
Каждый индекс Elasticsearch состоит из шардов. Шарды — это логическое и физическое разделение индекса. В этой статье мы расскажем о сайзинге шардов Elasticsearch — важной его части, серьёзно влияющей на производительность кластера. В высоконагруженных системах выбор правильной конфигурации архитектуры хранения позволит серьёзно сэкономить на железе. Бóльшая часть статьи основана на соответствующем разделе документации Elastic. Подробности под катом.
Сайзинг шардов Elasicsearch
Как Elasticsearch работает с шардами
Поисковые запросы обычно попадают в несколько шардов (в продукционных нагруженных средах рекомендуем использовать ноду с ролью coordinating). Каждый шард выполняет поисковый запрос в одном процессорном треде. Если запросов много, пул тредов поиска заканчивается (именно поиска, т.к. есть и другие), что приводит к возникновению очередей, снижению производительности и, как следствие, медленной скорости поиска.
Каждый шард использует ресурсы памяти и процессора. Небольшое количество бóльших по объёму шардов использует меньше ресурсов, чем множество мелких.
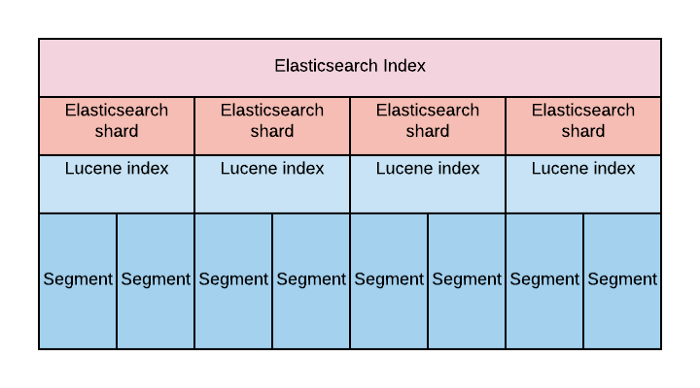
Давайте теперь краем глаза взглянем на сегменты (см. картинку ниже). Каждый шард Elasticsearch является индексом Lucene. Максимальное количество документов, которое можно закинуть в индекс Lucene — 2 147 483 519. Индекс Lucene разделен на блоки данных меньшего размера, называемые сегментами. Сегмент — это небольшой индекс Lucene. Lucene выполняет поиск во всех сегментах последовательно. Большинство шардов содержат несколько сегментов, в которых хранятся данные индекса. Elasticsearch хранит метаданные сегментов в JVM Heap, чтобы их можно было быстро извлечь для поиска. По мере роста объёма шарда его сегменты объединяются в меньшее количество более крупных сегментов. Это уменьшает количество сегментов, что означает, что в динамической памяти хранится меньше метаданных (см. также forcemerge, к которому мы вернемся чуть дальше в статье).
Еще стоит сказать о ребалансировке кластера. Если добавляется новая нода или одна из нод выходит из строя, происходит ребалансировка кластера. Ребалансировка сама по себе недешёвая с точки зрения производительности операция. Кластер сбалансирован, если он имеет равное количество шардов на каждой ноде и отсутствует концентрация шардов любого индекса на любой ноде. Elasticsearch запускает автоматический процесс, называемый ребалансировкой, который перемещает шарды между узлами в кластере, чтобы его сбалансировать. При перебалансировке применяются заранее заданные правила выделения сегментов (об allocation awareness и других правилах мы подробнее расскажем в одной из следующих статей). Если вы используете data tiers, Elasticsearch автоматически разместит каждый шард на соответствующем уровне. Балансировщик работает независимо на каждом уровне.
Как заставить Elasticsearch ещё лучше работать с шардами
Правильно удалять данные. Если вы удалили документ, из файловой системы он удалится не сразу. Вместо этого, Elasticsearch помечает документ как удаленный на каждом шарде. Отмеченный документ будет продолжать использовать ресурсы, пока он не будет удален во время периодического слияния сегментов. Если нужно физически освободить место, лучше всего сразу удалять индексы целиком, которые в итоге освободят файловую системы.
Создавать шарды размером от 10 до 50 ГБ. Elastic говорит, шарды размером более 50 ГБ потенциально могут снизить вероятность восстановления кластера после сбоя. Из-за той самой ребалансировки, о которой мы говорили в начале статьи. Ну, и большие шарды накладнее передавать по сети. Предел в 50 ГБ выглядит, конечно, как сферический конь в вакууме, поэтому мы сами больше склоняемся к 10 ГБ. Вот тут человек советует 10 ГБ и смотреть на размер документов в следующем плане:
- От 0 до 4 миллионов документов на индекс: 1 шард.
- От 4 до 5 миллионов документов на индекс: 2 шарда.
- Более 5 миллионов документов считать по формуле: (количество документов / 5 миллионов) + 1 шард.
20 или менее шардов на 1 ГБ JVM Heap. Количество шардов, которыми может жонглировать нода, пропорциональны объему JVM Heap ноды. Например, нода с 30 ГБ JVM Heap должна иметь не более 600 шардов. Чем меньше, тем, скорее всего, лучше. Если это пропорция не выполняется можно добавить ноду. Посмотрим сколько там используется JVM Heap на каждой ноде:
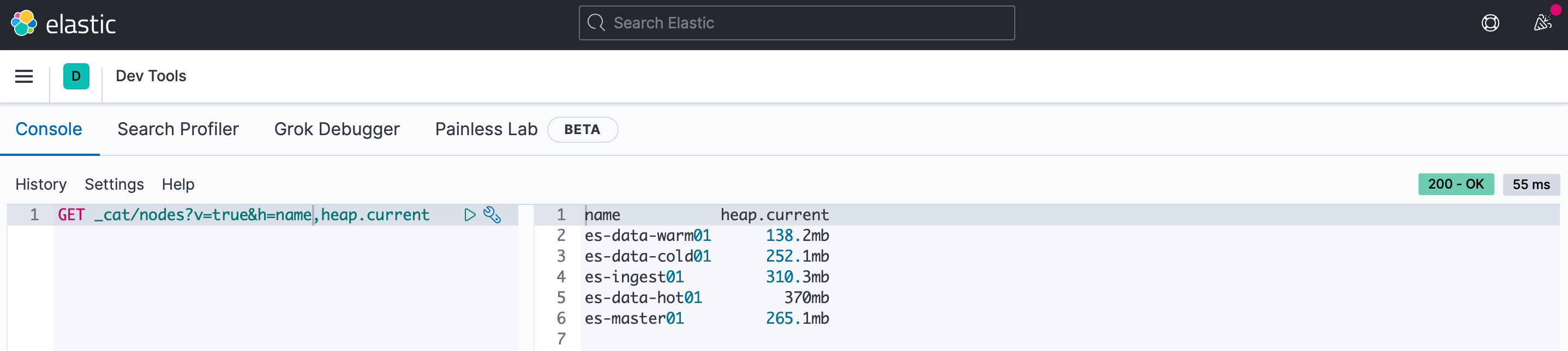
А теперь посмотрим сколько шардов на каждой ноде и видим, что с нашим тестовым стендов всё в порядке. Жить будет.
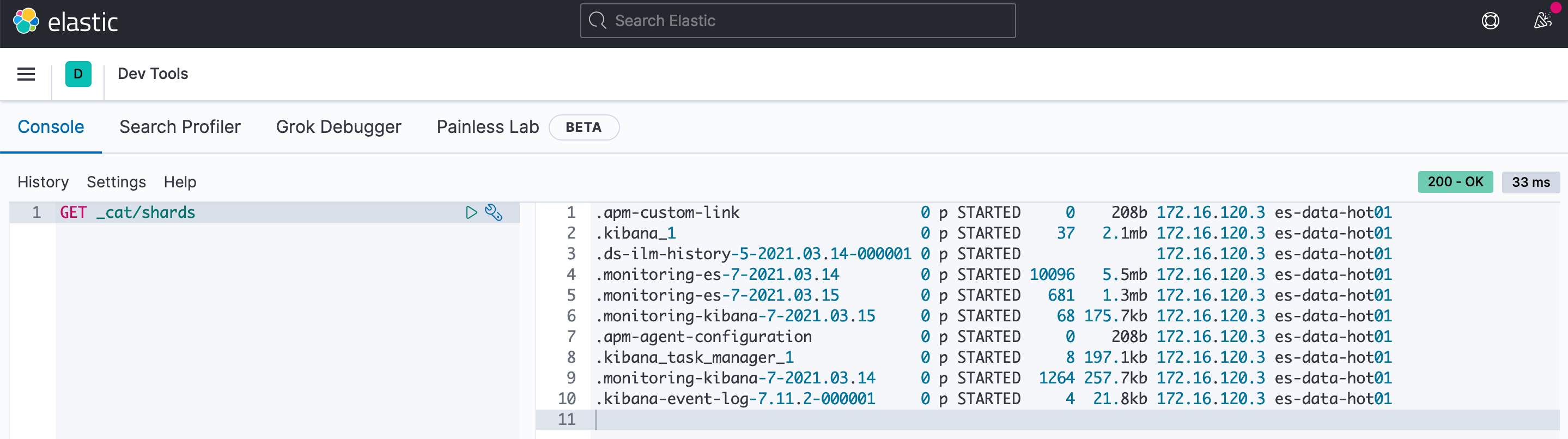
Количество шардов на узле можно ограничить при помощи опции index.routing.allocation.total_shards_per_node, но если их уже много, присмотритесь к Shrink API.
Совсем необязательно создавать индексы размером в 1 день. Часто встречали у заказчиков подход, при котором каждый новый день создавался новый индекс. Иногда это оправдано, иногда можно и месяц подождать. Ролловер ведь можно запускать не только с max_age, но и с max_size или max_docs. На Хабре была статья, в которой Адель Сачков, в ту пору из Яндекс Денег (сейчас уже нет), делился полезным лайфхаком: создавал индексы не в момент наступления новых суток, а заранее, чтобы этот процесс не аффектил на производительность кластера, но у него там были микросервисы.
… каждые сутки создаются новые индексы по числу микросервисов — поэтому раньше каждую ночь эластик впадал в клинч примерно на 8 минут, пока создавалась сотня новых индексов, несколько сотен новых шардов, график нагрузки на диски уходил «в полку», вырастали очереди на отправку логов в эластик на хостах, и Zabbix расцветал алертами как новогодняя ёлка. Чтобы этого избежать, по здравому размышлению был написан скрипт на Python для предварительного создания индексов.
С новогодней ёлкой неплохой каламбурчик получился.
Не пренебрегайте ILM и forcemerge. Индексы должны плавно перетекать между соответствующими нодами согласно ILM. В OpenDistro есть аналогичный механизм.
С индексами, в которые уже не ведется запись можно выполнить forcemerge — слияние меньших по размеру сегментов в более крупные. Это в итоге снизит накладные расходы на эксплуатацию шардов и повысит скорость поиска. Forcemerge требует значительных ресурсов, поэтому лучше это делать к какие-то в непиковые часы. Добавим, что forcemerge это фактические создание нового сегмента из двух старых, поэтому свободное место на диске лишним точно не будет.
Приходите в комментарии и расскажите о своём опыте с раскладыванием шардов по нодам. Было бы интересно узнать о том, что работает в вашем случае.
Анонс вебинара. Elastic приглашает посетить 17 марта в 12 часов по московскому времени вебинар Elastic Telco Day: Applications and operational highlights from telco environments. Эксперты расскажут о применении в решений Elastic в телекоме. Регистрация.
Предложения по митапу. Планируем проведение онлайн-митап по Elastic в апреле. Напишите в комментариях или в личку какие темы вам было бы интересно разобрать, каких спикеров услышать. Если бы вы хотели сами выступить и у вас есть что рассказать, тоже напишите. Вступайте в группу Elastic Moscow User Group, чтобы не пропустить анонс митапа.
Канал в телеге. Подписывайтесь на наш канал Elastic Stack Recipes, там интересные материалы и анонсы мероприятий.
Читайте наши другие статьи:
- Определение объёма кластера Elasticsearch и тестирование производительности в Rally
- Сайзинг Elasticsearch
- Как лицензируется и чем отличаются лицензии Elastic Stack (Elasticsearch)
- Разбираемся с Machine Learning в Elastic Stack (он же Elasticsearch, он же ELK)
- Elastic под замком: включаем опции безопасности кластера Elasticsearch для доступа изнутри и снаружи
Если вас интересуют услуги внедрения, администрирования и поддержки Elastic Stack, вы можете оставить заявку в форме обратной связи на специальной странице.



