
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Меня зовут Никита Василюк, я инженер по работе с данными в департаменте данных и аналитики Lamoda. Я и моя команда занимаемся всем, что связано с распределенной системой хранения и обработки данных.
Периодически нам приходится отвечать на вопросы, где у нас лежат те или иные данные. Поэтому однажды мы решили провести эксперимент и внедрить Data Catalog, чтобы запросы приходили уже не к нам, а в систему. Например, если человеку понадобилась информация, связанная с заказами, он может перейти в систему, ввести слово order и найти все, что ему нужно по этой теме. Мы рассмотрели три инструмента и в итоге… не стали ничего менять. Рассказываю почему.

В идеальном мире Data Catalog — это инструмент, в котором можно найти краткую сводку по данным в хранилище, увидеть их структуру, проследить lineage (путь данных от системы-источника до целевой таблицы), посмотреть profiling (краткую статистику по полям таблицы) и историю проверок качества данных, увидеть владельцев данных и запросить доступ. Сейчас у нас есть подобие этого каталога: все таблицы нашего хранилища описываются вручную аналитиками в Confluence.
Мы решили поставить небольшой эксперимент и представить, что было бы, если роль Data Catalog исполнял не Confluence, а другая система.
Требования к системе
Мы определили несколько важных требований к потенциальной системе, в которой бы начали строить Data Catalog:
- Автоматический сбор данных из разных СУБД. Это позволит нам избавить аналитиков от ручного обновления описаний таблиц.
- Отображение структуры датасета с понятными описаниями и полнотекстовым поиском по этой информации.
- Web UI с поиском. Это очень важное требование, поскольку в первую очередь Data Catalog задумывается как инструмент для поиска метаданных.
- Визуализация data lineage от системы-источника до отчета в BI-системе.
- Отображение data owner. С помощью этого можно понять, к какому человеку обратиться по всем вопросам, связанных с данными.
Остальные требования входят в разряд «хотелок» — их наличие упростило бы жизнь, однако отсутствие не так критично:
- SSO SAML авторизация;
- визуализация Data Profiling;
- визуализация Data Quality;
- добавление кастомной информации для отображения;
- трекинг изменения датасетов.
Мы решили рассмотреть три популярных open source проекта: Amundsen, LinkedIn DataHub и Marquez.
Amundsen
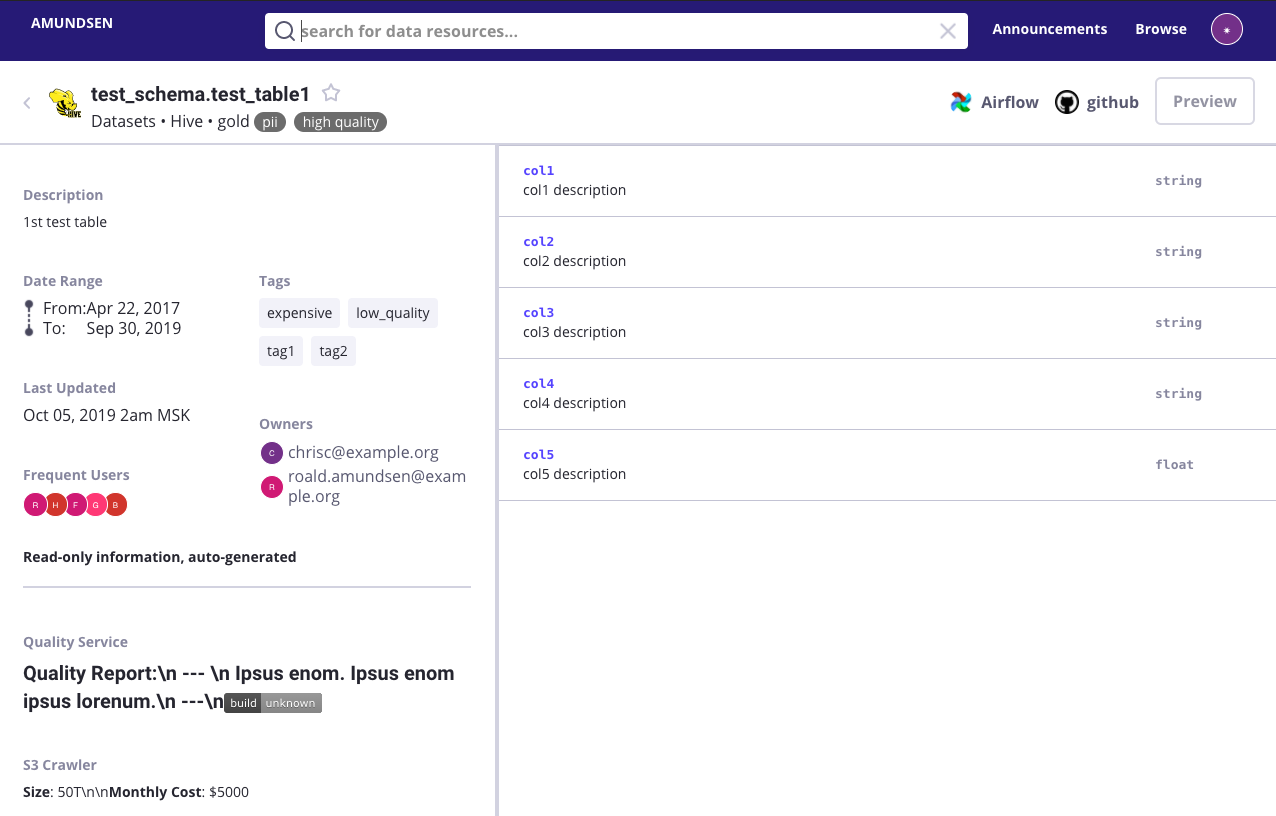
Amundsen — это типичный справочник. То есть просто хорошая штука, чтобы поискать информацию по имеющимся таблицам. Он состоит из следующих сервисов:
- neo4j — хранилище метаданных (также может использоваться Apache Atlas);
- elasticsearch — поисковый движок;
- amundsensearch — сервис для поиска по данным в Elasticsearch;
- amundsenfrontendlibrary — Web UI (написан на Flask);
- amundsenmetadatalibrary — отвечает за работу с метаданными в Neo4j или Atlas;
- amundsendatabuilder — библиотека для извлечения данных из различных СУБД.
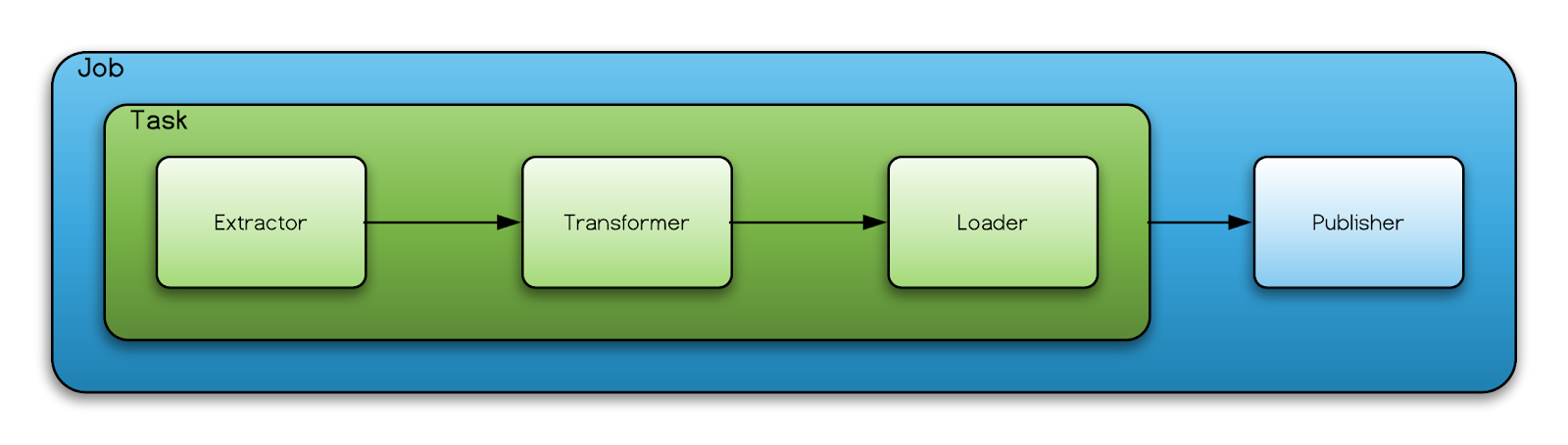
Принцип работы довольно простой. ETL-процесс сбора метаданных состоит из извлечения записей из источника при помощи выполнения SQL-запросов, преобразования записей и их загрузки в хранилище метаданных. Extractor выполняет запрос к хранилищу метаданных и преобразует их в набор вершин и связей между ними. Промежуточные результаты сохраняются в локальную директорию. Transformer преобразует загруженные данные в нужную структуру. Loader подхватывает промежуточные данные и складывает их либо во временный слой, либо сразу в финальное хранилище. Publisher подхватывает промежуточные данные и отправляет в хранилище.
В целом Amundsen — хороший справочник, который может отображать текущее состояние данных, но, к сожалению, он не способен хранить историю. Мы не можем отследить, когда таблица или колонка была добавлена, удалена или модифицирована.
Во время тестирования Amundsen показался достаточно сырым — например, из коробки не было авторизации, а поиск работал только по тегам и названиям баз, таблиц и колонок, не было возможности искать по описаниям. Но он действительно хорошо работает, когда нужно посмотреть, какие данные есть у нас в схемах.
Плюсы:
- автоматический сбор данных из разных СУБД;
- API для добавления или редактирования данных в автоматическом режиме за счет обращения напрямую к Metastore/information_schema;
- Web UI с полнотекстовым поиском;
- поиск по базам, таблицам, полям и тэгам;
- добавление кастомной информации для отображения (programmatic description)
- визуализация data profiling (например, количество записей, дата последнего обновления, исторические значения);
- визуализация data quality (какие проверки навешаны на датасет, история результатов проверок);
- отображение data owner.
Минусы:
- нет трекинга изменения датасетов (хранит только актуальное состояние и работает как справочник);
- нет data lineage (источник можно идентифицировать только в блоке с кастомной информацией);
- не нашли SSO-аутентификацию, доступна только OIDC;
- полнотекстовой поиск работает только для тегов, таблиц, баз и колонок (нет возможности искать по описаниям колонок).
LinkedIn DataHub
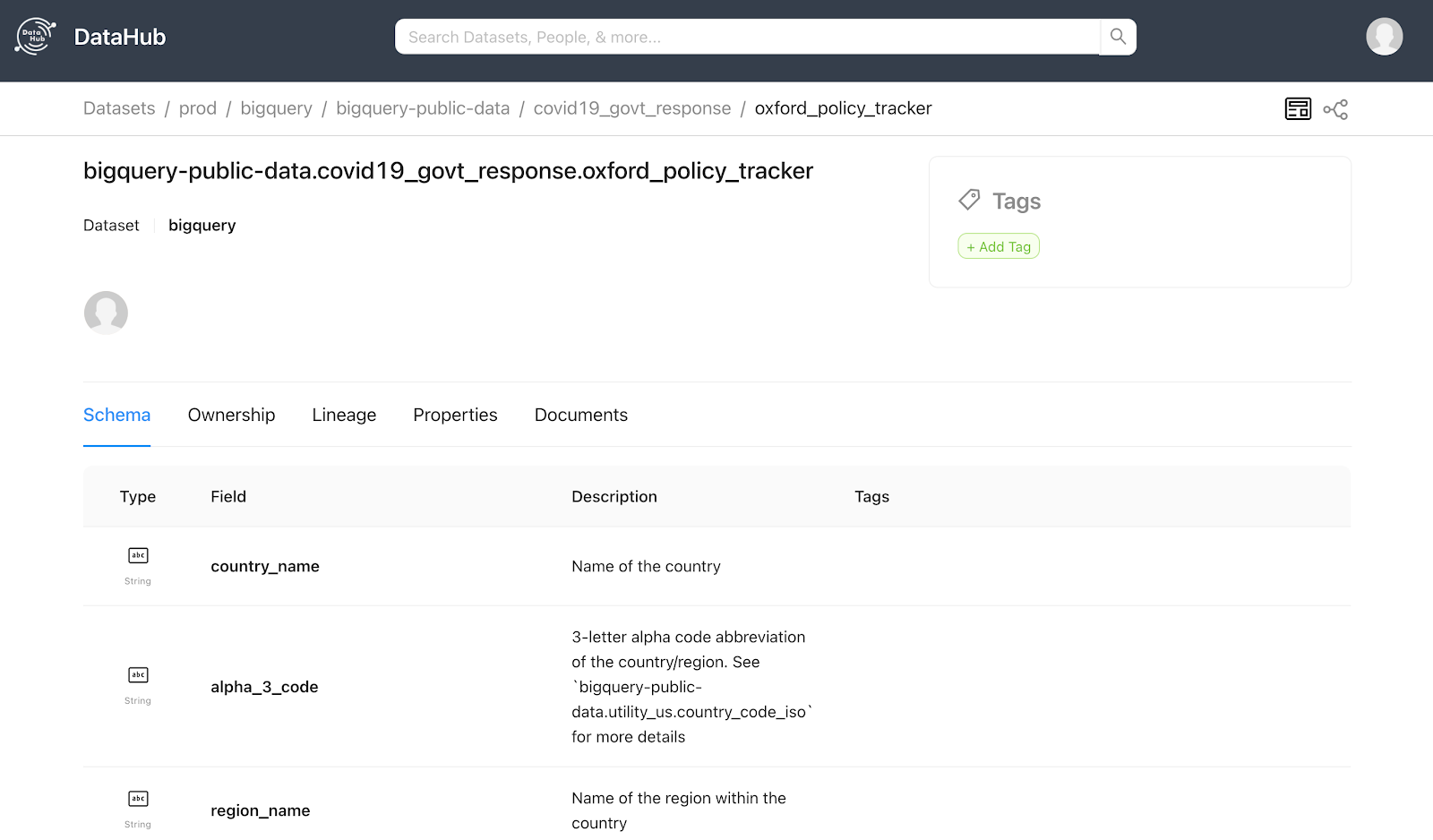
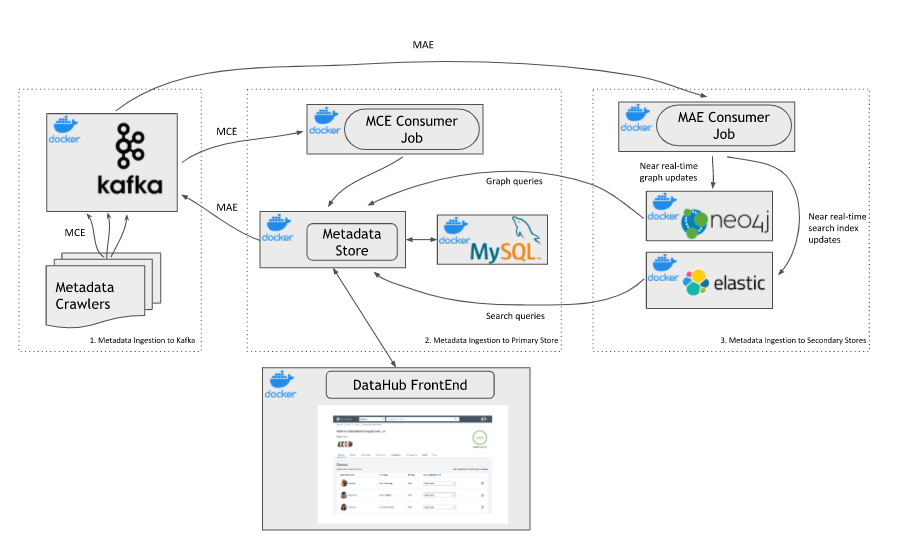
Как можно понять из названия, это платформа поиска и обнаружения метаданных от LinkedIn. Из коробки она состоит из целого зоопарка сервисов:
- kafka-broker — брокер Kafka;
- zookeeper — координатор для Kafka;
- kafka-rest-proxy — RESTful интерфейс для Kafka;
- kafka-topics-ui — Web UI для топиков Kafka;
- schema-registry — Kafka Schema Registry;
- schema-registry-ui — Kafka Schema Registry UI;
- elasticsearch — поисковый движок;
- kibana — дашборд для Elasticsearch;
- neo4j — графовая база данных;
- datahub-gms — Generalized Metadata Store;
- datahub-frontend — Web UI;
- datahub-mae-consumer — сервис для обработки сообщений Metadata Audit Events;
- datahub-mce-consumer — сервис для обработки сообщений Metadata Change Events;
- mysql — база данных для хранения метаданных.
Основная сущность DataHub — dataset. Он может включать в себя таблицы (RDBMS и не только), топики в Kafka, директории на HDFS или другие сущности, имеющие схему.
Датасет имеет:
- схему (включая типы и комментарии к полям),
- статус (active или deprecated),
- владельцев,
- relationships (он же lineage),
- docs с указанием ссылок на документацию.
Метаданные обновляются через отправку сообщений Metadata Change Event (MCE) в Kafka. MCE — это сообщение в формате AVRO с указанием пунктов, которые необходимо обновить. Гибкость обновления данных в системе достигается за счет возможности в одном сообщении обновить владельцев датасета, в другом — обновить схему, в третьем — upstream datasets.
Отличительная особенность DataHub — приятный веб-интерфейс. Он нам сразу понравился и запал в душу. У него все хорошо в плане поиска, обновлений типов таблиц и типов датасетов, информация о схеме датасета выглядит очень приятно. Можно добавлять владельцев датасетов, можно зайти в профиль пользователя и посмотреть, какими датасетами он владеет. У DataHub есть lineage, для каждого датасета можно наблюдать его взаимосвязи с другими объектами. Также есть возможность к каждому датасету прикладывать ссылки на документацию или исходный код.
Самый большой минус DataHub — он состоит из огромного числа компонентов. Плохо это тем, что за каждым надо следить и для каждого из них нужно настроить отказоустойчивость.
Плюсы:
- удобный UI с поиском;
- автоматический сбор данных из разных СУБД (большая гибкость, поддерживает сбор данных не только из СУБД, работает для всего, у чего есть схема);
- добавление или редактирование данных в автоматическом режиме через отправку AVRO-сообщений в Kafka;
- добавление ссылок на документацию к датасету;
- визуализация data lineage от источника до отчета в BI-системе (однако нет возможности отобразить всю цепочку сразу, отображается только upstream и downstream датасеты на один уровень вверх и вниз);
- отображение data owner;
- есть возможность сделать связку с интранетом компании.
Минусы:
- огромное количество внутренних сервисов, за каждым из которых нужно следить;
- отсутствует трекинг изменения датасетов;
- data lineage показывает только upstream и downstream датасеты;
- отсутствие визуализации data profiling;
- отсутствие визуализации data quality (в roadmap на Q2 2021 есть пункт про отображение визуализаций и интеграцию с такими системами, как Great Expectations и deequ);
- нет возможности добавить кастомную информацию для датасета;
- нет возможности прослеживать изменения в датасетах;
- поиск работает только для датасетов и пользователей.
Marquez
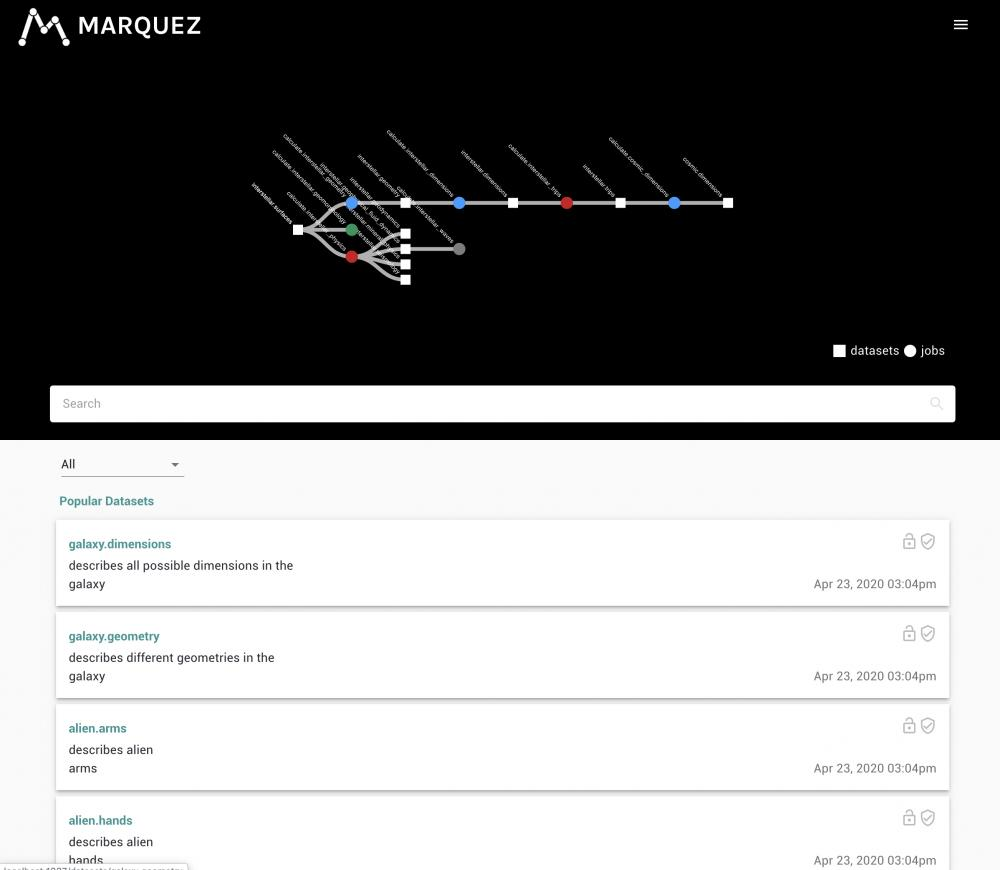
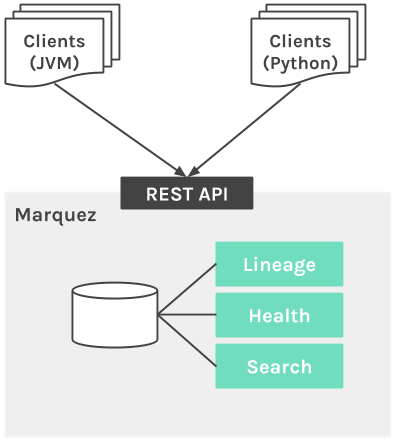
Третий инструмент — Marquez. Он состоит из основного приложения, базы данных и веб-интерфейса для отображения датасетов, джобов и связей между ними.
Метаданные в Marquez отправляются с помощью REST API. Еще он поддерживает создание следующих типов объектов:
- data source — системы-источники;
- dataset — таблицы, из которых читаются и в которые пишутся данные, обрабатываемые джобами;
- job — абстракция над процессом трансформации данных, которая принимает таблицы на вход и записывают в них данные;
- job run — запуск конкретной джобы.
Marquez на самом деле очень простой и не имеет в себе ничего лишнего. У него хорошая модель данных: абстракции, которые заложили в него разработчики, позволяют довольно полно описывать процессы обработки и трансформации данных.
Его самый главный минус — слишком минималистичный интерфейс, он плохо справляется с отображением lineage, в котором есть много таблиц и ветвлений. Нет возможности отображать владельца данных, нельзя в режиме справочника посмотреть, какие таблицы у нас есть. Нет возможности отображать информацию по качеству данных, по профилированию, невозможно добавить кастомную информацию. То есть Marquez — максимально простой инструмент, который может подойти для каких-то простых use-case’ов, но не подойдет для чего-то масштабного.
Плюсы:
- быстрый и минималистичный UI;
- поддержка airflow из коробки;
- простая, но гибкая модель данных, позволяет с минимальным набором абстракций описывать данные;
- понятный и простой API для добавления или редактирования данных;
- Web UI с поиском;
- есть lineage;
- минимум компонентов.
Минусы:
- слишком минималистичный UI;
- отсутствует авторизация;
- плохо работает в режиме «пробежаться глазами и посмотреть, какие данные вообще есть»;
- не отображается data owner;
- поиск работает только для датасетов и джобов;
- нет возможности прослеживать изменения в датасетах;
- отсутствует трекинг изменения датасетов;
- отсутствует визуализация data profiling;
- отсутствует визуализация data quality;
- нет возможности добавить кастомную информацию для датасета.
Бонус: загоняем lineage из DWH в Neo4j
В качестве бонуса мы решили попробовать графовую базу данных Neo4j для отображения lineage. Источником данных стала сервисная таблица в нашем хранилище, в которой для каждой другой таблицы указано, какие объекты участвовали в ее формировании. Мы взяли три самых массивных представления и прошлись по их lineage вплоть до систем-источников.

В первом подходе мы решили действовать в лоб: прошлись по всем таблицам в цепочке и соединили их промежуточными вершинами-джобами aka SQL-запросами, которые заполняют таблицу данными. Таким образом, получилось большое дерево связей, которое невозможно внятно читать (зато его забавно рассматривать и двигать).
Очевидно, что ничего дельного из этого графа мы не вычленим: вершин слишком много, для просмотра полного названия каждой вершины на нее нужно сначала нажать и не промазать, а поиск интересующей таблицы в графе может занять много времени.
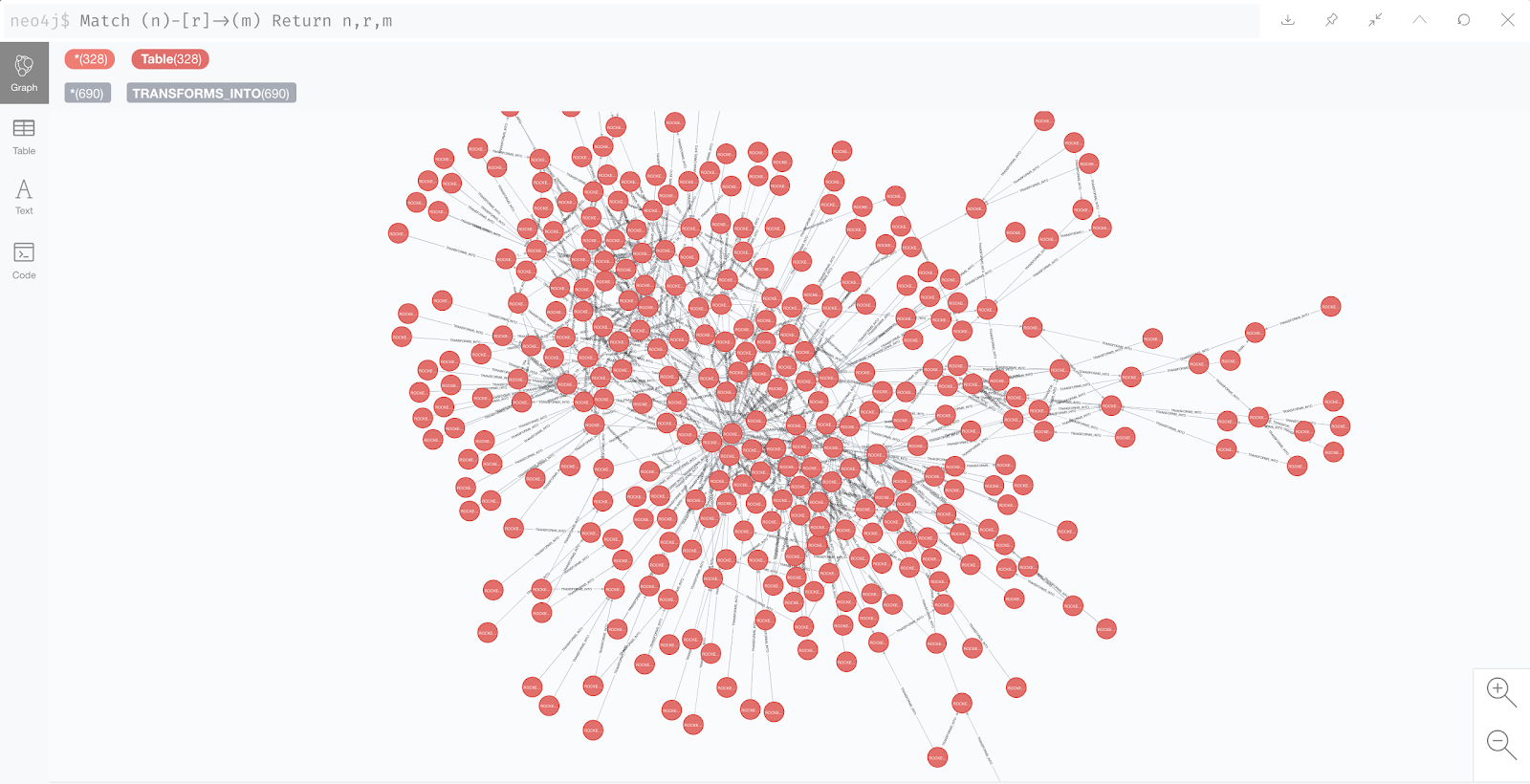
Во втором подходе мы попробовали убрать джобы и просто связать таблицы между собой. Вершин в графе стало очевидно меньше, однако читать его легче не стало.
После этого мы загнали данные из Neo4j в инструмент под названием neo4j-explorer, который создан для более структурированного отображения графа из Neo4j.

Зеленые блоки — джобы, серые — таблицы. Можно выделить джоб или таблицу и подсветить его зависимости в обе стороны. Несмотря на то, что выглядит это мощно (и напоминает кусок производства из игры Factorio), ничего полезного из этого мы вынести тоже не можем.
Что мы выбрали в итоге и почему не стали внедрять
В результате нашим фаворитом стал LinkedIn DataHub. Но мы поняли, что большинство текущих «хотелок» полностью покрываются Confluence, а у команд аналитиков сложились устоявшиеся процессы по работе с данными. Внедрять новую сложную систему и изменять текущие подходы к работе стоит только ради очень серьезных улучшений. Помимо этого, плюсы систем и их ограничения не перевешивают для нас трудоемкости внедрения и перехода.
Проведя Customer Development среди потенциальных пользователей, мы пришли к выводу, что ни одна из систем не поможет сэкономить рабочее время тех людей, которые работают с данными. При этом сложность внедрения и перестройки процессов будет существенной. Поэтому мы решили на какое-то время отложить выбор.
Мы отслеживаем развитие рассмотренных в статье сервисов, изучаем платные варианты Data Catalog и их возможности. Если у вас есть успешный (или не очень) опыт внедрения подобных систем, то поделитесь им в комментариях.



