
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Статья больше техническая, чем про бизнес, но какие-то итоги с точки зрения бизнеса мы тоже подведем. Больше всего внимания будет уделено автоматическому сопоставлению товаров из разных источников.
Работа интернет-магазина состоит из достаточно большого числа составляющих. И каким бы ни был план, получать прибыль прямо сейчас, или расти и искать инвесторов, или, например, развивать смежные направления, как минимум придется закрывать такие вопросы:
- Работа с поставщиками. Чтобы продать что-то ненужное, нужно сначала купить что-то ненужное.
- Управление каталогом. У кого-то узкая специализация, а кто-то продает сотни тысяч разных товаров.
- Управление розничными ценами. Тут придется учесть и цены поставщиков, и цены конкурентов, и доступные финансовые инструменты.
- Работа со складом. В принципе, можно и не иметь собственного склада, а забирать товар со складов партнеров, но так или иначе вопрос стоит.
- Маркетинг. Тут наполнение сайта контентом, размещение на площадках, реклама (онлайн и офлайн), акции и много чего еще.
- Прием и обработка заказов. Колл-центр, корзина на сайте, заказы через мессенджеры, заказы через площадки и маркетплейсы.
- Доставка.
- Бухгалтерия и прочие внутренние системы.
Магазин, о котором мы будем говорить, не имеет узкой специализации, а предлагает кучу всего от косметики до мини-трактора. Я расскажу, как у нас устроена работа с поставщиками, мониторинг конкурентов, управление каталогом и формирование цен (оптовых и розничных), работа с оптовыми клиентами. Немного затронем тему склада.
Чтобы лучше понимать некоторые технические решения, будет не лишним знать, что в
какой-то момент мы решили, что технологические вещи, если это возможно, будем делать не для себя, а универсальными. И, возможно, после нескольких попыток выйдет развить новый бизнес. Получается, условно, стартап внутри компании.
Так что рассматриваем отдельную систему, более-менее универсальную, с которой интегрирована остальная инфраструктура компании.
В чем проблема работы с поставщиками
А их много, на самом деле. Просто приведу некоторые:
- Поставщиков самих по себе много. У нас — порядка 400. Каждому нужно уделить какое-то время.
- Нет единого способа получить предложения поставщиков. Кто-то шлет на почту по расписанию, кто-то по запросу, кто-то загружает в файлообменники, кто-то размещает на сайте. Способов много, вплоть до пересылки файла по скайпу.
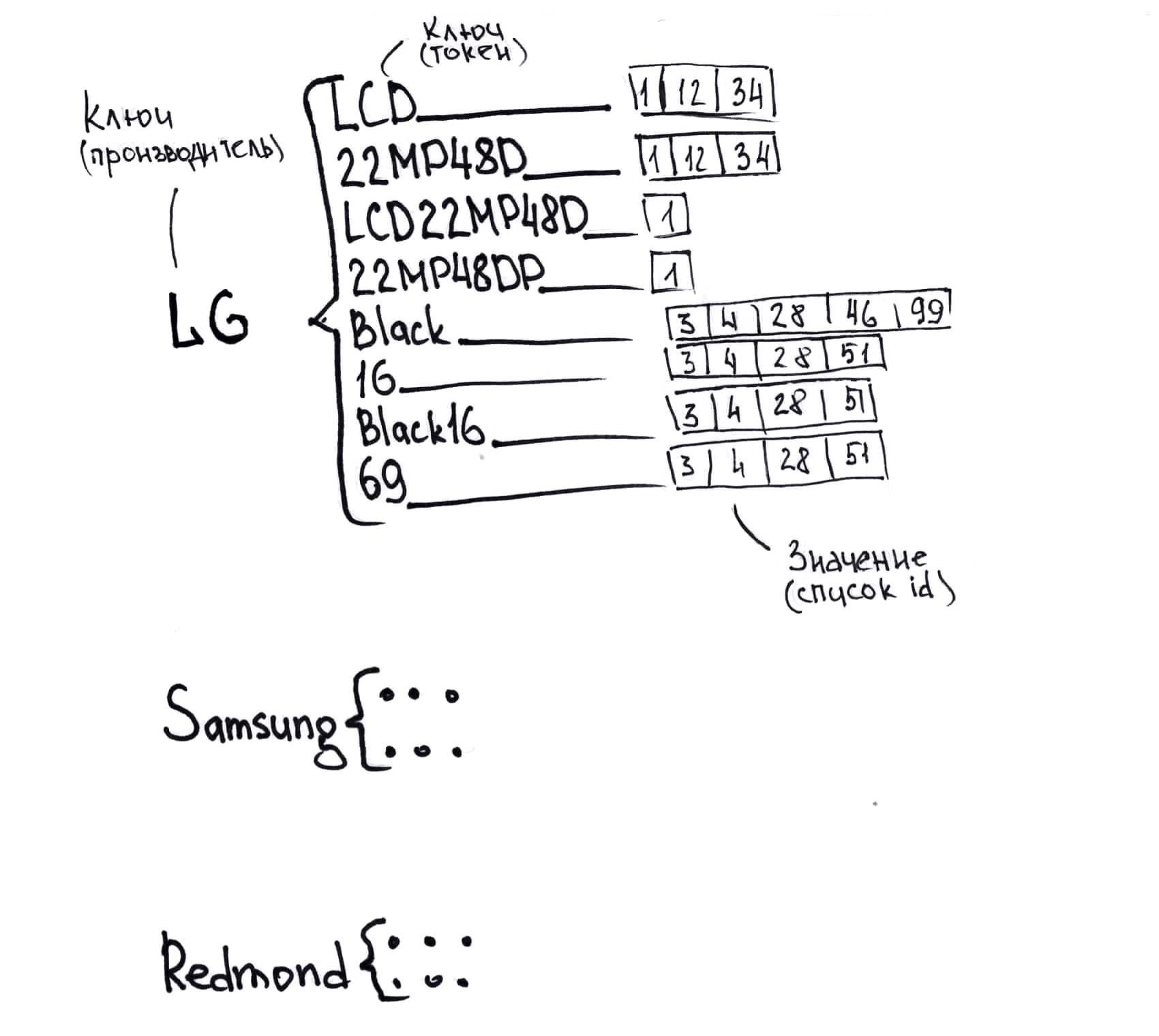
- Нет единого формата данных. Я даже картинку нарисовал на эту тему (она ниже, таблицы символизируют разные форматы).
- Существует понятие минимальных розничных и минимальных оптовых цен, которые нужно соблюдать, чтобы продолжать работать с поставщиком. Часто они предоставляются в своем собственном формате.
- Номенклатура у каждого поставщика своя. В итоге один и тот же товар называется по-разному, и нет уникального ключа, по которому их можно достаточно просто сопоставить. Поэтому мы сопоставляем сложно.
- Не автоматизирована система размещения заказа у поставщика. У кого-то заказываем по скайпу, у кого-то в личном кабинете, кому-то каждый вечер посылаем эксель-файл со списком заказов.

С этими проблемами мы научились справляться. Кроме последней, над последней работа в процессе. Сейчас будут технические подробности, а потом рассмотрим следующий список.
Собираем данные
Как было
Файлы поставщиков вручную собирались из разных источников и подготавливались. Подготовка включала в себя переименование по определенному шаблону и редактирование содержимого. В зависимости от файла, нужно было удалить некондицию, товары, которых нет в наличии, переименовать столбцы или пересчитать валюту, собрать данные из разных вкладок на одной.
Как стало
В первую очередь, мы научились проверять почту и забирать оттуда письма с вложениями. Потом автоматизировали работу с прямыми ссылками и ссылками на яндекс и гугл диски. Это решило вопрос с получением предложений примерно 75% наших поставщиков. Еще мы заметили, что именно по этим каналам предложения чаще обновляются, так что реальный процент автоматизации получился больше. Какие-то прайсы мы по-прежнему получаем в мессенджерах.
Во-вторых, мы больше не обрабатываем файлы вручную. Для этого мы завели профили поставщиков, где можно указать, что в каком столбце и на какой вкладке брать, как определять валюту и наличие, время доставки, график работы поставщика.
Получилось гибко. Естественно, не с первого раза все учли, но сейчас гибкости хватает чтобы настроить обработку всех 400 поставщиков с учетом того, что у всех разное форматирование файлов.
Что касается форматов файлов, то понимаем xls, xlsx, csv, xml (yml). В нашем случае этого оказалось достаточно.
Также придумали, как фильтровать записи. Завели список стоп-слов, и если предложение поставщика его содержит, то мы его не обрабатываем. Технические подробности такие: на небольшом списке можно и даже лучше “в лоб”, на больших списках быстрее фильтр Блума. С ним поэкспериментировали и оставили все как есть, потому что выигрыш ощущается на списке на порядок большем нашего.
Еще одна важная вещь — график работы поставщика. Наши поставщики работают по разным графикам, к тому же находятся в разных странах, выходные дни в которых не совпадают. А время доставки обычно указано в виде числа или диапазона чисел в рабочих днях. Когда мы будем формировать розничные и оптовые цены, нам придется как-то оценить время, когда мы сможем доставить товар клиенту. Для этого мы завели конфигурируемые календари, и в настройках каждого поставщика можно указать, по какому из календарей он работает.
Пришлось сделать конфигурацию скидок и наценок в зависимости от категории и производителя. Бывает так, что у поставщика общий файл для всех партнеров, но есть договоренности по скидкам с некоторыми партнерами. Благодаря этому еще оказалось возможно добавить или отнять НДС при необходимости.
Кстати, конфигурация правил скидок и наценок приводит нас к следующей теме. Ведь перед их применением нужно узнать, что это за товар.
Как работает сопоставление
Небольшой пример того, как один и тот же товар может быть назван у разных поставщиков, для понимания того, с чем придется работать:
Монитор LG LCD 22MP48D-P
21.5" LG 22MP48D-P Black (16:9, 1920x1080, IPS, 60 Гц, интерфейсы DVI+D-Sub (VGA))
COMP — Компьютерная периферия — Мониторы LG 22MP48D-P
до 22" включительно LG Монитор LG 22MP48D-P (21.5", черный, IPS LED 5ms 16:9 DVI матовая 250cd 1920x1080 D-Sub FHD) 22MP48D-P
Мониторы LG 22" LG 22MP48D-P Glossy-Black (IPS, LED, 1920x1080, 5 ms, 178°/178°, 250 cd/m, 100M:1 ,+DVI) Монитор
Мониторы LCD LG Монитор LCD 22" IPS 22MP48D-P LG 22MP48D-P
LG Монитор 21.5" LG 22MP48D-P gl.Black IPS, 1920x1080, 5ms, 250 cd/m2, 1000:1 (Mega DCR), D-Sub, DVI-D (HDCP), vesa 22MP48D-P.ARUZ
LG Монитор LG 22MP48D-P Black 22MP48D-P.ARUZ
Монитор LG 22MP48D-P 22MP48D-P
Мониторы LG 22MP48D-P Glossy-Black 22MP48D-P
Монитор 21.5" LG Flatron 22MP48D-P gl.Black (IPS, 1920x1080, 16:9, 178/178, 250cd/m2, 1000:1, 5ms, D-Sub, DVI-D) (22MP48D-P) 22MP48D-P
Монитор 22" LG 22MP48D-P
LG 22MP48D-P IPS DVI
LG LG 21.5" 22MP48D-P IPS LED, 1920x1080, 5ms, 250cd/m2, 5Mln:1, 178°/178°, D-Sub, DVI, Tilt, VESA, Glossy Black 22MP48D-P
LG 21.5" 22MP48D-P (16:9, IPS, VGA, DVI) 22MP48D-P
Монитор 21.5`` LG 22MP48D-P Black
LG МОНИТОР 21.5" LG 22MP48D-P Glossy-Black (IPS, LED, 1920x1080, 5 ms, 178°/178°, 250 cd/m, 100M:1 ,+DVI) 22MP48D-P
LG Монитор LCD 21.5'' [16:9] 1920х1080(FHD) IPS, nonGLARE, 250cd/m2, H178°/V178°, 1000:1, 16.7M Color, 5ms, VGA, DVI, Tilt, 2Y, Black OK 22MP48D-P
LCD LG 21.5" 22MP48D-P черный {IPS LED 1920x1080 5ms 16:9 250cd 178°/178° DVI D-Sub} 22MP48D-P.ARUZ
IDS_Monitors LG LG 22" LCD 22MP48D 22MP48D-P
21.5" 16x9 LG Монитор LG 21.5" 22MP48D-P черный IPS LED 5ms 16:9 DVI матовая 250cd 1920x1080 D-Sub FHD 2.7кг 22MP48D-P.ARUZ
Монитор 21.5" LG 22MP48D-P [Black]; 5ms; 1920x1080, DVI, IPS
Как было
Сопоставлением занималась 1С (сторонний платный модуль). Что касается удобства / скорости / точности, то такая система позволяла поддерживать каталог с 60 тысячами товаров в наличии на этом уровне силами 6 человек. То есть, каждый день устаревало и исчезало из предложений поставщиков столько сопоставленных товаров, сколько создавалось новых. Очень примерно — 0,5% от размеров каталога, т.е. 300 товаров.
Как стало: общее описание подхода
Чуть выше я привел пример того, что нам нужно сопоставлять. Исследуя тему сопоставления, я был немного удивлен, что ElasticSearch пользуется популярностью для задачи сопоставления, по-моему, у него есть концептуальные ограничения. Что касается нашего стека технологий, то для хранения данных мы используем MS SQL Server, но сопоставление работает на собственной инфраструктуре, а поскольку данных много и нужно обрабатывать их быстро, применяем оптимизированные под конкретную задачу структуры данных и стараемся без необходимости не обращаться к диску, базе и прочим медленным системам.
Очевидно, задачу сопоставления можно решать многими способами и очевидно, ни один из них не даст стопроцентную точность. Поэтому основная идея состоит в том, чтобы попытаться комбинировать эти способы, ранжировать их по точности и быстроте и применять по убыванию точности с учетом скорости.
План выполнения каждого нашего алгоритма (с оговоркой про вырожденные случаи) можно кратко представить такой общей последовательностью:
Токенизация. Разбиваем исходную строку на что-то значащие самостоятельные части. Можно сделать один раз и дальше использовать во всех алгоритмах.
Нормализация токенов. По-хорошему, нужно слова естественного языка привести к общему числу и склонению, а идентификаторы типа “АВС15МХ” (это кириллица, если что) конвертировать в латиницу. И привести все к одному регистру.
Категоризация токенов. Пытаемся понять, что каждая из частей значит. Например, можно выделить категорию, производителя, цвет и так далее.
Поиск лучшего кандидата на совпадение.
Оценка вероятности того, что исходная строка и лучший кандидат действительно обозначают один и тот же товар.
Два первых пункта у нас общие для всех алгоритмов, которые есть на данный момент, а дальше начинаются импровизации.
Токенизация. Тут мы поступили просто, разбиваем строку на части по специальным символам типа пробела, слэша и так далее. Набор символов со временем получился значительным, но ничего сложного в самом алгоритме мы не применяли.
Потом нам нужно нормализовать токены. Конвертируем их в нижний регистр. Вместо того, чтобы приводить все к именительному падежу, мы просто отрезаем окончания. Ещё у нас есть небольшой словарь, и мы переводим наши токены на английский. Помимо прочего, перевод избавляет нас от синонимов, похожие по смыслу русские слова на английский переводятся одинаково. Где не сумели перевести, меняем похожие по написанию кириллические символы на латиницу. (Совсем не лишнее, как оказалось. Даже там, где не ждешь подвоха, например, в строке “Samsung UЕ43NU7100U” кириллическая Е вполне может встретиться).

Категоризация токенов. Мы можем выделить категорию, производителя, модель, артикул, EAN, цвет. У нас есть каталог, где данные структурированы. У нас есть данные о конкурентах, которые нам предоставляют торговые площадки. При их обработке, где возможно, мы структурируем данные. Мы можем исправить ошибки или опечатки, например, производителя или цвет, которые встречаются только один раз во всех наших источниках, не считать за производителя и цвет соответственно. Как следствие, у нас есть большой словарь возможных производителей, моделей, артикулов, цветов, и категоризация токена — это просто поиск по словарю за O(1). Теоретически, можно иметь открытый список категорий и какой-то умный алгоритм классификации, но и наш базовый подход работает хорошо, а категоризация не является узким местом.
Тут следует оговориться, что иногда поставщик предоставляет уже структурированные данные, например, артикул находится в отдельной ячейке в таблице, или поставщик при оптовых продажах делает скидку от розницы, а розничные цены можно получить в yml (xml) формате. Тогда мы сохраняем структуру данных, а эвристически делим токены на категории только из неструктурированных данных.
А теперь о том, какие алгоритмы и в каком порядке применяем.
Точные и почти точные совпадения
Самый простой случай. Строки разбили на токены, привели их к одному виду. Дальше придумали хэш-функцию, не чувствительную к порядку токенов. К тому же, сопоставляя по хэшу, мы можем держать все данные в памяти, условные 16 мегабайт на словарь с миллионом ключей мы можем себе позволить. На практике алгоритм показал себя лучше, чем простое сравнение строк.
Что касается хэширования, то напрашивается применение «исключающего или» и функция типа такой:
public static long GetLongHashCode(IEnumerable<string> tokens)
{
long hash = 0;
foreach (var token in tokens.Distinct())
{
hash ^= GetLongHashCode(token);
}
return hash;
}Самое интересное на этом этапе — получение хэша отдельной строки. На практике выяснилось, что 32 бита мало, получается много коллизий. А еще — что нельзя просто взять исходный код функции из фреймворка и поменять тип возвращаемого значения, коллизий для отдельных строк становится меньше, но после «исключающего или» они все равно встречаются, поэтому мы написали свою. По сути, просто добавили в функцию из фреймворка нелинейности от входных данных. Стало однозначно лучше, с новой функцией с коллизией мы встретились только один раз на наших миллионах записей, записали и отложили до лучших времен.
Таким образом, мы ищем совпадения без учета порядка слов и их формы. Работает такой поиск за O(1).
К сожалению, редко, но бывает и так: “ABC 42 Type 16” и “ABC 16 Type 42”, и это два разных товара. С такими вещами мы тоже научились справляться, но об этом позже.
Сопоставление подтвержденных человеком товаров
У нас есть товары, сопоставленные вручную (чаще всего это товары, сопоставленные автоматически, но попавшие на ручную проверку). По сути, то же самое мы делаем и в этом случае, только у нас теперь добавился словарь сопоставленных хэшей, поиск по которому не изменил временную сложность алгоритма.
Сопоставленные вручную строки просто лежат в базе, на всякий случай, такие сырые данные позволят в будущем поменять алгоритм хэширования, все пересчитать и ничего не потерять.
Сопоставление по атрибутам
Первые два алгоритма быстрые и точные, но их недостаточно. Следующим мы применяем сопоставление по атрибутам.
Раньше мы уже представили данные в виде нормализованных токенов и даже отсортировали их по категориям. В этой главе я называю категории токенов атрибутами.
Самый надежный атрибут — это EAN (https://ru.wikipedia.org/wiki/European_Article_Number). Совпадения EAN дают почти стопроцентную гарантию того, что это один и тот же продукт. Несовпадение EAN, при этом, ничего не говорит, потому что у одного товара могут быть разные EAN. Все бы хорошо, но в наших данных EAN встречается редко, поэтому его влияние на сопоставление на уровне погрешности.
Артикул менее надежен. Туда часто попадает что-то странное прямо из структурированных данных поставщика, но в любом случае на данном этапе мы его используем.
Как и на прошлом этапе, тут мы используем словари (поиск за O(1)), а в качестве ключа используется хэш от (производитель + модель + артикул). Хэширование позволяет производить все операции в памяти. При этом учитываем еще и цвет, если он совпадает или его нет, то считаем, что товары совпали.
Поиск наилучшего совпадения
Предыдущие этапы были простыми, быстрыми и довольно надежными, но, к сожалению, они покрывают меньше половины сопоставлений.
В поиске наилучшего совпадения лежит простая идея: совпадение редких токенов имеет большой вес, совпадение частых — малый вес. Токены, содержащие цифры, ценятся больше, чем буквенные. Токены, которые совпадают в одинаковом порядке, ценятся больше, чем токены, которые переставлены местами. Длинные совпадения лучше коротких.
Теперь осталось придумать быструю структуру данных, которая может все это одновременно учесть и помещается в память на каталоге в пару миллионов записей.
Мы придумали представить наш каталог в виде словаря словарей, на первом уровне ключом будет хэш от производителя (данные в каталоге структурированы, производителя мы знаем), значением — словарь. Теперь второй уровень. Ключом на втором уровне будет хэш от токена, значением — список id товаров из каталога, где этот токен встречается. Причем в данном случае мы используем в том числе комбинации токенов в том порядке, в котором они встречаются в нашем каталоге. Что использовать как комбинацию, а что — нет решаем в зависимости от количества токенов, их длины и так далее, это компромисс между скоростью, точностью и требуемой памятью. На рисунке я упрощенно изобразил эту структуру, без хэшей и без нормализации.
Если на каждый товар в среднем использовать 20 токенов, то в наших списках, которые значения вложенного словаря, ссылка на товар встретится в среднем 20 раз. Различных токенов при этом будет не более чем в 20 раз больше, чем товаров в каталоге. Приблизительно можно посчитать память, которая требуется на каталог в миллион записей: 20 миллионов ключей по 4 байта на каждый, 20 миллионов id товаров по 4 байта на каждый, накладные расходы на организацию словарей и списков (порядок такой же, но поскольку размер списков и словарей мы не знаем заранее, а увеличиваем на ходу, умножаем на два). Итого — 480 мегабайт. В реальности получилось чуть больше токенов на товар, и нам требуется до 800 мегабайт на каталог в миллион товаров. Что приемлемо, возможности современного железа позволяют одновременно хранить в памяти больше сотни каталогов такого размера.
Вернемся к алгоритму. Имея строку, которую нам надо сопоставить, мы можем определить производителя (у нас есть алгоритм категоризации), а потом получить токены по такому же алгоритму, что и для товаров из каталога. Тут я подразумеваю в том числе комбинации токенов.
Дальше все сравнительно просто. Для каждого токена мы можем быстро найти все товары, в которых он встречается, оценить вес каждого совпадения с учетом всего того, о чем мы говорили раньше — длины, частоты, наличия цифр или спецсимволов, и оценить “похожесть” всех найденных кандидатов. В реальности тут тоже есть оптимизации, всех кандидатов мы не считаем, сначала формируем небольшой список по совпадениям токенов с большим весом, а совпадения токенов с малым весом применяем не ко всем товарам, а только к этому списку.
Выбираем лучшее соответствие, смотрим совпадения токенов, которые получилось отнести к категориям и считаем оценку сопоставления. Дальше у нас есть два пороговых значения П1 и П2, П1 < П2. Если оценка получилась больше порогового значения П2 — участия человека не требуется, все происходит автоматически. Если между двух значений — предлагаем посмотреть сопоставление вручную, до этого оно не будет участвовать в формировании цен. Если меньше П1 — скорее всего, такого товара нет в каталоге, ничего не возвращаем.
Вернемся к строкам “ABC 42 Type 16” и “ABC 16 Type 42”. Решение на удивление простое — если у нескольких товаров одинаковые хэши, то мы их не сопоставляем по хэшу. А последний алгоритм учтет порядок токенов. Теоретически, такие строки в прайсе поставщика нельзя сопоставить чему-то произвольному, где числа 16 и 42 не встречаются вообще. Практически с такой необходимостью мы не сталкивались.
Скорость и точность сопоставления
Теперь что касается скорости всего этого. Время, которое требуется на подготовку словарей, линейно зависит от размеров каталога. Время, которое требуется непосредственно на сопоставление, линейно зависит от количества сопоставляемых товаров. Все структуры данных, участвующие в поиске, не изменяются после создания. Это дает нам возможность использовать многопоточность на этапе сопоставления. Подготовительная работа для каталога в миллион записей занимает порядка 40-80 секунд. Сопоставление работает со скоростью 20-40 тысяч записей в секунду и не зависит от размера каталога. Потом, правда, нужно сохранить результаты. Выбранный подход в целом выгодный для больших объемов, но файл с десятком записей будет обрабатываться непропорционально долго. Поэтому мы используем кэш и пересчитываем наши поисковые структуры раз в 15 минут.
Правда, данные для сопоставления нужно где-то прочитать (чаще всего это эксель файл), а сопоставленные предложения нужно где-то сохранить, и это тоже занимает время. Так что итоговое число 2-4 тысячи записей в секунду.
Для того, чтобы оценить точность, мы подготовили тестовый набор из примерно 20 000 проверенных вручную сопоставлений разных поставщиков из разных категорий. Алгоритм после каждого изменения тестировался на этих данных. Результаты получились такие:
- товар есть в каталоге и был сопоставлен правильно — 84%
- товар есть в каталоге, но не был сопоставлен, требуется ручное сопоставление — 16%
- товар есть в каталоге и был сопоставлен неправильно — 0.2%
- товара нет в каталоге, и программа это правильно определила — 98.5%
- товара нет в каталоге, но программа его сопоставила какому-то из товаров — 1.5%
В 80% случаев, когда товар был сопоставлен, не требуется ручное подтверждение (автоматически подтверждаем сопоставление), среди таких подтвержденных автоматически предложений 0.1% ошибок.
Кстати, 0.1% ошибок — это много, оказывается. На миллион сопоставленных записей это тысяча записей, сопоставленных неправильно. А много это потому что покупатели именно такие записи находят лучше всего. Ну как не заказать трактор по цене фары от этого трактора. Впрочем, эта тысяча ошибок — это на старте работы на миллионе предложений, постепенно они были исправлены. Карантин для подозрительных цен, который закрывает этот вопрос, у нас появился позже, первые пару месяцев мы работали без него.
Есть еще одна категория ошибок, не связанная с сопоставлением, это неправильные цены наших поставщиков. Отчасти поэтому мы не учитываем цену в сопоставлении. Мы решили, что раз уж у нас есть дополнительная информация в виде цены, то будем с ее помощью пытаться определить не только свои, но и чужие ошибки.
Поиск неправильных цен
Это та часть, которая над которой мы сейчас активно экспериментируем. Базовая версия есть, и она не позволяет продавать телефон по цене чехла, но у меня есть ощущение, что можно лучше.
Для каждого товара находим границы приемлемых цен поставщиков. В зависимости того, какие данные есть, мы учитываем цены поставщиков на этот товар, цены конкурентов, цены поставщиков на товары этого производителя в этой категории. Те цены, которые не попали в границы, мы помещаем в карантин и игнорируем во всех наших алгоритмах. Вручную можно отметить такую подозрительную цену как нормальную, тогда мы для данного товара запоминаем это и пересчитываем границы приемлемых цен.
Непосредственно алгоритм расчета максимальной и минимальной приемлемой цены сейчас постоянно меняется, ищем компромисс между количеством ложных срабатываний и количеством выявленных неправильных цен.
Мы в расчетах используем медианные значения (средние дают худший результат) и пока не анализируем форму распределения. Анализ формы распределения — как раз место, где, как мне кажется, можно улучшить алгоритм.
Работа с базой данных
Из всего выше написанного можно сделать вывод, что данные по поставщикам и конкурентам мы обновляем часто и помногу, и работа с базой может стать узким местом. В принципе, мы изначально обратили на это внимание и попытались добиться максимальной производительности. При работе с большим количеством записей мы делаем следующее:
- удаляем индексы из таблицы, с которой работаем
- отключаем full text индексирование по этой таблице
- удаляем все записи с определенным условием (например, все предложения конкретных поставщиков, которых обрабатываем в данный момент)
- вставляем новые записи при помощи BULK COPY
- заново создаем индексы
- включаем full text индексирование
Bulk copy работает со скоростью 10-40 тысяч записей в секунду, почему такой большой разброс еще предстоит выяснить, но и так приемлемо.
Удаление записей занимает примерно такое же время, что и вставка. Еще некоторое время требуется на пересоздание индексов.
Кстати, для каждого каталога у нас отдельная база данных. Их мы создаем на лету. А сейчас расскажу, почему у нас больше одного каталога.
В чем проблема ведения каталога
А их тоже много. Сейчас будем перечислять:
- В каталоге примерно 400 тысяч товаров из совершенно разных категорий. Невозможно профессионально разбираться в каждой из категорий.
- Нужно соблюдать определенную стилистику, следовать общими для всего каталога правилами наименования, выделения подкатегорий и так далее. Таким образом мы пытаемся добиться стройной и логичной структуры каталога.
- Один и тот же товар можно создать несколько раз, и это проблема. Без инструмента, который анализирует похожие наименования, создание дублей происходит постоянно.
- Разумно добавлять в каталог те товары, которые есть у поставщиков в наличии. При этом нужно иметь приоритеты на товарные категории.
- Нам требуется несколько каталогов. Один свой, его мы ведем сами, другой — каталог агрегатора, его обновляем по апи. Смысл второго каталога в том, что площадка-агрегатор работает только с собственным каталогом, и, соответственно, предложения принимает в своей номенклатуре. Это еще одно место, где оказалось нужно сопоставление.
Мы посчитали, что логично и правильно вести каталог там же, где осуществляются сопоставления. Так мы сможем подсказать пользователям, которые администрируют каталог, что есть у поставщика, но нет у нас в каталоге.
Как мы ведем каталог
Речь пойдет о каталоге без подробных характеристик, характеристики — отдельная большая история, о ней как-нибудь в другой раз.
В качестве базовых свойств мы выбрали такие:
- производитель
- категория
- модель
- артикул
- цвет
- EAN
Для начала сделали апи для получения каталога из внешнего источника, а дальше работали над удобством создания, редактирования и удаления записей.
Как работает поиск
Удобство управления каталогом, в первую очередь — это возможность быстро найти товар в каталоге или предложение поставщика, причем есть нюансы. Например, нужно уметь искать строчку “LG 21.5" 22MP48D-P (16:9, IPS, VGA, DVI) 22MP48D-P” по запросу “2MP48”.
Полнотекстовый поиск sql сервера из коробки не годится, потому что он так не умеет, а поиск с помощью LIKE ‘%2MP48%’ слишком медленный.
Наше решение достаточно стандартно, мы используем N-граммы. Если точнее — то триграммы. А уже по триграммам строим полнотекстовый индекс и производим полнотекстовый поиск. Не уверен, что мы очень рационально используем место в этом случае, но по скорости такое решение подошло, в зависимости от запроса, работает от 50 до 500 миллисекунд, иногда до секунды на массиве в три миллиона записей.
Поясню, строка “LG 21.5" 22MP48D-P (16:9, IPS, VGA, DVI) 22MP48D-P” преобразуется в строку “lg2 g21 215 152 522 22m 2mp mp4 p48 48d 8dp dp1 p16 169 69i 9ip ips psv svg vga gad adv dvi vi2 i22”, которая сохраняется в отдельное поле, которое участвует в полнотекстовом индексе.
Кстати, триграммы нам еще пригодятся.
Создание нового товара
В большинстве своем, товары в каталоге создаются по предложениям поставщика. То есть, у нас уже есть информация, что поставщик предлагает “LG Монитор LCD 21.5'' [16:9] 1920х1080(FHD) IPS, nonGLARE, 250cd/m2, H178°/V178°, 1000:1, 16.7M Color, 5ms, VGA, DVI, Tilt, 2Y, Black OK 22MP48D-P” по цене 120 долларов, и на складе у него от 5 до 10 единиц.
При создании товара, в первую очередь, нам нужно убедиться, что такой товар в каталоге еще не создан. Эту задачу мы решаем в четыре этапа.
Во-первых, если товар у нас в каталоге есть, с большой вероятностью предложение поставщика будет сопоставлено этому товару автоматически.
Во-вторых, прежде чем показать пользователю форму создания нового товара, мы выполним поиск по триграммам и покажем самые релевантные результаты. (технически это делается с помощью CONTAINSTABLE).
В третьих, по мере заполнения полей нового товара мы будем показывать похожие существующие товары. Это решает две задачи: помогает избежать дублей и выдержать стилистику в наименованиях, похожие товары можно использовать как образец.
И в четвертых, помните мы разбивали строки на токены, нормализовали их, считали хэши? Сделаем то же самое и просто не дадим создать товары с одинаковыми хэшами.
Еще на этом этапе мы стараемся помочь пользователю. По строке, которая есть в прайсе, мы попытаемся определить производителя, категорию, артикул, EAN и цвет товара. Сначала — по токенам (мы умеем их делить на категории), потом, если не получилось, найдем самый похожий товар по триграммам. И, если он достаточно похож, заполним производителя и категорию.
Редактирование товара работает почти так же, просто не все применимо.
Как мы формируем свои цены
Задача такая: соблюсти баланс между количеством и маржинальностью продаж, по сути — добиться максимальной прибыли. Все остальные аспекты работы магазина тоже об этом, но именно то, что происходит на этапе формирования цен, оказывает наибольшее влияние.
Как минимум нам понадобится информация о предложениях поставщиков и конкурентов. Еще стоит учесть минимальные розничные и оптовые цены и затраты на доставку, а также финансовые инструменты — кредиты и рассрочки.
Собираем цены конкурентов
Начнем с того, что профилей собственных цен у нас много. Есть профиль для розницы, есть несколько для оптовых клиентов. Все они создаются и настраиваются в нашей системе.
Соответственно, и конкуренты для каждого профиля разные. В рознице — другие розничные магазины, в оптовых продажах — наши же поставщики.
С поставщиками все ясно, а для розницы данные о конкурентах собираем несколькими способами. Во-первых, некоторые агрегаторы предоставляют информацию о всех ценах на все товары, которые есть на площадке. В собственной номенклатуре, но мы умеем сопоставлять товары, так что это работает автоматически. И этого пока почти хватает. Во-вторых, у нас есть парсеры конкурентов. Поскольку они пока не автоматизированы и существуют в виде консольных приложений (которые иногда падают), то и пользуемся ими редко.
Настраимаем профиль
В профиле у нас есть возможность настроить разные диапазоны наценок в зависимости от цены товара у поставщика, категории, производителя, поставщика. Еще есть возможность указать, с какими поставщиками по какой категории или производителю работаем, а с какими — нет, кого из конкурентов учитываем.
Потом настраиваем финансовые инструменты, указываем, какие рассрочки доступны и сколько банк заберет себе.
И уже в границах наценок мы формируем собственные цены, пытаясь соблюсти тот самый баланс во-первых, и сделать так, чтобы наши складские товары лучше продавались во-вторых. Это в двух словах так, а на деле я не берусь объяснить простыми словами, что там происходит.
Могу рассказать, чего не происходит. К сожалению, мы пока не умеем прогнозировать спрос и учитывать затраты на хранение товаров на складе.
Интеграции со сторонними системами
Важная часть с точки зрения бизнеса, но неинтересная с технической точки зрения. В двух словах скажу, что мы умеем отдавать данные в сторонние системы (в том числе инкрементально, то есть, понимаем, что поменялось с прошлого обмена) и умеем делать почтовые рассылки.
Рассылки настраиваемые, так (и не только так) мы доставляем наши предложения оптовым клиентам.
Еще один способ работать с оптовыми клиентами — b2b портал. Он пока в активной разработке, заработает буквально через месяц.
Аккаунты, логирование изменений
Еще один неинтересный с технической точки зрения вопрос. У нас у каждого пользователя свой аккаунт.
Если кратко, то сказать можно следующее: если используется ORM, то в ней есть встроенный механизм отслеживания изменений. Если в него влезть (а в нашем случае это EF Core и там даже API есть), то можно получить логирование всего практически в две строчки.
Для истории изменений мы сделали интерфейс, и теперь можно проследить, кто и что менял в настройках системы, кто редактировал или сопоставлял определенные товары и так далее.
По логам можно считать статистику, что мы и делаем. Мы знаем, кто сколько товаров создал или отредактировал, сколько сопоставлений подтвердил вручную и сколько отклонил, можно посмотреть каждое изменение.
Немного об общем устройстве системы
У нас одна база для аккаунтов и не зависящих от каталога вещей, одна база для логов, и по базе на каждый каталог. Так и запросы к каталогу получаются легче, и анализировать данные проще, и код получается более понятным.
Кстати, система логирования самописная, нам очень нужно группировать логи, относящиеся к одному запросу или одной тяжелой задаче, кроме того, нужен базовый функционал для их анализа. С готовыми решениями это получалось сложно, плюс это еще одна зависимость, которую надо поддерживать.
Веб-интерфейс сделан на ASP.NET Core и бутстрапе, а тяжелые опрерации выполняются Windows — сервисом.
Еще одна особенность, которая пошла проекту на пользу, на мой взгляд, — разные модели на чтение и запись данных. Полноценный СQRS мы не внедряли, но одну из концепций оттуда взяли. Запись в базу у нас через репозитории, но объекты, которые используются для записи, никогда не покидают методов обновления / создания / удаления. Массовое обновление делаем посредством BULK COPY. Для чтения сделана отдельная модель и отдельная прослойка доступа к данным, таким образом мы читаем только то, что нужно в конкретный момент. Получилось, что можно пользоваться ORM, и при этом избежать тяжелых запросов, обращений к базе в неопределенные моменты (как с ленивой загрузкой), проблемы N + 1. А еще мы используем модель для чтения как DTO.
Из крупных зависимостей у нас ASP.NET Core, несколько сторонних nuget-пакетов и MS SQL Server. Пока возможно, стараемся не зависеть от множества сторонних систем. Для того, чтобы полностью развернуть проект локально, достаточно установить SQL Server, забрать исходный код из системы контроля версий и собрать проект. Нужные базы будут созданы автоматически, а больше ничего и не надо. Возможно, придется изменить одну-две строчки в конфигурации.
Что не сделали
Пока не сделали систему знаний по проекту. Хотим делать вики и подсказки по месту. Не сделали простого интуитивного интерфейса, тот, что есть неплох, но для неподготовленного человека немного запутан. CI/CD пока только в планах.
Не сделали обработку подробных характеристик товаров. Тоже планируем, но пока нет конкретного срока.
Итоги с точки зрения бизнеса
С момента начала активной разработки до запуска в продакшен над проектом работало два человека в течение 7 месяцев. На старте у нас был прототип, сделанный в свободное время. Сложнее всего дались интеграции с существующими системами.
За три месяца, которые мы в продакшене, количество товаров в наличии для оптовых клиентов выросло с 70 тысяч до 230 тысяч, количество товаров на сайте — с 60 тысяч до 140 тысяч. Сайт всегда запаздывает, потому что ему нужны характеристики, картинки, описания товаров. На агрегатор мы выгружаем 106 тысяч предложений вместо 40 тысяч три месяца назад. Количество человек, работающих с каталогом, не изменилось.
Мы работаем с 425 поставщиками, это число выросло почти в два раза за три месяца. Отслеживаем цены более тысячи конкурентов. Ну как отслеживаем — система для парсинга у нас есть, но в большинстве случаев мы берем готовые данные у тех, кто их регулярно предоставляет.
Про продажи, к сожалению, не могу рассказать, у меня самого нет надежных данных. Спрос сезонный, и напрямую сравнить месяц к предыдущему месяцу нельзя. А за год произошло слишком много всего, чтобы из всех факторов выделить влияние нашей системы. Очень и очень условно, плюс-минус километр, рост каталога, более гибкие и конкурентные цены и связанный с этим рост продаж уже окупили разработку и внедрение.
Еще один итог — получился проект, по сути не связанный с инфраструктурой конкретного магазина, и из него можно сделать публичный сервис. Так было задумано с самого начала, и этот план почти сработал. Коробочного решения еще, к сожалению, не получилось. Чтобы предлагать проект как сервис, где можно зарегистрироваться, поставить галочку “я согласен”, и который работает “как есть”, без адаптации к клиенту, нужно переработать интерфейс, добавить гибкости и создать вики. А еще сделать инфраструктуру легко масштабируемой и устранить единую точку отказа. Сейчас у нас из средств обеспечения надежности есть только регулярные бекапы. Как энтерпрайз решение, думаю, мы уже готовы решать задачи бизнеса. Дело за малым — найти бизнес.
Кстати, одного стороннего клиента мы уже привлекли, имея самый базовый функционал. Ребятам нужен был инструмент по сопоставлению товаров, а неудобства, связанные с активной разработкой, их не испугали.




