Привет, Хабр!
На связи Гончик, любитель APM (application performance monitoring) инструментов, в частности Glowroot.
Сегодня расскажу о том, как за кратчайшее время найти узкие места в Confluence On-Prem на основе одной промышленной инсталляции. Поскольку стенд использовался для обучения, где источником базы знаний был Confluence. А осень это пора наплыва пользователей-учеников и необходимо было провести аудит и подготовить изменения, поскольку система уже претерпевала ранее проблемы отдачи своевременно контента пользователям в периоды наплыва читателей.
Конечно, было первым шагом решить проверить ОС параметры и они прям с запасом по ресурсам - ок, и access log обратного прокси nginx, но их не было в связи с директивой access log off. Из полезного подтюнил терминацию ssl, подключил http2. Не стал фокусироваться на нем, поскольку стало ясно, что надо идти в сторону Tomcat (рекомендации вендора).
Далее у меня был один рестарт, где добавил агента Glowroot и пошел смотреть графики (о том как установить писал тут). Далее три разбора на разных уровнях управления и обслуживания приложением, которые мне показались полезным и интересным читателю.
Разбор первый (На старт)
Продолжил с анализа соединения СУБД и Confluence, поскольку Confluence - nginx, работал отлично.
Первым делом Glowroot, показал что на каждый запрос в БД, у нас Confluence делает проверки состояния соединения, следующим образом.

Но это количество равняется 11, и тратится от 0,20 мс до 0,32 мс на каждый запрос. То есть в среднем от 2 до 3 миллисекунд тратим на проверки состояния. И если у нас не будет кэширования на уровне приложения или при инвалидации кэширования то это узкое место.
Далее уточнив о версии субд и версии драйвера посредством данной ссылки {CONFLUENCE_URL}/admin/systeminfo.action появился простор для размышления. Особенно, со старой доброй табличкой по задержкам, так как она мне всегда помогает примерно на глаз определить узкие места.
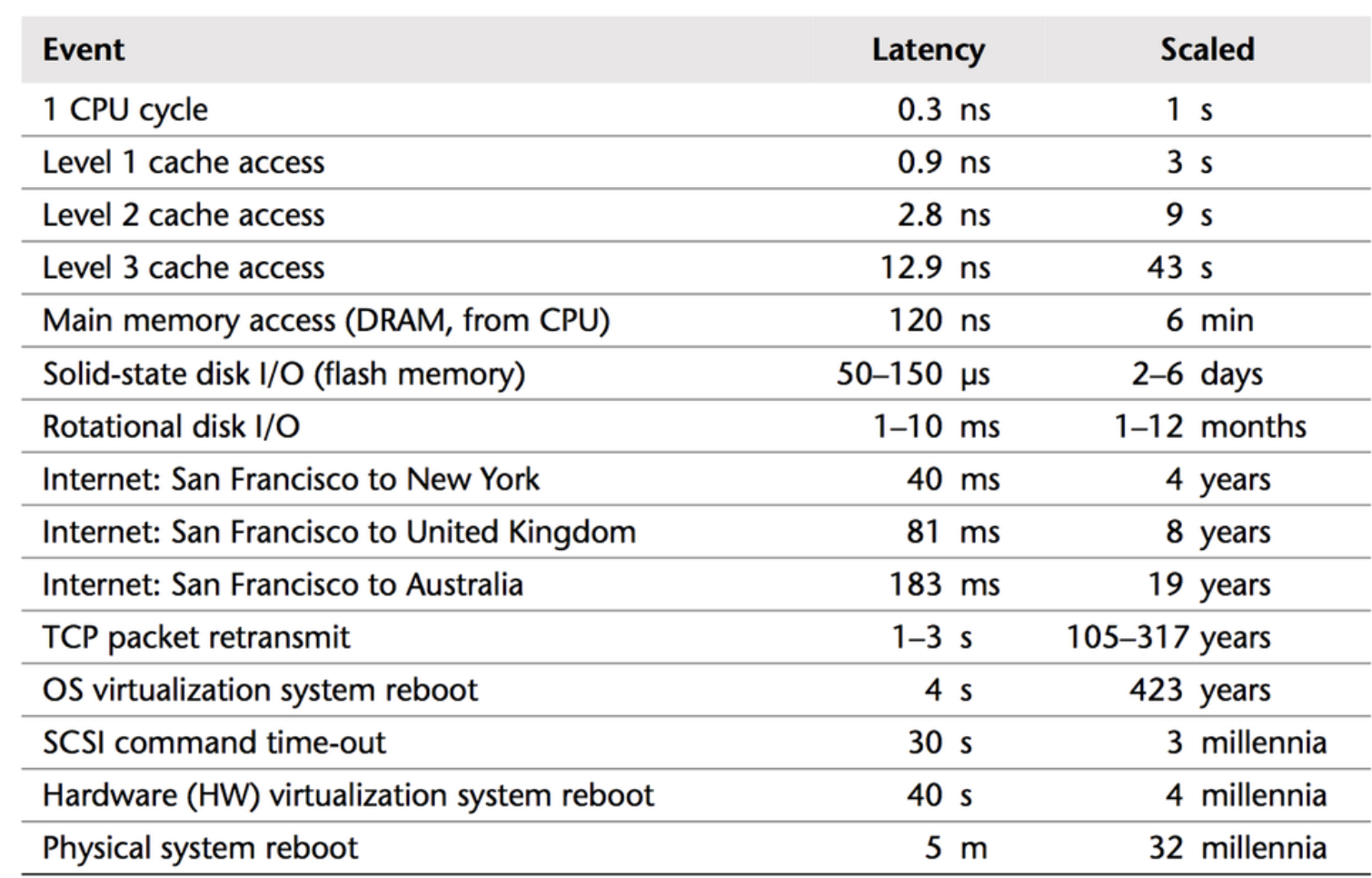
В принципе, вендор Атлассиан активно использует у себя PostgreSQL и видно, в принципе по поддерживаемым СУБД.
А так как у меня использует пока MySQL обновление драйвера традиционно снизило симптомы. Чтобы понять причины, мне помогла статья “После обновления онлайн-базы данных возникает проблема чрезмерного отката транзакций базы данных”. Где решением фактически был переход на другой пуллер (https://github.com/alibaba/druid/wiki/FAQ). А в моем случае, переход на PostgreSQL. (:
Про то как устроен параметр useSessionStatus, можно скачать коннектор и проверить использование метода isReadOnly.
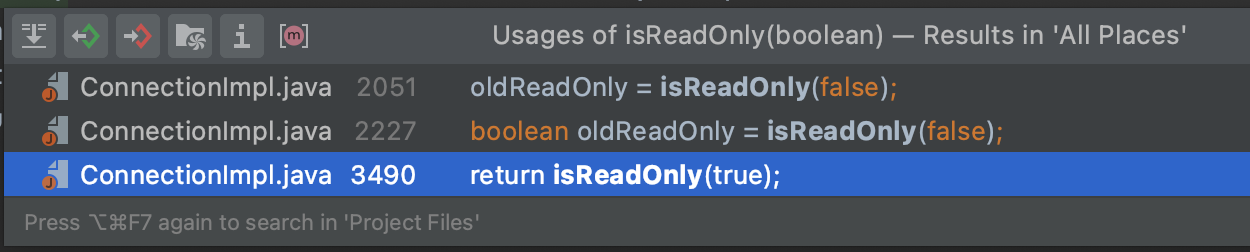
И зависимость версии легко проверить, посмотреть первое условие в методе.

Резюмируя, краткосрочное решение - принятие рисков и обновление драйвера коннектора к СУБД, а долгосрочного решения выбрал переход PostgreSQL 11.
Разбор второй (Внимание)
Часто в анализе, поиск паттернов таких как время жалоб и корреляция с графиками времени ответа приложения всегда помогает, особенно в процентилях, что есть понимание, где видно, что происходит с небольшим объемом запросов.
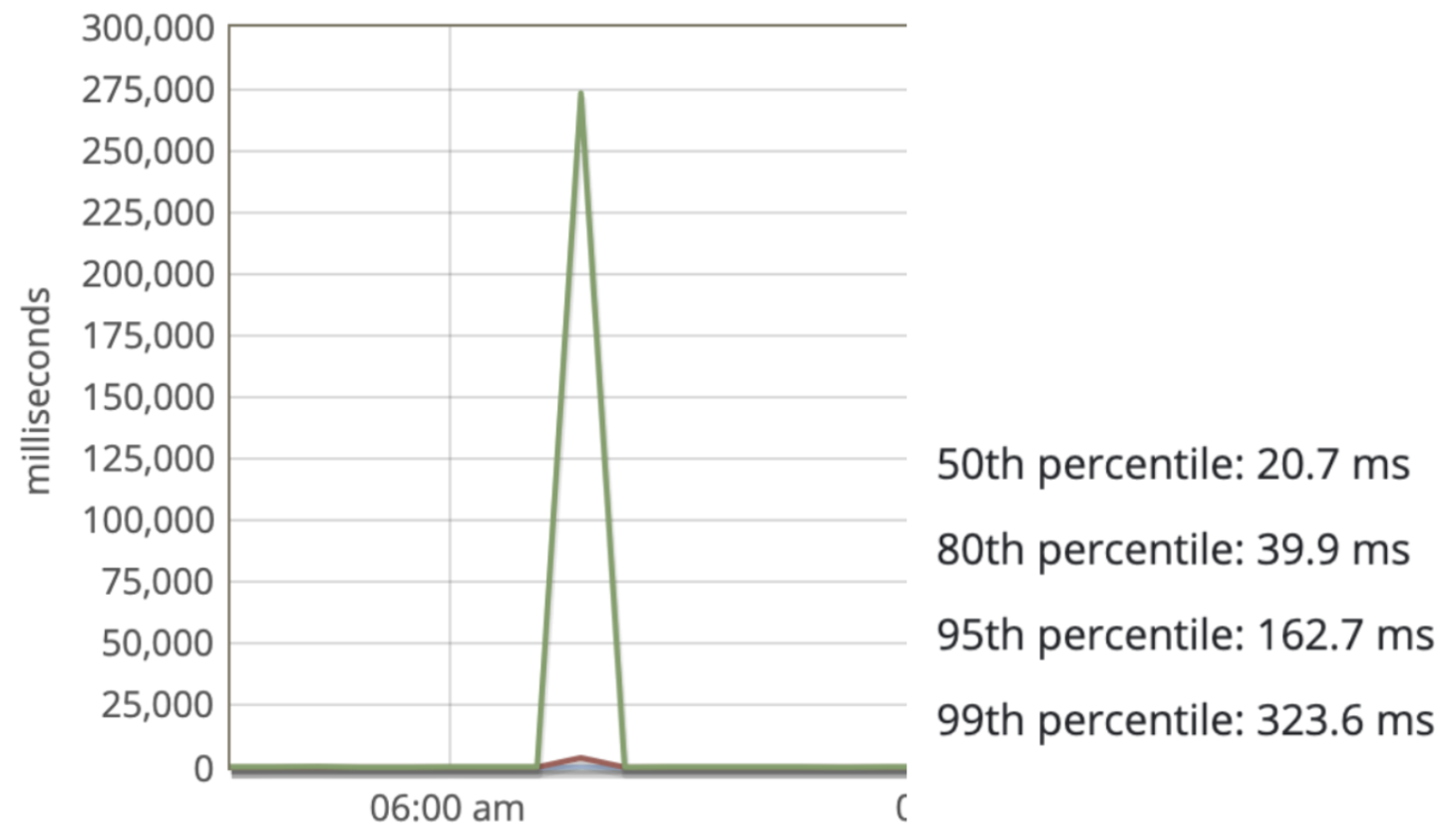
Перейдя в режим slow traces в панели мониторинга Glowroot, можно детальнее посмотреть на поведение системы.
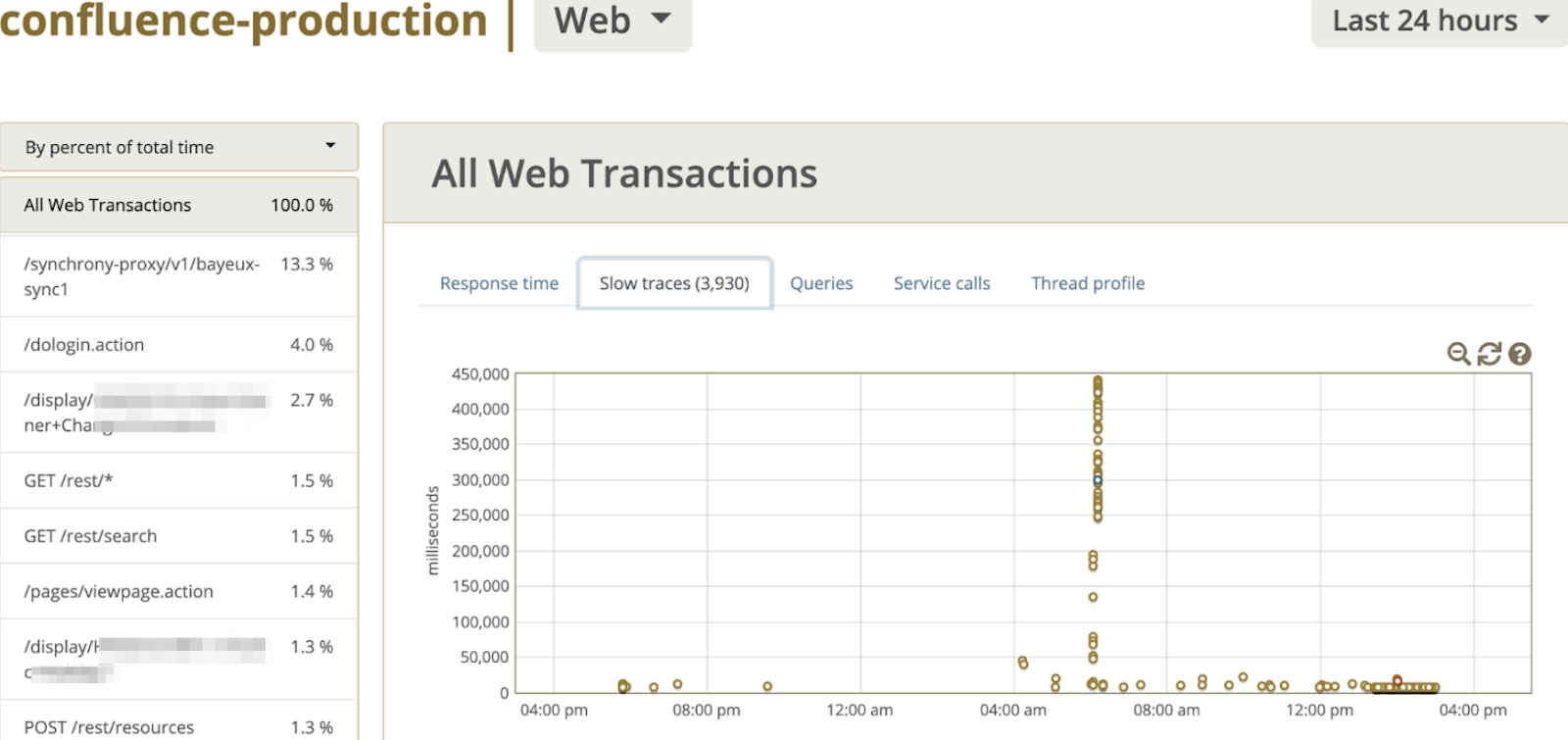
а также на следующий наблюдал следующее поведение.
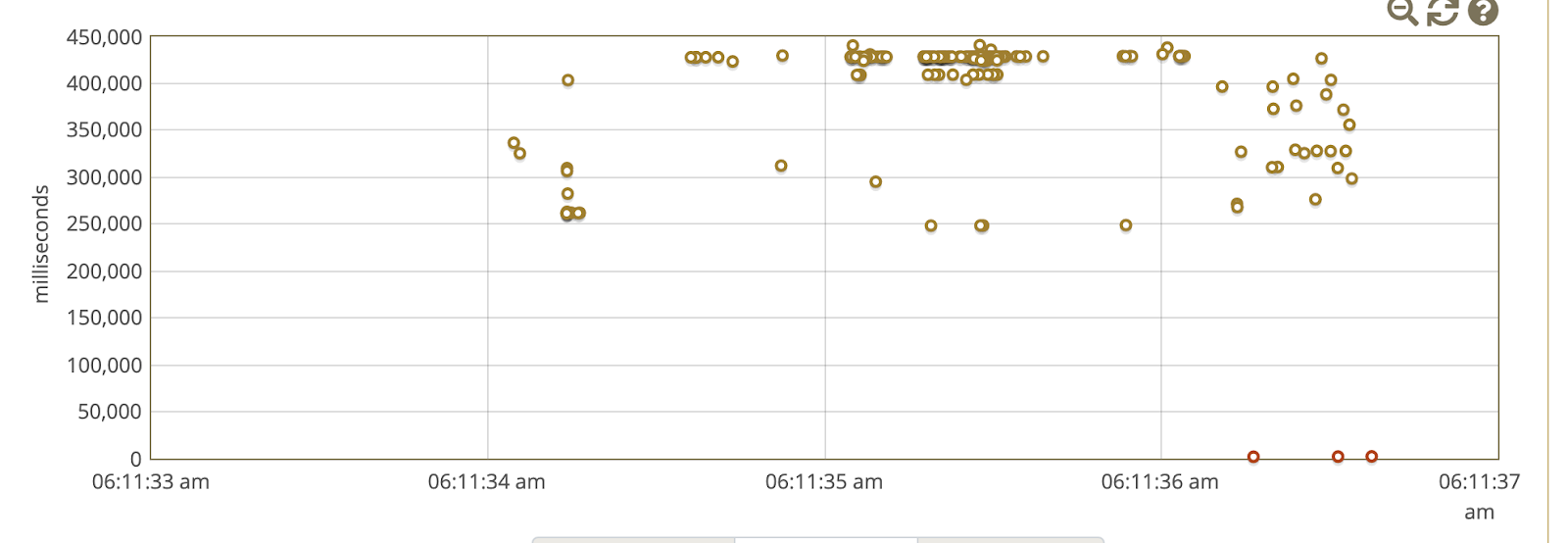
Все это меня натолкнуло на просмотр расписания пакетных операции, например время запуска процесса создания резервных копии.
Первым делом проверил в веб интерфейсе ({CONFLUENCE_URL}/admin/scheduledjobs/viewscheduledjobs.action) и отключил бэкапы в xml на уровне приложения. Так же можно увидеть историю запусков, и в принципе понять, что как раз к 6:30 утра заканчивается.

Но как только зайдя в систему с правами root, проверил crontab, где также увидел что запускается скрипт по резервному копированию с 5 утра и заканчивал около 6:15 утра по времени моего ПК. Так как это классическое узкое место, просто отключение в силу ненадобности. Так как на уровне виртуализации производится резервное копирование раз в час, и СУБД находится на другой сервере, поэтому самое основное это домашняя директория Confluence.
Резюмируя, простые причины всегда надо проверять. Расписание создания бэкапов это первое, что нужно проверить если поведение должно как-то коррелирует с проблемой.
Разбор третий (Марш)
Так как у нас разбор не был закончен именно с работой между СУБД и приложения, то перейдя во вкладку Queries и отсортировав именно по среднему времени выполнения увидел интересный паттерн, который можете увидеть на скриншоте ниже.
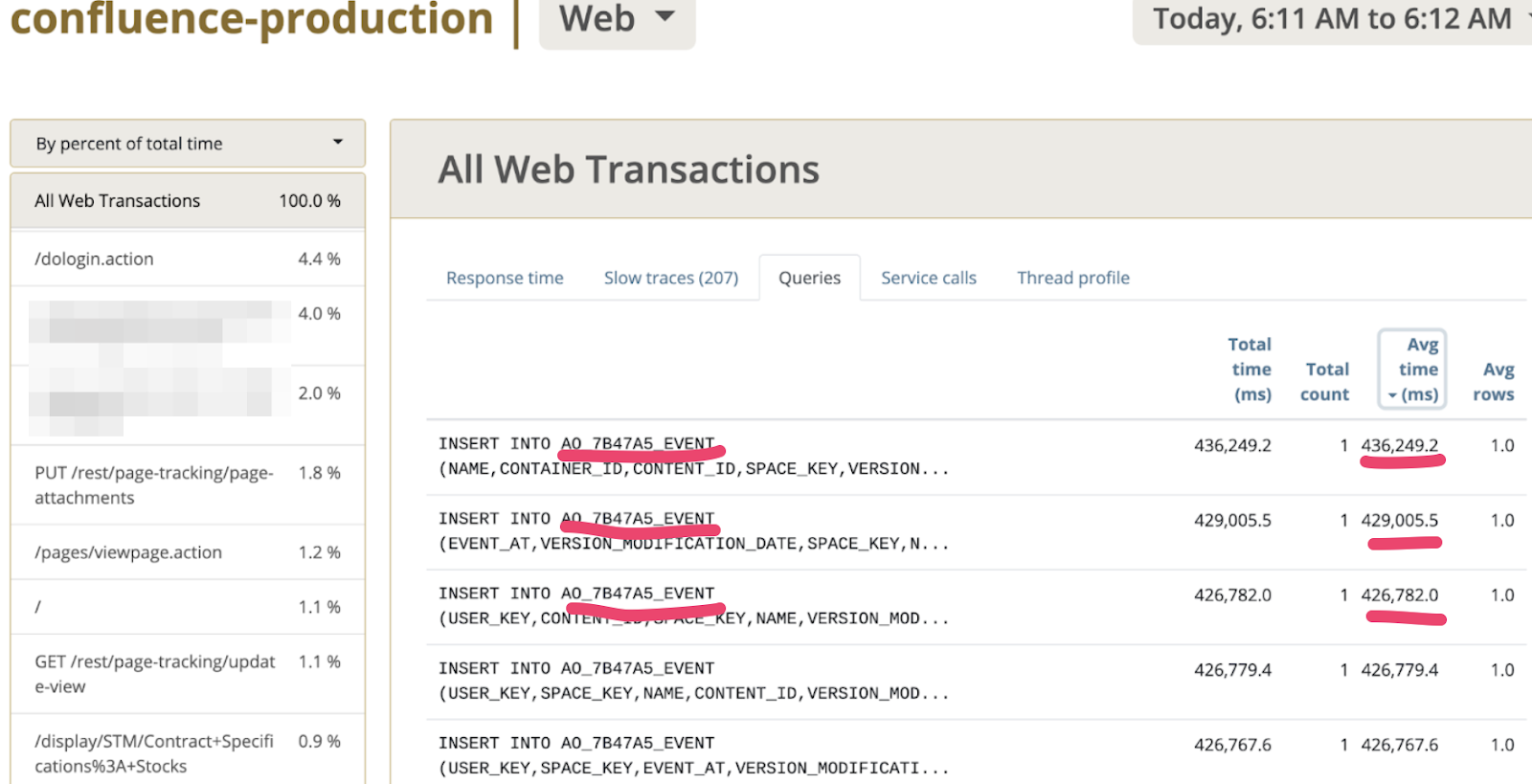
Да, именно в таблицу AO_7B47A5_EVENT эпизодически INSERT проходит медленно, когда большое количество пользователей открывает странички в Confluence. А так как префикс AO_* является индикатором таблиц созданных посредством ORM Active Objects. А как правило это плагины, устанавливаемые в платформу. Тут Гугл быстро навел на следующий тикет https://jira.atlassian.com/browse/CONFSERVER-69474, который указал что виновник приложение Confluence Analytics. Поискав в админке приложении (Managed Apps) находим его, предварительно выставив All Apps в скоупе поиска. Вуаля находим приложение, и еще оно не лицензировано, согласно скриншоту.
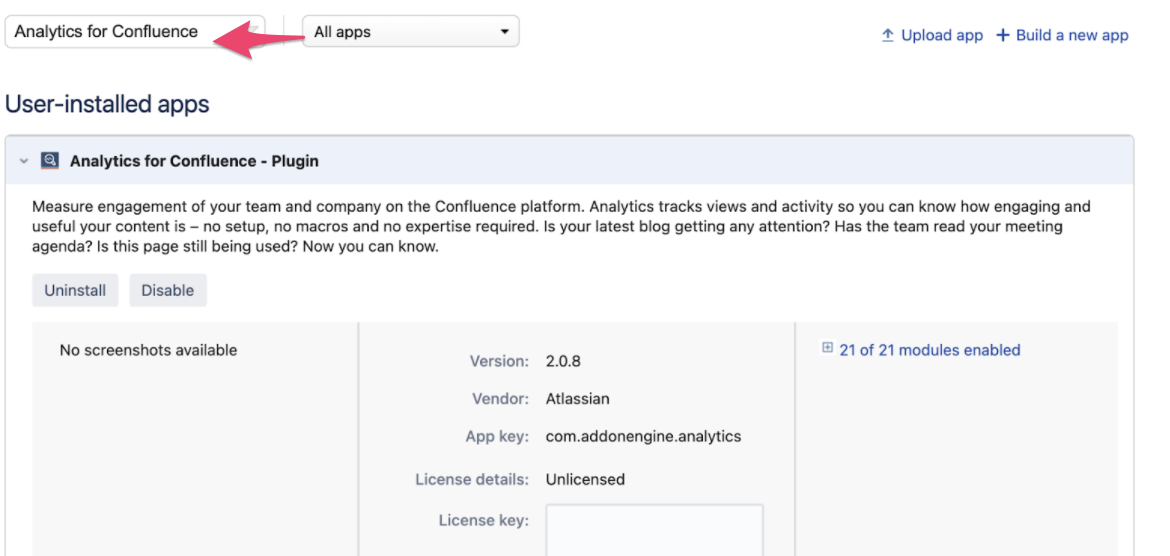
Так как данное не очень приемлемо, отправил запрос вендору о необходимости представлении метрик и предоставлении правил по retention policy логов аналитики в БД, полной асинхронной работы по аналитике. Так как после очистки записей в таблице, отдача контента на глазах ускорилась.
Резюмируя, что важно верифицировать медленные запросы, и смотреть логи медленных запросов (на тот момент не было их для анализа). Поскольку это сильно помогает предоставлять информацию вендорам, чтобы улучшили, например, расширение по аналитике в последней версии Confluence много лучше работает и не так аффектит систему, хотя есть проблема с работой с вложениями.
В качества вывода, основная бизнес метрика именно пользовательское ощущение спало, что подтверждается ответом от бизнес заказчика “Да, жалоб не было”. Но у нас есть, что продолжить делать, так как собрался довольно большой бэклог изменений по улучшению системы.
Спасибо, что прочитали до конца, буду рад если данные ситуации были интересные, то я продолжу делиться подобными историями использования инструментов трассировки и поисков.
Всегда рад Вашим вопросам, а также видеть Вас Телеграм чатике сообщества Atlassian.
Хорошего дня, Гончик.




