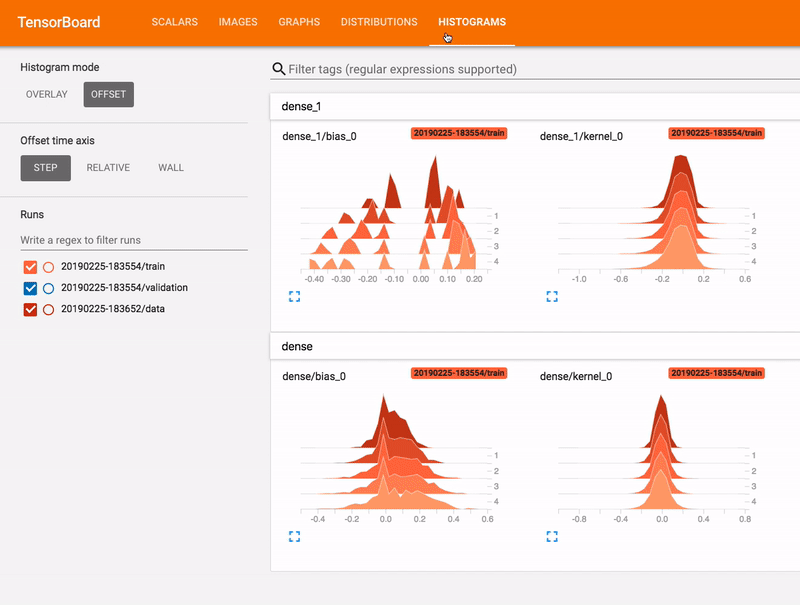
Источник изображения: домашняя страница TensorBoard
Отличной особенностью TensorBoard является то, что мы можем запустить его прямо в Google Colab. Если же вы экспериментируете с моделью локально в Jupyter ноутбуке, то вы можете установить TensorBoard как Python пакет и запустить его локально из консоли.
Для начала создадим папку ./logs, в которой во время тренировки будут храниться параметры модели.
mkdir -p logsДалее, мы загружаем расширение TensorBoard в Google Colab:
%load_ext tensorboardИ теперь мы можем запустить TensorBoard и указать папку ./logs в качестве папки с логами тренировки,
%tensorboard --logdir ./logsВ результате вы должны увидеть пустую панель TensorBoard:

После того, как мы начнем тренировку, мы сможем вернуться к этой панели и проверить насколько хорошо она обучается.
️ Тренировка модели
Настраиваем параметры тренировки
Теперь мы можем вернуться к ранее упомянутому файлу cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/pipeline.config. В этом файле собраны параметры для тренировки модели ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8.
Нам необходимо скопировать файл pipeline.config в корень нашего проекта и изменить следующие параметры:
- Необходимо количество классов с
90(количество классов набора данных COCO) на1(наш единственный классhttp) - Необходимо уменьшить размер тренировочного пакета (batch size) до
8изображений на один пакет, чтобы избежать проблем с недостатком памяти. - Необходимо указать нашей модели, где хранятся сохраненные слепки ранее натренированных параметров модели, поскольку мы не хотим тренировать ее с нуля.
- Необходимо установить параметр
fine_tune_checkpoint_typeвdetection. - Необходимо указать модели, где находится карта новых классов объектов.
- Необходимо указать модели, где находятся тренировочный и тестовый наборы данных.
Все эти изменения можно сделать вручную в файле pipeline.config, но это так же можно сделать программно:
import tensorflow as tf
from shutil import copyfile
from google.protobuf import text_format
from object_detection.protos import pipeline_pb2
# Adjust pipeline config modification here if needed.
def modify_config(pipeline):
# Model config.
pipeline.model.ssd.num_classes = 1
# Train config.
pipeline.train_config.batch_size = 8
pipeline.train_config.fine_tune_checkpoint = 'cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0'
pipeline.train_config.fine_tune_checkpoint_type = 'detection'
# Train input reader config.
pipeline.train_input_reader.label_map_path = 'dataset/printed_links/labels/label_map.pbtxt'
pipeline.train_input_reader.tf_record_input_reader.input_path[0] = 'dataset/printed_links/tfrecords/train.record'
# Eval input reader config.
pipeline.eval_input_reader[0].label_map_path = 'dataset/printed_links/labels/label_map.pbtxt'
pipeline.eval_input_reader[0].tf_record_input_reader.input_path[0] = 'dataset/printed_links/tfrecords/test.record'
return pipeline
def clone_pipeline_config():
copyfile(
'cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/pipeline.config',
'pipeline.config'
)
def setup_pipeline(pipeline_config_path):
clone_pipeline_config()
pipeline = read_pipeline_config(pipeline_config_path)
pipeline = modify_config(pipeline)
write_pipeline_config(pipeline_config_path, pipeline)
return pipeline
def read_pipeline_config(pipeline_config_path):
pipeline = pipeline_pb2.TrainEvalPipelineConfig()
with tf.io.gfile.GFile(pipeline_config_path, "r") as f:
proto_str = f.read()
text_format.Merge(proto_str, pipeline)
return pipeline
def write_pipeline_config(pipeline_config_path, pipeline):
config_text = text_format.MessageToString(pipeline)
with tf.io.gfile.GFile(pipeline_config_path, "wb") as f:
f.write(config_text)
# Adjusting the pipeline configuration.
pipeline = setup_pipeline('pipeline.config')
print(pipeline)Вот окончательная версия файла pipeline.config после редактирования:
model {
ssd {
num_classes: 1
image_resizer {
fixed_shape_resizer {
height: 640
width: 640
}
}
feature_extractor {
type: "ssd_mobilenet_v2_fpn_keras"
depth_multiplier: 1.0
min_depth: 16
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.9999998989515007e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.009999999776482582
}
}
activation: RELU_6
batch_norm {
decay: 0.996999979019165
scale: true
epsilon: 0.0010000000474974513
}
}
use_depthwise: true
override_base_feature_extractor_hyperparams: true
fpn {
min_level: 3
max_level: 7
additional_layer_depth: 128
}
}
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
box_predictor {
weight_shared_convolutional_box_predictor {
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.9999998989515007e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.009999999776482582
}
}
activation: RELU_6
batch_norm {
decay: 0.996999979019165
scale: true
epsilon: 0.0010000000474974513
}
}
depth: 128
num_layers_before_predictor: 4
kernel_size: 3
class_prediction_bias_init: -4.599999904632568
share_prediction_tower: true
use_depthwise: true
}
}
anchor_generator {
multiscale_anchor_generator {
min_level: 3
max_level: 7
anchor_scale: 4.0
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
scales_per_octave: 2
}
}
post_processing {
batch_non_max_suppression {
score_threshold: 9.99999993922529e-09
iou_threshold: 0.6000000238418579
max_detections_per_class: 100
max_total_detections: 100
use_static_shapes: false
}
score_converter: SIGMOID
}
normalize_loss_by_num_matches: true
loss {
localization_loss {
weighted_smooth_l1 {
}
}
classification_loss {
weighted_sigmoid_focal {
gamma: 2.0
alpha: 0.25
}
}
classification_weight: 1.0
localization_weight: 1.0
}
encode_background_as_zeros: true
normalize_loc_loss_by_codesize: true
inplace_batchnorm_update: true
freeze_batchnorm: false
}
}
train_config {
batch_size: 8
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
random_crop_image {
min_object_covered: 0.0
min_aspect_ratio: 0.75
max_aspect_ratio: 3.0
min_area: 0.75
max_area: 1.0
overlap_thresh: 0.0
}
}
sync_replicas: true
optimizer {
momentum_optimizer {
learning_rate {
cosine_decay_learning_rate {
learning_rate_base: 0.07999999821186066
total_steps: 50000
warmup_learning_rate: 0.026666000485420227
warmup_steps: 1000
}
}
momentum_optimizer_value: 0.8999999761581421
}
use_moving_average: false
}
fine_tune_checkpoint: "cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0"
num_steps: 50000
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
fine_tune_checkpoint_type: "detection"
fine_tune_checkpoint_version: V2
}
train_input_reader {
label_map_path: "dataset/printed_links/labels/label_map.pbtxt"
tf_record_input_reader {
input_path: "dataset/printed_links/tfrecords/train.record"
}
}
eval_config {
metrics_set: "coco_detection_metrics"
use_moving_averages: false
}
eval_input_reader {
label_map_path: "dataset/printed_links/labels/label_map.pbtxt"
shuffle: false
num_epochs: 1
tf_record_input_reader {
input_path: "dataset/printed_links/tfrecords/test.record"
}
}Запускаем процесс тренировки
Мы готовы запустить процесс тренировки модели используя TensorFlow 2 Object Detection API. API содержит файл model_main_tf2.py, который содержит всю логику тренировки. Вы можете детальнее ознакомиться с исходным Python кодом файла, в котором описаны входные параметры скрипта (например, num_train_steps, model_dir и пр.).
Мы будем тренировать модель в течение 1000 итераций (эпох).
%%bash
NUM_TRAIN_STEPS=1000
CHECKPOINT_EVERY_N=1000
PIPELINE_CONFIG_PATH=pipeline.config
MODEL_DIR=./logs
SAMPLE_1_OF_N_EVAL_EXAMPLES=1
python ./models/research/object_detection/model_main_tf2.py \
--model_dir=$MODEL_DIR \
--num_train_steps=$NUM_TRAIN_STEPS \
--sample_1_of_n_eval_examples=$SAMPLE_1_OF_N_EVAL_EXAMPLES \
--pipeline_config_path=$PIPELINE_CONFIG_PATH \
--checkpoint_every_n=$CHECKPOINT_EVERY_N \
--alsologtostderrВо время тренировки модели (это может занять ~10 минут для 1000 итераций с использованием GPU runtime в GoogleColab) вы можете увидеть как процесс тренировки в TensorBoard. Ошибки localization и classification должны уменьшаться, что означает, что модель все лучше и лучше локализует объекты и определяет их класс.
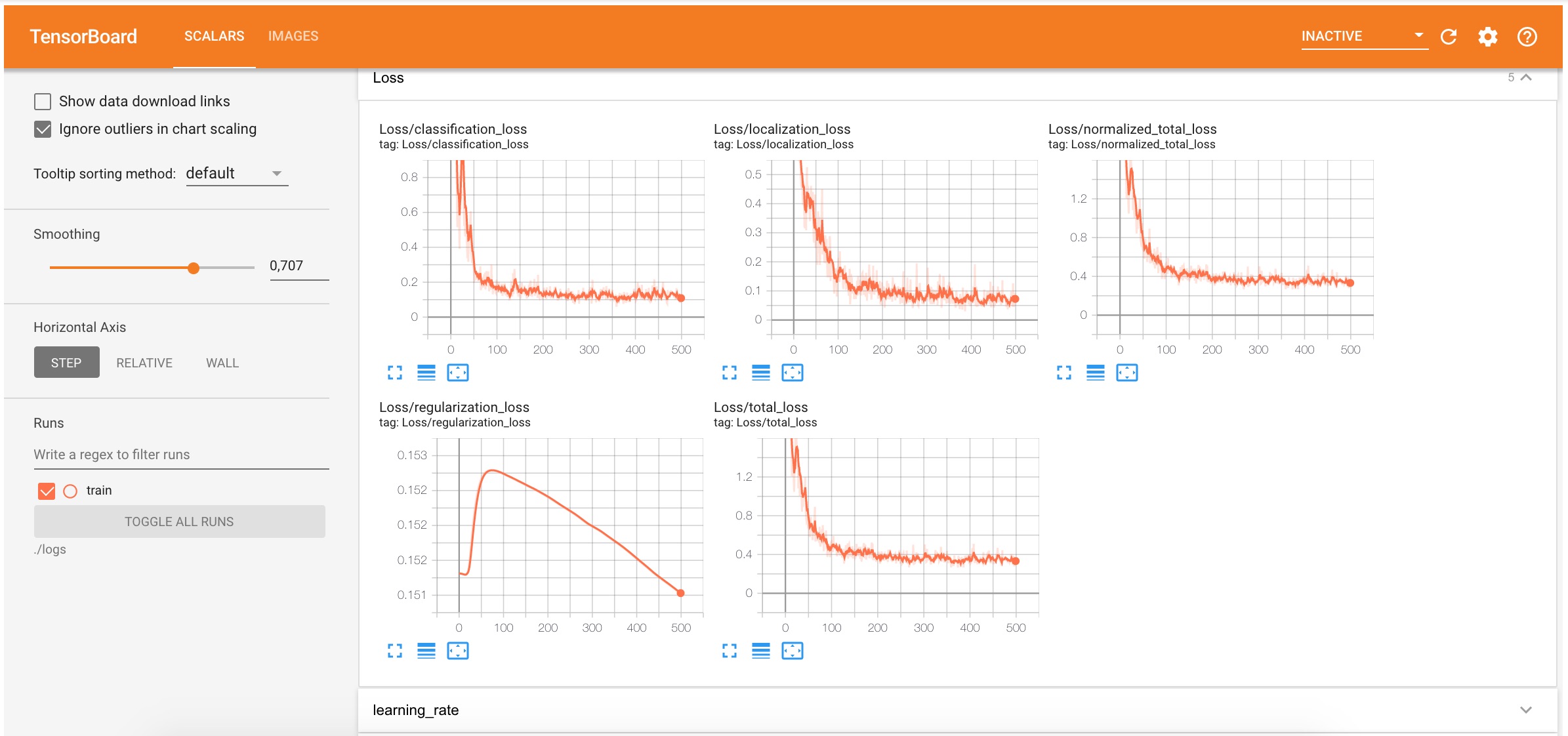
Также по мере обучения модели в папке logs будут создаваться новые чекпоинты (слепки) параметров модели.
Папка logs может выглядеть следующим образом:
logs
├── checkpoint
├── ckpt-1.data-00000-of-00001
├── ckpt-1.index
└── train
└── events.out.tfevents.1606560330.b314c371fa10.1747.1628.v2Оцениваем модель (опционально)
Чтобы оценить точность работы модели мы пробуем обнаружить объекты на изображения из тестового набора данных. Результат такой оценки обобщается в виде метрик, изменение которых мы можем наблюдать с течением времени. Вы можете более детально ознакомиться с тем, какие именно метрики используются здесь.
В этой статье мы пропустим этот шаг с метриками, но мы все-же можем воспользоваться панелью TensorBoard, чтобы увидеть, какие объекты модель обнаруживает на тестовом наборе данных:
%%bash
PIPELINE_CONFIG_PATH=pipeline.config
MODEL_DIR=logs
python ./models/research/object_detection/model_main_tf2.py \
--model_dir=$MODEL_DIR \
--pipeline_config_path=$PIPELINE_CONFIG_PATH \
--checkpoint_dir=$MODEL_DIR \После запуска скрипта вы сможете увидеть несколько изображений с обнаруженными в них предметами:

Экспортируем модель
После окончания тренировки необходимо сохранить модель для дальнейшего использования. Для экспортирования модели мы воспользуемся скриптом exporter_main_v2.py из Object Detection API. Этот скрипт подготавливает TensorFlow граф на основании чекпоинтов модели и ее тренировочной конфигурации. После выполнения скрипта мы получим папку с чекпоинтами, моделью в формате SavedModel и копией конфигурационного файла модели.
%%bash
python ./models/research/object_detection/exporter_main_v2.py \
--input_type=image_tensor \
--pipeline_config_path=pipeline.config \
--trained_checkpoint_dir=logs \
--output_directory=exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8Вот так выглядит содержимое папки exported:
exported
└── ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
├── checkpoint
│ ├── checkpoint
│ ├── ckpt-0.data-00000-of-00001
│ └── ckpt-0.index
├── pipeline.config
└── saved_model
├── assets
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.indexНа этом этапе у нас есть модель в папке saved_model, которую мы уже можем использовать для обнаружения объектов.
Использование экспортированной модели
Давайте посмотрим, как мы можем использовать модель, экспортированную на предыдущем этапе.
В начале нам необходимо создать функцию-обнаружитель, которая будет использовать сохраненную модель. Эта функция будет принимать изображение на вход и выдавать информацию об обнаруженных объектах:
import time
import math
PATH_TO_SAVED_MODEL = 'exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model'
def detection_function_from_saved_model(saved_model_path):
print('Loading saved model...', end='')
start_time = time.time()
# Load saved model and build the detection function
detect_fn = tf.saved_model.load(saved_model_path)
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(math.ceil(elapsed_time)))
return detect_fn
exported_detect_fn = detection_function_from_saved_model(
PATH_TO_SAVED_MODEL
)output →
Loading saved model...Done! Took 9 secondsДля сопоставления идентификаторов обнаруженных классов с именами классов нам также необходимо загрузить карту классов:
from object_detection.utils import label_map_util
category_index = label_map_util.create_category_index_from_labelmap(
'dataset/printed_links/labels/label_map.pbtxt',
use_display_name=True
)
print(category_index)output →
{1: {'id': 1, 'name': 'http'}}Тестируем нашу модель на тестовом наборе данных.
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from object_detection.utils import visualization_utils
from object_detection.data_decoders.tf_example_decoder import TfExampleDecoder
%matplotlib inline
def tensors_from_tfrecord(
tfrecords_filename,
tfrecords_num,
dtype=tf.float32
):
decoder = TfExampleDecoder()
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
images = []
for raw_record in raw_dataset.take(tfrecords_num):
example = decoder.decode(raw_record)
image = example['image']
image = tf.cast(image, dtype=dtype)
images.append(image)
return images
def test_detection(tfrecords_filename, tfrecords_num, detect_fn):
image_tensors = tensors_from_tfrecord(
tfrecords_filename,
tfrecords_num,
dtype=tf.uint8
)
for image_tensor in image_tensors:
image_np = image_tensor.numpy()
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = tf.expand_dims(image_tensor, 0)
detections = detect_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy() for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
image_np_with_detections = image_np.astype(int).copy()
visualization_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=100,
min_score_thresh=.3,
agnostic_mode=False
)
plt.figure(figsize=(8, 8))
plt.imshow(image_np_with_detections)
plt.show()
test_detection(
tfrecords_filename='dataset/printed_links/tfrecords/test.record',
tfrecords_num=10,
detect_fn=exported_detect_fn
)В результате вы должны увидеть 10 изображений из тестового набора данных с обнаруженными и подсвеченными https: префиксами:

Тот факт, что модель смогла обнаружить объекты (в нашем случае префиксы https://) в изображениях, которые она раньше не "видела" является хорошим знаком и, собственно, тем, что мы хотели достигнуть этой тренировкой.
Конвертируем модель в веб-совместимый формат
Как вы помните из начала данной статьи нашей целью была тренировка модели обнаружения объектов, которую мы могли бы использовать в браузере. К счастью, существует JavaScript версия TensorFlow — TensorFlow.js. В JavaScript мы не можем работать с сохраненной ранее моделью напрямую. Нам нужна еще одна последняя конвертация модели в формат tfjs_graph_model.
Для того, чтобы осуществить эту конвертацию, нам понадобится Python пакет tensorflowjs:
pip install tensorflowjs --quietТеперь мы можем конвертировать модель в нужный нам формат:
%%bash
tensorflowjs_converter \
--input_format=tf_saved_model \
--output_format=tfjs_graph_model \
exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model \
exported_web/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8Папка exported_web содержит .json файл с информацией об архитектуре модели, а несколько файлов в формате .bin содержат ее параметры.
exported_web
└── ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
├── group1-shard1of4.bin
├── group1-shard2of4.bin
├── group1-shard3of4.bin
├── group1-shard4of4.bin
└── model.jsonНаконец-то мы получили модель, которая способна обнаруживать https:// префиксы в изображениях и которая сохранена в формате, понятном JavaScript приложениям.
Давайте проверим размеры моделей, которые мы создали:
import pathlib
def get_folder_size(folder_path):
mB = 1000000
root_dir = pathlib.Path(folder_path)
sizeBytes = sum(f.stat().st_size for f in root_dir.glob('**/*') if f.is_file())
return f'{sizeBytes//mB} MB'
print(f'Original model size: {get_folder_size("cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')
print(f'Exported model size: {get_folder_size("exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')
print(f'Exported WEB model size: {get_folder_size("exported_web/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')output →
Original model size: 31 MB
Exported model size: 28 MB
Exported WEB model size: 13 MBКак вы можете заметить, модель, которую мы собираемся использовать на стороне клиента весит 13MB, что вполне допустимо и соответствует требованиям, которые мы определили в начале статьи.
Позже на стороне клиента мы сможем импортировать эту модель следующим образом:
import * as tf from '@tensorflow/tfjs';
const model = await tf.loadGraphModel(modelURL);Следующим шагом будет реализация пользовательского интерфейса для модели, что является темой для другой статьи. Но уже сейчас, при желании, вы можете ознакомиться с финальным примером кода приложения на TypeScript в репозитории links-detector на GitHub.
Заключение
В этой статье мы начали решать проблему распознавания печатных ссылок. В итоге мы обучили модель, способную распознавать префиксы https:// в текстовых изображениях (например, в кадрах видео-потока с камеры смартфона). Мы также конвертировали обученную модель в формат tfjs_graph_model для дальнейшего использования ее на стороне клиента в JavaScript/TypeScript приложении.
Вы можете запустить Links Detector со своего смартфона и попробовать, как он обнаруживает ссылки в вашей книге или журнале.
Финальное решение выглядит следующим образом:
Вы также можете ознакомиться с репозиторием links-detector на GitHub, в котором сможете найти исходный код клиентской части приложения.
На данный момент приложение находится в экспериментальной стадии и имеет множество недоработок и ограничений. Поэтому, до тех пор, пока вышеуказанные недоработки не будут ликвидированы, не ожидайте от приложения слишком многого


