
Этот день — яркий пример того, как несколько вещей, которые сами по себе не приводят к отказу, могут удачно совпасть. Итак, 23 апреля было совершенно обычным днём, с обычным трафиком и обычной загрузкой ресурсов. Как обычно, с запасом больше трети, чтобы при потере любого из ЦОДов пережить это без проблем. Никто не думал, что к серверному мониторингу нужно прикручивать ещё мониторинг того, что говорит президент на прямой линии, поэтому дальше случилось вот что:
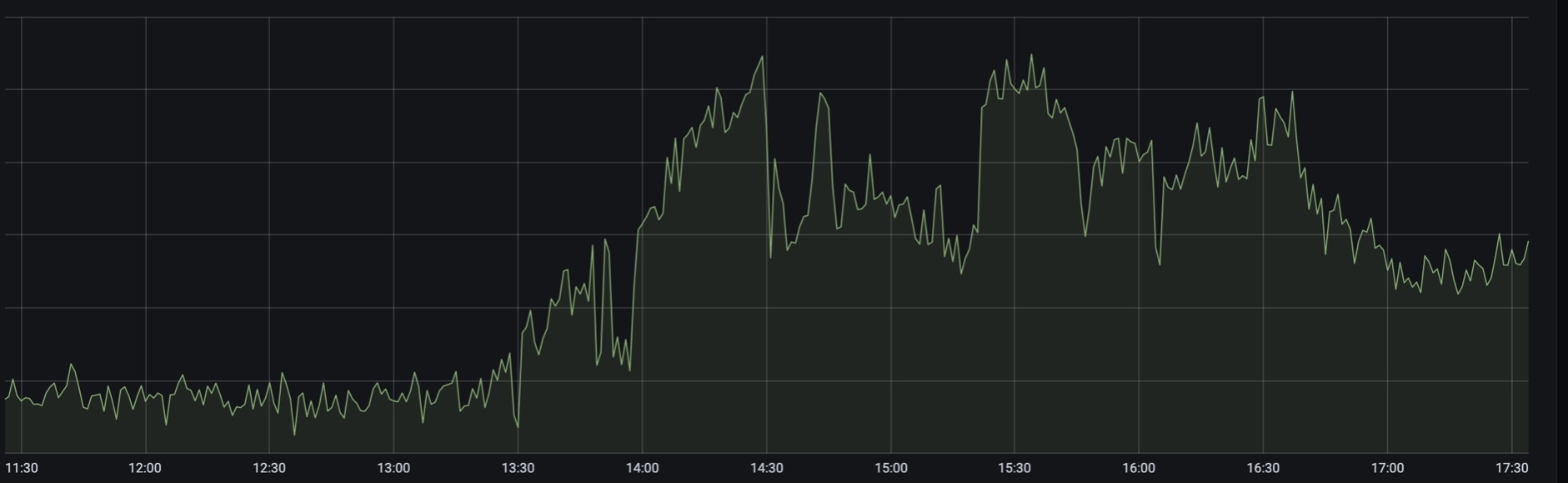
Примерно в 13:30 у нас резко подскочила нагрузка на поиск по авиации и по железнодорожным билетам. Где-то в этот момент РЖД сообщила о перебоях на сайте и в приложении, а мы начали экстренно наливать дополнительные инстансы бекендов во всех ЦОДах.
Но на самом деле проблемы начались раньше. Примерно в 8 утра мониторинг прислал алерт про то, что на одной из реплик базы данных у нас что-то подозрительно много долгоживущих процессов. Но мы это прошляпили, сочли не очень важным.
Наша инфраструктура за почти двадцать лет развития существенно разрослась. Приложения живут на трех платформах – старый код на php в монолите, первая версия микросервисов – на платформе с самодельной оркестрацией, вторая, стратегически правильная, это OKD, в котором живут сервисы на go, php и nodejs. Вокруг всего этого десятки баз на mysql с обвязкой для HA – основная «гирлянда», обслуживающая монолит, и много пар master-hotstandby для микросервисов. Помимо них мемкеши, кафки, монги, редисы, эластики, тоже далеко не в единственном экземпляре. Nginx и envoy в роли frontproxy. Все это дело живет в трех сетевых локациях и мы исходим из того, что потеря любой из них не отражается на пользователях.
У нас есть три нагруженных продукта. Расписание электричек, где просто очень много входного трафика. Расписание железной дороги по поездам дальнего следования и покупка-бронирование ж/д билетов — там и трафика много и поиск посложнее. Авиация с очень тяжелыми поисками, многоступенчатым кэшом, большим количеством вариантов из-за пересадок и вилок «плюс-минус 3 дня». Давным-давно все три продукта жили только в монолите, а потом мы начали потихоньку выносить отдельные части в микросервисы. Первыми разобрали электрички, и, несмотря на то, что обычно пик на майских приходится именно на них, новая архитектура очень удобно и просто позволяет масштабироваться под рост нагрузки. В случае с авиацией растащили большую часть монолита, и прямо в момент дня П уже неделю шло А/Б тестирование саджеста географии. Сравнивали две версии реализации – новую, на elasticsearch, и старую, исторически ходившую в основную гирлянду mysql. В момент ее запуска, 15 апреля, уже поймали пачку проблем, но тогда их быстро зачинили, поправили код и решили, что больше оно не выстрелит.
Выстрелило. Надо заметить, что старая версия – это своя реализация полнотекстового поиска и ранжирования на mysql. Не самое лучше решение, но проверенное временем и в основном работающее. Проблемы начинаются, когда любая из таблиц сильно фрагментируется, тогда все запросы с ее участием начинают тормозить и сильно грузить систему. И, очевидно, в 8 утра мы этот порог фрагментации переступили, о чем и сообщил алерт. Стандартная реакция на такую редкую, но всё-таки ожидаемую ситуацию, вывести затупившую реплику из-под нагрузки (с нашим проксирующим слоем из proxysql это делается элементарно), дальше запустить optimize + analyze и потом вернуть обратно. С учетом запаса по мощности в обычное время при обычной нагрузке это не приводит к каким-либо проблемам. Но тут в спокойное время мы этот алерт не обработали.
Примерно в это время звучит новость про майские праздники и нерабочие дни.
Как мы потом выяснили, буквально спустя несколько минут после того, как было объявлено про дополнительные выходные (которые не выходные, но «выходные») начался рост трафика. Нагрузка пошла резко. В пике было 2,5 — 3 раза от нормы и так продолжалось несколько часов.
Нам почти сразу же посыпались «оповещения о ЧП» — алерты уровня критичности «просыпайся и чини». В первую очередь это был алерт о росте 50*-х ошибок, которые мы отдаем клиентам с наших frontproxy. Уровнем ниже сработал алерт на ошибки подключения к БД и в логах мы видели примерно такое: «DB: Max connect timeout reached while reaching hostgroup 102 after 3162ms». Плюс алерты о нехватке мощностей на трех группах серверов приложений старой монолитной платформы. Alert storm в чистом виде.
Мысль о причинах пришла почти моментально, еще до захода на график с входящими запросами – новость о «каникулах» уже успела промелькнуть во внутренней переписке в чатах.
Немного придя в себя в ситуации почти полного ахтунга, начали реагировать. Масштабировать сервера приложений, разбираться с ошибками на стыке приложение – база. Быстро вспомнили про «горевший» с утра алерт и в processlist болеющей реплики нашли наших старых знакомых из саджеста географии. Списались с командой авиа, они подтвердили, что рост трафика в последние числа апреля, которого даже близко не было прошлые 15 лет, реален. И это не атака, не какая-то проблема в балансировке, а натуральные живые пользователи. И под их живыми запросами нашей уже и без того перегруженной реплике стало совсем нехорошо.
Алексей, наш ДБА, вывел реплику из-под нагрузки, прибил долгоживущие процессы и выполнил стандартную процедуру оптимизации таблиц. Это все быстро, пару минут, но за это время под таким трафиком оставшимся репликам стало еще чуть хуже. Мы это понимали, но выбрали, как наименьшее из зол.
Почти параллельно, где-то в 13:40, начали наливать новые сервера приложений, понимая, что эта нагрузка не то, что не уйдет быстро сама, а скорее и вырасти еще может, а сам процесс для монолитной части – сильно не быстрый.
Манипуляции с базой на какое-то время помогли. Примерно с 13:50 и до 14:30 все было спокойно.
В этот момент мониторинг сообщил нам, что лёг сайт РЖД. Ну то есть на самом деле он сказал, что бекендам поездов еще больше поплохело, а про РЖД мы узнали позже, когда вышла новость. В realtime для нас это выглядело так.

Нагрузка, похоже, связанная с перебоями на сайте РЖД
К сожалению, поезда преимущественно всё ещё живут в монолите и масштабировать на уровне приложения их можно только наливкой новых бекендов. А это, как я уже писал выше, процедура небыстрая и тяжело поддающаяся ускорению. Поэтому оставалось только ждать, пока отработает уже запущенная автоматика. В микросервисах все сильно проще, конечно, но вот сам переезд… хотя это другая история.
Ожидание не было скучным. Где-то за 5 минут узкое место системы каким-то до сих пор не совсем понятным образом «пропихнулось» с слоя приложения на слой БД, то ли на саму базу, то ли на proxysql. И к 14:40 у нас полностью остановилось запись в основной кластер mysql. Что именно там произошло, мы пока не разобрались, но смена мастера на hotstandby резерв помог. И минут через 10 запись мы вернули. Примерно в это же время решили принудительно перекинуть всю нагрузку от саджеста на эластик, пожертвовав результатами АБ кампании. Насколько это помогло, пока тоже не осознали, но хуже точно не стало.
Запись ожила, вроде все должно быть хорошо, и на репликах и на proxysql перед ними нагрузка в норме. Но почему-то ошибки при запросах на чтение из приложения к базе не заканчиваются. Примерно за 15-20 минут втыкания в графики по разным слоям и поиска хоть каких-то закономерностей осознали, что ошибки идут только с одного proxysql. Рестартанули его и ошибки ушли. Корневую причину раскопали уже существенно позже, при детальном анализе сбоя. Оказалось, что во время прошлого ЧП, за неделю до, во время старта АБ кампании про саджест, на proxysql не закрылись корректно соединения к одной из реплик гирлянды, с которой тогда производили манипуляции. И на этом экземпляре proxysql мы тупо уперлись в нехватку портов для исходящего трафика. Метрика эта, понятное дело, собирается, но вот вешать на неё алерт нам в голову не приходило. Теперь он уже есть.
Восстановили все продукты, кроме поездов.
Доналились последние бекенды поездов. Обычно это занимает не два часа, а час, но тут сами слегка накосячили в стрессовой ситуации.
Как часто бывает – починили в одном месте, сломалось в другом. Бекенды стали принимать больше соединений, фронтпрокси стали меньше отбрасывать клиентские запросы из-за переполнения апстримов, как следствие вырос внутренний межсервисный трафик. И сложился сервис авторизации. Это микросервис, но не в OKD, а на старой платформе. Там масштабирование попроще, чем в монолите, но хуже, чем в OKD. Поднимали минут 15, несколько раз выкручивая параметры и добавляя мощностей, но в итоге тоже заработало.
Ура, все работает, можно сходить пообедать.
Красивые они потому, что не до конца информативные, но оси не прошли проверку СБ.
График 500-х:

Общая картина по нагрузке за 2 дня:
Примерно в 13:30 у нас резко подскочила нагрузка на поиск по авиации и по железнодорожным билетам. Где-то в этот момент РЖД сообщила о перебоях на сайте и в приложении, а мы начали экстренно наливать дополнительные инстансы бекендов во всех ЦОДах.
Но на самом деле проблемы начались раньше. Примерно в 8 утра мониторинг прислал алерт про то, что на одной из реплик базы данных у нас что-то подозрительно много долгоживущих процессов. Но мы это прошляпили, сочли не очень важным.
Вводная
Наша инфраструктура за почти двадцать лет развития существенно разрослась. Приложения живут на трех платформах – старый код на php в монолите, первая версия микросервисов – на платформе с самодельной оркестрацией, вторая, стратегически правильная, это OKD, в котором живут сервисы на go, php и nodejs. Вокруг всего этого десятки баз на mysql с обвязкой для HA – основная «гирлянда», обслуживающая монолит, и много пар master-hotstandby для микросервисов. Помимо них мемкеши, кафки, монги, редисы, эластики, тоже далеко не в единственном экземпляре. Nginx и envoy в роли frontproxy. Все это дело живет в трех сетевых локациях и мы исходим из того, что потеря любой из них не отражается на пользователях.
АБ-тесты: mysql против эластика
У нас есть три нагруженных продукта. Расписание электричек, где просто очень много входного трафика. Расписание железной дороги по поездам дальнего следования и покупка-бронирование ж/д билетов — там и трафика много и поиск посложнее. Авиация с очень тяжелыми поисками, многоступенчатым кэшом, большим количеством вариантов из-за пересадок и вилок «плюс-минус 3 дня». Давным-давно все три продукта жили только в монолите, а потом мы начали потихоньку выносить отдельные части в микросервисы. Первыми разобрали электрички, и, несмотря на то, что обычно пик на майских приходится именно на них, новая архитектура очень удобно и просто позволяет масштабироваться под рост нагрузки. В случае с авиацией растащили большую часть монолита, и прямо в момент дня П уже неделю шло А/Б тестирование саджеста географии. Сравнивали две версии реализации – новую, на elasticsearch, и старую, исторически ходившую в основную гирлянду mysql. В момент ее запуска, 15 апреля, уже поймали пачку проблем, но тогда их быстро зачинили, поправили код и решили, что больше оно не выстрелит.
Выстрелило. Надо заметить, что старая версия – это своя реализация полнотекстового поиска и ранжирования на mysql. Не самое лучше решение, но проверенное временем и в основном работающее. Проблемы начинаются, когда любая из таблиц сильно фрагментируется, тогда все запросы с ее участием начинают тормозить и сильно грузить систему. И, очевидно, в 8 утра мы этот порог фрагментации переступили, о чем и сообщил алерт. Стандартная реакция на такую редкую, но всё-таки ожидаемую ситуацию, вывести затупившую реплику из-под нагрузки (с нашим проксирующим слоем из proxysql это делается элементарно), дальше запустить optimize + analyze и потом вернуть обратно. С учетом запаса по мощности в обычное время при обычной нагрузке это не приводит к каким-либо проблемам. Но тут в спокойное время мы этот алерт не обработали.
13:20
Примерно в это время звучит новость про майские праздники и нерабочие дни.
Пик трафика около 13:30
Как мы потом выяснили, буквально спустя несколько минут после того, как было объявлено про дополнительные выходные (которые не выходные, но «выходные») начался рост трафика. Нагрузка пошла резко. В пике было 2,5 — 3 раза от нормы и так продолжалось несколько часов.
Нам почти сразу же посыпались «оповещения о ЧП» — алерты уровня критичности «просыпайся и чини». В первую очередь это был алерт о росте 50*-х ошибок, которые мы отдаем клиентам с наших frontproxy. Уровнем ниже сработал алерт на ошибки подключения к БД и в логах мы видели примерно такое: «DB: Max connect timeout reached while reaching hostgroup 102 after 3162ms». Плюс алерты о нехватке мощностей на трех группах серверов приложений старой монолитной платформы. Alert storm в чистом виде.
Мысль о причинах пришла почти моментально, еще до захода на график с входящими запросами – новость о «каникулах» уже успела промелькнуть во внутренней переписке в чатах.
Немного придя в себя в ситуации почти полного ахтунга, начали реагировать. Масштабировать сервера приложений, разбираться с ошибками на стыке приложение – база. Быстро вспомнили про «горевший» с утра алерт и в processlist болеющей реплики нашли наших старых знакомых из саджеста географии. Списались с командой авиа, они подтвердили, что рост трафика в последние числа апреля, которого даже близко не было прошлые 15 лет, реален. И это не атака, не какая-то проблема в балансировке, а натуральные живые пользователи. И под их живыми запросами нашей уже и без того перегруженной реплике стало совсем нехорошо.
Алексей, наш ДБА, вывел реплику из-под нагрузки, прибил долгоживущие процессы и выполнил стандартную процедуру оптимизации таблиц. Это все быстро, пару минут, но за это время под таким трафиком оставшимся репликам стало еще чуть хуже. Мы это понимали, но выбрали, как наименьшее из зол.
Почти параллельно, где-то в 13:40, начали наливать новые сервера приложений, понимая, что эта нагрузка не то, что не уйдет быстро сама, а скорее и вырасти еще может, а сам процесс для монолитной части – сильно не быстрый.
Манипуляции с базой на какое-то время помогли. Примерно с 13:50 и до 14:30 все было спокойно.
Второй пик — около 14:30
В этот момент мониторинг сообщил нам, что лёг сайт РЖД. Ну то есть на самом деле он сказал, что бекендам поездов еще больше поплохело, а про РЖД мы узнали позже, когда вышла новость. В realtime для нас это выглядело так.
Нагрузка, похоже, связанная с перебоями на сайте РЖД
К сожалению, поезда преимущественно всё ещё живут в монолите и масштабировать на уровне приложения их можно только наливкой новых бекендов. А это, как я уже писал выше, процедура небыстрая и тяжело поддающаяся ускорению. Поэтому оставалось только ждать, пока отработает уже запущенная автоматика. В микросервисах все сильно проще, конечно, но вот сам переезд… хотя это другая история.
Ожидание не было скучным. Где-то за 5 минут узкое место системы каким-то до сих пор не совсем понятным образом «пропихнулось» с слоя приложения на слой БД, то ли на саму базу, то ли на proxysql. И к 14:40 у нас полностью остановилось запись в основной кластер mysql. Что именно там произошло, мы пока не разобрались, но смена мастера на hotstandby резерв помог. И минут через 10 запись мы вернули. Примерно в это же время решили принудительно перекинуть всю нагрузку от саджеста на эластик, пожертвовав результатами АБ кампании. Насколько это помогло, пока тоже не осознали, но хуже точно не стало.
15:00
Запись ожила, вроде все должно быть хорошо, и на репликах и на proxysql перед ними нагрузка в норме. Но почему-то ошибки при запросах на чтение из приложения к базе не заканчиваются. Примерно за 15-20 минут втыкания в графики по разным слоям и поиска хоть каких-то закономерностей осознали, что ошибки идут только с одного proxysql. Рестартанули его и ошибки ушли. Корневую причину раскопали уже существенно позже, при детальном анализе сбоя. Оказалось, что во время прошлого ЧП, за неделю до, во время старта АБ кампании про саджест, на proxysql не закрылись корректно соединения к одной из реплик гирлянды, с которой тогда производили манипуляции. И на этом экземпляре proxysql мы тупо уперлись в нехватку портов для исходящего трафика. Метрика эта, понятное дело, собирается, но вот вешать на неё алерт нам в голову не приходило. Теперь он уже есть.
15:20
Восстановили все продукты, кроме поездов.
15:50
Доналились последние бекенды поездов. Обычно это занимает не два часа, а час, но тут сами слегка накосячили в стрессовой ситуации.
Как часто бывает – починили в одном месте, сломалось в другом. Бекенды стали принимать больше соединений, фронтпрокси стали меньше отбрасывать клиентские запросы из-за переполнения апстримов, как следствие вырос внутренний межсервисный трафик. И сложился сервис авторизации. Это микросервис, но не в OKD, а на старой платформе. Там масштабирование попроще, чем в монолите, но хуже, чем в OKD. Поднимали минут 15, несколько раз выкручивая параметры и добавляя мощностей, но в итоге тоже заработало.
16:10
Ура, все работает, можно сходить пообедать.
Красивые картинки
Красивые они потому, что не до конца информативные, но оси не прошли проверку СБ.
График 500-х:
Общая картина по нагрузке за 2 дня:
Выводы от капитана
- Спасибо, что не вечером.
- С алертами нужно что-то делать. Их уже очень много, но, с одной стороны, всё равно иногда не хватает, а с другой – некоторые продалбываются, в том числе и из-за количества. Да и стоимость сопровождения с каждым новым алертом увеличивается. В общем тут пока есть понимание проблемы, но нет стратегического решения. Оно прячется где-то на стыке процессов и инструментов, ищем. Но пару алертов тактически мы уже запилили.
- Стоит внимательнее следить даже за минорными апдейтами софта. Багу, из-за которой proxysql не закрыл сокеты, скорее всего уже починили. Но это был минор и не про безопасность, а такое мы катим не слишком оперативно.
- Микросервисы лучше монолита, а OKD лучше нашей самодельной платформы. По крайней мере с точки зрения простоты масштабирования.
- Мы молодцы. Подготовленная инфраструктура дала хорошую основу, а команда, несмотря на пару факапов, отработала очень круто для такой стрессовой ситуации.


