
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
 Круг задач, которые можно решить с помощью технологий ABBYY, пополнился еще одной интересной возможностью. Мы обучили свой движок работе банковского андеррайтера – человека, который из гигантского потока новостей вылавливает события о контрагентах и оценивает риски.
Круг задач, которые можно решить с помощью технологий ABBYY, пополнился еще одной интересной возможностью. Мы обучили свой движок работе банковского андеррайтера – человека, который из гигантского потока новостей вылавливает события о контрагентах и оценивает риски. Сейчас такие системы на базе технологий ABBYY используют уже несколько крупных российских банков. Мы хотим рассказать о нюансах внедрения этого решения – довольно нетривиальных и неожиданных вызовах, с которыми столкнулись наши онтоинженеры.
Обуздать новостной поток
Банку для успешной работы необходимо точно знать, с кем он имеет дело, и оперативно реагировать на важные изменения в жизни контрагентов. Особенно когда это другие банки или крупные корпоративные клиенты – IT-компании, сельхозпредприятия и другие. Для этого в большинстве российских банков есть особые эксперты – андеррайтеры. Они анализируют информацию из различных источников, включая новостные сообщения, на предмет рисковых факторов для банка. Нужно не только прочесть новость, но и оценить то, как она повлияет на банк и его клиентов.
Факторы риска могут быть различными:
- банкротство,
- конфликт акционеров,
- изменения в структуре собственности или в составе руководства,
- факты мошенничества, угроза потери бизнеса клиентом,
- информация о наличии претензий и внеплановых проверках со стороны регулирующих ведомств,
- наличие исков,
- экономический кризис в стране, стихийные бедствия и другие обстоятельства непреодолимой силы
- и другие факторы риска.
Если андеррайтер выявляет рисковый фактор, то в перспективе сотрудничество с таким контрагентом может принести банку проблемы, вплоть до судебного разбирательства. И вероятность негативного исхода важно выяснить как можно быстрее. Почему это не так просто? В новостях важны не только упоминания контрагентов, но и контекст. Необходимо понять, какая связь у персоны или компании с факторами, которые банк относит к источникам риска.
Тем временем новостной поток, особенно если учитывать не только федеральные, но и региональные СМИ, огромен и продолжает расти. Одна только «Медиалогия», сервис мониторинга новостей, агрегирует контент из 52 тыс. источников. По данным Роскомнадзора, по состоянию на сентябрь 2019 в реестре российских СМИ было зарегистрировано более 67 тыс. действующих медиа. Человек физически не способен оперативно прочесть все новости, даже если речь идет только об интересующей его теме. Вот и приходится банкам либо постоянно пополнять штат андеррайтеров, либо искать альтернативное решение в области информационных технологий.
Варианты решений
Самый очевидный путь – сузить поток сообщений за счет платных подписок на закрытые ленты новостей по разным тематикам. Такие ленты предлагают «Интерфакс», «Прайм», Thomson Reuters, Bloomberg и другие информационные агентства. Новости в них уже частично структурированы: есть теги с названиями компаний, ключевые персоны, задействованные в новости. Но это не решает проблему полностью: работа с контекстом все равно ложится на андеррайтеров.
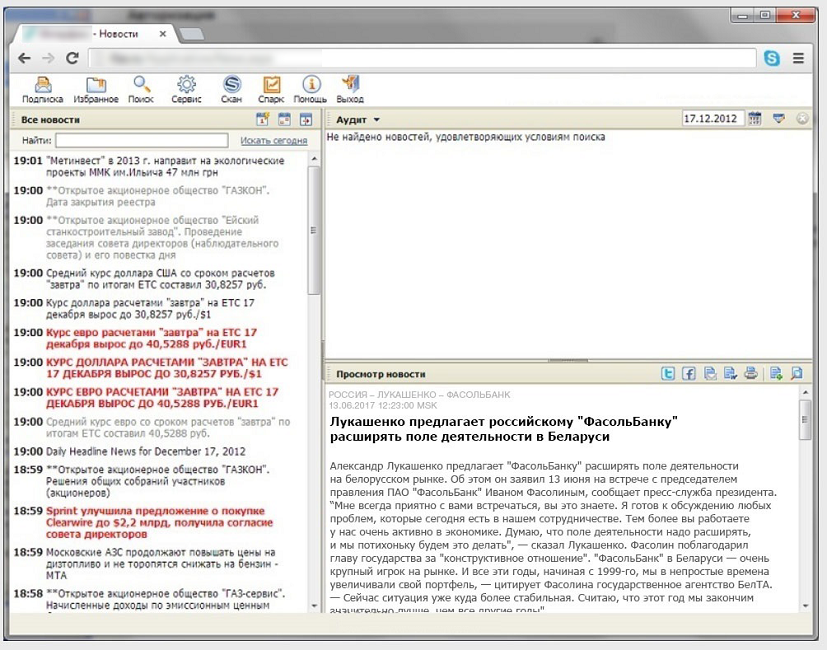
Многие существующие системы мониторинга СМИ в компаниях работают за счет поиска ключевых слов в тексте. Такой подход дает много информационного «шума» и не работает без дополнительных ухищрений в виде фильтров. Полнота и точность в сценарии с ключевыми словами оставляют желать лучшего, потому что:
- Ключевое слово и его однокоренные вариации могут упоминаться в тексте, но не относиться к делу. Например, компания может быть указана в исторической справке, которая напрямую не связана с сообщением.
- В новостях важны не просто упоминания контрагентов, но и контекст. Необходимо понять, какая связь у персоны или компании с факторами, которые банк относит к источникам риска. Если посмотреть на примеры рисковых факторов в текстах сообщений, то заметно, как много потенциально значимых новостей можно упустить при поиске по ключевым словам. Так, не всегда в новости упоминается словосочетание «конфликт акционеров». Между тем, если посмотреть на пример ниже, для андеррайтера конфликт или его потенциальная возможность налицо:

Кроме того, существует множество других негативных новостей, которые необходимо учитывать при анализе деятельности компании. При этом они не подпадают под одну категорию и отличаются в зависимости от специфики бизнеса клиента:
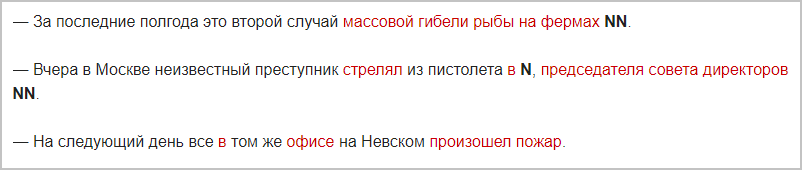
Быстро понять и проанализировать контекст можно еще одним способом. Как раз самое время вспомнить о наших NLP-технологиях, которые умеют автоматически определять тип контента и извлекать из него значимые сущности.
Первые пробы
Итак, один из крупнейших российских банков решил определить, какая из двух технологий лучше справится с задачей поиска рисков. Интеллектуальный классификатор документов определял риск-факторы на основе содержания новости. Решение на базе текстовой аналитики извлекало из новостей нужные данные. В итоге, как оказалось, лучший вариант – симбиоз двух решений: классификатор помогал сужать количество документов, которые поступают из ленты, и убирал совсем нерелевантную информацию, а дальше в работу включались технологии извлечения данных.
На первом этапе – Proof of concept (POC) – была протестирована сама возможность использования этих инструментов для поиска рисков. Заказчик выбрал один рисковый фактор – конфликтную ситуацию. Технология должна была выявить сообщения, в которых говорится о конфликте акционеров – физических или юридических лиц, топ-менеджеров банка или о конфликте банка с регулирующими ведомствами. Онтоинженеры ABBYY создали пробную модель, для разработки которой использовалась подборка из 1000 новостей. Она извлекала текст конфликта, дату новости и перечень его участников. Модель доказала состоятельность предложенного подхода: на этапе POC на предоставленной одним из банков контрольной выборке (новости, которые не использовались для разработки) из 50 документов были получены следующие результаты:
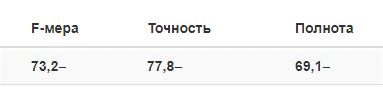
Полнота определяет, какой процент факторов из имеющихся в выборке мы нашли, а точность – какой процент факторов, которые мы определили, действительно таковыми являются. F-мера представляет собой гармоническое среднее между точностью и полнотой.
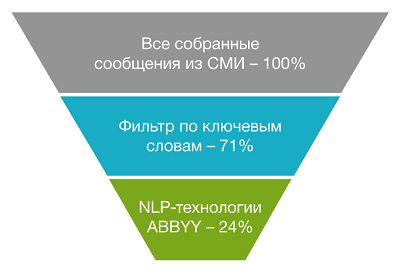
После удачного завершения POC был запущен пилот, и он показал неплохие результаты. Ниже — результаты пилота в одном из наших проектов. По сравнению с поиском новостей по ключевым словам NLP-модуль ABBYY умеет фильтровать в три раза больше нерелевантных сообщений. Это значит, что риск-менеджеру нужно будет анализировать в три раза меньше новостей.
Совершенствуем результат
В процессе разработки моделей онтоинженеры ориентируются на результаты регулярных автотестов, в которых фиксируются все расхождения между целевыми и полученными значениями. Для построения таких отчетов новости размечали в соответствии с инструкцией, которую предоставил заказчик. Размеченные файлы в формате xml, содержащие целевые значения, сравнивались с xml-файлами, полученными в результате использования текущей версии онтомодели. Результаты автотестов предоставляют как сводную информацию, содержащую показатели качества анализа всей коллекции новостей, так и частную информацию по каждому извлекаемому объекту и документу в отдельности. Так можно оценить, как повышается точность работы модели в динамике.
Вот пример такой таблицы:

Результаты работы модели также можно измерять с помощью Accuracy Metric, производной полноты и точности:

Accuracy Metric можно назвать базовой. Она измеряет количество верно классифицированных объектов относительно общего количества всех объектов. Accuracy Metric имеет некоторые недостатки: она не идеальна для несбалансированных классов, где может быть много экземпляров одного класса и мало другого.
Эту метрику использует другой крупный банк, тоже наш клиент. Показатель Accuracy Metric составил 85%.
В дальнейшем банки самостоятельно выполняли интеграцию продуктов ABBYY, внутри которых работала наша модель, и использовали их в своем контуре. Наши продукты интегрированы с банковской системой управления рисками: передают документы на анализ и забирают результаты.
Как работает система
С технической точки зрения система работает так: когда текст попадает на обработку в решение ABBYY, выполняется его многоэтапный лингвистический анализ. На лексико-морфологическом этапе определяются самые простые свойства слов: род, число, падеж. Затем на этапе синтаксического анализа определяется, где подлежащее, сказуемое, как слова связаны друг с другом. Знание синтаксиса позволяет перейти к определению семантики. Для каждого слова определяется его значение. Поверх этого лингвистического анализа работают правила извлечения информации, которые разрабатывают наши онтоинженеры. Онтомодель включает описание структуры данных, которую нужно получить из документов заказчика, и правила, которые позволяют эту структуру данных извлекать.


С точки зрения пользователя все выглядит максимально просто. В личном кабинете появляются ссылки на новости по выбранным клиентам, в которых технология увидела риски. Рядом с ссылкой размещается сам текст рискового фактора. Так что пользователю нет необходимости читать всю новость целиком. По желанию можно автоматически получать ссылки на новости по почте.
Ознакомившись с фрагментом текста, андеррайтер уже сам принимает решение, что с этой информацией делать дальше.
Неожиданные сложности
Риск – понятие абстрактное. Это очень специфическая профессиональная область, и здесь важно учитывать мнение специалистов, которые работают с рисками каждый день. Пользователи у наших заказчиков могут голосовать за новости и ставить условный «лайк»: правильно ли система определила наличие риска в новости или нет.
В процессе отладки системы мы столкнулись с тем, что часто андеррайтеры по-разному интерпретируют смысл новости и наличие в ней рискового фактора. Один пользователь хочет, чтобы определенный тип новостей появлялся в его ленте, а другой – считает подобные сообщения несущественными. Эта проблема решается так: банк собирает от андеррайтеров список новостей, которым специалисты дали разную трактовку, и принимает окончательное решение по интерпретации определенной новости: есть ли в ней рисковый фактор или нет. В зависимости от обратной связи в онтомодель вносятся доработки.
А что если новость на английском?
Многие российские банки используют такие источники, как Dow Jones, Bloomberg, Financial Times. Одним из преимуществ нашего подхода к разработке онтомоделей на базе NLP-технологий ABBYY оказалась быстрая адаптация моделей, разработанных для анализа новостей на русском языке, для работы с англоязычными текстами. Для этого требуется отладка модели на оригинальных английских новостях.
Оценим результаты
Теперь андеррайтеры могут следить за новостями в реальном времени, при этом им не надо читать все 100500 сообщений. В принципе даже не надо читать целиком всю новость, где система нашла рисковый фактор: в программе подсвечивается фрагмент с самым важным (сниппет). За пару минут можно автоматически составить отчет по одному банку, выделить только один риск-фактор или несколько значимых. С таким подходом сложнее упустить что-то важное. Дальше андеррайтер может открыть карточку контрагента и выбрать сообщения, которые он считает существенными. На их основании может быть пересмотрен кредитный рейтинг компании, изменена процентная ставка или может появиться повод связаться с руководством компании. Эти сообщения передаются дальше в workflow-систему.
Вы спросите, сколько новостей обрабатывает технология? Все зависит от новостного потока: в январе и мае, например, сообщений традиционно меньше. В месяц через нашу систему один банк может проверить до 2,5 млн новостей. И это число ограничено только лицензией и вычислительными мощностями.
Кстати, подобные технологии могут работать не только в банках, но и в любых компаниях, которые отслеживают большой поток сообщений о конкурентах, клиентах, партнерах и читают отзывы пользователей в соцсетях. Например, венчурные фонды с помощью NLP-технологий могут отслеживать информацию о перспективных стартапах с точки зрения потенциальных инвестиций, а государственные организации – ключевые новости о том, что происходит в конкретном регионе, какие есть проблемы, кто ответственный и т.п. Причем анализировать можно не только сообщения в СМИ, но и блоги и отзывы в социальных сетях.
А с какими задачами сталкивались вы, занимаясь проектами по обработке неструктурированных документов как для банков, так и для компаний других отраслей?
")
")

