
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Хотели бы вы добавить в JVM какую-нибудь полезную фичу? Теоретически каждый разработчик может внести свой вклад в OpenJDK, однако на практике любые нетривиальные изменения в HotSpot принимают со стороны не очень-то охотно, и даже с текущим укороченным релизным циклом могут пройти годы, прежде чем вашу фичу увидят пользователи JDK.
Тем не менее, в ряде случаев расширить функциональность виртуальной машины реально, даже не трогая её код. В этом помогает JVM Tool Interface — стандартный API для взаимодействия с JVM.
В статье я на конкретных примерах покажу, что можно сделать с его помощью, расскажу, что изменилось в Java 9 и 11, и честно предупрежу о сложностях (спойлер: придётся иметь дело с C++).
Этот материал я также рассказывал на JPoint. Если вам удобнее видео, то можете посмотреть видеозапись доклада.
Вступление
Социальная сеть «Одноклассники», где я работаю ведущим инженером, практически полностью написана на Java. Но сегодня я расскажу как раз про другую часть, которая не совсем на Java.
Как известно, самая популярная проблема у Java-разработчиков — NullPointerException. Однажды во время дежурства по порталу я тоже наткнулся на NPE в продакшене. Ошибка сопровождалась примерно таким стек-трейсом:

Разумеется, по стек-трейсу можно проследить место возникновения исключения вплоть до конкретной строчки в коде. Только в данном случае мне легче от этого не стало, потому что здесь NPE может встретиться много где:

Было бы здорово, если бы JVM подсказала, где именно эта ошибка, например, так:
java.lang.NullPointerException: Called 'getUsers()' method on null objectНо, к сожалению, сейчас NPE ничего подобного не содержит. Хотя просят об этом давно, как минимум с Java 1.4: вот этому багу уже 16 лет. Периодически открывались всё новые и новые баги на эту тему, но их неизменно закрывали как «Won't Fix»:

Так происходит не везде. Фолькер Симонис из SAP рассказывал, как у них в SAP JVM эта фича давно реализована и не раз выручала. Другой сотрудник SAP в очередной раз засабмиттил баг в OpenJDK и вызвался реализовать механизм, подобный тому, что есть в SAP JVM. И, о чудо, на этот раз баг не закрыли — есть шанс, что эта фича войдёт-таки в JDK 14.
Но когда ещё выйдет JDK 14, и когда мы на неё перейдём? Что делать, если хочется исследовать проблему здесь и сейчас?
Можно, конечно, поддерживать свой форк OpenJDK. Сама фича сообщения об NPE не ахти какая сложная, мы вполне могли бы её реализовать. Но при этом возникнут все проблемы поддержки собственной сборки. Было бы здорово реализовать фичу один раз, а потом к любой версии JVM просто подключать её, как плагин. И такое действительно возможно! В JVM есть специальный API (изначально разработанный для всевозможных отладчиков и профайлеров): JVM Tool Interface.
Cамое важное, что этот API стандартный. У него существует строгая спецификация, и при реализации фичи в соответствии с ней можно быть уверенным, что она будет работать и в новых версиях JVM.
Чтобы воспользоваться этим интерфейсом, нужно написать небольшую (или большую, смотря какие у вас задачи) программку. Нативную: обычно её пишут на C или C++. В стандартной поставке JDK есть заголовочный файл
jdk/include/jvmti.h, который требуется подключить.Компилируется программа в динамическую библиотеку, а подключается параметром
-agentpath во время старта JVM. Важно не путать его с другим похожим параметром: -javaagent. На самом деле Java-агенты — это частный случай JVM TI-агентов. Далее в тексте под словом «агент» подразумевается именно нативный агент. С чего начать
Посмотрим на практике, как пишется простейший JVM TI-агент, своего рода «hello world».
#include <jvmti.h>
#include <stdio.h>
JNIEXPORT jint JNICALL Agent_OnLoad(JavaVM* vm, char* options, void* reserved) {
jvmtiEnv* jvmti;
vm->GetEnv((void**) &jvmti, JVMTI_VERSION_1_0);
char* vm_name = NULL;
jvmti->GetSystemProperty("java.vm.name", &vm_name);
printf("Agent loaded. JVM name = %s\n", vm_name);
fflush(stdout);
return 0;
}
Первой же строчкой я подключаю тот самый заголовочный файл. Дальше идёт главная функция, которую нужно реализовать в агенте:
Agent_OnLoad(). Её вызывает сама виртуальная машина при загрузке агента, передавая указатель на объект JavaVM*. Используя его, можно получить указатель на JVM TI environment:
jvmtiEnv*. А через него, в свою очередь, уже вызывать JVM TI-функции. Например, с помощью GetSystemProperty прочитать значение системного свойства.Если теперь я запущу этот «hello world», передав в
-agentpath скомпилированный dll-файл, то напечатанная нашим агентом строчка появится в консоли ещё до того, как начнёт выполняться Java-программа:
Обогащение NPE
Поскольку «hello world» — не самый интересный пример, давайте вернёмся к нашим исключениям. Полный код агента, дополняющего сообщения об NPE, есть на GitHub.
Вот как выглядит
Agent_OnLoad() в том случае, если я хочу попросить виртуальную машину нотифицировать нас о всех возникающих исключениях:JNIEXPORT jint JNICALL Agent_OnLoad(JavaVM* vm, char* options, void* reserved) {
jvmtiEnv* jvmti;
vm->GetEnv((void**) &jvmti, JVMTI_VERSION_1_0);
jvmtiCapabilities capabilities = {0};
capabilities.can_generate_exception_events = 1;
jvmti->AddCapabilities(&capabilities);
jvmtiEventCallbacks callbacks = {0};
callbacks.Exception = ExceptionCallback;
jvmti->SetEventCallbacks(&callbacks, sizeof(callbacks));
jvmti->SetEventNotificationMode(JVMTI_ENABLE, JVMTI_EVENT_EXCEPTION, NULL);
return 0;
}
Сначала я запрашиваю у JVM TI соответствующую capability (can_generate_exception_events). Про capability ещё поговорим отдельно.
Следующим шагом подписываемся на события Exception. Всякий раз, когда JVM генерирует исключения (не важно, пойманные или нет), будет вызываться наша функция
ExceptionCallback().Последний шаг — вызов
SetEventNotificationMode(), чтобы включить доставку уведомлений.В ExceptionCallback JVM передаёт всё, что нужно нам для обработки исключений.
void JNICALL ExceptionCallback(jvmtiEnv* jvmti, JNIEnv* env, jthread thread,
jmethodID method, jlocation location,
jobject exception,
jmethodID catch_method, jlocation catch_location) {
class NullPointerException = env->FindClass(“java/lang/NullPointerException”);
if (!env->IsInstanceOf(exception, NullPointerException)) {
return;
}
jclass Throwable = env->FindClass("java/lang/Throwable");
jfieldID detailMessage = env->GetFieldID(Throwable, "detailMessage", "Ljava/lang/String;");
if (env->GetObjectField(exception, detailMessage) != NULL) {
return;
}
char buf[32];
sprintf(buf, “at location %id”, (intO location);
env->SetObjectField(exception, detailMessage, env->NewStringUTF(buf));
}
Здесь есть и объект потока, выкинувшего исключение (thread), и место, где это произошло (method, location), и сам объект исключения (exception), и даже то место в коде, которое поймает это исключение (catch_method, catch_location).
Что важно: в этот колбэк, помимо указателя на JVM TI environment, передаётся ещё JNI environment (env). Это значит, что мы можем использовать в нём все функции JNI. То есть JVM TI и JNI прекрасно сосуществуют, дополняя друг друга.
В своём агенте я пользуюсь и тем, и другим. В частности, через JNI проверяю, что мой exception имеет тип
NullPointerException, а дальше подменяю поле detailMessage сообщением об ошибке. Поскольку нам JVM сама передаёт location — индекс байткода, на котором произошло исключение, то я здесь просто этот location и проставил в сообщение:

Число 66 означает индекс в байткоде, где произошло это исключение. Но анализировать байткод вручную муторно: надо декомпилировать class-файл, искать 66-ю инструкцию, пытаться понять, что она делала… Было бы здорово, если бы наш агент сам мог показать что-то более человекочитабельное.
Впрочем, в JVM TI и на этот случай есть всё, что надо. Правда, придётся запросить дополнительные возможности JVM TI: получать байткод и constant pool метода.
jvmtiCapabilities capabilities = {0};
capabilities.can_generate_exception_events = 1;
capabilities.can_get_bytecodes = 1;
capabilities.can_get_constant_pool = 1;
jvmti->AddCapabilities(&capabilities);
Теперь расширю ExceptionCallback: через JVM TI-функцию
GetBytecodes() получу тело метода, чтобы проверить, что же в нём находится по индексу location. Далее идёт большой switch по байткод инструкции: если это обращение к массиву, будет одно сообщение об ошибке, если обращение к полю — другое сообщение, если вызов метода — третье, и так далее.Код ExceptionCallback
jint bytecode_count;
u1* bytecodes;
if (jvmti->GetBytecodes(method, &bytecode_count, &bytecodes) != 0) {
return;
}
if (location >= 0 && location < bytecode_count) {
const char* message = get_exception_message(bytecodes[location]);
if (message != NULL) {
...
env->SetObjectField(exception, detailMessage, env->NewStringUTF(buf));
}
}
jvmti->Deallocate(bytecodes);
Осталось только подставить название поля или метода. Достать его можно из constant pool, который доступен опять же благодаря JVM TI.
if (jvmti->GetConstantPool(holder, &cpool_count, &cpool_bytes, &cpool) != 0) {
return strdup("<unknown>");
}
Далее идёт немного магии, но в действительности ничего хитрого, просто в соответствии со спецификацией class file format мы анализируем constant pool и оттуда вычленяем строчку — название метода.
Анализ constant pool
u1* ref = get_cpool_at(cpool, get_u2(bytecodes + 1)); // CONSTANT_Fieldref
u1* name_and_type = get_cpool_at(cpool, get_u2(ref + 3)); // CONSTANT_NameAndType
u1* name = get_cpool_at(cpool, get_u2(name_and_type + 1)); // CONSTANT_Utf8
size_t name_length = get_u2(name + 1);
char* result = (char*) malloc(name_length + 1);
memcpy(result, name + 3, name_length);
result[name_length] = 0;
Ещё один важный момент: некоторые JVM TI-функции, например
GetConstantPool() или GetBytecodes(), аллоцируют некую структуру в нативной памяти, которую необходимо освободить по окончании работы с ней. jvmti->Deallocate(cpool);
Запустим исходную программу с нашим расширенным агентом, и вот уже совсем другое описание исключения: оно сообщает, что мы вызвали метод longValue() на нулевом объекте.

Другие применения
Вообще говоря, разработчики нередко хотят обрабатывать исключения по-своему. Например, автоматически перезапустить JVM, если произошёл
StackOverflowError. Это желание можно понять, поскольку
StackOverflowError — такая же фатальная ошибка, как и OutOfMemoryError, после её возникновения уже нельзя гарантировать корректную работу программы. Или, например, иногда для анализа проблемы хочется по возникновению какого-то исключения получать thread dump или heap dump. 
Справедливости ради, в IBM JDK такая возможность есть из коробки. Но теперь мы уже знаем, что с помощью JVM TI-агента можно реализовать то же самое и в HotSpot. Достаточно подписаться на exception callback и проанализировать исключение. Но как снять thread dump или heap dump из нашего агента? В JVM TI есть всё нужное и на этот случай:

Самому реализовывать весь механизм обхода хипа и создания дампа не очень удобно. Но я поделюсь секретом, как сделать проще и быстрее. Правда, это уже не входит в стандартный JVM TI, а является приватным расширением Хотспота.
Нужно подключить заголовочный файлик jmm.h из исходников HotSpot и вызвать функцию
JVM_GetManagement():#include "jmm.h"
JNIEXPORT void* JNICALL JVM_GetManagement(jint version);
void JNICALL ExceptionCallback(jvmtiEnv* jvmti, JNIEnv* env, ...) {
JmmInterface* jmm = (JmmInterface*) JVM_GetManagement(JMM_VERSION_1_0);
jmm->DumpHeap0(env, env->NewStringUTF("dump.hprof"), JNI_FALSE);
}
Она вернёт указатель на HotSpot Management Interface, который буквально одним вызовом сгенерирует Heap Dump или Thread Dump. Полностью код примера можно посмотреть в моём ответе на Stack Overflow.
Естественно, можно обрабатывать не только исключения, но и кучу других всевозможных событий, связанных с работой JVM: запуски/остановки потоков, загрузки классов, сборки мусора, компиляции методов, вход/выход из методов, даже обращение или модификацию конкретных полей Java-объектов.
У меня есть пример другого агента vmtrace, который подписывается на многие стандартные JVM TI-события и логирует их. Если запущу простую программку с этим агентом, получу подробный лог, что когда делалось, с временными отметками:
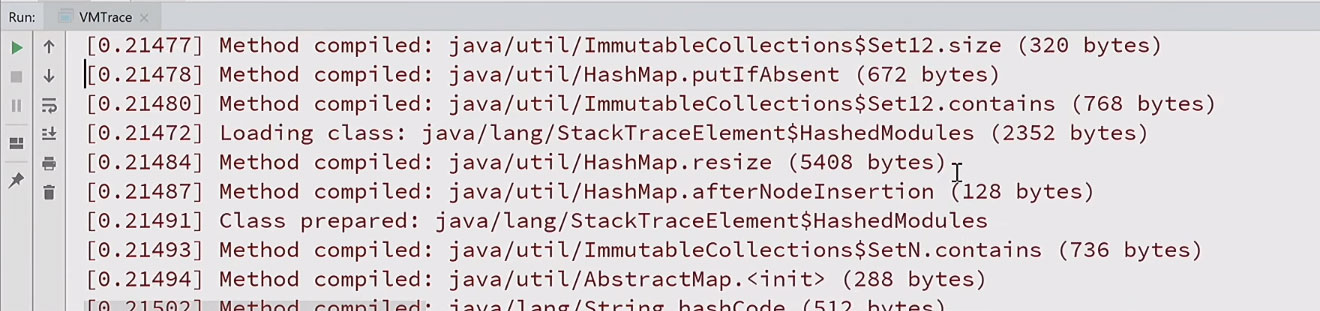
Как видно, чтобы просто напечатать hello world, грузятся сотни классов, генерируются и компилируются десятки и сотни методов. Становится понятно, почему Java так долго запускается. На всё про всё ушло более двухсот миллисекунд.
Что умеет JVM TI
Кроме обработки событий в JVM TI есть куча других возможностей. Их можно разделить на две группы.
Одна — обязательные, которые должна реализовывать любая JVM, поддерживающая JVM TI. К таким относятся операции анализа методов, полей, потоков, возможность добавления новых классов в classpath и так далее.
Есть и опциональные возможности, которые требуют предварительного запроса capabilities. JVM не обязана поддерживать их все, однако HotSpot реализует всю спецификацию полностью. Опциональные фичи делятся ещё на две подгруппы: те, что можно подключать только на старте JVM (например, возможность установки breakpoint или анализа локальных переменных), и те, что можно подключать в любой момент (в частности, получение байткода или constant pool, которые я использовал выше).

Можно заметить, что что список фич очень напоминает возможности отладчика. На самом деле, Java-дебаггер — это не что иное, как частный случай JVM TI-агента, который пользуется всеми этими возможностями и запрашивает все capabilities.
Разделение capabilities на те, которые можно включить в любой момент, и те, которые только при загрузке, сделано специально. Не все фичи бесплатные, некоторые несут в себе накладные расходы.
Если с прямыми накладными расходами, которыми сопровождается использование фичи, всё понятно, то есть ещё менее очевидные косвенные, которые проявляются, даже если фичу не используете, а просто через capabilities заявляете, что когда-то в будущем она понадобится. Связано это с тем, что виртуальная машина может по-другому компилировать код или добавить дополнительные проверки в runtime.
Например, уже рассмотренное capability подписки на исключения (can_generate_exception_events) приводит к тому, что все выбрасывания исключений будут идти по медленному пути. В принципе, это не так страшно, поскольку в хорошей Java-программе исключения — вещь редкая.
Чуть хуже обстоит дело с локальными переменными. Для can_access_local_variables, позволяющей получать значения локальных переменных в любой момент, требуется отключить некоторые важные оптимизации. В частности, полностью перестаёт работать Escape Analysis, что может давать ощутимый оверхед: в зависимости от приложения, 5-10%.
Отсюда вывод: если запускать Java с включенным debug-агентом, даже не используя его, приложения будут работать медленнее. Да и вообще, включать отладочный агент в продакшене — не очень хорошая идея.
А ряд фич, например, установка breakpoint или трассировка всех входов/выходов из метода, несут гораздо более серьёзные накладные расходы. В частности, некоторые JVM TI события (FieldAccess, MethodEntry/Exit) работают только в интерпретаторе.
Один агент — хорошо, а два — лучше
К одному процессу можно подключать несколько агентов, просто указав несколько параметров
-agentpath. У каждого будет свой JVM TI environment. Это значит, что каждый может подписываться на свои capabilities и перехватывать свои события независимо. А если два агента подписались на событие Breakpoint, и в одном поставлен breakpoint в каком-нибудь методе, то при выполнении этого метода получит ли событие второй агент?
В действительности такой ситуации возникнуть не может (по крайней мере, в HotSpot JVM). Потому что есть некоторые capabilities, которыми в каждый момент времени может владеть только один из агентов. К ним, в частности, относится breakpoint_events. Поэтому, если второй агент запросит тот же capability, в ответ получит ошибку.
Отсюда важный вывод: в агенте всегда стоит проверять результат запроса capabilities, даже если вы запускаетесь на HotSpot и знаете, что все они доступны. В спецификации JVM TI ничего не сказано про эксклюзивные capabilities, но у HotSpot есть такая особенность реализации.
Правда, не всегда изоляция агентов работает идеально. В процессе разработки async-profiler я наткнулся на такую проблему: когда у нас есть два агента и один запрашивает генерацию событий компиляции методов, то эти события получают все агенты. Я, конечно, зафайлил баг, но следует иметь в виду, что в вашем агенте могут возникать события, которых вы не ожидаете.
Использование в обычной программе
JVM TI может показаться узкоспецифичной штукой для отладчиков и профайлеров, но им можно пользоваться и в обычной Java-программе. Рассмотрим пример.
Сейчас распространена парадигма реактивного программирования, когда всё асинхронно, но с этой парадигмой есть проблема.
public class TaskRunner {
private static void good() {
CompletableFuture.runAsync(new AsyncTask(GOOD));
}
private static void bad() {
CompletableFuture.runAsync(new AsyncTask(BAD));
}
public static void main(String[] args) throws Exception {
good();
bad();
Thread.sleep(200);
}
}
Я запускаю две асинхронных задачи, которые отличаются только параметрами. И если что-то идёт не так, то возникает исключение:
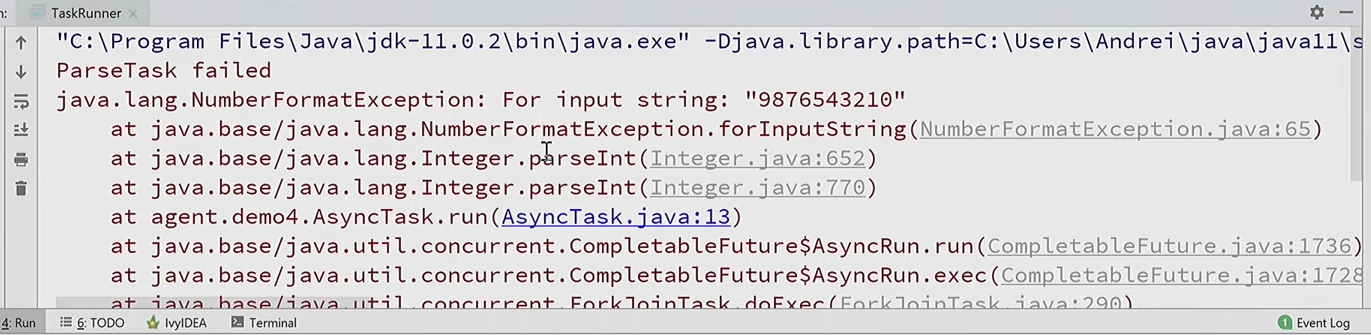
Из стек-трейса совершенно непонятно, какая из этих задач вызвала проблему. Потому что исключение возникает совсем в другом потоке, где у нас нет контекста. Как понять, в какой именно задаче?
Как одно из решений можно добавить в конструктор нашей асинхронной задачи информацию о том, где мы её создали:
public AsyncTask(String arg) {
this.arg = arg;
this.location = getLocation();
}
То есть запомнить location — конкретное место в коде, вплоть до строчки, откуда был вызван конструктор. А в случае возникновения исключения его залогировать:
try {
int n = Integer.parseInt(arg);
} catch (Throwable e) {
System.err.println("ParseTask failed at " + location);
e.printStackTrace();
}
Теперь, когда возникнет исключение, мы увидим, что случилось это на строчке 14 в TaskRunner (где создаётся задача с параметром BAD):

Но как получить то место в коде, откуда вызван конструктор? До Java 9 существовал единственный легальный способ это сделать: получить стек-трейс, пропустить несколько нерелевантных фреймов, и чуть ниже по стеку и будет то место, которое вызвало наш код.
String getLocation() {
StackTraceElement caller = Thread.currentThread().getStackTrace()[3];
return caller.getFileName() + ':' + caller.getLineNumber();
}
Но здесь есть проблема. Получение полного StackTrace работает довольно медленно. У меня этому посвящен целый доклад.
Это не было бы такой большой проблемой, если бы происходило редко. Но, например, у нас есть веб-сервис — фронтенд, который принимает HTTP запросы. Это большое приложение, миллионы строк кода. И для отлавливания ошибок рендеринга у нас используется схожий механизм: в компонентах для рендеринга мы запоминаем место, где они создаются. Таких компонентов у нас миллионы, поэтому получение всех стек-трейсов занимает ощутимое время на старте приложения, не одну минуту. Поэтому раньше такая фича была у нас в продакшене отключена, хотя для анализа проблем она как раз в продакшене и нужна.
В Java 9 появился новый способ обхода стеков потоков: StackWalker, который посредством Stream API умеет всё это делать лениво, по запросу. То есть можем пропустить нужное количество фреймов и достать только один интересующий нас.
String getLocation() {
return StackWalker.getInstance().walk(s -> {
StackWalker.StackFrame frame = s.skip(3).findFirst().get();
return frame.getFileName() + ':' + frame.getLineNumber();
});
}
Он работает чуть лучше, чем полное получение стек-трейса, но не на порядок и даже не в разы. В нашем случае он оказался быстрее где-то в полтора раза:

Есть известная проблема, связанная с неоптимальной реализацией StackWalker, и, скорее всего, её даже пофиксят в JDK 13. Но опять же, что нам делать прямо сейчас в Java 8, где StackWalker нет даже медленного?
На помощь опять приходит JVM TI. Там есть функция
GetStackTrace(), которая умеет всё, что нужно: достать фрагмент стектрейса заданной длины, начиная с указанного фрейма, и не делать ничего лишнего.GetStackTrace(jthread thread,
jint start_depth,
jint max_frame_count,
jvmtiFrameInfo* frame_buffer,
jint* count_ptr)
Остаётся только один вопрос: как из нашей программы на Java вызвать JVM TI-функцию? Точно так же, как и любой другой нативный метод: загрузить с помощью
System.loadLibrary() нативную библиотеку, где будет JNI-реализация нашего метода. public class StackFrame {
public static native String getLocation(int depth);
static {
System.loadLibrary("stackframe");
}
}
Указатель на JVM TI environment можно получать не только из Agent_OnLoad(), но и во время работы программы, и дальше пользоваться им из обычных нативных JNI-методов:
JNIEXPORT jstring JNICALL
Java_StackFrame_getLocation(JNIEnv* env, jclass unused, jint depth) {
jvmtiFrameInfo frame;
jint count;
jvmti->GetStackTrace(NULL, depth, 1, &frame, &count);
Такой подход работает уже в разы быстрее и позволил нам сэкономить несколько минут старта приложения:
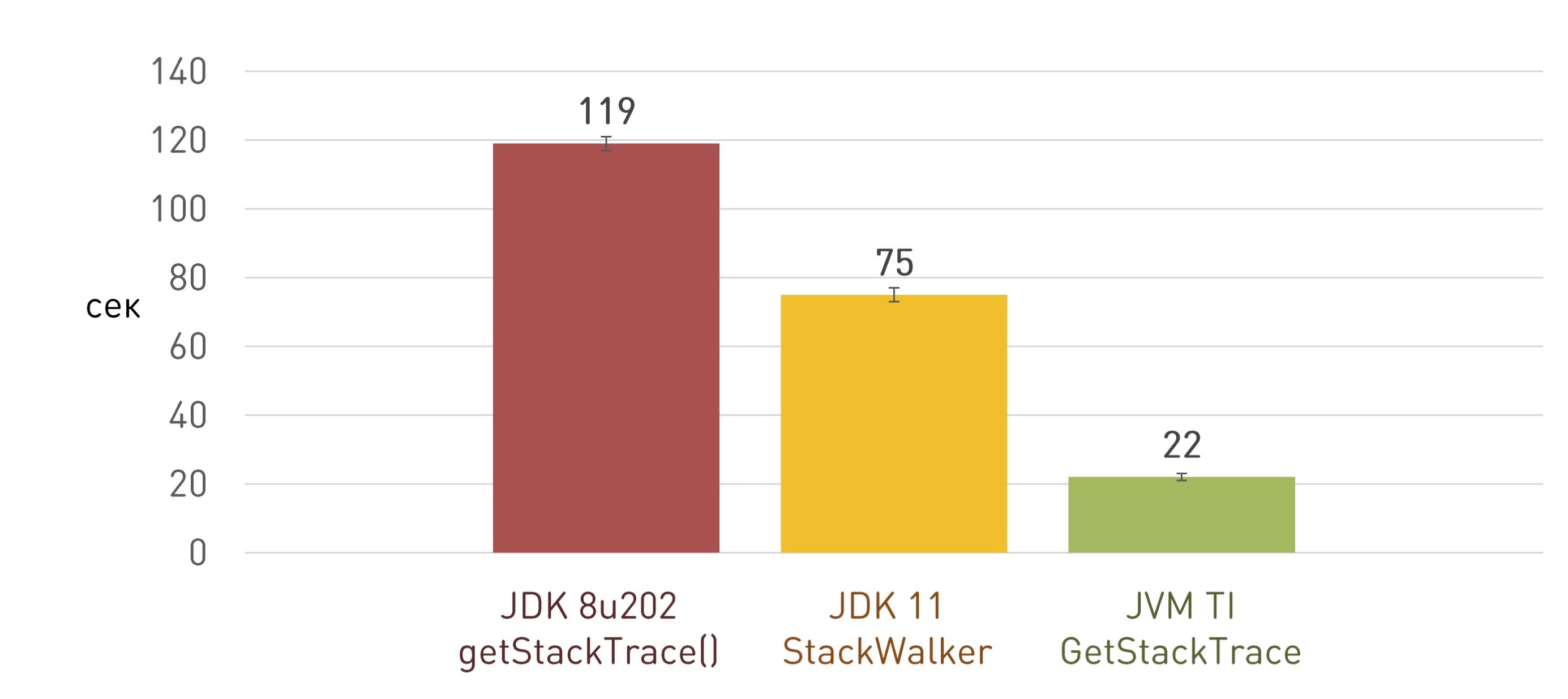
Правда, с очередным апдейтом JDK нас ждал сюрприз: приложение вдруг стало очень-очень медленно стартовать. Расследование привело к той самой нативной библиотеке для получения стек-трейсов. Разбираясь, пришли к выводу, что баг появился не у нас, а в JDK. Начиная с JDK 8u112, все JVM TI-функции, работающие с методами (GetMethodName, GetMethodDeclaringClass и так далее), стали жутко тормозить.
Я завёл баг, немного поисследовал, и обнаружил забавную история: в некоторые JVM TI-функции добавляли отладочные проверки, но не заметили, что они вызываются в том числе и из продакшен-кода. Этот сценарий использования не нашли, потому что он был не в исходниках на C++, а в файле jvmtiEnter.xsl.
Представьте себе: во время компиляции HotSpot часть исходников генерируется на лету через XSLT-преобразование. Вот так энтерпрайз нанёс ответный удар HotSpot.
Какое тут может быть решение? Просто не вызывать эти функции слишком часто, стараться кэшировать результаты. То есть, если для какого-то jmethodID получили информацию, запомнить её локально в своём агенте. Применив такое кэширование на уровне агента, мы вернули производительность на прежний уровень.
Динамическое подключение
Предыдущим примером я показал, что JVM TI можно использовать прямо из Java-кода с помощью обычных нативных методов, используя
System.loadLibrary. Кроме того, мы уже видели, как можно подключать JVM TI-агенты через
-agentpath при запуске JVM.А есть ещё третий способ: динамическое подключение (dynamic attach).
В чём идея? Если вы запустили в приложение и не подумали о том, что вам в дальнейшем потребуется какая-то фича, или вдруг понадобилось исследовать баг на продакшене, то можно загрузить JVM TI-агент прямо во время исполнения.
Начиная с JDK 9, это стало возможным прямо из командной строки с помощью утилиты jcmd:
jcmd <pid> JVMTI.agent_load /path/to/agent.so [arguments]
А для более старых версий JDK можно использовать мою утилиту jattach. Например, async-profiler умеет подключаться на лету к приложениям, запущенным без каких-либо дополнительных JVM-аргументов, как раз благодаря jattach.
Чтобы в своём JVM TI-агенте воспользоваться возможностью динамического подключения, нужно, помимо
Agent_OnLoad(), реализовать похожую функцию Agent_OnAttach(). Единственная разница: в Agent_OnAttach() нельзя использовать те capabilities, которые доступны только во время загрузки агента. Важно помнить, что можно динамически подключать одну и ту же библиотеку несколько раз, так что
Agent_OnAttach() может вызываться повторно.Продемонстрирую на примере. В роли продакшена будет IntelliJ IDEA: это ведь тоже Java-приложение, значит, мы тоже можем подключиться к нему на лету и что-то сделать.
Найдём process ID нашей IDEA, затем утилитой jattach подключим к этому процессу JVM TI-библиотеку patcher.dll:
jattach 8648 load patcher.dll trueИ прямо на лету она изменила цвет меню на красный:

Что делает этот агент? Находит все Java-объекты заданного класса (
javax.swing.AbstractButton) и вызывает через JNI метод setBackground(). Полностью код можно увидеть здесь.Что нового в Java 9
JVM TI существует уже давно, и, несмотря на существующие баги, там уже устоявшийся отлаженный API, который долгое время не менялся. Первые значительные нововведения появились в Java 9.
Как известно, Java 9 принесла разработчикам боль и страдания, связанные с модулями. Прежде всего, стало непросто пользоваться «секретами» JDK, без которых порой в принципе не обойтись.
Например, в JDK нет легального способа очистить Direct ByteBuffer. Только через приватный API:

Скажем, в Cassandra без этой возможности никуда, потому что вся работа СУБД построена на работе с MappedByteBuffer, и если их не очищать вручную, то JVM быстро упадёт.
А если вы тот же код попробуете запустить на JDK 9, получите IllegalAccessError:

Примерно также дело обстоит с Reflection: стало непросто достучаться к приватным полям.
Например, в Java доступны не все файловые операции из Linux. Поэтому для линукс-специфичных возможностей программисты доставали через рефлекшен из объекта
java.io.FileDescriptor системный дескриптор файла и с помощью JNI вызывали на нём какие-то системные функции. А теперь, если запустите это на JDK 9, то увидите ругань в логах:
Конечно, есть флажки JVM, открывающие нужные приватные модули и позволяющие пользоваться приватными классами и рефлекшеном. Но нужно вручную прописывать все пакеты, которые собираетесь использовать. Например, чтобы просто запустить Cassandra на Java 11, надо прописать такое полотнище:
--add-exports java.base/jdk.internal.misc=ALL-UNNAMED
--add-exports java.base/jdk.internal.ref=ALL-UNNAMED
--add-exports java.base/sun.nio.ch=ALL-UNNAMED
--add-exports java.management.rmi/com.sun.jmx.remote.internal.rmi=ALL-UNNAMED
--add-exports java.rmi/sun.rmi.registry=ALL-UNNAMED
--add-exports java.rmi/sun.rmi.server=ALL-UNNAMED
--add-exports java.sql/java.sql=ALL-UNNAMED
--add-opens java.base/java.lang.module=ALL-UNNAMED
--add-opens java.base/jdk.internal.loader=ALL-UNNAMED
--add-opens java.base/jdk.internal.ref=ALL-UNNAMED
--add-opens java.base/jdk.internal.reflect=ALL-UNNAMED
--add-opens java.base/jdk.internal.math=ALL-UNNAMED
--add-opens java.base/jdk.internal.module=ALL-UNNAMED
--add-opens java.base/jdk.internal.util.jar=ALL-UNNAMED
--add-opens jdk.management/com.sun.management.internal=ALL-UNNAMED
Однако вместе с модулями появились и функции JVM TI для работы с ними:
- GetAllModules
- AddModuleExports
- AddModuleOpens
- и т. д.
Глядя на этот список, решение напрашивается само собой: можно дождаться загрузки JVM, получить список всех модулей, пробежаться по всем пакетам, открыть всё для всех и радоваться.
Вот тот самый пример с Direct ByteBuffer:
public static void main(String[] args) {
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
((sun.nio.ch.DirectBuffer) buf).cleaner().clean();
System.out.println("Buffer cleaned");
}
Если запустим его без агентов, ожидаемо получим IllegalAccessError. А если добавить в agentpath написанный мной агент antimodule, то пример отработает без ошибок. То же самое с рефлекшеном.
Что нового в Java 11
Другое нововведение появилось в Java 11. Оно всего одно, но зато какое! Появилась возможность легковесного профилирования аллокаций: добавилось новое событие
SampledObjectAlloc, на которое можно подписаться, чтобы приходили выборочные нотификации об аллокациях.В callback будет передаваться всё, что нужно для дальнейшего анализа: поток, который аллоцирует, сам выделенный объект, его класс, размер. Другим методом
SetHeapSampingInterval можно изменить частоту, как часто будут эти нотификации приходить.
Зачем это нужно? Профилирование аллокаций было и раньше во всех популярных профайлерах, но работало через инструментирование, которое чревато большими накладными расходами. Единственным средством профилирования с низким оверхедом был Java Flight Recorder.
Идея нового метода в том, чтобы инструментировать не все аллокации, а только некоторые из них, иначе говоря, сэмплировать.
В самом быстром и самом частом случае аллокация происходит внутри Thread Local Allocation Buffer простым увеличением указателя. А с включением сэмплирования в TLAB добавляется виртуальная граница, соответствующая частоте сэмплирования. Как только очередная аллокация переваливает за эту границу, посылается событие о выделении объекта.

В некоторых случаях большие объекты, которые не влезают в TLAB, выделяются напрямую в хипе. Такие объекты тоже проходят по медленному пути аллокации через JVM runtime и тоже сэмплируются.
За счёт того, что теперь сэмплирование выполняется лишь для некоторых объектов, накладные расходы уже приемлемы для продакшена — в большинстве случаев менее 5%.
Что интересно, такая возможность была давно, ещё со времён JDK 7, сделанная специально для Flight Recorder. Но через приватный API Хотспота этим пользовался и async-profiler. А теперь, начиная с JDK 11, этот API стал публичным, вошёл в JVM TI, и им могут пользоваться другие профайлеры. В частности, YourKit уже тоже умеет. А как пользоваться этим API, можно посмотреть в примере, выложенном в нашем репозитории.
С помощью такого профайлера можно строить красивые диаграммы аллокаций. Смотреть, какие объекты выделяются, сколько их выделяется и, главное, откуда.

Вывод
JVM TI — отличное средство взаимодействия с виртуальной машиной.
Плагины, написанные на С или С++, можно запускать при старте JVM или же подключать динамически прямо во время работы приложения. Кроме того, функциями JVM TI может пользоваться и само приложение посредством нативных методов.
Все продемонстрированные примеры выложены в нашем репозитории на GitHub. Пользуйтесь, изучайте и задавайте вопросы.


