
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Это история про то, как нам удалось написать довольно сложную business-critical систему, и добиться, чтобы она была стабильной даже без юнит-тестов (WAT?!).
Представьте: ERP-система в области логистики. Сложная бизнес-логика, составление расписаний, электронный учет рабочего времени, планирование и управление ресурсами со статистическими подсказками на основе сотен миллионов записей геораспределенных исходных данных, мониторинг прогресса >1000 одновременно работающих водителей в реальном времени, интеграция с 7 другими системами (в том числе финансовыми), и т.д., в общем большая и сложная система.
Систему начали с нуля, писали на ASP.Net Web API, Entity Framework и AngularJs (Реакта и Vue тогда еще не было, дело было в далёком 2013), небольшой, но высокопрофессиональной командой, по Scrum, написали за 4 месяца первую базовую продакшн-версию с минимальным функционалом, впоследствии функционал постепенно наращивали, система развивается и по сей день. Через год после начала разработки, система уже была внедрена по всей компании и являлась business-critical, т.е. остановка системы даже на несколько часов могла повлечь довольно существенные убытки для компании.
И возможно, вам сейчас станет немного жутковато, но мы обошлись без unit-тестов и выделенных тестировщиков. При этом, на протяжении нескольких лет, разработка нового функционала шла очень активно, выгрузки на продакшн в среднем 1 раз в неделю, постоянно менялись люди в команде (потому что консалтинг компания), и… система не падала и даже совсем не возникало сколь-нибудь критичных багов, только мелкие баги и косметика. Просто везет, или есть какой-то секрет?
Бесспорно, юнит-тесты — очень хорошая штука. Прошу понять меня правильно, я ни в коем случае в этой статье не пытаюсь сказать что они не нужны или их не надо писать. Нужны. И надо.
Но с ними, нужно это понимать, немало тонкостей. Во-первых, конечно нужно, чтобы тесты писали грамотные квалифицированные люди, понимающие как это работает: иначе тесты начинают усложняться, проверять не то и не так, давать ложное чувство уверенности и т.д. Но наверное еще более важно, что тесты хорошо подходят не для всех возможных случаев.
Сколько раз я видел эти классические слова: «это не тесты у вас не работают, это вы просто их писать не умеете». Но ведь так можно любую неподходящую технологию оправдать… Нет, я думаю, не всё так просто. Вот с паттернами к примеру. Любой более-менее опытный программист знает: паттерны это не панацея, универсальных решений не бывает, всегда нужно смотреть по ситуации, что конкретно использовать и как именно.
Вот и тесты такие же на мой взгляд — да, есть случаи, когда автоматические тесты подходят идеально: например, если реализуешь какой-нибудь протокол, или пишешь компилятор, или библиотеку со строго заданным API и прочее. В таких случаях есть четкие требования и они описаны на низком уровне — и тесты работают замечательно. А по TDD такие проекты делать и вовсе сплошное удовольствие.
Но есть и бизнес-приложения. Требования вроде и есть, но они описаны на очень высоком уровне, и мапить их в тесты мягко сказать непросто. Вроде, потому что заказчик в начале проекта сам не до конца понимает, что конкретно ему нужно. Это выясняется в деталях только в процессе, на Sprint Demo или на дэйли. Если разработка действительно agile, то требования часто меняются, а знаете что такое изменение требований на высоком уровне, в разрезе тестов? А вот что: удаляем несколько десятков тестов и пишем заново. И это продолжается весь проект. Каждый второй спринт. Примерно так…
И да, с учетом того, что кода тестов при хорошем покрытии значительно больше, чем кода самого решения… Получается, в общем, довольно неэффективно.
На удивление, способов обеспечения качества ПО, помимо автоматических и ручных тестов, немало! Жалко и обидно, что они настолько недооценены, и о них мало кто говорит. Вот посмотришь хабр: тесты, тесты, тесты. Качество софта = всегда только тесты. И все, как будто нет альтернатив. Но ведь это не так: альтернативы есть, и в ряде случаев они подходят гораздо лучше.
В свое время меня эта тема очень интересовала и я изучал самые разнообразные методы. Интересовался, например, как делают космическое ПО, где одна ошибка может повлечь многомиллионные убытки. Наверное многим известно, что там используются такие супер-тяжелые методы, как формальная верификация, тотальное документирование, перекрестное тестирование независимыми командами тестеровщиков и прочее. Но оказывается, есть у них на вооружении и более дешевые средства (подробнее об этом ниже).
Другим «источником вдохновения» стал Брет Виктор, автор множества потрясающих концептов, и в том числе идеи Seeing spaces, и особенно той ее части (начиная примерно с 3:53 на видео), где речь идет о способах расследования и предотвращения багов. Идея в том, что для того, чтобы понять, что происходит внутри системы, нужно как бы «развернуть» эту систему, заглянуть внутрь, визуализировать ее во всех возможных плоскостях, увидеть как она работает изнутри. Если хорошо понимать, как работает система — то многих ошибок можно избежать. Здесь кстати снова пересечение с космической темой: это получается этакий локальный «Центр Управления Полетами» для данной системы.
(картинка взята отсюда: vimeo.com/97903574)
В свое время идея Брета меня совершенно захватила и наверное неделю я пытался придумать способ «развернуть» нашу конкретную систему, пока наконец-то не слепил из подручных средств утилитку-монитор, визуализирующий как минимум некоторые процессы происходящие внутри и позволяющий как бы заглянуть «под капот» системы. Эта утилитка впоследствии сэкономила мне много часов, позволила избежать кучи ошибок на ранней стадии, а в нескольких случаях — понять детально, что происходит на продакшене.
Безусловно, в современном вебдеве это решается с помощью логов, трейсинга (OpenTelemetry) и мониторинга, но многие успешные компании в добавление к этим вещам имеют свои собственные, специализированные утилиты, заточенные под визуализацию этого конкретно решения.
Кроме этих вещей, были недели поисков в гугле, десятки прочитанных статей, множество опробованных подходов и утилит, и конечно многие часы работы над кодом. Забегая вперед, одним из главных открытий для меня стал метод «fault tree analysis», но были и другие очень важные вещи. Всё это в совокупности позволило получить надежную и стабильную систему без юнит-тестов и тестировщиков.
Как пишут код, в котором не должно ошибок вообще? Ответ разочаровывающий: пишут его нудно и долго. Страшная бюрократия, документации больше чем кода и т.д. Никакого Scrum'а. И все же есть-таки чему поучиться и что позаимствовать у космического ПО!
Давайте рассмотрим последние два пункта немного подробнее.
Статический анализ выглядит привлекательно: позволяет отловить кучу проблем и дешево.
Кстати, самый простой тип статического анализа — это intellisense, то, что мы каждый день используем в IDE (ну и компиляция кода, как частный случай). Очень важно, чтобы ваш проект полностью покрывался интеллисенсом. Например, если не использовать Entity Framework, а писатьmagic strings stored procedures, то вероятность сделать ошибку при очередном рефакторинге резко возрастает.
Кроме стандартного intellisense, есть конечно же линтеры, такие как Stylecop или более современные и продвинутые, типа SonarQube.
А если хочется написать что-то совсем кастомное, заточенное под конкретный проект (и мне кажется, это очень даже полезно делать), то в C# есть ещё даже более крутая штука: Live Code Analyzers!
Начиная с Visual Studio 2015, с появлением Roslyn, были добавлены Live Code Analyzers — статические анализаторы кода, которые запускаются в IDE по мере создания кода. Иными словами, простая и доступная возможность создать кастомный intellisense.
В Live Code Analyzer есть доступ ко всему, с чем работает компилятор: лексическая свертка, AST, результаты семантического разбора. Можно комплексно анализировать код и обнаруживать довольно сложные ошибки.
В этой статье не хочется погружаться слишком глубоко в Code Analyzers, но давайте рассмотрим хотя бы вот такой простой пример — обнаружить все методы в solution больше 100 строк:
Как видите, все довольно просто. Некоторое количество обвязки, но сама проверка — буквально одна строка. Впрочем, более полезные проверки потребуют, конечно, намного больше кода.
Основная проблема со статическими анализаторами, это то, что они имеют некоторый потолок по сложности проверок. Дальше этого потолка код анализаторов становится слишком сложным.
Например, мне удалось создать анализатор, который ругается, если поместить запрос к БД за пределы методов Web API контроллера (чтобы работа с БД не размазывалась по всему решению, поскольку очень часто проблемы с производительностью возникают после того, как кто-нибудь использует метод, дергающий базу данных в цикле).
Но вот сделать более сложный анализатор, который бы следил, чтобы внутри endpoint'а типа
Вывод: Статический анализ применим и вполне актуален, однако решает лишь часть проблемы — позволяет избежать низкоуровневых, технических багов, но редко когда может помочь с логическими ошибками.
Простой код — это самый надежный способ борьбы с логическими ошибками. Простой, понятный, лаконичный код — это прекрасно! Но непросто.
Блоггеры и докладчики меня поймут: вот пишешь статью, или готовишь доклад, и хочется привести пример, который был бы одновременно и простым, и полезным. И вот на то чтобы изобрести такой пример, несколько дней может уйти (и еще не факт что придумаешь в итоге)! Найти те заветные 20 строчек кода, которые хорошо бы демонстрировали идею, делали бы что-то действительно полезное, и были бы простыми и понятными при этом — на практике оказывается очень нелегко.
Создание простого кода — это сложная задача, требующая глубоких знаний и большого количества времени.
Есть по этому поводу знаменитая цитата от Blaise Pascal (перевод с французского):
И в этой цитате, безусловно, — очень много правды!
Вот какие подходы и методы лично я использую (весьма успешно) для создания простого кода:
Давайте рассмотрим их подробно.
Термин мой собственный, выдуманный. Может быть это как-то по-другому официально называется. Но для меня — это просто то, как я пишу код, уже много лет, и весьма успешно.
Если грубо, идея заключается в том, чтобы не создавать детальную архитектуру кода проекта заранее. Накидали план в общих чертах, — и поехали. Как только какой-то класс или метод разрастается слишком сильно — ага, пора рефакторить. Видим, что слишком много контроллеров — ага, пора делать новый микросервис. И так далее. Таким образом, проект растёт инкрементно и «натурально», именно в тех местах, в которых действительно нужно.
Замечание: архитектура — понятие многогранное, здесь и далее я говорю именно про архитектуру кода — т.е. про то, как правильно структурировать проект, разбить на компоненты, сущности, файлы, классы и т.д.
Во-первых, такой подход прекрасно работает с заказчиком, который вначале проекта чётко не знает, чего хочет (т.е. с почти любым заказчиком). Во-вторых, нарисовать идеальную архитектуру для сложного проекта с первого раза в любом случае невозможно, в процессе обычно всплывает много такого, о чем на стадии планирования даже не задумывались.
Так что обычно все равно архитектуру приходится ревизить. Но если она была предварительно кропотливо создана, потрачено на это много времени и сил, то обычно совсем не хочется отказываться от сделанных раньше решений, и есть некое подсознательное желание все-таки впихнуть проект в старую архитектуру. А подсознание штука опасная, ему подчиняешься не думая. В общем, к добру это не приводит.
В итоге получается, что в изначально неправильную архитектуру пытаются впихнуть уже совершенно другое решение, городя в итоге кучу костылей и создавая очень сложный для понимания и дальнейшего развития код.
Поэтому, исходя из моего опыта, лучше совсем уж кропотливо ничего не планировать, а планировать только в общих чертах, и «открывать» детали архитектуры уже по мере создания проекта. Для этого, конечно, необходимы две вещи:
Я использую простой thresold, состоящий из двух условий:
При таком подходе архитектура строится соответственно росту проекта, и архитектурно продумываются именно те части проекта, которые растут и следовательно являются самыми важными и востребованными.
Правильная архитектура автоматически ведет к более простому коду.
Когда программисты сталкиваются с проблемами с производительностью, они начинают оптимизировать код. Частенько настоящую проблему поймать довольно сложно, поскольку она происходит только на продакшене, который так просто не подебажить. Так что оптимизируется всё что только можно, и по максимуму.
У нас был в случай, когда человек, не очень хорошо разбиравшийся в MS SQL, «соптимизировал» систему путем перевода почти всех запросов к БД с Entity Framework на stored procedures. Потом пришлось переводить обратно, потому что поддерживать T-SQL код, не покрытый интеллисенсом, довольно сложно (повторюсь, речь о бизнес-проекте, требования меняются постоянно, а с ними вместе и модель базы данных). Да, и к слову, перевод на stored procedures оказался бессмысленным — проблем это не решило. Решение было в добавлении индексов и предпросчёта.
К чему веду: очень легко переусердствовать с оптимизациями. Код при этом очень сильно усложняется, и соответственно сложнее становится избежать багов. Везде нужен компромисс, также и с оптимизациями.
Например, если выяснилось, что Entity Framework генерирует неоптимальный запрос, или не умеет генерировать запрос который вам нужен, это не повод переходить на хранимые процедуры. Покрутите проблему в голове, почитайте умные статьи, решение всегда найдётся. В частности, сложные T-SQL запросы это в любом случае зло — так что и не нужно пытаться их генерировать. Вместо этого, например, вытащите данные по отдельности простыми запросами и склейте их в памяти.
Вообще, 90% проблем с производительностью БД на средних объемах данных и не супер высокой нагрузке решаются пятью простыми способами:
Для абсолютного большинства обычных проектов, этого достаточно. И даже в сложных проектах с Big Data и с миллионами пользователей онлайн, дальше оптимизировать нужно только наиболее нагруженные участки системы.
Мораль: Когда чините производительность, не увлекайтесь, а то сломаете себеносcodebase.
Fault tree analysis — это по сути, просто метод для поиска возможных отказов, но его действенность, сложно переоценить.
Итак, для начала, уточняем у заказчика: какие части системы не должны отказывать ну ни при каких условиях, какие страницы наиболее критичны?
И дальше начинаем с этих страниц, и думаем: что может привести к тому, что страница не будет работать? И как это можно решить?
Например, примерно так я анализировал одну из критических страниц нашего сервиса — страницу со списком заданий и водителей, которая отображалась на InfoTV:
И так далее, для каждого из пунктов пытаемся найти возможные решения, или спускаемся ниже и смотрим какие могут быть причины — и пытаемся найти решения для них. В общем идея в том, чтобы иерархически проанализировать все возможные причины отказа.
На самом деле, пример упрощён: анализ критичных областей должен быть очень детальным. Нужно буквально смотреть на каждую строчку кода, и смотреть, при каких обстоятельствах она может упасть. Учитывать всё: потерю связи, пожар а дата-центре и т.д.
Что хочу сказать про fault tree analysis: несмотря на то, что более менее все архитекторы знают про reliability, про то, как его улучшать, но оценку проблем как правило проводят очень ситуативно, бессистемно, часто пытаясь применить обобщенное решение (что работает довольно плохо). Например, я работал в двух больших Unicorn-ах, и даже там подход к reliability всё ещё бессистемный, и только в Big Tech этим уже занимаются серьёзно.
Fault tree analysis позволяет сконцентрироваться на действительно критичных участках и провести полный, системный анализ возможных отказов на этих участках. Если вы так ещё не делаете — попробуйте, это действительно круто работает!
Предположим, что мы проанализировали возможные отказы, улучшили код, и всё стало хорошо! Но ведь код имеет свойство постоянно меняться, практически жить своей жизнью. Изменения могут быть небольшими, но постоянными, и на code review, когда ты видишь только diff, бывает нелегко оценить суммарную получившуюся сложность всего метода в целом.
И вот здесь, для поддержания кода в хорошем состоянии, очень хорошо подойдёт вычисление метрик кода, таких как Cyclomatic Complexity — это отлично умеет делать Visual Studio для C#, да и для других языков полно утилит, которые умеют это делать.
В Visual Studio основные метрики суммируются в характеристике под названием Maintainability Index (от 0 — совершенно невозможно этот код поддерживать, до 100 — очень легко поддерживать), а полный набор отображаемых метрик выглядит примерно так:
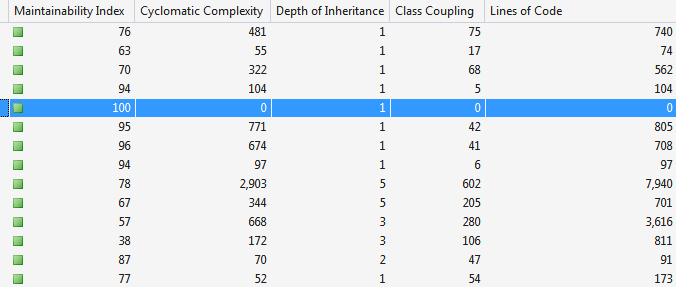
Строится дерево по всему решению, дерево можно развертывать и искать конкретные классы и методы, где все плохо. Это, даже без fault tree analysis, — первые кандидаты на рефакторинг, особенно если они относятся к важным частям системы.
Интересный факт: когда мы впервые вычислили метрики кода нашего решения, самое худшее качество кода было в самом главном, самом критическом методе всей системы (который если упадёт — то всё, это «full stop»). И я уверен, что такой феномен — совсем не редкость.
В итоге, мы потратили наверное целый человеко-спринт :) на то, чтобы этот метод переписать и максимально упростить.
Это довольно старая история, но всё ещё очень актульная. С тех пор, например, я основал свой стартап, ему уже 5 лет, десятки клиентов (B2B), десятки тысяч пользователей, и ни одного теста. Несмотря на кучу pivot-ов и глобальных рефакторингов, очень стабильная система, и я в состоянии поддерживать и развивать её в одиночку.
Конечно, с тестами было бы ещё лучше, ещё надежнее, — в идеале, все возможные способы улучшения надежности ПО должны использоваться в комбинации друг с другом.
Но в этой статье я хотел обратить внимание на то, что все эти «второстепенные» способы, на самом деле дают удивительно хороший результат, и могут использоваться даже без тестов. О них мало кто пишет, мало кто считает их серьезным подспорьем для улучшения надежности ПО. А зря, на самом деле, они отлично работают!
Представьте: ERP-система в области логистики. Сложная бизнес-логика, составление расписаний, электронный учет рабочего времени, планирование и управление ресурсами со статистическими подсказками на основе сотен миллионов записей геораспределенных исходных данных, мониторинг прогресса >1000 одновременно работающих водителей в реальном времени, интеграция с 7 другими системами (в том числе финансовыми), и т.д., в общем большая и сложная система.
Систему начали с нуля, писали на ASP.Net Web API, Entity Framework и AngularJs (Реакта и Vue тогда еще не было, дело было в далёком 2013), небольшой, но высокопрофессиональной командой, по Scrum, написали за 4 месяца первую базовую продакшн-версию с минимальным функционалом, впоследствии функционал постепенно наращивали, система развивается и по сей день. Через год после начала разработки, система уже была внедрена по всей компании и являлась business-critical, т.е. остановка системы даже на несколько часов могла повлечь довольно существенные убытки для компании.
И возможно, вам сейчас станет немного жутковато, но мы обошлись без unit-тестов и выделенных тестировщиков. При этом, на протяжении нескольких лет, разработка нового функционала шла очень активно, выгрузки на продакшн в среднем 1 раз в неделю, постоянно менялись люди в команде (потому что консалтинг компания), и… система не падала и даже совсем не возникало сколь-нибудь критичных багов, только мелкие баги и косметика. Просто везет, или есть какой-то секрет?
Почему без юнит-тестов?
Бесспорно, юнит-тесты — очень хорошая штука. Прошу понять меня правильно, я ни в коем случае в этой статье не пытаюсь сказать что они не нужны или их не надо писать. Нужны. И надо.
Но с ними, нужно это понимать, немало тонкостей. Во-первых, конечно нужно, чтобы тесты писали грамотные квалифицированные люди, понимающие как это работает: иначе тесты начинают усложняться, проверять не то и не так, давать ложное чувство уверенности и т.д. Но наверное еще более важно, что тесты хорошо подходят не для всех возможных случаев.
Сколько раз я видел эти классические слова: «это не тесты у вас не работают, это вы просто их писать не умеете». Но ведь так можно любую неподходящую технологию оправдать… Нет, я думаю, не всё так просто. Вот с паттернами к примеру. Любой более-менее опытный программист знает: паттерны это не панацея, универсальных решений не бывает, всегда нужно смотреть по ситуации, что конкретно использовать и как именно.
Вот и тесты такие же на мой взгляд — да, есть случаи, когда автоматические тесты подходят идеально: например, если реализуешь какой-нибудь протокол, или пишешь компилятор, или библиотеку со строго заданным API и прочее. В таких случаях есть четкие требования и они описаны на низком уровне — и тесты работают замечательно. А по TDD такие проекты делать и вовсе сплошное удовольствие.
Но есть и бизнес-приложения. Требования вроде и есть, но они описаны на очень высоком уровне, и мапить их в тесты мягко сказать непросто. Вроде, потому что заказчик в начале проекта сам не до конца понимает, что конкретно ему нужно. Это выясняется в деталях только в процессе, на Sprint Demo или на дэйли. Если разработка действительно agile, то требования часто меняются, а знаете что такое изменение требований на высоком уровне, в разрезе тестов? А вот что: удаляем несколько десятков тестов и пишем заново. И это продолжается весь проект. Каждый второй спринт. Примерно так…
И да, с учетом того, что кода тестов при хорошем покрытии значительно больше, чем кода самого решения… Получается, в общем, довольно неэффективно.
Если не юнит-тесты, то что?
На удивление, способов обеспечения качества ПО, помимо автоматических и ручных тестов, немало! Жалко и обидно, что они настолько недооценены, и о них мало кто говорит. Вот посмотришь хабр: тесты, тесты, тесты. Качество софта = всегда только тесты. И все, как будто нет альтернатив. Но ведь это не так: альтернативы есть, и в ряде случаев они подходят гораздо лучше.
В свое время меня эта тема очень интересовала и я изучал самые разнообразные методы. Интересовался, например, как делают космическое ПО, где одна ошибка может повлечь многомиллионные убытки. Наверное многим известно, что там используются такие супер-тяжелые методы, как формальная верификация, тотальное документирование, перекрестное тестирование независимыми командами тестеровщиков и прочее. Но оказывается, есть у них на вооружении и более дешевые средства (подробнее об этом ниже).
Другим «источником вдохновения» стал Брет Виктор, автор множества потрясающих концептов, и в том числе идеи Seeing spaces, и особенно той ее части (начиная примерно с 3:53 на видео), где речь идет о способах расследования и предотвращения багов. Идея в том, что для того, чтобы понять, что происходит внутри системы, нужно как бы «развернуть» эту систему, заглянуть внутрь, визуализировать ее во всех возможных плоскостях, увидеть как она работает изнутри. Если хорошо понимать, как работает система — то многих ошибок можно избежать. Здесь кстати снова пересечение с космической темой: это получается этакий локальный «Центр Управления Полетами» для данной системы.
(картинка взята отсюда: vimeo.com/97903574)
В свое время идея Брета меня совершенно захватила и наверное неделю я пытался придумать способ «развернуть» нашу конкретную систему, пока наконец-то не слепил из подручных средств утилитку-монитор, визуализирующий как минимум некоторые процессы происходящие внутри и позволяющий как бы заглянуть «под капот» системы. Эта утилитка впоследствии сэкономила мне много часов, позволила избежать кучи ошибок на ранней стадии, а в нескольких случаях — понять детально, что происходит на продакшене.
Безусловно, в современном вебдеве это решается с помощью логов, трейсинга (OpenTelemetry) и мониторинга, но многие успешные компании в добавление к этим вещам имеют свои собственные, специализированные утилиты, заточенные под визуализацию этого конкретно решения.
Кроме этих вещей, были недели поисков в гугле, десятки прочитанных статей, множество опробованных подходов и утилит, и конечно многие часы работы над кодом. Забегая вперед, одним из главных открытий для меня стал метод «fault tree analysis», но были и другие очень важные вещи. Всё это в совокупности позволило получить надежную и стабильную систему без юнит-тестов и тестировщиков.
«Космический» подход
Как пишут код, в котором не должно ошибок вообще? Ответ разочаровывающий: пишут его нудно и долго. Страшная бюрократия, документации больше чем кода и т.д. Никакого Scrum'а. И все же есть-таки чему поучиться и что позаимствовать у космического ПО!
- Формальная верификация. Использовать ее на бизнес-проектах конечно не получится (слишком дорого), но понимать — полезно. Понимать проблемы, с которыми формальная верификация сталкивается, понимать почему же так сложно доказать что цикл завершается, и понимать почему формальная верификация — не панацея, даже если есть возможность ее применить. Есть классный David Crocker's Verification Blog, где можно с этой темой ознакомиться, рекомендую. Когда-то давно я читал этот блог как худлит, на ночь, прямо с самой первой записи и дочитал «до наших дней» (причем это единственный блог вообще который я прочитал полностью в своей жизни). Да, часть информации специфична для C/C++, но все равно очень много полезного по теории формальной верификации и статическому анализу.
- Программирование по контракту. Контрактное программирование тоже хорошая штука, но снова очень не дешевая и далеко не панацея. Например, в упомянутом выше блоге Дэвида, есть интереснейшая статья о случае с взрывом ракеты Ariane 5 при взлете, где он небезосновательно утверждает, что runtime-проверки могут спасти, но только если: а) программа может сделать что-то полезное, если проверки не прошли; б) это что-то полезное было как следует протестировано. В общем, знать про контрактное программирование очень полезно, но для повсеместного применения в бизнес-решениях оно конечно дороговато.
- Статический анализ. Сейчас много мощных средств для статического анализа кода программ. Почему бы их не использовать? Например, эксперт Gerard Holzmann из лаборатории надежного ПО NASA в документе The Power of Ten — Rules for Developing Safety Critical Code пишет, что никаких оправданий просто не может быть чтобы не использовать. Потому что это очень дешево: запустил анализатор и все. А ведь статический анализатор очень хорош для отслеживания некоторых категорий технических багов, которые сложно заметить на глаз.
- Простой код. Простой код проще поддается статическому анализу, и в нем меньше вероятность сделать ошибку. Опять же согласно документу из предыдущего пункта, методы и функции желательно умещать в один лист печатного текста ака 60 строк кода: иначе психологически не воспринимается, как логическая единица. И желательно избегать рекурсии: рекурсивный алгоритм обычно сложнее понять, чем тот же алгоритм развернутый в цикл (и опять же статические анализаторы лучше с циклами работают чем с рекурсией).
Давайте рассмотрим последние два пункта немного подробнее.
Статический анализ
Статический анализ выглядит привлекательно: позволяет отловить кучу проблем и дешево.
Кстати, самый простой тип статического анализа — это intellisense, то, что мы каждый день используем в IDE (ну и компиляция кода, как частный случай). Очень важно, чтобы ваш проект полностью покрывался интеллисенсом. Например, если не использовать Entity Framework, а писать
Кроме стандартного intellisense, есть конечно же линтеры, такие как Stylecop или более современные и продвинутые, типа SonarQube.
А если хочется написать что-то совсем кастомное, заточенное под конкретный проект (и мне кажется, это очень даже полезно делать), то в C# есть ещё даже более крутая штука: Live Code Analyzers!
Live Code Analyzers
Начиная с Visual Studio 2015, с появлением Roslyn, были добавлены Live Code Analyzers — статические анализаторы кода, которые запускаются в IDE по мере создания кода. Иными словами, простая и доступная возможность создать кастомный intellisense.
В Live Code Analyzer есть доступ ко всему, с чем работает компилятор: лексическая свертка, AST, результаты семантического разбора. Можно комплексно анализировать код и обнаруживать довольно сложные ошибки.
В этой статье не хочется погружаться слишком глубоко в Code Analyzers, но давайте рассмотрим хотя бы вот такой простой пример — обнаружить все методы в solution больше 100 строк:
private void CheckMethodsAreShortEnoughToComprehend(SyntaxNodeAnalysisContext context)
{
var methodDeclaration = (MethodDeclarationSyntax)context.Node;
// собственно проверка
if (methodDeclaration.Body == null || methodDeclaration.Body.GetText().Lines.Count <= 100)
return;
// если проверку не прошли, кидаем ошибку
var diagnostic = Diagnostic.Create(ShortMethodsRule, methodDeclaration.Identifier.GetLocation(), methodDeclaration.Identifier.Value);
context.ReportDiagnostic(diagnostic);
}
Полный код класса анализатора
[DiagnosticAnalyzer(LanguageNames.CSharp)]
public class MyAnalyserAnalyzer : DiagnosticAnalyzer
{
private static DiagnosticDescriptor ShortMethodsRule = new DiagnosticDescriptor(
"MyAnalyser.ShortMethodsRule",
"Method is too long.",
"Method '{0}' is more than 100 lines long.",
"Database",
DiagnosticSeverity.Warning,
isEnabledByDefault: true,
description: "Long methods are hard to read and comprehend. Statistics shows, that long methods have much more mistakes. Please refactor.");
public override ImmutableArray<DiagnosticDescriptor> SupportedDiagnostics
{
get
{
return ImmutableArray.Create(ShortMethodsRule);
}
}
public override void Initialize(AnalysisContext context)
{
// для каждой ноды "method declaration" в solution будет запущен наш метод проверки
context.RegisterSyntaxNodeAction(CheckMethodsAreShortEnoughToComprehend, SyntaxKind.MethodDeclaration);
}
private void CheckMethodsAreShortEnoughToComprehend(SyntaxNodeAnalysisContext context)
{
var methodDeclaration = (MethodDeclarationSyntax)context.Node;
// собственно проверка
if (methodDeclaration.Body == null || methodDeclaration.Body.GetText().Lines.Count <= 100)
return;
// если проверку не прошли, кидаем ошибку
var diagnostic = Diagnostic.Create(ShortMethodsRule, methodDeclaration.Identifier.GetLocation(), methodDeclaration.Identifier.Value);
context.ReportDiagnostic(diagnostic);
}
}
Как видите, все довольно просто. Некоторое количество обвязки, но сама проверка — буквально одна строка. Впрочем, более полезные проверки потребуют, конечно, намного больше кода.
Основная проблема со статическими анализаторами, это то, что они имеют некоторый потолок по сложности проверок. Дальше этого потолка код анализаторов становится слишком сложным.
Например, мне удалось создать анализатор, который ругается, если поместить запрос к БД за пределы методов Web API контроллера (чтобы работа с БД не размазывалась по всему решению, поскольку очень часто проблемы с производительностью возникают после того, как кто-нибудь использует метод, дергающий базу данных в цикле).
Но вот сделать более сложный анализатор, который бы следил, чтобы внутри endpoint'а типа
PUT /user/{id}, невозможно было бы случайно изменить пользователей с другим ID (чтобы предотвратить случайный data corruption), уже не вышло.Вывод: Статический анализ применим и вполне актуален, однако решает лишь часть проблемы — позволяет избежать низкоуровневых, технических багов, но редко когда может помочь с логическими ошибками.
Простой код
Простой код — это самый надежный способ борьбы с логическими ошибками. Простой, понятный, лаконичный код — это прекрасно! Но непросто.
Блоггеры и докладчики меня поймут: вот пишешь статью, или готовишь доклад, и хочется привести пример, который был бы одновременно и простым, и полезным. И вот на то чтобы изобрести такой пример, несколько дней может уйти (и еще не факт что придумаешь в итоге)! Найти те заветные 20 строчек кода, которые хорошо бы демонстрировали идею, делали бы что-то действительно полезное, и были бы простыми и понятными при этом — на практике оказывается очень нелегко.
Создание простого кода — это сложная задача, требующая глубоких знаний и большого количества времени.
Есть по этому поводу знаменитая цитата от Blaise Pascal (перевод с французского):
Это письмо получилось таким длинным потому, что у меня не было времени написать его короче.
И в этой цитате, безусловно, — очень много правды!
Вот какие подходы и методы лично я использую (весьма успешно) для создания простого кода:
- Инкрементный рефакторинг. Этот подход позволяет избежать излишнего усложнения кода еще на стадии разработки проекта.
- Простые оптимизации. Подход к решению проблем с производительностью, чтобы сохранить качество кода.
- Fault tree analysis. Это способ для определения наиболее критичного кода, который можно себе позволить сделать совершенным, и это окупится.
- Maintainability Index. Вычисление метрик кода позволяет легко найти участки кода плохого качества.
Давайте рассмотрим их подробно.
1. Инкрементный рефакторинг
Термин мой собственный, выдуманный. Может быть это как-то по-другому официально называется. Но для меня — это просто то, как я пишу код, уже много лет, и весьма успешно.
Если грубо, идея заключается в том, чтобы не создавать детальную архитектуру кода проекта заранее. Накидали план в общих чертах, — и поехали. Как только какой-то класс или метод разрастается слишком сильно — ага, пора рефакторить. Видим, что слишком много контроллеров — ага, пора делать новый микросервис. И так далее. Таким образом, проект растёт инкрементно и «натурально», именно в тех местах, в которых действительно нужно.
Замечание: архитектура — понятие многогранное, здесь и далее я говорю именно про архитектуру кода — т.е. про то, как правильно структурировать проект, разбить на компоненты, сущности, файлы, классы и т.д.
Во-первых, такой подход прекрасно работает с заказчиком, который вначале проекта чётко не знает, чего хочет (т.е. с почти любым заказчиком). Во-вторых, нарисовать идеальную архитектуру для сложного проекта с первого раза в любом случае невозможно, в процессе обычно всплывает много такого, о чем на стадии планирования даже не задумывались.
Так что обычно все равно архитектуру приходится ревизить. Но если она была предварительно кропотливо создана, потрачено на это много времени и сил, то обычно совсем не хочется отказываться от сделанных раньше решений, и есть некое подсознательное желание все-таки впихнуть проект в старую архитектуру. А подсознание штука опасная, ему подчиняешься не думая. В общем, к добру это не приводит.
В итоге получается, что в изначально неправильную архитектуру пытаются впихнуть уже совершенно другое решение, городя в итоге кучу костылей и создавая очень сложный для понимания и дальнейшего развития код.
Поэтому, исходя из моего опыта, лучше совсем уж кропотливо ничего не планировать, а планировать только в общих чертах, и «открывать» детали архитектуры уже по мере создания проекта. Для этого, конечно, необходимы две вещи:
- Thresold. Нужен способ понять, когда пора остановиться и проревизить архитектуру.
- Рефакторинг. Рефакторинг бывает разный. Некоторые понимают под рефакторингом «переписать половину проекта нафиг». Такое бывает, если всё совсем запустили и накопилась целая гора технического долга — т.е. когда thresold или отсутствовал, или был выбран неудачно. Зато при правильно выбранном thresold'е рефакторинг происходит почти безболезненно, настолько, что его можно даже делать в проекте без тестов.
Я использую простой thresold, состоящий из двух условий:
- Копипастить код можно (о ужас!), но не более одного раза (т.е. максимум 2 «копии»). Если копипастишь в третий раз — пора писать абстракцию.
- Если файл достиг 200 строк, пора рефакторить — разбивать его на несколько файлов, и заодно ревизить общую архитектуру.
При таком подходе архитектура строится соответственно росту проекта, и архитектурно продумываются именно те части проекта, которые растут и следовательно являются самыми важными и востребованными.
Правильная архитектура автоматически ведет к более простому коду.
2. Простые оптимизации
Когда программисты сталкиваются с проблемами с производительностью, они начинают оптимизировать код. Частенько настоящую проблему поймать довольно сложно, поскольку она происходит только на продакшене, который так просто не подебажить. Так что оптимизируется всё что только можно, и по максимуму.
У нас был в случай, когда человек, не очень хорошо разбиравшийся в MS SQL, «соптимизировал» систему путем перевода почти всех запросов к БД с Entity Framework на stored procedures. Потом пришлось переводить обратно, потому что поддерживать T-SQL код, не покрытый интеллисенсом, довольно сложно (повторюсь, речь о бизнес-проекте, требования меняются постоянно, а с ними вместе и модель базы данных). Да, и к слову, перевод на stored procedures оказался бессмысленным — проблем это не решило. Решение было в добавлении индексов и предпросчёта.
К чему веду: очень легко переусердствовать с оптимизациями. Код при этом очень сильно усложняется, и соответственно сложнее становится избежать багов. Везде нужен компромисс, также и с оптимизациями.
Например, если выяснилось, что Entity Framework генерирует неоптимальный запрос, или не умеет генерировать запрос который вам нужен, это не повод переходить на хранимые процедуры. Покрутите проблему в голове, почитайте умные статьи, решение всегда найдётся. В частности, сложные T-SQL запросы это в любом случае зло — так что и не нужно пытаться их генерировать. Вместо этого, например, вытащите данные по отдельности простыми запросами и склейте их в памяти.
Вообще, 90% проблем с производительностью БД на средних объемах данных и не супер высокой нагрузке решаются пятью простыми способами:
- Индексы
- Простые запросы и склейка данных в памяти
- Кэш
- Предпросчёт
- Пейджинг
Для абсолютного большинства обычных проектов, этого достаточно. И даже в сложных проектах с Big Data и с миллионами пользователей онлайн, дальше оптимизировать нужно только наиболее нагруженные участки системы.
Мораль: Когда чините производительность, не увлекайтесь, а то сломаете себе
3. Fault tree analysis
Fault tree analysis — это по сути, просто метод для поиска возможных отказов, но его действенность, сложно переоценить.
Итак, для начала, уточняем у заказчика: какие части системы не должны отказывать ну ни при каких условиях, какие страницы наиболее критичны?
И дальше начинаем с этих страниц, и думаем: что может привести к тому, что страница не будет работать? И как это можно решить?
Например, примерно так я анализировал одну из критических страниц нашего сервиса — страницу со списком заданий и водителей, которая отображалась на InfoTV:
- Если нет связи с сервером — страница просто не загрузится.
- Решение: Можно использовать server workers, и в случае отказа сети, хотя бы показывать старый снапшот данных. Конечно, при этом желательно вывести уведомление, что данные старые, и показать дату, когда они последний раз были синхронизированы с сервера.
- Если ошибка в Javascript, то страница не сможет отобразить список заданий или же не сработает периодическое обновление страницы и она «застынет»
- Решение: максимально покрыть фронтенд-код интеллисенсом, вынести в отдельный файл главный код, который отображает список и обновляет страницу, упростить его, некритичные функции обернуть в try-catch, чтобы ошибка в этих функциях не повлияла на отображение списка
- Если API возвращает ошибку или данные в неожиданном формате
- Решение: продолжать показывать старые данные, как если бы система была оффлайн. Выводить соответствующее сообщение об ошибке.
- Кроме того, можно улучшить стабильность бэкенда. Для этого нужно проанализировать, в каком случае может возникнуть ошибка на бэкенде?
- Если допущена ошибка в коде и возникло исключение
- Если сервер упал
- Если нет связи с БД
- Если БД перегружена и запрос вылетел с таймаутом
- Если на сервере БД вышел из строя жесткий диск
И так далее, для каждого из пунктов пытаемся найти возможные решения, или спускаемся ниже и смотрим какие могут быть причины — и пытаемся найти решения для них. В общем идея в том, чтобы иерархически проанализировать все возможные причины отказа.
На самом деле, пример упрощён: анализ критичных областей должен быть очень детальным. Нужно буквально смотреть на каждую строчку кода, и смотреть, при каких обстоятельствах она может упасть. Учитывать всё: потерю связи, пожар а дата-центре и т.д.
Что хочу сказать про fault tree analysis: несмотря на то, что более менее все архитекторы знают про reliability, про то, как его улучшать, но оценку проблем как правило проводят очень ситуативно, бессистемно, часто пытаясь применить обобщенное решение (что работает довольно плохо). Например, я работал в двух больших Unicorn-ах, и даже там подход к reliability всё ещё бессистемный, и только в Big Tech этим уже занимаются серьёзно.
Fault tree analysis позволяет сконцентрироваться на действительно критичных участках и провести полный, системный анализ возможных отказов на этих участках. Если вы так ещё не делаете — попробуйте, это действительно круто работает!
4. Maintainability Index
Предположим, что мы проанализировали возможные отказы, улучшили код, и всё стало хорошо! Но ведь код имеет свойство постоянно меняться, практически жить своей жизнью. Изменения могут быть небольшими, но постоянными, и на code review, когда ты видишь только diff, бывает нелегко оценить суммарную получившуюся сложность всего метода в целом.
И вот здесь, для поддержания кода в хорошем состоянии, очень хорошо подойдёт вычисление метрик кода, таких как Cyclomatic Complexity — это отлично умеет делать Visual Studio для C#, да и для других языков полно утилит, которые умеют это делать.
В Visual Studio основные метрики суммируются в характеристике под названием Maintainability Index (от 0 — совершенно невозможно этот код поддерживать, до 100 — очень легко поддерживать), а полный набор отображаемых метрик выглядит примерно так:
Строится дерево по всему решению, дерево можно развертывать и искать конкретные классы и методы, где все плохо. Это, даже без fault tree analysis, — первые кандидаты на рефакторинг, особенно если они относятся к важным частям системы.
Интересный факт: когда мы впервые вычислили метрики кода нашего решения, самое худшее качество кода было в самом главном, самом критическом методе всей системы (который если упадёт — то всё, это «full stop»). И я уверен, что такой феномен — совсем не редкость.
В итоге, мы потратили наверное целый человеко-спринт :) на то, чтобы этот метод переписать и максимально упростить.
Заключение и выводы
Это довольно старая история, но всё ещё очень актульная. С тех пор, например, я основал свой стартап, ему уже 5 лет, десятки клиентов (B2B), десятки тысяч пользователей, и ни одного теста. Несмотря на кучу pivot-ов и глобальных рефакторингов, очень стабильная система, и я в состоянии поддерживать и развивать её в одиночку.
Конечно, с тестами было бы ещё лучше, ещё надежнее, — в идеале, все возможные способы улучшения надежности ПО должны использоваться в комбинации друг с другом.
Но в этой статье я хотел обратить внимание на то, что все эти «второстепенные» способы, на самом деле дают удивительно хороший результат, и могут использоваться даже без тестов. О них мало кто пишет, мало кто считает их серьезным подспорьем для улучшения надежности ПО. А зря, на самом деле, они отлично работают!




