
Если вы разработчик и перед вами стоит задача выбора кодировки, то почти всегда правильным решением будет Юникод. Конкретный способ представления зависит от контекста, но чаще всего тут тоже есть универсальный ответ — UTF-8. Он хорош тем, что позволяет использовать все символы Юникода, не тратя слишком много байт в большинстве случаев. Правда, для языков, использующих не только латиницу, «не слишком много» — это как минимум два байта на символ. Можно ли лучше, не возвращаясь к доисторическим кодировкам, ограничивающим нас всего 256 доступными символами?
Ниже предлагаю ознакомиться с моей попыткой дать ответ на этот вопрос и реализацию относительно простого алгоритма, позволяющего хранить строчки на большинстве языков мира, не добавляя той избыточности, которая есть в UTF-8.
Дисклеймер. Сразу сделаю несколько важных оговорок: описанное решение не предлагается как универсальная замена UTF-8, оно подходит только в узком списке случаев (о них ниже), и его ни в коем случае нельзя использовать для взаимодействия со сторонними API (которые о нём и знать не знают). Чаще всего для компактного хранения больших объемов текстовых данных подойдут алгоритмы сжатия общего назначения (например, deflate). Кроме того, уже в процессе создания своего решения я нашёл существующий стандарт в самом Юникоде, который решает ту же задачу — он несколько сложнее (и нередко хуже), но всё-таки является принятым стандартом, а не собранным на коленке. О нём я тоже расскажу.
О Unicode и UTF-8
Для начала — несколько слов о том, что вообще такое Unicode и UTF-8.
Как известно, раньше имели популярность 8-битные кодировки. С ними всё было просто: 256 символов можно занумеровать числами от 0 до 255, а числа от 0 до 255 очевидным образом представимы в виде одного байта. Если возвращаться к самым истокам, то кодировка ASCII и вовсе ограничивается 7 битами, поэтому самый старший бит в её байтовом представлении равен нулю, и большинство 8-битных кодировок с ней совместимы (они различаются только в «верхней» части, где старший бит — единица).
Чем же от тех кодировок отличается Юникод и почему с ним связано сразу множество конкретных представлений — UTF-8, UTF-16 (BE и LE), UTF-32? Разберёмся по порядку.
Основной стандарт Юникода описывает только соответствие между символами (а в некоторых случаях — отдельными компонентами символов) и их номерами. И возможных номеров в этом стандарте очень много — от
0x00 до 0x10FFFF (1 114 112 штук). Если бы мы хотели положить число в таком диапазоне в переменную, ни 1, ни 2 байт нам бы не хватило. А так как под работу с трехбайтовыми числами наши процессоры не очень заточены, мы были бы вынуждены использовать целых 4 байта на один символ! Это и есть UTF-32, но именно из-за этой «расточительности» этот формат не пользуется популярностью.К счастью, символы внутри Юникода упорядочены не случайно. Всё их множество разделено на 17 «плоскостей», каждая из которых содержит 65536 (
0x10000) «кодовых точек». Понятие «кодовой точки» тут — это просто номер символа, присвоенный ему Юникодом. Но, как было сказано выше, в Юникоде занумерованы не только отдельные символы, но также их компоненты и служебные пометки (а иногда и вовсе номеру ничего не соответствует — возможно, до поры до времени, но для нас это не так важно), поэтому корректнее всегда говорить именно про число самих номеров, а не символов. Однако далее для краткости я часто буду употреблять слово «символ», подразумевая термин «кодовая точка».Плоскости Юникода. Как видно, большая часть (плоскости с 4 по 13) всё ещё не использована.
Что самое замечательное — вся основная «мякотка» лежит в нулевой плоскости, она называется "Basic Multilingual Plane". Если строчка содержит текст на одном из современных языков (включая китайский), за пределы этой плоскости вы не выйдете. Но отсекать остальную часть Юникода тоже нельзя — например, эмодзи в основном находятся в конце следующей по счёту плоскости, "Supplementary Multilingual Plane" (она простирается от
0x10000 до 0x1FFFF). Поэтому UTF-16 поступает так: все символы, попадающие в Basic Multilingual Plane, кодируются «как есть», соответствующим им двухбайтовым числом. Однако часть чисел в этом диапазоне вообще не обозначают конкретные символы, а указывают на то, что следом за этой парой байт нужно рассмотреть ещё одну — скомбинировав значения этих четырёх байт вместе, у нас получится число, охватывающее весь допустимый диапазон Юникода. Такое представление называется «суррогатными парами» — возможно, вы о них слышали.Таким образом, UTF-16 требует два или (в очень редких случаях) четыре байта на одну «кодовую точку». Это лучше, чем постоянно использовать четыре байта, но латиница (и другие ASCII-символы) при таком кодировании расходует половину занимаемого места на нули. UTF-8 призван это поправить: ASCII в нём занимает, как раньше, всего один байт; коды от
0x80 до 0x7FF — два байта; от 0x800 до 0x7FFF — три, а от 0x8000 до 0x1FFFF — четыре. С одной стороны, латинице стало хорошо: вернулась совместимость с ASCII, да и распределение более равномерно «размазано» от 1 до 4 байт. Но алфавиты, отличные от латинского, увы, никак не выигрывают по сравнению с UTF-16, а многие и вовсе теперь требуют трёх байт вместо двух — диапазон, покрываемый двухбайтовой записью, сузился в 32 раза, с 0xFFFF до 0x7FF, и в него не попадает уже ни китайский, ни, к примеру, грузинский. Кириллице и ещё пяти алфавитам — ура — повезло, 2 байта на символ.Почему так выходит? Давайте посмотрим, как UTF-8 представляет коды символов:
Непосредственно для представления чисел тут использованы биты, помеченные символом
x. Видно, что в двухбайтовой записи таких бит лишь 11 (из 16). Ведущие биты тут несут только служебную функцию. В случае с четырёхбайтовой записью и вовсе под номер кодовой точки отведён 21 бит из 32 — казалось бы, тут хватило бы и трёх байт (которые дают суммарно 24 бита), но служебные маркеры съедают слишком много.Плохо ли это? На самом деле, не очень. С одной стороны — если мы сильно заботимся о занимаемом пространстве, у нас есть алгоритмы сжатия, которые легко устранят всю лишнюю энтропию и избыточность. С другой — целью Юникода было дать максимально универсальное кодирование. Например, закодированную в UTF-8 строчку мы можем доверить коду, который раньше работал только с ASCII, и не бояться, что он там увидит символ из ASCII-диапазона, которого там на самом деле нет (ведь в UTF-8 все байты, начинающиеся с нулевого бита — это именно ASCII и есть). А если мы захотим вдруг отрезать маленький хвост от большой строки, не декодируя её с самого начала (или восстановить часть информации после повреждённого участка) — нам несложно найти то смещение, где начинается какой-то символ (достаточно пропустить байты, имеющие битовый префикс
10).Зачем же тогда выдумывать что-то новое?
В то же время, изредка бывают ситуации, когда алгоритмы сжатия вроде deflate плохоприменимы, а добиться компактного хранения строк хочется. Лично я столкнулся с такой задачей, размышляя о построении сжатого префиксного дерева для большого словаря, включающего слова на произвольных языках. С одной стороны — каждое слово очень короткое, поэтому сжимать его будет неэффективно. С другой — реализация дерева, которую я рассматривал, была рассчитана на то, что каждый байт хранимой строки порождал отдельную вершину дерева, так что минимизировать их количество было очень полезно. В моей библиотеке Az.js (как и в pymorphy2, на котором она основана) подобная проблема решается просто — строки, упакованные в DAWG-словарь, хранятся там в старой доброй CP1251. Но, как нетрудно понять, это хорошо работает только для ограниченного алфавита — строчку на китайском в такой словарь уже не сложить.
Отдельно отмечу ещё один неприятный нюанс, который возникает при использовании UTF-8 в такой структуре данных. На картинке выше видно, что при записи символа в виде двух байт, биты, относящиеся к его номеру, не идут подряд, а разорваны парой бит
10 посередине: 110xxxxx 10xxxxxx. Из-за этого, когда в коде символа переполняются младшие 6 бит второго байта (т.е. происходит переход 10111111 → 10000000), то меняется и первый байт тоже. Получается, что буква «п» обозначается байтами 0xD0 0xBF, а следующая за ней «р» — уже 0xD1 0x80. В префиксном дереве это приводит к расщеплению родительской вершины на две — одной для префикса 0xD0, и другой для 0xD1 (хотя вся кириллица могла бы кодироваться только вторым байтом).Что у меня получилось
Столкнувшись с этой задачей я решил поупражняться в играх с битами, а заодно чуть лучше познакомиться со структурой Юникода в целом. Результатом стал формат кодирования UTF-C («C» от compact), который тратит не более 3 байт на одну кодовую точку, а очень часто позволяет тратить лишь один лишний байт на всю кодируемую строчку. Это приводит к тому, что на многих не-ASCII алфавитах такое кодирование оказывается на 30-60% компактнее UTF-8.
Я оформил примеры реализации алгоритмов кодирования и декодирования в виде библиотек на JavaScript и Go, вы можете свободно использовать их в своём коде. Но я всё же подчеркну, что в некотором смысле этот формат остаётся «велосипедом», и я не рекомендую его использовать без осознания того, зачем он вам нужен. Это всё-таки больше эксперимент, чем серьёзное «улучшение UTF-8». Тем не менее, код там написан аккуратно, лаконично, с большим числом комментариев и покрытием тестами.
Результат выполнения тестов и сравнение с UTF-8
Ещё я сделал демо-страничку, где можно оценить работу алгоритма, а далее я расскажу подробнее о его принципах и процессе разработки.
Устраняем избыточные биты
За основу я взял, конечно, UTF-8. Первое и самое очевидное, что в нём можно поменять — уменьшить число служебных бит в каждом байте. Например, первый байт в UTF-8 всегда начинается либо с
0, либо с 11 — а префикс 10 есть только у следующих байт. Заменим префикс 11 на 1, а у следующих байт уберём префиксы совсем. Что получится?0xxxxxxx — 1 байт 10xxxxxx xxxxxxxx — 2 байта 110xxxxx xxxxxxxx xxxxxxxx — 3 байтаСтоп, а где же четырёхбайтовая запись? А она стала не нужна — при записи тремя байтами у нас теперь доступен 21 бит и этого с запасом хватает на все числа до
0x10FFFF.Чем мы пожертвовали тут? Самое главное — обнаружением границ символов из произвольного места буфера. Мы не можем ткнуть в произвольный байт и от него найти начало следующего символа. Это — ограничение нашего формата, но на практике необходимость в таком встаёт нечасто. Обычно мы способны пробежать буфер с самого начала (особенно когда речь идёт о коротких строках).
Ситуация с покрытием языков 2 байтами тоже стала лучше: теперь двухбайтовый формат даёт диапазон в 14 бит, а это коды до
0x3FFF. Китайцам не везёт (их иероглифы в основном лежат в диапазоне от 0x4E00 до 0x9FFF), но вот грузинам и многим другим народам стало повеселее — их языки тоже укладываются в 2 байта на символ.Вводим состояние энкодера
Давайте теперь подумаем о свойствах самих строчек. В словаре чаще всего лежат слова, написанные символами одного алфавита, да и для многих других текстов это тоже верно. Было бы хорошо один раз указать этот алфавит, а дальше указывать только номер буквы внутри него. Посмотрим, поможет ли нам расположение символов в таблице Юникода.
Как было сказано выше, Юникод поделён на плоскости по 65536 кодов каждая. Но это не очень полезное деление (как уже сказано, чаще всего мы находимся в нулевой плоскости). Более интересным является деление на блоки. Эти диапазоны уже не имеют фиксированной длины, и несут больше смысла — как правило, каждый объединяет символы одного алфавита.
Блок, содержащий символы бенгальского алфавита. К сожалению, по историческим причинам, это пример не очень плотной упаковки — 96 символов хаотично раскиданы по 128 кодовым точкам блока.
Начала блоков и их размеры всегда кратны 16 — сделано это просто для удобства. Кроме того, многие блоки начинаются и заканчиваются на значениях, кратных 128 или даже 256 — например, основная кириллица занимает 256 байт от
0x0400 до 0x04FF. Это довольно удобно: если мы один раз сохраним префикс 0x04, то дальше любой кириллический символ можно записывать одним байтом. Правда, так мы потеряем возможность вернуться к ASCII (и к любым другим символам вообще). Поэтому делаем так:- Два байта
10yyyyyy yxxxxxxxне только обозначают символ с номеромyyyyyy yxxxxxxx, но и меняют текущий алфавит наyyyyyy y0000000(т.е. запоминаем все биты, кроме младших 7 бит); - Один байт
0xxxxxxxэто символ текущего алфавита. Его нужно просто сложить с тем смещением, которое мы запомнили на шаге 1. Пока алфавит мы не меняли, смещение равно нулю, так что совместимость с ASCII мы сохранили.
Аналогично для кодов, требующих 3 байт:
- Три байта
110yyyyy yxxxxxxx xxxxxxxxобозначают символ с номеромyyyyyy yxxxxxxx xxxxxxxx, меняют текущий алфавит наyyyyyy y0000000 00000000(запомнили всё, кроме младших 15 бит), и ставят флажок, что мы теперь в длинном режиме (при смене алфавита обратно на двухбайтовый этот флажок мы сбросим); - Два байта
0xxxxxxx xxxxxxxxв длинном режиме это символ текущего алфавита. Аналогично, мы складываем его со смещением из шага 1. Вся разница только в том, что теперь мы читаем по два байта (потому что мы переключились в такой режим).
Звучит неплохо: теперь пока нам нужно кодировать символы из одного и того же 7-битного диапазона Юникода, мы тратим 1 лишний байт в начале и всего по байту на каждый символ.
Работа одной из ранних версий. Уже нередко обходит UTF-8, но ещё есть что улучшать.
Что стало хуже? Во-первых, у нас появилось состояние, а именно смещение текущего алфавита и флажок длинного режима. Это нас дополнительно ограничивает: теперь одни и те же символы могут быть закодированы по-разному в разных контекстах. Поиск подстрок, например, придётся делать уже с учётом этого, а не просто сравнивая байты. Во-вторых, как только мы сменили алфавит, стало плохо с кодированием ASCII-символов (а это не только латиница, но и базовая пунктуация, включая пробелы) — они требуют повторной смены алфавита в 0, то есть снова лишнего байта (а потом ещё одного, чтобы вернуться к нашему основному).
Один алфавит хорошо, два — лучше
Попробуем чуть-чуть поменять наши битовые префиксы, втиснув к трём вышеописанным ещё один:
0xxxxxxx — 1 байт в обычном режиме, 2 в длинном 11xxxxxx — 1 байт 100xxxxx xxxxxxxx — 2 байта 101xxxxx xxxxxxxx xxxxxxxx — 3 байтаТеперь в двухбайтовой записи на один доступный бит стало меньше — помещаются кодовые точки вплоть до
0x1FFF, а не 0x3FFF. Впрочем, всё ещё ощутимо больше, чем в двухбайтовых кодах UTF-8, большая часть распространённых языков всё ещё влезает, самая заметная потеря — выпала хирагана и катакана, японцы в печали.Что же за новый код
11xxxxxx? Это небольшой «загашник» размером в 64 символа, он дополняет наш основной алфавит, поэтому я назвал его вспомогательным (auxiliary) алфавитом. Когда мы переключаем текущий алфавит, то кусок старого алфавита становится вспомогательным. Например, переключились с ASCII на кириллицу — в «загашнике» теперь 64 символа, содержащих латиницу, цифры, пробел и запятую (самые частые вставки в не-ASCII текстах). Переключились обратно на ASCII — и вспомогательным алфавитом станет основная часть кириллицы.Благодаря доступу к двум алфавитам, мы можем справиться с большим количеством текстов, имея минимальные затраты на переключение алфавитов (пунктуация чаще всего будет приводить к возврату в ASCII, но после этого многие не-ASCII символы мы будем доставать уже из дополнительного алфавита, без повторного переключения).
Бонус: обозначив допалфавит префиксом
11xxxxxx и выбрав его начальное смещение равным 0xC0, у нас получается частичная совместимость с CP1252. Иными словами, многие (но не все) западноевропейские тексты, закодированные в CP1252, будут выглядеть так же и в UTF-C.Тут, правда, возникает трудность: как из основного алфавита получить вспомогательный? Можно оставить то же самое смещение, но — увы — тут структура Юникода уже играет против нас. Очень часто основная часть алфавита находится не в начале блока (например, русская заглавная «А» имеет код
0x0410, хотя кириллический блок начинается с 0x0400). Таким образом, взяв в «загашник» первые 64 символа, мы, возможно, утратим доступ к хвостовой части алфавита.Для устранения этой проблемы я вручную прошёлся по некоторым блокам, соответствующим различным языкам, и указал для них смещение вспомогательного алфавита внутри основного. Латиницу, в порядке исключения, вообще переупорядочил наподобие base64.
Финальные штрихи
Давайте напоследок подумаем, где мы ещё можем что-то доработать.
Заметим, что формат
101xxxxx xxxxxxxx xxxxxxxx позволяет закодировать числа вплоть до 0x1FFFFF, а Юникод заканчивается раньше, на 0x10FFFF. Иными словами, последняя кодовая точка будет представлена как 10110000 11111111 11111111. Стало быть, мы можем сказать, что если первый байт имеет вид 1011xxxx (где xxxx больше 0), то он обозначает что-то ещё. Например, можно добавить туда ещё 15 символов, постоянно доступные для кодирования одним байтом, но я решил поступить по-другому.Посмотрим на те блоки Юникода, которые требуют трёх байт сейчас. В основном, как уже было сказано, это китайские иероглифы — но с ними трудно что-то сделать, их 21 тысяча. Но ещё туда улетела хирагана с катаканой — а их уже не так много, меньше двухсот. И, раз уж мы вспомнили про японцев — там же лежат эмодзи (на самом деле они много где раскиданы в Юникоде, но основные блоки в диапазоне
0x1F300 – 0x1FBFF). Если подумать о том, что сейчас существуют эмодзи, которые собираются из сразу нескольких кодовых точек (например, эмодзи Поэтому выбираем несколько избранных диапазонов, соответствующих эмодзи, хирагане и катакане, перенумеровываем их в один непрерывный список и кодируем в виде двух байт вместо трёх:
1011xxxx xxxxxxxx Отлично: вышеупомянутый эмодзи
Попробуем исправить ещё одну проблему. Как мы помним, основной алфавит это по сути старшие 6 бит, которые мы держим в уме, и приклеиваем к коду каждого очередного декодируемого символа. В случае с китайскими иероглифами, которые находятся в блоке
0x4E00 – 0x9FFF, это либо бит 0, либо 1. Это не очень удобно: нам нужно будет постоянно переключать алфавит между этими двумя значениями (т.е. тратить по три байта). Но заметим, что в длинном режиме из самого кода мы можем вычесть число символов, которое мы кодируем с помощью короткого режима (после всех вышеописанных хитростей это 10240) — тогда диапазон иероглифов сместится к 0x2600 – 0x77FF, и в этом случае на всём этом диапазоне старшие 6 бит (из 21) будут равны 0. Таким образом, последовательности иероглифов будут использовать по два байта на иероглиф (что оптимально для такого большого диапазона), не вызывая переключений алфавита. Альтернативные решения: SCSU, BOCU-1
Знатоки Unicode, ещё только прочитав название статьи, скорее всего, поспешат напомнить, что непосредственно среди стандартов Юникода есть Standard Compression Scheme for Unicode (SCSU), который описывает способ кодирования, весьма сходный с описанным в статье.
Признаюсь честно: о его существовании я узнал только уже глубоко погрузившись в написание своего решения. Знай о нём с самого начала, я, вероятно, попробовал бы написать его реализацию вместо придумывания собственного подхода.
Что занятно, SCSU использует идеи, очень похожие на те, к которым я пришёл самостоятельно (вместо понятия «алфавитов» там используются «окна», и их доступно больше, чем у меня). В то же время, у этого формата тоже есть минусы: он чуть ближе к алгоритмам сжатия, нежели кодирования. В частности, стандарт даёт множество способов представления, но не говорит, как выбрать из них оптимальный — для этого энкодер должен применять какие-то эвристики. Таким образом, SCSU-энкодер, дающий хорошую упаковку, будет сложнее и более громоздок, чем мой алгоритм.
Для сравнения я перенёс относительно простую реализацию SCSU на JavaScript — по объему кода она оказалась сравнима с моим UTF-C, но в ряде случаев показала результат на десятки процентов хуже (иногда она может и превосходить его, но ненамного). Например, тексты на иврите и греческом UTF-C закодировал аж на 60% лучше, чем SCSU (вероятно, из-за их компактных алфавитов).
Отдельно добавлю, что кроме SCSU существует также другой способ компактного представления Юникода — BOCU-1, но он ставит целью совместимость с MIME (что мне не требовалось), и использует несколько иной подход к кодированию. Его эффективность я не оценивал, но мне кажется, что она вряд ли будет выше, чем SCSU.
Возможные доработки
Приведённый мной алгоритм не универсален by design (в этом, наверное, мои цели сильнее всего расходятся с целями консорциума Unicode). Я уже упомянул, что он разрабатывался преимущественно под одну задачу (хранение мультиязычного словаря в префиксном дереве), и некоторые его особенности могут плохо подходить для других задач. Но тот факт, что он не является стандартом, может быть и плюсом — вы можете легко доработать его под свои нужды.
Например, очевидным образом можно избавиться от наличия состояния, сделать кодирование stateless — просто не обновлять переменные
offs, auxOffs и is21Bit в энкодере и декодере. В таком случае не получится эффективно упаковывать последовательности символов одного алфавита, зато будет гарантия, что один и тот же символ всегда кодируется одними и теми же байтами, независимо от контекста.Кроме того, можно заточить кодировщик под конкретный язык, поменяв состояние по умолчанию — например, ориентируясь на русские тексты, выставить в начале энкодера и декодера
offs = 0x0400 и auxOffs = 0. В особенности это имеет смысл именно в случае stateless режима. В целом это будет похоже на использование старой восьмибитной кодировки, только не лишает возможности вставлять символы из всего Юникода по необходимости.Ещё один недостаток, упомянутый ранее — в объемном тексте, закодированном в UTF-C, нет быстрого способа найти границу символа, ближайшего к произвольному байту. Отрезав от закодированного буфера последние, скажем, 100 байт, вы рискуете получить мусор, с которым ничего не сделать. На хранение многогигабайтных логов кодировка и не рассчитана, но в целом это можно поправить. Байт
0xBF никогда не должен встречаться в качестве первого байта (но может быть вторым или третьим). Поэтому при кодировании можно вставлять последовательность 0xBF 0xBF 0xBF каждые, скажем, 10 Кб — тогда при необходимости найти границу будет достаточно просканировать выбранный кусок до тех пор, пока не найдётся подобный маркер. Вслед за последним 0xBF гарантированно будет начало символа. (При декодировании эту последовательность из трёх байт, конечно, нужно будет игнорировать.)Подводя итог
Если вы дочитали досюда — поздравляю! Надеюсь, вы, как и я, узнали что-то новое (или освежили в памяти старое) об устройстве Юникода.
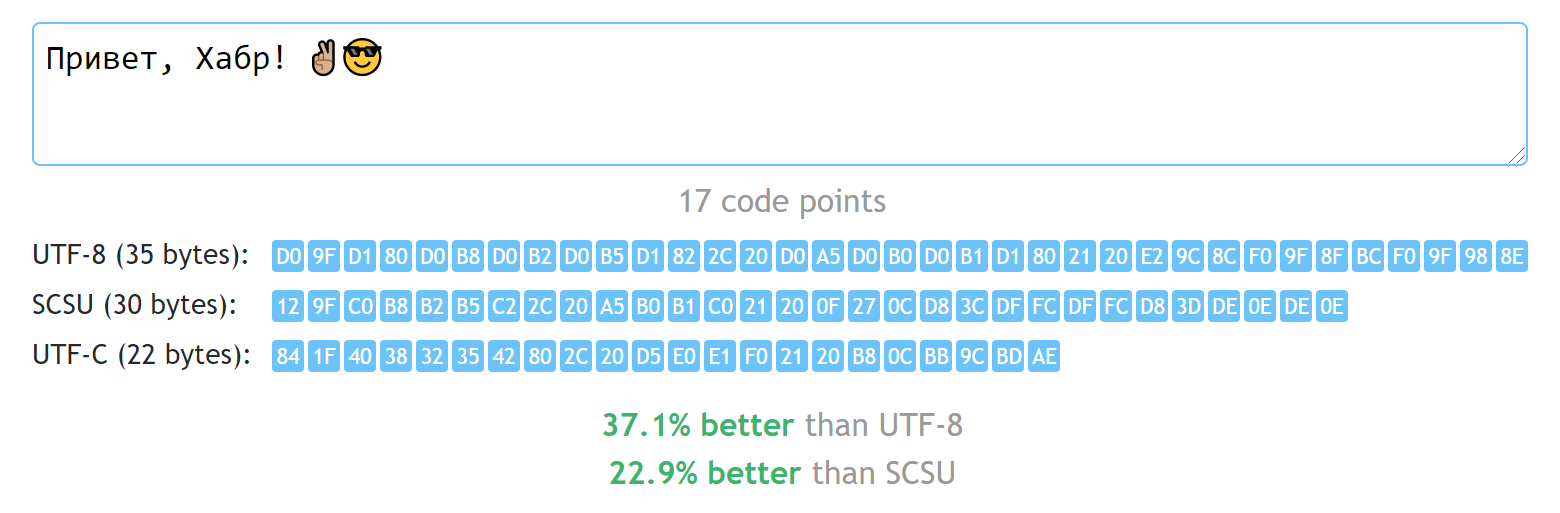
Демонтрационная страница. На примере иврита видны преимущества как перед UTF-8, так и перед SCSU.
Не стоит рассматривать вышеописанные изыскания как посягательство на стандарты. Однако я в целом доволен результатами своих наработок, поэтому рад ими поделиться: например, JS-библиотека в минифицированном виде весит всего 1710 байт (и не имеет зависимостей, конечно). Как я упоминал выше, с её работой можно ознакомиться на демо-страничке (там же есть набор текстов, на которых её можно посравнивать с UTF-8 и SCSU).
Напоследок ещё раз напомню, что закодированная с помощью UTF-C строка не обеспечивает ASCII transparency — в ней могут находиться байты, соответствующие ASCII-символам. Попросту говоря — использовать её можно только внутренне, в противном случае вы рискуете получить непредвиденные уязвимости.



