
HighLoad++ Moscow 2018, зал «Конгресс-холл». 9 ноября, 15:00
Тезисы и презентация: http://www.highload.ru/moscow/2018/abstracts/4066
Юрий Насретдинов (ВКонтакте): в докладе будет рассказано об опыте внедрения ClickHouse в нашей компании – для чего он нам нужен, сколько мы храним данных, как их пишем и так далее.

Дополнительные материалы: использование Clickhouse в качестве замены ELK, Big Query и TimescaleDB
Юрий Насретдинов: – Всем привет! Меня зовут Юрий Насретдинов, как уже представили меня. Я работаю во «ВКонтакте». Я буду рассказывать про то, как мы вставляем данные «КликХаус» с нашего парка серверов (десятки тысяч).
Вопрос: кто из вас был на таком же докладе, но на HighLoad Siberia… В общем, можете проматывать до 30-й минуты где-то сразу, и там будет новое.
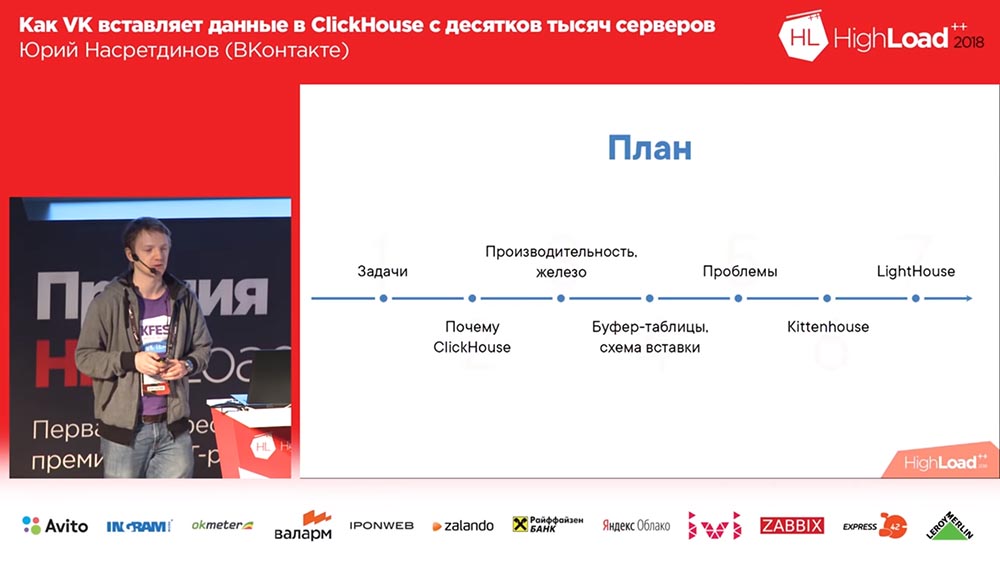
Что мы будем рассказывать: что мы делали, зачем нам понадобился «КликХаус», соответственно – почему мы его выбрали, какую производительность вы можете примерно получить, ничего не конфигурируя специально. Расскажу дальше про буферные таблицы, про проблемы, которые у нас с ними были и про наши решения, которые мы разработали из «опен-сорса» – KittenHouse и LifeHouse.
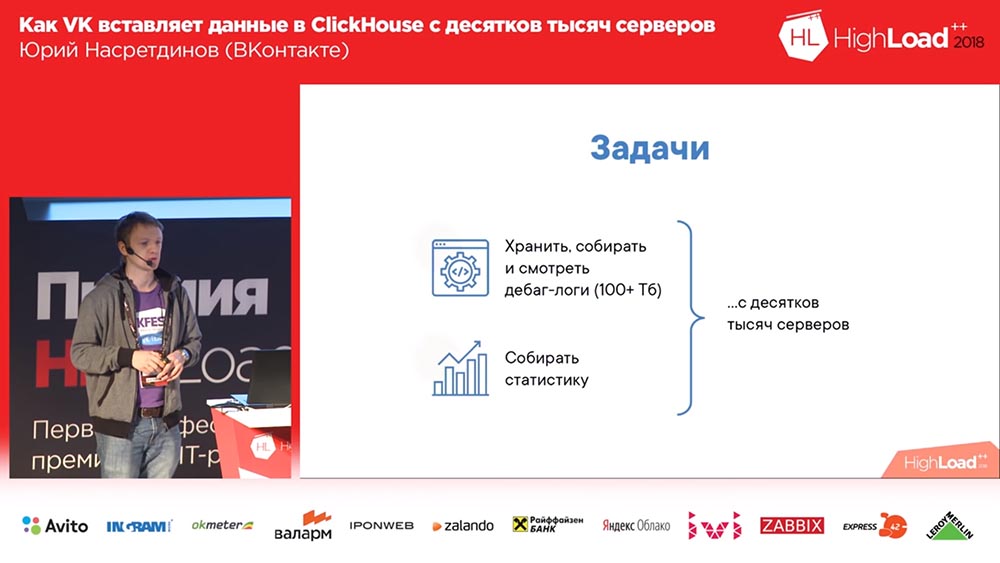
Зачем нам понадобилось вообще что-то делать (во «ВКонтакте» всегда всё хорошо, да?). Мы хотели собирать дебаг-логи (и их там было сотни терабайт данных), может, ещё как-то статистику поудобнее считать; и у нас парк серверов в десятки тысяч, с которых всё это нужно делать.
Почему мы решили? У нас же наверняка были решения для хранения логов. Вот – есть такой паблик «Бэкенд ВК». Очень рекомендую подписаться на него.

Что такое logs? Это движок, возвращающий пустые массивы. Движками в «ВК» называется то, что микросервисами остальные называют. И такой вот стикер улыбающийся (довольно много лайков). Как так? Ну, слушайте дальше!

Что вообще можно использовать для хранения логов? Нельзя не упомянуть «Хадуп». Потом, например, Rsyslog (хранение в файлах этих логов). LSD. Кто знает, что такое ЛСД? Нет, не этот ЛСД. Файлы хранить, соответственно, тоже. Ну и ClickHouse – странный вариант какой-то.
Что мы хотим? Мы хотим, чтобы нам не нужно было особо париться с эксплуатацией, чтобы она работала из коробки желательно, с минимальной настройкой. Хотим писать очень много, а писать быстро. И хотим хранить это всякие месяцы, годы, то есть долго. Мы можем хотеть разобраться в проблеме какой-то, с которой к нам пришли, сказали – «У нас тут что-то не работает», – а это было 3 месяца назад), и мы хотим иметь возможность посмотреть, чтобы было 3 месяца назад». Сжатие данных – понятно, почему оно будет плюсом, – потому что сокращается количество места, которое занимается.

И у нас есть такое интересное требование: мы иногда пишем output каких-нибудь команд (например, логи), оно может быть больше 4 килобайт совершенно спокойно. И если эта штука имеет работать по UDP, то ей не нужно тратить… у неё не будет никакого «грейхеда» на соединение, и для большого количества серверов это будет плюсом.

Давайте посмотрим, что предлагает «опен-сорс» нам. Во-первых, у нас есть Logs Engine – это наш движок; он в принципе всё умеет, даже длинные строки умеет писать. Ну, прозрачные данные он не сжимает – мы можем большие колонки сами сжимать, если захотим… мы, конечно, не хотим (по возможности). Единственная проблема – он умеет отдавать только то, что у него помещается в памяти; остальное, чтобы прочитать, нужно доставать binlog этого движка и, соответственно, это довольно долго. Хотя данные он хранит, потому что не может отдать (поэтому он отдаёт пустые массивы).

Какие есть варианты другие? Например, «Хадуп». Простота эксплуатации… Кто считает, что «Хадуп» легко настраивается? С записью, конечно же, проблем нет. С чтением вопросы иногда возникают. В принципе я сказал бы, что скорее нет, особенно для логов. Долговременное хранение – конечно, да, сжатие данных – да, длинные строки – понятно, что можно записывать. А вот записывать с большого количества серверов… Всё равно надо самим что-то делать!
Rsyslog. На самом деле мы его использовали как запасной вариант, для того чтобы можно было без дампа бинлога читать, но он не может в длинные строки, в принципе больше 4 килобайт не может записать. Сжатие данных точно так же самим надо делать. Чтение будет идти с файлов.

Потом есть «бадушная» разработка LSD. То же самое по сути, что и «Рсислог»: длинные строки поддерживает, но по UDP работать не умеет и, собственно, из-за этого, к сожалению, там довольно много чего переписывать нужно (поверьте, я его писал, чтобы с десятков тысяч серверов запись осуществлять).

А, вот! Смешной вариант – ElasticSearch. Ну, как сказать? С чтением у него всё хорошо, то есть он читает быстро, но с записью не очень хорошо. Во-первых, данные он, если и сжимает, то очень слабо. Скорее всего, для полноценного поиска требуются более объёмные структуры данных, чем исходный объём. Эксплуатировать тяжело, с ним часто проблемы возникают. И, опять же, запись в «Эластик» – всё мы сами должны делать.

Вот ClickHouse – идеальный вариант, понятное дело. Единственное, запись с десятков тысяч серверов – это проблема. Но она хотя бы одна, мы её можем попробовать как-то решить. И вот про эту проблему весь остальной доклад. Какую вообще производительность от «КликХауса» можно ожидать?
Кто из вас про «КликХаус» не слышал, не знает? Нужно рассказать, не нужно? Очень быстро. Ставка там – 1-2 гигабита в секунду, всплесками до 10 гигабит в секунду на самом деле может выдерживать на вот такой конфигурации – там два 6-ядерных «Ксеона» (то есть даже не самые мощные), 256 гигов оперативы, 20 терабайтов в «Рейде» (никто не настраивал, дефолтные настройки). Алексей, наверное, плачет сидит, что мы ничего не настраивали (у нас всё работало так). Соответственно, скорость сканирования, допустим, порядка 6 миллиардов строк в секунду можно получить, если данные хорошо сжимаются. Если вы like % по текстовой строке делаете – 100 миллионов строк в секунду, то есть кажется, что весьма быстро.

Как будем вставлять? Ну, вы знаете, что в «ВК» – на PHP. Мы из каждого PHP-воркера будем по HTTP вставлять в «КликХаус», в табличку MergeTree на каждую запись. Кто видит проблему в этой схеме? Почему-то не все подняли руки. Давайте расскажу.
Во-первых, серверов много – соответственно, соединений будет становиться много (плохо). Потом в MergeTree лучше вставлять данные не чаще, чем раз в секунду. А кто знает почему? Ладно, хорошо. Я расскажу чуть-чуть подробнее об этом. Ещё интересный вопрос – что мы как бы не аналитику делаем, нам не нужно обогащать данные, нам не нужны промежуточные сервера, мы хотим вставлять прямо в «КликХаус» (желательно – чем прямее, тем лучше).

Соответственно, как осуществляется вставка в MergeTree? Почему в него лучше вставлять не чаще, чем раз в секунду или реже? Дело в том, что «КликХаус» – столбцовая база данных и сортирует данные в порядке возрастания первичного ключа, и когда вы делаете вставку, создаётся количество файлов как минимум по количеству колонок, в которых данных отсортированы в порядке возрастания первичного ключа (создаётся отдельная директория, набор файлов на диске на каждый insert). Потом следующая вставка идёт, и в фоне они объединяются в большего размера «партиции». Поскольку данные отсортированы, то «смержить» два отсортированных файла можно без большого потребления памяти.
Но, как вы догадываетесь, если записать по 10 файлов на каждый insert, то «КликХаус» быстро закончится (или ваш сервер), поэтому рекомендуется вставлять большими пачками. Соответственно, схему первую мы никогда не запускали в продакшн. Мы сразу запустили такую, которая здесь № два имеет:

Здесь представьте себе, что есть около тысячи серверов, на которых мы запустили, там просто PHP. И на каждом сервере стоит наш локальный агент, который мы назвали «Киттенхаус», который держит одно соединение с «КликХаусом» и раз в несколько секунд вставляет данные. Вставляет данные не в MergeTree, а в буферную таблицу, которая как раз служит для того, чтобы не вставлять напрямую в MergeTree, сразу.
Что это такое? Буферные таблицы – это кусок памяти, пошардированный (то есть в него можно часто вставлять). Они состоят из нескольких кусков, и каждый из кусков работает как независимый буфер, и они независимо флашатся (если у вас много кусков у буфера, то и вставок будет много в секунду). Читать из этих таблиц можно – тогда вы читаете объединение содержимого буфера и родительской таблицы, но в этот момент блокируется запись, поэтому лучше не читать оттуда. И очень хороший QPS показывают буферные таблицы, то есть до 3 тысяч QPS у вас не возникнет вообще никаких проблем при вставке. Понятно, что, если пропало питание у сервера, то данные можно потерять, потому что они только в памяти хранились.

При этом схему с буфером усложняет Alter, потому что вам нужно сначала дропнуть старую буферную таблицу со старой схемой (данные никуда не пропадут при этом, потому что они зафлашатся перед тем, как таблица удалится). Потом вы «альтерите» нужную вам таблицу и создаёте буферную таблицу заново. Соответственно, пока нет буферной таблицы, у вас данные никуда не льются, но вы можете их на диске хотя бы локально.

Что из себя представляет KittenHouse? Это прокси. Угадайте, на каком языке? Я собрал самые хайповые темы в своём докладе – это «Кликхаус», Go, может, ещё что-нибудь вспомню. Да, на Го это написано, потому что я не очень умею писать на Си, не хочу.

Соответственно, оно держит соединение с каждым сервером, умеет писать в память. Например, если мы пишем error-логи в «Кликхаус», то, если «Кликхаус» не успевает вставлять данные (всё-таки если их слишком много пишется), то мы не распухаем по памяти – мы просто выбрасываем остальное. Потому, что, если у нас пишется несколько гигабит в секунду ошибок, то, наверное, нам можно какие-то выкинуть. «Киттенхаус» это умеет. Плюс, он умеет надёжную доставку, то есть запись на диск на локальной машине и раз в какое-то время (там, раз в пару секунд) пытается данные из этого файла доставить. И мы поначалу использовали обычный формат Values – не какой-то бинарный формат, текстовый формат (как в обычном SQL).

Но дальше произошло вот такое вот. Мы использовали надёжную доставку, писали логи, потом решили (это был такой, условно тестовый кластер)… На несколько часов его потушили и подняли обратно, и с тысячи серверов пошла вставка – оказалось, что у «Кликхауса» всё-таки модель «Тред на соединение» – соответственно, в тысячу соединений активная вставка приводит к load average на сервере где-то в полторы тысячи. На удивление, сервер принимал запросы, а данные такие всё-таки вставились через какое-то время; но очень тяжело было серверу это обслуживать…
Такое решение для модели Thread per connection – это nginx. Мы поставили nginx перед «Кликхаусом», заодно настроили балансировку на две реплики (у нас ещё в 2 раза увеличилась скорость вставки, хотя не факт, что так должно быть) и ограничили количество соединений к «Кликхаусу», к апстриму и, соответственно, больше, чем в 50 соединений, кажется, смысла вставлять нет.

Потом мы поняли, что вообще эта схема имеет недостатки, потому что у нас здесь – один nginx. Соответственно, если этот nginx ложится, несмотря на наличие реплик, мы данные теряем или, по крайней мере, никуда не пишем. Поэтому мы сделали свою балансировку нагрузки. Также мы поняли, что «Кликхаус» всё-таки для логов подходит и «демон» тоже начал писать свои логи тоже в «Кликхаус» – очень удобно, если честно. До сих пор используем ещё и для других «демонов».

Потом обнаружили такую интересную проблему: если вы используете не вполне стандартный способ вставки в SQL-режиме, то форсится полноценный SQL-парсер на основе AST, который довольно медленный. Соответственно, мы добавили настройки, чтоб такого не происходило никогда. Сделали балансировку нагрузки, helth-чеки, чтобы, если одна умирает, то мы всё равно оставляли данные. У нас стало достаточно много таблиц, чтобы нам стало нужно разные кластеры «Кликхауса» иметь. И ещё мы начали думать о других использованиях – например, мы хотели писать логи из nginx-модулей, а они по нашему RPC общаться не умеют. Ну, хотелось бы их хоть как-то научить отправлять – например, по UPD принимать события на localhost и потом уже их пересылать в «Кликхаус».
Итоговая схема стала выглядеть вот так (четвёртый вариант этой схемы): на каждом сервере перед «Кликхаусом» стоит nginx (на том же сервере причём) и просто на localhost проксирует запросы с ограничением по количеству соединений в 50 штук. И вот эта схема уже рабочая вполне была, с ней было всё довольно-таки хорошо.

Мы жили так где-то месяц. Все радовались, добавляли таблицы, добавляли, добавляли… В общем, оказалось, что то, как мы добавляли буферные таблицы, оно не очень оптимально (скажем так) было. Мы делали по 16 кусков в каждой таблице и флаш-интервал пару секунд; у нас было 20 таблиц и в каждую таблицу шло по 8 вставок в секунду – и в этом моменте «Кликхаус» начал… записи начинали тупить. Они даже не то что не проходили… У nginx’а по умолчанию была такая интересная штука, что, если коннекты заканчивались у апстрима, то на все новые запросы он просто отдаёт «502».

И вот у нас (это я просто по логам в самом же «Кликхаусе» я посмотрел) где-то полпроцента запросов фейлилось. Соответственно, утилизация диска была высокая, много мержей было. Ну, что я сделал? Я, естественно, не стал разбираться, почему именно заканчивается коннект и апстрим.
Я решил, что нам нужно управлять этим самим, не надо это давать на откуп nginx – nginx не знает, какие таблицы в «Кликхаусе» есть, и заменил nginx на reverse-прокси, который тоже я сам написал.
Он что делает? Он работает на основе библиотеки fasthttp «гошной», то есть быстрый, почти такой же быстрый, как nginx. Извините, Игорь, если вы тут присутствуете (прим.: Игорь Сысоев – русский программист, создавший веб-сервер nginx). Он умеет понимать, какие это запросы – Insert или Select – соответственно, разные пулы соединения держит для разных видов запросов.

Соответственно, даже если мы на вставку не успеваем выполнить запросы, то «селекты» будут проходить, и наоборот. И группирует данные по буферным таблицам – с небольшим буфером: если там были какие-то ошибки, синтаксические ошибки и так далее – чтобы они несильно влияли на остальные данные, потому что, когда мы вставляли просто в буферные таблицы, то у нас были маленькие «бачи», и все ошибки ошибки синтаксиса влияли только на этот маленький кусочек; а здесь они будут влиять уже на большой буфер. Маленький – это 1 мегабайт, то есть не такой уж и маленький.

Вставка синхрона по сути заменяет nginx, делает по сути то же самое, что и делал nginx до этого – «Киттенхаус» локальный менять для этого не нужно. И поскольку он использует fasthttp, он очень быстрый – можно больше 100 тысяч запросов в секунду единичных insert’ов делать через reverse-прокси. Теоретически можно вставлять по одной строке в «Киттенхаус», reverse-прокси, но мы, конечно, так не делаем.

Схема стала выглядеть вот так: «Киттенхаус», reverse-прокси группирует много запросов по таблицам и уже в свою очередь буферные таблицы вставляют их в основные.
Встала такая интересная проблема… Кто-нибудь из вас использовал fasthttp? Кто при этом использовал fasthttp с пост-запросами? Наверное, так не стоило делать на самом деле, потому что он буферизует тело запроса по умолчанию, а у нас размер буфера 16 мегабайт был выставлен. Вставка перестала успевать в какой-то момент, и со всех десятков тысяч серверов начали приходить 16-мегабайтные чанки, и они все буферизировались в памяти перед тем, как отдаться в «Кликхаус». Соответственно, память кончалась, Out-Of-Memory Killer приходил, убивал reverse-прокси (или «Кликхаус», который мог теоретически «жрать» больше, чем reverse-прокси). Цикл повторялся. Не очень приятная проблема. Хотя мы на это наткнулись только через несколько месяцев эксплуатации.
Что я сделал? Опять же, я не очень люблю разбираться в том, что именно произошло. Мне кажется, довольно очевидно, что не надо буферизировать память. Я не смог пропатчить fasthttp, хотя пытался. Но я нашёл способ, как сделать так, чтобы не нужно было ничего патчить, и придумал свой метод в http – назвал его Kitten. Ну, логично – «ВК», «Киттен»… Как ещё?..

Если приходит запрос на сервер с методом Kitten, то сервер должен ответить «мяу» (meow) – логично. Если он на это отвечает, то считается, что он понимает этот протокол, и дальше я перехватываю соединение (в http такой метод есть), и соединение переходит в «сырой» режим. Зачем мне это нужно? Я хочу управлять тем, как происходит чтение из TCP-соединений. У TCP есть замечательное свойство: если никто не читает с той стороны, то запись начинает ждать, и память особо не расходуется на это.
И вот я читаю где-то с 50 клиентов за раз (с пятидесяти потому, что пятидесяти уж точно должно хватить, даже если это из другого ДЦ ставка идёт)… Потребление уменьшилось с таким подходом как минимум в 20 раз, но я, если честно, не смог замерить, во сколько именно, потому что это уже бессмысленно (оно уже на уровне погрешности стало). Протокол бинарный, то есть там идёт имя таблицы и данные; нет http-заголовков, поэтому я не использовал веб-сокет (мне же с браузерами не нужно общаться – я сделал протокол, который подходит под наши нужды). И с ним стало всё хорошо.
Недавно мы столкнулись с ещё интересной особенностью буферных таблиц. И вот эта проблема уже намного больнее, чем остальные. Представим себе такую ситуацию: у вас уже активно используется «Кликхаус», у вас десятки серверов «Кликхауса», и у вас есть некоторые запросы, которые читают очень долго (допустим, больше 60 секунд); и вы такие приходите и делаете Alter в этот момент… А пока «селекты», которые начались до «Альтера», в эту таблицу не войдут, «Альтер» не начнётся – вероятно, какие-то особенности того, как работает «Кликхаус» в этом месте. Может быть это можно исправить? Или нельзя?

В общем, понятно, что на самом деле это не такая уж большая проблема, но с буферными таблицами она становится больнее. Потому что, если, допустим, у вас «Альтер» таймаутится (причём затаймаутиться может на другом хосте – не на вашем, а на реплике, например), то… Вы такие удалили буферную таблицу, у вас затаймаутился «Альтер» (или какая-то ошибка «Альтера» произошла) – надо же, чтобы всё-таки данные продолжали писаться: вы создаёте буферные таблицы обратно (по той же схеме, что была у родительской таблицы), потом «Альтер» проходит, всё-таки завершается, и буферная таблица начинает отличаться по схеме от родительской. В зависимости от того, что был за «Альтер», может вставка больше не идти в эту буферную таблицу – это очень печально.

Ещё есть такая табличка (может, кто её замечал) – называется в новых версиях «Кликхауса» query_thred_log. По умолчанию, в какой-то версии была единичка. Вот мы накопили 840 миллионов записей за пару месяцев (100 гигабайт). Связано это с тем, что туда писались (может, сейчас, кстати, и не пишутся) «инсёрты» (inserts). Как я вам рассказывал, у нас «инсёрты» маленькие – у нас очень много «инсёртов» в буферные таблицы шло. Понятно, что это отключается – это я вам просто рассказываю, что я видел у нас на сервере. Почему? Это ещё один аргумент против того, чтобы использовать буферные таблицы! Спотти очень грустит.

А кто знал, что этого товарища зовут Спотти? Подняли руки сотрудники «ВК». Ну ладно.
Обычно планами не делятся, да? Вдруг вы их не будете выполнять и будете выглядеть не очень хорошо в чужих глазах. Но я рискну! Мы хотим сделать следующее: буферные таблицы, как мне кажется, это всё-таки костыль и надо буферизировать вставку самим. Но мы всё ещё не хотим буферизировать её на диске, поэтому мы будем буферизировать вставку в памяти.

Соответственно, когда делается «инсёрт», он уже не будет синхронный – он будет уже работать как буферная таблица, будет вставлять в родительскую таблицу (ну, когда-нибудь потом) и по отдельному каналу сообщать, какие вставки прошли, какие – нет.

Почему нельзя вставить синхронную вставку? Она же намного удобнее. Дело в том, что, если вставляете с 10 тысяч хостов, то всё хорошо – у вас с каждого хоста будет литься по чуть-чуть, вы там раз в секунду вставляете, всё прекрасно. Но хочется, чтобы эта схема работала, например, и с двух машин, чтобы вы могли лить на большой скорости – может, не выжимать максимум из «Кликхауса», но хотя бы 100 мегабайт в секунду писать с одной машины через реверс-прокси – эта схема должна масштабироваться и на большое количество, и на маленькое, поэтому мы не можем ждать на каждую вставку по секунде, поэтому она должна быть асинхронной. И точно так же асинхронные подтверждения должны приходить после того, как вставка совершилась. Мы будем знать о том, прошла она или нет.
Самое главное, что в этой схеме мы точно знаем, прошла вставка или нет. Представьте себе такую ситуацию: у вас буферная таблица, вы в неё что-то записали, а потом, допустим, таблица перешла в read only и пытается зафлашиться буфер. Куда пойдут данные? Останутся в буфере. Но мы в этом уверены быть не можем – вдруг какая-то другая ошибка, из-за которой не останутся в буфере данные… (Обращается к Алексею Миловидову, «Яндекс», разработчик ClickHouse) Или останутся? Всегда? Алексей убеждает нас, что всё будет хорошо. У нас нет причин ему не верить. Но всё равно: если мы не используем буферные таблицы, то и проблем с ними точно не будет. Создавать в два раза больше таблиц тоже неудобно, хотя в принципе больших проблем нет. Это план.
А теперь давайте поговорим про чтение. Мы здесь тоже написали свой инструмент. Казалось бы, ну зачем здесь-то писать свой инструмент?.. А кто пользовался «Табиксом»? Как-то мало людей подняло руки… А кого устраивает производительность «Табикса»? Ну вот, нас не устраивает, и он не очень удобен для просмотра данных. Для аналитики он подходит нормально, а просто для просмотра он явно не оптимизирован. Поэтому я написал своё, свой интерфейс.

Он очень простой – он умеет только читать данные. Он не умеет графики показывать, ничего не умеет. Но умеет показывать то, что нам нужно: например, какое количество строк в таблице, сколько места она занимает (без разбивки по колонкам), то есть очень базовый интерфейс – то, что нам нужно.

И выглядит он очень похоже на Sequel Pro, но только сделанный на твиттеровском «Бутстрапе», причём второй версии. Вы спросите: «Юрий, а почему на второй версии-то?» Какой год? 2018-й? В общем, делал я это достаточно давно для «Мускуля» (MySql) и просто поменял там пару строчек в запросах, и он стал работать для «Кликхауса», за что отдельное спасибо! Потому что парсер очень похож на «мускулевский», и запросы очень похожи – очень удобно, особенно поначалу.
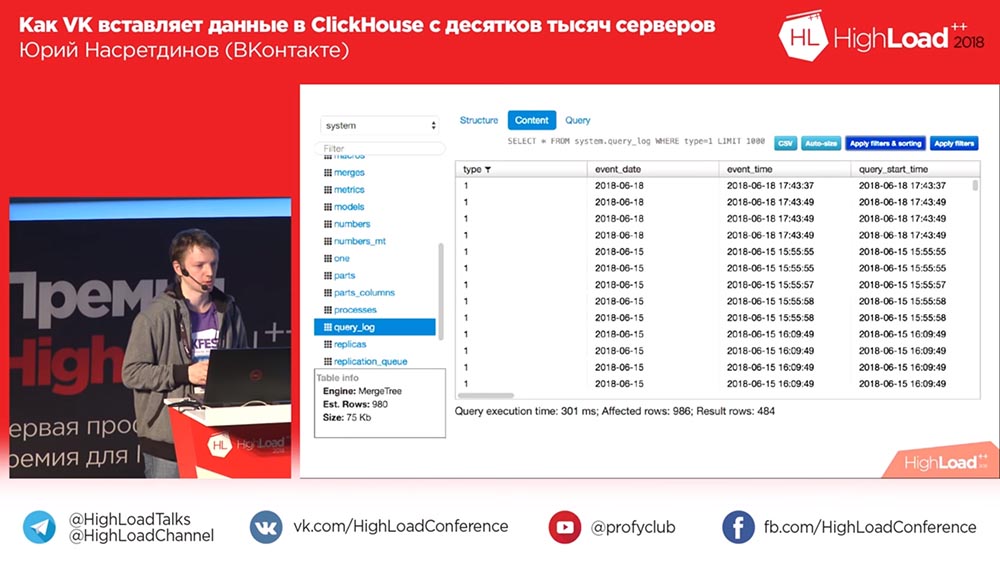
Ну, умеет он фильтрацию таблиц, умеет показывать структуру, содержимое таблицы, сортировать позволяет, фильтровать по колонкам, показывает запрос, который получился в итоге, affected rows (сколько в результате), то есть базовые вещи для просмотра данных. Довольно быстро.
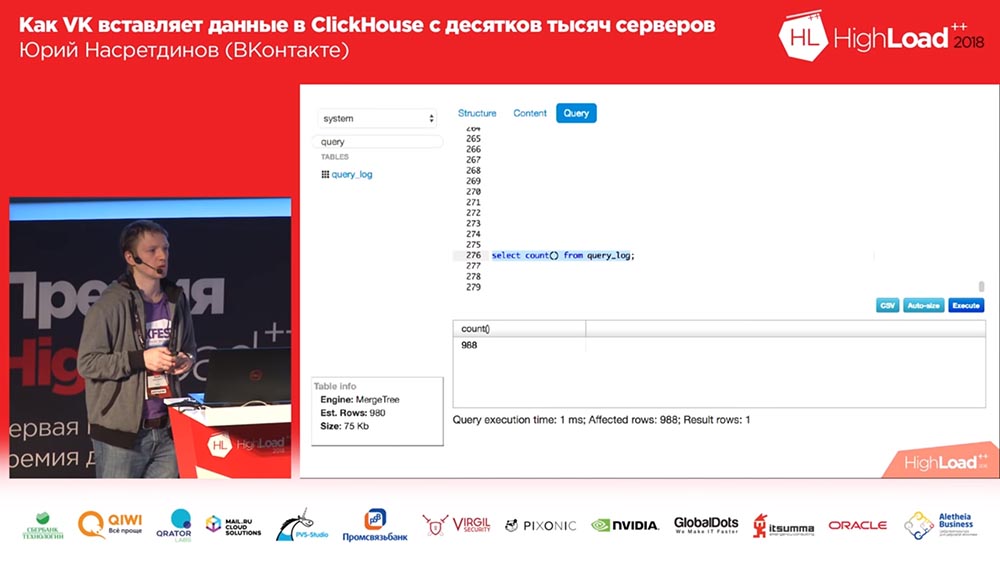
Редактор тоже есть. Я честно попытался украсть редактор целиком из «Табикса», но не смог. Но всё-таки как-то он работает. В принципе на этом всё.
Я вам хочу сказать, что «Кликхаус», несмотря на все описанные проблемы, очень хорошо подходит для логов. Он, самое главное, решает нашу проблему – он очень быстрый и позволяет фильтровать логи по колонкам. В принципе буферные таблицы показали себя не с лучшей стороны, но обычно никто не знает почему… Может, вы теперь больше знаете, где у вас будут проблемы.

TCP? Вообще, в «ВК» принято использовать UDP. И когда я использовал TCP… Мне, конечно, никто не говорил: «Юрий, ну ты что! Нельзя, надо UDP». Оказалось, что TCP не так уж и страшен. Единственное, если у вас десятки тысяч активных соединений, которые у вас пишут – надо чуть-чуть аккуратнее его готовить; но можно, и довольно легко.
«Киттенхаус» и «Лайтхаус» я обещал выложить на HighLoad Siberia, если все подпишутся на наш паблик «ВК бэкенд»… И знаете, не все подписались… Я уже с вас, конечно, требовать подписаться на наш паблик не буду. Вас всё-таки слишком много, кто-то может обидеться даже, но всё равно – подписывайтесь, пожалуйста (и я тут должен такие глаза, как у котика, сделать). Вот и ссылка на него кстати. Большое спасибо! Github наш вот тут. С «Кликхаусом» ваши волосы будут мягкими и шелковистыми.

Ведущий: – Друзья, а теперь вопросы. Сразу после того, как мы вручим благодарственную грамоту и твой доклад на VHS.
Юрий Насретдинов (далее – ЮН): – А как вы смогли записать мой доклад на VHS, если он только что закончился?

Ведущий: – Ты же тоже не можешь до конца определить, как «Кликхаус» – заработает или не заработает! Друзья, 5 минут на вопросы!
Вопрос из зала (далее – З): – Добрый день. Спасибо большое за доклад. У меня два вопроса. Начну с несерьёзного: влияет ли количество букв t в названии «Киттенхаус» на схемах (3, 4, 7…) на удовлетворённость котиков?
ЮН: – Количество чего?
З: – Букв t. Там три t, где-то три t.
ЮН: – Неужели я это не поправил? Ну, конечно, влияет! Это разные продукты – я просто вас обманывал всё это время. Ладно, я шучу – не влияет. А, вот здесь! Нет, это одно и то же, это я опечатался.

З: – Спасибо. Второй вопрос серьёзный. Насколько я понимаю, в «Кликхаусе» буферные таблицы живут исключительно в памяти, на диск не буферизуются и, соответственно, не являются per systems.
ЮН: – Да.
З: – А при этом у вас на клиенте осуществляется буферизация на диск, что подразумевает некоторую гарантию доставки этих самых логов. Но на «Кликхаусе» это никак не гарантируется. Поясните, как осуществляется гарантия, за счёт чего?.. Вот этот вот механизм подробнее
ЮН: – Да, теоретически противоречий здесь нет, потому что вы при падении «Кликхауса» можете детектить миллионом разных способов на самом деле. При падении «Кликхауса» (при некорректном завершении) вы можете, грубо говоря, отматывать немного свой лог, который вы записывали, и начинать с момента, когда точно всё было хорошо. Допустим, на минуту назад отмотать, то есть считается, что за минуту зафлашил всё.
З: – То есть «Киттенхаус» держит окно длиннее и в случае падения умеет его распознавать и отматывать?
ЮН: – Но это в теории. На практике мы этого не делаем, и надёжная доставка – это от нуля до бесконечности раз. Но в среднем один. Нас устраивает, что, если «Кликхаус» падает по какой-то причине или серверы «ребутают», то мы немножко теряем. Во всех остальных случаях ничего не будет происходить.
З: – Здравствуйте. Мне с самого начала казалось, что действительно вы будете использовать UDP с самого начала доклада. У вас – http, всё такое… И большинство проблем, которые вы описали, как я понял, были вызваны именно этим решением…
ЮН: – Что мы используем TCP?
З: – По сути да.
ЮН: – Нет.
З: – Именно с fasthttp были у вас проблемы, с соединением у вас были проблемы. Если бы вы просто использовали UDP, сэкономили бы себе время. Ну, были бы проблемы с длинными сообщениями или ещё что-то…
ЮН: – С чем?

З: – С длинными сообщениями, поскольку в MTU может не влезть, ещё что-то… Ну, там свои проблемы могут возникнуть. Вопрос-то в чём: почему всё-таки не UDP?
ЮН: – Я верю в то, что авторы, которые разрабатывали TCP/IP, намного умнее меня и умеют лучше меня делать серверизацию пакетов (чтобы они шли), одновременно регулировать окно отправки, не перегружать сеть, давать обратную связь о том, что не читает, не считая с той стороны… Все эти проблемы, по моему мнению, были бы и в UDP, только мне пришлось бы писать ещё больше кода, чем я уже написал, чтобы всё то же самое реализовать самому и скорее всего плохо. Я даже на Си не очень люблю писать, не то что там…
З: – Как раз удобно! Отправил ok и не ждёшь ничего – у тебя абсолютно асинхронно. Пришло назад уведомление о том, что всё хорошо – значит, пришло; не пришло – значит, плохо.
ЮН: – Мне нужно и то и другое – мне нужно уметь отправлять и с гарантией доставки, и без гарантии доставки. Это два разных сценария. Некоторые логи мне нужно не терять или не терять в пределах разумного.
З: – Не буду отнимать время. Это надо дольше обсуждать. Спасибо.
Ведущий: – У кого есть вопросы – ручки в небо!

З: – Привет, я – Саша. Где-то в середине доклада появилось ощущение, что можно было, кроме TCP, использовать готовое решение – «Кафку» какую-нибудь.
ЮН: – Ну как… Я же говорил, что не хочу использовать промежуточные серверы, потому что… в «Кафку» — окажется, что у нас десять тысяч хостов; на самом деле у нас больше – десятки тысяч хостов. С «Кафкой» без каких-либо проксей тоже может больно делать. К тому же, самое главное, оно всё равно даёт «лейтность», даёт лишние хосты, которые нужно иметь. А я не хочу их иметь – я хочу…
З: – А в итоге так и получилось всё равно.
ЮН: – Нет, никаких хостов нет! Это всё работает на хостах «Кликхауса».
З: – Ну а «Киттенхаус», ревёрс который – он где живёт?

ЮН: – На хосте «Кликхауса», он не пишет на диск ничего.
З: – Ну, допустим.
Ведущий: – Устраивает вас? Можем зарплату давать?
З: – Можно, да. На самом деле много костылей ради того, чтобы получилось то же самое, и вот – предыдущий ответ на тему TCP противоречит, на мой взгляд, вот этой ситуации. Просто такое ощущение, что можно было всё сделать на коленке за гораздо меньшее время.
ЮН: – А ещё почему я не хотел использовать «Кафку», потому что были в чатике «Кликхауса» телеграмовском довольно много жалоб на то, что, например, сообщения из «Кафки» терялись. Не из самой «Кафки», а в интеграции «Кафки» и «Кликхауса»; или там не коннектилось что-то. Грубо говоря, нужно было бы тогда и клиент для «Кафки» писать тогда. Я не думаю, что получилось бы более простое и более надёжное решение.
З: – Скажите, а почему какие-нибудь очереди не пробовали или какую-нибудь такую общую шину? Раз вы говорите, что у вас с асинхроном можно было через очередь гонять сами логи и в ответ получить тоже асинхронно через очередь?

ЮН: – Предложите, пожалуйста, какие можно было бы очереди использовать?
З: – Любые, даже без гарантии, что они по порядку идут. Redis какой-нибудь, RMQ…
ЮН: – У меня есть ощущение, что Redis скорее всего не сможет тянуть такой объём вставки даже на одном хосте (в смысле на нескольких серверах), который вытягивает «Кликхаус». Я не могу вам подтвердить это какими-то свидетельствами (я не бэнчмаркал его), но мне кажется, что Redis здесь – не самое удачное решение. В принципе можно рассматривать вот эту систему как импровизированную очередь сообщений, но которая заточена только под «Кликхаус»
Ведущий: – Юрий, спасибо большое. Я предлагаю на этом закончить вопросы и ответы и сказать, кому из задавших вопрос мы подарим книжку.
ЮН: – Я б хотел подарить книжку первому человеку, который задал вопрос.
Ведущий: – Прекрасно! Отлично! Великолепно! Спасибо огромное!
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Тезисы и презентация: http://www.highload.ru/moscow/2018/abstracts/4066
Юрий Насретдинов (ВКонтакте): в докладе будет рассказано об опыте внедрения ClickHouse в нашей компании – для чего он нам нужен, сколько мы храним данных, как их пишем и так далее.
Дополнительные материалы: использование Clickhouse в качестве замены ELK, Big Query и TimescaleDB
Юрий Насретдинов: – Всем привет! Меня зовут Юрий Насретдинов, как уже представили меня. Я работаю во «ВКонтакте». Я буду рассказывать про то, как мы вставляем данные «КликХаус» с нашего парка серверов (десятки тысяч).
Вопрос: кто из вас был на таком же докладе, но на HighLoad Siberia… В общем, можете проматывать до 30-й минуты где-то сразу, и там будет новое.
Что такое логи и зачем их собирать?
Что мы будем рассказывать: что мы делали, зачем нам понадобился «КликХаус», соответственно – почему мы его выбрали, какую производительность вы можете примерно получить, ничего не конфигурируя специально. Расскажу дальше про буферные таблицы, про проблемы, которые у нас с ними были и про наши решения, которые мы разработали из «опен-сорса» – KittenHouse и LifeHouse.
Зачем нам понадобилось вообще что-то делать (во «ВКонтакте» всегда всё хорошо, да?). Мы хотели собирать дебаг-логи (и их там было сотни терабайт данных), может, ещё как-то статистику поудобнее считать; и у нас парк серверов в десятки тысяч, с которых всё это нужно делать.
Почему мы решили? У нас же наверняка были решения для хранения логов. Вот – есть такой паблик «Бэкенд ВК». Очень рекомендую подписаться на него.
Что такое logs? Это движок, возвращающий пустые массивы. Движками в «ВК» называется то, что микросервисами остальные называют. И такой вот стикер улыбающийся (довольно много лайков). Как так? Ну, слушайте дальше!
Что вообще можно использовать для хранения логов? Нельзя не упомянуть «Хадуп». Потом, например, Rsyslog (хранение в файлах этих логов). LSD. Кто знает, что такое ЛСД? Нет, не этот ЛСД. Файлы хранить, соответственно, тоже. Ну и ClickHouse – странный вариант какой-то.
«Кликхаус» и конкуренты: требования и возможности
Что мы хотим? Мы хотим, чтобы нам не нужно было особо париться с эксплуатацией, чтобы она работала из коробки желательно, с минимальной настройкой. Хотим писать очень много, а писать быстро. И хотим хранить это всякие месяцы, годы, то есть долго. Мы можем хотеть разобраться в проблеме какой-то, с которой к нам пришли, сказали – «У нас тут что-то не работает», – а это было 3 месяца назад), и мы хотим иметь возможность посмотреть, чтобы было 3 месяца назад». Сжатие данных – понятно, почему оно будет плюсом, – потому что сокращается количество места, которое занимается.
И у нас есть такое интересное требование: мы иногда пишем output каких-нибудь команд (например, логи), оно может быть больше 4 килобайт совершенно спокойно. И если эта штука имеет работать по UDP, то ей не нужно тратить… у неё не будет никакого «грейхеда» на соединение, и для большого количества серверов это будет плюсом.
Давайте посмотрим, что предлагает «опен-сорс» нам. Во-первых, у нас есть Logs Engine – это наш движок; он в принципе всё умеет, даже длинные строки умеет писать. Ну, прозрачные данные он не сжимает – мы можем большие колонки сами сжимать, если захотим… мы, конечно, не хотим (по возможности). Единственная проблема – он умеет отдавать только то, что у него помещается в памяти; остальное, чтобы прочитать, нужно доставать binlog этого движка и, соответственно, это довольно долго. Хотя данные он хранит, потому что не может отдать (поэтому он отдаёт пустые массивы).
Какие есть варианты другие? Например, «Хадуп». Простота эксплуатации… Кто считает, что «Хадуп» легко настраивается? С записью, конечно же, проблем нет. С чтением вопросы иногда возникают. В принципе я сказал бы, что скорее нет, особенно для логов. Долговременное хранение – конечно, да, сжатие данных – да, длинные строки – понятно, что можно записывать. А вот записывать с большого количества серверов… Всё равно надо самим что-то делать!
Rsyslog. На самом деле мы его использовали как запасной вариант, для того чтобы можно было без дампа бинлога читать, но он не может в длинные строки, в принципе больше 4 килобайт не может записать. Сжатие данных точно так же самим надо делать. Чтение будет идти с файлов.
Потом есть «бадушная» разработка LSD. То же самое по сути, что и «Рсислог»: длинные строки поддерживает, но по UDP работать не умеет и, собственно, из-за этого, к сожалению, там довольно много чего переписывать нужно (поверьте, я его писал, чтобы с десятков тысяч серверов запись осуществлять).
А, вот! Смешной вариант – ElasticSearch. Ну, как сказать? С чтением у него всё хорошо, то есть он читает быстро, но с записью не очень хорошо. Во-первых, данные он, если и сжимает, то очень слабо. Скорее всего, для полноценного поиска требуются более объёмные структуры данных, чем исходный объём. Эксплуатировать тяжело, с ним часто проблемы возникают. И, опять же, запись в «Эластик» – всё мы сами должны делать.
Вот ClickHouse – идеальный вариант, понятное дело. Единственное, запись с десятков тысяч серверов – это проблема. Но она хотя бы одна, мы её можем попробовать как-то решить. И вот про эту проблему весь остальной доклад. Какую вообще производительность от «КликХауса» можно ожидать?
Как будем вставлять? MergeTree
Кто из вас про «КликХаус» не слышал, не знает? Нужно рассказать, не нужно? Очень быстро. Ставка там – 1-2 гигабита в секунду, всплесками до 10 гигабит в секунду на самом деле может выдерживать на вот такой конфигурации – там два 6-ядерных «Ксеона» (то есть даже не самые мощные), 256 гигов оперативы, 20 терабайтов в «Рейде» (никто не настраивал, дефолтные настройки). Алексей, наверное, плачет сидит, что мы ничего не настраивали (у нас всё работало так). Соответственно, скорость сканирования, допустим, порядка 6 миллиардов строк в секунду можно получить, если данные хорошо сжимаются. Если вы like % по текстовой строке делаете – 100 миллионов строк в секунду, то есть кажется, что весьма быстро.
Как будем вставлять? Ну, вы знаете, что в «ВК» – на PHP. Мы из каждого PHP-воркера будем по HTTP вставлять в «КликХаус», в табличку MergeTree на каждую запись. Кто видит проблему в этой схеме? Почему-то не все подняли руки. Давайте расскажу.
Во-первых, серверов много – соответственно, соединений будет становиться много (плохо). Потом в MergeTree лучше вставлять данные не чаще, чем раз в секунду. А кто знает почему? Ладно, хорошо. Я расскажу чуть-чуть подробнее об этом. Ещё интересный вопрос – что мы как бы не аналитику делаем, нам не нужно обогащать данные, нам не нужны промежуточные сервера, мы хотим вставлять прямо в «КликХаус» (желательно – чем прямее, тем лучше).
Соответственно, как осуществляется вставка в MergeTree? Почему в него лучше вставлять не чаще, чем раз в секунду или реже? Дело в том, что «КликХаус» – столбцовая база данных и сортирует данные в порядке возрастания первичного ключа, и когда вы делаете вставку, создаётся количество файлов как минимум по количеству колонок, в которых данных отсортированы в порядке возрастания первичного ключа (создаётся отдельная директория, набор файлов на диске на каждый insert). Потом следующая вставка идёт, и в фоне они объединяются в большего размера «партиции». Поскольку данные отсортированы, то «смержить» два отсортированных файла можно без большого потребления памяти.
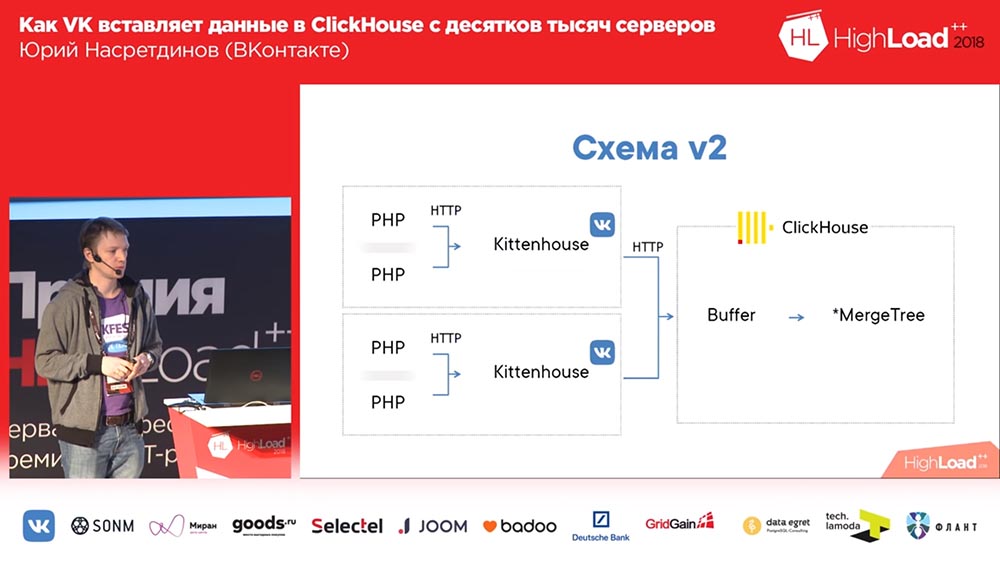
Но, как вы догадываетесь, если записать по 10 файлов на каждый insert, то «КликХаус» быстро закончится (или ваш сервер), поэтому рекомендуется вставлять большими пачками. Соответственно, схему первую мы никогда не запускали в продакшн. Мы сразу запустили такую, которая здесь № два имеет:
Здесь представьте себе, что есть около тысячи серверов, на которых мы запустили, там просто PHP. И на каждом сервере стоит наш локальный агент, который мы назвали «Киттенхаус», который держит одно соединение с «КликХаусом» и раз в несколько секунд вставляет данные. Вставляет данные не в MergeTree, а в буферную таблицу, которая как раз служит для того, чтобы не вставлять напрямую в MergeTree, сразу.
Работа с буферными таблицами
Что это такое? Буферные таблицы – это кусок памяти, пошардированный (то есть в него можно часто вставлять). Они состоят из нескольких кусков, и каждый из кусков работает как независимый буфер, и они независимо флашатся (если у вас много кусков у буфера, то и вставок будет много в секунду). Читать из этих таблиц можно – тогда вы читаете объединение содержимого буфера и родительской таблицы, но в этот момент блокируется запись, поэтому лучше не читать оттуда. И очень хороший QPS показывают буферные таблицы, то есть до 3 тысяч QPS у вас не возникнет вообще никаких проблем при вставке. Понятно, что, если пропало питание у сервера, то данные можно потерять, потому что они только в памяти хранились.
При этом схему с буфером усложняет Alter, потому что вам нужно сначала дропнуть старую буферную таблицу со старой схемой (данные никуда не пропадут при этом, потому что они зафлашатся перед тем, как таблица удалится). Потом вы «альтерите» нужную вам таблицу и создаёте буферную таблицу заново. Соответственно, пока нет буферной таблицы, у вас данные никуда не льются, но вы можете их на диске хотя бы локально.
Что такое «Киттенхаус» и как это работает?
Что из себя представляет KittenHouse? Это прокси. Угадайте, на каком языке? Я собрал самые хайповые темы в своём докладе – это «Кликхаус», Go, может, ещё что-нибудь вспомню. Да, на Го это написано, потому что я не очень умею писать на Си, не хочу.
Соответственно, оно держит соединение с каждым сервером, умеет писать в память. Например, если мы пишем error-логи в «Кликхаус», то, если «Кликхаус» не успевает вставлять данные (всё-таки если их слишком много пишется), то мы не распухаем по памяти – мы просто выбрасываем остальное. Потому, что, если у нас пишется несколько гигабит в секунду ошибок, то, наверное, нам можно какие-то выкинуть. «Киттенхаус» это умеет. Плюс, он умеет надёжную доставку, то есть запись на диск на локальной машине и раз в какое-то время (там, раз в пару секунд) пытается данные из этого файла доставить. И мы поначалу использовали обычный формат Values – не какой-то бинарный формат, текстовый формат (как в обычном SQL).
Но дальше произошло вот такое вот. Мы использовали надёжную доставку, писали логи, потом решили (это был такой, условно тестовый кластер)… На несколько часов его потушили и подняли обратно, и с тысячи серверов пошла вставка – оказалось, что у «Кликхауса» всё-таки модель «Тред на соединение» – соответственно, в тысячу соединений активная вставка приводит к load average на сервере где-то в полторы тысячи. На удивление, сервер принимал запросы, а данные такие всё-таки вставились через какое-то время; но очень тяжело было серверу это обслуживать…
Добавляем nginx
Такое решение для модели Thread per connection – это nginx. Мы поставили nginx перед «Кликхаусом», заодно настроили балансировку на две реплики (у нас ещё в 2 раза увеличилась скорость вставки, хотя не факт, что так должно быть) и ограничили количество соединений к «Кликхаусу», к апстриму и, соответственно, больше, чем в 50 соединений, кажется, смысла вставлять нет.
Потом мы поняли, что вообще эта схема имеет недостатки, потому что у нас здесь – один nginx. Соответственно, если этот nginx ложится, несмотря на наличие реплик, мы данные теряем или, по крайней мере, никуда не пишем. Поэтому мы сделали свою балансировку нагрузки. Также мы поняли, что «Кликхаус» всё-таки для логов подходит и «демон» тоже начал писать свои логи тоже в «Кликхаус» – очень удобно, если честно. До сих пор используем ещё и для других «демонов».
Потом обнаружили такую интересную проблему: если вы используете не вполне стандартный способ вставки в SQL-режиме, то форсится полноценный SQL-парсер на основе AST, который довольно медленный. Соответственно, мы добавили настройки, чтоб такого не происходило никогда. Сделали балансировку нагрузки, helth-чеки, чтобы, если одна умирает, то мы всё равно оставляли данные. У нас стало достаточно много таблиц, чтобы нам стало нужно разные кластеры «Кликхауса» иметь. И ещё мы начали думать о других использованиях – например, мы хотели писать логи из nginx-модулей, а они по нашему RPC общаться не умеют. Ну, хотелось бы их хоть как-то научить отправлять – например, по UPD принимать события на localhost и потом уже их пересылать в «Кликхаус».
В шаге от решения
Итоговая схема стала выглядеть вот так (четвёртый вариант этой схемы): на каждом сервере перед «Кликхаусом» стоит nginx (на том же сервере причём) и просто на localhost проксирует запросы с ограничением по количеству соединений в 50 штук. И вот эта схема уже рабочая вполне была, с ней было всё довольно-таки хорошо.
Мы жили так где-то месяц. Все радовались, добавляли таблицы, добавляли, добавляли… В общем, оказалось, что то, как мы добавляли буферные таблицы, оно не очень оптимально (скажем так) было. Мы делали по 16 кусков в каждой таблице и флаш-интервал пару секунд; у нас было 20 таблиц и в каждую таблицу шло по 8 вставок в секунду – и в этом моменте «Кликхаус» начал… записи начинали тупить. Они даже не то что не проходили… У nginx’а по умолчанию была такая интересная штука, что, если коннекты заканчивались у апстрима, то на все новые запросы он просто отдаёт «502».
И вот у нас (это я просто по логам в самом же «Кликхаусе» я посмотрел) где-то полпроцента запросов фейлилось. Соответственно, утилизация диска была высокая, много мержей было. Ну, что я сделал? Я, естественно, не стал разбираться, почему именно заканчивается коннект и апстрим.
Замена nginx на реверс-прокси
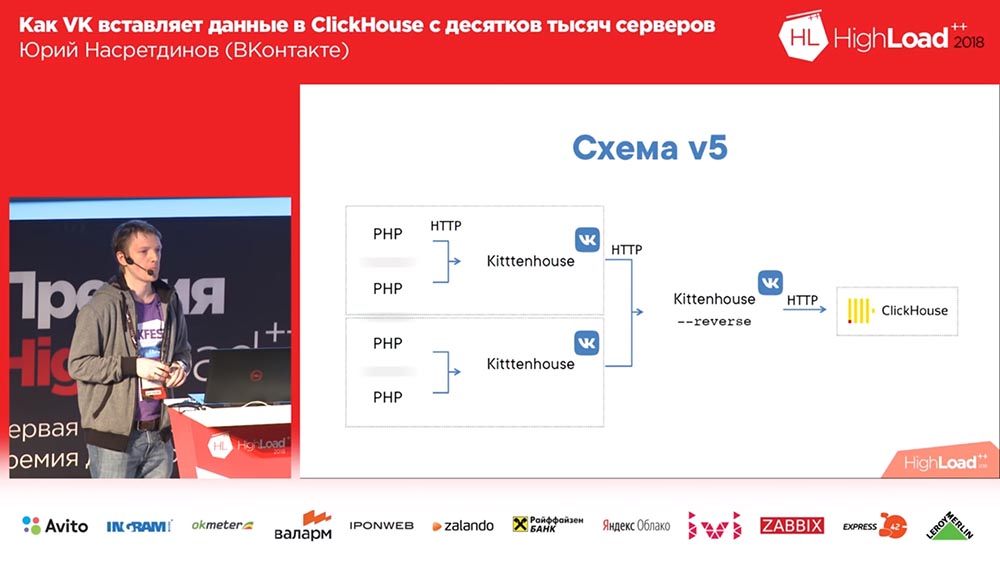
Я решил, что нам нужно управлять этим самим, не надо это давать на откуп nginx – nginx не знает, какие таблицы в «Кликхаусе» есть, и заменил nginx на reverse-прокси, который тоже я сам написал.
Он что делает? Он работает на основе библиотеки fasthttp «гошной», то есть быстрый, почти такой же быстрый, как nginx. Извините, Игорь, если вы тут присутствуете (прим.: Игорь Сысоев – русский программист, создавший веб-сервер nginx). Он умеет понимать, какие это запросы – Insert или Select – соответственно, разные пулы соединения держит для разных видов запросов.
Соответственно, даже если мы на вставку не успеваем выполнить запросы, то «селекты» будут проходить, и наоборот. И группирует данные по буферным таблицам – с небольшим буфером: если там были какие-то ошибки, синтаксические ошибки и так далее – чтобы они несильно влияли на остальные данные, потому что, когда мы вставляли просто в буферные таблицы, то у нас были маленькие «бачи», и все ошибки ошибки синтаксиса влияли только на этот маленький кусочек; а здесь они будут влиять уже на большой буфер. Маленький – это 1 мегабайт, то есть не такой уж и маленький.
Вставка синхрона по сути заменяет nginx, делает по сути то же самое, что и делал nginx до этого – «Киттенхаус» локальный менять для этого не нужно. И поскольку он использует fasthttp, он очень быстрый – можно больше 100 тысяч запросов в секунду единичных insert’ов делать через reverse-прокси. Теоретически можно вставлять по одной строке в «Киттенхаус», reverse-прокси, но мы, конечно, так не делаем.
Схема стала выглядеть вот так: «Киттенхаус», reverse-прокси группирует много запросов по таблицам и уже в свою очередь буферные таблицы вставляют их в основные.
Killer – решение временное, Kitten – постоянное
Встала такая интересная проблема… Кто-нибудь из вас использовал fasthttp? Кто при этом использовал fasthttp с пост-запросами? Наверное, так не стоило делать на самом деле, потому что он буферизует тело запроса по умолчанию, а у нас размер буфера 16 мегабайт был выставлен. Вставка перестала успевать в какой-то момент, и со всех десятков тысяч серверов начали приходить 16-мегабайтные чанки, и они все буферизировались в памяти перед тем, как отдаться в «Кликхаус». Соответственно, память кончалась, Out-Of-Memory Killer приходил, убивал reverse-прокси (или «Кликхаус», который мог теоретически «жрать» больше, чем reverse-прокси). Цикл повторялся. Не очень приятная проблема. Хотя мы на это наткнулись только через несколько месяцев эксплуатации.
Что я сделал? Опять же, я не очень люблю разбираться в том, что именно произошло. Мне кажется, довольно очевидно, что не надо буферизировать память. Я не смог пропатчить fasthttp, хотя пытался. Но я нашёл способ, как сделать так, чтобы не нужно было ничего патчить, и придумал свой метод в http – назвал его Kitten. Ну, логично – «ВК», «Киттен»… Как ещё?..
Если приходит запрос на сервер с методом Kitten, то сервер должен ответить «мяу» (meow) – логично. Если он на это отвечает, то считается, что он понимает этот протокол, и дальше я перехватываю соединение (в http такой метод есть), и соединение переходит в «сырой» режим. Зачем мне это нужно? Я хочу управлять тем, как происходит чтение из TCP-соединений. У TCP есть замечательное свойство: если никто не читает с той стороны, то запись начинает ждать, и память особо не расходуется на это.
И вот я читаю где-то с 50 клиентов за раз (с пятидесяти потому, что пятидесяти уж точно должно хватить, даже если это из другого ДЦ ставка идёт)… Потребление уменьшилось с таким подходом как минимум в 20 раз, но я, если честно, не смог замерить, во сколько именно, потому что это уже бессмысленно (оно уже на уровне погрешности стало). Протокол бинарный, то есть там идёт имя таблицы и данные; нет http-заголовков, поэтому я не использовал веб-сокет (мне же с браузерами не нужно общаться – я сделал протокол, который подходит под наши нужды). И с ним стало всё хорошо.
Буферная таблица – это печально
Недавно мы столкнулись с ещё интересной особенностью буферных таблиц. И вот эта проблема уже намного больнее, чем остальные. Представим себе такую ситуацию: у вас уже активно используется «Кликхаус», у вас десятки серверов «Кликхауса», и у вас есть некоторые запросы, которые читают очень долго (допустим, больше 60 секунд); и вы такие приходите и делаете Alter в этот момент… А пока «селекты», которые начались до «Альтера», в эту таблицу не войдут, «Альтер» не начнётся – вероятно, какие-то особенности того, как работает «Кликхаус» в этом месте. Может быть это можно исправить? Или нельзя?
В общем, понятно, что на самом деле это не такая уж большая проблема, но с буферными таблицами она становится больнее. Потому что, если, допустим, у вас «Альтер» таймаутится (причём затаймаутиться может на другом хосте – не на вашем, а на реплике, например), то… Вы такие удалили буферную таблицу, у вас затаймаутился «Альтер» (или какая-то ошибка «Альтера» произошла) – надо же, чтобы всё-таки данные продолжали писаться: вы создаёте буферные таблицы обратно (по той же схеме, что была у родительской таблицы), потом «Альтер» проходит, всё-таки завершается, и буферная таблица начинает отличаться по схеме от родительской. В зависимости от того, что был за «Альтер», может вставка больше не идти в эту буферную таблицу – это очень печально.
Ещё есть такая табличка (может, кто её замечал) – называется в новых версиях «Кликхауса» query_thred_log. По умолчанию, в какой-то версии была единичка. Вот мы накопили 840 миллионов записей за пару месяцев (100 гигабайт). Связано это с тем, что туда писались (может, сейчас, кстати, и не пишутся) «инсёрты» (inserts). Как я вам рассказывал, у нас «инсёрты» маленькие – у нас очень много «инсёртов» в буферные таблицы шло. Понятно, что это отключается – это я вам просто рассказываю, что я видел у нас на сервере. Почему? Это ещё один аргумент против того, чтобы использовать буферные таблицы! Спотти очень грустит.
А кто знал, что этого товарища зовут Спотти? Подняли руки сотрудники «ВК». Ну ладно.
О планах «Кликхауса»
Обычно планами не делятся, да? Вдруг вы их не будете выполнять и будете выглядеть не очень хорошо в чужих глазах. Но я рискну! Мы хотим сделать следующее: буферные таблицы, как мне кажется, это всё-таки костыль и надо буферизировать вставку самим. Но мы всё ещё не хотим буферизировать её на диске, поэтому мы будем буферизировать вставку в памяти.
Соответственно, когда делается «инсёрт», он уже не будет синхронный – он будет уже работать как буферная таблица, будет вставлять в родительскую таблицу (ну, когда-нибудь потом) и по отдельному каналу сообщать, какие вставки прошли, какие – нет.
Почему нельзя вставить синхронную вставку? Она же намного удобнее. Дело в том, что, если вставляете с 10 тысяч хостов, то всё хорошо – у вас с каждого хоста будет литься по чуть-чуть, вы там раз в секунду вставляете, всё прекрасно. Но хочется, чтобы эта схема работала, например, и с двух машин, чтобы вы могли лить на большой скорости – может, не выжимать максимум из «Кликхауса», но хотя бы 100 мегабайт в секунду писать с одной машины через реверс-прокси – эта схема должна масштабироваться и на большое количество, и на маленькое, поэтому мы не можем ждать на каждую вставку по секунде, поэтому она должна быть асинхронной. И точно так же асинхронные подтверждения должны приходить после того, как вставка совершилась. Мы будем знать о том, прошла она или нет.
Самое главное, что в этой схеме мы точно знаем, прошла вставка или нет. Представьте себе такую ситуацию: у вас буферная таблица, вы в неё что-то записали, а потом, допустим, таблица перешла в read only и пытается зафлашиться буфер. Куда пойдут данные? Останутся в буфере. Но мы в этом уверены быть не можем – вдруг какая-то другая ошибка, из-за которой не останутся в буфере данные… (Обращается к Алексею Миловидову, «Яндекс», разработчик ClickHouse) Или останутся? Всегда? Алексей убеждает нас, что всё будет хорошо. У нас нет причин ему не верить. Но всё равно: если мы не используем буферные таблицы, то и проблем с ними точно не будет. Создавать в два раза больше таблиц тоже неудобно, хотя в принципе больших проблем нет. Это план.
Поговорим о чтении
А теперь давайте поговорим про чтение. Мы здесь тоже написали свой инструмент. Казалось бы, ну зачем здесь-то писать свой инструмент?.. А кто пользовался «Табиксом»? Как-то мало людей подняло руки… А кого устраивает производительность «Табикса»? Ну вот, нас не устраивает, и он не очень удобен для просмотра данных. Для аналитики он подходит нормально, а просто для просмотра он явно не оптимизирован. Поэтому я написал своё, свой интерфейс.
Он очень простой – он умеет только читать данные. Он не умеет графики показывать, ничего не умеет. Но умеет показывать то, что нам нужно: например, какое количество строк в таблице, сколько места она занимает (без разбивки по колонкам), то есть очень базовый интерфейс – то, что нам нужно.
И выглядит он очень похоже на Sequel Pro, но только сделанный на твиттеровском «Бутстрапе», причём второй версии. Вы спросите: «Юрий, а почему на второй версии-то?» Какой год? 2018-й? В общем, делал я это достаточно давно для «Мускуля» (MySql) и просто поменял там пару строчек в запросах, и он стал работать для «Кликхауса», за что отдельное спасибо! Потому что парсер очень похож на «мускулевский», и запросы очень похожи – очень удобно, особенно поначалу.
Ну, умеет он фильтрацию таблиц, умеет показывать структуру, содержимое таблицы, сортировать позволяет, фильтровать по колонкам, показывает запрос, который получился в итоге, affected rows (сколько в результате), то есть базовые вещи для просмотра данных. Довольно быстро.
Редактор тоже есть. Я честно попытался украсть редактор целиком из «Табикса», но не смог. Но всё-таки как-то он работает. В принципе на этом всё.
«Кликхаус» подходит для логов
Я вам хочу сказать, что «Кликхаус», несмотря на все описанные проблемы, очень хорошо подходит для логов. Он, самое главное, решает нашу проблему – он очень быстрый и позволяет фильтровать логи по колонкам. В принципе буферные таблицы показали себя не с лучшей стороны, но обычно никто не знает почему… Может, вы теперь больше знаете, где у вас будут проблемы.
TCP? Вообще, в «ВК» принято использовать UDP. И когда я использовал TCP… Мне, конечно, никто не говорил: «Юрий, ну ты что! Нельзя, надо UDP». Оказалось, что TCP не так уж и страшен. Единственное, если у вас десятки тысяч активных соединений, которые у вас пишут – надо чуть-чуть аккуратнее его готовить; но можно, и довольно легко.
«Киттенхаус» и «Лайтхаус» я обещал выложить на HighLoad Siberia, если все подпишутся на наш паблик «ВК бэкенд»… И знаете, не все подписались… Я уже с вас, конечно, требовать подписаться на наш паблик не буду. Вас всё-таки слишком много, кто-то может обидеться даже, но всё равно – подписывайтесь, пожалуйста (и я тут должен такие глаза, как у котика, сделать). Вот и ссылка на него кстати. Большое спасибо! Github наш вот тут. С «Кликхаусом» ваши волосы будут мягкими и шелковистыми.
Ведущий: – Друзья, а теперь вопросы. Сразу после того, как мы вручим благодарственную грамоту и твой доклад на VHS.
Юрий Насретдинов (далее – ЮН): – А как вы смогли записать мой доклад на VHS, если он только что закончился?
Ведущий: – Ты же тоже не можешь до конца определить, как «Кликхаус» – заработает или не заработает! Друзья, 5 минут на вопросы!
Вопросы
Вопрос из зала (далее – З): – Добрый день. Спасибо большое за доклад. У меня два вопроса. Начну с несерьёзного: влияет ли количество букв t в названии «Киттенхаус» на схемах (3, 4, 7…) на удовлетворённость котиков?
ЮН: – Количество чего?
З: – Букв t. Там три t, где-то три t.
ЮН: – Неужели я это не поправил? Ну, конечно, влияет! Это разные продукты – я просто вас обманывал всё это время. Ладно, я шучу – не влияет. А, вот здесь! Нет, это одно и то же, это я опечатался.
З: – Спасибо. Второй вопрос серьёзный. Насколько я понимаю, в «Кликхаусе» буферные таблицы живут исключительно в памяти, на диск не буферизуются и, соответственно, не являются per systems.
ЮН: – Да.
З: – А при этом у вас на клиенте осуществляется буферизация на диск, что подразумевает некоторую гарантию доставки этих самых логов. Но на «Кликхаусе» это никак не гарантируется. Поясните, как осуществляется гарантия, за счёт чего?.. Вот этот вот механизм подробнее
ЮН: – Да, теоретически противоречий здесь нет, потому что вы при падении «Кликхауса» можете детектить миллионом разных способов на самом деле. При падении «Кликхауса» (при некорректном завершении) вы можете, грубо говоря, отматывать немного свой лог, который вы записывали, и начинать с момента, когда точно всё было хорошо. Допустим, на минуту назад отмотать, то есть считается, что за минуту зафлашил всё.
З: – То есть «Киттенхаус» держит окно длиннее и в случае падения умеет его распознавать и отматывать?
ЮН: – Но это в теории. На практике мы этого не делаем, и надёжная доставка – это от нуля до бесконечности раз. Но в среднем один. Нас устраивает, что, если «Кликхаус» падает по какой-то причине или серверы «ребутают», то мы немножко теряем. Во всех остальных случаях ничего не будет происходить.
З: – Здравствуйте. Мне с самого начала казалось, что действительно вы будете использовать UDP с самого начала доклада. У вас – http, всё такое… И большинство проблем, которые вы описали, как я понял, были вызваны именно этим решением…
ЮН: – Что мы используем TCP?
З: – По сути да.
ЮН: – Нет.
З: – Именно с fasthttp были у вас проблемы, с соединением у вас были проблемы. Если бы вы просто использовали UDP, сэкономили бы себе время. Ну, были бы проблемы с длинными сообщениями или ещё что-то…
ЮН: – С чем?
З: – С длинными сообщениями, поскольку в MTU может не влезть, ещё что-то… Ну, там свои проблемы могут возникнуть. Вопрос-то в чём: почему всё-таки не UDP?
ЮН: – Я верю в то, что авторы, которые разрабатывали TCP/IP, намного умнее меня и умеют лучше меня делать серверизацию пакетов (чтобы они шли), одновременно регулировать окно отправки, не перегружать сеть, давать обратную связь о том, что не читает, не считая с той стороны… Все эти проблемы, по моему мнению, были бы и в UDP, только мне пришлось бы писать ещё больше кода, чем я уже написал, чтобы всё то же самое реализовать самому и скорее всего плохо. Я даже на Си не очень люблю писать, не то что там…
З: – Как раз удобно! Отправил ok и не ждёшь ничего – у тебя абсолютно асинхронно. Пришло назад уведомление о том, что всё хорошо – значит, пришло; не пришло – значит, плохо.
ЮН: – Мне нужно и то и другое – мне нужно уметь отправлять и с гарантией доставки, и без гарантии доставки. Это два разных сценария. Некоторые логи мне нужно не терять или не терять в пределах разумного.
З: – Не буду отнимать время. Это надо дольше обсуждать. Спасибо.
Ведущий: – У кого есть вопросы – ручки в небо!
З: – Привет, я – Саша. Где-то в середине доклада появилось ощущение, что можно было, кроме TCP, использовать готовое решение – «Кафку» какую-нибудь.
ЮН: – Ну как… Я же говорил, что не хочу использовать промежуточные серверы, потому что… в «Кафку» — окажется, что у нас десять тысяч хостов; на самом деле у нас больше – десятки тысяч хостов. С «Кафкой» без каких-либо проксей тоже может больно делать. К тому же, самое главное, оно всё равно даёт «лейтность», даёт лишние хосты, которые нужно иметь. А я не хочу их иметь – я хочу…
З: – А в итоге так и получилось всё равно.
ЮН: – Нет, никаких хостов нет! Это всё работает на хостах «Кликхауса».
З: – Ну а «Киттенхаус», ревёрс который – он где живёт?
ЮН: – На хосте «Кликхауса», он не пишет на диск ничего.
З: – Ну, допустим.
Ведущий: – Устраивает вас? Можем зарплату давать?
З: – Можно, да. На самом деле много костылей ради того, чтобы получилось то же самое, и вот – предыдущий ответ на тему TCP противоречит, на мой взгляд, вот этой ситуации. Просто такое ощущение, что можно было всё сделать на коленке за гораздо меньшее время.
ЮН: – А ещё почему я не хотел использовать «Кафку», потому что были в чатике «Кликхауса» телеграмовском довольно много жалоб на то, что, например, сообщения из «Кафки» терялись. Не из самой «Кафки», а в интеграции «Кафки» и «Кликхауса»; или там не коннектилось что-то. Грубо говоря, нужно было бы тогда и клиент для «Кафки» писать тогда. Я не думаю, что получилось бы более простое и более надёжное решение.
З: – Скажите, а почему какие-нибудь очереди не пробовали или какую-нибудь такую общую шину? Раз вы говорите, что у вас с асинхроном можно было через очередь гонять сами логи и в ответ получить тоже асинхронно через очередь?
ЮН: – Предложите, пожалуйста, какие можно было бы очереди использовать?
З: – Любые, даже без гарантии, что они по порядку идут. Redis какой-нибудь, RMQ…
ЮН: – У меня есть ощущение, что Redis скорее всего не сможет тянуть такой объём вставки даже на одном хосте (в смысле на нескольких серверах), который вытягивает «Кликхаус». Я не могу вам подтвердить это какими-то свидетельствами (я не бэнчмаркал его), но мне кажется, что Redis здесь – не самое удачное решение. В принципе можно рассматривать вот эту систему как импровизированную очередь сообщений, но которая заточена только под «Кликхаус»
Ведущий: – Юрий, спасибо большое. Я предлагаю на этом закончить вопросы и ответы и сказать, кому из задавших вопрос мы подарим книжку.
ЮН: – Я б хотел подарить книжку первому человеку, который задал вопрос.
Ведущий: – Прекрасно! Отлично! Великолепно! Спасибо огромное!
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?




