Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Использование метрик в управлении - это прогрессивная и современная практика, тем более в настолько оцифрованной среде как ИТ-бизнес. А что в последнее десятилетие не ИТ-бизнес? От торговли цветами до автомобилестроения, везде ИТ - ключевой фактор успеха. Метрики позволяют принимать грамотные управленческие и инженерные решения, правильно распределять бюджет, повышать прозрачность, добиваться справедливости и объективности.
Но есть у этого благородного начинания серьезное препятствие (философскую проблему “Можно ли все свести к числу” оставим для другой, профильной площадки и антиутопий типа “Черного зеркала”). В бизнесе метрик очень и очень много, а в ИТ их страсть сколько. В результате объем данных растет, количество наблюдаемых параметров также увеличивается. Мы начинаем делить метрики на ключевые и второстепенные, на метрики для бизнеса и метрики для “технарей”. Мы теряем фокус и вместо прозрачности получаем несвязный набор тысяч показателей. Погружаясь в свои метрики, сотрудники теряют из вида ключевую цель организации: решать “боли” своих клиентов, делать их жизнь лучше и получать за это вознаграждение. В результате мы получаем то, что принято называть “эффектом арбуза”, когда кожура “зеленых” метрик скрывает “красную и накаленную” сердцевину нашего бизнеса: удовлетворенность клиентов.
Идеальная метрика
Впервые я с этим столкнулся в самом начале своей карьеры. Тогда я работал сетевым инженером в региональном операторе связи, и в мои обязанности входила обработка метрик из системы мониторинга для подготовки KPI-отчета по техническому блоку. За основу брались данные о том, “пингуется” или нет узел связи (без привязки количества абонентов, которые от него зависят). Но в жизни качество предоставляемых провайдером услуг измеряется далеко не прохождением ICMP-пакетов от сервера мониторинга до коммутатора в подъезде, тем более, когда эти коммутаторы находятся в своем “стерильном VLAN-е”. Этого, наверное, не знали, но смогли прочувствовать на себе абоненты, особенно, нового в то время сервиса: IPTV через multicast. Зависающие картинки на телевизорах абонентов никак не коррелировали с прекрасной зеленой картинкой, подаваемой на стол руководства, и премиальным фондом. Результатом стала проваленная маркетинговая кампания по продвижению IPTV и немного пошатнувшаяся репутация. А дальше по цепочке: пересмотр KPI для инженеров с включением в него кучи новых метрик (в том числе и с бизнес уклоном), весовых коэффициентов, которые было просто невозможно рассчитать, и на которые было сложно повлиять. И вишенка на торте: восприятие сотрудниками KPI в качестве репрессивного инструмента сокращения зарплаты, и полная неэффективность его регуляторной функции. Я думаю, что у вас будет много подобных примеров из практики, особенно если коснуться такой острой темы как KPI и SLA. Вообще тема KPI, особенно в IT, заслуживает отдельного остросюжетного романа.
Я вспомнил описанную выше историю, когда практически одновременно несколько корпоративных заказчиков обратились с проблемой непрозрачного расчета SLA и KPI своих ИТ-подразделений. Стоит пояснить, что сейчас я работаю над продуктом зонтичного мониторинга для оперативного обнаружения и устранения сбоев в ИТ нашим продуктом пользуется ряд очень крупных клиентов из разных сфер: от госуправления и финтеха до СМИ и авиакомпаний.
Памятуя о своем неудачном опыте на первом месте работы, я не очень хотел ввязываться в KPI и SLA. Вначале я предложил решить эту проблему через настройку соответствующих Service Desk, тем более так рекомендует нам ITSM (Service Desk - единая точка входа и агрегации всей информации об услугах), а мой продукт будет лишь продолжать регистрировать инциденты и помогать с их дедупликацией за счет определения массовых сбоев и понимания: относится ли новый алерт к проблеме, находящейся на контроле у инженеров, или нет. Но коллегам хотелось не отчетности и репрессивного контроля, как я изначально ошибочно предположил, - им хотелось инструмента управления, который бы помогал и бизнесу, и инженерам находить некий общий язык и добавлял бы прозрачности в их отношения.
В итоге мы сошлись во мнении, что одним из выходов является создание единой синтетической (интегральной) метрики, понятной всем сторонам. По крайней мере, введение такой метрики позволит снизить цифровой шум и, что немаловажно, задаст нашей ИТ-службе некий ориентир для принятия правильных для бизнеса решений. А еще, совсем идеально, если эта метрика позволяла бы непредвзято оценивать, на какой области нашего ИТ-окружения нам следует сосредоточить внимание (здравствуй, бюджетное планирование и портфель проектов). Таким образом, эта идеальная синтетическая метрика должна удовлетворять следующим условиям:
Бизнес-ориентация. Метрика должна отражать работу нашего ИТ-окружения не с позиции работоспособности какого-либо сервера, а с позиции того, насколько это важно нашим клиентам;
Понятность. Метрику можно однозначно интерпретировать как техническим специалистам, так и бизнесу.
Декомпозируемость. По результатам можно провести анализ, разложить нашу единую синтетическую метрику на компоненты/факторы и выделить наиболее критический. В идеальном случае на выходе получить root cause анализ.
В итоге было предложено два варианта реализации: 1) метрика доступности сервиса/объекта (Service Availability); 2) карта здоровья (Health Map). Карта здоровья в итоге оказалась более сложной как в реализации, так и в аналитическом сопровождении, и была определена как перспективная целевая схема, и на время ее доработки был выбран более простой и привычный подход с оценкой доступности сервиса, о котором и пойдет дальше речь.

Доступность сервиса - это про бизнес, но и про ИТ
Итак, что же такое доступность сервиса? Я сформулировал для себя следующее определение: Доступность сервиса (англ. Service Availability) - это такое состояние нашего ИТ-окружения, когда наши клиенты могут и хотят получить услугу и остаться в целом удовлетворенными. Стоит также подчеркнуть, что здесь может быть только два состояния: либо условия выполняются, либо нет. Все полутона только смазывают картинку. Никакой деградации, никакой сниженной производительности - все это технические показатели, необходимые исключительно инженерам для оценки динамики состояния системы.
Приведу пример: потенциальный клиент хочет подать онлайн-заявку на оформление кредита в банке, но система работает со сбоями. Из-за высокого времени ожидания ответа сервера форма постоянно сбрасывается или на ней возникают ошибки, но минут за 30 заявку можно подать. Это приводит к тому, что конверсия в воронке продаж резко падает. С позиции классического инженерного мониторинга это серьезная деградация, но услуга доступна, а вот с позиции бизнеса это неприемлемое состояние системы, когда он теряет потенциальных клиентов. В данном примере доступность сервиса должна считаться равной 0. Приведу обратный пример: у вас, в силу каких-то непредвиденных обстоятельств, полностью выключается целый ЦОД и ваши системы переходят на резервный, при этом клиенты в штатном режиме, правда, чуть дольше, чем обычно, но регистрируют заявки на кредит, и конверсия не падает. А тут мы говорим, что сервис доступен полностью и мы, как инженеры, молодцы - обеспечили горячее резервирование. Хотя при этом половина наших серверов и каналов связи находятся в коме и “не доступны”. Таким образом, определение доступности сервиса целиком находится на стороне бизнеса, а мы должны лишь зафиксировать в каком соответствующем состоянии должно находится наше ИТ-окружение. Можно поддаться искушению сделать все просто и повесить, например, метрику конверсии как KPI для ИТ-департамента, забывая при этом, что ИТ не про конверсию, его нормальная работа - необходимое, но недостаточное условие для продвижения клиентов по воронке продаж. Поэтому использование бизнес-метрики в лоб приведет к непониманию и отторжению инженерного состава. К сожалению, этому искушению простоты очень часто поддаются руководители и в результате получают прямо противоположный эффект.
Особенности реализации
Необходимо сразу пояснить, что в нашей системе зонтичного мониторинга мы зачастую имеем дело не с метриками, а с уже конкретными событиями, алертами, возникшими в различных системах мониторинга. Эти алерты мы распределяем по конфигурационным единицам (сервисы, сервера, виртуальные машины, кластеры и т.д., далее - КЕ) в ресурсно-сервисной модели. Также, в зависимости от пришедших событий, мы изменяем статус синтетических триггеров (синтетические - потому что могут рассчитываться на основании алертов из разных систем мониторинга, далее СТ). По сути синтетический триггер - это аналог аварийной ситуации / бизнес-проблемы, у которой есть начало и конец.
В нашей системе мы позволяем рассчитывать доступность, как отдельной КЕ, так и совокупную доступность группы КЕ. Метрика доступности для группы КЕ - это и есть искомая верхнеуровневая метрика доступности конечного сервиса, потому что сервис зачастую оказывается целым комплексом информационных систем и, в целом, представляет цепочку более мелких сервисов (ЦОД отвечает за сервис предоставления виртуальных машин, Облако за сервис системных компонентов, Информационная систем за прикладные сервисы и так далее). А доступность отдельной КЕ - это оценка работоспособности того или иного объекта с позиции оказания конечного сервиса. Взаимоувязка позволяет в дальнейшем проводить факторный анализ и определять вклад каждого объекта в общий результат, таким образом, находить узкое горлышко.
При построении отчета необходимо прежде всего определить список аварийных ситуаций или их совокупности, которые свидетельствуют о нарушении работы сервиса. Определить также такие дополнительные параметры (при необходимости), как:
Время работы сервиса. Например, нам важно, чтобы услуга была доступна только в дневные часы и только по праздникам;
Есть ли у нас RTO (recovery time objective) - максимально допустимое время, в течение которого наш объект может находиться в аварийном состоянии;
Учитываем или нет согласованные сервисные окна.
Вдобавок стоит учесть подтверждение аварийных ситуаций инженерами (если мы им доверяем, и такой механизм у нас есть). Потому что системы мониторинга имеют свойство иногда ошибаться.
Собственно методика
Итак, вначале рассчитаем доступность для одной КЕ. К этому этапу мы уже настроили все фильтры и определились с параметрами нашего расчета.
Для расчета доступности за период SA (Service Availability) необходимо построить функцию проблемного состояния КЕ от времени fProblem(t), которая в каждый момент времени принимает одно из четырех значений:
Значение (0) говорит о том, что в конкретный момент времени на КЕ не зафиксированы проблемы, отвечающие фильтру;
Значение (1) - в конкретный момент времени на КЕ зафиксирована проблема (-ы), подпадающая под условия;
Значение (N), что КЕ находится в необслуживаемом состоянии;
Значение (S), что КЕ находится в согласованном сервисном режиме.
В результате мы получим следующие показатели:
timeNonWorking - нерабочее время КЕ на исследуемом периоде. Значение функции равно "N";
timeWorkingProblem - время нахождения КЕ в не удовлетворяющим SLA состоянии на исследуемом промежутке времени. Значение функции равно "1";
timeWorkingService - время согласованного простоя, когда, в рабочее время, КЕ находилась в сервисном режиме. Значение функции равно "S";
timeWorkingOK - время, в которое наша КЕ удовлетворяла SLA. Функция fProblem(t) находилась в состоянии "0".
Расчет доступности за период для одиночной КЕ SA (Service Availability) осуществляется по формуле:
SA =timeWorkingOK / (timeWorkingOK+timeWorkingProblem) * 100%
 для одной КЕ")
")
Для группового расчета доступности за период SAG (Service Availability Group) необходимо построить функцию проблемного состояния КЕ от времени fProblem(t) для каждой КЕ, входящей в группу. Далее наложить получившиеся функции fProblem(t) по каждой КЕ друг на друга, исходя из определенных правил (см. Табл. 1)
ТАБЛИЦА 1.
f1 | f2 | fResult | f1 | f2 | fResult | f1 | f2 | fResult |
0 | 0 | 0 | 1 | 1 | 1 | N | N | N |
0 | 1 | 1 | 1 | S | 1 | N | S | S |
0 | N | 0 | 1 | N | 1 | S | S | S |
0 | S | 0 |
В результате получаем функцию fGroupProblem(t). Суммируем длительность участков данной функции следующим образом:
timeGroupService - время, когда fGroupProblem(t)= S;
timeGroupOK - время, когда fGroupProblem(t) = 0;
timeGroupProblem - время, когда fGroupProblem(t) = 1;
Таким образом, искомая метрика:
SAG = timeGroupOK / (timeGroupOK+timeGroupProblem) * 100%

Факторный анализ
Как я отмечал выше, важно не только получить метрику, но и суметь ее декомпозировать - разложить на составляющие, чтобы в итоге понять, какие проблемы стали критическими, а какие - наоборот, внесли меньше всего вклада в сложившуюся ситуацию. Это позволит нам, например, понять, куда стоит вкладывать наш ограниченный бюджет, где самая красная точка.
Факторный анализ позволяет определить: какой фактор-проблема повлиял за отчетный период на расчет доступности и сравнить степень такого влияния с остальным факторами-проблемами.
Предположения методики:
В методике определения доступности невозможно определить вес той или иной проблемы, если они произошли одновременно. Таким образом, единственным параметром будет длительность проблемы.
В случае, если одновременно произошли две и более проблемы, то на такой период будем считать длительность каждой с коэффициентом 1/N, где N - количество одновременно произошедших проблем.
Методика расчета:
Необходимо взять функцию fProblem(t), построенную при расчете SA.
Для каждого участка, где итоговая функция fProblem(t) = 1, составить список проблем данной КЕ, на основании которых данному участку было присвоено значение. При составлении списка необходимо учитывать и проблемы, которые начинались или заканчивались за пределами участка функции.
Проставить проблеме метрику влияния. Она равняется длительности проблемы на участке умноженную на вес. В случае, если на участке в области свой длительности проблема была единственная, то ей устанавливается вес, равный 1, в случае множественных проблем вес равен 1/N, где N - количество одновременно произошедших проблем.
При расчете следует учесть следующие моменты:
В общем случае на одном и том же участке на разных интервалах вес проблемы мог меняться из-за появления новых проблем.
Одна и та же проблема может присутствовать на разных участках fProblem(t) = 1. Например, проблема началась в пятницу, закончилась во вторник, а в выходные КЕ не обслуживается согласно SLA.
В итоге должен быть сформирован список проблем, которые участвовали в расчете функции fProblem(t). При этом у каждой проблемы должна быть посчитана метрика влияния на SA.
Необходимо обязательно верифицировать расчет. Сумма метрик влияния всех проблем должна равняться timeWorkingProblem.
Пользователю необходимо выводить относительное значение влияния в %. Для этого метрику влияния необходимо разделить на timeWorkingProblem и умножить на 100%.
В случае, если нужно группировать проблемы и показывать влияние группы, достаточно суммировать метрики всех входящих в группу проблем. Это утверждение справедливо, только если выполняется следующее условие: каждая проблема может одновременно входить только в одну группу.
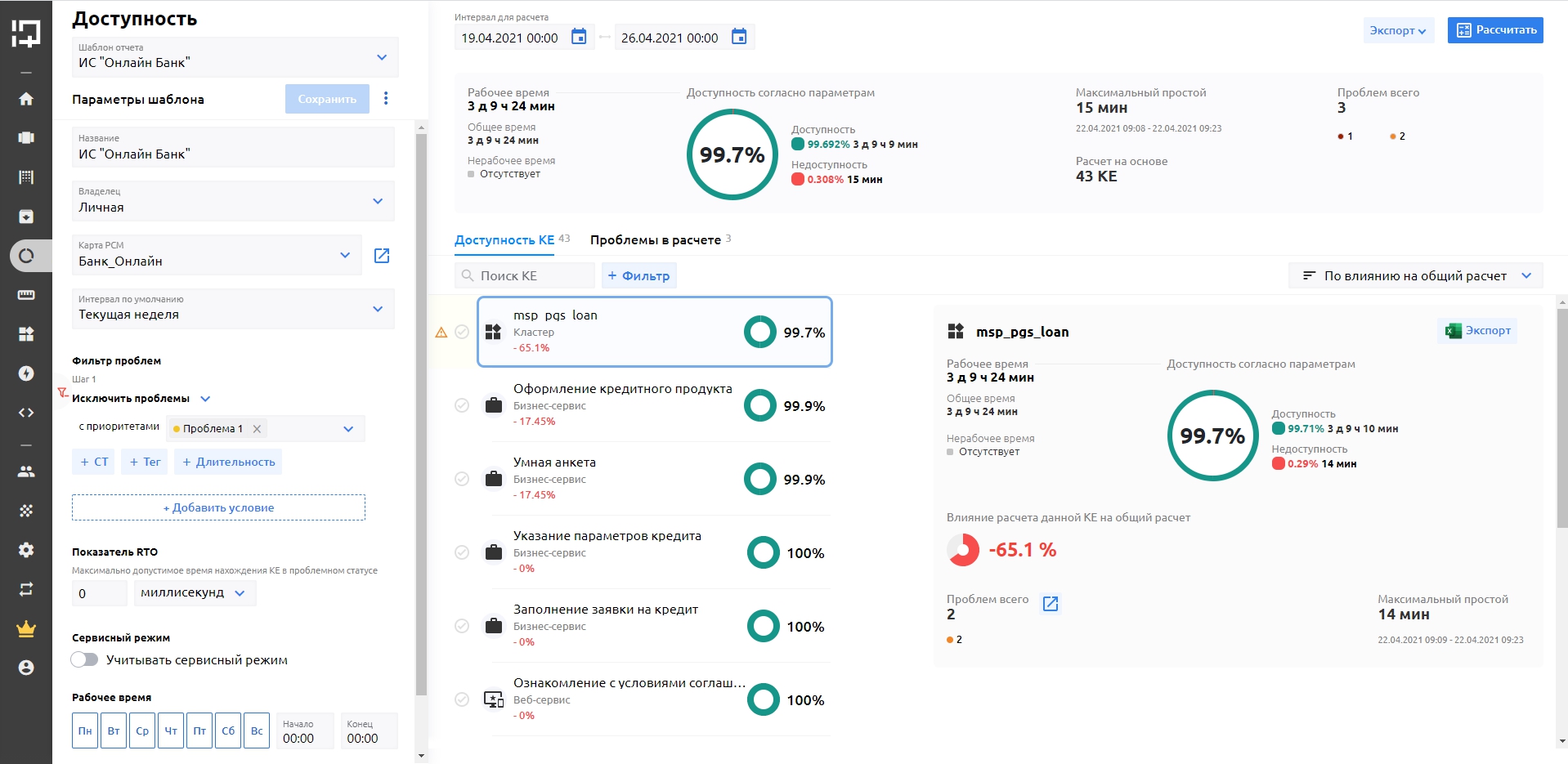
В результате получаем вот такую картину (см. рис 4.)

Промежуточные итоги
Метрика доступности сервиса обладает всеми тремя необходимыми свойствами идеальной метрики: понятность, декомпозируемость и бизнес-ориентация. Благодаря данной метрике можно однозначно оценить работоспособность ИТ-окружения с позиции вашего бизнеса, а инженерному составу держать в фокусе самое важное - уровень сервиса, который он предоставляет. Но есть и ряд серьезных недостатков: все-таки предложенная методика расчета метрик доступности носит ретроспективный характер, и не позволяет строить прогнозов; нет оценки рисков, что не позволяет принимать оперативные решения при ликвидации аварий.
Несмотря на ряд ограничений, предложенный метод был позитивно воспринят нашими пользователям, причем как со стороны менеджмента, так и со стороны инженерного состава. При разработке, для нас позитивное восприятие сразу двумя сторонами было самым важным показателем и индикатором - мы находимся на правильном пути. На текущий момент идет активное внедрение в практику работы ИТ-подразделений сразу у нескольких клиентов. Один из заказчиков, из сферы финтеха, предложил на полученные временные значения доступности сервисов накладывать финансовые потери и, таким образом, постараться в денежном выражении посчитать - насколько будут оправданы те или иные вложения в улучшение ИТ-инфраструктуры.
В любом случае, это не последняя наша попытка найти “Святой Грааль” - идеальную метрику и метод ее расчета, чтобы помочь нашим клиентам не превратить свое ИТ-окружение в тот самый “арбуз”. Следующая наша ставка на “Карту здоровья”. Надеюсь в дальнейшем продолжить делиться с вами полученными результатами.
В заключение несколько скриншотов расчета доступности в продукте MONQ.