
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Как быть, когда вокруг вроде бы девопсы, аджайлы и скрамы, но разработка и тестирование по-прежнему не живут в одном пайплайне душа в душу?
Из-за того, что необходимо преодолевать эту стену и находить общий язык, мы даже создали конференцию Heisenbug, предназначенную одновременно для тестировщиков и разработчиков. А ещё мы проводим Java-конференции, и осенью Артём Ерошенко выступил там с докладом «Как правильно (не) использовать тестировщиков». На примере Java-проекта он поделился своей болью и рассказал, что считает нужным делать.
И теперь, в преддверии нового Heisenbug и нового JPoint (обе конференции пройдут в формате «офлайн + онлайн»), мы решили сделать хабрапост на основе его доклада. Дальше повествование от имени Артёма.
Откуда у меня такой опыт: я один из сооснователей компании Qameta Software, мы разрабатываем инструменты тестирования Allure Report, Allure TestOps. Также я занимаюсь обучением автоматизации тестирования и консалтингом в области автоматизации. Я повидал много команд и в докладе хочу поделиться этим опытом. Если у вас другой опыт, обязательно расскажите о нем в комментариях к посту.
Цель моего консалтинга не просто построить много автотестов, которые будут находиться в отдельном репозитории, а в том, чтобы это всё вместе связать, чтобы автотесты приносили пользу, чтобы каждый участник процесса, пользуясь автотестами, понимал, зачем они нам нужны.
Что не так с тестированием в командах
Представим некую стандартную команду (персонажи вымышлены, совпадения случайны). Конечно же, они все проповедуют DevOps. Почему?
Есть поставка продукта клиенту. При ошибке весь пайплайн ломается и клиенты переживают. Раньше поставку пытался чинить разработчик, но он не знал тонкостей деплоя. И вообще разработчики, которые могут самостоятельно всё починить — это суперзвезды, таких мало и они дорого обходятся. Если же поставку чинит админ, то это тоже проблема, потому что он не знает нюансов кода (либо это уже админ-суперзвезда).
Самый понятный способ устранить проблему — это когда поставку чинит команда:

Каждый вносит свою лепту и продукт постоянно эволюционирует через жизненный цикл. В итоге команда действует следующим образом:
- Возникла проблема.
- Разработчики улучшают продукт, дописывают код, чтобы всё работало стабильнее.
- Админы настраивают метрики.
- QA добавляют и настраивают новые тесты.
И с помощью таких постоянных итераций у нас улучшается пайплайн, ошибки реже попадают в прод. То есть каждая роль вносит свой вклад.
Так ли это на самом деле?
Конечно, не так. В книжках, может, и написано, что всё должно работать именно так, но в реальности происходит по-другому. Я на своем опыте вижу, что QA практически всегда находятся отдельно от остальной команды. Разработчики и админы между собой договорились, научились выстраивать у себя действительно хорошие пайплайны, стабильно следят за деплоем. Часто в командах, куда я прихожу, вопрос поставки в продакшен уже даже не стоит. Всё всегда автоматизировано, двигается очень четко. Но команда тестирования почему-то всегда находится сбоку. То есть картина такая: всё хорошо, идет сборка, запускаются тесты, появляется тестовое окружение, потом — черное окно, там что-то делают тестировщики, потом они говорят «вроде всё протестировали», и опять начинается какая-то автоматика. Из-за этого у меня ощущение, что QA находится отдельно от команды.
Рассмотрим пример поставки:

Если всё работает и локально, и у клиента, тогда всё хорошо. Если обнаружена ошибка на стороне разработчика, то он сразу ее чинит, в продукт ошибка не попадет. А если наоборот, в продукте есть ошибка, но мы о ней не знаем, а клиент к нам приходит с этой ошибкой, то мы пишем тесты и так далее. То есть в принципе всё работает хорошо. Но если ошибка не обнаружена (такое бывает, я уверен, что в каждом софте есть много ошибок, которые до сих пор еще не выявлены), то в целом вроде бы и так сойдет.
Как шутят, «Буква Т в DevOps — это “тестирование”». Мы не знаем обо всех ошибках, может быть, они есть, может, их нет. Спросите сами себя: вот вы постоянно катите новые версии продуктов, вы понимаете, какие у вас есть автотесты со стороны тестирования? Что проверяет тестирование? Скорее всего, вы ответите, что нет, вы отдаете это на откуп тестировщикам и об этом не думаете. Ну и буква Т из шутки ровно это и означает — что вам особо не интересно, что там ребята делают, и так сойдет.
Как итог, я вижу, что появляется замкнутая экосистема: есть тестировщики, которые играют друг с другом в какую-то свою «тестировщицкую» игру, и есть отдельная команда админов и разработчиков, которые друг с другом договорились и отлично взаимодействуют. При этом можно точно сказать, что внутри QA всё хорошо: когда я прихожу в конкретную команду, я вижу, что у них неплохо выстроены процессы, просто эти процессы очень редко учитывают, что вокруг есть какая-то разработка. Часто продукт просто попадает в тестовое окружение, тестировщики говорят, что им нужно несколько дней, чтобы всё протестировать, и на этом всё. Меня это сильно печалит.
Как будем с этим разбираться
- Напишем автотесты: я почувствую себя разработчиком и покажу, с какими проблемами можно столкнуться.
- Сравним подходы: посмотрим на автотесты под разными углами.
- Соберем идеальную команду: по моему мнению, она существует.
Пишем автотесты
Представим, что нам пришла какая-то задача на разработку, сделать самую простую фичу — написать TodoList для Java-приложения. Для чистоты эксперимента я всё сделал самостоятельно: сгенерировал себе шаблон на JHipster, потому что мне было интересно, как пишется код, и добавил туда всё необходимое. Сейчас расскажу, как я вижу связь разработки и тестов.
Разработка и тесты
Формально разработчики не пишут тесты, они пишут фичи и пишут код, который описывает поведение фичи. И этот код случайно называется тестами. То есть писать тесты — не их основная задача.
Итак, если мы начнем писать этот код, то для начала мы сделаем обычную тудушку и todo-репозиторий.
Создаем класс Todo
@Entity
public class Todo implements Serializable {
@Id
@GeneratedValue(strategy = ..., generator = ...)
@SequenceGenerator(name = "sequenceGenerator")
private Long id;
@NonNull
@Size(max = 255)
public String title;
}
Может, нужно добавить еще какие-то поля, но пока нам точно нужен id, title 255, помечаем всё аннотацией Entity, Serializable — и поехали дальше.
Создаем репозиторий
Создаем репозиторий, помечаем его аннотацией @Repository, прописываем туда несколько методов.
@Repository
public interface TodoRepository
extends JpaRepository<Todo, Long> {
Long<Todo> findAllByUser(User user);
Optional<String> findFirstByUser(User user);
// какие-то дополнительные запросы в базу
}
У меня нет задачи рассказать о каких-то тонкостях и сложностях, поэтому показываю просто на пальцах. Тут могут быть какие-то дополнительные запросы, но мне для начала этого достаточно.
Пишем тест, помечаем его аннотацией @DataJpaTest, подключаем репозитории userRepository (достался нам в наследство), todoRepository.
@DataJpaTest(includeFilters = ...)
public class TodoRepositoryTest {
@Autowired
private UserRepository userRepository;
@Autowired
private TodoRepository todoRepository;
@Test
public void shouldSaveTodo() { ... }
}
Этого нам достаточно, чтобы описать, что будет происходить в нашем тесте.
Создаем пользователя, тудушку, проверяем результат
@DataJpaTest(includeFilters = ...)
public class TodoRepositoryTest {
@Test
void shouldSaveTodo() {
User user = userRepository.saveAndFlush(randomUser());
Todo todo = randomTodo((todo) -> todo.setUser(user));
todoRepository.saveAndFlush(todo);
List<Todo>(todoList).hasSize(1)
.extracting(Todo::getTitle)
.contains(todo.getTitle);
}
}
Сохраняем нашего рандомного пользователя, создаем рандомную тудушку и говорим, что она будет от имени этого пользователя. Сохраняем эту связь и говорим Flush. После этого мы делаем todoRepository, берем список всех сущностей конкретного юзера и запускаем тест.
Тест находит первую ошибку (todoRepository.saveAndFlush(todo);). Она заключается в том, что мы забыли добавить миграцию.
Добавляем миграцию
<changeSet id="00001-todo-table" author="eroshenkoam">
<createTable tableName="todo">
<column name="id" type="bigint">
<constraints primaryKey="true" nullable="false" />
</column>
<column name="title" type="varchar(256)"/>
<column name="user_id" type="bigint">
<constraints nullable="false" />
</column>
</createTable>
<addForeignKeyConstraint baseTableName="todo" ... />
</changeSet>
Мне для этих задач привычнее использовать XML. Вы можете делать это по-другому, но я использую Liquidbase с такой вот миграцией.
Добавляю его в общий список:
@DataJpaTest(includeFilters = ...)
public class TodoRepositoryTest {
@Test
void shouldSaveTodo() {
User user = userRepository.saveAndFlush(randomUser());
Todo todo = randomTodo((todo) -> todo.setUser(user));
todoRepository.saveAndFlush(todo);
List<Todo> todoList = todoRepository.findAllByUser(user);
assertThat(todoList).hasSize(1)
.extracting(Todo::getTitle)
.contains(todo.getTitle);
}
}
Запускаю автотест, он проходит. Я радуюсь, на душе от этого очень хорошо.
Какие еще тесты нужны?
У вас могут быть специфические запросы в базу, которые не генерируют JPA. В этом случае вам надо запустить этот тест на разных версиях базы, на разных базах. Для этого вы, скорее всего, подключите какой-нибудь тест-контейнер. Сейчас это делается довольно просто. Также надо, наверное, проверить на максимальный тайтл. Потому что, может быть, кто-то поменяет вашу миграцию, поменяет размер ячейки, будет там не 256 символов, а 128, и у вас сразу же упадет тест. Так что лучше написать как минимум несколько тестов — проверить, что будет, если пользователь будет null, и другие подобные кейсы.
Делаем DTO и примитивный Mapper
Создаем класс TodoDTO:
public class TodoDTO implements Serializable {
private Long id;
private Long userId;
private String title;
public Long getId() { ... };
public Long getUserId() { ... };
public String getTitle() { ... };
}
DTO будет выглядеть как-то так. Это совсем простая сущность, то, что мы будем потом отдавать по REST.
И делаем Mapper:
public class TodoMapper {
public TodoDTO daoToDto(final Todo todo) {
final TodoDto dto = new TodoDto();
dto.setId(todo.getId());
dto.setTitle(todo.getTitle());
dto.setUserId(todo.getUser().getId());
return dto;
}
public Todo dtoToDao(final TodoDTO dto) { ... }
}
Mapper в целом можно сгенерировать, но у меня была задача показать какую-то логику, как примерно выглядит Mapper, потому что потом его захочется протестировать.
Естественно, пишем тест.
@SpringTest
public class TodoMapperTest {
@Autowired
private TodoMapper todoMapper;
@Test
public void shouldConvertMap() {
Todo todo = randomTodo();
TodoDto dto = todoMapper.daoToDto(todo);
assertThat(dto)
.extracting(TodoDto::getTitle(), TodoDto::getUserId())
.constraints(todo.getTitle(), todo.getUser().getId());
}
}
Делаем TodoMapper, добавляем зависимость от TodoMapper и после этого генерируем рандомную тудушку. Сконвертируем ее, запустим наш тест и увидим, что у нас всё правильно работает. Мы создали юзера и потом получили userId, который соответствует getUser().getId().
Какие еще тесты нужны?
В принципе, тут еще можно добавить еще какие-то тесты. Круто, что тесты у нас получаются очень короткие. В каждый момент времени можно проверить очень маленькую логику. Здесь можно придумать тесты на валидацию размера строки, что будет, если id или user будет null и т. д.
Создаем класс TodoService для работы с тудушкой конкретного пользователя
@Service
@Transactional
public class TodoService {
public List<TodoDTO> findAllForCurrentUser() {
User user = getCurrentUser().orElseGet(...);
List<Todo> todoList = repository.findAllByUser(user);
return todoList.stream()
.map(todoMapper::daoToDto)
.collect(Collectors.toList())
};
}
Сделаем TodoService, напишем в нем единственный транзакционный метод. Внутри возьмем текущего пользователя или сделаем какое-либо другое условие (например, создание guest-пользователя или ошибка, что пользователь не авторизован). То есть просто представим, что либо у нас есть пользователь, либо это поведение нам пока не интересно. И дальше возьмем все тудушки текущего пользователя, Mapper, сконвертируем его в DTO и отдадим полным списком.
Пишем тест:
@DataJpaTest (includeFilters = ...)
public class TodoServiceTest {
@Autowirwed
private TodoService todoService;
@Autowirwed
private TodoRepository todoRepo;
@Test
void shouldFindTodos() { ... }
}
Для этого теста нам понадобится todoService и todoRepo.
Создаем тудушки:
@DataJpaTest(includeFilters = ...)
public class TodoServiceTest {
@Test
void shouldFindTodos() {
Todo firstTodo = todoRepo.saveAndFlush(randomTodo(firstUser));
Todo secondTodo = todoRepo.saveAndFlush(randomTodo(firstUser));
todoRepo.saveAndFlush(randomTodo(secondUser);
List<TodoDTO> todoList = todoService.findAllForCurrentUser();
assert.That(todoList).hasSize(2)
.extracting(TodoDTO::getTitle())
.contains(firstTodo.getTitle(), secondTodo.getTitle());
}
}
Делаем сначала firstTodo saveAndFlush, потом secondTodo saveAndFlush и создаем еще одну тудушку от второго пользователя. В итоге у нас получается две тудушки от первого пользователя и одна от второго пользователя. После этого найдем в сервисе все тудушки текущего пользователя, их должно быть две, и у них должны быть тайтлы, которые мы создали. Получается такой простенький тест.
Но если мы его запустим, у нас опять будет ошибка, потому что мы не авторизовались. Дело в findAllForCurrentUser() — сейчас у нас нет текущего пользователя, потому что у нас нет контекста авторизации, а значит, нам надо его добавить.
Забыли авторизацию
@DataJpaTest(includeFilters = ...)
public class TodoServiceTest {
@Test
@WithMockUser("...")
void shouldFindTodos() {
User firstUser = randomUser((user) -> user.setLogin("..."));
Todo firstTodo = todoRepo.saveAndFlush(randomTodo(firstUser));
Todo secondTodo = todoRepo.saveAndFlush(randomTodo(firstUser));
todoRepo.saveAndFlush(randomTodo(secondUser);
...
List<TodoDTO> todoList = todoService.findAllForCurrentUser();
assert.That(todoList).hasSize(2)
.extracting(TodoDTO::getTitle())
.contains(firstTodo.getTitle(), secondTodo.getTitle());
}
}
Авторизация делается очень просто: пишем @WithMockUser("..."), можно указать user name и потом сделать user set login с конкретным юзернеймом. Или можно просто сказать @WithMockUser("..."), потом взять текущий юзернейм и создать в базе пользователя с таким юзернеймом. Тут как вам больше захочется.
В чем прелесть: чтобы победить авторизацию, мне надо добавить всего одну аннотацию. Но вы это всё и так знаете, это всё довольно просто.
Какие тесты еще нужны?
Как минимум надо проверить, что будет, если пользователь не авторизован. Это поведение надо просто как минимум заложить. Кидать какой-то тупой exception здесь не надо, лучше корректно обработать эту ситуацию. Иногда бывают сессионные пользователи, которые не авторизованы, но у которых есть какая-то сессия. То есть в нашей системе не существует такого пользователя, но может, это какая-то демка, где пользователь может зайти, что-то покликать, через какое-то время вернуться на страницу, и у него отобразятся его тудушки. Пользователю это понравится, и он решит зарегистрироваться.
Мы можем обработать кучу логик в этом сервисе, и на всё мы должны написать тесты. Так что думаю, что тут еще пятерка тестов легко добавится на разные сложные кейсы, которые могут возникнуть.
Делаем TodoController для работы с сервисом по API
Это наш финальный этап. Создаем класс TodoController:
@RestController
@RequestMapping("/api/todo")
public class TodoController {
private TodoService todoService;
@GetMapping("/")
public List<TodoDTO> findAll() {
return todoService.findAllByCurrentUser();
}
@PostMapping("/")
public List<TodoDTO> create(@RequestBody TodoDTO dto){ ... }
}
Делаем RequestMapping("/api/todo"), добавляем todoService и пишем вот такой очень простой код. findAllByCurrentUser() или создание тудушки. В целом создание тудушки нам здесь не нужно. Мы можем его добавить, но сейчас и без него хорошо.
Пишем тест:
@AutoConfigureMockMvc
public class TodoControllerTest {
@MockBean
private TodoService todoService
@Autowired
private MockMvc mockMvc
@Test
void shouldGetAll() { ... }
}
Всё, что касается todoService, мы протестировали в отдельном тесте. Сейчас мы мокаем todoService и тестируем чисто связку контроллера и todoService, потому что здесь может находиться какой-то дополнительный код. У меня тут вообще получается линейный код, но в реальности тут может находиться какой-то дополнительный код, может быть какая-то конвертация, дефолтные значения и т. д., так что всё равно надо написать тест.
Используем Mock
Мы будем мокать todoService, и после напишем вот такой тест:
@AutoConfigureMockMvc
public class TodoControllerTest {
@Test
void shouldGetAll() {
TodoDTO firstTodo = randomTodoDTO();
TodoDTO secondTodo = randomTodoDTO();
when(todoService.findAllForCurrentUser())
.thenReturn(Arrays.asList(firstTodo, secondTodo));
mockMvc.perform(get("/api/todo")).andExpect(status().ok())
.andExpect(jsonPath("$.[*].title").value(hasItems(
firstTodo.getTitle(), secondTodo.getTitle()
)));
}
}
Создаем TodoDTO, вторую TodoDTO, потом говорим: если вызовется метод findAllForCurrentUser(), тогда возвращай список вот этих DTO.
После этого делаем запрос по API, проверяем, что у нас status().ok(), берем тайтлы (jsonPath для всех сущностей в массиве) и проверяем, что они содержат значение firstTodo.getTitle() и secondTodo.getTitle().
Получается тоже довольно простой тест, но интересно, что у нас опять нет какого-то контекста авторизации, у нас уже всё работает правильно, и тестом мы проверяем очень маленькую задачу.
Какие еще тесты нужны?
Здесь, как я уже и говорит, можно проверить всякие дефолтные значения, если они есть, пагинацию. Пагинация не используется в моем коде, но никто не будет писать List, все будут использовать pageable. Еще можно проверить конвертацию и роутинг, потому что бывает, что одна и та же ручка (хэндлер) в зависимости от разных параметров ведет на разные методы сервиса.
Ничего не написал, а уже получилось около 20 тестов
С точки зрения кода я не написал ничего, написал просто минимум кода, и получилось около 20 тестов. То есть на каждом этапе у меня было где-то пять тестов. Я показал, как примерно выглядит один из них, но за ним можно сразу увидеть еще штук 5 тестов. И получается, что на такую простецкую функциональность у нас уже находится 20 тестов. И мне, скажу честно, все эти 20 тестов было бы очень лень писать. В реальности их еще больше.
Типы тестов
Есть разные типы тестов.

Есть очень маленькие тесты (тест на Mapper, тест на репозиторий, на сервис и т. д).
Есть тесты среднего размера, медиум-тесты. Я специально не использую терминологию «unit-тесты», «интеграционные тесты», мне сейчас проще указать, что есть маленькие тесты, которые тестируют каждую конкретную функциональность, есть медиум-тесты, которые тестируют некоторую связность. И естественно, у нас нет ни одного большого теста. Я не написал ни одного теста, который проверяет всю функциональность целиком, потому что, если честно, пока я писал это код, я не почувствовал надобности в таком тесте. А зачем он мне нужен? Физически я могу его написать, но я каждый раз тестировал по чуть-чуть, и за счет этого мне кажется, что я покрыл все необходимые сценарии.
Тестирование и тесты
Теперь давайте посмотрим, как работают тестирование и тесты.
Если вы начнете погружаться в эту область, первое, что вы узнаете — это что есть автотесты и ручные тесты.
Второе: чтобы начать что-то тестировать, нам нужно тестовое окружение. Нужно попросить админа сделать нам его, чтобы фича, которую мы хотим протестировать, как-то доставилась в это окружение.
Дальше в ход идет ручное тестирование либо аналитик-тестирование. Когда я говорю «ручное тестирование», я не имею в виду людей, которые сидят и нажимают кнопочки. Это скорее «аналитик-тестирование», давайте пока назовем это так. С помощью Swagger проверяем, всё ли работает.
Довольно частая ситуация, когда выкатывается новая функциональность, она либо сразу же не соответствует требованиям, либо в Swagger она описана как-то по-другому. Я понимаю, что у всех Swagger автоматически генерируется, но поверьте, со стороны тестирования это постоянно выглядит как какая-то неразбериха. Поэтому мы:
- Берем Swagger и смотрим список запросов.
- В своей песочнице для ручных тестов Postman проверяем, что всё работает.
- Делаем дымовые тесты (smoke tests), чтобы проверить работоспособность.
После этого идет стадия сохранения тест-кейсов для будущей автоматизации. Нам надо всё оформить в виде тестовой документации. Тестовая документация нужна в проекте, чтобы понимать, что и как у нас тестируется с точки зрения функциональности, с точки зрения пользователя, какие тестовые сценарии проверяем, а какие нет. Поэтому тестировщик идет в Test case Management System (TMS) и пишет вот такие тесты:

Тесты следующие:
- Авторизуемся под новым пользователем.
- Создаем Todo с Title «Купить молока».
- Проверяем, что в списке Todo пользователя есть задача «Купить молока».
Тесты очень формально описаны, на языке, к которому привыкли тестировщики. Тесты могут быть очень подробными или менее подробными, но тем не менее зачастую появляются тест-кейсы, в которых описано, что и как надо делать.
Тест-кейс в TMS
Тест-кейсов на новую функциональность получается много. В этот момент тестировщик как раз прорабатывает разные варианты: какую длину тайтла можно прописать, какие действия доступны от авторизованных и неавторизованных пользователей, можно ли поделиться списком с другими пользователями и так далее. Тестировщик описывает много разнообразных тест-кейсов и добавляет их в TMS.
Дальше мы выбираем тест-кейсы на автоматизацию. Тут начинается работа ручного тестировщика и автоматизатора. Они составляют матрицу, в которой находятся два приоритета, критичность и сложность автоматизации. Тестировщики расставляют в тест-кейсе свои критичные тесты, а автоматизатор пишет, просто это или сложно. Получается такая матрица Эйзенхауэра:
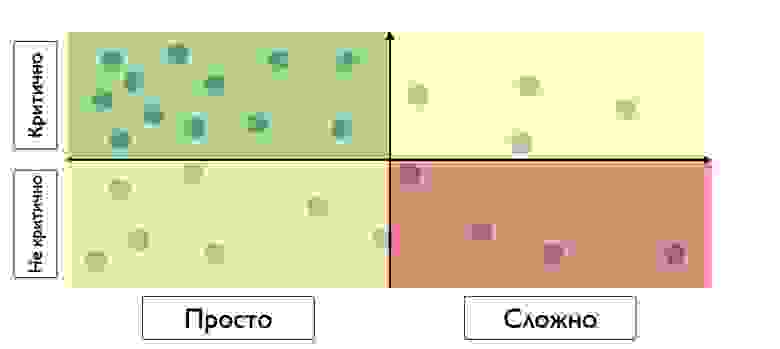
И мы выбираем только критичные тесты, которые просто автоматизировать.
Если у нас много сил, мы можем автоматизировать все тесты. Но зачастую мы выбираем конкретные тесты. Это сделано для того, чтобы мы не распылялись. Например, если мы не умеем тестировать PDF, то мы скорее всего сначала возьмем другие тесты, пока не научимся тестировать PDF.
То есть в основном мы пытаемся выбирать критичные тесты, которые мы уже умеем писать. Как только они заканчиваются, мы берем все остальные тесты и тоже их автоматизируем.
Автоматизатор автоматизирует тест-кейсы
Сначала автоматизатор создает пользователя, потому что если наши автотесты запустить в параллель, они будут конфликтовать. Просто запустится тест, один создаст тудушки, второй зачитает тудушки и увидит, что, внезапно, там не две тудушки, а три. Это и будет первой проблемой, поэтому начнем с создания пользователей.
public class TodoTest {
@Test
void testTodoList() {
RequestSpecification base = given()
.baseUri("https://testing.company.com")
.contentType("application/json");
UserDTO user = randomUser();
base.body(user).post("/api/user")
.then().statusCode(200);
...
}
}
Мы идем к разработчикам и просим их сделать нам ручки, которые будут создавать пользователя. Проблема авторизации довольно распространенная. Часто бывает, что когда ты создаешь пользователя, тебе надо прочитать какое-нибудь СМС или какой-то код. Так что обычно это первый камень преткновения. В такие моменты мы обычно приходим к разработке, вместе думаем, как это можно замокать, чтобы код приходил нам в конкретный модуль, откуда мы его сразу же можем собрать, иначе нам не создать пользователя. Поэтому много команд сидят под статическими пользователями, и у них с этим большая проблема. В нашем примере мы тоже сразу же утыкаемся в эту проблему, но решаем ее.
Получаем токен:
public class TodoTest {
@Test
void testTodoList() {
...
Map<String, String> authData = Maps.of(
"username", user.getUsername(),
"password", user.getPassword(),
)
String token = base.body(authData)
.post("/api/authenticate")
.path("id_token").toString();
}
}
Вводим логин/пароль, отправляем запрос на /api/authenticate, получаем id_token и начинаем выполнять реальную авторизацию.
public class TodoTest {
@Test
void testTodoList() {
...
String token = base.body(authData)
.post("/api/authenticate")
.path("id_token")
.toString();
RequestSpecification authorized = base
.header("Authorization", "Bearer" + token)
}
}
После этого мы авторизуемся: получаем токен, выставляем authorization-заголовок и проставляем его вот таким образом:
public class TodoTest {
@Test
void testTodoList() {
...
TodoDTO firstTodo = randomTodo();
TodoDTO secondTodo = randomTodo();
authorized.body(firstTodo).post("/api/todo")
.then().statusCode(200);
authorized.body(secondTodo).post("/api/todo")
.then().statusCode(200);
}
}
После этого мы создаем тудушки. К сожалению, мы не можем сразу же в базу записать какие-то данные, как это делали разработчики. У них там и с авторизацией всё просто — ставишь аннотацию, и ты авторизован. У нас же это всё через реальные данные. Пишем randomTodo() на первую и на вторую тудушку — и тут, к сожалению, разработчик не предусмотрел создание списка тудушек, поэтому мы каждый раз создаем по одной тудушке. Пострадаем немного, но что поделать.
Проверяем Todo:
public test TodoTest {
@Test
void testTodoList() {
...
List<TodoDTO> todoList = authorized.get("/api/todo")
.body().as(new TypeRef<List<TodoDTO>>(){});
assertThat(todoList).hasSize(2)
.extracting(TodoDTO::getTitle)
.contains(firstTodo.getTitle(), secondTodo.getTitle());
}
}
И под конец мы получаем от авторизованного пользователя некоторый список тудушек, проверяем, что тудушек действительно две, и пишем самый простенький сценарий.
Проверяем, что автотест всё делает правильно
Дальше включается ручное тестирование, оно проверяет, что автотест всё делает правильно. Для этого мы строим Allure-отчет:

Тест, как вы видите, получается очень длинный: надо создать пользователя, авторизоваться под каким-то пользователем, создать первую тудушку, потом вторую и так далее. И из-за того, что тестовые окружения бывают нестабильными, некоторые ручки меняются, потому что мы не близки к разработке. У нас выкатилось обновление к окружению, там находится сразу десяток пулл-реквестов, и каждый из этих пулл-реквестов может что-то поменять. И чтобы нам быть в курсе дела, мы очень много всего логируем, проверяем и отдаем этот отчет ручным тестировщикам, чтобы они убедились, что в случае ошибки они смогут по этому отчету быстро разобраться и понять, что произошло.
И если посмотреть на наши разные типы тестов, то у нас наоборот:
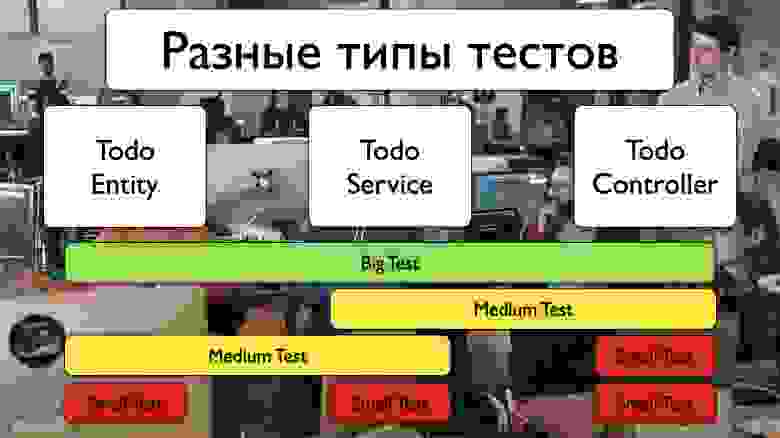
В основном мы сразу же пишем большие тесты, тесты end-to-end, которые всё проверяют без каких-либо моков. Но моки тоже бывают, когда мы можем подменить куски сервисов, например, чтобы у нас отсылалась ненастоящая СМС, чтобы ее отправлял какой-нибудь мок-сервер, и мы могли ее оттуда забрать. Обо всём этом мы договариваемся с разработкой, и делается это не быстро. Ведь это нужно нам, а у разработчика почти никогда нет на это времени. Приоритеты общие, но приоритеты сервиса зачастую важнее наших, поэтому мы находимся в хвосте. В итоге средние тесты мы пишем в меньшем количестве, а маленькие тесты вообще не пишем, потому что мы физически не можем их написать, у нас не такая область видимости, мы не можем так близко подлезть к коду.
Сравниваем подходы
В принципе кажется, что тесты не сильно отличаются: тут написал тест на тудушки, тут написал тест через REST на тудушки. Конечно, в первом случае тесты поменьше, во втором случае тесты будто бы больше, ну и ладно.
Давайте посмотрим, чем же они отличаются.
Сравним время создания такого теста
Разработка и тесты: «Можно написать за 10 минут, на сложный тест иногда может уйти до двух часов».
Сложный тест — это, например, новые PDF, какая-то функциональность, которой раньше не было. Надо подключить какую-нибудь библиотеку, с ее помощью посмотреть, как генерируется PDF, убедиться, что там есть какой-то текст, и в принципе этого достаточно. В основном тесты пишутся очень быстро и просто.
Тестирование и тесты: «На один тест уходит минимум 2 часа, на самом деле обычно больше».
Это происходит из-за самого процесса: нам надо соблюсти все формальности. Сама процедура написания тестов довольно долгая. И это уже не говоря о том, что сам тест долгий, и когда ты его дебажишь, у разработчиков проходит, грубо говоря, 30 секунд, а у нас создается пользователь, авторизуется, создаются тудушки, упали мы на тудушках — уже прошло где-то полторы минуты, пока всё собралось и т. д. Перезапустили тест — надо опять полторы минуты ждать. Тесты бывают и длиннее. Соответственно, на каждый тест уходит 2 часа, просто потому что они сами по себе большие.
Проблема заключается в том, что сначала мы пишем ручные тесты, после этого расставляем приоритеты, потом мы тест автоматизируем, валидируем, и всё это занимает время.
Поговорим про тестируемость продукта
Разработка и тесты: «Если мне что-то неудобно в тестах, то я изменяю код продукта»
Например, если бы мне было неудобно писать эти тудушки, я бы сразу в сервисе написал метод, который создает список тудушек. И я бы на это практически ничего не потратил. Для меня это такая минорная функциональность, которая занимает несколько минут. Поэтому как только разработчикам что-то неудобно, они подстраивают под тесты код продукта. Это повышает тестируемость, и многие разработчики предлагали писать больше тестов, чтобы код был красивее. И я с ними в принципе согласен.
Тестирование и тесты: «Я работаю с тем, что в тестовом окружении, прошу доработать что-то, когда совсем тяжело».
Тестировщики практически всегда работают с тем, что в тестовом окружении, куда очень редко доезжают какие-то доработки. Я могу рассказать вам кучу историй, в которых тестовое окружение тормозит. Команда тестирования работает с этим каждый день, окружение постоянно отваливается, все на это жалуются, в ответ говорят, что завтра появится новое тестовое окружение, новые ручки, но этого почему-то никогда не происходит.
Если у вас это не так, если у вас всё круто, вы слушаете свое тестирование, я считаю, что вы большие молодцы, я очень этому рад, продолжайте в том же духе. Но зачастую почему-то тестируемость продукта и тестирование как QA — разные вещи, и нам приходится есть кактус.
Запуск тестов
Разработка и тесты: «Все тесты запускаются на PR, если они упали, то фиксим».
Это круто, потому что даже думать не надо — тесты прошли, джоба зеленая, осталось пройти код-ревью, а так всё хорошо, код рабочий.
У разработчика получается такая картина: он создает PR, у него запускаются тесты, они чуть-чуть попадали, он их все озеленил, всё стало ок, можно делать код-ревью и в прод.
Тестирование и тесты: «Мы запускаем тесты после выкладки в тестовое окружение».
И это большая проблема, потому что когда запускается несколько пулл-реквестов, очень сложно угадать, какой пулл-реквест какую проблему нам принес.

Например, здесь у нас всё зелено, а на самом деле проблема в третьем PR. Но нам надо разобрать большое количество информации, собрать логи, поведение сервисов, чтобы точно указать, что ошибка здесь. Зачастую этого не происходит. Кроме того, ошибки, которые у нас находятся, постоянно фонят. Разработка их не правит моментально, она правит их на следующий день или еще позже. А тесты запускаются постоянно, так что постоянно с нами хвост падений от разработки. То есть известные проблемы постоянно присутствуют, и это раздражает.
Разбор падения тестов
Разработка и тесты: «Берешь StackTrace и вставляешь в IDE :)».
Можно вообще ни о чём не переживать. Открываете отчет, потом копипастите его в IDE, у вас сразу подсвечиваются тестовые методы:

Нажимаете прямо на метод и сразу разбираетесь, в чём проблема. Вы можете сразу его запустить, у вас запустится код продукта, вы можете пофиксить этот тест, убедиться, что он стал работать, и пойти работать дальше.
Тестирование и тесты: «Мы пишем много логов и строим подробные отчеты».
Очень часто причина падения тестов даже не всегда в продукте. Тормозит тестовое окружение, не работает Selenium, прокси загнулась, физический мок-сервер, который поднят в докер-контейнере, начал тормозить под нагрузкой, и прочее. Определять причины падения тестов для нас сложная штука.
Например, мы запустили 100 автотестов, падает 5% — повторюсь, что это в принципе более или менее нормально, потому что у нас постоянно есть тесты, которые падают из-за найденных ошибок. Это нормально, потому что тесты запускаются не на PR. Ну и получается в итоге 25 минут времени. А вот если у нас 1000 тестов и упало 5%, то 5 минут на одну проблему — это 250 минут, уже 4 часа времени.
И это сильно раздражает, особенно если еще и тормозит тестовое окружение, всё это превращается в большую проблему.
Мы строим Allure-отчет и анализируем тренды. Кстати, на этом отчете как раз видно, как у нас строится тренд, что тесты падают совсем по чуть-чуть:

Success rate наших тестов 99,14%, и это довольно круто.
Еще мы постоянно следим за трендами, за временем выполнения тестов, потому что, еще раз повторюсь, тесты зависят от разных источников, и надо постоянно держать себя в тонусе.
Анализ покрытия
Разработка и тесты: «Мы используем метрику “покрытие по строчкам кода”, запускаем на каждый PR».

Еще разработчики добавляют Codecov Report в пулл-реквест:
На мой взгляд, это правильная практика. Если ты написал код и не написал тесты вообще — речь не про правильные тесты, не про тесты, над которыми ты подумал, а просто не написал тесты, то это плохо. Хотя бы какие-то тесты надо написать. И этот плагин начинает ругаться и говорит, что слишком мало тестов написано.
Тестирование и тесты: «TMS для оценки покрытия требования и Swagger для покрытия API».
В тестировании у нас другая оценка. Мы не можем оценивать затронутые строчки кода — точнее, мы можем, но это не приносит нам никакой пользы. В основном мы оцениваем формальные требования. К продукту есть требования, они описываются в системе, мы пишем тест-кейсы на эти требования и всегда можем посмотреть, что проверяется.
Кроме того, мы строим отчеты по покрытию. Вот пример от команды, в которой я делал автоматизацию:

Команда сделала отчет Swagger Coverage. Идея заключается в том, что мы во время прохождения тестов снимаем все запросы, которые были вызваны, а потом делаем diff с обычным сваггером. И в итоге у нас видно, что покрыто, а что нет. Вы можете перейти и посмотреть, что полностью покрыто, а что частично.
Можно посмотреть, что конкретно не покрыто. Например, тут видно, что не покрыт параметр has_photo:

Значит, надо допокрыть, сделать так, чтобы на эти параметры тоже были тесты.
В итоге строим немножко менее формальное покрытие, не строчки кода, но при этом всё же довольно полезное. Такой отчет наши разработчики тоже с радостью смотрят.
Изоляция тестов
Разработка и тесты: «Я использую Mockito и TestContainers, они работают из коробки».
У разработчиков всё работает из коробки. Соответственно, они просто пишут @WithMockUser, и у них всё авторизовано:
@DataJpaTest(includeFilters = ...)
public class TodoServiceTest {
@Test
@WithMockUser("...")
void shouldFindTodos() {
User firstUser = randomUser((user) -> user.setLogin("..."));
Todo firstTodo = todoRepo.saveAndFlush(randomTodo(firstUser));
Todo secondTodo = todoRepo.saveAndFlush(randomTodo(firstUser));
todoRepo.saveAndFlush(randomTodo(secondUser);
...
List<TodoDTO> todoList = todoService.findAllForCurrentUser();
assert.That(todoList).hasSize(2)
.extracting(TodoDTO::getTitle())
.contains(firstTodo.getTitle(), secondTodo.getTitle());
}
}
Добавляя зависимости, просто пишут @MockBean, и после этого можно замокать любой сервис, даже внешний, к которому идут какие-то запросы:
@AutoConfigureMockMvc
public class TodoControllerTest {
@MockBean
private TodoService todoService
@Autowired
private MockMvc mockMvc
@Test
void shouldGetAll() { ... }
}
Всё работает очень хорошо и не вызывает никаких проблем.
Тестирование и тесты: «Я могу проверить часть системы через Сервер Заглушек!»
У нас это называется Сервер Заглушек. Мы поднимаем мок-сервер между фронтендом и бэкендом прямо в тестовом окружении, сохраняем Request/Response. Дальше тест ходит в мок-сервер, управляет им и посылает запросы, например, через браузер. Говорит ему: «Сейчас к тебе придет вот такой запрос, верни ему вот такой ответ»:

Если тестов много, то они пересекаются. Это большая проблема. Обычно мы приходим к разработке, просим их добавить заголовки — когда начинаем сессию тестов, просим сделать так, чтобы мы могли проставить TestID, и разработчики протащили его во все заголовки. Это нужно, чтобы когда мы в тесте попали на заглушку, на мок-сервер, то мы могли сказать: «Сейчас к тебе придет запрос вот с таким TestID, с таким заголовком, пожалуйста, только для него верни вот такой StatusCode, иначе у нас в многопоточной среде всё развалится».
new MockServerClient("mock.company.com", 1080)
.when(
request()
.withMethod("GET")
.withPath("/serach")
.withHeader("TestID", testID),
TimeToLive.exactly(TimeUnit.MINUTES, 5L)
)
.respond(
response()
.withStatusCode(200)
.withBody("{ ... }")
);
Обычно это сложная штука, разработчики не всегда идут на контакт и добавляют какие-то левые хедеры в запросы. Так что эта схема не всегда работает, зависит от компании. Но если разработчики пойдут навстречу, то можно вот так проверять поиск, что фронтенд правильно обращается в бэкенд.

Компетентность
Разработка и тесты: «Тесты писать сильно легче, чем писать код приложения».
Если говорить про компетентность, то, наверное, разработчикам тесты писать гораздо легче, чем писать код приложения, потому что в тестах практически не надо думать.
Тестирование и тесты: «Мы нанимаем сильных автоматизаторов для контроля качества тестов».
Автоматизаторы — это люди, которые близки к разработке и контролируют качество тестов. Я видел много проектов, где собрана команда не совсем компетентных людей, и они делают очень странные штуки. Например, за два года написано 200 тестов, из них только половина работает, половина вообще непонятно чем занята. Они пишут какие-то спринговые приложения для того, чтобы хранить тестовые данные и прочее. Со стороны вообще не понятно, что там у них в проекте. Поэтому компетентности нам порой не хватает даже для написания тестов.
Тестирование и тесты: «В больших компаниях есть такая роль в команде, QA Architect».
Это тоже удивительно.
Мотивация
Разработка и тесты: «Тест писать скучно, я трачу не больше 30% времени и понимаю, что тестов мало».
Я не уверен, что разработчики замотивированы писать автотесты, мне кажется, для них это часто скучно. От замотивированных разработчиков часто слышу: «Я бы хотел писать даже больше тестов, но у меня не всегда хватает времени, потому что надо писать фичи».
Тестирование и тесты: «Я пишу тесты 8 часов и мне нравится, еще я пишу клевые инструменты».
Мы занимаемся автоматизацией тестирования по 8 часов, нам это очень нравится. Вы можете спросить автоматизаторов, они всегда скажут, что им это очень нравится, что им хочется побольше задач, где нужно будет работать с какими-нибудь инструментами и заглушками. То есть у них очень высокая мотивация.
Я могу еще долго сравнивать эти два подхода. Но думаю, что основная мысль понятна.
Если очень коротко: у автоматизаторов есть мотивация, но не всегда хватает компетенции. У разработчиков есть компетенция, но не всегда хватает мотивации.
Автоматизаторы хотят развиваться, им хочется изучать новые инструменты и подходы, но не всегда хватает компетенции. Часто они даже боятся ходить к разработке задать какой-то глупый вопрос.
А у разработчиков наоборот, хватает компетенции, для них автотесты — это не что-то сверх, они привыкли писать тесты, но им не всегда хватает мотивации, времени, чтобы думать о тестировании и понимать, что у нас точно всё проверяется автоматически.
Как я вижу, в этом и есть проблема. И если это как-то совместить, начать вместе работать, то плюсы одного станут плюсами другого. Обе стороны очень хорошо совместимы. Поэтому очень обидно, когда тестирование находится отдельно и когда разработка о тестировании ничего не знает.
Собираем идеальную команду
И вот у меня появляется такая идеальная команда. Как она устроена?
Автоматизаторы в команде:
Пишут нативные автотесты. Автоматизаторы пишут нативные автотесты высокого и среднего уровня. Это значит, что они пишут нормальные тесты в спринговом приложении прямо через MockMVC. При этом они не используют какое-то тестовое окружение, не дожидаются, пока в нем появится фича. Они прямо рядом пишут бизнес-кейсы, пишут вообще как на черный ящик. А разработчик помогает с проблемами, когда надо что-то замокать, сделать честную или нечестную авторизацию, и делает ревью. Это здорово помогает автоматизатору втягиваться. Нативные тесты — это тесты на том же языке, что и код продукта. И лежат в том же репозитории. Spring Test, Espresso для Android, Playwright для веб-интерфейсов, XCUITest и так далее. Удобно, если вы хотите, чтобы разработка тоже думала про тестирование.
Делают ревью новых сценариев. Также нужно делать ревью новых сценариев. Автоматизаторы пишут тесты, и тестирование за них не думает, оно проводит ревью после того, как эти тесты уже написаны. Раньше у нас были тест-кейсы, а тут тестировщики просто проводят ревью новых сценариев.
Делают ревью автотестов от разработчиков. Разработчики пишут автотесты среднего и низкого уровня, автоматизаторы проводят ревью этих автотестов. То есть автоматизаторы тоже вовлекаются, смотрят, какие тесты были написаны, и если у разработчика не хватает времени на написание тестов, если автоматизатор видит, что можно написать 3-4 тестовых сценария, которые помогут сделать модель лучше, то он их дописывает. Разработчик потом тоже делает ревью этих тестов и видит, что именно дописал автоматизатор.
Дорабатывают фреймворк тестирования. И еще автоматизатору можно скидывать задачи по доработке фреймворка тестирования. Часто бывает, что разработчики написали новую функциональность, например, с PDF, и им неохота разбираться, как это тестировать. Автоматизатор с радостью возьмет эти задачи, потому что ему это интересно. Он подключит инструмент, разберется, как это тестировать, напишет автотест и покажет его разработчику. Разработчик потом делает ревью, оценивает, хорошее ли было предложено решение, использовать ли эту библиотеку или заменить, но тем не менее это будет большим плюсом для разработки, ведь автоматизатор в какой-то степени сделает работу за вас.
Отвечают за инфраструктуру тестирования. Админы, естественно, им помогают.
Делают интро по автотестам для новых разработчиков. Также автоматизатор может делать интро по автотестам для новых разработчиков, когда разработчик делает интро по коду. Разработчик рассказывает, как пишут код продукта, какие есть задачи. И тестировщик дополняет, как пишут тесты. Рассказывает, что разработчики пишут тесты вот такого уровня, а тестировщики помогают и так далее. Это сразу настраивает новых сотрудников на дружелюбный лад. Показывает, что вы все работаете вместе, одной командой.
Тестировщики в команде:
Отвечают за релизы и баги. Фича разрабатывается в нескольких командах, так что вам нужен человек, который знает всё — как обстоят дела в других командах, на какой они стадии, какие у них проблемы, какие есть баги и так далее. Такой человек вам точно поможет.
Отвечают за покрытие тестами. Тестировщик отвечает за покрытие, потому что у него большая компетенция. Кто-то может сказать, что писать тесты — это фигня. Отвечаю: посмотрите, какие кейсы придумывают ручные тестировщики, когда у них есть время хорошенько подумать, а не сидеть и заниматься регрессом. Они действительно придумывают интересные сценарии, которые потом зачастую стреляют. Они могут и многопоточным системам что-то подсказать, у них хорошо работает голова. Это их зона ответственности, они отвечают за полноту тестирования.
Тестируют релиз. Еще тестировщики проводят исследовательское тестирование релиза, чтобы не просыпаться по ночам. Автотесты прошли, мы проверили, что всё хорошо, и в продакшен всё катится нормально.
Как пишутся автотесты
Разработчик отводит бранч, создает пулл-реквест.
Автоматизатор делает ревью, добавляет недостающие тесты. Делает новые автотесты, фиксит псевдорабочий код — когда добавили тест, а код как-то неправильно отработал, и автоматизатор может его как-то поправить. Также добавляет ID в элементы, делает код более тестируемым, дорабатывает фреймворк.
Тестировщик делает ревью с точки зрения тест-кейсов.
Автотесты проходят, всё мержится и сливается с веткой, ура.
А что с тест-кейсами?
Тест-кейсов практически не существует. Всё, что может быть формализовано, автоматизируется. Это очень удобно, чтобы не держать всё в голове, чтобы не было увесистых тестовых документаций. Тестовая документация генерируется по тестам, примерно как Swagger. Вот Swagger генерируется по рестовым ручкам, а по автотестам генерируется такая же штука, прямо в тест-кейсах, в которых описан обычный сценарий, вроде «я создал пользователя, сделал вот это и это», как я показывал в примере чуть раньше. Это и есть ваша тестовая документация. Вы всегда знаете, что и как проверяется.
У тестировщика может быть пара чек-листов, но они больше для личных нужд.
Для новых фичей все тесты были написаны в пулл-реквесте, поэтому мы проверяем их в рамках исследовательского тестирования, когда пытаемся как-то поломать систему. Но все баги уже были найдены раньше, мы написали их на стадии PR. Если мы что-то забыли, мы просто добавляем новые автотесты через PR в тот же самый репозиторий.
Если у нас нашлись какие-то баги, то их заносят в Issues и они становятся частью регресса. То есть появился баг, автоматизатор сразу же написал на нее автотест, и разработчик баг поправил. Автоматизатор не просто говорит: «У нас баг», а понимает, что это за баг, пишет для разработчика автотест, делает PR. В этом автотесте у вас не работает функциональность, вы ее правите, она начинает работать, и для вас сразу же есть автотест и всё сразу исправлено. Это очень удобно.
Как запускаются автотесты?
Всё в рамках пулл-реквеста, все типы тестов:

Это очень дорого, это большая проблема, но это проблема всей команды, поэтому она решается. Вы в команде решаете, сколько у вас больших тестов, сколько средних и маленьких, какая для этого нужна инфраструктура, потому что вы ответственны за тестирование вместе и проблемы вы решаете вместе.
В итоге у нас уходит минимум времени на дебаг. Всё работает по принципу зеленого пайплайна: ошибка там, где мы ее закоммитили. Тесты выполняются быстро. Автоматизатор следит за скоростью тестов, но если что-то идет не так, то мы вместе оптимизируем фреймворк, подкручиваем инфраструктуру, делаем более мощные агенты, параллелим наши автотесты, разбиваем их на модули. Это всё очень просто делается, когда это проблема одной команды. Поэтому аналитика, которая у нас была раньше, практически не нужна.
А чья инфраструктура?
Инфраструктура уходит к тестировщикам. Тестировщик начинает отвечать за тестовое окружение, наливает его с помощью скриптов админа, разбирается с эмуляторами, отвечает за работу автотестов. Админ решает сложные задачи, отвечает за машинки, делает ревью скриптов, настраивает мониторинги.
Например, если у нас сломались какие-нибудь эмуляторы, то автоматизатор сначала быстро, за 15 минут, напишет автотест, начнет разбираться в докере, погрязнет в инфраструктуре, потратит очень много времени. У админа то же самое, у него всё есть, но он не может эту ошибку легко воспроизвести. Он тоже потратит много времени, просто в другую сторону. Но если это решает команда, то она тратит по чуть-чуть времени из-за заинтересованности каждого из членов команды. Автоматизатор может дойти до какого-то момента и понять, что не так с тестовым окружением, сформулировать проблему, потому что теперь он в этом тоже разбирается, и передать эту проблему с примерным тестом админу. Админ быстро разберется и пофиксит. Ура, тесты зеленые, всё работает.
Что особенного в такой команде?
Мне кажется, в идеальной команде:
- Автотесты пишутся на нативных языках в том же репозитории.
- Тесты запускаются при сборке.
- Автоматизация выше документации: нам не нужны ручные описания, они быстро устаревают.
- Команды межфункциональны: люди умеют и код писать, и фреймворк подправить, разработка интересуется тестированием и так далее.
- Инфраструктура общая: тестировщики тоже несут ответственность за тестовое окружение.
Я сейчас такие команды и строю, где тестирование — это общая ответственность, когда вся команда тестирования очень плотно общается с разработкой. Верить мне или нет, решайте сами.
Мне часто говорят: «Подход клёвый, но ты упрешься в людей, никому ничего не хочется». В ответ на это у меня есть одна табличка:

Если у вас разработка и тестирование не согласны с тем, что я говорю — ничего не поделаешь, этот доклад для вас бесполезен, спокойно пропустите его и забудьте о нём. Это нормально, никого не агитирую.
Если у вас есть тестировщик, который приходит к вам с такой идеей (а они обычно приходят), то просто не надо ему мешать. Дайте ему посмотреть репозиторий. Часто, когда я прихожу в команды и прошу посмотреть репозиторий, чтобы понять, что там в коде, мне не хотят ничего показывать. «А что вы там будете делать?» Очень странно. Мы же одна команда, я хочу посмотреть, что там с тестированием. Так что тут просто не надо вставлять палки в колеса. Мы посмотрим и может сможем сделать что-то хорошее. Если ничего хорошего не сделаем, то тогда и поговорим. Так что на этом этапе, пожалуйста, просто не мешайте.
Если наоборот, вы как разработчик согласны, а ваш QA не согласен — это тоже довольно распространенный вариант. Разработчики хотят, чтобы у них была автоматизация, но она обычно где-то там, сбоку. Как ей пользоваться, что для этого нужно сделать — никто не знает. Придите и покажите разработчикам, как пишутся ваши тесты. Поверьте, любой адекватный любопытный автоматизатор посмотрит, насколько просто и хорошо пишутся тесты, он точно проникнется энтузиазмом и вам поможет. Найдите самого любознательного.
Ну и если у вас и QA, и разработка согласны, то жду от вас доклад, как у вас всё получилось (к счастью, таких докладов становится всё больше).
Или напишите о своем опыте в комментариях.
А завершу скриншотом уже полученного комментария:

Минутка рекламы
Если для вас актуален этот текст, то интересное для вас может найтись и здесь:
- Heisenbug (тестирование): 30 мая–1 июня (онлайн), 21 июня (офлайн)
- JPoint (Java): 13–15 июня (онлайн), 24 июня (офлайн)
А если вас заинтересовал конкретно Артём и его Allure-проекты, нам не жаль и на них ссылок поставить: гитхаб и телеграм-чат Allure Framework, сайт и твиттер Qameta Software.
 Безопасный дайджест: хакер-инсайдер, шпионы в Google и мегаслив паспортов")



