
На Go можно реализовать тысячи goroutine одновременно без больших требований к железу. При этом горутины могут легко и просто обмениваться данными между собой и синхронизироваться с помощью каналов. Но как устроены каналы внутри? Об этом написано не так уж много, а в условиях многопоточки и асинхронного кода хорошо бы не просто работать с каналами, а понимать, как их использовать более практично и эффективно.
Егор Гришечко, старший разработчик в Insolar, разрабатывает блокчейн для b2b сегмента (по сути, стартап), и у команды как раз большая многопоточка и много асинхронного кода. Егор не только разобрался на практике, как работают каналы, что это такое и как они вообще устроены внутри. Он еще рассказал о каналах внутри команды, а потом, увидев интерес, поделился на конференции Golang Conf 2019.
Сегодня мы публикуем расшифровку его доклада.

Когда вы начинаете изучать каналы, вы конечно же набираете в поиске: Go channels. Уверен, вы увидите ссылку на A Tour of Go. Открыв этот прекрасный сервис-лайт, вы увидите, что каналы — это некий примитив, в который можно писать и из которого можно читать:

Но вот вам пример для наглядности. Я написал небольшую функцию, в которой стартует горутина, внутри которой в канал что-то пишется:

У нас есть небуферизированный канал, который хранит строки, и одна строка представляет собой еду. С другой стороны нас ждет голодный кот, который асинхронно пытается поесть из этой тарелки. Если мы запустим этот код, то — о чудо! — мы увидим результат: еда окажется внутри кота, кот доволен и счастлив, всё хорошо:

Теперь немного формализируем то, что мы получили, и подумаем о том, а что вообще умеют каналы.
Но это всё лирика. Если мы рассмотрим публичные API каналы, то обнаружим, что есть всего 4 публичных действия:
И это немного не коррелируется с тем, что умеют каналы. Мы не можем лочиться, мы не можем ничего — мы просто пишем и читаем. Это в какой-то мере прекрасно, но выглядит как магия. По крайней мере, когда я пришел в Go, для меня это выглядело магией. Потому что я слышал: «В Go нет сахара! Go — очень строгий язык. Он как Си, но немножко поновее». Но когда я начал разбираться с каналами, я понял, что это большой обман, так как каналы — это и есть синтаксический сахар.
Итак, что же такое каналы? Прежде чем мы окунемся во внутренности, я кратко скажу, что канал по сути — это структура с буфером, двумя очередями и локом внутри. А теперь по порядку.
На самом деле это составная машинерия, которая включает несколько частей:
Функции:
И есть еще много других функций и методов, о которых мы поговорим в ходе доклада.
Я покажу буферизированный канал на примере, а дальше мы рассмотрим небуферизированный, потому что это он же, просто с размером 0.
Рассмотрим простой пример:
Что происходит, когда вызывается этот код? Создается структура, которая содержит в себе около 10 полей, из них — 4 важных. Первое — Ring buffer (circle queue, или кольцевая очередь), которое хранит наши данные.
Обычно имплементация кольцевой очереди делается на массиве и на двух указателях (индексах) в этом массиве: один индекс мы постоянно пишем и инкрементируем, а другой индекс читаем и инкрементируем. И когда мы достигаем конца, то просто перемещаемся в начало. Здесь же у нас есть массив и два индекса, по которым пишем и читаем. И есть еще lock. При этом у нас пустая структура — и буфер, и индексы пустые:

Посмотрим, что произойдет, когда мы попытаемся записать в канал:
Когда мы пишем второй результат, происходит то же самое:

Когда мы пишем третий, sending index перемещается в 0 и начинает указывать на 0:

Но если в то же самое время мы читаем из канала, мы начнем с receiving index и инкрементируем его:

Очевидно, что если сейчас попытаться записать в канал, то запись будет в позицию 0, потому что она свободна и sending index указывает на 0. В случае, когда у нас полный буфер и мы не можем писать, начинает выстраиваться очередь из горутин. Но об этом чуть позже.
Чтобы не быть голословным, привожу всю структуру, чтобы вы видели, какая она чудесная и ужасная. Комментарии на русском мои:

Все поля очевидны. Буфер на самом деле лежит в псевдо-array — то есть это unsafe.pointer и по нему считаются смещения. У нас есть некоторые индексы для чтения/записи, лист ожидания на чтение/запись (листы горутин) и два моих любимых поля, elemsize и elemtype — наши псевдо-дженерики в Go. Когда вы создаете канал ints или канал strings — это не дженерик. Вы создаете просто hchan, и внутри лежат элементы size и type, причем со ссылкой. Ещё есть lock mutex, который по сути sync mutex.
ОК, это структура, а где она хранится?
Обычно в языках программирования есть две области памяти — Stack и Heap:

На Stack (грубо говоря, это стек нашего метода) мы храним переменные, вызовы, указатели на ссылочные типы. А в Heap обычно хранится то, что называется ссылочными (reference) объектами — всё, что не примитив. String обычно хранится на Heap почти во всех языках, а на Stack лежат boolean, int и указатели на эти референсные типы.
Почему такие названия — Stack и Heap? Потому что Stack — это стек. Представьте стопку тарелок — это стек. Вы всегда берёте тарелку сверху. А Heap — это когда их в кучу навалили и каждую ищите по примерному адресу — надо искать смещение, коллектить и прочее:

Чтобы посмотреть, где они хранятся, нам поможет функция:
Если посмотрим на ее результат, увидим маленькую-маленькую звездочку — как все ссылочные типы, он хранится на Heap. То есть когда мы создаем канал, мы кладем hchan в Heap и работаем, грубо говоря, через указатель.
Почему мы не видим этот указатель? Потому что это магия, это сахар в Go, которого нет. То есть мы не видим его как указатель, но на самом деле это указатель. Когда мы его копируем, передаем, еще что-то, мы не паримся за результат, потому что он всегда указывает на штуку в Heap, она всегда одна, мы работаем с ней, а в нашем коде всегда живет указатель:

Вернемся к нашему примеру с буферизированным каналом размера 0. Что произойдет, когда этот код начнет исполняться (там же нет буфера, в который можно это положить)? Ответ на это содержится в двух полях — receiving q и sending q (интересная игра слов, очень люблю «гошные» сокращения, хотя очень от них страдаю). Это очереди горутин, которые идут либо на чтение, либо на запись:

Представим, что у нас есть небуферизированный канал, и мы пытаемся что-то в него записать. Что произойдет, когда мы создаем такой канал? У нас создастся примерно та же самая структура. Я опустил locks и остальное, так как хочу сфокусировать ваше внимание на этих трех полях. Когда эта структура будет создана, в ней будет буфер, receiving q и sending q. Буфер будет всегда nil. Это тоже буферизированный канал, но с размером nil, он пустой. А receiving q и sending q будут выставлены просто в структуры:

Когда мы начнем читать из этого канала, мы начнем выстраиваться в очередь на нём, так как у нас нет ни пишущих горутин, ни буфера. У нас есть только две горутины, которые пытаются прочитать из канала. И они одна за одной выстроятся в очередь: «Ага, я подожду, пока кто-нибудь придет». Если приходит пишущая горутина, она подумает: «О, в списке получения есть что-то — запишу-ка я туда». Иначе — она точно так же встанет в запись и будет ждать. А waitq — указатель на голову и хвост linked листа горутин:

И вот она, чудесная структура sudog:
В конце стоит кольцевая ссылка на наш канал hchan. Тут отдельно всплывает моя нелюбовь к кольцевым ссылкам (circle reference) — в прошлом году в нашем проекте мы очень мучались с этим и даже написали свой самопальный DI, чтобы код не рос как на дрожжах. Я не нашел, для чего здесь circle reference, но header указывает на header, и мы держим структуру, которая указывает в свою очередь на header — и так можно бесконечно ходить.
Рассмотрим чуть более сложный пример. Мы создаем канал и на нем регистрируем двух голодных животных. Конечно, первым пускаем кота (пусть меня простят те, кто любит собак), потом собаку, и пытаемся их накормить. Что получится в рантайме?

Первой в очередь встанет горутина, которая отвечает за кота. У нее предыдущее состояние будет указывать на nil, следующее состояние будет указывать в никуда. Далее подъедет вторая структура, предыдущее состояние у которой будет указывать на кота, а следующее — nil. Если добавить третью структуру, она встанет следующей. У нее предыдущее будет показывать на собаку. Так мы строим нашу цепочку:

Давайте посмотрим на исходники. Начнем с элементарного примера — запустим функцию. И… после ее выполнения мы не видим никакого результата. Наш IDE написал кучу свойств, но результата нет:

Теперь откроем файл chango. Я не первый раз показываю флаг debugChan, который мне очень нравится — как только мы его выставляем в true, можно получить много интересных side-эффектов. И, когда мы его запустим, даже на пустой программе создается, как минимум, два канала. Причем мы даже что-то пишем в них и читаем из них. Один из них отвечает за garbage collector, а второй связан с memory:

Интересно то, что как только вы поменяете исходный файл, ваш output сразу расцветет — вы много всего интересного можете увидеть. Это общий паттерн почти для всех программ на Go: вы можете и с select так сделать, и с map. Но остерегайтесь редактировать этих файлы, потому что у меня три раза была забавная история. Когда я готовился к докладу, я в исходниках что-то удалял, что-то правил и условия выставлял, а когда собрал рабочий проект на том же компьютере, он перестал работать. Я разбирался часа два, пока не сделал brew reinstall go, чтобы переустановить инсталляцию Go на Mac, — и все потому, что я испортил исходную библиотеку.
Посмотрим, что у нас есть в этом файле. В функции на создание канала достаточно интересный код, потому что есть ветвление на три ветки. Небуферизированный канал мы создаем одним образом, канал с пойнтерами инициализируется по-другому, другие каналы инициализируются по-третьему, и т.д.:

Есть функция, которая считает смещение в буфере. По сути это массив, но на смещениях unsafe — всё, как мы любим:

Дальше начинается весьма хорошо документированный код. Например, есть функция entry point для записи в канал (c – это канал, x – переменная, куда мы пишем):

Есть огромная функция chansend, но я покажу только пару интересных вещей. Во-первых, почему по ссылке на нулевом канале виснет ваш рантайм навсегда? Ответ в первых трех строках. Мы проверяем канал на nil. Если канал nil, то мы повисли — все плохо. Такое бывает, если вы канал не инициализировали:

Следующий вопрос. Почему у нас посылка на закрытом канале вызывает мою любимую панику? Потому что мы проверяем флаг, и если он закрыт, мы взрываемся. Поэтому, когда мы работаем с каналом, мы делаем все под lock:

Этот код отвечает за чтение из очереди, ожидающей горутин — горутина, которая хочет записать что-то в канал, сначала проверяет список тех горутин, которые уже ожидают на чтение. Если там что-то есть, значит, у нас что-то не в порядке с буфером, и надо в первую очередь разгребать их. Поэтому мы их вычитываем, а дальше работаем с буфером:

Goparkunlock — рантаймовая функция, которая паркует горутины, чтобы они подождали чего-то интересного:

В рантайме есть место, где мы из стека одной горутины пишем в стек другой, когда одна горутина ждет на чтение, а вторая приходит на запись. В этом случае идет оптимизация всё работает чуть быстрее:

Моя любимая функция closechan. Почему мы падаем на закрытии пустого канала? Потому что мы проверяем на пустой канал и падаем с паникой. Почему мы падаем с паникой, когда закрываем закрытый канал? Потому что там флаг стоит. Что происходит, когда мы закрываем канал с нашими листами? Они по одному просто вычитываются и тоже закрываются. Соответственно горутины отпускаются, им возвращаются дефолтные значения, и они живут дальше:


С получением из канала примерно та же самая история. Сейчас расскажу подробнее.
Когда я начал программировать на Go, меня всегда интересовало: почему в примерах, когда нам просто нужен канал, или, допустим, хэш-сет, мы просто пишем пустую структуру?
Ответ: потому что все сложные примитивы примерно одинаково в Go работают. Когда у нас пустой struct, это по сути special case, элемент size — ноль, тип максимально упрощен. При использовании special case не грузится дополнительная информация, мы не таскаем с собой дополнительные размеры, экономим место, и поэтому счастливо живем:
Вот пример того, что я называю самым бесполезным бенчмарком на свете. Когда разговариваешь с кандидатом на работу про многопоточку и спрашиваешь, что можно сделать, чтобы убрать lock, иногда слышишь в ответ: «Давайте влепим канал, потому что там нет lock». И вот в левом углу ринга lock, сделанный на канале, в правом — просто lock:

В итоге я написал элементарнейший бенчмарк:
Принудительно выставил 50 млн прогонов, и увидел: если мы делаем наш чудесный BenchmarkChannelLock, мы работаем в 3 раза дольше, а аллоцируем в 12 раз больше.:

Очень полезная таблица, которая помогает, когда вы работаете с каналом:

Select — это вишенка на торте каналов в Go, потому что он помогает работать с каналами, например, группировать их в группе операций:
Если у нас есть select и два канала, select будет ждать, пока не выполнится хотя бы один из этих каналов. Самый грязный способ повесить горутину навсегда — это объявить пустой select. Если добавить default, а оба канала — блочащие, то мы не сможем прочитать или записать (буфер закончился, или читающих горутин нет, или еще что-то). В этом случае выполнится default:
Работа с select разделяется на две группы:
Когда у нас select состоит из case и default, он в compile-time разворачивается так:
Здесь функция просто чекает — можем мы прочитать или нет. Если можем, она выполняется, иначе — возвращается false, и мы уходим в if-else case:
Внутри нее используем обычное чтение из канала. Но есть интересный пункт — передача false. Обычно во всех функциях для работы с каналами (для чтения и для записи) передается параметр block. Он указывает (если горутина не может выполниться) заблокирована она или нет. И используется два аргумента, потому что когда вы читаете из закрытого канала, он вам может вернуть дефолтное значение, и за это отвечает второй аргумент — ОК или нет.
В случае с select это работает по-другому:
Select говорит: «Если не можешь прочитать, то возвращай управление» — и просто возвращает false:
If работает соответственно.
Я рекомендую посмотреть видео, которое быстро рассказывает про каналы и почитать go101 (там много полезной информации об исходниках):
И спасибо Ashley McNamara за гоферов. Все любят гоферов!

Егор Гришечко, старший разработчик в Insolar, разрабатывает блокчейн для b2b сегмента (по сути, стартап), и у команды как раз большая многопоточка и много асинхронного кода. Егор не только разобрался на практике, как работают каналы, что это такое и как они вообще устроены внутри. Он еще рассказал о каналах внутри команды, а потом, увидев интерес, поделился на конференции Golang Conf 2019.
Сегодня мы публикуем расшифровку его доклада.
Что такое каналы?
Когда вы начинаете изучать каналы, вы конечно же набираете в поиске: Go channels. Уверен, вы увидите ссылку на A Tour of Go. Открыв этот прекрасный сервис-лайт, вы увидите, что каналы — это некий примитив, в который можно писать и из которого можно читать:
Но вот вам пример для наглядности. Я написал небольшую функцию, в которой стартует горутина, внутри которой в канал что-то пишется:
У нас есть небуферизированный канал, который хранит строки, и одна строка представляет собой еду. С другой стороны нас ждет голодный кот, который асинхронно пытается поесть из этой тарелки. Если мы запустим этот код, то — о чудо! — мы увидим результат: еда окажется внутри кота, кот доволен и счастлив, всё хорошо:
Теперь немного формализируем то, что мы получили, и подумаем о том, а что вообще умеют каналы.
Что умеют каналы?
- У каналов есть размер. Это очевидно и понятно. Вы можете создать канал размером N, 10, 5, 1 и т.д. То есть даже когда вы создаете небуферизированный канал (как в предыдущем примере make(chan string)), вы на самом деле создаете буферизированный, у которого размер 0.
- Передавать данные между горутинами. Это цель существования каналов.
- Каналы горутино-безопасны. Мы не паримся локами, синхронизацией, ужасными CAS a loop, не думаем о data races и т.д. Мы просто берем канал, пишем с одной стороны, читаем с другой, и всё замечательно. Даже если мы вызовем close, мы не паримся — зачем нам локи, если они потоко-безопасны?
- FIFO. Канал работает как очередь, то есть First In — First Out. Это означает, что если 5 горутин пытаются записать в канал, они всегда сделают это в определенном порядке.
- Горутины ждут каналы. То есть канал может повесить горутину, которая может подождать результата из канала или подождать перед записью в канал и т.д.
- Каналы могут блокировать/разблокировать горутины. Вытекающий из предыдущего пункт.
Но это всё лирика. Если мы рассмотрим публичные API каналы, то обнаружим, что есть всего 4 публичных действия:
- newChan := make(chan int) — создать канал;
- newChan< — 1 — записать в канал;
- <-newChan — прочитать из канала;
- close(newChan) — закрыть канал.
И это немного не коррелируется с тем, что умеют каналы. Мы не можем лочиться, мы не можем ничего — мы просто пишем и читаем. Это в какой-то мере прекрасно, но выглядит как магия. По крайней мере, когда я пришел в Go, для меня это выглядело магией. Потому что я слышал: «В Go нет сахара! Go — очень строгий язык. Он как Си, но немножко поновее». Но когда я начал разбираться с каналами, я понял, что это большой обман, так как каналы — это и есть синтаксический сахар.
Итак, что же такое каналы? Прежде чем мы окунемся во внутренности, я кратко скажу, что канал по сути — это структура с буфером, двумя очередями и локом внутри. А теперь по порядку.
Из чего состоит канал
На самом деле это составная машинерия, которая включает несколько частей:
type hchan struct — структура, которая содержит основные данные;type sudog struct — это супер-сет of g со специальными полями, которые нужны для работы каналов, select и прочего.type waitq struct — структура, которая представляет собой linkedlist (связанный список) и хранит в себе два pointers — на голову и хвост.Функции:
func makechan(t *chantype, size int) *hchan — самая очевидная функция на свете. Когда вы вызываете создание канала и пишете make channel int, у вас вызывается именно она. Туда проваливается channel type и int, и на выходе вы получаете вашу структуру.func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool — функция для записи в канал.func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) — функция для чтения каналов.func closechan(c *hchan) — это причина моего любимого типа паники – «closing a closed channel». Потому что если вы ее ловите, то в многопоточке что-то явно пошло не так, и вы проведете следующие несколько дней очень интересно, разбираясь в этом.И есть еще много других функций и методов, о которых мы поговорим в ходе доклада.
Я покажу буферизированный канал на примере, а дальше мы рассмотрим небуферизированный, потому что это он же, просто с размером 0.
Hchan
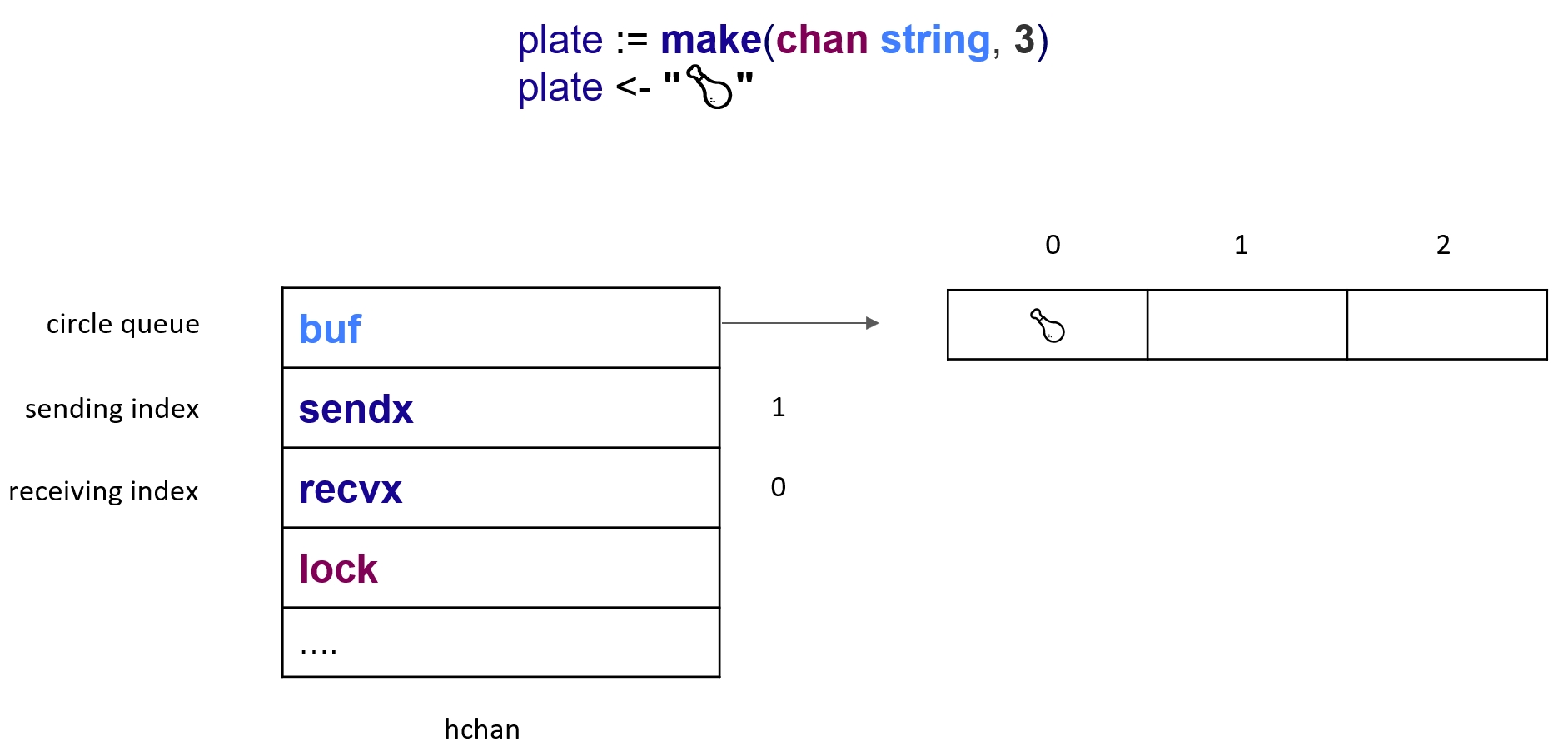
Рассмотрим простой пример:
plate := make(chan string, 3) Что происходит, когда вызывается этот код? Создается структура, которая содержит в себе около 10 полей, из них — 4 важных. Первое — Ring buffer (circle queue, или кольцевая очередь), которое хранит наши данные.
Обычно имплементация кольцевой очереди делается на массиве и на двух указателях (индексах) в этом массиве: один индекс мы постоянно пишем и инкрементируем, а другой индекс читаем и инкрементируем. И когда мы достигаем конца, то просто перемещаемся в начало. Здесь же у нас есть массив и два индекса, по которым пишем и читаем. И есть еще lock. При этом у нас пустая структура — и буфер, и индексы пустые:
Посмотрим, что произойдет, когда мы попытаемся записать в канал:
Когда мы пишем второй результат, происходит то же самое:
Когда мы пишем третий, sending index перемещается в 0 и начинает указывать на 0:
Но если в то же самое время мы читаем из канала, мы начнем с receiving index и инкрементируем его:
Очевидно, что если сейчас попытаться записать в канал, то запись будет в позицию 0, потому что она свободна и sending index указывает на 0. В случае, когда у нас полный буфер и мы не можем писать, начинает выстраиваться очередь из горутин. Но об этом чуть позже.
Чтобы не быть голословным, привожу всю структуру, чтобы вы видели, какая она чудесная и ужасная. Комментарии на русском мои:
Все поля очевидны. Буфер на самом деле лежит в псевдо-array — то есть это unsafe.pointer и по нему считаются смещения. У нас есть некоторые индексы для чтения/записи, лист ожидания на чтение/запись (листы горутин) и два моих любимых поля, elemsize и elemtype — наши псевдо-дженерики в Go. Когда вы создаете канал ints или канал strings — это не дженерик. Вы создаете просто hchan, и внутри лежат элементы size и type, причем со ссылкой. Ещё есть lock mutex, который по сути sync mutex.
ОК, это структура, а где она хранится?
Где хранится структура
Обычно в языках программирования есть две области памяти — Stack и Heap:
На Stack (грубо говоря, это стек нашего метода) мы храним переменные, вызовы, указатели на ссылочные типы. А в Heap обычно хранится то, что называется ссылочными (reference) объектами — всё, что не примитив. String обычно хранится на Heap почти во всех языках, а на Stack лежат boolean, int и указатели на эти референсные типы.
Почему такие названия — Stack и Heap? Потому что Stack — это стек. Представьте стопку тарелок — это стек. Вы всегда берёте тарелку сверху. А Heap — это когда их в кучу навалили и каждую ищите по примерному адресу — надо искать смещение, коллектить и прочее:
Чтобы посмотреть, где они хранятся, нам поможет функция:
func makechan(t *chantype, size int) *hchanЕсли посмотрим на ее результат, увидим маленькую-маленькую звездочку — как все ссылочные типы, он хранится на Heap. То есть когда мы создаем канал, мы кладем hchan в Heap и работаем, грубо говоря, через указатель.
Почему мы не видим этот указатель? Потому что это магия, это сахар в Go, которого нет. То есть мы не видим его как указатель, но на самом деле это указатель. Когда мы его копируем, передаем, еще что-то, мы не паримся за результат, потому что он всегда указывает на штуку в Heap, она всегда одна, мы работаем с ней, а в нашем коде всегда живет указатель:
Вернемся к нашему примеру с буферизированным каналом размера 0. Что произойдет, когда этот код начнет исполняться (там же нет буфера, в который можно это положить)? Ответ на это содержится в двух полях — receiving q и sending q (интересная игра слов, очень люблю «гошные» сокращения, хотя очень от них страдаю). Это очереди горутин, которые идут либо на чтение, либо на запись:
Представим, что у нас есть небуферизированный канал, и мы пытаемся что-то в него записать. Что произойдет, когда мы создаем такой канал? У нас создастся примерно та же самая структура. Я опустил locks и остальное, так как хочу сфокусировать ваше внимание на этих трех полях. Когда эта структура будет создана, в ней будет буфер, receiving q и sending q. Буфер будет всегда nil. Это тоже буферизированный канал, но с размером nil, он пустой. А receiving q и sending q будут выставлены просто в структуры:
Когда мы начнем читать из этого канала, мы начнем выстраиваться в очередь на нём, так как у нас нет ни пишущих горутин, ни буфера. У нас есть только две горутины, которые пытаются прочитать из канала. И они одна за одной выстроятся в очередь: «Ага, я подожду, пока кто-нибудь придет». Если приходит пишущая горутина, она подумает: «О, в списке получения есть что-то — запишу-ка я туда». Иначе — она точно так же встанет в запись и будет ждать. А waitq — указатель на голову и хвост linked листа горутин:
И вот она, чудесная структура sudog:
type sudog struct {
g *g
// isSelect – в select мы или нет?
isSelect bool
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
c *hchan // канал
}В конце стоит кольцевая ссылка на наш канал hchan. Тут отдельно всплывает моя нелюбовь к кольцевым ссылкам (circle reference) — в прошлом году в нашем проекте мы очень мучались с этим и даже написали свой самопальный DI, чтобы код не рос как на дрожжах. Я не нашел, для чего здесь circle reference, но header указывает на header, и мы держим структуру, которая указывает в свою очередь на header — и так можно бесконечно ходить.
Рассмотрим чуть более сложный пример. Мы создаем канал и на нем регистрируем двух голодных животных. Конечно, первым пускаем кота (пусть меня простят те, кто любит собак), потом собаку, и пытаемся их накормить. Что получится в рантайме?
Первой в очередь встанет горутина, которая отвечает за кота. У нее предыдущее состояние будет указывать на nil, следующее состояние будет указывать в никуда. Далее подъедет вторая структура, предыдущее состояние у которой будет указывать на кота, а следующее — nil. Если добавить третью структуру, она встанет следующей. У нее предыдущее будет показывать на собаку. Так мы строим нашу цепочку:
Demo
Давайте посмотрим на исходники. Начнем с элементарного примера — запустим функцию. И… после ее выполнения мы не видим никакого результата. Наш IDE написал кучу свойств, но результата нет:
Теперь откроем файл chango. Я не первый раз показываю флаг debugChan, который мне очень нравится — как только мы его выставляем в true, можно получить много интересных side-эффектов. И, когда мы его запустим, даже на пустой программе создается, как минимум, два канала. Причем мы даже что-то пишем в них и читаем из них. Один из них отвечает за garbage collector, а второй связан с memory:
Интересно то, что как только вы поменяете исходный файл, ваш output сразу расцветет — вы много всего интересного можете увидеть. Это общий паттерн почти для всех программ на Go: вы можете и с select так сделать, и с map. Но остерегайтесь редактировать этих файлы, потому что у меня три раза была забавная история. Когда я готовился к докладу, я в исходниках что-то удалял, что-то правил и условия выставлял, а когда собрал рабочий проект на том же компьютере, он перестал работать. Я разбирался часа два, пока не сделал brew reinstall go, чтобы переустановить инсталляцию Go на Mac, — и все потому, что я испортил исходную библиотеку.
Посмотрим, что у нас есть в этом файле. В функции на создание канала достаточно интересный код, потому что есть ветвление на три ветки. Небуферизированный канал мы создаем одним образом, канал с пойнтерами инициализируется по-другому, другие каналы инициализируются по-третьему, и т.д.:
Есть функция, которая считает смещение в буфере. По сути это массив, но на смещениях unsafe — всё, как мы любим:
Дальше начинается весьма хорошо документированный код. Например, есть функция entry point для записи в канал (c – это канал, x – переменная, куда мы пишем):
Есть огромная функция chansend, но я покажу только пару интересных вещей. Во-первых, почему по ссылке на нулевом канале виснет ваш рантайм навсегда? Ответ в первых трех строках. Мы проверяем канал на nil. Если канал nil, то мы повисли — все плохо. Такое бывает, если вы канал не инициализировали:
Следующий вопрос. Почему у нас посылка на закрытом канале вызывает мою любимую панику? Потому что мы проверяем флаг, и если он закрыт, мы взрываемся. Поэтому, когда мы работаем с каналом, мы делаем все под lock:
Этот код отвечает за чтение из очереди, ожидающей горутин — горутина, которая хочет записать что-то в канал, сначала проверяет список тех горутин, которые уже ожидают на чтение. Если там что-то есть, значит, у нас что-то не в порядке с буфером, и надо в первую очередь разгребать их. Поэтому мы их вычитываем, а дальше работаем с буфером:
Goparkunlock — рантаймовая функция, которая паркует горутины, чтобы они подождали чего-то интересного:
В рантайме есть место, где мы из стека одной горутины пишем в стек другой, когда одна горутина ждет на чтение, а вторая приходит на запись. В этом случае идет оптимизация всё работает чуть быстрее:
Моя любимая функция closechan. Почему мы падаем на закрытии пустого канала? Потому что мы проверяем на пустой канал и падаем с паникой. Почему мы падаем с паникой, когда закрываем закрытый канал? Потому что там флаг стоит. Что происходит, когда мы закрываем канал с нашими листами? Они по одному просто вычитываются и тоже закрываются. Соответственно горутины отпускаются, им возвращаются дефолтные значения, и они живут дальше:
С получением из канала примерно та же самая история. Сейчас расскажу подробнее.
Немного практики: Почему struct{}?
Когда я начал программировать на Go, меня всегда интересовало: почему в примерах, когда нам просто нужен канал, или, допустим, хэш-сет, мы просто пишем пустую структуру?
func main(){
c := make(chan struct{})
go func() {c <- struct{}{}}()
<- c
}Ответ: потому что все сложные примитивы примерно одинаково в Go работают. Когда у нас пустой struct, это по сути special case, элемент size — ноль, тип максимально упрощен. При использовании special case не грузится дополнительная информация, мы не таскаем с собой дополнительные размеры, экономим место, и поэтому счастливо живем:
makechan: chan=0xc0000700c0; elemsize=0; elemalg=0x10bef90; dataqsiz=0Вот пример того, что я называю самым бесполезным бенчмарком на свете. Когда разговариваешь с кандидатом на работу про многопоточку и спрашиваешь, что можно сделать, чтобы убрать lock, иногда слышишь в ответ: «Давайте влепим канал, потому что там нет lock». И вот в левом углу ринга lock, сделанный на канале, в правом — просто lock:
В итоге я написал элементарнейший бенчмарк:
func BenchmarkChannelLock(b *testing.B){
b.ReportAllocs()
for n := 0; n < b.N; n++ {
ChannelLock()
}
}
func BenchmarkLock(b *testing.B){
b.ReportAllocs()
for n := 0; n < b.N; n++ {
UsualLock()
}
}
Принудительно выставил 50 млн прогонов, и увидел: если мы делаем наш чудесный BenchmarkChannelLock, мы работаем в 3 раза дольше, а аллоцируем в 12 раз больше.:
Очень полезная таблица, которая помогает, когда вы работаете с каналом:
Select
Select — это вишенка на торте каналов в Go, потому что он помогает работать с каналами, например, группировать их в группе операций:
select {
case <-receiveOnly:
fmt.Println(”прочитали")
case sendOnly <- ”data":
fmt.Println(”записали")
}Если у нас есть select и два канала, select будет ждать, пока не выполнится хотя бы один из этих каналов. Самый грязный способ повесить горутину навсегда — это объявить пустой select. Если добавить default, а оба канала — блочащие, то мы не сможем прочитать или записать (буфер закончился, или читающих горутин нет, или еще что-то). В этом случае выполнится default:
select {
case <-receiveOnly:
fmt.Println(”прочитали")
case sendOnly <- ”data":
fmt.Println(”записали")
default:
fmt.Println("по умолчанию")
}Работа с select разделяется на две группы:
- Элементарные операции, когда есть select из одного case и одного default;
- Большие составные selectы.
Элементарный select
Когда у нас select состоит из case и default, он в compile-time разворачивается так:
if selectnbrecv(&val, receiveOnly) {
fmt.Println(”прочитали")
} else {
fmt.Println("по умолчанию")
}
Здесь функция просто чекает — можем мы прочитать или нет. Если можем, она выполняется, иначе — возвращается false, и мы уходим в if-else case:
func selectnbrecv(elem unsafe.Pointer, c *hchan) (bool) {
selected, _ := chanrecv(c, elem, false)
return selected
}Внутри нее используем обычное чтение из канала. Но есть интересный пункт — передача false. Обычно во всех функциях для работы с каналами (для чтения и для записи) передается параметр block. Он указывает (если горутина не может выполниться) заблокирована она или нет. И используется два аргумента, потому что когда вы читаете из закрытого канала, он вам может вернуть дефолтное значение, и за это отвечает второй аргумент — ОК или нет.
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) boolВ случае с select это работает по-другому:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool)Select говорит: «Если не можешь прочитать, то возвращай управление» — и просто возвращает false:
func selectnbrecv(elem unsafe.Pointer, c *hchan) (bool) {
selected, _ := chanrecv(c, elem, false)
return selected
}If работает соответственно.
Как работает составной select
- Case сортируются. Там есть собственная сортировка, собственный быстрый рандом — fastrand, который сортирует все кейсы по какому-то правилу. Это ответ на то, что если у нас select и несколько горутин, допустим, пять каналов, и они все разлочены, какой из них выполнится? Ответ: тот, который отсортируется и попадет на первое место.
- Выбирается первый, который может продолжить исполнение. Если не все могут продолжить выполнение, мы просто идем по всем кейсам и, грубо говоря, чекаем – залочен или нет. Функции, которые используются для этого, я вам показал (chanrecv, chansend), тоже передается block false, и мы работаем с этим.
- Если такого нет, горутина делает park и ждет, пока она не будет разбужена действием над каналом. Это ответ на то, почему пустой select все вешает – там нет ни одного кейса, мы ничего не можем прочитать, паркуемся и ждем. А так как никто нас не разбудит, будем ждать вечно.
- Отправка/чтение/закрытие канала в другой горутине вызывает функцию goready. Функция goready скажет: «Эгей! Я выполнила действия, давай разбудим горутины, которые что-то ждут»
- Select просыпается и продолжает выполнение. Проснувшись, select смотрит кейсы, выбирает и выходит из него.
В заключение
Я рекомендую посмотреть видео, которое быстро рассказывает про каналы и почитать go101 (там много полезной информации об исходниках):
- go101.org/article/channel-use-cases.html
- go101.org/article/channel.html
- go101.org/article/channel-closing.html
И спасибо Ashley McNamara за гоферов. Все любят гоферов!
Конференция HighLoad++ 2020, к сожалению, переносится. Но мы обязательно встретимся вживую и офлайн в новые даты — 17 и 18 февраля 2021 года, в Крокус-Экспо.
HighLoad++ — это не просто конференция, это место встречи всего IT-сообщества страны. Ежегодно с 2007 года мы встречались осенью, общались друг с другом, делились опытом, обсуждали новинки и подводили итоги года.
В этом году ставки ещё выше! Мы все устали от монитора и холодильника, мы все соскучились и не виделись вообще нигде вот уже почти год. Поэтому оргкомитет HIghLoad++ решил не переносить конференцию онлайн, а перенести даты нашей живой встречи.
Для получения анонсов о новых конференциях, полезных материалах и вдохновения — официальный telegram-канал, неофициальный telegram-канал и соцсети — Facebook, VK, Twitter и Youtube.



