
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

В предыдущей статье я рассказывал о том, можно ли использовать машинное обучение (в частности определение лица и маски) в браузере, подходах к детекции и оптимизации всех процессов.
Сегодня я хочу рассказать о технических подробностях реализации.
Использованные технологии

Основной язык для разработки в браузере это TypeScript. Клиентское приложение написано на React.js.
В приложении используется несколько нейронных сетей для детекции разных событий: детекция лица, детекция маски. Каждая модель/сеть запускается в отдельном потоке (Web Worker). Нейронные сети запускаются с использованием TensorFlow.js и в качестве backend-а используется Web Assembly или WebGL, что позволяет выполнять код со скоростью близкой к нативной. Выбор того или иного backend-а зависит от размера модели (мелкие модели быстрее работают на WebAssembly), но надо всегда проводить тестирование и выбирать, то что быстрее для конкретной модели.
Получение и отображение видео стрима с использованием WebRTC. Для работы с изображениями используется библиотека OpenCV.js.
Реализован был следующий подход:

Основной поток занимается только оркестрацией всего, он не загружает тяжелую библиотеку OpenCV для работы с изображениями и не использует TensorFlow.js. Все что он делает, получает изображения из видео потока и отправляет на обработку веб воркерам.
Пока воркер не сообщил основному потоку, что он освободился, новое изображение не посылается в него, тем самым не создается очередь, как только воркер говорит, что он освободился, текущее изображение со стрима отправляется к нему на обработку.
Первоначально изображение отправляется на распознавание лица, если лицо распознано, только тогда изображение отправляется на распознавание маски. Каждый результат работы воркера сохраняется и может быть отображен на UI.
Скорость работы
- Получение изображение со стрима — 31 мс
- Препроцессинг определения лица — 0-1 мс
- Определение лица — 51 мс
- Постпроцессинг определения лица — 8 мс
- Препроцессинг определения маски — 2 мс
- Определение маски — 11 мс
- Постпроцессинг определения маски — 0-1 мс
Итого:
- Определение лица — 60 мс + 31 мс = 91 мс
- Определение маски — 14 мс
Таким образом, за ~105 мс бы знаем всю информацию с изображения.
*Препроцессинг определения лица — это получение изображения со стрима и отправка в веб воркер
*Постпроцессинг определения лица — сохранение результата от воркера определения лица и его отрисовка на канвасе
*Препроцессинг определения маски — подготовка канваса с изображением выровненного лица и передача его в веб воркер
*Постпроцессинг определения маски — сохранение результатов определения маски

Для каждой модели (определение лица и определение маски) используется отдельный веб воркер, который загружает необходимые для его работы библиотеки (OpenCV.js, Tensorflow.js, модели).
Таких воркеров у нас 3:
- определение лица
- определение маски
- воркер-хелпер, который может заниматься трансформацией изображений, использовать тяжелый методы из OpenCV и Tensorflow для построения матрицы калибровки нескольких камер например.
Фичи и трюки, которые нам помогли при разработке и оптимизации
Веб воркеры и как оптимально с ними работать
Веб воркер — способ запустить скрипт в отдельном потоке.
Они позволяют выполнять тяжелую обработку параллельно с основным потоком без блокировки пользовательского интерфейса. Основной поток выполняет логику оркестрирования, все тяжелые вычисления переносятся в веб-воркеры. Веб-воркеры поддерживаются почти во всех браузерах.

Возможности и ограничения веб-воркеров
Возможности:
- Использование JavaScript
- Доступ к объекту navigator
- Доступ на чтение объекта location
- Использование для запросов XMLHttpRequest
- Возможность использовать setTimeout() / clearTimeout() и setInterval() / clearInterval()
- Application Cache
- Импорт сторонних скриптов с помощью importScripts()
- Создание других воркеров
Ограничения:
- Нет доступа к DOM
- Нет доступа к объекту windows
- Нет доступа к объекту document
- Нет доступа к объекту parent
Общение между основным потоком и веб воркерами происходит с помощью postMessage и обработчиком событий onmessage.
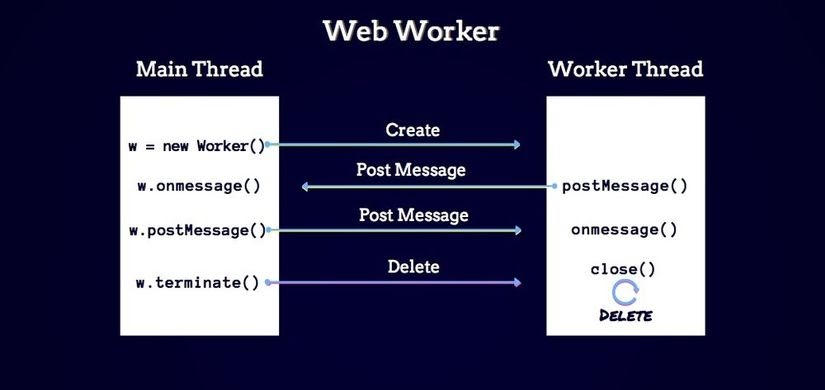
Если посмотреть в спецификацию метода postMessage(), можно заметить, что он принимает не только данные, но и второй аргумент — transferable object.
worker.postMessage(message, [transfer]);Давайте посмотрим, чем нам поможет использование его.
Transferable интерфейс представляет собой объект, который можно передавать между различными контекстами выполнения, такими как основной поток и веб-воркеры.
К ним относятся:
- ImageBitmap
- OffscreenCanvas
- ArrayBuffer
- MessagePort
Если мы хотим передать 500 Мб данных в воркер, мы можем это сделать и без второго аргумента, но разница будет во времени передачи и использовании памяти существенная.
Передача без transfer аргумента займет 149 мс и 1042 Мб для Google Chrome, в других браузерах еще больше.

При использовании transfer это займет 1 мс и сократит потребление памяти в 2 раза!
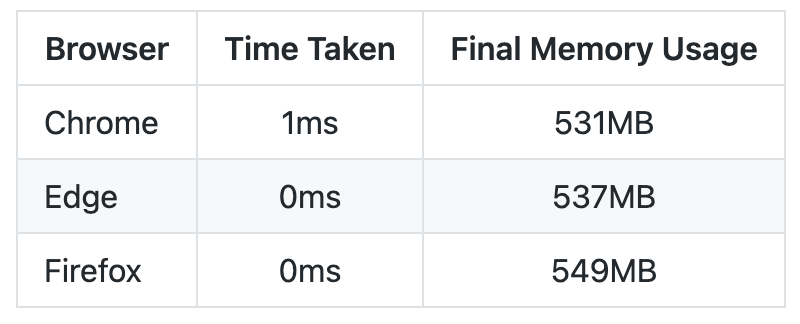
Так как из основного потока в веб воркеры изображения передаются часто, то нам важно это делать максимально быстро и эффективно по памяти, и эта фича нам в этом очень сильно помогает.
Использование OffscreenCanvas
В веб воркере нет доступа к DOM, соответственно нельзя использовать canvas напрямую. На помощь приходит OffscreenCanvas.
Преимущества:
— Не зависит от DOM
— Может быть использован как в основном потоке, так и в веб воркерах
— Имеет transferable интерфейс и не нагружает основной поток, если отрисовка происходит в веб воркере

Преимущества использования requestAnimationFrame
requestAnimationFrame позволяет получать изображения со стрима с максимальной производительностью (60 FPS) и ограничивается только возможностью камеры, не все камеры отдают видео с такой частотой.
Основными преимуществами являются:
— Браузер оптимизирует вызовы requestAnimationFrame с другими анимациями и перерисовками, что позволяет избежать ненужных перерисовок и как следствие «лагов».
— При использовании этого метода расход батареи значительно меньше, это особенно важно для мобильных девайсов.
— Он работает без стека вызова, тем самым не создавая очередь вызовов.
— Минимальная частота вызова 16.67 мс (1000 мс / 60 fps = 16.67 мс)
— Можно контролировать частоту вызова
Снятие и анализ метрик
Для отображения метрик приложения сейчас используется stats.js и по началу это казалось хорошей идеей, но после того, когда метрик стало 20+, основной флоу приложения начинал тормозить, из-за специфики работы браузер. Каждая метрика — это канвас, на который отрисовывается график (данные поступают очень часто туда) и браузер без остановки занимается отрисовкой, что негативно сказывается на работе приложения, следовательно и метрики заниженные получаются.
Для избежания такой проблемы лучше отказаться от использования «красоты», а выводить просто тестом значения текущее и просчитанное среднее за все время. Обновление значения в DOM будет гораздо быстрее, чем отрисовка.
Контролирование утечек памяти
Довольно часто при разработке мы сталкивались с утечкой памяти на мобильных устройствах, в то время как на десктопе работать могло очень долго.
При использовании веб воркеров нельзя узнать сколько памяти он потребляет в реальности (performance.memory не работает в веб воркерах).
На основе этого, мы предусмотрели запуск нашего приложения через веб воркеры и полностью в основном потоке. Запуская все наши модели детекции в основном потоке, можно снять метрики потребления памяти и увидеть, где утечка памяти и исправить это.
Основной код моделей в веб воркерах
Мы ознакомились с основными трюками, которые были использованы при реализации приложения, теперь рассмотрим саму реализацию.
Для работы с веб воркерами мы изначально использовали comlink-loader. Очень удобная библиотека, позволяющая работать с воркером как с объектом класса, не используя методы onmessage и postMessage, контролирование асинхронного кода с помощью async-await. Все это было удобно, пока приложение не запустили на планшете (Samsung Galaxy Tab S7) и неожиданно оно через 2 минуты работы крэшилось.
Проанализировав весь наш код, мы не нашли утечек памяти, кроме черного ящика в виде этой библиотеки для работы с воркерами. По какой-то причине запускаемые модели Tensorflow.js не очищались и где-то подвисали внутри этой библиотеки.
Было принято решение попробовать использовать worker-loader, который позволяет работать с веб воркерами как из чистого js без лишних прослоек. И это решило проблему, приложение работает сутками без вылетов.
Определение лица
Создаем воркер
this.faceDetectionWorker = workers.FaceRgbDetectionWorkerFactory.createWebWorker();
Создаем обработчик сообщений из воркера в основном потоке.
this.faceDetectionWorker.onmessage = async (event) => {
if (event.data.type === 'load') {
this.faceDetectionWorker.postMessage({
type: 'init',
backend,
streamSettings,
faceDetectionSettings,
imageRatio: this.imageRatio,
});
} else if (event.data.type === 'init') {
this.isFaceWorkerInit = event.data.status;
// When both workers inited it is run processes to grab and process frames only
if (this.isFaceWorkerInit && this.isMaskWorkerInit) {
await this.grabFrame();
}
} else if (event.data.type === 'faceResults') {
this.onFaceDetected(event);
} else {
throw new <i>Error</i>(`Type=${event.data.type} is not supported by RgbVideo for FaceRgbDatectionWorker`);
}
};
Отправка изображение на обработку лица
this.faceDetectionWorker.postMessage(
{
type: 'detectFace',
originalImageToProcess: this.lastImage,
lastIndex: lastItem!.index,
},
[this.lastImage], // transferable object
);
Код веб воркера определения лица
Метод init инициализирует все модели, библиотеки и канвас, которые ему пригодятся для работы.
export const init = async (data) => {
const { backend, streamSettings, faceDetectionSettings, imageRatio } = data;
flipHorizontal = streamSettings.flipHorizontal;
faceMinWidth = faceDetectionSettings.faceMinWidth;
faceMinWidthConversionFactor = faceDetectionSettings.faceMinWidthConversionFactor;
predictionIOU = faceDetectionSettings.predictionIOU;
recommendedLocation = faceDetectionSettings.useRecommendedLocation ? faceDetectionSettings.recommendedLocation : null;
detectedFaceThumbnailSize = faceDetectionSettings.detectedFaceThumbnailSize;
srcImageRatio = imageRatio;
await tfc.setBackend(backend);
await tfc.ready();
const [blazeModel] = await <i>Promise</i>.all([
blazeface.load({
// The maximum number of faces returned by the model
maxFaces: faceDetectionSettings.maxFaces,
// The width of the input image
inputWidth: faceDetectionSettings.faceDetectionImageMinWidth,
// The height of the input image
inputHeight: faceDetectionSettings.faceDetectionImageMinHeight,
// The threshold for deciding whether boxes overlap too much
iouThreshold: faceDetectionSettings.iouThreshold,
// The threshold for deciding when to remove boxes based on score
scoreThreshold: faceDetectionSettings.scoreThreshold,
}),
isOpenCvLoaded(),
]);
faceDetection = new FaceDetection();
originalImageToProcessCanvas = new <i>OffscreenCanvas</i>(srcImageRatio.videoWidth, srcImageRatio.videoHeight);
originalImageToProcessCanvasCtx = originalImageToProcessCanvas.getContext('2d');
resizedImageToProcessCanvas = new <i>OffscreenCanvas</i>(
srcImageRatio.faceDetectionImageWidth,
srcImageRatio.faceDetectionImageHeight,
);
resizedImageToProcessCanvasCtx = resizedImageToProcessCanvas.getContext('2d');
return blazeModel;
};
Метод isOpenCvLoaded дожидается загрузки openCV
export const isOpenCvLoaded = () => {
let timeoutId;
const resolveOpenCvPromise = (resolve) => {
if (timeoutId) {
clearTimeout(timeoutId);
}
try {
// eslint-disable-next-line no-undef
if (cv && cv.Mat) {
return resolve();
} else {
timeoutId = setTimeout(() => {
resolveOpenCvPromise(resolve);
}, OpenCvLoadedTimeoutInMs);
}
} catch {
timeoutId = setTimeout(() => {
resolveOpenCvPromise(resolve);
}, OpenCvLoadedTimeoutInMs);
}
};
return new <i>Promise</i>((resolve) => {
resolveOpenCvPromise(resolve);
});
};
Самый главный метод, это определение лица.
export const detectFace = async (data, faceModel) => {
let { originalImageToProcess, lastIndex } = data;
const facesThumbnailsImageData = [];
// Resize original image to the recommended BlazeFace resolution
resizedImageToProcessCanvasCtx.drawImage(
originalImageToProcess,
0,
0,
srcImageRatio.faceDetectionImageWidth,
srcImageRatio.faceDetectionImageHeight,
);
// Getting resized image
let resizedImageDataToProcess = resizedImageToProcessCanvasCtx.getImageData(
0,
0,
srcImageRatio.faceDetectionImageWidth,
srcImageRatio.faceDetectionImageHeight,
);
// Detect faces by BlazeFace
let predictions = await faceModel.estimateFaces(
// The image to classify. Can be a tensor, DOM element image, video, or canvas
resizedImageDataToProcess,
// Whether to return tensors as opposed to values
returnTensors,
// Whether to flip/mirror the facial keypoints horizontally. Should be true for videos that are flipped by default (e.g. webcams)
flipHorizontal,
// Whether to annotate bounding boxes with additional properties such as landmarks and probability. Pass in `false` for faster inference if annotations are not needed
annotateBoxes,
);
// Normalize predictions
predictions = faceDetection.normalizePredictions(
predictions,
returnTensors,
annotateBoxes,
srcImageRatio.faceDetectionImageRatio,
);
// Filters initial predictions by the criteri that all landmarks should be in area of interest
predictions = faceDetection.filterPredictionsByFullLandmarks(
predictions,
srcImageRatio.videoWidth,
srcImageRatio.videoHeight,
);
// Filters predictions by min face width
predictions = faceDetection.filterPredictionsByMinWidth(predictions, faceMinWidth, faceMinWidthConversionFactor);
// Filters predictions by recommended location
predictions = faceDetection.filterPredictionsByRecommendedLocation(predictions, predictionIOU, recommendedLocation);
// If there are any predictions it is started faces thumbnails extraction according to the configured size
if (predictions && predictions.length > 0) {
// Draw initial original image
originalImageToProcessCanvasCtx.drawImage(originalImageToProcess, 0, 0);
const originalImageDataToProcess = originalImageToProcessCanvasCtx.getImageData(
0,
0,
originalImageToProcess.width,
originalImageToProcess.height,
);
// eslint-disable-next-line no-undef
let srcImageData = cv.matFromImageData(originalImageDataToProcess);
try {
for (let i = 0; i < predictions.length; i++) {
const prediction = predictions[i];
const facesOriginalLandmarks = <i>JSON</i>.parse(<i>JSON</i>.stringify(prediction.originalLandmarks));
if (flipHorizontal) {
for (let j = 0; j < facesOriginalLandmarks.length; j++) {
facesOriginalLandmarks[j][0] = srcImageRatio.videoWidth - facesOriginalLandmarks[j][0];
}
}
// eslint-disable-next-line no-undef
let dstImageData = new cv.Mat();
try {
// eslint-disable-next-line no-undef
let thumbnailSize = new cv.Size(detectedFaceThumbnailSize, detectedFaceThumbnailSize);
let transformation = getOneToOneFaceTransformationByTarget(detectedFaceThumbnailSize);
// eslint-disable-next-line no-undef
let similarityTransformation = getSimilarityTransformation(facesOriginalLandmarks, transformation);
// eslint-disable-next-line no-undef
let similarityTransformationMatrix = cv.matFromArray(3, 3, cv.CV_64F, similarityTransformation.data);
try {
// eslint-disable-next-line no-undef
cv.warpPerspective(
srcImageData,
dstImageData,
similarityTransformationMatrix,
thumbnailSize,
cv.INTER_LINEAR,
cv.BORDER_CONSTANT,
new cv.Scalar(127, 127, 127, 255),
);
facesThumbnailsImageData.push(
new <i>ImageData</i>(
new <i>Uint8ClampedArray</i>(dstImageData.data, dstImageData.cols, dstImageData.rows),
detectedFaceThumbnailSize,
detectedFaceThumbnailSize,
),
);
} finally {
similarityTransformationMatrix.delete();
similarityTransformationMatrix = null;
}
} finally {
dstImageData.delete();
dstImageData = null;
}
}
} finally {
srcImageData.delete();
srcImageData = null;
}
}
return { resizedImageDataToProcess, predictions, facesThumbnailsImageData, lastIndex };
};
На вход подается изображение и индекс, для сопоставления лица и детекции маски в последующем.
Так как blazeface принимает изображения с максимальной стороной 128 px, то изображение с камеры нужно уменьшить.
Вызвав метод faceModel.estimateFaces мы запускаем анализ изображения с помощью blazeface и нам возвращаются предикшены с координатами области лица, носа, ушей, глаз, рта.
Перед тем, как с ними работать, нужно восстановить координаты для исходного изображения, мы же его сжали до 128 px.
Теперь можно использовать эти данные для принятия решения находится ли лицо в нужной области или нет, какой минимальный размер лица нам нужен, для последующей идентификации.
Следующий код вырезает лицо из изображения и выравнивает его, для идентификации и детекции маски с помощью методов openCV.
Детекция маски
Инициализация модели и webAssembly
export const init = async (data) => {
const { backend, streamSettings, maskDetectionsSettings, imageRatio } = data;
flipHorizontal = streamSettings.flipHorizontal;
detectedMaskThumbnailSize = maskDetectionsSettings.detectedMaskThumbnailSize;
srcImageRatio = imageRatio;
await tfc.setBackend(backend);
await tfc.ready();
const [maskModel] = await <i>Promise</i>.all([
tfconv.loadGraphModel(
`/rgb_mask_classification_first/MobileNetV${maskDetectionsSettings.mobileNetVersion}_${maskDetectionsSettings.mobileNetWeight}/${maskDetectionsSettings.mobileNetType}/model.json`,
),
]);
detectedMaskThumbnailCanvas = new <i>OffscreenCanvas</i>(detectedMaskThumbnailSize, detectedMaskThumbnailSize);
detectedMaskThumbnailCanvasCtx = detectedMaskThumbnailCanvas.getContext('2d');
return maskModel;
};
Для детекции маски нам необходимы координаты глаз, ушей, носа и рта и выровненное изображение, которое вернул воркер детекции лица.
this.maskDetectionWorker.postMessage({
type: 'detectMask',
prediction: lastItem!.data.predictions[0],
imageDataToProcess,
lastIndex: lastItem!.index,
});
Метод детекции
export const detectMask = async (data, maskModel) => {
let { prediction, imageDataToProcess, lastIndex } = data;
const masksScores = [];
const maskLandmarks = <i>JSON</i>.parse(<i>JSON</i>.stringify(prediction.landmarks));
if (flipHorizontal) {
for (let j = 0; j < maskLandmarks.length; j++) {
maskLandmarks[j][0] = srcImageRatio.faceDetectionImageWidth - maskLandmarks[j][0];
}
}
// Draw thumbnail with mask
detectedMaskThumbnailCanvasCtx.putImageData(imageDataToProcess, 0, 0);
// Detect mask via NN
let predictionTensor = tfc.tidy(() => {
let maskDetectionSnapshotFromPixels = tfc.browser.<i>fromPixels</i>(detectedMaskThumbnailCanvas);
let maskDetectionSnapshotFromPixelsFlot32 = tfc.<i>cast</i>(maskDetectionSnapshotFromPixels, 'float32');
let expandedDims = maskDetectionSnapshotFromPixelsFlot32.expandDims(0);
return maskModel.predict(expandedDims);
});
// Put mask detection result into the returned array
try {
masksScores.push(predictionTensor.dataSync()[0].toFixed(4));
} finally {
predictionTensor.dispose();
predictionTensor = null;
}
return {
masksScores,
lastIndex,
};
};
Результатом нейронной сети является вероятность, что маска есть, что мы и возвращаем из воркера. Это позволяет уменьшать или увеличивать трэшхолд детекции маски. По lastIndex мы можем сопоставить лицо и наличие маски и вывести на экран какую-то информацию по конкретному человеку.
Заключение:
Надеюсь эта статья поможет вам узнать много нового о возможностях работы с ML в браузере и путях оптимизации. Используя описанные трюки можно оптимизировать большинство приложений.
")

")
