
Всем привет! В современном мире крайне важна возможность масштабировать приложение по щелчку пальцев, ведь нагрузка на приложение может сильно отличаться в разное время. Наплыв клиентов, которые решили воспользоваться вашим сервисом, может принести как большую прибыль так и убытки. Разбиение приложения на отдельные сервисы решает проблемы с масштабированием, всегда можно добавить инстансов нагруженных сервисов. Это несомненно поможет справиться с нагрузкой и сервис не упадет от нахлынувших на него клиентов. Но микросервисы вместе с неоспоримой пользой, вносят и более сложную структуру приложения, а так же запутанность в их взаимосвязях. Что если даже успешно масштабировав свой сервис, проблемы продолжаются? Время ответа растет и ошибок становится все больше? Как понять, где именно проблема? Ведь каждый запрос к API может порождать за собой цепочку вызовов разных микросервисов, получение данных из нескольких БД и сторонних API. Может это проблема с сетью, или API вашего партнера не справляется с нагрузкой, а может это кеш виноват? В этой статье я постараюсь рассказать, как ответить на эти вопросы и быстро найти точку отказа. Добро пожаловать под кат.
Чтобы быстро определить точку отказа и решить проблему, необходимо собрать метрики прохождения каждого этапа запроса. Для решения этой задачи можно воспользоваться спецификацией OpenTracing. Этот инструмент описывает основные принципы и модели данных для работы с трассировками в распределенных системах, но не предоставляет реализации. В данной статье мы воспользуемся имплементацией для JavaScript, и будем писать примеры на TypeScript. Но для того, чтобы перейти к практике, необходимо разобраться с теорией.
Теория
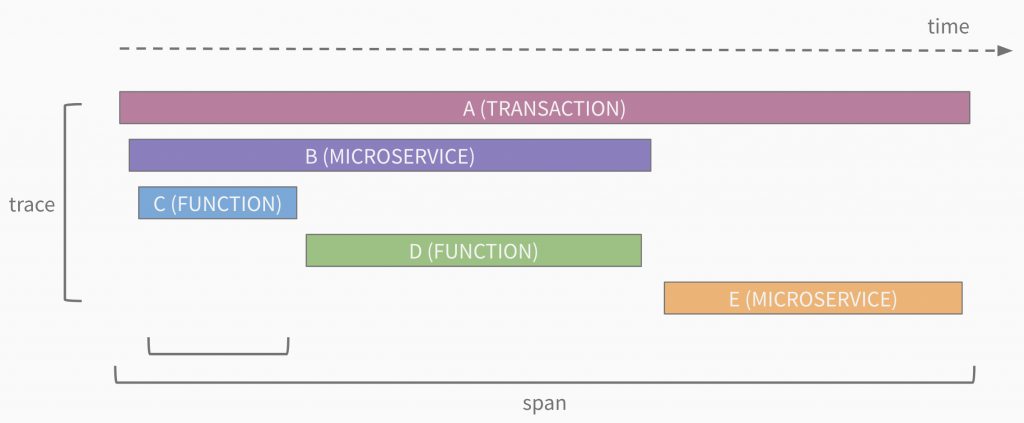
Основными понятиями в спецификации OpenTracing являются Trace, Span, SpanContext, Carrier, Tracer.
- Trace. Это временной интервал, в течение которого выполнялся один или несколько Span'ов, связанных между собой одним идентификатором traceId. Span'ы так же могут быть связаны между собой ссылками двух оcновных типов. ChildOf это обычная связь родитель — потомок. Она говорит о том, что для завершения родительского span'a требуется завершение дочернего. Связь FollowsFrom говорит лишь о том, что родительский span запустил другой span, но на завершение текущего он не влияет.
- Span. Это основная и минимальная единица информации в спецификации OpenTracing. Span описывает интервал во времени, в котором происходила работа. Например, вызов функции, которая делает запрос в БД за данными, можно описать как span, сохранив в нем необходимую информацию. Span создается с помощью конкретной реализации OpenTracing, которая называется Tracer (об этом чуть позже). При создании интервала обязательным полем является имя (например название функции), также неявно в Span записывается timestamp создания интервала и идентификатор spanId. Каждый интервал содержит traceId, если span является дочерним, то в него записывается traceId родительского интервала, если родительского spana'а нет, генерируется новый. Когда функция завершила свою работы, у объекта span мы должны вызвать метод finish. Этот метод запишет в Span timestamp завершения работы, а так же отправит получившийся span в Трассировщик (если это предусмотренно конкретной реализацией). В span можно добавлять Теги или Логи, которые являются объектами типа key:value. Ключи, этих объектов, могут обладать семантическими свойствами, которые описаны в соглашении OpenTracing. Например, если во время выполнения функции возникла ошибка, то к Span'у, который описывает эту функцию, можно добавить тег error: true. Обработка таких тегов, описанных в спецификации, может быть реализована в трейсере, который вы используете. Отличием логов, добавленных к интервалу, является то, что вместе с логом добавляется и timestamp лога. То есть это конкретная временная точка между стартом span'a и его завершением. У обычного тега нет этой метки.
- SpanContext. Это объект, описанный в спецификации OpenTracing, который содержит информацию, необходимую для связывания span'ов между собой при межсервисном взаимодействии. Контекст содержит идентификаторы traceId, spanId, а также любую информацию вида key:value, которую мы хотим передавать между микросервисами. В терминологии OpenTracing эта информация называется baggage. Если мы создаём новый интервал, но этот интервал дочерний по отношению к другому. Создав SpanContext, мы можем передать его новому span'у, указав его как родителя. За счет этого новый интервал получит ссылку на свой родительский span.
- Carrier. Этот простой объект типа key:value содержит информацию, с помощью которой можно создать SpanContext. Carrier можно создать с помощью реализации tracer. В спецификации OpenTracing описаны два типа этого объекта. Первый — это FORMAT_TEXT_MAP, простой объект типа key:value. Полученный объект можно передавать вместе с запросом к другому сервису. Второй FORMAT_BINARY трансформирует контекст в бинарный вид. Это минимальный набор, который должен реализовать tracer. Есть и другие форматы преобразования контекста, например FORMAT_HTTP_HEADERS, который сериализует контекст в объект заголовков для передачи по http.
- Tracer. Это конкретная имплементация спецификации OpenTracing, которая непосредственно предоставляет методы по созданию span'ов, генерации идентификаторов, создания контекстов и отправку завершенных интервалов на хранение в трассировщик (distributed tracing system) например Jaeger или Elastic APM. Tracer реализует два метода, с помощью которых мы можем преобразовывать объект контекста в carrier для передачи между сервисами. Это inject и extract
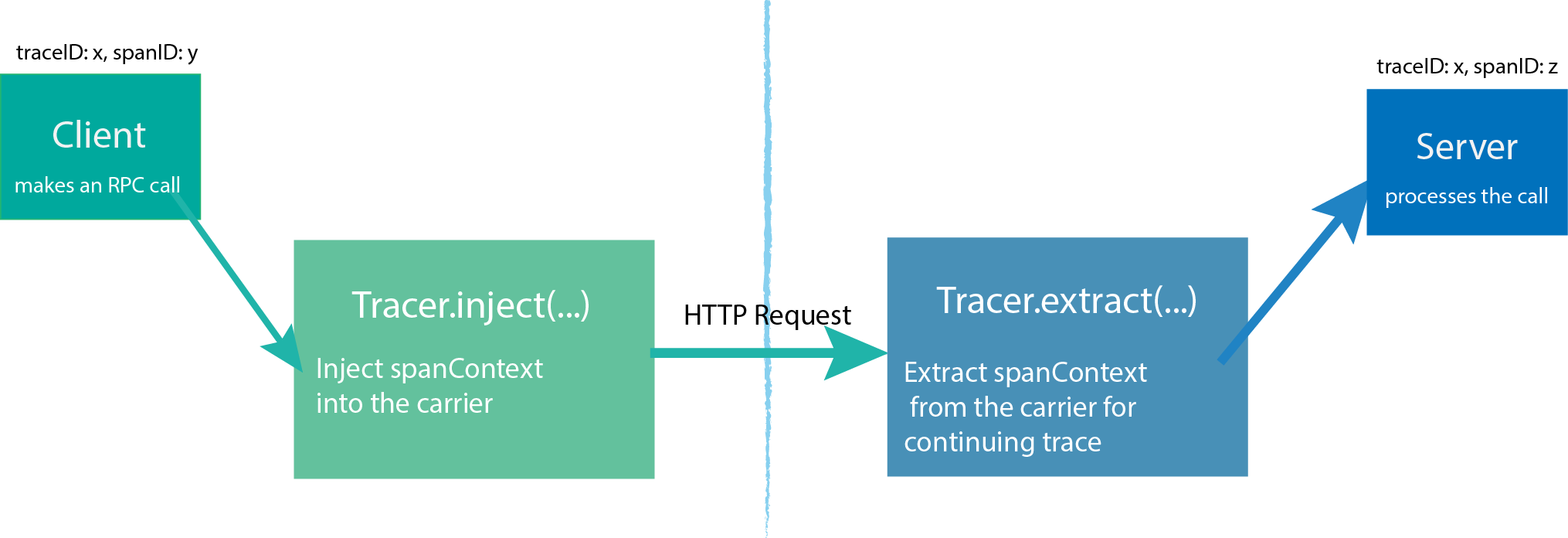
Extract принимает первым аргументом тип carrier'a, вторым сам carrier и возвращает объект контекста. Inject получает первым аргументом SpanContext, вторым тип желаемого объекта carrier и третьим пустой объект, в который будет добавлена вся необходимая информация из контекста, для дальнейшей передачи между сервисами. За счет работы этих функций мы можем связывать наши сервисы в единый трейс, состоящий из связанных между собой span'ов.
Используемые технологии
Для того, чтобы показать как это работает на практике, я напишу небольшой тестовый пример на typescript состоящий из трех микросервисов. Микросервисы будут общаться между собой через брокер NATS, а полученные трассировки будем отправлять в Jaeger.
NATS
Это быстрый, легкий и производительный брокер, написанный на golang. Через этот брокер можно реализовать две основные схемы взаимодействия микросервисов это Publish-Subscribe для асинхронных операций и Request-Reply для синхронных. NATS работает по простому текстовому протоколу, что упрощает разработку, а также предоставляет много разных полезных функций, таких как балансировку нагрузки и мониторинг подключенных сервисов. В тестовом проекте я буду использовать NATS как транспорт между сервисами, но в конечном счете для сбора трассировок транспорт не будет играть особой роли, это будет видно из примера. Для запуска проекта на локальной машине потребуется запустить NATS, что можно сделать с помощью Docker.
docker run -d --name nats -p 4222:4222 -p 6222:6222 -p 8222:8222 natsJaeger
Это система хранения и анализа трассировок, созданная и выпущенная в opensource компанией Uber. Jaeger предоставляет удобный интерфейс для анализа трассировок, а так же возможность отображать трассировки в виде графа зависимостей как отдельного метода, так и системы в целом, что можно использовать для самодокументирования системы в целом. В качестве хранилища трассировок Jaeger может использовать Cassandra, Elasticsearch а также просто хранить трейсы в памяти, что удобно для тестов. При большом количестве трассировок можно использовать Kafka, как буфер между коллектором, в который прилетают span'ы, и хранилищем. Также в библиотеках, реализующих трейсер Jaeger, можно настроить сэмплирование трейсов. Поддерживается несколько видов сэмплирования:
Const. Эта стратегия подойдет, если нужно хранить каждый трейс (если передать значение 1) или не сохранять ни один (значение 0)
Probabilistic. Значение этой стратегии говорит о том, какой процент трейсов Jaeger будет сохранять. Трейсы выбираются случайным образом. Например, при значении 0.1 будет сохранен только 1 трейс из 10.
Rate Limiting. Эта стратегия позволяет сохранять определенное значение полученных трейсов за секунду.
Remote. Стратегия говорит о том, что решение о сохранении трейса будет приниматься на стороне бэкенда Jaeger'a. Что позволяет гибко настраивать сэмплирование, не меняя настроек трейсера в коде приложения.
Для запуска тестового примера локально, также потребуется запустить Jaeger, например, с помощью Docker
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 9411:9411 \
jaegertracing/all-in-one:1.8Реализуем сбор трассировок
Напишем небольшой тестовый проект, что бы посмотреть как работает теория на практике. Приложение будет обрабатывать один пользовательский запрос по http. В ответ на get запрос по руту /devices/:regionId будет возвращаться json с данными, которые будут собраны из нескольких сервисов. Общая архитектура приложения такая.
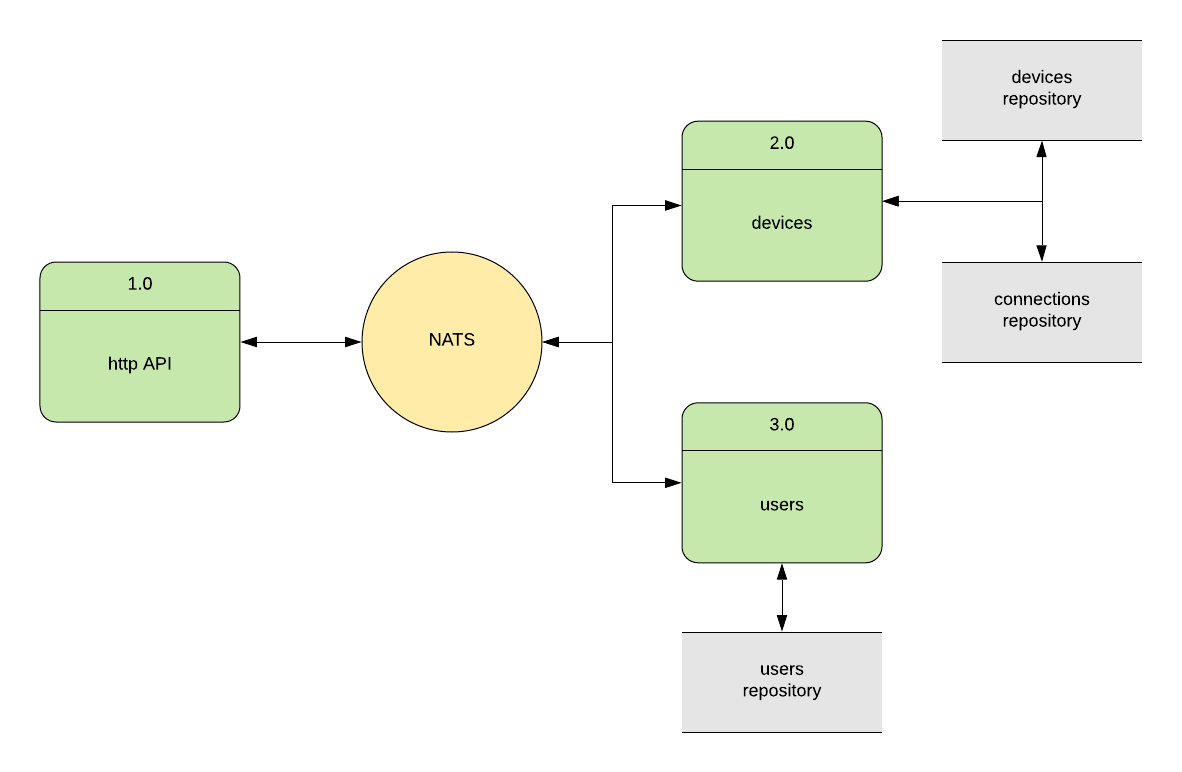
Все три микросервиса подключены к NATS. Единственный endpoint приложения отвечает за получение массива подключенных устройств, доступных в регионе, с информацией о пользователе этого устройства. После того, как запрос за устройствами пришел в http шлюз, микросервис api через NATS вызывает метод получения данныx из микросервиса devices. Микросервис devices для получения данных делает запрос в БД (например, mongodb), за объектами подключенных устройств, затем по количеству полученных устройств делает параллельнные запросы в другую БД (например redis) за получением геолокации каждого устройства. Далее микросервис devices передаёт массив id устройств в микросервис users для получения подробной информации о владельцах устройств. После получения массива пользователей данные агрегируются и возвращаются в api. Это выдуманный тестовый пример, но он хорошо продемонстрирует полезность сбора трассировок из подобных распределенных систем.
Для начала опишем основные интерфейсы данных, с которыми будем работать
// Координаты устройства
export interface Location {
lat: number;
lng: number;
}
export interface Device {
id: string;
regionId: string;
userId: string;
connected: boolean;
}
export interface User {
id: string;
name: string;
address: string;
}
// Результат работы приложения
export interface ConnectedDevice extends Device {
user: User;
connected: true;
location: Location;
}У микросервиса devices и users будет по одному методу
export const UsersMethods = {
getByIds: 'users.getByIds',
};
export const DevicesMethods = {
getByRegion: 'devices.getByRegion',
};Теперь напишем класс транспорта, который будет реализовывать подключение к NATS, а также два метода publish и subscribe. С помощью этих методов можно отправить данные подписчику по определенной теме и подписаться на них соответственно.
import * as Nats from 'nats';
import * as uuid from 'uuid';
export class Transport {
private _client: Nats.Client;
public async connect() {
return new Promise(resolve => {
this._client = Nats.connect({
url: process.env.NATS_URL || 'nats://localhost:4222',
json: true,
});
this._client.on('error', error => {
console.error(error);
process.exit(1);
});
this._client.on('connect', () => {
console.info('Connected to NATS');
resolve();
});
});
}
public async disconnect() {
this._client.close();
}
public async publish<Request = any, Response = any>(subject: string, data: Request): Promise<Response> {
const replyId = uuid.v4();
return new Promise(resolve => {
this._client.publish(subject, data, replyId);
const sid = this._client.subscribe(replyId, (response: Response) => {
resolve(response);
this._client.unsubscribe(sid);
});
});
}
public async subscribe<Request = any, Response = any>(subject: string, handler: (msg: Request) => Promise<Response>) {
this._client.subscribe(subject, async (msg: Request, replyId: string) => {
const result = await handler(msg);
this._client.publish(replyId, result);
});
}
}Для создания http api будем использовать express. В index файле api нам нужно создать экземпляр класса Transport, через него мы будем вызвать метод микросервиса devices.
(async () => {
const transport = new Transport();
const port = 5000;
await transport.connect();
const api = express();
api.get('/devices/:regionId', async (request, response) => {
const result = await transport.publish<GetByRegion, ConnectedDevice[]>(DevicesMethods.getByRegion, {
regionId: request.params.regionId,
});
response.send(result);
return result;
});
api.listen(port, () => {
console.info(`Server started on port ${port}`);
});
})();Далее реализуем микросервисы devices и users. Приведу пример кода только для devices, микросервис users реализуется аналогично.
Для работы с БД реализуем два репозитория. Один отвечает за работу с вымышленной mongodb, другой с redis
export class DeviceRepository {
private db = 'mongodb';
private devices: Device[] = [...];
public async getByRegion(regionId: string): Promise<Device[]> {
return new Promise(resolve => {
setTimeout(() => resolve(this.devices), 300);
});
}
}export class LocationRepository {
private db = 'redis';
private locations = new Map<string, Location>([...]);
public async getLocation(deviceId: string): Promise<Location> {
return new Promise(resolve => {
setTimeout(() => resolve(this.locations.get(deviceId)), 40);
});
}
}Теперь реализуем бизнес — логику микросервиса devices, которая будет находиться в функции getByRegion. Логика работы этого обработчика была описана ранее.
export async function getByRegion(request: Msg<GetByRegion>) {
try {
const deviceRepository = new DeviceRepository();
const locationRepository = new LocationRepository();
const regionId = request.regionId;
const devices = await deviceRepository.getByRegion(regionId);
const connectedDevices = await Promise.all(
devices.map(async device => {
const location = await locationRepository.getLocation(device.id);
return { ...device, location };
}),
);
const users: User[] = await transport.publish<GetByIds, User[]>(UsersMethods.getByIds, {
ids: devices.map(device => device.id),
});
return connectedDevices.map(device => {
const user = users.find(user => user.id === device.userId);
return {
...device,
user,
};
});
} catch (error) {
console.error(error);
(this as any).createError(error);
}
}В index файле devices нам осталось создать экземпляр класса Transport и подписаться на тему.
export const transport = new Transport();
(async () => {
try {
await transport.connect();
transport.subscribe(DevicesMethods.getByRegion, getByRegion);
} catch (error) {
console.error(error);
process.exit(1);
}
})();Теперь, запустив пример и сделав запрос на наш единственный endpoint, можно ощутить значительную задержку, прежде чем json с ответом появится на экране. Для того, чтобы разобраться в чем причина, начнем собирать трейсы между сервисами, а для этого нам потребуется класс Tracer. В качестве реализации OpenTracing будем использовать библиотеку jaeger-client.
import { JaegerTracer, initTracer } from 'jaeger-client';
export class Tracer {
private _client: JaegerTracer;
constructor(private serviceName: string) {
this._client = initTracer(
{
serviceName,
reporter: {
agentHost: process.env.JAEGER_AGENT_HOST || 'localhost',
agentPort: parseInt(process.env.JAEGER_AGENT_PORT || '6832'),
},
sampler: {
type: 'const',
param: 1,
},
},
{},
);
}
get client() {
return this._client;
}
}Здесь мы создаём объект трассировщика с настройками адреса коллектора Jaeger, куда он будет отсылать завершенные интервалы. Для тестов будем использовать тип сэмплирования const. Чтобы не менять наш код транспорта и не добавлять логику по созданию span'ов в методах publish и subscribe, напишем два декоратора для этих методов. Единственное, что потребуется поменять в классе Transport, это добавить конструктор, который будет принимать необязательный параметр в виде объекта Tracer.
constructor(private tracer?: Tracer) {}Сами декораторы рассмотрим подробнее. Декоратор subscribePerfomance для метода subscribe
export function subscribePerfomance(target: any, propertyKey: string, descriptor: PropertyDescriptor) {
const origin = descriptor.value;
descriptor.value = async function() {
if (this.tracer) {
const { client } = this.tracer as Tracer;
const subject: string = arguments[0];
const handler: Handler = arguments[1];
const wrapperHandler = async (msg: Msg) => {
const childOf = client.extract(FORMAT_TEXT_MAP, msg[CARRIER]); // 1
if (childOf) {
const span = client.startSpan(subject, { childOf }); // 2
this[CONTEXT] = span; // 3
try {
const result = await handler.apply(this, [msg]); // 4
span.finish(); // 5
return result;
} catch (error) {
span.setTag(Tags.ERROR, true); // 6
span.log({
'error.kind': error,
});
span.finish();
throw error;
}
} else {
return handler(msg);
}
};
return origin.apply(this, [subject, wrapperHandler]);
}
return origin.apply(this, arguments);
};
}- Через объект Tracer методом extract пытаемся извлечь из пришедшего в сообщении объекта carrier контекст. Если этого контекста нет, то мы просто возвращаем обратно результат вызова оригинального обработчика.
- Создаём новый объект span и при создании указываем ему как родительский полученный SpanContext
- Записываем полученный span в специальную переменную в this. Он нам понадобится, если из этого обработчика будут вызываться другие методы.
- Выполняем оригинальный обработчик
- Завершаем наш span.
В случае, если оригинальная функция вернула ошибку, записываем в span тег ошибки, а также саму ошибку и завершаем span
Декоратор publishPerfomance для метода publish
export function publishPerfomance(target: any, propertyKey: string, descriptor: PropertyDescriptor) { const origin = descriptor.value; let isNewSpan = false; descriptor.value = async function() { if (this.tracer) { const { client } = this.tracer as Tracer; const subject: string = arguments[0]; let data: Msg = arguments[1]; let context: Span | SpanContext | null = this[CONTEXT] || null; // 1 if (!context) { context = client.startSpan(subject); // 2 isNewSpan = true; } const carrier = {}; client.inject(context, FORMAT_TEXT_MAP, carrier); // 3 data[CARRIER] = carrier; // 4 try { const result = await origin.apply(this, [subject, data]); if (isNewSpan) { (context as Span).finish(); } return result; } catch (error) { if (isNewSpan) { const span = context as Span; span.setTag(Tags.ERROR, true); span.log({ 'error.kind': error, }); span.finish(); } throw error; } } return origin.apply(this, arguments); }; }
- Извлекаем из this контекст. Это нужно для того, чтобы получить родительский контекст в случае, если мы делаем publish из обработчика, который является так же и подписчиком. Как раз наш случай. Когда api делает запрос в devices, у микросервиса устройств уже есть родительский контекст, но он должен вызвать метод микросервиса users.
- Если у нас нет родительского контекста, мы создаём новый span.
- Создаём объект carrier для передачи его вместе с объектом запроса. Если context окажется пустым, трейсер создаст новый. Сгенерирует новый traceId.
- Модифицируем запрос, добавляя в него созданный объект carrier.
Осталось только задекорировать методы в классе Transport, перезапустить сервис и сделать запрос. Далее можно открыть интерфейс Jaeger и найти трейс, соответствующий нашему запросу. Он должен выглядеть так.


Мы видим, что основную часть времени выполнения запроса занимает метод микросервиса устройств getByRegion. А точнее 97.22% от времени выполнения всего запроса. Значит, проблема в этом методе. Более того, на таймлайне видно, что перед тем, как вызвать метод микросервиса users, был большой интервал во времени, когда мы обращаемся к БД. Но в какой базе именно проблема? Это можно узнать только собрав span'ы c методов репозиториев. Для этого напишем декоратор.
export function repositoryPerfomance({ client }: Tracer) {
return function(target: any, propertyKey: string, descriptor: PropertyDescriptor) {
const original = descriptor.value;
descriptor.value = async function() {
if (this.parent[CONTEXT]) { // 1
const span = client.startSpan(propertyKey, {
childOf: this.parent[CONTEXT], // 2
});
span.setTag(Tags.DB_TYPE, this.db); // 3
try {
const result = await original.apply(this, arguments);
span.finish();
return result;
} catch (error) {
span.setTag(Tags.ERROR, true);
span.log({
'error.kind': error,
});
span.finish();
throw error;
}
} else {
return original.apply(this, arguments);
}
};
};
}- Здесь мы проверяем, выполняется ли вызов метода в рамках другого span'a. Если родительского span'а нет, выполняем оригинальный метод и возвращаем результат.
- Создаём новый дочерний span.
- Присваиваем тег с названием базы, с которой работает репозиторий. В спецификации OpenTracing есть и другие полезные теги. Можно добавить тег с ip базы или текстом запроса.
Задекорировав методы репозиториев в Jaegere, трейс будет выглядеть следующим образом.

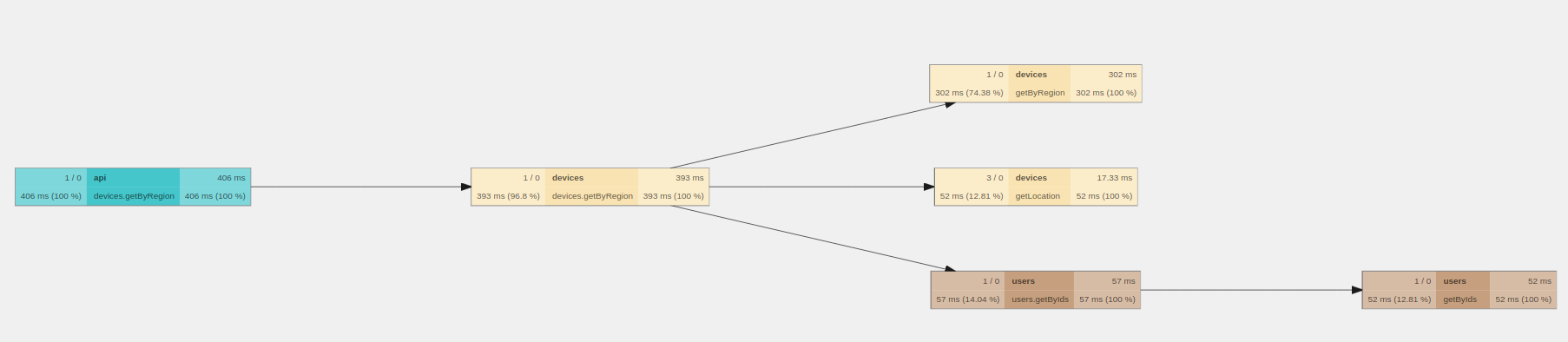
Теперь мы видим гораздо больше информации. И на графе и на таймлайне можно увидеть, в чем заключается проблема нашего приложения. 74.38% метода микросервиса devices занимает запрос к базе за списком устройств. Весь код, приведенный в качестве примера, можно посмотреть в репозитории на github.
В качестве транспорта мы использовали NATS, но из тестового приложения видно, что сам способ общения микросервисов не имеет особого значения для сбора трассировок. Модели данных и принципы работы с ними, описанные в спецификации OpenTracing, применимы и для других видов транспорта. Будь то запросы по http или асинхронные события через очереди. В больших распределенных приложениях крайне важно, при сбоях, быстро найти источник проблем. Ведь каждая минута простоя — это недовольный клиент, а значит, потеря денег. Быстро найти проблему, скорее всего, будет самой сложной задачей, которую можно решить быстрее и легче, обладая дополнительной информацией из собранных трассировок. Также, взглянув на граф трассировки, можно легко понять, какие микросервисы участвуют в работе метода. Если сравнить схему, которая была нарисована при проектировании и итоговый граф из Jaeger, можно увидеть, что между ними почти нет разницы.
Сбор и анализ трассировок из распределенного приложения похож на проведение МРТ с контрастом в медицине, с помощью которого можно не только решить текущие проблемы, но и выявить серьезное заболевание на ранней стадии.



 с CRM Битрикс24")