
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Несколько недель назад в разговоре за обедом коллега пожаловался на какой-то медленный процесс. Он подсчитал количество сгенерированных байт, количество циклов обработки, и в конечном счёте, объём оперативной памяти. Коллега заявил, что современный GPU с пропускной способностью памяти более 500 ГБ/с съел бы его задачу и не подавился.
Мне показалось, что это интересный подход. Лично я раньше не оценивал задачи производительности с такой стороны. Да, я знаю о разнице в производительности процессора и памяти.

Я знаю, как писать код, который активно использует кэш. Знаю примерые цифры задержки. Но этого недостаточно, чтобы сходу оценить пропускную способность памяти.
Вот мысленный эксперимент. Представьте, что в памяти непрерывный массив из миллиарда 32-разрядных целых чисел. Это 4 гигабайта. Сколько времени займёт перебор этого массива и суммирование значений? Сколько байт в секунду может CPU считать из оперативной памяти? Непрерывных данных? Произвольного доступа? Насколько хорошо можно распараллелить этот процесс?
Вы скажете, что это бесполезные вопросы. Реальные программы слишком сложны, чтобы имел смысл такой наивный ориентир. Так и есть! Реальный ответ — «зависит от ситуации».
Тем не менее, я думаю, что этот вопрос стоит изучить. Я не пытаюсь найти ответ. Но думаю, что мы можем определить некоторые верхние и нижние границы, некоторые интересные точки в середине и что-то узнать в процессе.
Если вы читаете блоги по программированию, то наверняка сталкивались с «цифрами, которые должен знать каждый программист». Они выглядят примерно так:
Источник: Жонас Бонер
Отличный список. Он всплывает на HackerNews как минимум раз в год. Каждый программист должен знать эти цифры.
Но эти цифры о другом. Задержка и пропускная способность не одно и то же.
Тот список составлен в 2012 году, а эта статья 2020 года, времена изменились. Вот цифры для Intel i7 со StackOverflow.
Интересно! Что изменилось?
Не станем делать далекоидущие выводы. Непонятно, как были рассчитаны исходные цифры. Не будем сравнивать яблоки с апельсинами.
Вот некоторые цифры из wikichip по пропускной способности и размеру кэша моего процессора.
Что хочется знать:
Проведём несколько тестов. Для замера пропускной способности я написал простенькую программу на C++. Очень приблизительно она выглядит так.
Некоторые детали опущены. Но вы поняли идею. Создать большой, непрерывный массив элементов. Разделить массив на отдельные фрагменты. Обработать каждый фрагмент в отдельном потоке. Накопить результаты.
Также нужно измерить случайный доступ. Это очень сложно. Я попробовал несколько способов, в итоге решил смешивать предварительно вычисленные индексы. Каждый индекс существует ровно один раз. Затем внутренний цикл перебирает индексы и вычисляет
В расчёте пропускной способности я не рассматриваю память массива индексов. Считаются только байты, которые вносят свой вклад в общую сумму
Проведём тесты с тремя типами данных:
Мой первый тест работает с большим блоком памяти. Блок размером 1 ГБ из
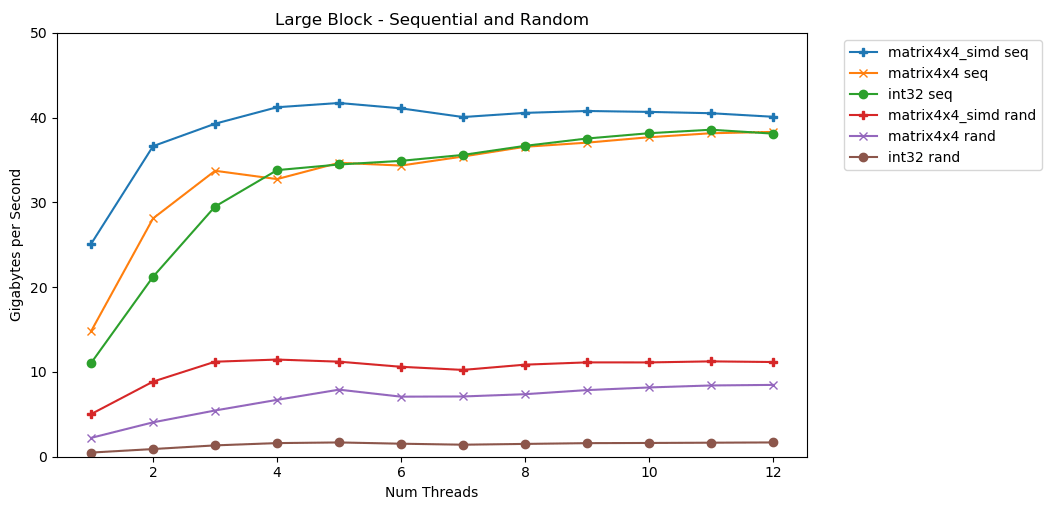
Тада! На этом графике мы берём среднее время выполнения операции суммирования и преобразуем его из
Довольно неплохой результат.
Существует чёткий и очевидный потолок, сколько данных мы можем считывать из оперативной памяти в секунду. На моей системе это примерно 40 ГБ/с. Это соответствует современным спецификациям, перечисленным выше.
Судя по трём нижним графикам, случайный доступ медленный. Очень, очень медленный. Производительность однопоточного
В моей системе размер кэша L1/L2/L3 для каждого потока составляет 32 КБ, 256 КБ и 2 МБ. Что произойдёт, если взять 32-килобайтный блок элементов и перебрать его 125 000 раз? Это 4 ГБ памяти, но мы всегда будем попадать в кэш.
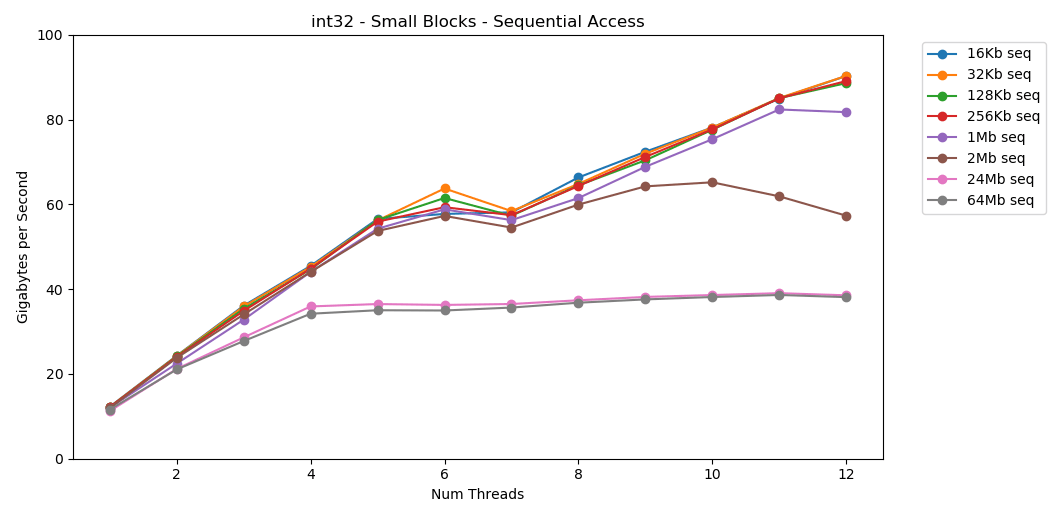
Потрясающе! Однопоточная производительность аналогична чтению большого блока, около 12 ГБ/с. За исключением того, что на этот раз многопоточность пробивает потолок 40 ГБ/с. В этом есть смысл. Данные остаются в кэше, так что узкое место оперативной памяти не проявляется. Для данных, которые не поместились в кэш L3, действует тот же потолок около 38 ГБ/с.
Тест
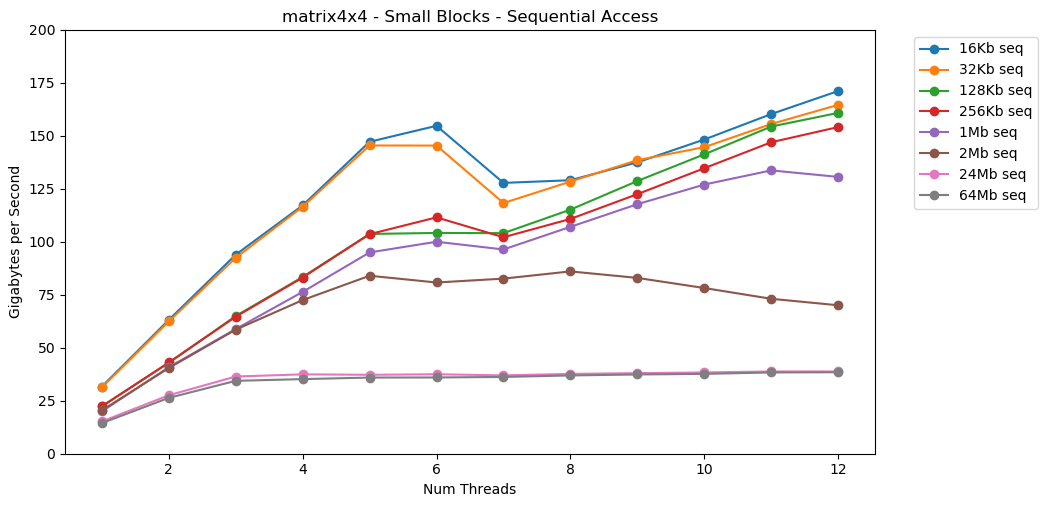
Теперь давайте посмотрим на
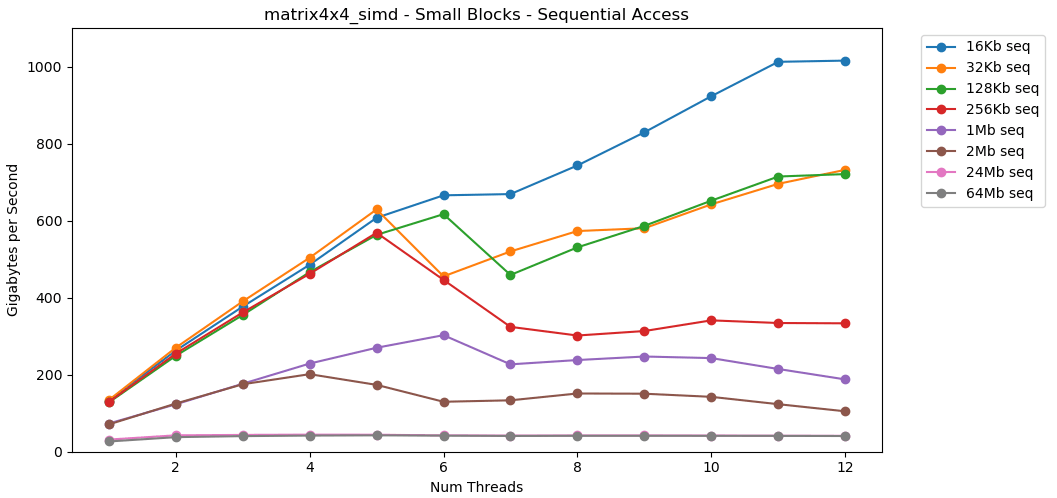
Очевидно, что это поверхностный синтетический тест. Большинство приложений не выполняют одну и ту же операцию с одними и теми же данными миллион раз подряд. Тест не показывает производительность в реальном мире.
Но урок понятен. Внутри кэша данные обрабатываются быстро. С очень высоким потолком при использовании SIMD: более 100 ГБ/с в однопоточном режиме, более 1000 ГБ/с в многопоточном. Запись данных в кэш происходит медленно и с жёстким лимитом около 40 ГБ/с.
Давайте сделаем то же самое, но теперь с произвольным доступом. Это моя любимая часть статьи.
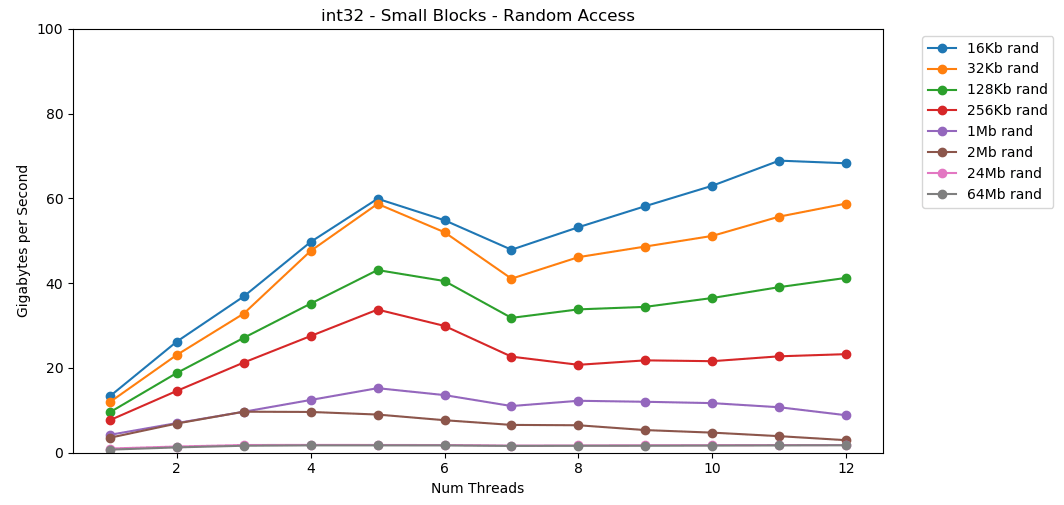
Чтение случайных значений из RAM происходит медленно, всего 0,46 ГБ/с. Чтение случайных значений из кэша L1 очень быстрое: 13 ГБ/с. Это быстрее, чем скорость чтения последовательных данных
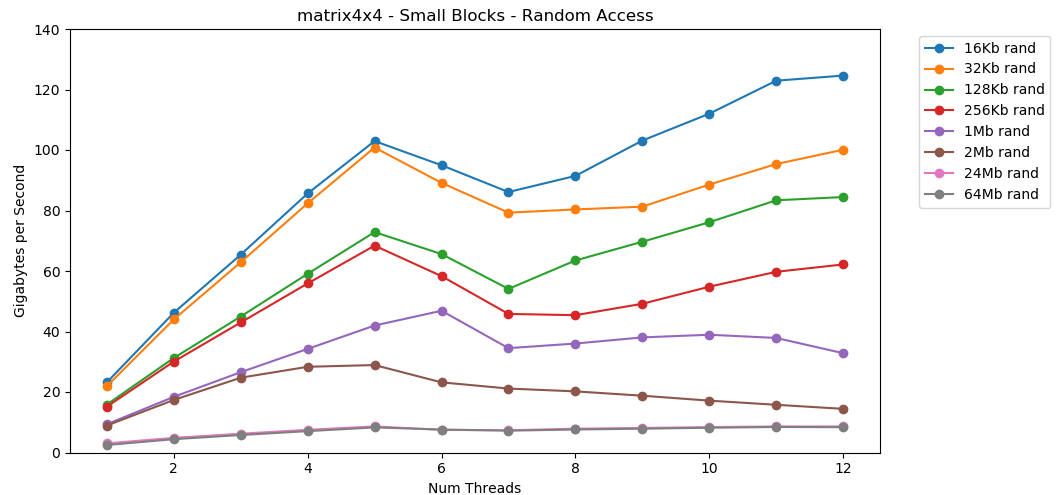
Тест
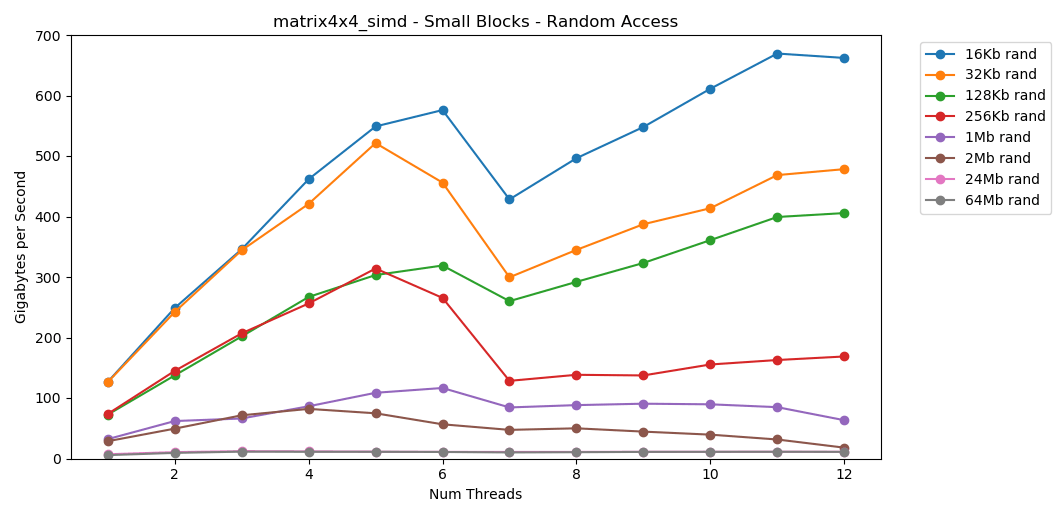
Произвольный доступ
Произвольное чтение из памяти осуществляется медленно. Катастрофически медленно. Менее 1 ГБ/с для обоих вариантов теста
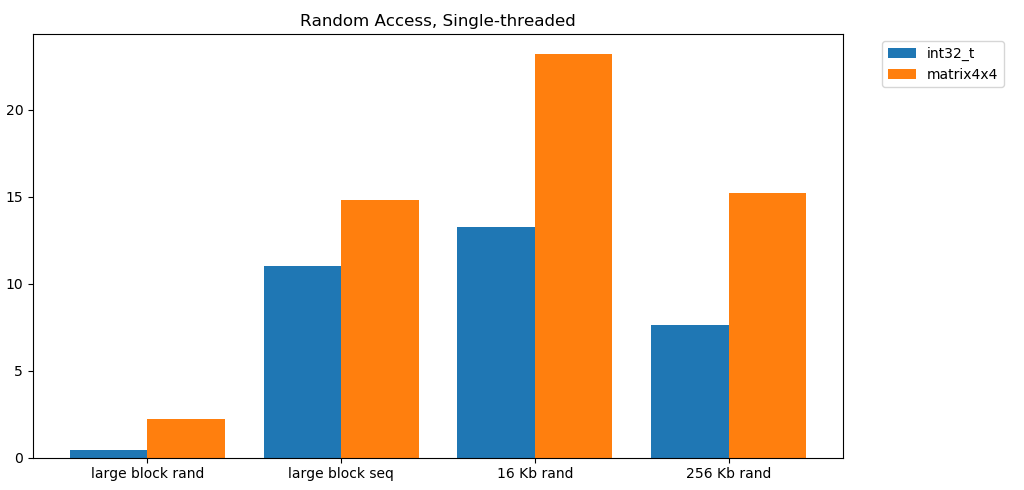
Это нужно переварить. Произвольный доступ к кэшу сопоставим по скорости с последовательным доступом к RAM. Падение от L1 16 КБ до L2 256 КБ всего в два раза или меньше.
Думаю, что это повлечёт глубокие последствия.
Погоня за указателем — это плохо. Очень, очень плохо. Насколько снижается производительность? Смотрите сами. Я сделал дополнительный тест, который обёртывает
Последовательное суммирование значений за указателем выполняется со скоростью менее 1 ГБ/с. Скорость произвольного доступа с двойным пропуском кэша составляет всего 0,1 ГБ/с.
Погоня за указателем замедляет выполнение кода в 10-20 раз. Не позволяйте своим друзьям использовать связанные списки. Пожалуйста, подумайте о кэше.
Для разработчиков игр привычно устанавливать предел (бюджет) нагрузки на CPU и объём памяти. Но я никогда не видел бюджет пропускной способности.
У современных игр FPS продолжает расти. Сейчас он на уровне 60 FPS. VR работает на частоте 90 Гц. У меня игровой монитор на 144 Гц. Это потрясающе, так что 60 FPS кажется дерьмом. Я ни за что не вернусь к старому монитору. У киберспортсменов и стримеров Twitch мониторы 240 Гц. В этом году Asus представила на выставке CES монстра на 360 Гц.
У моего процессора верхний предел около 40 ГБ/с. Это кажется большой цифрой! Однако при частоте 240 Гц получается всего лишь 167 МБ на кадр. Реалистичное приложение может генерировать трафик 5 ГБ/с на частоте 144 Гц, а это всего 69 МБ на кадр.
Вот таблица с несколькими цифрами.
Мне кажется, полезно оценить проблемы с такой стороны. Это позволяет понять, что некоторые идеи неосуществимы. Достигнуть 240 Гц непросто. Это не случится само собой.
Прошлый список устарел. Сейчас его необходимо обновить и привести в соответствие к 2020 году.
Вот несколько цифр для моего домашнего компьютера. Это смесь AIDA64, Sandra и моих бенчмарков. Цифры не дают полной картины и являются лишь отправной точкой.
Хорошо бы создать небольшой, простой опенсорсный бенчмарк. Какой-нибудь файл C, который можно запустить на настольных компьютерах, серверах, мобильных устройствах, консолях и т. д. Но я не тот человек, который напишет такой инструмент.
Измерить пропускную способность памяти сложно. Очень сложно. В моём коде наверняка есть ошибки. Много неучтённых факторов. Если у вас есть некое критическое замечание для моей методики, вероятно, вы правы.
В конечном счёте, я думаю, что это нормально. Это статья не о точной производительности моего десктопа. Речь о постановке проблем с определённой точки зрения. И о том, как научиться выполнять некоторые приблизительные математические расчёты.
Коллега поделился со мной интересным мнением о пропускной способности памяти GPU и производительности приложений. Это подтолкнуло меня к исследованию производительности памяти на современных компьютерах.
Для примерных расчётов вот некоторые цифры для современного десктопа:
Примерные оценки соотносятся с производительностью
Тем не менее, самое важное — это новый способ думать о проблемах. Представление проблемы в виде байтов в секунду или байтов на кадр — ещё одна линза, через которую нужно смотреть. Это полезный инструмент на всякий случай.
Спасибо за чтение.
Бенчмарк C++
График Python
data.json
Эта статья только слегка затронула тему. Вероятно, я не буду углубляться в неё. Но если это сделал, то мог бы охватить некоторые из следующих аспектов:
Тесты проводились на моём домашнем ПК. Только стоковые настройки, никакого разгона.
Мне показалось, что это интересный подход. Лично я раньше не оценивал задачи производительности с такой стороны. Да, я знаю о разнице в производительности процессора и памяти.
Я знаю, как писать код, который активно использует кэш. Знаю примерые цифры задержки. Но этого недостаточно, чтобы сходу оценить пропускную способность памяти.
Вот мысленный эксперимент. Представьте, что в памяти непрерывный массив из миллиарда 32-разрядных целых чисел. Это 4 гигабайта. Сколько времени займёт перебор этого массива и суммирование значений? Сколько байт в секунду может CPU считать из оперативной памяти? Непрерывных данных? Произвольного доступа? Насколько хорошо можно распараллелить этот процесс?
Вы скажете, что это бесполезные вопросы. Реальные программы слишком сложны, чтобы имел смысл такой наивный ориентир. Так и есть! Реальный ответ — «зависит от ситуации».
Тем не менее, я думаю, что этот вопрос стоит изучить. Я не пытаюсь найти ответ. Но думаю, что мы можем определить некоторые верхние и нижние границы, некоторые интересные точки в середине и что-то узнать в процессе.
Цифры, которые должен знать каждый программист
Если вы читаете блоги по программированию, то наверняка сталкивались с «цифрами, которые должен знать каждый программист». Они выглядят примерно так:
Ссылка в кэш L1 0,5 нс Неправильное предсказание 5 нс Ссылка в кэш L2 7 нс 14x к кэшу L1 Захват/освобождение мьютекса 25 нс Ссылка в основную память 100 нс 20x к кэшу L2, 200x к кэшу L1 Сжатие 1000 байт с Zippy 3000 нс 3 мкс Отправка 1000 байт по сети 1 Гбит/с 10 000 нс 10 мкс Случайное чтение 4000 с SSD 150 000 нс 150 мкс ~1ГБ/с SSD Последовательное чтение 1 МБ из памяти 250 000 нс 250 мкс Пакет туда-обратно внутри дата-центра 500 000 нс 500 мкс Последовательное чтение 1 МБ в SSD 1 000 000 нс 1 000 мкс 1 мс ~1ГБ/с SSD, 4х к памяти Поиск на диске 10 000 000 нс 10 000 мкс 10 мс 20x к дата-центру Чтение 1 МБ последовательно с диска 20 000 000 нс 20 000 мкс 20 мс 80x к памяти, 20х к SSD Отправка пакета CA->Нидерланды->CA 150 000 000 нс 150 000 мкс 150 мс
Источник: Жонас Бонер
Отличный список. Он всплывает на HackerNews как минимум раз в год. Каждый программист должен знать эти цифры.
Но эти цифры о другом. Задержка и пропускная способность не одно и то же.
Задержка в 2020 году
Тот список составлен в 2012 году, а эта статья 2020 года, времена изменились. Вот цифры для Intel i7 со StackOverflow.
Попадание в кэш L1, ~4 цикла (2,1 - 1.2 нс) Попадание в кэш L2, ~10 циклов (5,3 - 3,0 нс) Попадание в кэш L3, для одного ядра ~40 циклов (21,4 - 12,0 нс) Попадание в кэш L3, совместно для другого ядра ~65 циклов (34,8 - 19,5 нс) Попадание в кэш L3, с изменением для другого ядра ~75 циклов (40,2 - 22,5 нс) Локальная RAM ~60 нс
Интересно! Что изменилось?
- L1 стал медленнее;
0,5 → 1,5 нс
- L2 быстрее;
7 → 4,2 нс
- Соотношение L1 и L2 намного уменьшилось;
2,5x против 14х(ого!)
- Кэш L3 теперь стал стандартом;
от 12 до 40 нс
- Оперативная память стала быстрее;
100 → 60 нс
Не станем делать далекоидущие выводы. Непонятно, как были рассчитаны исходные цифры. Не будем сравнивать яблоки с апельсинами.
Вот некоторые цифры из wikichip по пропускной способности и размеру кэша моего процессора.
Пропускная способность памяти: 39,74 гигабайта в секунду Кэш L1: 192 килобайта (32 КБ на ядро) Кэш L2: 1,5 мегабайта (256 КБ на ядро) Кэш L3: 12 мегабайт (общий; 2 МБ на ядро)
Что хочется знать:
- Верхний предел производительности RAM
- Нижний предел
- Лимиты кэшей L1/L2/L3
Наивный бенчмаркинг
Проведём несколько тестов. Для замера пропускной способности я написал простенькую программу на C++. Очень приблизительно она выглядит так.
// Generate random elements
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i) // one billion ints
nums.push_back(rng() % 1024); // small nums to prevent overflow
// Run test with 1 to 12 threads
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
// for-each thread
for (size_t thread = 0; thread < thread_count; ++thread) {
// partition data
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
// spawn threads
futures.push_back(std::async([begin, end] {
// sum ints sequentially
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
// combine results
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}Некоторые детали опущены. Но вы поняли идею. Создать большой, непрерывный массив элементов. Разделить массив на отдельные фрагменты. Обработать каждый фрагмент в отдельном потоке. Накопить результаты.
Также нужно измерить случайный доступ. Это очень сложно. Я попробовал несколько способов, в итоге решил смешивать предварительно вычисленные индексы. Каждый индекс существует ровно один раз. Затем внутренний цикл перебирает индексы и вычисляет
sum += nums[index].std::vector<int> nums = /* ... */;
std::vector<uint32_t> indices = /* shuffled */;
// random access
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;В расчёте пропускной способности я не рассматриваю память массива индексов. Считаются только байты, которые вносят свой вклад в общую сумму
sum. Я не делаю бенчмарки своего железа, а оцениваю способность работать с наборами данных разных размеров и с разными схемами доступа.Проведём тесты с тремя типами данных:
int — основное 32-разрядное целое числоmatri4x4 — содержит int[16]; помещается в 64-байтовую строку кэшаmatrix4x4_simd — использует встроенные средства __m256iБольшой блок
Мой первый тест работает с большим блоком памяти. Блок размером 1 ГБ из
N элементов выделяется и заполняется небольшими случайными значениями. Простой цикл перебирает массив N раз, поэтому он обращается к памяти объёмом N ГБ для вычисления суммы int64_t. Несколько потоков разбивают массив, а каждый получает доступ к одинаковому количеству элементов.Тада! На этом графике мы берём среднее время выполнения операции суммирования и преобразуем его из
runtime_in_nanoseconds в gigabytes_per_second.Довольно неплохой результат.
int32 может последовательно считывать в одном потоке 11 ГБ/с. Он масштабируется линейно, пока не достигнет 38 ГБ/с. Тесты matrix4x4 и matrix4x4_simd быстрее, но упираются в тот же потолок. Существует чёткий и очевидный потолок, сколько данных мы можем считывать из оперативной памяти в секунду. На моей системе это примерно 40 ГБ/с. Это соответствует современным спецификациям, перечисленным выше.
Судя по трём нижним графикам, случайный доступ медленный. Очень, очень медленный. Производительность однопоточного
int32 составляет ничтожные 0,46 ГБ/с. Это в 24 раза медленнее, чем последовательное суммирование на скорости 11,03 ГБ/с! Тест matrix4x4 показывает лучший результат, потому что выполняется на полных кэш-линиях. Но он по-прежнему в четыре-семь раз медленнее, чем последовательный доступ, и достигает пика на уровне всего 8 ГБ/с.Малый блок: последовательное чтение
В моей системе размер кэша L1/L2/L3 для каждого потока составляет 32 КБ, 256 КБ и 2 МБ. Что произойдёт, если взять 32-килобайтный блок элементов и перебрать его 125 000 раз? Это 4 ГБ памяти, но мы всегда будем попадать в кэш.
Потрясающе! Однопоточная производительность аналогична чтению большого блока, около 12 ГБ/с. За исключением того, что на этот раз многопоточность пробивает потолок 40 ГБ/с. В этом есть смысл. Данные остаются в кэше, так что узкое место оперативной памяти не проявляется. Для данных, которые не поместились в кэш L3, действует тот же потолок около 38 ГБ/с.
Тест
matrix4x4 показывает аналогичные результаты схеме, но ещё быстрее; 31 ГБ/с в однопоточном режиме, 171 ГБ/с в многопоточном.Теперь давайте посмотрим на
matrix4x4_simd. Обратите внимание на ось y.matrix4x4_simd выполняется исключительно быстро. Он в 10 раз быстрее, чем int32. На блоке 16 КБ он даже пробивает 1000 ГБ/с!Очевидно, что это поверхностный синтетический тест. Большинство приложений не выполняют одну и ту же операцию с одними и теми же данными миллион раз подряд. Тест не показывает производительность в реальном мире.
Но урок понятен. Внутри кэша данные обрабатываются быстро. С очень высоким потолком при использовании SIMD: более 100 ГБ/с в однопоточном режиме, более 1000 ГБ/с в многопоточном. Запись данных в кэш происходит медленно и с жёстким лимитом около 40 ГБ/с.
Малый блок: случайное чтение
Давайте сделаем то же самое, но теперь с произвольным доступом. Это моя любимая часть статьи.
Чтение случайных значений из RAM происходит медленно, всего 0,46 ГБ/с. Чтение случайных значений из кэша L1 очень быстрое: 13 ГБ/с. Это быстрее, чем скорость чтения последовательных данных
int32 из RAM (11 ГБ/с). Тест
matrix4x4 показывает аналогичный результат по тому же шаблону, но примерно вдвое быстрее, чем int.Произвольный доступ
matrix4x4_simd безумно быстр.Выводы по произвольному доступу
Произвольное чтение из памяти осуществляется медленно. Катастрофически медленно. Менее 1 ГБ/с для обоих вариантов теста
int32. В то же время произвольное чтение из кэша на удивление быстрое. Оно сравнимо с последовательным чтением из оперативной памяти.Это нужно переварить. Произвольный доступ к кэшу сопоставим по скорости с последовательным доступом к RAM. Падение от L1 16 КБ до L2 256 КБ всего в два раза или меньше.
Думаю, что это повлечёт глубокие последствия.
Связанные списки считаются вредными
Погоня за указателем — это плохо. Очень, очень плохо. Насколько снижается производительность? Смотрите сами. Я сделал дополнительный тест, который обёртывает
matrix4x4 в std::unique_ptr. Каждый доступ проходит через указатель. Вот ужасный, просто катастрофический результат.
1 поток | matrix4x4 | unique_ptr | diff |
--------------------|---------------|------------|--------|
Large Block - Seq | 14,8 ГБ/с | 0,8 ГБ/с | 19x |
16 KB - Seq | 31,6 ГБ/с | 2,2 ГБ/с | 14x |
256 KB - Seq | 22,2 ГБ/с | 1,9 ГБ/с | 12x |
Large Block - Rand | 2,2 ГБ/с | 0,1 ГБ/с | 22x |
16 KB - Rand | 23,2 ГБ/с | 1,7 ГБ/с | 14x |
256 KB - Rand | 15,2 ГБ/с | 0,8 ГБ/с | 19x |
6 потоков | matrix4x4 | unique_ptr | diff |
--------------------|---------------|------------|--------|
Large Block - Seq | 34,4 ГБ/с | 2,5 ГБ/с | 14x |
16 KB - Seq | 154,8 ГБ/с | 8,0 ГБ/с | 19x |
256 KB - Seq | 111,6 ГБ/с | 5,7 ГБ/с | 20x |
Large Block - Rand | 7,1 ГБ/с | 0,4 ГБ/с | 18x |
16 KB - Rand | 95,0 ГБ/с | 7,8 ГБ/с | 12x |
256 KB - Rand | 58,3 ГБ/с | 1,6 ГБ/с | 36x |Последовательное суммирование значений за указателем выполняется со скоростью менее 1 ГБ/с. Скорость произвольного доступа с двойным пропуском кэша составляет всего 0,1 ГБ/с.
Погоня за указателем замедляет выполнение кода в 10-20 раз. Не позволяйте своим друзьям использовать связанные списки. Пожалуйста, подумайте о кэше.
Оценка бюджета для фреймов
Для разработчиков игр привычно устанавливать предел (бюджет) нагрузки на CPU и объём памяти. Но я никогда не видел бюджет пропускной способности.
У современных игр FPS продолжает расти. Сейчас он на уровне 60 FPS. VR работает на частоте 90 Гц. У меня игровой монитор на 144 Гц. Это потрясающе, так что 60 FPS кажется дерьмом. Я ни за что не вернусь к старому монитору. У киберспортсменов и стримеров Twitch мониторы 240 Гц. В этом году Asus представила на выставке CES монстра на 360 Гц.
У моего процессора верхний предел около 40 ГБ/с. Это кажется большой цифрой! Однако при частоте 240 Гц получается всего лишь 167 МБ на кадр. Реалистичное приложение может генерировать трафик 5 ГБ/с на частоте 144 Гц, а это всего 69 МБ на кадр.
Вот таблица с несколькими цифрами.
| 1 | 10 | 30 | 60 | 90 | 144 | 240 | 360 |
--------|-------|--------|--------|--------|--------|--------|--------|--------|
40 ГБ/s | 40 ГБ | 4 ГБ | 1.3 ГБ | 667 МБ | 444 МБ | 278 МБ | 167 МБ | 111 МБ |
10 ГБ/s | 10 ГБ | 1 ГБ | 333 МБ | 166 МБ | 111 МБ | 69 МБ | 42 МБ | 28 МБ |
1 ГБ/s | 1 ГБ | 100 МБ | 33 МБ | 17 МБ | 11 МБ | 7 МБ | 4 МБ | 3 МБ |
Мне кажется, полезно оценить проблемы с такой стороны. Это позволяет понять, что некоторые идеи неосуществимы. Достигнуть 240 Гц непросто. Это не случится само собой.
Числа, которые должен знать каждый программист (2020)
Прошлый список устарел. Сейчас его необходимо обновить и привести в соответствие к 2020 году.
Вот несколько цифр для моего домашнего компьютера. Это смесь AIDA64, Sandra и моих бенчмарков. Цифры не дают полной картины и являются лишь отправной точкой.
Задержка L1: 1 нс Задержка L2: 2,5 нс Задержка L3: 10 нс Задержка RAM: 50 нс (на один поток) Полоса L1: 210 ГБ/с Полоса L2: 80 ГБ/с Полоса L3: 60 ГБ/с (вся система) Полоса RAM: 45 ГБ/с
Хорошо бы создать небольшой, простой опенсорсный бенчмарк. Какой-нибудь файл C, который можно запустить на настольных компьютерах, серверах, мобильных устройствах, консолях и т. д. Но я не тот человек, который напишет такой инструмент.
Отказ от ответственности
Измерить пропускную способность памяти сложно. Очень сложно. В моём коде наверняка есть ошибки. Много неучтённых факторов. Если у вас есть некое критическое замечание для моей методики, вероятно, вы правы.
В конечном счёте, я думаю, что это нормально. Это статья не о точной производительности моего десктопа. Речь о постановке проблем с определённой точки зрения. И о том, как научиться выполнять некоторые приблизительные математические расчёты.
Вывод
Коллега поделился со мной интересным мнением о пропускной способности памяти GPU и производительности приложений. Это подтолкнуло меня к исследованию производительности памяти на современных компьютерах.
Для примерных расчётов вот некоторые цифры для современного десктопа:
- Производительность RAM
- Максимум:
45 ГБ/с - В среднем, примерно:
5 ГБ/с - Минимум:
1 ГБ/с
- Максимум:
- Производительность кэша L1/L2/L3 (на ядро)
- Максимум (c simd):
210 ГБ/с/80 ГБ/с/60 ГБ/с - В среднем, примерно:
25 ГБ/с/15 ГБ/с/9 ГБ/с - Минимум:
13 ГБ/с/8 ГБ/с/3,5 ГБ/с
- Максимум (c simd):
Примерные оценки соотносятся с производительностью
matrix4x4. Реальный код никогда не будет таким простым. Но для расчётов на салфетке это разумная отправная точка. Вам нужно скорректировать эту цифру исходя из шаблонов доступа к памяти в вашей программе, характеристик вашего оборудования и кода.Тем не менее, самое важное — это новый способ думать о проблемах. Представление проблемы в виде байтов в секунду или байтов на кадр — ещё одна линза, через которую нужно смотреть. Это полезный инструмент на всякий случай.
Спасибо за чтение.
Исходный код
Бенчмарк C++
График Python
data.json
Дальнейшие исследования
Эта статья только слегка затронула тему. Вероятно, я не буду углубляться в неё. Но если это сделал, то мог бы охватить некоторые из следующих аспектов:
- Производительность записи
- Ложное совместное использование (false sharing)
- Производительность
std::atomic(или её отсутствие)
- Счётчики производительности
- Производительность TLB
- Протоколы кэша
Спецификации системы
Тесты проводились на моём домашнем ПК. Только стоковые настройки, никакого разгона.
- ОС: Windows 10 v1903 build 18362
- CPU: Intel i7-8700k @ 3,70 ГГц
- RAM: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 @ 1600 МГц)
- Материнская плата: Asus TUF Z370-Plus Gaming




