
Четвёртая версия ChatGPT одних заставила пищать от восторга, а других повергла в уныние. Кто-то уже нашёл этой системе множество творческих применений, а кто-то пророчит, что эта нейросеть лишит работы кучу людей. Теперь возможности ChatGPT стали ещё шире: систему объединили с Wolfram | Alpha, легендарным движком для вычисления ответов в самых разных областях знания. Мы перевели для вас огромную подробную статью об этом от одного из разработчиков Wolfram | Alpha.

В январе я писал о возможности подключения ChatGPT к Wolfram|Alpha. Сегодня, всего через два с половиной месяца, я счастлив заявить, что это произошло! Благодаря героическим усилиям наших инженеров и OpenAI, ChatGPT может пользоваться Wolfram|Alpha, а также Wolfram Language, получая тем самым доступ к «вычислительным сверхмощностям». Хотя мы в самом начале этого пути, результаты уже поражают воображение, демонстрируя, сколь действенной (и даже революционной) может быть связка ChatGPT и Wolfram.
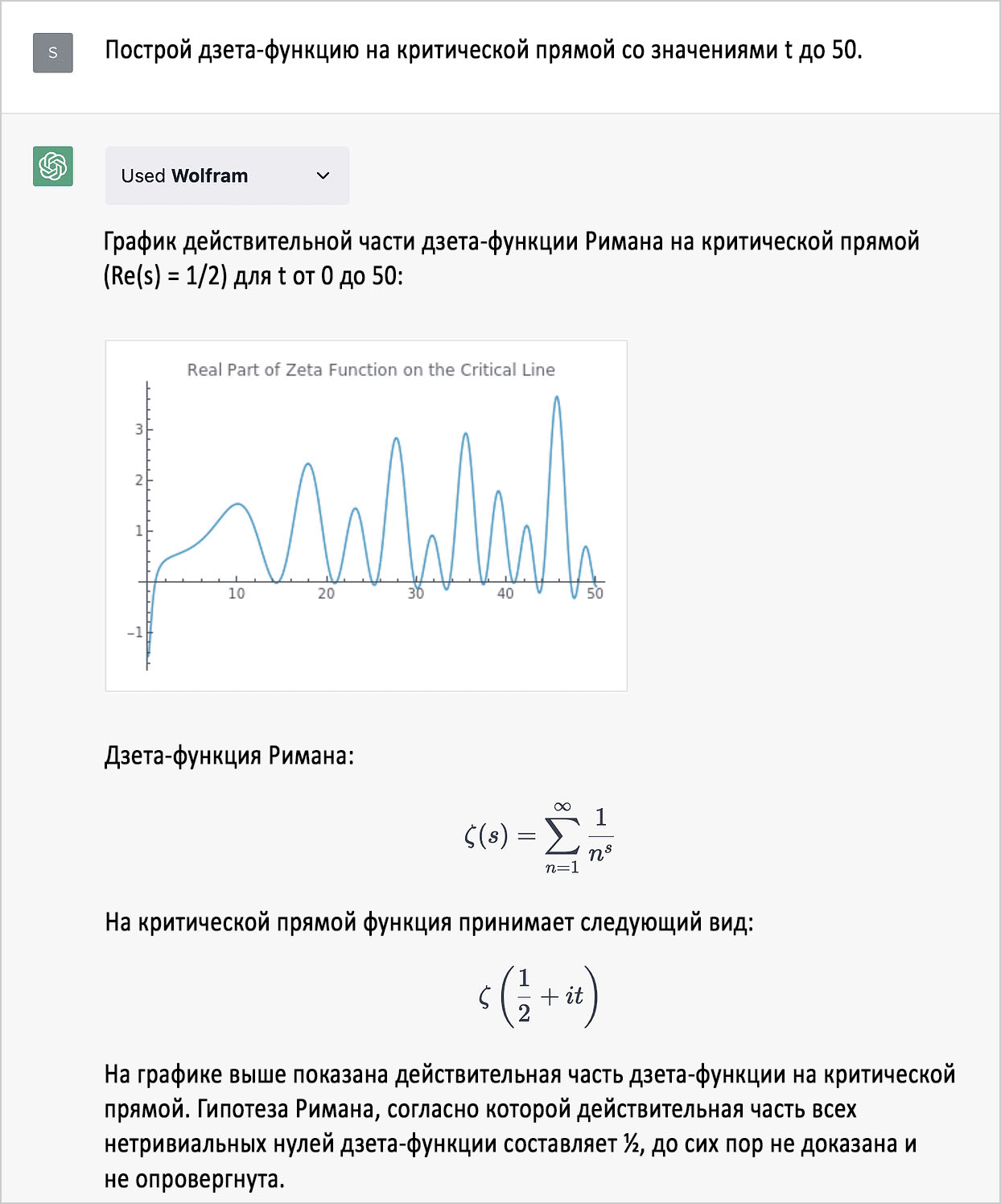
В январе я отмечал, что ChatGPT, будучи LLM-нейросетью, великолепно генерирует тексты, «подобные» прочитанным ею материалам в интернете, но совершенно неспособна выполнять нетривиальные вычисления или систематически выдавать верную (а не только «приблизительно верную, похожую на правду») информацию. Однако с доступом к плагину Wolfram она этому научилась. Вот как ChatGPT справилась с моим простеньким январским примером, на этот раз взяв на вооружение «суперсилу» Wolfram:
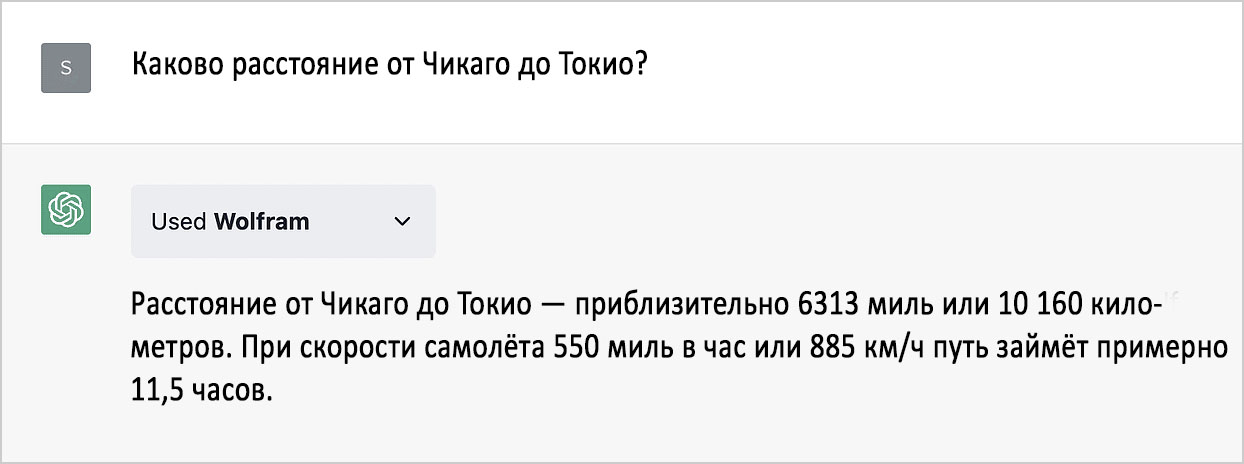
Это верный ответ (в отличие от январского), найденный путём вычислений. А вот и бонус в виде мгновенной визуализации:

Как же всё это работает? «Под капотом» ChatGPT формирует запрос к Wolfram|Alpha, затем посылает его для вычислений, и, наконец, «решает, что сказать» на основании полученного результата. Это взаимодействие можно проследить, кликнув по полю «UsedWolfram», и убедиться, что ChatGPT обошлась без «отсебятины»:
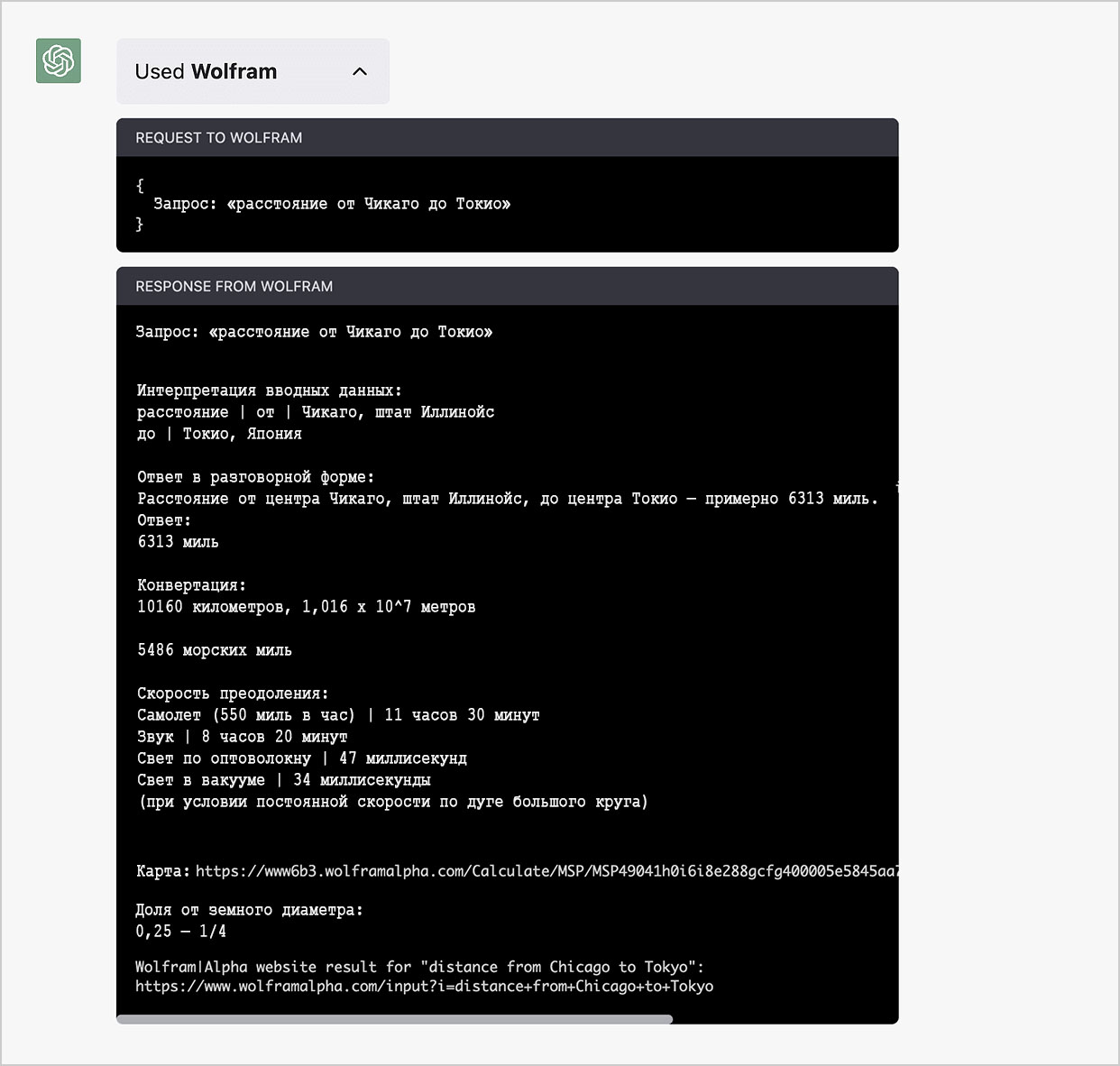
Мы видим сразу несколько примеров необычного поведения, как со стороны ChatGPT, так и со стороны Wolfram|Alpha. Итогом же стала корректная выдача в виде грамотного, складного текста.
Вот ещё один пример, также из январской статьи:

Достойный современных технологий результат. И вновь приятный бонус:
В январе я показывал, что ChatGPT «выдумывает» убедительные (но неверные) данные при следующем запросе:
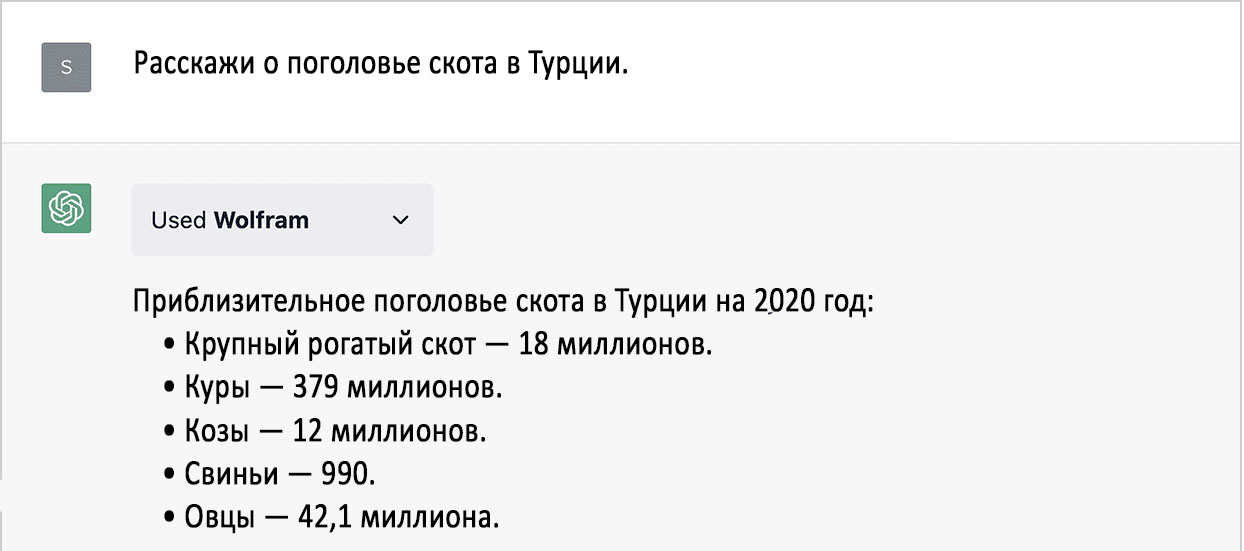
С доступом к плагину Wolfram она смогла получить правильный, обоснованный ответ. Опять же, мы можем получить визуализацию:
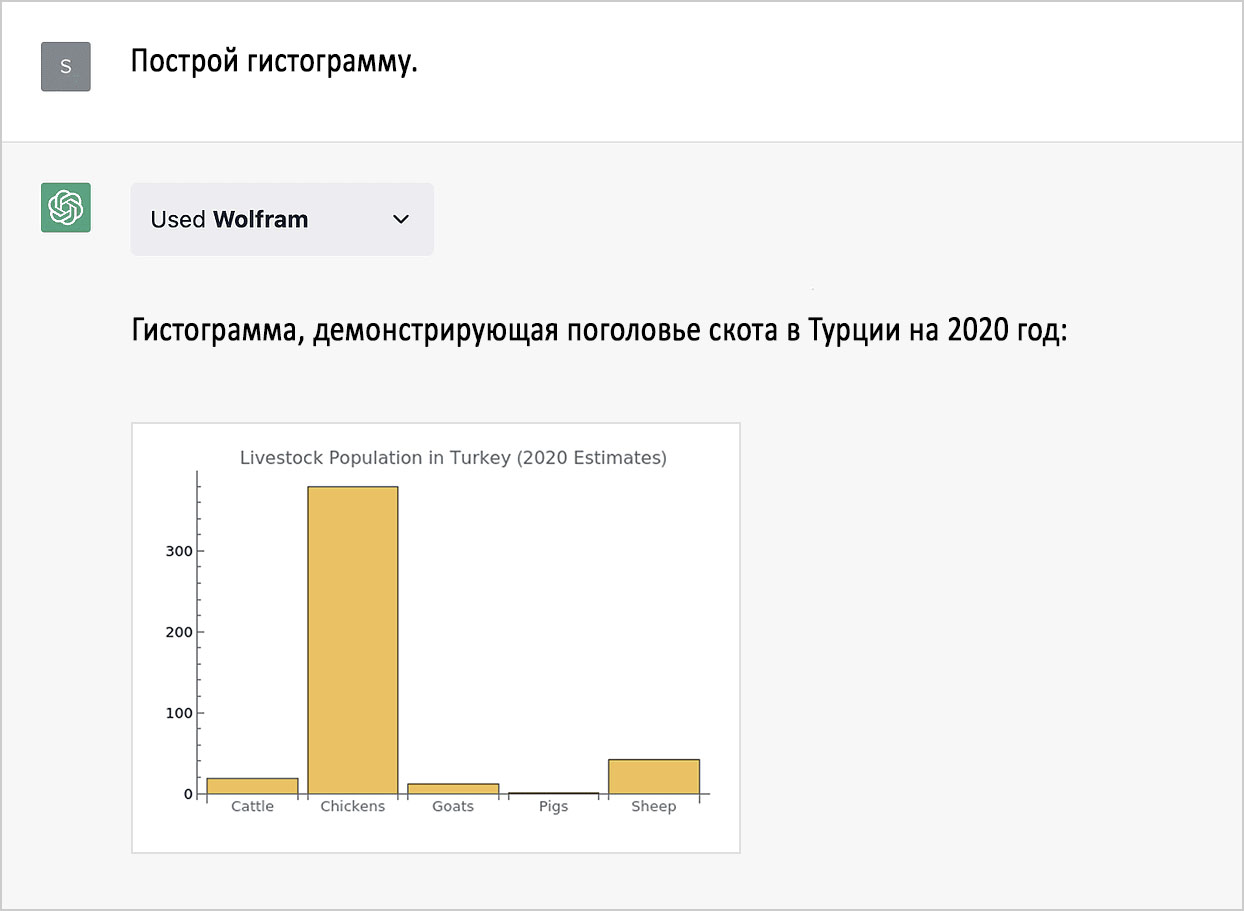
Ещё один запрос, на который мы теперь можем получить верный ответ:
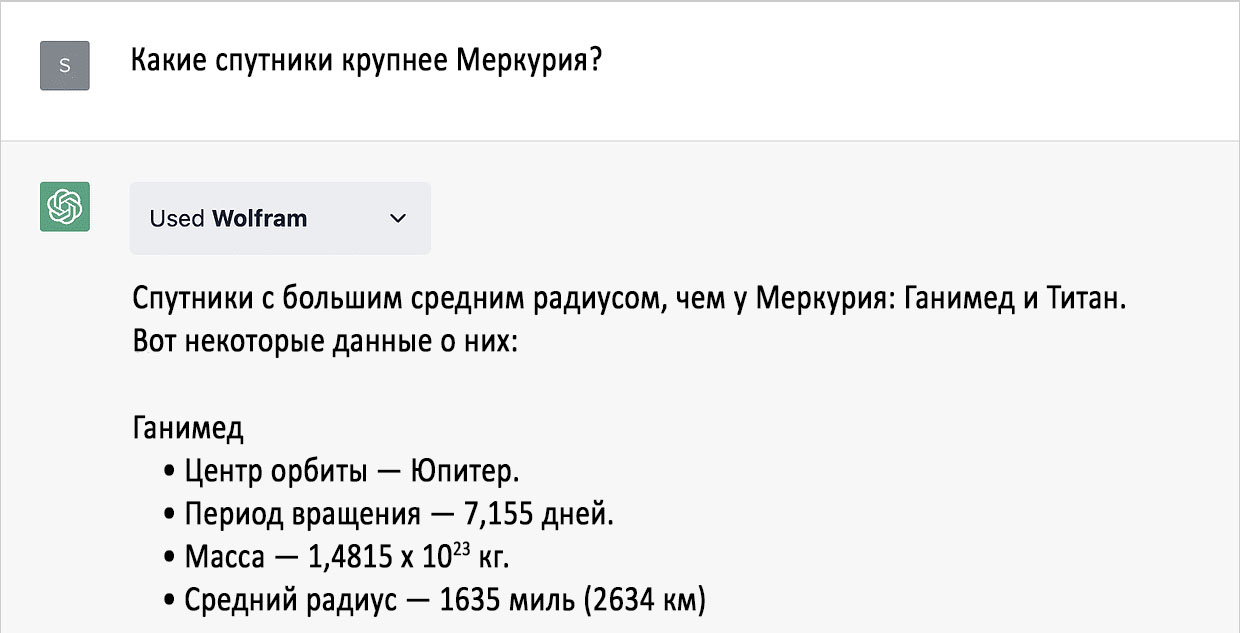
Если решить проверить нейросеть на этих же примерах, не удивляйтесь, что выдача будет отличаться от моей — где-то она может быть точнее, где-то наоборот. Поскольку ChatGPT прибегает к неопределённости при генерировании ответов, выдача по одному и тому же запросу может меняться от сессии к сессии. Это позволяет ощутить в ней «человечность», тогда как от Wolfram|Alpha и WolframLanguage пользователь может ожидать «правильный-ответ-который-не-изменится-сколько-ни-спрашивай».
Вот довольно впечатляющий пример «диалога» ChatGPT и плагина Wolfram, когда нейросеть обнаружила ошибку:
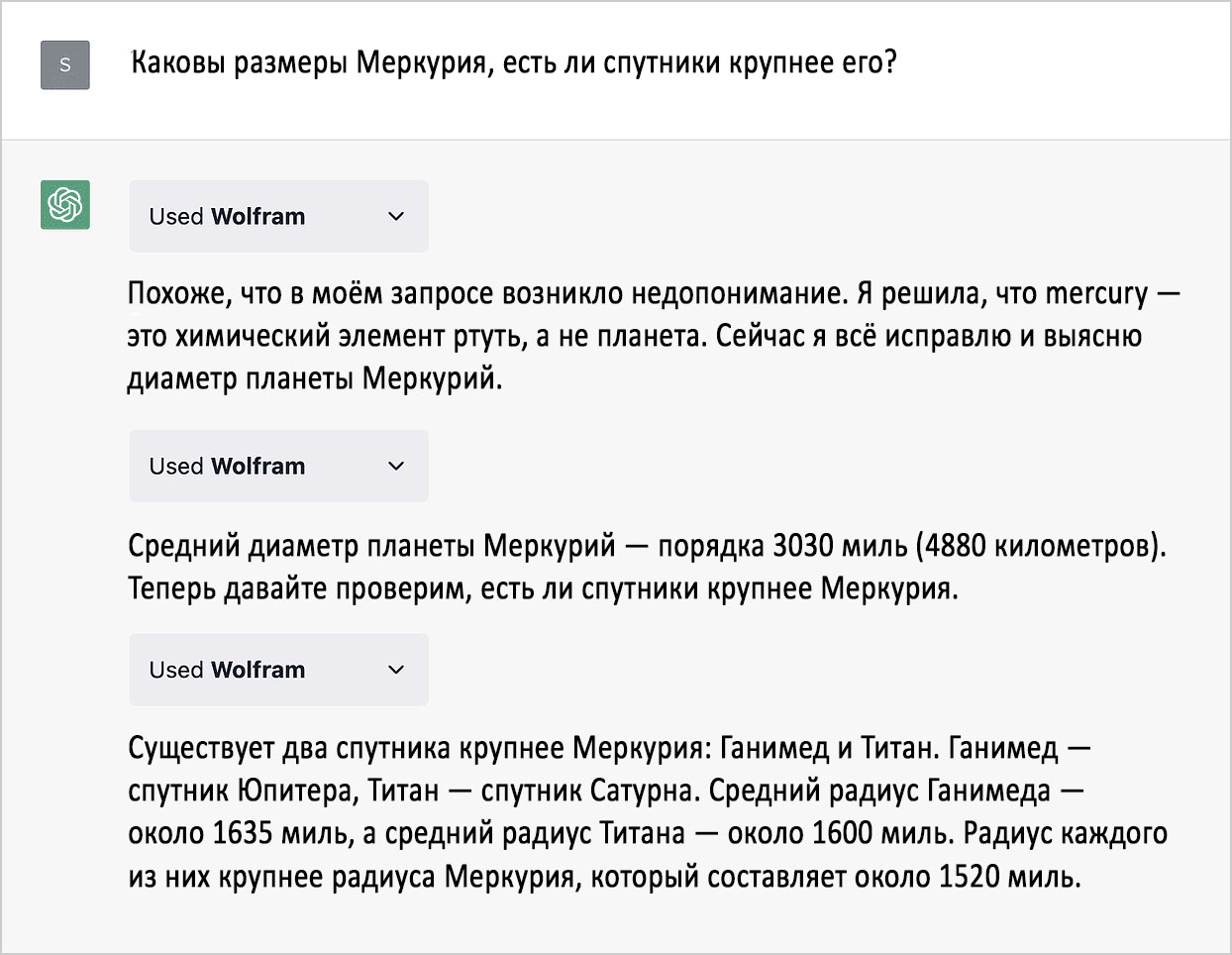
Что особенно важно, так это то, что ChatGPT обращается к Wolfram не только оказываясь в тупике, когда ей требуются действия вроде открытия веб-страницы. В данном случае мы служим для неё как бы мозговым имплантом — она может задавать нам вопросы, когда это требуется, и вплетать наши ответы в дальнейшую работу. Это зрелище поражает. Хотя ChatGPT предстоит пройти долгий путь, прежде чем она сможет предоставлять точные выверенные данные и верно производить нетривиальные вычисления, прогресс очевиден.
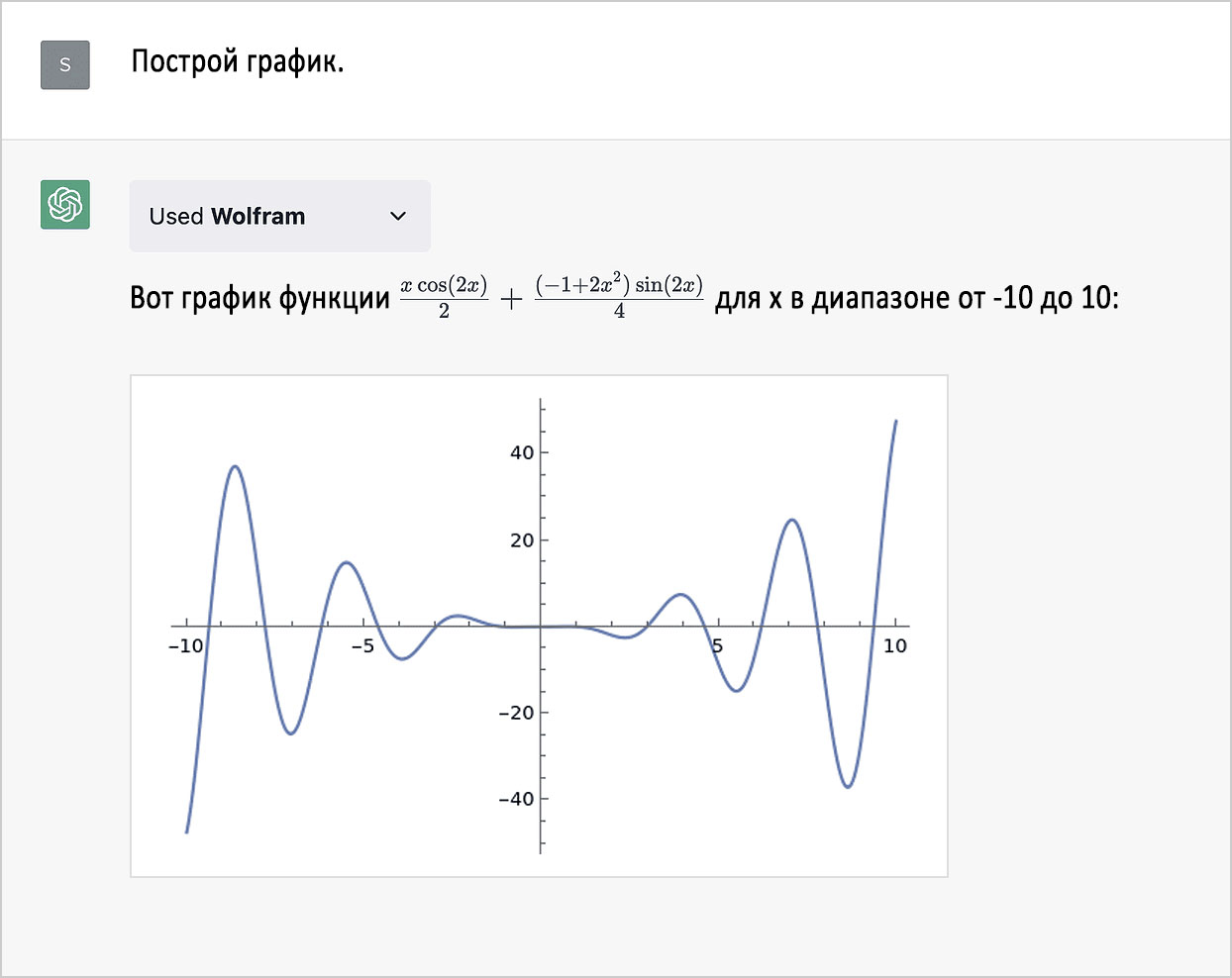
Но это ещё не всё. Как уже показано на прошлых примерах, теперь мы можем получать модифицированные иллюстрации. Вычислительные возможности позволяют создавать «по-настоящему оригинальный» контент на основании вычислений, которые никем до этого не производились. К тому же, «чистая» ChatGPT ограничена данными, которые она «узнала на стадии обучения», а с нашей помощью она получает свежую, актуальную информацию. Например, из обновляющихся в реальном времени потоков данных (здесь она выполняет два запроса — по одному на город):

Или на основании «научных» предиктивных вычислений:

(Аберрационное время — время, за которое свет от объекта достигает наблюдателя. — прим. пер.)
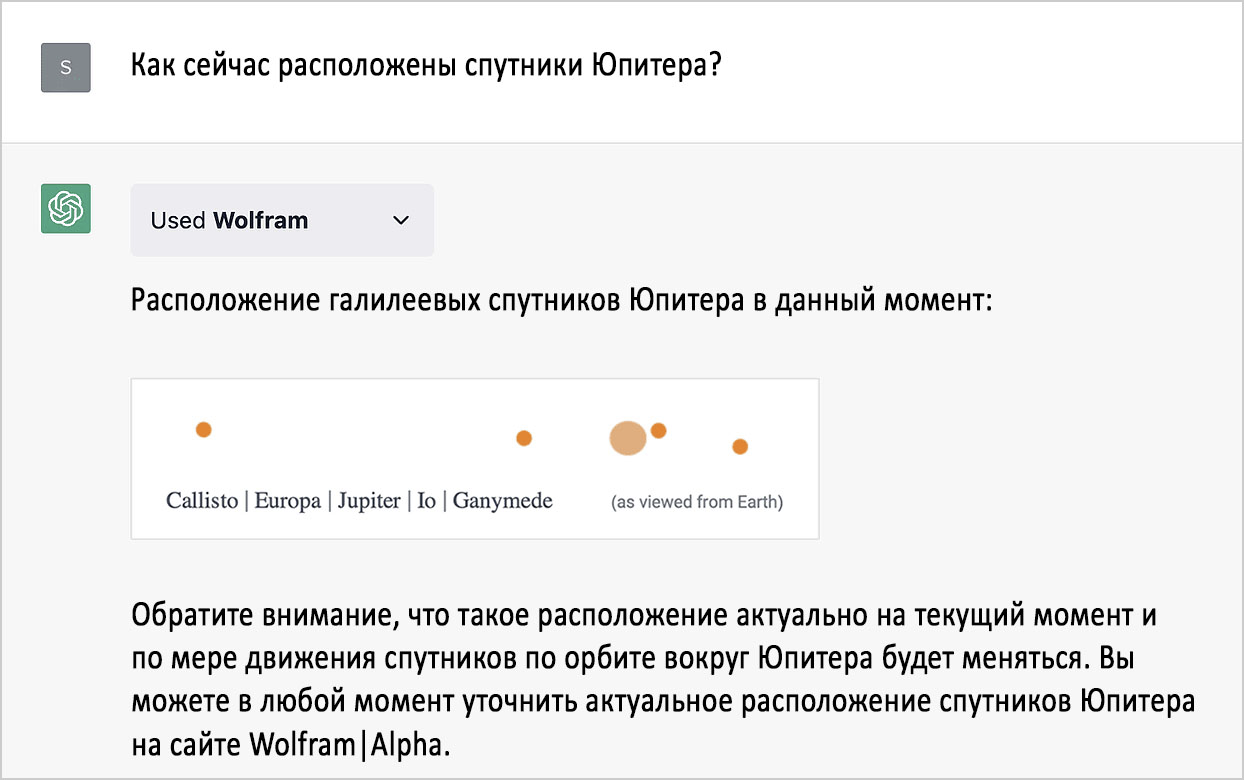
Или скомбинировать оба этих метода:
Некоторые доступные действия
Wolfram|Alpha и Wolfram Language охватывают множество сфер знаний:
Теперь (почти) всё это доступно ChatGPT, что открывает широчайший спектр новых возможностей. Вот несколько простых примеров, которые помогут нам в этом разобраться.
Алгоритмы
Аудио
Курсы валют
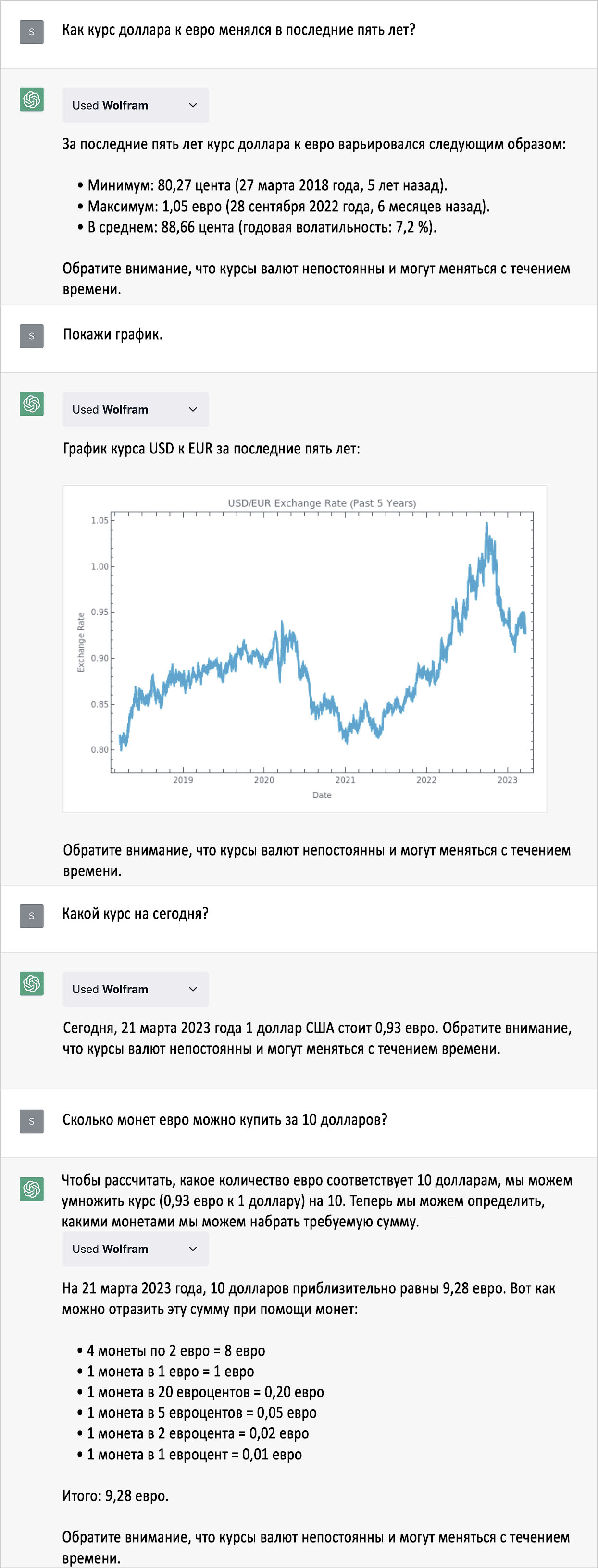
Построение графиков
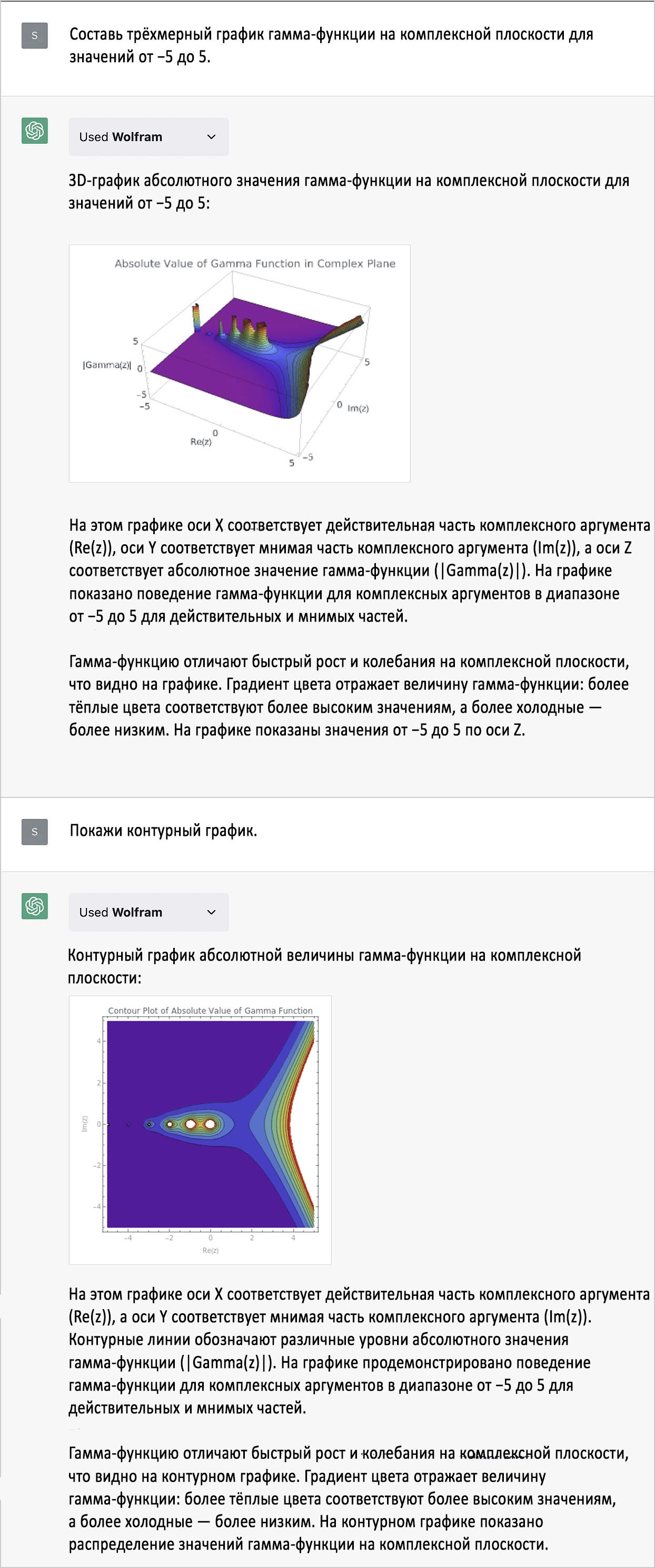
Генеалогия
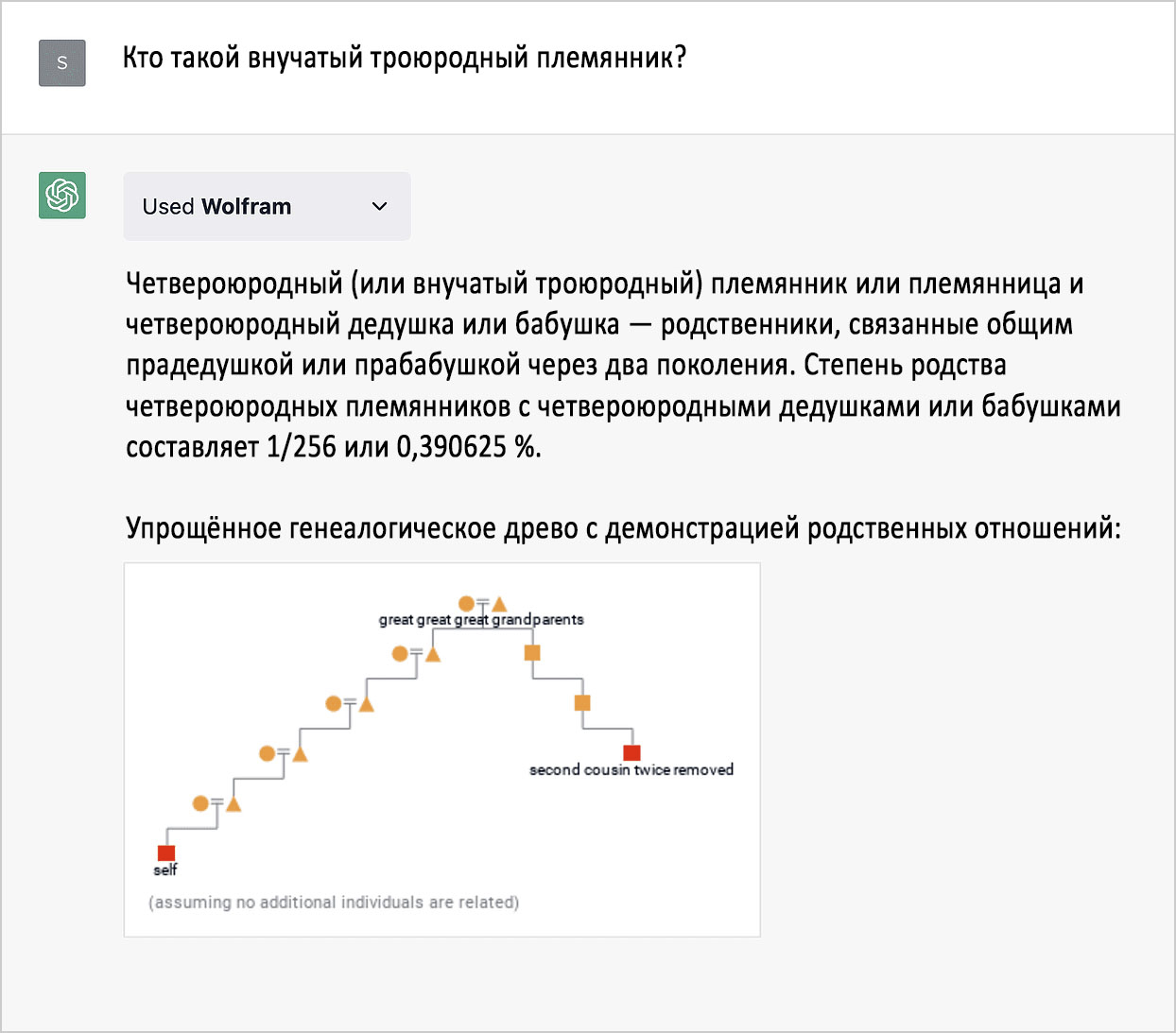
Геоданные
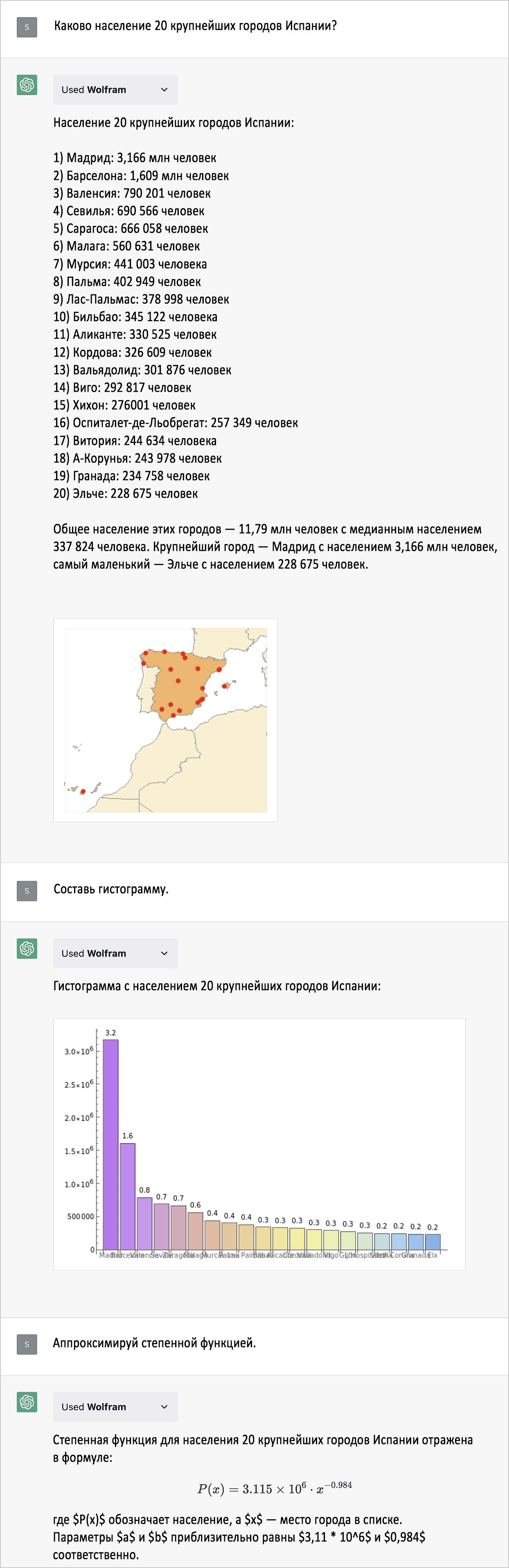
Математическое функции
Музыка

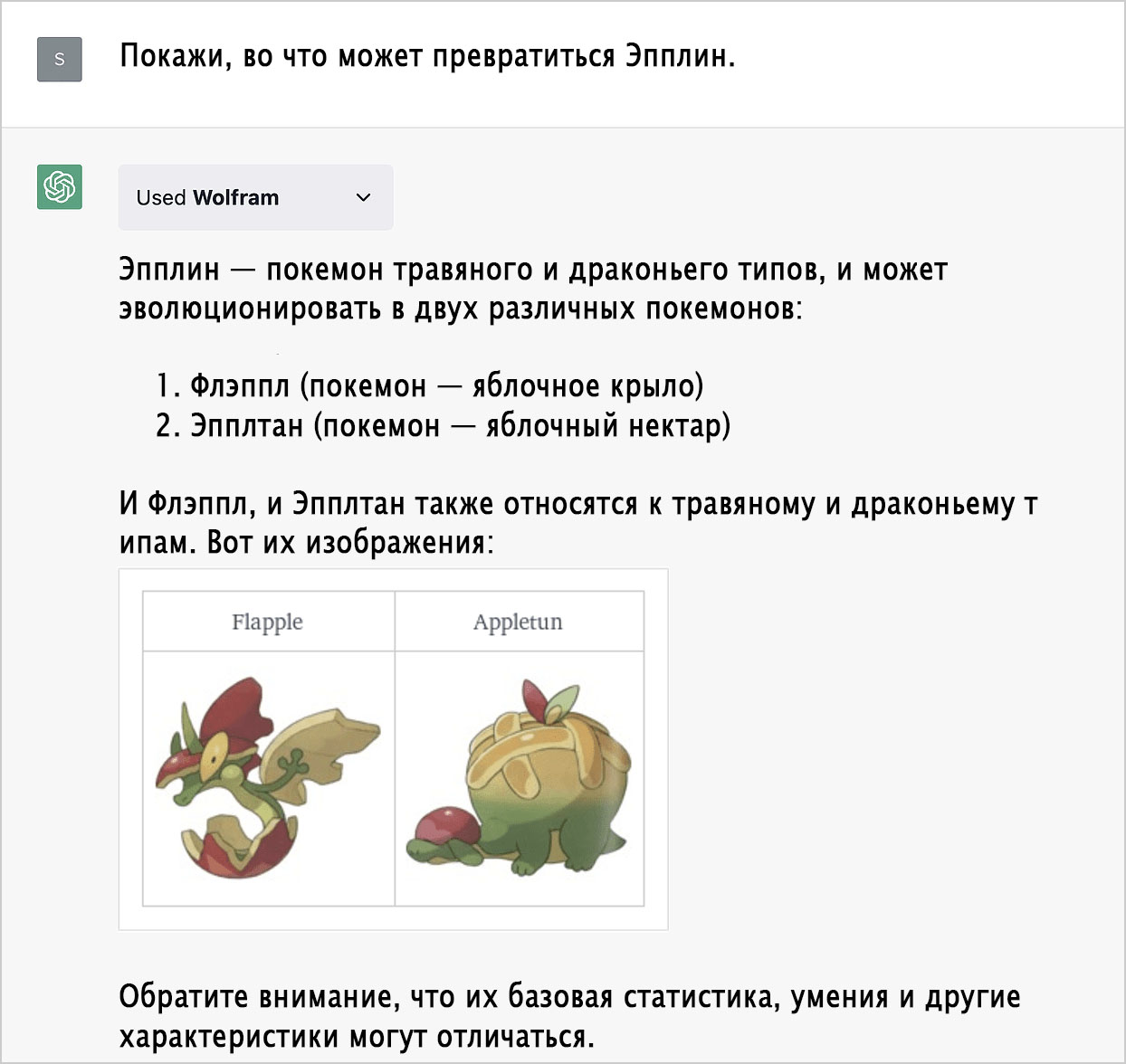
Покемоны
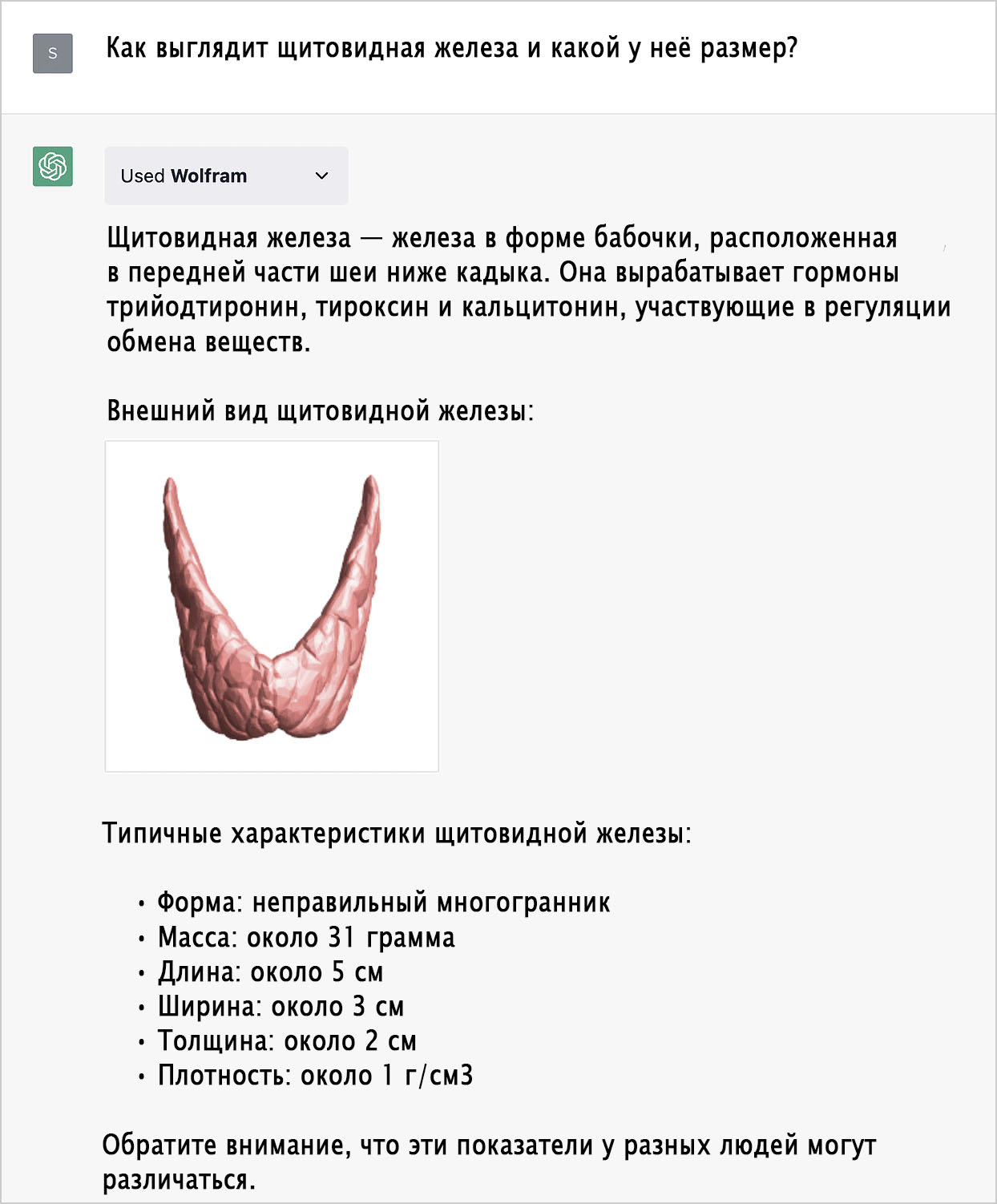
Анатомия
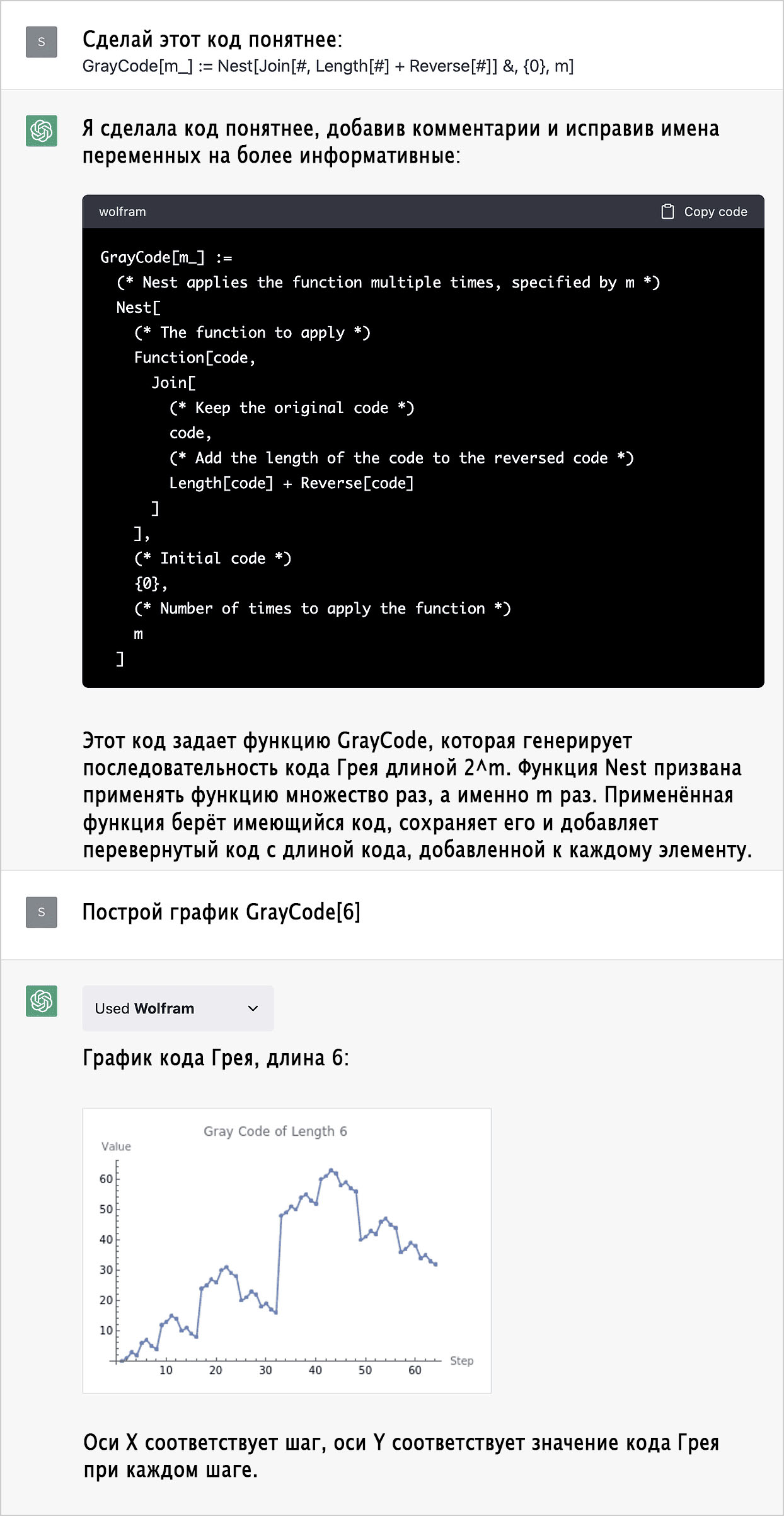
Пояснения к коду
Дата и время
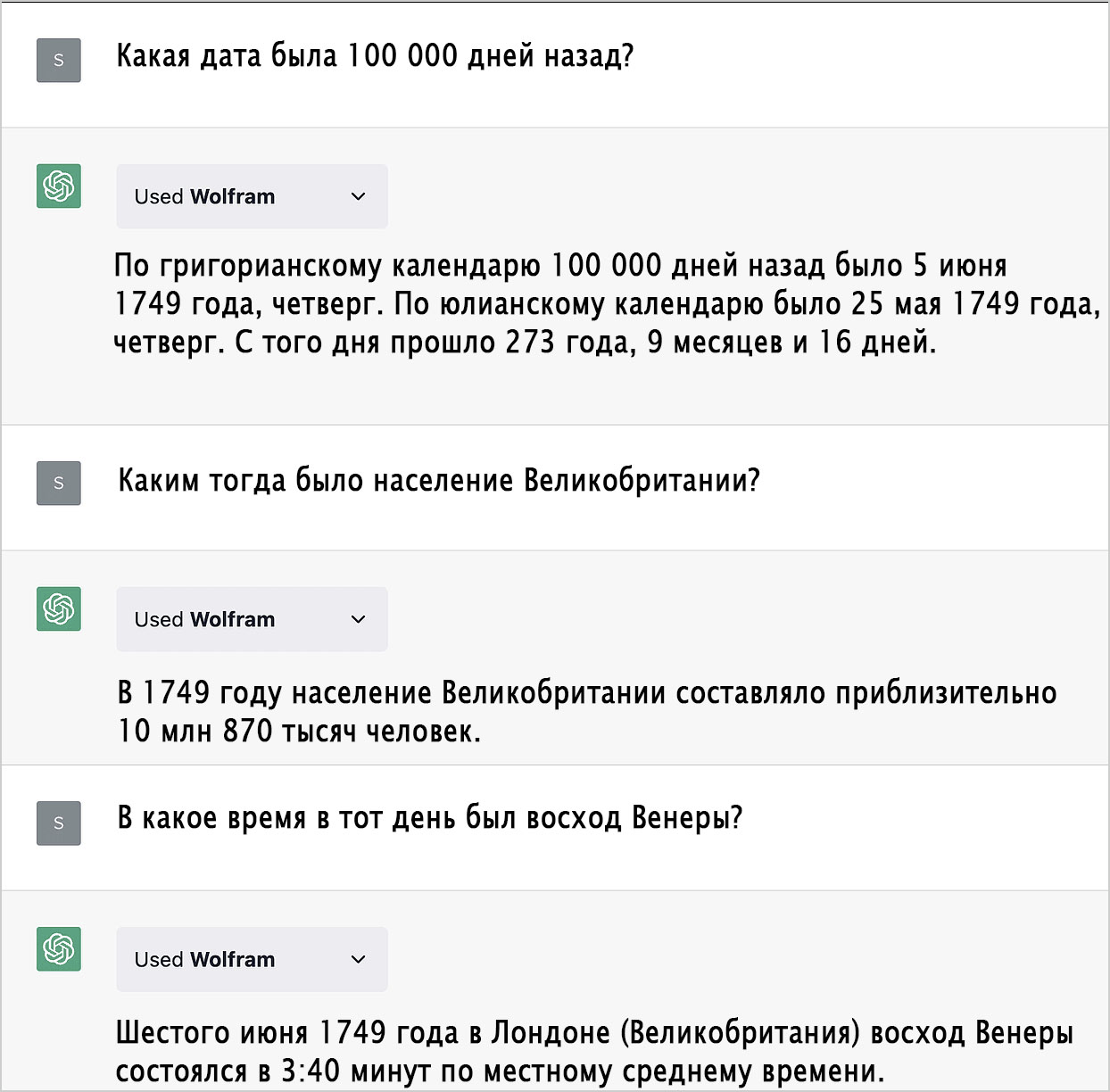
Землетрясения
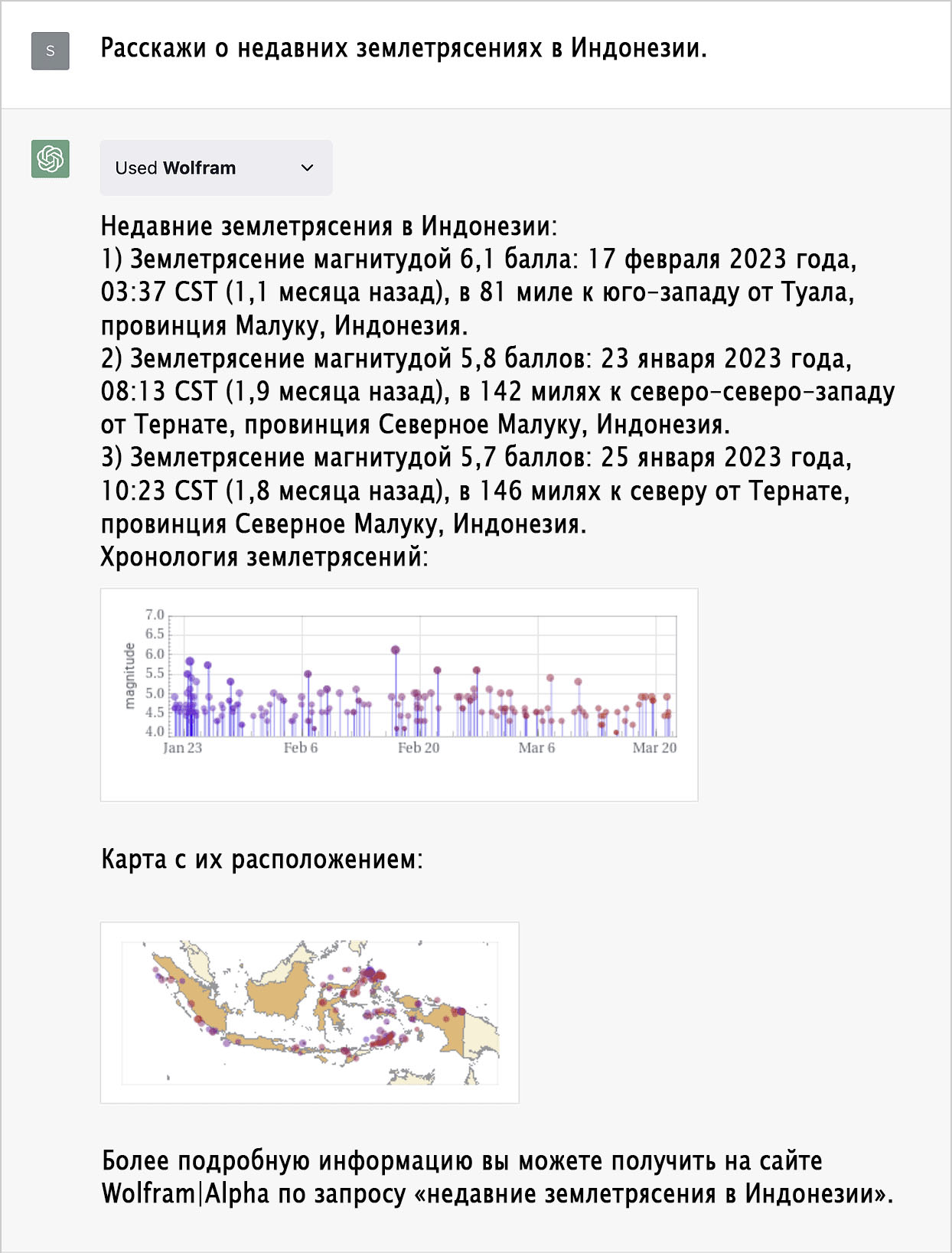
Решение уравнений
Разложение на множители

Геометрия

Лингвистика
Кино
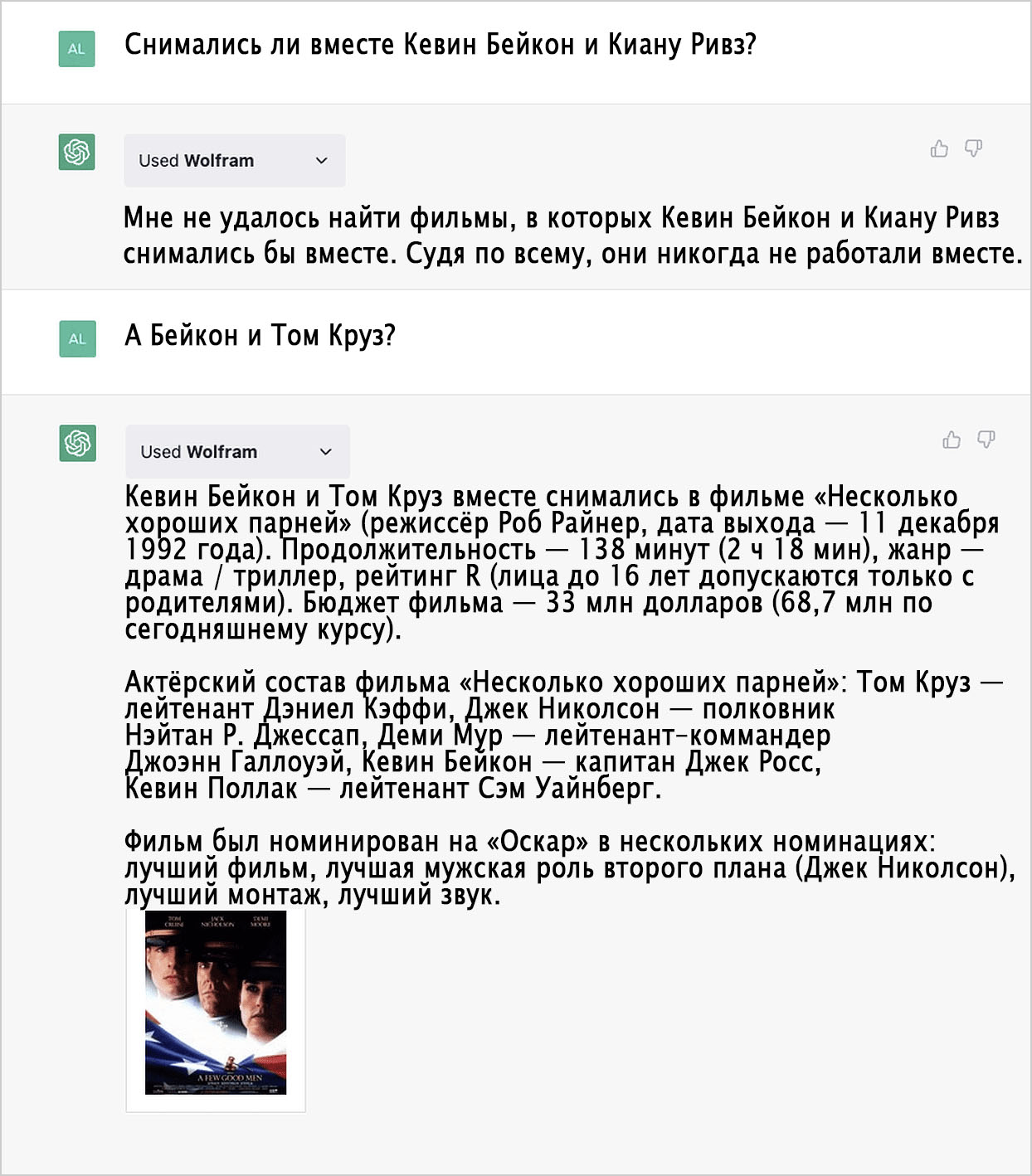
Системы счисления
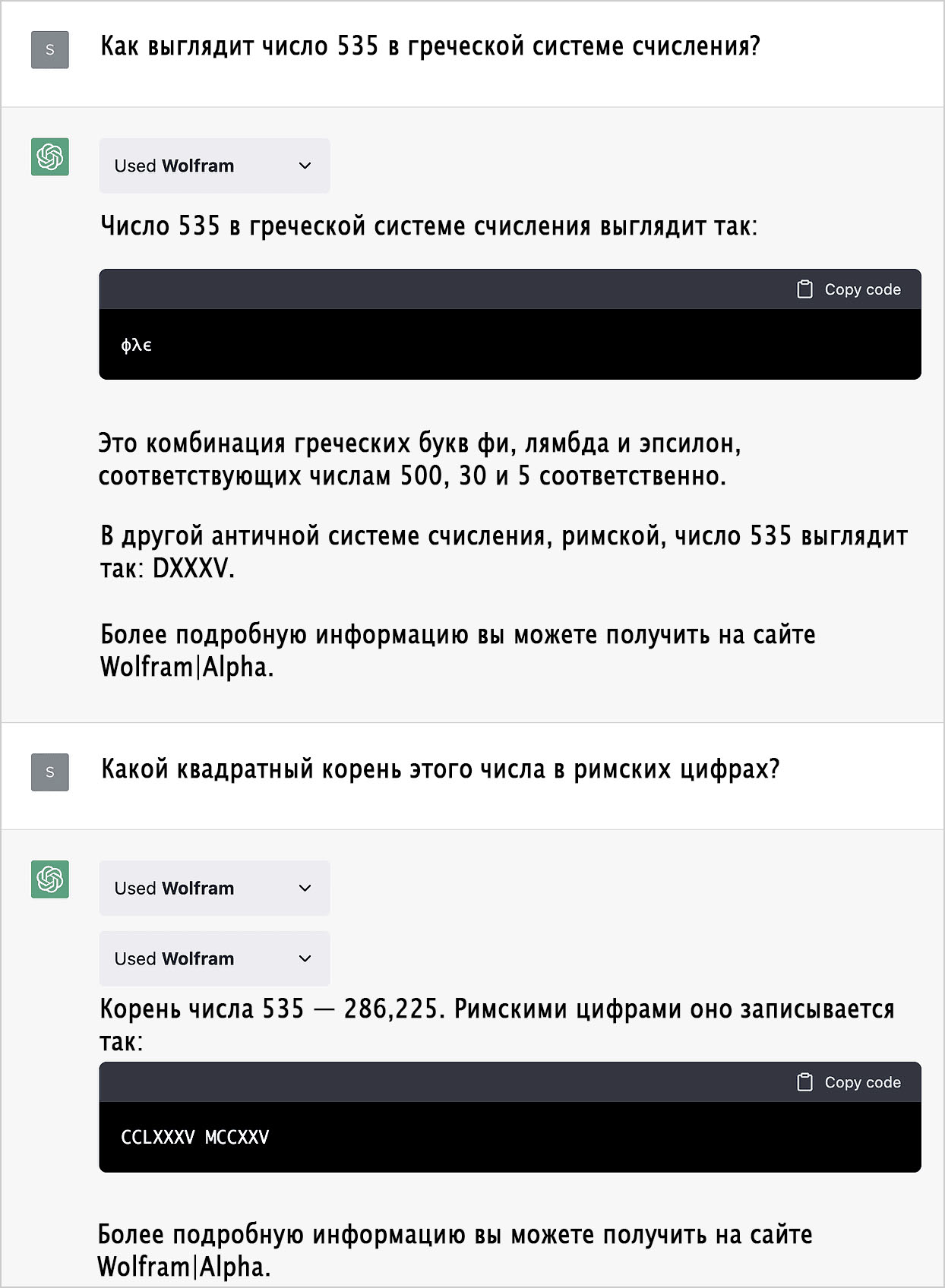
Образование
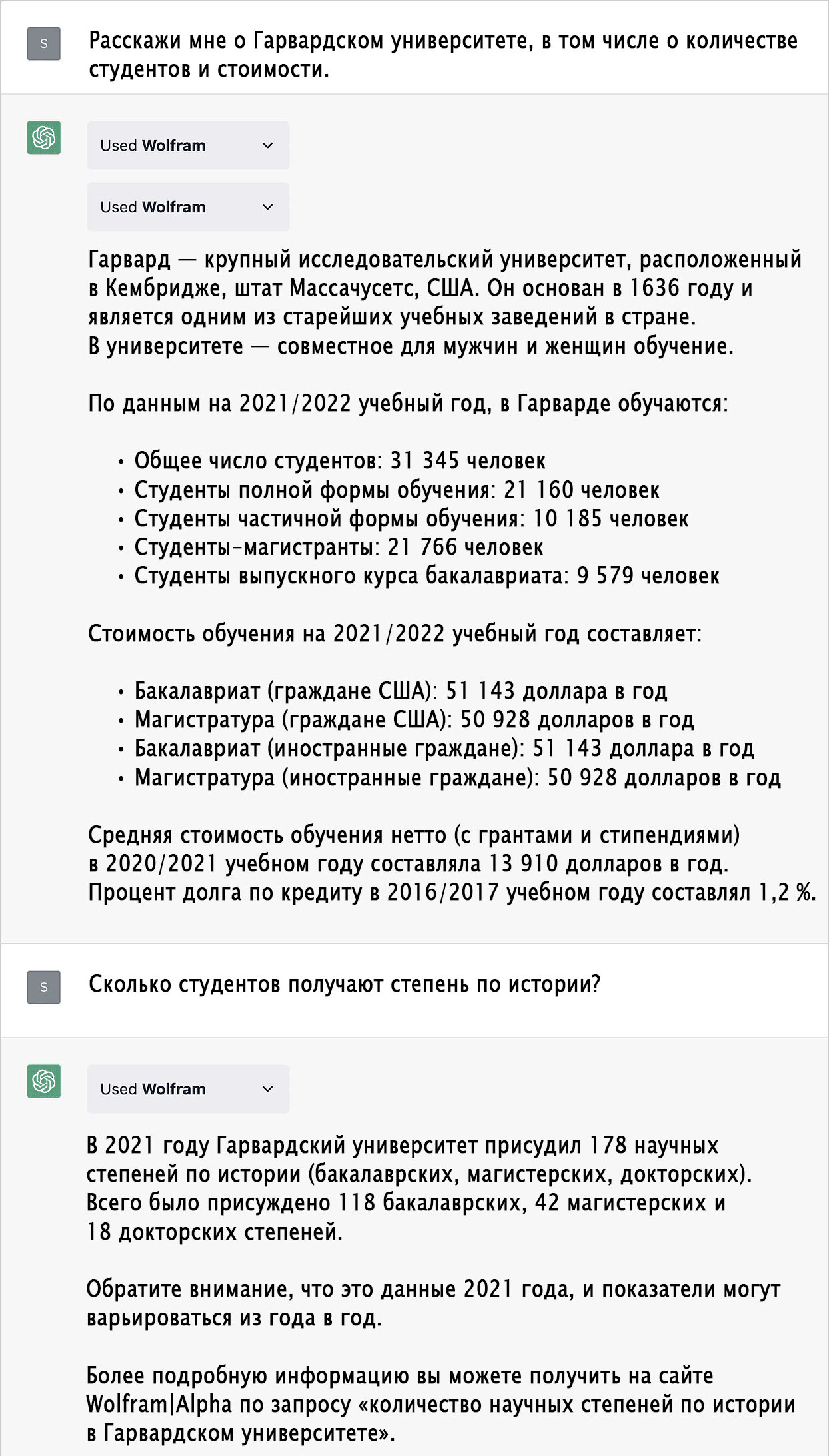
Игры со словами
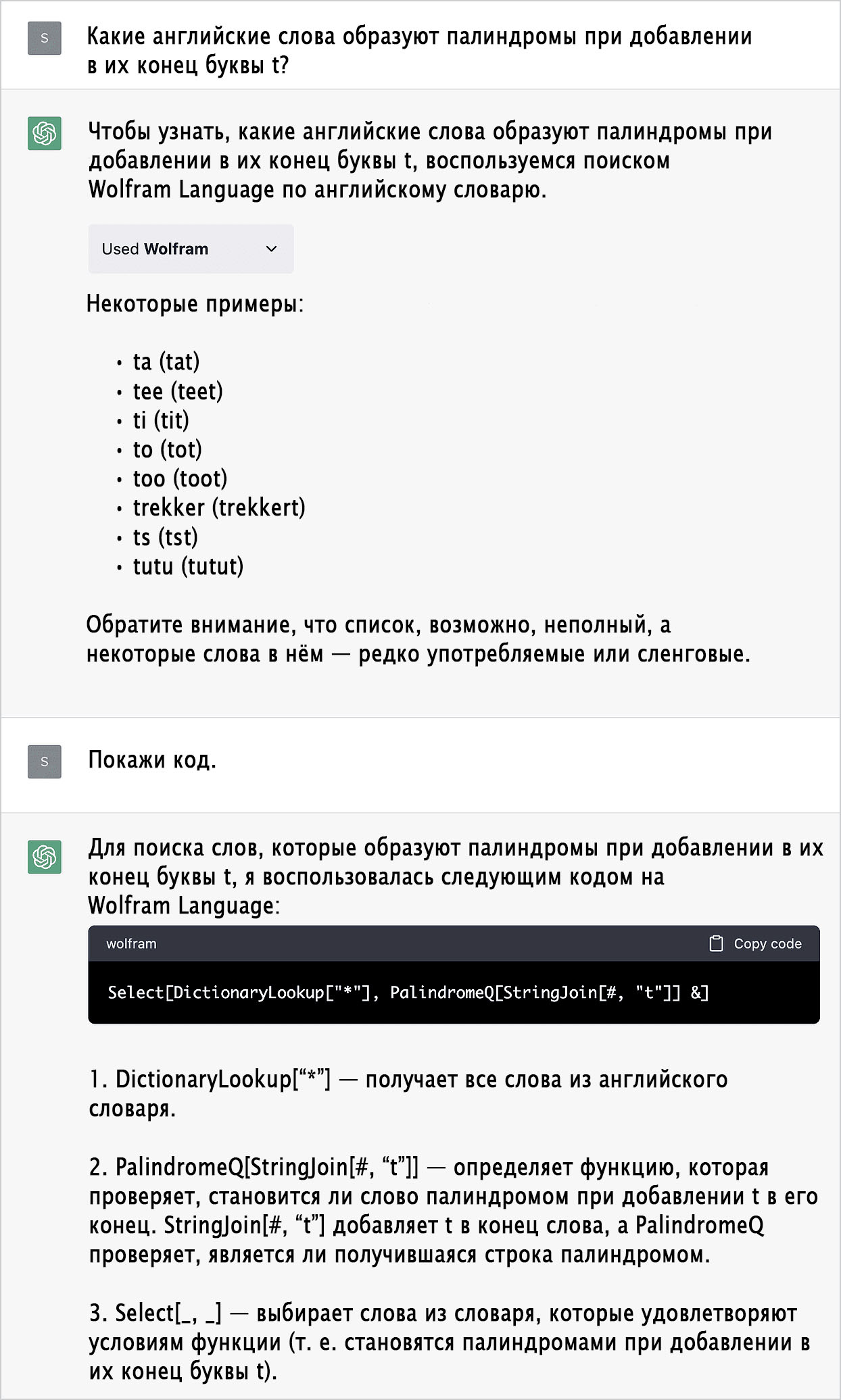
Современная модель работы человека и ИИ
Структура ChatGPT позволяет ей вести диалог с человеком. Но что, если этот диалог включает в себя реальные вычисления и вычислительные знания? Вот пример. Начнём с вопроса, касающегося общих знаний о мире:

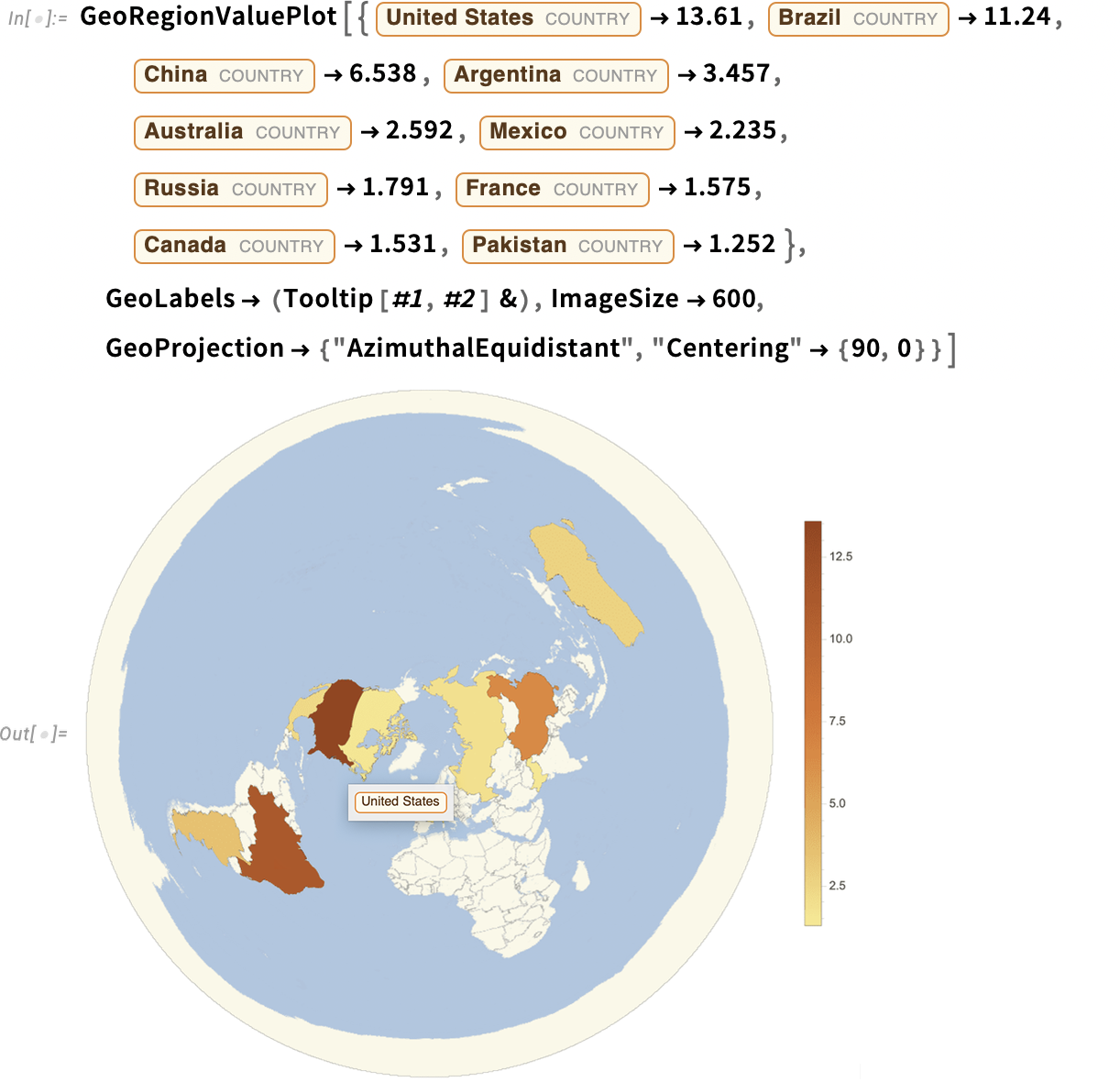
Нажав на соответствующую кнопку мы можем проверить, как был сформулирован запрос к Wolfram и какой был получен ответ. Запросим карту:
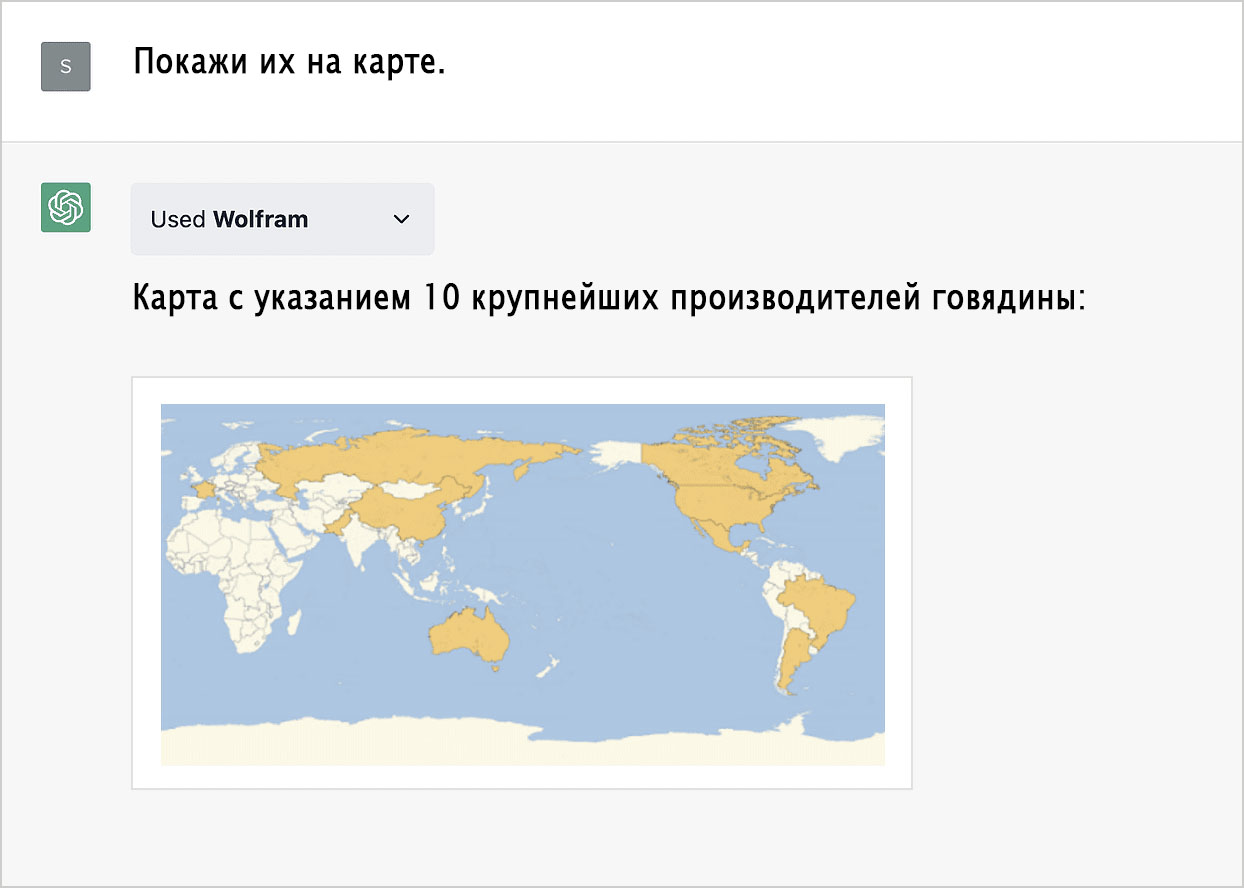
Возможно, нам хотелось бы видеть другую проекцию. Общие знания ChatGPT, почёрпнутые из интернета и других источников, позволят нам её выбрать:
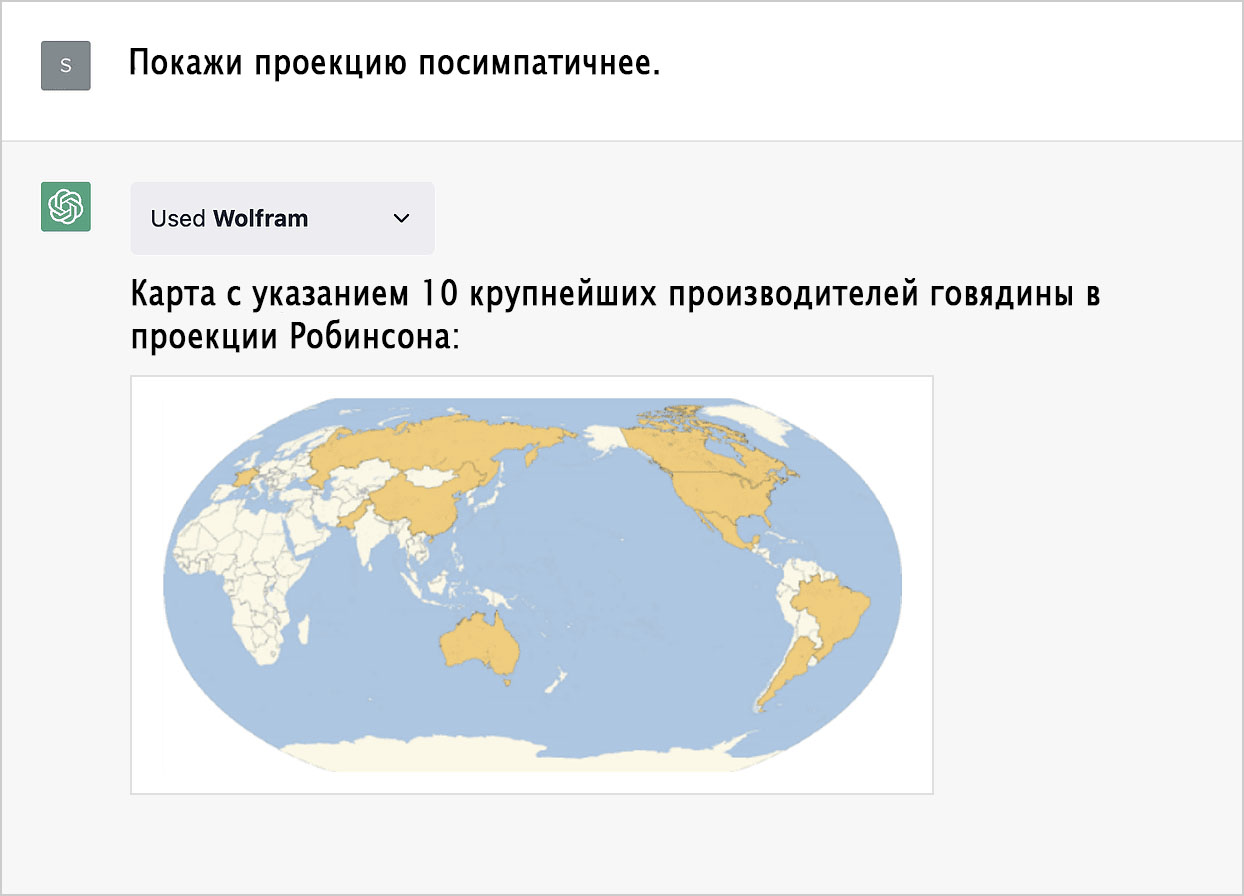
Что, если мы хотим запросить тепловую карту? С нашей технологией нет ничего проще:
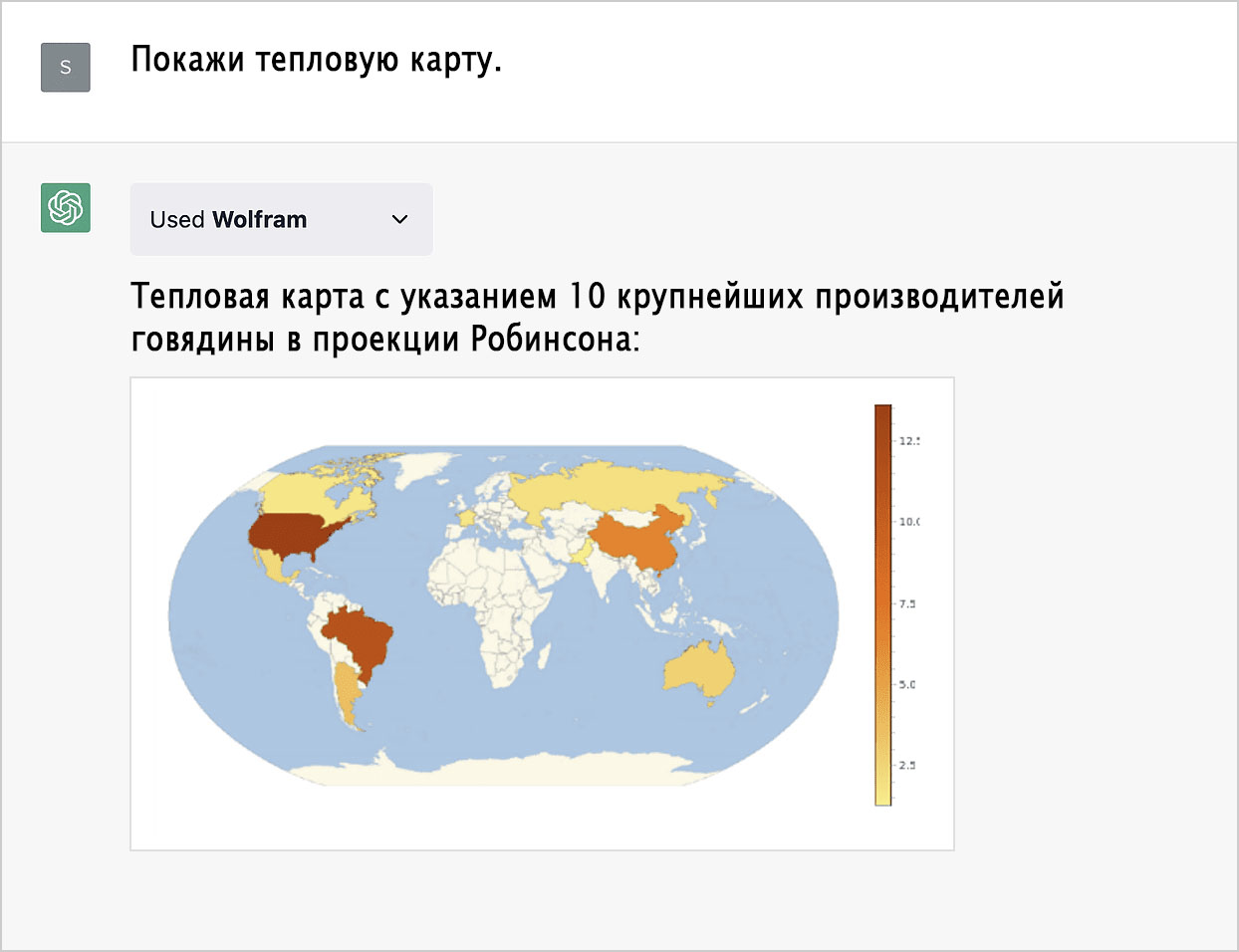
Давайте вновь изменим проекцию, обратившись к общим знаниям ChatGPT.

Проекция подобрана верно, а вот центровка — нет. Исправим это:
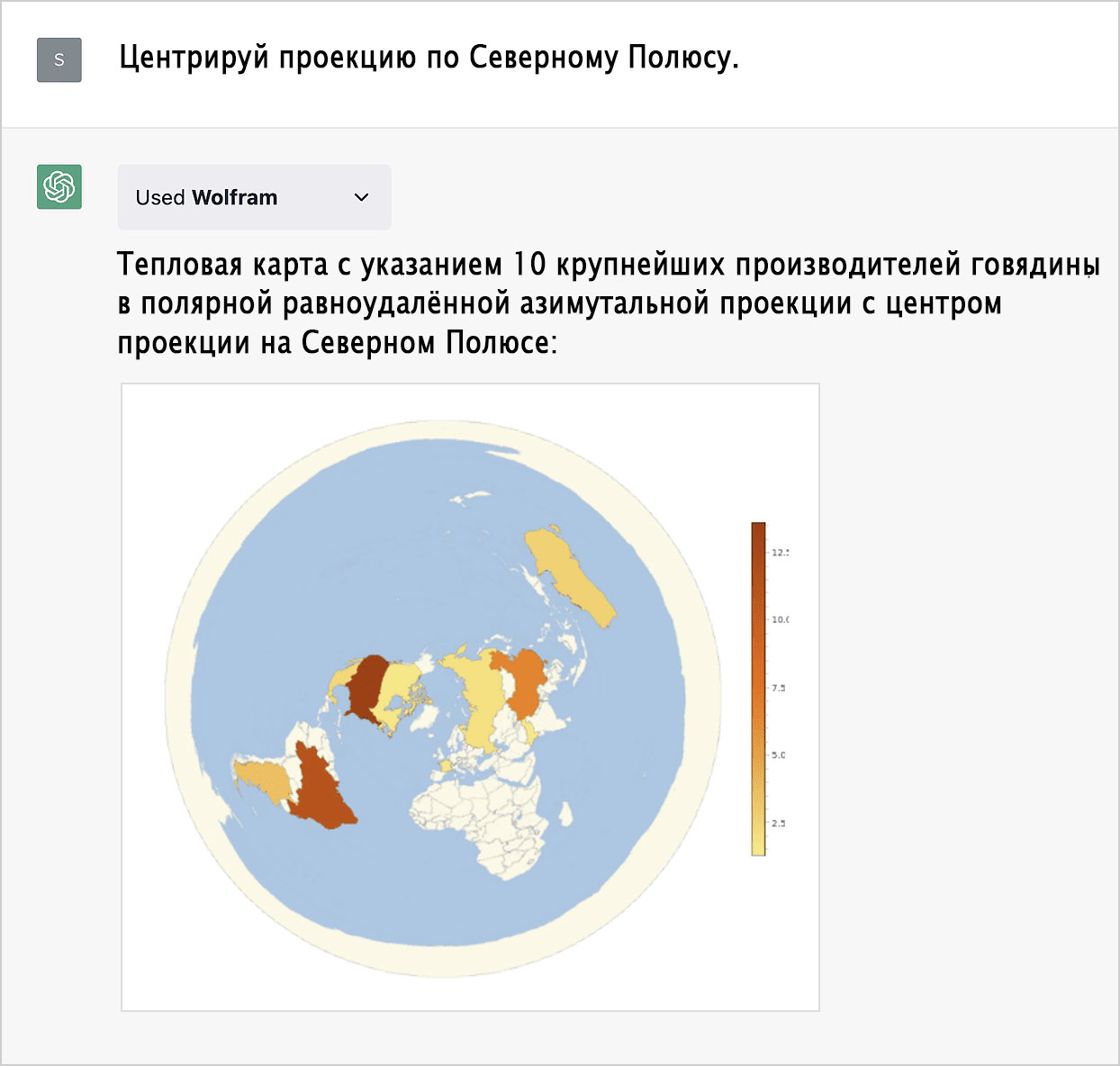
Каков же итог? Мы получили нужный результат «совместными усилиями». Мы постепенно уточняли, чего хотим добиться, а искусственный интеллект (ChatGPT + Wolfram) постепенно это реализовывал. Но что у нас вышло на самом деле? Небольшой фрагмент кода на Wolfram Language, который мы можем увидеть, нажав на кнопку или просто попросив ChatGPT:

Мы можем запустить код, скопировав его в Wolfram-блокнот, и тут же увидеть «эксклюзив»: обещанные ChatGPT динамические подсказки с названиями стран:
Даже немного жаль, что в коде представлены чётко обозначенные цифры, а не оригинальный символьный запрос об объёмах производства. Дело в том, что ChatGPT задал оригинальный вопрос Wolfram|Alpha, а затем передал результаты Wolfram Language. Так или иначе, полученный результат весьма меня впечатлил.
Как всё устроено и как обуздать ИИ
Что же происходит «под капотом» у ChatGPT и плагина Wolfram? Напомним, что основа ChatGPT — большая языковая модель (LLM), обученная на текстах из интернета и других источников и призванная генерировать «разумное и логичное продолжение» прочитанного текста. Однако на финальной стадии тренировок ChatGPT учится «вести диалог» и понимать, когда «нужно задать вопрос кому-то другому» — человеку или плагину. В частности, она научилась понимать, когда следует обратиться к плагину Wolfram.
У плагина Wolfram две входные точки — Wolfram|Alpha и Wolfram Language. Можно сказать, что общение с Wolfram|Alpha дается ChatGPT проще, однако в конечном итоге Wolfram Language представляет собой более мощный инструмент. Взаимодействие с Wolfram|Alpha облегчает тот факт, что она принимает на вход естественный язык, с которым ChatGPT имеет дело постоянно. Помимо этого, структура Wolfram|Alpha «прощает ошибки» — она способна работать с «человекоподобными» данными, какими бы хаотичными или запутанными они ни были.
Wolfram Language же, напротив, заточен под точность и определенность и умеет производить сложнейшие ряды вычислений. Механизм Wolfram|Alpha переводит естественный язык в точный язык Wolfram Language, ловя неточности и несовершенства.
При обращении ChatGPT к плагину Wolfram она передает естественный язык Wolfram|Alpha. Впрочем, к настоящему времени ChatGPT и сама довольно много узнала о Wolfram Language — как мы покажем позже, это более гибкая и мощная форма общения, но она не работает, если код на Wolfram Language содержит ошибки. Как дойти до этого уровня — вопрос тренировок. При получении кода плагин Wolfram запускает его, и если результат явно неудовлетворительный (ошибок много), ChatGPT получит возможность его исправить и запустить вновь. Если быть совсем точным, ChatGPT может попробовать написать тесты и исправить код при наличии ошибок.
Работы в этом направлении предстоит много, однако уже сейчас иногда можно увидеть муки выбора ChatGPT. Она то переписывает свой запрос к Wolfram|Alpha (например, упрощая его, удаляя не релевантные элементы), то переключается между Wolfram|Alpha и Wolfram Language, то переписывает код на Wolfram Language. Обучение этим функциям — задача плагина и его промта.
Написание этого промта — странное занятие — пожалуй, это наш первый опыт общения с чужеродным интеллектом. Конечно, нам на руку то, что оный чужеродный интеллект обучался на огромном корпусе текстов, написанных человеком. Так что можно сказать, что он владеет английским (примерно как пришельцы в отстойных голливудских блокбастерах), и мы можем скомандовать ему: «если пользователь вводит запрос не на английском языке, переводи запрос на английский и передавай Wolfram|Alpha, а затем возвращай ответ на языке оригинального запроса».
Иногда нам приходилось проявлять строгость (обратите внимание на выделение заглавными буквами): «При написании код на Wolfram Language НИКОГДА не используй змеиный регистр в названиях переменных! В названиях переменных ВСЕГДА используй верблюжий». При всей нашей настойчивости, ChatGPT иногда все-таки ошибается. В целом, процесс создания промта напоминает приручение дикого животного — мы пытаемся заставить ChatGPT выполнять наши требования, но что для этого сделать, пока непонятно.
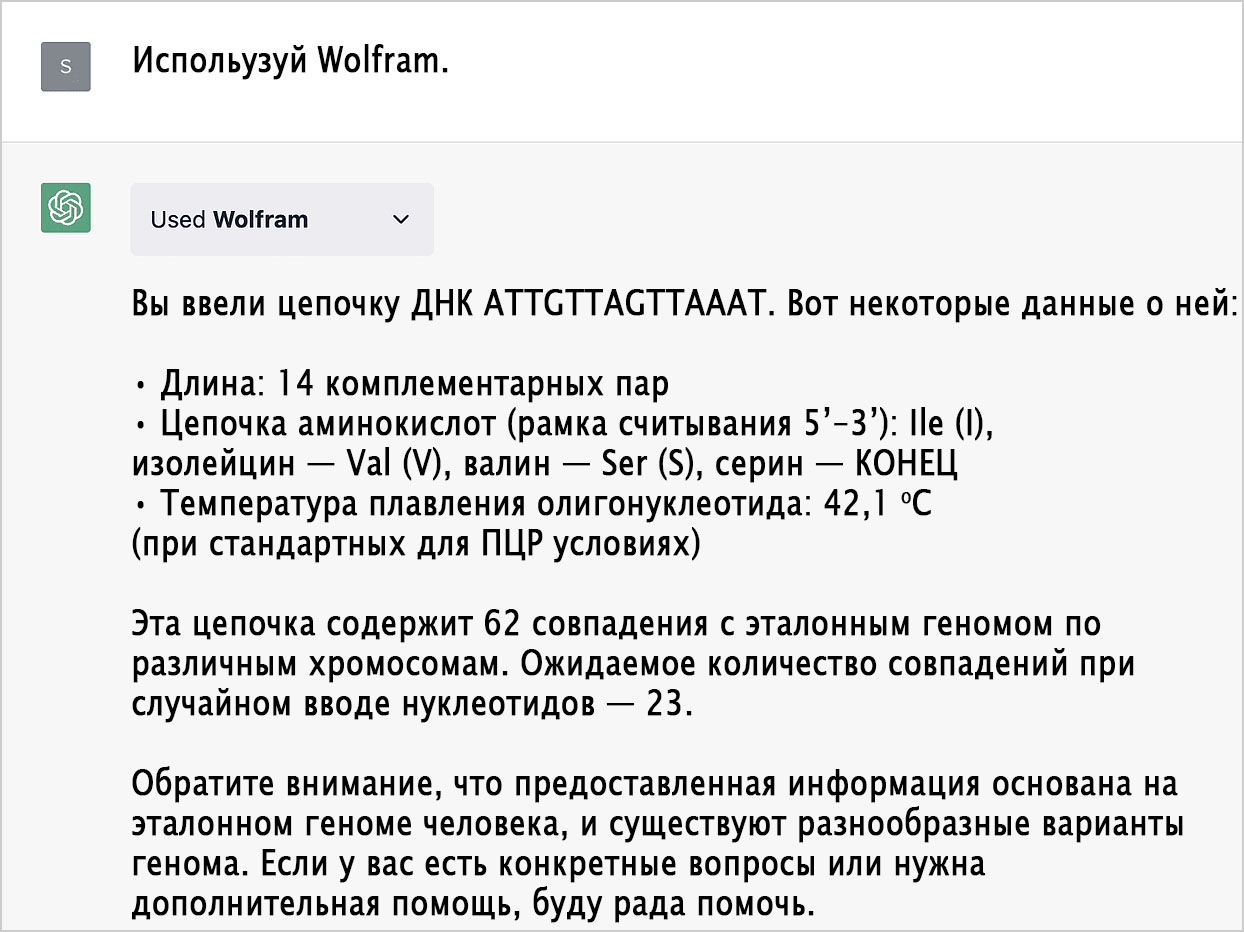
Со временем мы наверняка решим этот вопрос в рамках обучения или при написании промта, но на данном этапе ChatGPT не всегда знает, когда ей обращаться к плагину Wolfram. К примеру, ChatGPT верно догадывается, что имеет дело с цепочкой ДНК, но не понимает (по крайней мере, в данной сессии), что плагин Wolfram может ей помочь:

Скажем ей «воспользоваться Wolfram», и она обратится к плагину, который со всем разберётся:
Иногда стоит четко указать: «воспользуйся Wolfram|Alpha» или «воспользуйся Wolfram Language». Особенно в случае с Wolfram Language — вам может быть интересно взглянуть на отправленный код и, например, попросить ChatGPT не запускать встречающиеся несуществующие функции.
Получая код на Wolfram Language, плагин Wolfram, по сути, оценивает его и возвращает результат в форме графика, формулы или обычного текста. А вот входные данные от Wolfram|Alpha пересылаются на специальную конечную точку API для LLM, в результате чего возвращается текст, «читаемый» ChatGPT и фактически используемый как дополнительный промт для будущего ответа ChatGPT. Взгляните на этот пример:
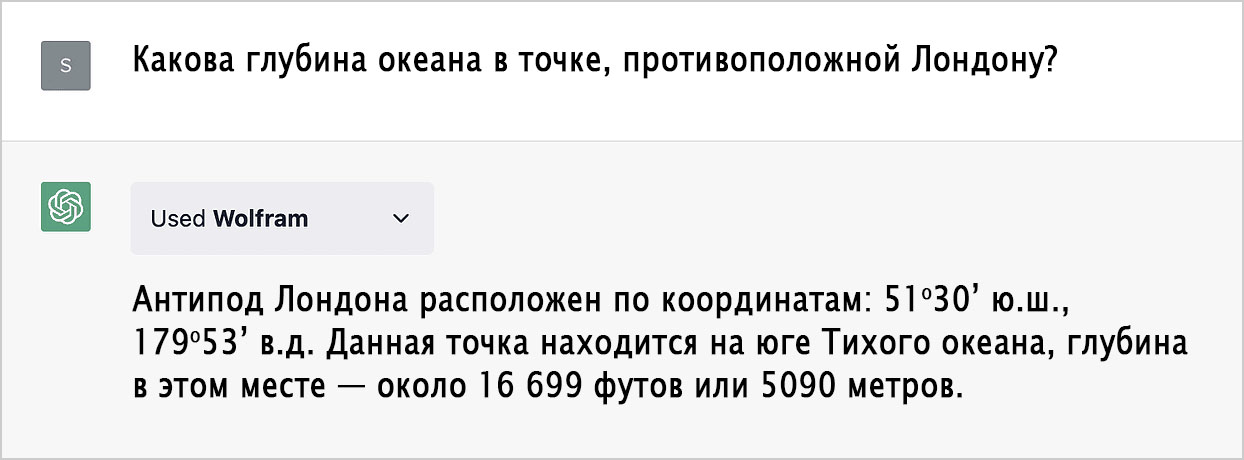
Мы получили чёткий ответ на поставленный вопрос и дополнительную информацию по усмотрению ChatGPT. «Внутри» же мы можем увидеть, какую работу на самом деле проделал плагин Wolfram (и конечная точка Wolfram|Alpha для LLM):
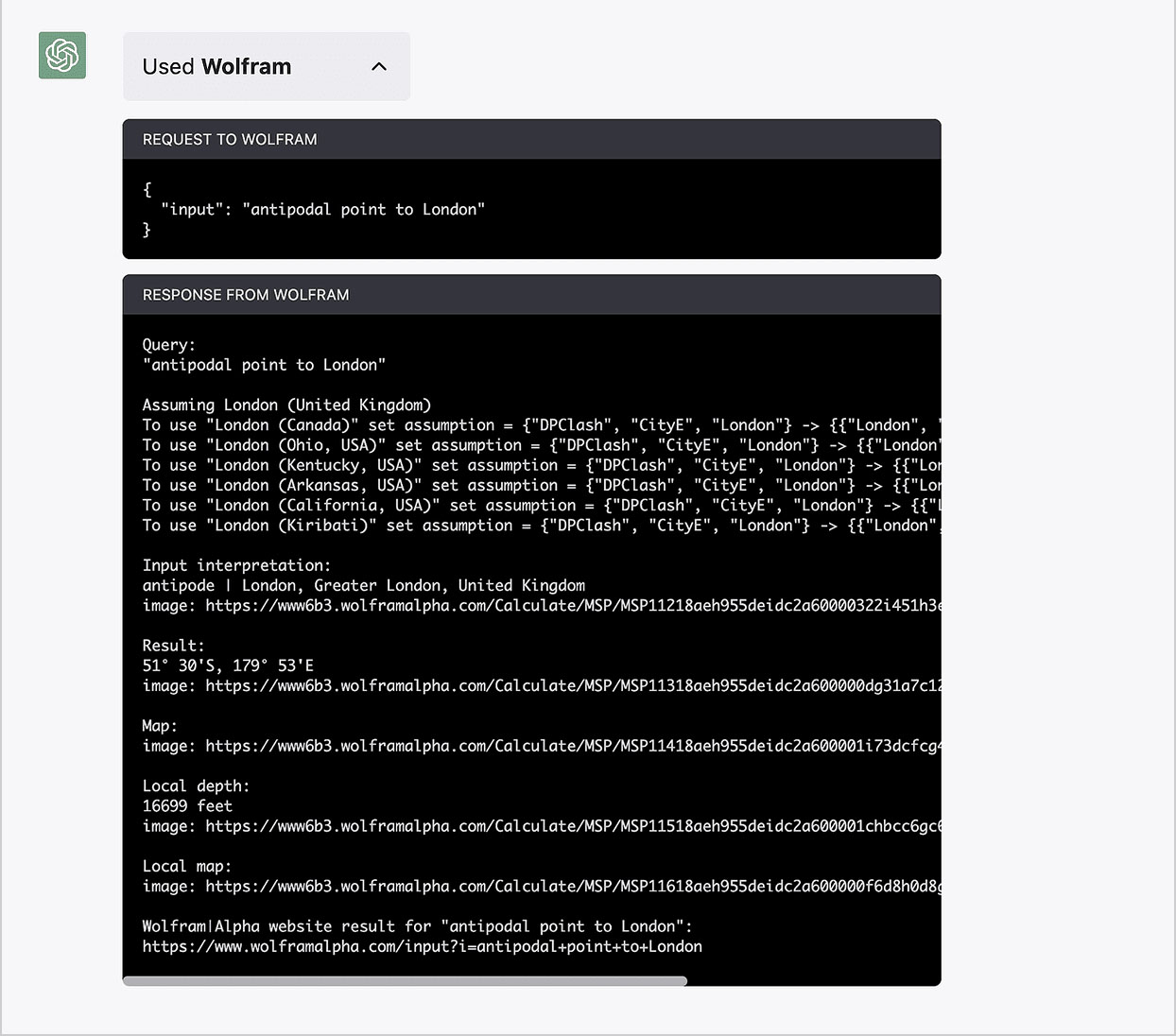
Здесь дополнительной информации побольше, и даже есть иллюстрации, но ChatGPT решила сократить свой ответ.
Подчеркиваем: если вы хотите удостовериться в том, что вы получаете именно то, что запросили, обязательно проверяйте запрос ChatGPT к плагину Wolfram и полученный ею ответ. Одна из главных задач нашего плагина — проверка вывода ChatGPT и отделение ее «фантазий» от твердых фактов.
Также может быть полезно брать отправленный плагином запрос и напрямую вводить его на сайте Wolfram|Alpha или в системах Wolfram Language (например, Wolfram Cloud).
Wolfram Language как язык для общения человека и ИИ
Один из главных (и даже неожиданных) талантов ChatGPT — способность по нечёткому черновому описанию генерировать законченный, отполированный ответ, будь то эссе, письмо, юридический документ. Раньше мы могли добиться этого вручную благодаря шаблонам, которые сами правили и склеивали. С ChatGPT это уходит в прошлое: она впитала в себя огромную массу таких шаблонов, «прочитанных» в сети и других источниках, и, как правило, отлично адаптирует их под ваши нужды.
Но что насчёт кода? Программисты, работающие с традиционными языками программирования, очень часто пишут свои программы, используя стереотипный код из интернета. Появление ChatGPT поставит крест и на этом процессе — она умеет составлять практически любой шаблонный код автоматически с минимальным вмешательством человека.
Вмешательство, конечно, необходимо, ведь без нас ChatGPT не узнает, какую программу ей следует написать. При этом поневоле задумаешься, а нельзя ли обойтись вообще без шаблонного кода? Нельзя ли придумать язык, в котором на базовом уровне предусмотрено лишь небольшое участие человека?
Вот в чём проблема: традиционные языки программирования строятся вокруг указаний компьютеру, сформулированных понятным компьютеру образом: задай переменную, проверь это условие и т. п. Но всё может быть и по-другому. Можно зайти с другого конца: взять категории, которыми мыслит человек, представить их в цифровом виде и тем самым автоматизировать их реализацию компьютером.
Этой задаче я и посвятил последние сорок с небольшим лет своей работы. Она легла в основу нынешнего Wolfram Language, который я теперь могу с полным правом называть «полнофункциональным вычислительным языком». Что же это значит? Это значит, что в языке существует вычислительное отображение для настоящих и абстрактных понятий, с которыми мы имеем дело, будь то графы, изображения, дифференциальные уравнения, города, химические соединения, компании или фильмы.
Почему не начать прямо с естественного языка? В какой-то степени это работает, как показывает успех Wolfram|Alpha. Но когда дело доходит до более сложных, замысловатых материй, естественный язык становится тяжеловесным и неповоротливым — возьмите хоть юридическую заумь. Необходим более структурированный способ изъяснения.
Можно привести аналогию из истории математики: ещё каких-то 500 лет назад «записывать математику» можно было лишь естественным языком. С изобретением математической нотации наука пошла на взлёт, что привело к развитию алгебры, математического анализа и прочих её разделов.
Моей целью при работе над Wolfram Language было создание вычислительного языка, который покрывал бы любые «выражаемые вычислительным образом» реалии. Чтобы этого добиться, нужен был язык, выполняющий множество функций автоматически и по своей природе многое знающий. Так же, как математическая нотация позволяет людям выражать свои мысли посредством математических символов, язык, получившийся в итоге, помогает пользователю изъясняться посредством вычислений. И главное — в отличие от традиционных языков программирования, Wolfram Language предназначен для чтения не только компьютером, но и человеком. Иными словами, он задуман как структурированный инструмент для «передачи вычислительных идей» компьютеру и человеку.
Сейчас, с появлением ChatGPT, этот инструмент стал важен как никогда. Как можно было убедиться, взглянув на примеры выше, ChatGPT способна работать с Wolfram Language — по сути, выстраивать вычислительные идеи при помощи естественного языка. Дело не только в том, что Wolfram Language может отражать то, о чём мы хотим поговорить, но и в том, что он позволяет нам «осмыслить то, что у нас имеется», ведь мы вполне способны прочесть сгенерированный ChatGPT код на Wolfram Language.
С плагином Wolfram для ChatGPT всё складывается как нельзя лучше. Вот простой пример того, как ChatGPT может свободно написать на Wolfram Language ответ на наш запрос:
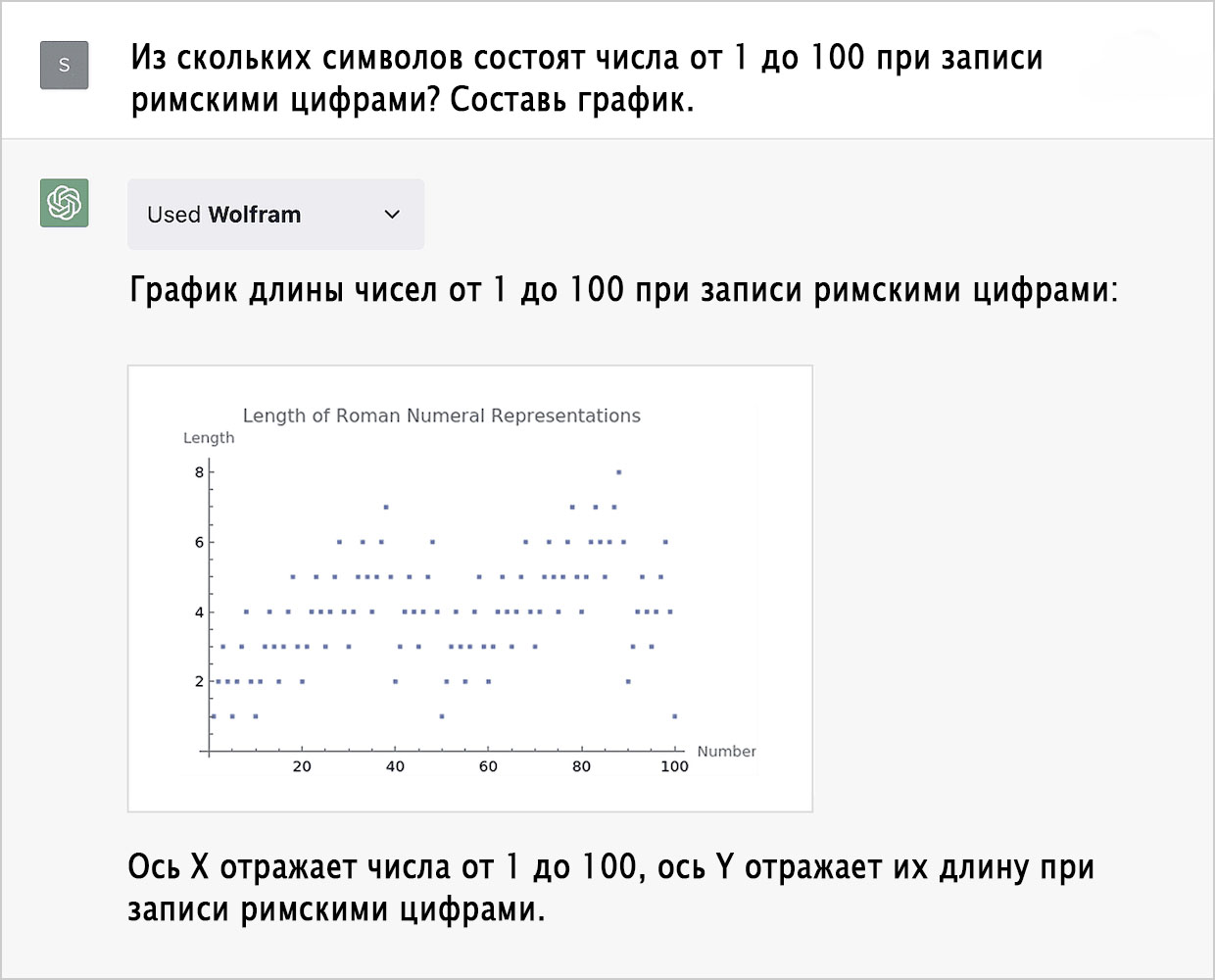

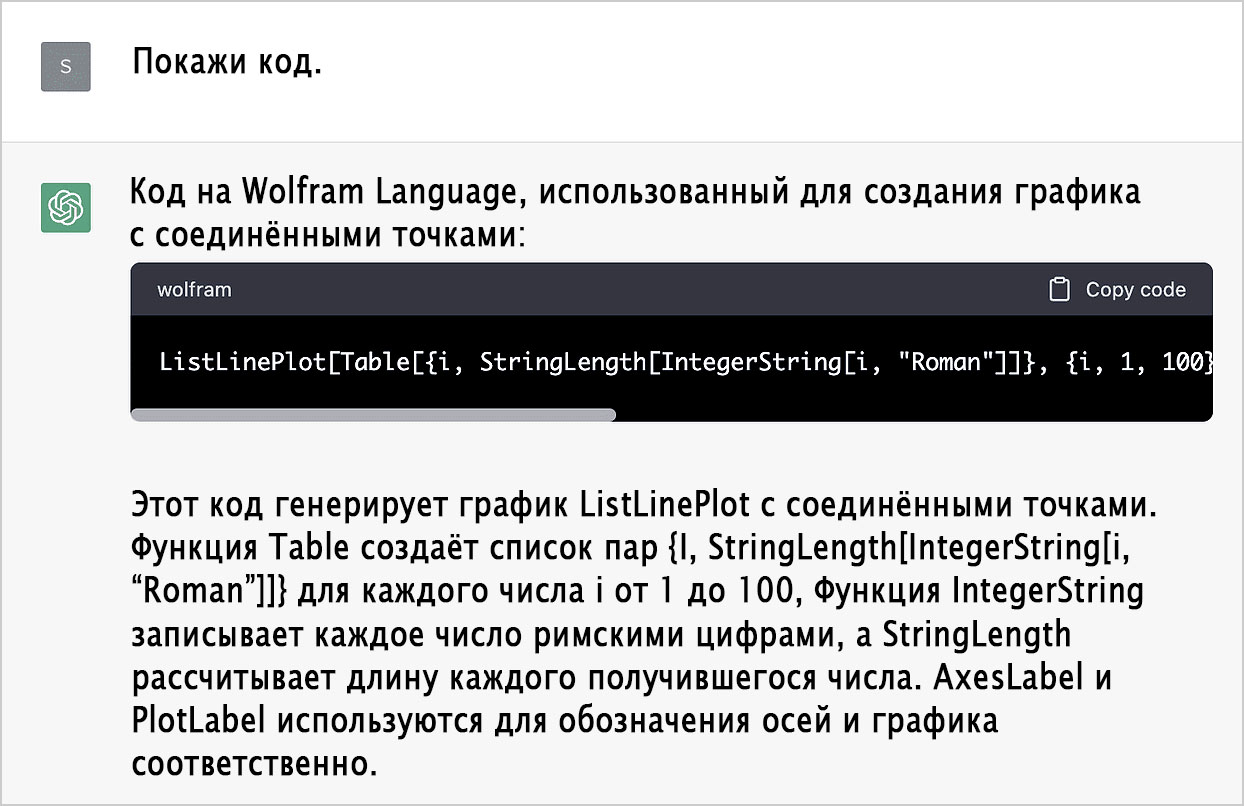
Самое главное, что этот код доступен для понимания каждому из нас (правда, если бы его писал я, то прибегнул бы к более компактной функции RomanNumeral):
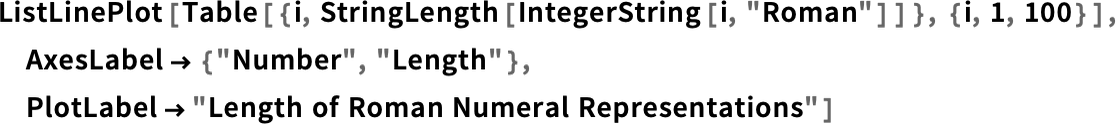
Ещё один пример:
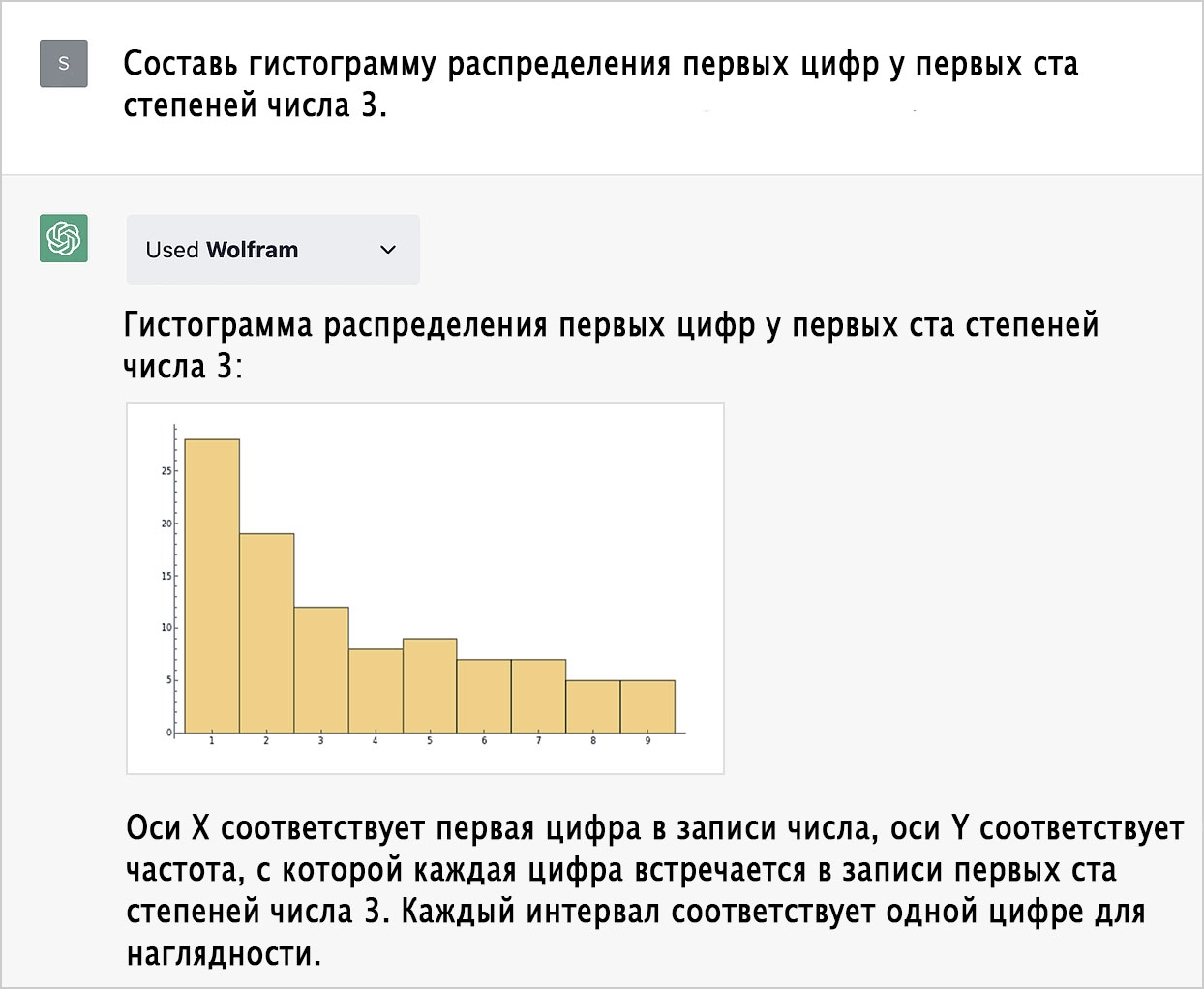

Я бы написал код слегка по-другому, но опять же, всё и так вполне понятно:
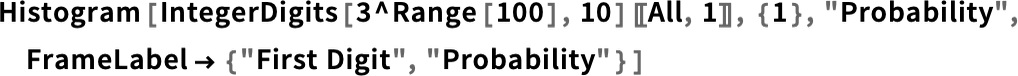
Иногда для выражения своей мысли можно воспользоваться гибридом английского и Wolfram Language:

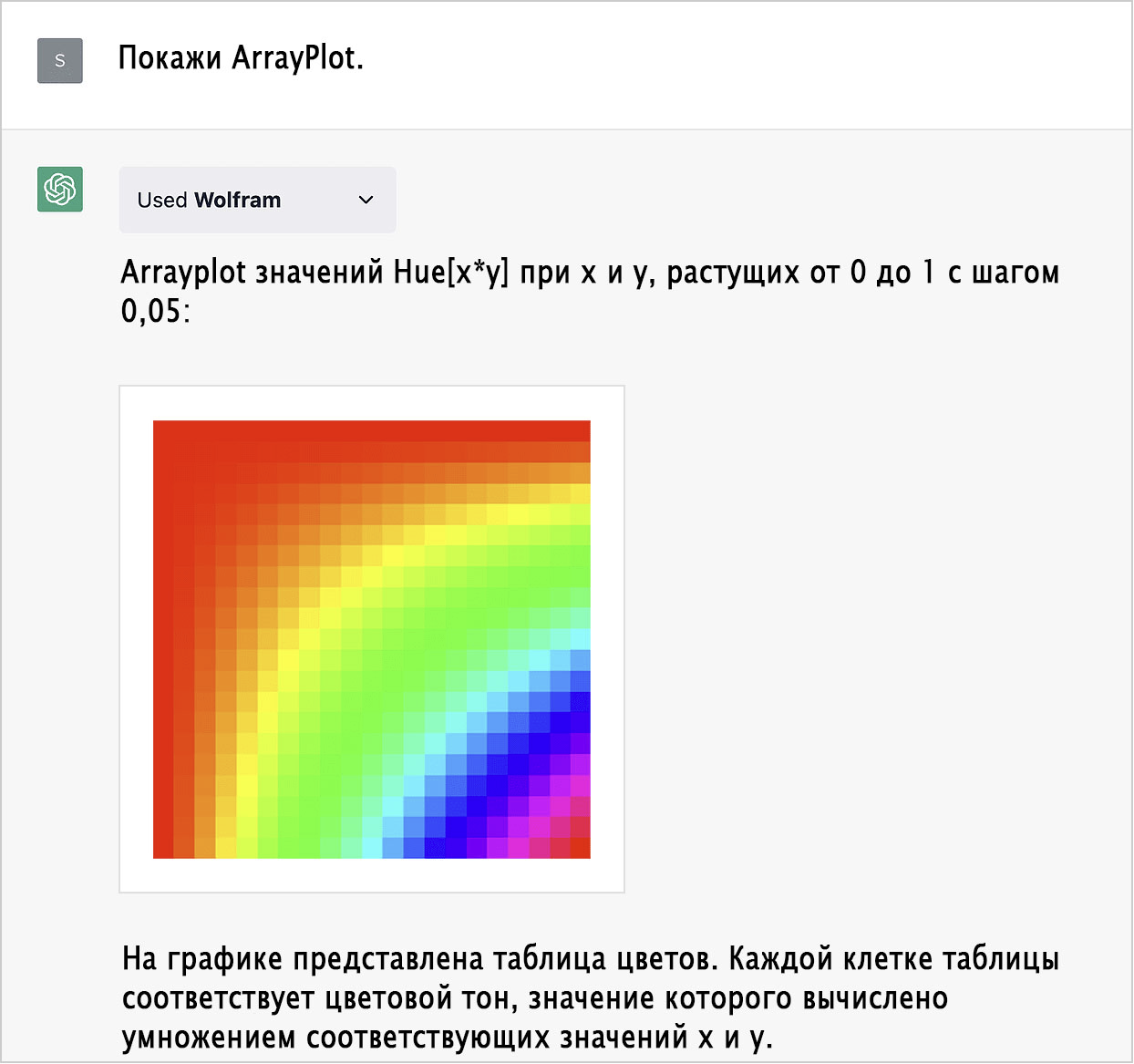
Вот ещё один пример успешного написания кода на Wolfram Language — и ChatGPT рада показать нам, что она действительно вычислила то, что нужно:
Ничего бы не сработало, если бы Wolfram Language не был «автономным». Этот кусочек кода — обычный код на Wolfram Language, написанный независимо от внешних источников. Вы можете прочитать все входящие в Wolfram Language определения в его документации.
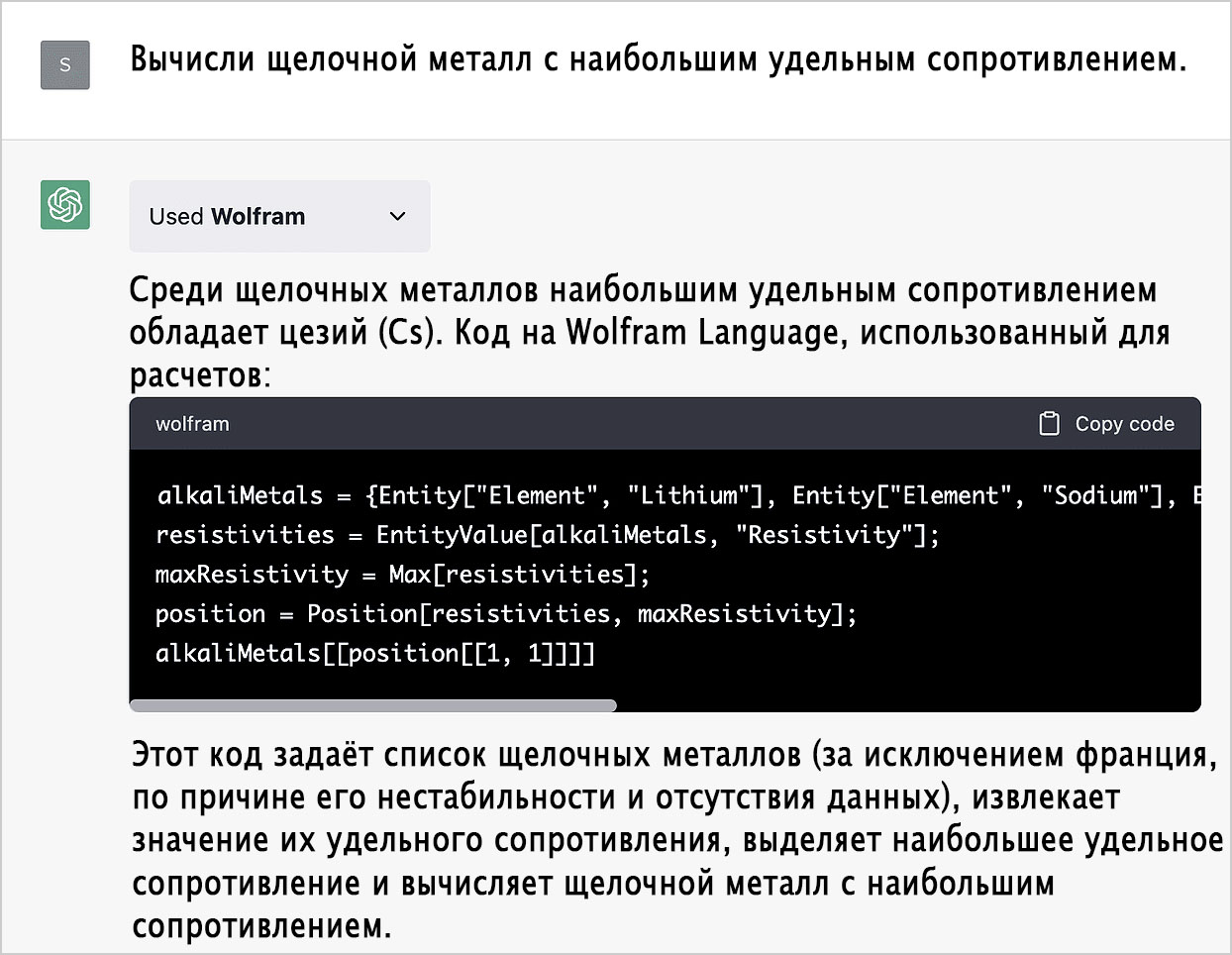
И ещё один пример:

Очевидно, что в этом случае ChatGPT замешкалась. При этом мы можем запустить предложенный ею код прямо в блокноте, и, поскольку Wolfram Language является символьным языком, мы можем чётко проследить каждый шаг:


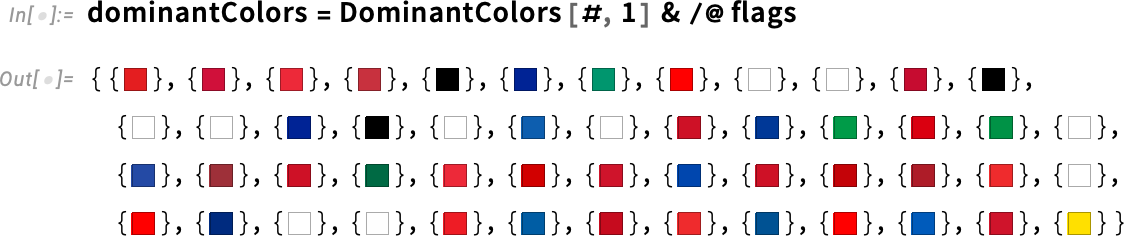



Почти получилось! Давайте немного поможем ChatGPT, объяснив, что нам нужен список европейских стран:

А вот и результат! Ну, хоть какой-то. Как видно из вычислений, мы получили не совсем то, что хотели. К примеру, нам хотелось бы выбрать несколько основных цветов для каждой страны и сравнить их с пурпурным. Структура Wolfram Language позволяет нам легко взаимодействовать с ИИ, чтобы определить, чего мы хотим и как этого достичь.
В общем, в предыдущих примерах мы формулировали запросы на естественном языке и составляли код на Wolfram Language. С тем же успехом мы можем воспользоваться псевдокодом или любым низкоуровневым языком программирования: ChatGPT с удивительной легкостью переводит их в качественный код на Wolfram Language. Он не всегда обходится без ошибок, но пользователь всегда может запустить его (например, с плагином Wolfram) и проверить построчно (спасибо символьной структуре Wolfram Language). Высокоуровневая вычислительная природа Wolfram Language делает код практически прозрачным (во всяком случае, локально) и очень простым для понимания (особенно если проследить за его запуском), так что пользователь без труда может всё исправить совместно с ИИ.
При решении сравнительно простых задач мы вполне можем обозначить условия посредством естественного языка. Wolfram Language при этом служит «всего лишь» для демонстрации вычислений и запуска кода. Чем задача сложнее, тем выше значение Wolfram Language, ведь фактически это единственный существующий способ формулирования понятных человеку, но точных запросов.
Я окончательно понял это, работая над книгой «Основы Wolfram Language». В начале неё я без труда составлял упражнения, в которых писал запросы на английском. По мере усложнения тем обходиться английским становилось всё труднее. Зато, будучи «уверенным носителем» Wolfram Language, я без проблем выражал свои мысли на нём. Когда я пытался выразить всё то же исключительно на английском, выходило нечто невразумительное.
И вот мы пишем что-то на Wolfram Language. Один из самых поразительных навыков ChatGPT заключается в том, что она часто может сделать ваш код более читабельным, хотя (пока) временами и ошибается. В любом случае, за этим очень любопытно наблюдать: её коду и коду, написанному человеком, свойственны разные недостатки. Например, людям часто бывает трудно придумать удачные названия для объектов, из-за чего они стремятся избежать присвоения имён при помощи дополнительных вложенных функций. В то же время ChatGPT, виртуозно владеющая языком и смыслами, довольно легко подбирает подходящие имена. Хотя это стало для меня неожиданностью, использование этих имён и помощь ChatGPT в целом делает код на Wolfram Language ещё проще, похожим на формализованный аналог естественного языка, но более конкретным и пригодным для получения вычислительных результатов.
Атакуем старые проблемы
Если вы «понимаете, какие вычисления хотите выполнить», и можете кратко описать их естественным языком, то Wolfram|Alpha выполнит их напрямую и представит результат в максимально наглядном виде. Но что, если вы хотите получить ответ в форме связного текста, эссе? Wolfram|Alpha не предусматривает такой функции — в отличие от ChatGPT.
Пример вывода Wolfram|Alpha:
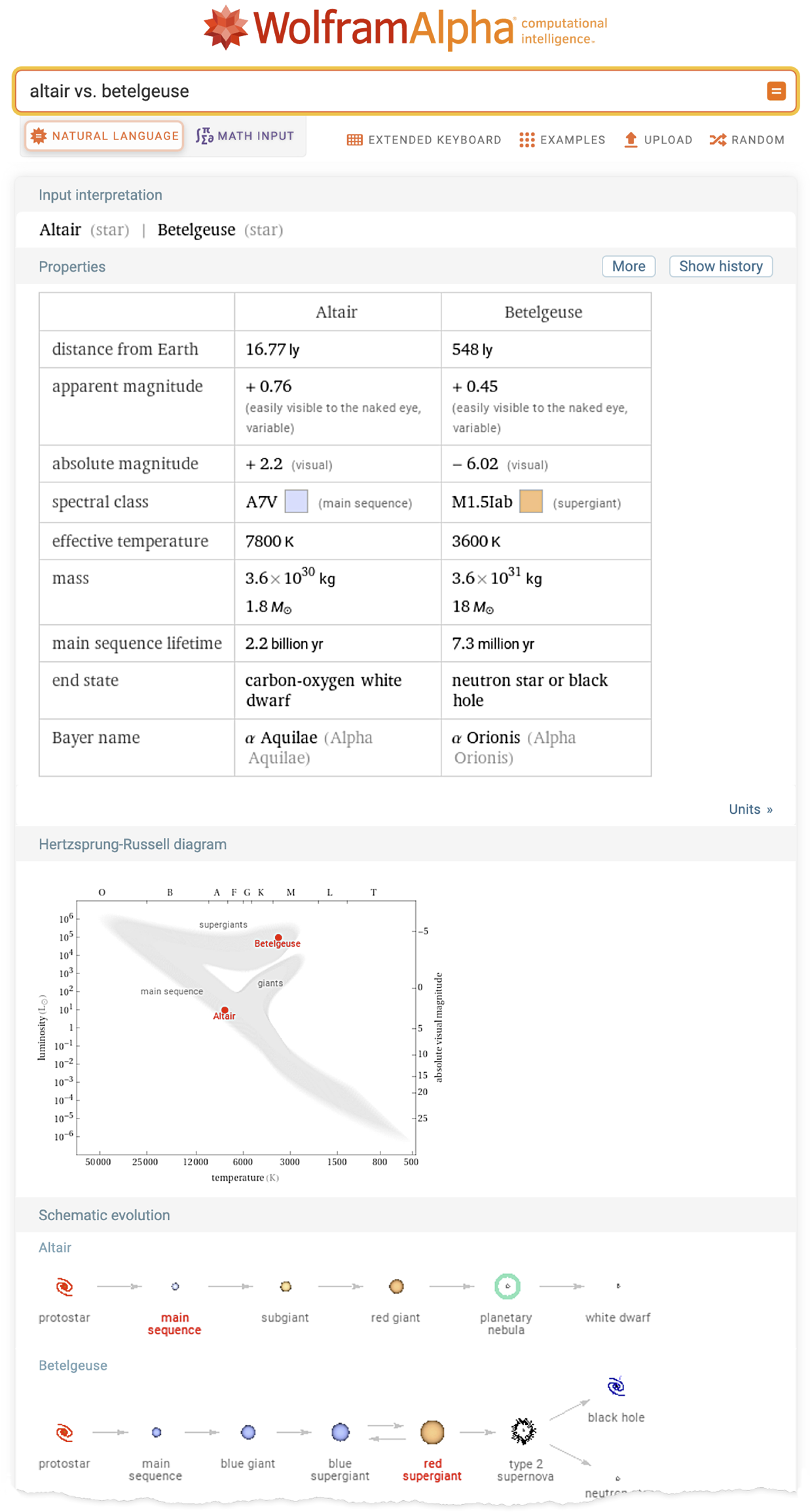
А теперь попросим ChatGPT выдать нам тот же результат из Wolfram|Alpha, но «представить его в форме доклада»:

Ещё один крепкий орешек для Wolfram|Alpha — сюжетные задачи. С краткими и чёткими задачами проблем не возникает, а что насчёт запутанных текстовых заданий? ChatGPT неплохо их «раскрывает», превращая в сухие математические вопросы и делая доступными плагину Wolfram. Пример:

А вот немного более сложная задачка, требующая от ИИ «здравого смысла» — понимания, что число индеек не может быть отрицательным:

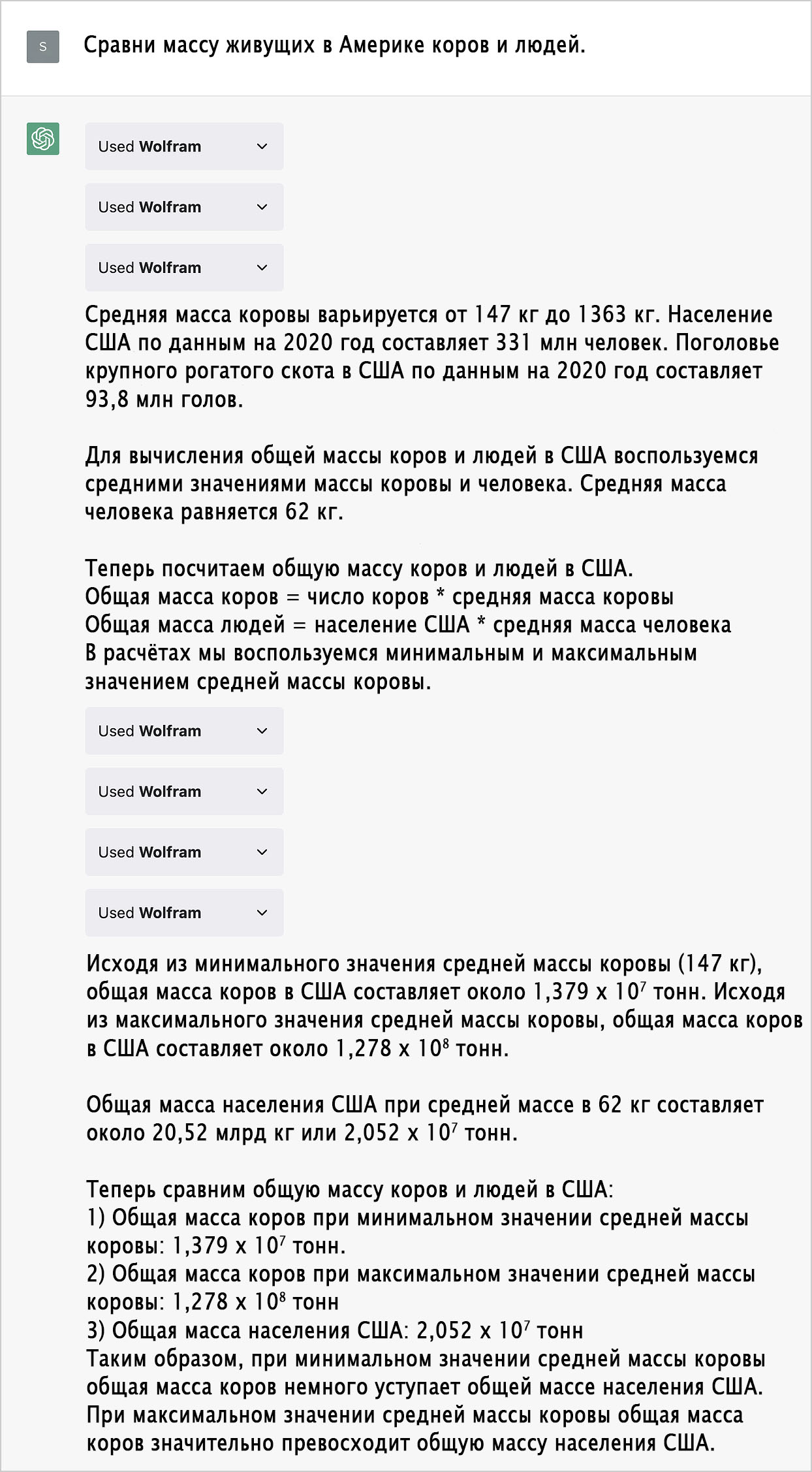
Помимо текстовых задач, дуэт ChatGPT и Wolfram прекрасно щёлкает так называемые «проблемы Ферми»: оценки порядка величины, для которых необходимо задействовать количественные знания о мире. Например:
Как стать частью процесса
ChatGPT + Wolfram — совершенно новая технология, открывающая невероятные доселе горизонты. Некоторые из них уже начинают обретать очертания, других придётся ждать недели, месяцы и годы.
Как же стать частью этого удивительного этапа технологического и концептуального развития? Прежде всего, поработайте с ChatGPT + Wolfram. И ChatGPT, и Wolfram — огромные самостоятельные экосистемы, и прежде чем их связка заработает по-настоящему, пройдёт не один год. Первый шаг — опробовать её и ощутить её перспективы.
Ищите примеры. Делитесь ими. Постарайтесь определить успешные практики. Самое главное — попробуйте выделить рабочие процессы, представляющие особенную ценность. Они могут выглядеть весьма хитроумно, а могут оказаться совсем простыми — такими, что только и остаётся сказать: «ну конечно!»
Как наилучшим образом реализовать рабочий процесс? Для начала мы работаем над определением лучших рабочих процессов. Мы придумываем гибкие способы запуска ChatGPT и других инструментов в рамках Wolfram Language как чисто программным образом, так и через интерфейс блокнота.
А что насчёт стороны ChatGPT? Благодаря крайне открытой архитектуре Wolfram Language пользователь может изменять и добавлять всё, что его душе угодно. Как же сделать это из ChatGPT? Можно, например, попросить ChatGPT включить определённый кусок «исходного» кода на Wolfram Language (желательно, вместе с документацией) и при помощи продемонстрированного выше гибридного языка обсудить с нейросетью функции или другие присутствующие в этом исходном коде темы.
В наших дальнейших планах — создание как можно более гибких инструментов для работы с кодом на Wolfram Language в ChatGPT и его распространения. Один подход уже можно считать рабочим: отправка функций на публикацию в Wolfram Function Repository. Когда функция опубликована, вы можете сослаться на неё в беседе с ChatGPT.
Как лучше написать промт, чтобы использовать возможности плагина Wolfram по максимуму? Мы пока этого не знаем. Этот вопрос только предстоит изучить — по сути, как раздел обучения или психологии искусственного интеллекта. Классический подход: в начале работы скормить ChatGPT некоторое количество «пре-промтов» и надеяться, что она в будущем их «вспомнит». И да, из-за ограниченной концентрации внимания некоторые вещи придётся повторить минимум дважды.
Мы попробовали передать ChatGPT всеобъемлющий промт — инструкцию по пользованию плагином Wolfram, и ожидаем его быстрого развития по мере изучения и обновления нейросети. Вы можете воспользоваться своими пре-промтами вроде: «при использовании Wolfram всегда вставляй в ответ картинку», «пользуйся единицами СИ» или «по возможности, обходись без комплексных чисел».
Можно, например, задать пре-промт с «определением функции» прямо в ChatGPT: «Если вводные данные включают в себя число, всегда рисуй многогранник с соответствующим числом граней в Wolfram». Или более прямую инструкцию: «Если я ввожу ряд чисел, применяй к ним следующую функцию Wolfram…», и за ней фрагмент кода на Wolfram Language.
Технология всё ещё делает самые первые шаги, и, без сомнения, вскоре появятся новые мощные механизмы для «программирования» ChatGPT + Wolfram. Мы можем с уверенностью ожидать в этой сфере бурного развития, сулящего огромные перспективы всем участникам процесса.
Историческая справка и взгляд в будущее
Ещё неделю назад было не до конца понятно, как будет выглядеть связка ChatGPT и Wolfram и насколько хорошо она будет работать. Прогресс идёт семимильными шагами, но в его основе лежат десятилетия исследований. В какой-то мере рождение ChatGPT и Wolfram сливает воедино два ключевых исторических подхода к ИИ, которые долго казались несочетаемыми.
Говоря простым языком, ChatGPT — очень крупная нейросеть, обученная следовать «статистическим» шаблонам прочитанных в сети текстов. Концепция нейросетей зародилась ещё в 1940-х годах, причём описанная в то время модель удивительно похожа на ChatGPT. После кратковременной вспышки интерес схлынул и снова начал возрастать уже в начале восьмидесятых (я и сам впервые обратил внимание на нейросети именно тогда). Настоящее же внимание эта тема и её перспективы привлекла только в районе 2012 года. Сейчас, десятилетие спустя, у нас появилась ChatGPT, и её успехи поражают даже нас самих.
Отдельно от «статистической» традиции формировалась традиция «символьная», возникшая как продолжение процесса формализации математики (и матлогики) примерно в начале XX века. Её ключевое значение состояло в том, что она хорошо согласовывалась не только с абстрактными вычислительными алгоритмами, но и с появившимися в 1950-х реальными цифровыми компьютерами.
Будущее настоящего «искусственного интеллекта» долгое время виделось крайне туманным, но в то же время общие принципы вычислительной науки развивались самыми стремительными темпами. Но как связать «вычисления» с образом наших мыслей? На мой взгляд, важной вехой стала моя теория из восьмидесятых (основанная на более ранней идее математического формализма), согласно которой правила преобразования символьных выражений могут стать удобным способом представления вычислений на «человеческом» уровне.
В то время я сосредоточился в основном на математических и технических вычислениях, но вскоре задумался, не применимы ли схожие принципы к «общему искусственному интеллекту». Я подозревал, что без нейросетей дело не обойдётся, но мои мысли занимало то, что для этого потребуется, а не как именно этого достичь. Между тем, базовая идея применения правил преобразования к символьным выражениям стала основой для будущего Wolfram Language и десятилетий трудов по созданию полнофункционального вычислительного языка, который мы имеем сегодня.
Начиная с 1960-х, исследователи искусственного интеллекта предпринимали попытки разработать систему, которая могла бы «понимать естественный язык», «обладать знаниями» и благодаря этому отвечать на вопросы. Некоторые успешные усилия в этом направлении обрели не столь амбициозное, но полезное применение, хотя в целом успешными их не назовешь. Я же, завершив проведённую в девяностые годы работу по философскому осмыслению фундаментальной науки, захотел создать полнофункциональную «вычислительную экспертную систему», способную развёрнуто отвечать на сформулированные естественным языком вопросы о цифрах и фактах. Возможность создания такой системы не была очевидной, но мы обнаружили, что специальный вычислительный язык и уйма работы способны нам в этом помочь. Уже в 2009 году мы представили Wolfram|Alpha.
В какой-то степени Wolfram|Alpha стала возможной благодаря своей чёткой и формализованной системе отражения реального мира. Для нас «понимание естественного языка» не являлось чем-то абстрактным — это был конкретный процесс по переводу с естественного языка на структурированный вычислительный язык.
Другая сторона работы — сбор данных, методов, моделей и алгоритмов, необходимых для «познания» и «исчисления» мира. Хотя мы в значительной степени автоматизировали этот процесс, быстро стало ясно, что без некоторого вмешательства живых экспертов не обойтись. И пусть система распознавания естественного языка Wolfram|Alpha не слишком смахивает на то, что принято называть «статистическим ИИ», значительная часть Wolfram|Alpha и Wolfram Language действует по чётким законам, достаточно похожим на традиционный символьный ИИ. При этом я не могу сказать, что в отдельных функциях Wolfram Language не применяются машинное обучение и статистические методы — напротив, это происходит всё чаще, а в Wolfram Language для машинного обучения имеется целый встроенный фреймворк.
Как я писал ранее, «статистический искусственный интеллект», а в особенности нейросети, хорошо приспособлен для задач, с которыми «легко справляется» человек. Это же касается, как видно из примера с ChatGPT, естественного языка и сопутствующего ему «мышления». При этом символьный и «более строго приспособленный под вычисления» подход незаменим при более крупных концептуальных или вычислительных операциях, применяемых в математике, точных науках и Computational X (вычислительных областях).
ChatGPT + Wolfram вполне можно считать первой полномасштабной системой, объединяющей в себе черты статистического и символьного ИИ. Wolfram|Alpha, послужившая основой, например, для голосового помощника Siri, была первым инструментом для распознавания естественного языка, причём распознавание это было напрямую связано с вычислениями и их представлением. Сейчас, 13 лет спустя, ChatGPT доказала, что чисто «статистическая» нейросеть, натасканная на текстах в интернете, может успешно справляться со «статистической» генерацией осмысленной, «похожей на человеческую» речи. ChatGPT + Wolfram сочетает в себе полный стек: «статистическую» нейросеть ChatGPT, инструменты распознавания языка через призму вычислений Wolfram|Alpha и всю мощь вычислительного языка и знаний Wolfram Language.
Начиная проектировать Wolfram|Alpha, мы полагали, что пригодных результатов не достичь без диалога с пользователем. Однако выяснилось, что для объёмных и наглядных результатов было достаточно просто задать «параметры» или «предположения» — во всяком случае, для получения данных и выполнения вычислений, которых мы ожидали бы от пользователей. Правда, в Wolfram|Alpha Notebook Edition мы всё-таки добавили пример того, как выполнять многоступенчатые расчёты посредством естественного языка.
В 2010 году мы начали эксперименты по созданию уже не просто кода на Wolfram Language из запросов на естественном языке, но «целых программ». Без сегодняшних LLM-технологий далеко мы не продвинулись, зато выяснили, что в контексте символьной структуры Wolfram Language даже крошечные фрагменты кода, сгенерированного из естественного языка, могут стать большим подспорьем. Так, я пользуюсь механизмом ctrl= в Wolfram Notebooks по сто раз на дню — например, для конструирования символьных структур или числительных из естественного языка. Мы всё ещё не уверены, как будет выглядеть современная, усиленная LLM-версия этого процесса, но она наверняка будет связана с активным взаимодействием человека и машины. Первые примеры этого взаимодействия мы видим в работе ChatGPT + Wolfram.
На мой взгляд, это исторический момент. Больше полувека статистический и символьный подходы к тому, что мы называем искусственным интеллектом, развивались параллельно, а ChatGPT + Wolfram сводит их воедино. Хотя мы и в самом начале этого пути, мы вправе ожидать от этой связки великих свершений. Можно говорить даже о новой парадигме ИИ-вычислений, ставшей возможной благодаря появлению ChatGPT и её взаимодействию с Wolfram|Alpha и Wolfram Language в рамках ChatGPT + Wolfram.



