
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Как и любое другое облако, Yandex.Cloud — это многослойная иерархия абстракций: SaaS, лежащий поверх PaaS, запущенный на IaaS. Связность виртуальной инфраструктуры обеспечивает виртуальная же сеть, которая является, по сути, оверлеем. И только в самой глубине этой системы обнаруживается физическая сеть из проводов и коммутаторов. Мало кто вспоминает о ней, пока всё работает. А меж тем она — кровеносная система всей платформы.
Привет, я Марат Сибгатулин, сетевой инженер Yandex.Cloud. Яндекс про свою сеть рассказывал уже не раз. И про её физическую инфраструктуру, и про особенности устройства Yandex.Cloud, и про то, как вообще работает виртуальная сеть. Не буду повторяться. Расскажу о том, как мы запустили публичное облако на том, что было — на двух стойках, и масштабировали его до сети для десятков тысяч серверов, не наращивая неоплатный технический долг.
Мы практикуем следующий подход к созданию и развитию чего бы то ни было: прототип → минимально необходимая функциональность и масштаб → рост → эволюционное развитие. На первый взгляд он естественен и очевиден, в отличие от подхода «сделать сразу идеально и на века». На деле — требует вдумчивого предварительного планирования, чтобы потом не подставлять в горячке новые костыли под старые, пытаясь поспеть за внезапным ростом.
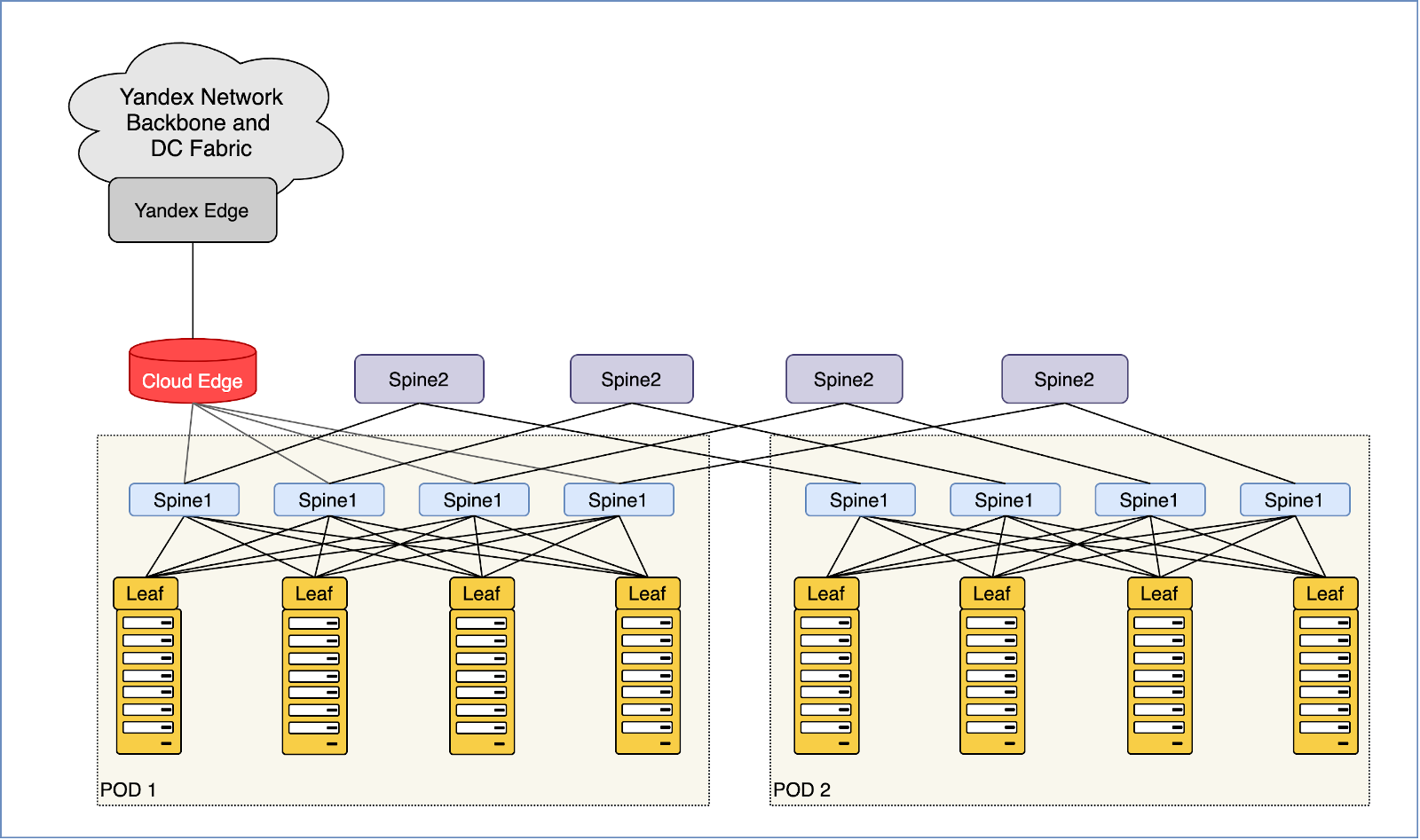
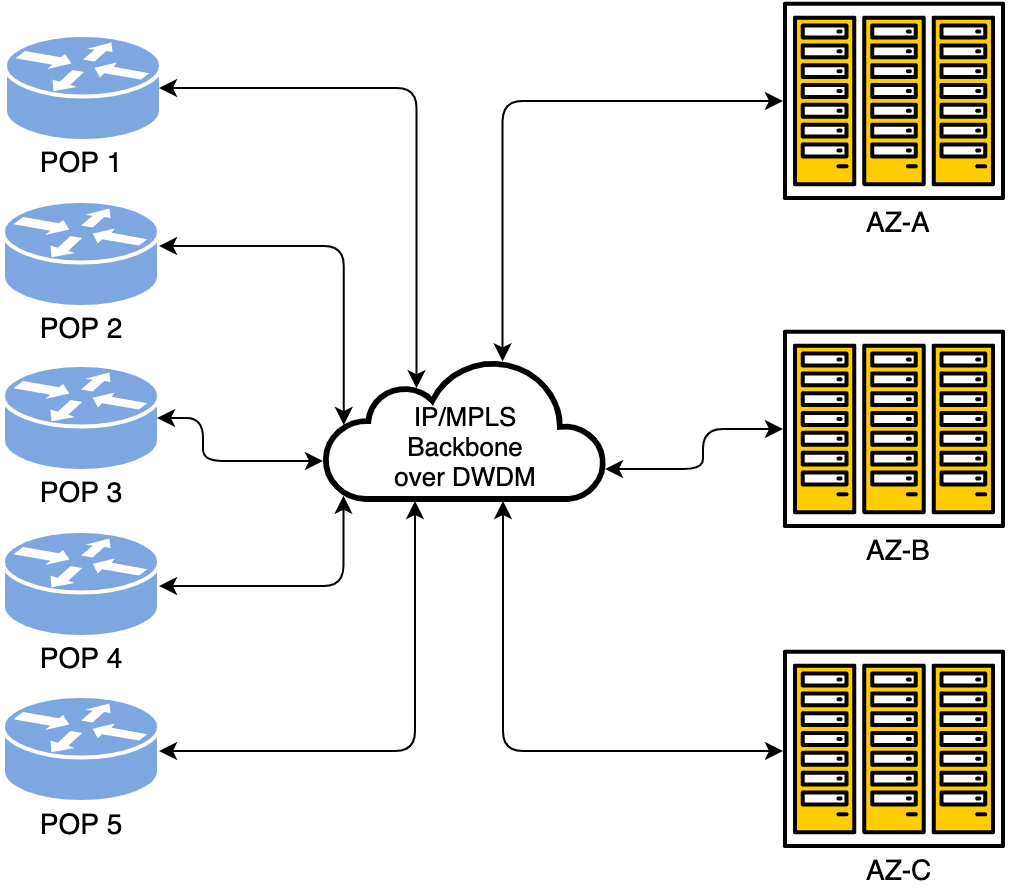
У Yandex.Cloud 3 зоны доступности (Avialability Zone — AZ) и 5 точек присутствия (Point of Presence — POP). Внутри AZ — классическая для датацентров сеть Клоза. Между разными AZ и POP — магистральная DWDM-сеть. Выход в магистраль реализован через специальные граничные устройства.
В AZ находятся стойки с серверами. Каждая, набитая более чем тридцатью машинами, подключена в сеть на скорости 400 ГБ/с. Внутри одной AZ мы можем прокачивать десятки терабит. Наружу — в совокупности между ДЦ, в большой Яндекс, в интернет — из каждого ДЦ мы сможем выпустить около 1 ТБ/с.
Как вы думаете, когда всё началось? Ответ может сильно удивить: в 60-е, когда француз Чарльз Клоз (строго говоря, Шарль Кло — он же француз) придумал для телефонных станций особую топологию. Она позволяла недорого подключить n входов к m выходам без блокировок и необходимости использовать n*m соединений.
История, конечно, интереснейшая, но длинная. Ограничусь самым важным: пережив несколько инкарнаций, сеть Клоза нашла своё применение и в датацентрах, где требуется соединить друг с другом большое количество физических машин.
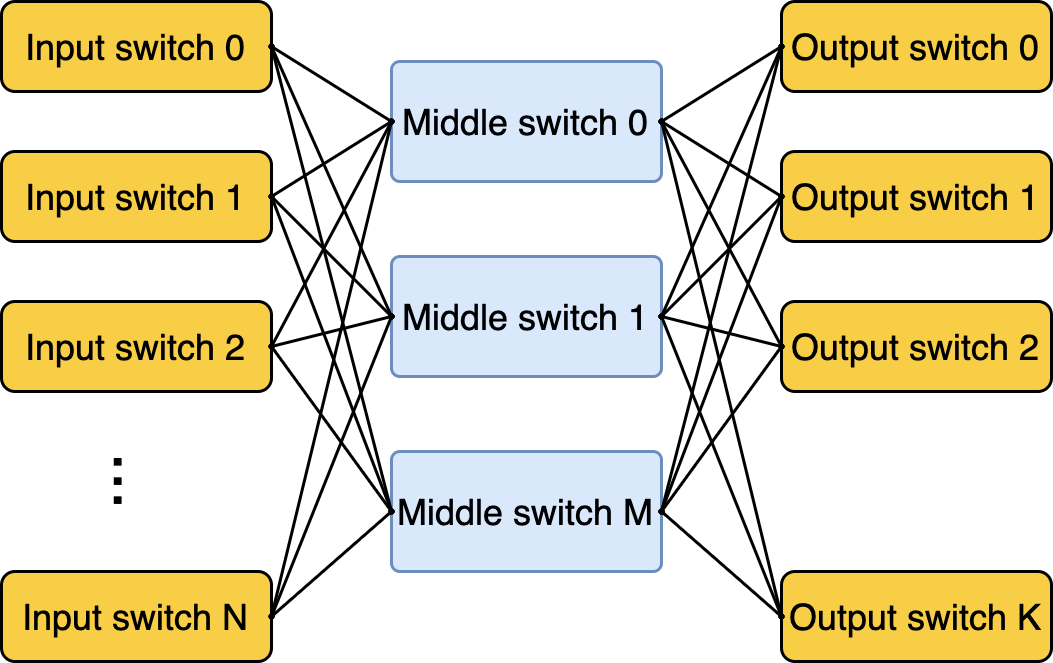
Классическая сеть Клоза
Фабрика коммутации Yandex.Cloud, связывающая между собой физические машины — воплощение сети Клоза. Её регулярная и плотная топология обеспечивает высокую отказоустойчивость системы и широкополосную передачу данных как внутри, так и вовне сети.
Входы (они же выходы) называются лифами (в оригинале — «Leaf»), а соединяющие их устройства — спайнами («Spine»).
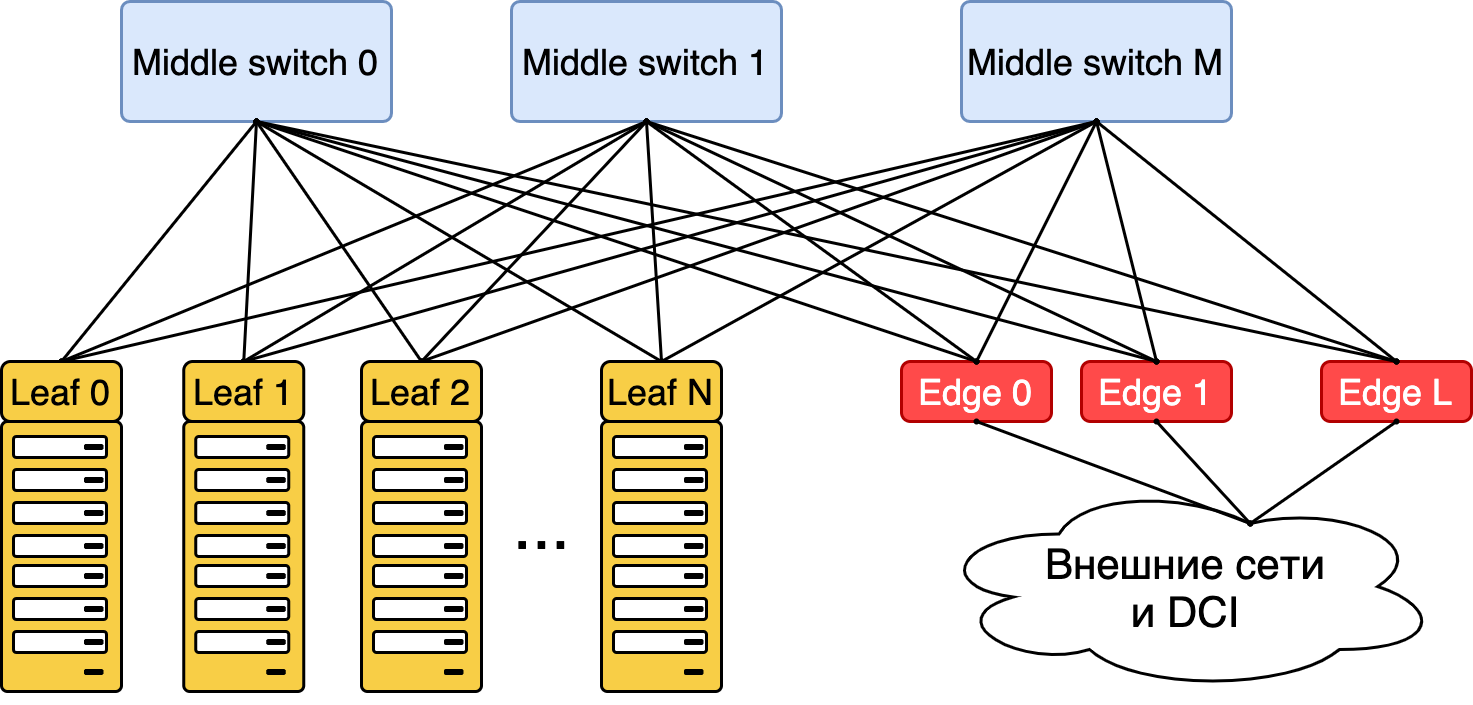
Сеть датацентра, она же фабрика, она же Folded Clos
Однако наиболее важное для наших задач качество такой топологии — возможность практически неограниченно наращивать её, не принося в жертву ширину полосы. Именно поэтому она стала основой для всех гипер- и экзаскейлеров и клауд-титанов.
Но обо всём по порядку.
Для Yandex.Cloud всё началось без малого 4 года назад, когда где-то в каморках датацентров Яндекса завелись первые стойки с дев-окружением. Тогда же начала формироваться команда сетевой инфраструктуры.
Выше я упоминал, как важно предварительное вдумчивое планирование. На стыке 2017–2018 мы думали и рисовали. Ещё думали и ещё рисовали. Потом передумывали и перерисовывали. В нашем распоряжении были огромные белые стены и сочные маркеры.

А в июле 2018-го мы построили нашу первую сеть.
Она была достаточно простой, чтобы быстро налить первый препродовый стенд. Но при этом достаточно зрелой, чтобы вписаться в дальнейшее развитие. К четвёртому году жизни Yandex.Cloud, мы успели сменить 2 мажорных поколения дизайна датацентровой фабрики, а стойки, введённые в работу в 2018, всё ещё органично вписываются в сеть и работают в проде. Более того: мы до сих пор продолжаем строить платформу по дизайну, который задумали в 2017.
В 2018 у нас ещё не было своей сетевой инфраструктуры: мы подключали стойки платформы к существовавшим системам большого Яндекса. Фактически сеть Yandex.Cloud состояла только из стоечных свитчей — а дальше начинался NOC Яндекса. Из-за того, что нам не пришлось сразу строить всю фабрику и организовывать границу датацентра, удалось быстро стартануть. А инфраструктурные сервисы смогли начать разработку в среде близкой к продовой. На этой сети мы и запустили первый прод в 2018-м.
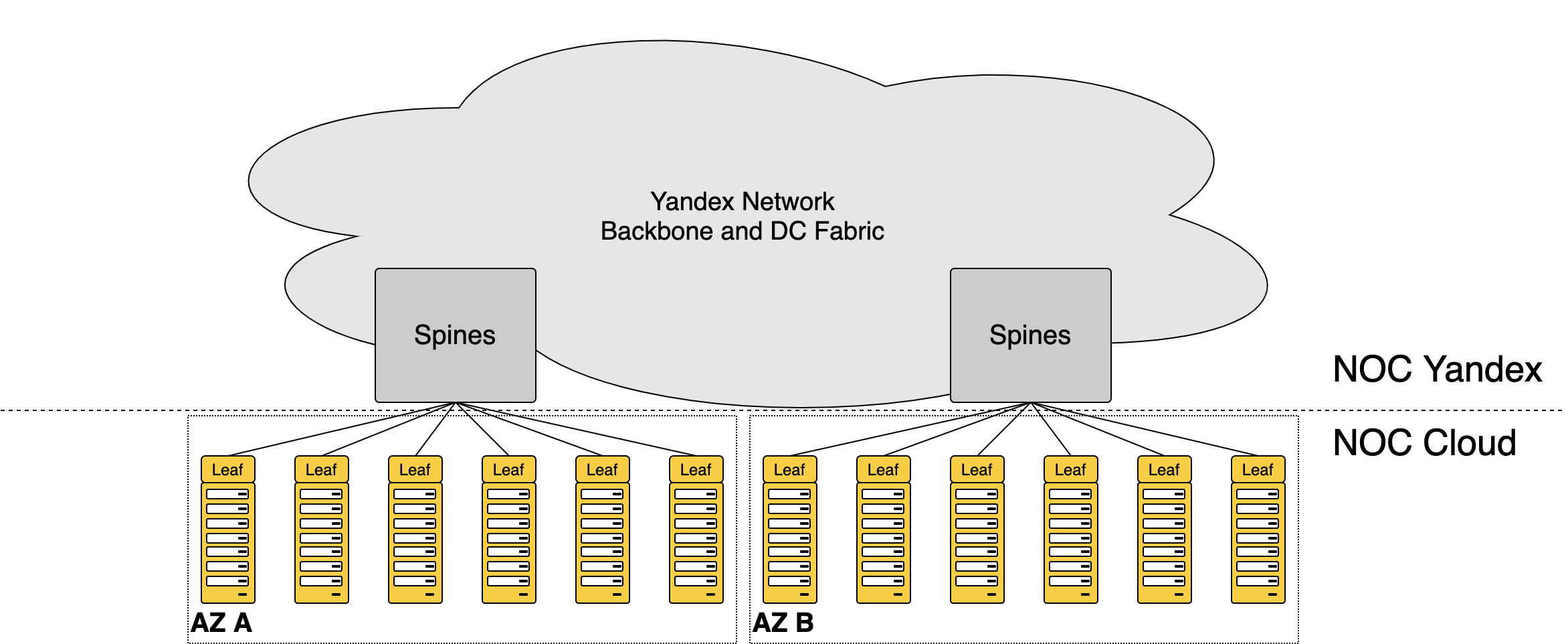
Тут следует заметить, что мощности Yandex.Cloud располагаются в датацентрах Яндекса. Платформа использует такие же сервера и стойки внутренней разработки, такие же свитчи и маршрутизаторы, включается в ту же СКС. Даже в дизайне сети мы идём одной тропой. То есть пользуемся плодами и опытом двадцатилетней разработки внутренней инфраструктуры компании.
Но при этом быть органической частью Яндекса не можем в силу как отличающейся бизнес-модели, так и требований регуляторов. Так PCI DSS, ISO 27001, ISO 27017 и ISO 27018 требуют особого отношения к доступам в стойки, обращению с дисками, видеонаблюдению, TPM. Ни для кого не секрет, что оверлейная сеть, обеспечивающая мультитенантность Yandex.Cloud, реализована на OpenContrail (ныне Tungsten Fabric). Он, в свою очередь, требует IPv4-связности. А как всем известно, Яндекс одним из первых стал IPv6-only.
Ещё одно радикальное отличие — это MPLS. Облачным платформам он необходим как составная часть нескольких решений. Но у этого механизма есть существенный минус — ограничения масштабируемости. Яндекс отказался от MPLS в пользу максимального упрощения сети.
Иными словами мы с NOC большого Яндекса всё дальше и дальше расходились в своих перспективах. В начале 2019-го стало окончательно понятно: в обозримом будущем сохранить общую сеть не выйдет. Впрочем, история любит спирали — кто знает, что впереди?
На тот момент, к счастью, мы уже были готовы разворачивать новое поколение нашей собственной фабрики.
Иметь единые с большим Яндексом инфраструктуру и инструментарий было бы очень удобно. Но ради этого нам пришлось бы пожертвовать скоростью развития платформы. Сеть NOC, строившаяся под задачи большого Яндекса и ориентированная на внутренних клиентов, плохо решала задачи Yandex.Cloud:
И мы решили строить свою независимую фабрику. Сейчас, оглядываясь назад, мы понимаем, что это решение было очень правильным и своевременным.
Вторая половина 2018-го — вновь время раздумий и больших сложных картинок на стенах офиса. Потом — закупки и подготовка базовой автоматизации, пока едет оборудование.
Проекция процесса творческого поиска на маркерную стену
Предполагая, какими объёмами будет прирастать серверный флот, с самого первого дня мы стали думать про автоматизацию одновременно с планированием самой сети. Первые же прод-свитчи мы настраивали не вручную, тем самым избежав человеческих ошибок.
В этот же момент завели молодёжный NetBox и собственные системы: инвентарную, учёта IP-ресурсов, первый прототип общего сетевого API-интерфейса с модным REST. А скрипты автоматизации обрастали мышцами и кожей, пока плавно не обрели форму системы, которая обеспечила конвейером жизненного цикла каждое устройство в сетевой инфраструктуре.
Если коротко, то после установки нового устройства на позицию мы:
Но не буду отвлекаться: про всю автоматизацию когда-нибудь расскажем отдельно. Эта долгая и интересная история требует особого внимания.
Летом 2019-го мы разворачивали и тестировали Cloud Fabric — полностью независимую от большого Яндекса инфраструктуру внутри датацентров: торы (они же лифы), спайны, граничные устройства. Для сообщения между ДЦ и выхода во внешний мир мы подключились в развитую магистральную сеть Яндекса. Чтобы добиться связности с его сервисами, организовали стык через датацентровые бордеры. Ещё раз спасибо автоматизации: настройка заняла один день и обошлась без происшествий.
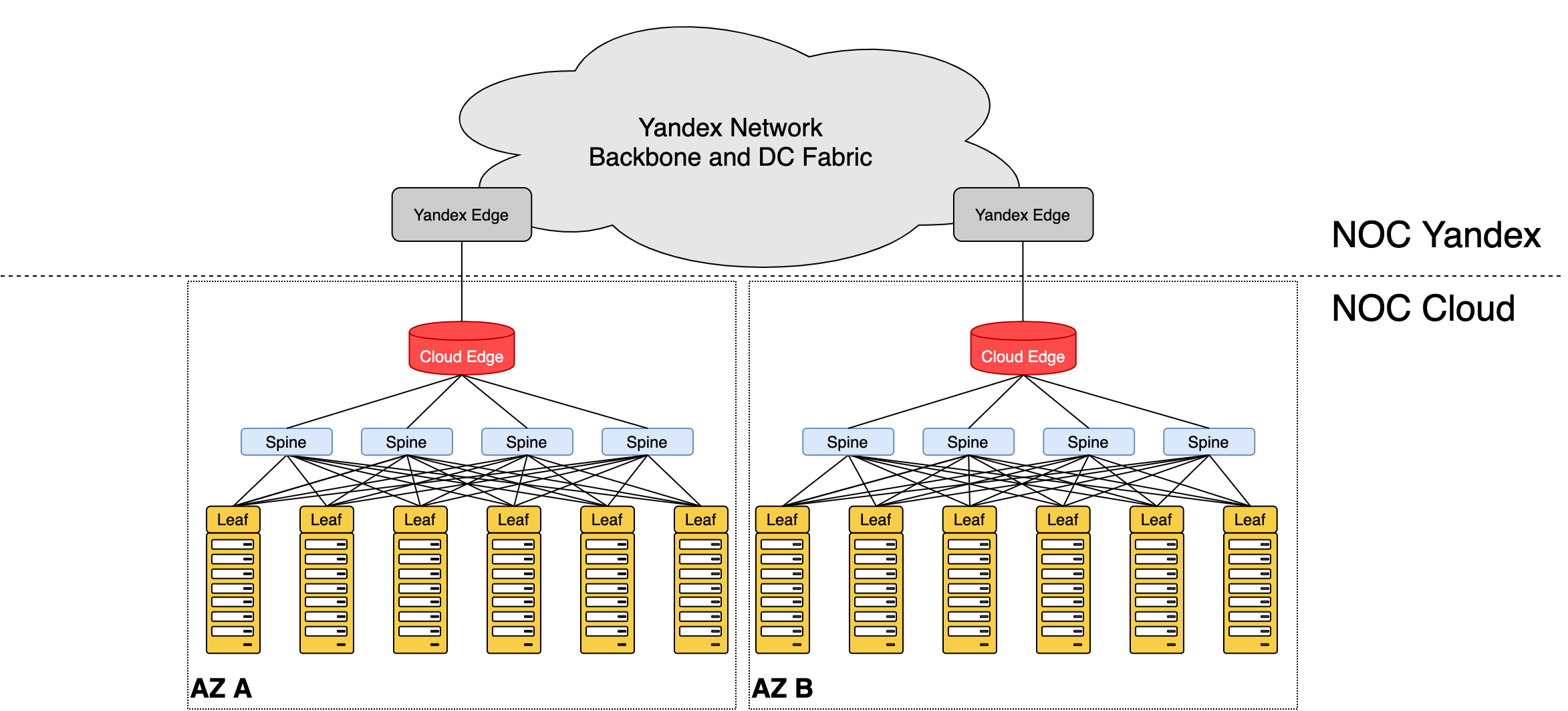
Уже собственная сеть Облака, использующая Яндекс только для транспорта и как пира
О том, как устроена наша сеть, расскажу поподробнее.
Знакомьтесь — наши серверные стойки:

Стандартные стойки Яндекса
В каждой из них около 30 машин, которые включаются в свитч, установленный в этой же стойке. Он называется ToR (Top of the Rack)-switch. Название подсказывает, что свитч должен стоять наверху, но для более рациональной коммутации, он установлен по центру стойки.

Здесь и далее ToR выступает синонимом Leaf. С помощью лифов машины могут общаться друг с другом в пределах стойки.

Внутри стойки
Для того, чтобы могли общаться машины в разных стойках, торы тоже нужно тоже соединить друг с другом. Сделать это в лоб теоретически возможно. Есть даже такие топологии: Full Mesh, Ring, Star. Но все они или не работают в датацентрах, где преобладает трафик внутри ДЦ между машинами, или будут стоить дороже, чем серверные мощности. Да, можно подключиться по радио и даже через светодиоды. Но делать этого мы, конечно же, не будем.
Как всегда, всё уже придумано до нас. Помогла нам упомянутая выше топология Клоза. Мы поставили большие молотилки трафика, единственной задачей которых было — передать трафик из одной стойки в другую. Выше я рассказывал, что они называются «спайны».
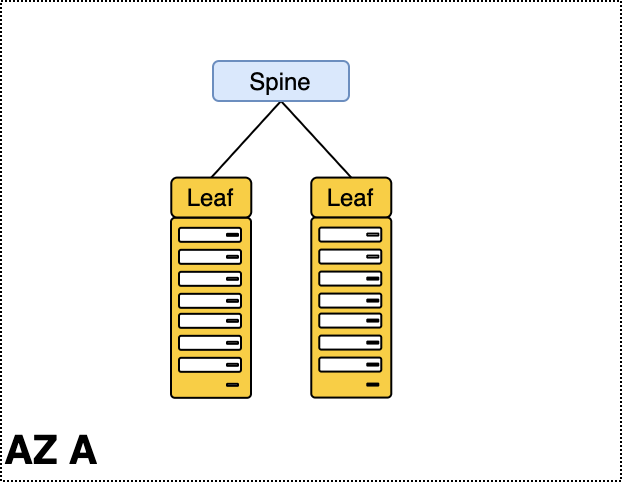
Между стойками
Для того, чтобы могли взаимодействовать машины, находящиеся в разных ДЦ, мы организовали выход из локальной фабрики через граничные устройства — Edge Leaf.
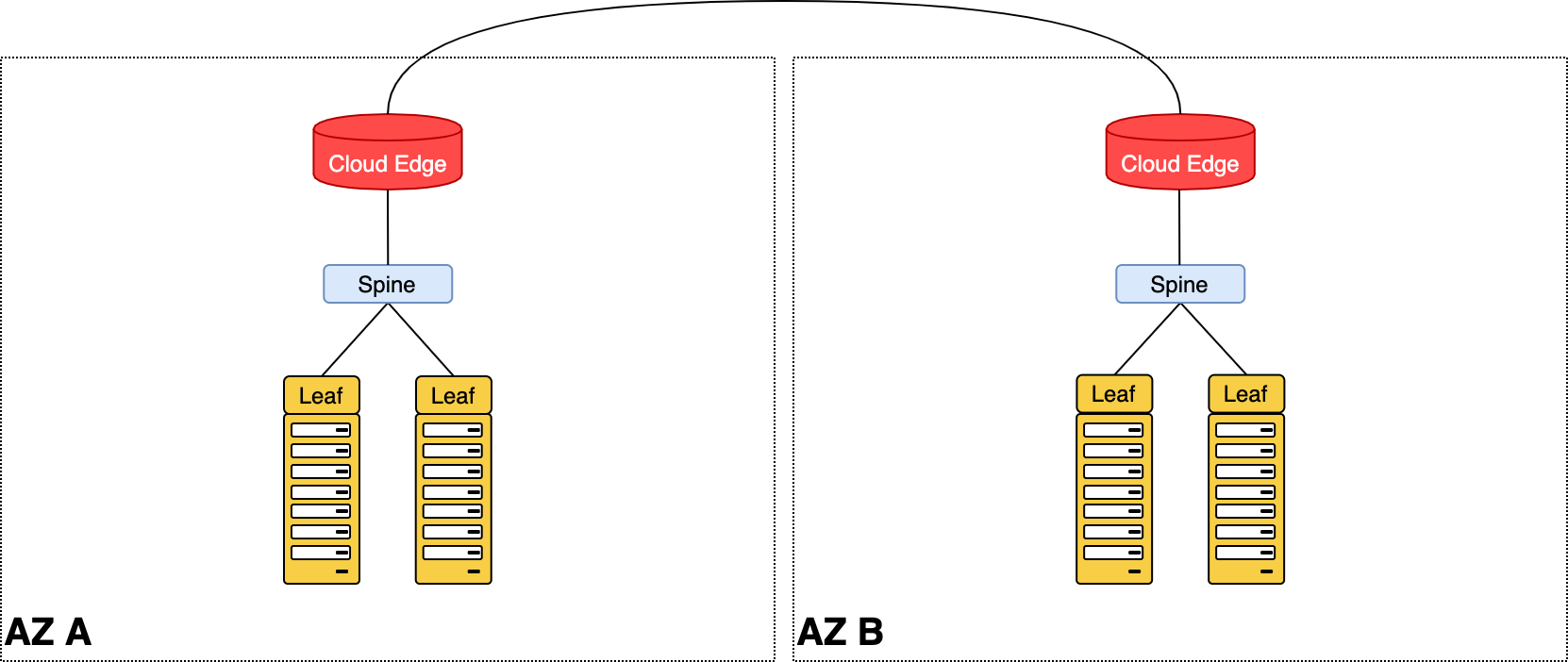
Между ДЦ
Для уровня спайнов и Cloud Edge мы установили в каждой AZ отдельные инфраструктурные стойки. Вот так выглядели они в тот момент:

После этого все новые серверные стойки запускались уже в новой сети, подключаясь именно в наши спайны, а не общеяндексовые.
С августа по декабрь 2019 мы бесшовно мигрировали все стойки, запущенные ранее, в нашу новую-кленовую фабрику. И как раз успели перед большим редизайном NOC Яндекса, целью которого было существенно упростить инфраструктуру. После него платформа Yandex.Cloud уже не могла работать по старой схеме.
В 2020-й мы вошли с независимой фабрикой. Теперь Облако никоим образом не затрагивали и не тормозили любые работы и неисправности, отсутствие MPLS и IPv4 на датацентровой сети большого Яндекса. А мы в свою очередь не мешали ему развиваться.
Есть и ещё один нюанс. В Яндексе регулярно проводятся учения по полному отключению датацентров, чтобы убедиться, что все, даже самые маленькие и незаметные, сервисы способны жить при -1 ДЦ.
Все, кроме Yandex.Cloud.
Дело в том, что сервисы Яндекса изначально разрабатываются так, что за свою доступность каждый отвечает самостоятельно, перераспределяя нагрузку на оставшиеся в живых узлы и масштабируя ресурсы по мере необходимости. Наша платформа, будучи плотью от плоти Яндекса, тоже придерживается этой парадигмы. Вся внутренняя инфраструктура, начиная c контроллеров сети, продолжая DBaaS и заканчивая serverless, высокодоступна и переживёт многое. Но требовать того же от клиентов мы не можем.
Клиент на свой страх и риск может развернуть единственную ВМ в одной AZ без балансировщика. И эта машина благополучно канет в лету в случае недоступности хоста, стойки, AZ. Но клиент на закономерный вопрос «Зощто?», вряд ли удовлетворится ответом «Мы просто проводили учения». Поэтому независимая сеть для Облака — необходимость, а не реализация амбиций.
2020: новый год, новая сеть, новая напасть. В построенную нами фабрику можно было подключить ограниченное число серверов. А именно — чуть больше 2000 машин (если закрыть глаза и совсем не задумываться о будущем). Платформа при этом росла весьма быстро, удваиваясь через равные промежутки времени.
Задумываться о будущем мы начали параллельно с миграциями, ещё в 2019 году. Топология Клоза хороша тем, что её сравнительно легко масштабировать — добавляя новый уровень спайнов, многократно увеличиваешь число машин, которые можно подключить.
Так мы добавили спайн для спайнов, он же суперспайн, он же Spine2, он же ToF (Top of Fabric) и подключили в него существующую сеть, после чего последняя стала лишь маленьким кусочком мозаики.
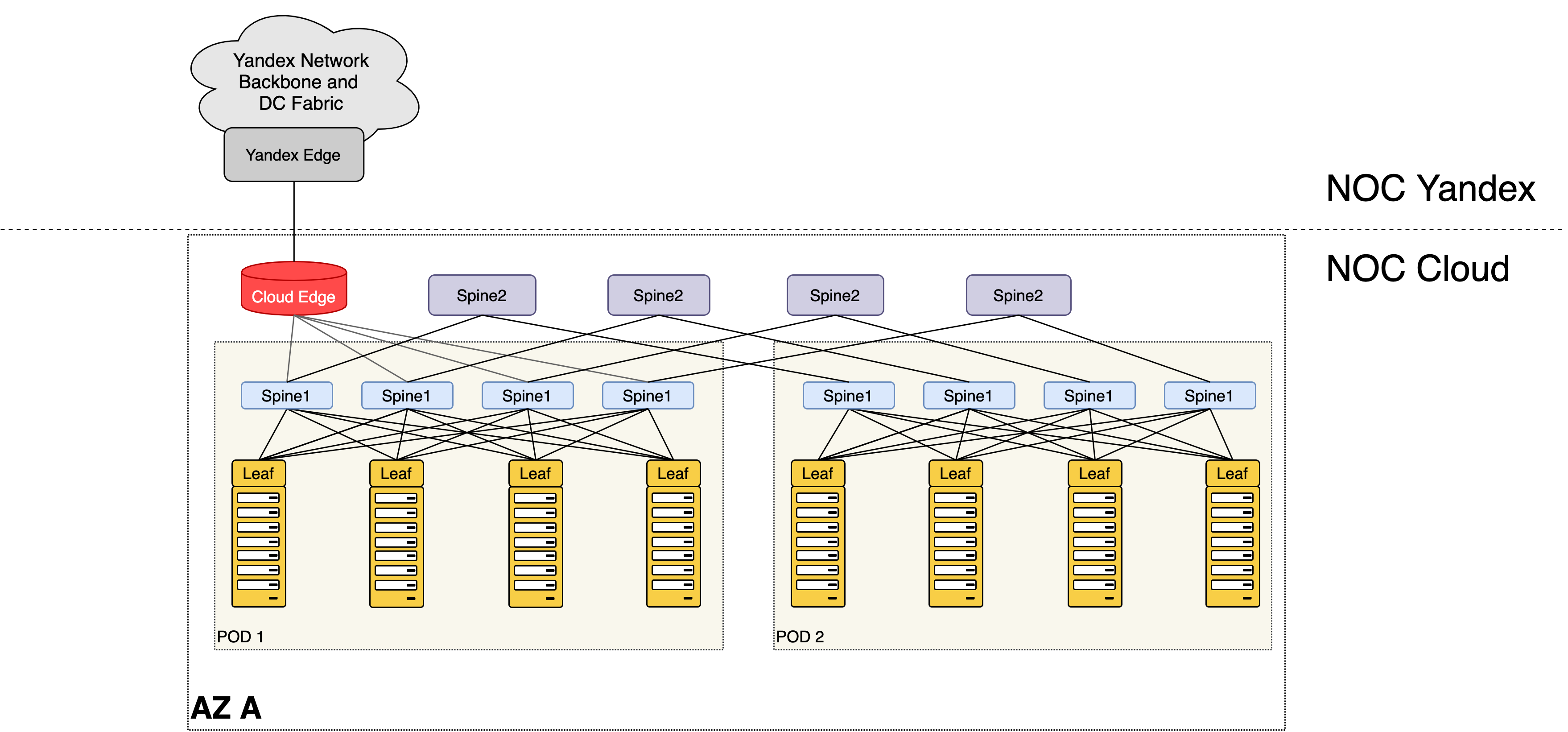
Текущий вид сети ДЦ Облака
Каждый такой кусочек называется PoD — Point of Delivery. Это универсальные блоки сети, её кирпичики, а спайны второго уровня — скрепляющий цементный раствор. На иллюстрации два POD, но их может быть от 32 до 128 в зависимости от радикса (числа портов) используемых свитчей.
Каждый POD обладает ограниченной портовой ёмкостью. В нашем дизайне — это 32 серверные стойки или порядка 1000 серверов. Каждый раз, когда порты для подключения серверных стоек в текущем POD заканчиваются, мы строим типовой новый POD и начинаем подключать стойки в него. Принципиальных архитектурных изменений при этом не требуется.
Чуть более приближенное к реальности схематическое представление многоуровневой датацентровой фабрики:
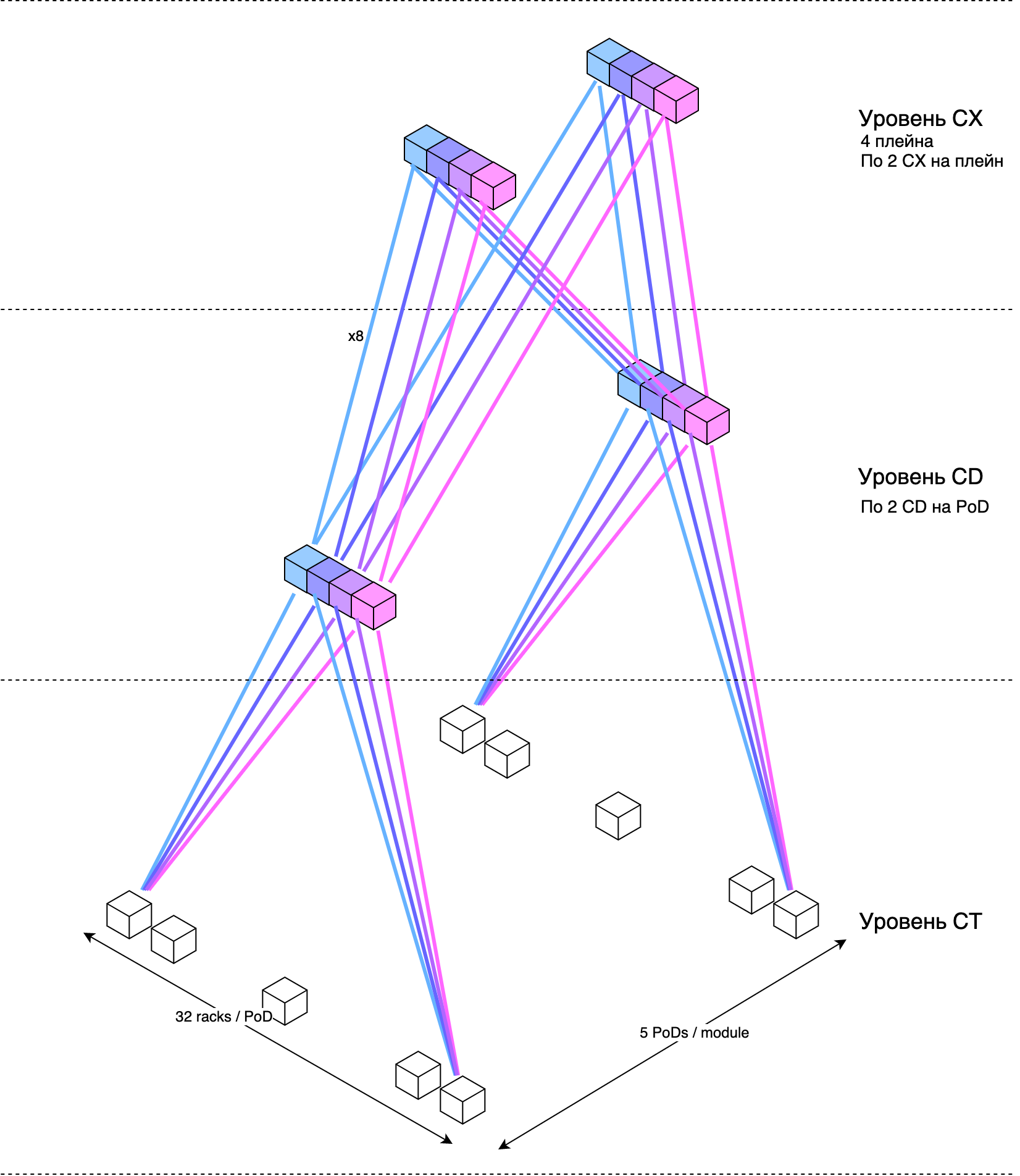
Для этого нам пришлось добавить ещё по несколько инфраструктурных стоек в AZ. Каждая стойка и устройства в ней зарезервированы по питанию независимыми вводами. Сеть выдерживает любой двойной отказ устройств или линков и даже полное выключение двух стоек с приемлемым уменьшением полосы.
Но всё было бы не так интересно, если бы можно было просто взять готовое решение и применить его как есть.
Топология Кло для ДЦ — это очень хорошо, но вместе с тем — весьма дорого. Причём с увеличением числа уровней, стоимость растёт нелинейно.
Классический подход предполагает один линк между парой устройств разных уровней.

Когда компания планирует поставить сразу 30 000 хостов, арифметика следующая: ставим 32 POD по 32 стойки по 32 машины и подключаем их в 32 спайна второго уровня на каждый плейн — грубый абстрактный счёт. 4 плейна — 1280 свитчей. Если каждый из них стоит $10 000, получается, что только на коробки надо потратить 13 миллионов долларов. А ещё столько же понадобится на СКС и трансиверы. Полагаю, так строят новые ДЦ Amazon и Google.
Но Yandex.Cloud растёт более плавно. Нам не нужно сразу 32 POD и полностью собранный уровень Spine2. Если, к примеру, у нас есть 4 POD, то при классическом подходе в каждом из Spine2 будет занято только 4 порта — остальное греет горячий коридор.
Мы решили сделать усечённый уровень Spine2 — вместо 32 свитчей, мы ставим в него 4. А Spine1 подключаем в Spine2 не одним линком, а, условно, восемью, чтобы добиться нужной полосы между POD. Тогда 4 POD займут 32 порта на Spine2. Когда мы ощутим потребность расти дальше, просто нарастим группировку Spine2 до 8, а линки перераспределим из старых в новые. По мере роста повторим.
Таким образом мы существенно снижаем CAPEX на начальных этапах.
Очевидно, что линки между парой устройств должны использоваться все и равномерно. Для этого:
1) Их можно объединить в LAG.
2) А можно каждый из них настроить как самостоятельный L3-интерфейс и использовать силу ECMP.
Мы много думали, спорили, собирали лабы, считали аппаратные ресурсы коммутаторов, прогнозировали рост. LAG в результате выиграл по большинству позиций:
* Меньше использует ECMP-группы в случае MPLS (есть в наших ДЦ).
* Меньше контрольной информации — одна BGP-сессия вместо нескольких.
* Меньше шума на сети при флапах интерфейса.
* Проще переконфигурировать сеть, когда меняем группировку Spine2.
* Проще автоматизировать.
Есть у LAG, безусловно, и особенности. Но для тех из них, которые могут сделать платформе больно, мы нашли компенсационные меры.
Dual-homing машин в два тора — весьма противоречивая идея, которая реализована мало у кого из облачных провайдеров.
Парадигма архитектуры облачных инфраструктур предполагает, что клиент разворачивает несколько экземпляров своего приложения в разных AZ, прячет их за балансером и к тому же настраивает auto-scaling. Выключение физической машины, где крутилось его приложение, в этом случае никак не скажется на работоспособности сервиса. Но реалии иные — зачастую у клиента может быть всего одна виртуалочка, на которой крутится весь прод.
Аварийное выключение свитча — это вопрос вероятностей. Чем больше флот и чем дольше он существует, тем больше шансов, что вскроется баг, деградирует элемент, случится битфлип. И какая-то стойка потеряется. Для предотвращения таких ситуаций и комфортного планового обслуживания коммутаторов было бы удобно иметь схему с двумя ToR.
Кроме того это один из вариантов увеличения полосы, это возможность разнести тяжёлый трафик хранилища/дисков и клиентский на разные интерфейсы и бесшовно обновлять forwarding-агенты на хостах. Однако это влечёт за собой огромный фронт работ по переделке СКС, редизайну маршрутизации и схем отказоустойчивости, разработке хостовых агентов.
Мы сделали прототип двуторья с BGP с хоста, разработали схему отказоустойчивости, спланировали возможную СКС, проверили в виртуальных лабах на больших масштабах и пока отложили в стол. Возможно, мы ещё вернёмся к этой идее.
Во всём этом немалом хозяйстве нужно уметь быстро находить (а ещё лучше предвидеть) проблемы до того, как к нам придёт смежный сервис, и уж тем более клиент. Для этого у нас есть количественные и качественные мониторинги. Они составляют большую часть обвязки нашей внутренней разработки.
Количественные мониторинги у нас весьма типичные: CPU, Memory, утилизация интерфейсов, счётчики ошибок, уровни сигнала.
Различные счётчики комбинируем во всевозможные сочетания и выносим на дашборды, чтобы с первого взгляда было можно оценить, например, общий объём трафика на любом срезе или «зажечь аварию» при превышении допустимого числа ошибок в AZ.
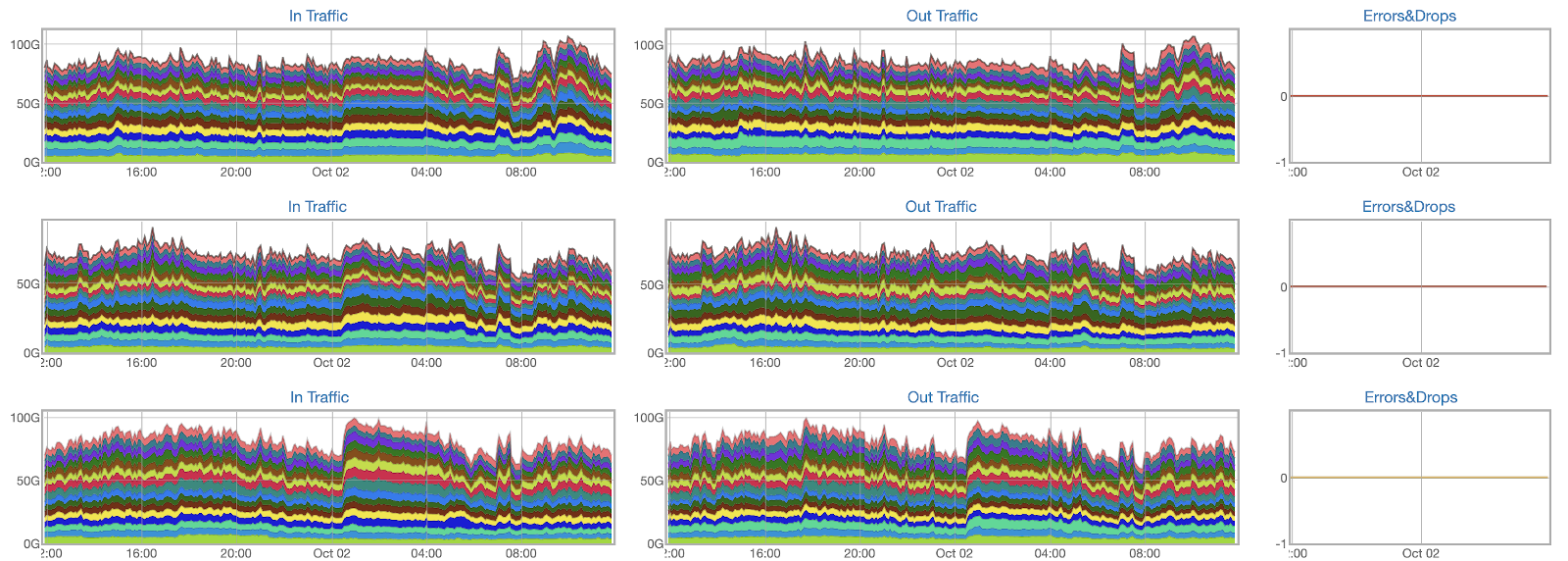
На все известные проблемы создаются триггеры, которые зажигают явную аварию. Благодаря этому в нашей команде нет необходимости в дежурной смене, которая бы денно и нощно не сводила глаз с графиков в поисках аномалий.
Качественные мониторинги поинтереснее. Наша система раз в 2 минуты опрашивает каждое сетевое устройство, забирая с него состояние BGP и интерфейсов. Ответ парсим на специальных серверах, приводим к общему виду, независящему от вендора и интерфейса, и сравниваем с бейслайном. Далее создаём событие (OK, WARN, CRIT). Некритичные попадут на дашборд. Самые страшные — прилетят в телеграм или отправятся железной женщине, которая в любое время суток беспринципно позвонит дежурному, чтобы сообщить об аварии и пригрозить эскалацией, если тот не возьмёт проблему в работу.
Например, мы проверяем сколько всего BGP-сессий настроено на ToR. Должно быть 4. Сколько из них в состоянии Established? А как давно — больше 5 минут или меньше? Если лежит хотя бы одна сессия, это WARN и сообщение в телеграм. 2 — уже CRIT и звонок --родителям-- дежурному.
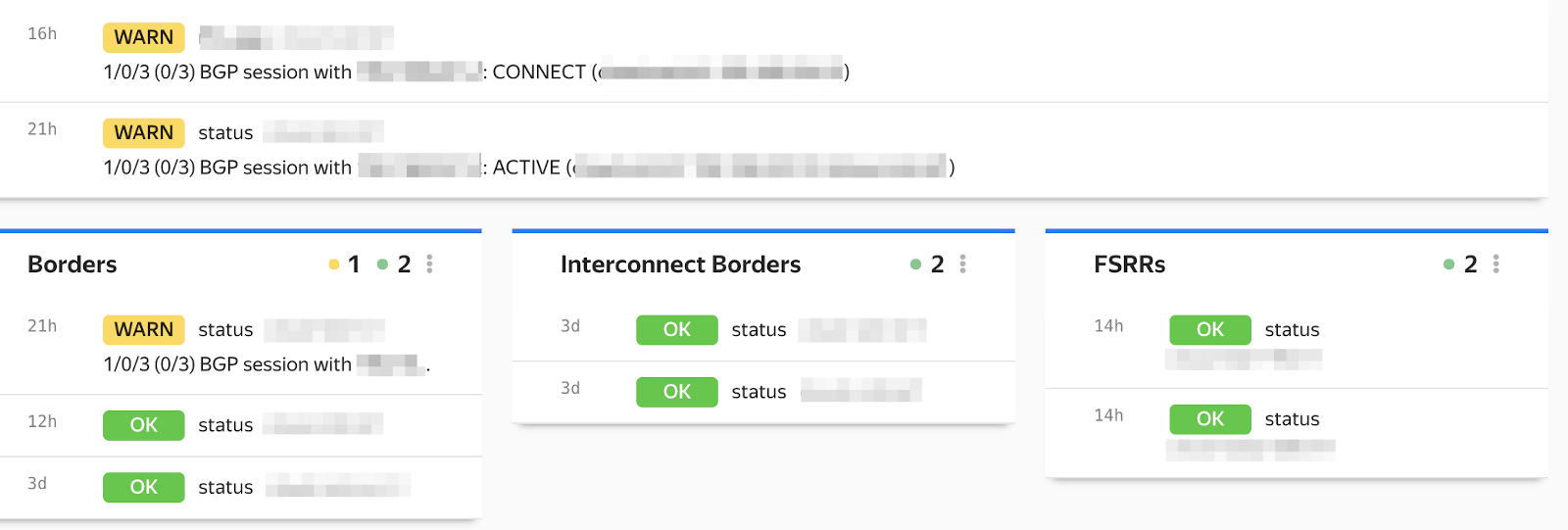
Ещё мы отслеживаем количество анонсируемых и принимаемых маршрутов. Если оно внезапно выходит за допустимые пределы, это сигнал: что-то случилось. Нужно проверить, не упало ли какое-то устройство. Прилетела неожиданного размера пачка маршрутов — нет ли угрозы аппаратным ресурсам устройства?
Также мы сравниваем число активных членов LAG с настроенным, иначе можно незаметно деградировать по полосе.
На каждой машине стоит агент e2e-мониторинга, который веерно пингует по ICMP/UDP/TCP весь флот хостов и рисует матрицу связности, по которой мы можем в пару кликов понять характер проблемы и локализовать её.
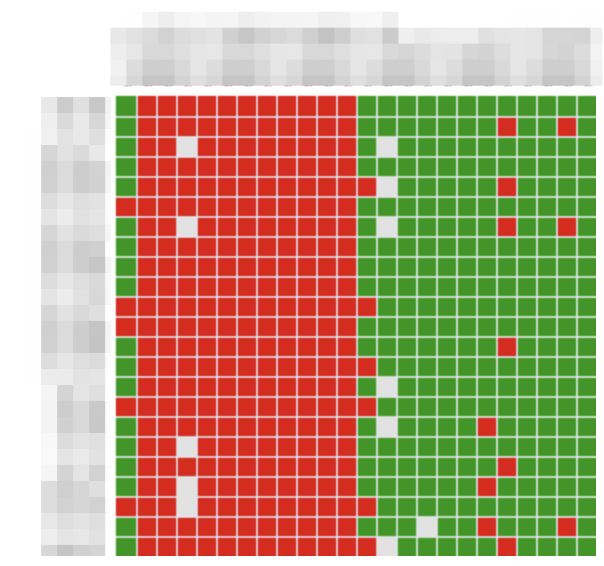
В каждой AZ внутри нашей фабрики стоят выделенные проберы, которые пытаются доступиться до определённых сегментов: сервисов Yandex.Cloud, большого Яндекса, разных областей интернета. И делают это с учётом ECMP. Так мы, во-первых, узнаём о существовании проблемы связности. Во-вторых, понимаем локализуется ли она каким-то ДЦ, внешкой, стойкой или конкретным сетевым устройством. И уже через несколько минут после аварии понимаем, что нужно проверить в первую очередь.
Повторюсь: главная задача мониторингов — обнаружить отказ до того, как клиент придёт с жалобой. Ещё лучше — успеть его исправить. Например, если флапает интерфейс, мониторинг создаст тикеты в службу эксплуатации ДЦ и уведёт трафик с нестабильного линка.
Но при этом он должен быть не шумным и однозначно указывать на существующую проблему.
Мы прошли большой путь от картинок на стенах своего уютного офиса до собственной сети на сотни устройств. Но впереди ещё много работы.
Например, сейчас у нас 4 плоскости или по 400 ГБ/с аплинка со стойки. На следующей итерации развития Yandex.Cloud это потенциально может стать узким местом — мы будем расширять его. Сделать это можно разными способами:
* Добавить оптические линии или использовать существующую кабельную инфраструктуру с помощью спектрального уплотнения.
* Увеличить число плоскостей или сделать LAG в существующие спайны.
* Радикальное решение — перейти от интерфейсов 100 ГБ/с к 400 ГБ/с.
Последний вариант кажется соблазнительным в далёкой перспективе, но это новый тип модуляции. А значит — замена существующих свитчей. С другой стороны, это решение поможет нам решить другую актуальную задачу: перейти на более высокоскоростные интерфейсы хост-тор — 50 ГБ/с или 100 ГБ/с. А это само по себе отдельный большой проект: изменится не только скорость, но и вся внутрянка драйверов и способов взаимодействия хоста с NIC.
В схеме с двуторьем мы тоже видим потенциальную пользу, помимо упрощения обслуживания: сможем разнести пользовательский и массивный служебный трафик (например БД) по разным интерфейсам/торам.
Но не буду спойлерить следующие публикации. В этом посте я хотел рассказать именно о датацентровой фабрике. А ведь ещё есть POP для выхода во внешний мир и организации услуги Yandex Cloud Interconnect, приватные инсталляции, Yandex DDoS Protection, VNF, автоматизация и многое другое, выходящее за пределы сетевой инфраструктуры.
Напоследок поделюсь полезными материалами коллег по теме:
Cпасибо, что дочитали до конца! Приходите обсудить в комментарии.
Привет, я Марат Сибгатулин, сетевой инженер Yandex.Cloud. Яндекс про свою сеть рассказывал уже не раз. И про её физическую инфраструктуру, и про особенности устройства Yandex.Cloud, и про то, как вообще работает виртуальная сеть. Не буду повторяться. Расскажу о том, как мы запустили публичное облако на том, что было — на двух стойках, и масштабировали его до сети для десятков тысяч серверов, не наращивая неоплатный технический долг.
Мы практикуем следующий подход к созданию и развитию чего бы то ни было: прототип → минимально необходимая функциональность и масштаб → рост → эволюционное развитие. На первый взгляд он естественен и очевиден, в отличие от подхода «сделать сразу идеально и на века». На деле — требует вдумчивого предварительного планирования, чтобы потом не подставлять в горячке новые костыли под старые, пытаясь поспеть за внезапным ростом.
Общая схема платформы
У Yandex.Cloud 3 зоны доступности (Avialability Zone — AZ) и 5 точек присутствия (Point of Presence — POP). Внутри AZ — классическая для датацентров сеть Клоза. Между разными AZ и POP — магистральная DWDM-сеть. Выход в магистраль реализован через специальные граничные устройства.
В AZ находятся стойки с серверами. Каждая, набитая более чем тридцатью машинами, подключена в сеть на скорости 400 ГБ/с. Внутри одной AZ мы можем прокачивать десятки терабит. Наружу — в совокупности между ДЦ, в большой Яндекс, в интернет — из каждого ДЦ мы сможем выпустить около 1 ТБ/с.
3 поколения Кло
Как вы думаете, когда всё началось? Ответ может сильно удивить: в 60-е, когда француз Чарльз Клоз (строго говоря, Шарль Кло — он же француз) придумал для телефонных станций особую топологию. Она позволяла недорого подключить n входов к m выходам без блокировок и необходимости использовать n*m соединений.
История, конечно, интереснейшая, но длинная. Ограничусь самым важным: пережив несколько инкарнаций, сеть Клоза нашла своё применение и в датацентрах, где требуется соединить друг с другом большое количество физических машин.
Классическая сеть Клоза
Фабрика коммутации Yandex.Cloud, связывающая между собой физические машины — воплощение сети Клоза. Её регулярная и плотная топология обеспечивает высокую отказоустойчивость системы и широкополосную передачу данных как внутри, так и вовне сети.
Входы (они же выходы) называются лифами (в оригинале — «Leaf»), а соединяющие их устройства — спайнами («Spine»).
Сеть датацентра, она же фабрика, она же Folded Clos
Однако наиболее важное для наших задач качество такой топологии — возможность практически неограниченно наращивать её, не принося в жертву ширину полосы. Именно поэтому она стала основой для всех гипер- и экзаскейлеров и клауд-титанов.
Но обо всём по порядку.
Первое поколение
Для Yandex.Cloud всё началось без малого 4 года назад, когда где-то в каморках датацентров Яндекса завелись первые стойки с дев-окружением. Тогда же начала формироваться команда сетевой инфраструктуры.
Выше я упоминал, как важно предварительное вдумчивое планирование. На стыке 2017–2018 мы думали и рисовали. Ещё думали и ещё рисовали. Потом передумывали и перерисовывали. В нашем распоряжении были огромные белые стены и сочные маркеры.
А в июле 2018-го мы построили нашу первую сеть.
Она была достаточно простой, чтобы быстро налить первый препродовый стенд. Но при этом достаточно зрелой, чтобы вписаться в дальнейшее развитие. К четвёртому году жизни Yandex.Cloud, мы успели сменить 2 мажорных поколения дизайна датацентровой фабрики, а стойки, введённые в работу в 2018, всё ещё органично вписываются в сеть и работают в проде. Более того: мы до сих пор продолжаем строить платформу по дизайну, который задумали в 2017.
В 2018 у нас ещё не было своей сетевой инфраструктуры: мы подключали стойки платформы к существовавшим системам большого Яндекса. Фактически сеть Yandex.Cloud состояла только из стоечных свитчей — а дальше начинался NOC Яндекса. Из-за того, что нам не пришлось сразу строить всю фабрику и организовывать границу датацентра, удалось быстро стартануть. А инфраструктурные сервисы смогли начать разработку в среде близкой к продовой. На этой сети мы и запустили первый прод в 2018-м.
Яндекс и Yandex.Cloud
Тут следует заметить, что мощности Yandex.Cloud располагаются в датацентрах Яндекса. Платформа использует такие же сервера и стойки внутренней разработки, такие же свитчи и маршрутизаторы, включается в ту же СКС. Даже в дизайне сети мы идём одной тропой. То есть пользуемся плодами и опытом двадцатилетней разработки внутренней инфраструктуры компании.
Но при этом быть органической частью Яндекса не можем в силу как отличающейся бизнес-модели, так и требований регуляторов. Так PCI DSS, ISO 27001, ISO 27017 и ISO 27018 требуют особого отношения к доступам в стойки, обращению с дисками, видеонаблюдению, TPM. Ни для кого не секрет, что оверлейная сеть, обеспечивающая мультитенантность Yandex.Cloud, реализована на OpenContrail (ныне Tungsten Fabric). Он, в свою очередь, требует IPv4-связности. А как всем известно, Яндекс одним из первых стал IPv6-only.
Ещё одно радикальное отличие — это MPLS. Облачным платформам он необходим как составная часть нескольких решений. Но у этого механизма есть существенный минус — ограничения масштабируемости. Яндекс отказался от MPLS в пользу максимального упрощения сети.
Иными словами мы с NOC большого Яндекса всё дальше и дальше расходились в своих перспективах. В начале 2019-го стало окончательно понятно: в обозримом будущем сохранить общую сеть не выйдет. Впрочем, история любит спирали — кто знает, что впереди?
На тот момент, к счастью, мы уже были готовы разворачивать новое поколение нашей собственной фабрики.
Третье поколение
Иметь единые с большим Яндексом инфраструктуру и инструментарий было бы очень удобно. Но ради этого нам пришлось бы пожертвовать скоростью развития платформы. Сеть NOC, строившаяся под задачи большого Яндекса и ориентированная на внутренних клиентов, плохо решала задачи Yandex.Cloud:
- У них IPv6-only сеть — у нас IPv4: требования OpenContrail/Tungsten Fabric.
- У них тенденция к отказу от MPLS — для нас это основной способ туннелирования трафика.
- У них автоматизация, заточенная под их задачи — у нас весьма специфический дизайн.
- Их сервисы выдерживают выключение одной или нескольких стоек и даже всего ДЦ — наши сервисы для внешних клиентов и помышлять об этом не могут.
И мы решили строить свою независимую фабрику. Сейчас, оглядываясь назад, мы понимаем, что это решение было очень правильным и своевременным.
Вторая половина 2018-го — вновь время раздумий и больших сложных картинок на стенах офиса. Потом — закупки и подготовка базовой автоматизации, пока едет оборудование.
Проекция процесса творческого поиска на маркерную стену
Автоматизация широкими мазками
Предполагая, какими объёмами будет прирастать серверный флот, с самого первого дня мы стали думать про автоматизацию одновременно с планированием самой сети. Первые же прод-свитчи мы настраивали не вручную, тем самым избежав человеческих ошибок.
В этот же момент завели молодёжный NetBox и собственные системы: инвентарную, учёта IP-ресурсов, первый прототип общего сетевого API-интерфейса с модным REST. А скрипты автоматизации обрастали мышцами и кожей, пока плавно не обрели форму системы, которая обеспечила конвейером жизненного цикла каждое устройство в сетевой инфраструктуре.
Если коротко, то после установки нового устройства на позицию мы:
- Вводим его в NetBox.
- Генерируем для него и тут же применяем первичную конфигурацию.
- Актуализируем устройство в NetBox: по LLDP изучаем и добавляем соседей, вычисляем IP-адреса, создаём виртуальные интерфейсы, выделяем ASN.
- Генерируем файлы с инвентарной информацией и целевой конфиг.
- Выкатываем новую версию конфигурации на устройство.
- Обновляем устройство.
- Радуемся и проверяем: мониторинги, скрипты бэкапов, проверки версий, коммитов и другие полезные штуки остальные системы подхватывают автоматически.
Но не буду отвлекаться: про всю автоматизацию когда-нибудь расскажем отдельно. Эта долгая и интересная история требует особого внимания.
Летом 2019-го мы разворачивали и тестировали Cloud Fabric — полностью независимую от большого Яндекса инфраструктуру внутри датацентров: торы (они же лифы), спайны, граничные устройства. Для сообщения между ДЦ и выхода во внешний мир мы подключились в развитую магистральную сеть Яндекса. Чтобы добиться связности с его сервисами, организовали стык через датацентровые бордеры. Ещё раз спасибо автоматизации: настройка заняла один день и обошлась без происшествий.
Уже собственная сеть Облака, использующая Яндекс только для транспорта и как пира
О том, как устроена наша сеть, расскажу поподробнее.
Устройство сети
Знакомьтесь — наши серверные стойки:
Стандартные стойки Яндекса
В каждой из них около 30 машин, которые включаются в свитч, установленный в этой же стойке. Он называется ToR (Top of the Rack)-switch. Название подсказывает, что свитч должен стоять наверху, но для более рациональной коммутации, он установлен по центру стойки.
Здесь и далее ToR выступает синонимом Leaf. С помощью лифов машины могут общаться друг с другом в пределах стойки.
Внутри стойки
Для того, чтобы могли общаться машины в разных стойках, торы тоже нужно тоже соединить друг с другом. Сделать это в лоб теоретически возможно. Есть даже такие топологии: Full Mesh, Ring, Star. Но все они или не работают в датацентрах, где преобладает трафик внутри ДЦ между машинами, или будут стоить дороже, чем серверные мощности. Да, можно подключиться по радио и даже через светодиоды. Но делать этого мы, конечно же, не будем.
Как всегда, всё уже придумано до нас. Помогла нам упомянутая выше топология Клоза. Мы поставили большие молотилки трафика, единственной задачей которых было — передать трафик из одной стойки в другую. Выше я рассказывал, что они называются «спайны».
Между стойками
Для того, чтобы могли взаимодействовать машины, находящиеся в разных ДЦ, мы организовали выход из локальной фабрики через граничные устройства — Edge Leaf.
Между ДЦ
Для уровня спайнов и Cloud Edge мы установили в каждой AZ отдельные инфраструктурные стойки. Вот так выглядели они в тот момент:
После этого все новые серверные стойки запускались уже в новой сети, подключаясь именно в наши спайны, а не общеяндексовые.
С августа по декабрь 2019 мы бесшовно мигрировали все стойки, запущенные ранее, в нашу новую-кленовую фабрику. И как раз успели перед большим редизайном NOC Яндекса, целью которого было существенно упростить инфраструктуру. После него платформа Yandex.Cloud уже не могла работать по старой схеме.
В 2020-й мы вошли с независимой фабрикой. Теперь Облако никоим образом не затрагивали и не тормозили любые работы и неисправности, отсутствие MPLS и IPv4 на датацентровой сети большого Яндекса. А мы в свою очередь не мешали ему развиваться.
Есть и ещё один нюанс. В Яндексе регулярно проводятся учения по полному отключению датацентров, чтобы убедиться, что все, даже самые маленькие и незаметные, сервисы способны жить при -1 ДЦ.
Все, кроме Yandex.Cloud.
Дело в том, что сервисы Яндекса изначально разрабатываются так, что за свою доступность каждый отвечает самостоятельно, перераспределяя нагрузку на оставшиеся в живых узлы и масштабируя ресурсы по мере необходимости. Наша платформа, будучи плотью от плоти Яндекса, тоже придерживается этой парадигмы. Вся внутренняя инфраструктура, начиная c контроллеров сети, продолжая DBaaS и заканчивая serverless, высокодоступна и переживёт многое. Но требовать того же от клиентов мы не можем.
Клиент на свой страх и риск может развернуть единственную ВМ в одной AZ без балансировщика. И эта машина благополучно канет в лету в случае недоступности хоста, стойки, AZ. Но клиент на закономерный вопрос «Зощто?», вряд ли удовлетворится ответом «Мы просто проводили учения». Поэтому независимая сеть для Облака — необходимость, а не реализация амбиций.
Второе поколение
2020: новый год, новая сеть, новая напасть. В построенную нами фабрику можно было подключить ограниченное число серверов. А именно — чуть больше 2000 машин (если закрыть глаза и совсем не задумываться о будущем). Платформа при этом росла весьма быстро, удваиваясь через равные промежутки времени.
Задумываться о будущем мы начали параллельно с миграциями, ещё в 2019 году. Топология Клоза хороша тем, что её сравнительно легко масштабировать — добавляя новый уровень спайнов, многократно увеличиваешь число машин, которые можно подключить.
Так мы добавили спайн для спайнов, он же суперспайн, он же Spine2, он же ToF (Top of Fabric) и подключили в него существующую сеть, после чего последняя стала лишь маленьким кусочком мозаики.
Текущий вид сети ДЦ Облака
Каждый такой кусочек называется PoD — Point of Delivery. Это универсальные блоки сети, её кирпичики, а спайны второго уровня — скрепляющий цементный раствор. На иллюстрации два POD, но их может быть от 32 до 128 в зависимости от радикса (числа портов) используемых свитчей.
Каждый POD обладает ограниченной портовой ёмкостью. В нашем дизайне — это 32 серверные стойки или порядка 1000 серверов. Каждый раз, когда порты для подключения серверных стоек в текущем POD заканчиваются, мы строим типовой новый POD и начинаем подключать стойки в него. Принципиальных архитектурных изменений при этом не требуется.
Чуть более приближенное к реальности схематическое представление многоуровневой датацентровой фабрики:
Для этого нам пришлось добавить ещё по несколько инфраструктурных стоек в AZ. Каждая стойка и устройства в ней зарезервированы по питанию независимыми вводами. Сеть выдерживает любой двойной отказ устройств или линков и даже полное выключение двух стоек с приемлемым уменьшением полосы.
Но всё было бы не так интересно, если бы можно было просто взять готовое решение и применить его как есть.
Архитектурные особенности
Топология Кло для ДЦ — это очень хорошо, но вместе с тем — весьма дорого. Причём с увеличением числа уровней, стоимость растёт нелинейно.
Классический подход предполагает один линк между парой устройств разных уровней.
Когда компания планирует поставить сразу 30 000 хостов, арифметика следующая: ставим 32 POD по 32 стойки по 32 машины и подключаем их в 32 спайна второго уровня на каждый плейн — грубый абстрактный счёт. 4 плейна — 1280 свитчей. Если каждый из них стоит $10 000, получается, что только на коробки надо потратить 13 миллионов долларов. А ещё столько же понадобится на СКС и трансиверы. Полагаю, так строят новые ДЦ Amazon и Google.
Но Yandex.Cloud растёт более плавно. Нам не нужно сразу 32 POD и полностью собранный уровень Spine2. Если, к примеру, у нас есть 4 POD, то при классическом подходе в каждом из Spine2 будет занято только 4 порта — остальное греет горячий коридор.
Усечённый Кло
Мы решили сделать усечённый уровень Spine2 — вместо 32 свитчей, мы ставим в него 4. А Spine1 подключаем в Spine2 не одним линком, а, условно, восемью, чтобы добиться нужной полосы между POD. Тогда 4 POD займут 32 порта на Spine2. Когда мы ощутим потребность расти дальше, просто нарастим группировку Spine2 до 8, а линки перераспределим из старых в новые. По мере роста повторим.
Таким образом мы существенно снижаем CAPEX на начальных этапах.
LAG vs ECMP
Очевидно, что линки между парой устройств должны использоваться все и равномерно. Для этого:
1) Их можно объединить в LAG.
2) А можно каждый из них настроить как самостоятельный L3-интерфейс и использовать силу ECMP.
Мы много думали, спорили, собирали лабы, считали аппаратные ресурсы коммутаторов, прогнозировали рост. LAG в результате выиграл по большинству позиций:
* Меньше использует ECMP-группы в случае MPLS (есть в наших ДЦ).
* Меньше контрольной информации — одна BGP-сессия вместо нескольких.
* Меньше шума на сети при флапах интерфейса.
* Проще переконфигурировать сеть, когда меняем группировку Spine2.
* Проще автоматизировать.
Есть у LAG, безусловно, и особенности. Но для тех из них, которые могут сделать платформе больно, мы нашли компенсационные меры.
Двуторье
Dual-homing машин в два тора — весьма противоречивая идея, которая реализована мало у кого из облачных провайдеров.
Парадигма архитектуры облачных инфраструктур предполагает, что клиент разворачивает несколько экземпляров своего приложения в разных AZ, прячет их за балансером и к тому же настраивает auto-scaling. Выключение физической машины, где крутилось его приложение, в этом случае никак не скажется на работоспособности сервиса. Но реалии иные — зачастую у клиента может быть всего одна виртуалочка, на которой крутится весь прод.
Аварийное выключение свитча — это вопрос вероятностей. Чем больше флот и чем дольше он существует, тем больше шансов, что вскроется баг, деградирует элемент, случится битфлип. И какая-то стойка потеряется. Для предотвращения таких ситуаций и комфортного планового обслуживания коммутаторов было бы удобно иметь схему с двумя ToR.
Кроме того это один из вариантов увеличения полосы, это возможность разнести тяжёлый трафик хранилища/дисков и клиентский на разные интерфейсы и бесшовно обновлять forwarding-агенты на хостах. Однако это влечёт за собой огромный фронт работ по переделке СКС, редизайну маршрутизации и схем отказоустойчивости, разработке хостовых агентов.
Мы сделали прототип двуторья с BGP с хоста, разработали схему отказоустойчивости, спланировали возможную СКС, проверили в виртуальных лабах на больших масштабах и пока отложили в стол. Возможно, мы ещё вернёмся к этой идее.
Мониторинги
Во всём этом немалом хозяйстве нужно уметь быстро находить (а ещё лучше предвидеть) проблемы до того, как к нам придёт смежный сервис, и уж тем более клиент. Для этого у нас есть количественные и качественные мониторинги. Они составляют большую часть обвязки нашей внутренней разработки.
Количественные
Количественные мониторинги у нас весьма типичные: CPU, Memory, утилизация интерфейсов, счётчики ошибок, уровни сигнала.
Различные счётчики комбинируем во всевозможные сочетания и выносим на дашборды, чтобы с первого взгляда было можно оценить, например, общий объём трафика на любом срезе или «зажечь аварию» при превышении допустимого числа ошибок в AZ.
На все известные проблемы создаются триггеры, которые зажигают явную аварию. Благодаря этому в нашей команде нет необходимости в дежурной смене, которая бы денно и нощно не сводила глаз с графиков в поисках аномалий.
Качественные
Качественные мониторинги поинтереснее. Наша система раз в 2 минуты опрашивает каждое сетевое устройство, забирая с него состояние BGP и интерфейсов. Ответ парсим на специальных серверах, приводим к общему виду, независящему от вендора и интерфейса, и сравниваем с бейслайном. Далее создаём событие (OK, WARN, CRIT). Некритичные попадут на дашборд. Самые страшные — прилетят в телеграм или отправятся железной женщине, которая в любое время суток беспринципно позвонит дежурному, чтобы сообщить об аварии и пригрозить эскалацией, если тот не возьмёт проблему в работу.
Например, мы проверяем сколько всего BGP-сессий настроено на ToR. Должно быть 4. Сколько из них в состоянии Established? А как давно — больше 5 минут или меньше? Если лежит хотя бы одна сессия, это WARN и сообщение в телеграм. 2 — уже CRIT и звонок --родителям-- дежурному.
Ещё мы отслеживаем количество анонсируемых и принимаемых маршрутов. Если оно внезапно выходит за допустимые пределы, это сигнал: что-то случилось. Нужно проверить, не упало ли какое-то устройство. Прилетела неожиданного размера пачка маршрутов — нет ли угрозы аппаратным ресурсам устройства?
Также мы сравниваем число активных членов LAG с настроенным, иначе можно незаметно деградировать по полосе.
E2E
На каждой машине стоит агент e2e-мониторинга, который веерно пингует по ICMP/UDP/TCP весь флот хостов и рисует матрицу связности, по которой мы можем в пару кликов понять характер проблемы и локализовать её.
В каждой AZ внутри нашей фабрики стоят выделенные проберы, которые пытаются доступиться до определённых сегментов: сервисов Yandex.Cloud, большого Яндекса, разных областей интернета. И делают это с учётом ECMP. Так мы, во-первых, узнаём о существовании проблемы связности. Во-вторых, понимаем локализуется ли она каким-то ДЦ, внешкой, стойкой или конкретным сетевым устройством. И уже через несколько минут после аварии понимаем, что нужно проверить в первую очередь.
Повторюсь: главная задача мониторингов — обнаружить отказ до того, как клиент придёт с жалобой. Ещё лучше — успеть его исправить. Например, если флапает интерфейс, мониторинг создаст тикеты в службу эксплуатации ДЦ и уведёт трафик с нестабильного линка.
Но при этом он должен быть не шумным и однозначно указывать на существующую проблему.
Что дальше
Мы прошли большой путь от картинок на стенах своего уютного офиса до собственной сети на сотни устройств. Но впереди ещё много работы.
Например, сейчас у нас 4 плоскости или по 400 ГБ/с аплинка со стойки. На следующей итерации развития Yandex.Cloud это потенциально может стать узким местом — мы будем расширять его. Сделать это можно разными способами:
* Добавить оптические линии или использовать существующую кабельную инфраструктуру с помощью спектрального уплотнения.
* Увеличить число плоскостей или сделать LAG в существующие спайны.
* Радикальное решение — перейти от интерфейсов 100 ГБ/с к 400 ГБ/с.
Последний вариант кажется соблазнительным в далёкой перспективе, но это новый тип модуляции. А значит — замена существующих свитчей. С другой стороны, это решение поможет нам решить другую актуальную задачу: перейти на более высокоскоростные интерфейсы хост-тор — 50 ГБ/с или 100 ГБ/с. А это само по себе отдельный большой проект: изменится не только скорость, но и вся внутрянка драйверов и способов взаимодействия хоста с NIC.
В схеме с двуторьем мы тоже видим потенциальную пользу, помимо упрощения обслуживания: сможем разнести пользовательский и массивный служебный трафик (например БД) по разным интерфейсам/торам.
Но не буду спойлерить следующие публикации. В этом посте я хотел рассказать именно о датацентровой фабрике. А ведь ещё есть POP для выхода во внешний мир и организации услуги Yandex Cloud Interconnect, приватные инсталляции, Yandex DDoS Protection, VNF, автоматизация и многое другое, выходящее за пределы сетевой инфраструктуры.
Напоследок поделюсь полезными материалами коллег по теме:
- Глеб Холодов про виртуальную сеть Yandex.Cloud
- Сергей Еланцев про архитектуру сетевого балансировщика Yandex.Cloud
- Александр Вирилин про устройство сетевой инфраструктуры Yandex.Cloud
- Дмитрий Афанасьев про датацентровые сети Яндекса
- Владимир Неверов про балансировку в Яндексе
- Марат Сибгатулин про Clos и маршрутизацию в нём и про ECMP
Cпасибо, что дочитали до конца! Приходите обсудить в комментарии.



